
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Endocrinol. , 14 July 2021
Sec. Pediatric Endocrinology
Volume 12 - 2021 | https://doi.org/10.3389/fendo.2021.713592
This article is part of the Research Topic Exploring Obesity Risk, Prevention, and Research Innovation in the First 2000 Days of Life View all 8 articles
 Ziwei Lin1,2†
Ziwei Lin1,2† Wenhuan Feng3†
Wenhuan Feng3† Yanjun Liu4†
Yanjun Liu4† Chiye Ma5
Chiye Ma5 Dooman Arefan2Donglei Zhou1Xiaoyun Cheng1Jiahui Yu4Long Gao2,6Lei Du1Hui You1Jiangfan Zhu1,5Dalong Zhu3
Dooman Arefan2Donglei Zhou1Xiaoyun Cheng1Jiahui Yu4Long Gao2,6Lei Du1Hui You1Jiangfan Zhu1,5Dalong Zhu3 Shandong Wu2,7*‡
Shandong Wu2,7*‡ Shen Qu1*‡
Shen Qu1*‡Background and objective: Clinical characteristics of obesity are heterogenous, but current classification for diagnosis is simply based on BMI or metabolic healthiness. The purpose of this study was to use machine learning to explore a more precise classification of obesity subgroups towards informing individualized therapy.
Subjects and Methods: In a multi-center study (n=2495), we used unsupervised machine learning to cluster patients with obesity from Shanghai Tenth People’s hospital (n=882, main cohort) based on three clinical variables (AUCs of glucose and of insulin during OGTT, and uric acid). Verification of the clustering was performed in three independent cohorts from external hospitals in China (n = 130, 137, and 289, respectively). Statistics of a healthy normal-weight cohort (n=1057) were measured as controls.
Results: Machine learning revealed four stable metabolic different obese clusters on each cohort. Metabolic healthy obesity (MHO, 44% patients) was characterized by a relatively healthy-metabolic status with lowest incidents of comorbidities. Hypermetabolic obesity-hyperuricemia (HMO-U, 33% patients) was characterized by extremely high uric acid and a large increased incidence of hyperuricemia (adjusted odds ratio [AOR] 73.67 to MHO, 95%CI 35.46-153.06). Hypermetabolic obesity-hyperinsulinemia (HMO-I, 8% patients) was distinguished by overcompensated insulin secretion and a large increased incidence of polycystic ovary syndrome (AOR 14.44 to MHO, 95%CI 1.75-118.99). Hypometabolic obesity (LMO, 15% patients) was characterized by extremely high glucose, decompensated insulin secretion, and the worst glucolipid metabolism (diabetes: AOR 105.85 to MHO, 95%CI 42.00-266.74; metabolic syndrome: AOR 13.50 to MHO, 95%CI 7.34-24.83). The assignment of patients in the verification cohorts to the main model showed a mean accuracy of 0.941 in all clusters.
Conclusion: Machine learning automatically identified four subtypes of obesity in terms of clinical characteristics on four independent patient cohorts. This proof-of-concept study provided evidence that precise diagnosis of obesity is feasible to potentially guide therapeutic planning and decisions for different subtypes of obesity.
Clinical Trial Registration: www.ClinicalTrials.gov, NCT04282837.
The effects of weight loss treatments on patients with obesity vary greatly between cohorts/individuals. This may relate to the heterogeneity of the disease in terms of clinical presentation and pathogenesis (1–5). Conventional classification of obesity is mainly by a single dimension, e.g., body mass index (BMI) (6) or healthy/unhealthy metabolism (7). However, the coarse classification made by BMI inaccurately reflects the complexity and heterogeneity of obesity (6, 8). The metabolic healthy/unhealthy classification criteria are also controversial (7, 9, 10), where the patient distribution in the unhealthy group can vary substantially, ranging from 25% to 94% in reported studies (11). Towards precision treatment, a more refined metabolic classification of obesity phenotypes is highly demanded for a personalized diagnosis, aiming to identify patients at elevated risk of certain metabolic disorders or obesity comorbidities at the initial diagnostic visit. This kind of refined classification can provide a more precise diagnosis and enable more individualized preventive interventions and early treatments (12).
Artificial intelligence techniques have been quickly adopted in medicine. Data-driven machine learning modeling provides an intelligent method to mine up large and multi-dimensional data for refined classification and quantitative analysis. Applying machine learning to the obesity field is emerging but limited (13–16). Recent work shows encouraging preliminary evidences that some latent phenotypes of obesity could be revealed by machine learning (14–16). However, these obesity classification paradigms lack the consideration of an important clinical factor, i.e., metabolic abnormality, are limited to using data measured from specific devices that are not routinely available in clinical practice, or are short of external validation.
The purpose of this study was to develop a refined obesity classification criterion through an unsupervised machine learning approach in the setting of a multi-center study, where four independent study cohorts (a total of 1438 patients with obesity and 1057 normal-weight controls) were used for obesity classification and validation, using three common/key clinical variables representing a multi-dimensional characterization of obesity progression in terms of metabolism, hormone, inflammation, and oxidation (17).
We conducted a multicenter study (ClinicalTrials No. NCT04282837) with approval from a local ethical committee and an institutional review board of the participating institutions. As shown in Figure 1, we retrospectively collected four patients cohorts (BMI ≥ 24kg/m2 according to the WHO criteria for overweight/obesity (6)) and one normal-weight control cohort from four different hospitals in P.R. China. We used one patient cohort (main cohort) for model learning and the rest three patient cohorts (verification cohorts) for verification. Detailed data analyses of the identified obesity subgroups were performed on the main cohort with a comparison to the control cohort.
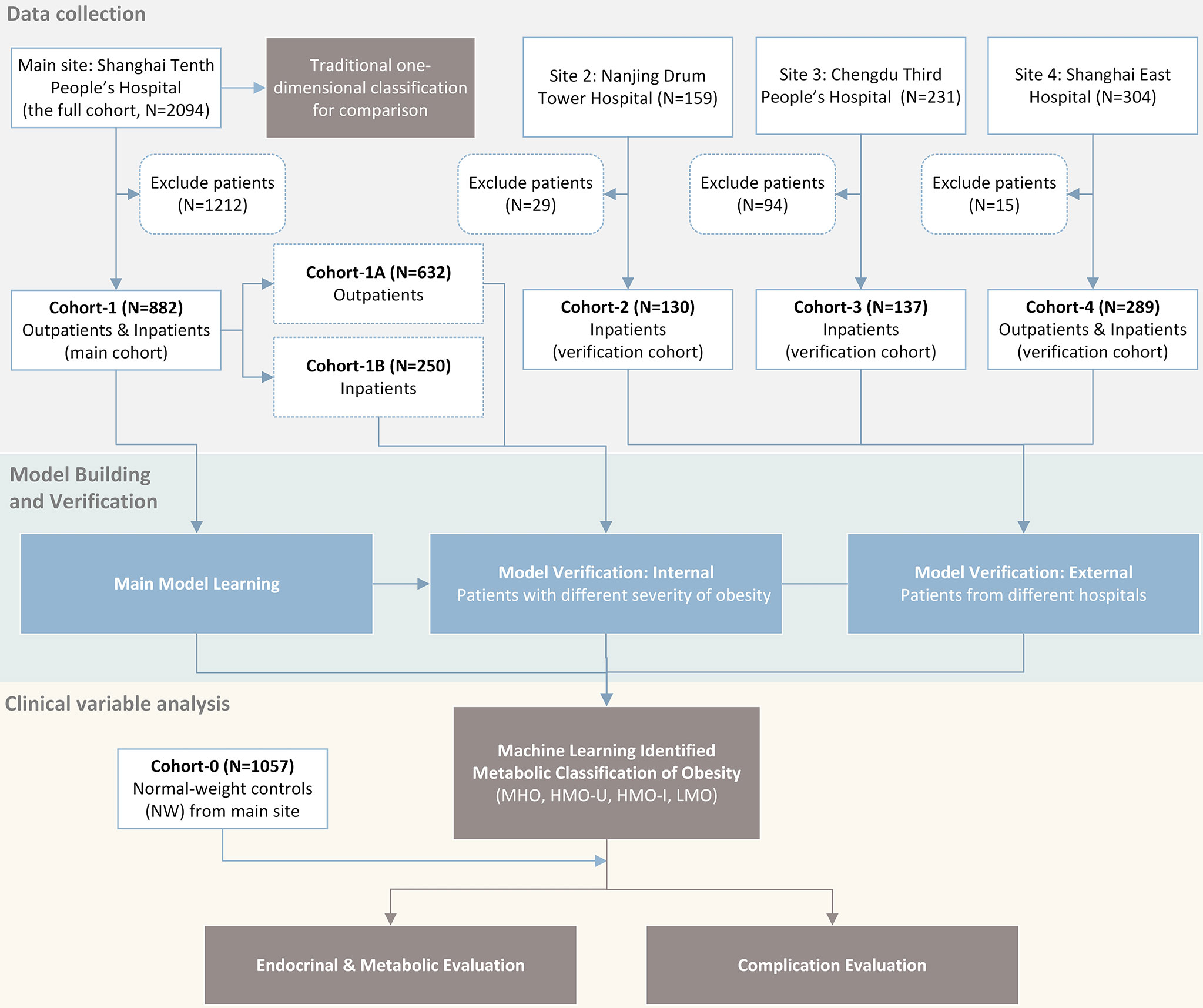
Figure 1 Flow chart of study design.
Patients’ inclusion and exclusion criteria were shown in the Supplemental Appendix. From January 2010 to December 2019, at the Endocrinology and Metabolic Center of Shanghai Tenth People’s Hospital (main site), 2094 patients (the full cohort at the main site) with obesity were included, and 882 patients were included in Cohort-1 (main cohort) after exclusion (400 men and 482 women, median age 29 years, median BMI 35.9 kg/m2). Cohort-1 consisted of two sub-cohorts: Cohort-1A included 632 outpatients with obesity (296 men and 336 women, median age 28 years, median BMI 33.6 kg/m2). Most of these patients had relatively lower BMIs, mild to moderate obesity comorbidities, and were treated mainly with lifestyle interventions and weight-loss drugs. Cohort-1B included 250 inpatients with morbid obesity (104 men and 146 women, median age 31 years, median BMI 39.3 kg/m2) who were candidates for bariatric surgery according to the American Society of Metabolic and Bariatric Surgery/The Obesity Society/American Association of Clinical Endocrinologists guidelines (18) that are adjusted for Chinese patients. Pre-surgical examinations were performed before bariatric surgeries. Three follow-ups were conducted at 3, 6, and 12 months after surgery.
For the three verification cohorts, Cohort-2 included 130 patients with morbid obesity from Nanjing Drum Tower Hospital (60 men and 70 women, median age 30 years, median BMI 38.7 kg/m2). Cohort-3 included 137 patients with morbid obesity from Chengdu Third People’s Hospital (50 men and 87 women, median age 29 years, median BMI 38.0 kg/m2). Cohort-4 included 289 patients with moderate to morbid obesity from Shanghai East Hospital (81 men and 208 women, median age 30 years, median BMI 36.8 kg/m2). In addition, we collected a normal-weight healthy cohort (Cohort-0, n=1057) along with the main cohort from the main site, to use as controls (223 men and 834 women, median age 30 years, median BMI 21.2 kg/m2). These participants presented to clinics for routine health examinations. Key patient characteristics are shown in Table 1. Details on the measurement, calculation, and definition of endocrinological and metabolic disorders for each cohort were included in the Supplemental Appendix.
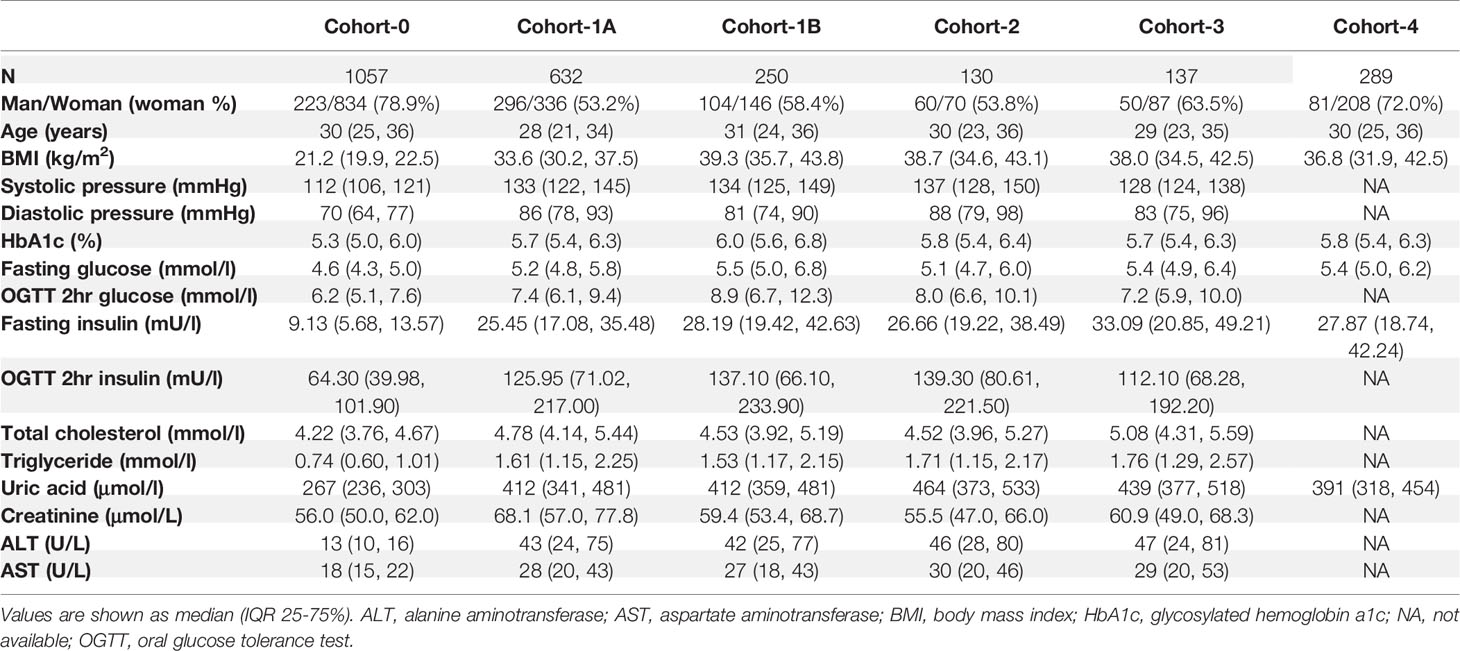
Table 1 Key characteristics of patients in each cohort.
Based on the consensus of our study team consisting of multiple expert physicians in obesity/endocrinology, the clinical variables we used to build classification models should be those related to metabolism, hormones, inflammation, and antioxidation, which represent the underlying progression mechanisms of obesity comorbidities. We selected key clinical variables out of hundreds of metabolic parameters based on the following criteria: (i) essential to characterize obesity, (ii) routinely acquired/measured in clinics, and (iii) easy to interpret with a physical meaning. We also intended to select a small number of variables to improve the generalizability of the classification models. Based on these criteria, we performed a data-driven experiment to select potential variables and optimal model parameters for the classification.
We used and compared two clustering algorithms [i.e., k-means (19) and two-step (20)] for machine learning. Clustering was implemented by SPSS Modeler version 18 (IBM, Chicago, USA). All variables were normalized (mean value of 0 and standard deviation [SD] of 1) before the cluster analysis. The k-means clustering was implemented with different k values (maximum iterations of 30 and change tolerance of 0.00001) and the one with minimum silhouette widths was used in the end. In the two-step clustering, the first step estimates the optimal number of clusters on the basis of silhouette width and the second step performs hierarchical clustering using log-likelihood as a distance measure and Schwarz’s Bayesian criterion for clustering. Considering the notable differences of key patient characteristics induced by patient sex, we built a model with two sub-models that were separately trained on female and male patients, and then the classification results of the sub-models were pooled for further analysis.
Clustering algorithms were first applied to the main cohort, Cohort-1, and the resulting clusters were used as the main classification model. Verification was performed by applying the same clustering algorithms to Cohort-1A, Cohort-1B, Cohort-2, Cohort-3, and Cohort-4, separately, and the resulting clusters of each verification cohort were compared to the clusters of the main model in terms of patients’ distribution percentages and characteristics in each cluster. The denotation of clusters was assigned referring to the characteristics of the three classification variables. In order to further measure the generalizability of the classification models, we also assigned patients in each verification cohort to the clusters derived from the main model, according to the similarity of a patient’s characteristics to each of the clusters in the main model. The similarity was calculated as their Euclidian distance (for k-means clustering) or log-likelihood distance (for two-step clustering) from the nearest cluster center derived from the main model. Then sensitivity, specificity, and accuracy for clustering, as well as the inter-cluster Jaccard coefficients (21), were calculated.
The area under the curve (AUC) of glucose (glucose AUC) and insulin (insulin AUC) were calculated using the trapezoidal rule at four data points of 0, 30, 60, and 120 min during oral glucose tolerance test (OGTT) for patients in Cohort-1 and Cohort-2. However, since the four-time-points OGTT was not a routine measurement for patients in Cohort-3 and Cohort-4 (which is not uncommon in certain hospitals), certain time-points of the OGTT data were missing for these patients. Thus, we built a group of linear regression models using the complete OGTT data available in Cohort-1, and employed one to three time-points of OGTT to estimate the four-time-points glucose AUC and insulin AUC. The linear regression models for the estimation of glucose AUC and insulin AUC were trained and tested in 70% and 30%, respectively, of the data from Cohort-1 using stepwise method. The F test was performed with P < 0.05 for inclusion and P > 0.1 for exclusion, and outlier tolerance of 0.0001. The estimates of the glucose AUC and insulin AUC showed an average adjusted R in the test set of 0.954 (range: 0.860-0.996) for glucose AUC and 0.873 (range: 0.643-0.984) for insulin AUC (Tables S1 and S2).
Clinical implications of variables related to metabolism and morbidity were compared with respect to the four obesity clusters. Continuous variables were expressed as the median (interquartile range 25-75%), since most of them were a skewed distribution. Variables not normally distributed were logarithmically or square root transformed before statistical analysis, which was performed with SPSS version 26 (IBM, Chicago, USA). Differences for continuous variables were assessed by performing ANOVA or ANCOVA, as appropriate. Bonferroni correction was used for the post hoc analysis. Differences in ratio variables were assessed by Chi-square test. To identify the odds of obesity comorbidities in different subgroups, a binary logistic regression analysis was performed, and odd ratio (OR) or OR adjusted (AOR) for sex and age and the corresponding 95% confidence interval (CI) were calculated. For all analyses, p values were two-tailed and p < 0.05 was considered statistically significant.
Of the 2094 patients (i.e., the full cohort at the main site), 300 (14%) and 1794 (86%) were overweight and obese, respectively, in terms of BMI. The proportions of metabolic unhealthy patients varied substantially, where 36-93% overweight and 55-97% obese patients were observed according to different criteria (Figure S1A–D). In the BMI-based categorization, while the incidence of several metabolic diseases (e.g., hypertension, metabolic syndromes, and hyperuricemia) increased gently along with the BMI categories, there were no obvious differences in the clinical characteristics among the four BMI subgroups (Figure S1E–F).
Data-driven experiments selected the following three variables as key clustering factors: 1) glucose AUC, reflecting the severity of disturbances in energy metabolism; 2) insulin AUC, reflecting the compensatory balance of hormones to the increased somatogenic need; and 3) uric acid (UA), reflecting the inflammation and oxidation in the body. In Cohort-1 (the main cohort), k-means yielded four distinct clusters with minimum silhouette widths (Figure 2A). The two-step clustering showed similar clustering results as k-means (Jaccard similarity 0.831, Figure S2A). The cluster centers were shown in Table 2 and Table S3. Here we report the results on k-means only (see Supplemental Appendix for two-step results).
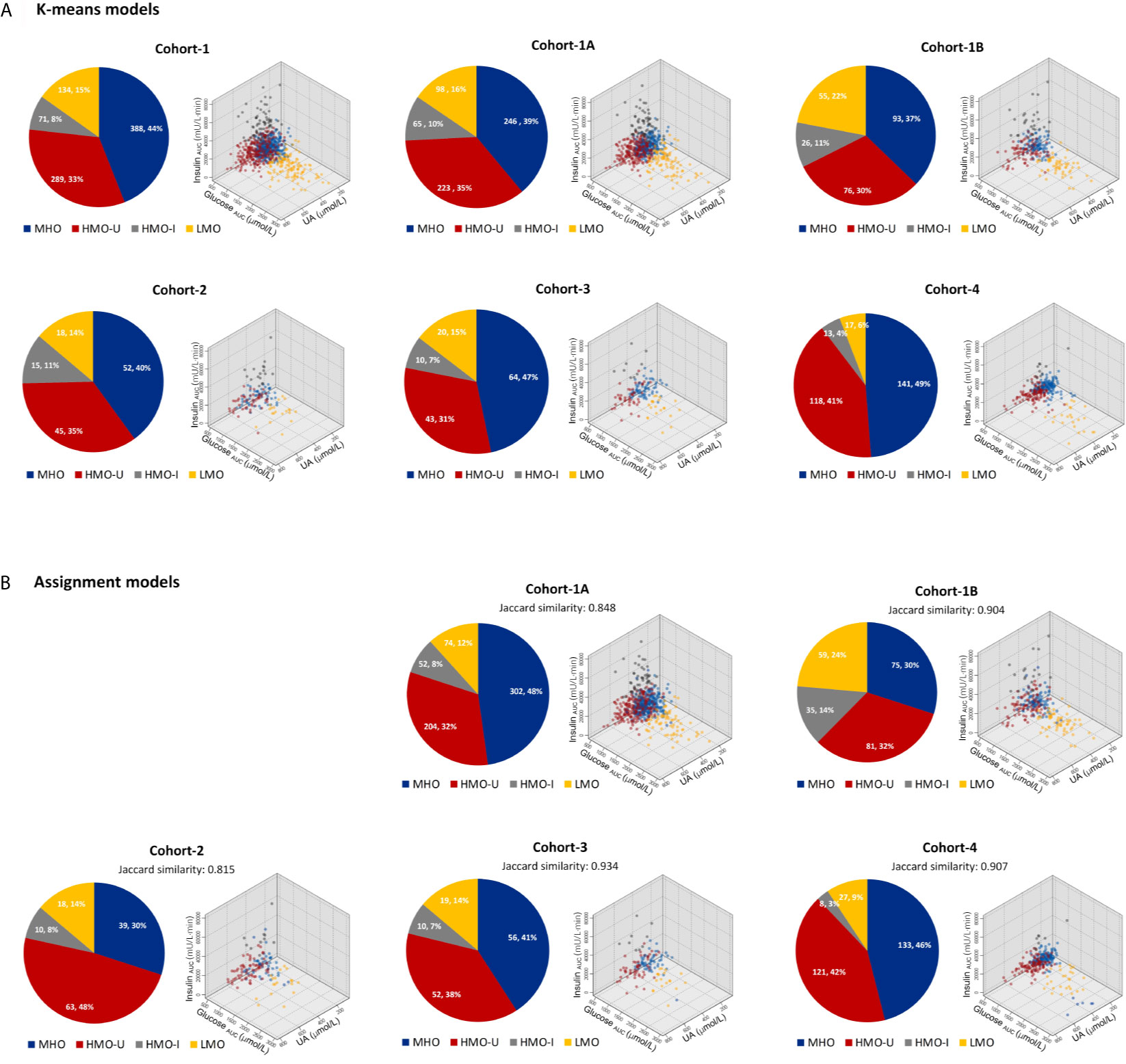
Figure 2 Patient distributions and characteristics in each cohort with respect to the four clusters generated from machine learning. (A) Clusters generated independently from each individual cohort by using k-means. (B) Clusters generated by assigning patients in each verification cohort to the main model generated from Cohort-1. Data in the pie plots were shown as N (patient number) and its percentage over the full cohort. HMO-I, hypermetabolic obesity hyperinsulinemia subtype; HMO-U, hypermetabolic obesity hyperuricemia subtype; LMO, hypometabolic obesity; MHO, metabolic healthy obesity.
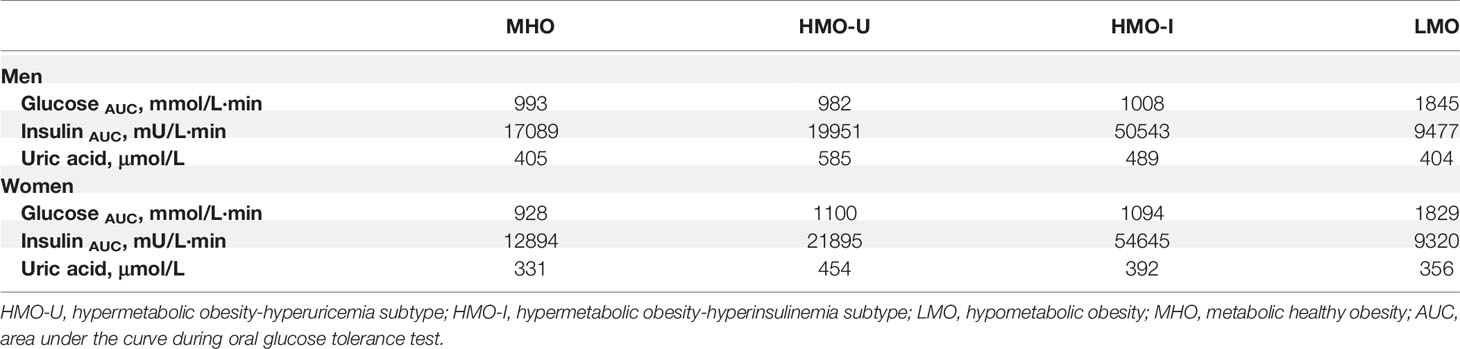
Table 2 Cluster centers in Cohort-1 with k-means method.
The four clusters that resulted from Cohort-1 were as follows (Figure 3A): Cluster 1 (denoted as metabolic healthy obesity [MHO]): 388 (44%) patients characterized by relatively healthy-metabolic statues, with normal glucose (median glucose AUC: 928 vs. 886 mmol/l·min in normal-weight), slight compensated insulin secretion (median insulin AUC: 13775 vs. 7252 mU/l·min in normal-weight), and mild increased UA (median: 363 vs. 267 μmol/l in normal-weight). Cluster 2 (denoted as hypermetabolic obesity hyperuricemia subtype [HMO-U]) and cluster 3 (denoted as hypermetabolic obesity hyperinsulinemia subtype [HMO-I]): included 289 (33%) and 71 (8%) patients, respectively, both characterized by slightly increased glucose, compensated insulin secretion, and increased UA. HMO-U was distinguished by high UA (median: 501 vs. 363-451 μmol/l in other three subgroups), whereas HMO-I was distinguished by overcompensated insulin secretion (median insulin AUC: 47061 vs. 8244-20186 mU/l·min in other three subgroups). Cluster 4 (denoted as hypometabolic obesity [LMO]): 134 (15%) patients characterized by high glucose (median glucose AUC: 1748 vs. 928-1030 mmol/l·min in other three subgroups) with decompensated insulin secretion (median insulin AUC: 8244 vs. 13775-47061 mU/l·min in the other three subgroups). The characteristics of the four clusters were similar between the clusters generated by male and female patients, separately (Figure S3). HMO-U, HMO-I, and LMO can be grouped with a single notion of metabolic unhealthy obesity (MUO) in comparison to MHO. Figure 3B showed the glucose and insulin curves during OGTT across the four clusters.
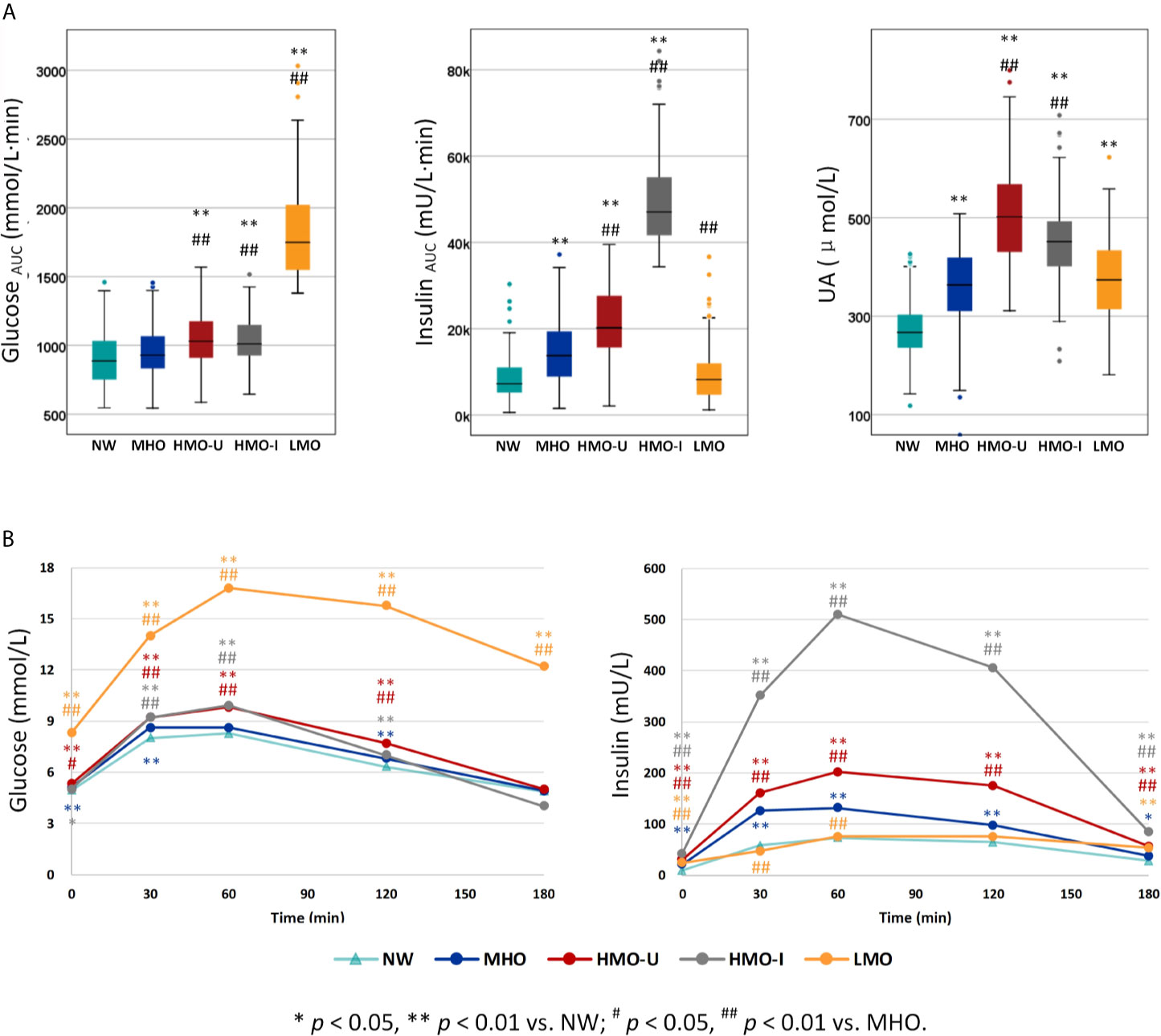
Figure 3 Comparison of the three classification variables across the four clusters generated from Cohort-1 using k-means. (A) The three classification variables. (B) Oral glucose tolerance test (OGTT) curves for glucose and insulin. P values refer to results after adjustment for age and sex. HMO-I, hypermetabolic obesity hyperinsulinemia subtype; HMO-U, hypermetabolic obesity hyperuricemia subtype; LMO, hypometabolic obesity; MHO, metabolic healthy obesity; NW, normal-weight control; UA, uric acid.
In each verification cohort, there were also four distinct clusters generated with similar patient distributions and characteristics to the corresponding clusters of the main model (Figure 2A). In Cohort-4, the proportions of patients clustered into LMO and HMO-I were relatively small, which may potentially have to do with the estimation of missing values for glucose AUC and insulin AUC, respectively.
As shown in Figure 2B and Table 3, in terms of the assignment of patients into the clusters derived from the main model, the mean assignment accuracy was 0.941, ranging from 0.908 to 0.967; the mean Jaccard similarity coefficient was 0.882, ranging from 0.815 to 0.934 for assignment-generated clusters vs. independent k-means-generated clusters, except for two notable and reasonable differences as explained in the following: (i) A higher proportion of patients were assigned to MUO in Cohort-1B in comparison to Cohort-1A, which actually reflects the difference of patients’ severity of obesity in the two sub-cohorts. (ii) A higher proportion of patients were assigned to HMO-U in Cohort-2, which reflects the higher average UA in this cohort (Table 1). Similar results were also observed with the two-step clustering methods (Figure S2, Table S4).
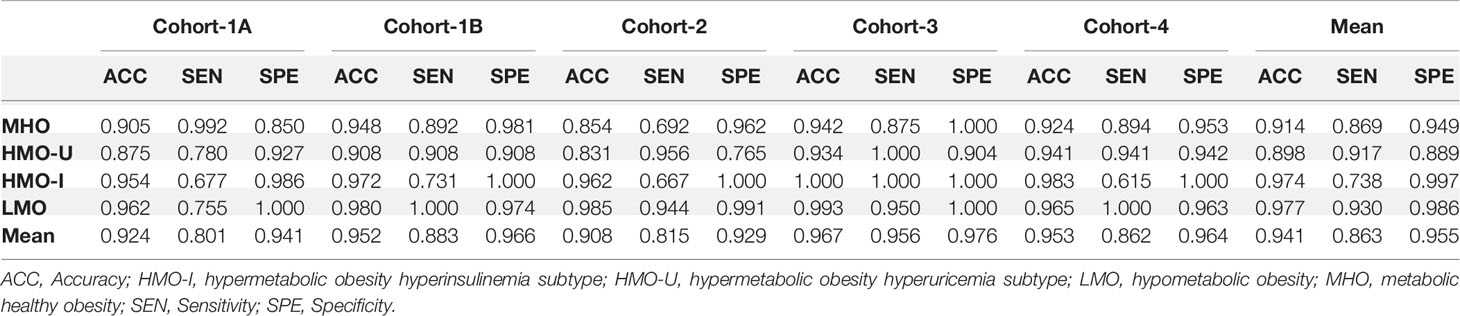
Table 3 Performance of assigning patients in each verification cohort to the four clusters generated by k-means on the main cohort, Cohort-1.
As shown in Table 4, HMO-I contained more male patients (67.6 vs. 41.2-48.5% in other three subgroups) and had the lowest age at onset of obesity (median: 13 vs. 16-20 years in other three subgroups), while LMO had the longest duration of obesity at visit (median: 12 vs. 8-9 years in other three subgroups). Patients in LMO presented the most severe central obesity with the highest percentage of fat mass deposited at the trunk (median trunk/limb fat mass ratio: 1.41 vs. 1.18-1.26 in other three subgroups; median trunk/leg fat percentage ratio: 1.24 vs. 1.10-1.18 in other three subgroups). Patients in HMO-I had the highest incidence of acanthosis nigricans (74.6 vs. 36.9-59.1% in other three subgroups).
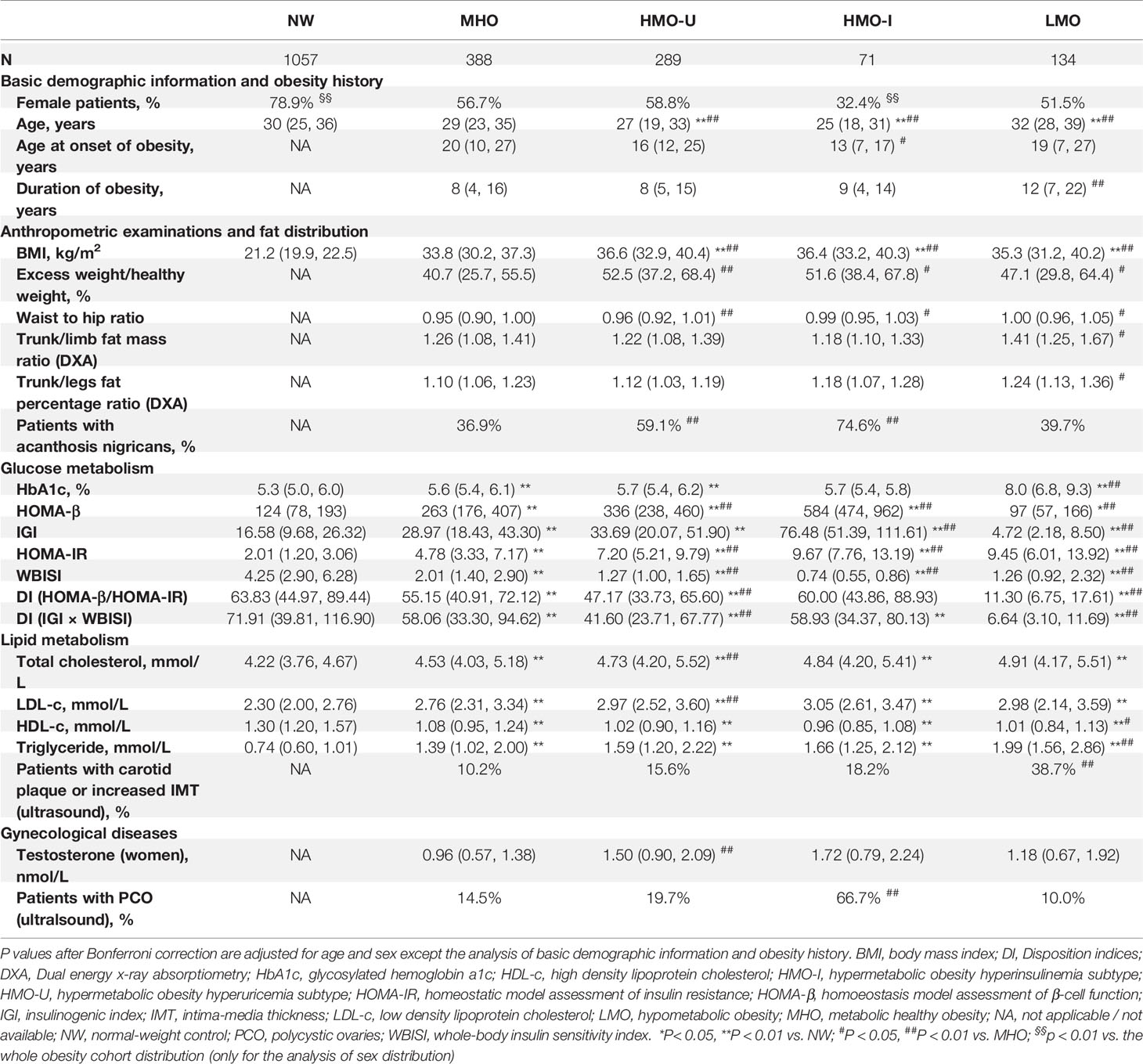
Table 4 Comparison of clinical variables across the four clusters generated from Cohort-1 using k-means and from the normal-weight controls.
As expected, patients in MHO showed a relatively healthy endocrinal and metabolic status in the four subgroups of obesity. Patients in HMO-I showed the worst hepatic and peripheral insulin sensitivity (median whole-body insulin sensitivity index [WBISI]: 0.74 vs. 1.26-2.01 in other three subgroups) and overcompensated insulin secretion (median insulinogenic index [IGI]: 76.5 vs. 4.7-33.7 in other three subgroups; median homoeostasis model assessment of β-cell [HOMA-β]: 583 vs. 97-336 in other three subgroups), which resulted in a balance and made the disposition index of glucose (DI) and glycosylated hemoglobin a1c (HbA1c) similar to MHO or even to normal-weight (median DI [IGI×WBISI]: 58.9 vs. 58.06 and 71.9 in MHO and normal-weight, respectively; median DI [HOMA-β/HOMA-IR]: 60.0 vs. 55.1 and 63.8 in MHO and normal-weight, respectively; median HbA1c: 5.7 vs. 5.6 and 5.3% in MHO and normal-weight, respectively). Patients in LMO also showed severe hepatic insulin resistance (median homeostatic model assessment of insulin resistance [HOMA-IR]: 9.45 vs. 4.78-9.67 in other three subgroups) but decompensated insulin secretion (median IGI: 4.7 vs. 28.9-76.5 in other three subgroups; median HOMA-β: 97 vs. 262-583 in other three subgroups), which resulted in the significantly decreased disposition ability of glucose (median DI [IGI×WBISI]: 6.6 vs. 41.6-58.9 in other three subgroups; median DI [HOMA-β/HOMA-IR]: 11.3 vs. 47.1-60.0 in other three subgroups) and increased HbA1c (median: 8.0 vs. 5.6-5.7% in other three subgroups). Meanwhile, LMO showed the most severe lipid metabolism (median triglyceride [TG]: 1.99 vs. 1.39-1.66 in other three subgroups of obesity), together with the highest incidence of carotid plaque and increased intima-media thickness (IMT) (38.7 vs. 10.2-18.2% in other three subgroups). In the examination of gonad disorders in women, patients in HMO-I showed a greater increased incidence of polycystic ovaries (PCO) examined by ultrasound (66.7 vs. 10.0-19.7% in other three subgroups). See Tables S5, S6 for more comparisons of data.
Comorbidity analyses were shown in Figure 4 and Table 5. Consistent with the metabolic examinations described above, patients in MHO showed a relatively low risk of comorbidities in the four subgroups of obesity. Patients in HMO-U and HMO-I showed a slightly increased risk of metabolic diseases compared to MHO, except for a significant increased risk of hyperuricemia (AOR 73.67 to MHO, 95%CI 35.46-153.06) and polycystic ovary syndrome (PCOS) (AOR 14.44 to MHO, 95%CI 1.75-118.99), respectively. Patients in LMO showed the worst metabolism with the highest risk of diabetes (AOR 105.85 to MHO, 95%CI 42.00-266.74) and metabolic syndrome (AOR 13.50 to MHO, 95%CI 7.34-24.83). The prognosis analyses of bariatric surgery patients were shown in Figure S4. The summary of the clinical characteristics and suggested treatments with respect to the four subgroups were shown in Table 6.
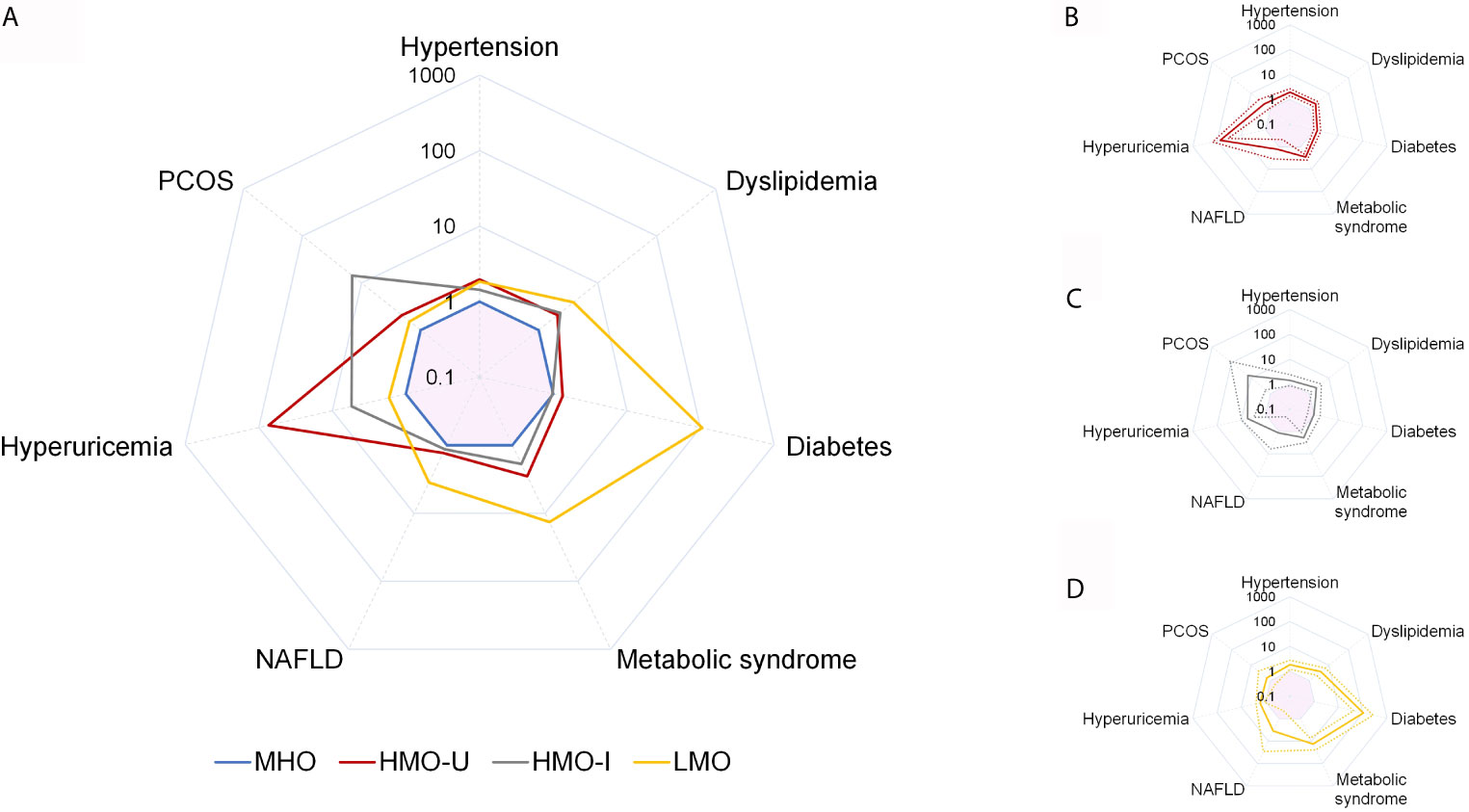
Figure 4 Comparison of adjusted odds ratio (AOR) for obesity comorbidities across the four clusters generated from Cohort-1 using k-means. Comparison of AOR across the four clusters (A), and AOR and 95%CI for HMO-U (B), HMO-I (C), and LMO (D). MHO is used as the reference category. Analyses are adjusted for sex and age. Values are shown as AOR (solid line) and/or 95%CI (dash line). Pink shadow in the center of each spider diagram is area for AOR < 1. HMO-I, hypermetabolic obesity hyperinsulinemia subtype; HMO-U, hypermetabolic obesity hyperuricemia subtype; LMO, hypometabolic obesity; MHO, metabolic healthy obesity; NAFLD, nonalcoholic fatty liver disease; PCOS, polycystic ovary syndrome.
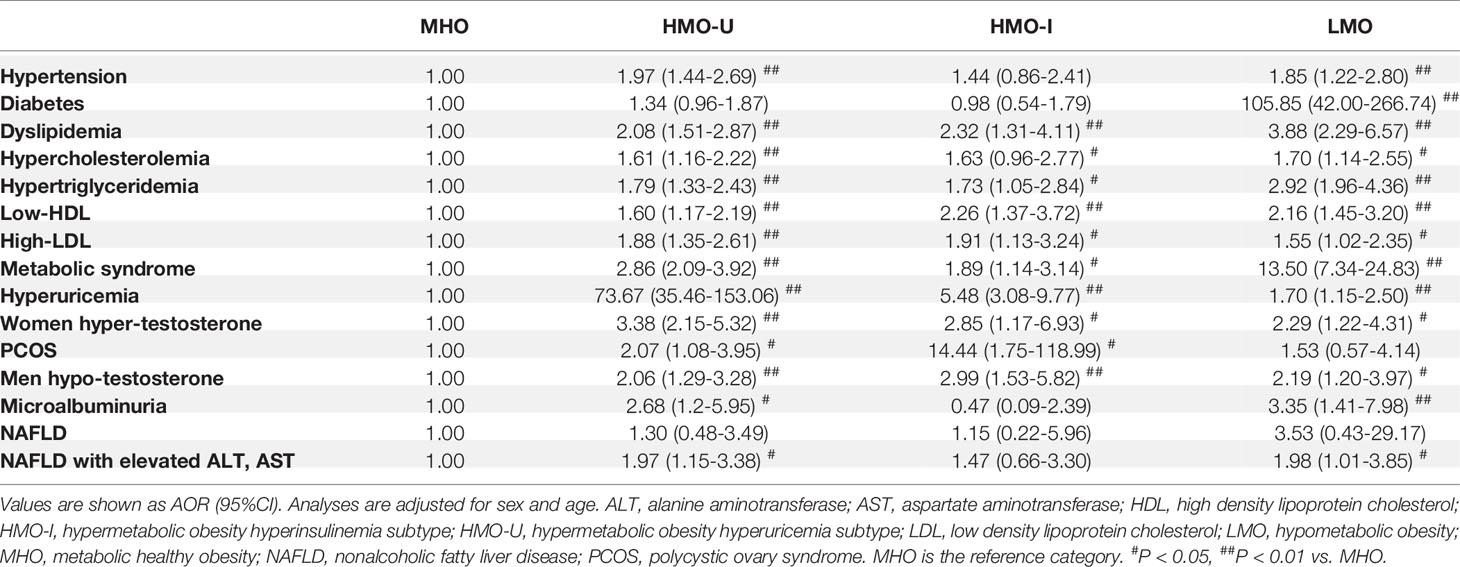
Table 5 The adjusted odds ratio (AOR) of comorbidities across the four clusters generated from Cohort-1 using k-means.
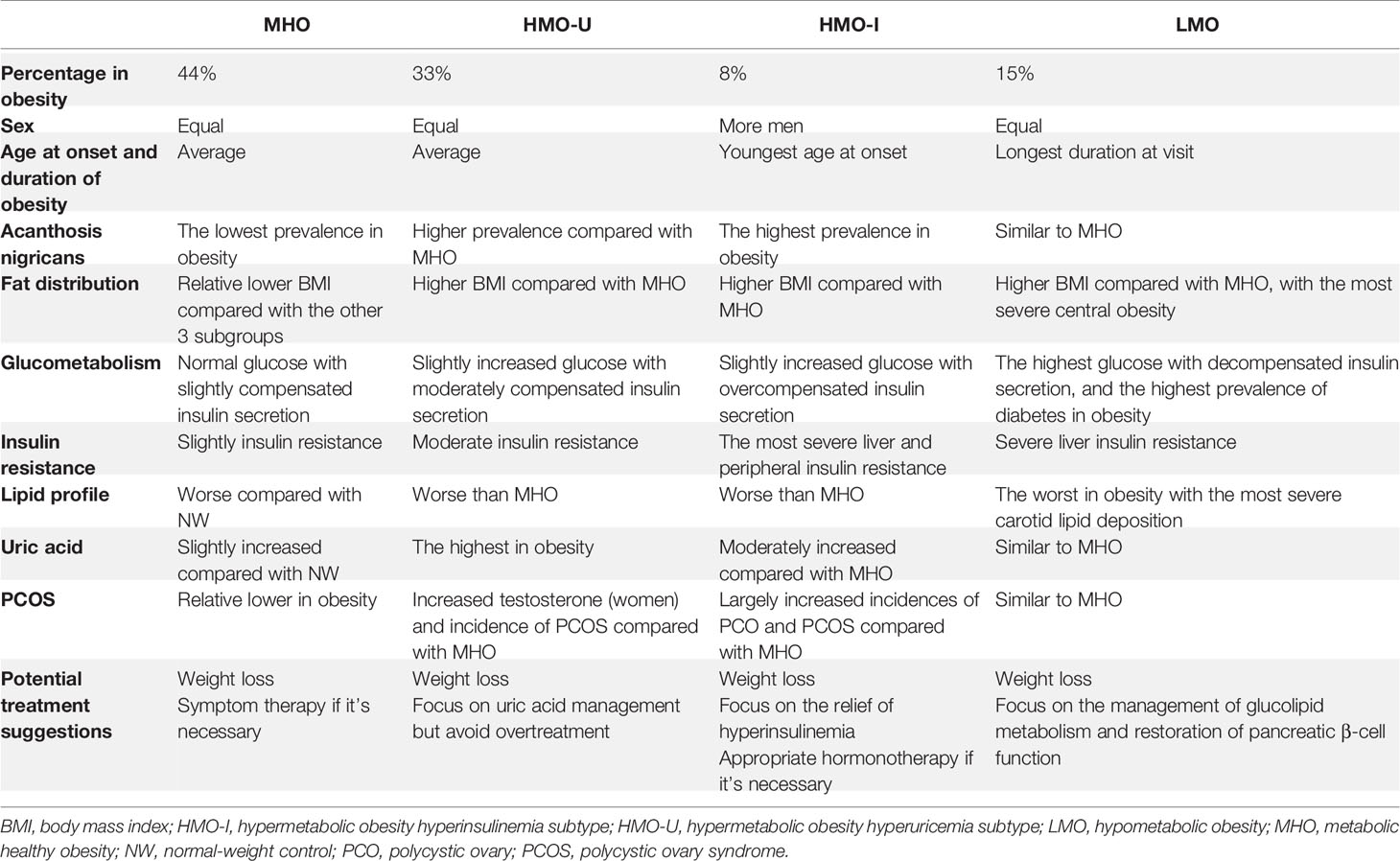
Table 6 Summarization of the patient characteristics in the four obesity subtypes.
We leveraged machine learning to identify a refined classification of patients with obesity from multiple hospitals. The classification yielded four metabolically distinct clusters (i.e., MHO, HMO-U, HMO-I, and LMO), which showed a high degree of agreement/reproducibility among the four independent cohorts. This multi-dimensional classification provides an enhanced capacity over traditional healthy/unhealthy obesity and BMI categorizations to reflect the complexity and heterogeneity of metabolic disorders, thereby having the potential to enable more precise preventions, diagnoses, and therapy planning. To the best of our knowledge, this is the first study to apply unsupervised machine learning to common clinical variables to refine metabolic classification of obesity in a multi-center setting.
The algorithms for unsupervised clustering of data are critical for a machine learning study. We used independently two mature algorithms, i.e., k-means and two-step, and observed highly similar classification results, indicating our data clustering is relatively robust. The assignment of patients in the verification cohorts to the main model led to high Jaccard similarity coefficients (range 0.815-0.934), indicating our classification effects are stable when tested on the multiple cohorts Jaccard similarity of greater than 0.750 is considered as a stable clustering (21).
We used three common clinical variables for classification. While this is a relatively large granularity for clustering, the three variables reflect important dimensions (i.e., metabolism, hormone, as well as inflammation and oxidation) in characterizing obesity progression and are critical in providing important interpretation of etiopathogenesis to guide therapies. Four obesity subgroups were yielded from the three variables, and our analyses have revealed clinical insights associated with each subgroup to help us better understand obesity and guide clinical treatment planning. If more clinical variables are used for classification, more refined clustering may be identified. While that we emphasize the importance of applicability and generalizability of an obesity classification model - more variables for classification could lead to overfitting and may reduce applicability on patients without complete clinical variables. This study using three variables showed promising generalizability and, in future work, further evaluation on a different number of clinical variables on substantially larger cohorts are warranted. In addition, our study used clinically routinely acquired variables for classifications, which can enable a broader utility of such classification models. It was different from previous studies that used lifestyle data (14, 16) or data acquired using specific research devices (e.g., hypothalamic blood flow, gastric empty rate, and energy expenditure) (15). The limited body of previous work (14–16) also did not consider the important information on metabolic abnormality.
The four subgroups in our study have important implications on treatments. MHO showed a relative healthy metabolic statues and hormone balance, where patients should be motivated to achieve a normal weight for long-term considerations, as risks of metabolic disorders are still higher than normal-weight subjects and may increase over time (22). In contrast, LMO showed the most severe central obesity due to the severe hepatic insulin resistance (23), decompensated insulin secretion, and resultant poor metabolism (diabetes, dyslipidemia, and carotid lipid deposition). These patients may be more vulnerable to atherosclerosis and cardiometabolic diseases (24). Suggested treatments may include management of glucolipid metabolism and restoration of pancreatic β-cell function. HMO-U showed the worst UA metabolism but still relatively healthy glucolipid metabolism. For these patients, UA regulation may be an effective therapy, but note that overtreatment may attenuate the benefits of antioxidation by UA (25). HMO-I showed the worst hepatic and peripheral insulin sensitivity but overcompensated insulin secretion, which to some extent balanced the glucolipid metabolism. Severe insulin resistance may have resulted in the highest incidence of acanthosis nigricans (26) and PCOS (27). Therapies may be directed to relieve hyperinsulinemia for these patients.
Our study has some limitations. First, all patients are of Chinese in China. The applicability of our classification models to patients of other ethnicities requires further evaluation. Second, since this is a multi-center retrospective study, there may be noticeable differences in measurements and lab tests across different institutions. Third, the data imputation for patients with missing OGTT time point data may have introduced inaccurate estimates, while consistent classification results have been observed when using the imputed data. Finally, we acknowledge that this is a proof-of-concept study of using machine learning to explore refined subtype classification of obesity. In future work, further analysis using pooled data of the multi-center cohorts with random data split for training and testing/verification may further evaluate the model’s performance. The more important research that we are planning to follow up is to validate the clinical value of the identified subtypes in a prospective setting, that is, to evaluate the treatment and adverse effects of both surgical and non-surgical therapies with respect to the four obesity subtypes. This study provides feasibility data and premises to design future clinical evaluation studies.
In summary, this multi-center retrospective study identified a refined classification of obesity subtypes by mining the clinical characteristics using a machine learning approach. The four subtypes appeared to be consistent across four independent patient cohorts. This proof-of-concept study provided evidence that precise diagnosis of obesity is feasible, which has a great potential to guide therapeutic planning and decisions for different subtypes of obesity. Prospective studies are warranted to further evaluate the findings of this study.
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
The studies involving human participants were reviewed and approved by The Ethical Committee of Shanghai Tenth People’s Hospital. The patients/participants provided their written informed consent to participate in this study.
SQ and SW jointly conceived the concept and supervised the study. ZL, WF, and YL performed data processing, variable selection, and data analysis. SW, DA, and LG contributed in analytical methods. XC, HY, DoZ, LD, DaZ, JY, JZ, and CM supervised, performed, and/or coordinated all data collection from the four participating hospitals and conducted data pre-processing. ZL, SW, SQ, and DA drafted the manuscript. All authors contributed to data and result interpretation. All authors contributed to the article and approved the submitted version.
This study was supported by National Key R&D Program of China (2018YFC1314100), National Natural Science Foundation of China (81970677), Shanghai Municipality: Shanghai Outstanding Academic Leaders Plan (049), National Natural Science Foundation of China for Youth (81500687), China Scholarship Council, Shanghai Medicine and Health Development Foundation (DMRFP_I_07), Fundamental Research Funds for the Central Universities of Tongji University (22120190210). Funding sources had no involvement in study design; in the collection, analysis, or interpretation of data; in the writing of the report; or in the decision to submit the paper for publication.
SW is a scientific consultant of COGNISTX, Inc. SW has a research grant funded by Amazon.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
We thank all patients included in this study. We thank the involved health-care providers and students for their support to this study. A half-page abstract of initial preliminary results of a subset study cohort was presented as a poster at the 80th Scientific Sections of American Diabetes Association (ADA) in June 2020.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fendo.2021.713592/full#supplementary-material
1. Purcell K, Sumithran P, Prendergast LA, Bouniu CJ, Delbridge E, Proietto J. The Effect of Rate of Weight Loss on Long-Term Weight Management: A Randomised Controlled Trial. Lancet Diabetes Endocrinol (2014) 2:954–62. doi: 10.1016/S2213-8587(14)70200-1
2. LeBlanc ES, Patnode CD, Webber EM, Redmond N, Rushkin M, O’Connor EA. Behavioral and Pharmacotherapy Weight Loss Interventions to Prevent Obesity-Related Morbidity and Mortality in Adults: Updated Evidence Report and Systematic Review for the US Preventive Services Task Force. JAMA (2018) 320:1172–91. doi: 10.1001/jama.2018.7777
3. Tobias DK, Chen M, Manson JE, Ludwig DS, Willett W, Hu FB. Effect of Low-Fat Diet Interventions Versus Other Diet Interventions on Long-Term Weight Change in Adults: A Systematic Review and Meta-Analysis. Lancet Diabetes Endocrinol (2015) 3:968–79. doi: 10.1016/S2213-8587(15)00367-8
4. Godino JG, Merchant G, Norman GJ, Donohue MC, Marshall SJ, Fowler JH, et al. Using Social and Mobile Tools for Weight Loss in Overweight and Obese Young Adults (Project SMART): A 2 Year, Parallel-Group, Randomised, Controlled Trial. Lancet Diabetes Endocrinol (2016) 4:747–55. doi: 10.1016/S2213-8587(16)30105-X
5. Lin Z, Qu S. Legend of Weight Loss: A Crosstalk Between the Bariatric Surgery and the Brain. Obes Surg (2020) 30:1988–2002. doi: 10.1007/s11695-020-04474-8
6. Consultation WE. Appropriate Body-Mass Index for Asian Populations and its Implications for Policy and Intervention Strategies. Lancet (2004) 363:157–63. doi: 10.1016/S0140-6736(03)15268-3
7. Stefan N, Häring H-U, Hu FB, Schulze MB. Metabolically Healthy Obesity: Epidemiology, Mechanisms, and Clinical Implications. Lancet Diabetes Endocrinol (2013) 1:152–62. doi: 10.1016/S2213-8587(13)70062-7
8. Global BMIMC, Di Angelantonio E, Bhupathiraju S, Wormser D, Gao P, Kaptoge S, et al. Body-Mass Index and All-Cause Mortality: Individual-Participant-Data Meta-Analysis of 239 Prospective Studies in Four Continents. Lancet (2016) 388:776–86. doi: 10.1016/S0140-6736(16)30175-1
9. Expert Panel on Detection, Evaluation, and Treatment of High Blood Cholesterol in Adults. Executive Summary of The Third Report of The National Cholesterol Education Program (NCEP) Expert Panel on Detection, Evaluation, And Treatment of High Blood Cholesterol In Adults (Adult Treatment Panel III). JAMA (2001) 285:2486–97. doi: 10.1001/jama.285.19.2486
10. Karelis AD, Rabasa-Lhoret R. Inclusion of C-Reactive Protein in the Identification of Metabolically Healthy But Obese (MHO) Individuals. Diabetes Metab (2008) 34:183–4. doi: 10.1016/j.diabet.2007.11.004
11. Rey-López JP, de Rezende LF, Pastor-Valero M, Tess BH. The Prevalence of Metabolically Healthy Obesity: A Systematic Review and Critical Evaluation of the Definitions Used. Obes Rev: An Off J Int Assoc Study Obes (2014) 15:781–90. doi: 10.1111/obr.12198
12. Frühbeck G, Kiortsis DN, Catalán V. Precision Medicine: Diagnosis and Management of Obesity. Lancet Diabetes Endocrinol (2018) 6:164–6. doi: 10.1016/S2213-8587(17)30312-1
13. DeGregory KW, Kuiper P, DeSilvio T, Pleuss JD, Miller R, Roginski JW, et al. A Review of Machine Learning in Obesity. Obes Rev: An Off J Int Assoc Study Obes (2018) 19:668–85. doi: 10.1111/obr.12667
14. Green M, Strong M, Razak F, Subramanian S, Relton C, Bissell P. Who are the Obese? A Cluster Analysis Exploring Subgroups of the Obese. J Public Health (2016) 38:258–64. doi: 10.1093/pubmed/fdv040
15. Acosta A, Camilleri M, Shin A, Vazquez-Roque MI, Iturrino J, Burton D, et al. Quantitative Gastrointestinal and Psychological Traits Associated With Obesity and Response to Weight-Loss Therapy. Gastroenterology (2015) 148:537–46.e534. doi: 10.1053/j.gastro.2014.11.020
16. Ogden LG, Stroebele N, Wyatt HR, Catenacci VA, Peters JC, Stuht J, et al. Cluster Analysis of the National Weight Control Registry to Identify Distinct Subgroups Maintaining Successful Weight Loss. Obes (Silver Spring) (2012) 20:2039–47. doi: 10.1038/oby.2012.79
17. Heymsfield SB, Wadden TA. Mechanisms, Pathophysiology, and Management of Obesity. New Engl J Med (2017) 376:254–66. doi: 10.1056/NEJMra1514009
18. Mechanick JI, Apovian C, Brethauer S, Timothy Garvey W, Joffe AM, Kim J, et al. Clinical Practice Guidelines for the Perioperative Nutrition, Metabolic, and Nonsurgical Support of Patients Undergoing Bariatric Procedures - 2019 Update: Cosponsored by American Association of Clinical Endocrinologists/American College of Endocrinology, The Obesity Society, American Society for Metabolic and Bariatric Surgery, Obesity Medicine Association, and American Society of Anesthesiologists. Obes (Silver Spring) (2020) 28(4). doi: 10.1002/oby.22719
19. Ahmad A. Dey L. A K-Mean Clustering Algorithm for Mixed Numeric and Categorical Data. Data Knowledge Engineer (2007) 63:503–27. doi: 10.1016/j.datak.2007.03.016
21. Jaccard P. The Distribution of the Flora in the Alpine Zone. 1. New Phytol (1912) 11:37–50. doi: 10.1111/j.1469-8137.1912.tb05611.x
22. Eckel N, Li Y, Kuxhaus O, Stefan N, Hu FB, Schulze MB. Transition From Metabolic Healthy to Unhealthy Phenotypes and Association With Cardiovascular Disease Risk Across BMI Categories in 90 257 Women (the Nurses’ Health Study): 30 Year Follow-Up From a Prospective Cohort Study. Lancet Diabetes Endocrinol (2018) 6:714–24. doi: 10.1016/S2213-8587(18)30137-2
23. Tchernof A, Després J-P. Pathophysiology of Human Visceral Obesity: An Update. Physiol Rev (2013) 93:359–404. doi: 10.1152/physrev.00033.2011
24. Neeland IJ, Ross R, Després J-P, Matsuzawa Y, Yamashita S, Shai I, et al. Visceral and Ectopic Fat, Atherosclerosis, and Cardiometabolic Disease: A Position Statement. Lancet Diabetes Endocrinol (2019) 7:715–25. doi: 10.1016/S2213-8587(19)30084-1
25. Álvarez-Lario B, Macarrón-Vicente J. Uric Acid and Evolution. Rheumatol (Oxford) (2010) 49:2010–5. doi: 10.1093/rheumatology/keq204
26. Sinha S, Schwartz RA. Juvenile Acanthosis Nigricans. J Am Acad Dermatol (2007) 57:502–8. doi: 10.1016/j.jaad.2006.08.016
Keywords: obesity, metabolism, insulin, uric acid, machine learning, clustering
Citation: Lin Z, Feng W, Liu Y, Ma C, Arefan D, Zhou D, Cheng X, Yu J, Gao L, Du L, You H, Zhu J, Zhu D, Wu S and Qu S (2021) Machine Learning to Identify Metabolic Subtypes of Obesity: A Multi-Center Study. Front. Endocrinol. 12:713592. doi: 10.3389/fendo.2021.713592
Received: 23 May 2021; Accepted: 25 June 2021;
Published: 14 July 2021.
Edited by:
Li Ming Wen, The University of Sydney, AustraliaReviewed by:
Yue Zhao, Peking University Third Hospital, ChinaCopyright © 2021 Lin, Feng, Liu, Ma, Arefan, Zhou, Cheng, Yu, Gao, Du, You, Zhu, Zhu, Wu and Qu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Shandong Wu, d3VzM0B1cG1jLmVkdQ==; Shen Qu, cXVzaGVuY25AaG90bWFpbC5jb20=
†These authors have contributed equally to this work and share first authorship
‡These authors share senior authorship
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.