 Håkan Runvik*
Håkan Runvik* Alexander Medvedev
Alexander Medvedev- Department of Information Technology, Uppsala University, Uppsala, Sweden
This work considers the estimation of impulsive time series pertaining to biomedical systems and, in particular, to endocrine ones. We assume a signal model in the form of the output of a continuous linear time-invariant system driven by a sequence of instantaneous impulses, which concept is utilized here, in particular, for modeling of the male reproductive hormone axis. An estimation method to identify the impulsive sequence and the continuous system dynamics from sampled measurements of the output is proposed. Hinging on thorough mathematical analysis, the method improves upon a previously developed least-squares algorithm by resolving the trade-off between model fit and input sparsity, thus removing the need for manual tuning of user-defined estimation algorithm parameters. Experiments with synthetic data and Markov chain Monte-Carlo estimation demonstrate the viability of the proposed method, but also indicate that measurement noise renders the estimation problem ill-posed, as multiple estimates along a curve in the parameter space yield similar fits to data. The method is furthermore applied to clinical luteinizing hormone data collected from healthy males and, for comparability, one female, with similar results. Comparison between the estimated and theoretical elimination rates, as well as simulation of the estimated models, demonstrate the efficacy of the method. The sensitivity of the impulse distribution to the estimated elimination rates is investigated on a subject-specific data subset, revealing that the input sequence and elimination rate estimates can be interdependent. The dose-dependent effect of a selective gonadotropin releasing hormone receptor antagonist on the frequency and weights of the estimated impulses is also analyzed; a significant impact of the medication on the impulse weights is confirmed. To demonstrate the feasibility of the estimation approach for other hormones with pulsatile secretion, the modeling of cortisol data sets collected from three female adolescents was performed.
1 Introduction
Despite the critical role of the endocrine system in the normal functioning of the organism, it remains an open question how to mathematically model the process of hormone release and interaction in a parsimonious way and yet explain experimentally observed behaviors. Two challenges in this regard are the complex interactions involved and the limitations regarding sampling frequency, experiment length, and total amount of blood drawn from a subject in clinical studies. One key feature that is required in endocrine models is the representation of both continuous hormone release and pulsatile concentration bursts, as a majority of hormone secretion patterns display pulsatility (1). It is therefore judicious to use hybrid models, i.e., models that combine continuous and discrete dynamics in the system description.
The hybrid model and the corresponding estimation problems that we investigate below, originate from the male testosterone regulation model introduced in (2, 3). Three main hormones are involved in this regulation: gonadotropin-releasing hormone (GnRH), luteinizing hormone (LH), and testosterone (Te). In the present work, the estimation of the pulsatile release of GnRH and the elimination rates of GnRH and LH from sampled serum measurements of LH are considered in detail. Modeling of cortisol is also performed, but without much subsequent analysis as only limited data have been made available to the authors. We term the considered signal model, where an unknown sequence of impulses drives a continuous linear time-invariant system of a given structure but with unknown parameters, an impulsive time series. The resulting estimation problem is, however, of a general nature and applications both to cortisol regulation (4) and to pharmacokinetics (5) have been considered in the past.
The conventional approach to pulsatile endocrine data analysis can be briefly summarized as follows. The hormone concentration C(t) with the initial condition C(0) is modeled as the convolution of the secretion rate S(t) and the impulse response of the system E(t) describing the hormone elimination rate
A number of techniques have been proposed for recovering the input signal or/and the parameters for this type of system. In an experimental data set, only measurements of C(t) are typically available, with the rest of the involved quantities being more or less unknown. A classical approach to resolving this issue, termed deconvolution, is to assume the function E(t) known and estimate the secretion profile S(t) as the input of a dynamical system. An early work covering a comparison of three linear methods, namely least-squares deconvolution, Maximum a Posteriori (MAP) deconvolution, and Wiener deconvolution, is found in DeNicoalo, 1993 (6). The linear approaches are known to exhibit high sensitivity of the estimate to modeling uncertainty and signal uncertainty, i.e., disturbance. This is due to the fact that the deconvolution operation attempts to invert the system dynamics, which operation is inherently ill-conditioned.
To yield biologically meaningful estimates, assumptions on the signal shape of S(t) are required. For instance, a Gaussian-shaped input is assumed in (7) with the deconvolution performed using nonlinear least squares, given prior information on the approximate location of the pulsatile secretion episodes. Another popular option accounting for the experimentally observed skewed shape of pulsatile hormone concentration excursions is a Gamma function shaped input, e.g (8). Numerous improvements to the deconvolution-based estimation algorithms have been suggested since then, including the Bayesian setup in (9) and the automated deconvolution algorithm presented in (10).
Software packages supporting hormone data deconvolution analysis are publicly available. The most widespread and validated software is AutoDecon described in (10). AutoDecon employs a further development of the Cluster algorithm presented in (11) and estimates hormone half-life time, basal secretion, and initial hormone concentration. Another example is WINSTODEC (12), based on stochastic deconvolution.
It is, however, important to note that even with disturbance-free measurement data, the joint impulse and time-constant estimation problem is ill-posed since there are always multiple solutions. The reason for this is that the faster dynamics of the linear system can be compensated for by introducing more input impulses. However, as shown in (13), a unique solution can be identified under the assumption that the impulses of the generating process are sufficiently sparse. Under uncertainty, the ill-posedness necessitates a trade-off between model fit and impulse sparsity. To resolve this issue, either regularization or statistical tools such as cross-validation or information criteria can be used. The ℓ1 -regularized least-squares formulation in (14) is an example of the former, while a statistical test based on variance-of-fit is employed in (10). In (4), both regularization and cross-validation are used. For Bayesian algorithms, regularization can instead be implemented through the choice of prior distributions (but, as we will note later in this work, it is not clear whether regularization is as important in such a setup).
Many of the algorithms mentioned above rely on tuning parameters or heuristics to determine the degree of estimate regularization. Instead, we employ here a method that was proposed in (13), where the correct trade-off between fit and sparsity is derived mathematically and included in the estimation algorithm. It is based on the least-squares method from (14), but instead of the regularized formulation that is combined with gridding in that work, a parameter-dependent optimization formulation is used. It utilizes the way in which the residual sum of squares depends on the parameters of the linear system, so that the time constants can be determined without the need for user-defined regularization.
In addition to the trade-off between impulse sparsity and model fit, a second type of ill-posedness is identified in this work. It is linked to the well-researched problem of estimating sums of exponential functions (see e.g (15), for an overview of the topic), and manifests itself as a functional relation between the parameters of the linear plant, i.e., a curve in the corresponding plane. A subset of the parameter estimates located along this curve typically give very similar fits to the data. This problem type is also well-known in pharmacokinetic models, but the particular relationship highlighted here has, to the best of the knowledge of the authors, not been discussed previously.
The rest of this paper is organized as follows. First, the model, estimation problem, and the least-squares estimation method are presented, along with a Markov chain Monte-Carlo (MCMC) method. The latter is used in the following section, to demonstrate the validity of the approach on synthetic data. Further, estimation was performed on clinical LH data, investigating the distribution of time constants between individuals as well as the dose-dependent effect of a GnRH-receptor antagonist on impulse weights and amplitudes. Finally, estimation is performed on three data sets constituting cortisol data to illustrate an application to other endocrine axes.
2 Materials and methods
The model at hand includes GnRH, which is released in a pulsatile manner, and LH, whose secretion is stimulated by the GnRH concentration. The LH concentration can be measured in blood samples, while GnRH cannot be directly measured in humans for ethical reasons. Under the idealized assumption that the GnRH-bursts correspond to instantaneous releases of the hormone into the bloodstream, the bursts can be portrayed by a sequence of weighted Dirac impulses. Then the firing times of the impulses mark the GnRH release events, while the impulse weights represent the secreted hormone amounts. Assuming linear elimination, the system can be expressed in state space form as
where
x1 is the concentration of GnRH, x2 is the concentration of LH, b1 and b2 are the (positive) time constants of their eliminations, and g1 is a positive parameter that describes the stimulation of LH production by GnRH. The input signal is given by
where δ(·) is the Dirac delta function and dn and τn determine the positive impulse weights and times. The output signal of this system is evaluated to
where
and H(t) is the Heaviside step function. The output y(t) of Equation (4) is then termed an impulsive time series. It is a time series since the signal ξ(t) is not available for measurement and the time series is impulsive since ξ(t) consists of instantaneous impulses.
Assuming the model structure above, the impulse times and weights as well as the linear elimination rates are to be estimated from measurements of the output y(t) sampled at times tk, where k=1,…,K and tk<tk+1. Notice also that ξ(t) is a theoretical construct and cannot be captured by sampling. Although this problem is presented here in the context of the male reproductive hormone axis, the general character of the linear plant and the input signal permits application to other biomedical systems.
Two assumptions are needed to secure the feasibility of the formulated estimation problem. First, the parameter g1 cannot be uniquely identified from the output and is, without loss of generality, set g1=1. This can also be seen as a normalization of the weights dn . Second, we also restrict the estimates of the impulse times to coincide with the sampling times of the measurements of y(t). Since impulse times in between sampling instances cannot be identified, as proved in (14), this is not a restrictive assumption, but it rather reflects an inherent ambiguity in the estimation problem, which can only be resolved by more frequent sampling, see (16). Notice also that model (4) is defined for t ∈ [0,∞) whereas only a finite data set is available in practice. Therefore, the actual number of δ -functions captured in the data set is unknown. By allowing one impulse at each sampling time of the data set and selecting proper weights dn, a solution to the estimation problem yielding a zero output estimation error can be obtained. Thus, in contrast with stochastic time series analysis, the output estimation error cannot be considered here as the sole model performance criterion.
Two distinct methods were employed to solve the estimation problem at hand. The first one, which is covered in Least squares estimation, is based on a least-squares setup formulated in (14). The second one, presented in Adaptive Metropolis estimation, utilizes a probabilistic approach where Markov Chain Monte-Carlo (MCMC) estimation is used to derive posterior probability distributions for the parameters. The latter method will in particular be exploited to investigate the functional relation between the estimated time constants of the system that which is predicted by the former.
2.1 Least-squares estimation
To obtain a least squares formulation of the estimation problem, introduce the measurement vector
which, using Equation (4) for the output, enables the matrix formulation
Here
where
and
Notice that the impulse and sampling times, as specified before, are assumed to coincide, and that in this discretized formulation, zero impulse weights are permitted, as opposed to the expression in Equation (3) for the input. The initial state of the system is encoded in the first two elements of θ (a nonzero x1(t1) can equivalently be represented by an impulse).
We thus aim to estimate the parameters b1,b2 and the vector θ from the measurements in Y, which are typically corrupted by noise. However, with unknown parameters in both Φ (b1,b2) and θ, ordinary least squares cannot alone be used to perform the estimation. In particular, for sufficiently high values of b1 and b2 , a perfect match to an arbitrary data set can be obtained with positive impulse weights di at every sampling instant. However, this does not correspond to a physiologically relevant or practically useful solution. In view of these challenges, the problem will be recast as a parameter-dependent optimization problem, via the formulation
where ‖·‖ is the Euclidean vector norm and the values of b1,b2 are determined in an outer level optimization. We will present the key parts of this method here, with further details provided in Supplementary Material. The full derivation can be found in (13).
2.1.1. Outer level optimization
In the outer level optimization, noise-corrupted measurements generated from system (2) with and the impulse weights are assumed, i.e.,
where
and ε is a zero-mean noise vector. The goal of the optimization is to find estimates of . As it will be shown later, this goal is often not achievable in practice, and the estimation of a curve γP in the b1 - b2 -plane will be the focus of this section. The curve γP is defined as the boundary of the region where, if noise-free measurements were available, non-negatively constrained impulses would give a perfect fit (zero loss) to the data for the optimization problem in Equation (5). In particular, as shown in Figure 1, the point always belongs to γP since the measurements are generated by positively weighted impulses, but, if the values of b1 or b2 are decreased, the residual sum of squares becomes non-zero.
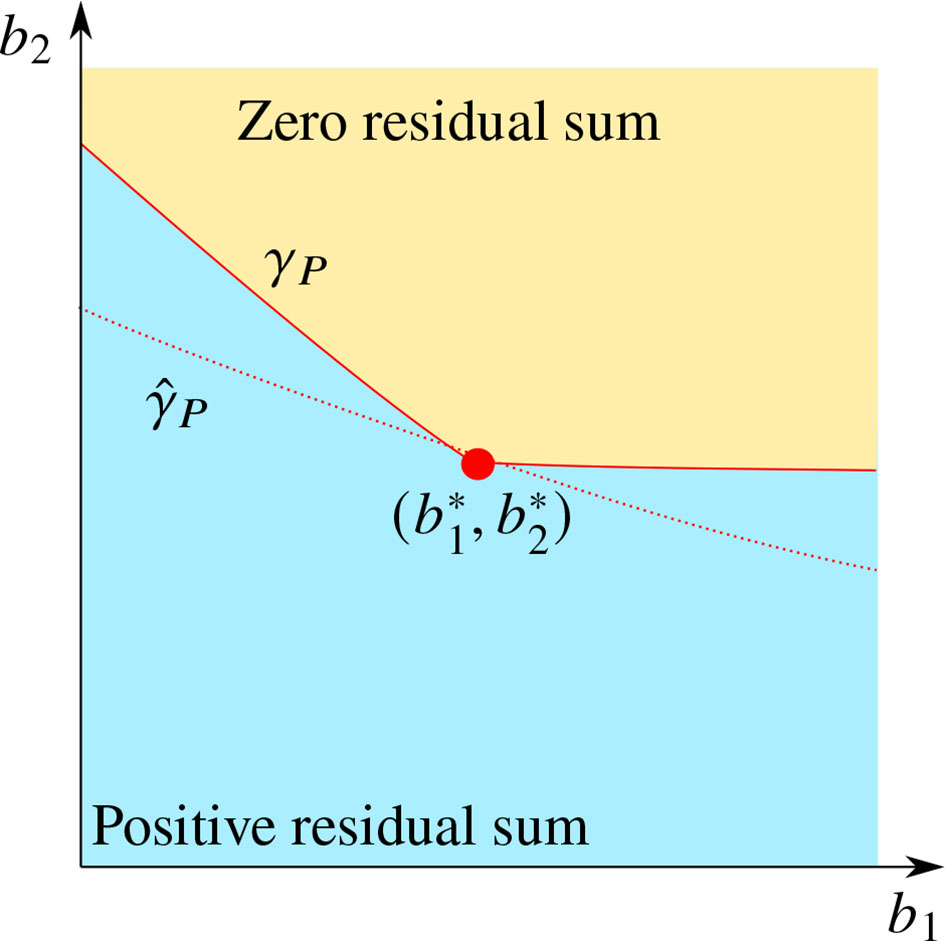
Figure 1 Illustration of the qualitative behavior of the curve γP (red solid line) and its estimate (red dotted line) in the b1 - b2 -parameter space, in relation to the true parameter values (red dot).
Introduce the residual error g(b1,b2) , i.e.,
Under measurement noise or model uncertainty, an estimate of the sought curve can be found by approximating g(b1,b2) as a quadratic function of the form given in the lemma below, when
and where .
Lemma 1. (13) Let f(x)=c1(x−x*)2+c2, where c1,c2>0. Define Nf(x) and by
Then .
Note that Nf(x) corresponds to a step in Newton’s root finding method and that the above construction is equivalent to letting be the intersection between the tangent line of and the x -axis, where is the point where the step size is minimized, see Figure 2.
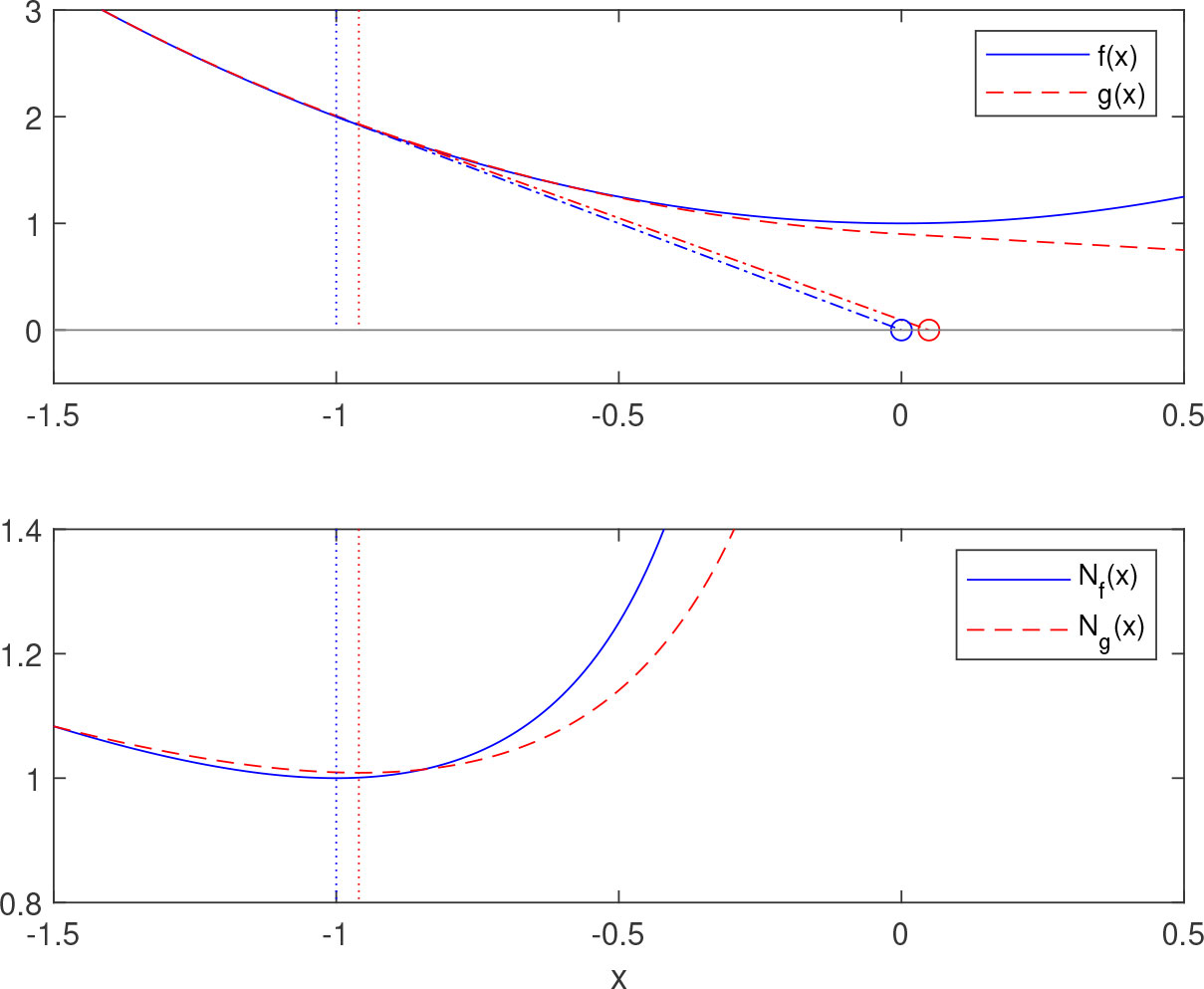
Figure 2 Minimization of a quadratic function according to Lemma 1. The function f(x) is quadratic and the corresponding Nf(x) in the lower plot attains the minimal value 1 for x=−1 (blue dotted line). In the upper plot, the intersection of the tangent of f(−1) and the X-axis corresponds to the minimizer X=0. The function g(x) is an approximation of f(x) . By minimizing Ng(x) (red dotted line) and drawing the tangent in the same way, an approximation of the minimized of f(x) is obtained.
We therefore define
and formulate the estimation of a point as
where # denotes set cardinality and dΠ>0 , Π∈ℕ are chosen to prohibit solutions with redundant input impulses. This corresponds to the condition on min Nf(x) in Lemma 1. We thus assume that the residual sum is quadratic inb2 below γP, See Figure 1. Note that this is not the case above γP as the faster dynamics then permits more impulses and, therefore, a better fit to the data. We then utilize Lemma 1 that permits the minimization of such a function without actually evaluating the function close to the minimum. This is illustrated in Figure 2, where g(x) can be used to approximate the minimum of f(x) even though g(x) itself is monotonous, which means the residual sum is expected to be with respect to both b1 and b2.
A typical qualitative behavior of the estimate , observed in numerical experiments, is indicated in Figure 1; the shape of γP is not reproduced, but the distance between and the point is small.
In (13), an optimization formulation over both b1 and b2 was also presented to estimate and directly, rather than γP. However, this method is only useful when the noise level is quite low, and will therefore not be considered here, as an application to clinical data is foreseen.
2.1.2. Estimation algorithm
The main part of the estimation algorithm consists of the estimation of the curve γP . We therefore suggest gridding over a suitable range of values for b1 and solving the optimization problem in Equation (6) at each point to obtain an estimate of the curve using Equation (7). Since this optimization problem is not necessarily convex, we use gridding in the b2-direction to find the minimum in all experiments, except for the setup with different levels of administered GnRH-receptor antagonist described in Effects of GnRH-receptor antagonist and age. The estimation results from the data set of each unmedicated individual are used to initiate a local optimization that is utilized in the cases when medication is administered. To obtain impulse estimates, optimization problem (5) is then solved along the curve, after the removal of impulses with weights below a threshold dmin>0. In the present work, this parameter is chosen as a few percent of the maximal estimated impulse weight. In general, a smaller value of dmin is suitable when the noise level is lower, since the risk of misattributing noise impact to the effect of small impulses is then lower. Adjacent impulses are then merged according to the formula in (14). The steps of the estimation are summarized in Algorithm 4.1.2, with further details provided in Supplementary Material.

Algorithm 1 Impulse and time constant estimation.
One may note that even though this algorithm does rely on regularization in the sense that impulses below a given threshold are removed, and that for this regularization, another approach, such as ℓ1-regularization, could be potentially preferable. However, there is an important distinction between obtaining a sparse input sequence when the time constants are fixed, compared to deciding the trade-off between sparsity and model fit with free time constants. In the former case, the characteristics of the simulated output of the estimated system are largely unaffected by the removal of impulses, so changing the impulse threshold does not result in significant quantitative changes in the solution. In the experimental setup described in Functional relation between the elimination rates, for example, most of the estimated impulse weights are smaller than 1% of the maximal estimated impulse weight. In the latter case, on the contrary, the characteristics of the solution could change significantly depending on the regularization. For example, as the value of the regularization parameter λmax in (14) is increased, the solution converges towards faster dynamics and impulse weights that are significantly greater than zero at every sampling time.
2.2. Adaptive Metropolis estimation
The estimates resulting from the method presented in the preceding section will be compared against posterior parameter distributions obtained with the adaptive Metropolis (AM) algorithm (17). A brief description of Markov Chain Monte-Carlo (MCMC) and the AM algorithm will be given here. For a more comprehensive exposition, see e.g (18), and (17).
The AM algorithm is a version of the Metropolis–Hastings algorithm (19), which is an MCMC method. Here we use it to generate samples from the posterior distributions of the parameters of the system, i.e., the parameters τn, dn, b1, and b2 are treated as random variables whose joint posterior probability distribution is sought. In contrast with the least-squares algorithm, the MCMC setup does not rely on an explicit formulation of the optimization problem. Instead, the forward model, i.e (4), is used together with the calculation of a likelihood function. In particular, it is not assumed that the impulses occur at the sampling times. With the uncertainty modeled as additive Gaussian noise, the logarithmic likelihood can be explicitly calculated from the residual sum of squares. We furthermore assume uniform priors, making the posterior probability distribution proportional to the likelihood. The AM algorithm, which samples this distribution through a random walk in the parameter space, is characterized by the use of an empirical covariance matrix to scale the proposal distributions, i.e., the proposed steps of the random walk.
A challenge with performing MCMC estimation for the problem at hand is the unknown number of impulses, which means that the dimension of the parameter space is unknown. In (9), a birth-death MCMC method was employed to solve this problem [see also the reversible jump MCMC developed in (20)]. Here we use an algorithmically simpler approach of performing the estimation with a few more impulses than expected to be needed (in our experiments, five rather than three) and then removing or merging superfluous impulses from the generated samples of the posterior distribution in a post-processing step. For synthetic data, it is of course also possible to use the true number of impulses for the AM algorithm, but, even in this case, a higher number can be beneficial, as it reduces the risk of impulses being missed due to the algorithm being stuck at local posterior distribution maxima. The superfluous impulses are identified by their low weight, being close to the end of the estimation time horizon, or being so close to a neighboring impulse that they can be merged with minimal or no effect on the output at the sampling times using the technique proposed in (14). The convergence of the Markov chain is then evaluated using the Gelman–Rubin statistic (21) for the reduced parameter set. More details on the MCMC estimation are provided in the Supplementary Material.
The adopted approach relies on the MCMC setup providing sparsity implicitly, i.e., that proposals with a larger number of significant impulses than the generating model are unlikely to be accepted. This is in contrast to the least-squares approach, where, as shown by the analysis in Least squares estimation, explicit measures are needed to obtain a sparse solution. An intuitive explanation for the inherent sparsity of the MCMC estimation is that solutions with many impulses, which could result in a better fit for noisy data, correspond to very narrow peaks in the probability distribution, which makes them unlikely to be sampled. However, a formal analysis of this hypothesis has not been performed.
3 Results
Experimental results with synthetic and clinical data are presented in this section. More details on the specific estimation setups used in each experiment are provided in the Supplementary Material.
3.1. Functional relation between the elimination rates
The derivation of the least-squares algorithm indicated that the estimation problem could be ill-posed in the presence of noise, in the sense that multiple (b1,b2) -pairs along the -curve give similar fits to the data. To examine this hypothesis, the estimated curve obtained from the least-squares method is compared with the posterior distributions obtained using the AM algorithm. Synthetic data were used in this experiment; the parameters used to generate the data are given in the Supplementary Material. Note that the synthetic data do not mimic LH measurements; the elimination rates are instead chosen to be more similar in magnitude to those of GnRH and LH. With a large discrepancy between the elimination rates, it is clear that the estimation uncertainty will mostly be in the direction of the faster rate, while the parameter ranges used here permit significant uncertainty in both parameters (compare Figures 3, 4). This makes the setup more suitable for highlighting the capabilities of the estimation algorithm.
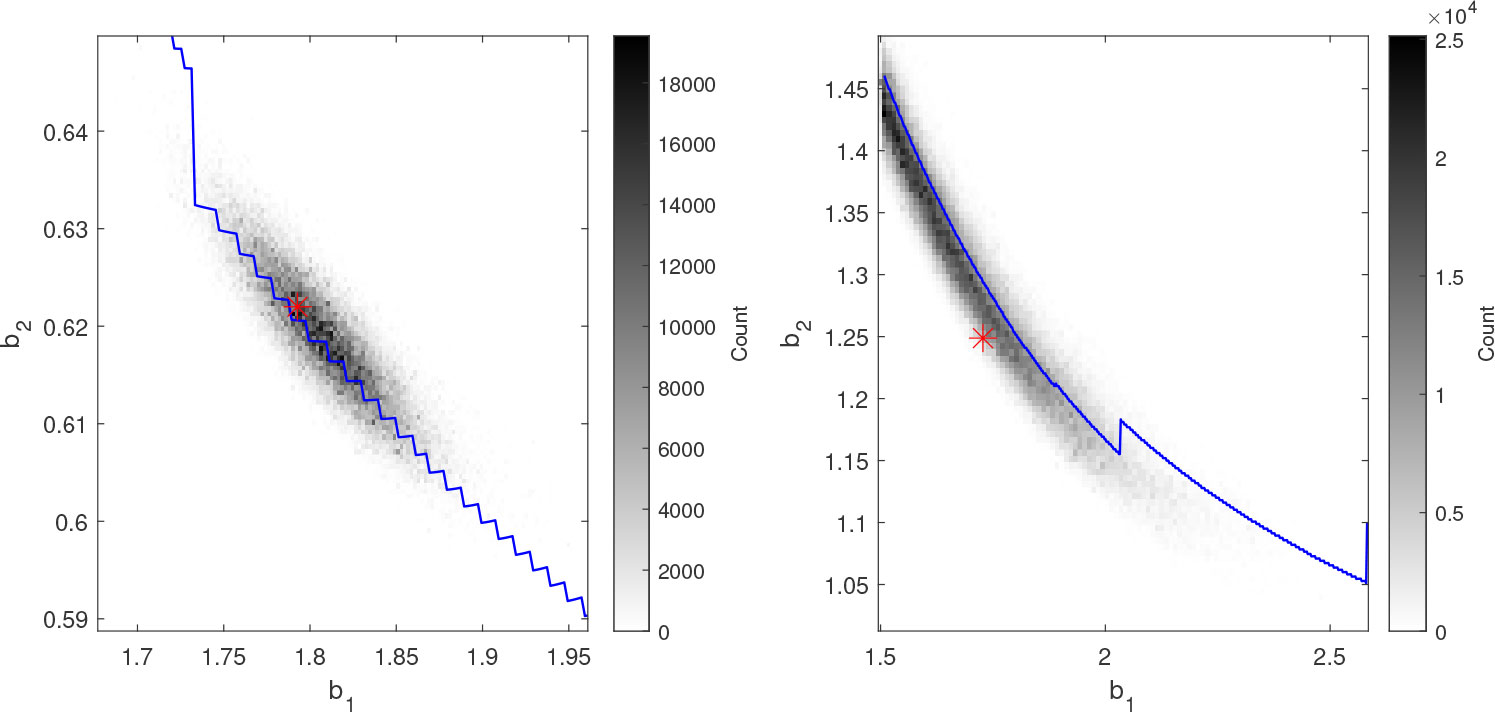
Figure 3 Histograms of the posterior distribution of b1 and b2 from the AM algorithm (gray-scale) together with the estimated (blue curves) and the generating parameter values (red asterisks) for two synthetic data sets. The -curves coincide with ridges in the posterior distributions and the minimal distances between the curves and the generating parameters are short.

Figure 4 Estimated γP for LH-data from 15 healthy males (solid black lines), one female (solid red) and the theoretical parameter ranges (dotted box) given in (22).
For each data set, four chains of length 3e6 are generated with the AM algorithm, with a burn-in of 1e6 . The results are then merged to give an approximation of the posterior distribution. Using the Parallel Computing Toolbox in Matlab, the MCMC estimation for each data set takes approximately 5 to 10 min on a standard laptop with four 1.9 GHz cores. The estimate obtained from the least-squares algorithm, on the other hand, takes approximately 40 s per data set to compute. One should, however, note that no particular optimization of the code in terms of performance has been performed.
To ensure that only converged chains are included in the analysis of the results, a simple strategy of discarding data sets where the mean Gelman-Rubin statistic exceeds 1.2 is employed. This might introduce a bias in the results, but since the number of rejected data sets is low and the AM algorithm is only used for comparison, this problem is deemed negligible in the current context.
3.1.1. Experimental results
In Figure 3, the marginal posterior distribution in the b1 - b2-plane is illustrated with histograms together with the estimate for two runs. The probability distributions are consistent with the least-squares estimates as the ridges which represent the highest densities approximately coincide with the -curves. However, the regions of highest density do not necessarily coincide with the true parameter values. This is particularly evident for the plot to the right. It therefore appears as the defines a direction along which the uncertainty of the parameter estimates is high.
To formalize the analysis, we introduce the set ΩP with as its boundary:
For each sample of the posterior, the signed Euclidean distance to ΩP and the corresponding closest point on are calculated. The distributions of these distances and points respectively characterize how well the posterior distribution is centered around and the length of the curve which is covered by the posterior. To summarize the results from all the runs, 50% equal-tailed credible intervals for the two distributions were estimated for each run. Two of the 30 runs were rejected due to insufficient convergence of the Markov chains. For the remaining runs, the average interval-length along the curve is 0.148 (estimated as the Euclidean distance between the end-points, i.e., not taking the curvature into account), while the length perpendicular to the curve is 0.0127. For 22 of the 28 accepted runs, is within the perpendicular 50% credible interval, and it is within the 90% credible interval for all runs.
3.2. LH data
In this section, the estimation is performed on male and female LH data. The male data were collected in a clinical experiment described in detail in (23). A cohort of 18 healthy male test subjects participated in the study, where blood samples were drawn every 10 min over a time period of 21 h in four sessions. During three of the sessions, a dose of a selective GnRH-receptor antagonist, ganirelix, was administered 2 h into the session. In the remaining sessions, saline was administered instead. Three escalating doses of the GnRH-receptor antagonist were used, enabling analysis of the effect on the LH concentration when GnRH is suppressed to various extents. The female LH data were obtained through digitizing the representative LH profile of a woman in midluteal phase of the menstrual cycle depicted in Figure 2 of (24).
We analyze these data in three ways. First, the curve γP is estimated from the 18-hour long male LH data sets without drug administration, and the female LH data set. Furthermore, we use a subset of one of the data sets used above to illustrate how the estimated time constants can influence the impulse estimation. Finally, the effect of the GnRH-receptor antagonist on the frequency and amplitude of the impulses is investigated along with the dependence of those on the age of the male test subjects. Here, the data points from hour 10 to hour 18 are used for the non-zero dose data, to ensure an approximately constant level of LH suppression by the antagonist.
Data from three individuals of age 68, 61 and 52 were excluded from the analysis in these experiments, as their LH profiles clearly deviated from the expected behaviour of sparse rapid bursts followed by slower elimination, which rendered the estimation unreliable. A figure comparing a typical included data set with an excluded one is provided in the Supplementary Material. In general, it is challenging to capture such dissimilar data sets with a single modeling framework. The higher ages of the excluded individuals are consistent with the experimentally established fact that the frequency of GnRH impulses increases, while their amplitudes decrease with age (25). Therefore, a higher sampling rate is required to distinguish between the individual pulsatile episodes and the LH signal.
To account for the unknown basal level of the hormone, the nadir value is subtracted from the data points of each data set. One outlier was removed from one data set as its implausibly low value interfered with establishing the basal level. There exist outlier detection methods that can be applied to hormonal data (26), but they are typically not adapted to the pulsatile nature of the signals, thus limiting their utility. In our case, the outlier was detected through visual inspection of the data. The distribution of all measurements for this individual, with the outlier highlighted, is shown in the Supplementary Material.
3.2.1. Time constant estimation
The preceding results indicate that reliable estimates of b1 and b2 cannot be expected when there is significant uncertainty due to measurement noise or model mismatch. Since this is believed to be the case for the present data set, we will instead estimate the curve γP . It is, however, known from the underlying biochemistry that the true parameter values satisfy the inequalities (22)
To evaluate the proposed estimation approach, γP is estimated for the given range of b1, which produces a range of estimates . These are then compared with the theoretical time-constant ranges, with the results displayed in Figure 4. There, 12 out of 16 curves are consistent with the theoretical parameter range, with no curve being 15% higher than the upper limit or 20% below the lower. The curve corresponding to female LH data is highlighted in the plot. No particular difference can be observed in either the measured concentrations or the estimation results between the male and midluteal female LH data. In Figure 5, the simulated LH concentration and the estimated GnRH-impulses for one individual of age 23 are shown. Here the output corresponding to the highest and lowest estimates in the b1-range are compared. The residual sum of squares is similar for the two cases; 2.71 and 2.59 (IU/L)2.
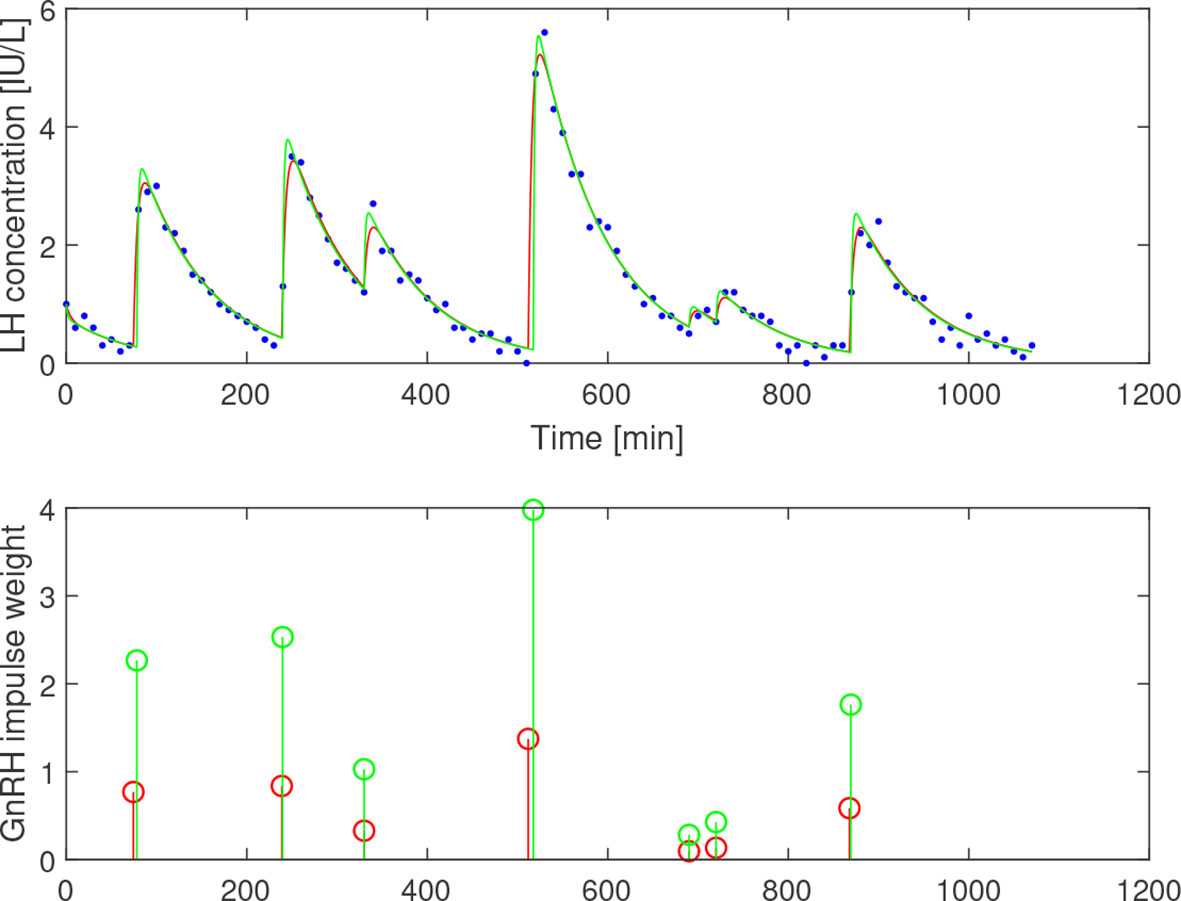
Figure 5 Estimation results assuming b1=0.23 (red) and b1=0.69 (green) based on LH data from a 23-year-old subject. Top: Simulated LH concentration and measured values (blue dots). Bottom: GnRH-impulses. b1 mainly influences the weights of the impulses, while the firing times are largely unaffected.
3.2.2. Impulse–time constant relation
The -curve provides a range of feasible solutions in terms of (b1,b2)-parameter pairs. However, the time constants also affect the estimated impulses. A subset of the LH-data from a 34-year-old individual is used here to demonstrate how variations in parameter values can lead to qualitatively different impulse distributions. The estimate is shown in Figure 6 together with the estimated impulse locations and residual sum of squares along this curve. In the range of estimates, there are solutions with one, two, and four impulses, generally with a higher residual sum for the solutions with fewer impulses. The discontinuity of corresponds to a qualitative shift from two to four impulses. Simulated solutions for three values of b1, according to the markings in the middle plot in Figure 6, are displayed in Figure 7. One should note that the time constants used here are not within the theoretical bounds specified by (8).
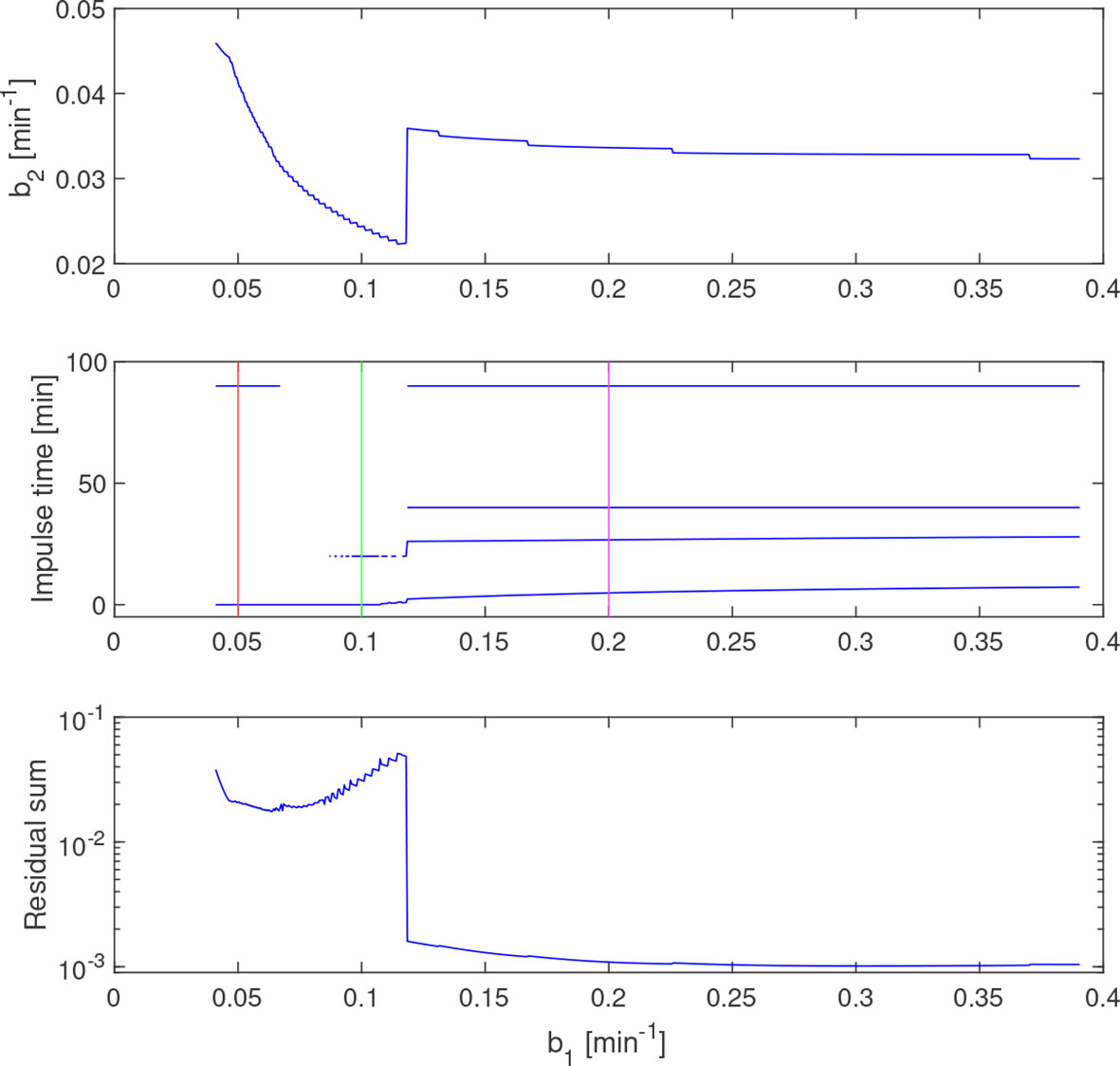
Figure 6 Estimated (top) and impulse times (middle) and residual sum of squares (bottom) along the curve . Vertical lines (red and green) correspond to the simulated concentrations in Figure 7. The discontinuity of coincides with the introduction of a fourth estimated impulse, which also reduces the residual sum.
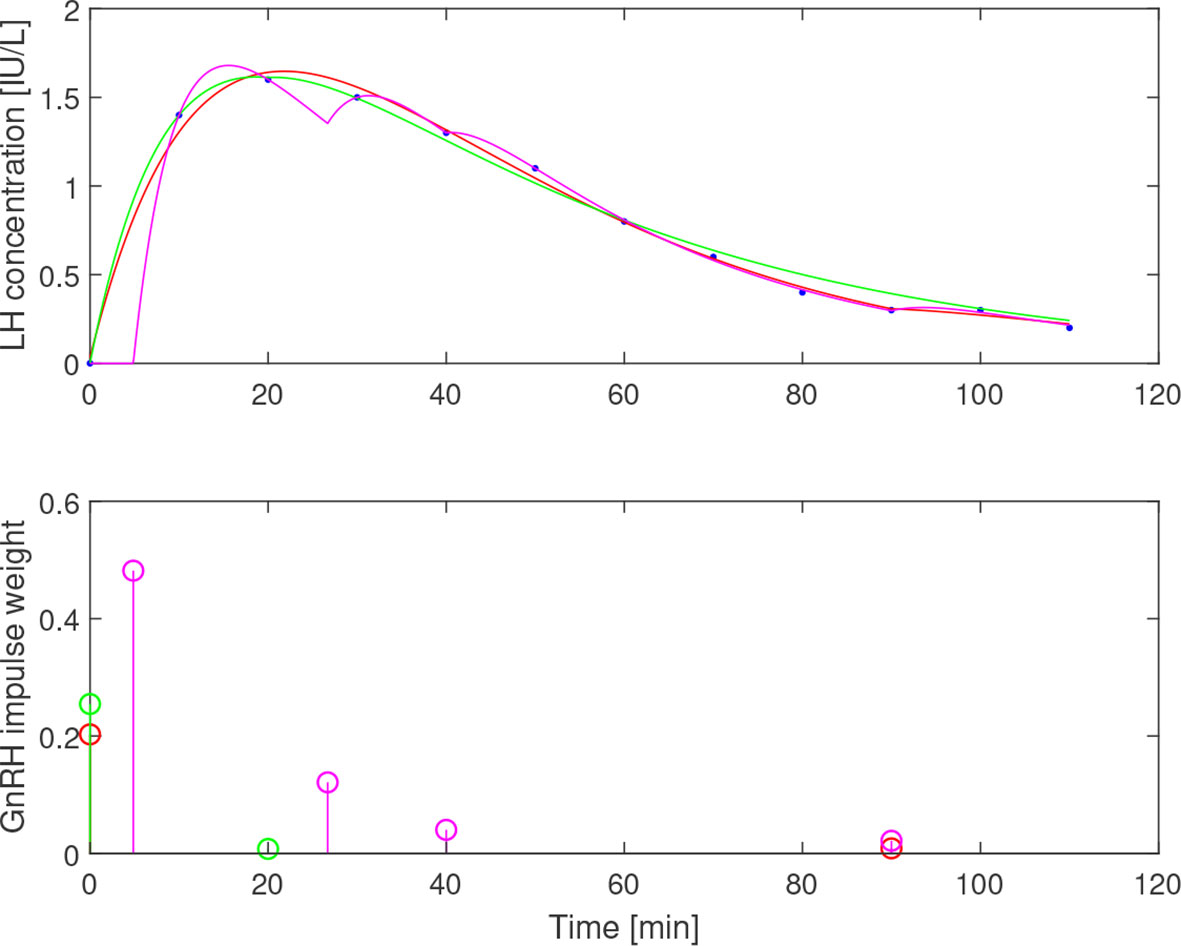
Figure 7 Simulated LH concentration (top) together with measured values (blue dots) and GnRH-impulses (bottom) from estimation assuming b1=0.05 (red), b1=0.1 (green) and b1=0.2 (magenta). Varying b1 results in qualitatively different impulse distributions, yet all three choices give a reasonable fit to the data.
3.2.3. Effects of GnRH-receptor antagonist and age
The estimation is here performed on LH data sets affected by doses of 0.1, 0.3, and 1.0 mg/m2 of the GnRH-receptor antagonist ganirelix administered prior to the experiment. The weights and frequencies of the estimated impulses under medication are compared to those estimates without the drug. The latter estimation followed what is described in Time constant estimation, but with a fixed value b1=0.5 min−1 . Similar results are obtained with other values of b1, i.e., the sensitivity with respect to the parameter value is low, See Supplementary Material.
In Figure 8, the influence of the GnRH-receptor antagonist on the LH concentration of one individual is illustrated. The trend of lower amplitude and frequency of the LH peaks as the dose is increased, which can be observed in this plot, is summarized for all individuals in Table 1 along with the estimated values of . In Figure 9, the distributions of the averages of the impulse time separations and weights are depicted, denoted as and , respectively. One-way repeated measures analysis of variance was performed on (the logarithm of) these data, grouped by the administered doses of ganirelix. For , there is no statistically significant difference between the group means (p=.24), while the difference in is significant (p <.001) Post-hoc analysis with a significance level of .05 and using Bonferroni correction shows that the highest ganirelix dose results in a d-mean that is significantly different from the rest of the groups and that the dose of 0.3 mg/m2 gives a mean that is significantly different from the unmedicated group. The short duration of the experiment in relation to the impulse frequency and uncertain estimates due to low signal-to-noise ratio are possible explanations for the inconclusive results for the effect of ganirelix on the impulse time separation.
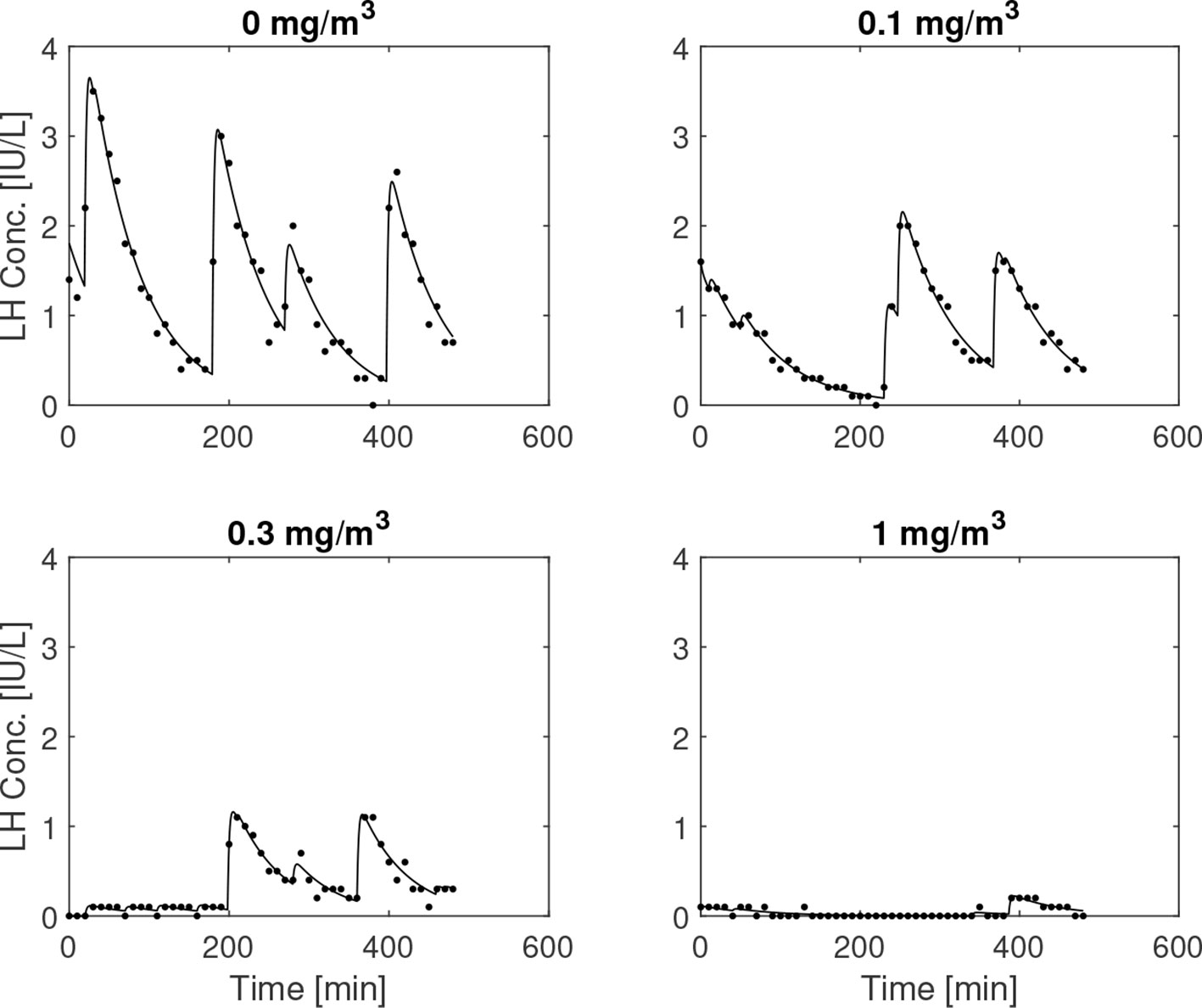
Figure 8 Simulated and measured LH concentration for escalating doses of ganirelix administered to a 24-year-old. The medication tends to lower both the amplitude and the frequency of the pulsatile episodes for this subject.

Table 1 Parameter estimates with standard deviations for escalating doses of ganirelix.
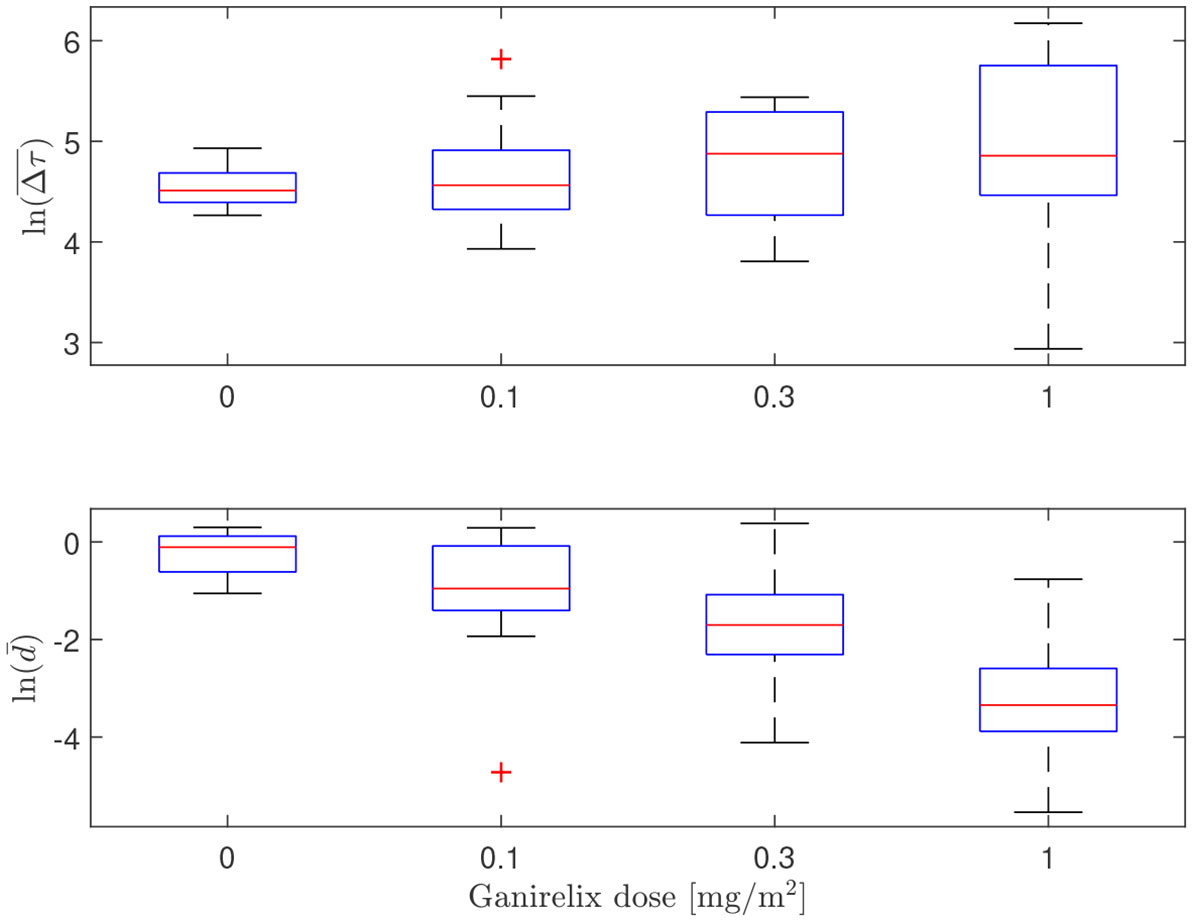
Figure 9 Box plot illustrating the distributions of estimated average impulse separation time (top) and impulse weights (bottom) for escalating doses of ganirelix administered to fifteen test subjects. Median values are indicated by the center line, the 25th and 75th percentiles are given by the box edges, whiskers show the most extreme values not considered outliers and outliers are marked by red crosses. Notice logarithmic scale on the ordinate axes.
Finally, the distribution of impulse weights and time separation for all subjects is shown in Figure 10, along with the age dependence of the average impulse time separation and weight, with fitted affine functions provided for reference. The weights display a unimodal distribution of dk with a peak close to zero and a rapid decay for higher values, while the time separation shows less regularity. The relatively large number of instances of small impulse separation could indicate that impulses of non-instantaneous time-duration are present or, alternatively, nonlinearity of the hormone pharmacokinetics. It is expected that the impulse weights are reduced and the impulse frequency is increased with age (25). This behavior can be observed in the estimate averages where the time separation decreases with 0.30 min per year and the weights decrease with 0.011 per year. However, only the change in impulse weight is statistically significant with p=.029, while for time separation p=.19. The limitations in data-quality mentioned above presumably contribute to the observed uncertainty.
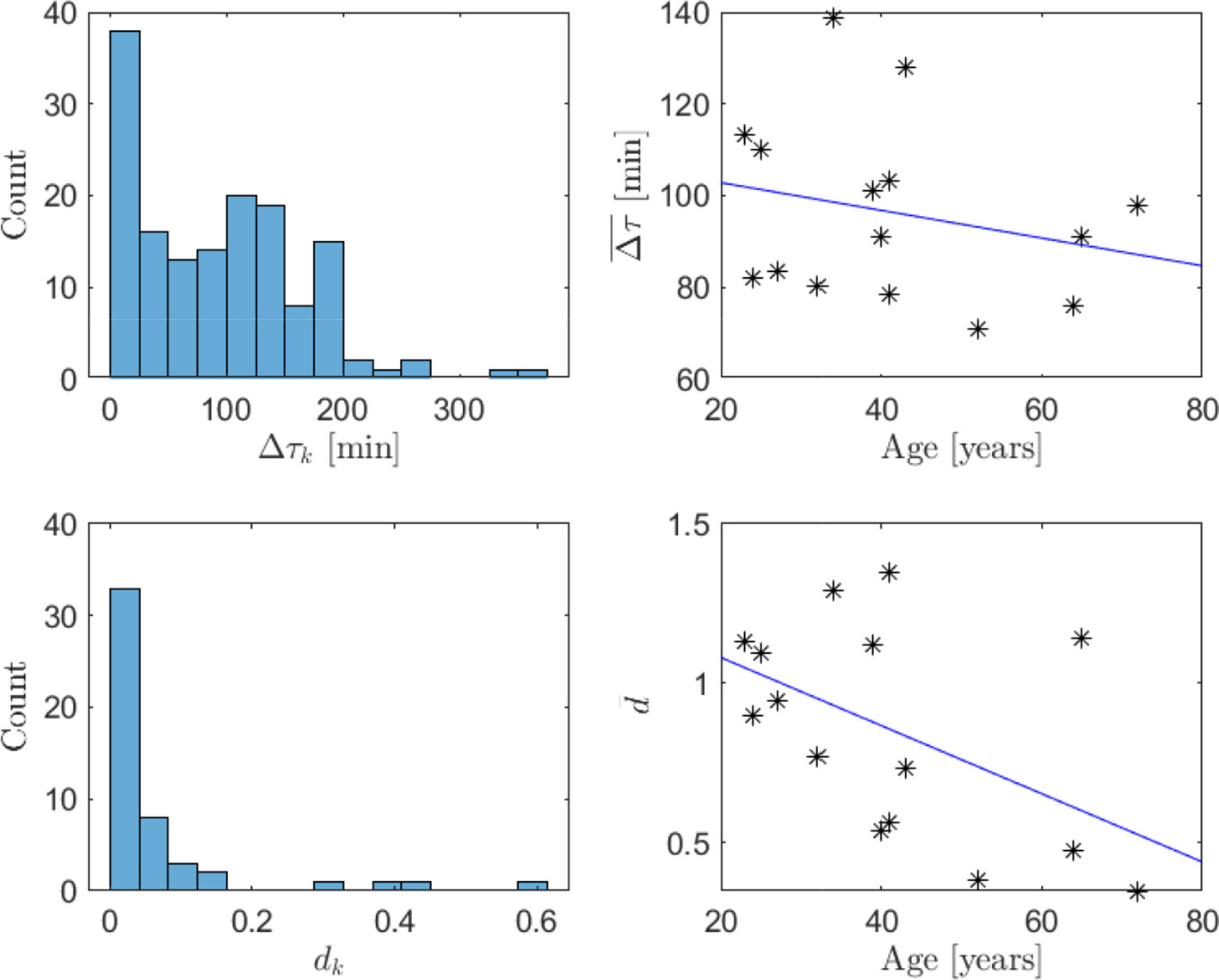
Figure 10 Histograms of impulse time separation (top left) and impulse weight (bottom left) for all individuals and average impulse time separation (top right) and impulse weight (bottom right) depending on age (both represented with asterisks), with fitted affine functions (in blue). The dependence of impulse weights on age is statistically significant (p=.029 ), whereas the dependence of time separation on age is not (p=.19).
3.3. Cortisol data
The feasibility of the estimation method for other than LH hormone axes with pulsatile secretion is demonstrated in this section and exemplified by cortisol serum concentration data collected from three female adolescents, see (27). The subjects recruited in the study were 14–21 years old and included amenorrhoeic exercisers (AE), eumenorrhoeic exercisers (EE), and non-athletic controls (NE). The goal of the study was to demonstrate that higher levels of cortisol associated with physical exercise lead to lower LH secretion and might lie behind menstrual dysfunction in female athletes. Interestingly, a direct connection between the levels of LH and the secretion of cortisol in the female organism was observed in animal experiments, indicating that cortisol inhibits pituitary responsiveness to GnRH rather than suppresses hypothalamic GnRH release (28).
The data points for modeling are obtained through digitizing the figures provided in (27) as typical cortisol profile examples for the corresponding subject group. For each subject, blood samples were drawn every 10 min during an eight-hour overnight period, with an assessment for cortisol applied to every second sample. We refer to (27) for more details on the experimental protocol.
Notice that the sampling frequency for the cortisol data set is only half of what is considered in LH data. The half-life time of cortisol is approximately three times longer than that of LH. The regulation of cortisol involves two more hormones, namely corticotropin releasing hormone (CRH) and adrenocorticotropic hormone (ACTH). The pharmacokinetics of CRH cannot be captured in the data due to its fast half-life time of 4 min. Even for ACTH, the sampling rate of 20 min is slow as the half-life time is known to vary in the range of 10–30 min. Undersampling of a signal is known to lead to aliasing artifacts, i.e., spurious components of lower frequency.
The data were analyzed in (27) by means of AutoDecon yielding estimates of cortisol half-life time and the parameters of the secretion episodes. For the half-life time, the reported estimates are 60.7 min, 47.3 min, and 49.8 min for the AE, EE, and NE cohorts, respectively.
After subtracting the basal concentration assumed to coincide with the minimal measured concentration, we estimated for the three subjects. The impulse times and weights were then estimated for two values of the elimination rate b1=0.05 min−1 and b1=0.065 min−1 that correspond to half-life of ACTH of 13.9 min and 10.7 min, respectively. The resulting impulses and concentration profiles are displayed in Figures 11–13. The corresponding half-life estimates for cortisol are 38.1 min and 48.4 min (AE), 31.1 min and 26.4 min (EE), and 37.6 min and 50.0 min (NE). Compared to the population-wide estimates in (27), these estimates are within the same range and feasible from a biochemical point of view, despite the already mentioned undersampling issue.
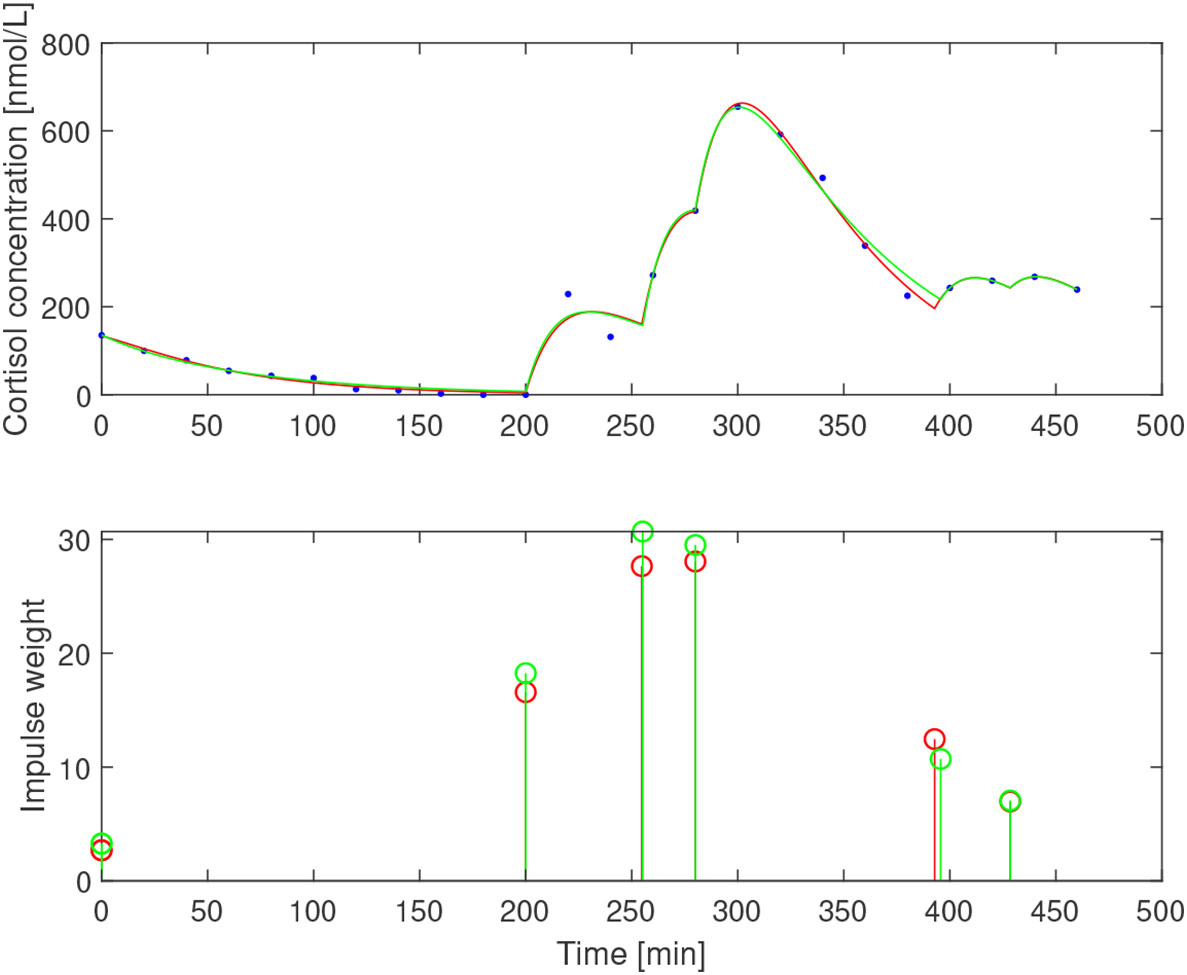
Figure 11 Simulated cortisol concentration (top) together with measured values (blue dots) and impulse estimates (bottom) from estimation assuming b1=0.05 min−1 (red) and b1=0.065 min−1 (green) for amenorrheic exerciser.
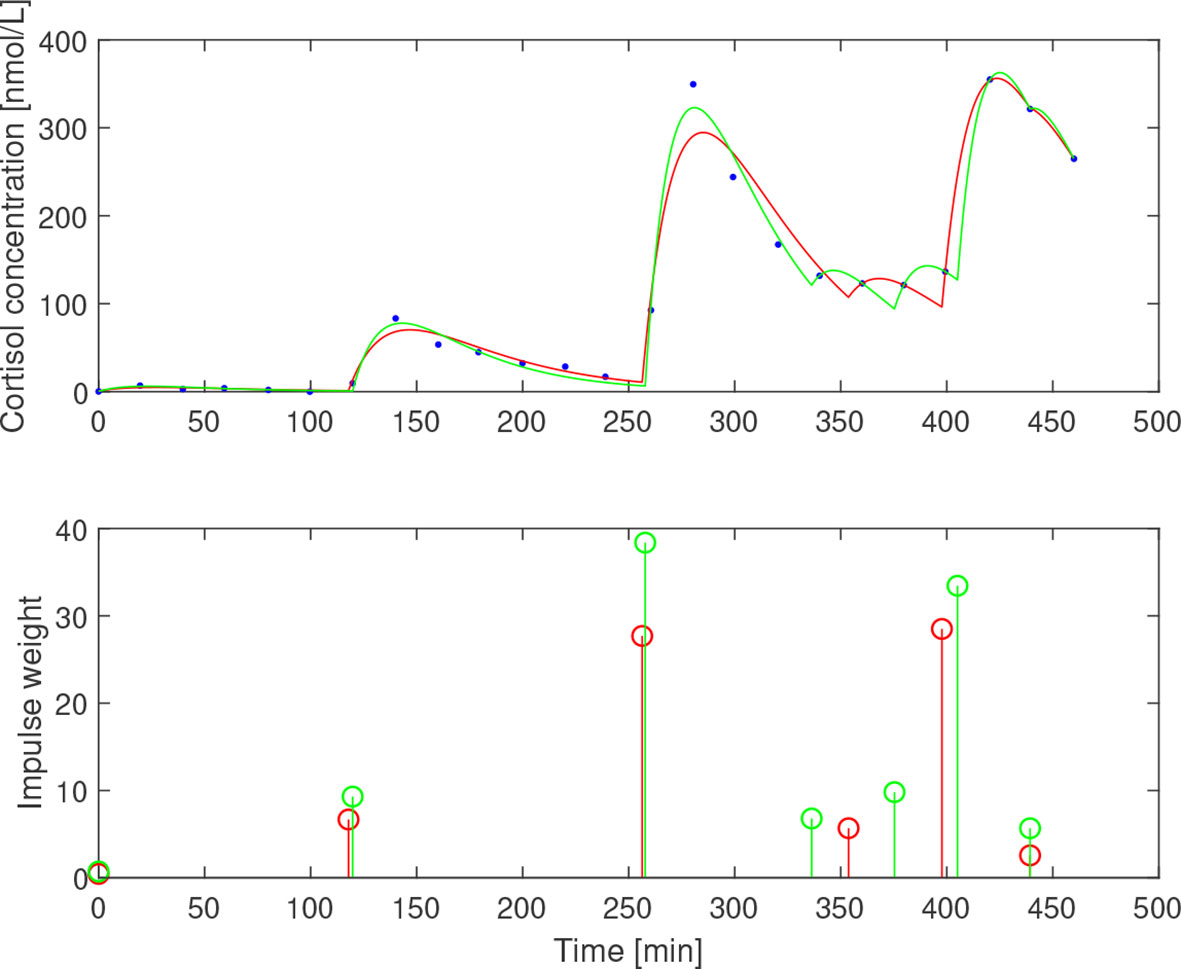
Figure 12 Simulated cortisol concentration (top) together with measured values (blue dots) and impulse estimates (bottom) from estimation assuming b1=0.05 min−1 (red) and b1=0.065 min−1 (green) for eumenorrheic exerciser.
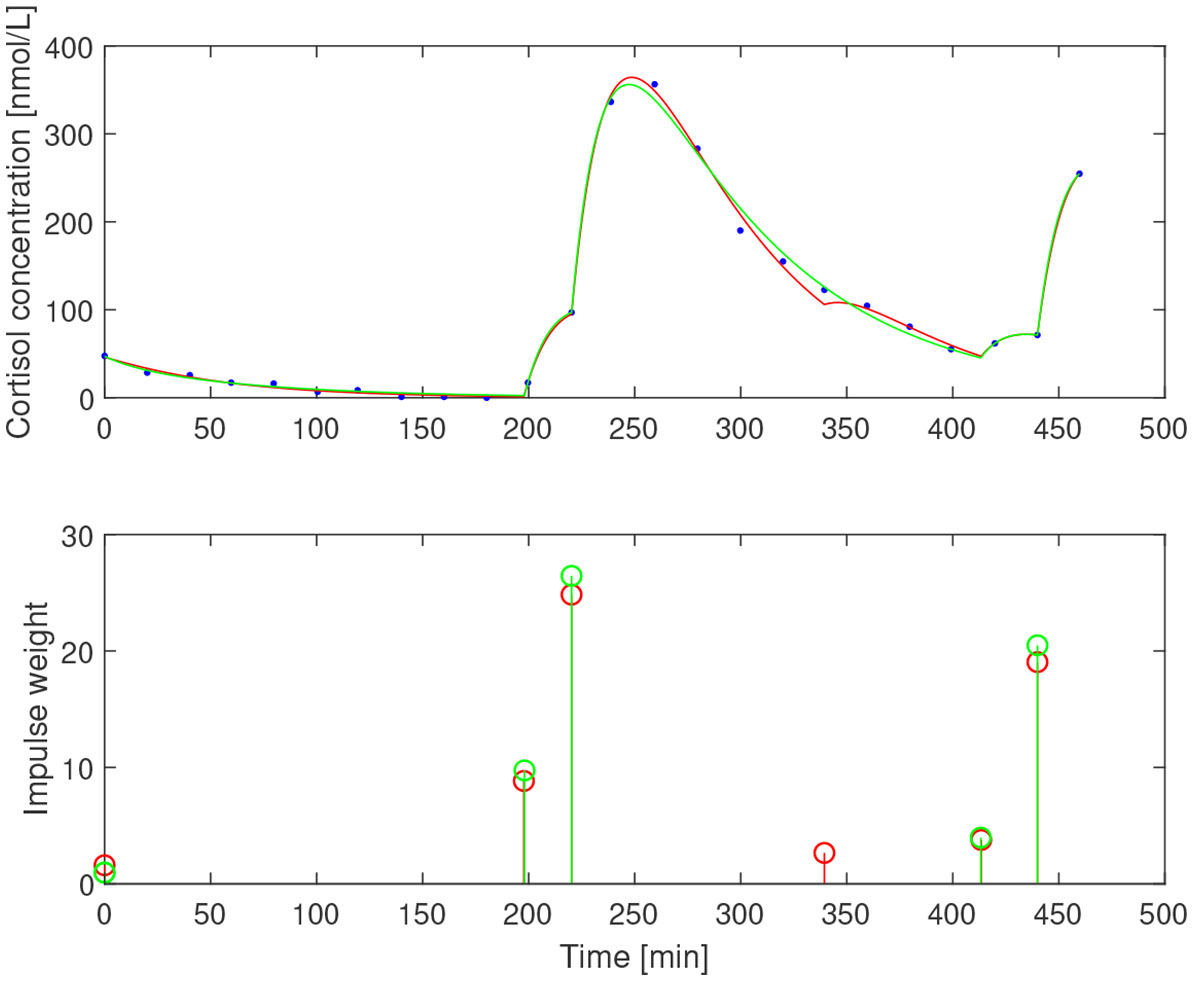
Figure 13 Simulated cortisol concentration (top) together with measured values (blue dots) and impulse estimates (bottom) from estimation assuming b1=0.05 min−1 (red) and b1=0.065 min−1 (green) for non-exerciser.
The time series estimation performance deteriorates for the data for AE and EE subjects when a lower value of b1 is chosen, as the corresponding estimate of b2 then tends to be too low and results in a bad fit to the data. For the AE subject, this problem is mitigated by removing the data point at 220 min, which indicates a sensitivity of the estimate to outliers on undersampled data, as expected. In Figure 14, the estimates of evaluated with and without this outlier point are depicted for comparison. In the region 0.027 min−1≤b1≤0.047 min−1 , the higher value of b2 improves the model fit significantly, resulting in approximately 30 times lower residual error.
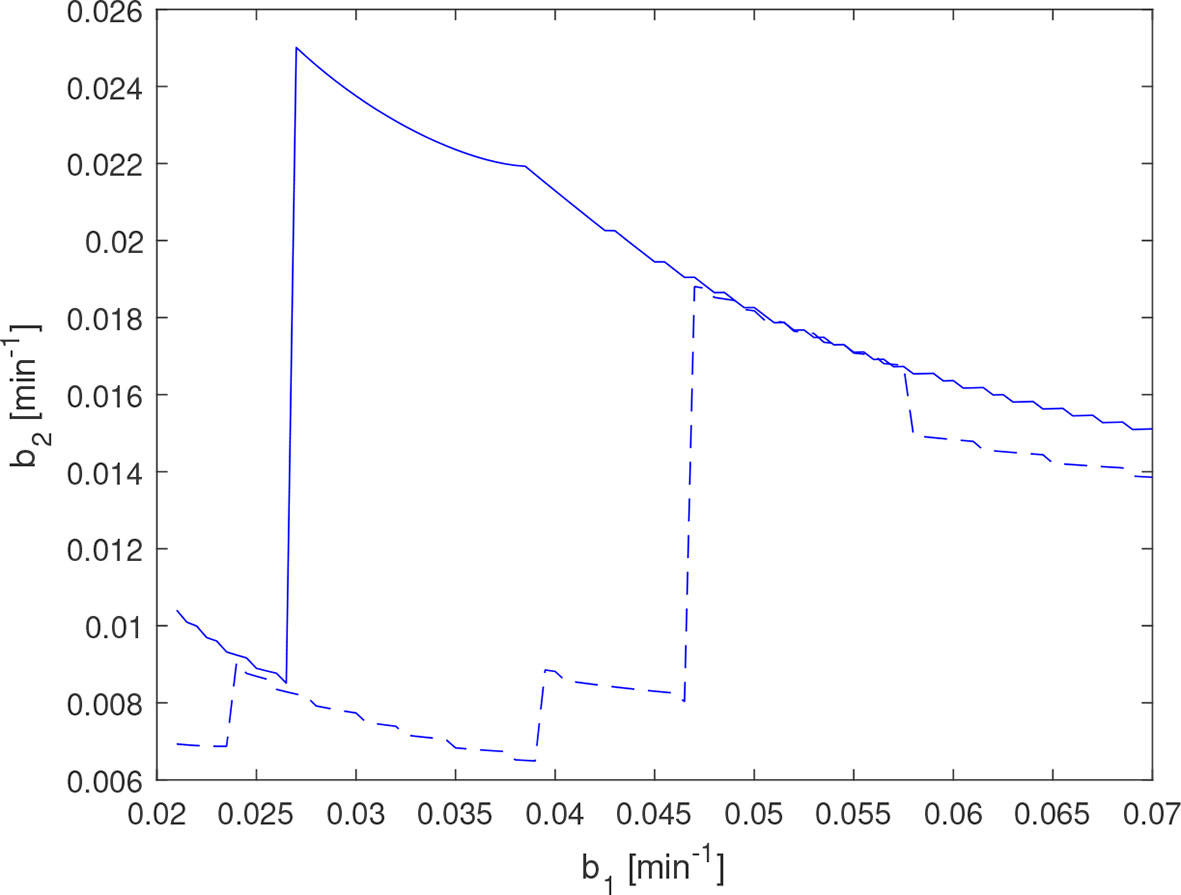
Figure 14 for amenorrheic exerciser estimated with complete data (dashed line) and with the 220 min measurement in the data set (see Figure 11) removed (solid line). The discontinuity at b1=0.047 min−1 for the dashed line corresponds to a reduction in the number of estimated impulses for b1≤0.047min−1 , which in this instance results in a significantly worse model fit.
4 Discussion
We have presented a model-based method for estimating the pulsatile bursts and elimination rates in biochemical data, e.g., endocrine data. The properties of the method have been examined using synthetic data, and its utility has been demonstrated on clinical male and female LH as well as cortisol data.
In the experiments with synthetic data, it can be seen that the estimated curve coincides with the region of maximum-likelihood obtained from the AM algorithm. The least-squares algorithm that is employed to derive the curve is however, computationally cheaper compared to the MCMC estimation (see Functional relation between the elimination rates). It is also shown that additive noise renders the estimation problem ill-posed, as the parameter combinations along produce similar posterior probability densities. This is an instance of the notoriously difficult problem of estimating the parameters of sums of exponentials, but the particular functional relationship it results in the problem at hand seems to have been overlooked in the past. One reason for this is that the model parameters are often characterized by their point estimates (with or without uncertainties) or confidence intervals, while capturing a functional relationship requires an analysis of the covariance between the parameters or a visualization of the marginal probability density to be observed. However, as the noise level decreases, the problem becomes more well-posed. Furthermore, even with significant noise, the marginal posterior distribution has a bounded support that does not cover the full range of the -curve. It therefore appears that true parameter values and other feasible parameter values are necessarily close to the -curve, but being close to the curve is not a sufficient condition for a parameter set to be feasible. Finding a sufficient feasibility condition based on the least-squares formulation is a relevant question for further research.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: The modeling part of this study makes use of clinical data described in https://doi.org/10.1152/ajpregu.00138.2005. The authors do not own the data and therefore cannot make them available. Requests to access these datasets should be directed to dmVsZGh1aXMuam9oYW5uZXNAbWF5by5lZHU=. Code for the estimation algorithms is publicly available and can be downloaded at https://github.com/HRunvik/Impulsive-Time-Series-Modeling.
Ethics statement
The studies involving human participants were reviewed and approved by The Mayo Clinic Institutional Review Board, Mayo Clinic. The patients/participants provided their written informed consent to participate in this study.
Author contributions
HR conceived and implemented the least-squares estimation algorithm, implemented the MCMC algorithm, and performed the experiments, under the guidance of AM. HR prepared the manuscript, with input from AM. Both authors revised the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This work is funded in part by the PhD program at the Centre for Interdisciplinary Mathematics, Uppsala University, Sweden and the Swedish Research Council Grant 2019-04451 for the project “Synchronization and entrainment in the impulsive Goodwins oscillator.”
Acknowledgments
The authors gratefully acknowledge the contribution of clinical data for this study by Prof. Johannes D. Veldhuis.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fendo.2022.957993/full#supplementary-material
References
1. Veldhuis JD, Keenan DM, Pincus SM. Motivations and methods for analyzing pulsatile hormone secretion. Endocrine Rev (2008) 29:823–64. doi: 10.1210/er.2008-0005
2. Medvedev A, Churilov A, Shepeljavyi A. Mathematical models of testosterone regulation. Stochastic Optimization Informatics (In Russian) (St. Petersburg State University) (2006) 2:147–58. Available at: https://www.math.spbu.ru/user/gran/sb2/churilov.pdf.
3. Churilov A, Medvedev A, Shepeljavyi A. Mathematical model of non-basal testosterone regulation in the male by pulse modulated feedback. Automatica (2009) 45:78–85. doi: 10.1016/j.automatica.2008.06.016
4. Faghih RT, Dahleh MA, Adler GK, Klerman EB, Brown EN. Deconvolution of serum cortisol levels by using compressed sensing. PloS One (2014) 9:e85204. doi: 10.1371/journal.pone.0085204
5. Runvik H, Medvedev A, Kjellsson MC. Impulsive feedback modeling of levodopa pharmacokinetics subject to intermittently interrupted gastric emptying. Am Control Conf (ACC) (2020) 1323–8. doi: 10.23919/ACC45564.2020.9147668
6. De Nicolao G, Liberati D. Linear and nonlinear techniques for the deconvolution of hormone time-series. IEEE Trans Biomed Eng (1993) 40:440–55. doi: 10.1109/10.243417
7. Veldhuis JD, Carlson ML, Johnson ML. The pituitary gland secretes in bursts: appraising the nature of glandular secretory impulses by simultaneous multiple-parameter deconvolution of plasma hormone concentrations. Proc Natl Acad Sci USA (1987) 84:7686–90. doi: 10.1073/pnas.84.21.7686
8. Keenan DM, Veldhuis JD. Pulsatility of hypothalamo-pituitary hormones: A challenge in quantification. Physiol (Bethesda) (2016) 31:34–50. doi: 10.1152/physiol.00027.2015
9. Johnson TD. Bayesian Deconvolution analysis of pulsatile hormone concentration profiles. Biometrics (2003) 59:650–60. doi: 10.1111/1541-0420.00075
10. Johnson ML, Pipes L, Veldhuis PP, Farhy LS, Nass R, Thorner MO, et al. Chapter 15 AutoDecon: A robust numerical method for the quantification of pulsatile events. Methods Enzymology (Academic Press) (2009) 454:367–404. doi: 10.1016/S0076-6879(08)03815-9
11. Veldhuis J, Johnson M. Cluster analysis: A simple, versatile, and robust algorithm for endocrine pulse detection. Am J Physiol (1986) 250:E486–93. doi: 10.1152/ajpendo.1986.250.4.E486
12. Sparacino G, Pillonetto G, Capello M, De Nicolao G, Cobelli C. WINSTODEC: a stochastic deconvolution interactive program for physiological and pharmacokinetic systems. Comput Methods Programs Biomedicine (2002) 67:67–77. doi: 10.1016/S0169-2607(00)00151-6
13. Runvik H, Medvedev A. Input sequence and parameter estimation in impulsive models for biomedical applications. Eur Control Conf (London Great Britain) (2022) 253–258. doi: 10.23919/ECC55457.2022.9837971
14. Mattsson P, Medvedev A. Modeling of testosterone regulation by pulse-modulated feedback. Adv Exp Med Biol (Springer) (2015) 823:23–40. doi: 10.1007/978-3-319-10984-8_2
15. Holmström K, Petersson J. A review of the parameter estimation problem of fitting positive exponential sums to empirical data. Appl Mathematics Comput (2002) 126:31–61. doi: 10.1016/S0096-3003(00)00138-7
16. Mattsson P, Medvedev A. State estimation in linear time- invariant systems with unknown impulsive inputs. Eur Control Conf (Zürich Switzerland) (2013) 1675–80. doi: 10.23919/ECC.2013.6669727
17. Atchadé YF, Rosenthal JS. On adaptive Markov chain Monte Carlo algorithms. Bernoulli (2005) 11:815–28. doi: 10.3150/bj/1130077595
18. Liu JS. Monte Carlo Strategies in scientific computing. Springer Science & Business Media (2001) (Springer, New York).
19. Metropolis N, Rosenbluth AW, Rosenbluth MN, Teller AH, Teller E. Equation of state calculations by fast computing machines. J Chem Phys (1953) 21:1087–92. doi: 10.1063/1.1699114
20. Green PJ. Reversible jump Markov chain Monte Carlo computation and bayesian model determination. Biometrika (1995) 82:711–32. doi: 10.1093/biomet/82.4.711
21. Gelman A, Rubin DB. Inference from iterative simulation using multiple sequences. Stat Sci (1992) 7:457–72. doi: 10.1214/ss/1177011136
22. Keenan DM, Veldhuis JD. A biomathematical model of time-delayed feedback in the human male hypothalamic-pituitary-Leydig cell axis. Am J Physiology-Endocrinology Metab (1998) 275:E157–76. doi: 10.1152/ajpendo.1998.275.1.E157
23. Liu PY, Takahashi PY, Roebuck PD, Iranmanesh A, Veldhuis JD. Age-specific changes in the regulation of LH-dependent testosterone secretion: assessing responsiveness to varying endogenous gonadotropin output in normal men. Am J Physiology-Regulatory Integr Comp Physiol (2005) 289:R721–8. doi: 10.1152/ajpregu.00138.2005
24. Johnson ML, Pipes L, Veldhuis PP, Farhy LS, Boyd DG, Evans WS. Autodecon, a deconvolution algorithm for identification and characterization of luteinizing hormone secretory bursts: description and validation using synthetic data. Analytical Biochem (2008) 381:8–17. doi: 10.1016/j.ab.2008.07.001
25. Veldhuis JD, Keenan DM, Liu PY, Iranmanesh A, Takahashi PY, Nehra AX. The aging male hypothalamic–pituitary–gonadal axis: Pulsatility and feedback. Special Issue: Endocrinol Aging (2009) 299:14–22. doi: 10.1016/j.mce.2008.09.005
26. van der Spoel E, Choi J, Roelfsema F, Sl C, van Heemst D, Dekkers OM. Comparing methods for measurement error detection in serial 24-h hormonal data. J Biol rhythms (2019) 34:347–63. doi: 10.1177/0748730419850917
27. Ackerman KE, Patel KT, Guereca G, Pierce L, Herzog DB, Misra M. Cortisol secretory parameters in young exercisers in relation to LH secretion and bone parameters. Clin Endocrinol (2013) 78:114–9. doi: 10.1111/j.1365-2265.2012.04458.x
Keywords: endocrine regulation, impulsive hormone secretion, mathematical modeling, luteinizing hormone, gonadotropin-releasing hormone, ganirelix, cortisol, adrenocorticotropic hormone
Citation: Runvik H and Medvedev A (2022) Impulsive time series modeling with application to luteinizing hormone data. Front. Endocrinol. 13:957993. doi: 10.3389/fendo.2022.957993
Received: 31 May 2022; Accepted: 05 October 2022;
Published: 01 November 2022.
Edited by:
Frédérique Clément, Inria Saclay - Île-de-France Research Centre, FranceReviewed by:
Taous Meriem Laleg, King Abdullah University of Science and Technology, Saudi ArabiaMargaritis Voliotis, University of Exeter, United Kingdom
Copyright © 2022 Runvik and Medvedev. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Håkan Runvik, SGFrYW4ucnVudmlrQGl0LnV1LnNl