
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Digit. Health , 08 February 2022
Sec. Health Informatics
Volume 4 - 2022 | https://doi.org/10.3389/fdgth.2022.750226
This article is part of the Research Topic Digital Health Services Research: The Role of Health Information Technologies in the Organization of Health Care Systems View all 8 articles
 Md. Zahangir Alam1,2
Md. Zahangir Alam1,2 Albino Simonetti1,3
Albino Simonetti1,3 Raffaele Brillantino1,3Nick Tayler4Chris Grainge5,6Pandula Siribaddana7
Raffaele Brillantino1,3Nick Tayler4Chris Grainge5,6Pandula Siribaddana7 S. A. Reza Nouraei8,9James Batchelor8
S. A. Reza Nouraei8,9James Batchelor8 M. Sohel Rahman2
M. Sohel Rahman2 Eliane V. Mancuzo10
Eliane V. Mancuzo10 John W. Holloway1,11
John W. Holloway1,11 Judith A. Holloway12,13†
Judith A. Holloway12,13† Faisal I. Rezwan1,14*†
Faisal I. Rezwan1,14*†Introduction: To self-monitor asthma symptoms, existing methods (e.g. peak flow metre, smart spirometer) require special equipment and are not always used by the patients. Voice recording has the potential to generate surrogate measures of lung function and this study aims to apply machine learning approaches to predict lung function and severity of abnormal lung function from recorded voice for asthma patients.
Methods: A threshold-based mechanism was designed to separate speech and breathing from 323 recordings. Features extracted from these were combined with biological factors to predict lung function. Three predictive models were developed using Random Forest (RF), Support Vector Machine (SVM), and linear regression algorithms: (a) regression models to predict lung function, (b) multi-class classification models to predict severity of lung function abnormality, and (c) binary classification models to predict lung function abnormality. Training and test samples were separated (70%:30%, using balanced portioning), features were normalised, 10-fold cross-validation was used and model performances were evaluated on the test samples.
Results: The RF-based regression model performed better with the lowest root mean square error of 10·86. To predict severity of lung function impairment, the SVM-based model performed best in multi-class classification (accuracy = 73.20%), whereas the RF-based model performed best in binary classification models for predicting abnormal lung function (accuracy = 85%).
Conclusion: Our machine learning approaches can predict lung function, from recorded voice files, better than published approaches. This technique could be used to develop future telehealth solutions including smartphone-based applications which have potential to aid decision making and self-monitoring in asthma.
Asthma is a common respiratory condition that affects 235 million people worldwide (1). Around 5.4 million people in the UK are currently receiving treatment for asthma, ~1 in 11 children and 1 in 12 adults (2). Every 10 s, at least one person is facing a potentially life-threatening asthma attack in the UK, and on an average, three people die from it daily, regardless the effective treatments developed in recent years (3). Appropriate, effective management and treatment for asthma is therefore of vital importance.
Many different techniques can monitor the complex nature of asthma, including subjective symptom assessments, lung function testing, and measurement of biomarkers. Regular monitoring of asthma can help patients receive appropriate treatment in time, which can help to reduce symptoms, frequency of exacerbation, and risks of hospitalisation. The ability to monitor asthma and modify treatment appropriately could help to reduce both disease morbidity and the economic cost of treatment. Identifying symptoms via questionnaire and lung function measurement via spirometry identifying of biomarkers (e.g. exhaled nitric oxide or sputum eosinophils) can all be used in regular monitoring of asthma (4). In practise, however, the combination of these is impractical in community-based care due to expense and/or complexity.
Self-monitoring of asthma has the potential to play an important role in empowering the patient and maintaining disease control; such monitoring needs to be simple, convenient, and accurate. Equipment such as smart spirometers and, accompanying smartphone apps used to record peak expiratory flow rates (PEFR) and provide reminders to manage asthma more efficiently are currently available to simplify self-monitoring (5). However, smart spirometers are still expensive for personal use. As more people use smartphones, an application measuring lung function that could alert patients to modify their treatment without the need for a spirometer would be a convenient and inexpensive way to monitor asthma, particularly in Lower- and Middle-Income Country (LIMC) settings.
At present, assessment of the ability to speak and the sounds associated with breathing are a recognised part of an assessment of asthma severity, such as: “speaking full sentences” to “unable to speak at all” together with wheeze on auscultation (6–8). Although no standardised assessment or quantitative measures of these features have been developed, the effects on speech and breathing patterns and sounds due to increased airway resistance are noticeable in acute asthma (9). Thus, pitch from speech and quality of the breathing sound can potentially be utilised as surrogate measures of symptoms and/or to predict lung function, which can then be used to monitor asthma.
Three kinds of sounds have been analysed to predict lung function using machine learning techniques: (1) lung and breathing sounds from the chest, (2) symptom-based sounds (such as a cough sound), and (3) voice sounds. Quantitative breath sound measurements, such as Vibration Response Imaging (VRI), have been used to predict postoperative lung function (10, 11). Cough and wheeze sound-based analyses have been shown to have potential in predicting spirometer readings (12–14).
In parallel to symptom-based sounds (such as a cough sound), there are a number of studies, which involve voice sounds only. A recent review identified 20 studies to date. It confirmed the idea of respiratory function correlating significantly to phonation sound. Some of these studies showed that voice evaluation might allow recognition of asthma contributing to voice dysfunction subjected to lung function (15). However, most of these studies required the use of specialised instruments and software to quantify specialised phonetic sounds. Using machine learning techniques, one of these studies showed that sustained phonation of the vowel sound demonstrated potential utility in the diagnosis and classification of severity of asthma (16).
Assessing the quality of sound produced by an asthma patient, primarily via speech, is a common way to assess acute asthma. We have previously demonstrated that recorded speech correlates well with lung function during induced bronchoconstriction (17). To date, only two studies have utilised machine learning techniques to predict lung function from the recorded voice. Saleheen et al. proposed a convenient mobile-based approach that utilises a monosyllabic voice segment called “A-vowel” sound or “Aaaa…” sound from voice to estimate lung function (18). Chun et al. proposed two algorithms for passive assessment of pulmonary conditions: one for detection of obstructive pulmonary disease and the other for estimation of the pulmonary function in terms of ratio of forced expiratory volume in 1 s (FEV1) and forced vital capacity (FVC) also denoted as FEV1/FVC and percentage predicted FEV1 (FEV1%) (19). However, these studies showed moderate performance and did include comparison with previous studies.
This study proposes a new methodology to predict lung function from recorded speech using machine learning techniques to monitor asthma. Bronchoprovocation tests were given to participants to help diagnose asthma, and their voices were recorded for 1 min while the subjects read standard texts with lung function measured. This study aims to identify features from recorded speech files that correlate with measured lung function. We subsequently use those features to predict lung function, potentially enabling identification of deterioration of asthma control via a smartphone application in the future.
Twenty-six non-smoking, clinically stable subjects, with physician-diagnosed mild atopic asthma, were recruited on step one of treatment according to 2012 GINA guidelines (20). The study was approved by the local ethics committee (number 12/EE/0545), by the Medicines and Healthcare Products Regulation Agency (MHRA) (MHRA number 11709/0246/001-0001) (21). The study was performed in compliance with the protocol and additional methodologic details provided in the Supplementary Material. All participants underwent a standardised inhaled methacholine challenge (21) and after each challenge dose, the participant read a standardised text for 30 s into a digital recorder fitted with an external microphone set at 10 cm from the mouth (Olympus DM450 Speech Recorder with Olympus ME34 Microphone, Tokyo, Japan). After each dose of the bronchial challenge, the voice of each subject was recorded, and lung function was measured as FEV1% predicted. Spirometry was performed with a dry bellows spirometer (Vitalograph, UK) and the best of at least three successive readings within 100 ml of each other was recorded as the FEV1 in accordance with established guidelines (22). In total 323 voice recorded sound files with their associated FEV1% were recorded for these 26 subjects. Details of the method is shown in the Supplementary Methods section. Additionally, an overview of the basic biological attributes (i.e., sex, height and weight) of these samples is reported in Supplementary Table 1.
An exploratory analysis was carried out on a segment of speech and breathing separately in the frequency domain and considerable differences were noticed in the spectrograms generated by librosa (23) (Supplementary Figure 1). The parts of the sound file containing breathing and speech were separated from five randomly selected sound files using Audacity software (24). Features (including roll-off at 85/95%, spectral fitness, root mean square energy, zero crossing rate, spectral centroid, spectral bandwidth, spectral contrast, spectral flatness, mean amplitude, and mean breath cycle duration) (described in Supplementary Methods) were extracted for individual breathing and speech segments, using the librosa tool. These features were analysed to explore differences between breathing and speech segments and determine the appropriate thresholds to separate breathing and speech segments.
After analysing the values for individual speech and breathe segments, only five features (Spectral contrast, Roll-off at 95%, Root mean squared energy, Spectral bandwidth, and Mean amplitude) showed substantial differences between breathing and speech segments (Supplementary Figure 2). Based on the observed information, using a threshold, these 5 features were defined (Supplementary Table 2), which separate the breathing and speech segments from all available sound files.
All extracted features were Min-max normalised. As there was a low number of features, it was impossible to utilise a feature engineering method to identify informative features. The use of Pearson correlation coefficient calculated the correlation between the features and FEV1%.
Training and testing samples were separated randomly at a ratio of 70%:30%, respectively (i.e., the training dataset contained 70% of the samples, whereas the testing dataset kept the remaining 30% of the samples). This defined the following three types of predictive models:
Model1: A regression model to predict FEV1% predicted based on the features extracted from recorded sound data. The techniques and the feature set for which this model performs best were applied for the other following models. The performances of these models are reported in terms of Root Mean Square Error (RMSE) and mean absolute error (MAE).
Model2: A multi-class classification model to predict the severity of abnormality of lung function according to American Thoracic Society (ATS) grades (as defined in Supplementary Table 3) (25).
Model3: A binary classification model to predict FEV1% classified either as normal or abnormal based on the ATS definition of abnormal lung function (Supplementary Table 3), where lung function is normal if FEV1% > 80%, otherwise lung function is abnormal.
Three machine learning algorithms following other studies (19, 26, 27) available in this contextual domain and/or in other similar domains, i.e., Random Forest (RF), Support Vector Machine (SVM) (using Radial Basis Function kernel), and Linear Regression/Logistic Regression (for the binary task), were implemented to develop the predictive models. Training the models was undertaken on the “training set,” and 10-fold cross-validation was used to measure the models training performances. The models use default values of hyperparameters, and tuning did not show any improvements over default parameters. Finally, the models were run on the testing samples to assess the final performances.
Further basic biological factors, including sex, height and weight of the subjects were added as features in addition to the features extracted from the sound file as mentioned above to develop three additional models (denoted as Model1P, Model2P, and Model3P, respectively for Model1, Model2, and Model3).
Initially, we investigated the effect of features extracted from speech and breathing parts both individually and combined on lung function using Model1. We also explored the issue of imbalances of distribution of lung function in random partitioning and performed balanced partitioning of training and test samples as follows:
1. Using intervals of 5% on the FEV1% values 15 groups were prepared. For example, groups are 51–55%, 56–60%, 61–65% etc.
2. Based on the groups sample distribution was prepared.
3. Based on the sample distribution in each group balanced training and test sets were prepared, such that training and test sets followed the same distribution.
Supplementary Table 4 shows the severity of abnormal lung function among 323 data samples. It is evident that 72.14% of samples exhibited normal lung function during corresponding recording and the rest (27.86%) exhibited abnormal lung function.
Fourteen breathing segments and nine speech segments were retrospectively extracted from the sound files (Supplementary Table 5). The results show no correlation between the features and FEV1% (Supplementary Figure 3).
Initially, we explored the ability to predict lung function from extracted features of speech and breath both individually and in combination. Regression models developed using the combined features from speech and breathing to predict FEV1%, showed lower mean absolute error (MAE) than that of models developed from features from speech and breathing separately (Figure 1A). The RF model [Model1(RF)] performed better in comparison to all other algorithms (the lowest Root Mean Square Error, RMSE = 12·59) (Figure 1B).
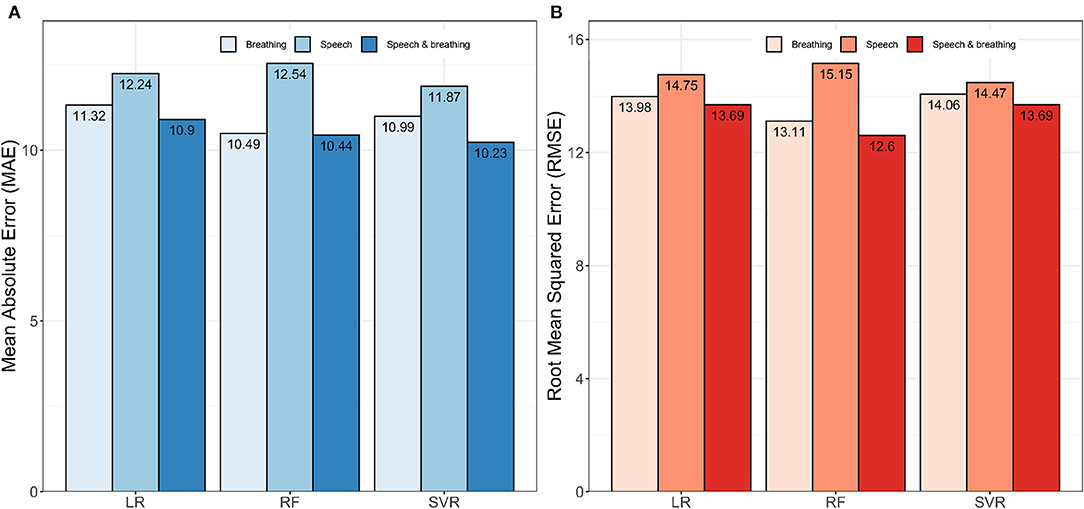
Figure 1. Impact of speech and breathing features individually and combined on model development. (A) Shows the performances of the models in terms of mean absolute error (MAE) and (B) presents the performances of the models in terms of root mean squared error (RMSE). Here, LR, Linear Regression; RF, Random Forest; SVR, Support Vector Regression.
The samples were not uniformly distributed amongst the ranges of FEV1% (Supplementary Figure 4). The frequency of the samples is the highest around 100 of the FEV1% values and no sample was found with the FEV1% ≤ 50. As a result, samples were not uniformly distributed among the ranges of FEV1% values. Therefore, when the training and test samples were divided randomly, the pattern in the training dataset may not follow the pattern in the test dataset (Supplementary Figure 5A). The balanced separation of training and test samples shows a similar pattern of the samples among each range of FEV1% (Supplementary Figure 5B).
Balanced partitioning of the training and the test sets led to improved performance compared to random partitioning. This is evident for all regression models, where balanced partitioning shows lower RMSE and MAE scores in comparison to the random partition model (Supplementary Figure 6). Again, the RF based model [Model1(RF),] performed better than other models (RMSE = 12·51 and MAE = 9·83).
The performance of the models when biological factors were added are shown in Figure 2. The RF based algorithm performed better with MAE (%) score of 10.86 and RMSE score of 11·47 in comparison to other algorithms. Supplementary Table 6 shows the comparison of Model1(RF), and Model1P(RF) for predicting FEV1%. Model1P(RF) showed better predictive performance than that of Model1(RF).
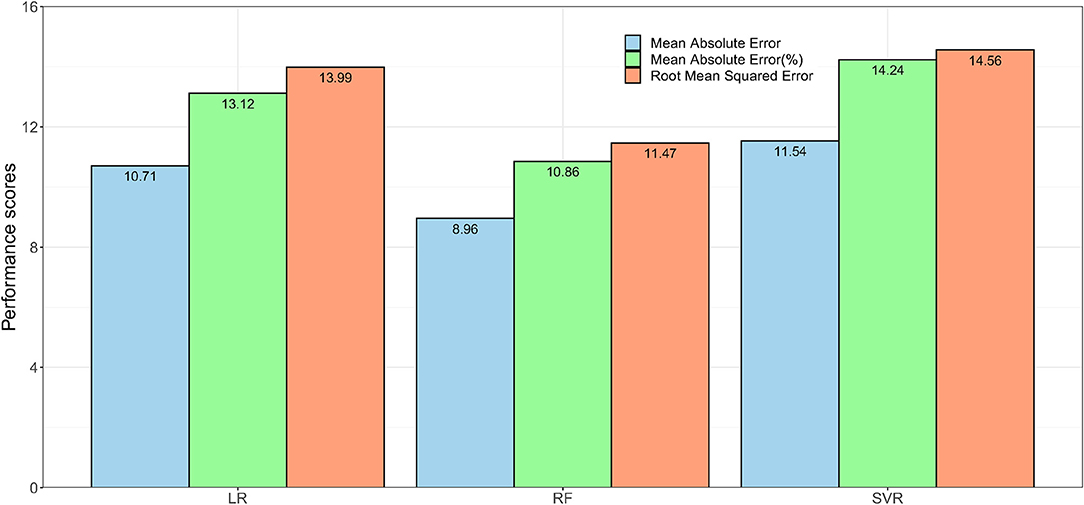
Figure 2. The performance of the regression models. Model1P used extracted features from speech and breath parts with sex, height and weight to predict lung function in terms of FEV1%. Here, LR = Linear Regression, RF = Random Forest, and SVR = Support Vector Regression.
The performance of Model2 and Model2P in predicting lung function severity from the sound files, is shown in Table 1. Model2(SVC) predicted abnormal lung function with 71% accuracy, while Model2P(SVC) predicted this with 73.2% accuracy.
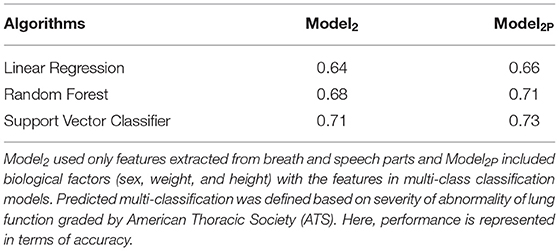
Table 1. Comparison of the performances of Model2 and Model2P in predicting the severity of abnormality of lung function.
The performance of the models (without and with biological factors) in predicting normal vs. abnormal lung function are shown in detailed in Supplementary Tables 7, 8. The best performance (without adding biological factors) was observed for the RF model, Model3(RF), with 80% accuracy and 79% F1-score. The RF based model clearly performs better (AUC = 0.84) than the other models (Supplementary Tables 7, 8; Figure 3A).
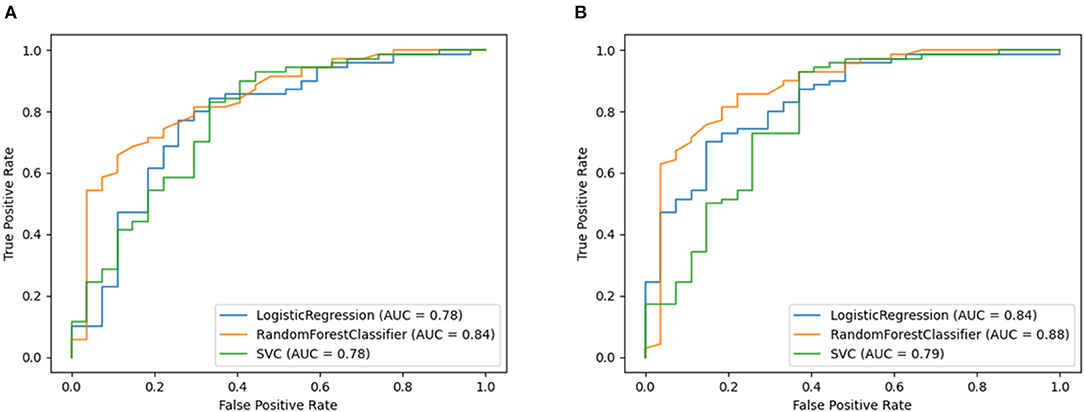
Figure 3. Receiver operating characteristic curve plots of Model3 and Model3P. Model3 used only features extracted from breath and speech parts and Model3P included biological factors (sex, weight, and height) with the features in binary class classification models. Predicted binary classification was defined based on FEV1% classified either as normal (FEV1% < 80%) or abnormal (FEV1% ≥ 80%) based on the ATS definition of abnormal lung function. These plots show the area under Receiver Operating Characteristic curve of model's showing performance for predicting normal vs. abnormal lung function. (A) showing the ROC curve for Model3 and (B) showing the ROC curve for Model3p.
This held true when adding physical attributes, with the RF-based model again showing the best performance (accuracy = 85%, F1-score = 84%, and AUC = 88% AUC (Supplementary Tables 9, 10, Figure 3B).
This study focused on predicting lung function from recorded voice sounds in three ways and has developed a predictive model (for FEV1%), which can be utilised in real-time applications for asthma management. A model to predict the severity of abnormal lung function as defined by the ATS (22) was also developed, as well as a model to predict normal vs. abnormal lung function (i.e., FEV1% ≤ 80). By detecting abnormal lung function, this can be used to prompt the patient to take appropriate action to manage their condition.
A threshold-based mechanism was defined to separate the breathing and speech features from the recorded sound files and 23 features extracted to develop the predictive models. Using both breathing and speech features in combination improved the performance of the predictive models. This is consistent with standard clinical practise to identify acute asthma by listening to both speech and breathing patterns.
Handling partitioning of the training and the testing dataset is an important factor in developing the prediction model. Considering the American Thoracic Society Grades for the severity of a Pulmonary Function Test Abnormality (28), this study utilised a balanced partitioning technique for predicting FEV1% for asthma patients and, consequently, the model's performance was improved in comparison to random partitioning given the imbalance in the available data set.
Initially, the RF based predictive models showed better performance in comparison to other models except for the prediction of severity of abnormality of lung function. The RF based models predicted FEV1% with lower RMSE and MAE, and abnormality in lung function with high accuracy. In contrast, SVM predicted severity of lung function with higher accuracy compared with that of RF and LR based models. Given the feature space in this study is not highly dimensional (with only 26 features in total), these results are consistent with previous studies that have reported better performance of RF based models when working with a limited number of features (14, 19). Generally, SVM is applied to highly dimensional space for best results. In addition, the correlational matrix showed no strong correlation of any feature with FEV1%, and RF performs better with non-linear problems.
Furthermore, due to their nature, RF models are less likely to overfit. While most of the scores of the RF-based models are quite reasonable, the sensitivity of the RF based classifier to predict abnormality of lung function was not high (sensitivity = 44%). This could be due to the imbalanced distribution of the available samples to normal vs. abnormal lung function (~3:1). Although RF based models (Model1 and Model3) showed better performance, the SVM based model performed well on predicting severity of lung function (Model2). This is possibly due to grouping samples (i.e., grouping of FEV1%) based on the severity of abnormality of the lung function and heterogeneous distribution of the samples into these groups (e.g., the samples with normal and with moderate to severely abnormal lung functions are 72.14% and 2.79% respectively in the dataset).
Adding biological factors (sex, height and weight), to the model, along with the features extracted from speech and breathing, improved the performances of the models. This improvement was observed for all three methods (RF, SVM and LR) used in this study.
Breathing becomes more difficult for people with obstructive pulmonary disease due to increased airway resistance. As their pulmonary symptoms worsen, they frequently notice increased breathlessness and may have higher respiratory rates (29). Previous predictive models for respiratory disease severity have used many pulmonary features, such as Mean Breath Cycle Duration and Breath Number, that relate to airway resistance in patients with pulmonary disease (e.g. asthma). For example, an earlier study reported a higher rate of increase in the intensity of the sound for equal increments in flow rate in chronic bronchitis and asthma than in healthy subjects (30). The pulmonary features extracted in this study that predict lung function are in line with these previous observations. However, the inclusion of additional features in the prediction models such as Roll off 95%, Mean Amplitude, Spectral Bandwidth etc., are also important in the prediction performance of our models.
Only two recent studies have used voice sounds to predict lung function. Saleheen et al. extracted the “A-vowel” segments from the voice sound and then extracted features from the ‘A-vowel' sounds and predicted lung function in terms of the FEV1/FVC ratio (18). Due to the unavailability of FVC values in this study, it is not possible to directly compare results. Chun et al. developed models to predict lung function in terms of the FEV1/FVC ratio and FEV1% (19). Their reported prediction efficiency in terms of MAE (%) score is 20.6%, which is significantly large for any regression problem. The RF based regression model reported in this study achieved a MAE (%) score of 10.86%, a significant improvement over that of Chun et al.
This pilot study has limitations, including the limited sample size of matched audio and lung function measurements and the range of machine learning algorithms utilised to develop the predictive models. To overcome this, the balanced partitioning technique was applied. The performance of the predictive regression model in estimating FEV1% values was reasonable, and better than previous studies found in the literature, in addition to being able to predict normal vs. abnormal lung function and the severity of abnormality of lung function. To avoid overfitting and increase the likelihood of the model being generalizable, 10-fold cross validation was used during training of the model. Furthermore, no feature selection method was applied to identify important features among the 23 features. However, due to the limited number of features, this study did not consider feature engineering. Future work utilising a large set of samples, together with an independent validation sample will allow the predictive model to be better generalised and allow validation. A recent study included Mel Frequency Cepstral Coefficient (MFCC) value as a feature to predict COVID-19 subjects from a forced-cough cell-phone recording (31). In contrast, our study has used 23 features excluding MFCC due to the nature (breathing and speech) of pattern-finding for acute asthma prediction from sound files. MFCC represents a full signal at a time in the signal processing. On the other hand, 23 features extracted here present the micro-information of different parts of a signal (e.g., breathing chunks and speech chunks of a voice sound file). However, the application of MFCC along with these features may have the potential to further improve the predictions.
This study used the sound recordings available from a previous study (17). While comparing the performances between recorded speech between external microphone and smartphone will be helpful to understand the future use of this method using smartphone, this was beyond the scope of this study. As we wanted to establish the proof of concept that lung function can be predicted from voice recordings, a future work is warranted to predict lung function using recorded voice from the smartphone.
Asthma puts pressure on health services due to the associated cost and workforce required to treat and care for the people with the condition. Therefore, regular monitoring and early intervention can help control the disease, reducing hospital admissions and economic and social burden to the patient and healthcare system. The predictive models developed in this study can be implemented in smartphone applications offering a convenient and straightforward way to predict lung function. Embedding the algorithm in an app for self-monitoring asthma will potentially enable patients to achieve improved symptom control, via early treatment of exacerbations. The demonstration that it is possible to use machine learning as a surrogate measure for underlying lung function has the potential to lead to the development of telemedicine solutions to improve early diagnosis, reduce unplanned hospital admissions and mortality for respiratory disease through supporting clinical decision making and patient self-monitoring. Further development of this AI speech/breathing technology will allow assessment of lung function in a cross-cultural, language-independent manner in order to assist in the remote monitoring of patients with a range of chronic lung conditions, including asthma, COPD, and pulmonary fibrosis.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The study was 120 approved by the Local Ethics Committee (number 12/EE/0545), by the Medicines and Healthcare 121 Products Regulation Agency (MHRA) (MHRA number 11709/0246/001-0001).
JAH and FR conceptualised the study. JWH, JAH, and FR designed the study. NT and CG collected the data. MA, AS, and RB analysed data. MA, JAH, and FR contributed to data interpretation and drafted the article. NT, CG, PS, SN, JB, MR, EM, and JWH critically reviewed the article. All authors reviewed the literature, read, and approved the final article.
The study was funded by the Asthma, Allergy and Inflammation Research Charity, Southampton, UK. MA is a Commonwealth Scholar, funded by the UK government.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The authors thank the Southampton Biomedical Research Unit nurses, all the patients and health care professionals for their participation.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fdgth.2022.750226/full#supplementary-material
1. WHO. World Health Organization. WHO Scope: Asthma. (2021). Available online at: https://www.who.int/respiratory/asthma/scope/en/ (accessed July 16, 2021).
2. British Lung Foundation. Asthma statistics. London: British Lung Foundation (2021). Available online at: https://statistics.blf.org.uk/asthma (accessed July 16, 2021).
3. Asthma.org.uk. Asthma Facts Statistics (2021). Available online at: https://www.asthma.org.uk/about/media/facts-and-statistics
4. Petsky HL, Cates CJ, Lasserson TJ Li AM, Turner C, Kynaston JA, et al. A systematic review and meta-analysis: tailoring asthma treatment on eosinophilic markers (exhaled nitric oxide or sputum eosinophils). Thorax. (2012) 67:199–208. doi: 10.1136/thx.2010.135574
5. Larson EC, Goel M, Boriello G, Heltshe S, Rosenfeld M, Patel SN. SpiroSmart: using a microphone to measure lung function on a mobile phone. In: Proceedings of the 2012 ACM Conference on Ubiquitous Computing - UbiComp '12. Pittsburgh, PA: ACM Press (2012). Available online at: http://dl.acm.org/citation.cfm?doid=2370216.2370261 (accessed July 16, 2021).
6. Bell D, Layton AJ, Gabbay J. Use of a guideline based questionnaire to audit hospital care of acute asthma. BMJ. (1991) 302:1440–3. doi: 10.1136/bmj.302.6790.1440
7. Lai CKW, Beasley R, Crane J, Foliaki S, Shah J, Weiland S, et al. Global variation in the prevalence and severity of asthma symptoms: phase three of the International Study of Asthma and Allergies in Childhood (ISAAC). Thorax. (2009) 64:476–83. doi: 10.1136/thx.2008.106609
8. McCormack MC, Enright PL. Making the diagnosis of asthma. Respir Care. (2008) 53:583–90; discussion: 590–2.
9. Veiga J, Lopes AJ, Jansen JM, de Melo PL. Within-breath analysis of respiratory mechanics in asthmatic patients by forced oscillation. Clin São Paulo Braz. (2009) 64:649–56. doi: 10.1590/S1807-59322009000700008
10. Detterbeck F, Gat M, Miller D, Force S, Chin C, Fernando H, et al. A new method to predict postoperative lung function: quantitative breath sound measurements. Ann Thorac Surg. (2013) 95:968–75. doi: 10.1016/j.athoracsur.2012.07.045
11. Westhoff M, Herth F, Albert M, Dienemann H, Eberhardt R. A new method to predict values for postoperative lung function and surgical risk of lung resection by quantitative breath sound measurements. Am J Clin Oncol. (2013) 36:273–8. doi: 10.1097/COC.0b013e3182467fdc
12. Rao MVA, Kausthubha NK, Yadav S, Gope D, Krishnaswamy UM, Ghosh PK. Automatic prediction of spirometry readings from cough and wheeze for monitoring of asthma severity. In: 2017 25th European Signal Processing Conference (EUSIPCO). Kos (2017). p. 41–5. Available online at: http://ieeexplore.ieee.org/document/8081165/ (accessed July 16, 2021).
13. Sharan RV, Abeyratne UR, Swarnkar VR, Claxton S, Hukins C, Porter P. Predicting spirometry readings using cough sound features and regression. Physiol Meas. (2018) 39:095001. doi: 10.1088/1361-6579/aad948
14. Rudraraju G, Palreddy S, Mamidgi B, Sripada NR, Sai YP, Vodnala NK, et al. Cough sound analysis and objective correlation with spirometry and clinical diagnosis. Inform Med Unlocked. (2020) 19:100319. doi: 10.1016/j.imu.2020.100319
15. Tong JY, Sataloff RT. Respiratory function and voice: The role for airflow measures. J Voice. (in Press). doi: 10.1016/j.jvoice.2020.07.019
16. Yadav S, Nk K, Gope D, Krishnaswamy UM, Ghosh PK. Comparison of cough, wheeze and sustained phonations for automatic classification between healthy subjects and asthmatic patients. In: 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Honolulu, HI (2018). p. 1400–3. Available online at: https://ieeexplore.ieee.org/document/8512496/ (accessed July 16, 2021).
17. Tayler N, Grainge C, Gove K, Howarth P, Holloway J. Clinical assessment of speech correlates well with lung function during induced bronchoconstriction. Npj Prim Care Respir Med. (2015) 25:15006. doi: 10.1038/npjpcrm.2015.6
18. Saleheen N, Ahmed T, Rahman MM, Nemati E, Nathan V, Vatanparvar K, et al. Lung function estimation from a monosyllabic voice segment captured using smartphones. In: 22nd International Conference on Human-Computer Interaction with Mobile Devices and Services. Oldenburg: ACM (2020). p. 1–11. Available online at: https://dl.acm.org/doi/10.1145/3379503.3403543 (accessed July 16, 2021).
19. Chun KS, Nathan V, Vatanparvar K, Nemati E, Rahman MM, Blackstock E, et al. Towards passive assessment of pulmonary function from natural speech recorded using a mobile phone. In: 2020 IEEE International Conference on Pervasive Computing and Communications (PerCom) [Internet]. Austin, TX (2020). p. 1–10. Available online at: https://ieeexplore.ieee.org/document/9127380/ (accessed July 16, 2021).
20. Global Initiative for Asthma. Global Initiative for Asthma - GINA. (2021). Available online at: https://ginasthma.org/ (accessed July 16, 2021).
21. Grainge CL, Lau LCK, Ward JA, Dulay V, Lahiff G, Wilson S, et al. Effect of bronchoconstriction on airway remodeling in asthma. N Engl J Med. (2011) 364:2006–15. doi: 10.1056/NEJMoa1014350
22. British Thoracic Society Bronchoscopy Guidelines Committee, a Subcommittee of the Standards of Care Committee of the British Thoracic Society. British Thoracic Society guidelines on diagnostic flexible bronchoscopy. Thorax. (2001) 56(Suppl. 1):i1–21. doi: 10.1136/thx.56.suppl_1.i1
23. McFee B, Raffel C, Liang D, Ellis D, McVicar M, Battenberg E, et al. Librosa: v0.4.0. Zenodo. (2015). doi: 10.5281/zenodo.18369
24. Audacity Team. Audacity(R): Free Audio Editor and Recorder. The Audacity Team (2012). Available online at: https://www.audacityteam.org/
25. Johnson JD, Theurer WM. A stepwise approach to the interpretation of pulmonary function tests. Am Fam Physician. (2014) 89:359–66.
26. Alam MZ, Rahman MS, Rahman MS. A Random Forest based predictor for medical data classification using feature ranking. Inform Med Unlocked. (2019) 15:100180. doi: 10.1016/j.imu.2019.100180
27. Alam MZ, Masud MM, Rahman MS, Cheratta M, Nayeem MA, Rahman MS. Feature-ranking-based ensemble classifiers for survivability prediction of intensive care unit patients using lab test data. Inform Med Unlocked. (2021) 22:100495. doi: 10.1016/j.imu.2020.100495
28. Pellegrino R. Interpretative strategies for lung function tests. Eur Respir J. (2005) 26:948–68. doi: 10.1183/09031936.05.00035205
29. Wiechern B, Liberty KA, Pattemore P, Lin E. Effects of asthma on breathing during reading aloud. Speech Lang Hear. (2018) 21:30–40. doi: 10.1080/2050571X.2017.1322740
Keywords: pulmonary function, FEV1, speech, breathe, machine learning, human voice, asthma
Citation: Alam MZ, Simonetti A, Brillantino R, Tayler N, Grainge C, Siribaddana P, Nouraei SAR, Batchelor J, Rahman MS, Mancuzo EV, Holloway JW, Holloway JA and Rezwan FI (2022) Predicting Pulmonary Function From the Analysis of Voice: A Machine Learning Approach. Front. Digit. Health 4:750226. doi: 10.3389/fdgth.2022.750226
Received: 30 July 2021; Accepted: 14 January 2022;
Published: 08 February 2022.
Edited by:
Katherine Blondon, Geneva University Hospitals (HUG), SwitzerlandReviewed by:
Terri Elizabeth Workman, George Washington University, United StatesCopyright © 2022 Alam, Simonetti, Brillantino, Tayler, Grainge, Siribaddana, Nouraei, Batchelor, Rahman, Mancuzo, Holloway, Holloway and Rezwan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Faisal I. Rezwan, Zi5yZXp3YW5AYWJlci5hYy51aw==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.