 Alisher Ikramov
Alisher Ikramov Shakhnoza Mukhtarova4
Shakhnoza Mukhtarova4 Saodat Abdullaeva
Saodat Abdullaeva
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Endocrinol. , 04 April 2024
Sec. Systems Endocrinology
Volume 15 - 2024 | https://doi.org/10.3389/fendo.2024.1305640
Blood glycosylated hemoglobin level can be affected by various factors in patients with type 2 diabetes and cardiovascular diseases. Frequent measurements are expensive, and a suitable estimation method could improve treatment outcomes.
Patients and methods: 93 patients were recruited in this research. We analyzed a number of parameters such as age, glucose level, blood pressure, Body Mass Index, cholesterol level, echocardiography et al. Patients were prescribed metformin. One group (n=60) additionally was taking sitagliptin. We applied eight machine learning methods (k nearest neighbors, Random Forest, Support Vector Machine, Extra Trees, XGBoost, Linear Regression including Lasso, and ElasticNet) to predict exact values of glycosylated hemoglobin in two years.
Results: We applied a feature selection approach using step-by-step removal of them, Linear Regression on remaining features, and Pearson’s correlation coefficient on the validation set. As a result, we got four different subsets for each group. We compared all eight Machine Learning methods using different hyperparameters on validation sets and chose the best models. We tested the best models on the external testing set and got R2 = 0.88, C Index = 0.857, Accuracy = 0.846, and MAE (Mean Absolute Error) = 0.65 for the first group, R2 = 0.86, C Index = 0.80, Accuracy = 0.75, and MAE = 0.41 for the second group.
Conclusion: The resulting algorithms could be used to assist clinical decision-making on prescribing anti-diabetic medications in pursuit of achieving glycemic control.
Cardiovascular diseases and type 2 diabetes pose significant challenges to global healthcare systems, with a growing prevalence and associated morbidity and mortality rates (1). Achieving optimal glycemic control is crucial in managing type 2 diabetes and reducing the risk of cardiovascular complications. Glycosylated hemoglobin (HbA1c) is an important biomarker (2) that reflects the average blood glucose levels over a prolonged period, typically three months. Regular monitoring of HbA1c levels assists in assessing the effectiveness of treatment regimens and guiding therapeutic interventions. Hong et al. (3) provided a proof that high level of baseline HbA1c appeared to be an independent predictor for the severity of coronary artery disease (CAD) and poor outcome in patients with stable coronary artery disease.
Metformin and sitagliptin are commonly prescribed medications for the management of type 2 diabetes. These drugs have demonstrated efficacy in reducing HbA1c levels, but the individual response to treatment can vary significantly (4). Predicting HbA1c levels in patients with cardiovascular diseases and type 2 diabetes who are prescribed metformin and sitagliptin can aid in identifying patients at higher risk of poor glycemic control. By incorporating patient-specific factors, such as demographic characteristics, baseline HbA1c levels, comorbidities, and other factors, a predictive model can be developed to estimate HbA1c levels over a two-year follow-up period. This model can assist clinicians in optimizing treatment strategies and improving patient outcomes.
The primary objective of this study is to develop a predictive model for estimating HbA1c levels in patients with cardiovascular diseases and type 2 diabetes who were prescribed metformin and sitagliptin over a two-year follow-up period. The specific objectives include:
1. Collecting baseline demographic and clinical data, including age, gender, body mass index (BMI), duration of type 2 diabetes, baseline HbA1c levels, lipid profile, blood pressure, and other entries in anamnesis.
2. Utilizing statistical analysis and machine learning algorithms to identify significant predictors of HbA1c levels.
3. Developing a predictive model that incorporates patient-specific factors to estimate HbA1c levels over the two-year follow-up period.
4. Evaluating the performance of the predictive model using appropriate metrics, such as mean average error and R2.
Previous studies have investigated the prediction of HbA1c levels in patients with type 2 diabetes, but limited research has focused on patients with cardiovascular diseases and type 2 diabetes who are prescribed metformin and sitagliptin. Several predictive models have been developed using various machine learning algorithms, such as linear regression, decision trees, support vector machines, and artificial neural networks. These models have incorporated different sets of predictors, including demographic characteristics, clinical parameters, genetic markers, and lifestyle factors.
Tao et al. (5) built 16 machine learning models (Logistic regression, Decision Tree, Random Forest, Extra Tree, Stochastic Gradient Descent, Gaussian Naive Bayes, Bernoulli Naive Bayes, Multinomial Naive Bayes, Quadratic Discriminant Analysis, Linear Discriminant Analysis, Passive Aggressive, AdaBoost, Bagging, Gradient Boosting, XGBoost, and Ensemble Learning) to predict levels of HbA1c in a 3-month period. They included data on 100 000 patients to predict fasting blood glucose and over 2000 for Glycosylated Hemoglobin. XGBoost demonstrated AUC of 0.80 as the best model. Among most significant features they listed fasting blood glucose, body mass index (BMI), Age, Heart rate, alanine transaminase (ALT) and aspartate aminotransferase (AST), triglyceride (TG), metformin. However, their study did not include sitagliptin.
In another study by Wang et al. (6), a linear regression model was shown to be less effective in comparison with Random Forest, Support Vector Machines, and Neural Networks. They estimated HbA1c levels in patients with type 2 diabetes. Their model incorporated demographic characteristics, clinical parameters, and lifestyle factors. The model demonstrated good predictive performance, with an accuracy value of 0.73. After authors applied dimensionality reduction, the predictive accuracy rose to 0.75. Selected features included Hypertension, anamnesis, exercise, and total cholesterol (TC) as protective factors for HbA1c control. Central adiposity, family history, duration of type 2 diabetes mellitus, typical disease characteristics, complications, insulin dose, Oral hypoglycemic agents (OHA), fasting blood glucose (FBG), 2-hour postload blood glucose (2HBG), blood pressure, high-density lipoprotein-cholesterol (HDL-C), Low-density lipoprotein-cholesterol (LDL-C), and hypertension were risk factors for HbA1c control.
Five different machine learning algorithms were used by Fu et al. (7). They found statistically significant variables such as body mass index (BMI), pulse, Na, Cl, Alkaline Phosphatase (AKP). Among the used algorithms XGBoost had the highest accuracy of 78.18% and Area under the curve (AUC) value of 0.68 in testing set. They achieved a very high accuracy of 99% and AUC of 1 in training set but failed to produce same levels in testing set.
Wu et al. (8) built a model to predict Post-operative Acute Kidney Injury in patients based on Glycosylated Hemoglobin levels and other features. They demonstrated a link between kidneys and HbA1c that inspired inclusion of several blood test results related to kidneys in our study.
Zhang et al. (9) reviewed medical database to establish association between chronic and an increased risk for cardiovascular outcomes and all-cause mortality among patients with diabetes mellitus. Based on their research we selected a series of cardiovascular features into our study to represent that connection.
Research by Zeng et al. (10) demonstrated no significant difference between sitagliptin group and the control group on cardiovascular diseases in patients with type 2 diabetes mellitus. Thus, use of sitagliptin is not associated with an increased risk of poor outcomes in such patients.
While these studies provide valuable insights into predicting HbA1c levels in patients with type 2 diabetes, there is a need for research specifically focusing on patients with cardiovascular diseases and type 2 diabetes who are prescribed metformin and sitagliptin. This study aims to bridge this gap in the literature and develop a predictive model tailored to this population.
This prospective study aimed to develop a predictive model for estimating glycosylated hemoglobin (HbA1c) levels in patients with cardiovascular diseases (CVD) and type 2 diabetes (T2D) who were prescribed metformin and sitagliptin. Ethical approval was obtained from the institutional review board prior to study initiation, all patients signed the agreement to allow future use of their clinical data. Patients were prescribed medications based on medical standards by Ministry of Healthcare of Republic of Uzbekistan.
The study included a cohort of 93 patients of Republican scientific cardiology center diagnosed with both cardiovascular diseases and type 2 diabetes, aged 35-86 years, who received treatment with metformin or metformin and sitagliptin as part of their standard therapy. Patients with other forms of diabetes, such as type 1 diabetes or gestational diabetes, were excluded from the study. Additionally, patients with severe renal impairment (estimated glomerular filtration rate <30 mL/min/1.73m²) or significant liver dysfunction were excluded.
Our study aimed at predicting levels of glycosylated hemoglobin in patients with cardiovascular diseases and type 2 diabetes mellitus in a 2-year period based on the prescribed anti-diabetic medication: metformin and sitagliptin or just metformin. We performed detailed diagnostics of each patient in the study in the beginning and after two years. We recorded their anamnesis vitae, blood lab tests, Echocardiography results, prescribed medications, etc. All recordings were made both in the beginning and at the end of study. We tracked over 42 features and analysed their dynamics.
As the cost per patient of all tests is considerably higher than average income, the dataset was limited with only 93 patients. Additional 27 patients that took liraglutide were not included in this study.
Baseline demographic and clinical data were collected from the participants at the start of the study. We included age (63.9 ± 8.8), gender (53.1% females), body mass index (BMI, 32.6 ± 6.4), duration of type 2 diabetes (7.3 ± 3.9 years), fasting blood glucose (10.07 ± 3.37 in the first group and 8.49 ± 2.79 in the second group), baseline HbA1c levels (9.34 ± 2.54 in the first group and 8.22 ± 2.10 in the second group), lipid profile (Total Cholesterol 184.19 ± 51.24, triglyceride 290.03 ± 304.80 in the first group and 197.12 ± 135.21 in the second group), blood pressure (139.35 ± 23.34 by 85.81 ± 11.99 in the first group, 140.61 ± 23.22 by 86.36 ± 13.22 in the second group), creatinine (93.5 ± 27.96), glomerular filtration rate (70.95 ± 19.63 in the first group, 63.22 ± 16.19 in the second group), ejection fraction (60.13 ± 6.79 in the first group, 56.47 ± 7.92 in the second group), presence of other comorbidities, and others. Over 30% of the patients had COVID-19 in their anamnesis by the end of the study.
HbA1c levels were measured at baseline and after the two-year follow-up period. Blood samples were collected using standard procedures and analyzed using high-performance liquid chromatography (HPLC) or a similar validated method.
We eliminated all features that were missing in more than 10% cases. Then, we conducted a step-by-step procedure of excluding one feature, building a Linear Regression model on the training set, evaluating its performance on the validation set using Pearson’s correlation coefficient. Subsets with the highest performance values were selected. We continued the process until the correlation dropped below 95%.
The process was repeated for different objectives, such as glycosylated hemoglobin, fasting blood glucose, postprandial blood glucose, and ejection fraction.
To develop the predictive model, various machine learning algorithms were utilized, including Random Forest, Support Vector Machine (SVM), XGBoost, Linear Regression (Least Squares, Lasso, ElasticNet), Extra Trees, and k nearest neighbors (k-NN). These algorithms were chosen based on their suitability for regression task, as well as their ability to handle complex and high-dimensional data in similar environment (7).
The dataset was randomly divided into training, validation, and external test sets in a ratio of 72:8:20. The training set was used to train the predictive models, while the validation set was used to evaluate their performance and perform hyperparameter tuning.
For each algorithm, a grid search approach was employed to optimize the hyperparameters. Cross-validation techniques, such as 10-fold cross-validation, were utilized to ensure robustness and prevent overfitting. The performance of each model was evaluated using various metrics, including mean absolute error (MAE), and R-squared value. We chose 10-fold validation as it provided sufficient data for training.
The predictive models were evaluated using the validation set. The performance metrics, including mean absolute error (MAE), and R-squared value, were calculated to assess the accuracy and goodness-of-fit of each model. We selected the best model based on its performance on the validation set.
The best models were evaluated on the external test set afterwards. The validation test was not included in the final test as it was already used for best model selection and was no longer independent.
Descriptive statistics were used to summarize the baseline characteristics of the study participants. Continuous variables were presented as mean ± standard deviation (SD), range and interquartile range. Categorical variables were presented as frequencies and percentages.
Statistical analysis was performed using Python 3.7. Pearson’s correlations coefficient was used in feature selection process.
Analysis of the dynamics of lipid spectrum indicators showed that the initial average values of cholesterol demonstrated the absence of a statistically significant difference between groups with different levels of HbA1c. However, there is a high positive correlation between postprandial glycose level and Metabolic Index (TG/HDL) (Kruskal test r=0.367; p=0.009) in patients with constantly decompensated HbA1 levels. The data obtained in our study allow us to consider HbA1c as a prognostically important indicator that allows us to retrospectively predict the lipid profile in patients with type 2 diabetes. Žďárská et al. (11) also found a significant correlation between dyslipidemia and postprandial glycemia (p = 0.013).
It is noteworthy that the main indicators of left ventricular diastolic pressure (LVDP) with a fairly high statistically significant power respond to therapy precisely in the group where 7.0<HbA1c<8.0. These indicators include a decrease in the time of isovolumetric relaxation for the left ventricular and right ventricular (Isovolumetric Relaxation Time (IVRT) ↓ Δ 4.5 (p = 0.008), the time of deceleration of early diastolic blood flow (early mitral flow deceleration time (DTE) ↓ Δ 20.12 (p = 0.01), the ratio of transmitral and transtricuspid velocity flows in early diastole to the speed of movement of the lateral part of the fibrous ring of the mitral and tricuspid valves (ratio between early mitral inflow velocity and mitral annular early diastolic velocity (E/e`) ↓ Δ 0.68 (p=0.08), as well as an increase in the speed of movement of the mitral valve ring in early diastole in the septal part e`septal ↑ Δ 0.97 (p=0.012), and, accordingly, its average e`average ↑Δ 0.52 (p=0.05). Negative dynamics of the e`average indicator were revealed in the groups HbA1c < 8 and HbA1c > 8 after 2 years of observation in contrast to the subgroups in which transitions in HbA1c were observed. The E/e` ratio in all groups showed a tendency to increase throughout the entire observation period, which indirectly indicates progression of diastolic dysfunction.
Ejection fraction, sizes of atriums and ventriculars, their filling velocities are included in the prediction of left ventricular diastolic dysfunction (LVDD). Chaudhary et al. (12) found HbA1C and age to be strong indicators of LVDD in newly diagnosed cases of Type 2 diabetes.
Patients with diabetes and hypertension belong to a group with very high cardiovascular risk according to Przezak et al. (13). Thus, blood pressure was found to be very important predictor of future development of cardiovascular diseases in patients with type 2 diabetes mellitus.
According to Hur et al. (14) Metformin can be used safely when the estimated glomerular filtration rate (eGFR) is ≥45 mL/min/1.73 m2. The range of eGFR in patients in our study was 37-100. If the eGFR is between 30 and 44 mL/min/1.73 m2 a daily dose of ≤1,000 mg is recommended to be continued. Therefore, close control of the state of kidneys’ function is very important when metformin is prescribed.
Among the patients who received both metformin and sitagliptin, the Extra Trees algorithm exhibited the best performance in predicting glycosylated hemoglobin (HbA1c) levels. On the validation set, the Extra Trees model achieved an R-squared value of 0.5967 and a mean absolute error (MAE) of 0.997. These metrics indicated a moderate level of accuracy in predicting HbA1c levels over the two-year follow-up period. Statistical data on the selected features is demonstrated in Table 1.
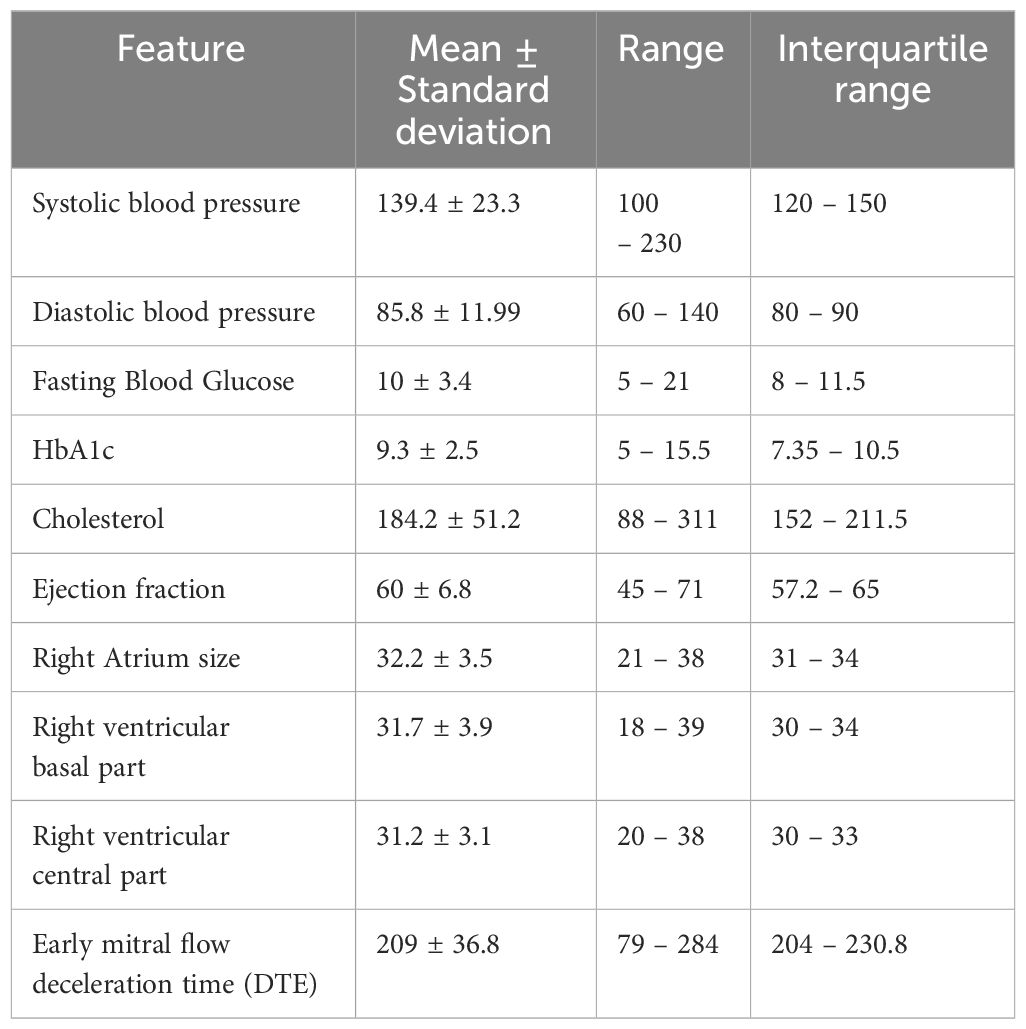
Table 1 Statistical description of selected features used in the best model to predict glycosylated hemoglobin (HbA1c) in patients who took both metformin and sitagliptin.
Furthermore, the Extra Trees model continued to demonstrate promising results when evaluated on the test set. It obtained a R-squared value of 0.88, C Index = 0.857, Accuracy of 0.846, and a MAE of 0.65, indicating good generalization performance. These findings suggest that the Extra Trees algorithm effectively captures the underlying patterns and relationships in the data, enabling accurate prediction of HbA1c levels in patients with cardiovascular diseases and type 2 diabetes who were prescribed both metformin and sitagliptin.
For patients who received only metformin, the Random Forest algorithm emerged as the best model in predicting HbA1c levels. On the validation set, the Random Forest model achieved an R-squared value of 0.3509 and a MAE of 0.6947, indicating a moderate level of accuracy. The model’s performance was further validated on the test set, where it achieved an R-squared value of 0.86, C Index of 0.8, Accuracy of 0.75, and a MAE of 0.41. These results demonstrate the ability of the Random Forest algorithm to effectively predict HbA1c levels in patients receiving only metformin. Statistical data on the selected features for this model is demonstrated in Table 2.
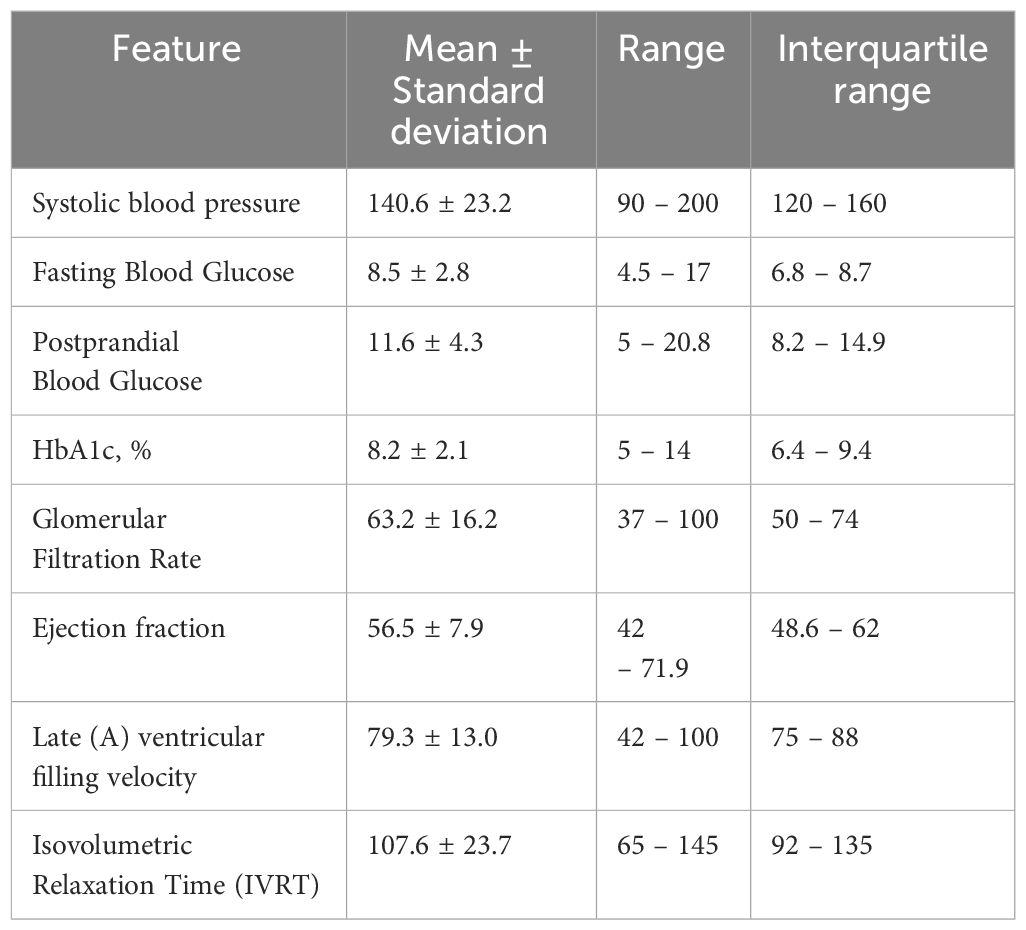
Table 2 Statistical description of selected features used in the best model to predict glycosylated hemoglobin (HbA1c) in patients who took only metformin.
The results of this study demonstrate the effectiveness of machine learning algorithms in predicting glycosylated hemoglobin (HbA1c) levels in patients with cardiovascular diseases and type 2 diabetes who were prescribed metformin and sitagliptin. In comparison to the Extra Trees and Random Forest models, the other algorithms, including Support Vector Machine (SVM), XGBoost, Linear Regression, and k nearest neighbors, underperformed on the validation set as shown in Table 3. These models exhibited lower R-squared values and higher MAE values, indicating a weaker predictive performance in estimating HbA1c levels in patients with cardiovascular diseases and type 2 diabetes who were prescribed either both metformin and sitagliptin or only metformin.
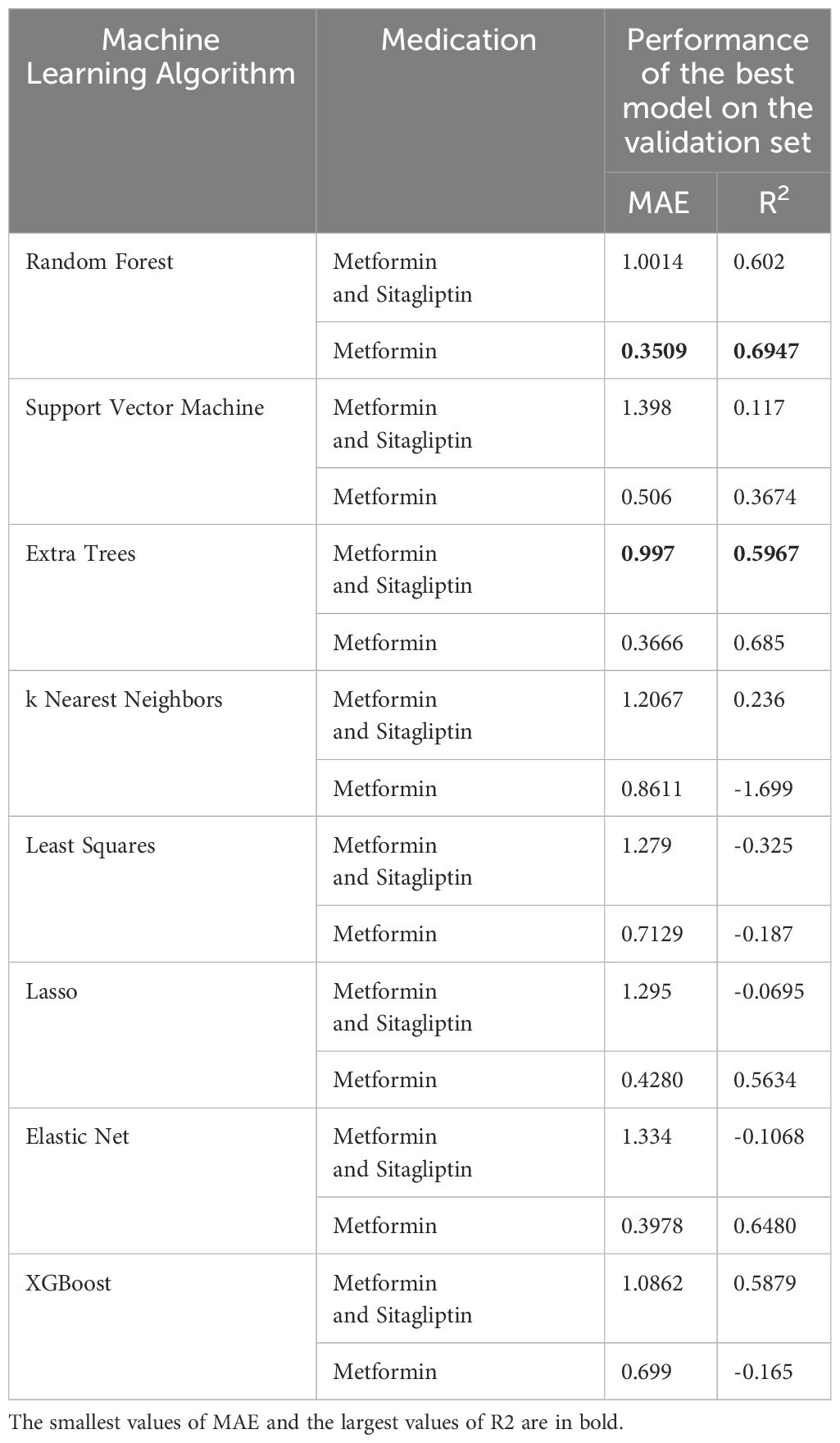
Table 3 Performance of the best models after their hyperparameter tuning on the validation set.
These findings suggest that the Extra Trees and Random Forest algorithms are better suited for predicting HbA1c levels in patients with cardiovascular diseases and type 2 diabetes who were prescribed either both metformin and sitagliptin or only metformin.
Our models outperformed Tao et al.’s best model (5) that got ROC AUC of 0.8 while our C Index achieved 0.86 in the first group. Fu et al. (7) used XGBoost that is prone to overfitting. The contrast between performance of their model on training set (99%) and test set (68%) demonstrates overfitting of the training process. Use of simple tree models such as Random Forest and Extra Trees helps fighting such a problem as each tree uses only subset of features.
Wang et al. (6) did not use ROC AUC to measure their performance. Accuracy of their model was 0.75 which is the same as accuracy of our model in the second group. However, our first group’s model achieved accuracy of 0.85.
Accurate prediction of HbA1c levels in patients with cardiovascular diseases and type 2 diabetes is crucial for optimizing treatment strategies and improving long-term glycemic control. The findings of this study provide valuable insights into the use of machine learning algorithms for predicting HbA1c levels in patients prescribed metformin and sitagliptin. The Extra Trees and Random Forest models, in particular, demonstrate promising performance in estimating HbA1c levels over a two-year follow-up period. These models can assist clinicians in identifying patients at higher risk of poor glycemic control, enabling personalized treatment interventions and potentially reducing the risk of cardiovascular complications.
The results of this study highlight the effectiveness of machine learning algorithms, specifically the Extra Trees and Random Forest models, in predicting glycosylated hemoglobin (HbA1c) levels in patients with cardiovascular diseases and type 2 diabetes who were prescribed metformin and sitagliptin. The Extra Trees model demonstrated good performance in patients receiving both medications, while the Random Forest model was effective for patients receiving only metformin. These models can contribute to personalized treatment strategies and improved long-term glycemic control in this patient population. However, further research and validation in larger cohorts are warranted to confirm the findings and enhance the clinical applicability of these predictive models.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving humans were approved by Shek Aleksandr Borisovich, Professor at Republican Specialized Scientific Cardiology Center. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
AI: Methodology, Writing – original draft. SM: Data curation, Investigation, Resources, Writing – original draft. RT: Project administration, Supervision, Validation, Writing – original draft. DA: Data curation, Methodology, Resources, Writing – review & editing. SA: Conceptualization, Formal Analysis, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. The work was supported by the Ministry of Innovative development of the Republic of Uzbekistan under grant № ПЗ-202007041, Institute of Mathematics fund from Academy of Sciences, and New Uzbekistan University.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1. Dal Canto E, Ceriello A, Rydén L, Ferrini M, Hansen TB, Schnell O, et al. Diabetes as a cardiovascular risk factor: An overview of global trends of macro and micro vascular complications. Eur J Prev Cardiol. (2019) 26:25–32. doi: 10.1177/2047487319878371
2. Lyons TJ, Basu A. Biomarkers in diabetes: hemoglobin A1c, vascular and tissue markers. Transl Res. (2012) 159:303–12. doi: 10.1016/j.trsl.2012.01.009
3. Hong LF, Li XL, Guo YL, Luo SH, Zhu ChG, Qing P, et al. Glycosylated hemoglobin A1c as a marker predicting the severity of coronary artery disease and early outcome in patients with stable angina. Lipids Health Dis. (2014) 13:89. doi: 10.1186/1476-511X-13-89
4. Du Q, Wu B, Wang YJ, Yang S, Zhao YY, Liang YY. Comparative effects of sitagliptin and metformin in patients with type 2 diabetes mellitus: a meta-analysis. Curr Med Res Opin. (2013) 29:1487–94. doi: 10.1185/03007995.2013.833090
5. Tao X, Jiang M, Liu Y, Hu Q, Zhu B, Hu J, et al. Predicting three-month fasting blood glucose and glycated hemoglobin changes in patients with type 2 diabetes mellitus based on multiple machine learning algorithms. Sci Rep. (2023) 13:16437. doi: 10.1038/s41598-023-43240-5
6. Wang J, Wang MY, Wang H, Liu HW, Lu R, Duan TQ, et al. Status of glycosylated hemoglobin and prediction of glycemic control among patients with insulin-treated type 2 diabetes in North China: a multicenter observational study. Chin Med J. (2020) 133:17–24. doi: 10.1097/CM9.0000000000000585
7. Fu X, Wang Y, Cates RS, Li N, Liu J, Ke D, et al. Implementation of five machine learning methods to predict the 52-week blood glucose level in patients with type 2 diabetes. Front Endocrinol. (2023) 13:1061507. doi: 10.3389/fendo.2022.1061507
8. Wu L-P, Pang K, Li B, Le Y, Tang Y-Z. Predictive value of glycosylated hemoglobin for post-operative acute kidney injury in non-cardiac surgery patients. Front Med. (2022) 9:886210. doi: 10.3389/fmed.2022.886210
9. Zhang Y, Hu G, Yuan Z, Chen L. Glycosylated hemoglobin in relationship to cardiovascular outcomes and death in patients with type 2 diabetes: A systematic review and meta-Analysis. PloS One. (2012) 7:e42551. doi: 10.1371/journal.pone.0042551
10. Zeng DK, Xiao Q, Li FQ, Tang YZ, Jia CL, Tang XW. Cardiovascular risk of sitagliptin in treating patients with type 2 diabetes mellitus. Biosci Rep. (2019) 39:BSR20190980. doi: 10.1042/BSR20190980
11. Žďárská DJ, Hill M, Kvapil M, Piťhová P, Brož J. Analysis of postprandial glycemia in relation to metabolic compensation and other observed parameters of outpatients with type 2 diabetes mellitus in the Czech Republic. Diabetes Ther. (2018) 9:665–72. doi: 10.1007/s13300-018-0379-3
12. Chaudhary AK, Aneja GK, Shukla S, Razi SM. Study on diastolic dysfunction in newly diagnosed type 2 diabetes mellitus and its correlation with glycosylated haemoglobin (HbA1C). J Clin Diagn Res. (2015) 9:OC20–2. doi: 10.7860/JCDR/2015/13348.6376
13. Przezak A, Bielka W, Pawlik A. Hypertension and type 2 diabetes-the novel treatment possibilities. Int J Mol Sci. (2022) 23:6500. doi: 10.3390/ijms23126500
Keywords: glycosylated hemoglobin, metformin, diabetes mellitus, random forest, sitagliptin
Citation: Ikramov A, Mukhtarova S, Trigulova R, Alimova D and Abdullaeva S (2024) Prediction of glycosylated hemoglobin level in patients with cardiovascular diseases and type 2 diabetes mellitus with respect to anti-diabetic medication. Front. Endocrinol. 15:1305640. doi: 10.3389/fendo.2024.1305640
Received: 02 October 2023; Accepted: 25 March 2024;
Published: 04 April 2024.
Edited by:
Ifigenia Kostoglou-Athanassiou, Asklepeion General Hospital, GreeceReviewed by:
Khojasteh Malekmohammad, Shiraz University, IranCopyright © 2024 Ikramov, Mukhtarova, Trigulova, Alimova and Abdullaeva. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Alisher Ikramov, YS5pa3JhbW92QG5ld3V1LnV6
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.