 Tao Ku
Tao Ku Jin Li
Jin Li Jinxin Liu1,2,3
Jinxin Liu1,2,3
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Energy Res. , 08 August 2022
Sec. Smart Grids
Volume 10 - 2022 | https://doi.org/10.3389/fenrg.2022.957869
This article is part of the Research Topic Evolutionary Multi-Objective Optimization Algorithms in Microgrid Power Dispatching View all 16 articles
To solve the motion planning of the live working manipulator, this research proposes a hybrid data-model–driven algorithm called the P-SAC algorithm. In the model-driven part, to avoid obstacles and make the trajectory as smooth as possible, we designed the trajectory model of the sextic polynomial and used the PSO algorithm to optimize the parameters of the trajectory model. The data generated by the model-driven part are then passed into the replay buffer to pre-train the agent. Meanwhile, to guide the manipulator in reaching the target point, we propose a reward function design based on region guidance. The experimental results show that the P-SAC algorithm can reduce unnecessary exploration of reinforcement learning and can improve the learning ability of the model-driven algorithm for the environment.
With the rapid growth of the economy, electricity demand continues to rise, posing higher and higher challenges to the power supply. To meet these challenges, the application of deep reinforcement learning (Zhang et al., 2018), robotics (Menendez et al., 2017), swarm intelligence (SI) algorithms (Ma et al., 2021c), and other artificial intelligence technologies to solve resource scheduling (Ma et al., 2021d), inspection, maintenance, and others has become the smart grid’s development direction.
The live work of overhauling the circuit under the premise of continuous power supply of the power grid can significantly improve the safety of the power supply. However, there are many restrictions on manual live work due to the danger of live work itself and the working environment. Therefore, it is critical to use technology to replace manual live work with robots. The working environment of live working manipulators is always complicated and ever-changing. So, the major challenge is how to determine a suitable path/trajectory in a complex and changeable environment with obstacles so that the manipulator can reach the target point (Siciliano et al., 2009; Lynch and Park 2017).
The motion planning of manipulators can be divided into two categories: joint angle coordinate motion planning and Cartesian coordinate motion planning. The manipulator’s end-effector is the planning reference object in the Cartesian coordinate. However, due to the inverse kinematics of the manipulator, there may be many problems, such as a lot of calculation, ease to reach the singularity, the near-point in the Cartesian coordinate system taking a large rotation joint angle, and large instantaneous speed (Choset et al., 2005; Gasparetto et al., 2015; Lynch and Park 2017). The motion planning in the joint angular coordinate system differs much from human intuitive feelings, but it can successfully avoid problems in the rectangular coordinate system while also planning the manipulator’s joint angular velocity and angular acceleration. So, it can get a whole trajectory of the manipulator’s joint after planning, which is why it is also known as trajectory planning (Gasparetto et al., 2012; Gasparetto et al., 2015; Lynch and Park 2017).
The obstacle avoidance motion planning of the manipulator has always been a research hotspot. The artificial potential field method (Khatib 1985) is an earlier algorithm, which designs the target position as a gravitational field and the obstacle position as a repulsion field, so that the real-time avoidance of the manipulator can be accomplished. However, such algorithms tend to fall into local minima and move slowly near the obstacles. Some search-based algorithms, such as rapidly exploring random trees (RRTs) (Wei and Ren 2018; Cao et al., 2019), find the obstacle avoidance path of the manipulator through searching, but such algorithms generally only consider obstacle avoidance of the manipulator end-effector and find it too difficult to consider global obstacle avoidance. At the same time, such algorithms also need to increase the computational cost of path smoothing.
In recent years, deep learning and deep reinforcement learning have brought remarkable results to many fields, such as computer vision (Krizhevsky et al., 2017; Yang et al., 2021), natural language processing (Devlin et al., 2019), and industrial process optimization (Ma et al., 2021b). Many achievements have been made using deep learning and deep reinforcement learning for manipulators (Yu et al., 2021; Hao et al., 2022). Wu Yunhua applied the deep reinforcement learning algorithm to the trajectory planning of a space dual manipulator (Wu et al., 2020). Kalashnikov proposed a vision-based closed-loop grasping algorithm framework for manipulators (Kalashnikov et al., 2018). Ignasi Clavera proposed a modular and reward-guided reinforcement learning algorithm for manipulator pushing tasks (Clavera et al., 2017). The intelligence and learning ability of the manipulator are substantially improved by these algorithms; however, the training period is excessively long and consumes more resources. For example, QT-opt (Kalashnikov et al., 2018) employed seven robots and ten GPUs and took 4 months to train.
Model-driven algorithms are built on the foundation of developing a mechanism model, and the correctness of the model is directly tied to the algorithm’s performance. Model-driven algorithms’ key priority is to figure out how to optimize model parameters to improve model performance. Swarm algorithms, such as the genetic algorithm (GA) (Holland 1992), particle swarm optimization (PSO) (Kennedy and Eberhart 1995), and brainstorming optimization (BSO) (Shi 2011), are commonly used in parameter optimization. In difficult multi-objective optimization situations, these algorithms can get good results (Ma et al., 2021a; Ma et al., 2021c). In the aspect of manipulator motion planning, some achievements have been made in optimizing the parameters of the trajectory model by using the swarm intelligence algorithm. The trajectory model after optimizing the parameters can make the robotic arm avoid obstacles and successfully reach the target point (Rulong and Wang 2014; Wang et al., 2015). However, such algorithms rely on offline training and find it difficult to avoid obstacles in real time. When the environment changes, the algorithms must be retrained and generalization capacity becomes poor. Furthermore, these methods are incapable of avoiding model-building errors.
Based on the above research, this research provides a hybrid data-model–driven algorithm framework that can avoid non-essential exploration during the early stages of deep reinforcement learning and can solve the problems of model-driven algorithms’ poor generalization. The main contributions are as follows:
1) A framework for algorithms driven by data and model, which uses the reward function to merge model-driven and data-driven algorithms, is proposed.
2) The P-SAC algorithm, which mixed PSO and SAC, is proposed based on the proposed hybrid data-model–driven algorithm framework. The algorithm optimizes the model parameters with PSO first and then pre-trains the agent before letting it study to interact with the environment.
3) P-SAC is applied to the motion planning of the live working manipulator, and the manipulator can successfully reach the target point without colliding with obstacles. Compared with the SAC that is not model-driven, P-SAC has a faster convergence speed and better final performance.
The motion planning problem of the manipulator can be described as follows.
Given the source point
Definition 1: Let
In 1995, Kennedy and Eberhart (1995) proposed a particle swarm optimization algorithm based on the idea of birds foraging. In PSO, the potential solution to the optimization problem is a “particle” in the search space, and all particles have two properties: fitness value and speed. The fitness value is determined by the function to be optimized. And the larger fitness value (or smaller) means the particle is better. The speed determines the flying direction and distance of the particle. The process of PSO is that the particle follows the current optimal particle to search in the solution space.
Deep reinforcement learning combines the data representation ability of deep learning and the decision-making ability of reinforcement learning. In 2013, the proposal of the DQN (Mnih et al., 2013) algorithm marked the beginning of the era of deep reinforcement learning algorithms. Since DQN is difficult to solve the continuous action space problem, Lillicrap Timothy proposed DDPG, which combined with the actor–critic framework (Lillicrap et al., 2019). However, the DDPG algorithm is sensitive to hyperparameters and is challenging to use, so the SAC (Haarnoja et al., 2018; Haarnoja et al., 2019) algorithm is proposed.
SAC introduces the entropy of the strategy into the objective function to maximize the expected cumulative return while making the strategy as random as possible. Its objective function is as follows:
The temperature coefficient
There are a lot of ineffective explorations in the early stages of deep reinforcement learning, and model-driven algorithms cannot avoid errors in model design and lack intelligence. As illustrated in Figure 1, this research provides a hybrid data-model–driven algorithm framework. The details are as follows:
1)
2)
3)
4)
5)
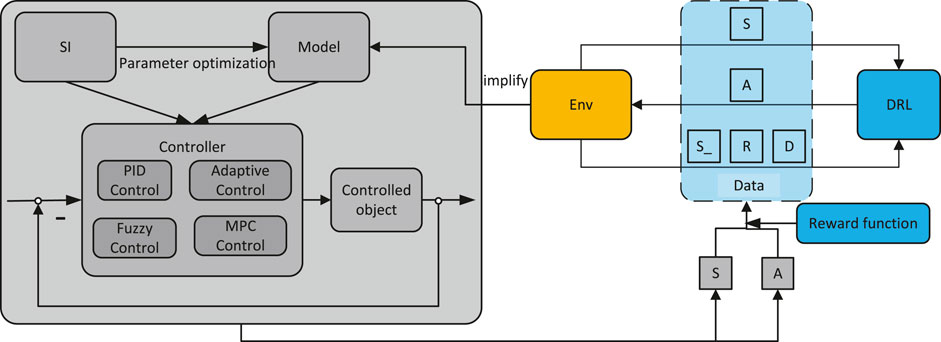
FIGURE 1. Framework for algorithms driven by data and model.
The motion planning of the manipulator inevitably involves the forward and inverse kinematics of the manipulator, that is, getting the position and pose of the manipulator’s end-effector from each joint angle and getting the angle of each joint from the position and pose of the manipulator’s end-effector.
The creation of the manipulator’s kinematics model is the most fundamental task in manipulator motion planning. The DH model (Denavit and Hartenberg, 2021) is a way proposed in the 1950s to express the coordinate system pose relationship between the two manipulator joints.
Taking the Puma 560 robot selected in this research as an example, the coordinate relationship of each joint is shown in Figure 2, and the DH parameter table is shown in Table 1.
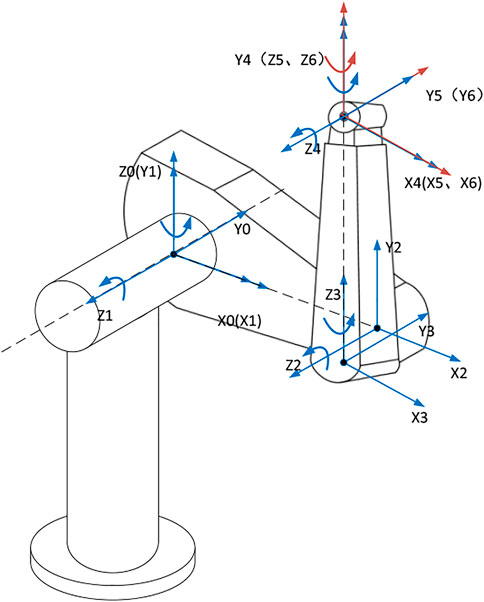
FIGURE 2. Transformation relationship of the coordinate system of each joint of the manipulator Puma 560.
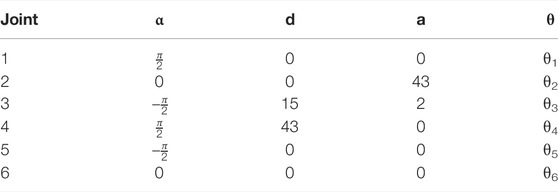
TABLE 1. DH model parameters of the manipulator Puma 560.
Since most of the obstacles in the working environment of the live working manipulator should be wires, the obstacles are simplified as cylinders in this research. The obstacle avoidance of the manipulator, on the contrary, cannot be attributed just to the obstacle avoidance problem at the manipulator’s end-effector, and the obstacle avoidance of each manipulator’s link must also be considered. As a result, to solve the manipulator’s obstacle avoidance problem, geometric knowledge must be combined. This research employs the cylindrical to envelope links and obstacle, as illustrated in Figure 3.
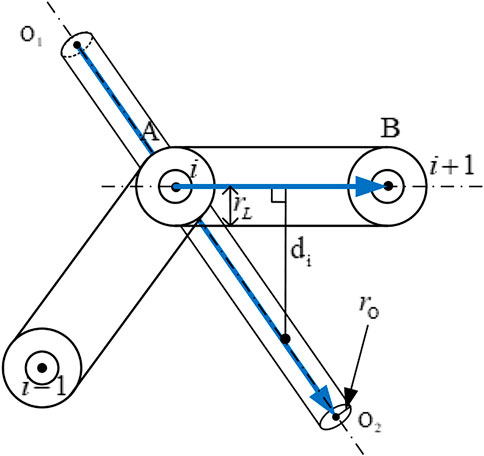
FIGURE 3. Schematic diagram of the manipulator obstacle avoidance detection model.
The link between the manipulator’s joints
where
where
and
Here,
Here,
So, it can be determined whether the manipulator collides with the obstacle by finding out whether each link of the manipulator collides with the obstacle; that is,
Combining with Eq. 1, we define
Since there are infinite solutions for the manipulator to reach the target point from the source point, this research establishes an ideal model of the manipulator’s motion trajectory. The trajectory model is set as a sextic polynomial in this research; that is,
Substituting the source point and the set intermediate point, we can get
Here,
The joint angle of the source point and the target point are known conditions, angular velocity, and angular acceleration of the source point, and the target point is always set at 0. So, parameters
According to Definition 1 and Eq. 4, it is evident that the manipulator motion planning problem can be considered a multi-objective optimization problem, that is,
where
where
For the motion planning problem of the manipulator, it is difficult to obtain the complete state of the manipulator, so this problem is a partially observable Markov decision process (POMDP). Define the Markov decision process
1) Design of the state space. To improve the generalization performance of the algorithm, we take the current joint angle
2) Design of the action space. The motion increment of each joint angle of the manipulator is the algorithm’s output action in manipulator motion planning. As a result, the action proposed in this work is the angle increment of the manipulator’s six joints
3) State transition. This work introduces the action scaling parameter
4) Design of reward function. The problem in this research is very complex, there is only a direct relationship with the action
As shown in Figure 4, when the manipulator learns by interacting with the environment, in order to avoid obstacles and reach the target point, the training process is actually the process of learning the kinematics model of the robotic arm and the obstacle avoidance detection model.
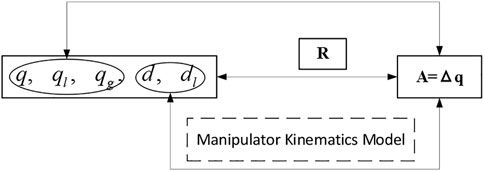
FIGURE 4. State space and action space.
Simple sparse rewards make it difficult for the manipulator to successfully complete the task and get a positive reward under the simple sparse reward conditions, making learning easy to fall into the local optimum (the manipulator collides with the obstacle). So, the D-SAC algorithm is proposed in this research. The reward function designed in D-SAC is as follows:
where
where
Target guidance item
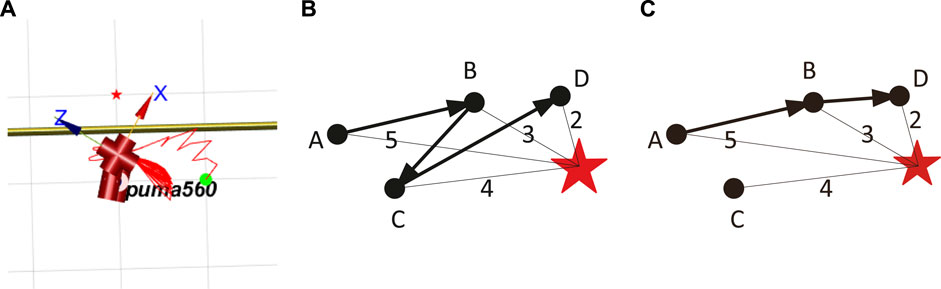
FIGURE 5. Back-and-forth dilemma. (A) Back-and-forth dilemma of the manipulator. (B) Simulation 1st of back-and-forth dilemma. (C) Simulation 2nd of back-and-forth dilemma.
Definition 2: The back-and-forth dilemma: the manipulator moves repeatedly in certain positions in order to get a larger cumulative reward.
It would be better to calculate the difference between the current joint angle’s Euclidean norm and the last joint angle’s Euclidean norm:
However, the reward function of Eq. 15 cannot avoid the manipulator’s back-and-forth dilemma. The following uses a 2D space as an example to prove this. The joint angle space of the manipulator is 6D, but the reason is the same.
As shown in Figures 5B,C, the distances from point A, point B, point C, and point D to the target point are 5, 3, 4, and 2. When the manipulator moves according to the trajectory shown in Figure 5B, the cumulative reward obtained during this period is
Therefore, to avoid the back-and-forth dilemma, we introduce the guiding coefficient
In summary, the process of the D-SAC algorithm is as follows (for the meaning of relevant parameters, refer to Table 2).

TABLE 2. Symbol description table of P-SAC.
Algorithm 1. D-SAC algorithm.

To summarize, this research proposes P-SAC, a fusion algorithm of PSO and SAC for the live working manipulator’s motion planning, based on the proposed algorithm framework, which is driven by data and model. The algorithm is broken into the following three sections:
Step 1: Optimize the model’s parameters. Establish the
Step 2: Pre-train the agent. The dataset
Step 3: Learn from the environment. Interactive learning between the agent obtained by pre-training in Step 2 and the environment improves the robustness of the algorithm.
The P-SAC algorithm flow is as follows (for the meaning of relevant parameters, refer to Table 2).
Algorithm 2. : P-SAC algorithm.

The architecture diagram of P-SAC applied to the live working manipulator is shown in Figure 6.
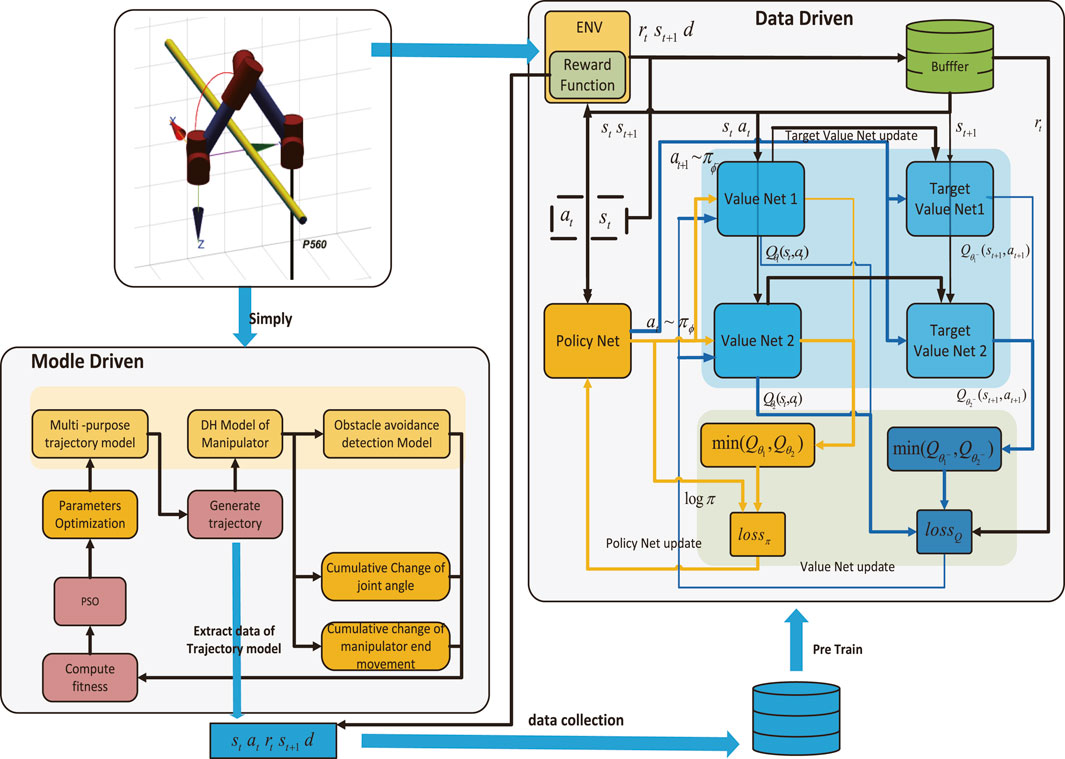
FIGURE 6. Architecture diagram of P-SAC applied to the live working manipulator.
In this research, Robotics Toolbox is used to model a six-DOF live working manipulator to verify the algorithm. The experimental software and hardware environment is shown in Table 3.
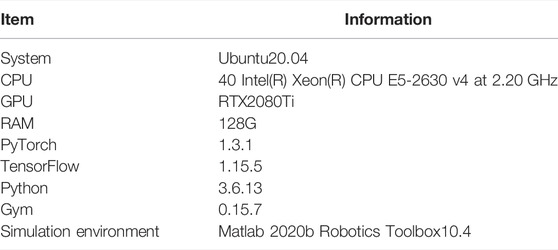
TABLE 3. Environment of experimental software and hardware.
The source point of the joint of the manipulator is

TABLE 4. Algorithm hyperparameters.
The reward curves of D-SAC and P-SAC applied in the live working manipulator are shown in Figure 7. The reward values for the final convergence of P-SAC and D-SAC are shown in Table 5. It is evident that P-SAC reaches the convergence state earlier, and its final convergence value is higher than that of D-SAC. It is evident from the curve that P-SAC reaches near the optimal value earlier but begins to decrease after a period of time and finally rises to the optimal value. This shows that the initial pre-training of the P-SAC algorithm lets the agent acquire a certain ability to learn about the environment, but then it starts to learn what actions are bad in the process of interacting with the environment, which leads to a decrease in the reward value.
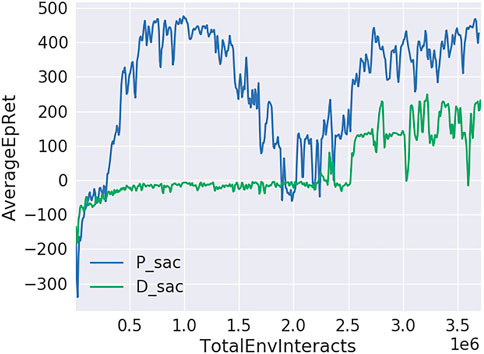
FIGURE 7. Average epoch reward curves of D-SAC and P-SAC.

TABLE 5. Final convergence value of D-SAC and P-SAC.
The motion process of P-SAC, D-SAC, and PSO is shown in Figure 8. It is evident that all three algorithms can effectively avoid obstacles.
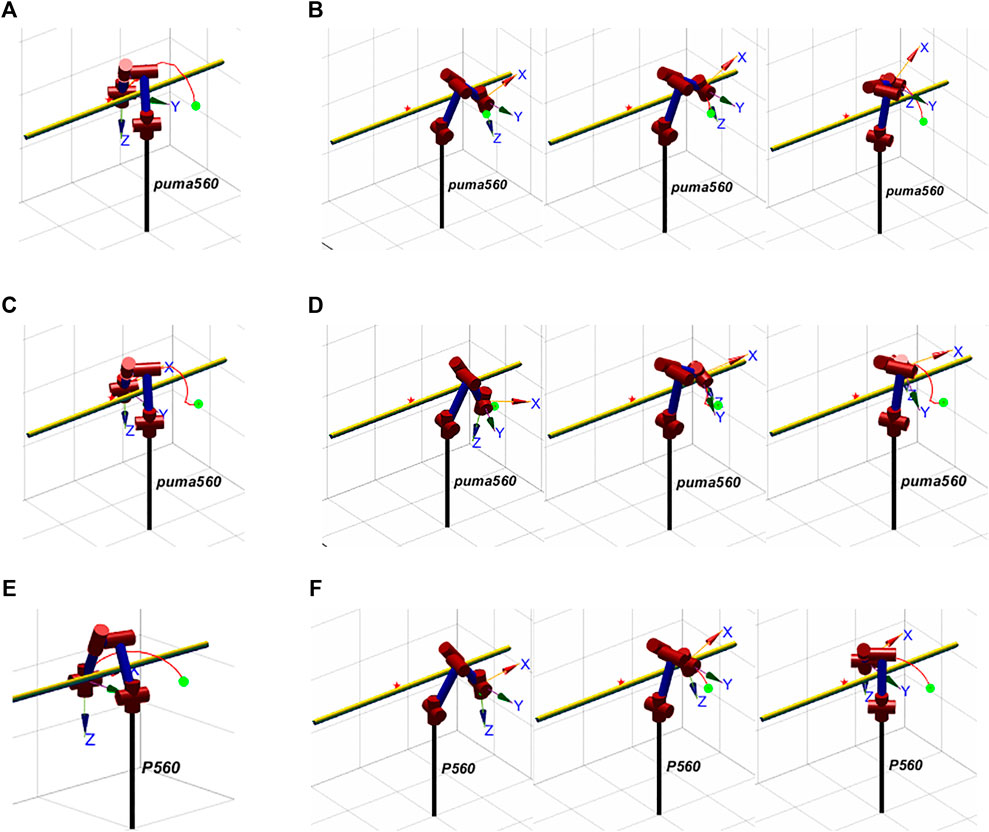
FIGURE 8. Process of manipulator’s motion. (A) Complete motion trajectory of D-SAC. (B) Obstacle avoidance process of D-SAC. (C) Complete motion trajectory of P-SAC. (D) Obstacle avoidance process of P-SAC. (E) Complete motion trajectory of PSO. (F) Obstacle avoidance process of PSO.
The curves of each joint angle of the manipulators using P-SAC, D-SAC, and PSO with time are shown in Figure 9. The joint angle change curves of P-SAC and D-SAC are relatively smooth, but there is a certain gap compared with the joint angle change of the PSO algorithm, especially for D-SAC, and it is evident that the curve has obvious jitter. Since PSO pre-plans a perfect trajectory, its curve must be extremely smooth, while D-SAC and GP-SAC are real-time changing curves, so the curves are not so perfect. However, there is no sudden change in its curve, and it is enough for the manipulator to work effectively.
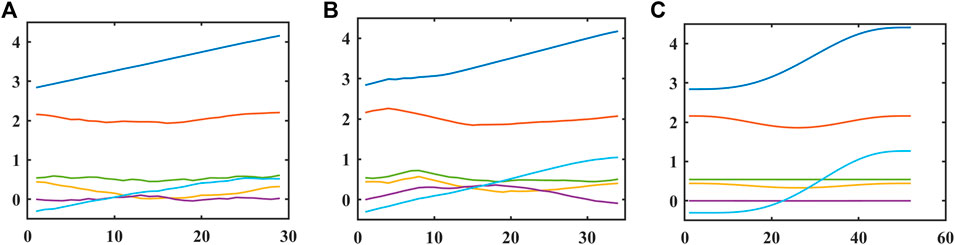
FIGURE 9. Change curve of the angle of each joint of the manipulator. (A) D-SAC. (B) P-SAC. (C) PSO.
In conclusion, using P-SAC proposed in this paper can effectively improve the training efficiency of the data-driven algorithm and can complete the real-time motion planning of the live working manipulator.
Aiming at the shortcomings of data-driven algorithms represented by deep reinforcement learning, which take too long in the early stage of training, and model-driven algorithms that have poor generalization ability to environmental changes and cannot avoid model design errors, this study proposes a hybrid data-model–driven algorithm framework. Under this framework, this study proposes the P-SAC algorithm that integrates PSO and reinforcement learning and applies the P-SAC algorithm to the motion planning problem of live working manipulators. The experimental results show that the proposed P-SAC algorithm has a faster convergence rate than the SAC algorithm, reduces the training time, and can better adapt to the changing environment than the model-driven algorithm.
The hybrid data-model–driven algorithm proposed in this paper can be applied to control problems with controllers or planning problems without controllers and has good application value and algorithm versatility.
The original contributions presented in the study are included in the article/Supplementary Material, and further inquiries can be directed to the corresponding author.
This is a joint work, and the authors were in charge of their expertise and capability. All authors participated in the design of the algorithm framework and algorithm process. TK was in charge of analysis, model design, and revision. JLi was in charge of writing, methodology validation and revision; JLiu was in charge of validation and revision; YL was in charge of data analysis. XL was in charge of manuscript revision.
This work was supposed by the National Key Research and Development Program of China under Grant 2020YFB1708503.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Cao, X., Zou, X., Jia, C., Chen, M., and Zeng, Z. (2019). RRT-based Path Planning for an Intelligent Litchi-Picking Manipulator. Comput. Electron. Agric. 156, 105–118. doi:10.1016/j.compag.2018.10.031
Choset, H., Lynch, K. M., Hutchinson, S., Kantor, G. A., and Burgard, W. (2005). Principles of Robot Motion: Theory, Algorithms, and Implementations. Cambridge, MA, USA: MIT Press.
Clavera, I., Held, D., and Abbeel, P. (2017). “Policy Transfer via Modularity and Reward Guiding,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Vancouver, BC, Canada: IEEE Press), 1537–1544. doi:10.1109/IROS.2017.8205959
Denavit, J., and Hartenberg, R. S. (2021). A Kinematic Notation for Lower-Pair Mechanisms Based on Matrices. J. Appl. Mech. 22 (2), 215–221. doi:10.1115/1.4011045
Devlin, J., Chang, M., Lee, K., and Toutanova, K. (2019). “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Minneapolis, Minnesota: Association for Computational Linguistics. Long and Short Papers 1, 4171–4186. doi:10.18653/v1/N19-1423
Gasparetto, A., Boscariol, P., Lanzutti, A., and Vidoni, R. (2015). “Path Planning and Trajectory Planning Algorithms: A General Overview,” in Motion and Operation Planning of Robotic Systems. Editors G. Carbone, and G. B. Fernando (Cham: Springer International Publishing), 29, 3–27. Mechanisms and Machine Science. doi:10.1007/978-3-319-14705-5_1
Gasparetto, A., Boscariol, P., Lanzutti, A., and Vidoni, R. (2012). Trajectory Planning in Robotics. Math. Comput. Sci. 6 (3), 269–279. doi:10.1007/s11786-012-0123-8
Haarnoja, T., Zhou, A., Abbeel, P., and Levine, S. (2018). “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,” in Proceedings of the 35th International Conference on Machine Learning (PMLR), 1861–1870. Available at: https://proceedings.mlr.press/v80/haarnoja18b.html (Accessed July 13, 2022).
Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., et al. (2019). Soft Actor-Critic Algorithms and Applications. ArXiv. 1812.05905 [Cs, Stat]. doi:10.48550/arXiv.1812.05905
Hao, D., Li, S., Yang, J., Wang, J., and Duan, Z. (2022). Research Progress of Robot Motion Control Based on Deep Reinforcement Learning. Control Decis. 37 (02), 278–292. doi:10.13195/j.kzyjc.2020.1382
Holland, J. H. (1992). Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence. Cambridge, MA, USA: MIT Press.
Kalashnikov, D., Irpan, A., Pastor, P., Ibarz, J., Herzog, A., Jang, E., et al. (2018). QT-opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation. ArXiv. 1806.10293 [Cs, Stat]. doi:10.48550/arXiv.1806.10293
Kennedy, J., and Eberhart, R. (1995). “Particle Swarm Optimization,” in Proceedings of ICNN’95 - International Conference on Neural Networks (Perth, WA, Australia: IEEE Press), 1942–1948. doi:10.1109/ICNN.1995.4889684
Khatib, O. (1985). Real-Time Obstacle Avoidance for Manipulators and Mobile Robots. IEEE Int. Conf. Robotics Automation Proc. 2, 500–505. doi:10.1109/ROBOT.1985.1087247
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2017). ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 60 (6), 84–90. doi:10.1145/3065386
Lillicrap, T. P., Hunt, J. J., Pritzel, A., Heess, N. M., Erez, T., Tassa, Y., et al. (2019). “Continuous Control with Deep Reinforcement Learning,” in 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, May 2–4, 2016. Available at: https://dblp.org/rec/journals/corr/LillicrapHPHETS15.bib.
Lynch, K. M., and Park, F. C. (2017). Modern Robotics: Mechanics, Planning, and Control. Cambridge, UK: Cambridge University Press.
Ma, L., Cheng, S., and Shi, Y. (2021c). Enhancing Learning Efficiency of Brain Storm Optimization via Orthogonal Learning Design. IEEE Trans. Syst. Man. Cybern. Syst. 51 (11), 6723–6742. doi:10.1109/TSMC.2020.2963943
Ma, L., Huang, M., Yang, S., Wang, R., and Wang, X. (2021a). An Adaptive Localized Decision Variable Analysis Approach to Large-Scale Multiobjective and Many-Objective Optimization. IEEE Trans. Cybern. 99, 1–13. doi:10.1109/TCYB.2020.3041212
Ma, L., Li, N., Guo, Y., Wang, X., Yang, S., Huang, M., et al. (2021b). Learning to Optimize: Reference Vector Reinforcement Learning Adaption to Constrained Many-Objective Optimization of Industrial Copper Burdening System. IEEE Trans. Cybern., 1–14. doi:10.1109/TCYB.2021.3086501
Ma, L., Wang, X., Wang, X., Wang, L., Shi, Y., and Huang, M. (2021d). TCDA: Truthful Combinatorial Double Auctions for Mobile Edge Computing in Industrial Internet of Things. IEEE Trans. Mob. Comput., 1. doi:10.1109/TMC.2021.3064314
Menendez, O., Auat Cheein, F. A., Perez, M., and Kouro, S. (2017). Robotics in Power Systems: Enabling a More Reliable and Safe Grid. EEE Ind. Electron. Mag. 11 (2), 22–34. doi:10.1109/MIE.2017.2686458
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., et al. (2013). Playing Atari with Deep Reinforcement Learning. ArXiv. 1312.5602 [Cs, Stat], 9. doi:10.48550/arXiv.1312.5602
Rulong, Q., and Wang, T. (2014). An Obstacle Avoidance Trajectory Planning Scheme for Space Manipulators Based on Genetic Algorithm. ROBOT 36 (03), 263–270. doi:10.3724/SP.J.1218.2014.00263
Shen, Y., Jia, Q., Chen, G., Wang, Y., and Sun, H. (2015). “Study of Rapid Collision Detection Algorithm for Manipulator,” in 2015 IEEE 10th Conference on Industrial Electronics and Applications (ICIEA) (Auckland, New Zealand: IEEE), 934–938. doi:10.1109/ICIEA.2015.7334244
Shi, Y. (2011). “Brain Storm Optimization Algorithm,” in Advances in Swarm Intelligence. Editors Y. Tan, Y. Shi, Y. Chai, and G. Wang (Berlin, Heidelberg: Springer), 303–309. Lecture Notes in Computer Science. doi:10.1007/978-3-642-21515-5_36
Siciliano B., Sciavicco L., Villani L., and Oriolo G. (Editors) (2009). “Motion Planning,” Robotics: Modelling, Planning and Control (London: Springer), 523–559. doi:10.1007/978-1-84628-642-1_12
Wang, M., Luo, J., and Walter, U. (2015). Trajectory Planning of Free-Floating Space Robot Using Particle Swarm Optimization (PSO). Acta Astronaut. 112, 77–88. doi:10.1016/j.actaastro.2015.03.008
Wei, K., and Ren, B. (2018). A Method on Dynamic Path Planning for Robotic Manipulator Autonomous Obstacle Avoidance Based on an Improved RRT Algorithm. Sensors 18 (2), 571. doi:10.3390/s18020571
Wu, Y.-H., Yu, Z.-C., Li, C.-Y., He, M.-J., Hua, B., and Chen, Z.-M. (2020). Reinforcement Learning in Dual-Arm Trajectory Planning for a Free-Floating Space Robot. Aerosp. Sci. Technol. 98, 105657. doi:10.1016/j.ast.2019.105657
Yang, Q., Ku, T., and Hu, K. (2021). Efficient Attention Pyramid Network for Semantic Segmentation. IEEE Access 9, 18867–18875. doi:10.1109/ACCESS.2021.3053316
Yu, N., Nan, L., and Ku, T. (2021). Multipolicy Robot-Following Model Based on Reinforcement Learning. Sci. Program. 2021, 8. doi:10.1155/2021/5692105
Keywords: hybrid data-model–driven, P-SAC, DRL, live working manipulator, PSO, motion planning
Citation: Ku T, Li J, Liu J, Lin Y and Liu X (2022) A Motion Planning Algorithm for Live Working Manipulator Integrating PSO and Reinforcement Learning Driven by Model and Data. Front. Energy Res. 10:957869. doi: 10.3389/fenrg.2022.957869
Received: 31 May 2022; Accepted: 13 June 2022;
Published: 08 August 2022.
Edited by:
Lianbo Ma, Northeastern University, ChinaReviewed by:
Xianlin Zeng, Beijing Institute of Technology, ChinaCopyright © 2022 Ku, Li, Liu, Lin and Liu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jin Li, bGlqaW4yMDdAbWFpbHMudWNhcy5hYy5jbg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.