 Ruoyuan Zhang
Ruoyuan Zhang Yuan Wang2
Yuan Wang2- 1Anhui Water Conservancy Technical College, Hefei, China
- 2School of Computer Science and Engineering, North Minzu University, Yinchuan, China
In the process of traditional power load identification, the load information of V-I track is missing, the image similarity of V-I track of some power loads is high and the recognition effect is not good, and the training time of recognition model is too long. In view of the abovementioned situation, this study proposes a power load recognition method based on color image coding and the improved twin support vector machine (ITWSVM). First, based on the traditional voltage–current gray trajectory method, the bilinear interpolation technique is used to solve the pixel discontinuity problem effectively. Considering the complementarity of features, the numerical features are embedded into the gray V-I trajectory by constructing three channels, namely, current (R), voltage (G), and phase (B), so the color V-I image with rich electrical features is obtained. Second, the two-dimension Gabor wavelet is used to extract the texture features of the image, and the dimension is reduced by means of local linear embedding (LLE). Finally, the artificial fish swarm algorithm (AFSA) is used to optimize the twin support vector machine (TWSVM), and the ITWSM is used to train the load recognition model, which greatly enhances the model training speed. Experimental results show that the proposed color V-I image coding method and the ITWSVM classification method, compared with the traditional V-I track image construction method and image classification algorithm, improve the accuracy by 6.12% and reduce the model training time by 1071.23 s.
1 Introduction
NILM is the main tool to analyze the electrical behavior of residential users. It can collect, store, and analyze important electrical information through the data acquisition and communication device installed at the user’s power supply entrance. In this way, users can accurately perceive the running state and energy consumption of each electrical equipment (Sun et al., 2017; Guo et al., 2021). Compared with the traditional invasive monitoring device for the analysis of each electrical equipment installation, NILM without further user internal can grasp the electricity situation of all kinds of equipment, on the one hand; reduce the hardware investment, on the other hand; and also remove the existing transformation and maintenance of electrical lines, to a great extent, to protect the user’s privacy (Deng et al., 2020). NILM has a large number of applications in energy efficiency monitoring, fault diagnosis, load modeling, and demand response (Wang and Liu, 2019). In particular, the energy consumption information provided by NILM is of great value for users to understand their own energy consumption structure and guide them to use electricity reasonably, thus realizing energy saving and loss reduction and reducing electricity costs (Zhou et al., 2018; Sun et al., 2020). Therefore, NILM has received extensive attention and strong support from the industry in recent years, and significant progress has been made in related research (Cui et al., 2020; Xiang et al., 2022).
The flow of NILM can be divided into data acquisition, feature extraction, model training, and online recognition. Among them, feature extraction and model training directly affect the accuracy of the algorithm. Feature extraction refers to the use of digital signal processing technology or circuit analysis theory to extract valuable indicators from the collected electrical signals to distinguish different types of electrical equipment. In noninvasive load identification tasks, common load characteristics include voltage and current waveform, current harmonics (Cui et al., 2020), active and reactive power, V-I trajectory (Liu et al., 2021; Xiang et al., 2022), instantaneous power (Li et al., 2021), etc. Among them, V-I trajectory features are characterized by high repeatability and strong stability (Gao et al., 2016; Wu et al., 2020). However, traditional identification methods are prone to misjudge different types of equipment with highly overlapping load characteristics into the same category.
In order to reduce the category and number of misjudgment and realize more efficient model training, new recognition techniques still need to be developed. Scholars at home and abroad have conducted a large number of in-depth studies on V-I trajectory. Liu et al. (2020) extracted the binary V-I trajectory contour to realize the full mining of trajectory shape features. Tu et al. (2018) proposed for the first time to map V-I trajectories into binary grid images, which reduced the computational cost. Zhang et al. (2020) took the binary V-I track image as input to transform the load identification problem into an image classification problem. Due to the outstanding performance of the artificial intelligence algorithm in the field of image classification, the ant colony algorithm is introduced by Du et al. (2016) to extract key features of the weighted pixelated track image, which improves the accuracy of load recognition. Niu et al. (2009) adopted the Fryze power theory to extract reactive current from current, which increased the distinguishing degree of current characteristics. Li et al. (2019) constructed the voltage-reactive current trajectory on the basis of Fryze theory and color-coded the trajectory to integrate other load characteristics. However, its defect was that the trajectory could not reflect the power of the device without combining power characteristics. Wang et al. (2019a) and Chen et al. (2019) used Gram matrix transformation and genetic algorithm, respectively, for power feature fusion, which improves load feature diversity. Although the V-I load identification model and algorithm of trajectory is increasingly mature, there still exists the following problems: trajectory image binary V-I can only transfer trajectory shape information, in principle cannot reflect the power, phase information, such as equipment, and because there are many different kinds of electrical appliances and working principle of the similarity between the different kinds of load V-I trajectory characteristics of overlapping phenomenon. Although the electrical information contained in binary images is more comprehensive, the discontinuity of pixels in V-I image construction will lead to the loss of a lot of useful information, especially the traditional methods cannot fully excavate the advanced features of images. Therefore, the accuracy of load identification still has room for further improvement.
Different from the abovementioned feature extraction and recognition methods, a noninvasive load recognition method based on image coding and the improved twin support vector machine is proposed. This method combines digital features with image features and exploits the outstanding advantages of the improved twin support vector machine in image recognition field to mine the important information contained in electrical signals as much as possible. The main methods are as follows: first, based on the grayscale V-I image, continuous V-I pixels are realized by bilinear interpolation, and three channels, current (R), voltage (G), and phase (B), are constructed by image coding technology to form a continuous color image. Second, two-dimensional Gabor wavelet (Wei et al., 2020) is used to effectively filter the image data to obtain the key texture features of the color V-I image, and LLE dimension reduction is carried out for multiple texture features to reduce the huge amount of calculation caused by high dimension. Third, the parameters of the TWSVM were taken as the position information of artificial fish, and the classification accuracy was taken as the objective function. Then, the optimal location and optimal solution were updated by foraging, clustering, trailing, and random behaviors of ant colony, and the optimal parameters and optimal classification accuracy were obtained at the end of iteration. The algorithm can automatically determine the parameters of the TWSVM in the training process, avoid the blindness of parameter selection, and improve the classification performance of the TWSVM. The characteristics of V-I images are classified by the ITWSVM, the classification results of color V-I images are obtained, and the corresponding electrical equipment classification is completed. Finally, the effectiveness of the proposed method is verified by using the PLAID public data set.
1.1 Continuous V-I Color Image Encoding of Pixel Points
V-I trajectory is a two-dimensional image drawn by a series of voltage and current sampling points in a steady period. For most electrical equipment with different operating principles, the V-I trajectory presents great differences in shape, so various shape parameters (such as area, curvature, number of self-intersection points, and circulation direction) can be extracted from it and used as the basis to distinguish different types of electrical equipment. It is difficult to extract shape parameters, and the parameters after dimensionality reduction cannot fully reflect their original information. Therefore, in the study by Fan et al. (2020), the V-I track is mapped to a binary gray image by using the gridding method while preserving the shape information as much as possible, and the image is used for load identification directly. Compared with the extraction of shape parameters, the process of constructing the binary gray image is simpler. At the same time, the retention of original information is higher, so the accuracy of load identification is further improved.
1.2 Continuous V-I Image Mapping Method
Considering that the V-I image may have pixel discontinuity in the process of mapping, it is not conducive to subsequent training and recognition. Therefore, bilinear interpolation technology is used to improve the traditional mapping method, and the specific process is as follows:
1) A sampling system comprising current clamp, voltage probe, and high-frequency oscilloscope is used to sample the voltage and current waveform of electrical equipment at high frequency, and
2) Given a grid or image resolution of
In Eq. 1,
3) According to Eq. 2, the distance between two adjacent sampling points after mapping is
In the equations,
4) According to Eq. 5, the mapping coordinates of sample points
5) Construct a zero matrix with dimension
According to the abovementioned method, the gray V-I image of a fluorescent lamp device can be obtained, as shown in Figure 1, with a resolution of 32 × 32. The V-I image obtained by the traditional mapping method has the phenomenon of pixel discontinuity, while the image obtained by the method in this study does not have this problem. The results demonstrate the effectiveness of the abovementioned image construction method.
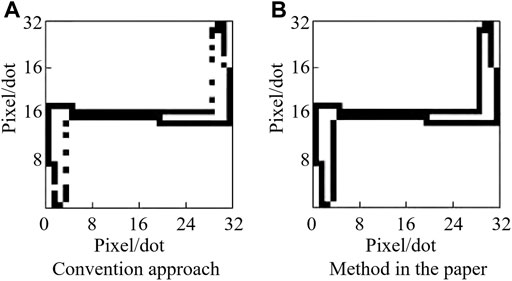
FIGURE 1. Binary V-I trajectory mapping for a fluorescent lamp.
1.3 V-I Color Image Coding Method
According to the analysis in Section 2.1, voltage and current signals of all kinds of electrical equipment are normalized in the process of forming V-I images, and only 0 or one state tables are used for each pixel point. As a result, the V-I image only retains the shape characteristics of voltage–current signals but cannot reflect the numerical differences between devices, especially the numerical characteristics of average current, voltage, power, and phase of devices. For example, the average current of the washing machine and air conditioner is bigger, and the average current of the equipment such as incandescent lamp and computer is lesser. When normalized and mapped, all devices have current values of 0 or 1. Obviously, the gray V-I image has lost a lot of valuable information, so it is difficult to improve the accuracy of load recognition by relying on it alone. Therefore, it is necessary to combine the gray V-I image with the numerical feature to enhance the recognition ability of the algorithm by using the complementarity between the two.
As mentioned earlier, the gray V-I image is a single-channel two-dimensional pixel matrix. Each point in the matrix is 0 or 1, which, respectively, represents whether the point has a V-I trajectory, while the size and direction of the trajectory and other information cannot be reflected. In contrast, for a color image, as shown in Figure 2, it is formed by the superposition of three channels: current (R), voltage (G), and phase (B). Each channel corresponds to a two-dimensional matrix, in which each element can change continuously from 0 to 1. Color images contain more information than gray images. If the numerical information can be embedded into the RGB channel in combination with the shape characteristics of the V-I track, the gray V-I image can be transformed into the corresponding color image. Using this image to classify will undoubtedly improve the recognition accuracy of the whole algorithm.
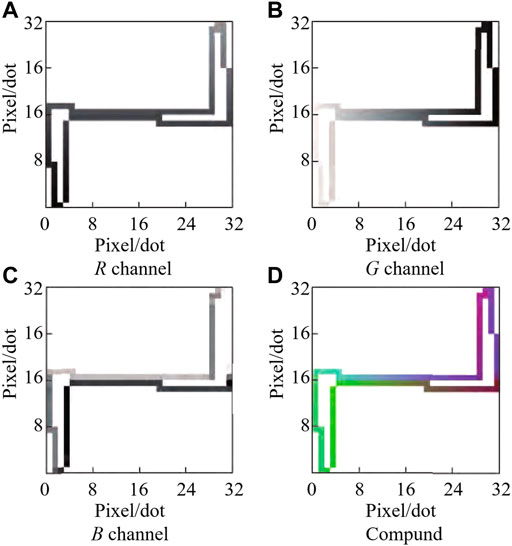
FIGURE 2. Image of each channel of a fluorescent lamp and the synthesized V-I color image.
The core of color image coding lies in the formation of
1) Initialize
2) According to
3) Construct the current
In Eq. 8, the equation is used to scale the current signal to ensure that elements change continuously from
4) Construct voltage
Similarly,
5) Construct the phase
In the equation,
After
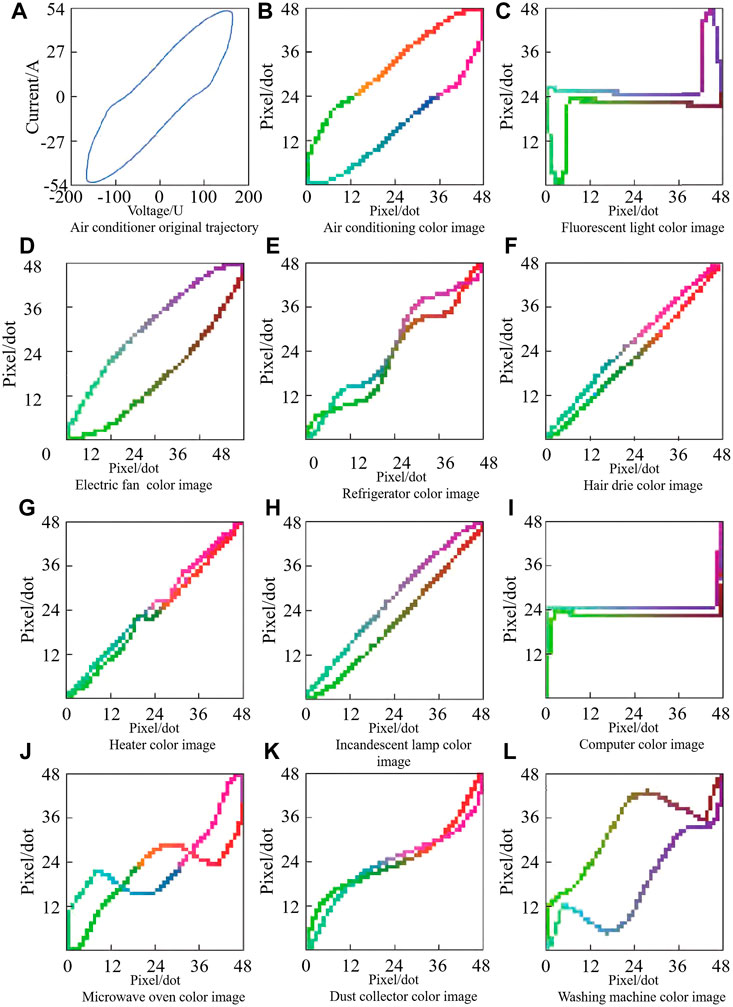
FIGURE 3. Color V-I images of various electrical equipment.
2 Feature Extraction and Dimension Reduction of V-I Color Image
2.1 Two-Dimensional Gabor Wavelet Feature Extraction
In order to extract V-I color image features, this study tries to use two-dimensional Gabor wavelet to extract image texture features and achieve more effective image key texture extraction. Combining with LLE, feature dimension reduction can alleviate feature redundancy and efficiency of high-dimensional feature operation to a certain extent.
As a common tool of image-scale representation and feature analysis, two-dimensional Gabor wavelet can easily realize image scale change. For gray image
In Eq. 14,
When two-dimensional Gabor wavelet is carried out, in order to obtain comprehensive image data without loss, it is necessary to set the main parameters
2.2 LLE Dimension Reduction
The dimension of the image features obtained by Gabor filtering is high. Considering the problem of feature redundancy and the efficiency of high-dimensional feature operation and storage, it is necessary to effectively reduce the dimension of the image features. The following is a mathematical description of LLE dimension reduction. To achieve dimension reduction for m sample points, suppose that sample
In Eq. 17,
In the actual operation, multiple adjacent samples can be selected for
Suppose
In Eq. 19,
LLE can keep
In Eq. 20,
3 AFSA Optimize TWSVM
3.1 TWSVM
The TWSVM uses two hyperplanes for classification. The number of samples of the two types is
In Eq. 21,
TWSVM1:
TWSVM2:
In the equations,
The test sample belongs to whichever hyperplane it is near, if
3.2 AFSA
The artificial fish swarm algorithm is an optimization algorithm based on swarm intelligence, which is inspired by the behavior of fish. In the AFSA, each AF adjusts its behavior according to its current state and the state of the surrounding environment. During each iteration, the AF updated themselves through four behaviors: foraging, clustering, tailgating, and randomness (Wu et al., 2007).
Suppose
The four behaviors of artificial fish are described as follows:
1) Foraging behavior:
2) Swarm behavior: Assuming
3) Rear-end behavior: Assume that
4) Random behavior:
These four behaviors switch between each other under different conditions, and the artificial fish will choose the appropriate behavior to find the location of the better solution.
3.3 TWSVM Improved Based on the AFSA
The core idea of the ITWSVM is to find the optimal parameters of the TWSVM through the AFSA. The position
The algorithm steps of the ITWSVM are as follows:
1) Initial settings include artificial fish swarm size
2) Taking the position of artificial fish as a parameter, the classification accuracy of the twin support vector machine was calculated, and the classification accuracy was optimized as the objective function. The fitness value of each artificial fish was obtained, and the optimal position of artificial fish in the whole bureau was recorded.
3) Each artificial fish performed swarm and tail chasing behaviors and judged whether the individual had improved. If it is improved, a better behavior is selected; otherwise, the foraging behavior is performed.
4) Perform the action of artificial fish selection and update the position of each artificial fish.
5) Update the status of the globally optimal artificial fish.
6) Judge whether the maximum number of iterations is reached. If so, output the optimal solution and the corresponding parameter combination; otherwise, increase the number of iterations by one and jump to two).
The flow chart of the ITWSVM is shown in Figure 4, through which the process of the algorithm proposed in this study can be seen intuitively.
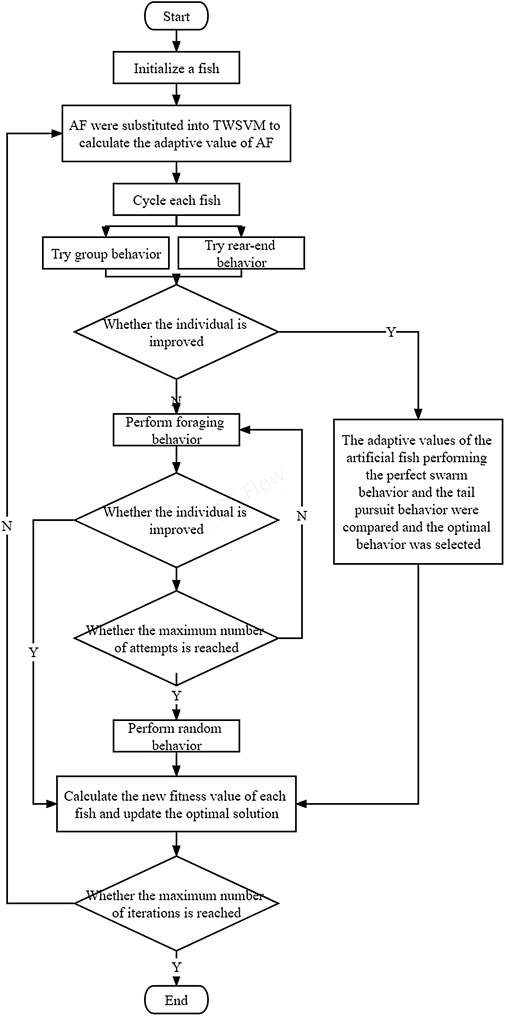
FIGURE 4. Flow chart of the AFSA–TWSVM algorithm.
3.4 Experimental Results and Analysis
In order to prove the effectiveness of the ITWSVM proposed in this study after dimension reduction by LLE, twin support vector machines based on artificial fish swarm algorithm (AFSA–TWSVM) (Li and Ding, 2019) without LLE dimension reduction, twin support vector machines based on particle swarm optimization (PSO–TWSVM) (Shao et al., 2013), twin support vector machines based on fruit fly optimization algorithm (FOA–TWSVM) (Ding et al., 2016), twin support vector machines based on genetic algorithm (GA–TWSVM) (Wang et al., 2013), and twin support vector machines based on glowworm swarm optimization algorithm (GSO–TWSVM) (Ding et al., 2017) were selected as comparative experiments to compare. Considering the rapid development of deep learning in recent years and the excellent performance of the convolutional neural network (CNN) in image classification, this study takes it as a comparative experiment. The V-I color images in section 2 were input into the VGGNet-16 model (Simonyan and Zisserman, 2014) and Fast R-CNN model (Girshick, 2015) for training, and the results were compared.
3.5 The Data Set
The PLAID common data set is used to test the load identification algorithm. The data set comprises voltage and current operation sampling data of 235 electrical equipment in 11 categories of 55 households, with a sampling frequency of 30 kHz and a total sample number of 1074 groups. Considering that the large difference in sample numbers of various electrical equipment in the PLAID data set, it is easy to lead to poor recognition effect of some equipment. For this reason, the synthetic minority over-sampling technique (SMOTE) was used to synthesize and expand a few samples, and the number of expanded samples was 1925. A total of 220 samples (20 samples for each type of equipment) were randomly selected to form the test set, and the remaining 1705 samples were used as the training set.
3.6 Evaluation Functions
For binary classification problems, receiver operating characteristic (ROC) and confusion matrix are important performance indicators for classifier comparison (Zhu and Tang, 2004). Four basic indicators of confusion matrix can be obtained by using the classification results of the test set: true positive (TP), false positive (FP), false negative (FN), and true negative (TN). Based on the abovementioned four basic indicators, the harmonic mean F1 score of accuracy, precision, and recall can be calculated using Eqs. 27,28,29, and30.
The ordinate of the ROC curve is true positive rate (TPR), which is the true positive rate, and the ordinate is false positive rate (FPR), which is the false positive rate. TPR and FPR can be obtained by using the basic indicators in the confusion matrix, such as Eq. 31 and Eq. 32.
3.7 Analysis
In order to ensure the fairness of algorithm comparison, V-I color track images drawn by the PLAID dataset are used as samples. The maximum number of iterations is 100 because the running period of each intelligent optimization algorithm is different. Each algorithm can only be tested three times, and

TABLE 1. Comparison of optimization results of different algorithms.
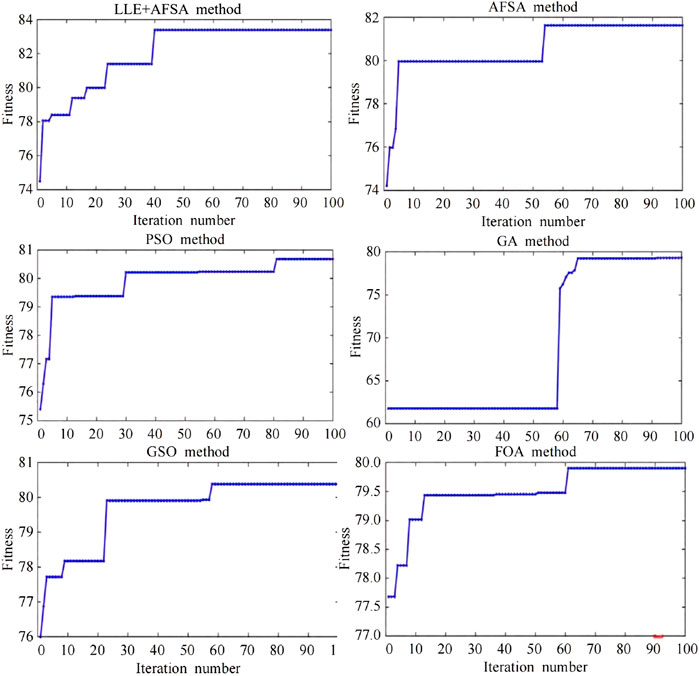
FIGURE 5. Optimization process curve of different algorithm parameters.
Figure 6 shows the ROC curves of eleven algorithms. AUC (area under curve) is defined as the area enclosed by the ROC curve and the coordinate axis. AUC provides a digital basis for performance comparison of classification algorithms. To calculate the AUC, only the area under the ROC curve needs to be obtained. Table 2 shows the comparison of the eight algorithms in the four performance indicators of accuracy, F1 score, AUC, and algorithm running time (the running time of TWSVM algorithms includes parameter optimization time) in the test set.
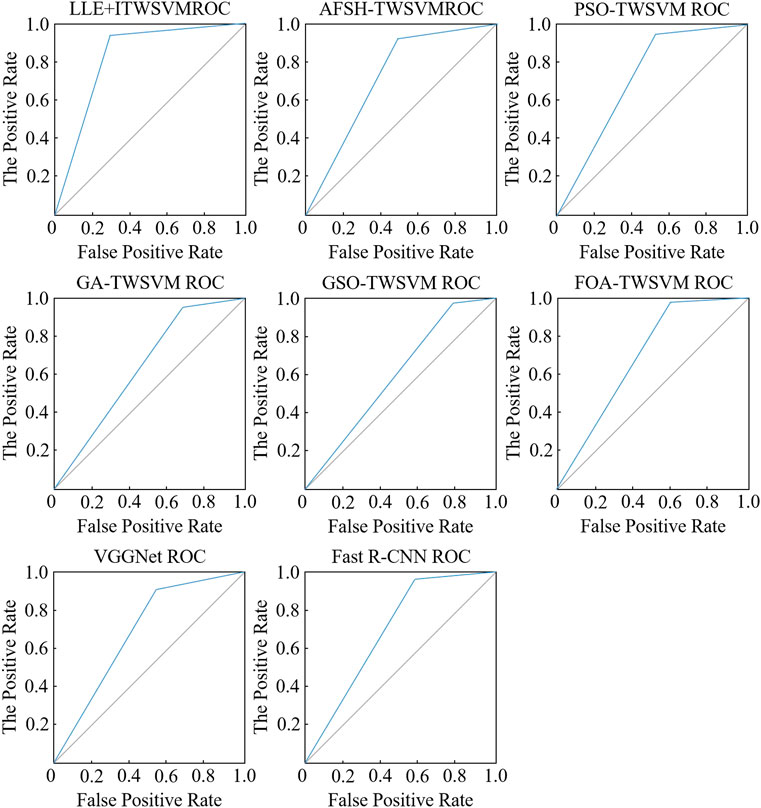
FIGURE 6. ROC curves of different algorithms.

TABLE 2. Comparison of performance indexes of different algorithms.
According to Table 2 and Figure 6, LLE + ITWSVM proposed in this study can find the optimal parameters of the TWSVM faster with fewer iterations. According to Table 2, the proposed LLE + ITWSVM achieves optimal results in the three performance indicators of accuracy, F1 score, and AUC. Meanwhile, the proposed algorithm has the shortest running time and the best real-time performance. It can also be seen from Table 2 that although the Fast R-CNN algorithm achieves a good classification effect, the algorithm is time-consuming because it uses the selective search method to extract candidate regions and there are many redundant operations. All performance indicators of the VGGNET-16 deep convolutional neural network are close to that of the ITWSVM algorithm. In addition, the VGGNET-16 algorithm runs for a long time due to the large amount of computation in the convolutional layer of VGGNET-16 and the larger number of parameters compared with the LLE + ITWSVM algorithm.
Among the six algorithms based on the TWSVM, the proposed LLE + ITWSVM algorithm has the shortest operation time and the best classification performance index. This is mainly due to the dimensionality reduction of V-I color image by LLE, and the calculation of the algorithm after dimensionality reduction is greatly reduced. In addition, the AFSA improved by the TWSVM can jump out of the local optimal solution at a faster speed and find the global optimal parameters suitable for the TWSVM. It solves the problems of TWSVM parameter selection difficulty and parameter optimization algorithm time-consuming in image recognition.
4 Conclusion
Due to the lack of load information of the V-I track in the traditional power load identification process, some power load features overlap and it is difficult to perform equipment identification. The identification model training time is too long. This study presents an intelligent sensing method of power load based on color coding and improved TWSVM. In this method, continuous V-I pixels are realized by bilinear interpolation technology, and the numerical characteristics such as current, voltage, and phase are embedded into the V-I trajectory in the form of different channels so as to form a high-resolution color V-I image. The two-dimensional Gabor wavelet is used to extract image features, and the feature vectors obtained by LLE dimensionality reduction are used for recognition. In addition, an image recognition method based on the AFSA–TWSVM is proposed. This method uses the AFSA algorithm to find the optimal parameters of the TWSVM, which improves the convergence speed and recognition rate of the TWSVM algorithm and overcomes the shortcomings of previous optimization algorithms such as slow convergence speed and easy to fall into local optimal. It provides a new and effective method for the application of TWSVM in V-I color image recognition. Compared with some advanced algorithms, the accuracy of load identification and the speed of model training can be significantly improved by the proposed method, which proves the superiority of the proposed method.
The identification effect of the proposed method for multistate loads needs to be further improved, and a more advanced identification model needs to be built. At the same time, the practical application is still faced with the lack of the domestic data set, high cost of high-frequency sampling, and low universality of the recognition model. Therefore, NILM technology needs further research.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author Contributions
Conceive, experiment, and write articles.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fenrg.2022.906458/full#supplementary-material
References
Chen, T., Gao, T., and Zhao, X. M. (2019). Single Sample Description Based on Gabor Fusion. IET image process 13 (14), 2840–2849. doi:10.1049/iet-ipr.2018.6665
Cui, L. J., Sun, Y., and Liu, Y. X. (2020). Non-intrusive Load Disaggregation Method Considering Time-Phased State Behavior. Automation Electr. Power Syst. 44 (5), 215–222.
Deng, X., Zhang, G. Q., and Wei, Q. L. (2020). A Survey on the Non-intrusive Load Monitoring. Acta Autom. Sin. 47 (2), 1–21.
Ding, S., An, Y., Zhang, X., Wu, F., and Xue, Y. (2017). Wavelet Twin Support Vector Machines Based on Glowworm Swarm Optimization. Neurocomputing 225, 157–163. doi:10.1016/j.neucom.2016.11.026
Ding, S., Zhang, X., and Yu, J. (2016). Twin Support Vector Machines Based on Fruit Fly Optimization Algorithm. Int. J. Mach. Learn. Cyber. 7 (2), 193–203. doi:10.1007/s13042-015-0424-8
Du, L., He, D., Harley, R. G., and Habetler, T. G. (2016). Electric Load Classification by Binary Voltage-Current Trajectory Mapping. IEEE Trans. Smart Grid 7 (1), 358–365. doi:10.1109/tsg.2015.2442225
Fan, L. Y., Hu, C. Z., and Chen, S. Y. (2020). Dimensionality Reduction of Image Feature Based on Geometric Parameter Adaptive LLE Algorithm. Ifs 38 (2), 1569–1577. doi:10.3233/jifs-179520
Gao, J., Kara, E. C., and Giri, S. (2016). “A Feasibility Study of Automated Plug-Load Identification from High-Frequency Measurements,” in IEEE Global Conference on Signal & Information Processing Piscataway, New Jersey, USA, 220–224.
Girshick, R. (2015). “Fast R-CNN,” in IEEE International Conference on Computer Vision. doi:10.1109/iccv.2015.169
Guo, H. X., Liu, J. W., and Yang, P. (2021). Review on Key Techniques of Non-intrusive Load Monitoring. Electr. Power Autom. Equip. 41 (1), 135–144.
Gupta, U., and Gupta, D. (2021). Regularized Based Implicit Lagrangian Twin Extreme Learning Machine in Primal for Pattern Classification. Int. J. Mach. Learn. Cyber. 12 (5), 1311–1342. doi:10.1007/s13042-020-01235-y
Li, C., Liang, G. Q., Zhao, G., and Chen, G. (2021). A Demand-Side Load Event Detection Algorithm Based on Wide-Deep Neural Networks and Randomized Sparse Backpropagation. Front. Energy Res. 9, 720831. doi:10.3389/fenrg.2021.720831
Li, C. R., Huang, Y. Y., and Xue, Y. (2019). Dependence Structure of Gabor Wavelets Based on Copula for Face Recognition. Expert Syst. Appl. 137, 453–470. doi:10.1016/j.eswa.2019.05.034
Li, J. C., and Ding, S. F. (2019). Twin Support Vector Machines Based on Artificial Fish Swarm Algorithm. J. Intelligent Syst. 14 (6), 1121–1126.
Liu, S., Liu, Y., and Gao, S. (2020). Non-intrusive Load Monitoring Method Based on PCA-ILP Considering Multi-Feature Objective Function. Electr. Power Constr. 41 (8), 1–8.
Liu, Y., Wang, J. R., Deng, P. X., Sheng, W., and Tan, P. (2021). Non-Intrusive Load Monitoring Based on Unsupervised Optimization Enhanced Neural Network Deep Learning. Front. Energy Res. 9, 718916. doi:10.3389/fenrg.2021.718916
Moosaei, H., Ketabchi, S., Razzaghi, M., and Tanveer, M. (2021). Generalized Twin Support Vector Machines. Neural Process Lett. 53 (2), 1545–1564. doi:10.1007/s11063-021-10464-3
Niu, H., Quan, C., and Tay, C. J. (2009). Phase Retrieval of Speckle Fringe Pattern with Carriers Using 2D Wavelet Transform. Opt. Lasers Eng. 47 (12), 1334–1339. doi:10.1016/j.optlaseng.2008.10.005
Shao, Y., Wang, Z., Chen, W., and Deng, N.-Y. (2013). Least Squares Twin Parametric-Margin Support Vector Machine for Classification. Appl. Intell. 39 (3), 451–464. doi:10.1007/s10489-013-0423-y
Simonyan, K., and Zisserman, A. (2014). Very Deep Convolutional Networks for Large-Scale Image Recognition. Available at https://www.arXiv.com/1409-1666.
Sun, Y., Cui, Can., and Lu, Jun. (2017). Non-intrusive Load Monitoring Method Based on Delta Feature Extraction and Fuzzy Clustering. Automation Electr. Power Syst. 41 (4), 86–91.
Sun, Y., Li, H. Y., and Liu, Y. X. (2020). Non-intrusive Home-Load Identification Based on Improved Hidden Markov Model. Electr. Power Constr. 41 (4), 73–80.
Tu, J., Zhou, M., and Song, X. F. (2018). Comparison of Supervised Learning-Based Non-intrusive Load Monitoring Algorithms. Electr. Power Autom. Equip. 38 (12), 128–134.
Wang, J. S., Ruan, Y. L., and Zheng, B. W. (2019). Face Recognition Method Based on Improved Gabor Wavelet Transform Algorithm. IAENG Int. J. Comput. Sci. 46 (1), 12–24.
Wang, J., Wong, R. K., and Lee, T. C. M. (2019). Locally Linear Embedding with Additive Noise. Pattern Recognit. Lett. 123, 47–52. doi:10.1016/j.patrec.2019.02.030
Wang, P., and Liu, M. (2019). Day-ahead Dispatching Optimization of Active Distribution Network Considering Demand Response. Sci. Technol. Eng. 19 (28), 152–158.
Wang, Z., Shao, Y., and Wu, T. (2013). A GA-based Model Selection for Smooth Twin Parametric-Margin Support Vector Machine. Pattern Recognit. 46 (8), 2267–2277. doi:10.1016/j.patcog.2013.01.023
Wei, H., Hu, C. Z., and Chen, S. Y. (2020). Establishing a Software Defect Prediction Model via Effective Dimension Reduction. Inf. Sci. 477, 399–409.
Wu, J., Liu, J., and Song, G. T. (2007). Artificial Fish Swarm Algorithm Suitable to Transmission Network Planning. Power Syst. Technol. 31 (8), 63–67.
Wu, X., Jiao, D., and Gao, Y. C. (2020). Construction of Adaptive Feature Library and Load Identification Based on Decomposition of Non-intrusive Power Consumption Data. Automation Electr. Power Syst. 44 (4), 101–109.
Xiang, Y. Z., Ding, Y. F., Luo, Q., Wang, P., Li, Q., Liu, H., et al. (2022). Non-Invasive Load Identification Algorithm Based on Color Coding and Feature Fusion of Power and Current. Front. Energy Res. 10, 899669. doi:10.3389/fenrg.2022.899669
Zhang, T. Y., Deng, C. Y., and Liu, Y. K. (2020). Non-intrusive Load Identification Algorithm Based on Convolution Neural Network. Power Syst. Tech. 44 (6), 2038–2044.
Zhou, M., Song, X. F., and Tu, J. (2018). Residential Electricity Consumption Behavior Analysis Based on Non-intrusive Load Monitoring. Power Syst. Technol. 42 (10), 3268–3276.
Keywords: nonintrusive load monitoring 1, V-I trajectory 2, color encoding 3, two-dimensional Gabor wavelet 4, local linear embedding 5, artificial fish swarm algorithm 6, win support vector machine 7
Citation: Zhang R, Wang Y and Song Y (2022) Nonintrusive Load Monitoring Method Based on Color Encoding and Improved Twin Support Vector Machine. Front. Energy Res. 10:906458. doi: 10.3389/fenrg.2022.906458
Received: 28 March 2022; Accepted: 22 June 2022;
Published: 22 July 2022.
Edited by:
Bo Yang, Kunming University of Science and Technology, ChinaReviewed by:
Jieming Ma, Xi’an Jiaotong-Liverpool University, ChinaPuyu Wang, Nanjing University of Science and Technology, China
Copyright © 2022 Zhang, Wang and Song. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ruoyuan Zhang, MzE0MDU2MzI1QHFxLmNvbQ==