 Long Wang
Long Wang Haibin Liu
Haibin Liu Minghao Xia2
Minghao Xia2
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Energy Res. , 29 December 2023
Sec. Smart Grids
Volume 11 - 2023 | https://doi.org/10.3389/fenrg.2023.1251335
Traditional manufacturing enterprises cannot adjust their production line structure in the short term. They face significant challenges in adapting to the rapidly changing market environment and meeting various variable batch production requirements. Building a suitable and convenient multi-layer planning and scheduling model is an important goal to solve the efficient operation of manufacturing enterprises. This paper proposes a planning and scheduling design that meets the needs of enterprise and the production workshop using the APERT-VC model through a top-down design methodology. APERT is an enterprise-level plan that uses attention mechanisms to collect job plan time and decomposes project plans into workshop plans through PERT technology. virtual command is workshop level plan management, which converts workshop plans into time series vectors and achieves rapid and comprehensive guidance of workshop resource planning for enterprises through multiple classification and decision-making. Through experiments, the algorithm achieved production scheduling accuracy improvement of over 30% compared to previous algorithms and a decision accuracy rate of over 90%. The first half of the new model solves the problem of collecting work time for multi variety and variable batch products, and improves the accuracy of algorithm input. The second half of the new algorithm innovatively combines image recognition technology with dispatcher behavior, achieving efficient simulation results.
With rapid changes in market demand, manufacturing enterprises are no longer just producing one or several specific product projects but accepting diversified projects. In this market environment, manufacturing enterprises attach great importance to research on flexible production lines and strive to carry out customized production. Heavy assets are one of the important characteristics of the vast majority of manufacturing enterprises. The initial investment in human and financial resources for the construction of flexible production lines is very significant. Moreover, considering the long-term, stable, and healthy development of the enterprise, production cannot be discontinued until the flexible production line is renovated. Furthermore, existing processing resources are needed to complete various product projects on time and with good quality. The market is cruel. If a company cannot complete certain projects on time, customers will immediately turn to other companies for the next project opportunity. This is a problem that most manufacturing enterprises encounter.
The primary feature of a planning and scheduling system is its multi-layer nature. The planning and scheduling system is mainly divided into enterprise-level planning systems, production unit- or department-level production planning systems, and section-level production planning systems according to the organizational structure of the enterprise. The coordination of plans needs to be maintained among various levels of planning systems. The larger the enterprise is, the more production units and sections it will have, and the more difficult it will be to express the coordination of the plan.
Additionally, controllers need to give attention to the unique nature of the production environment. The products on the pulse production line have linear characteristics. This linear feature is usually called production line balance. This is a technical means and method of averaging all production processes and adjusting the workload to make each operation time as close as possible. Pulse production lines easily achieve line balance, but in a production environment with multiple varieties and varying batches, it is difficult to achieve this linear characteristic. The operation time for products with multiple varieties and varying batches is not a fixed value. If the production site of the enterprise is not a pulsating production line, then the operation time of product production will not be linear, and it is likely that nonlinear characteristics will appear. This nonlinear characteristic will increase the difficulty of designing the planning and scheduling system.
The paper notes that the multilevel planning and scheduling model is of great significance for studying the operating mode of manufacturing enterprises in a multi-variety and variable batch production environment. Currently, many enterprises lack such research, which has led to the occurrence of multi-project resource conflicts, inadequate planning and monitoring, bloated management, and even endangered enterprise survival.
The paper proposes a two-level intelligent planning and scheduling model (APERT-VC) based on machine learning and PERT technology, which can solve the complex production environment of multiple varieties and variable batches. This model can accurately predict the operation time of variable batch products, supplement the data foundation of the planning and scheduling system, achieve precise decomposition and control of project plans, and replace scheduling personnel to issue commands to each piece of equipment or workstation on site. The paper proposed method consists of two various modules, namely, the APERT module and the VC module. The function of the APERT module is to import product homework time and accurately decompose project plans. The function of the VC module is to complete the classification and decision-making of production data for on-site equipment or workstation resources. The results show that the accuracy of this method is 1.3 times that of traditional methods, and the classification decision accuracy reaches over 95%. On-site management decision transmission can be completed in a few minutes.
Adding imprecise data to excellent scheduling algorithms often results in unsatisfactory results. Product operation time is one of the important input data. The algorithm proposed in this article focuses on solving the problem of time collection and prediction in a multi variety and variable batch production environment. These relatively accurate time data are the key to task decomposition in the APERT algorithm.
In addition, traditional scheduling algorithms often focus on resource allocation techniques and rarely pay attention to the behavior of scheduling personnel. How to make management experience explicit for an excellent plan scheduling manager is a new approach for future scheduling algorithm research. The paper first focuses on the decision-making behavior of scheduling personnel on resource demand histograms, and extracts human perception of scheduling information from the perspective of image recognition. Then, the algorithm utilized machine learning technology and achieved satisfactory results. At the same time, these new ideas and methods have significant inspiration for the development of future new scheduling algorithms.
The rest of this paper will be organized as follows. After introducing cutting-edge researches on scheduling algorithms in Section 2, Section 3 describes the data processing method and model structure of the APERT-VC algorithm. Then Section 4 conducts data experiments and comparative analysis of the APERT-VC algorithm, and evaluates and discusses the advantages of the new algorithm. Section 5 summarizes the results of the APERT-VC algorithm. Future work and limitation of this study are finally given in Section 6.
Currently, research on scheduling can be divided based on whether machine learning is used. One is a heuristic scheduling algorithm that does not use machine learning, and the other is a scheduling algorithm that uses machine learning to leverage its advantages in feature learning, complex logic expression, and other aspects to solve the challenges of heuristic scheduling algorithms.
Scholars refer to random search optimization algorithms similar to biological evolution and genetics as genetic algorithms (GA). A new model combining a genetic algorithm with neighborhood search was proposed by Wang et al. (2017), which can further enhance search functionality by utilizing information in the search space. A multiobjective minimization method for the production cycle and energy consumption based on a genetic algorithm was proposed by Chen et al. (2020), which can be used to solve the scheduling issue of pulsating production lines. A new model combining the fuzzy assembly shop scheduling mode, heuristic algorithm, and genetic algorithm was proposed by Liu et al. (2017), which can improve the energy consumption of work time. A total delay rate objective genetic algorithm solution for mixed flow workshop scheduling based on unrelated parallel machines was proposed by Yu et al. (2018), which provides a new decoding method that achieves compact scheduling results through chromosomes. A genetic algorithm-based solution considering task allocation, process sequencing, and machine allocation was proposed by Lu et al. (2018), which can solve distributed flexible workshop scheduling problems. This algorithm provides a new chromosome representation method for modeling three-dimensional problems through one-dimensional schemes.
Neighborhood search is one of the salient features of the tabu search algorithm (TS) (Gmira et al., 2021). It starts from the global solution and gradually searches in its neighborhood. A tabu search algorithm for scheduling problems based on a replacement flow shop was proposed by Arik et al. (2021) that has crossover and mutation operators, focusing on the best candidate in the search solution during each iteration. A dual objective tabu search algorithm was proposed by Wang et al. (2020), which can solve the two-phase hybrid flow shop scheduling problem, with the goal of reducing energy consumption. A nonwaiting two-stage scheduling problem based on tabu search was proposed by Harbaoui and Khalfallah. (2020), and its solution results are attributed to traditional genetic algorithms. A new model combining the tabu search algorithm and the Pareto evolutionary strategy algorithm was proposed by Gonzalez Neira et al. (2019). It is also combined with Monte Carlo simulation to solve the robust scheduling problem of multiobjective alternative flow shop scheduling with random processing time. A new algorithm based on parallel tabu search called BożEjko et al. (2017) proposed that it can solve periodic workshop scheduling problems. A hybrid Pareto tabu search algorithm based on the maximum workload, manufacturing cycle, total workload, and lead time was designed by Li et al. (2018) to solve multiobjective problems.
Imitating the activities of birds and fish is a prominent feature of particle swarm optimization (PSO). An improved particle swarm optimization algorithm considering human factors was designed by Marichelvam et al. (2020), which can solve the multilevel flow shop scheduling problem of parallel machines. Wu et al. (2018) further validated the performance of six particle swarm optimization algorithms through analysis of variance. A particle swarm optimization algorithm based on a population adaptive mechanism was proposed by Zhao et al. (2019), which is oriented to the maximum duration criterion to solve the no wait flow shop scheduling problem. A new model combining particle swarm optimization and a genetic algorithm was designed by Jamrus et al. (2017). It can find the optimal process sequence and shorten the scheduling time of flexible job shops in semiconductor manufacturing. A two-stage particle swarm optimization algorithm was proposed by Nouiri et al. (2017), which can solve the job shop scheduling problem considering machine failure. A particle swarm optimization algorithm based on hierarchical methods was designed by Kato et al. (2018), which solves path optimization and plan optimization problems. A dynamic scheduling algorithm model for task random arrival was proposed by Wang et al. (2019), which has significant advantages over the PSO algorithm in solving random task problems. A two-layer particle swarm optimization algorithm was proposed by Zarrouk et al. (2019). Its upper layer is used to process the mapping of the process to equipment, and the lower layer is used to process the prescheduling sequence.
Simulating ants' foraging habits is a prominent feature of ant colony optimization algorithms (ACO). An optimization algorithm solution based on a mutation mechanism and crossover was proposed by Engin and Guclu. (2018), whose results can reduce the maximum completion time. A cuckoo search algorithm based on ant colony optimization algorithms was proposed by Zhang et al. (2019), which can solve the permutation flow scheduling problem. A multiobjective hybrid ant colony optimization algorithm was proposed by Zhang et al. (2020), Zheng et al. (2020). It takes into account the situation of two-stage replacement flow and better finds the equant between the energy cost and the maximum completion time. A hybrid ant colony optimization algorithm was proposed by Huang and Yu. (2017), which can solve multiobjective flexible workshop scheduling problems with fixed batch sizes. Chaouch et al. (2017) compared three ant colony optimization algorithm schemes that can solve the distributed job shop scheduling problem and proposed an improved scheme. A multirobot scheduling model based on ant colony optimization was proposed by Elmi and Topaloglu. (2017), which can determine the optimal task allocation and process arrangement for robots. The enhanced ACO and hybrid ACO algorithms were proposed by Deepalakshmi and Shankar. (2020), who investigated the role of ant colony optimization in planning and scheduling problems.
The statistical model is the main feature of the distribution estimation algorithm (EDA). Compared with traditional genetic algorithms, it does not have crossover and mutation operations but relies on learning and sampling statistical models. A P-EDA algorithm based on completion time criteria was proposed by Shao et al. (2018), which introduces path reconstruction technology and improves convergence. A multi-objective distribution estimation algorithm model based on the distance index was proposed by Zangari et al. (2017), which can solve multi-objective optimization problems in permutation flow shop scheduling. A multi-objective distribution estimation algorithm based on dual criteria random operations was proposed by Hao et al. (2017), which uses the Monte Carlo method to sample the processing time of each process. These also derive the firefly algorithm (Fan et al., 2019), leapfrog algorithm (Lei et al., 2017), etc. Li et al. (2023) proposed a dual population based distribution estimation algorithm to solve flexible workshop scheduling problems with the goal of minimizing the maximum completion time.
The above algorithms are basically based on classic metaheuristic algorithms and lack a solution to the production planning problem of tree-shaped product structures. In certain fields, the final product is achieved through pushing and pulling. For example, the final assembly pulls the partial assembly, the partial assembly pulls the complete set of parts, and the complete set of parts pulls the supply of raw materials. Some scholars are conducting research on the comprehensive scheduling problem of complex products and proposing comprehensive scheduling solutions (Komaki et al., 2019; Zhang et al., 2019; Xie et al., 2020). A temporal comprehensive scheduling algorithm considering the fallback strategy was proposed by Zhang et al. (2019), which effectively solves the compactness problem of serial processes. A dual objective multi workshop scheduling algorithm based on process transfer was proposed by Xie et al. (2020), which finds a balance between the total completion time and total cost of the product. In addition, comprehensive solutions based on process relationship matrix tables and hybrid comprehensive scheduling solutions based on improved bottleneck device conversion strategies have also been proposed by scholars (Lei et al., 2018; Shi et al., 2020). Li et al. (2021) also focused on the impact of transportation turnover when studying flexible workshop scheduling problems.
These algorithms always have certain limitations, so an increasing number of scholars are turning their research direction toward task scheduling algorithms based on artificial intelligence neural networks, leveraging the advantages of deep reinforcement learning algorithms in machine learning. A priority-based parallel reinforcement learning task scheduling method was proposed by Sha et al. (2019), which solves the rate of convergence problem of reinforcement learning tasks in a large state space. Zhang et al. (2019) automatically learned PDR through end-to-end deep reinforcement learning agents. Swarup et al. (2021) proposed a dual deep Q-learning algorithm that utilizes target networks and relay technology. Luo (2020) extracted seven universal state features to represent the rescheduled production state and trained them using deep Q-learning (DQL). A reinforcement learning mechanism based on a genetic algorithm was proposed by Asghari et al. (2021), which can be used to manage cloud resources. Silva et al. (2019) utilized the concept of reinforcement learning to enable agents to interact with other agents and environments. Park et al. (2021) proposed an RL strategy based on near-end strategy optimization, which is trained end-to-end. Du et al. (2022) solved the problem of optimizing resource allocation within the workshop through reinforcement learning.
Ahmed et al. (2023) discussed the optimal planning of an industrial microgrid considering integrated energy resources, and paid more attention to the impact of scheduling models on economic effects. Both traditional scheduling algorithms and intelligent scheduling algorithms represented by machine learning are focused on production problems in certain special environments, mainly in the production workshop or a certain section. However, controllers often face a problem at the enterprise level. It is difficult to systematically solve the production planning problems that exist in a complex production environment with multiple varieties and batches by only solving the problems of a certain workshop and a certain section. Therefore, inspired by previous scholars' research, this article takes the enterprise problem as the starting point, the hierarchical relationship of production planning as a systematic consideration, and the characteristics of multiple varieties and variable batches as the foundation. Efforts are made to achieve the integration of enterprise to workshop planning, the specific command and decision-making from enterprise to workshop, and the establishment of an intelligent scheduling model for the interconnection of enterprise and workshop level planning and scheduling.
The APERT-VC algorithm includes data acquisition, preprocessing, operation time prediction, dynamic path optimization and multiclassification decision-making.
This study focuses on a certain type of manufacturing enterprise and the manufacturing process of its products, which is described in Figure 1. Its product manufacturing process is a tree structure, raw materials are processed into parts, parts are assembled into components, and components constitute finished products.
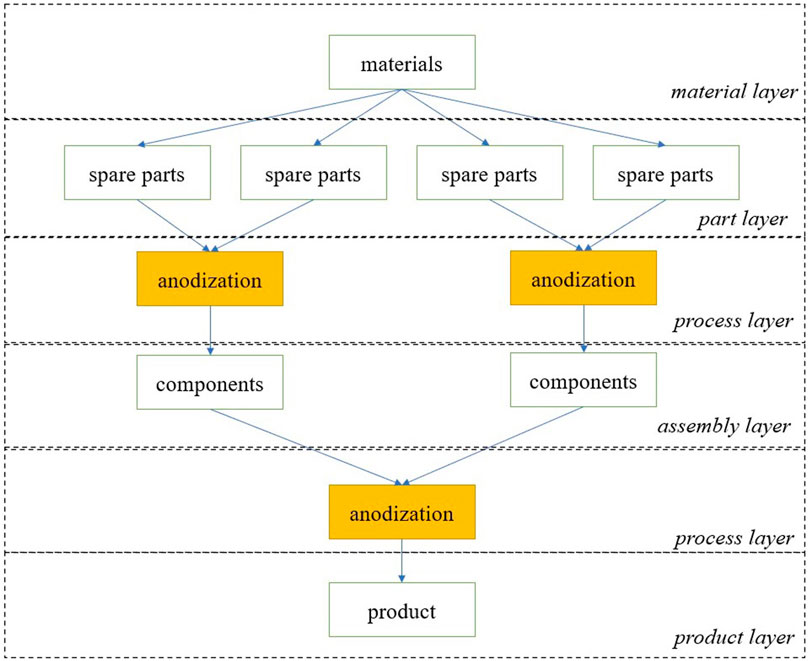
FIGURE 1. Concept diagram of the product production process. The white squares represent the tree structure of the product. The yellow squares represent the main research object of the paper, which is the anodizing process.
Anodizing treatment uses the principle of oxidation to generate aluminum oxide through electrolytic oxidation, which spontaneously generates a colored anodic oxide film with corrosion resistance and oxidation resistance. It is widely used in the manufacturing of aerospace and automotive products. Faced with the complex production environment of multi-variety and variable batch, enterprises can still collect the production cycle of parts and components through the industrial internet, but it is difficult to obtain anodized operation time. Although the operation time for a single variety can be obtained, after multiple varieties of products arrive at the anodizing workshop, a mixed line processing state is formed. In this complex production state, the uncertainty of product processing increases, such as the mutual influence between different varieties of products, waiting before processing, waiting for product inspection after processing, etc., ultimately leading to inconsistent product operation time. Anodizing, as the main process of product processing, if not accurately estimated, will significantly decrease the accuracy of product production planning arrangements. To further verify the actual situation of anodizing production, this article converts the anodizing task into a product order, collects the time when the anodizing workshop receives the product order and completes the product order, and obtains the operation time of a certain anodizing task through the difference between them. A schematic diagram of the time collection process for this assignment is shown in Figure 2.
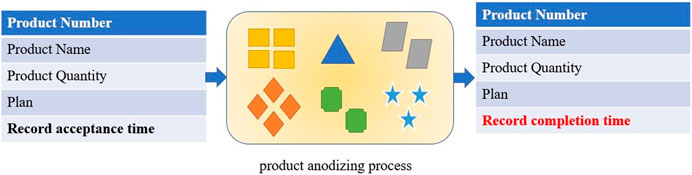
FIGURE 2. Design of the anodization process acquisition process. The tables on the left and right represent the production data of anodized orders recorded in the field in this article. The middle section displays the mixed production status of various types and batches of products.
The tasks in anodizing order are represented by
The acceptance time in Figure 2 will be stored in
In this paper, these anodization task data are transformed into the time vector of single product processing. This time vector is
The advantage of data preprocessing in this way is that it improves the convergence of calculations. At the same time, it facilitates predicting the running time of different batches of products in the future.
Through the data acquisition and pretreatment methods described in Section 3.1 and 3.2, the actual operation time data of the quenching process are obtained in this paper.
Over the past 2 years, the company collected a total of 4,689 samples of anodizing operation time. Through data preprocessing described in Section 3.2, 235 samples were obtained and plotted as the actual anodizing operation time curve, as shown in Figure 3. From Figure 3, it can be seen that in the state of multi-variety and batch mixed production, the product anodizing operation time exhibits nonlinear characteristics. Meanwhile, the graph shows the annual average homework time curve in orange. Compared to 2021, the average annual homework time in 2022 has increased and shows a nonlinear characteristic of higher fluctuations. Analysis reveals the reason for this distribution trend is the strong market demand in 2022, with an increase in orders held by enterprises and a clear conflict in anodizing resources. Instead, it increases the fluctuation of operation time, resulting in an increase in single piece anodizing operation time. In addition, from the actual operation time results collected, it can be seen that the standard anodizing operation time does not take into account the market rules of enterprise production and cannot be used for actual planned production scheduling. If the anodizing standard operation time is used during the scheduling of production, it will seriously affect the accuracy of the planned production. Therefore, accurately predicting the future anodizing operation time is crucial for enterprises to implement accurate production planning and scheduling.
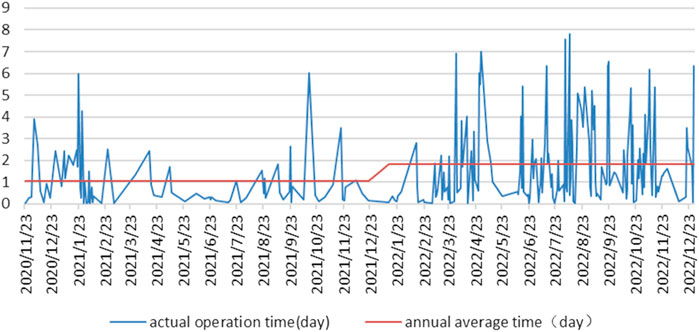
FIGURE 3. Actual anodizing operation time curves. The blue curve represents the actual working time of anodized products over the past 2 years. The red curve represents the average of the first and second halves of the blue curve.
The APERT-VC algorithm structure is shown in Figure 4. In this algorithm, A represents the attention mechanism, and PERT represents the program evaluation and review technique. VC represents the virtual command model.
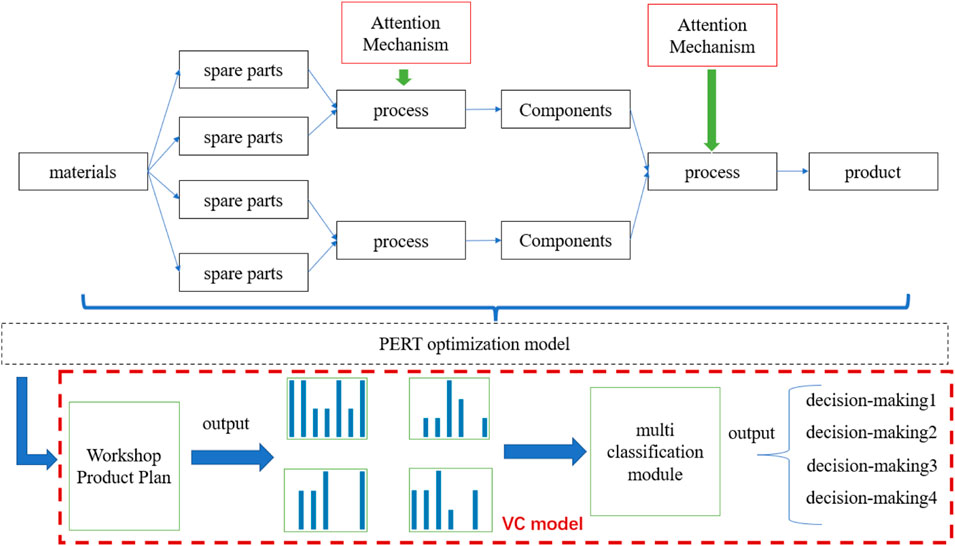
FIGURE 4. APERT-VC algorithm structure. The upper part of the figure shows that the operation time of the process is predicted through the attention mechanism, and the operation temporal database is improved. As the input of the PERT optimization model, the job temporal database forms the resource demand histogram. The histogram is used to make multiclassification decisions through the VC model.
From the above figure, it can be seen that the algorithm model is divided into two parts: upper and lower. The input is the product operation time data recorded in the production information system. The working time of parts and components can be determined using standard working time, while the working time of processes (anodizing) can be nonlinearly fitted and predicted using attention mechanisms. Why consider using attention mechanisms? The operation time of products with multiple varieties and varying batches exhibits nonlinear characteristics and fluctuates greatly. The attention mechanism can extract key information while ignoring irrelevant information to prevent gradient explosion and achieve better prediction results. This article combines the RNN model with an attention mechanism to predict and analyze production data with significant fluctuations. After accurately predicting the operation time using neural networks, the actual production data will be used as input conditions for the PERT model. The PERT model uses a network diagram to express the progress of various activities in a project and their interrelationships. Based on this, network analysis is conducted to calculate the time majority of each activity in the network, determine key activities and critical routes, and continuously adjust and optimize the network using time differences to obtain the shortest cycle and complete the project plan decomposition. The decomposed project plan has become the workshop product plan. The end of the workshop product plan is reflected in specific equipment and workstations. This article designs a VC model behind it. By using the VC model to classify specific resource plan diagrams on equipment and workstations, different classifications represent different production decisions, thus achieving the goal of enterprise management to assign decisions to each piece of equipment and workstation.
Manufacturing enterprises use PERT technology to plan and manage complex projects. PERT technology not only uses time parameters to discover the critical path of a project and perform real-time control but also derives the latest end time of each task through time parameters. Controllers often ask for specific product plans based on the latest completion schedule. To better integrate the predicted working time with the PERT model, this article defines the task in the PERT model as
If there are multiple paths on the left side of node i, the calculation formula for the earliest start time of work
Using the same approach, the latest start time
According to the connotation of PERT technology,
The core of PERT technology is to monitor critical work and critical paths through
After collecting and preprocessing actual production data, this paper found that in a multi-variety and variable batch production environment, the anodizing operation time of parts and components exhibits nonlinear characteristics and significant fluctuations. To select an appropriate algorithm for job time prediction, this paper uses four different algorithms, namely, MLP (multilayer perceptron), LSTM (long-term and short-term memory), enhanced local transformer and the convolutional attention mechanism. These four algorithms are widely accepted in time series data prediction projects. The convolutional attention mechanism has been proposed in recent years and is mostly applied in the medical industry, but has not yet been applied in manufacturing enterprise planning problems. The paper compares the convergence and prediction accuracy of different algorithms, verifies the advantages of the attention mechanism mechanism through comparative experiments, and analyzes the mechanism by which the advantages are achieved. Through calculation, the paper obtained the prediction results of different algorithms and the convergence process, as shown in Figure 5 and Figure 6.
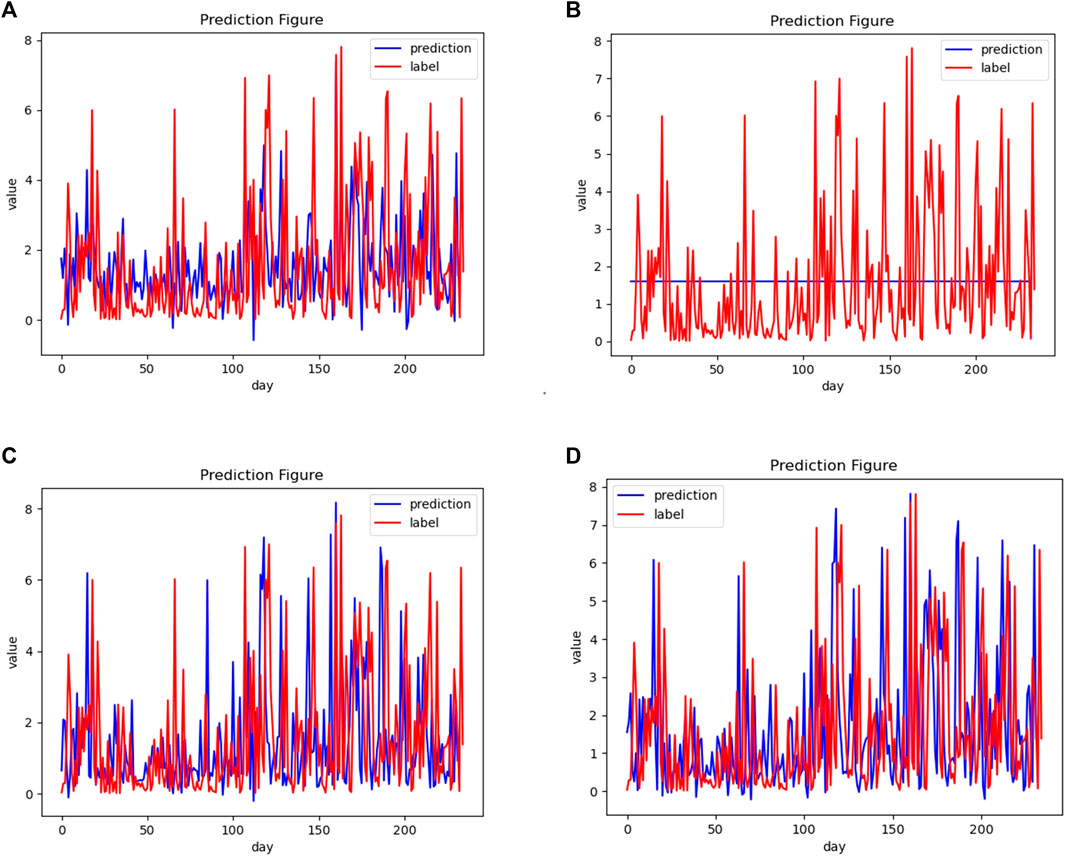
FIGURE 5. The fitting results of four different algorithms. The horizontal axis represents the number of days, and the vertical axis represents the operation time. The red curve represents the actual homework time data, while the blue curve represents the predicted homework time. (A) is the MLP algorithm result, (B) is the LSTM algorithm result, (C) is the TRANS algorithm result, and (D) is the AM algorithm result.
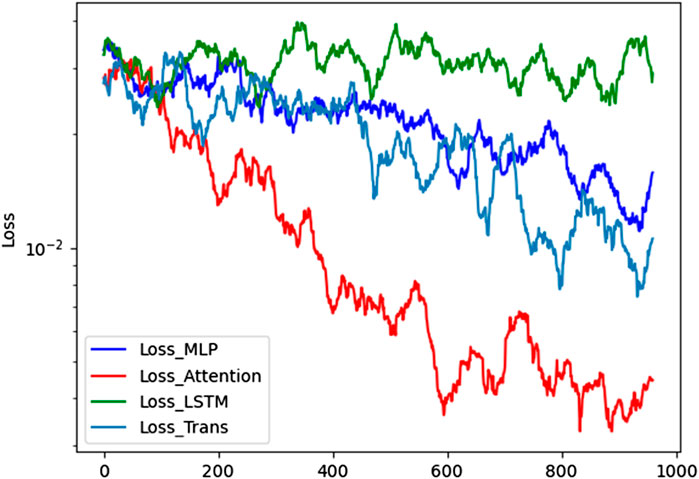
FIGURE 6. Comparison of loss values of four algorithms. The abscissa represents the number of cycles, and the ordinate represents the value of the loss function. The blue curve represents the MLP algorithm, the red curve represents the AM algorithm, the green curve represents the LSTM algorithm, and the blue curve represents the Trans algorithm.
It can be seen from Figure 5 and Figure 6 that the convolutional attention mechanism has obvious advantages over MLP, LSTM and Trans in predicting the operation time of multivariety and variable batch mixed production.
In these results, paper further validated the LSTM gradient vanishing problem. LSTM processes tags in order and maintains a hidden state. This state updates with each new input and represents the entire sequence. In theory, LSTM can maintain the propagation of important information over infinitely long sequences. However, for time series data with large fluctuations, the vanishing gradient problem is very serious. From Figure 5, it can be seen that the LSTM model has almost lost its fitting ability for time series data with large fluctuations. Similarly, from Figure 6, it can be seen that the LSTM model is difficult to obtain convergence results.
In addition, this article uses a locally enhanced transformer model. Compared to the initial transformer model, this model adds a casual convolutional, which can better solve the problem of the initial transformer model being insensitive to pre- and postinformation and better integrate local information. Therefore, the operational results of the locally enhanced transformer model are slightly higher than those of the MLP model but lower than those of the convolutional attention mechanism. The convolutional attention mechanism adopts a global attention mechanism architecture, which can consider more data source information and achieve better computational results compared to the locally enhanced transformer model.
Then, the paper compared the data of the first week of operation in 2023 predicted by the four models, the data of the traditional mean method and the actual data collected, as shown in Table 1.
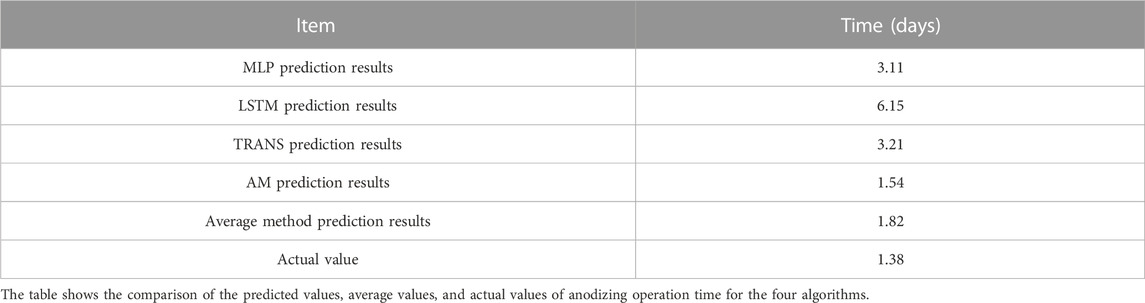
TABLE 1. Multiple prediction results and actual results.
From the final results of the prediction, the attention mechanism prediction obtained the optimal result, with a predicted value of 1.54 days, which is only a 10% error compared to the true value of 1.38. Due to the poor convergence of the MLP, LSTM, and TRANS models, there is a significant gap between the actual values and the lack of predictability. The average achieved a good result of 1.82 days, but the error was approximately 30%. The predictive accuracy of the attention mechanism is three times that of the average. Y Yao et al. (2023) found in the medical field that the AM algorithm does have advantages over other algorithms in predicting long-term continuous time series. The results of this interdisciplinary study indirectly support our analysis. In addition, the paper conducted comparative experiments on the homework time data of heat treatment. The prediction errors of MLP and LSTM are 247% and 351%, respectively, and the prediction error of attention mechanism is 11%.
Accurate time is the foundation of planning and scheduling. After obtaining accurate homework time in this article, the project plan was decomposed using the APERT model mentioned earlier. The decomposed plan was communicated to the workshop planning system through the smarteam system to complete the specific production task dispatch.
Usually, in a large factory, there are thousands of sets of equipment. All dispatch tasks will be assigned to specific equipment. Each device outputs a real-time resource demand plan histogram. In a complex production environment with multiple varieties and varying batches, these histograms have many possibilities. Managers will analyze the situation in the histogram and provide improvement strategies. Assuming the factory has 1,000 devices, according to the weekly drawing method, 50,000 images will appear every year. It is difficult to manage such a large amount of on-site data solely relying on manual labor.
The VC algorithm proposed in this article is a novel concept. Managers will recognize the features in the resource demand plan histogram and make decision intentions. The VC algorithm utilizes the advantages of deep learning in feature recognition and multiclassification problems, allowing machines to replace manual histogram classification. Each classification result corresponds to one or several strategies. In this way, machines can be used instead of managers to issue commands to equipment or workstations. The logic of the VC algorithm is shown in Figure 7.
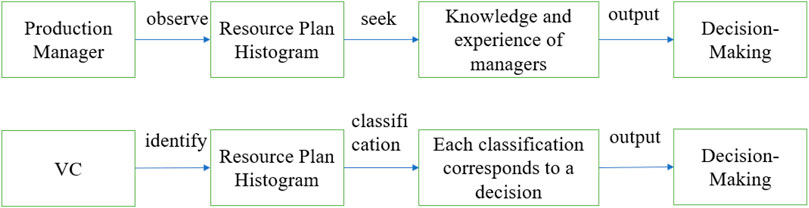
FIGURE 7. Flowchart of the VC algorithm. The upper half of the figure represents the process by which enterprise managers identify and make decisions on resource demand histograms. The lower half of the figure represents the process of VC model classifying and making decisions on resource demand histograms.
Below, the paper will demonstrate the application of the VC algorithm in specific engineering aspects. Based on the knowledge and experience of managers, this paper has summarized four forms of demand histograms using machined shell segment products as an example, as shown in Figure 8. These four forms are left distribution, right distribution, middle distribution, and two end distribution.
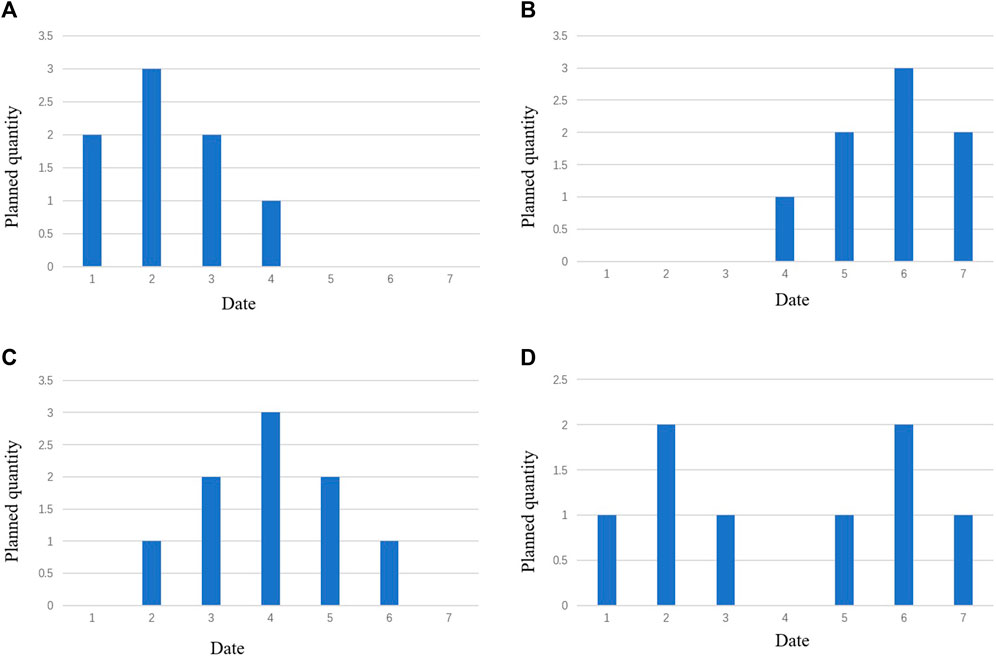
FIGURE 8. Four distribution forms of resource histograms. The horizontal axis represents 1–7 days, while the vertical axis represents the number of tasks undertaken on the device. (A) represents the left distribution, (B) represents the right distribution, (C) represents the middle distribution, and (D) represents the two end distributions.
Figure 8A shows the distribution curve on the left, with the optimization direction on the right. The specific management strategy is to delay the plans that exceed production capacity, ensuring that all tasks are completed within 7 days and minimizing the impact. Figure 8B shows the distribution curve on the right side, with the optimization direction on the left side. The specific management strategy is to schedule centralized tasks during device idle periods. Due to the plan moving forward, it will not affect the total project duration. Figure 8C shows the middle distribution curve, with the optimization direction on both sides. The specific management strategy is to prioritize moving centralized tasks to the left, and if the left side cannot bear it, then moving to the right is considered. Figure 8D shows the distribution curve at both ends, with four optimization directions. The specific management strategy is to move the plan toward the intermediate idle period.
Therefore, the paper can classify all histograms, and each classification result corresponds to management decisions and optimization methods. In addition, controllers can also monitor in real time whether the current production situation is high risk or low risk. This article tends to use the iResNet algorithm for classification. The iResNet algorithm is an improved version of the ResNet algorithm. On the basis of ResNet, a new network structure is introduced to enhance the information flow and network expression ability, reduce information loss, and increase the learning ability of the residual module. Therefore, this paper will compare and analyze the results of iResNet and ResNet later to prove that algorithm engineers have chosen a better algorithm. To increase the effectiveness of the algorithm comparison, the paper also included comparative experiments with the SAE algorithm.
This article compares the accuracy and convergence of three algorithms. The training sample is 700, and the testing sample is 300. The training process of the three various algorithms is shown in Figure 9.
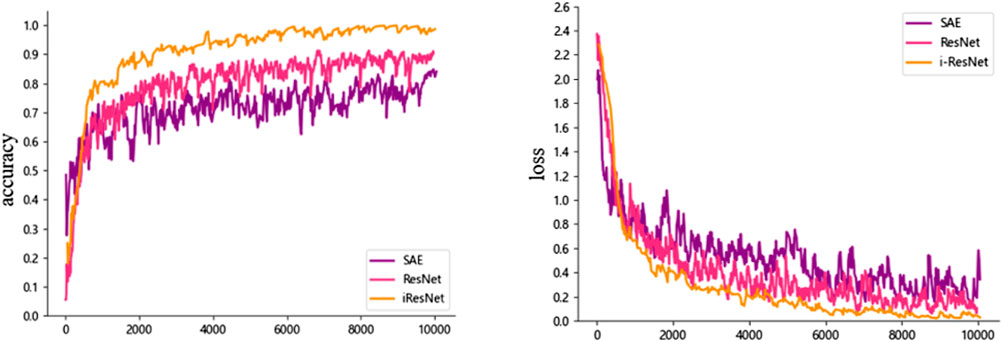
FIGURE 9. Accuracy and loss values during the training process of the three algorithms. The horizontal axis represents the number of training sessions, and the vertical axis represents the accuracy and loss values. The purple curve represents the SAE algorithm, the red curve represents the ResNet algorithm, and the orange curve represents the i-ResNet algorithm.
From the training process, it can be seen that the convergence of the iResNet model performs best among the three algorithms. This article presents a comparison between the predicted and true values of the four classifications in an explicit manner, as shown in Figure 10.

FIGURE 10. Test results of the three algorithms. The vertical axis represents four classifications of true values, while the horizontal axis represents four classifications of predicted values. Each small grid represents the proportion of predicted results, with a larger proportion indicating a darker color. Diagonal lines indicate the consistency between predicted and true values, where a darker the color of the diagonal corresponds with a higher accuracy of the prediction.
In addition to the explicit treatment, the paper evaluated the classification results using four classification evaluation indicators: accuracy, precision, recall, and F1 score, as shown in Table 2. From Table 2, it can be seen that the accuracy, precision, recall, and F1 score of iResNet all reached 98%, performing the best among the three algorithms. Next is ResNet. ResNet’s Accuracy, Precision, Recall, and F1 Score all reached over 90%. The worst classification result is SAE. By enhancing the information flow, reducing the information loss, and enhancing the learning ability of the residual module, iResNet is indeed better than ResNet in dealing with multiclassification problems. From this example, the accuracy of iResNet has increased by 6.5% compared to ResNet.

TABLE 2. Comparison table of multiple classification evaluation indicators for three algorithms.
This paper focuses on manufacturing enterprises in a complex production environment with multiple varieties and varying batches. Aiming at the hierarchical nature of planning, an APERT-VC model is proposed to solve the problems of mixed line operation time prediction, workshop plan decomposition, and rapid decision-making of equipment plan classification.
The APERT-VC model is divided into two layers, where the attention mechanism is used to collect work plan time in APERT, and the project plan is decomposed into workshop plans through PERT technology. Through comparative experiments, it was found that the results of the attention mechanism have better accuracy compared to LSTM, MLP, and locally enhanced TRAN.
This article innovatively proposes a new concept, namely, the VC (virtual command) of the APERT-VC model. The VC model utilizes the advantages of machine learning in feature extraction and multiclassification and makes multiclassification decisions based on the resource demand histogram of management. Through comparative experiments, it was found that iResNet has significant advantages in handling multiclassification problems, with VC models having an accuracy rate of up to 98%, which can be used for engineering applications.
The paper mainly focuses on the research work of project planning and workshop resource planning. The new model proposed in the paper solves the problem of precise decomposition of project plans and management of workshop resource plans, and is suitable for the two-level planning structure of enterprises and workshops. Through machine learning algorithms, the paper solved the problem of difficult to predict the operation time of multi variety and variable batch products, and successfully learned the behavior and knowledge of scheduling personnel in making workshop resource planning decisions. This study can simulate scheduling personnel conducting on-site command and decision-making.
This study is suitable for traditional manufacturing enterprises such as aerospace, aviation, and shipbuilding. Through the application of this algorithm, a connection can be established between factory level planning and workshop planning, and the workload of on-site scheduling personnel can be reduced to a certain extent.
The algorithm generates different decisions and measures by simulating the behavior of scheduling personnel. However, these decisions and measures still rely on the dispatcher’s knowledge base. In the future, the research team will establish a plan optimization model for high-risk resources based on this algorithm. Continue to study the behavior of scheduling personnel in adjusting and optimizing plans, and establish a new type of plan optimization model through reinforcement learning.
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
LW and HL contributed to the conceptualization and design of this study. ML proposed a method for data processing. LW organized a database, conducted statistical analysis, and wrote the first draft of the manuscript. MX and YW contributed to revising the manuscript. All authors contributed to the article and approved the submitted version.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the National Key Research and Development Program of China (2021YFB1716200) and the Research Funds for Leading Talents Program (048000514122549).
Authors LW, MX, and YW were employed by Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ahmed, M. A., Abbas, G., Jumani, T. A., Rashid, N., Bhutto, A. A., and Eldin, S. M. (2023). Techno-economic optimal planning of an industrial microgrid considering integrated energy resources. Front. Energy Res. 11, 1145888. doi:10.3389/fenrg.2023.1145888
Arık, O. A. (2021). Population-based Tabu search with evolutionary strategies for permutation flow shop scheduling problems under effects of position-dependent learning and linear deterioration. Soft Comput. 25 (2), 1501–1518. doi:10.1007/s00500-020-05234-7
Asghari, A., Sohrabi, M. K., and Yaghmaee, F. (2021). Task scheduling, resource provisioning, and load balancing on scientific workflows using parallel SARSA reinforcement learning agents and genetic algorithm. J. Supercomput. 77, 2800–2828. doi:10.1007/s11227-020-03364-1
Bożejko, W., Gnatowski, A., Pempera, J., and Wodecki, M. (2017). Parallel tabu search for the cyclic job shop scheduling problem. Comput. Industrial Eng. 113, 512–524. doi:10.1016/j.cie.2017.09.042
Chaouch, I., Driss, O. B., and Ghedira, K. (2017). A modified ant colony optimization algorithm for the distributed job shop scheduling problem. Procedia Comput. Sci. 112, 296–305. doi:10.1016/j.procs.2017.08.267
Chen, T. L., Cheng, C. Y., and Chou, Y. H. (2020). Multi-objective genetic algorithm for energy-efficient hybrid flow shop scheduling with lot streaming. Ann. Operations Res. 290, 813–836. doi:10.1007/s10479-018-2969-x
Deepalakshmi, P., and Shankar, K. (2020). Role and impacts of ant colony optimization in job shop scheduling problems: a detailed analysis. Evol. Comput. Sched., 11–35. doi:10.1002/9781119574293.ch2
Du, Y., Li, J. Q., Chen, X. L., Duan, P. Y., and Pan, Q. K. (2022). Knowledge-based reinforcement learning and estimation of distribution algorithm for flexible job shop scheduling problem. IEEE Trans. Emerg. Top. Comput. Intell. 7, 1036–1050. doi:10.1109/tetci.2022.3145706
Elmi, A., and Topaloglu, S. (2017). Cyclic job shop robotic cell scheduling problem: ant colony optimization. Comput. industrial Eng. 111, 417–432. doi:10.1016/j.cie.2017.08.005
Engin, O., and Güçlü, A. (2018). A new hybrid ant colony optimization algorithm for solving the no-wait flow shop scheduling problems. Appl. Soft Comput. 72, 166–176. doi:10.1016/j.asoc.2018.08.002
Fan, B., Yang, W., and Zhang, Z. (2019). Solving the two-stage hybrid flow shop scheduling problem based on mutant firefly algorithm. J. Ambient Intell. Humaniz. Comput. 10, 979–990. doi:10.1007/s12652-018-0903-3
Gmira, M., Gendreau, M., Lodi, A., and Potvin, J. Y. (2021). Tabu search for the time-dependent vehicle routing problem with time windows on a road network. Eur. J. Operational Res. 288 (1), 129–140. doi:10.1016/j.ejor.2020.05.041
González-Neira, E. M., Urrego-Torres, A. M., Cruz-Riveros, A. M., Henao-García, C., Montoya-Torres, J. R., Molina-Sánchez, L. P., et al. (2019). Robust solutions in multi-objective stochastic permutation flow shop problem. Comput. Industrial Eng. 137, 106026. doi:10.1016/j.cie.2019.106026
Hao, X., Gen, M., Lin, L., and Suer, G. A. (2017). Effective multiobjective EDA for bi-criteria stochastic job-shop scheduling problem. J. intelligent Manuf. 28, 833–845. doi:10.1007/s10845-014-1026-0
Harbaoui, H., and Khalfallah, S. (2020). Tabu-search optimization approach for no-wait hybrid flow-shop scheduling with dedicated machines. Procedia Comput. Sci. 176, 706–712. doi:10.1016/j.procs.2020.09.043
Huang, R. H., and Yu, T. H. (2017). An effective ant colony optimization algorithm for multi-objective job-shop scheduling with equal-size lot-splitting. Appl. Soft Comput. 57, 642–656. doi:10.1016/j.asoc.2017.04.062
Jamrus, T., Chien, C. F., Gen, M., and Sethanan, K. (2017). Hybrid particle swarm optimization combined with genetic operators for flexible job-shop scheduling under uncertain processing time for semiconductor manufacturing. IEEE Trans. Semicond. Manuf. 31 (1), 32–41. doi:10.1109/tsm.2017.2758380
Kato, E. R. R., de Aguiar Aranha, G. D., and Tsunaki, R. H. (2018). A new approach to solve the flexible job shop problem based on a hybrid particle swarm optimization and random-restart hill climbing. Comput. Industrial Eng. 125, 178–189. doi:10.1016/j.cie.2018.08.022
Komaki, G. M., Sheikh, S., and Malakooti, B. (2019). Flow shop scheduling problems with assembly operations: a review and new trends. Int. J. Prod. Res. 57 (10), 2926–2955. doi:10.1080/00207543.2018.1550269
Lei, D., Zheng, Y., and Guo, X. (2017). A shuffled frog-leaping algorithm for flexible job shop scheduling with the consideration of energy consumption. Int. J. Prod. Res. 55 (11), 3126–3140. doi:10.1080/00207543.2016.1262082
Lei, Q., Guo, W., and Song, Y. (2018). Integrated scheduling algorithm based on an operation relationship matrix table for tree-structured products. Int. J. Prod. Res. 56 (16), 5437–5456. doi:10.1080/00207543.2018.1442942
Li, J., Han, Y., Gao, K., Xiao, X., and Duan, P. (2023). Bi-population balancing multi-objective algorithm for fuzzy flexible job shop with energy and transportation. IEEE Trans. Automation Sci. Eng., 1–17. doi:10.1109/tase.2023.3300922
Li, J. Q., Du, Y., Gao, K. Z., Duan, P. Y., Gong, D. W., Pan, Q. K., et al. (2021). A hybrid iterated greedy algorithm for a crane transportation flexible job shop problem. IEEE Trans. Automation Sci. Eng. 19 (3), 2153–2170. doi:10.1109/tase.2021.3062979
Li, J. Q., Duan, P., Cao, J., Lin, X. P., and Han, Y. Y. (2018). A hybrid Pareto-based tabu search for the distributed flexible job shop scheduling problem with E/T criteria. IEEE Access 6, 58883–58897. doi:10.1109/access.2018.2873401
Liu, G. S., Zhou, Y., and Yang, H. D. (2017). Minimizing energy consumption and tardiness penalty for fuzzy flow shop scheduling with state-dependent setup time. J. Clean. Prod. 147, 470–484. doi:10.1016/j.jclepro.2016.12.044
Lu, P. H., Wu, M. C., Tan, H., Peng, Y. H., and Chen, C. F. (2018). A genetic algorithm embedded with a concise chromosome representation for distributed and flexible job-shop scheduling problems. J. Intelligent Manuf. 29, 19–34. doi:10.1007/s10845-015-1083-z
Luo, S. (2020). Dynamic scheduling for flexible job shop with new job insertions by deep reinforcement learning. Appl. Soft Comput. 91, 106208. doi:10.1016/j.asoc.2020.106208
Marichelvam, M. K., Geetha, M., and Tosun, Ö. (2020). An improved particle swarm optimization algorithm to solve hybrid flowshop scheduling problems with the effect of human factors–A case study. Comput. Operations Res. 114, 104812. doi:10.1016/j.cor.2019.104812
Nouiri, M., Bekrar, A., Jemai, A., Trentesaux, D., Ammari, A. C., and Niar, S. (2017). Two stage particle swarm optimization to solve the flexible job shop predictive scheduling problem considering possible machine breakdowns. Comput. industrial Eng. 112, 595–606. doi:10.1016/j.cie.2017.03.006
Park, J., Chun, J., Kim, S. H., Kim, Y., and Park, J. (2021). Learning to schedule job-shop problems: representation and policy learning using graph neural network and reinforcement learning. Int. J. Prod. Res. 59 (11), 3360–3377. doi:10.1080/00207543.2020.1870013
Shao, Z., Pi, D., and Shao, W. (2018). Estimation of distribution algorithm with path relinking for the blocking flow-shop scheduling problem. Eng. Optim. 50 (5), 894–916. doi:10.1080/0305215x.2017.1353090
Sha, Z., Xue, F., and Zhu, J. (2019). Scheduling strategy of cloud robots based on parallel reinforcement learning. J. Comput. Appl. 39 (2), 501. doi:10.11772/j.issn.1001-9081.2018061406
Shi, F., Zhao, S., and Meng, Y. (2020). Hybrid algorithm based on improved extended shifting bottleneck procedure and GA for assembly job shop scheduling problem. Int. J. Prod. Res. 58 (9), 2604–2625. doi:10.1080/00207543.2019.1622052
Silva, M. A. L., de Souza, S. R., Souza, M. J. F., and Bazzan, A. L. C. (2019). A reinforcement learning-based multi-agent framework applied for solving routing and scheduling problems. Expert Syst. Appl. 131, 148–171. doi:10.1016/j.eswa.2019.04.056
Swarup, S., Shakshuki, E. M., and Yasar, A. (2021). Task scheduling in cloud using deep reinforcement learning. Procedia Comput. Sci. 184, 42–51. doi:10.1016/j.procs.2021.03.016
Wang, K., Luo, H., Liu, F., and Yue, X. (2017). Permutation flow shop scheduling with batch delivery to multiple customers in supply chains. IEEE Trans. Syst. Man, Cybern. Syst. 48 (10), 1826–1837. doi:10.1109/tsmc.2017.2720178
Wang, S., Wang, X., Chu, F., and Yu, J. (2020). An energy-efficient two-stage hybrid flow shop scheduling problem in a glass production. Int. J. Prod. Res. 58 (8), 2283–2314. doi:10.1080/00207543.2019.1624857
Wang, Z., Zhang, J., and Yang, S. (2019). An improved particle swarm optimization algorithm for dynamic job shop scheduling problems with random job arrivals. Swarm Evol. Comput. 51, 100594. doi:10.1016/j.swevo.2019.100594
Wu, C. C., Chen, J. Y., Lin, W. C., Lai, K., Liu, S. C., and Yu, P. W. (2018). A two-stage three-machine assembly flow shop scheduling with learning consideration to minimize the flowtime by six hybrids of particle swarm optimization. Swarm Evol. Comput. 41, 97–110. doi:10.1016/j.swevo.2018.01.012
Xie, Z., Pei, L., Jia, Q., and Yu, X. (2020). A process migration oriented multi-shop integrated scheduling algorithm for double objectives. Int. J. Coop. Inf. Syst. 29 (01n02), 2040008. doi:10.1142/s0218843020400080
Xie, Z., Yang, D., Ma, M., and Yu, X. (2020). An improved artificial bee colony algorithm for the flexible integrated scheduling problem using networked devices collaboration. Int. J. Coop. Inf. Syst. 29 (01n02), 2040003. doi:10.1142/s0218843020400031
Yao, Y., Liu, L., Liu, X., Wang, M., and Sai, X. (2023). Internet of medical things for VTE patients in ICU: a self-attention mechanism-based energy-efficient risk identification scheduling algorithm. Mod. Phys. Lett. B 37 (03), 2250192. doi:10.1142/s0217984922501925
Yu, C., Semeraro, Q., and Matta, A. (2018). A genetic algorithm for the hybrid flow shop scheduling with unrelated machines and machine eligibility. Comput. Operations Res. 100, 211–229. doi:10.1016/j.cor.2018.07.025
Zangari, M., Mendiburu, A., Santana, R., and Pozo, A. (2017). Multiobjective decomposition-based mallows models estimation of distribution algorithm. A case of study for permutation flowshop scheduling problem. Inf. Sci. 397, 137–154. doi:10.1016/j.ins.2017.02.034
Zarrouk, R., Bennour, I. E., and Jemai, A. (2019). A two-level particle swarm optimization algorithm for the flexible job shop scheduling problem. Swarm Intell. 13, 145–168. doi:10.1007/s11721-019-00167-w
Zhang, C., Song, W., Cao, Z., Zhang, J., Tan, P. S., and Chi, X. (2020). Learning to dispatch for job shop scheduling via deep reinforcement learning. Adv. Neural Inf. Process. Syst. 33, 1621–1632.
Zhang, X., Ma, C., and Wu, J. (2019). Multi-batch integrated scheduling algorithm based on time-selective. Multimedia Tools Appl. 78, 29989–30010. doi:10.1007/s11042-018-6805-8
Zhang, X., Xie, Z., Xin, Y., and Yang, J. (2019). Time-selective integrated scheduling algorithm with backtracking adaptation strategy. Expert Syst. 36 (3), e12305. doi:10.1111/exsy.12305
Zhang, Y., Yu, Y., Zhang, S., Luo, Y., and Zhang, L. (2019). Ant colony optimization for Cuckoo Search algorithm for permutation flow shop scheduling problem. Syst. Sci. Control Eng. 7 (1), 20–27. doi:10.1080/21642583.2018.1555063
Zhao, F., Qin, S., Yang, G., Ma, W., Zhang, C., and Song, H. (2019). A factorial based particle swarm optimization with a population adaptation mechanism for the no-wait flow shop scheduling problem with the makespan objective. Expert Syst. Appl. 126, 41–53. doi:10.1016/j.eswa.2019.01.084
Keywords: mixed production lines, multiple varieties, variable batches, APERT-VC, machine learning
Citation: Wang L, Liu H, Xia M, Wang Y and Li M (2023) Research on a multilevel scheduling model for multi variety and variable batch production environments based on machine learning. Front. Energy Res. 11:1251335. doi: 10.3389/fenrg.2023.1251335
Received: 10 July 2023; Accepted: 30 November 2023;
Published: 29 December 2023.
Edited by:
Chixin Xiao, University of Wollongong, AustraliaReviewed by:
Marichelvam M. K., Mepco Schlenk Engineering College, IndiaCopyright © 2023 Wang, Liu, Xia, Wang and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Haibin Liu, bGl1aGJAYmp1dC5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.