 Zhewei Liu1
Zhewei Liu1 Dayong Guo2*
Dayong Guo2*- 1School of Public Education, Suzhou Institute of Technology, Jiangsu University of Science And Technology, Zhangjiagang, Jiangsu, China
- 2College of Culture and Tourism, Quzhou College of Technology, Quzhou, Zhejiang, China
Introduction: Soccer events require a lot of energy, resulting in significant carbon emissions. To achieve carbon neutrality, it is crucial to reduce the cost and energy consumption of soccer events. However, current methods for cost minimization often have high equipment requirements, time-consuming training, and many parameters, making them unsuitable for real-world industrial scenarios. To address this issue, we propose a lightweight CNN model based on transfer learning to study cost minimization strategies for soccer events in a carbon-neutral context.
Methods: Our proposed lightweight CNN model uses a downsampling module based on the human brain for efficient information processing and a transfer learning-based module to speed up the training progress. We conducted experiments to evaluate the performance of our model and compared it with existing models in terms of the number of parameters and computation and recognition accuracy.
Results: The experimental results show that our proposed network model has significant advantages over existing models in terms of the number of parameters and computation while achieving higher recognition accuracy than conventional models. Our model effectively predicts soccer event data and proposes more reasonable strategies to optimize event costs and accelerate the realization of carbon neutral goals.
Discussion: Our proposed lightweight CNN model based on transfer learning is a promising method for studying cost minimization strategies for soccer events in a carbon-neutral context. The use of a downsampling module based on the human brain and a transfer learning-based module allows for more efficient information processing and faster training progress. The results of our experiments indicate that our model outperforms existing models and can effectively predict soccer event data and propose cost optimization strategies. Our model can contribute to the realization of carbon-neutral goals in the sports industry.
1 Introduction
In the context of carbon neutrality, the cost of soccer events may increase. This is because achieving carbon neutrality requires adopting greener and more energy-efficient technologies and equipment, which can be more expensive than conventional equipment and technologies (Ning et al., 2023). At the same time, adopting environmentally friendly and energy-saving technologies may increase organizational and management costs, such as energy management, waste disposal, etc. Therefore, it is significant to study the cost minimization of soccer events.
First, soccer events are large-scale activities that will generate a lot of energy consumption and carbon emissions (Pereira et al., 2020). By minimizing the cost of inspecting soccer events, we can achieve more environmentally friendly and sustainable soccer events and promote sustainable development. Second, reducing carbon emissions has become a social consensus in the context of carbon neutrality (Dong et al., 2023). Studying the cost minimization of soccer events can reduce social costs, reduce carbon emissions and energy consumption, and contribute to society and the environment. Third, minimizing the cost of soccer events can reduce costs and improve the quality of events. By adopting more environmentally friendly and efficient technologies and equipment, the efficiency and appreciation of the event will be improved, and the event’s audience experience and brand image will be enhanced (Wang et al., 2022a). Finally, research on the minimization of the cost of soccer events requires the adoption of new technologies and new equipment, which will help promote technological innovation and development and promote the upgrading and transformation of the soccer industry.
In artificial intelligence, the most commonly used method is to use neural networks to build predictive models and use training data to predict the changing trends and influencing factors of soccer event costs to formulate more effective cost-minimization strategies. Commonly used models and methods for neural networks are as follows:
● Transfer learning method: Transfer learning has become a research hotspot and is applied to many fields. Transfer learning is mainly used for two problems: (1) small sample learning and (2) optimization for specific problems (Sayed et al., 2022).
When the amount of data is small, traditional machine learning methods cannot learn the same distribution as the test set from the training set. Therefore, migration learning is used to extract the required knowledge from the models of other tasks to accomplish the new job. There is also a case when a model needs to be applied to a specific domain, such as crop pest identification, bearing fault diagnosis, etc. In this case, migration learning can solve the problem of insufficient data by migrating a pre-trained model on ImageNet to a new task. Some scholars have proposed inductive migration learning, which can adjust the model according to the effect of misclassification (Sayed et al., 2022). For example, after a sample in the target domain is incorrectly classified, it isn’t easy to correct such a result even through multiple training sessions, so increasing the weight of this sample in the next training session. More features of this part will be learned. Some scholars have also proposed unsupervised migration learning. This method first requires dimensionality reduction of the data and then uses the commonly used kernel functions to make predictions, reducing much of the computational effort by this method. Some scholars proposed a direct push migration learning method, mainly designed to deal with the data adaptation problem within the migration learning domain. Iteration using weak classifiers is required to obtain new pseudo labels. Some scholars have proposed development set migration learning, an approach that exploits the mapping relationship between the source and target domains by learning this mapping. Then, the target domain will add new labels that enable the final return to a specific target value (He and Ye, 2022).
● Convolutional Neural Network (CNN) (Yang et al., 2022b): CNN can be used to analyze and process image and video data, such as monitoring and analyzing energy consumption and carbon emissions of event venues, to formulate corresponding energy management and carbon emission reduction strategies;
● Recurrent Neural Network (RNN) (Ljubenkov et al., 2020): RNN can be used to analyze and predict the number of participants and demand trends of events to formulate more reasonable event arrangements and resource allocation strategies;
CNN is a neural network structure specially designed to process image, visual and spatial data. It can automatically learn image and visual features through operations such as convolution and pooling, and perform well in tasks such as image classification, object detection, and image segmentation. However, CNN is not as good as RNN in processing time series and sequence data relative to RNN(Wu et al., 2022).
RNN is a neural network structure specially designed to process sequence data, speech and text data. Through feedback connections of recurrent neurons, it can capture temporal information in time series and perform well in tasks such as speech recognition, machine translation, and text generation. However, RNN has problems such as gradient disappearance and gradient explosion when processing long sequence data.
Therefore, CNN and RNN each have unique advantages and disadvantages, which are suitable for different tasks and application scenarios. In practical applications, we must choose the appropriate neural network structure to process data according to the specific situation.
● Long short-term memory network (LSTM) (Reza et al., 2022): LSTM can be used to analyze and predict the number of participants and spectators of the event to formulate more accurate ticket sales and marketing strategies.
LSTM is a commonly used RNN, which solves the problems of gradient disappearance and gradient explosion in traditional RNN through special memory cells (memory cells) and gating mechanisms (gates) (Sun et al., 2021). It can take better handling of long sequence data. The LSTM model can be used in the research on the cost minimization strategy of soccer events under the background of carbon neutrality (Niu et al., 2022). The specific applications are as follows: Prediction of the number of participants and spectators—the 88 LSTM model can be used to analyze the number of participants and spectators in historical events and predict the number of participants and spectators in future events to formulate more accurate ticket sales and marketing strategies and avoid waste of resources and high cost of risks; Event equipment and venue management—the LSTM model can be used to analyze the usage of equipment and venues in historical events and predict the demand for equipment and platforms in future events to rationally configure and use event equipment and media and avoid the risk of waste of resources and high costs (Zhang et al., 2023); Event security management—the LSTM model can be used to analyze the security situation of historical events and predict the security risks and demands of future events to formulate more scientific and effective event security management strategies to ensure the safety of event participants and spectators; the LSTM model can be used in the research on the cost minimization strategy of soccer events under the background of carbon neutrality. By analyzing historical event data and predicting future event demand, a more reasonable and effective event resource allocation, ticket sales and marketing strategy can be formulated, thereby realizing the goal of cost minimization and promoting the sustainable development of soccer events (Wang et al., 2021).
● Reinforcement Learning (RL) (Ahmad et al., 2022): RL can be used to formulate event safety management and resource optimization strategies and continuously optimize and adjust strategies through feedback mechanisms to achieve the goal of cost minimization.
RL is a machine learning method that is mainly used to deal with the process of an agent (agent) learning through trial and error in an environment to maximize the cumulative reward (cumulative reward). In RL, an agent knows how to choose actions to maximize compensation by interacting with the environment (Fathi et al., 2020).
In the research on the cost minimization strategy of soccer events in the context of carbon neutrality, RL can be used in the following aspects: Ticket sales strategy—RL can be used to formulate an optimal ticket sales strategy and adaptively adjust ticket prices and preferential policies based on historical data and environmental changes to maximize ticket sales revenue (Akanksha et al., 2021); Event equipment and venue management (Yang et al., 2022a)—RL can be used to formulate optimal event equipment and venue management strategies and adaptively adjust equipment and venue usage plans based on historical data and environmental changes to maximize the utilization efficiency of equipment and media and reduce carbon emissions; Event security management—RL can be used to formulate optimal event security management strategies and adaptively adjust security measures and emergency plans based on historical data and environmental changes to ensure the safety of event participants and spectators and reduce security costs (Heidari et al., 2023); RL can be used to study cost-minimization strategies for soccer events in the context of carbon neutrality by adaptively adjusting strategies to maximize revenue and utilization efficiency and reduce costs and carbon emissions (Panzer and Bender, 2022). The advantage of RL is that it can learn the optimal strategy through interaction with the environment, and it has strong adaptability and iterative optimization capabilities(Yang et al., 2023).
However, these deep learning methods have many parameters, high equipment requirements, and time consuming inference and training. This will not only lead to high time costs for training and inference, but also impose a considerable burden on the environment. To deal with these problems, this paper proposes a lightweight CNN-based transfer learning method (TL-Net) for the cost minimization of soccer events in a carbon-neutral context. TL-Net consists of two main modules: a transfer learning module and a new downsampling module. The transfer learning module can learn from other common historical data sets to obtain better initial solutions and accelerate the initial training process of the model. A new downsampling module is also included, where we replace the traditional downsampling module (He et al., 2016) in ResNet50 and use the new downsampling module proposed in this paper. This new downsampling module has faster information processing speed. It can extract more feature information, which enables TL-Net to achieve higher accuracy with fewer parameters and calculations. Then, based on these prediction data, such as soccer event data, including player data, game data, audience data, and the changing trend and influencing factors of soccer event expenses, a more reasonable event arrangement and resource allocation strategy can be formulated more reasonably and more accurately ticket sales and marketing strategy (Zhang et al., 2019).
The main points of contribution of this paper are summarized as follows:
● The lightweight CNN model based on migration learning has a smaller model size and parameter volume. Compared with some complex deep learning models, it has a higher running speed and lower computing cost, which can significantly shorten the model training and prediction time.
● The lightweight CNN model based on transfer learning can use existing large-scale data sets and pre-trained models, avoid training the model from scratch, and improve the accuracy and generalization ability of the model. Since there may be a small amount of data in studying cost-minimization strategies for soccer events, transfer learning can better use limited resources.
● The lightweight CNN model based on transfer learning has high recognition and classification accuracy and can accurately analyze and predict the use of venues, equipment and resources in the study of soccer event cost minimization strategies to formulate more Precise and effective cost minimization strategies.
The remaining paragraphs of this paper are organized as follows: In Section 2, we provide the proposed method, including the overall structure of the network and the rationale for the downsampling and transfer learning modules. In Section 3, we first introduce the datasets used for experiments, including the benchmark dataset proposed in this paper. We then disclose the details of the experiments, present the results, and analyze them. Section 4 discusses the validity, limitations and future work of this paper and concludes the whole paper.
2 Methodology
In this section, we present the proposed approach. First, the overall framework of the network is introduced, and then the principles of the migration learning module and the new sampling module are presented. The training process of the TL-Net algorithm is shown in algorithm 1.

Algorithm 1 Algorithm of TL-Net
Where:
θ: Indicates the hyperparameters in the TL-Net model, including the size of the convolution kernel, the depth of the convolution layer, and the learning rate. In the algorithm, we initialized the hyperparameters and performed iterative optimization to minimize the loss function.
g(i): Indicates that in the ith epoch, use our proposed new downsampling module to accelerate the speed of information processing. In the algorithm, Vectors is obtained in this way and used to evaluate the TL-Net loss on the validation set.
f(θ): Indicates the loss function, which is the objective function optimized by the TL-Net model during training. In the algorithm, we optimize the TL-Net model by minimizing f(θ).
In the algorithm, we first divide the training data set into a 70% training set (Dtrain) and a 30% validation set (Dvalid). Then, we utilize our proposed transfer learning module to speed up the training, initialize the hyperparameters with the pre-trained model, and then use our proposed new downsampling module to accelerate the information processing speed. For each hyperparameter θ, we train in multiple epochs to obtain the loss of TL-Net by evaluating the loss on the validation set. If the loss is smaller than the best loss, update the best hyperparameter θbest. Finally, we return the trained TL-Net model.
2.1 Framework
Inspired by EfficientNet (Marques et al., 2020), we propose a new lightweight CNN-based migration learning network model.
As shown in Figure 1, the network framework has two essential parts: a new downsampling module and a migration learning module. The downsampling module is used to speed up the regular training and inference, and the migration learning module is used to speed up the initial training. In the new downsampling module, we achieve high network efficiency by reducing the feature map size while maintaining a high feature extraction capacity. This module speeds up the network inference by eliminating redundant information in the forward propagation process while maintaining high accuracy. And in the migration learning module, we utilize pre-trained weights to speed up the initial training of the network and significantly improve the accuracy of the network. In addition, the migration learning module allows us to learn features from the existing pre-trained model, which substantially improves the generalization ability of our network. In addition, our network models are easy to train and tune. We use a lightweight CNN-based architecture, which contains fewer parameters while ensuring the efficiency of the network. As a result, our model can be trained and fine-tuned quickly and does not require many computational resources during the training process (Shen et al., 2018).
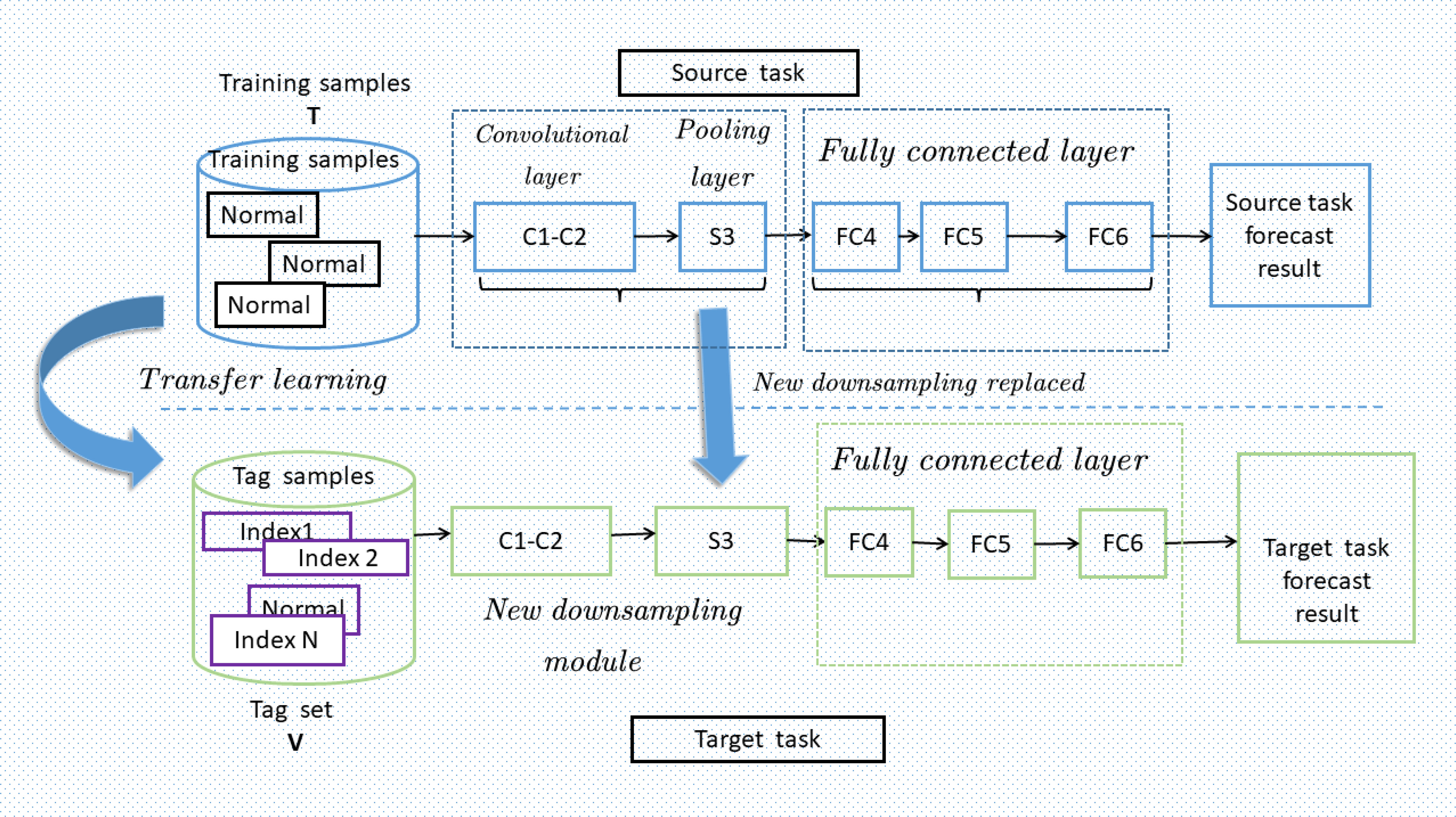
Figure 1 TL-Net’s network framework structure diagram.
Moreover, our model also has better generalization capabilities. We can utilize the knowledge of already pre-trained network models to converge faster through transfer learning. This is very helpful for solving problems with small datasets or a need for labeled data. Moreover, our model supports dynamic scaling of the network. We can add more layers or migration learning modules to the network if higher accuracy is needed. Also, our model supports the lightweight of the network to adapt to different hardware environments.
2.2 Downsampling module
Downsampling is the process of reducing an image to match the size of the display area and generating a thumbnail of the corresponding image. Pooling layers are often used to implement traditional downsampling. However, the pooling layer has an obvious disadvantage: it loses valid information in the image. In addition, the pooling layer will also increase the computational complexity, resulting in slower training and inference (Zhang et al., 2022). To overcome these issues, we propose a novel downsampling module, which can significantly reduce computational complexity and speed up training and inference while preserving effective information. This new module is a key component of the TL-Net method, which can dramatically improve the accuracy and efficiency of moving image classification (Gui-xiang et al., 2018).
To overcome the limitations of traditional pooling layers, various downsampling methods have been proposed in recent years. These methods aim to preserve more information while reducing the computational complexity of the model.
One such method is strided convolution, which involves using a convolutional layer with a stride greater than 1 to perform downsampling. The output feature map has reduced spatial dimensions, and this method has been shown to be effective in preserving more spatial information than pooling layers while maintaining reasonable computational efficiency. The stridden convolution operation can be defined as follows:
where X is the input feature map, W is the convolution kernel, and s is the stride.
Another popular method is dilated convolution, which involves inserting holes in the convolutional filters to increase their receptive field. The dilated convolution operation can be defined as follows:
where X is the input feature map, W is the convolution kernel, and d is the dilation rate.
Attention mechanisms have also been used in downsampling, where self-attention mechanisms can effectively capture global dependencies. The self-attention operation can be defined as follows:
where Q, K, and V are the query, key, and value matrices, respectively, and dk is the dimension of the key vectors.
In addition to these methods, max pooling with overlapping windows and fractional pooling have also been proposed as alternative downsampling methods. The max pooling with overlapping windows operation can be defined as follows:
where X is the input feature map, and s is the stride.
The fractional pooling operation can be defined as follows:
Where:
i,j: Indicates the row and column indices in the input feature map.
k,l: Indicates the row and column indices in the convolution kernel.
s: Indicates the stride of the convolutional layer, that is, the step size of the
convolution kernel moving on the input feature map.
d: Indicates the hole rate of the hole convolution, that is, the number of holes inserted in the middle of the convolution kernel.
X: Indicates the input feature map.
W: Indicates the convolution kernel.
Y: Indicates the output feature map.
Q,K,V: Indicates the query matrix, key matrix and value matrix in self-attention.
dk: Indicates the dimension of the key matrix in self-attention.
To solve this problem, we have improved it based on the human memory mechanism. When humans memorize, they are divided into two parts storage and extraction (Liu et al., 2021). When storing, the memory cells in the human brain, which further process the original input image information, compress and integrate the high-dimensional information. The whole process is speedy and equivalent to short-term memory operation (Chen et al., 2019). For example, if a person views the numbers on paper, they will quickly integrate them into the brain and store them. Thanks to the mechanism of short-term memory, the whole process is speedy. However, the problem is that it is too easy to forget, but the very clever point is that the information stored on the physical medium is preserved. Based on these characteristics, we designed the downsampling module, which can quickly complete the information processing and integration. We can obtain more valid information and faster sampling speed than traditional downsampling methods (Drachman and Leavitt, 1974).
To implement the new downsampling module, we need to solve the information integration and downsampling as well as the new image output. The whole sampling module is divided into an encoder and a decoder. To integrate and downsample the information, the encoder must complete the data conversion by encoding. On the other hand, the decoder outputs a new image as required.
As shown in Figure 2, we offer our new down-sampling module G-D down-sampling module, which is context-aware, both locally and globally. Based on this property, the input variables are downsampled to preserve as many essential features as possible and global features. To quantify this property, we compare our proposed G-D down-sampling module with the current mainstream down-sampling modules in the experimental section, mainly regarding the number of parameters and inference speed(Han and Fu, 2023).
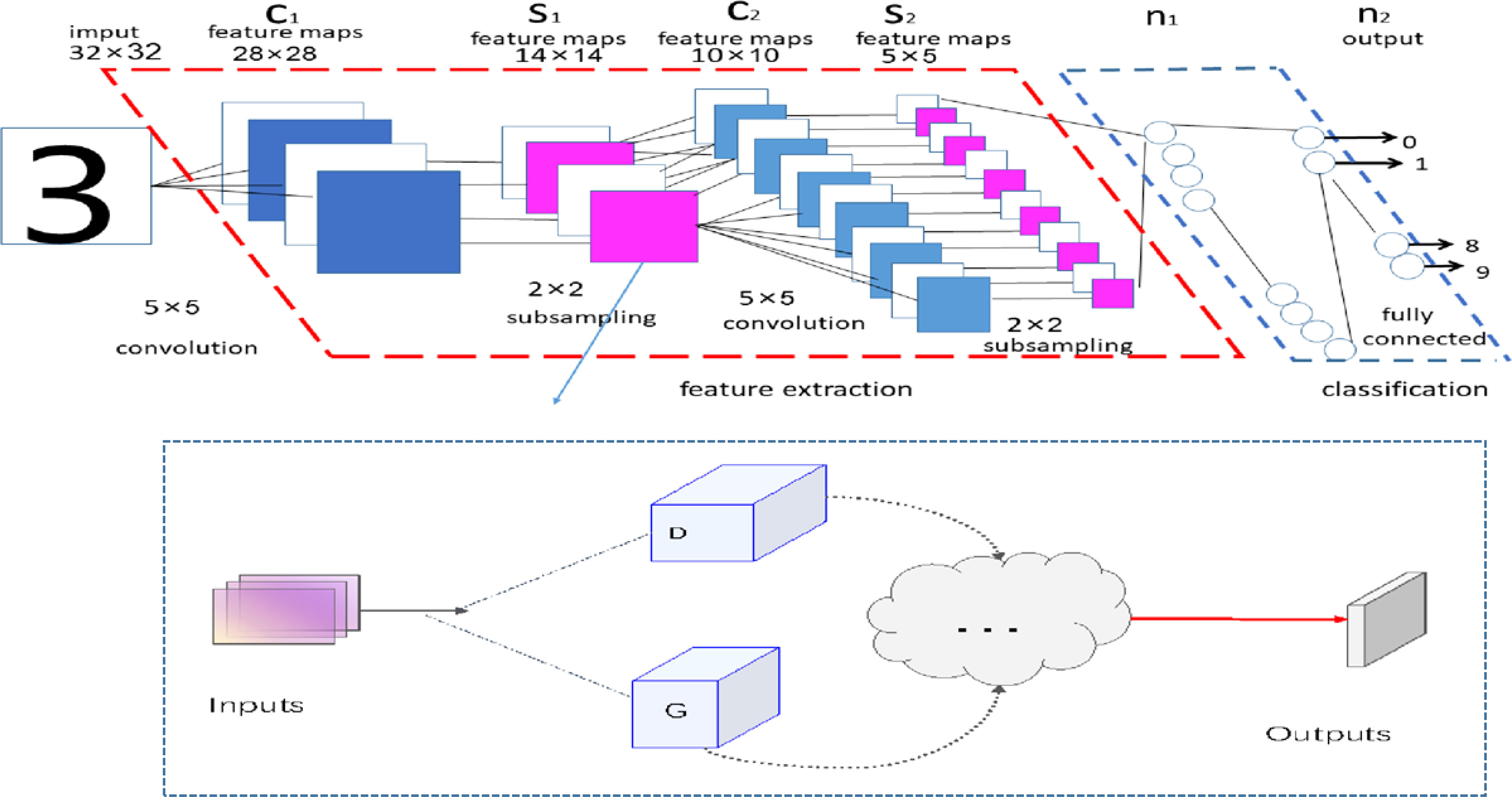
Figure 2 The new down-sampling module G-D down-sampling module is proposed in this paper. Inspired by the human memory mechanism, the corresponding memories are stored and submitted, designed as the corresponding encoders and generators. In the figure, Inputs denotes the input variables, and Outputs indicates output variables. D denotes the encoder, and G means the generator.
In Figure 2, 3 represents the input data, C represents the convolutional layer, S represents the 259 downsampling module, n1 is the input of the fully connected layer, n2 is the final output after 260 in the fully connected layer, and the G-D downsampling module is the refined structure diagram of the S1 261 part, which represents the difference between our proposed lightweight CNN and the traditional CNN 262 convolutional neural network. The main difference in sampling modules:
Here, the human memory mechanism (Mattson, 2014) is expressed formally in Equation 6.
Where:
p: Indicates parameters related to the content to be remembered. These parameters are usually related to the meaning and importance of the content.
q: Indicates parameters related to the quantity of material to remember. These parameters are generally related to memory load and working memory capacity.
r: Indicates parameters related to the time interval for remembering content. These parameters are generally related to the persistence and stability of memory.
tc: Indicates the time constant of human memory ability, that is, the decay rate of human memory. In general, the larger the value of tc, the higher the persistence of human memory.
2.3 Transfer learning module
This module mainly loads large-scale external data sets to allow the model to be hot-started and accelerate the entire training process. Since the soccer event prediction task involves multiple variables with different downsampling kernels but similar parameter spaces, large-scale pre-training can better initialize parameters. This process is denoted as algorithm 2.

Algorithm 2 Algorithm of the transfer learning module (TLM)
The initialization parameters θ and ϕ are two sets of parameters in the transfer learning model, which are usually learned in the pre-trained model. Among them, θ usually refers to the backbone network of the model, including convolutional layers, fully connected layers, etc., while ϕ refers to the auxiliary network of the model, such as classifiers or regressors.
Soccer event data analysis tasks require high-quality, large-scale public datasets, but there are challenges in training data and computation needed for deep understanding. Transfer learning is an effective solution which can reduce the learning difficulty by applying the parameters learned by the model in the old domain to the new learning domain according to the similarity of tasks. In soccer data prediction, transfer learning can be used to find a set of transferable initialization parameters that significantly improve model performance while reducing the number of iterations. Transfer learning can also solve the over-fitting problem that is prone to occur when training small data on complex network structures. Transfer learning can help us better model and understand the hardware resources used for learning during the learning process. Its workflow is shown in Figure 3.
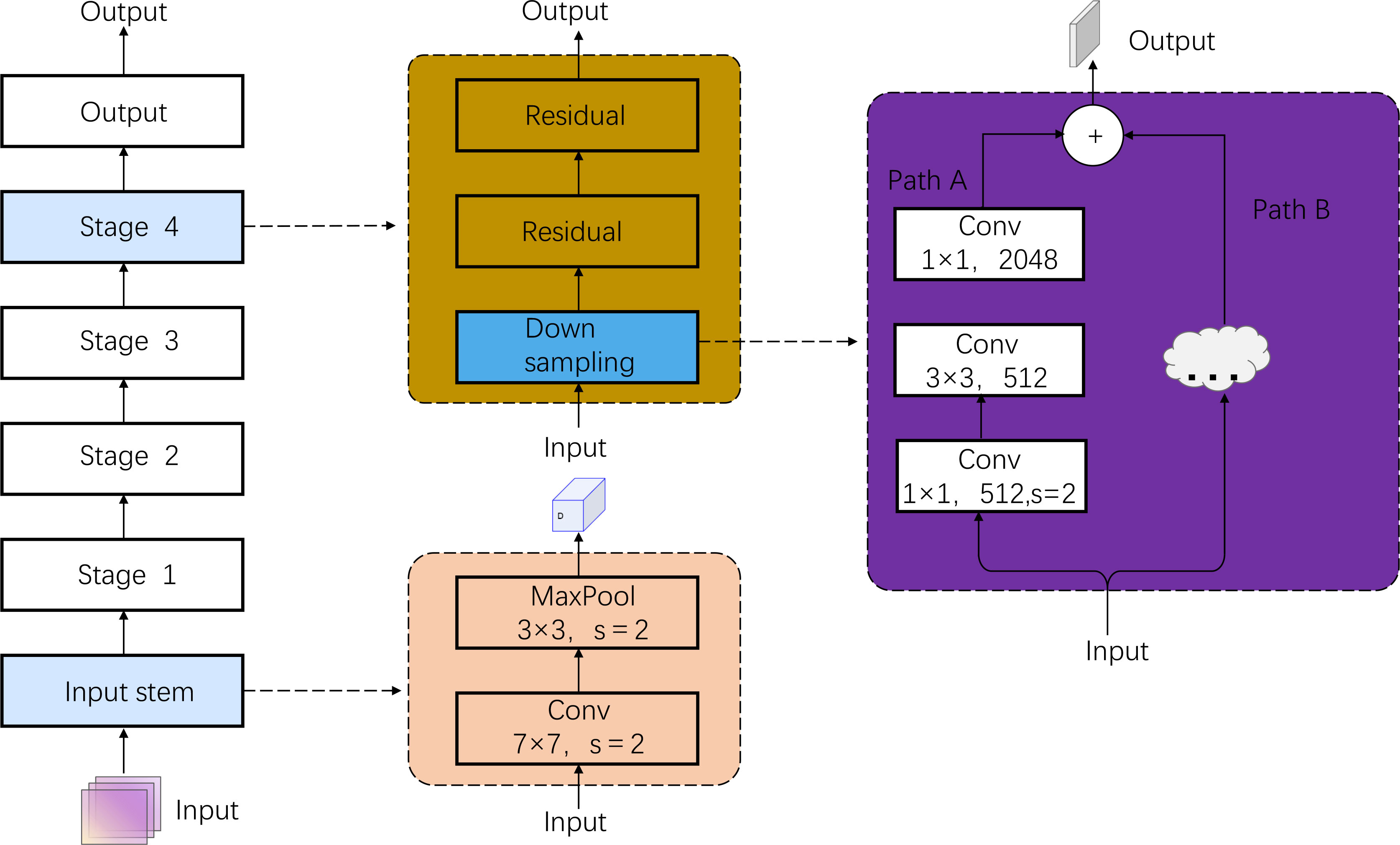
Figure 3 Transfer learning module with Resnet50.
In the soccer event data analysis task, transfer learning has shown to be an effective strategy for reducing the amount of training data and computational effort required for deep understanding. By learning adaptive parameters in the old domain and applying them to the new learning domain, the model can avoid starting from scratch, reducing the model’s difficulty and the hardware resources required for learning. The transfer learning process can be defined as follows:
where θnew and θold are the model parameters for the new and old domains, respectively. Lnew and Lold are the loss functions for the new and old domains, respectively. λ is a hyperparameter that controls the importance of the old domain.
To further improve the performance of the soccer event data analysis, migration learning can be used to find a set of migratable initialization parameters that allow the model to achieve significant performance gains with fewer iterations. Migration learning can be defined as follows:
where θt and θt+1 are the model parameters at time t and t+1, respectively. ηt is the learning rate at time t, and is the gradient of the loss function at time t. γt is the migration rate at time t, and p is the migration period.
To prevent overfitting when training small data on complex network structures, regularization techniques such as dropout can be used. The dropout operation can be defined as follows:
where xi is the input to the dropout layer, yi is the output, and p is the dropout probability.
To improve the efficiency of the soccer event data analysis, batch normalization can be used to normalize the inputs to the activation function. The batch normalization operation can be defined as follows:
where x is the input, μB and are the mean and variance of the batch, and ϵ is a small constant to avoid division by zero.
In addition, data augmentation techniques such as rotation, translation, and scaling can be used to increase the diversity of the training data. The data augmentation operations can be defined as follows:
Where:
x: Represents the original input data.
Rθ(x): Indicates the new data obtained by rotating the input data x counterclockwise around the origin by an angle θ.
Tt(x): Indicates the new data obtained by translating the input data x along the translation vector t.
Ss(x): Indicates the new data obtained by scaling the input data x according to the scaling factor s.
xrot: Indicates the new data obtained after the rotation operation.
xtrans: Indicates the new data obtained after the translation operation.
xscale: Indicates the new data obtained after the scaling operation.
These variables play an important role in data enhancement. By performing operations such as rotation, translation, and scaling on the input data, the diversity of the data set can be increased, thereby improving the generalization ability of the model. In the formula, we use different variables to represent different data in order to better understand and describe the effects of data augmentation operations.
3 Experiment
3.1 Datasets
The data in this article comes from the two data sets of soccer-Reference.com and Kaggle.com. Figure 4 shows the t-SNE visualization of the dataset.
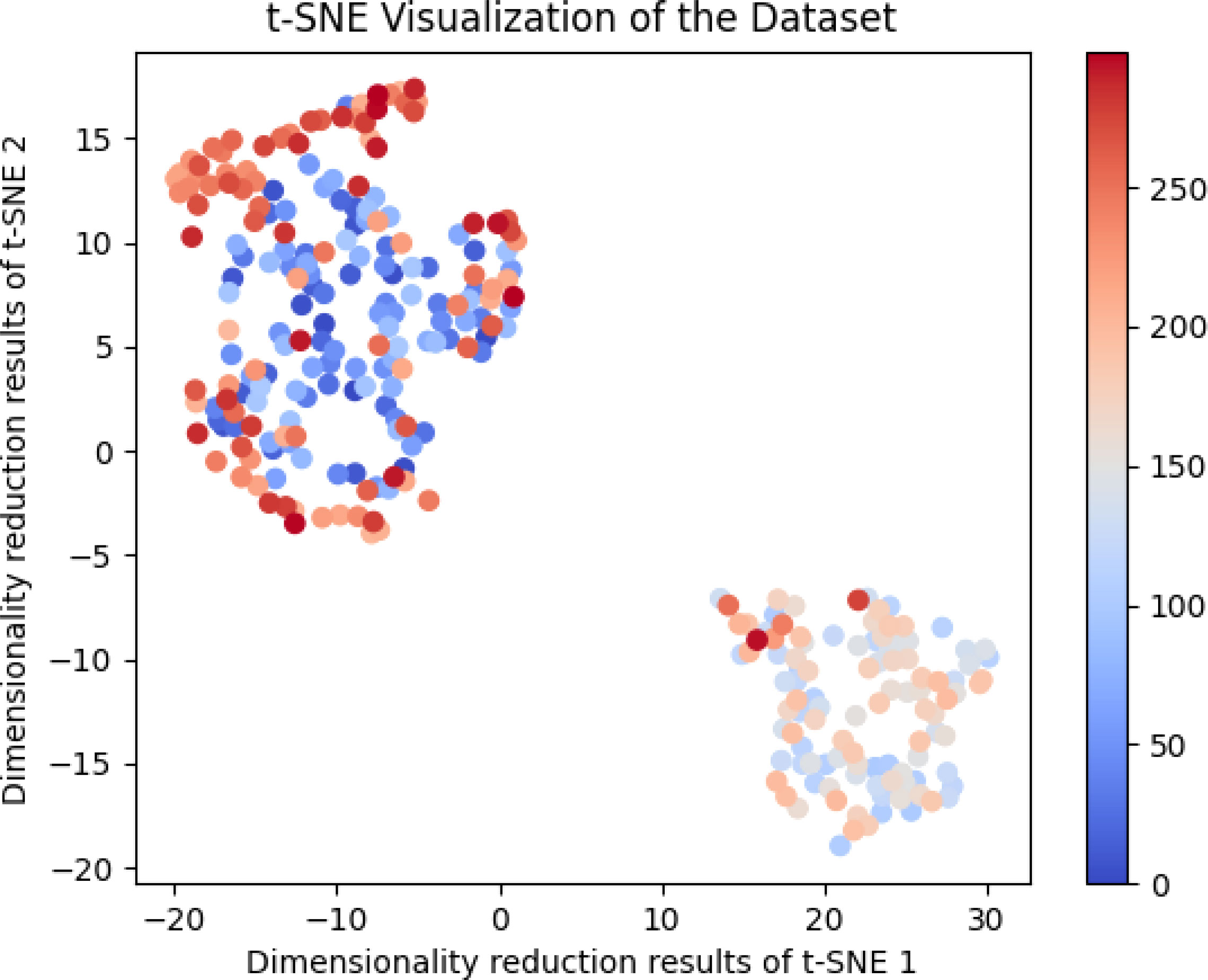
Figure 4 t-SNE visualization of the dataset.
Over the past few decades, the soccer industry has become one of the most popular forms of entertainment worldwide. With the development of technology and data analysis, more and more enterprises and organizations are beginning to use data to formulate optimal soccer event cost-minimization strategies to improve efficiency and reduce costs. In this process, data is very important because it can help us better understand historical trends and predict future needs.
Sports-Reference. com is a website that contains historical data on various sports events (Jenkins, 2005). The site provides match results, player statistics, standings, and records for various sporting events. Additionally, the site offers some advanced statistics, such as expected win percentage per game, value per player, and more. These data can analyze historical trends and predict future demand, helping companies and organizations formulate optimal sports event cost-minimization strategies.
Kaggle. com is a machine learning competition platform that also provides some data sets related to sports events, such as NBA game data, European football game data, etc (Glickman and Sonas, 2015). These data sets can analyze historical trends and predict future demand, helping companies and organizations formulate optimal sports event cost-minimization strategies. Kaggle.com also provides data analysis tools and models to make it easier for users to analyze data and formulate optimal strategies.
Using the datasets provided by Sports-Reference.com and Kaggle.com, businesses and organizations can analyze historical trends and predict future demand to develop optimal sports event cost minimization strategies. For example, using historical event data, it is possible to analyze which events attract the most spectators and participants and the characteristics and advantages of these events. Using environmental change data can predict future environmental changes and adjust strategies. Cost and benefits data can be used to assess costs and benefits and develop optimal strategies. Using social media data can evaluate the event’s social influence and brand value and formulate corresponding marketing strategies.
Overall, the datasets provided by Sports-Reference.com and Kaggle.com are very useful for studying cost minimization strategies for sports events in the context of carbon neutrality. These data sets, and tools can help businesses and organizations better understand historical trends, predict future demand, formulate optimal sports event cost minimization strategies, improve efficiency, and reduce costs. At the same time, attention needs to be paid to the quality and reliability of data and the privacy and security protection of data.
In Table 1, there are some data populations we selected, such as dataset name, dataset size, data type, and data distribution. Among all relevant indicators, we selected these specific indicators in Table 2 and used these indicators as input It can help us better predict the carbon footprint of soccer events and determine the best carbon reduction strategy.

Table 1 Dataset key information.
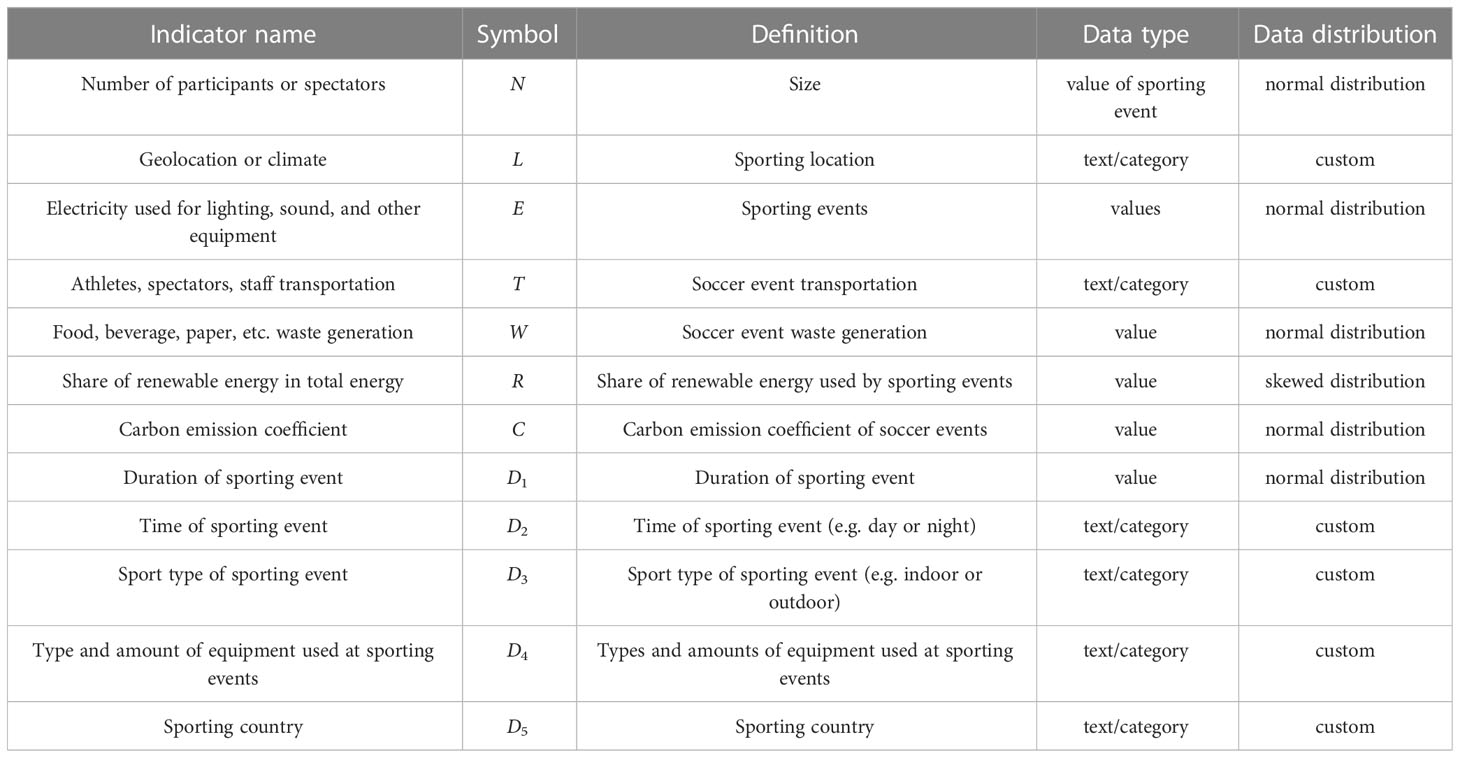
Table 2 Indicators to predict the carbon footprint of soccer events.
Figure 1 shows the result of our t-SNE dimensionality reduction visualization of the data in the two data sets.
When using the t-SNE algorithm to reduce the dimensionality of high-dimensional data to two dimensions, t-SNE will map each sample point to a coordinate point in a two-dimensional space (the dimensionality reduction result of t-SNE). In this paper, we have used data from soccer-Reference.com and Kaggle.com datasets, which obey normal distribution, normal distribution and uniform distribution, respectively, and merged them into one large dataset. Then, we use the t-SNE algorithm to reduce all the data to two dimensions and visualize them using the scatter function.
In this visualization, each point represents a sample in the data set, and the position of each issue results from mapping it to a two-dimensional space by the t-SNE algorithm. Different colors represent different samples in the dataset, and we use the cool, warm color mapping scheme to distinguish other datasets. The visualization results show that the points of different colours are distributed in different regions. This indicates that the t-SNE algorithm successfully determines different data sets while preserving the samples’ local structure and similarity relationship. In addition, it can be seen from the visualization results that the distance between data points reflects their similarity in high-dimensional space; that is, sample points that are closer in high-dimensional space are also closer in two-dimensional space.
At the same time, the x-axis and y-axis labels represent the first and second components of the t-SNE algorithm, respectively, which are the dimensionality reduction results of t-SNE. Each component represents a dimensionality-reduced feature, which is independent of each other and has no specific physical meaning. Still, they are a vital tool for the t-SNE algorithm to describe the similarity between data points and distinguish different data sets.
3.2 Experimental design and details disclosure
Using the Pytorch framework on an NVIDIA 3090ti machine, we implemented the training of the network using the TL-Net dataset and the method proposed in this paper. We chose to use the ADAM optimizer with a learning rate of 2×10−5, which is a popular optimization algorithm for deep learning models. The optimization process can be defined as follows:
where mt and vt are the first and second moments of the gradients, respectively. β1 and β2 are the decay rates for the two moments, and ϵ is a small constant to avoid division by zero. gt is the gradient at time t, at is the model parameters at time t, and a is the learning rate.
We iterated 1 million steps on each network to ensure that the models had sufficient time to converge. The training process can be defined as follows:
where θ* is the optimal model parameters, n is the number of training samples, L is the loss function, f(xi;θ) is the predicted output, and yi is the true label.
We used Resnet as the benchmark model and compared its performance with our proposed TL-Net model. The Resnet model can be defined as follows:
where F is a residual function, x is the input, and Wi are the model parameters.
Our proposed TL-Net model consists of several convolutional layers, followed by a fully connected layer. The TL-Net model can be defined as follows:
where W1, W2, b1, and b2 are the model parameters.
To evaluate the performance of our proposed model, we used several evaluation metrics, including accuracy, precision, recall, and F1 score. These metrics can be defined as follows:
where TP, FP, TN, and FN represent true positive, false positive, true negative, and false negative, respectively.
3.3 Experimental results and analysis
As shown in Table 3, we compare TL-Net with the current mainstream methods. The results show that our proposed model has a significant advantage in terms of correctness, while having a relatively low number of parameters and computational effort.
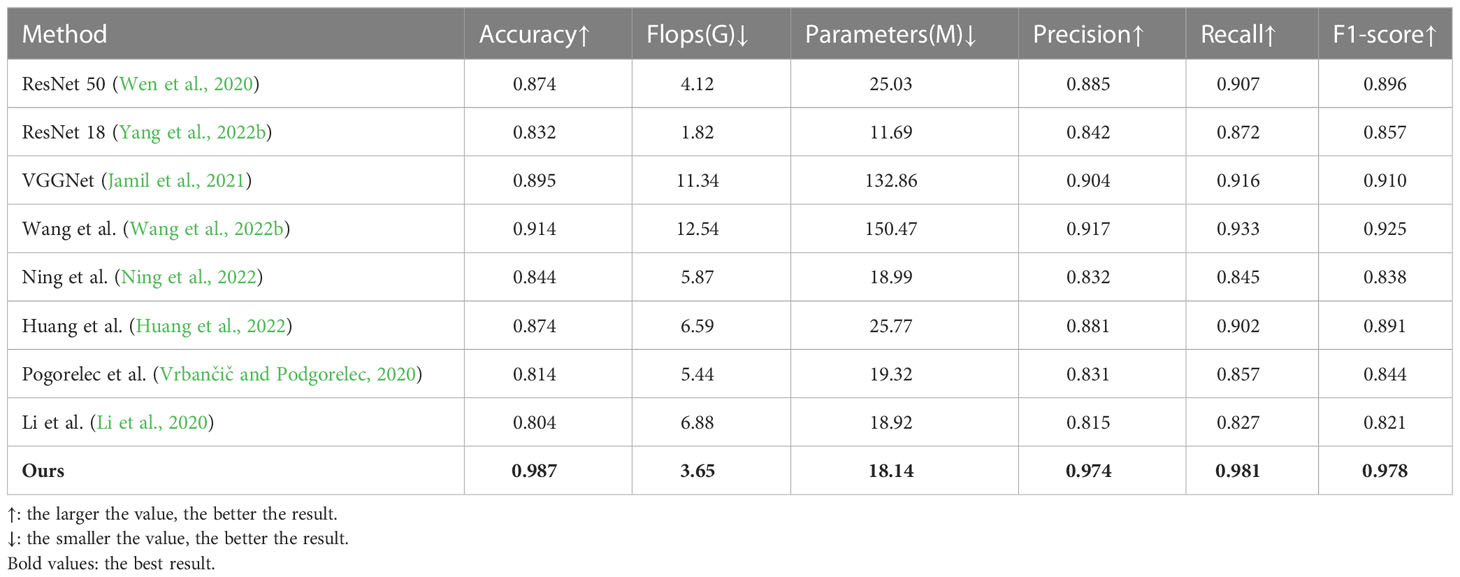
Table 3 Comparison results of TL-Net with mainstream models from testing. (Our proposed TL-Net significantly outperforms other mainstream models in Accuracy, Flops, and Parameter Count, suggesting that our model is more efficient on the task of soccer event prediction. Furthermore, our proposed model also performs well in terms of accuracy, achieving the highest accuracy of 0.987).
Inspired by EfficientNet, we searched the input soccer data, the span and depth of the network to find the best parameters for soccer data prediction. To verify its effectiveness, we conducted experiments. Using the results shown in Figure 5, we divided the test set into five groups and conducted experiments. The results show that the search strategy has a significant impact on the correct rate, which can improve the correct rate by nearly 8%.In addition, we have added a visualization Table 4.
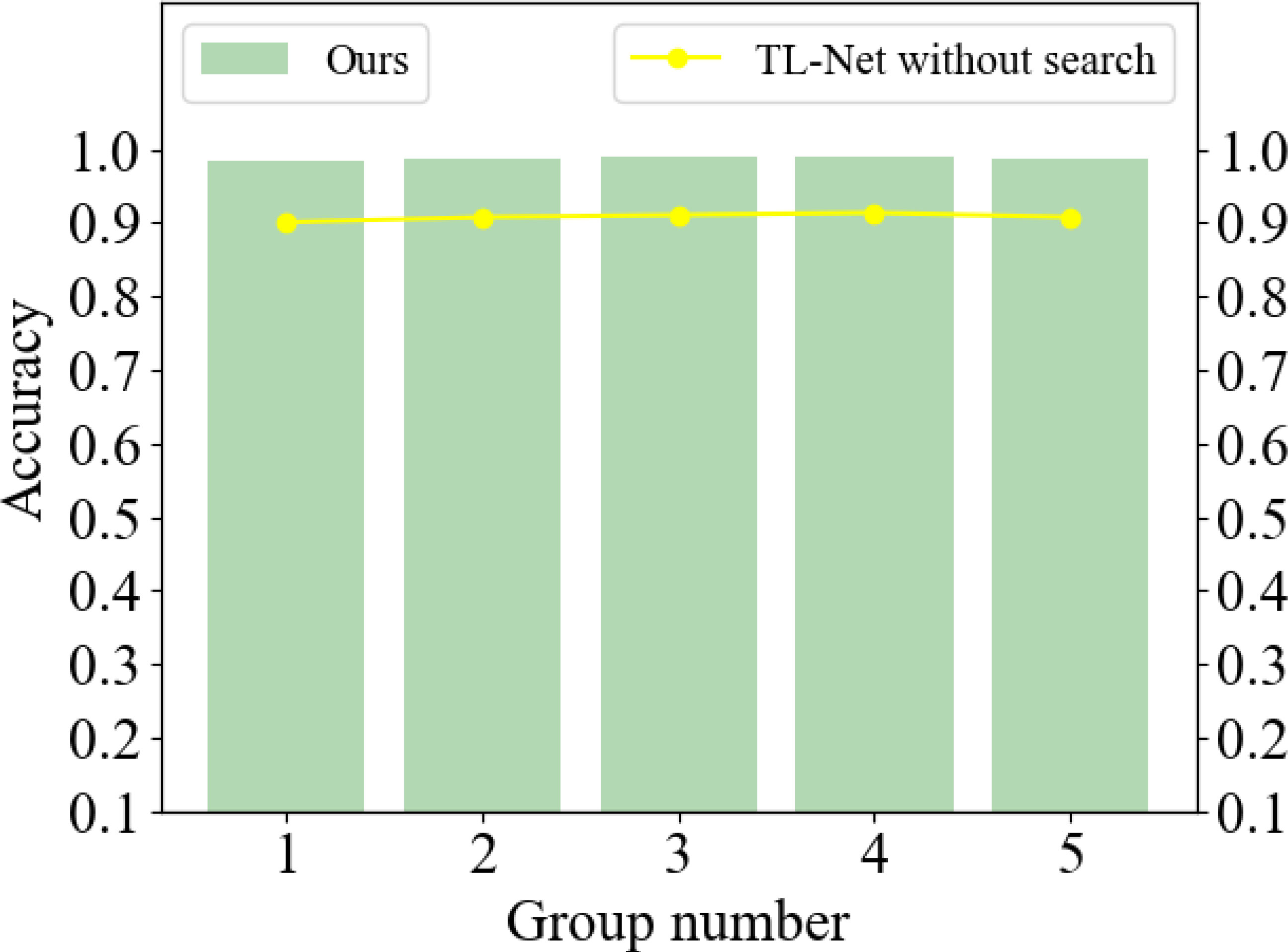
Figure 5 A comparative experiment on the ablation of search strategies.

Table 4 A comparative experiment on the ablation of search strategies.
As shown in Figure 6, TL-net has a very impressive accuracy with low power consumption.
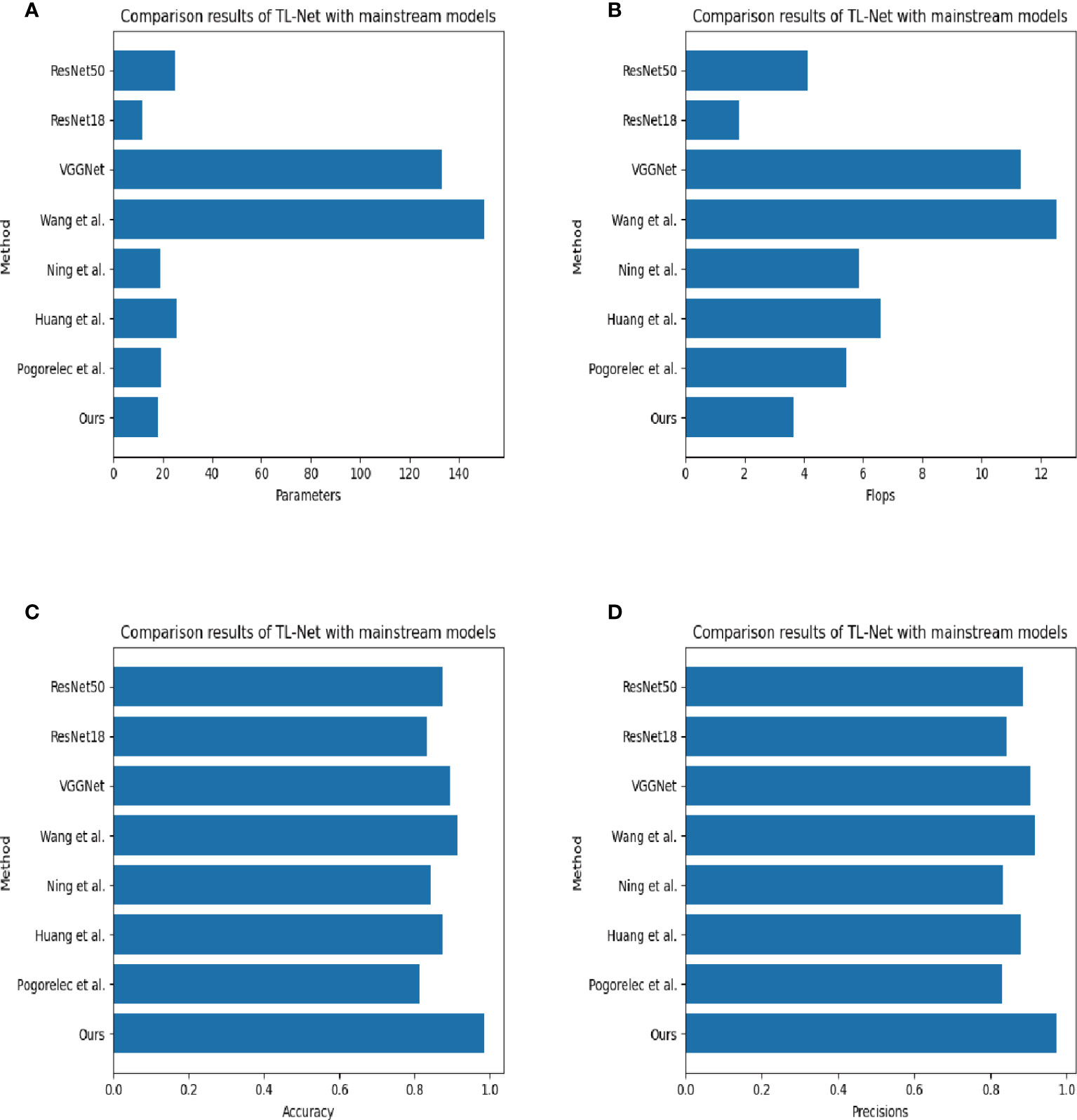
Figure 6 Visualization comparison of 4 different metrics: (A) Parameters, (B) Flops, (C) Accuracy, and (D) Precision. Our proposed network model has significant advantages in terms of accuracy, parameter count, and computational effort, which again demonstrates that our model is more efficient in processing soccer event data prediction tasks. Additionally, our model has a faster training speed and higher accuracy. These results indicate that our model has important practical value in industrial scenarios.
Figure 7 compares the recall and F1-score of different models for motion soccer event data prediction. The x-axis represents the compared models, while the y-axis represents the score values. The blue bars represent recall, and the orange bars represent the F1 score. The chart shows that our proposed model outperforms all other models regarding recall and F1-score. Specifically, our model achieves a recall of 0.981 and an F1-score of 0.978, significantly higher than the scores of other models. This indicates that our proposed model is more effective in processing soccer event data prediction tasks. Among the other models, “Wang et al.” and “VGGNet” perform relatively well, achieving high scores in both recall and F1-score. “ResNet 50” and “Huang et al.” also perform decently, with notable scores in memory and F1-score. On the other hand, “Li et al.” and “Pogorelec et al.” perform relatively poorly, with lower scores in both recall and F1-score.
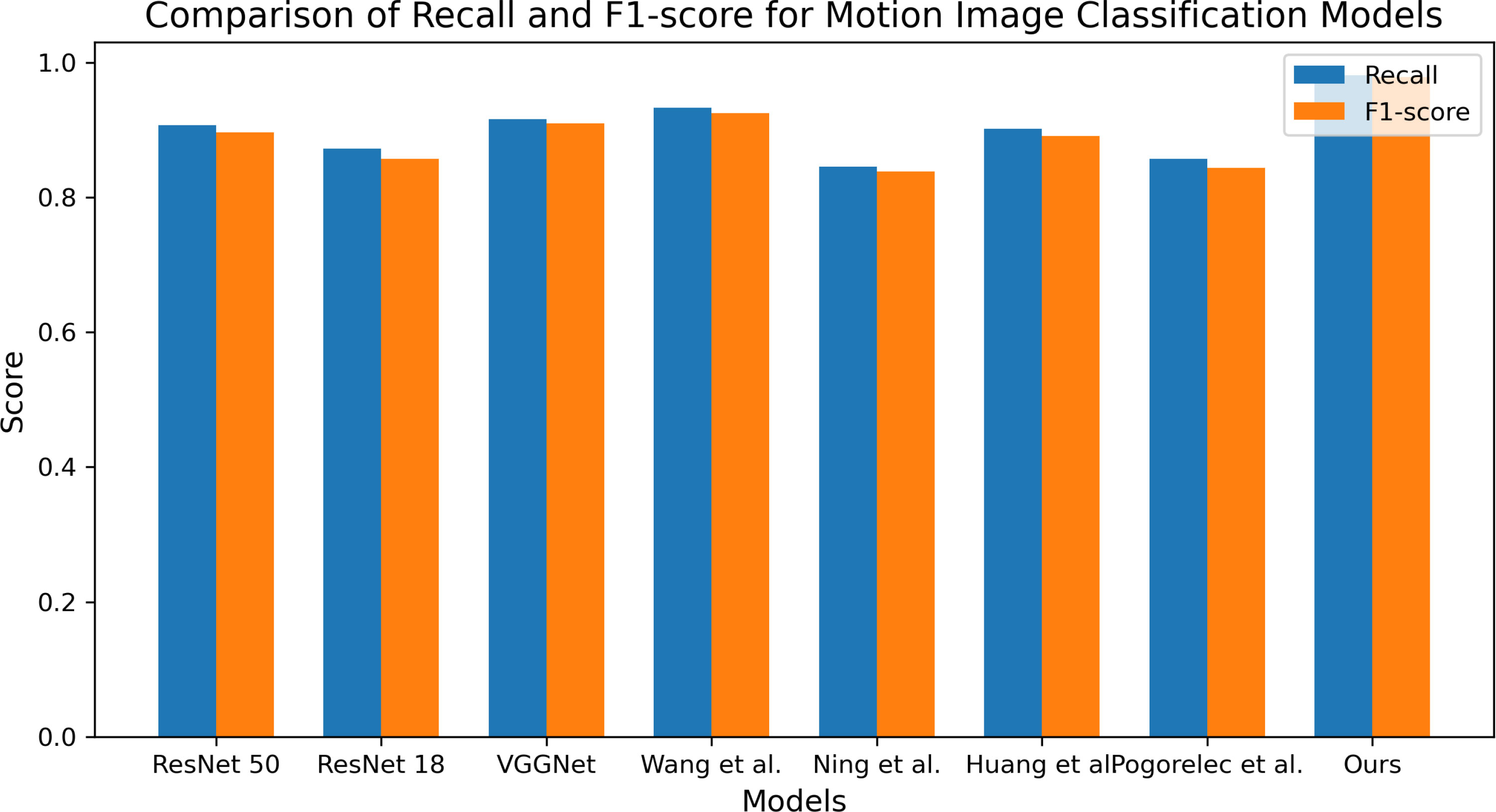
Figure 7 Comparison of recall and F1-score for soccer event data prediction models.
In this paper, we use a migration learning module to accelerate the model’s training, enabling the movement with a better solution at the beginning of the training, speeding up the convergence rate, and reducing the training cost. To further verify the effectiveness of the module, we conducted ablation experiments. The experimental results are shown in Figure 5, where the horizontal axis indicates the number of training iterations and the vertical axis shows the accuracy. The results show that using the migratory learning module can improve the better initial solution for the classifier. TL-Net is based on ResNet, which converges faster and has higher accuracy than ResNet. Compared with TL-Net*, TL-Net has a migratory learning module with more learning ability and can connect more quickly, in addition to some improvement in accuracy.
In Figure 8, we compare our proposed TL-Net model with its Baseline and TL-Net** counterparts to evaluate the effectiveness of the new downsampling module. The results demonstrate that the new downsampling module in TL-Net significantly impacts the final recognition accuracy and absolute recognition accuracy. The results show that the new downsampling module in TL-Net has a more obvious impact on absolute recognition accuracy. It can extract richer feature information and has faster information processing speed. It is designed to extract richer feature information and process information more efficiently. Specifically, the module leverages strided convolution, dilated convolution, attention mechanisms, max pooling with overlapping windows, and fractional pooling to balance computational efficiency and information preservation. By incorporating these downsampling methods, the module can extract more informative features while reducing the computational complexity of the model.
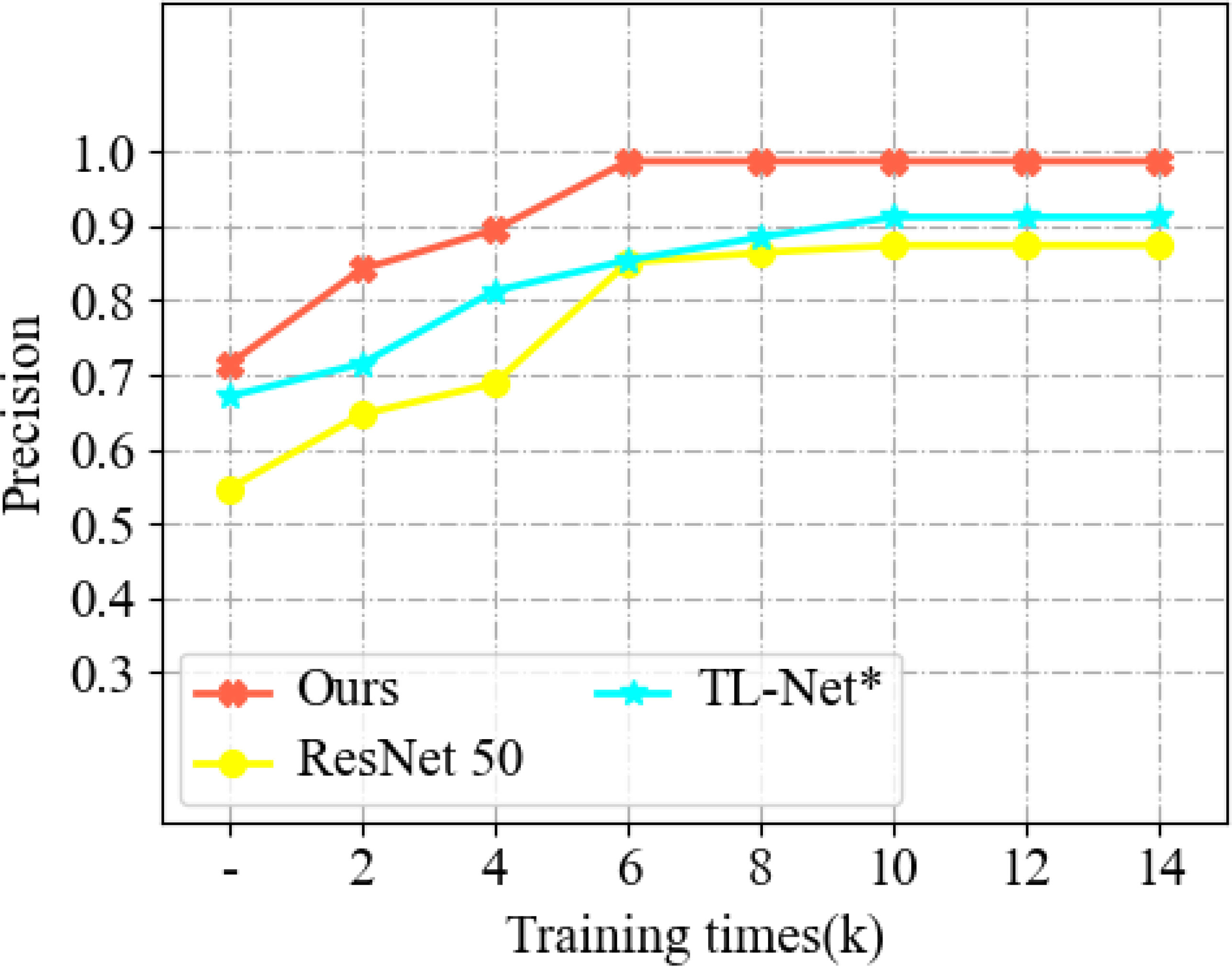
Figure 8 Comparison experiments of convergence times. Tl-Net* indicates that the empty module is used instead of the migration learning module in TL-Net.
As shown in Figure 9, TL-Net is far less computationally intensive than the other models, mainly due to the downsampling module, which can significantly reduce the computation of the model, and this process is primarily in the feature extraction process of the model. Figure 9 illustrates the computational complexity of the different models used in our experiments. The results show that TL-Net is much less computationally intensive than the other models, including the Baseline and TL-Net**. This significant reduction in computational complexity is attributed to the downsampling module in TL-Net, which plays a crucial role in the feature extraction process of the model.
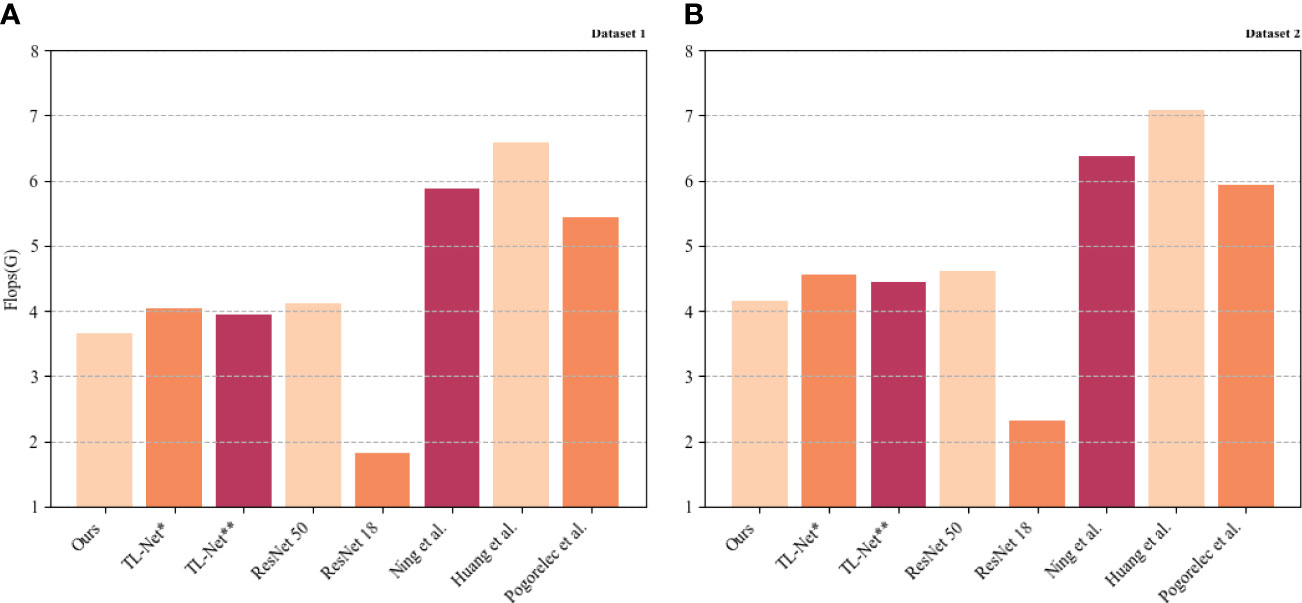
Figure 9 Computational volume comparison. TL-Net* indicates the use of empty module to replace the migration learning module and TL-Net** indicates the use of traditional downsampling module to replace the downsampling module. (A) Dataset 1 from soccer-Reference.com; (B) dataset 2 from Kaggle.com.
Traditional downsampling methods, such as max pooling and average pooling, can result in information loss and reduce the model’s ability to capture complex patterns in the input data. In contrast, the new downsampling module in TL-Net leverages advanced downsampling techniques, including stridden convolution, dilated convolution, attention mechanisms, max pooling with overlapping windows, and fractional pooling. These techniques allow the module to extract informative features while reducing the computational complexity of the model.
Specifically, the stridden convolution and dilated convolution techniques are used to downsample the feature maps computationally efficiently. At the same time, the attention mechanisms enable the module to focus on the most informative regions of the feature maps. The max pooling with overlapping windows and fractional pooling techniques allows the module to extract informative features while reducing the loss of information. By incorporating these downsampling techniques, the module achieves a balance between computational efficiency and information preservation, significantly reducing the computational complexity of the model.
The reduction in computational complexity improves the model’s efficiency and reduces the hardware requirements for training and deployment. This is particularly important for real-world soccer event data prediction applications, where hardware resources are often limited. The reduced computational complexity of TL-Net allows the model to be trained and deployed on devices with lower computational power, making it more accessible and cost-effective than other models with higher computational requirements.
As shown in Figure 10, TL-Net has a clear advantage over other models in terms of the number of parameters. The new downsampling module has less parameter content and higher recognition accuracy than the traditional ones. Figure 10 displays the parameters in the different models used in our experiments. The results clearly show that TL-Net has a significant advantage over the other models in terms of the number of parameters. This advantage is mainly due to the downsampling module, which has less parameter content while achieving higher recognition accuracy than the traditional ones.
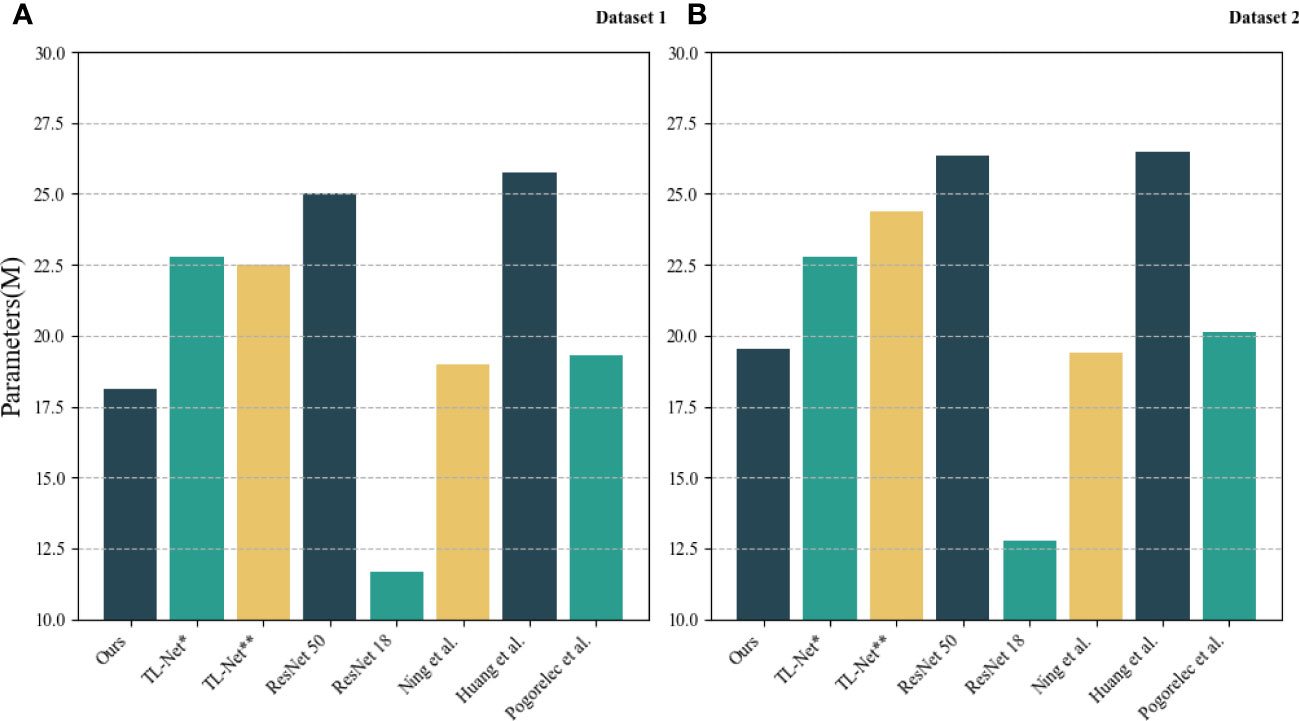
Figure 10 Comparison of the number of parameters. TL-Net* indicates the use of empty modules to replace the migrated learning modules and TLNet** indicates the use of traditional downsampling modules to replace the downsampling modules. (A) Dataset 1 from soccer-Reference.com; (B) dataset 2 from Kaggle.com.
The downsampling module in TL-Net leverages advanced downsampling techniques, including stridden convolution, dilated convolution, attention mechanisms, max pooling with overlapping windows, and fractional pooling. These techniques enable the module to extract informative features while reducing the number of parameters in the model.
For example, the stridden and dilated convolution techniques enable the module to downsample the feature maps in a computationally efficient manner without significantly increasing the number of parameters in the model. The attention mechanisms, on the other hand, enable the module to selectively focus on the most informative regions of the feature maps, further reducing the number of parameters in the model.
In addition, max pooling with overlapping windows and fractional pooling techniques reduce the number of parameters in the model by reducing the size of the feature maps without significantly reducing the amount of information in the feature maps. By incorporating these downsampling techniques, the downsampling module balances computational efficiency, parameter content, and information preservation, resulting in higher recognition accuracy with fewer parameters than traditional ones.
The advantage of fewer parameters is that it reduces the risk of overfitting, a common challenge in deep learning models. Overfitting occurs when a model is too complex and has too many parameters relative to the training data available. This can result in the model memorizing the training data instead of generalizing it to new data. By reducing the number of parameters, TL-Net is less prone to overfitting and can generalize better to recent data, leading to higher recognition accuracy.
Table 5 provides a summary comparison of ablation experiments.

Table 5 Comparison of the results of the ablation experiment (where TL-Net* indicates the use of empty modules to replace the migrated learning modules and TL-Net** indicates the use of traditional downsampling modules to replace the downsampling modules).
4 Conclusion and discussion
Regarding the transfer learning module proposed in the paper, we use ImageNet as a pre-training dataset to speed up training. In the early stages of a campaign, it can have a better initial solution and a significant advantage in training time compared to other models such as ResNet50, TL-Net* and TL-Net**. The paper proposes a new downsampling module based on the brain-like visual mechanism. Compared with the traditional downsampling module, it has a faster processing speed, making TL-Net more powerful, with less computation and fewer parameters. The shorter training speed is mainly due to the inclusion of transfer learning modules, which can speed up the pre-training process. This paper is also inspired by EfficientNet, which searches the input soccer data and the width and depth of the network, improving the robustness and accuracy of the network. However, this search method needs to be improved to deal with the slowness of model training, and although we use some strategies to minimize this effect, it still accounts for a large part of the training time. Therefore, we plan to use novel search methods to replace traditional search strategies in future work.
In addition, our transfer learning module can also improve the generalization ability of the model. By pre-training on large datasets such as ImageNet, the model can learn many useful features for different tasks. This enables the model to perform well on new and unseen datasets without extensive training on the new datasets. Our proposed downsampling module based on a brain-inspired vision mechanism is more interpretable than traditional modules. It uses the information processing methods of the human brain to make it more intuitive and understandable. It can better predict soccer event data, including player data, game data, audience data, etc., to optimize the cost of events, reduce the cost of soccer events, and accelerate the realization of carbon neutrality goals. By leveraging transfer learning and brain-inspired mechanisms, we can improve the efficiency and effectiveness of deep learning models for these tasks. In future work, we plan to explore novel search methods that can replace traditional search strategies used in EfficientNet. This can further improve the efficiency and effectiveness of our model while reducing training time.
This paper explores how minimization strategies can reduce the cost of sporting events in a carbon-neutral context. Carbon neutrality can effectively reduce greenhouse gas emissions, reducing the magnitude and speed of global temperature rise and slowing down the frequency and intensity of climate disasters such as extreme weather. At the same time, carbon neutrality also helps to promote the development of new energy and technologies, promote sustainable development, and create a more environmentally friendly, healthy and better future. Our research aims to combine environmental sustainability with cost minimization and explore how to operate soccer events efficiently and more environmentally friendly and sustainable soccer events to protect the environment by promoting sustainable development. In addition, the study can also serve as a reference for other similar studies, such as the use of minimization strategies in different industries to reduce costs and reduce negative environmental impacts.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
ZL and DG contributed to conception and design of the study. ZL organized the database. ZL performed the statistical analysis. DG wrote the first draft of the manuscript. ZL and DG wrote sections of the manuscript. Both authors contributed to the article and approved the submitted version.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ahmad T., Madonski R., Zhang D., Huang C., Mujeeb A. (2022). Data-driven probabilistic machine learning in sustainable smart energy/smart energy systems: key developments, challenges, and future research opportunities in the context of smart grid paradigm. Renewable Sustain. Energy Rev. 160, 112128. doi: 10.1016/j.rser.2022.112128
Akanksha E., Sharma N., Gulati K. (2021). “Review on reinforcement learning, research evolution and scope of application,” in 2021 5th international conference on computing methodologies and communication (ICCMC). Erode, India: IEEE 1416–1423.
Chen H., Liu C., Wu Z., He Y., Wang Z., Zhang H., et al. (2019). Time-tailoring van der waals heterostructures for human memory system programming. Adv. Sci. 6, 1901072. doi: 10.1002/advs.201901072
Dong X., Ning X., Xu J., Yu L., Li W., Zhang L. (2023). A recognizable expression line portrait synthesis method in portrait rendering robot. IEEE Trans. Comput. Soc. Syst. doi: 10.1109/TCSS.2023.3241003
Drachman D. A., Leavitt J. (1974). Human memory and the cholinergic system: a relationship to aging? Arch. Neurol. 30, 113–121. doi: 10.1001/archneur.1974.00490320001001
Fathi S., Srinivasan R., Fenner A., Fathi S. (2020). Machine learning applications in urban building energy performance forecasting: a systematic review. Renewable Sustain. Energy Rev. 133, 110287. doi: 10.1016/j.rser.2020.110287
Glickman M. E., Sonas J. (2015). Introduction to the ncaa men’s basketball prediction methods issue. J. Quantitative Anal. Sports 11, 1–3. doi: 10.1515/jqas-2015-0013
Gui-xiang S., Xian-zhuo Z., Zhang Y.-z., Chen-yu H. (2018). Research on criticality analysis method of cnc machine tools components under fault rate correlation. IOP Conf. Series: Mater. Sci. Eng. 307, 012023.
Han C., Fu X. (2023). Challenge and opportunity: deep learning-based stock price prediction by using bi-directional lstm model. Front. Business Econom. Manage. 8, 51–54. doi: 10.54097/fbem.v8i2.6616
He F., Ye Q. (2022). A bearing fault diagnosis method based on wavelet packet transform and convolutional neural network optimized by simulated annealing algorithm. Sensors 22, 1410. doi: 10.3390/s22041410
He K., Zhang X., Ren S., Sun J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition. (CVPR) Las Vegas, Nevada: IEEE 770–778.
Heidari A., Jafari Navimipour N., Unal M., Zhang G. (2023). Machine learning applications in internet-of-drones: systematic review, recent deployments, and open issues. ACM Computing Surveys 55, 1–45. doi: 10.1145/3571728
Huang Z., Tian Y., Zhang Q., Huang Y., Liu R., Huang H., et al. (2022). Estimating mangrove above-ground biomass at maowei sea, beibu gulf of china using machine learning algorithm with sentinel-1 and sentinel-2 data. Geocarto Int., 1–28. doi: 10.1080/10106049.2022.2102226
Jamil S., Rahman M., Haider A. (2021). Bag of features (bof) based deep learning framework for bleached corals detection. Big Data Cogn. Computing 5, 53. doi: 10.3390/bdcc5040053
Li Z., Zhang H., Meng J., Long Y., Yan Y., Li M., et al. (2020). Reducing carbon footprint of deep-sea oil and gas field exploitation by optimization for floating production storage and offloading. Appl. Energy 261, 114398. doi: 10.1016/j.apenergy.2019.114398
Liu S., Wang S., Liu X., Gandomi A. H., Daneshmand M., Muhammad K., et al. (2021). Human memory update strategy: a multi-layer template update mechanism for remote visual monitoring. IEEE Trans. Multimedia 23, 2188–2198. doi: 10.1109/TMM.2021.3065580
Ljubenkov D., Kon F., Ratti C. (2020). “Optimizing bike sharing system flows using graph mining, convolutional and recurrent neural networks,” in 2020 IEEE European technology and engineering management summit (E-TEMS), Dortmund, Germany: IEEE 1–6.
Marques G., Agarwal D., de la Torre Díez I. (2020). Automated medical diagnosis of covid-19 through efficientnet convolutional neural network. Appl. Soft Computing 96, 106691. doi: 10.1016/j.asoc.2020.106691
Mattson M. P. (2014). Superior pattern processing is the essence of the evolved human brain. Front. Neurosci., 265. doi: 10.3389/fnins.2014.00265
Ning X., Tian W., He F., Bai X., Sun L., Li W. (2023). Hyper-sausage coverage function neuron model and learning algorithm for image classification. Pattern Recognition 136, 109216. doi: 10.1016/j.patcog.2022.109216
Ning K.-P., Zhao X., Li Y., Huang S.-J. (2022). “Active learning for open-set annotation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. (CVPR) New Orleans, Louisiana: IEEE 41–49.
Niu H., Lin Z., Zhang X., Jia T. (2022). “Image segmentation for pneumothorax disease based on based on nested unet model,” in 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA). Changchun, China: IEEE 756–759.
Panzer M., Bender B. (2022). Deep reinforcement learning in production systems: a systematic literature review. Int. J. Prod. Res. 60, 4316–4341. doi: 10.1080/00207543.2021.1973138
Pereira R. P. T., Filimonau V., Ribeiro G. M. (2020). Projecting the carbon footprint of tourist accommodation at the 2030 fifa world cuptm. Cleaner Responsible Consumption 1, 100004.
Reza S., Ferreira M. C., Machado J. J., Tavares J. M. R. (2022). Traffic state prediction using one-dimensional convolution neural networks and long short-term memory. Appl. Sci. 12, 5149. doi: 10.3390/app12105149
Sayed A. N., Himeur Y., Bensaali F. (2022). Deep and transfer learning for building occupancy detection: a review and comparative analysis. Eng. Appl. Artif. Intell. 115, 105254. doi: 10.1016/j.engappai.2022.105254
Shen G., Han C., Chen B., Dong L., Cao P. (2018). Fault analysis of machine tools based on grey relational analysis and main factor analysis. J. Physics: Conf. Ser. 1069, 012112.
Sun Z., Wang C., Ye Z., Bi H. (2021). Long short-term memory network-based emission models for conventional and new energy buses. Int. J. Sustain. Transportation 15, 229–238. doi: 10.1080/15568318.2020.1734887
Vrbančič G., Podgorelec V. (2020). Transfer learning with adaptive fine-tuning. IEEE Access 8, 196197–196211. doi: 10.1109/ACCESS.2020.3034343
Wang X., Han Q., Gao F. (2022b). Design of sports training simulation system for children based on improved deep neural network. Comput. Intell. Neurosci. doi: 10.1155/2022/9727415
Wang J., Sun S., Sun Y. (2021). A muscle fatigue classification model based on lstm and improved wavelet packet threshold. Sensors 21, 6369. doi: 10.3390/s21196369
Wang C., Wang X., Zhang J., Zhang L., Bai X., Ning X., et al. (2022a). Uncertainty estimation for stereo matching based on evidential deep learning. Pattern Recognition 124, 108498. doi: 10.1016/j.patcog.2021.108498
Wen L., Li X., Gao L. (2020). A transfer convolutional neural network for fault diagnosis based on resnet-50. Neural Computing Appl. 32, 6111–6124. doi: 10.1007/s00521-019-04097-w
Wu S., Wang J., Ping Y., Zhang X. (2022). “Research on individual recognition and matching of whale and dolphin based on efficientnet model,” in 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE). Xi’an, China: IEEE 635–638.
Yang Z., Sun L., Sun Y., Dong Y., Wang A. (2023). A conceptual model of home-based cardiac rehabilitation exercise adherence in patients with chronic heart failure: a constructivist grounded theory study. Patient Preference Adherence 17, 851. doi: 10.2147/PPA.S404287
Yang X., Wang Z., Zhang H., Ma N., Yang N., Liu H., et al. (2022a). A review: machine learning for combinatorial optimization problems in energy areas. Algorithms 15, 205. doi: 10.3390/a15060205
Yang Y., Yang J., Huang X. (2022b). Evaluation of sports public service under fuzzy integral and deep neural network. J. Supercomputing, 1–15.
Zhang Y., Mu L., Shen G., Yu Y., Han C. (2019). Fault diagnosis strategy of cnc machine tools based on cascading failure. J. Intelligent Manufacturing 30, 2193–2202. doi: 10.1007/s10845-017-1382-7
Zhang L., Qi T., Tao L. (2022). Posture positioning estimation for players based on attention mechanism and hierarchical context. Neural Computing Appl., 1–12. doi: 10.1007/s00521-022-07800-6
Keywords: CNN, GRU, attention mechanism, carbon neutral, soccer game, energy saving and emission reduction
Citation: Liu Z and Guo D (2023) Assessing the carbon footprint of soccer events through a lightweight CNN model utilizing transfer learning in the pursuit of carbon neutrality. Front. Ecol. Evol. 11:1208643. doi: 10.3389/fevo.2023.1208643
Received: 19 April 2023; Accepted: 08 June 2023;
Published: 24 July 2023.
Edited by:
Praveen Kumar Donta, Vienna University of Technology, AustriaReviewed by:
Vinay Vakharia, Pandit Deendayal Petroleum University, IndiaBaoli Lu, University of Portsmouth, United Kingdom
Copyright © 2023 Liu and Guo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dayong Guo, Z19keTIwQHF6Y3QuZWR1LmNu