 Matthew N. George
Matthew N. George Karla F. Leavens
Karla F. Leavens Paul Gadue
Paul Gadue
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Endocrinol. , 02 June 2021
Sec. Diabetes: Molecular Mechanisms
Volume 12 - 2021 | https://doi.org/10.3389/fendo.2021.682625
This article is part of the Research Topic Advances in Stem Cell Technology to Model and Treat Diabetes View all 13 articles
A mechanistic understanding of the genetic basis of complex diseases such as diabetes mellitus remain elusive due in large part to the activity of genetic disease modifiers that impact the penetrance and/or presentation of disease phenotypes. In the face of such complexity, rare forms of diabetes that result from single-gene mutations (monogenic diabetes) can be used to model the contribution of individual genetic factors to pancreatic β-cell dysfunction and the breakdown of glucose homeostasis. Here we review the contribution of protein coding and non-protein coding genetic disease modifiers to the pathogenesis of diabetes subtypes, as well as how recent technological advances in the generation, differentiation, and genome editing of human pluripotent stem cells (hPSC) enable the development of cell-based disease models. Finally, we describe a disease modifier discovery platform that utilizes these technologies to identify novel genetic modifiers using induced pluripotent stem cells (iPSC) derived from patients with monogenic diabetes caused by heterozygous mutations.
Diabetes mellitus is a worldwide healthcare problem that is rapidly increasing in prevalence. In the United States alone, over 10% of the population is affected, with approximately 1.5 million Americans newly diagnosed with diabetes each year (1). Particularly troubling is the dramatic increase in the incidence of diabetes in children, the consequences of which are expected to lead to increased complications and comorbidity as adults (2, 3). With obesity rates projected to increase in the United States over the upcoming decades, there is little chance that the trend of increasing diabetes prevalence will reverse itself (4). In addition to decreasing quality of life, diabetes is associated with significant morbidity and mortality, including retinopathy, neuropathy, cardiovascular and kidney disease (5). Diabetes also puts individuals at risk of having more complicated courses of common illnesses, with recent studies documenting increased morbidity and mortality in patients with diabetes who contracted COVID-19 (6–8).
Though often referred to as a single condition, diabetes is likely many overlapping diseases, with most stemming from pancreatic β-cell dysfunction and the disruption of glucose homeostasis due to abnormal insulin secretion and/or responsiveness (9). The two most common forms of diabetes, type I (T1D) and type II (T2D), are associated with the eventual loss of insulin-secreting pancreatic β-cells, which can occur either early (T1D) or late (T2D) in disease progression. In the case of T1D, autoimmune destruction results in β-cell death and subsequent insulinopenia, although there is increasing support for the role of β-cell stress in T1D onset (10, 11); T2D is characterized by a combination of peripheral insulin resistance and inadequate β-cell compensation, resulting in a metabolic syndrome that leads to eventual β-cell exhaustion and loss of β-cell mass (12, 13). T1D and T2D display a multifactorial etiology on both a population and individual level, likely motivated by a complex combination of genetic, epigenetic, and environmental factors (14). Furthermore, there is substantial heterogeneity within the underlying β-cell pathophysiology of each of these disorders (9).
Apart from the two major types, there are also 14 known types of monogenic diabetes, historically called MODYs (mature onset diabetes of the young), which are caused by single gene mutations that result in β-cell dysfunction (15–18). Monogenic diabetes is typically underrecognized and underdiagnosed, with identified subtypes likely making up 2-5% of all diabetes cases while additional causative genes undoubtably remain to be discovered (17). To complicate matters further, a number of MODY genes have been associated with the development of T1D and T2D (19–21), suggesting that the pathophysiology of the diabetes subtypes can often overlap. For example, there are additional genes that can cause neonatal diabetes through downstream impacts on pancreatic development, such as GATA6 and NKX2.2, which are not traditionally included as MODYs, although overlap in disease pathology occurs depending on the timing of their presentation (22). There are also numerous monogenic syndromes that have diabetes as a component in all or some affected individuals, including cystic fibrosis and Friedreich’s ataxia. While the underlying pathogenesis of monogenic and neonatal diabetes predominantly involves intrinsic defects of the β-cell, syndrome-associated forms of diabetes may result from both peripheral and β-cell defects, with the latter being understudied in many cases (15, 16). Better studies of all forms of diabetes are necessary to understanding the underlying pathophysiology of this complex disease.
For decades, studies using mouse models greatly advanced our knowledge of diabetes (23). Mice are inexpensive relative to larger animal models (i.e., non-human primates), recapitulate human disease more closely than more basal organismal models, and were genetically-manipulatable even before the invention of modern genome editing techniques. As a result, mouse models continue to be incredibly valuable for the study of whole-body physiology, capable of providing complex metabolic readouts of multiorgan systems, as is the case in oral glucose tolerance tests and hyperinsulinemic euglycemic clamp studies. However, while mouse models play an essential role in the study of diabetes, important differences in rodent versus human physiology have sometimes limited the translatability of rodent datasets to the complex presentation of the human diabetes subtypes. Therefore, the development of in vitro human β-cell models will provide an important adjunct to in vivo rodent models in the study of diabetes.
While a variety of T1D and T2D mouse models exist, none have been able to comprehensively mimic human diabetes (23–25). For T1D, both genetic and chemically-induced models are used, with the latter resulting in β-cell destruction and insulinopenia, but neither method allowing for the study of the autoimmune processes that drive disease pathophysiology (24, 25). Even mouse models with an autoimmune component do not exactly resemble T1D due to interspecies differences, including well described mechanisms for the regulation of immune cell activation, homing, and target cell interactions (26). As a result, diabetes manifests differently in the two species: for example, the commonly-used non-obese diabetic (NOD) mouse strain exhibits pronounced insulitis and rapid β-cell destruction, while β-cell loss in human T1D is associated with gradual and milder infiltration of islets (27). In the case of T2D, there are a myriad of diet-induced obesity and genetic models that can be used (23, 25). However, the complex polygenic nature of human obesity can be difficult to model using inbred mice strains, and observed effects of sex, age, and epigenetic factors on diet-induced obesity may not be the same between species, though these differences may provide some insight into genetic loci that result in phenotypic variation (23).
While mouse models have yielded significant insights into monogenic causes of diabetes, they do not always fully recapitulate the human disease. One example involves GATA6 and GATA4, members of the GATA family of transcription factors, which are the most highly expressed isoforms in the pancreas. Heterozygous, largely de novo, mutations in GATA6 are the most common cause of pancreatic agenesis, resulting in neonatal diabetes as described by multiple groups (28–37). Though less common, GATA4 haploinsufficiency can also result in neonatal and early childhood-onset diabetes (38, 39). However, in mice, GATA4 and GATA6 appear to be completely redundant isoforms, as the loss of a single allele of either GATA4 or GATA6 does not appear to impact pancreatic development or glucose homeostasis, and the loss of three of the four Gata4/6 alleles is needed to recapitulate the human phenotype (40, 41). Another example is the most common form of monogenic diabetes, MODY3, caused by heterozygous mutations in the transcription factor HNF1α. Mice with heterozygous mutations in HNF1A are healthy (42) and mice with HNF1A null mutations can have a diabetic phenotype, but with significant variability dependent on genetic background (43). These results suggest that there are complex, human-specific genome-phenotype interactions that must be additionally investigated using human models. Therefore, the combined and complementary use of both in vitro human β-cell models and in vivo rodent models will greatly advance our knowledge of the pathophysiology of diabetes.
While mouse models have and certainly will continue to advance our knowledge of diabetes, β-cell-centric research in diabetes has unfortunately been hindered by the lack of human models. Most immortalized β-cell lines are rodent-derived, though several human lines, including the EndoC-βH1 (and subsequent βH2 and βH3) line, are becoming more widely used (44, 45). However, β-cell lines can exhibit differences from in vivo human β-cells due to their immortalized status, can be difficult to genetically manipulate, and cannot be used to study β-cell development. While the use of cadaveric human islets in research has greatly expanded due to the success of programs such as the Network for Pancreatic Organ Donors with Diabetes (https://www.jdrfnpod.org) and the Integrated Islet Distribution Program (https://iidp.coh.org), these resources unfortunately remain scarce and precocious. Furthermore, the genetic, epigenetic, and environmental characteristics of donors are largely unknown, while islets themselves cannot be genetically manipulated efficiently.
To address these limitations, great strides have been made over the last two decades in the development of human pluripotent stem cells (hPSC), a term which includes both embryonic stem cells (ESC) and induced pluripotent stem cells (iPSC) [reviewed in (46, 47)]. Efficient methods for the production of hPSCs have completely changed the face of biomedical research and have opened new avenues of therapeutic development for a multitude of diseases. The subsequent development of techniques to differentiate hPSCs into pancreatic β-cells have enormous potential to contribute to the study of diabetes. Built upon foundational research within mouse developmental biology [reviewed in (48)], modern techniques of stem cell differentiation leverage known inductive signals that drive development in vivo by replicating these signals temporally and spatially to drive development in vitro [reviewed in (49)]. The first lab-guided hPSC differentiation protocols were developed to generate definitive endoderm (50), followed quickly by protocols capable of driving hPSCs towards pancreatic progenitors and endocrine cells (51). While these protocols initially required that pancreatic progenitors be transplanted into mice to mature into functional β-cells, current protocols can achieve functionality in vitro without transplantation (52–54) This field has become robust with technical advancements being published regularly by laboratories around the world, resulting in the generation of β-like cells that are closer and closer to their natural counterparts, though continued optimization of functionality is required (55–62).
With advances in directed in vitro differentiation, stem cell-derived β-cells provide a tremendous opportunity to study pancreatic development and endocrine diseases in a human model system, particularly when combined with recent advances in genome editing technology. Using clustered regularly interspaced short palindromic repeats (CRISPR)-Cas9 technology (63, 64) (see Section 2), targeted mutations in hESC lines can be made, generating mutant and control isogenic lines that avoid confounding results due to differing genetic backgrounds. In addition, iPSCs can be generated from reprogramed patient donor blood or skin fibroblasts (46, 47), resulting in a unique platform within which to study the specific contribution of single mutations to β-cell development and/or function. While these systems certainly have caveats, including expense, labor-intensiveness, and lab-to-lab variability, the expanding use of stem cell-derived β-cells stands to drive our knowledge of diabetes pathophysiology forward beyond the prior limitations of mouse and cell line models. In this review, we will review the current methods of genome editing in hPSCs, discuss how this can be applied to the evaluation of candidate genes in the study of diabetes, and examine the use of stem cell-derived β-cells as a platform for the identification of novel genetic modifiers of diabetes.
The development of genome editing technologies capable of selectively targeting sites within the human genome has revolutionized our ability to investigate the genetic underpinnings of disease. In the case of diabetes, ESCs and patient-derived iPSCs from multiple genetic backgrounds can now be genetically edited and paired with lab-guided differentiation protocols to build powerful and scalable cell-based models of multiple diabetes subtypes (65, 66). Genome modifications in each system are achieved through nuclease localization with a target sequence, the induction of a double stranded DNA break (DSB), and the activation of endogenous cellular DNA repair mechanisms such as homologous recombination (HR) and non-homologous end-joining (NHEJ) (67, 68). Several types of gene modification can be accomplished through these mechanisms, including (1) ‘gene disruption’ through the addition/subtraction of short nucleotide sequences and frame shift mutation induction (2), ‘gene correction’ through targeted base substitutions that restore gene function using a homologous donor DNA construct as a template, and (3) ‘gene addition’ through the introduction of a complete transgene into a specific locus. Here we briefly review several of the most popular methods for the selective editing of hPSCs, each of which exhibit advantages and disadvantages when editing specific cell types (69).
Zinc finger nuclease (ZFN) and transcription activator-like effector nuclease (TALEN) are structurally similar in that they both rely on the C-terminal FokI endonuclease domain to generate DSBs within a targeted sequence (70–72). ZFN architecture combines multiple zinc finger protein DNA-binding domains (motifs) (73) with the nuclease domain of the FokI restriction enzyme that performs optimally when targeting long (12-18 bp) and unique sequences within the eukaryotic genome (74). In contrast, TALENs employ multiple transcription activator-like effector (TALE) DNA binding domains – a class of proteins isolated from the Xanthomonas bacteria that have evolved to alter the transcription of host plants (75). In either case, the two distinct regions of the nuclease each perform a unique function, with zinc finger motifs or TALEs binding to DNA while the FokI nuclease domain induces a DSB within a target sequence upon dimerization (76, 77).
While structurally similar, there are distinct advantages and disadvantages of each system. Typically, ZFN-based platforms afford greater flexibility in targeting, while also allowing for independent optimization of the two subunits for simplified retargeting (78). Drawbacks of ZFNs include the cost of application, a suite of complex design constraints that must account for context-dependent interactions between fingers (79), and a higher prevalence off-target effects and translocations than other methods (80). In contrast, the highly conserved stretches of 33-35 amino acids (AA) that TALEN-based approaches employ addresses many of the design complexity concerns of ZFNs, while maintaining high cleavage activity rates, a broad targeting range specificity, and improved cytotoxicity (81). However, TALEN-based approaches have been shown to produce off-target effects and suffer from dramatically lower efficiencies when targeting sequences that are methylated or do not include thymidine (82, 83). Comprehensive reviews that provide specific recommendations for the design and reproducible integration of ZFN (78, 84) and TALEN-based (85) genome editing approaching in hESCs and iPSCs are available elsewhere.
(CRISPR)/Cas-based gene editing platforms have become incredibly popular tools to modify the genome of hPSCs since the introduction of the technology in 2012 (86). Based on the adaptive immune system of bacteria and archaea, CRISPR was made possible by the discovery of DNA fragments within the E. coli genome from past viral and bacteriophage invaders known as clustered regularly interspaced short palindromic repeats (CRISPRs). Unlike ZFNs and TALENs which use proteins, CRISPR loci are transcribed during viral infections to produce an RNA-guided DNA endonuclease that selectively binds and cuts invading viral DNA (87). CRISPR sequences exhibit a repetitive pattern, wherein short DNA sequences (24-48 bp) are followed by their reverse complement and a protospacer that matches part of the viral genome. Through coordination with RNase III, CRISPR-associated (Cas) proteins, and trans-activating CRISPR RNA (tracrRNA), long RNA transcribed from CRISPR loci are cleaved into short, spacer-derived RNA (crRNA) (88). TracrRNA and crRNA then act together to guide the Cas9 protein to a target cut site located within the genome of an invading virus, causing a DSB [for a review, see (89)].
When used in genome-editing platforms, tracrRNA and crRNA can now be combined into a single “guide RNA” (gRNA) molecule (86) and administered with the Cas9 protein to selectively cut target DNA sequences (90). Multiple CRISPR/Cas9 systems have been developed specifically for hPSCs that are capable of editing or replacing genome sequences (91, 92) and are quickly replacing TALEN-based systems due to their ease of generation, efficiency, and cytocompatibility (93, 94). Drawbacks of CRISPR-based methods include the re-cutting of target regions after DSB repair and the prevalence of erroneous insertion or deletions (indels) on the non-targeted allele, making the generation of single allele edits difficult. Recent protocols, including one from our laboratory (95), address these issues through the use of two single stranded oligonucleotide repair templates, with one expressing the desired sequence change and the other maintaining the normal sequence. These repair templates also contain silent mutations that prevent gRNA recognition and re-cutting, facilitating the selective editing of a single allele with an average efficiency of close to 10%. In addition, off target cutting of CRISPR/Cas9 at other sites in the genome is also an issue but it can be mitigated. First, in the hPSC system, off target cutting is less prevalent than in somatic cells, mostly likely due to the fact the pluripotent stem cells are very sensitive to DNA damage and cells that have undergone multiple DNA cuts are less likely to survive (96). Second, careful design and testing of potential off target sites can also be used to minimize the impact of off target cutting. Overall, genome editing technologies in hPSCs are advancing to the stage where virtually all coding mutations can be repaired or introduced in a single allele manner, an important advance given the majority of monogenic genetic diseases of the pancreas are caused by heterozygous mutations.
The availability of standardized laboratory protocols for the generation of glucose responsive β-cells from hPSCs that have undergone selective genome editing has the potential to dramatically increase our knowledge of genes that contribute to diabetes. Traditionally, the functional contribution of genes to disease states has come from the deletion or mutation of a single gene target. The use of candidate genes, chosen as they are known clinically to cause disease, has been employed for the study of monogenic diabetes. However, given the increasing ease of genome and exome sequencing, comparisons of genetic variants between diabetic and non-diabetic populations through GWAS analysis using genome sequencing has generated a large list of variants associated with all forms of diabetes, most of which are in non-coding regions of the genome (97–100). Newly developed stem cell platforms can be used to target these variants, initially by targeted mutation of the gene thought to be regulated by a given variant (101). The direct targeting of a non-coding variant has been studied in neonatal diabetes caused by GATA6 (102), and similar approaches could also be used for variants associated with more common causes of diabetes. Care will need to be taken as it is possible that most non-coding variants may have a small impact on gene expression and disease penetrance on their own. While we are still in the early stages of utilizing these approaches in stem cell-derived β-cells to interrogate the roles of specific genes in β-cell development and function, we predict that this will become more commonplace and contribute to our understanding of β-cell physiology and disease.
There are dozens of types of diabetes caused by single gene mutations, including monogenic, neonatal and syndrome-associated diabetes (15–17, 103–105). Monogenic forms of diabetes are often caused by heterozygous coding mutations within genes that influence β-cell function [reviewed in (106)]. Many forms of monogenic diabetes have been recognized for decades and more gene causes are likely to be found in the upcoming years with the increasing use of exome and genome sequencing (17, 18). In addition, many of the genes associated with monogenic diabetes have numerous reported mutations with potentially different consequences on protein function and therefore on β-cell dysfunction (107–109). Stem cell-derived β-cells may provide a platform in which to investigate some of these polymorphisms, and may help to provide some insight into genotype-phenotype correlations.
The modeling of monogenic diabetes using stem cell-derived β-cells has been extensively described. To date, hPSC lines have been made with mutations in HNF1A (110–114), HNF1B (112, 115, 116), HNF4A (112, 117–119), PDX1 (107, 120, 121), KCNJ11 (122), GCK (112), and CEL (112). Of the studies listed, only two used genome-editing to make mutant hESC lines (113, 121), with the remainder generating patient-derived iPSC lines. While some studies simply described the derivation of iPSC lines from patient samples, most publications included lab-guided differentiations to β-cells and subsequent studies on β-cell gene expression and biology (111, 113–115, 117–119, 121).
MODY3, caused by heterozygous mutations in the transcription factor HNF1α, is the most common form of monogenic diabetes (15, 103) and is currently the most extensively-researched monogenic form of diabetes using stem cell-derived β-cells. HNF1α has been of particular interest because of its additional association with T1D and T2D in several large population studies (19–21, 123). Several studies on the role of HNF1A has been performed in mice, but mouse models with heterozygous deletion of HNF1A do not have diabetes and thus have provided limited insight into MODY3 (124). To date, three publications from different groups have modeled HNF1A-deficiency in stem cell derived β-cells, with two employing patient-derived iPSC lines (111, 114) and the other using hESC lines (113). These studies have yielded significant insights into the complex role HNF1α plays in controlling β-cell development, metabolism and function and have discovered new downstream targets of this transcription factor that had not previously been identified in mouse studies.
While the underlying pathogenesis of monogenic diabetes results from intrinsic β-cell defects, the role of β-cell dysfunction in many syndrome-associated forms of diabetes, such as cystic fibrosis (CF)-related diabetes, is largely unknown (105). There is significant interest in these fields to generate syndrome-related iPSC lines for use in multiple areas, but this will ultimately aid in the study of rare causes of diabetes by providing accessible resource lines. Groups have already generated stem cell derived β-cells to model β-cell dysfunction in Wolfram syndrome (125, 126) and Friedreich’s ataxia (127). In addition, CF iPSC lines have been made and differentiated in the pancreatic ductal endothelium to study the effects of CF-related pancreatic exocrine function (128). These lines and others generated for non-diabetes study can always be used to produce stem cell derived β-cells and advance our knowledge of these understudied forms of diabetes.
Another avenue of study using stem cell derived β-cells as a model is to focus on genes that are thought to play a role in β-cell development, identity, or function but that may not have been described as monogenic causes of disease. In an impressive paper by Zhu and colleagues, researchers used genome editing to generate hPSCs knockout lines to further probe the role of 8 known pancreatic transcription factors, including PDX1, RFX6, PTF1A, GLIS3, MNX1, NGN3, HES1 and ARX (121). Many of these factors had only been studied previously in rodent models and, through lab-directed differentiation, their role in human β-cell development and function could be interrogated for the first time. This reverse candidate approach using stem cell derived β-cells will provide a significant basis for future advances.
As genome editing techniques improve and become more well-established, the field is turning more to the use of isogenic lines in which to study the contribution of a specific genes on β-cell physiology. This involves making targeted mutations in hESC lines or correcting mutations in patient-derived iPSC lines, generating mutant and control isogenic lines that avoid confounding results due to differing genetic backgrounds. In all studies above using patient-derived iPSC lines to study monogenic diabetes, the mutant stem cell-derived β-cells were compared to unaffected family members or unrelated wild type iPSC lines and not isogenic controls (111, 114, 115, 117–119). With the increasing use of CRISPR/Cas9 technology, we advocate the use of at least 2 pairs of isogenic lines, examining a single clone for each, for interrogating the impact of a given genome alteration. Alternatively, if using a single stem cell line, the examination of several genome edited clones has been suggested by leading stem cell journals such as Stem Cell Reports (Information for authors). We would argue that 2 isogenic pairs is superior because it controls for both artifact due to an acquired mutation in a single genome edited clone as well as confirm any phenotype is general enough to be seen in 2 independent genetic backgrounds. The use of a single edited clone per isogenic pair we feel is a good tradeoff between the effort required to differentiate and analyze these clones while still minimizing the impacts of clonal artifacts.
The cause of T1D and T2D is likely a complex combination of genetic, epigenetic and environmental factors (14). In addition, there is substantial heterogeneity within each of these disorders, so that the disease-causing combination in each affected individual is slightly different (9). Therefore, a single gene-to-disease strategy is not always effective in the study of T1D and T2D. Technological advancements in next generation sequencing, combined with the targeted efforts of several consortia, continue to expand the size and scope of available genomic datasets from diabetic patients (129–131). Previously, the identification of diabetes-linked genes was the product of quantitative trait mapping (QTL), obtained through the cross of genetically engineered mice (132–134). Over the past decade as the cost and availability of sequencing technology has improved, GWAS have identified more than 60 loci for T1D (135) and more than 240 associated with T2D (136), with the hereditability of each now explaining approximately 15% (137) and 25-80% (138) of the disease-risk for each subtype, respectively.
The explosion of available GWAS datasets for both T1D and T2D can be leveraged by using stem cell derived β-cells. Using this technique, novel genes that are revealed by GWAS, individual exome, or genome sequencing associated with diabetic populations can be targeted for study either in isolation or as part of co-cultures where interactions between adipocytes, immune cells, critical biological components and β-cells are replicated in vitro (139–141). Through the use of stem cell derived β-cells, these systems can ascertain whether a specific locus causes β-cell-intrinsic dysfunction, while also probing the contributions of the surrounding environment. For example, polymorphisms in the human leukocyte antigen (HLA) DR and DQ alleles increase T1D-risk by altering T-cell binding [reviewed in (142)], which is predictably a β-cell-extrinsic effect that can be observed in cell culture studies. Alternatively, some polymorphisms in the insulin (INS) gene, a β-cell-specific gene, have been described to influence T1D risk due to changing insulin mRNA production in the thymus altering immune tolerance (143, 144). However, other mutations in INS lead to neonatal diabetes, thought to be caused by β-cell death due to increased cell stress from misfolded insulin protein [reviewed in (145)]. While the difference between polymorphisms and mutations may be determined by their prevalence in the population, modeling these gene differences in stem cell derived β-cells may prove useful for understanding their significance.
While GWAS studies can yield a potential target gene which could be directly involved in disease, sometimes they identify an associated region of unclear significance. GWAS comparing the islets of diabetic and non-diabetic individuals suggest that most T2D-associated variants do not reside in coding regions (146, 147). In order to understand the role of these variants, iPSC banks from T1D, T2D and non-diabetic patients can be used to probe these differences on a multigene scale. Multiple iPSCs from T1D and T2D patients have been made (148–151), and there are consortia and foundations that are focused on making larger banks of available diabetes and non-diabetes iPSC lines, including the Human Islet Research Network (HIRN, https://hirnetwork.org/hpap-overview) and the New York Stem Cell Foundation (NYSCF, https://nyscf.org/research-institute/repository-stem-cell-search/). Several groups have also recently performed lab-directed differentiations on patient-derived iPSC lines to generate stem cell derived β-cells to examine broad molecular and functional differences (150, 151). Unlike the need for the generation of isogenic lines in the study of monogenic diabetes, making banks of T1D, T2D, and non-diabetic stem cell derived β-cells can be used to study many factors contributing to β-cell pathophysiology in diabetes. One caveat of the use of non-isogeneic lines is that differences in genetic background amongst disease and control lines leads to tremendous variability in phenotype and necessitates large sample numbers to dissect the underlying biology.
The way genetic factors interact with disease can be highly variable. Even in canonical examples of monogenic Mendelian diseases such as cystic fibrosis and sickle-cell anemia where a disease endophenotype is linked to a single mutation (152), fraternal twins that reside within the same household can present vastly discordant phenotypes (153). The results of longitudinal twin studies add to a growing body of clinical evidence that underscores the importance of ‘disease modifiers’ that alter the penetrance, expressivity, rate of progression, and/or presence of disease endophenotypes through the modification of disease-linked genes (154, 155). While the terminology used to describe the mechanisms of oligogenic inheritance continues to evolve, for the purposes of this review we have chosen to classify genetic disease modifiers within two groups based on their mode of action, or as either ‘protein coding’ or ‘non-protein coding’.
Protein coding disease modifiers typically affect the phenotypic expression of a disease through mutations in the coding sequence of intact genes, leading to changes in protein function (156). These changes can be either sufficient to elicit a diseased state (i.e., a frame shift mutation within a coding sequence of an important functional protein), or can affect the molecular expression of other disease-linked genes through alterations in regulatory DNA such as promoters and enhancers (e.g. modifier genes) (157). In contrast, non-protein coding disease modifiers include non-coding regulatory elements and non-coding RNAs (ncRNA) (158). In either case, disease modifiers can act to either enhance, silence, or modify the expression of genes that can modify the activity of important proteins whose dysregulation result in changes in the penetrance, expressivity, and/or presence of a disease endophenotype.
Diabetes is a complex disease wherein patients express significant heterogeneity in the progression, clinical phenotype, and response to treatment. T1D and T2D show clear evidence of a genetic component and familial reoccurrence (159, 160), with observed associations with lifestyle, obesity, and cancer playing a particularly significant role in T2D (161). In the face of this variability, it is important to note that the direct influence of specific mutations within protein-coding regions on the etiology of diabetes have been described (162, 163). However, while allelic variants have been shown to confer an increased risk of T1D/T2D, other subtypes of diabetes, such as monogenic diabetes, are causally linked to single mutations, as described above. Apart from changes in coding sequences, there is substantial evidence that disease progression and severity of all forms of diabetes results from the interaction of multiple non-coding genetic, epigenetic, and environmental factors, which act in concert to cause β-cell dysregulation and islet dysfunction (164, 165).
The influence of protein coding and non-protein coding disease modifiers on each of the diabetes subtypes remain active areas of research. In the case of monogenic diabetes, modifier genes have been shown to explain some degree of clinical variability (166), while several studies suggest that non-coding disease modifiers influence the development of gestational diabetes (167, 168). In this section, we provide a brief overview of the two classes of disease modifiers, discussing known associations with the diabetes subtypes when available. To facilitate the further discovery of such mechanisms, we then outline a disease modifier discovery platform that leverages recent advancements in RNA sequencing, genome editing, and laboratory-guided stem cell differentiation to identify genetic disease modifiers of genetic disease caused by heterozygous mutations, using monogenic diabetes as a model. Given the limited availability of research on this topic, it is our hope that the platform outlined here will support the discovery of novel protein coding and non-protein coding disease modifiers that can help explain the heterogeneity observed in diabetes subtypes.
The influence of modifier genes and allelic heterogeneity on human disorders has been the subject of an ongoing discussion within medicine for over a century (169), with multiple parallel avenues of investigation within genetics (e.g. epistasis, oligogenic inheritance) dedicated to understanding the effect of one gene/allele on the phenotypic expression of a second gene/allele (154, 155). In the case of diabetes, there is a growing body of evidence that some subtypes may be the result of oligogenic inheritance, wherein the underlying etiology of the disorder is primarily genetic, but still requires the synergistic action of several genetic modifiers at disparate disease-linked loci (156, 170, 171). In this continuum between classical Mendelian and complex traits, possible protein coding disease modifiers include allelic heterogeneity that results from mutations within disease-linked loci, the activity of modifier genes that regulate others with important roles in glucose homeostasis, and the presence/absence of single nucleotide polymorphisms (SNPs) that are either necessary or sufficient to change the presence, penetrance, expressivity/heritability, or rate of progression of a disease.
As GWAS datasets expand to include sampling of diabetic patients from varied ethnic backgrounds that present different endophenotypes, the technology is poised to assist in the identification of candidate disease-linked genes and SNPs that reside within ‘modifier loci’ (172). While hundreds of candidate genes that are linked with increased diabetes-risk have been identified, the mechanisms underlying their action often remain unclear. One of the first identified and best understood examples of how genetic protein coding disease modifiers modulate the phenotypic expression of diabetes are the multiple identified polymorphisms within the base pair sequence of the HLA region of chromosome 6p21.3 on T1D (173). In this case, variation within the coding sequence of the HLA DR and DQ alleles produce changes in the amino acid sequence of cell surface receptors, altering their binding affinity to T-cells and increasing T1D-risk [reviewed in (142)].
Apart from polymorphisms in the HLA region, coding mutations within genes that encode important pancreatic transcription factors (TFs) have also been shown to modify the phenotypic expression of diabetes (162, 163). Coding mutations within the TCF7L2 (174), PDX1 (107), HNF1A (108), HNF4A (175), and TM6SF2 (176) genes can result in the dysregulation of blood glucose homeostasis by altering TF expression or imparting direct functional consequences on β-cell or islet function through alterations in a TF’s amino acid sequence. For example, hundreds of missense mutations within PDX1 coding regions have been identified, with mutations within the transactivation domain reducing gene activation and impairing both β-cell development and function (107). In the case of HNF1A, 11 rare coding variants have been identified that result in a >40% reduction in transcription and are strongly associated with monogenic diabetes (MODY3) in the general population (108, 109). Similarly, a number of coding SNPs can impart T1D and T2D susceptibility within groups with a shared ancestral heritage, including SNPs in the SUMO4 (177) and MGEA5 (178) genes, identified within Japanese and Mexican populations, respectively.
Recent advances in targeted RNA sequencing technology (RNA Seq, RNA CaptureSeq) have greatly expanded our understanding of transcriptomics (179), underscoring the potential importance of regulatory elements in the control of disease-linked genes (180–182). Rather than coding for a protein directly, non-coding RNA (ncRNA) regulate the transcriptional or post-transcriptional production and modification of proteins. ncRNA make up 98% of the transcripts in the human genome, can be either trans- or cis-acting, and are classified into groups according to their length, morphology, and function (179, 183). ‘Short’ ncRNAs are less than 200 bp in length and perform a diversity of functions during gene regulation, protein synthesis, and the post-translational modification of proteins. Short ncRNA include nuclear RNAs (snRNAs), small nucleolar RNAs (snoRNAs), micro-RNAs (miRNAs), and transfer RNA (tRNA), to name a only a few (184). In contrast, long non-coding RNAs (lncRNAs) are 200 bps or longer and are generally only involved in the regulation of gene transcription and epigenetic regulation, although in some rare occasions they may produce peptides (185).
To date, the influence of non-protein coding disease modifiers on the pathogenesis of diabetes remains underdefined, providing an exciting avenue for future research. GWAS comparing the islets of diabetic and non-diabetic individuals suggest that most T2D-associated variants do not reside in coding regions (146, 147), adding to a growing, yet sparse, body of evidence that glucose homeostasis is heavily controlled by the activity of non-coding regulatory elements (186). For example, thousands of miRNAs and lncRNAs have been isolated from islets (136), with preliminary evidence suggesting that some miRNA are required for islet development in mice (187) and β-cell function (188, 189). LncRNA in particular have been linked to several important processes in diabetes (190), with overexpression resulting in enhanced cell proliferation and fibrosis in the early state of diabetic nephropathy [LncRNA CYP4B1-PS1-001 (191)].
Non-coding single nucleotide polymorphisms (ncSNPs), or variations in a single DNA base pair that code for non-coding regulatory elements, can also act as disease modifiers of diabetes (182). More than 90% of disease-associated SNPs are located within non-coding regions, resulting in possible functional variants of promoters, enhancers, and ncRNA genes (192). Through this mechanism, ncSNPs within important regulatory regions can alter the splicing, binding, degradation, or sequence of a ncRNA, which in turn can modulate the activity of multiple regulatory elements that act to control other cellular processes, such as transcription factor binding and chromatin states (193, 194). As an example, a recent study from our laboratory that used genome editing to knock-out HNF1A in hESCs identified a human-specific lncRNA (LINKA) that is a target of HNF1A and is necessary for normal mitochondrial respiration within stem cell-derived β-cells (113). Given that there is recent evidence that islet-specific lncRNA and transcription factors co-regulate genes associated with enhancer clusters (195, 196), we expect that additional studies that expand upon the functional consequences on ncSNPs and the potential targets of lncRNA in human islets have great potential to explain some of the clinical heterogeneity each diabetes subtype (197, 198).
The discovery of genetic modifiers of diabetes have been slowed by the complex presentation of the diabetes subtypes, with the cause of each existing on a multi-dimensional continuum of genetic, epigenetic, and environmental factors (14). However, while progress has been hindered in some areas, success has been achieved over the past two decades within monogenic diabetes, with advancements in molecular genetics enabling the definition of discrete etiological disease subtypes that can inform preventative treatments through precision medicine (199). As discussed in section 3, monogenic forms of diabetes result from coding mutations in single identified genes which cause β-cell-intrinsic dysfunction. This has allowed for targeted studies focused on elucidating the role of the specific causative gene in β-cell development and function. However, disease penetrance and presentation can vary among individuals with the same underlying pathogenic mutation, suggesting that additional factors can influence the genotype-phenotype association (15–18).
The multifaceted nature of monogenic diabetes provides a unique opportunity to model gene-phenotype relationships that contribute to endophenotypes seen in the more common forms of the diabetes and aid in the discovery of novel disease modifiers (200, 201). Recent technological advancements in sequencing technology, genome editing (see Section 2), and the generation and guided-differentiation of iPSCs (see Section 1.2) now provide the foundation for an iPSC-based discovery platform that can identify novel protein coding and non-protein coding genetic elements that modify the presentation and penetrance of endophenotypes. Presented in Figure 1, genetic disease modifier discovery begins with the identification of a heterozygous coding mutation that results in monogenic diabetes. Coding variant identification can be done on demand through partial or whole genome sequencing given available information regarding candidate genes (97), through exome sequencing (98), or by leveraging publicly available GWAS datasets that compare non-diabetic and diabetic patients (99) (see Section 3). A useful database for monogenic diabetes includes the products of the DIAbetes Genetics Replication And Meta-analysis (DIAGRAM) Consortium (https://www.diagram-consortium.org/).
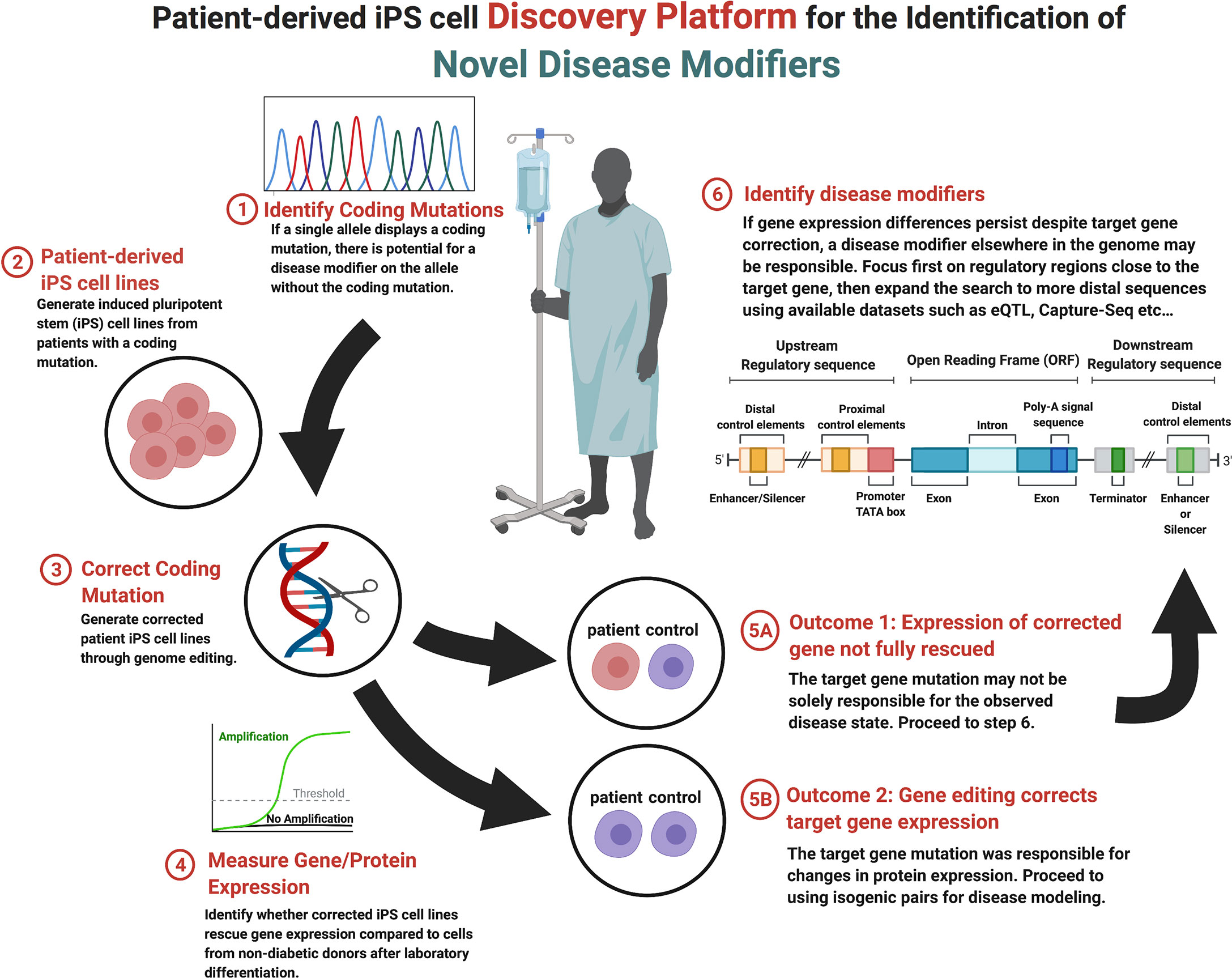
Figure 1 Stepwise flow diagram of the process of genetic disease modifier discovery.
Upon candidate allele or gene selection, the next step within the disease modifier discovery platform is the production of iPSC lines from diabetic patients with the desired coding mutation (step 2, Figure 1). Due to recent technological advancements, iPSCs can easily be generated from adult cells that are harvested from blood or skin tissue (112, 202, 203). Once generated, endodermal cells with the desired coding mutation can be produced from iPSCs through exposure to the inductive signals that drive in vivo development (48, 204). To this end, several stepwise protocols that move cells through the multiple stages of pancreatic development in vitro over a few weeks have been developed (52–54). This process represents a relatively efficient method for the generation of pancreatic β-cells using tissue from multiple donors that share the identified coding mutation but have varied genetic backgrounds that result in different genetic modifiers, a distinct advantage when addressing observed heterogeneity in phenotypic expression.
After the generation of stable iPSC lines, the next step within the disease modifier discovery platform is to selectively correct the identified coding mutation and compare the resulting gene mRNA and protein expression before and after correction (step 3, Figure 1). As described in section 2, there are a number of genome editing technologies available to accomplish line correction, although CRISPR/cas9-mediated systems are becoming the most frequency used within stem cell models (63, 64). The goal of model generation is to compare corrected and non-corrected lines to non-diabetic controls, to which the mRNA and protein expression of the corrected gene can be measured (step 4, Figure 1). Throughout this process, one of two outcomes may be observed. Outcome 1: the correction of the observed coding mutation can result in the complete normalization of gene/protein expression. This result implies that the coding mutation was completely responsible for the decrease in gene expression and/or function (step 5A, Figure 1). Outcome 2: the expression of the monogenic diabetes gene is not rescued to the levels observed in non-diabetic control cells. In this case, expression is possibly being regulated by a modifier elsewhere in the genome (step 5B, Figure 1). It is possible that certain coding mutations may disrupt protein function while not impacting mRNA or protein expression. Such a mutation can still be studied with this platform as regulatory region variants which decrease gene expression may still be detectable when comparing the patient iPSC cell line to control lines.
In the event that the candidate gene expression is not normalized by selective correction of the coding mutation, the target gene may be under the regulatory control of one or more disease modifiers (step 6, Figure 1). Disease modifiers can reside either proximally or distally with respect to the coding mutation, as well as either upstream or downstream from the affected gene, making their location difficult to determine. An effective search strategy can be to focus on proximal regulatory regions near the gene of interest first, although if this approach doesn’t prove fruitful then there are a number of computational approaches that are specifically designed for the identification of regulatory elements [reviewed in (205)]. Similarly, the sequencing and chromatin mapping efforts of the ENCODE (https://www.encodeproject.org/) (206), Epigenome Roadmap Consortia (https://egg2.wustl.edu/roadmap/web_portal/) (207), and Common Metabolic Diseases Knowledge Portal (https://hugeamp.org) have provided extensive annotation of coding and non-coding regions within the human genome, as well as the likelihood of variants to impact metabolic disease.
Through the use of public databases, it is now possible to determine likely regulatory regions of the target gene of interest that can then be interrogated by targeted sequencing of patient iPS cell lines that could not be completely rescued by correction of the coding mutation. If variants are discovered, they can be studied by genome editing in the context of coding mutations or in isolation to determine the impact on expression of the target gene. For example, this strategy has been successfully used to study pancreas agenesis caused by mutations in GATA6 within our laboratory (102). A non-coding SNP was discovered in a patient iPS cell line that regulated expression of GATA6 during pancreas development in vitro and when interrogated in a cohort of patients with the disorder was confirmed to be a disease modifier. This strategy is especially useful in studying variants that impact genetic disease caused by heterozygous coding mutations. Variants that may have only a small influence on gene expression and no impact on disease alone can synergize with heterozygous coding mutations to bring target gene expression below a critical threshold needed for function. This platform does have some limitations including the requirement to focus of monogenic heterozygous disorders and may not be scalable to examine large numbers of genes with current differentiation technologies. We suggest that this methodology could be applied secondarily to any heterozygous iPSC disease modeling project that entails the creation of isogenic corrected lines with minimal additional effort.
The recent development of techniques to differentiate hPSCs into pancreatic β-cells has opened up new pathways to study the pathogenesis of diabetes. These human-centric models, combined with rapidly advancing genome editing techniques, provide incredibly powerful and scalable platforms in which to study the contribution of genetic elements to β-cell function, while also addressing the limitation of mouse models. Furthermore, the use of hPSCs provide unique opportunities in which to accomplish the targeted study of β-cell dysfunction as well as provide a platform to discover protein coding and non-protein coding genetic modifiers. Given recent evidence that large numbers of disease-linked variants do not reside in coding regions and the presence of variants can be population-specific, iPSC platforms that use patient-derived tissue hold great promise for the discovery of novel genetic disease modifiers that may help to explain the variability seen across and within diabetes subtypes.
While hPSC-based platforms represent a great leap forward in our ability to study β-cell function, there are caveats to their use that must be taken into account. hPSC derived β-cell generation and culture is labor-intensive, requiring approximately 40 days of differentiation and maturation. Additionally, though they do have some degree of insulin secretion in response to glucose and other secretagogues, significant uncertainty regarding their functionality and maturity still exists (66, 208–211). Ideally, these protocols need to be optimized to support the efficiency and accuracy of discovery platforms utilizing stem cell-derived β-cells. However, further fine-tuning of the established differentiation protocols will drive us closer to an ideal ex vivo human model of pancreatic β-cells. In addition to improving β-cell function, protocols need to be improved so that they are more universally successful, as certain hPSC lines can more easily differentiated into β-cells than others using current protocols.
The development of more universally-applicable protocols is required as the use of patient iPSC lines expands. There has been a recent flurry of publications that promise improved protocols with better function and wider applicability, and advances will continue to build on those already made (57, 212). Finally, generation of islet cells in platforms combining different stem cell-derived cell types will allow for more complex modeling of the genetic and environmental factors driving all forms of diabetes. Improving our knowledge of pancreatic β-cells function and development in humans is essential for the development of treatments for the millions of people affected by diabetes.
MG and KL conducted the literature review, designed figures, and wrote the manuscript. MG, KL, and PG conceived of the topic and edited the text. All authors contributed to the article and approved the submitted version.
Authors were supported by grants K12DK94723 (KL), R01DK118155 (PG), UG3DK122644 (PG), R01DK123162 (PG) and UM1DK126194 (PG).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Figure 1 was created using BioRender.com.
1. Prevention CfDCa. National Diabetes Statistics Report, 2020. Atlanta, GA: Centers for Disease Control and Prevention, U.S. Dept of Health and Human Services (2020).
2. Divers J, Mayer-Davis E, Lawrence L, Isom S, Dabelea D, Dolan L, et al. Trends in Incidence of Type 1 and Type 2 Diabetes Among Youths — Selected Counties and Indian Reservations, United States, 2002–2015. MMWR Morb Mortal Wkly Rep (2020) 69:161–5. doi: 10.15585/mmwr.mm6906a3
3. Mayer-Davis EJ, Lawrence JM, Dabelea D, Divers J, Isom S, Dolan L, et al. Incidence Trends of Type 1 and Type 2 Diabetes Among Youths, 2002-2012. N Engl J Med (2017) 376:1419–29. doi: 10.1056/NEJMoa1610187
4. Ward ZJ, Bleich SN, Cradock AL, Barrett JL, Giles CM, Flax C, et al. State-Level Prevalence of Adult Obesity and Severe Obesity. N Engl J Med (2019) 381:2440–50. doi: 10.1056/NEJMsa1909301
5. Huang ES, Brown SE, Ewigman BG, Foley EC, Meltzer DO. Patient Perceptions of Quality of Life With Diabetes-Related Complications and Treatments. Diabetes Care (2007) 30:2478–83. doi: 10.2337/dc07-0499
6. Barron E, Bakhai C, Kar P, Weaver A, Bradley D, Ismail H, et al. Associations of Type 1 and Type 2 Diabetes With COVID-19-Related Mortality in England: A Whole-Population Study. Lancet Diabetes Endocrinol (2020) 8:813–22. doi: 10.1016/S2213-8587(20)30272-2
7. Holman N, Knighton P, Kar P, O’Keefe J, Curley M, Weaver A, et al. Risk Factors for COVID-19-Related Mortality in People With Type 1 and Type 2 Diabetes in England: A Population-Based Cohort Study. Lancet Diabetes Endocrinol (2020) 8:823–33. doi: 10.1016/S2213-8587(20)30271-0
8. Riddle MC, Buse JB, Franks PW, Knowler WC, Ratner RE, Selvin E, et al. Covid-19 in People With Diabetes: Urgently Needed Lessons From Early Reports. Diabetes Care (2020) 43:1378–81. doi: 10.2337/dci20-0024
9. Polonsky KS. The Past 200 Years in Diabetes. N Engl J Med (2012) 367:1332–40. doi: 10.1056/NEJMra1110560
10. von Scholten BJ, Kreiner FF, Gough SC, von Herrath M. Current and Future Therapies for Type 1 Diabetes. Diabetologia (2021) 64:1037–48. doi: 10.1007/s00125-021-05398-3
11. Roep BO, Thomaidou S, van Tienhoven R, Zaldumbide A. Type 1 Diabetes Mellitus as a Disease of the β-Cell (Do Not Blame the Immune System)? Nat Rev Endocrinol (2020) 17:150–61. doi: 10.1038/s41574-020-00443-4
12. DeFronzo RA, Ferrannini E, Groop L, Henry RR, Herman WH, Holst JJ, et al. Type 2 Diabetes Mellitus. Nat Rev Dis Primers (2015) 1:1–22. doi: 10.1038/nrdp.2015.19
13. Katsarou A, Gudbjörnsdottir S, Rawshani A, Dabelea D, Bonifacio E, Anderson BJ, et al. Type 1 Diabetes Mellitus. Nat Rev Dis Primers (2017) 3:1–17. doi: 10.1038/nrdp.2017.16
14. Katsanis N. The Continuum of Causality in Human Genetic Disorders. Genome Biol (2016) 17:233. doi: 10.1186/s13059-016-1107-9
15. Fajans SS, Bell GI, Polonsky KS. Molecular Mechanisms and Clinical Pathophysiology of Maturity-Onset Diabetes of the Young. N Engl J Med (2001) 345:971–80. doi: 10.1056/NEJMra002168
16. Nyunt O, Wu JY, McGown IN, Harris M, Huynh T, Leong GM, et al. Investigating Maturity Onset Diabetes of the Young. Clin Biochemist Rev (2009) 30:67.
17. Shields BM, Shepherd M, Hudson M, McDonald TJ, Colclough K, Peters J, et al. Population-Based Assessment of a Biomarker-Based Screening Pathway to Aid Diagnosis of Monogenic Diabetes in Young-Onset Patients. Diabetes Care (2017) 40:1017–25. doi: 10.2337/dc17-0224
18. Naylor R, Knight JA, del Gaudio D. Maturity-Onset Diabetes of the Young Overview. In: Adam MP, Pagon RA, Wallace SE, Bean LJH, Mirzaa G, Amemiya A, editors. Seattle: University of Washington (2018).
19. Fuchsberger C, Flannick J, Teslovich TM, Mahajan A, Agarwala V, Gaulton KJ, et al. The Genetic Architecture of Type 2 Diabetes. Nature (2016) 536:41–7. doi: 10.1038/nature18642
20. Grarup N, Sandholt CH, Hansen T, Pedersen O. Genetic Susceptibility to Type 2 Diabetes and Obesity: From Genome-Wide Association Studies to Rare Variants and Beyond. Diabetologia (2014) 57:1528–41. doi: 10.1007/s00125-014-3270-4
21. Mishra R, Chesi A, Cousminer DL, Hawa MI, Bradfield JP, Hodge KM, et al. Relative Contribution of Type 1 and Type 2 Diabetes Loci to the Genetic Etiology of Adult-Onset, Non-Insulin-Requiring Autoimmune Diabetes. BMC Med (2017) 15:88. doi: 10.1186/s12916-017-0846-0
22. Lemelman MB, Letourneau L, Greeley SAW. Neonatal Diabetes Mellitus: An Update on Diagnosis and Management. Clin Perinatol (2018) 45:41–59. doi: 10.1016/j.clp.2017.10.006
23. Kleinert M, Clemmensen C, Hofmann SM, Moore MC, Renner S, Woods SC, et al. Animal Models of Obesity and Diabetes Mellitus. Nat Rev Endocrinol (2018) 14:140. doi: 10.1038/nrendo.2017.161
24. Al-Awar A, Kupai K, Veszelka M, Szucs G, Attieh Z, Murlasits Z, et al. Experimental Diabetes Mellitus in Different Animal Models. J Diabetes Res (2016) 2016:9051426. doi: 10.1155/2016/9051426
25. Rodrigues R. A Comprehensive Review: The Use of Animal Models in Diabetes Research. J Analytical Pharm Res (2016) 3. doi: 10.15406/japlr.2016.03.00071
26. Kitada M, Ogura Y, Koya D. Rodent Models of Diabetic Nephropathy: Their Utility and Limitations. Int J Nephrol Renovascular Dis (2016) 9:279. doi: 10.2147/IJNRD.S103784
27. Driver JP, Serreze DV, Chen Y-G. Mouse Models for the Study of Autoimmune Type 1 Diabetes: A NOD to Similarities and Differences to Human Disease. Semin Immunopathol Springer (2011) 33(1):67–87. doi: 10.1007/s00281-010-0204-1
28. Bonnefond A, Clément N, Fawcett K, Yengo L, Vaillant E, Guillaume J-L, et al. Rare MTNR1B Variants Impairing Melatonin Receptor 1B Function Contribute to Type 2 Diabetes. Nat Genet (2012) 44:297–301. doi: 10.1038/ng.1053
29. Catli G, Abaci A, Flanagan S, De Franco E, Ellard S, Hattersley A, et al. A Novel GATA6 Mutation Leading to Congenital Heart Defects and Permanent Neonatal Diabetes: A Case Report. Diabetes Metab (2013) 39:370–4. doi: 10.1016/j.diabet.2013.01.005
30. Chao A, Whittemore R, Minges KE, Murphy KM, Grey M. Self-Management in Early Adolescence and Differences by Age at Diagnosis and Duration of Type 1 Diabetes. Diabetes Educator (2014) 40:167–77. doi: 10.1177/0145721713520567
31. Eifes S, Chudasama KK, Molnes J, Wagner K, Hoang T, Schierloh U, et al. A Novel GATA6 Mutation in a Child With Congenital Heart Malformation and Neonatal Diabetes. Clin Case Rep (2013) 1:86. doi: 10.1002/ccr3.33
32. Gong H, Zhang X, Cheng B, Sun Y, Li C, Li T, et al. Bisphenol A Accelerates Toxic Amyloid Formation of Human Islet Amyloid Polypeptide: A Possible Link Between Bisphenol A Exposure and Type 2 Diabetes. PLoS One (2013) 8:e54198. doi: 10.1371/journal.pone.0054198
33. Allen HL, Flanagan SE, Shaw-Smith C, De Franco E, Akerman I, Caswell R, et al. GATA6 Haploinsufficiency Causes Pancreatic Agenesis in Humans. Nat Genet (2012) 44:20–2. doi: 10.1038/ng.1035
34. Stanescu DE, Hughes N, Patel P, De León DD. A Novel Mutation in GATA6 Causes Pancreatic Agenesis. Pediatr Diabetes (2015) 16:67–70. doi: 10.1111/pedi.12111
35. Bonnefond A, Sand O, Guerin B, Durand E, De Graeve F, Huyvaert M, et al. GATA6 Inactivating Mutations Are Associated With Heart Defects and, Inconsistently, With Pancreatic Agenesis and Diabetes. Diabetologia (2012) 55:2845–7. doi: 10.1007/s00125-012-2645-7
36. Gong M, Simaite D, Kuhnen P, Heldmann M, Spagnoli F, Blankenstein O, et al. Two Novel GATA6 Mutations Cause Childhood-Onset Diabetes Mellitus, Pancreas Malformation and Congenital Heart Disease. Horm Res Paediatr (2013) 79:250–6. doi: 10.1159/000348844
37. Chao CS, McKnight KD, Cox KL, Chang AL, Kim SK, Feldman BJ. Novel GATA6 Mutations in Patients With Pancreatic Agenesis and Congenital Heart Malformations. PLoS One (2015) 10:e0118449. doi: 10.1371/journal.pone.0118449
38. D’Amato E, Giacopelli F, Giannattasio A, d’Annunzio G, Bocciardi R, Musso M, et al. Genetic Investigation in an Italian Child With an Unusual Association of Atrial Septal Defect, Attributable to a New Familial GATA4 Gene Mutation, and Neonatal Diabetes Due to Pancreatic Agenesis. Diabetic Med (2010) 27:1195–200. doi: 10.1111/j.1464-5491.2010.03046.x
39. Shaw-Smith C, De Franco E, Allen HL, Batlle M, Flanagan SE, Borowiec M, et al. GATA4 Mutations Are a Cause of Neonatal and Childhood-Onset Diabetes. Diabetes (2014) 63:2888–94. doi: 10.2337/db14-0061
40. Carrasco M, Delgado I, Soria B, Martín F, Rojas A. GATA4 and GATA6 Control Mouse Pancreas Organogenesis. J Clin Invest (2012) 122:3504–15. doi: 10.1172/JCI63240
41. Xuan S, Borok MJ, Decker KJ, Battle MA, Duncan SA, Hale MA, et al. Pancreas-Specific Deletion of Mouse Gata4 and Gata6 Causes Pancreatic Agenesis. J Clin Invest (2012) 122:3516–28. doi: 10.1172/JCI63352
42. Dukes ID, Sreenan S, Roe MW, Levisetti M, Zhou Y-P, Ostrega D, et al. Defective Pancreatic β-Cell Glycolytic Signaling in Hepatocyte Nuclear Factor-1α-Deficient Mice. J Biol Chem (1998) 273:24457–64. doi: 10.1074/jbc.273.38.24457
43. Garcia-Gonzalez MA, Carette C, Bagattin A, Chiral M, Makinistoglu MP, Garbay S, et al. A Suppressor Locus for MODY3-Diabetes. Sci Rep (2016) 6:33087. doi: 10.1038/srep35697
44. Skelin M, Rupnik M, Cencic A.Pancreatic Beta Cell Lines and Their Applications in Diabetes Mellitus Research. ALTEX (2011) 27:105–13. doi: 10.14573/altex.2010.2.105
45. Scharfmann R, Staels W, Albagli O. The Supply Chain of Human Pancreatic Beta Cell Lines. J Clin Invest (2019) 129:3511–20. doi: 10.1172/JCI129484
46. Takahashi K, Yamanaka S. A Decade of Transcription Factor-Mediated Reprogramming to Pluripotency. Nat Rev Mol Cell Biol (2016) 17:183–93. doi: 10.1038/nrm.2016.8
47. Wu J, Izpisua Belmonte JC. Stem Cells: A Renaissance in Human Biology Research. Cell (2016) 165:1572–85. doi: 10.1016/j.cell.2016.05.043
48. Zorn AM, Wells JM. Vertebrate Endoderm Development and Organ Formation. Annu Rev Cell Dev (2009) 25:221–51. doi: 10.1146/annurev.cellbio.042308.113344
49. Nair G, Hebrok M. Islet Formation in Mice and Men: Lessons for the Generation of Functional Insulin-Producing β-Cells From Human Pluripotent Stem Cells. Curr Opin Genet Dev (2015) 32:171–80. doi: 10.1016/j.gde.2015.03.004
50. D’Amour KA, Agulnick AD, Eliazer S, Kelly OG, Kroon E, Baetge EE. Efficient Differentiation of Human Embryonic Stem Cells to Definitive Endoderm. Nat Biotechnol (2005) 23:1534–41. doi: 10.1038/nbt1163
51. D’Amour KA, Bang AG, Eliazer S, Kelly OG, Agulnick AD, Smart NG, et al. Production of Pancreatic Hormone–Expressing Endocrine Cells From Human Embryonic Stem Cells. Nat Biotechnol (2006) 24:1392–401. doi: 10.1038/nbt1259
52. Kroon E, Martinson LA, Kadoya K, Bang AG, Kelly OG, Eliazer S, et al. Pancreatic Endoderm Derived From Human Embryonic Stem Cells Generates Glucose-Responsive Insulin-Secreting Cells In Vivo. Nat Biotechnol (2008) 26:443–52. doi: 10.1038/nbt1393
53. Pagliuca FW, Millman JR, Gürtler M, Segel M, Van Dervort A, Ryu JH, et al. Generation of Functional Human Pancreatic β Cells In Vitro. Cell (2014) 159:428–39. doi: 10.1016/j.cell.2014.09.040
54. Rezania A, Bruin JE, Arora P, Rubin A, Batushansky I, Asadi A, et al. Reversal of Diabetes With Insulin-Producing Cells Derived In Vitro From Human Pluripotent Stem Cells. Nat Biotechnol (2014) 32:1121. doi: 10.1038/nbt.3033
55. Alvarez-Dominguez JR, Donaghey J, Rasouli N, Kenty JH, Helman A, Charlton J, et al. Circadian Entrainment Triggers Maturation of Human In Vitro Islets. Cell Stem Cell (2020) 26:108–22:e10. doi: 10.1016/j.stem.2019.11.011
56. Davis JC, Alves TC, Helman A, Chen JC, Kenty JH, Cardone RL, et al. Glucose Response by Stem Cell-Derived β Cells In Vitro is Inhibited by a Bottleneck in Glycolysis. Cell Rep (2020) 31:107623. doi: 10.1016/j.celrep.2020.107623
57. Hogrebe NJ, Augsornworawat P, Maxwell KG, Velazco-Cruz L, Millman JR. Targeting the Cytoskeleton to Direct Pancreatic Differentiation of Human Pluripotent Stem Cells. Nat Biotechnol (2020) 38:460–70. doi: 10.1038/s41587-020-0430-6
58. Li X, Yang KY, Chan VW, Leung KT, Zhang X-B, Wong AS, et al. Single-Cell RNA-Seq Reveals That CD9 is a Negative Marker of Glucose-Responsive Pancreatic β-Like Cells Derived From Human Pluripotent Stem Cells. Stem Cell Rep (2020) 15:1111–26. doi: 10.1016/j.stemcr.2020.09.009
59. Mahaddalkar PU, Scheibner K, Pfluger S, Sterr M, Beckenbauer J, Irmler M, et al. Generation of Pancreatic β Cells From CD177+ Anterior Definitive Endoderm. Nat Biotechnol (2020) 28:1061–72. doi: 10.1038/s41587-020-0492-5
60. Nair GG, Liu JS, Russ HA, Tran S, Saxton MS, Chen R, et al. Recapitulating Endocrine Cell Clustering in Culture Promotes Maturation of Human Stem-Cell-Derived β Cells. Nat Cell Biol (2019) 21:263–74. doi: 10.1038/s41556-018-0271-4
61. Lithovius V, Saarimäki-Vire J, Balboa D, Ibrahim H, Montaser H, Barsby T, et al. SUR1-Mutant iPS Cell-Derived Islets Recapitulate the Pathophysiology of Congenital Hyperinsulinism. Diabetologia (2021) 64:630–40. doi: 10.1007/s00125-020-05346-7
62. Veres A, Faust AL, Bushnell HL, Engquist EN, Kenty JH-R, Harb G, et al. Charting Cellular Identity During Human In Vitro β-Cell Differentiation. Nature (2019) 569:368–73. doi: 10.1038/s41586-019-1168-5
63. Hsu PD, Lander ES, Zhang F. Development and Applications of CRISPR-Cas9 for Genome Engineering. Cell (2014) 157:1262–78. doi: 10.1016/j.cell.2014.05.010
64. Ran FA, Hsu PD, Wright J, Agarwala V, Scott DA, Zhang F. Genome Engineering Using the CRISPR-Cas9 System. Nat Protoc (2013) 8:2281–308. doi: 10.1038/nprot.2013.143
65. Millette K, Georgia S. Gene Editing and Human Pluripotent Stem Cells: Tools for Advancing Diabetes Disease Modeling and Beta-Cell Development. Curr Diabetes Rep (2017) 17:116. doi: 10.1007/s11892-017-0947-3
66. Balboa D, Saarimäki-Vire J, Otonkoski T. Concise Review: Human Pluripotent Stem Cells for the Modeling of Pancreatic β-Cell Pathology. Stem Cells (2019) 37:33–41. doi: 10.1002/stem.2913
67. Lieber MR. The Mechanism of Double-Strand DNA Break Repair by the Nonhomologous DNA End-Joining Pathway. Annu Rev Biochem (2010) 79:181–211. doi: 10.1146/annurev.biochem.052308.093131
68. Jackson SP, Bartek J. The DNA-Damage Response in Human Biology and Disease. Nature (2009) 461:1071–8. doi: 10.1038/nature08467
69. Waryah CB, Moses C, Arooj M, Blancafort P. Zinc Fingers, TALEs, and CRISPR Systems: A Comparison of Tools for Epigenome Editing, Epigenome Editing. Springer (2018). p. 19–63.
70. Miller JC, Tan S, Qiao G, Barlow KA, Wang J, Xia DF, et al. A TALE Nuclease Architecture for Efficient Genome Editing. Nat Biotechnol (2011) 29:143–8. doi: 10.1038/nbt.1755
71. Zhang F, Cong L, Lodato S, Kosuri S, Church GM, Arlotta P. Efficient Construction of Sequence-Specific TAL Effectors for Modulating Mammalian Transcription. Nat Biotechnol (2011) 29:149–53. doi: 10.1038/nbt.1775
72. Wright DA, Li T, Yang B, Spalding MH. TALEN-Mediated Genome Editing: Prospects and Perspectives. Biochem J (2014) 462:15–24. doi: 10.1042/BJ20140295
73. Segal DJ, Crotty JW, Bhakta MS, Barbas CF III, Horton NC. Structure of Aart, A Designed Six-Finger Zinc Finger Peptide, Bound to DNA. J Mol Biol (2006) 363:405–21. doi: 10.1016/j.jmb.2006.08.016
74. Porteus MH, Carroll D. Gene Targeting Using Zinc Finger Nucleases. Nat Biotechnol (2005) 23:967–73. doi: 10.1038/nbt1125
75. Boch J, Bonas U. Xanthomonas AvrBs3 Family-Type III Effectors: Discovery and Function. Annu Rev Phytopathol (2010) 48. doi: 10.1146/annurev-phyto-080508-081936
76. Bibikova M, Carroll D, Segal DJ, Trautman JK, Smith J, Kim Y-G, et al. Stimulation of Homologous Recombination Through Targeted Cleavage by Chimeric Nucleases. Mol Cell Biol (2001) 21:289–97. doi: 10.1128/MCB.21.1.289-297.2001
77. Kim Y-G, Cha J, Chandrasegaran S. Hybrid Restriction Enzymes: Zinc Finger Fusions to Fok I Cleavage Domain. Proc Natl Acad Sci (1996) 93:1156–60. doi: 10.1073/pnas.93.3.1156
78. Urnov FD, Rebar EJ, Holmes MC, Zhang HS, Gregory PD. Genome Editing With Engineered Zinc Finger Nucleases. Nat Rev Genet (2010) 11:636–46. doi: 10.1038/nrg2842
79. Pabo CO, Peisach E, Grant RA. Design and Selection of Novel Cys2His2 Zinc Finger Proteins. Annu Rev Biochem (2001) 70:313–40. doi: 10.1146/annurev.biochem.70.1.313
80. Mussolino C, Cathomen T. On Target? Tracing Zinc-Finger-Nuclease Specificity. Nat Methods (2011) 8:725–6. doi: 10.1038/nmeth.1680
81. Joung JK, Sander JD. Talens: A Widely Applicable Technology for Targeted Genome Editing. Nat Rev Mol Cell Biol (2013) 14:49–55. doi: 10.1038/nrm3486
82. Cox DBT, Platt RJ, Zhang F. Therapeutic Genome Editing: Prospects and Challenges. Nat Med (2015) 21:121–31. doi: 10.1038/nm.3793
83. Bultmann S, Morbitzer R, Schmidt CS, Thanisch K, Spada F, Elsaesser J, et al. Targeted Transcriptional Activation of Silent Oct4 Pluripotency Gene by Combining Designer TALEs and Inhibition of Epigenetic Modifiers. Nucleic Acids Res (2012) 40:5368–77. doi: 10.1093/nar/gks199
84. Carroll D. Progress and Prospects: Zinc-Finger Nucleases as Gene Therapy Agents. Gene Ther (2008) 15:1463–8. doi: 10.1038/gt.2008.145
85. Ding Q, Lee Y-K, Schaefer EA, Peters DT, Veres A, Kim K, et al. A TALEN Genome-Editing System for Generating Human Stem Cell-Based Disease Models. Cell Stem Cell (2013) 12:238–51. doi: 10.1016/j.stem.2012.11.011
86. Jinek M, Chylinski K, Fonfara I, Hauer M, Doudna JA, Charpentier E. A Programmable Dual-RNA–Guided DNA Endonuclease in Adaptive Bacterial Immunity. Science (2012) 337:816–21. doi: 10.1126/science.1225829
87. Barrangou R, Fremaux C, Deveau H, Richards M, Boyaval P, Moineau S, et al. CRISPR Provides Acquired Resistance Against Viruses in Prokaryotes. Science (2007) 315:1709–12. doi: 10.1126/science.1138140
88. Deltcheva E, Chylinski K, Sharma CM, Gonzales K, Chao Y, Pirzada ZA, et al. Crispr RNA Maturation by Trans-Encoded Small RNA and Host Factor RNase III. Nature (2011) 471:602–7. doi: 10.1038/nature09886
89. Doudna JA, Charpentier E. The New Frontier of Genome Engineering With CRISPR-Cas9. Science (2014) 346. doi: 10.1126/science.1258096
90. Zhang Z, Zhang Y, Gao F, Han S, Cheah KS, Tse H-F, et al. CRISPR/Cas9 Genome-Editing System in Human Stem Cells: Current Status and Future Prospects. Mol Therapy-Nucleic Acids (2017) 9:230–41. doi: 10.1016/j.omtn.2017.09.009
91. González F, Zhu Z, Shi Z-D, Lelli K, Verma N, Li QV, et al. An iCRISPR Platform for Rapid, Multiplexable, and Inducible Genome Editing in Human Pluripotent Stem Cells. Cell Stem Cell (2014) 15:215–26. doi: 10.1016/j.stem.2014.05.018
92. Hockemeyer D, Jaenisch R. Induced Pluripotent Stem Cells Meet Genome Editing. Cell Stem Cell (2016) 18:573–86. doi: 10.1016/j.stem.2016.04.013
93. Ding Q, Regan SN, Xia Y, Oostrom LA, Cowan CA, Musunuru K. Enhanced Efficiency of Human Pluripotent Stem Cell Genome Editing Through Replacing TALENs With Crisprs. Cell Stem Cell (2013) 12:393. doi: 10.1016/j.stem.2013.03.006
94. Nerys-Junior A, Braga-Dias LP, Pezzuto P, Cotta-de-Almeida V, Tanuri A. Comparison of the Editing Patterns and Editing Efficiencies of TALEN and CRISPR-Cas9 When Targeting the Human CCR5 Gene. Genet Mol Biol (2018) 41:167–79. doi: 10.1590/1678-4685-gmb-2017-0065
95. Maguire JA, Cardenas-Diaz FL, Gadue P, French DL. Highly Efficient CRISPR-Cas9-Mediated Genome Editing in Human Pluripotent Stem Cells. Curr Protoc Stem Cell Biol (2019) 48:e64. doi: 10.1002/cpsc.64
96. Veres A, Gosis BS, Ding Q, Collins R, Ragavendran A, Brand H, et al. Low Incidence of Off-Target Mutations in Individual CRISPR-Cas9 and TALEN Targeted Human Stem Cell Clones Detected by Whole-Genome Sequencing. Cell Stem Cell (2014) 15:27–30. doi: 10.1016/j.stem.2014.04.020
97. Ellard S, Allen HL, De Franco E, Flanagan S, Hysenaj G, Colclough K, et al. Improved Genetic Testing for Monogenic Diabetes Using Targeted Next-Generation Sequencing. Diabetologia (2013) 56:1958–63. doi: 10.1007/s00125-013-2962-5
98. Johansson S, Irgens H, Chudasama KK, Molnes J, Aerts J, Roque FS, et al. Exome Sequencing and Genetic Testing for MODY. PLoS One (2012) 7:e38050. doi: 10.1371/journal.pone.0038050
100. Cai L, Wheeler E, Kerrison ND, Ja L, Deloukas P, PW F, et al. Genome-Wide Association Analysis of Type 2 Diabetes in the EPIC-InterAct Study. Sci Data (2020) 7:1–6. doi: 10.1038/s41597-020-00716-7
101. Guo M, Zhang T, Dong X, Xiang JZ, Lei M, Evans T, et al. Using hESCs to Probe the Interaction of the Diabetes-Associated Genes CDKAL1 and MT1E. Cell Rep (2017) 19:1512–21. doi: 10.1016/j.celrep.2017.04.070
102. Kishore S, De Franco E, Cardenas-Diaz FL, Letourneau-Freiberg LR, Sanyoura M, Osorio-Quintero C, et al. A Non-Coding Disease Modifier of Pancreatic Agenesis Identified by Genetic Correction in a Patient-Derived iPSC Line. Cell Stem Cell (2020). doi: 10.1016/j.stem.2020.05.001
103. Colclough K, Bellanne-Chantelot C, Saint-Martin C, Flanagan SE, Ellard S. Mutations in the Genes Encoding the Transcription Factors Hepatocyte Nuclear Factor 1 Alpha and 4 Alpha in Maturity-Onset Diabetes of the Young and Hyperinsulinemic Hypoglycemia. Hum Mutat (2013) 34:669–85. doi: 10.1002/humu.22279
104. Fajans SS, Bell GI. MODY: History, Genetics, Pathophysiology, and Clinical Decision Making. Diabetes Care (2011) 34:1878–84. doi: 10.2337/dc11-0035
105. Tamaroff J, Kilberg M, Pinney SE, McCormack S. Overview of Atypical Diabetes. Endocrinol Metab Clin North Am (2020) 49:695–723. doi: 10.1016/j.ecl.2020.07.004
106. Steck AK, Winter WE. Review on Monogenic Diabetes. Curr Opin Endocrinol Diabetes Obes (2011) 18:252–8. doi: 10.1097/MED.0b013e3283488275
107. Wang X, Sterr M, Burtscher I, Böttcher A, Beckenbauer J, Siehler J, et al. Point Mutations in the PDX1 Transactivation Domain Impair Human β-Cell Development and Function. Mol Metab (2019) 24:80–97. doi: 10.1016/j.molmet.2019.03.006
108. Najmi LA, Aukrust I, Flannick J, Molnes J, Burtt N, Molven A, et al. Functional Investigations of HNF1A Identify Rare Variants as Risk Factors for Type 2 Diabetes in the General Population. Diabetes (2017) 66:335–46. doi: 10.2337/db16-0460
109. Haliyur R, Tong X, Sanyoura M, Shrestha S, Lindner J, Saunders DC, et al. Human Islets Expressing HNF1A Variant Have Defective β Cell Transcriptional Regulatory Networks. J Clin Invest (2019) 129:246–51. doi: 10.1172/JCI121994
110. Griscelli F, Ezanno H, Soubeyrand M, Feraud O, Oudrhiri N, Bonnefond A, et al. Generation of an Induced Pluripotent Stem Cell (iPSC) Line From a Patient With Maturity-Onset Diabetes of the Young Type 3 (MODY3) Carrying a Hepatocyte Nuclear Factor 1-Alpha (HNF1A) Mutation. Stem Cell Res (2018) 29:56–9. doi: 10.1016/j.scr.2018.02.017
111. Stepniewski J, Kachamakova-Trojanowska N, Ogrocki D, Szopa M, Matlok M, Beilharz M, et al. Induced Pluripotent Stem Cells as a Model for Diabetes Investigation. Sci Rep (2015) 5:8597. doi: 10.1038/srep08597
112. Teo AK, Windmueller R, Johansson BB, Dirice E, Njolstad PR, Tjora E, et al. Derivation of Human Induced Pluripotent Stem Cells From Patients With Maturity Onset Diabetes of the Young. J Biol Chem (2013) 288:5353–6. doi: 10.1074/jbc.C112.428979
113. Cardenas-Diaz FL, Osorio-Quintero C, Diaz-Miranda MA, Kishore S, Leavens K, Jobaliya C, et al. Modeling Monogenic Diabetes Using Human ESCs Reveals Developmental and Metabolic Deficiencies Caused by Mutations in HNF1A. Cell Stem Cell (2019) 25:273–89. doi: 10.1016/j.stem.2019.07.007
114. Yabe SG, Nishida J, Fukuda S, Takeda F, Nasiro K, Yasuda K, et al. Expression of Mutant mRNA and Protein in Pancreatic Cells Derived From MODY3- iPS Cells. PLoS One (2019) 14:e0217110. doi: 10.1371/journal.pone.0217110
115. Teo AK, Lau HH, Valdez IA, Dirice E, Tjora E, Raeder H, et al. Early Developmental Perturbations in a Human Stem Cell Model of MODY5/HNF1B Pancreatic Hypoplasia. Stem Cell Rep (2016) 6:357–67. doi: 10.1016/j.stemcr.2016.01.007
116. Yabe SG, Iwasaki N, Yasuda K, Hamazaki TS, Konno M, Fukuda S, et al. Establishment of Maturity-Onset Diabetes of the Young-Induced Pluripotent Stem Cells From a Japanese Patient. J Diabetes Investig (2015) 6:543–7. doi: 10.1111/jdi.12334
117. Braverman-Gross C, Nudel N, Ronen D, Beer NL, McCarthy MI, Benvenisty N. Derivation and Molecular Characterization of Pancreatic Differentiated MODY1-Ipscs. Stem Cell Res (2018) 31:16–26. doi: 10.1016/j.scr.2018.06.013
118. Ng NHJ, Jasmen JB, Lim CS, Lau HH, Krishnan VG, Kadiwala J, et al. Hnf4a Haploinsufficiency in MODY1 Abrogates Liver and Pancreas Differentiation From Patient-Derived Induced Pluripotent Stem Cells. iScience (2019) 16:192–205. doi: 10.1016/j.isci.2019.05.032
119. Vethe H, Bjorlykke Y, Ghila LM, Paulo JA, Scholz H, Gygi SP, et al. Probing the Missing Mature Beta-Cell Proteomic Landscape in Differentiating Patient iPSC-derived Cells. Sci Rep (2017) 7:4780. doi: 10.1038/s41598-017-04979-w
120. Wang X, Chen S, Burtscher I, Sterr M, Hieronimus A, Machicao F, et al. Generation of a Human Induced Pluripotent Stem Cell (iPSC) Line From a Patient Carrying a P33T Mutation in the PDX1 Gene. Stem Cell Res (2016) 17:273–6. doi: 10.1016/j.scr.2016.08.004
121. Zhu Z, Li QV, Lee K, Rosen BP, González F, Soh C-L, et al. Genome Editing of Lineage Determinants in Human Pluripotent Stem Cells Reveals Mechanisms of Pancreatic Development and Diabetes. Cell Stem Cell (2016) 18:755–68. doi: 10.1016/j.stem.2016.03.015
122. Griscelli F, Feraud O, Ernault T, Oudrihri N, Turhan AG, Bonnefond A, et al. Generation of an Induced Pluripotent Stem Cell (iPSC) Line From a Patient With Maturity-Onset Diabetes of the Young Type 13 (MODY13) With a the Potassium Inwardly-Rectifying Channel, Subfamily J, Member 11 (KCNJ11) Mutation. Stem Cell Res (2017) 23:178–81. doi: 10.1016/j.scr.2017.07.023
123. Voight BF, Scott LJ, Steinthorsdottir V, Morris AP, Dina C, Welch RP, et al. Twelve Type 2 Diabetes Susceptibility Loci Identified Through Large-Scale Association Analysis. Nat Genet (2010) 42:579. doi: 10.1038/ng.609
124. Pontoglio M, Sreenan S, Roe M, Pugh W, Ostrega D, Doyen A, et al. Defective Insulin Secretion in Hepatocyte Nuclear Factor 1alpha-Deficient Mice. J Clin Invest (1998) 101:2215–22. doi: 10.1172/JCI2548
125. Maxwell KG AP, Velazco-Cruz L, Kim MH, Asada R, Hogrebe NJ, Morikawa S, et al. Gene-Edited Human Stem Cell-Derived β Cells From a Patient With Monogenic Diabetes Reverse Preexisting Diabetes in Mice. Sci Trans Med (2020) 12:eaax9106. doi: 10.1126/scitranslmed.aax9106
126. Shang L HH, Foo K, Martinez H, Watanabe K, Zimmer M, Kahler DJ, et al. β-Cell Dysfunction Due to Increased ER Stress in a Stem Cell Model of Wolfram Syndrome. Diabetes (2014) 63:923–33. doi: 10.2337/db13-0717
127. Igoillo-Esteve M, Oliveira AF, Cosentino C, Fantuzzi F, Demarez C, Toivonen S, et al. Exenatide Induces Frataxin Expression and Improves Mitochondrial Function in Friedreich Ataxia. JCI Insight (2020) 5. doi: 10.1172/jci.insight.134221
128. Simsek S, Zhou T, Robinson CL, Tsai SY, Crespo M, Amin S, et al. Modeling Cystic Fibrosis Using Pluripotent Stem Cell-Derived Human Pancreatic Ductal Epithelial Cells. Stem Cells Transl Med (2016) 5:572–9. doi: 10.5966/sctm.2015-0276
129. Bennett SN, Caporaso N, Fitzpatrick AL, Agrawal A, Barnes K, Boyd HA, et al. Phenotype Harmonization and Cross-Study Collaboration in GWAS Consortia: The GENEVA Experience. Genet Epidemiol (2011) 35:159–73. doi: 10.1002/gepi.20564
130. Zeggini E, Scott LJ, Saxena R, Voight BF, Marchini JL, Hu T, et al. Meta-Analysis of Genome-Wide Association Data and Large-Scale Replication Identifies Additional Susceptibility Loci for Type 2 Diabetes. Nat Genet (2008) 40:638–45. doi: 10.1016/S0084-3741(08)79224-2
131. Rich S, Akolkar B, Concannon P, Erlich H, Hilner J, Julier C, et al. Overview of the Type I Diabetes Genetics Consortium. Genes Immun (2009) 10:S1–4. doi: 10.1038/gene.2009.84
132. Yaguchi H, Togawa K, Moritani M, Itakura M. Identification of Candidate Genes in the Type 2 Diabetes Modifier Locus Using Expression QTL. Genomics (2005) 85:591–9. doi: 10.1016/j.ygeno.2005.01.006
133. Laber S, Cox RD. Mouse Models of Human GWAS Hits for Obesity and Diabetes in the Post Genomic Era: Time for Reevaluation. Front Endocrinol (2017) 8:11. doi: 10.3389/fendo.2017.00011
134. Takeshita S, Suzuki T, Kitayama S, Moritani M, Inoue H, Itakura M. Bhlhe40, A Potential Diabetic Modifier Gene on Dbm1 Locus, Negatively Controls Myocyte Fatty Acid Oxidation. Genes Genet Syst (2012) 87:253–64. doi: 10.1266/ggs.87.253
135. Bakay M, Pandey R, Grant SF, Hakonarson H. The Genetic Contribution to Type 1 Diabetes. Curr Diabetes Rep (2019) 19:1–14. doi: 10.1007/s11892-019-1235-1
136. Mahajan A, Taliun D, Thurner M, Robertson NR, Torres JM, Rayner NW, et al. Fine-Mapping Type 2 Diabetes Loci to Single-Variant Resolution Using High-Density Imputation and Islet-Specific Epigenome Maps. Nat Genet (2018) 50:1505–13. doi: 10.1038/s41588-018-0241-6
137. Pociot F. Type 1 Diabetes Genome-Wide Association Studies: Not to be Lost in Translation. Clin Trans Immunol (2017) 6:e162. doi: 10.1038/cti.2017.51
138. Szabó M, Máté B, Csép K, Benedek T. Epigenetic Modifications Linked to T2D, the Heritability Gap, and Potential Therapeutic Targets. Biochem Genet (2018) 56:553–74. doi: 10.1007/s10528-018-9863-8
139. Green AD, Vasu S, Moffett RC, Flatt PR. Co-Culture of Clonal Beta Cells With GLP-1 and Glucagon-Secreting Cell Line Impacts on Beta Cell Insulin Secretion, Proliferation and Susceptibility to Cytotoxins. Biochimie (2016) 125:119–25. doi: 10.1016/j.biochi.2016.03.007
140. Seo H, Son J, Park J-K. Controlled 3D Co-Culture of Beta Cells and Endothelial Cells in a Micropatterned Collagen Sheet for Reproducible Construction of an Improved Pancreatic Pseudo-Tissue. APL Bioeng (2020) 4:046103. doi: 10.1063/5.0023873
141. Nguyen DTT, van Noort D, Jeong I-K, Park S. Endocrine System on Chip for a Diabetes Treatment Model. Biofabrication (2017) 9:015021. doi: 10.1088/1758-5090/aa5cc9
142. Pociot F, Akolkar B, Concannon P, Erlich HA, Julier C, Morahan G, et al. Genetics of Type 1 Diabetes: What’s Next? Diabetes (2010) 59:1561–71. doi: 10.2337/db10-0076
143. Vafiadis P, Bennett ST, Todd JA, Nadeau J, Grabs R, Goodyer CG, et al. Insulin Expression in Human Thymus Is Modulated by INS VNTR Alleles at the IDDM2 Locus. Nat Genet (1997) 15:289–92. doi: 10.1038/ng0397-289
144. Pugliese A, Zeller M, Fernandez A, Zalcberg LJ, Bartlett RJ, Ricordi C, et al. The Insulin Gene is Transcribed in the Human Thymus and Transcription Levels Correlate With Allelic Variation at the INS Vntr-IDDM2 Susceptibility Locus for Type 1 Diabetes. Nat Genet (1997) 15:293–7. doi: 10.1038/ng0397-293
145. Stoy J, Steiner DF, Park SY, Ye H, Philipson LH, Bell GI. Clinical and Molecular Genetics of Neonatal Diabetes Due to Mutations in the Insulin Gene. Rev Endocr Metab Disord (2010) 11:205–15. doi: 10.1007/s11154-010-9151-3
146. Maurano MT, Humbert R, Rynes E, Thurman RE, Haugen E, Wang H, et al. Systematic Localization of Common Disease-Associated Variation in Regulatory DNA. Science (2012) 337:1190–5. doi: 10.1126/science.1222794
147. Gusev A, Lee SH, Trynka G, Finucane H, Vilhjálmsson BJ, Xu H, et al. Partitioning Heritability of Regulatory and Cell-Type-Specific Variants Across 11 Common Diseases. Am J Hum Genet (2014) 95:535–52. doi: 10.1016/j.ajhg.2014.10.004
148. Maehr R, Chen S, Snitow M, Ludwig T, Yagasaki L, Goland R, et al. Generation of Pluripotent Stem Cells From Patients With Type 1 Diabetes. Proc Natl Acad Sci USA (2009) 106:15768–73. doi: 10.1073/pnas.0906894106
149. Kudva YC, Ohmine S, Greder LV, Dutton JR, Armstrong A, De Lamo JG, et al. Transgene-Free Disease-Specific Induced Pluripotent Stem Cells From Patients With Type 1 and Type 2 Diabetes. Stem Cells Transl Med (2012) 1:451–61. doi: 10.5966/sctm.2011-0044
150. Millman JR, Xie C, Van Dervort A, Gurtler M, Pagliuca FW, Melton DA. Generation of Stem Cell-Derived Beta-Cells From Patients With Type 1 Diabetes. Nat Commun (2016) 7:11463. doi: 10.1038/ncomms11463
151. Kim MJ, Lee EY, You YH, Yang HK, Yoon KH, Kim JW. Generation of iPSC-derived Insulin-Producing Cells From Patients With Type 1 and Type 2 Diabetes Compared With Healthy Control. Stem Cell Res (2020) 48:101958. doi: 10.1016/j.scr.2020.101958
152. van Heyningen V, Yeyati PL. Mechanisms of Non-Mendelian Inheritance in Genetic Disease. Hum Mol Genet (2004) 13:R225–33. doi: 10.1093/hmg/ddh254
153. Walia S, Fishman GA, Swaroop A, Branham KE, Lindeman M, Othman M, et al. Discordant Phenotypes in Fraternal Twins Having an Identical Mutation in Exon ORF15 of the RPGR Gene. Arch Ophthalmol (2008) 126:379–84. doi: 10.1001/archophthalmol.2007.72
154. Dipple KM, McCabe ER. Phenotypes of Patients With “Simple” Mendelian Disorders Are Complex Traits: Thresholds, Modifiers, and Systems Dynamics. Am J Hum Genet (2000) 66:1729–35. doi: 10.1086/302938
155. Badano JL, Katsanis N. Beyond Mendel: An Evolving View of Human Genetic Disease Transmission. Nat Rev Genet (2002) 3:779–89. doi: 10.1038/nrg910
156. Kousi M, Katsanis N. Genetic Modifiers and Oligogenic Inheritance. Cold Spring Harbor Perspect Med (2015) 5:a017145. doi: 10.1101/cshperspect.a017145
157. Genin E, Feingold J, Clerget-Darpoux F. Identifying Modifier Genes of Monogenic Disease: Strategies and Difficulties. Hum Genet (2008) 124:357. doi: 10.1007/s00439-008-0560-2
158. Goyal N, Kesharwani D, Datta M. Lnc-Ing non-Coding RNAs With Metabolism and Diabetes: Roles of Lncrnas. Cell Mol Life Sci (2018) 75:1827–37. doi: 10.1007/s00018-018-2760-9
159. Franks PW, Pearson E, Florez JC. Gene-Environment and Gene-Treatment Interactions in Type 2 Diabetes: Progress, Pitfalls, and Prospects. Diabetes Care (2013) 36:1413–21. doi: 10.2337/dc12-2211
160. Knip M, Simell O. Environmental Triggers of Type 1 Diabetes. Cold Spring Harbor Perspect Med (2012) 2:a007690. doi: 10.1101/cshperspect.a007690
161. Lega IC, Lipscombe LL. Diabetes, Obesity, and Cancer—Pathophysiology and Clinical Implications. Endocrine Rev (2020) 41:33–52. doi: 10.1210/endrev/bnz014
162. Krentz NA, Gloyn AL. Insights Into Pancreatic Islet Cell Dysfunction From Type 2 Diabetes Mellitus Genetics. Nat Rev Endocrinol (2020) 16:202–12. doi: 10.1038/s41574-020-0325-0
163. Redondo MJ, Concannon P. Genetics of Type 1 Diabetes Comes of Age. Diabetes Care (2020) 43:16–8. doi: 10.2337/dci19-0049
164. Sheikhpour M, Abolfathi H, Khatami S, Meshkani R, Barghi TS. The Interaction Between Gene Profile and Obesity in Type 2 Diabetes: A Review. Obes Med (2020) 18:100197. doi: 10.1016/j.obmed.2020.100197
165. Redondo MJ, Steck AK, Pugliese A. Genetics of Type 1 Diabetes. Pediatr Diabetes (2018) 19:346–53. doi: 10.1111/pedi.12597
166. Nadeau JH. Modifier Genes in Mice and Humans. Nat Rev Genet (2001) 2:165–74. doi: 10.1038/35056009
167. Franzago M, Fraticelli F, Stuppia L, Vitacolonna E. Nutrigenetics, Epigenetics and Gestational Diabetes: Consequences in Mother and Child. Epigenetics (2019) 14:215–35. doi: 10.1080/15592294.2019.1582277
168. Singh R, Chandel S, Dey D, Ghosh A, Roy S, Ravichandiran V, et al. Epigenetic Modification and Therapeutic Targets of Diabetes Mellitus. Bioscience Rep (2020) 40. doi: 10.1042/BSR20202160
169. Haldane J. The Relative Importance of Principal and Modifying Genes in Determining Some Human Diseases. J Genet (1941) 41:149–57. doi: 10.1007/BF02983018
170. Verge CF, Vardi P, Babu S, Bao F, Erlich HA, Bugawan T, et al. Evidence for Oligogenic Inheritance of Type 1 Diabetes in a Large Bedouin Arab Family. J Clin Invest (1998) 102:1569–75. doi: 10.1172/JCI3379
171. Gioeva OA, Zubkova NA, Tikhonovich YV, Petrov VM, Vasilyev EV, Kiyaev AV, et al. Clinical and Molecular Genetic Characteristics of MODY Cases With Digenic and Oligogenic Inheritance as Defined by Targeted Next-Generation Sequencing. Problems Endocrinol (2016) 62:20–7. doi: 10.14341/probl201662620-27
172. Vardarli I, Baier LJ, Hanson RL, Akkoyun I, Fischer C, Rohmeiss P, et al. Gene for Susceptibility to Diabetic Nephropathy in Type 2 Diabetes Maps to 18q22. 3-23. Kidney Int (2002) 62:2176–83. doi: 10.1046/j.1523-1755.2002.00663.x
173. Nerup J, Platz P, Andersen OO, Christy M, Lyngsøe J, Poulsen J, et al. HL-a Antigens and Diabetes Mellitus. Lancet (1974) 304:864–6. doi: 10.1016/S0140-6736(74)91201-X
174. Grant SF, Thorleifsson G, Reynisdottir I, Benediktsson R, Manolescu A, Sainz J, et al. Variant of Transcription Factor 7-Like 2 (TCF7L2) Gene Confers Risk of Type 2 Diabetes. Nat Genet (2006) 38:320–3. doi: 10.1038/ng1732
175. Mahajan A, Wessel J, Willems SM, Zhao W, Robertson NR, Chu AY, et al. Refining the Accuracy of Validated Target Identification Through Coding Variant Fine-Mapping in Type 2 Diabetes. Nat Genet (2018) 50:559–71. doi: 10.1038/s41588-018-0084-1
176. Mahdessian H, Taxiarchis A, Popov S, Silveira A, Franco-Cereceda A, Hamsten A, et al. TM6SF2 Is a Regulator of Liver Fat Metabolism Influencing Triglyceride Secretion and Hepatic Lipid Droplet Content. Proc Natl Acad Sci (2014) 111:8913–8. doi: 10.1073/pnas.1323785111
177. Guo D, Li M, Zhang Y, Yang P, Eckenrode S, Hopkins D, et al. A Functional Variant of SUMO4, a New Iκbα Modifier, Is Associated With Type 1 Diabetes. Nat Genet (2004) 36:837. doi: 10.1038/ng1391
178. Lehman DM, Fu D-J, Freeman AB, Hunt KJ, Leach RJ, Johnson-Pais T, et al. A Single Nucleotide Polymorphism in Mgea5 Encoding O-Glcnac–Selective N-Acetyl-β-D Glucosaminidase Is Associated With Type 2 Diabetes in Mexican Americans. Diabetes (2005) 54:1214–21. doi: 10.2337/diabetes.54.4.1214
179. Hon C-C, Ramilowski JA, Harshbarger J, Bertin N, Rackham OJ, Gough J, et al. An Atlas of Human Long Non-Coding RNAs With Accurate 5′ Ends. Nature (2017) 543:199–204. doi: 10.1038/nature21374
180. Gordon CT, Lyonnet S. Enhancer Mutations and Phenotype Modularity. Nat Genet (2014) 46:3–4. doi: 10.1038/ng.2861
181. Thurman RE, Rynes E, Humbert R, Vierstra J, Maurano MT, Haugen E, et al. The Accessible Chromatin Landscape of the Human Genome. Nature (2012) 489:75–82. doi: 10.1038/nature11232
182. Zhang F, Lupski JR. Non-Coding Genetic Variants in Human Disease. Hum Mol Genet (2015) 24:R102–10. doi: 10.1093/hmg/ddv259
183. Maston GA, Evans SK, Green MR. Transcriptional Regulatory Elements in the Human Genome. Annu Rev Genomics Hum Genet (2006) 7:29–59. doi: 10.1146/annurev.genom.7.080505.115623
184. Djebali S, Davis CA, Merkel A, Dobin A, Lassmann T, Mortazavi A, et al. Landscape of Transcription in Human Cells. Nature (2012) 489:101–8. doi: 10.1038/nature11233
185. Cabili MN, Trapnell C, Goff L, Koziol M, Tazon-Vega B, Regev A, et al. Integrative Annotation of Human Large Intergenic Noncoding RNAs Reveals Global Properties and Specific Subclasses. Genes Dev (2011) 25:1915–27. doi: 10.1101/gad.17446611
186. Ruan X. Long Non-Coding RNA Central of Glucose Homeostasis. J Cell Biochem (2016) 117:1061–5. doi: 10.1002/jcb.25427
187. Lynn FC, Skewes-Cox P, Kosaka Y, McManus MT, Harfe BD, German MS. MicroRNA Expression is Required for Pancreatic Islet Cell Genesis in the Mouse. Diabetes (2007) 56:2938–45. doi: 10.2337/db07-0175
188. Kameswaran V, Bramswig NC, McKenna LB, Penn M, Schug J, Hand NJ, et al. Epigenetic Regulation of the DLK1-MEG3 microRNA Cluster in Human Type 2 Diabetic Islets. Cell Metab (2014) 19:135–45. doi: 10.1016/j.cmet.2013.11.016
189. Morán I, Akerman I, Van De Bunt M, Xie R, Benazra M, Nammo T, et al. Human β Cell Transcriptome Analysis Uncovers lncRNAs That Are Tissue-Specific, Dynamically Regulated, and Abnormally Expressed in Type 2 Diabetes. Cell Metab (2012) 16:435–48. doi: 10.1016/j.cmet.2012.08.010
190. He X, Ou C, Xiao Y, Han Q, Li H, Zhou S. LncRNAs: Key Players and Novel Insights Into Diabetes Mellitus. Oncotarget (2017) 8:71325. doi: 10.18632/oncotarget.19921
191. Wang M, Wang S, Yao D, Yan Q, Lu W. A Novel Long Non-Coding RNA Cyp4b1-PS1-001 Regulates Proliferation and Fibrosis in Diabetic Nephropathy. Mol Cell Endocrinol (2016) 426:136–45. doi: 10.1016/j.mce.2016.02.020
192. Ricaño-Ponce I, Wijmenga C. Mapping of Immune-Mediated Disease Genes. Annu Rev Genomics Hum Genet (2013) 14:325–53. doi: 10.1146/annurev-genom-091212-153450
193. Sakabe NJ, Savic D, Nobrega MA. Transcriptional Enhancers in Development and Disease. Genome Biol (2012) 13:1–11. doi: 10.1186/gb-2012-13-1-238
194. Sanyal A, Lajoie BR, Jain G, Dekker J. The Long-Range Interaction Landscape of Gene Promoters. Nature (2012) 489:109–13. doi: 10.1038/nature11279
195. Akerman I, Tu Z, Beucher A, Rolando DM, Sauty-Colace C, Benazra M, et al. Human Pancreatic β Cell lncRNAs Control Cell-Specific Regulatory Networks. Cell Metab (2017) 25:400–11. doi: 10.1016/j.cmet.2016.11.016
196. Pasquali L, Gaulton KJ, Rodríguez-Seguí SA, Mularoni L, Miguel-Escalada I, Akerman I, et al. Pancreatic Islet Enhancer Clusters Enriched in Type 2 Diabetes Risk-Associated Variants. Nat Genet (2014) 46:136–43. doi: 10.1038/ng.2870
197. Mirza AH, Kaur S, Pociot F. Long Non-Coding RNAs as Novel Players in β Cell Function and Type 1 Diabetes. Hum Genomics (2017) 11:17. doi: 10.1186/s40246-017-0113-7
198. Leung A, Natarajan R. Long Noncoding RNAs in Diabetes and Diabetic Complications. Antioxidants Redox Signaling (2018) 29:1064–73. doi: 10.1089/ars.2017.7315
199. Hattersley AT, Patel KA. Precision Diabetes: Learning From Monogenic Diabetes. Diabetologia (2017) 60:769–77. doi: 10.1007/s00125-017-4226-2
200. Vaxillaire M, Bonnefond A, Froguel P. The Lessons of Early-Onset Monogenic Diabetes for the Understanding of Diabetes Pathogenesis. Best Pract Res Clin Endocrinol Metab (2012) 26:171–87. doi: 10.1016/j.beem.2011.12.001
201. Yang Y, Chan L. Monogenic Diabetes: What it Teaches Us on the Common Forms of Type 1 and Type 2 Diabetes. Endocrine Rev (2016) 37:190–222. doi: 10.1210/er.2015-1116
202. Maguire JA, Gagne AL, Jobaliya CD, Gandre-Babbe S, Gadue P, French DL. Generation of Human Control iPS Cell Line CHOPWT10 From Healthy Adult Peripheral Blood Mononuclear Cells. Stem Cell Res (2016) 16:338–41. doi: 10.1016/j.scr.2016.02.017
203. Yang W, Mills JA, Sullivan S, Liu Y, French DL, Gadue P. iPSC Reprogramming From Human Peripheral Blood Using Sendai Virus Mediated Gene Transfer. Stem Book (2008) 1–6. doi: 10.3824/stembook.1.73.1
204. Tsonkova VG, Sand FW, Wolf XA, Grunnet LG, Ringgaard AK, Ingvorsen C, et al. The Endoc-βh1 Cell Line Is a Valid Model of Human Beta Cells and Applicable for Screenings to Identify Novel Drug Target Candidates. Mol Metab (2018) 8:144–57. doi: 10.1016/j.molmet.2017.12.007
205. Doane AS, Elemento O. Regulatory Elements in Molecular Networks. Wiley Interdiscip Rev Syst Biol Med (2017) 9:e1374. doi: 10.1002/wsbm.1374
206. Dunham I, Birney E, Lajoie BR, Sanyal A, Dong X, Greven M, et al. An Integrated Encyclopedia of DNA Elements in the Human Genome. Nature (2012) 489(7414):57–74. doi: 10.1038/nature11247
207. Kundaje A, Meuleman W, Ernst J, Bilenky M, Yen A, Heravi-Moussavi A, et al. Integrative Analysis of 111 Reference Human Epigenomes. Nature (2015) 518:317–30. doi: 10.1038/nature14248
208. Johnson JD. The Quest to Make Fully Functional Human Pancreatic Beta Cells From Embryonic Stem Cells: Climbing a Mountain in the Clouds. Diabetologia (2016) 59:2047–57. doi: 10.1007/s00125-016-4059-4
209. Tremmel DM, Mitchell SA, Sackett SD, Odorico JS. Mimicking Nature-Made Beta Cells: Recent Advances Towards Stem Cell-Derived Islets. Curr Opin Organ Transplant (2019) 24:574. doi: 10.1097/MOT.0000000000000687
210. Melton D. The Promise of Stem Cell-Derived Islet Replacement Therapy. Diabetologia (2021) 64:1030–36. doi: 10.1007/s00125-020-05367-2
211. Velazco-Cruz L, Goedegebuure MM, Millman JR. Advances Toward Engineering Functionally Mature Human Pluripotent Stem Cell-Derived β Cells. Front Bioeng Biotechnol (2020) 8:786. doi: 10.3389/fbioe.2020.00786
Keywords: IPS (induced pluripotent stem) cell, pluripotent stem cell (PSC), beta cell (β cell), diabetes, disease modifier, MODY (mature onset diabetes of the young), candidate gene approach, GWAS (genome-wide association study)
Citation: George MN, Leavens KF and Gadue P (2021) Genome Editing Human Pluripotent Stem Cells to Model β-Cell Disease and Unmask Novel Genetic Modifiers. Front. Endocrinol. 12:682625. doi: 10.3389/fendo.2021.682625
Received: 18 March 2021; Accepted: 13 May 2021;
Published: 02 June 2021.
Edited by:
Holger Andreas Russ, University of Colorado Anschutz Medical Campus, United StatesReviewed by:
Jason Spaeth, Indiana University School of Medicine, United StatesCopyright © 2021 George, Leavens and Gadue. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Paul Gadue, Z2FkdWVwQGNob3AuZWR1
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.