 Shanshan Wang
Shanshan Wang Cai Dai
Cai Dai Xingsi Xue
Xingsi Xue
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Energy Res. , 28 June 2022
Sec. Smart Grids
Volume 10 - 2022 | https://doi.org/10.3389/fenrg.2022.928744
This article is part of the Research Topic Evolutionary Multi-Objective Optimization Algorithms in Microgrid Power Dispatching View all 16 articles
The transmission security problem in the industrial Internet of Things is the focus of industrial manufacturing development. Blockchain technology can well solve this problem. The massive data generated in the Industrial Internet of Things will be transmitted to the blockchain system through the gateway, the throughput and deployment costs need to be considered. This paper proposes a pigeon flock algorithm based on decomposition to solve this problem. It uses the excellent navigation ability of carrier pigeons to improve search efficiency. At the same time, two independent archives are used to balance convergence and diversity. After the solution set in the convergence archives is classified, the solution set is evaluated by the Tchebycheff function, and some better solutions are retained. The diversity archive chooses some solutions that are quite different from other solutions to maintain diversity. This article uses this algorithm to obtain the solutions with low throughput and high deployment when the blockchain is implemented in the Industrial Internet of Things. Finally, 7 questions in the DTLZ test question are selected to prove the validity of the proposed algorithm. These questions have 5, 10, and 15 goals. In the experimental results, it can be seen that the proposed algorithm is better than NSGAIII, MOEADD and NSGAII on most of the test problems.
The Internet of Things can connect all objects in a specific space environment for anthropomorphic information perception and collaborative interaction. With the strategic goals of “German Industry 4.0,” “United States. Industrial Internet” and “Made in China 2025” successively proposed (Ouaddah et al., 2017), the Industrial Internet of Things is widely used (Ma et al., 2021a). However, the industrial Internet of Things relies too much on the data transmission process of a centralized server, and its centralized data storage mechanism has problems such as difficult supervision and unclear access permissions, so there will be a certain degree of security risks, and at the same time, its scalability will be seriously affected. Therefore, the data transmission security and scalability issues of the Industrial Internet of Things have become a hot spot in the development of industrial manufacturing. Blockchain technology does not rely on third-party trust institutions, and performs data decentralized management based on time stamps, consensus mechanisms, and smart contracts, which can well solve the transmission security problem in the industrial Internet of Things. In the Industrial Internet of Things, massive amounts of data generated by sensors and actuators will be transmitted to the blockchain system through the gateway. If the number of blockchain nodes is small, the throughput requirement cannot be met. However, the deployment of high-performance, high-configuration hardware nodes will invest a lot of money, which will double the deployment overhead. How to determine the optimal number of blockchain nodes is very important (Liu et al., 2021). This paper is based on the proposed algorithm to solve the above-mentioned Internet of Things problems.
The mathematical definition of the multi-objective optimization problem is as follows (Veldhuizen, 1999):
Among them,
This article also considers the minimization of many-objective optimization problems which the number of objective functions is more than three. Under normal circumstances, it is difficult to find the best solution for all objectives, so the best solution will be found within the scope. That is to find the solution that maximizes the effect of most goals. If
Most existing many-objective optimization algorithms are generally classified according to selection strategies, which can be roughly divided into three categories, namely, many-objective optimization algorithms based on improved Pareto dominance relations, many-objective optimization algorithms based on indicators, and many-objective optimization algorithm based on decomposition.
The first category is to solve the many-objective optimization problem based on the improved Pareto dominance relation. In this algorithm, first obtain all non-dominated solutions based on the improved Pareto dominance relationship, and then use another strategy to select among these non-dominated solutions. For example, a-dominance method (Liu et al., 2019), contraction-dominance interval method (Dai et al., 2014) and so on. However, because in the target space, a large number of solutions are non-dominated solutions (Li et al., 2015), so that it has a low selection pressure on the real PF.
The second category is evolutionary algorithms based on decomposition. It turns the many-objective optimization problem into some sub-problem. Based on the information of a certain amount of adjacent problems, the evolutionary algorithm is used to collaboratively optimize these sub-problems. The MOEA/D algorithm proposed by Zhang and Li in 2007 (Qingfu Zhang and Hui Li, 2007) is the most representative of this type of algorithm, Based on this algorithm, many scholars have also proposed its variants (Jiang and Yang, 2015; Wang et al., 2015; Elarbi et al., 2017). After that, many decomposition-based methods appeared, For example, RVEA (Cheng et al., 2016), EFR-RR (Yuan et al., 2015a), θ-DEA (Yuan et al., 2015b), and adaptive localized decision variable analysis approach under the decomposition-based (Ma et al., 2021c), etc. Such an algorithm must solve two problems (Li et al., 2015). One is how to specify a set of uniformly distributed weight vectors or reference points. The second is how to efficiently solve the highly irregular PF problem. According to an article published by Ishibuchi et al. (2017), It can see that the shape of PF can affect the effect of evolutionary algorithms based on decomposition to a certain extent. Especially in the highly irregular PF problem, the effect of this kind of algorithm is not very good. This method has great advantages in maintaining the diversity of solutions, by analyzing the information of adjacent problems to optimize; it can avoid falling into the local optimum.
The third type of method is an evolutionary algorithm based on indicators. Such as the hypervolume (HV) (Bader and Zitzler, 2011) and other indicators. These indicators can balance the convergence and diversity of the solution set. Its disadvantage lies in the relatively high computational complexity, which makes the computational cost very large.
According to the literature (Praditwong and Yao, 2006), it can see that as the number of targets increases, the effects of some MOEAs will also decrease. Yao et al. proposed two archiving algorithms in 2006, which are more effective in dealing with targets. It mainly divides the obtained non-dominated solution set into two archives, so it is called the “Two-Archive” algorithm. The evolutionary laws of nature have been running through the development of technology. Our exploration and simulation of natural mechanisms can be applied to many practical problems. Therefore, in recent years, more and more scholars have begun to pay attention to this swarm intelligence algorithm inspired by the laws of biological evolution. Such as particle swarm optimization (PSO), genetic algorithm (GA), artificial bee colony (ABC), and brain storm optimization algorithm based on orthogonal learning design (Ma et al., 2021b), etc. The essence of this algorithm is to simulate the biological evolution system in nature. In 2014, Duan and Qiao proposed a Pigeon-Inspired Optimization (PIO) algorithm (Duan and Qiao, 2014). The algorithm is designed based on the behavior of pigeons homing. In the past few years since it was proposed, many improved PIO algorithms have appeared, the application is very wide.
This paper combines this “Two-Archive” algorithm with the pigeon group algorithm. The main contributions can be summarized as follows:
1) Pigeon algorithm has the characteristics of easy to understand principle, less parameters and easy to implement. And it has obvious advantages such as simple calculation and strong robustness. Therefore, this paper integrates the crossover operator update of the pigeon algorithm to generate the next generation.This paper proposes a suitable evolution strategy based on the pigeon algorithm to effectively improve the search performance of the high-dimensional multi-objective evolutionary algorithm.
2) The disadvantage of the pigeon algorithm is that the convergence accuracy is low, local optimum is prone to occur, and the stability is poor. Therefore, this paper adopts convergent archive and diversity archive to balance convergence and diversity to obtain a set of uniformly distributed excellent solutions.The problem-solving ability of the decomposition-based high-dimensional multi-objective evolutionary algorithm is improved.
3) For diversified archives, we choose solutions with large distances and differences as much as possible to maintain the diversity of solutions.
4) The proposed algorithm is applied to the logistics service transaction matching problem under the blockchain.
The rest of this article is organized as follows: Section 2 briefly introduces the blockchain-related foundations and PIO algorithms based on the Industrial Internet of Things, as well as the decomposition-based multi-objective optimization algorithm. Section 3 elaborates on the proposed algorithm. Section 4 show the experimental results of the algorithms and Section 5 gives the analysis of related results respectively. Finally, the experimental conclusions and work that can be continued in the future will be presented in Section 6.
Blockchain is a new application mode of computer technology such as distributed data storage, point-to-point transmission, consensus mechanism, and encryption algorithm. It is essentially a decentralized database, and the blockchain has the characteristics of decentralization, time series data, collective maintenance, programmable, safe and reliable (Yuan and Wang, 2016). Decentralization enables the blockchain to build a distributed system with the chain as the core. Time series data can add a time scale to the data stored in the blockchain, which can improve the traceability of the system and facilitate product traceability. Collective maintenance is to ensure the consistency of the system by requiring the blockchain to be implemented by a consensus algorithm, and a unique encouragement mechanism is used to allow blockchain users to participate in the verification process of consistency. Programmability makes it possible to intelligently manage the blockchain, and use Turing’s complete scripting and endorsement system to build safe and reliable transactions. Security and credibility means that the data of the blockchain technology cannot be tampered with or forged, which are all based on the hash algorithm (Liu et al., 2021).
Blockchain proposes the concept of decentralization, which is a chain storage structure that combines blocks in a sequential manner in chronological order (Elarbi et al., 2017), and its core is distributed. Without relying on third-party trust organizations, cryptographic methods are used to ensure that user data cannot be tampered with or forged. The core value of blockchain is to establish open and transparent rules and trust networks based on algorithms to ensure transaction security and make information credible in complex environments (Liu et al., 2021).
How the pigeons accurately returning to their nest from foraging fly back to their nest is still unknown. Many scholars believe that the reason why the pigeon has such a precise ability to return to the nest is inseparable from the two factors of the earth’s magnetic field and ground construction. When pigeons find their way back to the nest, they will use different navigation tools according to different situations. On the one hand, the pigeons returning to the nest first use the earth’s magnetic field to roughly judge the relative position of the pigeon’s nest. On the other hand, the returning pigeons use the sun to convert their relative positions into actual flight positions. As the pigeon gets closer and closer to the dove’s nest, the influence of the earth’s magnetic field and the sun on the direction of the pigeon’s flight will gradually decrease. At this time, it will be replaced by more familiar ground structures as a new flight navigation factor, so as to perfectly find the pigeon’s nest. This biologically inspired evolutionary algorithm contains two operators: a compass operator and a landmark operator. The compass operator model is obtained on the basis of the earth’s magnetic field and the sun, and the landmark operator model is obtained on the basis of ground construction.
In the D-dimensional search space, we assume that there are
Among them,
When the number of iterations
Among them,
The decomposition-based many-objective optimization method assigns and aggregates the weight vectors of the various objectives of the many-objective problem to form a set of sub-problems. Then the sub-problems co-evolve in the neighborhood, and the optimal solution is obtained through multiple iterations. Therefore, it is very important to choose a good decomposition method.
The three common types of aggregation functions in the decomposition strategy are weighted sum approach, Tchebycheff approach, and penalty-based boundary intersection approach.
The weighted sum approach is the most common decomposition method. The weighted sum approach adds a weight vector to each goal of a many-objective problem. Its mathematical definition is as follows:
The tchebycheff approach can deal with the problem that the Pareto surface is convex as well as the problem that the Pareto surface is concave.
The penalty-based boundary intersection approach is a direction-based aggregation method.
The algorithm randomly generates a set of initial populations, and assigns a set of uniformly distributed weight vectors, using the original objective function as the fitness. In each iteration process, the key to getting better and better solution set lies in evolution strategy. The following describes the evolution strategy of the algorithm in detail.
In order to avoid prematurely falling into the local optimum when solving the problem, this paper integrates the pigeon swarm algorithm and differential mutation into the cross update operation of the population.
When performing cross-update operations on each solution, on the one hand, there is a certain probability to select the pigeon group algorithm for cross-update. The specific operations are: a randomly generated set of values between
The basic framework based on crossover and differential mutation of pigeons is as follows:
Algorithm 1. Cross-mutation algorithm framework:

The population is selected based on the two archives algorithm. It is to sequentially obtain new candidate solutions in the population. First, when the new candidate solution is a non-dominated solution in the population, and none of the two archives can dominate its solution, then it can become a new member of the archive. Second, the new member has to observe its dominance relationship with other existing members. If the new member can dominate some other members, then it will be put into the convergence archive
Based on a set of weight vectors
In order to maintain the diversity of the population, it is necessary to choose a solution that is quite different from other solutions as much as possible. In this way, the global optimal solution can be obtained without falling into the local optimal solution early. That is, in the
Based on the two archiving strategy described in Section 3.2 above, a pigeon group algorithm based on decomposition PIO/D is proposed to solve multi-objective and many-objective problems.
The main ideas of this article are as follows: In each iteration process, the pigeon flock crossover of the population produces offspring P1, and the traditional binary crossover on the population produces offspring P2. On the one hand, in order to obtain a set of uniformly distributed solutions, Eq. 7 is used to classify the population. After classification, there may be 0 or more solutions in each category. In order to promote convergence, the Tchebycheff aggregation function is used to evaluate the solutions in each category, and only the best in each category is kept in the convergence archives. On the other hand, in order to maintain diversity, use Eq. 8 to select solutions from P2 and release them into the diversity archives, so that the sum of solutions and the solution in the convergence archives is exactly
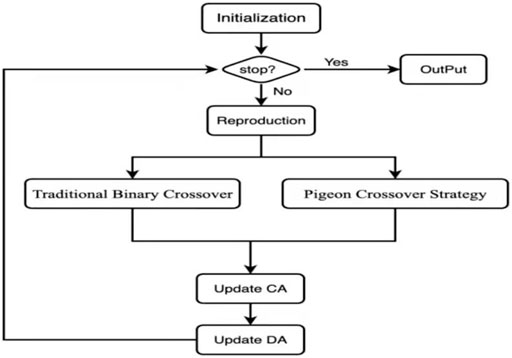
FIGURE 1. PIO/D algorithm flowchart.
Algorithm 2. Proposed algorithm framework.

Blockchain logistics service transaction matching is an important part of the smart contract process of logistics service transactions under the blockchain, and it is also the main work of this paper. The blockchain logistics service transaction matching problem consists of two aspects: logistics service providers and logistics service users. In this process, logistics service providers and logistics service users provide each other’s expectations to the blockchain system, and the blockchain system objectively provides the actual information of both parties based on its own database and historical information. The big data information of the platform is matched according to the expected information and actual situation information of both parties to achieve the goal of mutual satisfaction.
The set of logistics service users is
The expected value range of the logistics service user
Through the objective evaluation of various historical data of
Logistics service provider
In the same way, through the objective evaluation of various historical data of
The mutual satisfaction values of the logistics service provider and the user on each index are
(1) Calculation of the amount of real satisfaction information
The expected value of
(2) Calculation of Interval Index Satisfaction Information Volume
When the indicator of
In the same way, the amount of information about Pj’s satisfaction with
(3) Calculation of the amount of information about the satisfaction of the triangular fuzzy number index
The expected range of
In the same way, the amount of information about
(4) Intuitionistic Fuzzy Number Index Satisfaction Information Calculation
Where
In the same way, the amount of information about
The multi-objective model of logistics service transaction matching under the blockchain is as follows:
The overall satisfaction information volume of logistics service user
The smaller the value of
In the experiment, the number of logistics service users and providers is set to 10, the number of iterations is 1,000, the population number is 101, and the target number is 2. Let
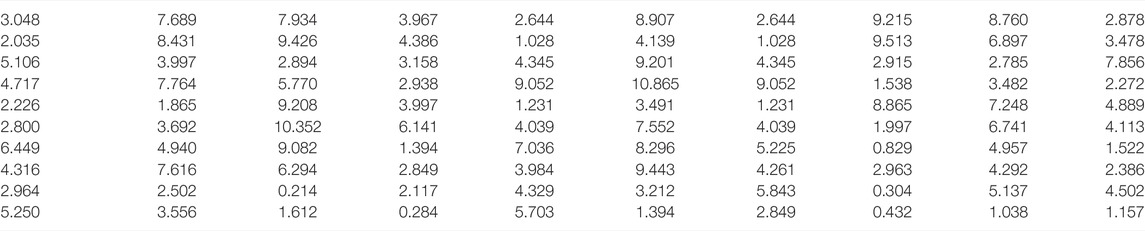
TABLE 1. The amount of information on the satisfaction of logistics service users to the provider.

TABLE 2. The amount of information on the satisfaction of logistics service provider to the users.
The following Table 3 shows the HV values obtained when using PIO/D, MOEADD and NSGAIII algorithms to solve this multi-objective optimization problem. It can be seen intuitively from the table that PIO/D has the largest HV value, and MOEADD has the smallest HV value. Therefore, the overall performance of PIO/D is better than MOEADD、NSGAIII and NSGAII.

TABLE 3. PIO/D, MOEADD, NSGAIII, and NSGAII give HV indicators.
This article tests the 7 classic problems of DTLZ1∼DTLZ7, compared with the three algorithms of MOEADD、NSGAIII and NSGAII, 5-dimensional, 10-dimensional, and 15-dimensional targets. Each test problem was evaluated 100,000 times, and it was run independently and continuously for 20 times, and the average value was taken as the final result. For the parameters of the pigeon algorithm part, the compass factor
We choose the inverted generational distance (IGD) (Cai et al., 2019) as the performance index of the algorithm. The inverse generation distance represents the distance from the obtained solution set to the reference solution set. It comprehensively measures the diversity and convergence of the solutions we have obtained. If the inverse generation distance is 0, it means that all solutions of the population converge to the reference solution set, which means that all solutions are optimal solutions.
For 7 DTLZ test problems, we use the PIO/D algorithm to compare with the three algorithms MOEADD, NSGAIII, and NSGAII. The MOEADD algorithm aggregates multiple targets into a set of single targets, making the algorithm simpler. Based on the MOEA/D algorithm, it combines the decomposition method and the dominant method. The combination of the two methods balances convergence and diversity. The NSGAII algorithm sorts the non-dominated solutions, and selects good non-dominated solutions through the ranking. The framework of NSGA-III is basically the same as NSGAII. The difference is that NSGAII uses crowded comparison operations to select to maintain diversity, while NSGAIII uses well-distributed reference points to maintain population diversity. Table 4 shows the mean and standard deviation of the IGD metrics obtained by the MOEADD, NSGAIII, and PIO/D on the seven test questions. Among them, M represents the target dimension, and D represents the decision variable dimension.The best performance for each test question is marked in black. It can be seen from Table 4 that on the 5-dimensional target, the IGD metric values obtained by PIO/D on the two problems of DTLZ5, DTLZ6 is significantly better than MOEADD, NSGAIII, and NSGAII. On the 10-dimensional target, the IGD metric values obtained by PIO/D on the four problems of DTLZ1, DTLZ2, DTLZ5, and DTLZ6 are significantly better than MOEADD, NSGAIII, and NSGAII. On the 15-dimensional target, PIO/D’s IGD metric values obtained on the five problems of DTLZ1, DTLZ2, DTLZ5, DTLZ6, DTLZ7 are significantly better than MOEADD, NSGAIII, and NSGAII. On the other hand, we can see in the table that the performance of the PIO/D algorithm is very close to the performance of the optimal algorithm even if the effect of the PIO/D algorithm is not optimal. In short, it can be seen from the experimental data that for most test problems, the performance of the PIO/D algorithm is better than MOEADD, NSGAIII, and NSGAII. This also shows that the PIO/D algorithm can maintain a better diversity and convergence of the solution set.
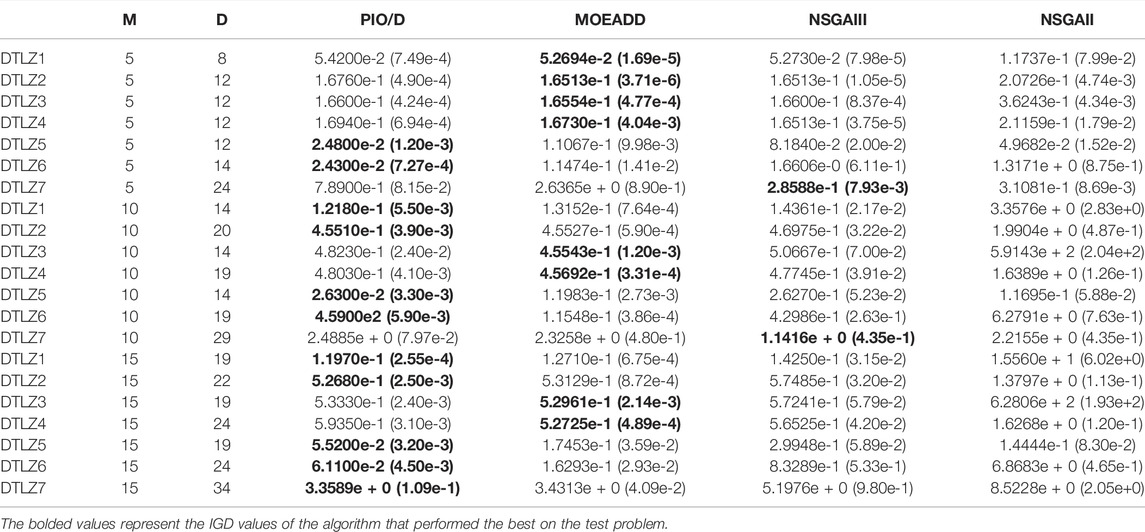
TABLE 4. PIO/D, MOEADD, and NSGAIII give the mean and standard deviation of the IGD metrics.
This article uses two archives (CA and DA) to balance diversity while ensuring convergence. Based on this idea, the differential mutation and pigeon crossover operator are combined to improve the search efficiency, so as to obtain a better solution with uniform distribution. This article optimizes the multi-objective optimization problem of the blockchain based on the industrial Internet of Things, and balances the throughput and communication overhead. The experimental results show that the algorithm can optimize the current blockchain technology at the algorithm level under the background that the blockchain has been proved to be feasible to realize the Industrial Internet of Things. In this way, it can not only meet the massive data transmission of IIoT by increasing the block chain throughput rate, but also rely on the characteristics of the block chain technology to ensure the safety of the transmission process and increase the feasibility of deployment.
Finally, this article verifies 7 problems in the DTLZ test problem, and compares our algorithm with MOEADD, NSGAIII, and NSGAII respectively. From the obtained IGD, we can see that our algorithm is superior to these two algorithms.
What can be done in the future is that the crossover operator of the pigeon swarm algorithm can be further improved, or be modified in combination with some other crossover operators.
The original contributions presented in the study are included in the article/Supplementary Materials, further inquiries can be directed to the corresponding author.
Conceptualization (Ideas, formulation or evolution of overarching research goals and aims) and Methodology (Development or design of methodology): CD; Software (Implementation of the computer code and supporting algorithms): SW; Data Curation: SW, CD, and XX; Investigation (Conducting a research and investigation process, specifically performing the experiments, or data/evidence collection): SW; Supervision (Oversight and leadership responsibility for the research activity planning and execution, including mentorship external to the core team): CD and XX; Writing—Original Draft: SW; Writing—Review and Editing, Funding acquisition: CD.
This work was supported by National Natural Science Foundations of China (No. 61806120, No. 61502290, No. 61401263, No. 61672334, and No. 61673251), China Postdoctoral Science Foundation (No. 2015M582606), Industrial Research Project of Science and Technology in Shaanxi Province (No. 2015GY016, No. 2017JQ6063), Fundamental Research Fund for the Central Universities (No. GK202003071), Natural Science Basic Research Plan in Shaanxi Province of China (No. 2016JQ6045).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Bader, J., and Zitzler, E. (2011). HypE: An Algorithm for Fast Hypervolume-Based Many-Objective Optimization. Evol. Comput. 19 (1), 45–76. doi:10.1162/evco_a_00009
Cai, X., Zhang, M., Wang, H., Xu, M., Chen, J., and Zhang, W. (2019). Analyses of Inverted Generational Distance for Many-Objective Optimisation Algorithms. Int. J. Bio-Inspired Comput. 14 (1), 62–68. doi:10.1504/IJBIC.2019.10022705
Cheng, R., Jin, Y., Olhofer, M., and Sendhoff, B. (2016). A Reference Vector Guided Evolutionary Algorithm for Many-Objective Optimization. IEEE Trans. Evol. Comput. 20 (5), 773–791. doi:10.1109/tevc.2016.2519378
Dai, C. (2019). Two-archive Evolutionary Algorithm Based on Multi-Search Strategy for Many-Objective Optimization. IEEE Access 7, 79277–79286. doi:10.1109/access.2019.2917899
Dai, C., Wang, Y., and Ye, M. (2014). A New Evolutionary Algorithm Based on Contraction Method for Many-Objective Optimization Problems. Appl. Math. Comput. 245, 191–205. doi:10.1016/j.amc.2014.07.069
Duan, H., and Qiao, P. (2014). Pigeon-inspired Optimization: a New Swarm Intelligence Optimizer for Air Robot Path Planning. Int. J. intelligent Comput. Cybern. 7 (1), 24–37. doi:10.1108/ijicc-02-2014-0005
Duan, H., and Qiu, H. (2019). Advancements in Pigeon-Inspired Optimization and its Variants. Sci. China Inf. Sci. 62 (7), 5–14. doi:10.1007/s11432-018-9752-9
Elarbi, M., Bechikh, S., Gupta, A., Said, B., and Ong, S. (2017). A New Decomposition-Based NSGA-II for Many-Objective Optimization. IEEE Trans. Syst. man, Cybern. Syst. 48 (7), 1191–1210. doi:10.1109/TSMC.2017.2654301
Hu, Y., Wang, J., Liang, J., Yu, K., Song, H., Guo, Q., et al. (2019). A Self-Organizing Multimodal Multi-Objective Pigeon-Inspired Optimization Algorithm. Sci. China Inf. Sci. 62 (7), 1–17. doi:10.1007/s11432-018-9754-6
Ishibuchi, H., Setoguchi, Y., Masuda, H., and Nojima, Y. (2017). Performance of Decomposition-Based Many-Objective Algorithms Strongly Depends on Pareto Front Shapes. IEEE Trans. Evol. Comput. 21 (2), 169–190. doi:10.1109/TEVC.2016.2587749
Jiang, S., and Yang, S. (2015). An Improved Multiobjective Optimization Evolutionary Algorithm Based on Decomposition for Complex Pareto Fronts. IEEE Trans. Cybern. 46 (2), 421–437. doi:10.1109/TCYB.2015.2403131
Li, B., Li, J., Tang, K., and Yao, X. (2015). Many-Objective Evolutionary Algorithms: A Survey. ACM Comput. Surv. 48 (1), 1–35. doi:10.1145/2792984
Liu, J., Wang, Y., Wang, X., Guo, S., and Sui, X. (2019). A New Dominance Method Based on Expanding Dominated Area for Many-Objective Optimization. Int. J. Pattern Recognit. Artif. Intell. 33 (3), 1959008. doi:10.1142/s0218001419590080
Liu, J., Zhang, J., Dong, Z., and Ji, H. (2021). Multi-objective Optimization of Blockchain Based on Industrial of the Things. Comput. Integr. Manuf. Syst. 27 (8), 2382. doi:10.13196/j.cims.2021.08.020
Ma, L., Huang, M., Yang, S., Wang, R., and Wang, x. (2021c). An Adaptive Localized Decision Variable Analysis Approach to Large-Scale Multiobjective and Many-Objective Optimization. IEEE Trans. Cybern., 1–13. doi:10.1109/TCYB.2020.3041212
Ma, L., Cheng, S., and Shi, Y. (2021b). Enhancing Learning Efficiency of Brain Storm Optimization via Orthogonal Learning Design. IEEE Trans. Syst. Man. Cybern. Syst. 51 (11), 6723–6742. doi:10.1109/tsmc.2020.2963943
Ma, L., Wang, X., Wang, X., Wang, L., Shi, Y., and Huang, M. (2021a). TCDA: Truthful Combinatorial Double Auctions for Mobile Edge Computing in Industrial Internet of Things. IEEE Trans. Mob. Comput., 1. doi:10.1109/TMC.2021.3064314
Ouaddah, A., Elkalam, A. A., and Ouahman, A. A. (2017). “Towards a Novel Privacy-Preserving Access Control Model Based on Blockchain Technology in IoT,” in Europe and MENA Cooperation Advances in Information and Communication Technologies (Berlin/Heidelberg, Germany: Springer), 523–533. doi:10.1007/978-3-319-46568-5_53
Praditwong, K., and Yao, X. (2006). A New Multi-Objective Evolutionary Optimisation Algorithm: The Two-Archive Algorithm,” in International Conference on Computational Intelligence and Security, Guangzhou, China. IEEE. doi:10.1109/iccias.2006.294139
Qingfu Zhang, Q., and Hui Li, H. (2007). MOEA/D: A Multiobjective Evolutionary Algorithm Based on Decomposition. IEEE Trans. Evol. Comput. 11 (6), 712–731. doi:10.1109/tevc.2007.892759
Qiu, H., and Duan, H. B. (2015). Multi-objective Pigeon-Inspired Optimization for Brushless Direct Current Motor Parameter Design. Sci. China Technol. Sci. 58 (11), 1915–1923. doi:10.1007/s11431-015-5860-x
Veldhuizen, D. V. (1999). Multiobjective Evolutionary Algorithms: Classifications, Analyses, and New Innovations. Dayton, Ohio, U.S: Air Force Institute of Technology.
Wang, L., Zhang, Q., Zhou, A., Gong, M., and Jiao, L. (2015). Constrained Subproblems in a Decomposition-Based Multiobjective Evolutionary Algorithm. IEEE Trans. Evol. Comput. 20 (3), 475–480. doi:10.1109/TEVC.2015.2457616
Wang, R., Purshouse, R. C., and Fleming, P. J. (2012). Preference-inspired Coevolutionary Algorithms for Many-Objective Optimization. IEEE Trans. Evol. Comput. 17 (4), 474–494. doi:10.1109/TEVC.2012.2204264
Yuan, Y., and Wang, F. Y. (2016). Blockchain: the State of the Art and Future Trends. Acta Autom. Sin. 42 (4), 481. doi:10.16383/j.aas.2016.c160158
Yuan, Y., Xu, H., Wang, B., and Yao, X. (2015). A New Dominance Relation-Based Evolutionary Algorithm for Many-Objective Optimization. IEEE Trans. Evol. Comput. 20 (1), 16–37. doi:10.1109/TEVC.2015.2420112
Keywords: many-objective optimization, internet of things, two archives, pigeon-inspired optimization, evolutionary algorithm
Citation: Wang S, Dai C and Xue X (2022) A Pigeon Group Decomposition Based Algorithm for Logistics Service Transaction Matching Under Blockchain. Front. Energy Res. 10:928744. doi: 10.3389/fenrg.2022.928744
Received: 26 April 2022; Accepted: 09 May 2022;
Published: 28 June 2022.
Edited by:
Lianbo Ma, Northeastern University, ChinaReviewed by:
Xiaofang Guo, Xi’an Technological University, ChinaCopyright © 2022 Wang, Dai and Xue. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Cai Dai, Y2RhaTAzMjBAc25udS5lZHUuY24=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.