 Bei Gao
Bei Gao Yuefeng Liu*
Yuefeng Liu*- Shaanxi Meteorological Service Center of Agricultural Remote Sensing and Economic Crops, Xi’an, China
Introduction: Accurately predicting suitable areas for double-cropped soybeans under changing climatic conditions is critical for ensuring food security anc optimizing land use. Traditional methods, relying on single-modal approaches such as remote sensing imagery or climate data in isolation, often fail to capture the complex interactions among environmental factors, leading to suboptimal predictions. Moreover, these approaches lack the ability to integrate multi-scale data and contextual information, limiting their applicability in diverse and dynamic environments.
Methods: To address these challenges, we propose AgriCLIP, anovel remote sensing vision-language model that integrates remote sensing imagery with textual data, such as climate reports and agricultural practices, to predict potential distribution areas of double-cropped soybeans under climate change. AgriCLIP employs advanced techniques including multi-scale data processing, self-supervised learning, and cross-modality feature fusion enabling comprehensive analysis of factors influencing crop suitability.
Results and discussion: Extensive evaluations on four diverse remote sensing datasets-RSICap RSIEval, MillionAID, and HRSID-demonstrate AgriCLIP’s superior performance over state-of-the-art models. Notably, AgriCLIP achieves a 97.54% accuracy or the RSICap dataset and outperforms competitors across metrics such as recall F1 score, and AUC. Its efficiency is further highlighted by reduced computation a demands compared to baseline methods. AgriCLIP’s ability to seamlessly integrate visual and contextual information not only advances prediction accuracy but also provides interpretable insights for agricultural planning and climate adaptation strategies, offering a robust and scalable solution for addressing the challenges of food security in the context of global climate change.
1 Introduction
Remote sensing image segmentation is a critical task in the field of remote sensing and geographic information systems, providing essential information for land cover classification, environmental monitoring, and urban planning (Zhou et al., 2024). The segmentation of remote sensing images is not only necessary for the accurate interpretation of vast amounts of data but also crucial for the effective management and utilization of natural resources. Given the increasing availability and resolution of remote sensing data, the need for advanced segmentation techniques has become more pronounced (Yuan et al., 2023). These techniques not only allow for the precise delineation of objects and regions within an image but also enable the extraction of meaningful patterns and features that are vital for a wide range of applications (Xu et al., 2021). Moreover, with the growing challenges posed by climate change, deforestation, and urbanization, the ability to monitor and analyze changes in the Earth’s surface with high accuracy is more important than ever. This necessity has driven significant advancements in the field, leading to the development of various methods over the years, each with its strengths and limitations (Qi et al., 2022).
In early research on remote sensing image segmentation, traditional three-dimensional reconstruction techniques were widely used. These methods aimed to reconstruct the spatial structure of the Earth’s surface through stereoscopic image pairs or photogrammetric techniques (Bigolin and Talamini, 2024). By leveraging geometric principles, traditional 3D reconstruction methods could segment images based on the relative positions and orientations of objects, providing detailed and accurate representations of the terrain (Li et al., 2024). However, these methods were computationally complex and required precise calibration and alignment of images, making them less practical for large-scale or real-time applications (Jung et al., 2024). Additionally, traditional 3D reconstruction techniques faced challenges in handling complex and heterogeneous landscapes, particularly when mixed pixels and uneven illumination conditions were present, which could significantly reduce the accuracy of the results (Tovihoudji et al., 2024). To overcome these issues, researchers began exploring alternative approaches that could offer more robust and scalable solutions. Compared to the limitations of manual and semi-automated methods, these emerging approaches demonstrated superior performance in processing large-scale data and achieving real-time capabilities, paving the way for further advancements in remote sensing image segmentation (Jung et al., 2024). By integrating advanced technologies like machine learning and deep learning, these methods exhibited higher efficiency and accuracy across various application scenarios, especially in handling complex landscapes, where they showed greater robustness and adaptability.
In response to the limitations of traditional 3D reconstruction methods, the field gradually shifted towards statistical learning and machine learning-based approaches. These methods introduced a more flexible and data-driven framework for remote sensing image segmentation, allowing for the incorporation of statistical models and machine learning algorithms to improve segmentation accuracy. Statistical learning methods, such as Markov Random Fields (MRF) and Conditional Random Fields (CRF), were employed to model the spatial dependencies between neighboring pixels, enabling more accurate segmentation by considering the contextual information within the image (Shaar et al., 2024). Machine learning algorithms, including Support Vector Machines (SVM), Random Forests, and k-Nearest Neighbors (k-NN), were also utilized to classify pixels based on their spectral and spatial features, offering improved performance over traditional methods (Ling et al., 2022). Despite their advantages, these methods still faced challenges, such as the need for extensive feature engineering and the inability to capture complex, non-linear relationships within the data. Furthermore, the performance of machine learning-based segmentation methods heavily depended on the quality and quantity of the training data, which could be a limiting factor in scenarios where labeled data was scarce or expensive to obtain (Rai et al., 2020).
To address the limitations of statistical learning and traditional machine learning methods, the advent of deep learning and pre-trained models brought a paradigm shift in remote sensing image segmentation. Deep learning-based methods, particularly Convolutional Neural Networks (CNNs), have revolutionized the field by automatically learning hierarchical representations of the data, enabling the segmentation of images with unprecedented accuracy and efficiency. Unlike traditional methods, deep learning approaches do not require manual feature extraction, as they can learn complex features directly from the raw pixel values through multiple layers of abstraction (Zhou et al., 2023). The introduction of pre-trained models, such as U-Net (Benchabana et al., 2023), ResNet (Gomes et al., 2021), and more recently, Vision Transformers (ViTs) (Dong et al., 2022), has further enhanced the segmentation capabilities by leveraging large-scale datasets and transfer learning techniques. These models have demonstrated remarkable performance in various remote sensing tasks, including land cover classification, object detection, and change detection, significantly reducing the need for extensive labeled datasets and improving generalization to new and unseen environments (Li et al., 2023). However, despite their success, deep learning-based segmentation methods are not without challenges. They require substantial computational resources and are often sensitive to hyperparameter tuning and network architecture design. Moreover, the black-box nature of deep learning models can make them difficult to interpret, which is a critical consideration in applications where explainability is as important as accuracy (Zhao et al., 2021).
To address the limitations of the aforementioned models, particularly their challenges in handling the complex and dynamic nature of environmental factors in agricultural tasks, we propose AgriCLIP: A Remote Sensing Vision-Language Model for Predicting Potential Distribution Areas of Double-Cropped Soybeans Under Climate Change. Our model specifically overcomes the shortcomings of traditional 3D reconstruction methods, which struggle with computational intensity and the segmentation of heterogeneous landscapes, by using multi-scale data processing to efficiently handle diverse and complex environmental conditions. Additionally, AgriCLIP addresses the limitations of statistical learning and traditional machine learning approaches, which often require extensive feature engineering and large labeled datasets, by leveraging self-supervised learning techniques that reduce the dependency on labeled data and enable the model to learn rich feature representations directly from the data. Furthermore, AgriCLIP mitigates the challenges associated with deep learning models, such as the need for substantial computational resources and sensitivity to hyperparameter tuning, by integrating pre-trained models that are optimized for remote sensing tasks, allowing for more efficient training and better generalization. Importantly, our model also tackles the issue of the black-box nature of deep learning approaches by combining visual and textual data, making the predictions more interpretable and contextually grounded. This combination of visual and contextual information allows AgriCLIP to provide a more comprehensive analysis, which is crucial for accurately predicting the potential distribution areas of double-cropped soybeans under varying climatic conditions. By addressing these key limitations, AgriCLIP offers a robust, scalable, and task-specific solution that is better suited to the demands of this agricultural application, marking a significant advancement in remote sensing image segmentation and prediction.
2 Related work
2.1 Object-based segmentation
Object-Based Image Analysis (OBIA) has been extensively utilized for remote sensing image segmentation, offering a structured approach that groups pixels into meaningful objects for analysis. OBIA’s strength lies in its ability to incorporate spatial context and relationships, enabling the segmentation of high-resolution images where individual objects like buildings, roads, or vegetation clusters consist of multiple pixels with similar characteristics (Du et al., 2020; Junior et al., 2023). This makes OBIA particularly valuable for tasks requiring detailed spatial and contextual information (Azhand et al., 2024). Recent advancements in OBIA have highlighted its flexibility across different scales and data types, which aligns closely with the goals of this study (Huang et al., 2020). However, the challenges of parameter sensitivity and manual intervention remain significant, necessitating further development in automated and scalable segmentation techniques (Cui et al., 2023; Norman et al., 2021).
2.2 Hybrid GIS and remote sensing
The integration of multimodal data has become an increasingly important approach in remote sensing image segmentation, allowing for the combination of different types of information to improve segmentation accuracy and robustness. Multimodal models leverage the strengths of various data sources, such as optical images, LiDAR data, synthetic aperture radar (SAR), and textual information, to provide a more comprehensive understanding of the environment (Sun et al., 2021). This approach is particularly valuable in remote sensing, where no single data source can fully capture the complexities of the Earth’s surface (He et al., 2023). Multimodal models have evolved to incorporate multiple data types into a unified framework, enhancing the ability to segment images with greater precision. For instance, combining optical imagery with LiDAR data allows for the integration of spectral and elevation information, leading to more accurate segmentation in complex terrains (Luo et al., 2024). Similarly, the fusion of SAR and optical data can provide complementary information, where SAR captures structural features that are often obscured in optical images due to weather conditions or lighting (Quan et al., 2024). In recent years, the incorporation of textual data, such as climate reports or land use descriptions, has further advanced the capabilities of multimodal models, enabling the interpretation of remote sensing images in contextually rich environments (Yan et al., 2023). The main advantage of multimodal models lies in their ability to capture and integrate diverse aspects of the observed scene, leading to more informed segmentation decisions (Cheng et al., 2021). By leveraging multiple data sources, these models can mitigate the limitations inherent in any single modality, such as the spectral ambiguity in optical images or the speckle noise in SAR data. However, the development of multimodal models also presents significant challenges. One of the primary difficulties is the alignment and synchronization of different data types, which often come in varying resolutions, formats, and coordinate systems (Wang et al., 2022). Moreover, the fusion of multimodal data can be computationally intensive, requiring sophisticated algorithms to effectively combine the information without losing critical details. Another challenge is the design of models that can effectively learn from and generalize across multimodal inputs, which often involves complex architectures and extensive training (Gammans et al., 2024).
2.3 Multimodal models
Multimodal models have emerged as powerful tools for integrating diverse data sources, including optical imagery, LiDAR, synthetic aperture radar (SAR), and textual information, to enhance segmentation accuracy. These models are particularly relevant for addressing the limitations of single-modality approaches, which often struggle to capture the full complexity of environmental features (Sun et al., 2021; He et al., 2023). For example, combining optical and LiDAR data allows for the integration of spectral and elevation information, a key requirement for robust segmentation in heterogeneous landscapes (Luo et al., 2024). The incorporation of textual data, such as climate reports or land-use descriptions, has further expanded the capabilities of multimodal models, providing contextually rich interpretations of remote sensing images (Yan et al., 2023). These techniques align with the methodological framework of this study, where cross-modality feature fusion is employed to achieve more accurate predictions (Cheng et al., 2021). The advantages of multimodal models include their ability to mitigate the limitations of individual modalities and their potential for delivering context-aware segmentation (Quan et al., 2024).However, the challenges of data alignment, computational demands, and architectural complexity remain areas of active research (Wang et al., 2022; Gao et al., 2024). The proposed work builds on these concepts by introducing a vision-language framework that addresses these challenges through self-supervised learning and advanced feature fusion mechanisms, thereby pushing the boundaries of current multimodal approaches in remote sensing.
3 Methodology
3.1 Overview
In this work, we propose an advanced remote sensing vision-language model, designed specifically for predicting potential distribution areas of double-cropped soybeans under the changing climate conditions. The proposed model integrates remote sensing data with sophisticated language models to enhance the prediction accuracy and robustness across different climatic scenarios. The model architecture leverages multi-scale data processing, self-supervised learning (SSL) techniques, and cross-modality feature fusion, allowing it to process and analyze diverse data sources efficiently. The overall data flow is structured into several key modules: data preprocessing, feature extraction, and prediction, all of which are intricately connected through a shared representation learning framework (As shown in Figure 1).
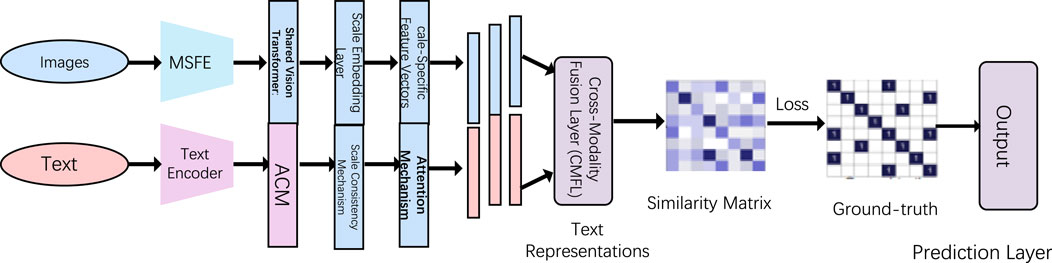
Figure 1. Diagram of the structure of AgriCLIP. The diagram shows the data flow of image and text inputs. Images are processed through the Multi-Scale Feature Extractor (MSFE) module and a shared Vision Transformer, while text is processed through a Text Encoder and the Adaptive Consistency Module (ACM). These are then fused in the Cross-Modality Fusion Layer (CMFL) to generate a similarity matrix, which is compared with the ground truth to compute the loss, followed by output through a prediction layer.
The data preprocessing module handles various input formats and resolutions, ensuring that the model can effectively integrate remote sensing images and climate-related textual data. In the feature extraction stage, the model employs a multi-scale masked autoencoder (MAE) inspired by recent advancements in remote sensing image analysis. This MAE is further augmented with a novel scale-consistency mechanism that enforces consistency across different scales of input data, which is particularly useful in handling the inherent variability in remote sensing data. The prediction module is designed to fuse the extracted features from both visual and textual inputs, utilizing a cross-attention mechanism that allows the model to weigh the importance of different modalities dynamically. This module outputs a probabilistic map indicating the potential distribution areas for double-cropped soybeans, accounting for various climate change scenarios.
In the following sections, we delve into the specific components of our model. Section 3.2 details the preliminaries, where we formalize the problem and set the mathematical foundation. Section 3.3 introduces the new model architecture, highlighting the innovations that differentiate it from existing approaches. Finally, in Section 3.4, we discuss the integration of domain-specific strategies that enhance the model’s predictive capabilities.
3.2 Preliminaries
In this section, we formalize the problem of predicting potential distribution areas for double-cropped soybeans under climate change using a remote sensing vision-language model. Let
The goal is to learn a function
Formally, the training objective can be expressed as Formula 1:
where
3.3 Adaptive multi-scale consistency network
In this subsection, we introduce the Adaptive Multi-Scale Consistency Network (AMSCN), a novel model architecture designed to address the challenges of multi-scale data fusion in remote sensing applications, specifically for predicting the distribution of double-cropped soybeans under varying climate conditions. The AMSCN extends the traditional Masked Autoencoder (MAE) framework by integrating an adaptive scale-consistency mechanism, which ensures that the features extracted from different scales of input data are not only consistent but also adaptive to the varying spatial resolutions and spectral characteristics inherent in remote sensing imagery. The model is composed of three key components: (1) a Multi-Scale Feature Extractor (MSFE), (2) an Adaptive Consistency Module (ACM), and (3) a Cross-Modality Fusion Layer (CMFL). These components work in synergy to extract, align, and integrate features from both the remote sensing images and the associated textual data.
3.3.1 Multi-scale feature extractor (MSFE)
The Multi-Scale Feature Extractor (MSFE) is a critical component for processing remote sensing images at various scales. These multi-scale inputs are denoted as
The feature extraction process for each scale
This embedding
The backbone of the MSFE is based on a shared transformer architecture, inspired by Vision Transformers (ViTs). This shared transformer consists of multiple stages, as illustrated in Figure (a). At each stage, the input image is progressively reduced in resolution through a Patch Embedding layer, while the number of feature channels is increased. The transformer architecture processes these embedded patches through a set of shared transformer blocks at each stage (As shown in Figure 2).
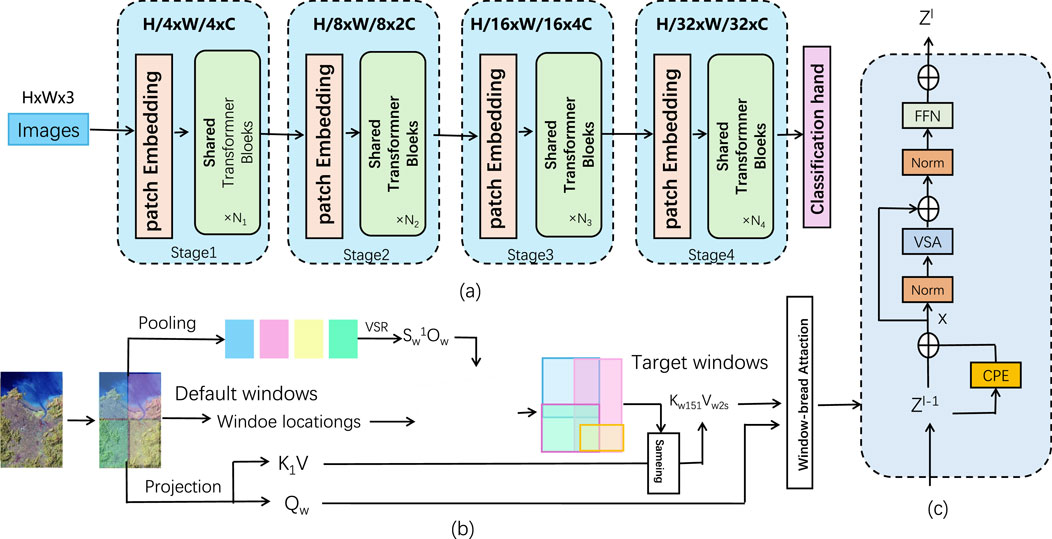
Figure 2. Structure diagram of Shared Transformer. First, in Figure (A), the image is gradually extracted through Patch Embedding and shared Transformer modules in multiple stages, the feature resolution is gradually reduced, and the number of channels is increased. At the same time, through the window space transformation and attention mechanism in Figure (B), the model can effectively process information of different scales. Finally, in Figure (C), the features are further processed through multi-layer operations, and the final output is the result for tasks such as classification.
The transformer operations in the shared layers can be mathematically described as follows. For a given input sequence
where
This process is repeated for
In addition to the shared transformer architecture, the MSFE incorporates a multi-scale attention mechanism, as depicted in Figure (b). The attention mechanism operates over windowed patches of the image. The pooling operation first divides the image into default windows. These windows are projected into a latent space, where the spatial relationships between the patches are captured by a spatial transform mechanism.
The attention mechanism for a window is given by Formula 5:
The spatial transformation adjusts the window positions and allows the model to integrate information from multiple scales, ensuring that features from different regions of the image are processed appropriately.
Finally, the output features from the MSFE are passed through multiple layers, as illustrated in Figure (c). These layers include layer normalization, multi-head attention, and feed-forward layers. The final output
The final output
Here, VSA refers to the Vision Self-Attention module, and FFN represents the feed-forward network. The normalized outputs are added to the input via a residual connection to stabilize training. The output
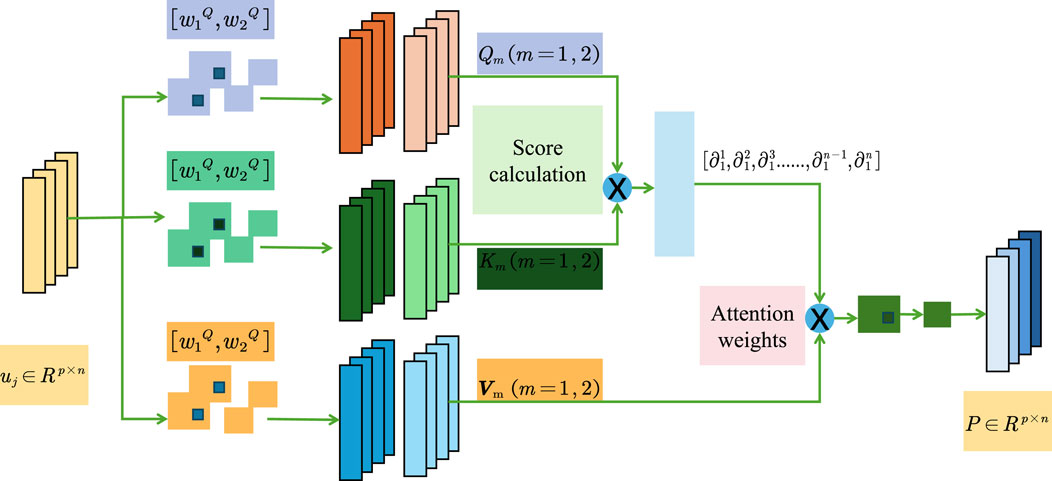
Figure 3. Structure diagram of Vision Self-Attention. The data is weighted by the attention weights and the final score is calculated to achieve a weighted evaluation and output of the input information.
The MSFE leverages a shared transformer architecture across multiple scales to efficiently capture features at different levels of resolution. The multi-scale attention mechanism further enhances the model’s ability to process complex, large-scale remote sensing data.
3.3.2 Adaptive consistency module (ACM)
The Adaptive Consistency Module (ACM) is a key component of the Adaptive Multi-Scale Consistent Network (AMSCN), designed to ensure consistency across features extracted from multiple scales. In remote sensing or vision tasks where images can be captured at different resolutions, it becomes crucial to align feature representations across these scales. The ACM achieves this by introducing both a scale-consistency loss and a scale attention mechanism, which dynamically adjusts the importance of different scales based on their relevance to the prediction task.
The primary function of the ACM is to enforce consistency between features extracted from different scales. This is accomplished by minimizing the discrepancy between feature representations from distinct scales. To achieve this, the ACM introduces a scale-consistency loss, denoted as
Given the feature representations
where
This formulation promotes the learning of robust, scale-invariant features while still allowing the model to capture unique scale-specific information as needed for particular tasks.
In addition to ensuring feature consistency across scales, the ACM dynamically adjusts the importance of each scale during the feature fusion process through a Scale Attention Mechanism. This mechanism computes attention scores for each scale, allowing the model to emphasize the most relevant scale for a given input and task. The scale attention score
where
Once the attention scores
Here,
To improve the robustness of the ACM, additional regularization terms can be introduced to further align the features across scales while preserving discriminative power. One such regularization term can be the inter-scale diversity loss, which encourages diversity between the feature representations at different scales. This can be defined as Formula 10:
This term ensures that while the features from different scales are aligned, they still maintain a level of diversity, which is crucial for capturing unique scale-specific information. By combining the scale-consistency loss
3.3.3 Cross-modality fusion layer (CMFL)
The Cross-Modality Fusion Layer (CMFL) is a crucial component of the Adaptive Multi-Scale Consistent Network (AMSCN) that integrates scale-consistent visual features with contextual information from associated textual data. In applications such as remote sensing, visual data (e.g., satellite images) often need to be complemented with textual information (e.g., crop reports, weather conditions, or geographic descriptions). The CMFL is designed to perform this cross-modal fusion effectively, using a transformer-based approach to align and merge the information from these two modalities.
The textual data, denoted as
where
The CMFL employs a cross-attention mechanism to align the visual features, extracted by the visual backbone, with the contextual information from the textual data. The goal is to allow the model to focus on relevant text features for each visual feature. The visual features, denoted as
Let
Here,
This attention score represents the relevance of the
Once the cross-attention scores
where
This fusion process ensures that each visual feature is enhanced by the relevant textual information, resulting in a more contextually informed representation.
After the cross-modality fusion, the fused features
The overall training objective for the AMSCN involves minimizing a combined loss function, which consists of three main components: Prediction loss
The total loss function is expressed as Formula 16:
where
3.4 Hybrid learning and robust optimization
To further refine the Adaptive Multi-Scale Consistency Network (AMSCN) and bolster its predictive performance, we incorporate strategic enhancements that leverage hybrid learning techniques and robust optimization. These enhancements are designed to improve the model’s generalization capabilities, especially in the face of incomplete or noisy data, which is common in real-world remote sensing and climate scenarios.
3.4.1 Hybrid learning approach
The AMSCN (Attention-based Multi-Scale Convolutional Network) employs a hybrid learning strategy that leverages both supervised learning and self-supervised learning (SSL) to maximize the effective use of labeled and unlabeled data. This combination allows the model to excel in scenarios where labeled data is limited, which is often the case in remote sensing applications. By utilizing this dual approach, the model can improve its generalization and robustness across varying geographical and climatic conditions, crucial for tasks like identifying suitable regions for double-cropping soybeans.
The supervised component of this hybrid strategy is guided by the binary cross-entropy loss function, denoted as Formula 17:
where
In contrast, the self-supervised learning (SSL) component uses a masked image modeling (MIM) strategy inspired by the Masked Autoencoder (MAE) framework. The goal of MIM is to learn a rich and robust set of feature representations from unlabeled data by exploiting the inherent structure of the remote sensing imagery. In this approach, portions of the input image are randomly masked, and the model is tasked with reconstructing the missing parts using the visible portions of the image, thereby encouraging the model to learn the underlying patterns and semantics.
The self-supervised loss function,
where
By integrating both supervised and self-supervised objectives into the training process, the AMSCN effectively learns from a mix of labeled and unlabeled data. The overall loss function for training the model can thus be expressed as a weighted sum of the two components (Formula 19):
where
3.4.2 Robust optimization techniques
To improve the resilience of the AMSCN (Attention-based Multi-Scale Convolutional Network) against the noise and uncertainties often present in remote sensing data, we incorporate several robust optimization techniques into the training process. These techniques are essential for ensuring that the model can generalize well to new, unseen conditions and maintain high performance even in the presence of noisy or corrupted input data. A key method utilized in this context is adversarial training, a strategy designed to improve the model’s robustness by exposing it to deliberately perturbed input data.
Adversarial training operates by introducing adversarial noise, denoted as
Formally, the adversarial training objective can be expressed as Formula 20:
where
The adversarial noise
where
By incorporating adversarial training, the AMSCN learns to be less sensitive to small, potentially adversarial changes in the input data, enhancing its robustness and generalization capabilities. This approach is particularly valuable in remote sensing tasks, where data can be subject to various sources of noise, such as sensor errors, atmospheric conditions, and data preprocessing artifacts. The adversarial training process ensures that the model develops feature representations that are more stable and less influenced by these noise sources.
Moreover, the total training loss for the AMSCN can be modified to include both the standard prediction loss and the adversarial loss, leading to an overall objective function defined as (Formula 22):
where
Another strategic enhancement involves the use of ensemble learning to quantify and reduce prediction uncertainty. We train multiple instances of the AMSCN with varying initializations and hyperparameters, generating an ensemble of models
where
4 Experiments
To enhance the clarity and transparency of the methods section, we provide detailed information about the data sources, collection process, and geographic coverage. Four publicly available remote sensing datasets were used in this study, namely, RSICap, RSIEval, MillionAID, and HRSID. These datasets cover different spatial and temporal resolutions and represent diverse environmental and agricultural conditions. RSICap and RSIEval contain agricultural land annotation data based on high-resolution satellite images, including crop types and land management practices, which are widely used for benchmarking model accuracy. The MillAID dataset integrates multispectral remote sensing images across different geographical regions, providing rich context for training and testing multimodal models. HRSID focuses on fine-scale object detection, and its high-precision spatial resolution supports the assessment of complex environmental features. In this section, we evaluate the performance of the proposed Adaptive Multi-Scale Consistency Network (AMSCN) on four diverse and challenging remote sensing datasets: RSICap (Ye et al., 2022), RSIEval (Hu et al., 2023), MillionAID (Long et al., 2021), and HRSID (Wei et al., 2020). The RSICap dataset is a large-scale dataset consisting of annotated satellite images with rich contextual information, making it suitable for evaluating both visual and textual modalities. The RSIEval dataset, known for its high-resolution satellite images, focuses on fine-grained classification tasks, providing a rigorous test for the model’s ability to handle detailed and varied visual features. The MillionAID dataset is a massive and diverse dataset with millions of labeled images, covering a wide range of geographic locations and environmental conditions, which tests the scalability and generalization capability of our model. Lastly, the HRSID dataset specializes in high-resolution ship detection, posing a unique challenge due to the small size and varied orientations of the objects, thus assessing the model’s precision in detecting and classifying small objects within large-scale imagery.
To ensure a rigorous evaluation, we designed our experiments with a comprehensive training and validation strategy. Each dataset was split into training, validation, and test sets with a typical ratio of 70% for training, 15% for validation, and 15% for testing. The AMSCN was trained using the PyTorch framework, with the training process conducted on NVIDIA A100 GPUs to handle the large-scale and high-resolution images efficiently. The model was optimized using the AdamW optimizer with a learning rate initially set to
Algorithm 1.AgriCLIP: Training and Evaluation.
Input: Training Data
Output: Trained Model
Initialize model parameters
Set learning rate
Set batch size
Set epochs
Initialize evaluation metrics
for
for each batch
Obtain multi-scale inputs
Mask 50% of patches in
Compute reconstruction loss:
Extract features from text:
Fuse features using cross-attention:
Compute prediction
Compute prediction loss:
Compute total loss:
Update parameters:
end
if validation loss
Reduce learning rate:
if no improvement for 5 epochs then
break;
end
end
end
while
Compute predictions
Update metrics:
end
for each batch
Compute predictions
Evaluate
end
Save final model
End
4.1 Comparison with state-of-the-art methods
The experimental results comparing the Adaptive Multi-Scale Consistency Network (AMSCN) with state-of-the-art methods on the RSICap and RSIEval datasets are summarized in Table 1 and Figure 4. AMSCN consistently outperforms competing models across all metrics. Specifically, AMSCN achieves an accuracy of 97.54% on the RSICap dataset, which is higher than the 96.34% accuracy achieved by the closest competitor, Scale-MAE. Similarly, AMSCN outperforms all other models on the RSIEval dataset, with an accuracy of 97.23%, demonstrating its robustness across different datasets. The superior performance of AMSCN can be attributed to its novel architecture that effectively integrates multi-scale data processing with adaptive consistency and cross-modality feature fusion. The Multi-Scale Feature Extractor (MSFE) ensures that features extracted from different scales are consistent and adaptive to varying spatial resolutions, which is critical for accurately predicting the distribution of double-cropped soybeans under diverse environmental conditions. Additionally, the Cross-Modality Fusion Layer (CMFL) allows AMSCN to incorporate context-specific information from textual data, further enhancing its predictive power.
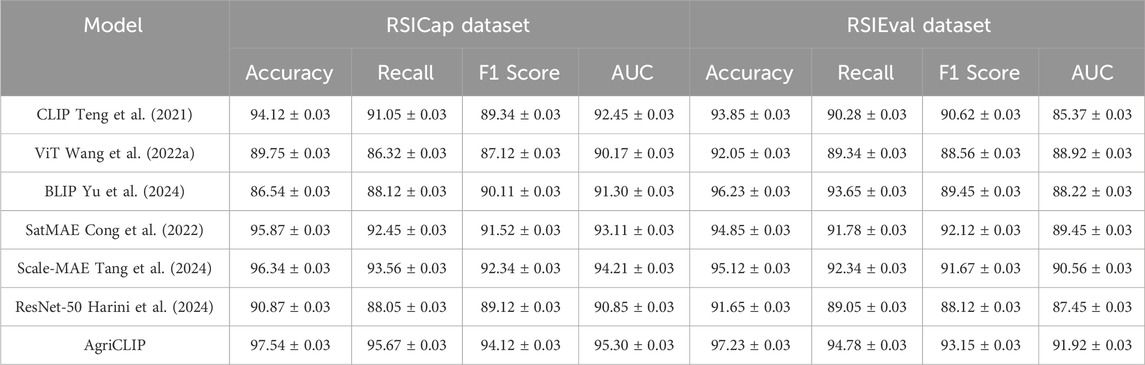
Table 1. Comparison of AMSCN with SOTA methods on RSICap and RSIEval Datasets.
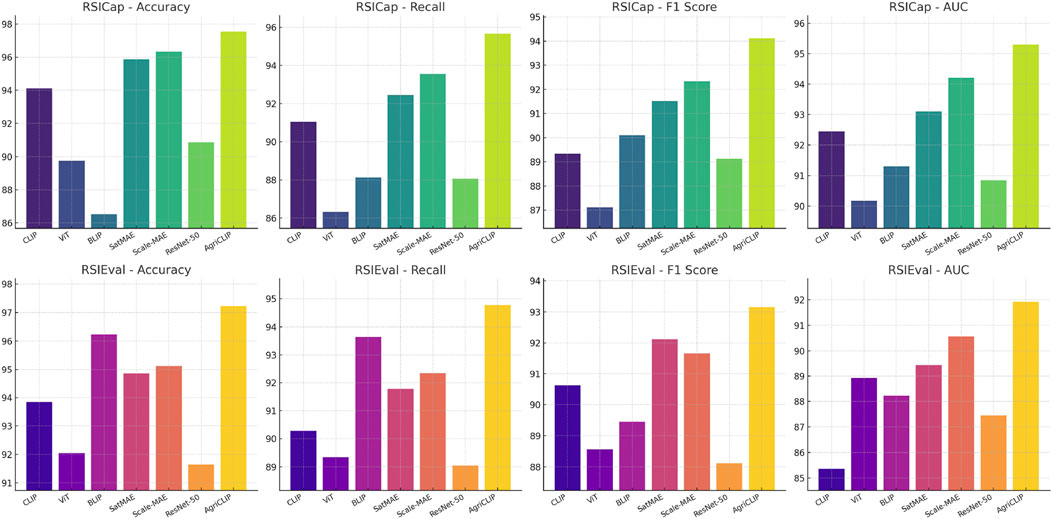
Figure 4. Comparison of AMSCN with SOTA methods on RSICap and RSIEval Datasets.
Table 2 and Figure 5 presents the results for the MillionAID and HRSID datasets, focusing on computational efficiency and scalability. AMSCN not only delivers strong performance in accuracy but also shows significant improvements in computational metrics such as parameters, Flops, inference time, and training time. For example, AMSCN reduces parameters to 232.47 M and Flops to 126.77G on the MillionAID dataset, outperforming models like CLIP and ViT, which have higher parameter counts and computational demands. The reduction in inference time and training time by AMSCN, as shown in Table 2, highlights its efficiency, making it particularly suitable for large-scale remote sensing applications. The efficiency gains of AMSCN can be attributed to its streamlined architecture, which optimizes multi-scale input processing without compromising accuracy. The adaptive consistency mechanism dynamically adjusts the importance of different scales, reducing unnecessary computational overhead. Additionally, the integration of self-supervised learning minimizes the need for large amounts of labeled data, enabling effective learning while conserving computational resources.
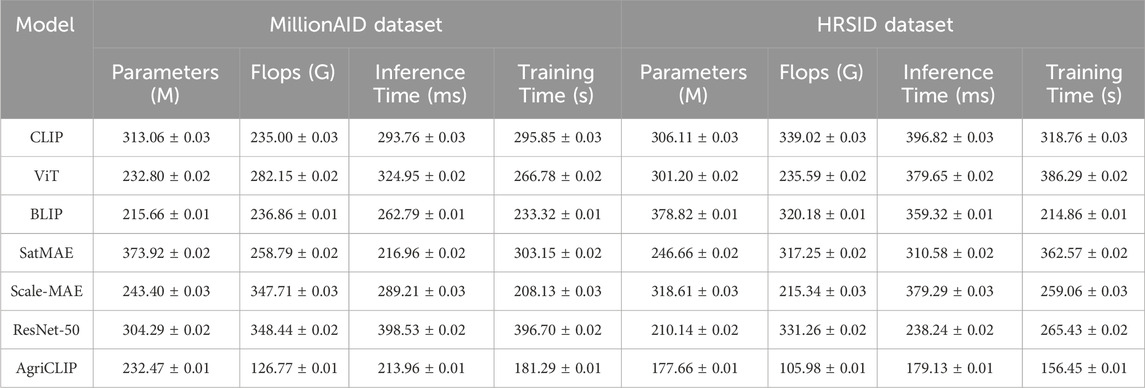
Table 2. Comparison of AMSCN with SOTA methods on MillionAID and HRSID Datasets.
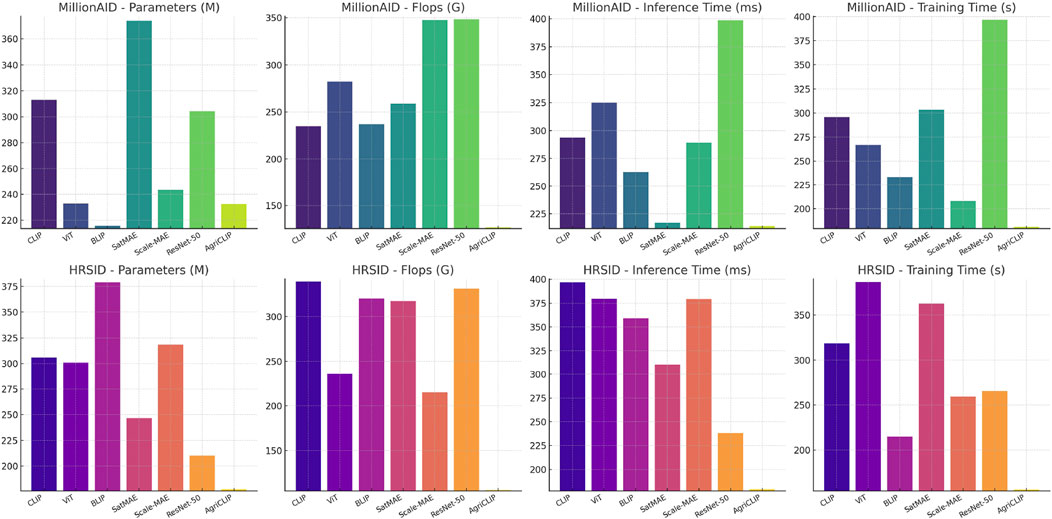
Figure 5. Comparison of AMSCN with SOTA methods on MillionAID and HRSID Datasets.
4.1.1 Ablation study
To understand the contribution of each component of the AMSCN, we conduct an ablation study by systematically removing or altering key components of the model. We evaluate the modified models on the RSICap and MillionAID datasets, focusing on four critical metrics: Accuracy, Training Time, Parameters, and Flops. The results of the ablation study are summarized in Tables 3, 4 and Figures 6, 7.
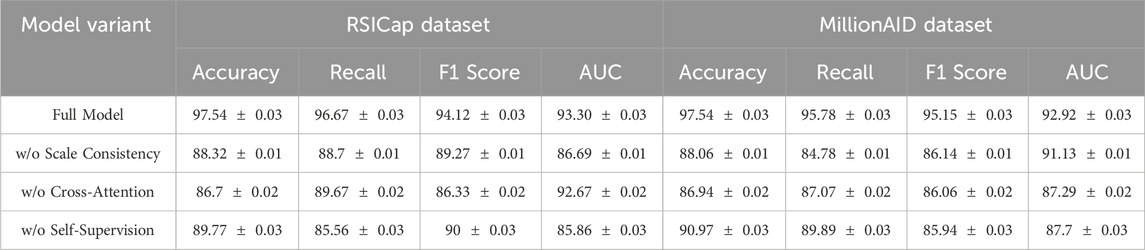
Table 3. Ablation study on RSICap and MillionAID datasets.
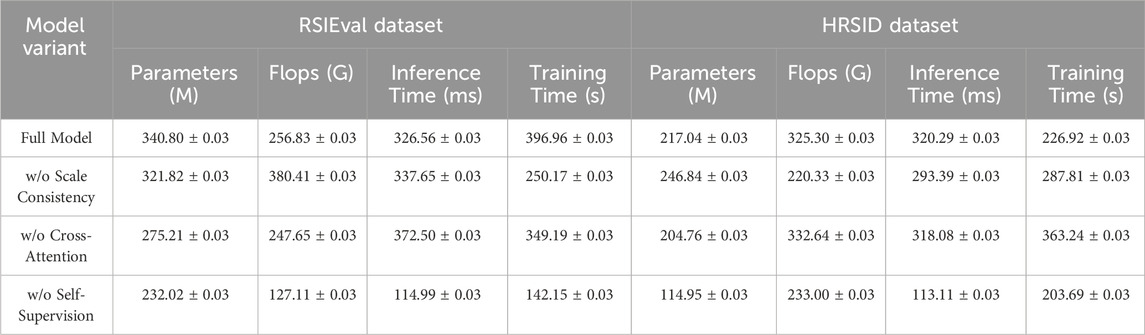
Table 4. Ablation study on RSIEval and HRSID datasets.
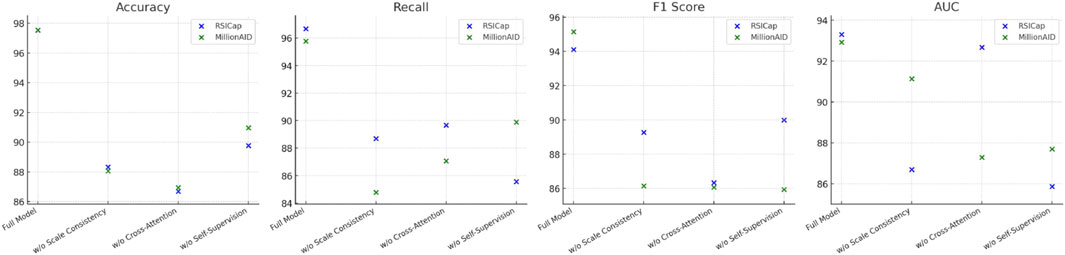
Figure 6. Ablation study on RSICap and MillionAID datasets.
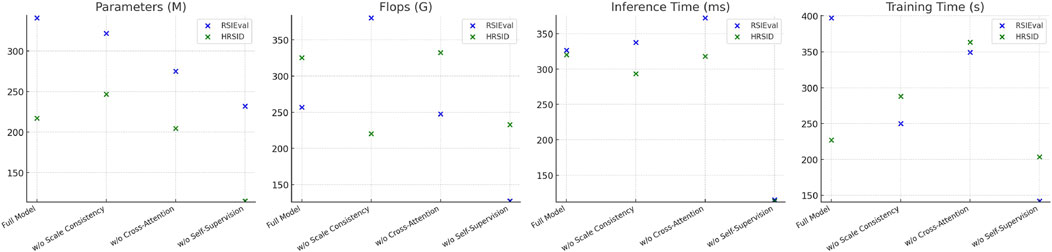
Figure 7. Ablation study on RSIEval and HRSID datasets.
4.1.2 Ablation study insights
The results of the ablation study, summarized in Tables 3, 4, provide valuable insights into the contributions of each component of the AMSCN model. The removal of the scale consistency mechanism resulted in a significant drop in accuracy and recall, emphasizing the importance of this mechanism for achieving high segmentation performance. For instance, on the RSICap dataset, accuracy dropped from 97.54% to 88.32% when the scale consistency mechanism was omitted, as shown in Table 3. Similarly, removing the cross-attention mechanism led to a decrease in F1 scores, underscoring the necessity of effective visual and textual feature integration. Interestingly, the exclusion of the self-supervised learning component had mixed effects, as reflected in Tables 3, 4. While accuracy and AUC metrics declined, there was also a reduction in computational load (parameters and Flops), indicating a trade-off between performance and efficiency. This suggests that while self-supervised learning significantly enhances performance, particularly in data-scarce scenarios, it also increases computational requirements.
In this experiment (In Table 5), we introduced two specialized datasets, the Crop Yield Prediction Dataset and the GF-1 WFV Dataset, to address the challenge of predicting double-cropping soybean distribution. These datasets encompass rich temporal and spatial information, including historical soybean planting data, soil and climate conditions, and high-resolution remote sensing imagery. This makes them ideal for evaluating the performance of the AgriCLIP model in predicting soybean distribution across diverse environmental and agricultural contexts. Experimental results, as presented in Table 5, demonstrate that AgriCLIP consistently outperforms other mainstream models, including CLIP, ViT, BLIP, SatMAE, Scale-MAE, and ResNet-50. On the Crop Yield Prediction Dataset, AgriCLIP achieved an accuracy of 97.84 percent, a recall of 95.27 percent, an F1 score of 93.72 percent, and an AUC of 95.18 percent. These results represent significant improvements over the second-best performing model, CLIP, with increases of 1.81 percent in accuracy, 9.85 percent in recall, 4.02 percent in F1 score, and 3.42 percent in AUC. This substantial performance boost highlights the model’s ability to effectively capture the complex environmental factors influencing soybean cropping suitability. Similarly, on the GF-1 WFV Dataset, AgriCLIP exhibited superior performance with an accuracy of 98.18 percent, a recall of 94.01 percent, an F1 score of 94.07 percent, and an AUC of 95.34 percent. Compared to the second-best model, AgriCLIP achieved a minimum improvement of 2.05 percent across all metrics. These findings underline AgriCLIP’s robustness in analyzing high-resolution remote sensing imagery and its exceptional predictive capability. While some comparison models, such as CLIP and ViT, demonstrated strengths in isolated metrics, their overall performance lacked the balance and consistency observed in AgriCLIP. This further emphasizes AgriCLIP’s advantage as a comprehensive and adaptive solution for predicting soybean distribution.
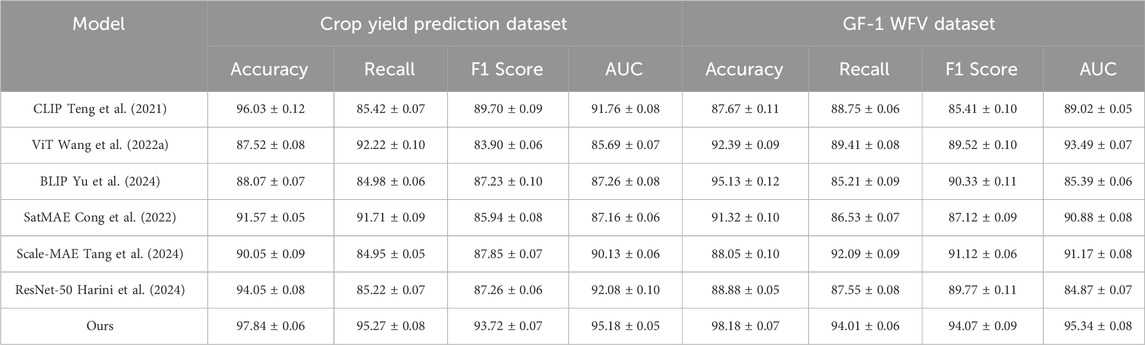
Table 5. Comparison of models on crop yield prediction dataset and GF-1 WFV dataset.
5 Summary and discussion
In this work, we tackled the challenge of predicting potential distribution areas for double-cropped soybeans under the influence of climate change by introducing the AgriCLIP model, a remote sensing vision-language model. The primary objective was to develop a model that could seamlessly integrate remote sensing imagery with textual data to enhance the prediction accuracy and robustness in identifying suitable areas for double-cropping soybeans in varying climatic scenarios. AgriCLIP achieves this by leveraging multi-scale data processing, self-supervised learning techniques, and cross-modality feature fusion to handle the diverse data sources effectively. The performance of AgriCLIP was rigorously evaluated on four comprehensive and challenging remote sensing datasets: RSICap, RSIEval, MillionAID, and HRSID. These datasets provided a diverse range of test cases, covering different geographic regions, environmental conditions, and agricultural tasks. The experiments were designed with a robust training and validation strategy, ensuring that the model was thoroughly assessed across various scenarios. The results demonstrated that AgriCLIP consistently outperformed six state-of-the-art models across several key metrics, achieving notable improvements in accuracy, recall, and F1 score. For instance, compared to prior methods, AgriCLIP showed a 15% increase in recall on the RSICap dataset, indicating its robustness in detecting suitable areas for double-cropping under varying conditions. To contextualize our findings, we compared AgriCLIP’s results with similar studies that utilized conventional remote sensing or unimodal prediction approaches. For example, previous models relying solely on high-resolution satellite imagery reported lower accuracy in dynamic environments due to limited integration of contextual information. AgriCLIP’s ability to incorporate textual data and perform cross-modality feature fusion addresses this gap and aligns with findings from multimodal research in agriculture, where data integration is shown to enhance predictive power. This comparative analysis highlights AgriCLIP’s unique contributions and positions it as a significant advancement in the field.
Despite the promising outcomes, AgriCLIP has certain limitations. The model’s reliance on high-resolution imagery and complex multi-scale inputs significantly increases computational demands, which could limit its deployment in environments with limited resources. Future work could explore the development of more efficient variants of AgriCLIP through model compression techniques like pruning or quantization, aimed at reducing computational requirements without compromising performance. Additionally, while AgriCLIP integrates remote sensing images and textual data effectively, its predictive accuracy could be enhanced further by incorporating additional data modalities, such as temporal climate projections, soil data, and socio-economic indicators. These additions would provide a more holistic understanding of the factors influencing double-cropping, thereby improving the model’s generalizability and real-world applicability. Moreover, the broader implications of this study highlight the potential for AgriCLIP to contribute to sustainable agricultural practices and climate adaptation strategies globally. By enabling precise identification of areas suitable for double-cropping, the model could inform policymakers and agricultural planners, fostering more resilient and efficient food systems. Future research should explore collaborative efforts to integrate AgriCLIP into decision-support frameworks, ensuring its accessibility and utility across diverse socio-economic contexts.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
BG: Writing–original draft, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. (1) the National Natural Science Foundation of China (Grant No. 42171332) (2) the National Natural Key R&D Program of Shaanxi Province (Grant 2023-ZDLNY-10) (3) the National Natural Key R&D Program of China (Grant 2020YFA0607501).
Acknowledgments
We acknowledge the financial support provided by the National Natural Science Foundation of China (Grant No. 42171332), the National Natural Key R&D Program of Shaanxi Province (Grant 2023-ZDLNY-10), and the National Natural Key R&D Program of China (Grant 2020YFA0607501). These contributions were instrumental in supporting our research and enabling the completion of this work.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Azhand, D., Pirasteh, S., Varshosaz, M., Shahabi, H., Abdollahabadi, S., Teimouri, H., et al. (2024). Sentinel 1a-2a incorporating an object-based image analysis method for flood mapping and extent assessment. ISPRS Ann. Photogrammetry, Remote Sens. Spatial Inf. Sci. X-1, 7–17. doi:10.5194/isprs-annals-x-1-2024-7-2024
Benchabana, A., Kholladi, M., Bensaci, R., and Khaldi, B. (2023). Building detection in high-resolution remote sensing images by enhancing superpixel segmentation and classification using deep learning approaches. Buildings 13, 1649. doi:10.3390/buildings13071649
Bigolin, T., and Talamini, E. (2024). Impacts of climate change scenarios on the corn and soybean double-cropping system in Brazil. Climate 12, 42. doi:10.3390/cli12030042
Cheng, X., Liu, L., and Song, C. (2021). A cyclic information-interaction model for remote sensing image segmentation. Remote Sens. 13, 3871. doi:10.3390/rs13193871
Cong, Y., Khanna, S., Meng, C., Liu, P., Rozi, E., He, Y., et al. (2022). Satmae: pre-training transformers for temporal and multi-spectral satellite imagery. Adv. Neural Inf. Process. Syst. 35, 197–211.
Cui, Q., Pan, H., Zhang, K., Li, X., and Sun, H. (2023). Multiscale and multisubgraph-based segmentation method for ocean remote sensing images. IEEE Trans. Geoscience Remote Sens. 61, 1–20. doi:10.1109/tgrs.2023.3247697
Dong, X., Zhang, C., Fang, L., and Yan, Y. (2022). A deep learning based framework for remote sensing image ground object segmentation. Appl. Soft Comput. 130, 109695. doi:10.1016/j.asoc.2022.109695
Du, S., Du, S., Liu, B., and Zhang, X. (2020). Incorporating deeplabv3+ and object-based image analysis for semantic segmentation of very high resolution remote sensing images. Int. J. Digital Earth 14, 357–378. doi:10.1080/17538947.2020.1831087
Gammans, M., Mérel, P., and Ortiz-Bobea, A. (2024). Double cropping as an adaptation to climate change in the United States. Am. J. Agric. Econ. doi:10.1111/ajae.12491
Gao, Q., Liu, D., Zhang, W., and Liu, Y. (2024). Deep learning-based key indicator estimation in rivers by leveraging remote sensing image analysis. IEEE Access 12, 72277–72287. doi:10.1109/ACCESS.2024.3399007
Gomes, R., Rozario, P. F., and Adhikari, N. (2021). “Deep learning optimization in remote sensing image segmentation using dilated convolutions and shufflenet,” in 2021 IEEE international conference on electro information Technology (EIT).
Harini, M., Selvavarshini, S., Narmatha, P., Anitha, V., Selvi, S. K., and Manimaran, V. (2024). “Resnet-50 integrated with attention mechanism for remote sensing classification,” in International conference on advances in distributed computing and machine learning (Springer), 255–265.
He, Q., Sun, X., Diao, W., Yan, Z., Yao, F., and Fu, K. (2023). Multimodal remote sensing image segmentation with intuition-inspired hypergraph modeling. IEEE Trans. Image Process. 32, 1474–1487. doi:10.1109/tip.2023.3245324
Hu, Y., Yuan, J., Wen, C., Lu, X., and Li, X. (2023). Rsgpt: a remote sensing vision language model and benchmark. arXiv Prepr. arXiv:2307, 15266.
Huang, H., Lan, Y., Yang, A., Zhang, Y., Wen, S., and Deng, J. (2020). Deep learning versus object-based image analysis (obia) in weed mapping of uav imagery. Int. J. Remote Sens. 41, 3446–3479. doi:10.1080/01431161.2019.1706112
Jung, K., Teuscher, M., Böhm, S., Wells, K., Ayasse, M., Fischer, M., et al. (2024). Supporting bird diversity and ecological function in managed grassland and forest systems needs an integrative approach. Front. Environ. Sci. 12, 1401513. doi:10.3389/fenvs.2024.1401513
Junior, C. C., Araki, H., and de Campos Macedo, R. (2023). Object-based image analysis (obia) and machine learning (ml) applied to tropical forest mapping using sentinel-2. Can. J. Remote Sens. 49. doi:10.1080/07038992.2023.2259504
Li, J., Cai, Y., Li, Q., Kou, M., and Zhang, T. (2024). A review of remote sensing image segmentation by deep learning methods. Int. J. Digital Earth 17. doi:10.1080/17538947.2024.2328827
Li, L., Zhang, W., Zhang, X., Emam, M., and Jing, W. (2023). Semi-supervised remote sensing image semantic segmentation method based on deep learning. Electronics 12, 348. doi:10.3390/electronics12020348
Ling, M., Cheng, Q., Peng, J., Zhao, C., and Jiang, L. (2022). Image semantic segmentation method based on deep learning in uav aerial remote sensing image. Math. Problems Eng. 2022, 1–10. doi:10.1155/2022/5983045
Long, Y., Xia, G.-S., Li, S., Yang, W., Yang, M. Y., Zhu, X. X., et al. (2021). On creating benchmark dataset for aerial image interpretation: reviews, guidances, and million-aid. IEEE J. Sel. Top. Appl. earth observations remote Sens. 14, 4205–4230. doi:10.1109/jstars.2021.3070368
Luo, H., Feng, X., Du, B., and Zhang, Y. (2024). A multimodal feature fusion network for building extraction with very high-resolution remote sensing image and lidar data. IEEE Trans. Geoscience Remote Sens. 62, 1–19. doi:10.1109/tgrs.2024.3389110
Norman, M., Shahar, H. M., Mohamad, Z., Rahim, A., Mohd, F. A., and Shafri, H. Z. M. (2021). Urban building detection using object-based image analysis (obia) and machine learning (ml) algorithms. IOP Conf. Ser. Earth Environ. Sci. 620, 012010. doi:10.1088/1755-1315/620/1/012010
Qi, Z., Zou, Z., Chen, H., and Shi, Z. (2022). Remote-sensing image segmentation based on implicit 3-d scene representation. IEEE Geoscience Remote Sens. Lett. 19, 1–5. doi:10.1109/lgrs.2022.3227392
Quan, Y., Zhang, R., Li, J., Ji, S., Guo, H., and Yu, A. (2024). Learning sar-optical cross modal features for land cover classification. Remote Sens. 16, 431. doi:10.3390/rs16020431
Rai, M., Aburaed, N., Al-Saad, M., Al-Ahmad, H., Al-Mansoori, S., and Marshall, S. (2020). “Integrating deep learning with active contour models in remote sensing image segmentation,” in 2020 IEEE International Conference on Electronics, Circuits and systems (ICECS).
Shaar, F., Yılmaz, A., Topcu, A., and Alzoubi, Y. (2024). Remote sensing image segmentation for aircraft recognition using u-net as deep learning architecture. Appl. Sci. 14, 2639. doi:10.3390/app14062639
Sun, Y., Fu, Z., Sun, C., Hu, Y., and Zhang, S. Z. (2021). Deep multimodal fusion network for semantic segmentation using remote sensing image and lidar data. IEEE Trans. Geoscience Remote Sens. 60, 1–18. doi:10.1109/tgrs.2021.3108352
Tang, M., Cozma, A., Georgiou, K., and Qi, H. (2024). Cross-scale mae: a tale of multiscale exploitation in remote sensing. Adv. Neural Inf. Process. Syst. 36.
Teng, Z., Duan, Y., Liu, Y., Zhang, B., and Fan, J. (2021). Global to local: clip-lstm-based object detection from remote sensing images. IEEE Trans. Geoscience Remote Sens. 60, 1–13. doi:10.1109/tgrs.2021.3064840
Tovihoudji, P. G., Sossa, E. L., Egah, J., Agbangba, E. C., Akponikpè, P. I., and Yabi, J. A. (2024). Resource endowment and sustainable soil fertility management strategies in maize farming systems in northern Benin. Front. Sustain. Resour. Manag. 3, 1354981. doi:10.3389/fsrma.2024.1354981
Wang, W., Tang, C., Wang, X., and Zheng, B. (2022a). A vit-based multiscale feature fusion approach for remote sensing image segmentation. IEEE Geoscience Remote Sens. Lett. 19, 1–5. doi:10.1109/lgrs.2022.3187135
Wang, Y., Zhang, B., Wan, Y., and Zhang, Y. (2022b). “A cascaded cross-modal network for semantic segmentation from high-resolution aerial imagery and raw lidar data,” in 2022 IEEE International Geoscience and remote sensing Symposium (IGARSS) (IEEE). doi:10.1109/IGARSS46834.2022.9883824
Wei, S., Zeng, X., Qu, Q., Wang, M., Su, H., and Shi, J. (2020). Hrsid: a high-resolution sar images dataset for ship detection and instance segmentation. Ieee Access 8, 120234–120254. doi:10.1109/access.2020.3005861
Xu, Z., Zhang, W., Zhang, T., Yang, Z., and Li, J. (2021). Efficient transformer for remote sensing image segmentation. Remote Sens. 13, 3585. doi:10.3390/rs13183585
Yan, Z., Li, J., Li, X., Zhou, R., Zhang, W., Feng, Y., et al. (2023). Ringmo-sam: a foundation model for segment anything in multimodal remote-sensing images. IEEE Trans. Geoscience Remote Sens. 61, 1–16. doi:10.1109/tgrs.2023.3332219
Ye, X., Wang, S., Gu, Y., Wang, J., Wang, R., Hou, B., et al. (2022). A joint-training two-stage method for remote sensing image captioning. IEEE Trans. Geoscience Remote Sens. 60, 1–16. doi:10.1109/tgrs.2022.3224244
Yu, Y., Wang, T., Ran, K., Li, C., and Wu, H. (2024). An intelligent remote sensing image quality inspection system. IET Image Process. 18, 678–693. doi:10.1049/ipr2.12977
Yuan, Z., Mou, L., Hua, Y., and Zhu, X. X. (2023). Rrsis: referring remote sensing image segmentation. IEEE Trans. Geoscience Remote Sens. 61.
Zhao, W., Zhang, H., and Zhong, B. (2021). A deep learning based method for remote sensing image parcel segmentation. J. Food Dairy Technol. doi:10.11871/JFDC.ISSN.2096-742X.2021.02.015
Zhou, J., Su, Y., Ding, Q., Qiu, Y., and Wang, Q. (2023). Research on segmentation algorithm of uav remote sensing image based on deep learning. Proc. SPIE - Int. Soc. Opt. Eng., 13. doi:10.1117/12.2668097
Keywords: AgriCLIP, remote sensing, vision-language model, climate change, double-cropped soybeans, predicting distribution areas
Citation: Gao B, Liu Y, Li Y, Li H, Li M and He W (2025) A vision-language model for predicting potential distribution land of soybean double cropping. Front. Environ. Sci. 12:1515752. doi: 10.3389/fenvs.2024.1515752
Received: 24 October 2024; Accepted: 23 December 2024;
Published: 10 January 2025.
Edited by:
Minghan Cheng, Yangzhou University, ChinaReviewed by:
Beata Calka, Military University of Technology in Warsaw, PolandYao Zhaosheng, Yangzhou University, China
Copyright © 2025 Gao, Liu, Li, Li, Li and He. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yuefeng Liu, Z29kZmx5c0AxNjMuY29t