 Hui Tian
Hui Tian Xin Su
Xin Su Yanfang Hou
Yanfang Hou- 1Key Laboratory of Industrial Internet of Things and Networked Control, Ministry of Education, Chongqing University of Posts and Telecommunications, Chongqing, China
- 2School of Electrical and Electronic Engineering, Chongqing University of Technology, Chongqing, China
Background: As an important mathematical model, the finite state machine (FSM) has been used in many fields, such as manufacturing system, health care, and so on. This paper analyzes the current development status of FSMs. It is pointed out that the traditional methods are often inconvenient for analysis and design, or encounter high computational complexity problems when studying FSMs.
Method: The deep Q-network (DQN) technique, which is a model-free optimization method, is introduced to solve the stabilization problem of probabilistic finite state machines (PFSMs). In order to better understand the technique, some preliminaries, including Markov decision process, ϵ-greedy strategy, DQN, and so on, are recalled.
Results: First, a necessary and sufficient stabilizability condition for PFSMs is derived. Next, the feedback stabilization problem of PFSMs is transformed into an optimization problem. Finally, by using the stabilizability condition and deep Q-network, an algorithm for solving the optimization problem (equivalently, computing a state feedback stabilizer) is provided.
Discussion: Compared with the traditional Q learning, DQN avoids the limited capacity problem. So our method can deal with high-dimensional complex systems efficiently. The effectiveness of our method is further demonstrated through an illustrative example.
1 Introduction
The finite state machine (FSM), also known as finite automata (Yan et al., 2015b), is an important mathematical model, which has been used in many different fields, such as manufacturing system (Wang et al., 2017; Piccinini et al., 2018), health care (Shah et al., 2017; Zhang, 2018; Fadhil et al., 2019), and so on. The deterministic finite state machine (DFSM) is known for its deterministic behaviors, in which each subsequent state is uniquely determined by its input event and preceding state (Vayadande et al., 2022). However, DFSMs may not be effective in dealing with random behaviors (Ratsaby, 2019), for example, the randomness caused by component failures in sequential circuits (El-Maleh and Al-Qahtani, 2014). To address the challenge, a probabilistic finite state machine (PFSM) was proposed in the study by Vidal et al. (2005), which provides a more flexible framework for those systems that exhibit random behaviors. Especially, it gives an effective solution to practical issues, such as the reliability assessment of sequential circuits (Li and Tan, 2019). Therefore, the PFSM offers a new perspective for the theoretical research of FSMs.
On the other hand, the stabilization of systems is an important and fundamental research topic, and there have been many excellent research results in various fields, for example, Boolean control network (Tian et al., 2017; Tian and Hou, 2019), time-delay systems (Tian and Wang, 2020), neural networks (Ding et al., 2019), and so on. The stabilization research of FSMs is no exception and has also attracted the attention of many scholars. The concepts of stability and stabilization of discrete event systems described by FSMs were given in the study by Özveren et al. (1991). A polynomial solution of stability detection and a method for constructing stabilizers were presented. Passino et al. (1994) utilzed the Lyapunov method to study the stability and stabilization of FSMs. Tarraf et al. (2008) proposed some new concepts, including gain stability, incremental stability and external stability, and then established a research framework for robust stability of FSMs. Kobayashi et al. developed a linear state equation representation method for modeling DFSMs in the study by Kobayashi (2006) and Kobayashi and Imura (2007) and derived a necessary and sufficient condition for DFSM to be stabilizable at a target equilibrium node in the study by Kobayashi et al. (2011).
However, as we know, the FSM is most often non-linear. Moreover, none of the above methods are convenient when analyzing and designing various FSMs. In the last decade, scholars applied the semi-tensor product (STP) of matrices to FSMs and derived many excellant results. First, with the help of STP, an algebraic form of DFSMs was given in the study by Xu et al. (2013). This algebraic form is a discrete-time bilinear equation. Then, the classic control theory can be used to investigate FSMs. Especially, under the algebraic form, necessary and sufficient conditions for the stabilizability of DFSMs were derived in the study by Xu et al. (2013), and a state feedback controller was obtained by computing a corresponding matrix inequality. Moreover, Yan et al. (2015a) provided a necessary and sufficient condition to check whether a set of states can be stabilized. Han and Chen (2018) considered the set stabilization of DFSMs and provided an optimal design approach for stabilizing controllers. Later, Zhang et al. used the STP method to investigate PFSMs and non-deterministic FSMs. Specifically, a necessary and sufficient condition for stabilization with probability one and a design method for optimal state feedback controller were provided in the study by Zhang et al. (2020a). Moreover, a systematic procedure was designed to get a static output feedback stabilizer for non-deterministic FSMs in the study by Zhang et al. (2020b). Although the STP method is very useful in analyzing discrete event systems, including various FSMs, it suffers from high computational complexity and can only handle small-scale or even micro-scale discrete event systems. To solve the problem, this study refers to techniques developed by Acernese et al. (2019) to solve the stabilization problem of high-dimensional PFSMs, and then provides a reinforcement learning algorithm to compute a state feedback stabilizer for PFSMs. The algorithm is especially advantageous in dealing with high-dimensional systems.
The rest of this study is arranged as follows: Section 2 introduces some preliminary knowledge, including PFSM, Markov decision process (MDP), deep Q newtwork (DQN), and ϵ-greedy strategy. In Section 3, a stabilizabillity condition is derived and an algorithm based on DQN is provided. An illustrative example is employed to show the effectiveness of our results, as shown in Section 4, which is followed by a brief conclusion in Section 5.
2 Methods
For the convenience of statement, some symbol explanations are provided first.
Notation: ℝ expresses the set of all real numbers. ℤ+ stands for the set of all positive integers. denotes the set {a, a+1, ⋯ , b}, where a, b ∈ ℤ+, a ≤ b. |A| is the cardinality of set A.
2.1 Probabilistic finite state machine
A PFSM is a five-tuple
where the set represents a finite set of states, and is the initial state. denotes a finite set of events. is a transition probability function, and expresses the probability of PFSM (1), transiting from state to state under the input event , satisfying
or
The state transition function describes that PFSM (1) may reach different states from one state under the same input event, where is the power set of .
2.2 Markov decision process and optimization methods
A Markov decision process (MDP) is characterized by a quintuple
where S is a set of states, A is a set of actions, P is a state transition probability function, R is a reward function, and γ ∈ [0, 1] is a discount factor that determines the trade-off between short-term and long-term gains.
MDP (2) may reach state st+1 from state st ∈ S under the chosen action at ∈ A, and its probability is determined by the function . The expected one-step reward from state st to state st+1 via action at is as follows:
where rt+1 = rt+1(st, at, st+1) represents the immediate return after adopting action at at time t, and [·] is the expected value of [·].
The objective of MDP (2) is to determine an optimal policy π. This policy can maximize the expected return π[Gt] under policy π where
For a given policy π, the value function of a state st, denoted by vπ(st), is the expected return of MDP (2) taking an action according to the policy π at time step t:
The optimal policy is as follows:
where Π is the set of all admissible policies.
From (4), it is easy to understand . Since vπ(·) satisfies the Bellman equation, we have
Similarly, the action-value function describes the cumulative return from state-action (st, at) under policy π
By substituting (3) into (6), we can obtain
which represents the expected return of action at adopted by MDP (2) at state st, following policy π. The action-value function under optimal strategy π* is called as the optimal action-value function,i.e., . Since , from (5), we can get
Therefore, if MDP (2) exists an optimal deterministic policy, it can be expressed as follows:
DQN is such a technique that combines Q leaning with arificial neural networks (ANNs), providing an effective approach to decision-making problems in dynamic and uncertain environments. It uses ANNs to construct parametric models and estimate action value functions online. Compared with Q learning, the main advantages of DQN are as follows: (1) DQN uses ANNs to approximate Q functions, overcoming the issue of limited capacity in Q tables and enabling the algorithm to handle high-dimensional state spaces. (2) DQN makes full use of empirical knowledge.
Q learning updates the value function according to the following temporal difference (TD) formula:
where is the TD target, is the TD error δ, and 0 < α ≤ 1 is a constant that determines how quickly the past experiences are forgotten.
When dealing with high-dimensional complex systems, the action-value function q(s, a), as described in Equation (7), is approximated by an ANN to reduce computational complexity. This can be achieved by minimizing the following loss function
where the parameter is a periodic copy of the current network parameter θt.
By differentiating Equation (8), we have
where ▽θtq(st, at; θt) represents the gradient of q(st, at; θt) with respect to the parameter θt.
We choose the gradient descent method as the optimization strategy
By substituting Equations (9) into (10), we obtain an update formula for parameter θt
Finally, the ϵ-greedy strategy is used for action selection. Specifically, an action is chosen randomly with probability ϵ ∈ ℝ(0 < ϵ ≤ 1), and the best estimated action is chosen with probability 1−ϵ. As learning progresses, ϵ gradually decreases, and the policy is shifted from exploring the action space to exploiting the learned Q values. The policy π(a∣s) is as follows:
where π(a∣s) is the probability of MDP (2) selecting action a at state s. stands for the action with the highest estimated Q value for state s.
3 Results
We first give a definition.
Definition 1: Assume that is an equilibrium state of PFSM (1). The PFSM is said to be feedback stabilizable to with probability one, if for any initial state , there exists a control sequence , such that .
We define an attraction domain for an equilibrium state , which is a set of states that can reach in k steps.
Next, we give an important result.
Theorem 1: Assume that is an equilibrium state of PFSM (1). The PFSM is feedback stabilizable to with probability one, if and only if there exists an integer ρ ≤ n−1 such that
Proof (Necessity): Assume that PFSM (1) is feedback stabilizable to the equilibrium state with probability one. Then, according to Definition 1, for any initial state , there exists a control sequence , such that , namely . Due to the fact that the state space is a finite set, there must be an integer ρ, such that holds.
(Sufficiency): Assume that Equation (12) holds. For any initial state , we have . From Equation (11), there exists a positive integer ρ and a control sequence such that can be driven to by U in ρ steps with probability one. According to Definition 1, PFSM (1) is feedback stabilizable to with probability one. ■
We cast the feedback control problem of PFSM (1) into a model-free reinforcement learning framework. The main aim is to find a state feedback controller, which can guarantee the finite time stabilization of PFSM (1). This means that all states can be controlled and brought to an equilibrium state within finite steps. Therefore, PFSM (1) is rewritten as , where P is unknown. The stabilization problem of PFSM (1) is formulated as follows:
subject to (1),
where
The objective of Equation (13) is to find an action U that maximizes the action-value function q* among all possible actions in . Therefore, for any state and external condition , the optimal state feedback control law of PFSM (1) is as follows:
Based on the above discussion, we are ready to introduce an algorithm to design an optimal feedback controller (see Algorithm 1). It should be noted that in this algorithm, DQN uses two ANNs. The structure diagram of DQN is shown in Figure 1.

Algorithm 1. State feedback stabilization of PFSM (1) based on deep Q-network.
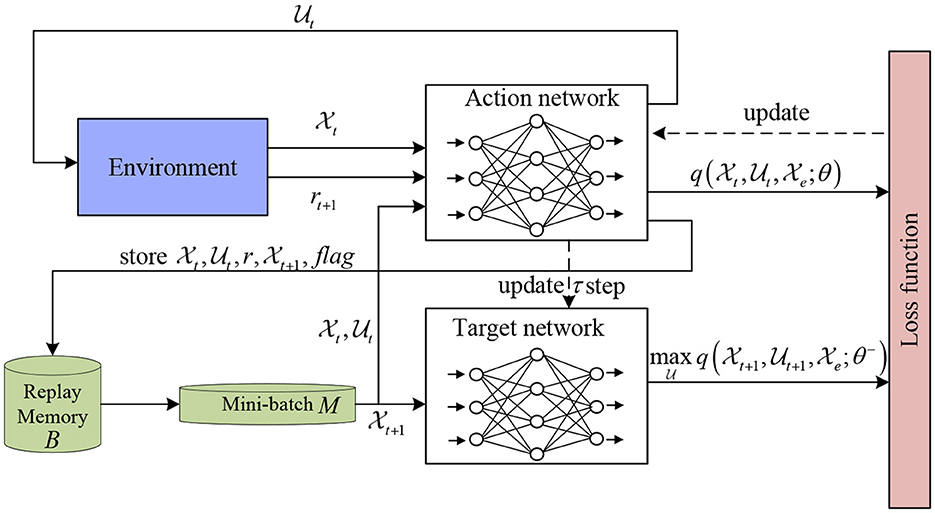
Figure 1. Structure diagram of DQN.
Remark 1: This algorithm is mainly used to solve the stabilization problem of high dimensional PFSMs. For small or micro-scale PFSMs, it is slightly more complex. In this case, we can choose the STP method. Therefore, Algorithm 1 and the STP method complement each other.
According to the results calculated by Algorithm 1, a state feedback controller can be given. Specifically, from Algorithm 1, the result is an optimal policy. Assume that is the calculation result. Then, we get a state feedback controller , .
4 Discussion
Example 1: Consider a PFSM
where represents the i-th state of PFSM (14) at time step t. It is easy to observe that is an equilibrium state.
We now use Algorithm 1 to compute a state feedback controller to stabilize PFSM (14) to . The computation is performed on a computer with Intel i5-11300H processor, 2.6 GHz frequency, 16 GB RAM, and Python 3.7 software. We adopt TensorFlow in Keras to train the DQN model, where the discount factor γ is 0.99, the rang for ϵ in ϵ-greedy policy is from 0.05 to 1.0, and the sizes of memory buffer B and mini-batch M are 10,000 and 128, respectively.
Through calculation, we obtain a state feedback controller
which is shown in Table 1.

Table 1. A state feedback controller of PFSM (14).
Model (14) is a PFSM with 20 states, which is not a simple system. Here, we utilize average rewards to track the performance during training (see Figure 2). It is easy to observe that as training time goes on, the performance inceases and tends to be stable. We put the state feedback controller (15), as shown in Table 1, into PFSM (14) and get a closed-loop system.
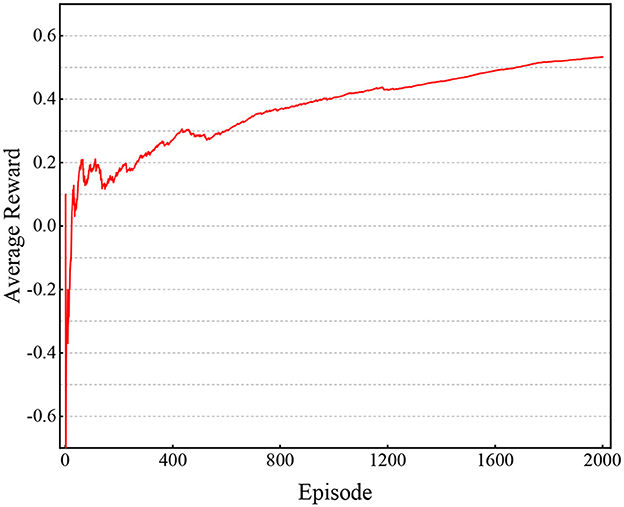
Figure 2. Performance of Algorithm 1 in Example 1.
The state transition trajectory of the closed-loop system (16) starting from any initial state is shown in Figure 3. It can be observed from Figure 3 that all states reach after a finite number of steps and then stay at forever with probability one. This demonstrates the effectiveness of our controller. The number of steps required to reach for each state is shown in Figure 4. From these results, we can observe that based on DQN, Algorithm 1 can solve the stabilization problem of non-small-scale PFSMs.
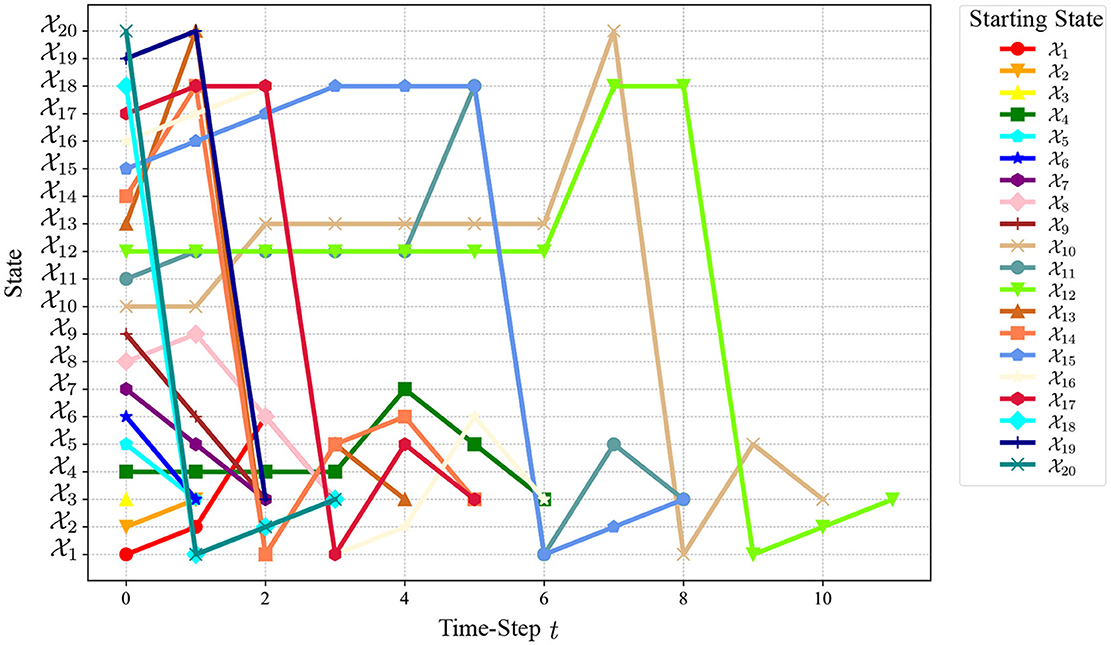
Figure 3. Evolution of the closed-loop system (16).
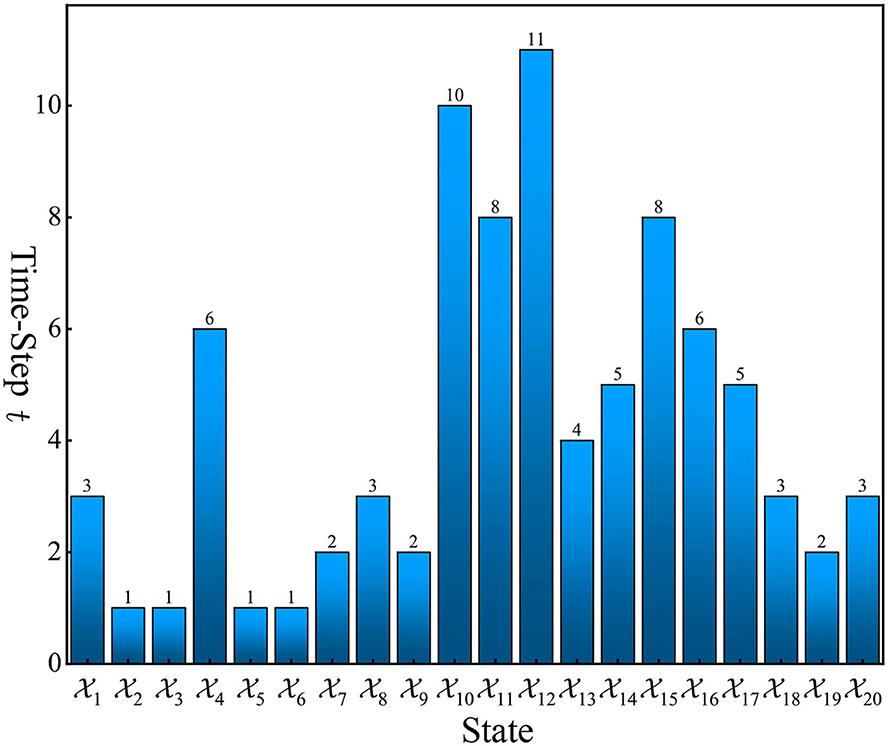
Figure 4. The number of steps required to stabilize PFSM (14) to .
5 Conclusion
This article studied the state feedback stabilization of PFSMs using the DQN method. The feedback stabilization problem of PFSMs was first transformed into an optimization problem. A DQN was built, whose two key parts: TD target and Q function, are approximated through neural networks. Then, based on the DQN and a stabilizability condition derived in this paper, an algorithm was developed. The algorithm can be used to calculate the optimization problem mentioned above and then solves the feedback stability problem of PFSMs. Since DQN avoids the limited capacity problem of Q learning, our algortithm can handle high-dimensional complex systems. Finally, an illustrative example is provided to show the effectiveness of our method.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
HT: Conceptualization, Formal analysis, Funding acquisition, Methodology, Project administration, Supervision, Writing—review & editing. XS: Conceptualization, Formal analysis, Investigation, Methodology, Validation, Writing—original draft. YH: Formal analysis, Investigation, Writing—review & editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was funded by the National Key R&D Program of China (2021YFB3203202) and Chongqing Nature Science Foundation (cstc2020jcyj-msxmX0708).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Acernese, A., Yerudkar, A., Glielmo, L., and Vecchio, C. D. (2020). Double deep-Q learning-based output tracking of probabilistic Boolean control networks. IEEE Access 8, 199254–199265. doi: 10.1109/ACCESS.2020.3035152
Ding, S., Wang, Z., and Zhang, H. (2019). Quasi-synchronization of delayed memristive neural networks via region-partitioning-dependent intermittent control. IEEE Trans. Cybern. 49, 4066–4077. doi: 10.1109/TCYB.2018.2856907
El-Maleh, A., and Al-Qahtani, A. (2014). A finite state machine based fault tolerance technique for sequential circuits. Microelectron. Reliab. 54, 654–661. doi: 10.1016/j.microrel.2013.10.022
Fadhil, A., Wang, Y., and Reiterer, H. (2019). Assistive conversational agent for health coaching: a validation study. Methods Inf. Med. 58, 9–23. doi: 10.1055/s-0039-1688757
Han, X., and Chen, Z. (2018). A matrix-based approach to verifying stability and synthesizing optimal stabilizing controllers for finite-state automata. J. Franklin Inst. 355, 8642–8663. doi: 10.1016/j.jfranklin.2018.09.009
Kobayashi, K. (2006). “Modeling of discrete dynamics for computational time reduction of model predictive control,” in Proceedings of the 17th International Symposium on Mathematical Theory of Networks and Systems (Tokyo), 628–633.
Kobayashi, K., and Imura, J. (2007). “Minimalilty of finite automata representation in hybrid systems control,” in Hybrid Systems: Computation and Control (Berlin Heidelberg: Springer), 343–356. doi: 10.1007/978-3-540-71493-4_28
Kobayashi, K., Imura, J., and Hiraishi, K. (2011). Stabilization of finite automata with application to hybrid systems control. Discret. Event Dyn. Syst. 21, 519–545. doi: 10.1007/s10626-011-0110-2
Li, J., and Tan, Y. (2019). A probabilistic finite state machine based strategy for multi-target search using swarm robotics. Appl. Soft Comput. 77, 467–483. doi: 10.1016/j.asoc.2019.01.023
Özveren, C., Willsky, A., and Antsaklis, P. (1991). Stability and stabilizability of discrete event dynamic systems. J. ACM 38, 729–751. doi: 10.1145/116825.116855
Passino, K., Michel, A., and Antsaklis, P. (1994). Lyapunov stability of a class of discrete event systems. IEEE Trans. Automat. Contr. 39, 269–279. doi: 10.1109/9.272323
Piccinini, A., Previdi, F., Cimini, C., Pinto, R., and Pirola, F. (2018). Discrete event simulation for the reconfiguration of a flexible manufactuing plant. IFAC-PapersOnLine 51, 465–470. doi: 10.1016/j.ifacol.2018.08.362
Ratsaby, J. (2019). On deterministic finite state machines in random environments. Probab. Eng. Inf. Sci. 33, 528–563. doi: 10.1017/S0269964818000451
Shah, S., Velardo, C., Farmer, A., and Tarassenko, L. (2017). Exacerbations in chronic obstructive pulmonary disease: identification and prediction using a digital health system. J. Med. Internet Res. 19:e69. doi: 10.2196/jmir.7207
Tarraf, D., Megretski, A., and Dahleh, M. (2008). A framework for robust stability of systems over finite alphabets. IEEE Trans. Automat. Contr. 53, 1133–1146. doi: 10.1109/TAC.2008.923658
Tian, H., and Hou, Y. (2019). State feedback design for set stabilization of probabilistic boolean control networks. J. Franklin Inst. 356, 4358–4377. doi: 10.1016/j.jfranklin.2018.12.027
Tian, H., Zhang, H., Wang, Z., and Hou, Y. (2017). Stabilization of k-valued logical control networks by open-loop control via the reverse-transfer method. Automatica 83, 387–390. doi: 10.1016/j.automatica.2016.12.040
Tian, Y., and Wang, Z. (2020). A new multiple integral inequality and its application to stability analysis of time-delay systems. Appl. Math. Lett. 105:106325. doi: 10.1016/j.aml.2020.106325
Vayadande, K., Sheth, P., Shelke, A., Patil, V., Shevate, S., Sawakare, C., et al. (2022). Simulation and testing of deterministic finite automata machine. International Journal of Comput. Sci. Eng. 10, 13–17. doi: 10.26438/ijcse/v10i1.1317
Vidal, E., Thollard, F., de la Higuera, C., Casacuberta, F., and Carrasco, R. (2005). Probabilistic finite-state machines - part I. IEEE Trans. Pattern Anal. Mach. Intell., 27, 1013–1025. doi: 10.1109/TPAMI.2005.147
Wang, L., Zhu, B., Wang, Q., and Zhang, Y. (2017). Modeling of hot stamping process procedure based on finite state machine (FSM). Int. J. Adv. Manuf. Technol. 89, 857–868. doi: 10.1007/s00170-016-9097-z
Xu, X., Zhang, Y., and Hong, Y. (2013). “Matrix approach to stabilizability of deterministic finite automata,” in 2013 American Control Conference (Washington, DC), 3242–3247.
Yan, Y., Chen, Z., and Liu, Z. (2015a). Semi-tensor product approach to controllability and stabilizability of finite automata. J. Syst. Eng. Electron. 26, 134–141. doi: 10.1109/JSEE.2015.00018
Yan, Y., Chen, Z., and Yue, J. (2015b). Stp approach to controlliability of finite state machines. IFAC-PapersOnLine 48, 138–143. doi: 10.1016/j.ifacol.2015.12.114
Zhang, X. (2018). Application of discrete event simulation in health care: a systematic review. BMC Health Serv. Res. 18, 1–11. doi: 10.1186/s12913-018-3456-4
Zhang, Z., Chen, Z., Han, X., and Liu, Z. (2020a). Stabilization of probabilistic finite automata based on semi-tensor product of matrices. J. Franklin Inst. 357, 5173–5186. doi: 10.1016/j.jfranklin.2020.02.028
Keywords: probabilistic finite state machine (PFSM), deep Q-network (DQN), feedback stabilization, artificial neural network (ANN), controller
Citation: Tian H, Su X and Hou Y (2024) Feedback stabilization of probabilistic finite state machines based on deep Q-network. Front. Comput. Neurosci. 18:1385047. doi: 10.3389/fncom.2024.1385047
Received: 11 February 2024; Accepted: 08 April 2024;
Published: 02 May 2024.
Edited by:
Yang Cui, University of Science and Technology Liaoning, ChinaCopyright © 2024 Tian, Su and Hou. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hui Tian, dGlhbmh1aUBjcXVwdC5lZHUuY24=