 Ulrich J. Frey
Ulrich J. Frey Shima Sasanpour
Shima Sasanpour Thomas Breuer
Thomas Breuer Jan Buschmann
Jan Buschmann Karl-Kiên Cao
Karl-Kiên Cao
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Environ. Econ. , 23 October 2024
Sec. Energy Economics
Volume 3 - 2024 | https://doi.org/10.3389/frevc.2024.1398358
This paper identifies and addresses three key challenges in energy systems analysis—varying assumptions, computational limitations, and coverage of a few indicators only. First, results depend strongly on assumptions, i.e., varying input data. Hence, comparisons and robust results are hard to achieve. To address this, we use a broad range of possible inputs through an extensive literature review by scenario experts. Second, we overcome computational limitations using high-performance computing (HPC) and an automated workflow. Third, by coupling models and developing 13 indicators to evaluate the overall quality of energy systems in Germany for 2030, we include many aspects of security of supply, market impact, life cycle analysis and cost optimization. A cluster analysis of scenarios by indicators reveals three recognizable clusters, separating systems with a high share of renewables clearly from more conventional sets. Additionally, scenarios can be identified which perform very positive for many of the 13 indicators. We conclude that an automated, coupled workflow on supercomputers based on a broad parameter space is able to produce robust results for many important aspects of future energy systems. Since all models and software components are released as open-source, all components of a multi-perspective model-chain are now available to the energy system modeling community.
Energy systems analysis has made great progress in the last years. Yet, three key challenges for modeling future energy systems remain. A first challenge is that results depend heavily on scenario assumptions, making robust results elusive (Gils et al., 2022a). A second challenge is that computational limitations hinder analyzing multiple pathways (Cao et al., 2019). This means that testing many different inputs or calculating additional scenarios often does not happen. A third challenge is the blind spot of many models which tend to represent only the modeled aspects, but do not provide quantitative evidence for other parts of future energy system pathways. For example, energy system optimization models (ESOMs) concentrate usually on system costs (Ringkjøb et al., 2018), macro-economic models on GDP, income and related indicators and agent-based modeling and simulation (ABMS) on the individual behavior of actors. Taken together, these three challenges reduce the robustness of results and the credibility of evidence provided to the policymaking process.
As of now, there are a number of solutions for these challenges. For example, one strategy for making scenario assumptions (the first challenge) is to be very conservative about inputs or to average parameters of existing studies. In order to overcome computational limitations (the second challenge), mainly the strategy of saving computational time has been applied by either limiting the spatial or temporal resolution or analyzing only incomplete timeseries (Cao et al., 2019). Another viable way is non-probabilistic approaches, e.g., integrated scenario methodologies (Prehofer et al., 2021). Finally, dealing with aspects outside the modeling methodology (the third challenge) has been addressed either by constraining model assertions and conclusions to the core of the model, which is scientifically unsatisfying, or extending the model (which often takes years, and is thus hardly feasible for many modelers). This paper addresses each of these challenges with its own dedicated approach for Germany for 2030 (details in Section 2).
First, to make scenarios more independent from assumptions, we develop—based on an extensive literature review by scenario experts—a scenario parameter generator. This generator samples many scenario variations from both truncated normal and uniform distributions of the input parameters from a large and consistent parameter space. The parameters, serving as input for the models, are based on peer-reviewed studies. This approach may be called probabilistic approach to uncertainty.
Second, computational limitations are overcome by parallelizing an automated workflow of coupled models, e.g., by adaption to a high-performance computing (HPC) environment and the application of the newly developed solver PIPS-IPM++.
Third, the blind spot of each modeling methodology is addressed by coupling different model types, namely an optimization model (Gils et al., 2017) and an agent-based simulation (Deissenroth et al., 2017). For the analysis of the various scenarios, we developed a set of 13 indicators covering for example security of supply, market impact, life cycle analysis and cost optimization. In this way, not just one, but multiple perspectives on future energy systems can be examined within the same run.
Hence, we try to answer the research question of how to model a much larger part of future energy systems in a more robust way, based on a broader base of assumptions. This contributes to closing the research gap toward a more comprehensive assessment of optimal future energy systems. Furthermore, we aim to increase reproducibility by making all models and other parts of the workflow described open source and enable the modeling community to re-use our model chain.
At the same time, we are aware that some factors, in particular socio-cultural and institutional ones, cannot be captured by ESOMs. In addition, using historical data to capture future trends is problematic due to non-linearities and black swans.
Energy scenarios are subject to a multitude of uncertainties. For those engaged in modeling, these uncertainties manifest themselves in three broad areas, namely data acquisition, model construction and model application.
Concerning Prehofer et al. (2021), energy system modelers have only partial control over their models, because they have to rely on a large variety of required model inputs. However, uncertainties that stem from errors made in empirical measurements can be addressed by using more data sources (see Section 2.2.1).
Structural uncertainty in model construction is the necessity of abstracting an already complex real-world system. This introduces a degree of bias into the model-building process. One approach to quantify structural uncertainties is model comparisons. Here, similar scenario data sets (combinations of empirical data and assumptions) are computed using different modeling approaches or implementations (Gils et al., 2022b). The IPCC notes the importance of combining qualitative and quantitative approaches in order to cover weaknesses of one method with the strengths of another. We implement a complex model coupling approach to address this (see Section 1.2.3).
Finally, uncertainties in model application can either originate from unknown or unavailable exact values (parameter uncertainty), such as exogenous framework conditions (e.g., regulations to be implemented in the future), or from a lack of knowledge regarding the variability of parameter values (parametric uncertainty), such as investment costs for the considered technologies (Usher, 2016).
In energy system analysis, the scenario technique combined with sensitivity analyses represents the most common approach to dealing with uncertainties in model application (Trutnevyte et al., 2016). However, this approach is limited to a small number of scenarios whose construction cannot be easily automated. In this paper, a large number of scenarios is calculated to avoid this (see Section 2.2).
Nevertheless, further quantification approaches exist, most notably, Monte Carlo analysis, stochastic programming and modeling to generate alternatives (Yue et al., 2018), each having their advantages and disadvantages. For example, Rozenberg et al. (2014) define a set of drivers that are transformed into a large set of scenarios using an integrated assessment model that combines two general modeling approaches: top-down and bottom-up modeling. However, one disadvantage is always the additional computational effort.
Besides the general distinction between top-down and bottom-up modeling, a large number of modeling approaches exist that can be separated into simulations, equilibrium models, or optimizations (Pfenninger et al., 2014; Hall and Buckley, 2016). Further distinctions can, for example, be made according to their coverage of technologies and sectors and their spatial and temporal resolution (Hall and Buckley, 2016). For understanding the particular role of certain technologies in techno-economic scenarios, bottom-up models are widely used. For example, ABMS are especially suited to analyse individual or prototypical human decision-making (Bandini et al., 2009), to serve as a linking hub for different model types (Klein et al., 2019), and to estimate the effects of different policies on the energy system (Chappin et al., 2017). Despite these strengths, ABMS is still a niche application for studying future energy systems.
This research field is dominated by energy system optimization models (ESOMs). They optimize the dispatch and expansion of energy systems from a central planner's perspective usually by minimizing the total system costs (Neumann and Brown, 2021). The optimization is subject to constraints which can be of technical, political and environmental nature, such as limitations of the power flow (Zhang et al., 2018), self-sufficiency requirements (Sasanpour et al., 2021) or carbon emission limits (Boffino et al., 2019). Optimization approaches can have a quite detailed inclusion of technologies and a high spatial and temporal resolution (Cao et al., 2021a), and thus are quite capable of representing an energy system in its different levels and alternative technological configurations. For example, the spatial representation can range from a continental scope with country-wise resolution (Haller et al., 2012) to national models with transmission grid level resolution (Cao et al., 2019). Detailed models are more complex (Kotzur et al., 2021) and therefore require much higher computational times (Neumann and Brown, 2021). Research to keep the computation of complex models manageable mainly focuses on reducing the model size by smart pre-processing of input data, i.e., on the temporal dimension. However, there is no one-size-fits-all approach that ensures good computing performance and accuracy across a broad variety of ESOMs. To this end, ESOMs are usually solved using commercial solver software on shared-memory computers.
To overcome structural uncertainties that are related to using a single modeling approach, combining the strengths of different modeling approaches is a useful approach to increase methodological diversity. However, coupling models requires at least overcoming three major problems. The first one is that different models typically operate on different spatial and temporal scales. Getting them to work together in a meaningful way is hard and requires different ways of soft or hard coupling (Cao et al., 2021a). A second problem is making different models converge on a stable system state. Sometimes, coupled models end up in different, incompatible system states, even if calibration was done carefully. Third, models need to be empirically validated before coupling. While ESOMs validation by replicating energy systems of the past has been both successful and unsuccessful (Trutnevyte et al., 2016), ABMS in particular have been criticized as problematic concerning validation (Fagiolo et al., 2007). Validation includes validating the input data, calibrating the model itself with historical data, and using sensitivity analysis for evaluating the influence of parameter changes.
To address parametric uncertainty, we strive for analysing a multitude of scenarios. This allows exploring the scenario space thoroughly, including plausible extreme cases. To address structural uncertainty, we use different modeling approaches—ESOM, ABMS and a multi-criterial ex-post assessment—enabling us to bring blind spots into the light.
Since both solutions require large computational efforts, the workflow is implemented on a supercomputing cluster. Our study aims to uncover patterns in scenarios that have previously been hidden, while considering both parametric and structural uncertainties.
The remaining paper is structured as follows: the following Materials and Methods section presents our approach to tackling uncertainties in energy systems analysis. The Results section analyses the interdependencies of the indicators used for evaluation of the systems and tries to extract robust findings from the multitude of scenarios.
This section covers a more detailed description of our methodology. It introduces the modeling frameworks applied, the HPC-workflow, explains the indicators which assess the modeled energy system, describes the solver development, and the scenario construction through the scenario generator tool.
For our analyses, we use instances of two established modeling frameworks to construct scenarios of future power systems and to assess their performance. In this way, we combine the different modeling approaches introduced in Section 1.2: energy system optimization and agent-based simulation. In particular, the ESOM REMix determines the capacities of power generation, storage and transmission technologies, while the ABMS AMIRIS serves as tool to evaluate the results of the optimization model, to check whether the optimized scenarios are economically viable for the actors involved.
REMix is an open-source framework for energy system optimization modeling (Wetzel et al., 2024). It is usually applied to optimize the expansion and dispatch for the energy system by minimizing the total system costs. In REMix, various sectors, such as power, heat and transport and different technology groups, e.g., conventional and renewable converters, storage and transport technologies can be considered. REMix model instances usually optimize one target year with hourly resolution with a linear optimization approach. However, myopic or path optimization approaches are implemented as well. Further features that are available in REMix include mixed-integer programming both for discrete capacity expansion and unit commitment, modeling to generate alternatives and pareto fronts. The input of REMix includes weather and demand profiles based on historic data and techno-economic parameters, such as technology-specific investment and operational costs and efficiencies.
AMIRIS (Agent-based Market model for the Investigation of Renewable and Integrated energy Systems) is an electricity market simulation model (Deissenroth et al., 2017; Schimeczek et al., 2023b). A detailed description of its code can be found in Schimeczek et al. (2023b). It relies on the open-source framework FAME (Framework for distributed Agent-based models of energy systems; available at https://gitlab.com/fame-framework/) (Schimeczek et al., 2023a). FAME has been developed to suit the needs of the HPC-environment like the one described in this paper. It is able to adequately model many scenarios quickly, since the framework has been developed for fast execution speed in Java. In addition, it is parallelizable, a key feature for high-performance environments.
Exploring a scenario space in considerable depth requires testing a large number of input parameters (assumptions) which results in a large number of scenarios (hundreds to thousands). Hence, coupling models means to automate the workflow completely, so that parallelization can play out its benefits of increasing speed. One practical problem is to keep the workflow working while all models and scripts are in continuous development over the course of years. Since each step depends on all the steps before it, not breaking the workflow is a major undertaking. A first step to develop such a workflow is to port all models to an HPC-environment and making them run without breaking the chain of models.
For benchmarking and the automated execution of the workflow, the software JUBE (Jülich Supercomputing Centre, 2022) is used on the supercomputer JUWELS (Alvarez, 2021). JUBE is a generic, lightweight, configurable environment to run, monitor and analyze application execution in a systematic way. We have modified JUBE so that individual scenario pipelines are processed in parallel. In other words, it is used for performing ensemble runs in parallel. This has significantly reduced the total time required to execute thousands of scenarios. Moreover, JUBE is used to store the paths of the workflow's most important output files in a database so that there is a central location for downstream programs for further data processing.
The workflow starts with the scenario generator that is fed by the minima, maxima and medians of a parameter space, resulting from an extensive literature research (Simon and Xiao, 2022). The scenario generator then samples inputs for REMix. In a next step, dump files that include GAMS source code and data are compiled and passed to the solver software. For this, the parallel PIPS-IPM++ solver (Rehfeldt et al., 2022) or commercial alternatives can be used. Finally, the results of the solved scenarios are further processed in the post-solving step, so that AMIRIS can analyze them. Finally, various python scripts extract the indicators from all models. Figure 1 shows the HPC-workflow. In the following sub-chapters, we present its core components in detail.
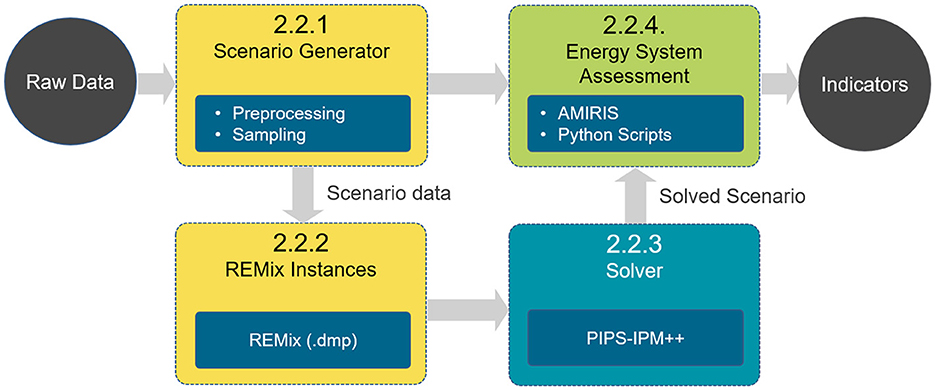
Figure 1. Simplified HPC-workflow.
Scenario results of ESOMs are often subject to a variety of assumptions and thus to high parametric uncertainties (Yue et al., 2018). To take care of these uncertainties, a large scenario parameter space is explored by a Monte-Carlo approach based on defined parameter distributions. For this, the parameter ranges are defined. Most of this raw data is derived from a literature study using 26 different sources in total and a meta-analysis of scenarios (Simon and Xiao, 2022). The source stock includes data sets like Ruiz et al. (2019) or Pfluger et al. (2017), but also data sets compiled from different sources that have been used for scenario studies at the German Aerospace Center in the past. This approach has been complemented by a Google Scholar search.
Typical values to be varied are techno-economic parameters, such as efficiencies, operations and maintenance costs (fixed and variable), capital expenditures, conversion efficiencies, CO2-prices and fuel costs. In addition, annual power demands for each node of the modeled electricity network are subject to parameter sampling, using statistical metrics (minimum, maximum, mean, and median) from the initial parameter space as input.
Furthermore, to produce consistent parameter sets (in the following referred to as scenario data), we create a pseudo-correlation matrix based on expert interviews. In order to identify the most impactful model parameters on the resulting scenarios, two experienced REMix modelers agreed on a list of 79 scalar parameters (excluding weather time series). To quantify the interrelations of the model parameters, an empty matrix was constructed, comprising these parameters. This matrix was presented in the context of a seminar, where an interdisciplinary team of experts working in the field of energy systems analysis was asked to assess the strength of the correlations between the parameters as follows: strong correlation (3), correlation (1), no correlation (empty), anti-correlation (−1), and strong anti-correlation (−3).
This matrix is considered as an additional input to our sampling approach that uses a Gaussian Copula to compute correlated scenario data sets. In this way, we avoid implausible value combinations such as prices for oil and gas being at their minimum and maximum, respectively. Apart from that, the sampling uses a uniform probability distribution. Weather time series—used for modeling the dispatch of renewable energies—are randomly drawn out of 24 historical data sets. However, since these are historical patterns, not all possible scenarios can be mapped this way. The resulting scenario data is then used to build REMix model instances.
Every workflow run uses a basic REMix model which is parametrized by the individual scenario data. In the basic REMix model, partially resolved data is provided for the German power transmission network with each model node representing a transformer substation. Additionally, the import and export to Germany's neighboring countries is considered by historical exchange time series. For solving, the model nodes are partially aggregated assuming perfect power exchange between the aggregated nodes. In our case, we consider half of Germany in high spatial resolution and aggregate the rest of Germany to 6 model nodes, which results in a network of 270 nodes. In terms of problem dimension this translates into about 53 million variables, 35 million constraints and 123 million non-zeros after pre-solving. The model focuses on the power sector, which is represented by renewable and conventional power plants, battery and pumped hydro storage and the electricity grid, which need to satisfy the hourly electricity demand in each region. Besides the renewable energies, CCGT power plants are the only conventional technology that can be further expanded than their currently available capacities. To further limit the expansion and dispatch of conventional power plants, the model considers different prices for carbon emissions.
After combining the basic REMix model with the scenario data, the specific model instances are compiled to solver readable files that serve as input to the solver.
Different solvers can be chosen for finding an optimal solution of the generated REMix model instance of a particular scenario. However, for our study, we apply the newly developed parallel interior-point solver PIPS-IPM++ based on an initial development from the Argonne National Laboratory (Petra et al., 2014). With it, very large model instances, previously unsolvable, can be calculated, using much less memory. In contrast to the widely used commercial solvers, which are optimized for shared memory architectures (i.e., limited to one compute node), PIPS-IPM++ solves the optimization problem distributed over several compute nodes, using MPI and OpenMP.
The important feature for solving ESOMs is its capability to treat linking variables and linking constraints. In particular, it is able to treat the doubly-bordered arrowhead block structure of an mathematical optimization problem's coefficient matrix (Rehfeldt et al., 2022). PIPS-IPM++ has been tested in several benchmarks with generic and applied ESOMs. Both for medium (~5 million rows and 5.6 million columns, see Figure 2) and large problems (~230 million rows and 210 million columns) it outperforms the benchmark (Cao et al., 2021b).
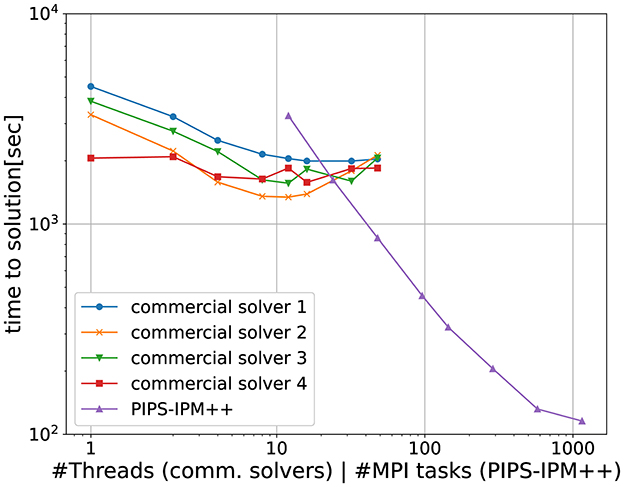
Figure 2. Scaling of different commercial solvers and PIPS-IPM++ on small ESOM instances (Cao et al., 2023).
To apply PIPS-IPM++ to our workflow, additional hyperparameters are required. In particular, the block structure of the mathematical optimization problem needs to be defined by the modeler based on domain knowledge. In our case, this so-called annotation defines 144 time blocks that translate into 144 tasks that are computed using 12 compute nodes and 4 cores per task.
Since the goal is a comprehensive overview of future energy systems (see, for example Lehtveer et al., 2021 for a study with 13 indicators), particular care needs to be taken to assess it by using the right indicators (Buschmann et al., 2022).
Therefore, both the optimization's outputs and some of the input parameters are used to calculate indicators for future energy systems from different perspectives:
• general system,
• markets,
• resources,
• human health,
• ecosystem quality,
• security of supply, and
• resilience.
For each perspective, different sets of indicators are computed. The aim of this indicator selection is to ensure both a broad coverage of aspects for the target triangle of energy supply (affordability, sustainability, security) and a clear assessment of desired and undesired directions of each indicator.
For example, in addition to the established indicators for total system costs (desired direction: low) and CO2 equivalents (desired direction: low) generated by the power system, we calculate the total resource use of minerals and metals for manufacturing the technologies in the energy scenario. This indicator is of particular interest because resource-saving scenarios tend to be neither cost-efficient nor to have significant low greenhouse gas emissions.
The comprehensive list of indicators can be found in Buschmann et al. (2022). This list of indicator candidates is pre-evaluated to remove highly correlated indicator combinations to avoid an unbalanced weighting. Finally, the applied indicator set is selected in a way that it punishes scenarios that favor greenhouse-gas emissions that are not in line with the climate targets. The final short list of indicators consists of two indicators per category to describe the performance of a solved energy scenario (see Table 1).
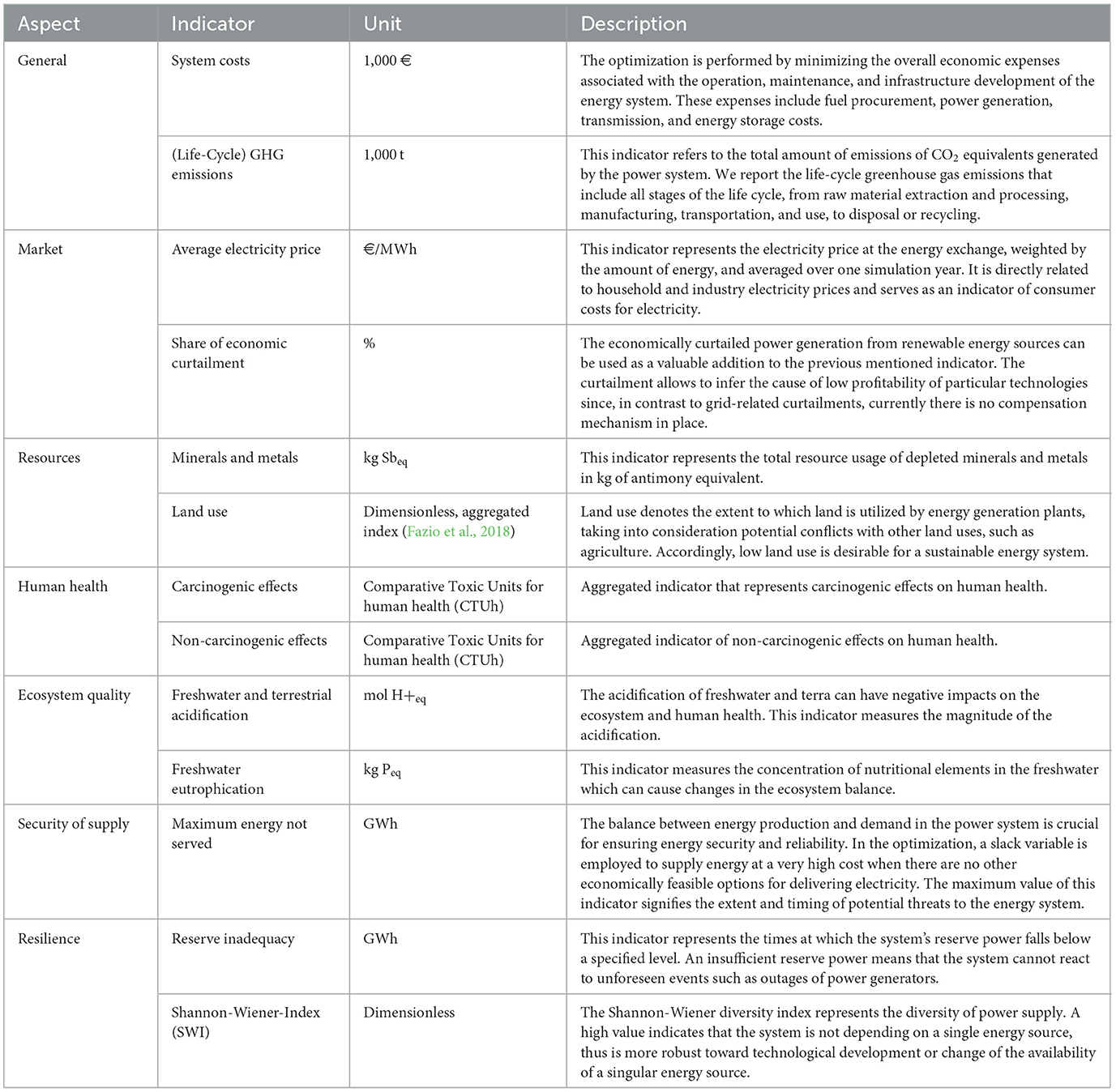
Table 1. Selection of indicators for assessing affordability, security and sustainability of a scenario.
These indicators are implemented as independent components of the HPC-workflow. They can be activated or deactivated and thus, offer the possibility for further (parallelized) post-processing of the solved REMix instances, e.g., for the calculation of additional indicators.
Considering the fact that system cost minimizing optimization rely on strong assumptions concerning decision making of decentral actors, we use AMIRIS for determining economic indicators. AMIRIS simulates different agents, each with individual operation strategies on the electricity market. Main outputs are electricity prices produced by the strategic bidding behavior of market actors. It has been calibrated and validated with historical data (Nitsch et al., 2021). Although changes of policy instruments like feed-in tariffs of renewables or different strategies (e.g., profit maximization or system optimal strategies) for individual actors can be modeled (Frey et al., 2020), for this study, we opt for a setup without such mechanisms.
After the HPC-workflow ends, a statistical analysis of the indicators derived from the solved scenarios is conducted in R Core Team (2022). As a first step, the result files from REMix and the indicators from other indicator models are read into data frames. Next, all scenario data—inputs, results, indicators—are combined. A third script handles clustering, including k-means and k-medoids, as well as automatically determining the cluster size. Other steps include calculating correlations, descriptive statistics, and tests for difference (t-tests), as well as plotting clusters and other results.
Since all scenarios are evaluated through the 13 indicators, it is important to know about their relationships among each other. Figure 3 presents an overview of the indicator correlations.
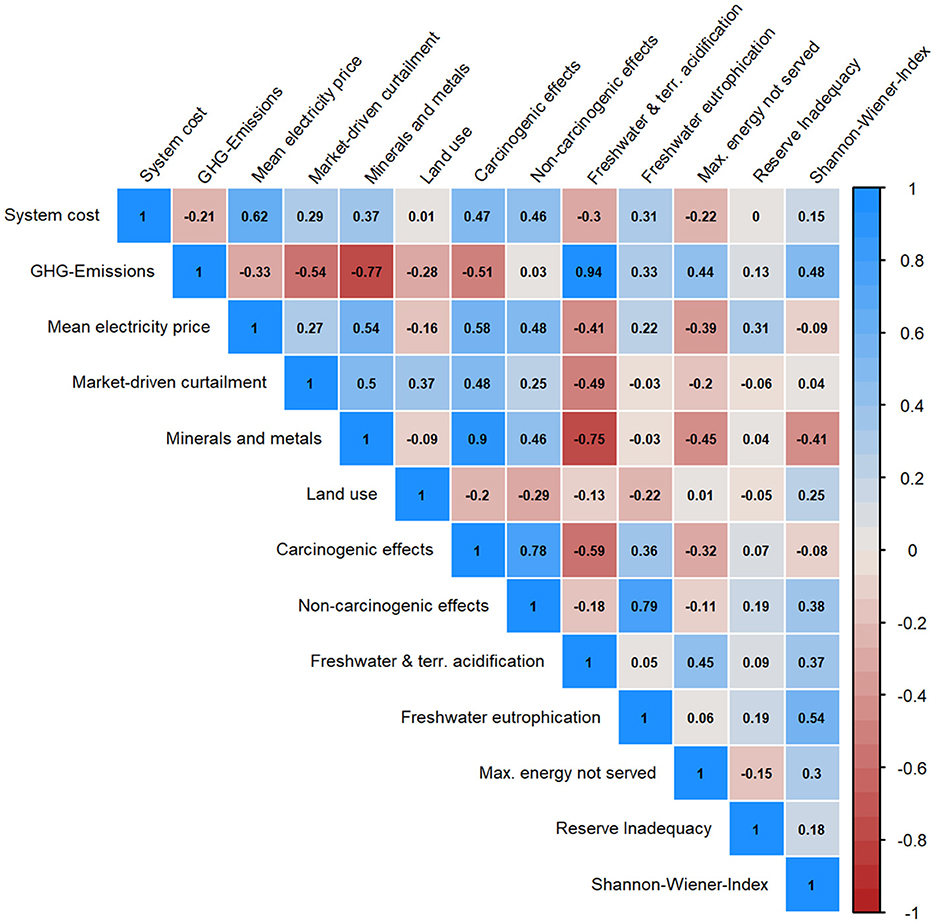
Figure 3. Pearson correlations for all 13 indicators.
First, correlations, e.g., between GHG-emissions and Freshwater and terrestrial acidification (r = 0.94, p < 0.001) are as expected. They confirm the general validity of the 700 scenario runs. Second, indicators from one aspect of the target triangle, e.g., economics, correlate positively, showing consistency. One example is the mean electricity price and system cost (r = 0.62, p < 0.001). The highest positive correlation exists between acidification and emissions (r = 0.94, p < 0.001).
To discover patterns in the data, a cluster analysis is performed. Clustering the 504 scenarios (out of 516, deleting scenarios with missing data) along the 13 indicators results in three clearly distinguishable clusters with almost no overlap, as shown in Figure 4.
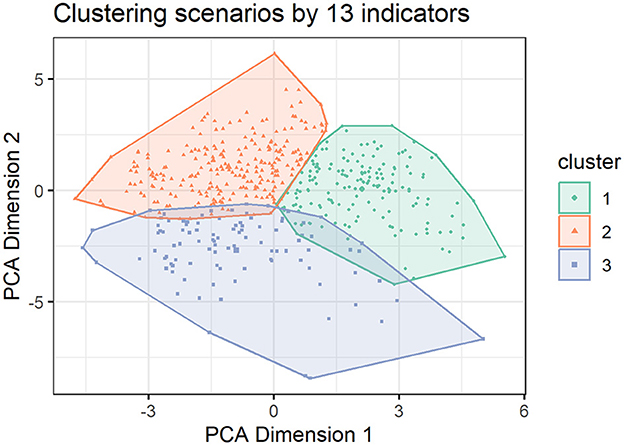
Figure 4. Three clusters by two PCA (principal component analysis) axes.
Note that only systems with a share of renewables ≥70% are analyzed, since all other systems are incompatible with Germany's goals for 2030 of 80% (Presse- und Informationsamt der Bundesregierung, 2024). This reduces the number of scenarios from n = 700 to n = 504.
Interpretation of these three clusters (1: 165, 2: 240, 3: 99 scenarios) is straightforward. They allow to distinguish clearly between three pathways. The second cluster (blue) is the most desirable one from a sustainability perspective: it has by far the lowest GHG-emissions and the lowest values for life cycle assessment (LCA) indicators, e.g. freshwater eutrophication or acidification, as well as the lowest system costs.
Cluster 1 (red) is the most expensive in terms of system costs, has intermediate GHG-emissions and a high use of minerals and metals, as well as the highest carcinogenic effects. However, it has the lowest land use of the three clusters. Cluster 3 (green) is the one with the largest conventional power plant park. System costs are lower than in cluster 1, but higher than in cluster 2, while acidification and freshwater eutrophication are the highest. The technology mix is the most diverse.
Electricity prices are almost identical for cluster 2 and 3 scenarios. Concerning security of supply: more conventional systems in cluster 3 had less hours with inadequate reserve capacities available for unforeseen events and energy not served than clusters 1 and 2.
It is of interest if scenarios can be distinguished by their inputs. Clustering scenarios by selected inputs only, i.e., the annual demand, the carbon cost, fuel costs for biomass, coal, and gas, as well as the annuities for biomass and natural gas power plants, lithium ion batteries, PV, wind offshore, and wind onshore results in two clusters. Like the clusters by indicators, they can be clearly distinguished. For the input clusters, the largest difference is between high fuel and carbon costs (n = 272) and low costs (n = 232). Annuities for the technologies or the annual demand do not differ much (for the values, see Supplementary Table S2 in the SOM).
We shift to the analysis of scenarios that are particularly interesting. Interesting means that a scenario scores low (e.g., GHG-emissions, less is better) or high (e.g., Shannon-Wiener-Index, measuring diversity, more is better) on an indicator. Scoring is done by calculating the overall mean for each of the 13 indicators across all scenarios. If an indicator is one standard deviation below or above the mean in the desired direction, this suggests that in this particular scenario the indicator is particularly good. The same is true for the opposite direction, resulting in particularly undesirable scenarios.
If a scenario scores on a lot of these indicators, this points to a particularly positive system overall, below called scenarios of interest, short SOI (n = 16). If it scores on a lot of indicators in the wrong direction, it is classified as a particularly undesirable system (n = 23), short AntiSOI. An AntiSOI-example would be a scenario with high GHG-emissions, high system costs, etc. The large rest of scenarios (n = 477) is classified as normal.
Analyzing these three subsets in terms of technology expansion leads to some interesting differences, as shown in Figure 5.
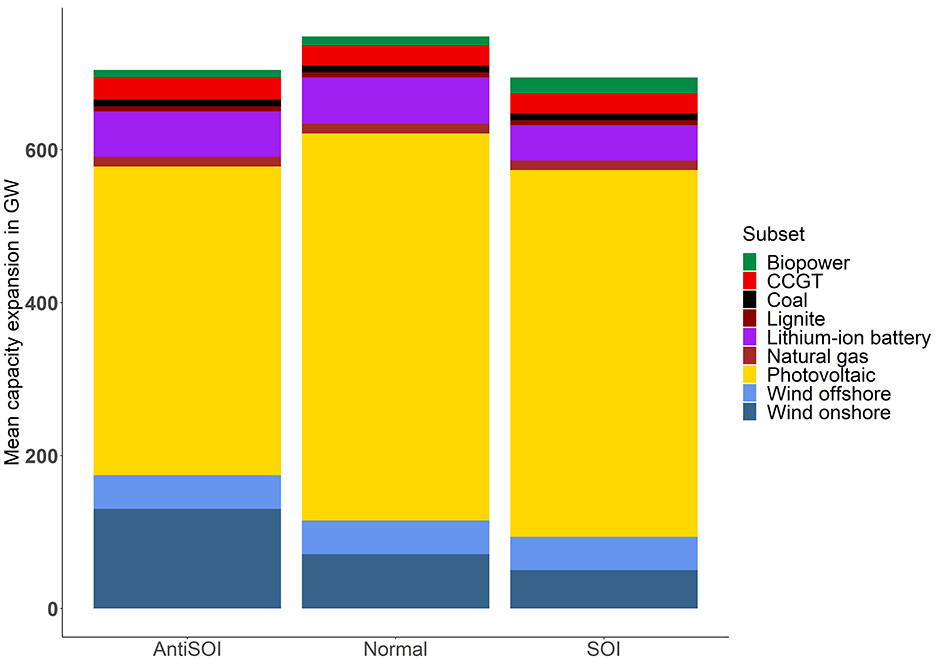
Figure 5. Mean capacities by subset.
As can be seen, PV (SOI: 480 GW, Normal: 507 GW, AntiSOI: 404 GW) and wind offshore are comparable, but wind onshore is much higher for AntiSOI (130 GW) than for SOI with 50 GW (see SOM, Supplementary Table S3 for the complete data).
In the case of SOI, less expansion of lithium-ion batteries positively impacts several indicators since e.g., less minerals and metals need to be extracted. The lack of storage flexibility is replaced by higher biomass power plant capacities.
Having defined these subsets, it becomes possible to calculate “no-regret”-thresholds, i.e., the minimum expansion for each renewable technology for the SOI. To be not biased by extreme outliers, the thresholds of the 25th percentile are considered.
Such no-regret expansions feature PV capacities of at least 327 GW, 45 GW wind offshore, 44 GW wind onshore, and 15 GW biomass power plants. Note that normal scenarios build another 50 GW of PV and 6 GW onshore but no more wind offshore and 7 GW less biomass on top of that. This apparently leads to increased efforts to integrate fluctuating PV into a complex system and has other negative side effects.
For 11 out of 13 indicators, the differences between SOI and AntiSOI are highly significantly different (8 at p < 0.001; 3 at p < 0.05), with all indicators being lower for SOI, i.e., better in terms of sustainability, except for land use (see Supplementary Table S1 in the SOM). Only the two indicators acidification and max. energy not served show non-significant differences between these two subsets.
Comparing all three subsets shows various differences as well. Figure 6 shows the two key indicators, system costs and GHG-emissions.
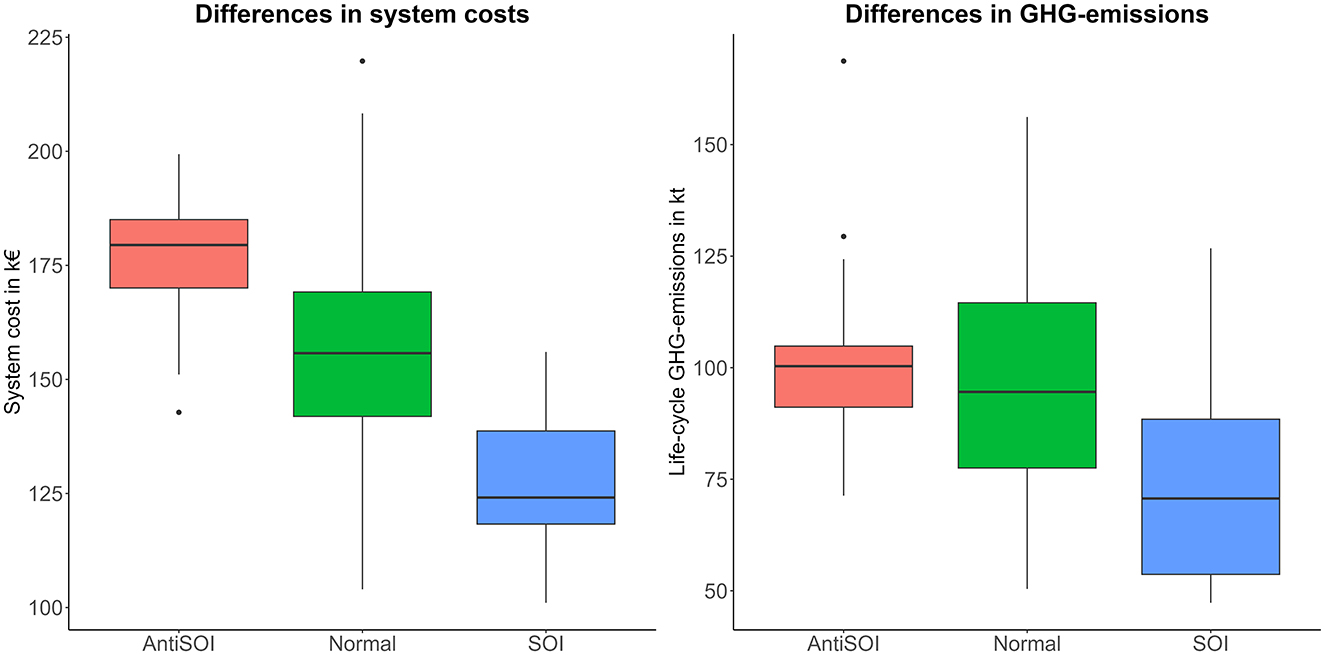
Figure 6. Differences in system costs and GHG-emissions between three subsets of scenarios.
Distinguishing SOI from AntiSOI and normal scenarios by their inputs only is inconclusive. A random forest linking the inputs, i.e., the parametrization of the scenarios, like efficiencies of technologies, annuities, and fuel costs, to the classification whether a scenario is SOI or AntiSOI achieves a classification accuracy for these two classes of only 60% on the test set. This suggests that single inputs are not decisive for a scenario to be either SOI or AntiSOI, but rather their combination.
The shown analyses represent only a part of several methodological variations that have been conducted using the described HPC-workflow. Implementing this workflow, coupling the models and getting the workflow to run in a stable manner took about three years for a team of 10 researchers located in different institutions across Germany. The use of computational time was significant—about 7,600,000 core hours. All scenario runs together required around 3,400,000 files in 260,000 directories, totaling 33 TB of data. In order not to lose track of the large number of files we had to develop a new hierarchical directory structure that covered all the needs of the individual components. With it, the individual components of the workflow could store and read in their data in a structured manner.
Model coupling is one of many approaches to explore scenarios from different perspectives and to analyze a variety of indicators. Only if multiple aspects of future energy pathways can be evaluated, a comprehensive and more robust picture of possible energy systems emerges.
Depending on the degree of coupling this tends to be a fragile process. Keeping the workflow intact had to be ensured, while all models were under continuous development over three years. Once one component of the workflow was ready for production, it was immediately tested with the next link of the chain. Here, testing means not only no technical errors, but also validation of results (e.g., Nitsch et al., 2021). Once this next component was running, the next component was tested in the same way. For this, each model had to be on GitLab. For each new workflow, the newest version was pulled and an overall versioning system for all models in one working model-flow was introduced. During this development, model interfaces had to be rewritten and modified to fit the needs of the project. Our practical experiences underline the importance of a flexible architecture, clean interfaces that are easy to adapt and the ability of a model to outsource complex calculations to a cluster, hence to make them as independent as possible.
One result that merits discussion is that no input—except PV annuity (p < 0.001)—is significant in the tests for difference (two-sided t-tests). However, we are hesitant to conclude that they do not seem to play a major role for future energy systems.
A second result that was consistent across all scenarios was the large expansion of PV and, at the same time, comparatively little build-up of wind onshore. Hence, the lower costs of PV seem to dominate the optimization, while the ABMS confirms that these are valid systems from a market perspective.
We also find many LCA indicators consistently pointing in the same direction in scenarios with a high share of renewables. While this is in line with existing findings (Naegler et al., 2022), these findings suggest that running 700 scenarios does lead to robust results.
One limitation of our assessment approach is that “good” systems are defined statistically, not from a system's perspective. This may be more objective on the one hand, but may miss some systems that experts would have tagged as promising candidates for overall good future energy systems on the other hand.
With regard to the employed indicator set, it is important to note that the employed quantitative approach for describing energy scenarios is susceptible to subjectivity. For example, a combination of qualitative and quantitative approaches has been suggested by the IPCC to tackle uncertainty challenges. That also applies to the expert interviews used to generate the quantifiable interrelations of model parameters. Filtering to a manageable list of parameters is biased by the experience of the modelers. Furthermore, it would be desirable to extend scenarios to encompass social aspects, such as participation and acceptance.
The parameter sampling approach used utilizes a uniform distribution for all parameters. However, this may be a generalized assumption. Hence, it was assumed that all parameter values from the literature study have the same quality. In addition, there may be dependencies between sources from the literature, influencing the mean values. To amend that, comparative calculations were carried out whenever we applied a normal distribution across all parameters varied. Finally, the mean values from the literature review do not necessarily indicate a high probability of occurrence in the future.
Another limitation is that we find subset results (SOI vs. AntiSOI) to be highly dependent on indicator selection even though we deliberately decided to evenly weight the indicators. While we present results for a balanced set of 13 indicators for the target triangle of energy supply, namely affordability, sustainability and security, limiting the selection to two indicator per category resulted in SOI-scenarios having much more emissions. This high sensitivity should lead to a more cautious interpretation of results.
Figure 7 shows the run times of all 700 scenarios which were preprocessed and sampled in batch sizes of 100. Therefore, the timings for batches of 100 of those workflow steps show the same timing. The overall execution time of the workflow—note the log-scale—was dominated by the solver, followed by the model calculations.
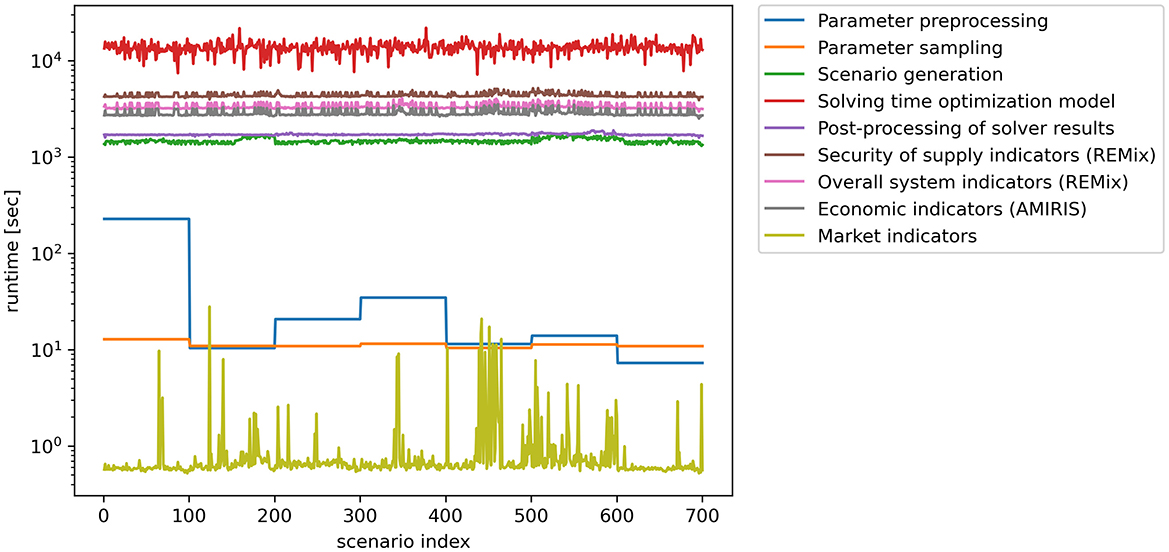
Figure 7. Time per model for each of the 700 scenarios.
Only by using a supercomputer like JUWELS we were able to perform our study in a realistic time frame. This rough estimate based on our actual run times impressively demonstrates the potential of HPC and opens up new possibilities for further developing complex ESOMs and processing large amounts of data in the order of several terabytes: Assuming that we had to process each scenario individually one after the other through the workflow, but still run the solver step in parallel with PIPS-IPM++, it would have taken ~219 days to process all 700 scenarios. Using commercial solvers would have significantly increased this time. However, with our approach we still spent more than 20 days of continuous computing time since we could not exclusively reserve JUWELS for our application.
Three challenges have been addressed—the strong influence on varying input parameters into models, the computational limitations, and the restriction to few aspects of one type of model. It was demonstrated that all can be overcome in a concerted way and move the energy systems community toward more robust, comparable, and comprehensive results.
In this paper, we demonstrated one robust and comprehensive assessment of future pathways of energy systems while many other approaches to deal with uncertainties exist. This approach should not be confused with direct robust optimizations. Our setup couples the optimization model REMix, the agent-based simulation AMIRIS, based on the framework FAME, and an elaborate indicator development. Implementing this workflow on a supercomputer, using the newly developed solver PIPS-IPM++, and combining it with a scenario space generator, 700 large scenarios for Germany 2030 were calculated. By calculating 700 scenarios with 13 indicators each, we go beyond a narrow set of indicators when analyzing future energy systems.
With all components—FAME, AMIRIS, REMix, PIPS-IPM++ and JUBE—being open-source software, and the indicator development published, we hope to provide the research community with all the building blocks to continue such analyses. All parts of the chain are easily reusable.
However, we are aware that coupling models in a supercomputer-environment is a major undertaking. Scaling up the number of scenarios and automating such a complex workflow comes with its own challenges. The Methods section described all the many steps to develop such a complex coupled model workflow. It requires researchers to find a trade-off between early, but stable prototypes of their models and the rapid integration into an ever-changing workflow.
With the infrastructure in place, it is now easy to extend existing analyses. Many desirable requests of the energy system modeling community can be implemented with a few changes in the workflow—e.g., sampling from different distributions, using different inputs, trying different grid resolutions or indeed implementing any other model change to address current and cutting-edge research questions.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
UF: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing. SS: Data curation, Methodology, Software, Writing – review & editing. TB: Data curation, Software, Resources, Visualization, Writing – review & editing. JB: Data curation, Methodology, Software, Writing – review & editing. K-KC: Data curation, Funding acquisition, Methodology, Resources, Supervision, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. The research was funded by the German Federal Ministry for Economic Affairs and Energy under grant number 03EI1004A-E.
The authors appreciate the support of Anna-Lena Bock and Andreas Meurer with visually exploring the data. We thank Aileen Böhme for developing and supporting the parameter sampling tool. We further appreciate the help of Manuel Wetzel for resolving issues with REMix and PIPS-IPM++. Further thanks go to Kai von Krbek, Sonja Simon, and Mengzhu Xiao for their work related to the parameter space and indicator calculation, as well as Ben Fuchs for making that work possible. The authors gratefully acknowledge the Gauss Center for Supercomputing e.V. (http://www.gauss-centre.eu) for funding this project by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS at Jülich Supercomputing Center (JSC).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frevc.2024.1398358/full#supplementary-material
Alvarez, D. (2021). JUWELS cluster and booster: exascale pathfinder with modular supercomputing architecture at Juelich supercomputing centre. J. Large-Scale Res. Facil. JLSRF 7:183. doi: 10.17815/jlsrf-7-183
Bandini, S., Manzoni, S., and Vizzari, G. (2009). Agent based modeling and simulation: an informatics perspective. J. Artif. Soc. Soc. Simul. 12:4.
Boffino, L., Conejo, A. J., Sioshansi, R., and Oggioni, G. (2019). A two-stage stochastic optimization planning framework to decarbonize deeply electric power systems. Energy Econ. 84:104457. doi: 10.1016/j.eneco.2019.07.017
Buschmann, J., von Krbek, K., and Schimeczek, C. (2022). Energy System Indicators. Available at: https://b2share.eudat.eu (accessed January 23, 2024).
Cao, K.-K., Haas, J., Sperber, E., Sasanpour, S., Sarfarazi, S., Pregger, T., et al. (2021a). Bridging granularity gaps to decarbonize large-scale energy systems—the case of power system planning. Energy Sci. Eng. 9, 1052–1060. doi: 10.1002/ese3.891
Cao, K.-K., von Krbek, K., Wetzel, M., Cebulla, F., and Schreck, S. (2019). Classification and evaluation of concepts for improving the performance of applied energy system optimization models. Energies 12:4656. doi: 10.3390/en12244656
Cao, K.-K., Wetzel, M., Frey, U. J., Sasanpour, S., Buschmann, J., von Krbek, K., et al. (2023). “Tackling challenges in energy system research with HPC,” in ISC High Performance 2023. Available at: http://hdl.handle.net/2128/34525 (accessed March 07, 2024).
Cao, K.-K., Wetzel, M., Kempke, N.-C., and Koch, T. (2021b). “Pushing computational boundaries: solving integrated investment planning problems for large-scale energy systems with PIPS-IPM+ 2021,” in Operations Research. Available at: https://elib.dlr.de/143744/ (accessed March 07, 2024).
Chappin, E. J., de Vries, L. J., Richstein, J. C., Bhagwat, P., Iychettira, K., and Khan, S. (2017). Simulating climate and energy policy with agent-based modelling: the Energy Modelling Laboratory (EMLab). Environm. Model. Softw. 96, 421–431. doi: 10.1016/j.envsoft.2017.07.009
Deissenroth, M., Klein, M., Nienhaus, K., and Reeg, M. (2017). Assessing the plurality of actors and policy interactions: agent-based modelling of renewable energy market integration. Complexity 2017, 1–24. doi: 10.1155/2017/7494313
Fagiolo, G., Moneta, A., and Windrum, P. (2007). A critical guide to empirical validation of agent-based models in economics: methodologies, procedures, and open problems. Comput. Econ. 30, 195–226. doi: 10.1007/s10614-007-9104-4
Fazio, S., Castellani, V., Sala, S., and Schau, E. (2018). “Supporting information to the characterisation factors of recommended EF Life Cycle Impact Assessment method: new models and differences with ILCD,” in European Commission. Available at: https://eplca.jrc.ec.europa.eu/permalink/supporting_Information_final.pdf (accessed October 11, 2023).
Frey, U. J., Klein, M., Nienhaus, K., and Schimeczek, C. (2020). Self-reinforcing electricity price dynamics under the variable market premium scheme. Energies 13:5350. doi: 10.3390/en13205350
Gils, H. C., Gardian, H., Kittel, M., Schill, W.-P., Murmann, A., Launer, J., et al. (2022a). Model-related outcome differences in power system models with sector coupling—Quantification and drivers. Renew. Sustain. Energy Rev. 159:112177. doi: 10.1016/j.rser.2022.112177
Gils, H. C., Linßen, J., Möst, D., and Weber, C. (2022b). Improvement of model-based energy systems analysis through systematic model experiments. Renew. Sustain. Energy Rev. 167:112804. doi: 10.1016/j.rser.2022.112804
Gils, H. C., Scholz, Y., Pregger, T. D, and Luca de Tena, H. D. (2017). Integrated modelling of variable renewable energy-based power supply in Europe. Energy 123, 173–188. doi: 10.1016/j.energy.2017.01.115
Hall, L. M. H., and Buckley, A. R. (2016). A review of energy systems models in the UK: prevalent usage and categorisation. Appl. Energy 169, 607–628. doi: 10.1016/j.apenergy.2016.02.044
Haller, M., Ludig, S., and Bauer, N. (2012). Decarbonization scenarios for the EU and MENA power system: considering spatial distribution and short term dynamics of renewable generation. Energy Policy 47, 282–290. doi: 10.1016/j.enpol.2012.04.069
Jülich Supercomputing Centre (2022). JUBE Benchmarking Environment 2008-2022. Available at: http://www.fz-juelich.de/jsc/jube (accessed January 24, 2023).
Klein, M., Frey, U. J., and Reeg, M. (2019). Models within models – agent-based modelling and simulation in energy systems analysis. J. Artif. Soc. Soc. Simulat. 22:4129. doi: 10.18564/jasss.4129
Kotzur, L., Nolting, L., Hoffmann, M., Groß, T, Smolenko, A., Priesmann, J., et al. (2021). A modeler's guide to handle complexity in energy systems optimization. Adv. Appl. Energy 4:100063. doi: 10.1016/j.adapen.2021.100063
Lehtveer, M., Göransson, L., Heinisch, V., Johnsson, F., Karlsson, I., Nyholm, E., et al. (2021). Actuating the European energy system transition: indicators for translating energy systems modelling results into policy-making. Front. Energy Res. 9:677208. doi: 10.3389/fenrg.2021.677208
Naegler, T., Buchgeister, J., Hottenroth, H., Simon, S., Tietze, I., Viere, T., et al. (2022). Life cycle-based environmental impacts of energy system transformation strategies for Germany: are climate and environmental protection conflicting goals? Energy Rep. 8, 4763–4775. doi: 10.1016/j.egyr.2022.03.143
Neumann, F., and Brown, T. (2021). The near-optimal feasible space of a renewable power system model. Elect. Power Syst. Res. 190:106690. doi: 10.1016/j.epsr.2020.106690
Nitsch, F., Schimeczek, C., and Wehrle, S. (2021). Back-Testing the Agent-Based Model AMIRIS for the Austrian Day-Ahead Electricity Market. Available at: https://elib.dlr.de/147128/1/Nitsch2021BacktestingAMIRIS.pdf (accessed January 24, 2023).
Petra, C. G., Schenk, O., and Anitescu, M. (2014). Real-time stochastic optimization of complex energy systems on high-performance computers. Comput. Sci. Eng. 16, 32–42. doi: 10.1109/MCSE.2014.53
Pfenninger, S., Hawkes, A., and Keirstead, J. (2014). Energy systems modeling for twenty-first century energy challenges. Renew. Sustain. Energy Rev. 33, 74–86. doi: 10.1016/j.rser.2014.02.003
Pfluger, B., Tersteegen, B., Franke, B., Bernath, C., Boßmann, T., Deac, G., et al. (2017). “Langfristszenarien für die Transformation des Energiesystems in Deutschland,” in Modul 3: Referenzszenario und Basisszenario. Munich: Fraunhofer-Gesellschaft.
Prehofer, S., Kosow, H., Naegler, T., Pregger, T., Vögele, S., and Weimer-Jehle, W. (2021). Linking qualitative scenarios with quantitative energy models: knowledge integration in different methodological designs. Energy Sustain. Soc. 11:1. doi: 10.1186/s13705-021-00298-1
Presse- und Informationsamt der Bundesregierung (2024). Mehr Energie aus erneuerbaren Quellen. Available at: https://www.bundesregierung.de/breg-de/schwerpunkte/klimaschutz/energiewende-beschleunigen-2040310 (accessed March 04, 2024).
R Core Team (2022). R: A Language and Environment for Statistical Computing. (Vienna: R Core Team). Available at: https://www.R-project.org/
Rehfeldt, D., Hobbie, H., Schönheit, D., Koch, T., Möst, D., and Gleixner, A. (2022). A massively parallel interior-point solver for LPs with generalized arrowhead structure, and applications to energy system models. Eur. J. Oper. Res. 296, 60–71. doi: 10.1016/j.ejor.2021.06.063
Ringkjøb, H.-K., Haugan, P. M., and Solbrekke, I. M. (2018). A review of modelling tools for energy and electricity systems with large shares of variable renewables. Renew. Sustain. Energy Rev. 96, 440–459. doi: 10.1016/j.rser.2018.08.002
Rozenberg, J., Guivarch, C., Lempert, R., and Hallegatte, S. (2014). Building SSPs for climate policy analysis: a scenario elicitation methodology to map the space of possible future challenges to mitigation and adaptation. Clim. Change 122, 509–522. doi: 10.1007/s10584-013-0904-3
Ruiz, P., Nijs, W., Tarvydas, D., Sgobbi, A., Zucker, A., Pilli, R., et al. (2019). ENSPRESO - an open, EU-28 wide, transparent and coherent database of wind, solar and biomass energy potentials. Energy Strat. Rev. 26:100379. doi: 10.1016/j.esr.2019.100379
Sasanpour, S., Cao, K.-K., Gils, H. C., and Jochem, P. (2021). Strategic policy targets and the contribution of hydrogen in a 100% renewable European power system. Energy Rep. 7, 4595–4608. doi: 10.1016/j.egyr.2021.07.005
Schimeczek, C., Deissenroth-Uhrig, M., Frey, U., Fuchs, B., Ghazi, A. A. E., Wetzel, M., et al. (2023a). FAME-core: an open framework for distributed agent-based modelling of energy systems. J. Open Source Softw. 8:5087. doi: 10.21105/joss.05087
Schimeczek, C., Nienhaus, K., Frey, U., Sperber, E., Sarfarazi, S., Nitsch, F., et al. (2023b). AMIRIS: agent-based market model for the investigation of renewable and integrated energy systems. J. Open Source Softw. 8:5041. doi: 10.21105/joss.05041
Simon, S., and Xiao, M. (2022). A Multi-Perspective Approach for Exploring the Scenario Space of Future Power Systems: Input Data. Available at: https://b2share.eudat.eu
Trutnevyte, E., Guivarch, C., Lempert, R., and Strachan, N. (2016). Reinvigorating the scenario technique to expand uncertainty consideration. Clim. Change 135, 373–379. doi: 10.1007/s10584-015-1585-x
Usher, P. W. (2016). The Value of Learning about Critical Energy System Uncertainties. (doctoral thesis). London: University College London. Available at: https://discovery.ucl.ac.uk/id/eprint/1504608/ (accessed February 29, 2024).
Wetzel, M., Ruiz, E. S. A., Witte, F., Schmugge, J., Sasanpour, S., Yeligeti, M., et al. (2024). REMix: a GAMS-based framework for optimizing energy system models. J. Open Source Softw. 9:6330. doi: 10.21105/joss.06330
Yue, X., Pye, S., DeCarolis, J., Li, F. G., Rogan, F., and Gallachóir, B. Ó. (2018). A review of approaches to uncertainty assessment in energy system optimization models. Energy Strat. Rev. 21, 204–217. doi: 10.1016/j.esr.2018.06.003
Keywords: energy system optimization model, agent-based modeling and simulation, model coupling, high-performance computing, uncertainty
Citation: Frey UJ, Sasanpour S, Breuer T, Buschmann J and Cao K-K (2024) Tackling the multitude of uncertainties in energy systems analysis by model coupling and high-performance computing. Front. Environ. Econ. 3:1398358. doi: 10.3389/frevc.2024.1398358
Received: 09 March 2024; Accepted: 02 October 2024;
Published: 23 October 2024.
Edited by:
Ozgu Turgut, Independent Researcher, Istanbul, TürkiyeReviewed by:
Tadhg O'Mahony, University College Dublin, IrelandCopyright © 2024 Frey, Sasanpour, Breuer, Buschmann and Cao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ulrich J. Frey, dWxyaWNoLmZyZXlAZGxyLmRl
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.