 Léonie Trouillet
Léonie Trouillet Ricarda Bothe
Ricarda Bothe Nivedita Mani
Nivedita Mani Birgit Elsner
Birgit Elsner- 1Developmental Psychology, University of Potsdam, Potsdam, Germany
- 2Department for Psychology of Language, Georg-Elias-Müller-Institut für Psychologie, Georg-August University Goettingen, Goettingen, Germany
- 3Leibniz ScienceCampus “Primate Cognition”, Goettingen, Germany
This study was an unmoderated online experiment to investigate the impact of the semantic content of verbal cues on toddlers' action learning. 18- and 24-month-olds (N = 89) watched videos of two tool-use actions accompanied by specific (“pressing in/pulling out”) or unspecific information (“doing that”). Learning was measured via looking times coded from webcam recordings. Regardless of age and verbal cue, toddlers looked equally long to test pictures of correct or incorrect tool-use, suggesting that meaningful verbal information did not improve the challenging video-based action learning. However, low drop-out rates and high webcam data quality confirm the feasibility of online experiments with toddlers.
Introduction
Toddlers learn through observation of others. Although most everyday action learning takes place in live settings with face-to-face interaction, toddlers' exposure to television significantly increased over the last decades (Rideout, 2013), and screen time further rose during the COVID-19 pandemic and the associated lockdowns (Kahn et al., 2021; Bergmann et al., 2022). With the wide availability of screens and mobile devices, screen exposure will become even more prominent (Barr et al., 2020), providing toddlers with opportunities but also challenges to learn from video. This study aimed to examine toddlers' abilities to learn tool-use actions from video demonstrations in their naturalistic home setting, taking into consideration the potentially supportive influence of verbal information provided by the experimenter.
Research investigating action learning from video consistently points toward a video deficit effect (Barr, 2010; Strouse and Samson, 2021), that is, toddlers learn less from videos than live demonstrations. This effect is however mediated by communicative information. When action demonstrations were accompanied by pedagogical cues (i.e., the experimenter narrating the action while looking at the object or audience), there was no difference in 15- and 18-month-olds' imitation between live and video demonstrations (Lauricella et al., 2016). Furthermore, naturalistic descriptions of action steps derived from mothers' narration style improved imitation from video demonstrations in 18-month-olds compared to empty speech (Seehagen and Herbert, 2010). We aimed to extend this research to online learning of complex tool-use actions, where a learner must associate the functionally relevant properties of a tool with a specific movement to achieve an intended effect (Hernik and Csibra, 2009).
The basis for the online study was a laboratory-based study (Trouillet et al., 2024), where 18- and 24-month-olds observed live demonstrations of tool-use actions, accompanied by verbal information either labeling the tool with a pseudo-noun (Tanu/Löki) and the action with a pseudo-verb (silling lupp/fapsing eel) or a meaningful verb (pressing in/pulling out; specific cue condition), or by empty speech (“With this, I doing that.”, unspecific cue condition). Toddlers performed more correct imitative actions when tools or actions were labeled than in the empty speech condition, with no difference between groups that heard the meaningful verbs and the pseudo-verbs. Thus, different labels for tools and actions–and not the semantic content–seemed to facilitate action learning, maybe by highlighting differences between the two tools or the two demonstrated actions.
In light of the growing availability and significance of digital content from a young age, we were interested if different labels for tools and actions would also help toddlers to overcome their difficulties in learning from video and to learn these more complex tool-use actions from videos watched at home. For this purpose, we adapted the tool-use actions from our imitation study (Trouillet et al., 2024) to be suitable for video presentations on a small screen. In line with other online studies during the COVID-19 pandemic that examined toddlers' development and behavior in their natural home settings (Tsuji et al., 2022), we tested toddlers at home through an unmoderated online experiment and measured their action learning through looking times. This study expands the use of preferential looking time measurements in online studies, which have previously been used to capture visual preferences (Nelson and Oakes, 2021), word recognition (Bacon et al., 2021), and matching emotional utterances to corresponding pictures (Smith-Flores et al., 2022), by applying them to action learning.
In the current study, 18- and 24-month-olds watched videos featuring an experimenter demonstrating two actions using different tools. To potentially enhance learning from video, the experimenter labeled the tool-action associations for one group of toddlers (specific cue) and provided verbal information that did not differentiate between the actions for the second group (unspecific cue). At test, toddlers were shown still-frames displaying correct and incorrect tool-use side-by-side (Figure 1C). We assessed their action learning by analyzing webcam recordings of toddlers' looking times at the pictures. Previous studies have shown that toddlers look longer at the part of a dual-ended tool that is incongruent with an actor's goal (Ní Choisdealbha et al., 2016) and that infants look longer at unexpected outcomes of a tool-use action (Hernik and Csibra, 2015). Based on these findings, we took longer looking times to the incorrect than to the correct tool use pictures as an indicator of the toddlers' action learning. Given that specific verbal information has been shown to benefit toddlers' learning of tool-use actions from live demonstrations (Trouillet et al., 2024), we expected to find a larger difference in looking times between the two pictures in the specific cue condition than in the unspecific cue condition. Furthermore, we expected this impact of the verbal cues to be more pronounced in 24-month-olds due to their advanced language development (see Gampe and Daum, 2014).

Figure 1. Exemplary still frames of learning phase videos and test trial pictures. (A) Depicts the action with the pressing tool, (B) with the pulling tool. When the action is completed (i.e., the yellow circle reaches the opening on the right side), there is a blinking light and a sound effect. (C) Depicts two exemplary test trials, with a correct and incorrect tool-use picture presented side-by-side. Left: correct use of the pulling tool (right picture), incorrect use of the pressing tool. Right: Correct use of the pressing tool (right picture), incorrect use of the pulling tool. The identity of the correctly used tool and the position of the correct test picture were varied across four test trials per participant.
Materials and methods
We preregistered the methods and analysis at https://osf.io/txqyz, and the data are openly available at https://osf.io/7stb8/. The final sample included 89 full-term German-speaking toddlers: forty-four 18-month-olds (M = 17.73 months, SD = 0.59, range = 17–19, 21 girls) and forty-five 24-month-olds (M = 23.67 months, SD = 0.77, range = 22–26; 27 girls). An equal number of toddlers per age group was randomly assigned to the two verbal cue conditions (n = 22; with one additional 24-month-old toddler in the unspecific verbal cue condition). We based the sample size on prior research that investigated the role of verbal information in action learning (n = 22–26 children per group; Lauricella et al., 2016; Patzwald and Elsner, 2019), as well as on a similar, still ongoing imitation study conducted in our lab. Fourteen additional toddlers were excluded due to technical issues (n = 11; bad quality of the webcam recording, toddler not visible, black recording), parental interference (n = 1), missing age information (n = 1), and toddler's participation in a similar study in our lab (n = 1). Most families were recruited via phone call from databases from two German infant research labs, although a few families were recruited via a website with study links for infant and children online studies in Germany (KinderSchaffenWissen). Parents gave informed consent specific to online data collection, data protection and storage at the beginning of the experiment, and the study and those procedures were approved by the local ethics committee.
The experiment was conducted using LabVanced (Finger et al., 2017) and families participated from home using their personal computer or laptop. For the webcam recordings, parents were instructed to place their toddler onto their lap and make sure that their toddler was visible in the recoding. Toddlers first watched videos of a female experimenter demonstrating two tool-use actions on an effect box (learning phase, Figures 1A, B), followed by a test phase with four trials presenting two pictures side-by-side (Figure 1C). A video with an exemplary walk-through of the experiment from a participant's point-of-view is available on https://osf.io/7stb8/. The effect box had one opening in which a pressing tool (colored stick, Figure 1A) could be inserted; and one hook in which a pulling tool (differently colored stick with a loop, Figure 1B) could be hooked. There were two sets of tools with switched colors (red and blue), and toddlers were randomly assigned to one of the sets. The videos of the learning phase started with a complete view of the experimenter providing a verbal cue for the first action (Table 1) for 9 s, followed by a close-up showing the respective action demonstration with the first tool (i.e., pressing or pulling; 4 s) ending with an action effect (appearance of a blinking star on a yellow circle together with a ringing sound). Then the experimenter provided a shortened version of the same verbal cue in full view (5 s), followed by another close-up action demonstration. This was repeated once, leading to a total duration of 31 s per video. After viewing an attention getter, toddlers watched the video presenting the second action with the other tool. Toddlers were randomly assigned to one of the orders of videos (pressing/pulling first). Toddlers were very attentive during the learning phase, with a mean looking time per video toward the screen of 30.84 s (99.5% of total duration of learning videos, SD = 1.23).

Table 1. Verbal cues during the learning phase.
After the learning phase, toddlers were presented with four test trials (10 s each), each presenting two pictures side-by-side: one depicting one tool being used at the correct location of the effect box (= correct tool-use), the other depicting the other tool being used at the same (but for this tool incorrect) location (= incorrect tool-use, Figure 1C). Toddlers were randomly assigned to one of four test trial set-ups that varied the order of picture sets and within these sets the identity of the correctly used tool and the left or right position of the correct tool-use picture (Supplementary Table 1). Each toddler saw the pressing and the pulling tool used incorrectly twice. Toddlers' attention to the static pictures was quite high, with average looking times of 7.66 s (76.6%; SD = 1.09) to both pictures in each trial. After the test phase, parents were asked to indicate on a 5-point-Likert scale from 1 (very bad) to 5 (very good) how their child liked the participation in the experiment. On average, parents indicated that their child enjoyed participating (n = 86, M = 4.15, SD = 0.78). To ensure that toddlers understood the presented specific verbal cues, we also collected parental reports on their child's understanding of the German words ziehen, drücken, raus, rein (i.e., pulling, pressing, out, in; Table 1). Parents reported that children understood the majority of the presented words (18-month-olds: M = 3.41, SD = 0.85; 24-month-olds: M = 3.59, SD = 0.8).
One person coded toddlers' looking behavior in the four test trials to the left or the right picture manually and frame-by-frame from the webcam recordings. A second coder re-coded the recordings of 25% of the toddlers, and interrater reliability was excellent (ICC = 0.93). Coders were unaware of the language condition under which the toddlers were tested. We needed to exclude only few test trials with a disturbance (n = 4), in which toddlers moved a lot (n = 3), or looked at the screen for < 2 s (n = 4). This left n = 345 test trials (97%) for analysis. Quality of webcam recordings was thus very satisfactory. For each test trial, we calculated proportional target looking time by diving the looking time to the picture showing the incorrect tool-use by the total looking time toward both pictures. Data were analyzed in R (version 4.2.2, R Core Team, 2019) by means of a linear mixed effect model (lme4, version 1.1.29, Bates et al., 2015) with proportional target looking time as dependent variable, verbal cue and age group (and their interaction) as fixed effects, and participant-ID as a random effect. We compared the full model with an intercept-only model. In addition, we averaged the proportional target looking times across the four test trials for each participant and tested the four experimental groups against 0.5 with one-sample t-tests (Bonferroni-Holm corrected), to determine whether toddlers' looking behavior deviated from chance. All tests were two-tailed and alpha was set at p < 0.05. Given the null results obtained from our initial analyses, we calculated Bayes factors to provide additional evidence regarding the null hypothesis, using the BayesFactor package (version 0.9.12-4.7, Morey and Rouder, 2024) with the default JZS prior. We originally planned (and pre-registered) to also analyze whether toddlers' first look was directed toward the correct or incorrect tool-use picture. However, we realized that it was difficult for a participant to recognize whether the tools were used correctly or incorrectly on the test trial pictures through peripheral vision alone. We therefore excluded the analyses of the direction of the first look from our study, as we deemed it not reliable for measuring action learning.
Results
We tested proportional looking time across the four test trials (Figure 2) against 0.5 (i.e., chance) and applied Bonferroni-Holm correction to the p-values. Toddlers' looking behavior in all groups did not differ from chance, 18 months specific cue: t(21) = 0.22, padj = 1, BF10 = 0.23; 18 months unspecific cue: t(21) = −1.1, padj = 1, BF10 = 0.38; 24 months specific cue: t(21) = 1.11, padj = 1, BF10 = 0.38; 24 months unspecific cue: t(22) = −0.1, padj = 1, BF10 = 0.22. This indicates that the toddlers looked for a similar amount of time to the pictures depicting incorrect and correct tool-use. Bayesian one-sample t-tests confirmed anecdotal to moderate evidence for the null hypothesis (chance level), with Bayes factors BF10 ranging from 0.22 to 0.38. Furthermore, the linear mixed model on proportional looking time during the test trials comprising age group, verbal cue, and their interaction (Table 2) did not show a significant improvement over the intercept-only model, χ2(3) = 1.81, p = 0.61 (see Supplementary Table 2 for model comparison statistics). Finally, a Bayes factor analysis comparing the full model with the intercept-only model also indicated strong evidence for the latter, BF10 = 0.006.
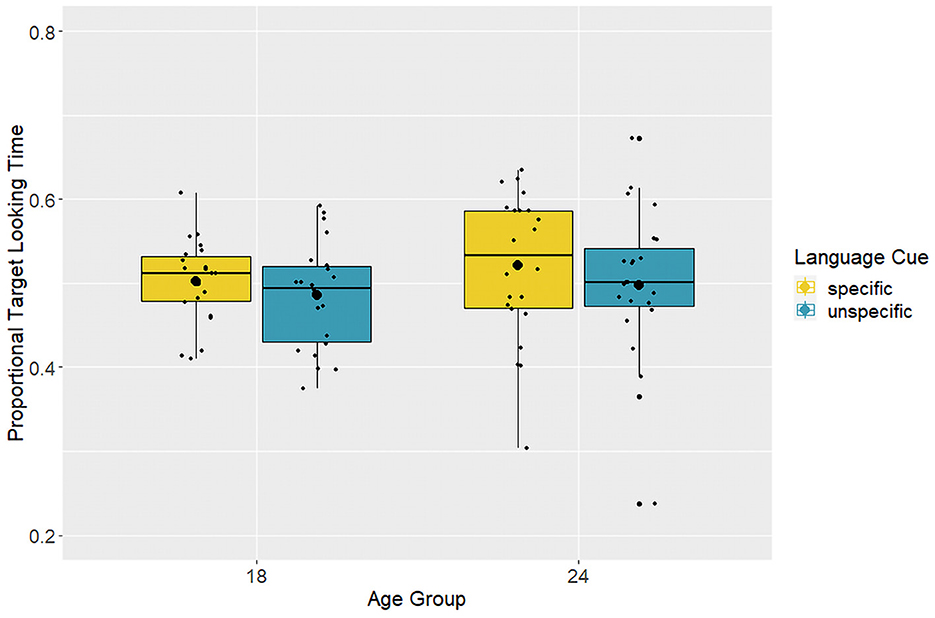
Figure 2. Box-plots with individual data points for proportional target looking time toward the incorrect tool use picture, averaged across the four test trials. The larger black dot represents the group mean.
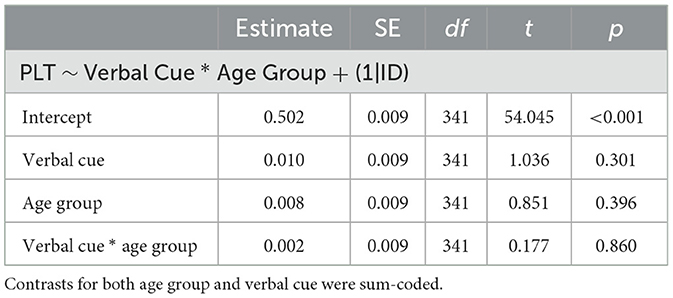
Table 2. Model estimates for the proportional looking time.
Discussion
Our analysis revealed that toddlers' proportional looking times to the pictures depicting correct and incorrect tool-use during test did not vary between the 18- and 24-month-olds or between the groups that had heard specific or unspecific verbal cues during action demonstration. Furthermore, proportional looking times in all groups did not differ from chance, suggesting that the toddlers did not learn to associate the two tools with their respective functional actions. These results were corroborated by the calculation of Bayes factors, which also showed moderate to strong evidence for the null hypothesis. Learning actions from videos in a naturalistic home setting thus entails important challenges for toddlers, challenges öwhich are not counteracted by the presentation of meaningful verbal cues.
Despite the consistent findings of a video deficit effect in screen-based action learning (Barr, 2010; Strouse and Samson, 2021), research has shown that toddlers can learn actions from videos under certain circumstances, for instance when demonstrations include pedagogical cues (Lauricella et al., 2016) or naturalistic action descriptions (Seehagen and Herbert, 2010). Furthermore, in a laboratory-based imitation study, 18- and 24-month-olds were able to learn and imitate similar pressing and pulling actions after observing a live demonstration, with more correct imitation when actions were presented with specific cues that labeled tools and actions (pulling out, pressing in) than with unspecific cues (doing that; Trouillet et al., 2024). We had therefore expected that toddlers would be able to learn the tool-use actions from video demonstrations when the same specific verbal cues were provided. Taken together, the lack of learning in this online study suggests that while toddlers were able to learn to associate tools with their respective actions when observing a live demonstration, they were either unable to do so from videos in this unmoderated online study, or they did learn the association but our method of measuring learning–through looking times at static test pictures–was not effective.
Several factors could have impacted learning in this online experiment. First, online presentations diverge from laboratory-based video and live presentations in several key ways. For instance, testing occurs in the child's personal environment. On the one hand, this is an advantage because it is easier and more comfortable for families to participate when they do not have a specific appointment, making it more flexible. On the other hand, children participate in their familiar and potentially more stimulating environment, devoid of direct experimenter contact. While Seehagen and Herbert (2010) suggested that an experimenter's familiarity does not influence learning from videos, the personal interaction and atmosphere stemming from a lab or home visit by an experimenter might still enhance learning outcomes. Given these considerations, it would be interesting to determine if toddlers could learn these actions from interactive experiences in a moderated online experiment conducted via video chat. Here, the experimenter would engage with the toddler before the task and respond in a contingent manner to the toddler's behaviors and communication signals. Such interactivity has proven beneficial for learning words (Roseberry et al., 2014; Myers et al., 2017), discerning patterns (Myers et al., 2017), locating hidden toys (Troseth et al., 2018), and imitating actions after a brief delay (Nielsen et al., 2008).
Second, in our live study (Trouillet et al., 2024), toddlers had the opportunity to manually explore the tools before observing the action demonstrations. This hands-on experience may have enhanced children's processing of the demonstrations (as for example demonstrated for 10-month-olds' understanding of others' tool-use-actions; Sommerville et al., 2008). Additionally, we maintained a consistent number of repetitions for the demonstrations in both the live and the online studies. It is possible that three instances per tool were not enough for toddlers to encode and learn the actions. Fittingly, research suggests that increasing the number of repetitions could mitigate the deficit effect for imitating from videos (e.g., Barr et al., 2007). In sum, live demonstrations offer potential advantages for toddlers' learning through interactivity between the experimenter and the child, as well as hands-on experiences, both of which are absent in online studies.
On a different note, toddlers might have learned the tool-action associations, but looking times toward static test pictures may not have been an adequate measure for their learning. While data gathered online often mirrors data collected in traditional lab settings (Scott et al., 2017; Bacon et al., 2021), there are instances where online studies failed to replicate in-lab results (Bochynska and Dillon, 2021; Smith-Flores et al., 2022). For instance, 7-month-olds did not discriminate shape changes in an unmoderated online study measuring proportional target looking times, which contradicted laboratory-based findings (Bochynska and Dillon, 2021). Similarly, an online experiment that violated expectations about solidity of objects was unable to replicate common findings in 15- to 16-month-olds (Smith-Flores et al., 2022). In both cases, replication failures could have resulted from the use of small personal screens, which might have limited the visibility of subtle shape changes (Bochynska and Dillon, 2021) or distorted the visual angle of the stimuli (Smith-Flores et al., 2022). It is possible that the visibility of critical tool features (specifically, the colored functional parts) was similarly compromised in our study. This could have prevented toddlers from perceiving differences between the tools, and in turn, hindered their ability to identify incorrect tool-use at test. Additionally, the static test pictures may not have been as effective as test videos in enabling toddlers to distinguish between correct and incorrect tool uses [as for example in Hernik and Csibra (2015)].
Specific verbal cues did also not impact toddlers' learning, contradicting previous findings of a positive influence of specific verbal cues on imitative learning from live (Bonawitz et al., 2010; Chen and Waxman, 2013; Trouillet et al., 2024) and video demonstrations (Seehagen and Herbert, 2010; Lauricella et al., 2016). While tool and action labels improved toddlers' imitation of tool-use actions when presented in a live setting (Trouillet et al., 2024), they may not have been as effective in facilitating action learning when presented in a video setting. Communicative cues can direct toddlers' attention to certain aspects of a demonstration (e.g., Fukuyama and Myowa-Yamakoshi, 2013) and labels can facilitate the perception of differences between objects (as found in object individuation studies; e.g., LaTourrette and Waxman, 2020). However, if these aspects and differences are difficult to discern on a small screen, the cues may not be effective for toddlers' action learning. In sum, neither specific nor unspecific verbal cues appeared to aid toddlers in learning the tool-use actions from videos at home. It remains therefore uncertain whether these cues had a neutral effect or perhaps impeded learning. To draw definitive conclusions, future research would need to incorporate a control condition without any verbal cues.
Although we did not find evidence of action learning in toddlers, our study supports the feasibility of conducting an online looking-time experiment with 18-and 24-month-olds. Only 14% of participants had to be excluded. For the remaining participants, the vast majority of webcam recordings in the test trials was of high quality and therefore straightforward to code, which was underscored by our excellent interrater-reliability. This also shows that parents understood and followed the webcam placement instructions displayed on screen. Most toddlers remained attentive throughout the experiment, and a majority of parents reported that their child enjoyed the experience. These observations support the viability of online experiments as a method for collecting webcam-based looking time data from toddlers at home [as seen in studies like Bacon et al. (2021) and Nelson and Oakes (2021)]. However, our null results raise the question of whether this method was suited to capture this particular area of cognitive development. So far, preferential looking times in online studies have successfully captured visual preferences in 4- to 12-month-olds for handled vs. non-handled objects (Nelson and Oakes, 2021), familiar word recognition in 23- to 26-month-olds (Bacon et al., 2021), and 16-month-olds' matching of emotional utterances to corresponding pictures (Smith-Flores et al., 2022). Yet, to our knowledge, our study has been the first to investigate toddlers' action learning. Our research, therefore, raises awareness about the importance of carefully considering the suitability of online studies in that domain. Regarding recruitment, we found it most effective to contact parents personally over the phone to confirm their participation. Only a few families joined through online study advertisements, suggesting that while online experiments offer broader accessibility, personal contact remains crucial for participant recruitment.
In sum, this research demonstrated that online studies can be a feasible method for data collection with toddlers, providing looking time data through webcam recording and offline coding of satisfactory quality. However, this method may not be suited for all research questions. This study found no evidence that 18- and 24-month-olds transferred their observational experience with two tools and their respective functional actions to subsequently presented static pictures of correct or incorrect tool use. This finding suggests that live demonstrations provide specific aspects that enhance toddlers' tool-use action learning (e.g., contingent social interaction, haptic exploration and handling of objects), and that online methods have methodological caveats when the presented stimuli have subtle differences that might not be easily distinguishable on personal screens. Especially for infants and toddlers, with their limited cognitive capacities, future research should continue to investigate factors that support learning, such as contingency of interaction via video chat. Such efforts acknowledge the fact that screens and mobile devices have become integral parts of toddlers' learning environments.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this work the author(s) used ChatGPT in order to check grammar and spelling and to improve the readability and language of their own writing. After using this tool/service, the author(s) reviewed and edited the content as needed and take(s) full responsibility for the content of the publication.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://osf.io/7stb8/.
Ethics statement
The studies involving humans were approved by University of Potsdam Ethics Committee. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation in this study was provided by the participants' legal guardians/next of kin. Written informed consent was obtained from the individual(s) for the publication of any identifiable images or data included in this article.
Author contributions
LT: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Project administration, Software, Visualization, Writing – original draft. RB: Conceptualization, Investigation, Methodology, Project administration, Writing – review & editing. NM: Conceptualization, Funding acquisition, Methodology, Resources, Supervision, Writing – review & editing. BE: Conceptualization, Funding acquisition, Methodology, Resources, Supervision, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by Deutsche Forschungsgemeinschaft (DFG; Research Unit FOR 2253, grant no. EL 253/7-2 granted to BE).
Acknowledgments
We thank the families and their toddlers for participating in the study and Dr. Markus Studtmann for helping us to create the stimuli used in this study.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fdpys.2024.1411276/full#supplementary-material
References
Bacon, D., Weaver, H., and Saffran, J. (2021). A framework for online experimenter-moderated looking-time studies assessing infants' linguistic knowledge. Front. Psychol. 12:703839. doi: 10.3389/fpsyg.2021.703839
Barr, R. (2010). Transfer of learning between 2D and 3D sources during infancy: informing theory and practice. Dev. Rev. 30, 128–154. doi: 10.1016/j.dr.2010.03.001
Barr, R., Kirkorian, H., Radesky, J., Coyne, S., Nichols, D., Blanchfield, O., et al. (2020). Beyond screen time: a synergistic approach to a more comprehensive assessment of family media exposure during early childhood. Front. Psychol. 11:1283. doi: 10.3389/fpsyg.2020.01283
Barr, R., Muentener, P., Garcia, A., Fujimoto, M., and Chávez, V. (2007). The effect of repetition on imitation from television during infancy. Dev. Psychobiol. 49, 196–207. doi: 10.1002/dev.20208
Bates, D., Maechler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Bergmann, C., Dimitrova, N., Alaslani, K., Almohammadi, A., Alroqi, H., Aussems, S., et al. (2022). Young children's screen time during the first COVID-19 lockdown in 12 countries. Sci. Rep. 12, 2015. doi: 10.1038/s41598-022-05840-5
Bochynska, A., and Dillon, M. R. (2021). Bringing home baby Euclid: testing infants' basic shape discrimination online. Front. Psychol. 12:734592. doi: 10.3389/fpsyg.2021.734592
Bonawitz, E. B., Ferranti, D., Saxe, R., Gopnik, A., Meltzoff, A. N., Woodward, J., et al. (2010). Just do it? Investigating the gap between prediction and action in toddlers' causal inferences. Cognition 115, 104–117. doi: 10.1016/j.cognition.2009.12.001
Chen, M. L., and Waxman, S. R. (2013). “Shall we blick?” Novel words highlight actors' underlying intentions for 14-month-old infants. Dev. Psychol. 49, 426–431. doi: 10.1037/a0029486
Finger, H., Goeke, C., Diekamp, D., Standvoß, K., and König, P. (2017). “LabVanced: a unified JavaScript framework for online studies,” in International Conference on Computational Social Science (Cologne). Available online at: https://www.labvanced.com/publication.html (accessed July 25, 2024).
Fukuyama, H., and Myowa-Yamakoshi, M. (2013). Fourteen-month-old infants copy an action style accompanied by social-emotional cues. Infant Behav. Dev. 36, 609–617. doi: 10.1016/j.infbeh.2013.06.005
Gampe, A., and Daum, M. M. (2014). Productive verbs facilitate action prediction in toddlers. Infancy 19, 301–325. doi: 10.1111/infa.12047
Hernik, M., and Csibra, G. (2009). Functional understanding facilitates learning about tools in human children. Curr. Opin. Neurobiol. 19, 34–38. doi: 10.1016/j.conb.2009.05.003
Hernik, M., and Csibra, G. (2015). Infants learn enduring functions of novel tools from action demonstrations. J. Exp. Child Psychol. 130, 176–192. doi: 10.1016/j.jecp.2014.10.004
Kahn, M., Barnett, N., Glazer, A., and Gradisar, M. (2021). Covid-19 babies: auto-videosomnography and parent reports of infant sleep, screen time, and parent well-being in 2019 vs 2020. Sleep Med. 85, 259–267. doi: 10.1016/j.sleep.2021.07.033
LaTourrette, A. S., and Waxman, S. R. (2020). Naming guides how 12-month-old infants encode and remember objects. Proc. Natl. Acad. Sci. USA. 117, 21230–21234. doi: 10.1073/pnas.2006608117
Lauricella, A. R., Barr, R., and Calvert, S. L. (2016). Toddler learning from video: effect of matched pedagogical cues. Infant Behav. Dev. 45, 22–30. doi: 10.1016/j.infbeh.2016.08.001
Morey, R., and Rouder, J. (2024). BayesFactor: Computation of Bayes Factors for Common Designs. [Computer software]. Available online at: https://CRAN.R-project.org/package=BayesFactor (accessed July 25, 2024).
Myers, L. J., LeWitt, R. B., Gallo, R. E., and Maselli, N. M. (2017). Baby FaceTime: can toddlers learn from online video chat? Dev. Sci. 20:e12430. doi: 10.1111/desc.12430
Ní Choisdealbha, A., Westermann, G., Dunn, K., and Reid, V. (2016). Dissociating associative and motor aspects of action understanding: processing of dual-ended tools by 16-month-old infants. Br. J. Dev. Psychol. 34, 115–131. doi: 10.1111/bjdp.12116
Nelson, C. M., and Oakes, L. M. (2021). “May I Grab Your Attention?”: an investigation into infants' visual preferences for handled objects using Lookit as an online platform for data collection. Front. Psychol. 12:733218. doi: 10.3389/fpsyg.2021.733218
Nielsen, M., Simcock, G., and Jenkins, L. (2008). The effect of social engagement on 24-month-olds' imitation from live and televised models. Dev. Sci. 11, 722–731. doi: 10.1111/j.1467-7687.2008.00722.x
Patzwald, C., and Elsner, B. (2019). Do as I say - or as I do?! How 18- and 24-month-olds integrate words and actions to infer intentions in situations of match or mismatch. Infant Behav. Dev. 55, 46–57. doi: 10.1016/j.infbeh.2019.03.004
R Core Team (2019). R: A Language and Environment for Statistical Computing [Computer software]. Vienna: R Foundation for Statistical Computing. Available online at: https://www.R-project.org/ (accessed July 25, 2024).
Rideout, V. (2013). Zero to Eight: Children's Media Use in America. San Francisco, CA: Common Sense Media.
Roseberry, S., Hirsh-Pasek, K., and Golinkoff, R. M. (2014). Skype me! Socially contingent interactions help toddlers learn language. Child Dev. 85, 956–970. doi: 10.1111/cdev.12166
Scott, K., Chu, J., and Schulz, L. (2017). Lookit (Part 2): assessing the viability of online developmental research, results from three case studies. Open Mind 1, 15–29. doi: 10.1162/OPMI_a_00001
Seehagen, S., and Herbert, J. S. (2010). The role of demonstrator familiarity and language cues on infant imitation from television. Infant Behav. Dev. 33, 168–175. doi: 10.1016/j.infbeh.2009.12.008
Smith-Flores, A. S., Perez, J., Zhang, M. H., and Feigenson, L. (2022). Online measures of looking and learning in infancy. Infancy 27, 4–24. doi: 10.1111/infa.12435
Sommerville, J. A., Hildebrand, E. A, and Crane, C. C. (2008). Experience matters: the impact of doing versus watching on infants' subsequent perception of tool-use events. Dev. Psychol. 44, 1249–1256. doi: 10.1037/a0012296
Strouse, G. A., and Samson, J. E. (2021). Learning from video: a meta-analysis of the video deficit in children ages 0 to 6 years. Child Dev. 92, e20–e38. doi: 10.1111/cdev.13429
Troseth, G. L., Strouse, G. A., Verdine, B. N., and Saylor, M. M. (2018). Let's chat: on-screen social responsiveness is not sufficient to support toddlers' word learning from video. Front. Psychol. 9:411949. doi: 10.3389/fpsyg.2018.02195
Trouillet, L., Bothe, R., Mani, N., and Elsner, B. (2024). Distinctive verbal cues support the learning of tool-use actions in 18- and 24-month-olds. Psyarxiv [Preprint]. Available online at: osf.io/preprints/psyarxiv/4m9da (accessed April 2, 2024).
Keywords: tool-use, action learning, language, online study, development
Citation: Trouillet L, Bothe R, Mani N and Elsner B (2024) Investigating the role of verbal cues on learning of tool-use actions in 18- and 24-month-olds in an online looking time experiment. Front. Dev. Psychol. 2:1411276. doi: 10.3389/fdpys.2024.1411276
Received: 02 April 2024; Accepted: 17 July 2024;
Published: 02 August 2024.
Edited by:
Nayeli Gonzalez-Gomez, Oxford Brookes University, United KingdomReviewed by:
Yifei He, University of Marburg, GermanyJane S. Herbert, University of Wollongong, Australia
Copyright © 2024 Trouillet, Bothe, Mani and Elsner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Léonie Trouillet, bGVvbmllLnRyb3VpbGxldEB1bmktcG90c2RhbS5kZQ==