 Jeongwon Seo
Jeongwon Seo Hany S. Abdel-Khalik1
Hany S. Abdel-Khalik1
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Energy Res., 23 December 2021
Sec. Nuclear Energy
Volume 9 - 2021 | https://doi.org/10.3389/fenrg.2021.773255
This article is part of the Research TopicReactor Physics: Methods and ApplicationsView all 27 articles
A key challenge for the introduction of any design changes, e.g., advanced fuel concepts, first-of-a-kind nuclear reactor designs, etc., is the cost of the associated experiments, which are required by law to validate the use of computer models for the various stages, starting from conceptual design, to deployment, licensing, operation, and safety. To achieve that, a criterion is needed to decide on whether a given experiment, past or planned, is relevant to the application of interest. This allows the analyst to select the best experiments for the given application leading to the highest measures of confidence for the computer model predictions. The state-of-the-art methods rely on the concept of similarity or representativity, which is a linear Gaussian-based inner-product metric measuring the angle—as weighted by a prior model parameters covariance matrix—between two gradients, one representing the application and the other a single validation experiment. This manuscript emphasizes the concept of experimental relevance which extends the basic similarity index to account for the value accrued from past experiments and the associated experimental uncertainties, both currently missing from the extant similarity methods. Accounting for multiple experiments is key to the overall experimental cost reduction by prescreening for redundant information from multiple equally-relevant experiments as measured by the basic similarity index. Accounting for experimental uncertainties is also important as it allows one to select between two different experimental setups, thus providing for a quantitative basis for sensor selection and optimization. The proposed metric is denoted by ACCRUE, short for Accumulative Correlation Coefficient for Relevance of Uncertainties in Experimental validation. Using a number of criticality experiments for highly enriched fast metal systems and low enriched thermal compound systems with accident tolerant fuel concept, the manuscript will compare the performance of the ACCRUE and basic similarity indices for prioritizing the relevance of a group of experiments to the given application.
Model validation is one of the key regulatory requirements to develop a scientifically-defendable process in support of establishing confidence in the results of computerized physics models for the various developmental stages starting from conceptual design to deployment, licensing, operation, and safety. To ensure that model predictions can be trusted for a given application, e.g., the domain envisaged for code usage, the regulatory process requires the consolidation of two independent sources of knowledge, one from measurements collected from experimental conditions that are similar to the application, and the other from code predictions that model the same experimental conditions. For criticality safety applications, representing the focus of this manuscript, model validation plays a critical role in supporting design changes, e.g., the introduction of high burnup fuel, high assay low enrichment fuel, etc., or new fuel designs, e.g., accident tolerant fuel, both typically challenged by the scarcity of experimental data.
It is thus paramount to devise a methodology that can consolidate knowledge from both the experimental and computational domains in some optimal manner. The optimality of this consolidation process needs to recognize the possible scarcity of relevant experimental data expected with new designs, the cost for constructing new validation experiments, and the infeasibility of duplicating of all application conditions in the experimental domain. Ideally, the consolidation methodology should be able to optimally leverage existing experimental data in order to minimize the need for new experiments.
In our context, model validation entails a mapping process in which the experimental biases (differences between measurements and model predictions) are to be mapped to the application’s responses of interest in the form of calculational (i.e., best-estimate) biases along with their uncertainties. The goal is to improve the analyst’s confidence in the calculated application response. Mathematically, the confidence is measured in terms of the response uncertainty. The initial uncertainty propagated throughout the model is referred to as the prior uncertainty which accounts for parameter uncertainties, modeling assumptions, numerical approximations, initial, and boundary conditions, etc. The consolidation of experimental biases with the prior uncertainties results in a calculational bias that is intended to correct for the prior uncertainties. A successful consolidation process would result in a reduced bias uncertainty, i.e., as compared to the prior uncertainty, implying increased confidence in the calculated response.
The prior uncertainties are often grouped into two categories, aleatory, and epistemic. This manuscript will focus on epistemic uncertainties resulting from the lack of knowledge of the true values of the nuclear cross-section data. The implied assumption here is that cross-sections constitute the major source of uncertainty in neutronic calculations (Glaeser, 2008; Avramova and Ivanov, 2010; Abdel-Khalik et al., 2013; Wieselquist, 2016). Specifically, we focus on a single consolidation methodology for reducing the impact of epistemic uncertainties, the so-called generalized linear least-squares (GLLS) methodology which may be derived using Bayesian estimation theory (Williams et al., 2016). It is designed to calculate an optimal bias for any calculated response based on an optimal adjustment of the nuclear cross-sections.
In the neutronic community, the GLLS methodology has been independently developed by various researchers (Gandini, 1967; Salvatores, 1973; Broadhead et al., 2004; Cacuci and Ionescu-Bujor, 2010) with varying levels of generalization and mathematical formulation, e.g., Gaussianity assumption of the uncertainty source, degree of nonlinearity of the response variations with cross-sections, mathematical formulation in the cross-section space or the response space, etc. Under the same set of assumptions however, one can show the equivalence of these various formulations. For example, for Gaussian prior cross-section uncertainties and assumed linear approximations, the noted GLLS optimality criterion reduces to an L2 minimization of the sum of two terms, see Eq. 4. The first term minimizes the L2 norm of the adjustments of the cross-sections to ensure their consistency with their prior values, and the second term minimizes the discrepancy between the measurements and predictions for the selected experimental responses. The GLLS methodology is briefly discussed in Section 2.
A prerequisite for the GLLS methodology is to select the experiments that are most relevant to the application conditions1. The premise is that with higher relevance biases with higher confidence, i.e., reduced uncertainties, can be calculated. In the neutronic community, sensitivity methods have been adopted to determine experimental relevance using a scalar quantity, denoted by the similarity index ck (Broadhead et al., 2004)—also called representativity factor by other researchers (Palmiotti and Salvatores, 2012)—which can be used to prioritize/rank the experiments and possibly judge the value of a new experiment before it is constructed.
To measure the similarity index ck, sensitivity methods are first employed to calculate the first-order variations in select quantities of interest that can be experimentally measured, e.g., critical eigenvalue, reaction rate ratios, etc., with respect to the cross-section variations by isotope, reaction type, and incident neutron energy. This is done with both the experimental models as well as the application model of interest, e.g., calculating the criticality conditions for a new fuel design, resulting in one sensitivity vector per model. The sensitivity vector comprises the first-order derivatives, i.e., sensitivity coefficients, of a given response with respect to all cross-sections. Next, the sensitivity vector of the experiment is folded with that of the application and the prior cross-section covariance matrix to calculate the similarity index.
The result of this folding process, see Eq. 5, is an integral quantity (ck) taken to measure the degree of similarity between the first order derivatives of a single quantity of interest with respect to all cross-sections as calculated from both the experiment and the application models2. The prior uncertainties are used as weighting parameters, assigning more weight to cross-sections with higher uncertainties. The resulting similarity index ck is thus expected to be heavily influenced by cross-sections exhibiting both high prior uncertainties as well as strong sensitivities. This helps the GLLS methodology find the optimal adjustments for cross-sections with strong sensitivities as well as high uncertainties. This is justified as follows: cross-sections with weak sensitivities would require large adjustments to change the response, potentially rendering them statistically inconsistent with their prior values. Similarly, adjusting low-uncertainty cross-sections would violate their prior values, also considered a form of fudging that cannot be mathematically justified as it violates the basic assumption of the GLLS methodology, that is the observed discrepancies are mainly originating from the prior cross-section uncertainties.
The resulting similarity index ck is a scalar quantity which lies between −1.0 and 1.0 and may be interpreted as follows: a zero value implies no correlations, i.e., cross-sections with strong sensitivities and high uncertainties, exist between the application, and the experimental conditions. This implies that experimental bias cannot be used to infer the application bias, i.e., it cannot be used to improve the prior estimate of the application response and hence the experiment is judged to have no value to the given application. Conversely, a high similarity value, i.e., close to 1.0, implies that the associated experimental bias can be reliably used to infer the application bias. More important, the bias uncertainty can be reduced with highly relevant experiments. Theoretically, the inclusion of a zero-similarity experiment would keep the prior uncertainty for the application unchanged—not increasing the confidence—while a perfectly similar experiment, e.g., ck
One key limitation of the similarity index is that it does not account for the impact of measurement uncertainties. Essentially, the ck value is obtained by normalizing the covariance matrix for the calculated responses. This further implies that the measurements uncertainties have no impact on the ck value calculation. To explain this, consider two experiments with analogous similarity as measured by the ck value but with different measurement uncertainties. The experiment with the lower uncertainty would result in the calculation of lower bias uncertainty, i.e., more confidence. This implies that an experiment with a lower ck value and a low measurement uncertainty could result in a lower bias uncertainty than that obtained from an experiment with higher ck value and higher measurement uncertainty. Thus, it is important to include the measurement uncertainty in the definition of relevance. This brings value to the design of future experiments, often involving an optimization of sensors’ types and placements. Inclusion of measurement uncertainty would allow the analyst to compare the value of different experiments (and sensors selection) prior to the conduction of the experiment.
Another limitation of the similarity index is that it does not consider the impact of past experiments. As the ck value is calculated by normalizing the weighted inner product of two sensitivity vectors, with more experiments involved in the relevance evaluation process, the ck value cannot be employed to capture a weighted relevance between two subspaces. To explain this, consider that the analyst has calculated the application bias using ideal conditions, i.e., with a highly relevant experiment and near zero measurement uncertainty. In this scenario, the inclusion of additional experiments, even if highly relevant, is unlikely to lead to further noticeable reduction in the bias uncertainty. Thus, two experiments with the same ck value should be assigned different relevance depending on which experiment is employed first. This provides a lot of value when designing new experiments by quantifying the maximum possible increase in confidence while accounting for past experiments. Addressing these two limitations will help analysts determine the minimum number of experiments required to meet a preset level of increased confidence as well as compare the value of planned experiments, providing a quantitative approach for their optimization.
In response to these limitations, this manuscript employs the concept of experimental relevance as opposed to similarity in order to distinguish between the possible added value of a new experiment, if any, and the value available from past experiments. This is possible by extending the definition of the ck similarity index4 via a new analytical expression for experimental relevance, denoted by the ACCRUE index, designed to account for the experiment’s measurement uncertainty and the prior confidence associated with past experiments. The symbol jk is used to distinguish the ACCRUE index from the similarity index ck, where the j denotes the ability to jointly assess the relevance of an experiment with past experiments. The ACCRUE index is short for Accumulated Correlation Coefficient for Relevance of Uncertainties in Experimental validation.
The TSURFER code, representing the GLLS rendition under the ORNL’s SCALE code suite, is employed to exemplify the application of the ACCRUE index jk. Specifically, we develop three sorting methods for the available experiments based respectively on the similarity index ck, the ACCRUE index jk, and pure random sampling. Two different sets of experiments are employed to compare the performance of the various sorting methods. The first set involves low-enriched uranium thermal compound systems with the accident-tolerant fuel (ATF) concept BWR assembly, and the second comprises highly enriched uranium fast metal systems. Finally, numerical experiments will be employed to verify the analytically-calculated values for jk.
This manuscript is organized as follows. Section 2 provides a background on sensitivity theory and the details of mathematical description of the GLLS nuclear data adjustment methodology. Section 3 introduces ACCRUE algorithm and an extension of the non-intrusive stochastic verification with mathematical details. Section 4 verifies the performance of the proposed algorithm by numerical experiments to compare the results made by one of the conventional integral similarity indices, ck¸ and the ACCRUE index, jk. Concluding remarks and further research are summarized in Section 5.
This section presents a brief background on three key topics: 1) sensitivity methods employed for the calculation of first-order derivatives; 2) the GLLS adjustment theory, employed to calculate the application bias; and 3) the extant similarity index ck definition. The material in this section may be found in the literature, however compiled here to help set the stage for the proposed ACCRUE index.
Sensitivity coefficients are the key ingredients for the GLLS methodology, as they are used to relate the response variations to the model parameter variations, with the latter assumed to represent the dominant sources of uncertainties. A sensitivity coefficient measures the first-order variation of a response that is caused by a change in one input model parameter. For the numerical experiments employed in this paper, we focus on the multiplication factor, keff, i.e., critical eigenvalue, as the response of interest and the reaction-wise cross-sections by isotope and energy group as the model parameters.
While sensitivity coefficients can be readily evaluated using finite differencing, the adjoint-based perturbation theory methodology (Usachev, 1964; Gandini, 1967; Stacey, 1974; Oblow, 1976; Cacuci and Ionescu-Bujor, 2010) has been adopted as the most efficient way to calculate derivatives. This follows because adjoint-based sensitivity theory requires one adjoint solution per response, implying that one can calculate the first-order derivatives of the given response with respect to all cross-sections using a single adjoint model evaluation, whereas finite differencing requires an additional forward model evaluation for each cross-section. The general idea behind adjoint-based sensitivity analysis is summarized below for the evaluation of the first order derivatives of the critical eigenvalue.
The Boltzmann transport equation for an assembly containing fissionable material, referred to as the forward model, can be symbolically expressed as (Williams, Broadhead and Parks, 2001):
where
The two operators
where
and aggregated in a vector (referred to as the sensitivity vector or profile) with the superscript “T” representing vector/matrix transpose:
Eq. 2 implies that a finite-difference-based sensitivity analysis would require
The adjoint formulation of sensitivity coefficients may be described by the following equation:
The brackets represent an inner product operation corresponding to an integration over entire phase-space (e.g., energy groups, direction of neutron travel, and space) using the forward solution obtained from Eq. 1 and a new quantity, called the adjoint solution, obtained from:
where
Several computer codes have embodied the adjoint methodology to calculate sensitivity coefficients (Lucius et al., 1981; Becker et al., 1982; Gerald; Rimpault et al., 2002). Of interest to us is the SCALE TSUNAMI methodology (Rearden and Jessee, 2016) which is used as a basis for the evaluation of the sensitivity coefficients for the GLLS-based TSURFER code, discussed in the next section.
As discussed earlier, the main goal of GLLS is to consolidate knowledge from computations and experiments. This is illustrated in Figure 1 using two representative PDFs describing the best available knowledge about the keff from the experiments (shown in red) and model predictions (blue). The spread of each PDF is taken as a measure of confidence. The confidence in the model predictions is determined by the propagated prior uncertainties, and the experiment’s confidence is tied to its measurement uncertainties. The GLLS methodology represents a disciplined mathematical approach to consolidate these two PDFs into one (yellow) that provides higher confidence for the calculated response as compared to the prior confidence from model predictions.
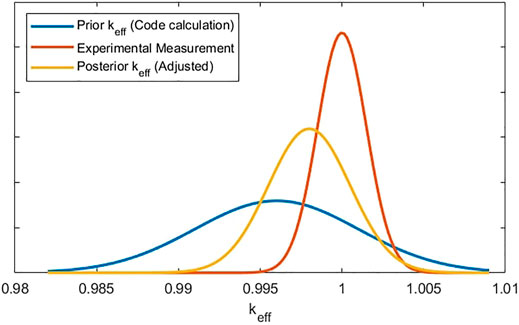
FIGURE 1. keff consolidated confidence from experiment and prior calculations.
To achieve that, GLLS assumes that the uncertainties originate from the cross-sections. Therefore, it attempts to identify the optimal cross-section adjustments which minimize the discrepancies between measured and predicted responses. Based on the optimal adjustments, one can calculate the corresponding change in the application’s response, with the application representing the conditions for which no experimental values exist. The change in the code-calculated application response, i.e., from its prior value, is denoted by the application bias.
Considering that the analyst is interested in calculating the bias for the keff value for a given application, and there exist
where the last component is the prior value for the application keff. The corresponding measurements for the first
The prior cross-section uncertainties are described by a multi-variable Gaussian PDF with a vector of means representing the reference multi-group cross-sections and a covariance matrix given by:
The adjusted cross-sections are calculated as the minimizer of the following minimization problem subject to the constraint
where
The objective function in Eq. 4 may be re-written in terms of the calculated and adjusted keff values as:
where
and
where (j, i) element represents the relative sensitivity coefficient of the jth experiment [or application,
Assuming that the linearization of the constraint
where
The posterior (i.e., post the consolidation of experimental and prior values) covariance matrix for the keff values is given by:
The diagonal elements of this matrix describe the confidence one has in the posterior keff values. The
The definition of the similarity index ck naturally appears in the GLLS formulation of the prior covariance matrix. Specifically, one can expand Eq. 5 as follows:
The diagonal entries of this matrix represent the uncertainty (in the units of variance) of the prior keff values and the off-diagonal entries are the correlations between these uncertainties. Ideally, one would want to maximize the correlations between the application and all experiments, described by the last row or last column of the matrix. A standardized form of this matrix may be obtained by multiplying it from both sides by the inverse of the square root of its diagonal elements to produce the matrix
In this representation, the value of any off-diagonal terms is standardized between
This equation may be used to pre-calculate the similarities of all available experiments with respect to the given application. To achieve that one needs to calculate the corresponding sensitivity profiles for the experiments and the application which are readily calculated using the adjoint sensitivity theory presented in Section 2.1. In our work, the SCALE TSUNAMI code is employed to calculate the sensitivity profiles as well as the similarity indices.
Next, it is instructive to give a geometric interpretation of the similarity index. To do that, rewrite the expressions in Eq. 8 using the Cholesky decomposition of
where
Performing this transformation for both the numerator and denominator in Eq. 8, the ck index reduces to:
As illustrated in Figure 2, this expression is interpreted as cosine angle between two vectors, one related to the application and the other to an experiment.
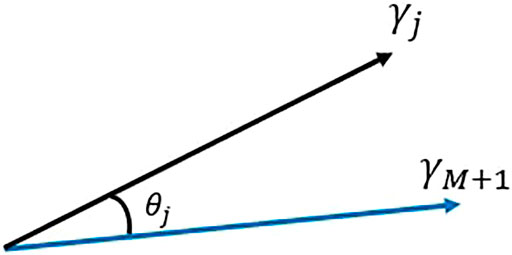
FIGURE 2. Geometrical interpretation for the similarity index, ck.
Further, it has been shown in earlier research (Huang et al., 2020) that one can calculate ck using randomized forward model evaluations taking advantage of the equivalence between the ck definition and the standard correlation coefficient. This requires sampling of the cross-sections within their prior uncertainties a few hundred times to obtain sufficiently approximate estimates of the similarity index, as shown below. As demonstrated in earlier work using the Sampler code under the SCALE environment (Wieselquist, 2016), this forward-based approach provides two advantages; first, it allows one to calculate similarity indices when the adjoint solver is not available; and second, it provides a way to verify the results of adjoint-based calculations.
It has been shown in earlier work that these two vectors may be interpreted as the directional sensitivity profiles with respect to the dominant eigen directions of the prior covariance matrix. To illustrate the mechanics of the forward-based approach for calculating the similarity index, first consider re-writing the cross-section covariance matrix decomposed by Cholesky methodology as follows:
where
If
By the law of large numbers, one can show that as
This limit is readily reached with a few hundred samples. Verification with numerical experiments is provided in the following section.
Then, Eq. 10 can be re-written by the cross-section samples, such as:
With the linearity assumption valid, e.g.,
where
Thus, the construction of the
The deviation vector of jth experiment (or application denoted by subscript
Each term in
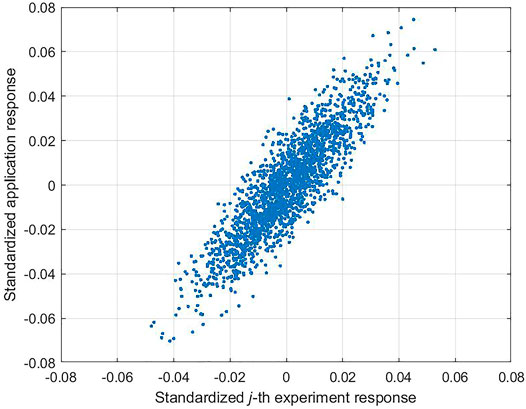
FIGURE 3. Representative scatter plot of two perturbation vectors.
Their similarity index thus reduces to the standard correlation coefficient between the two vectors
With a large number of samples, the inner-products of any two sample vectors reduce to the elements of the
Thus,
In this manuscript, the ACCRUE index will be calculated using both the analytical definition, presented in Section 3, as well as the noted forward-based approach for verification.
This section details the theoretical derivation of the ACCRUE index jk, discusses its relationship to the ck index, and shows how it can be calculated both analytically using the adjoint approach and statistically using the forward approach. The jk index is designed to address two limitations of the ck index, first the impact of measurement uncertainty on the relevance of a given experiment, and second, the diminished value of an experiment resulting from its similarity with previously consolidated experiments. With regard to the first limitation, the ck index bases the similarity on the code-calculated values only. In practice however, an experiment with a high ck index could prove less valuable to estimating the application bias if its measurements have high uncertainties. The second limitation calls for an approach to identify experimental redundancy. The high level premise of any inference procedure is that additional measurements will result in more confidence in the calculated application bias. In practice however, the confidence gleaned from multiple highly relevant experiments could be equally obtained from a smaller number of experiments if high level of redundancy exists between the experiments, a common phenomenon observed in many fields, often referred to as the law of diminished return. The ck index does not capture this effect because it is based on a single experiment.
Different from the ck index which relies on the
The discrepancies can be aggregated in a vector such that:
where the last element,
Then the covariance matrix for the discrepancy vector,
where
Similarly to before, consider the expressions in Eq. 11 using the Cholesky decomposition of
where
Geometrically, the ACCRUE index jk with a single experiment thus is defined as the cosine angle defined by two vectors of
Figure 4 graphically shows how the measurement uncertainty impacts on the jk value with a single experiment (the jth experiment denoted by subscript “j”) as compared to the ck value. Due to the measurement uncertainty, the cosine angles estimated by ck and jk respectively change from
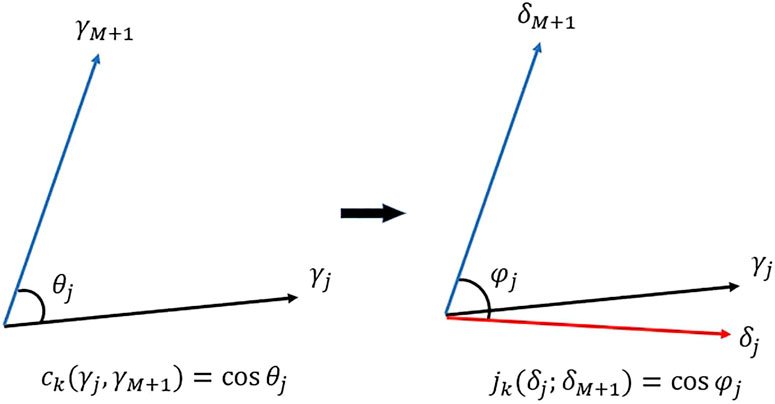
FIGURE 4. Impact of measurement uncertainty inclusion.
With regard to the matrix notations of both equations,
As discussed in Section 2.3, the covariance matrix,
where
Then the measurement sample vector for jth experiment,
Thus, the discrepancy sample vector for jth experiment,
where
Thus,
The ACCRUE index may be viewed as the similarity between a group of experiments and the application of interest when the experimental uncertainties are excluded from the analysis. Its true value however is in assessing the relevance of a new experiment by taking into account both the experiment’s measurement uncertainty and the value gleaned from past experiments. In this section, the detailed analytical derivation for jk value with multiple experiments is provided with the
Analytically, the jk index for the first
where the
These terms can be evaluated analytically given access to the sensitivity coefficients, the prior cross-section covariance matrix, and the measurement uncertainties. By way of an example, consider the simple case with
This expression equivalent to the ck index assuming zero measurement uncertainty, i.e.,
Eq. 15 shows that the relevance of two experiments may be expressed as the sum of two terms, one very similar to the ck index representing the relevance of the first experiment, and the other subtracting away the impact of the first experiment. To help interpret the jk index for
Consider the case with two experiments (denoted by the subscripts “1” and “2”, respectively) as illustrated in Figure 5, where jk calculates the angle between the
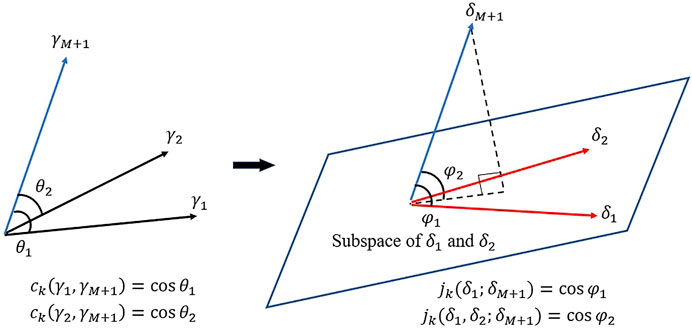
FIGURE 5. Geometrical interpretation of jk value with two experiments.
The cosine angle between any two subspaces can be calculated by orthogonal projection techniques, e.g., QR decomposition or Singular Value Decomposition (SVD). For example, consider the jk value of the first
Then, the associated jk expression can be written as:
where
For example, consider the case where
where
Thus, the jk value is
which is equivalent to Eq. 14
If
where
Thus, the jk value is:
which is equivalent to Eq. 15
Consequently, the general expression for jk value can be written as:
where
which evaluates the same scalar quantity as that calculated by the matrix element notations in earlier this section.
Figure 6 shows the overall process for evaluating the similarity or relevance of an experiment to a given application. The similarity accounts for the correlation between two responses, e.g., one from the application and the other from the experiment, as calculated by a computer code. The ACCRUE index extends the concept of similarity to quantify the relevance, as measured by the added value of the experiment, taking into account both the experiment’s measurement uncertainties as well as past experiments. As shown in this figure, the first step is to check if an adjoint solver is available which allows one to employ sensitivity coefficients. If no experimental measurement uncertainty is available and only a single experiment is available, the ACCRUE index jk reduces to the similarity index ck. If the experimental uncertainty is available, Eq. 12 is employed to evaluate the jk index. If additional experiments are available, then the most general expression for jk is employed per Eq. 13.
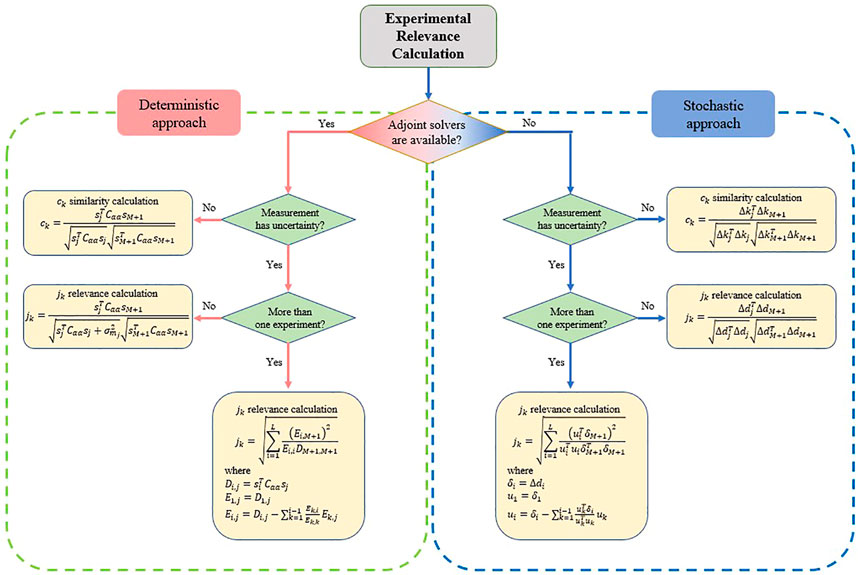
FIGURE 6. Approach for evaluating experimental relevance.
Numerical experiments have been conducted with two different case studies. The first case study assumes that the applications have low ck values for all available experiments which are in the order of 0.7, referred to as the low relevance applications, and the second case study considers applications with high ck values that are greater than 0.9. An application with low relevant experiments represents a realistic scenario expected with first-of-a-kind designs, i.e., advanced reactor designs and new fuel concepts, with no prior or rare strongly relevant experiments. It also highlights the expected high cost of new experiments, and the need to employ modeling and simulation to design a minimal number of targeted validation experiments. When the ck values are low for the given application, it is important to figure out a way to prioritize the selection of past available experiments, as well as judge the value of new/planned experiments. We compare the performance of the jk and ck indices for both the high relevance and low relevance applications for a range of assumed values for the experimental uncertainties. This is also important when designing new experiments, as it provides quantitative value for different types of instrumentations with varying levels of measurement uncertainties.
The low relevance case study employs 17 critical benchmark experiments from the low enriched uranium thermal compound systems (LCT-008-001—LCT-008-017) in the ICSBEP handbook (NEA, 2011) as experiments and the accident-tolerant fuel (ATF) concept BWR assembly as an application. The selected LCT benchmark experiment set (LCT-008) cases are critical lattices with UO2 fuel rods of 2.9% enrichment and perturbing rods in borated water in common, but have different boron concentrations and various rods arrangements. Their similarity indices, ck, to the BWR ATF model are all around 0.7 as reported by TSUNAMI-IP. The BWR ATF model is a
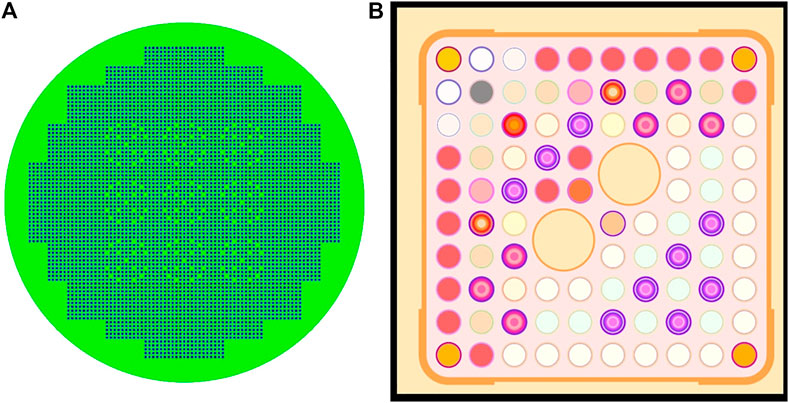
FIGURE 7. Low-relevant case layouts of the representative models. (A) Experiment model: LCT-008-001 (B) Application model: ATF assembly.
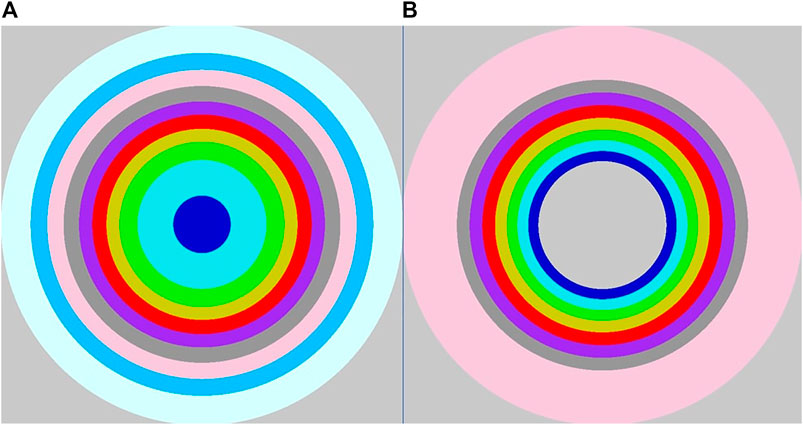
FIGURE 8. High-relevant case layouts of the representative models. (A) Experiment model: HMF-020-001 (B) Application model: HMF-019-001.
To identify the possible impact of initial discrepancies, i.e., differences between calculated and measured responses, on the GLLS-estimated biases, three critical experiments having different biases (high, intermediate, and low) are selected as applications and the remaining experiments are used as validation experiments. The high bias application is selected to have an initial keff discrepancy in the order of 1,000 pcm, while the intermediate in the order of 300–500 pcm, and the low 200 pcm.
Figure 9 shows representative results for the high relevance case study for three different applications with high, intermediate, and low biases. The x-axis explores the change in the GLLS-estimated biases when adding one experiment at a time, wherein the experiments are ordered according to their ck values (top graphs), and jk values (bottom graphs). The ck-sorting is straightforward as each experiment is employed once in conjunction with the given application. Markedly different, the jk value depends on the number and order of experiments included, hence each sorting is expected to give rise to different profiles for jk and the associated bias and bias uncertainty. The goal is thus to identify the order that allows the analyst to reach a certain level of confidence in the calculated bias with minimal number of experiments. In the current study, the search for this optimal order is initiated with the experiment having the highest ck value, with the second experiment selected to maximize the jk value among all remaining experiments, and so on. In practice, one may start with any experiment, and adds experiments as they become available, or may employ the jk value to quantify the value of new/planned experiments. For each added experiment, the GLLS bias and bias uncertainty are calculated to help compare the ck and jk-sorting. The goal is to achieve a stable prediction of the bias with minimal uncertainty.
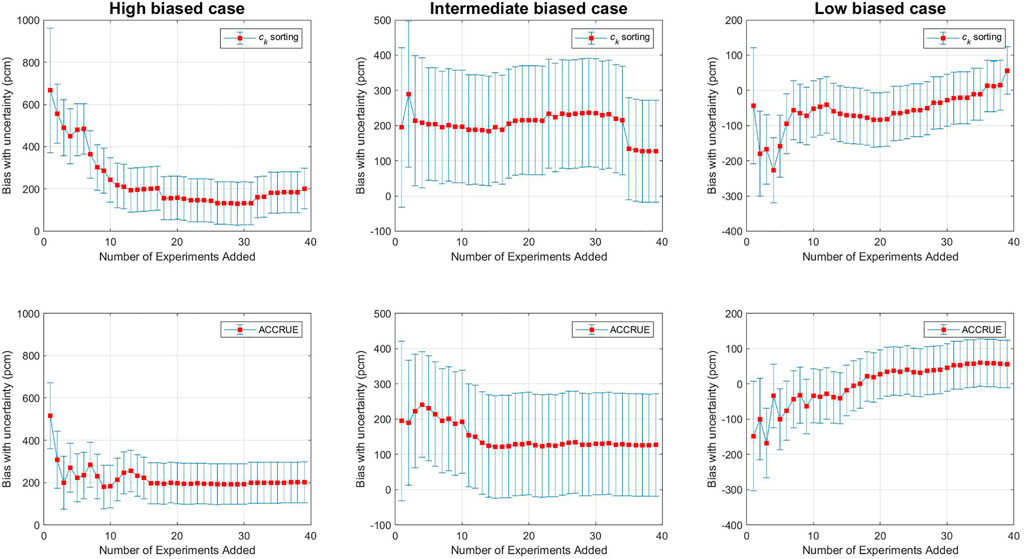
FIGURE 9. Bias and uncertainty estimation for high relevance case.
These results show that the bias stabilizes quicker with the jk sorting. More important, the ck-sorting could show sudden changes after a period of stable behavior. For all considered applications using the ck-sorting, the biases continue to experience sudden or gradual changes following a period of stable behavior. For example, for the low bias application, the estimated bias exhibits an upward trend after the 20th experiment. The implication is that the additional experiments continue to provide value to the GLLS procedure despite their lower relevance. With the jk-sorting, a more explainable trend is achieved whereby the bias trend shows stable behavior after the 20th experiment.
Regarding the bias uncertainties, shown in Figure 9 as error bars, they are plotted in Figures 10, 11 as a function of the number of experiments using both the ck and jk-sorting for, respectively, one application with high relevance experiments and one application with low relevance experiments. The results highlight a key limitation of the ck-sorting, that is the addition of low relevance experiments could change the trend of both the bias and the bias uncertainty. The jk-sorting however does not suffer from this limitation, implying that one can select the minimal number of experiments required to reach a certain pre-determined level of confidence for the calculated bias. Comparison of the uncertainty values in both figures indicate that the impact is much less pronounced when highly relevant experiments are available. This highlights the value of the jk-sorting when limited number of experiments are available, as is the case with first-of-a-kind designs.

FIGURE 10. Bias uncertainty reduction for a low relevance application.
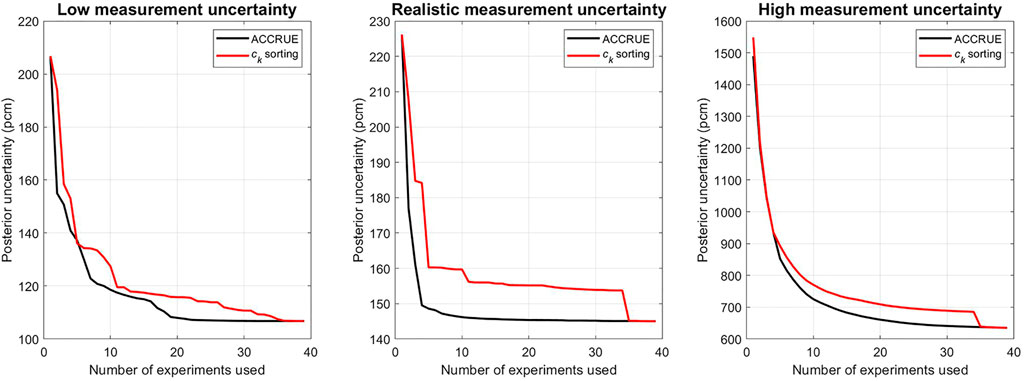
FIGURE 11. Bias uncertainty reduction for a high relevance application.
These results are compared in Figure 12 with randomized orders (shown as multi-color solid lines) for one of the low relevance applications at different levels of measurement uncertainty, specifically 10 pcm (representing a highly accurate measurement), 100 pcm (a realistic measurement), and 500 pcm (a low confidence measurement) for the measured keff values. The results show that pure random sampling could be superior to ck-sorting, with the jk sorting still exhibiting the best behavior in terms of reducing the bias uncertainty with minimal number of experiments. When the measurement uncertainty is too high, the ordering of the experiments is no longer important. This is a key observation highlighting the value of ordering experiments as experimentalists continue to improve their measurements in support of model validation.
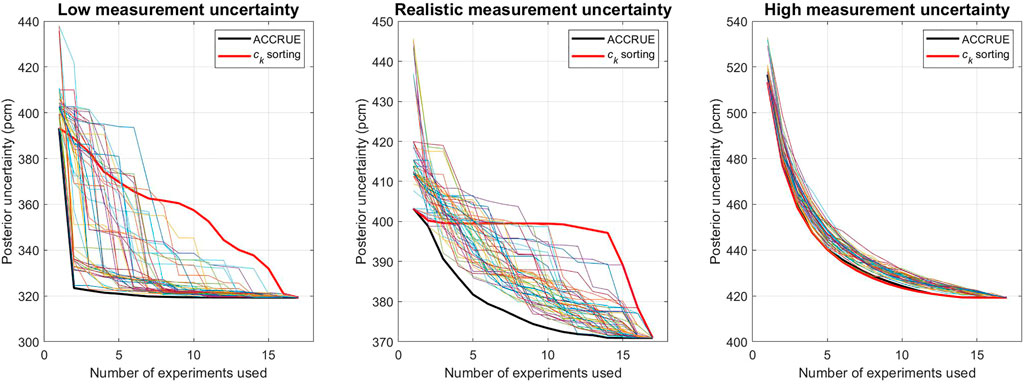
FIGURE 12. Bias uncertainty reduction with random orders.
To help understand the changes in the bias and bias uncertainty associated with the ck-sorting, the left plot in Figure 13 orders the experiments according to their ck values, and the middle plot calculates the corresponding jk values using the ck-sorting. Notice that although the first few experiments, i.e., #15, #13, #12, …, to #4 have higher relevance than later experiments, they do not change the jk value, and hence the bias and bias uncertainty as shown in the earlier figures. The jk values start to show larger increase when additional lower relevance experiments are added, explaining the sudden or gradual change in the bias and its uncertainty. However, when the experiments are ordered according to their jk values, as shown in the right plot, a smoother jk profile is obtained which is consistent with the bias and bias uncertainty profiles obtained using the GLLS procedure. The implication is that one can employ the jk profile to develop insight into the amount of experimental effort necessary to reach a target confidence in the calculated bias, even before the actual measurements are recorded. This follows because jk only requires access to the prior uncertainties and the expected measurement uncertainty, not the actual measured bias.
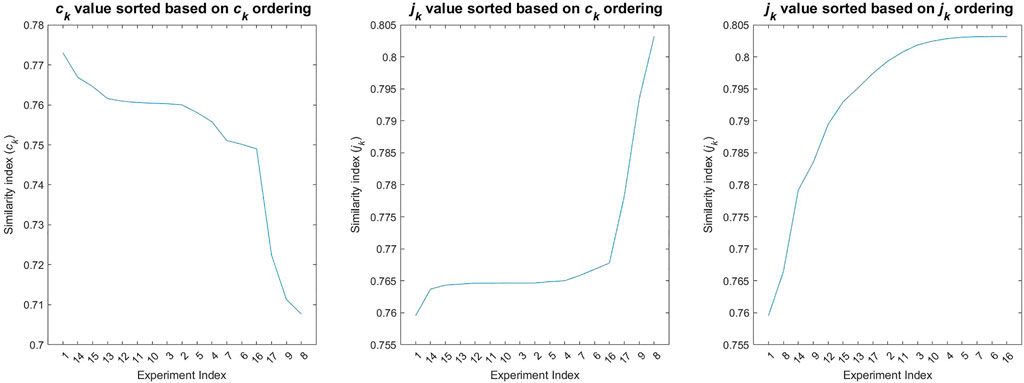
FIGURE 13. Comparison of the ck and jk profiles.
As mentioned earlier, the analytical expressions for the similarity or relevance metrics such as ck and jk require access to derivatives which may not be readily available. To address this challenge, earlier work has developed an alternative to the estimation of ck value using a non-intrusive forward-based stochastic method (Huang et al., 2020). In this section, we present numerical results comparing the results of the analytically-calculated jk value to that estimated by the noted stochastic method. This will serve two purposes: the first is to provide a simple approach for the calculation of the jk value when derivatives are unavailable, and the second to help verify the calculated jk value using the stochastic method by comparing it to the analytically-calculated value. To achieve that, two benchmark experiments (HMF-005-001 and 005-002) are selected to calculate the jk value. Their calculated response uncertainties are 1,492 pcm and 1721 pcm respectively, and measurement uncertainties are 360 pcm. A total of 1,000 samples are generated to examine the convergence of forward-based jk value, whose corresponding analytical value is 0.9445 as given by Eq. 15, shown in Figure 14 as a horizontal line. The results indicate that the forward-based approach produces acceptable approximation of the analytical value using few hundred simulations, which is consistent with the results reported previously for the ck value (Huang et al., 2020).
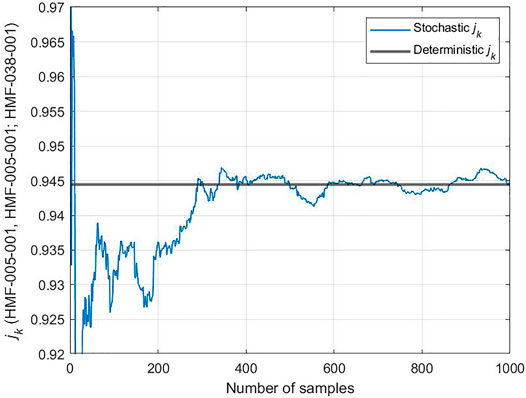
FIGURE 14. Non-intrusive stochastic estimation of jk.
This manuscript has introduced an extension of the basic similarity metric, denoted by the ACCRUE metric and mathematically symbolized by the jk index to distinguish it from the ck similarity metric. The ACCRUE metric takes into account the impact of multiple experiments and the associated experimental uncertainties, both currently missing from the extant similarity definition. The results show that the ACCRUE metric is capable of finding the optimal sorting of the experiments, the one that leads to the most stable variation in the GLLS calculated bias and bias uncertainty. When the experiments available are highly relevant and numerous, the performance of the ck metric approaches that of the jk metric. However, when highly-relevant experiments are scarce and when experimental uncertainties are low, the jk metric is capable of identifying the minimal number of experiments required to reach a certain confidence for the calculated bias, whereas the ck metric may be outperformed by random sorting of the experiments. The results of this work are expected to be valuable to the validation of computer models for first-of-a-kind designs where little or rare experimental data exist. Another important value for the jk metric is that it can be calculated using forward samples of the model responses, thereby precluding the need for derivatives, which allows one to extend the concept to non-keff responses. This will allow one to extend its definition to models exhibiting nonlinear behavior often resulting from multi-physics coupling, e.g., different geometry, compositions, and types of reactor. This will pave the way to the development of relevance metrics that goes beyond the first-order variations currently captured by the extant similarity analysis.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
JS: Writing the original draft, methodology, investigation, visualization. HA-K: Conceptualization, methodology, writing/editing, supervision. AE: Supervision, review/editing.
This work was supported in part by an Idaho National Laboratory project (Grant no. 74000576).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The authors would like to acknowledge Dr. Ugur Mertyurek of Oak Ridge National Laboratory for providing the models used in this study.
1In theory the GLLS can incorporate any experimental data regardless of their relevance to the application conditions. In practice however, one limits the analysis to the most relevant experiments for various practical considerations. For example, inclusion of many weakly-relevant experiments may adversely impact the χ2 value making it difficult to interpret the GLLS results.
2Other empirical forms for the similarity index have been proposed, but are not covered here. (Broadhead et al., 2004). Examples include the use of the absolute difference in the sensitivity coefficients, D, and the inner products of two sensitivity profiles, E, etc.
3In this hypothetical scenario, the minimum uncertainty would be controlled by the measurement uncertainty and other administrative uncertainties that are typically added for unaccounted sources of uncertainties.
4The development here will be limited to the GLLS methodology; it is thus implicitly assumed that the GLLS assumptions are satisfied, i.e., Gaussianity of the cross-section prior uncertainty and linearity of the response variation with cross-section perturbations.
5Other dependencies for the two operators, such as geometry, composition, etc., are suppressed in the current discussion, since GLLS focuses only on the epistemic uncertainties associated with nuclear cross-sections.
6The subscript j (denoting the jth experiment) will be suppressed for other quantities in Eqs. 2, 3 to reduce notational clutter, and because they do not contribute to the discussion.
Abdel-Khalik, H. S., Bang, Y., and Wang, C. (2013). Overview of Hybrid Subspace Methods for Uncertainty Quantification, Sensitivity Analysis. Ann. Nucl. Energ. 52, 28–46. doi:10.1016/j.anucene.2012.07.020
Avramova, M. N., and Ivanov, K. N. (2010). Verification, Validation and Uncertainty Quantification in Multi-Physics Modeling for Nuclear Reactor Design and Safety Analysis. Prog. Nucl. Energ. 52, 601–614. doi:10.1016/j.pnucene.2010.03.009
Broadhead, B. L., Rearden, B. T., Hopper, C. M., Wagschal, J. J., and Parks, C. V. (2004). Sensitivity- and Uncertainty-Based Criticality Safety Validation Techniques. Nucl. Sci. Eng. 146, 340–366. doi:10.13182/NSE03-2
Cacuci, D. G., and Ionescu-Bujor, M. (2010). Best-Estimate Model Calibration and Prediction through Experimental Data Assimilation-I: Mathematical Framework. Nucl. Sci. Eng. 165, 18–44. doi:10.13182/NSE09-37B
Gandini, A. (1967). A Generalized Perturbation Method for Bi-linear Functionals of the Real and Adjoint Neutron Fluxes. J. Nucl. Energ. 21, 755–765. doi:10.1016/0022-3107(67)90086-X
Glaeser, H. (20082008). GRS Method for Uncertainty and Sensitivity Evaluation of Code Results and Applications. Sci. Tech. Nucl. Installations 2008, 1–7. doi:10.1155/2008/798901
Huang, D., Mertyurek, U., and Abdel-Khalik, H. (2020). Verification of the Sensitivity and Uncertainty-Based Criticality Safety Validation Techniques: ORNL's SCALE Case Study. Nucl. Eng. Des. 361, 110571. doi:10.1016/j.nucengdes.2020.110571
Lucius, J. L., Weisbin, C. R., Marable, J. H., Drischler, J. D., Wright, R. Q., and White, J. E. (1981). Users Manual for the FORSS Sensitivity and Uncertainty Analysis Code System. Oak Ridge, TN. doi:10.2172/6735933
Oblow, E. M. (1976). Sensitivity Theory from a Differential Viewpoint. Nucl. Sci. Eng. 59, 187–189. doi:10.13182/nse76-a15688
Palmiotti, G., and Salvatores, M. (20122012). Developments in Sensitivity Methodologies and the Validation of Reactor Physics Calculations. Sci. Tech. Nucl. Installations 2012, 1–14. doi:10.1155/2012/529623
Rimpault, G., Plisson, D., Tommasi, J., Jacqmin, R., Rieunier, J-M., Verrier, D., et al. (2002). The ERANOS Code and Data System for Fast Reactor Neutronic Analysis.
Salvatores, M. (1973). Adjustment of Multigroup Neutron Cross Sections by a Correlation Method. Nucl. Sci. Eng. 50, 345–353. doi:10.13182/nse73-a26569
Stacey, W. B. (1974). Variational Methods in Nuclear Reactor Physics. Academic Press. doi:10.1016/b978-0-12-662060-3.x5001-2
Stark, H., and Woods, J. W. (2012). Probability, Statistics, and Random Processes for Engineers. Fourth Edition4th editio. Upper Saddle River: Pearson.
Usachev, L. N. (1964). Perturbation Theory for the Breeding Ratio and for Other Number Ratios Pertaining to Various Reactor Processes. J. Nucl. Energ. Parts A/B. Reactor Sci. Tech. 18, 571–583. doi:10.1016/0368-3230(64)90142-9
Wieselquist, W. A., 2016. SAMPLER: A Module for Statistical Uncertainty Analysis with SCALE Sequences, 6.2.3. ed. Ornl/Tm-2005/39.
Keywords: similarity index, generalized linear least squares, model validation, criticality safety, correlation coefficient
Citation: Seo J, Abdel-Khalik HS and Epiney AS (2021) ACCRUE—An Integral Index for Measuring Experimental Relevance in Support of Neutronic Model Validation. Front. Energy Res. 9:773255. doi: 10.3389/fenrg.2021.773255
Received: 09 September 2021; Accepted: 25 November 2021;
Published: 23 December 2021.
Edited by:
Tengfei Zhang, Shanghai Jiao Tong University, ChinaReviewed by:
Qian Zhang, Harbin Engineering University, ChinaCopyright © 2021 Seo, Abdel-Khalik and Epiney. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jeongwon Seo, c2VvNzFAcHVyZHVlLmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.