 Emmanuel Calvet
Emmanuel Calvet Bertrand Reulet
Bertrand Reulet Jean Rouat
Jean Rouat- 1Neurosciences Computationelles et Traitement Intelligent des Signaux (NECOTIS), Faculté de Génie, Génie Électrique et Génie Informatique (GEGI), Université de Sherbrooke, Sherbrooke, QC, Canada
- 2Département de Physique, Institut Quantique, Faculté des Sciences, Université de Sherbrooke, Sherbrooke, QC, Canada
Reservoir Computing (RC) is a paradigm in artificial intelligence where a recurrent neural network (RNN) is used to process temporal data, leveraging the inherent dynamical properties of the reservoir to perform complex computations. In the realm of RC, the excitatory-inhibitory balance b has been shown to be pivotal for driving the dynamics and performance of Echo State Networks (ESN) and, more recently, Random Boolean Network (RBN). However, the relationship between b and other parameters of the network is still poorly understood. This article explores how the interplay of the balance b, the connectivity degree K (i.e., the number of synapses per neuron) and the size of the network (i.e., the number of neurons N) influences the dynamics and performance (memory and prediction) of an RBN reservoir. Our findings reveal that K and b are strongly tied in optimal reservoirs. Reservoirs with high K have two optimal balances, one for globally inhibitory networks (b < 0), and the other one for excitatory networks (b > 0). Both show asymmetric performances about a zero balance. In contrast, for moderate K, the optimal value being K = 4, best reservoirs are obtained when excitation and inhibition almost, but not exactly, balance each other. For almost all K, the influence of the size is such that increasing N leads to better performance, even with very large values of N. Our investigation provides clear directions to generate optimal reservoirs or reservoirs with constraints on size or connectivity.
1 Introduction
Reservoir computing (RC) is a promising approach that could drastically reduce the cost of learning as the input gets projected into a higher dimensional space, the reservoir, read out by a single output layer. As such, when the reservoir is adequately designed, a simple linear fitting can be used to train the weights of the readout layer (Maass et al., 2002), alleviating the computational burden of other traditional machine learning methods. The Echo State Network (ESN) developed by Jaeger (2005) comprises reservoirs with continuous activation functions, while Liquid State Machine (LSM) (Maass et al., 2002) typically includes discontinuous activation functions, among which we find the Random Boolean Network (RBN) (Glass and Hill, 1998).
Research on both models has demonstrated that two critical factors influence the dynamics and performance in tasks. These include the topology of the connectivity graph (Cattaneo et al., 1997; Luque and Solé, 2000; Hajnal and Lőrincz, 2006; Snyder et al., 2012; Aljadeff et al., 2015; Cherupally, 2018; Echlin et al., 2018; Galera and Kinouchi, 2020; Steiner et al., 2023) and the synaptic weights that connect the neurons (Bertschinger and Natschläger, 2004; Natschläger et al., 2005; Embrechts et al., 2009; Büsing et al., 2010; Goudarzi et al., 2014; Jalalvand et al., 2018; Krauss et al., 2019a). Such a graph depends on many parameters, in particular its number of nodes N and the degree of vertices K, i.e., the number of synapses per neuron.
In practice, the graph of reservoirs is often random (Bertschinger and Natschläger, 2004; Pontes-Filho et al., 2020), even though other types of connectivity have been studied, such as scale-free and small world (Haluszczynski and Räth, 2019). In the context of Random Boolean Networks (RBNs), such a connectivity graph is generally constructed by randomly selecting synapses between neurons with the given degree K (Bertschinger and Natschläger, 2004; Natschläger et al., 2005; Snyder et al., 2013; Burkow and Tufte, 2016; Echlin et al., 2018). The connectivity degree can be homogeneous, implying a fixed value of K for all neurons in the network (Bertschinger and Natschläger, 2004), or heterogeneous, where K has some distribution among neurons (Snyder et al., 2013). The analysis of the link between connectivity, dynamics and performance is simpler in the former case, and numerous studies have investigated the correlation between a fixed K and the dynamic and performance of the RBNs (Luque and Solé, 2000; Bertschinger and Natschläger, 2004; Büsing et al., 2010; Burkow and Tufte, 2016). For example, when K > 2, it is widely recognized that these systems can yield a phase transition, referred to as the edge of chaos, which is associated with enhanced memory and computation (Bertschinger and Natschläger, 2004; Natschläger et al., 2005). Furthermore, compared to Echo State Networks (ESN), the region conducive to improved performance is more restricted with RBNs (Büsing et al., 2010), while ESNs have been demonstrated to be less sensitive to this parameter (Hajnal and Lőrincz, 2006; Büsing et al., 2010; Krauss et al., 2019a; Metzner and Krauss, 2022). This makes RBNs more challenging to parameterize, and their performance also diminishes rapidly with increasing K, indicating that they perform optimally with very sparse weight matrices (Luque and Solé, 2000; Bertschinger and Natschläger, 2004; Büsing et al., 2010; Snyder et al., 2012; Burkow and Tufte, 2016; Echlin et al., 2018). Therefore, precise fine-tuning of K is essential for achieving good performance.
Regarding the number of neurons, on the other hand, it is well known that increasing N improves performance (Bertschinger and Natschläger, 2004; Snyder et al., 2012; Cherupally, 2018; Cramer et al., 2020; Steiner et al., 2023). However, most literature on RBN compared reservoirs with rather small sizes around 1, 000 neurons (Bertschinger and Natschläger, 2004; Natschläger et al., 2005; Büsing et al., 2010; Snyder et al., 2013; Burkow and Tufte, 2016), while studies on the ESN compared reservoirs from 500, up to 20, 000 neurons (Triefenbach et al., 2010).
In this article, we want to study the effect of these topology parameters (N and K) with another control parameter, less studied in this context, which is the excitatory-inhibitory balance b, controlling the proportion of positive and negative synaptic weights (Krauss et al., 2019a; Metzner and Krauss, 2022; Calvet et al., 2023). More specifically, the balance is equal to b = (S+−S−)/S, with S = KN the total number of synapses and S± the number of positive and negative synapses. For a positive balance, the network has a majority of excitatory synapses and reverse, and when it is zero, the network has a perfect balance between the two, S+ = S−. The excitatory-inhibitory balance has a long history in neurosciences (Van Vreeswijk and Sompolinsky, 1996; Brunel, 2000). Primarily, this balance is fundamental to the principle of homeostasis, which prevents the brain from overflowing with spikes and keeps the average activity in a certain range (Sprekeler, 2017). It has been shown that strong excitation can provoke irregular activity patterns (Van Vreeswijk and Sompolinsky, 1996, 2005; Krauss et al., 2019b; Sanzeni et al., 2022; Calvet et al., 2023), and that an imbalance of excitation and inhibition could be linked to pathologies such as epilepsy (Nelson and Valakh, 2015) and autism (Arviv et al., 2016). In our present context, studies on models (Ehsani and Jost, 2022), in vitro (Sandvig and Fiskum, 2020) and in vivo (Yang et al., 2012), showed that the meticulous balancing of excitatory and inhibitory neurons was also linked to the edge of chaos (Poil et al., 2012).
Despite its importance in neurosciences, the excitatory-inhibitory balance has only been recently introduced for investigating the design of RBN (Calvet et al., 2023). Previous work on the ESN (Krauss et al., 2019a,b; Metzner and Krauss, 2022) has studied the influence of density d = K/N and balance on the dynamics of reservoirs, showing that b was a key parameter controlling phase transitions. In particular, Metzner and Krauss (2022) suggested a more complex picture than previously thought, exposing two critical points, each for a positive and negative balance, while for higher densities, an asymmetry could arise in the reservoir responses to inputs, and as a result, only the edge of chaos occurring for positive b was optimal for information propagation inside the reservoir. In line with Krauss and Metzner, recent work on RBN reservoirs demonstrated that the excitatory-inhibitory balance b was also key in driving dynamics and performance (Calvet et al., 2023). In particular, it was shown that the weight statistics, typically used in RBN literature (Bertschinger and Natschläger, 2004; Natschläger et al., 2005; Büsing et al., 2010) are related to the balance. More striking, the RBN reservoirs also displayed an asymmetry around b = 0. The two signs of the balance produced distinct relations to performance in tasks and a reduced reservoir-to-reservoir variability for a majority of inhibition. However, this occurred for a network with extremely low density as d = K/N = 16/10, 000 = 0.0016, in contrast with studies on ESN.
As far as the authors are aware, the influence of the excitatory-inhibitory balance for different connectivity has yet to be studied, except for the single value of K = 16 previously mentioned (Calvet et al., 2023). This article aims to explore the combined effect of connectivity (K, N) and the balance on the dynamics and performance of the RBN. The article is organized as follows: in the first section (Section 3.1) the effect of K and b is studied, both on the dynamics of free-evolving reservoirs (Section 3.1.1), and their performance in a memory and prediction task (Section 3.1.2), showing that the asymmetry in fact vanishes for very small K. In the second section (Section3.2) we perform a similar analysis (dynamics in Section 3.1.1, and performance in Section 3.2.2), but this time, we vary both K and N conjointly, and explore the relationship with b. This reveals a complex interplay between parameters and suggests that K is, in fact, governing it. Finally, in Section 4, we discuss our results and their implication for RBN reservoir design, revealing that in contrast with ESN, the careful selection of K leads to a significant simplification of the fine-tuning of the other topology parameters in the tested tasks.
2 Methodology
2.1 The model
Our model is an ensemble of three parts (Figure 1), the input node u(t), which is projecting to half of the neurons of the recurrently connected reservoir , among which the other half is projecting to the output node y(t), this way, the output node never directly sees the input (Eq. 1), and information must propagate inside the reservoir for the readout (Eq. 2) to accomplish the task at hand:
With ui(t) the input of the neuron i, the input weights form a vector, projecting to half of the reservoir, while the other half of the weights are zeros, and reserve for the output weight matrice Wout. This way, a neuron in the reservoir is never connected to both the input and output. The activation function f of the output node is the sigmoid, with a bias c. Each component xi(t) of corresponds to the state of the neuron i inside the reservoir. It is given by Eq. 3:
Where each neuron is connected to K other neurons, and wij is the synaptic weight connecting neuron j to neuron i, drawn in a normal distribution , with parameters μ (mean) and σ (standard deviation). The activation function θ is a Heaviside, thus xi is binary. t∈N and corresponds to a time step. Remark that if the input is zero, the state of a given neuron only depends on the states of its neighbors at the previous time step. Such neurons are thus said to be “memoryless”, and for such a system, to sustain memory, information needs to cascade via the propagation of spikes inside the reservoir. The attractive feature of the reservoir framework is that only the output weight and bias are trainable parameters, as all other parameters are usually kept fixed, including the reservoir weights.
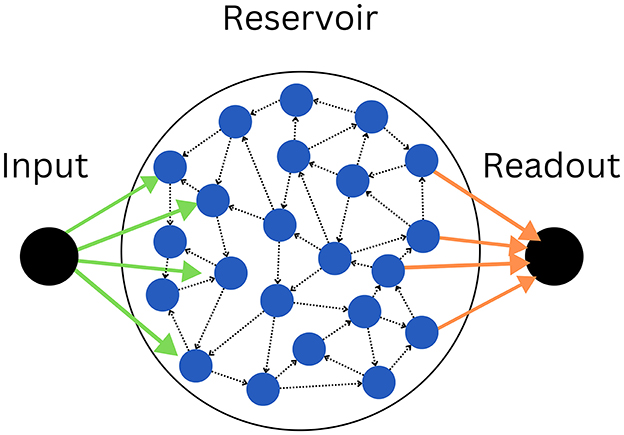
Figure 1. The model consists of an input node (left), connected by input weights (green arrows), to the reservoir (center), itself connecting via output weights (orange arrows) to the output node (right). As illustrated by the dotted black arrows, the reservoir is recurrently connected, forming a random graph. The illustrated graph has K = 2 and N = 22. Note that in practice, half of the neurons (blue circles) connect to the input, and the other half to the readout.
We use a mean square error (MSE) loss function for the training process. For training the readout weights, we opted for the ADAM optimizer (Kingma and Ba, 2015), providing superior results in our testings, superseding the commonly utilized Ridge regression (Burkow and Tufte, 2016) in most literature. The execution is facilitated through the PyTorch library, with parameters set at α = 0.001 and 4000 epochs (Supplementary material 6 for additional information).
2.2 The control parameters
The three control parameters used in this study are σ⋆, K, and N. Among these, σ⋆ represents the coefficient of variation of the weight distribution within the reservoir, defined as σ⋆ = σ/μ. This parameter is linked to b, the excitatory/inhibitory balance, as (Calvet et al., 2023). The balance is also equal to b = (S+−S−)/S, with S the total number of synapses, and S± the number of positive and negative synapses, respectively. We display in Figure 2 the relationship between the two, noting that when σ⋆ is positive, we have a majority of excitatory synapses b > 0, and when σ⋆ is negative, we have a majority of inhibitory synapses b < 0. In all experiments, we play with values of σ⋆ that allow our reservoirs to span the full range of b, corresponding to σ⋆∈[10−2, 103].
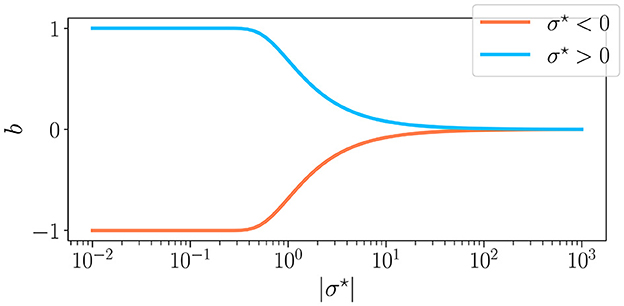
Figure 2. The excitation-inhibition balance b as a function of the synaptic weight parameter σ⋆. For σ⋆ < 0 ( ) and σ⋆>0 (
) and σ⋆>0 ( ). σ⋆ is the coefficient of variation (σ/μ) of the weight distribution, which is why b is of the sign of σ⋆. For low values of |σ⋆|, only μ controls the synaptic balance, meaning that for a positive mean, the weights are all excitatory, and reverse. On the other hand, when |σ⋆| → ∞, the mean becomes irrelevant, and b is at a perfect balance between excitation and inhibition.
). σ⋆ is the coefficient of variation (σ/μ) of the weight distribution, which is why b is of the sign of σ⋆. For low values of |σ⋆|, only μ controls the synaptic balance, meaning that for a positive mean, the weights are all excitatory, and reverse. On the other hand, when |σ⋆| → ∞, the mean becomes irrelevant, and b is at a perfect balance between excitation and inhibition.
Since recent work showed that the dynamics and performance of reservoirs were asymmetric about b = 0 (Metzner and Krauss, 2022; Calvet et al., 2023), we study the influence of two other control parameters with respect to the sign of b. These parameters are captured by the density d = K/N, following the work of Hajnal and Lőrincz (2006), Krauss et al. (2019a), and Metzner and Krauss (2022) on ESN. However, we show in Supplementary material 6.1 that the density d is not a control parameter for the RBN, since, at a fixed density, reservoirs can possess very different dynamics as K and N are concurrently varied. As such, we consider them as independent control parameters in this article. Following work in RBN (Büsing et al., 2010; Calvet et al., 2023), the connectivity degree is chosen between 1 and 16. In addition, to compare the more recent results (N = 10, 000) (Calvet et al., 2023) with older literature (N ≤ 1, 000) (Bertschinger and Natschläger, 2004; Natschläger et al., 2005; Büsing et al., 2010; Snyder et al., 2013; Burkow and Tufte, 2016), we study three values of N = {100, 1, 000, 10, 000}.
2.3 The experiments
We perform two types of tasks: the first to probe the intrinsic dynamics of reservoirs, while they are freely evolving, and the second to test the ability to process inputs while performing memory and prediction tasks.
2.3.1 Free-running
Each reservoir is freely running without input for a duration of D = 2, 000 time steps, with a random initial state with 20% of neurons to one. During a run, the activity signal A(t) (Eq. 4) is recorded, which is the average of states xi at a given time step t:
Afterwards, we compute the BiEntropy (Hb) (Croll, 2014) of the binarized activity signals. The binary entropy is interesting because, in contrast to the Shanon entropy, it can quantify the degree of order and disorder of a bit string, Hb = 0 for completely periodic, and Hb = 1 for totally irregular. To compute it, we need to binarize the steady activity As, obtained after 1, 000 time step. To do so, we subtract the mean As−Ās and clip all positive values to one and negative values to zero. After converting this binarized sequence into a string, we can now compute the binary entropy for a given run. For each triplet (N, K, σ⋆), we randomly generate R = 100 reservoirs, and we then compute the average (Eq. 5) and variance (Eq. 6) over reservoirs having the same control parameters:
Next, we classify the steady-state activity A(t), for t > 1, 000 time steps, into four distinct attractor categories. For each triplet (N, K, σ⋆), we then compute the histograms over the 100 reservoirs and compute the percentage of reservoir belonging to each attractor category as a function of each control parameter value. The attractors are defined according to Calvet et al. (2023) :
• Extinguished: the activity has died out, and the steady activity is zero at all time steps.
• Fixed attractor: the steady activity is non-zero, but its derivative is zero at all time steps.
• Cyclic: the steady activity repeats, with a period larger than one time-step.
• Irregular: if none of the above categories apply, the signal is irregular. Note that our model is deterministic and discrete, as such, all attractors are in theory, cyclic; however, since the duration D = 2, 000 is extremely small compared to the maximal period of 2N, in practice, we find a statistically significant proportion of attractors in that category.
2.3.2 Performance in tasks
To test the computational capabilities of our reservoirs, we perform two distinct tasks. The first one consists of memorizing white-noise input received |δ| time steps in the past. We test our reservoirs with various difficulties for δ = {−18, −14, −10, −6, −2}. The higher in absolute value, the more difficult the task, since it demands the reservoir of memoryless neurons to integrate and reverberate input information through spikes cascade for longer time scales (Metzner and Krauss, 2022; Calvet et al., 2023). The second task consists of predicting future Mackey-Glass time series, δ = 10 time steps. Mackey-Glass is a common benchmark in reservoir computing (Hajnal and Lőrincz, 2006; Bianchi et al., 2016; Zhu et al., 2021), which is given by the following Eq. 7:
We choose a = 0.9, b = 0.2, c = 0.9, d = 10, and x0 = 0.1, and we use τ, the time constant parameter of Mackey-Glass, to control the signal dynamics, ranging from τ = 5 (periodic), τ = 15, to τ = 28 (chaotic).
To evaluate the performance of our reservoirs, we compute the correlation coefficient Corr(y, T) between the target vector T, and the output vector y. A reservoir that performs poorly will yield uncorrelated vectors y and T, resulting in a correlation coefficient of zero. On the other hand, an ideal score is achieved when the vectors are identical, leading to a correlation coefficient of one. It is important to note that while the correlation can technically be negative, this scenario is infrequent. This calculation is performed over 20 reservoirs for each triplet (N, K, σ⋆). The details of the task execution and training process align with the methods in this study (Calvet et al., 2023).
3 Results
3.1 The connectivity degree controls the optimal balance
In this section, we fix the size of the reservoir to its largest value N = 10, 000. We study the effect of K and b on the dynamics of free-running reservoirs (Section 3.1.1). Then, we study the performance in two demanding tasks (Section 3.1.2). We show that the asymmetry about b = 0 is strongly K dependent and vanishes for low K, while the optimal balance bopt is entirely controlled by K.
Additionally, we exhibit the shift of control parameters from the more natural weight distribution statistics (σ⋆) (Calvet et al., 2023) to the excitatory-inhibitory balance (b). To do so, we begin by exhibiting the dynamics over σ⋆, to then display the attractor statistics over the excitatory balance b, revealing insights into the reservoir design.
3.1.1 Impact of the connectivity degree and balance on dynamics
In Figure 3, we display the average over reservoirs of the BiEntropy of the steady activities for reservoirs as a function of |σ⋆| (lower x-axis), both with a negative (left) or positive (right) balance b (the upper x-axis displays the corresponding b values). In Figures 3A, B blue regions represent an ordered phase with low BiEntropy, and red regions represent a disordered phase with a BiEntropy close to one. The regions are separated by a phase transition where the BiEntropy is intermediate, also captured by the variance of the BiEntropy (Figures 3C, D). The scenario is similar for both signs of b but differs in the details. The transition (abrupt for b < 0, wider for b > 0) occurs at a value of σ⋆ that depends on K (strongly for b < 0, weakly for b > 0). The transition widens when K decreases (strongly for b > 0). At high K, i.e., when each neuron is connected with many, there seems to be an asymptotic value for σ⋆ (or b, indicated on the upper part of the plots), which is different for b > 0 and b < 0 (Calvet et al., 2023). For K = 2, the disordered phase never reaches a BiEntropy of 1, and for K = 1 the reservoir is always in its ordered phase (Bertschinger and Natschläger, 2004).
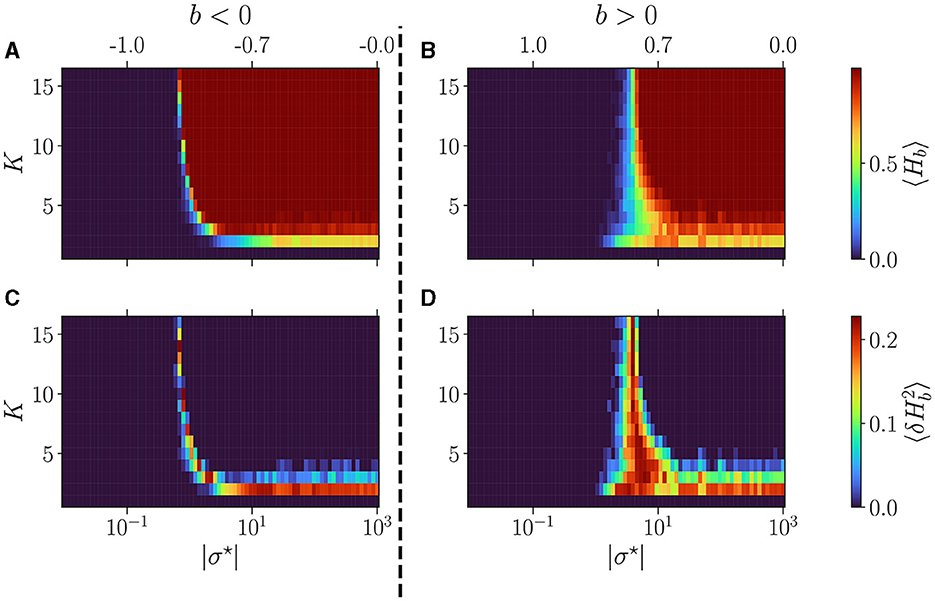
Figure 3. Dynamics of free evolving reservoirs as controlled by the connectivity degree K (y-axis) and |σ⋆| (x-axis). The upper x-axis displays the corresponding b values, for b < 0 (A, C), and b > 0 (B, D). The BiEntropy is computed on the steady activities of 100 reservoirs per couple (K, σ⋆). (A, B) The upper row displays the average BiEntropy of the steady state activities (upper left colormap). (C, D) The lower row shows the variance of BiEntropy over reservoirs (bottom left colormap).
In Figure 4, we plot the statistics of attractors for reservoirs with K = 16 (upper panel), K = 8 (middle), and K = 4 (lower), as a function of the balance b. This time |σ⋆| is reported in the upper x-axis. The left column shows the results for b < 0 and the right column for b > 0. The phase transition is characterized by going from attractors with essentially no (b < 0) or fixed (b > 0) activity in the ordered phase, to attractors being all irregulars in the disordered phase, with cyclic attractors showing up at the transition. In all plots, we report the non-zero BiEntropy variance (highlighted by light-grey hatching) to indicate the critical region (Calvet et al., 2023). This transition region is clearly defined for K = 16, widens for K = 8 and becomes very different for K = 4. When b < 0, there is a transition region around b~−0.7 (gray hashed region) and a re-entrance of the critical region (orange hatching in Figure 4E). Indeed, for b between −0.7 and −0.08 (σ⋆ between −10 and −2) all attractors are irregular, and cyclic ones reappear for a balance closer to zero. For K = 4 and b > 0 the phase transition is never complete, there is no fully disordered phase. Lastly, near b = 0, the attractor statistics are very close from one sign to the other. For example, with K = 16 and K = 8 we observe a horizontal line for chaotic attractors, while for K = 4, the statistics of cyclic and irregular attractors closely match on both sides, a fact that is even more visible in the results of Section 3.2.1 when varying N.
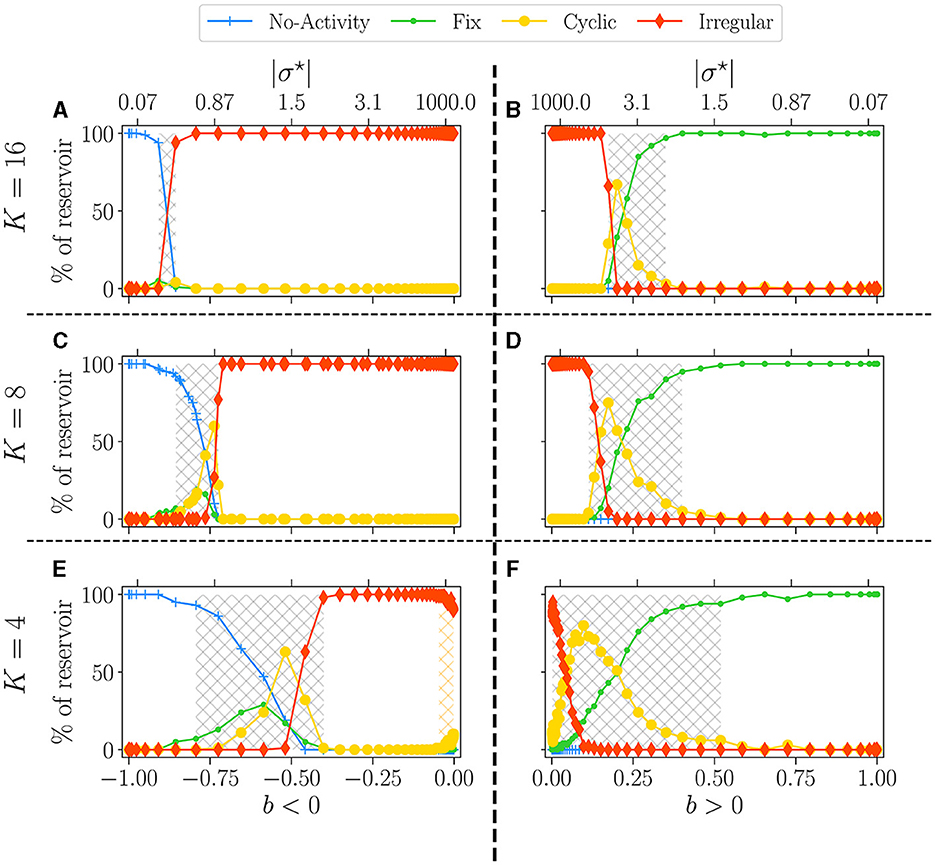
Figure 4. Attractor statistics of free-evolving RBN reservoirs, controlled by K (rows), and the balance b (x-axis). The upper x-axis represents the corresponding |σ⋆| values, for b < 0 (A, C, E), and b > 0 (B, D, F). All reservoirs are of size N = 10, 000. Each steady activity signal is classified into one of the four categories of attractors: no-activity ( ), fix (
), fix ( ), cyclic (
), cyclic ( ), irregular (
), irregular ( ). The statistics of attractors are computed over 100 reservoirs run once (y-axis). Results are shown for K = 16 (A, B), K = 8 (C, D), and K = 4 (E, F). The light-gray hatched areas represent the critical regions (Calvet et al., 2023), defined as the region of non-zero BiEntropy variance; the threshold is chosen to 0.0001. In (E), the orange hatched area represents a region of re-entrance of criticality with non-zero BiEntropy variance, distinct from the critical region. All hatched areas are computed from the data shown in Figures 3C, D.
). The statistics of attractors are computed over 100 reservoirs run once (y-axis). Results are shown for K = 16 (A, B), K = 8 (C, D), and K = 4 (E, F). The light-gray hatched areas represent the critical regions (Calvet et al., 2023), defined as the region of non-zero BiEntropy variance; the threshold is chosen to 0.0001. In (E), the orange hatched area represents a region of re-entrance of criticality with non-zero BiEntropy variance, distinct from the critical region. All hatched areas are computed from the data shown in Figures 3C, D.
Regarding the control parameter shift from σ⋆ to b, the phase transition appears inflated in b, as indicated by the dot positions, particularly for b < 0. These positions are generated on an evenly spaced logarithmic scale in σ⋆. The irregular regime is notably compressed, demonstrated by the re-entrant critical region (refer to Figure 4E), spanning from 2.101 to 103. This observation suggests that the dynamics remain relatively consistent despite significant variations in the weight distribution parameter. In line with Metzner and Krauss (2022) and Calvet et al. (2023), we make the case that underlying b is what is driving the dynamics of these reservoirs. As such, in the rest of the article, we use b as a reference for all further investigations.
In conclusion, K has a strong influence on the dynamics of the network. For large values of K, a variety of attractors can be found only in a narrow region of b (σ⋆), which is different for both signs of the balance. In contrast, for lower values of K, the co-existence of several attractors is found over a very wide range of σ⋆ which corresponds to the region where b is small, positive or negative.
3.1.2 Impact of the connectivity degree and balance on performance
In Figure 5, we show the performance of the reservoirs for memory tasks as a function of the control parameter b (|σ⋆| upper x-axis). Five difficulties are operated, with δ varying from −2 to −18. The left column comprises reservoirs with a negative balance and the right column with a positive one. We show the results for K = 16 (upper row), K = 8 (middle), and K = 4 (bottom).
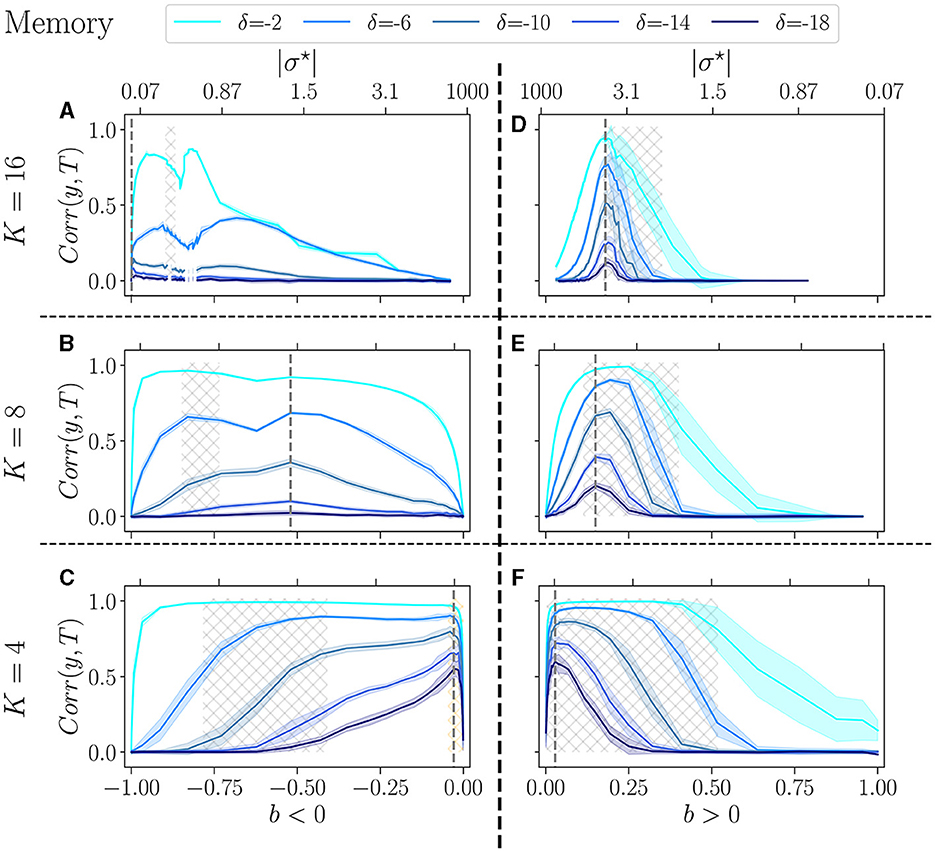
Figure 5. Performance of RBN reservoirs in the memory task of white-noise signals, for various δ, the higher in absolute, the more difficult the task. The correlation between the target and the output (y-axis), is plotted as a function of the control parameter b (x-axis), for a positive balance (A–C), and a negative balance (D–F). The upper x-axis represents the corresponding |σ⋆| values. The solid lines represent the average over 20 reservoirs, higher values signify better performance, while the shaded area represents one standard deviation. (A, D) The upper row displays K = 16, the middle row (B, E) K = 8, and bottom row (C, F) K = 4. The light-gray hatched areas represent the critical regions of BiEntropy variance above a threshold of 0.0001, and the dotted gray lines represent the optimal balance bopt in the most difficult task.
For each value of the delay, reservoirs perform better at low K, and show good performance over a broader range of b. Similar observations have been reported for other tasks (Büsing et al., 2010). The balance for which performance is best bopt (dotted gray line) strongly depends on K: this is the most visible for b < 0 and δ = −18 (the most difficult task), where bopt goes from almost −1 for K = 16, to almost 0 for K = 4 (see Supplementary Table 1). For other values of δ the effect is less pronounced but clearly always present. For b > 0 the same phenomenon appears and bopt shifts from ~0.2 for K = 16, to ~0 for K = 4. Thus, the asymmetry between b > 0 and b < 0 fades as K decreases. For K = 4, the optimal balance, whether positive or negative, is almost zero, i.e., it corresponds to an almost perfect balance between excitation and inhibition. However, notes that performance drops abruptly for b = 0: the unbalance, even very small, is essential.
In the prediction task (Figure 6), a similar trend is observed: as K decreases, the high-performing region shifts toward b values close to zero. Furthermore, the range of b values within the high-performing region is also broader. Still, for K = 4, our task may not be sufficiently challenging for the reservoirs, since at bopt, the three values of τ give very close results. When b < 0, the critical region (gray hashed area) does not align well with the performance peaks, and this discrepancy is even more pronounced for lower K = 4. The peak of performance is still within the orange-hashed region, indicative of re-entrant criticality. In the case where b > 0, in line with previous work (Calvet et al., 2023), the variance is exceptionally high, especially for simpler signals τ = 5 and τ = 15. Surprisingly, for K = 16 and K = 4, reservoirs perform better at the complex task than at the simpler task τ = 5.
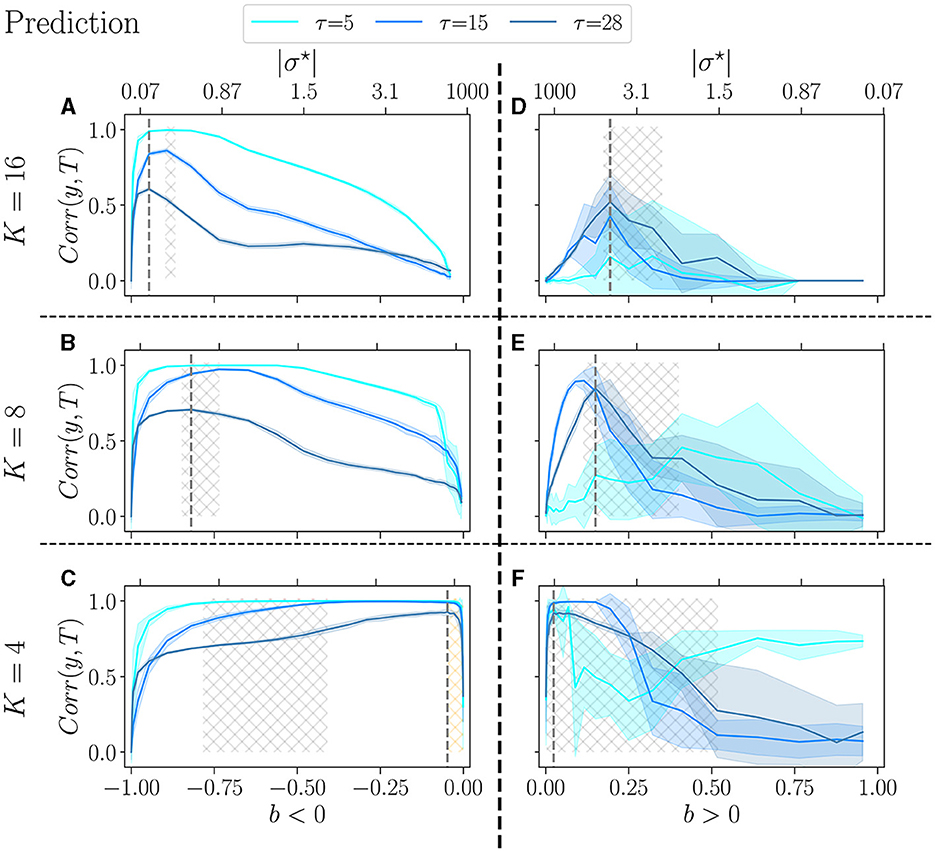
Figure 6. Performance of RBN reservoirs in the prediction task of Mackey-Glass time series, for various τ, the higher, the more complex the signal. The correlation between the target and the output (y-axis), is plotted as a function of the control parameter b (x-axis), for a positive balance (A–C), and a negative balance (D–F). The upper x-axis represents the corresponding |σ⋆| values. The solid lines represent the average over 20 reservoirs, higher values signify better performance, while the shaded area represents one standard deviation. (A, D) K = 16, with similar result to Calvet et al. (2023), (B, E) K = 8, and (C, F) K = 4. As in the previous figure, the light-gray hashed areas represent the phase transition region, and the dotted gray lines represent the optimal balance bopt in the most difficult task.
Trying to relate criticality with peak performance, we observe that if there is a link between the two, it is rather loose. For b < 0 the region of best performance is much broader than the critical region, indicated as hatched gray areas. In many cases, bopt does not lie within the critical region. For b > 0, criticality and optimal performance seem more correlated, as optimal performance is usually obtained within the critical region. However, focusing on K = 4, b < 0 and the hardest memory task (Figure 5C), there is a striking difference between criticality and optimal performance: performance is almost zero in the critical region while it peaks in the region of re-entrance observed in the dynamics of the free running reservoirs, indicated in Figure 5C as an orange hatched area. Both regions show a variety of attractors, but only one corresponds to good performance.
To conclude, in Figure 7, we show a summary of the best performance in the memory (upper panel), and prediction (lower panel). In the plot, each dot represents the average over 20 reservoirs obtained with the same connectivity parameters (N, K, bopt), where bopt is the value that maximizes the average performance at the most difficult setting of each task (δ = −18 and τ = 28), see Supplementary Tables 1, 2. As previously, we separated the case b < 0 (left panel) and b > 0 (right panel). We compare the performance for K = 1 up to 16.
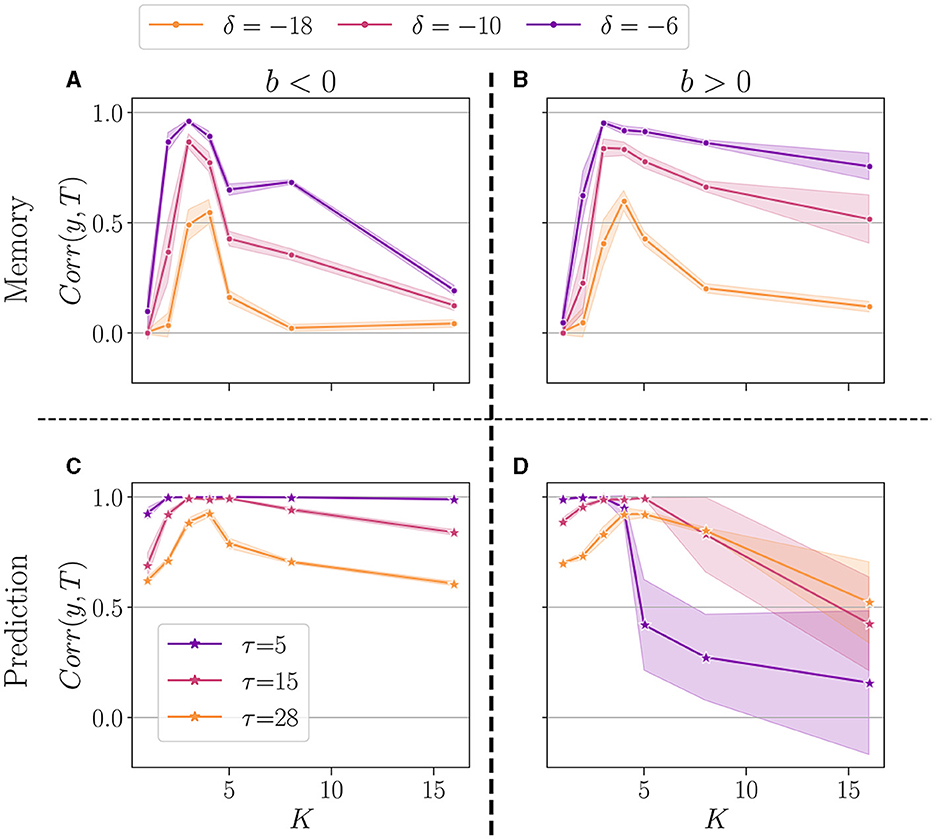
Figure 7. Summary of performance for various connectivity degrees K, in the memory (A, B)and the prediction (C, D) tasks. For both b < 0 (left panel), and b > 0 (right panel). For each value of K, we selected the bopt value giving the highest average performance, in the most difficult task (δ = −18 for memory, and τ = 28 for prediction). We plot the performance (higher is better) of reservoirs Corr(y, T) (y-axis), plotted as a function of K (x-axis). The solid line represents the average over 20 reservoirs (generated with the same bopt and K value), and the shaded area represents one standard deviation. Performance is shown for various δ in the memory task (A, B), and τ in the prediction (A, B).
For all tasks, we note that the highest performances are consistently achieved with K = 3 and K = 4, irrespective of whether b is positive or negative. However, the optimal value of K exhibits some task dependency. In the memory task, for the more challenging task (δ = −18), K = 4 yields the best performance, despite K = 3 occasionally outperforming less demanding tasks. This suggests that the optimal K may depend on the complexity of the task at hand. The sign of b has no discernible impact on the optimal K, however, it is observed that the performance for higher K values is superior when b > 0, in line with Calvet et al. (2023).
In the prediction task, again, the most challenging setup (τ = 28) shows K = 4 as the optimal value, irrespective of the sign of b. In general, the reservoir-to-reservoir variance is very small for b < 0. As previously observed, for higher K, we observe a significant reservoir variability, and this time, the performance is higher when b < 0.
Taken together, these findings suggest that once an optimal value for K is selected, the system's performance becomes mainly insensitive to the sign of the balance b, even though the optimal K can be dependent on the task at hand.
3.1.3 Discussion
In line with Calvet et al. (2023), for a positive balance, the critical region is reasonably aligned with the performing region, for all tested K. Yet our findings somewhat challenge the idea that the edge of chaos is always optimal for computation, as it does not necessarily overlap with the region of best performance. This is especially visible in the memory tasks and reservoirs with a negative balance. Indeed, for K = 4, the re-entrant region provides the best reservoirs, while being very far from criticality.
By looking at dynamics, one might wonder if this re-entrant region of attractor diversity (b < 0) does not belong to the critical region of the positive side, which, by shifting toward the left, overlaps on the negative sign. On the other hand, we observe a drastic dip in performance with both signs around b = 0. This suggests that a breaking of symmetry is at play (Goldenfeld, 2018), acting as a crucial driver for performance while being surprisingly imperceptible in the dynamic.
Regarding reservoir design, we show that the optimal excitatory/inhibitory balance is intricately tied to the number of connections. For a high number of connections, a pronounced asymmetry is observed depending on whether there is a majority of inhibition or excitation.
However, when K = 4, the optimal b value is almost identical and closely balanced between excitation and inhibition, regardless of whether b is positive or negative. Consequently, the dynamics of reservoirs are nearly identical for both positive and negative b, resulting in similar performance outcomes. The task of choosing the optimal bopt becomes much simpler, as the asymmetry fades away.
3.2 The interplay between reservoir size and connectivity degree
This section studies the joint effect of the reservoir size N (=100, 1,000, 10,000) and K, in relation to b. We show that N has a comparable impact on the dynamics as K, but also impacts asymmetrically around b the performance in tasks.
3.2.1 Impact of reservoir size and connectivity degree on dynamics
In Figure 8, we set K = 4 and present the attractor statistics over b for three different values of N: N = 10, 000 (upper panel), N = 1, 000 (middle panel), and N = 100 (lower panel). We analyze these values in two cases, b < 0 (left panel) and b > 0 (right panel).
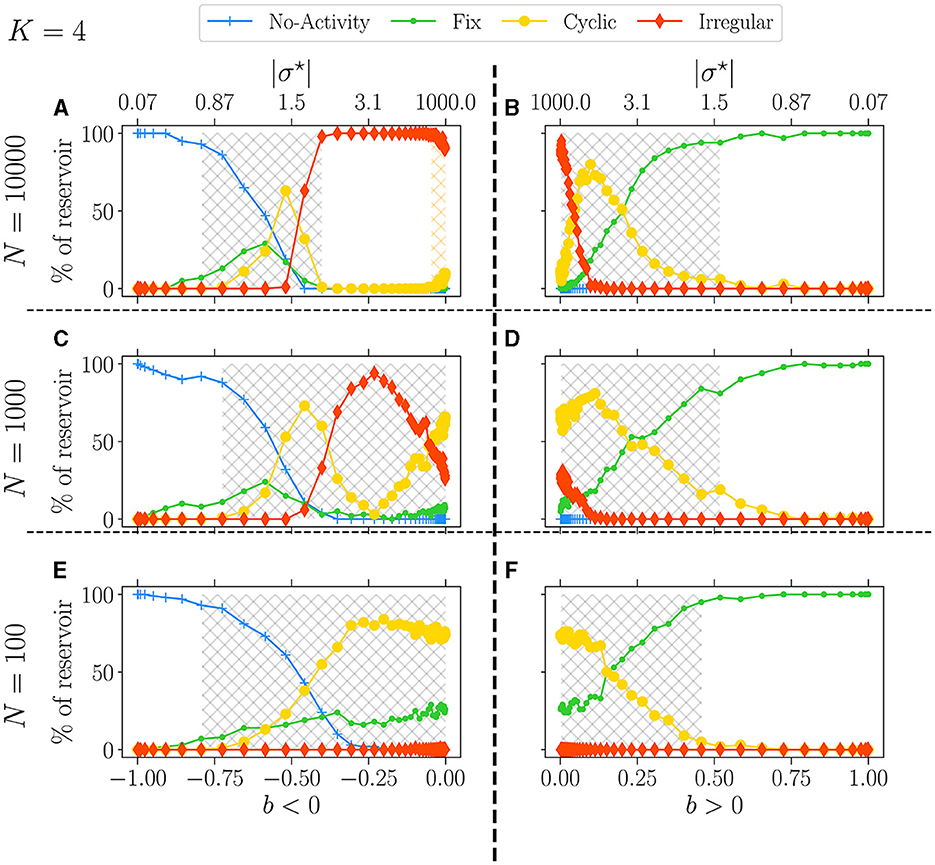
Figure 8. Attractor statistics of free-evolving RBN reservoirs for fixed K = 4, with N = 10, 000 (A, B), N = 1, 000 (C, D), and N = 100 (E, F). Statistics of attractors over 100 reservoirs run once (y-axis) vs. b (x-axis). The upper x-axis displays the corresponding |σ⋆|, both for b < 0 (left panel) and b > 0 (right panel). Each activity signal is classified into one of the six categories of attractors: extinguished, fixed, cyclic, and irregular, defined in methodology Section 2.3. The light-gray hatched areas represent the critical regions defined; the threshold is chosen to 0.0001. In (A), the orange hatched area represents the region of re-entrance of criticality with non-zero BiEntropy variance.
From our observations, it is evident that reducing N leads to a decrease in the complexity of the attractors, as indicated by the reduction of irregular attractors. In the case of b < 0 and as N decreases, the re-entrant region (orange hashed area) observed with N = 10, 000 (Figure 8A) merges with the critical one (gray hashed area) for N = 1, 000 (Figure 8C), resulting in a spike of irregular attractors and eventually leaving room for predominantly cyclic ones as N = 100 (Figure 8C).
Contrarily, for b > 0 and N = 1, 000, this spike or irregular attractor is missing, and the critical phase is largely dominated by cyclic attractors, with only a few fixed and irregular ones. Interestingly, when N = 100, both signs yield very similar results, with no irregular attractors at all. This observation underscores the impact of N on the nature and complexity of the attractors.
Lastly, when discussing Figure 4, we briefly mentioned the continuity in attractor statistics as going from a negative to a positive balance. This fact is even more salient in Figure 8. Statistics of attractors closely match on both sides, reinforcing the picture that the critical region can span both signs, at least from the dynamic lens.
3.2.2 Impact of reservoir size and connectivity degree on performance
Results for the memory task and prediction are, respectively, displayed in Figures 9, 10. We tested the performance for K = 4 (upper panel), K = 8 (middle), and K = 16 (bottom). Reservoirs with b < 0 are displayed in the left panel and b > 0 in the right panel. We compare the performance for three distinct values of N: N = 10, 000 (green curves), N = 1, 000 (orange curves), and N = 100 (blue curves). As in the previous Section 3.1.2, performance is shown for bopt, established for the most difficult setting in each task (δ = −18 and τ = 28).
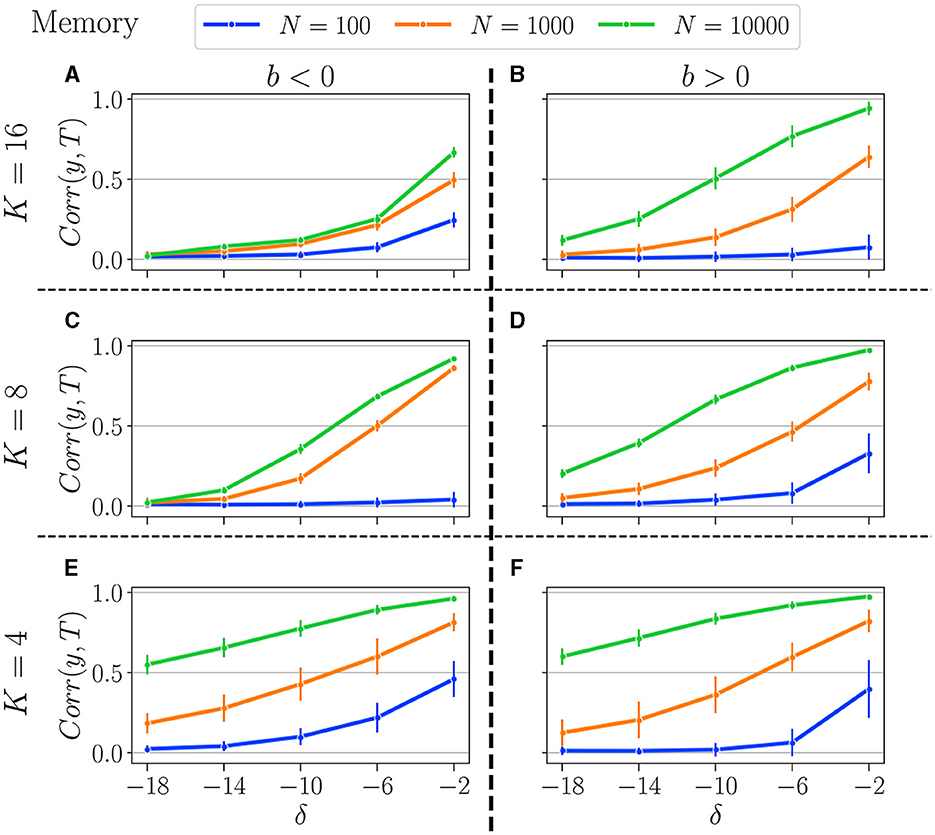
Figure 9. Summary of performance in the memory tasks, for various connectivity degrees K, and size of the reservoirs N: for N = 10, 000 (green curves), N = 1, 000 (orange curves), and N = 100 (blue curves). K = 16 (A, B), K = 8 (C, D), K = 4 (E, F). b < 0 (left column), and b > 0 (right column). Solid lines represent the average over all reservoirs generated with the same reservoir (N, K, bopt), and the error bar represents one standard deviation. As explained in Section 3.1.2, bopt is obtained by selecting the balance that gives the best average performance at the most difficult setting in each respective task.
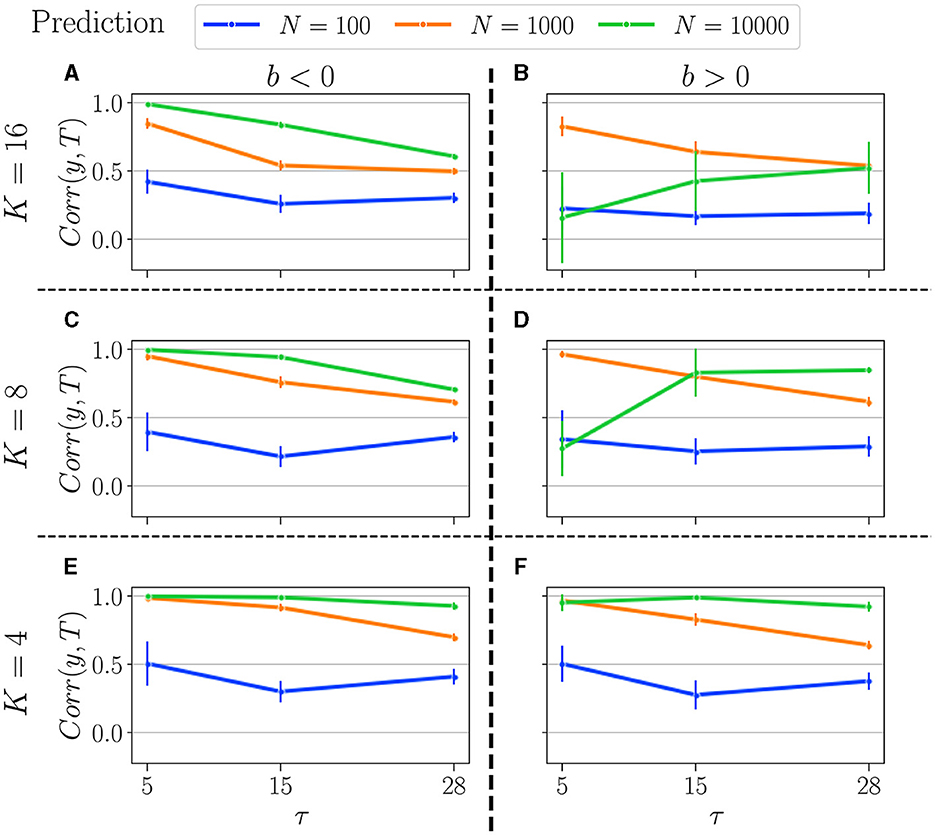
Figure 10. Summary of performance in the prediction tasks, for various connectivity degrees K, and size of the reservoirs N: for N = 10, 000 (green curves), N = 1, 000 (orange curves), and N = 100 (blue curves). K = 16 (A, B), K = 8 (C, D), K = 4 (E, F). b < 0 (left column), and b > 0 (right column). For more information on the plots, see the caption of Figure 9.
In the memory task, as expected, reducing the number of neurons diminishes the reservoirs's memory capacity, and the more difficult the task, the lower the performance. In addition, decreasing the reservoir size generally increases the reservoir-to-reservoir variance, as indicated by the larger error bars, even though this is not always the case, especially when performance is already low.
The number of neurons exerts a greater influence when K is lower. Indeed, for K = 4, we observe a significant disparity between all three N values across all difficulty levels (δ). Surprisingly, for higher K, and especially when b < 0, performances for N = 1, 000 and N = 10, 000 are relatively comparable, and increasing the reservoir size is not improving performance, especially for tasks requiring longer memory. As previously noted, when K = 4, performance is similar regardless of whether b is positive or negative, a finding that is now corroborated across all tested N values.
It appears that K has minimal influence when N = 100, as reservoirs perform similarly regardless of K. The same holds true for both positive and negative b, which their identical dynamics profiles might explain. This suggests that, for low neuron counts, the system's dynamics and performance are more strongly influenced by the balance parameter b than by the number of connections K.
In the prediction task, we observe some surprising trends. Notably, having a higher N is not always advantageous, as the optimal N appears to depend on both the task and the control parameter.
Firstly, for b < 0, the performance profile is similar to that in the memory task: higher N yields better performance, and performance decreases with increasing task difficulty (τ). However, the performances of N = 10, 000 and N = 1, 000 are closer to each other and significantly higher than that of N = 100, which again remains unaffected by K.
Secondly, for b > 0, the value of K strongly influences the relationship between performance and reservoir size. With K = 4, the performance profile is similar to that for b < 0: performance decreases monotonically with τ and N. However, for K = 8 and especially for K = 16, we observe some unexpected results. Smaller reservoirs (N = 1, 000) can outperform larger ones (N = 10, 000) in some tasks. This phenomenon is even more pronounced for higher K, as the orange line (representing N = 1, 000) consistently outperforms the green line (representing N = 10, 000) across all tested tasks.
4 Discussion
Our study reveals that the edge of chaos, or the critical region, does not consistently align with the peak performance region (Gallicchio, 2020), and this alignment is contingent upon the sign of excitatory-inhibitory balance b. For b > 0, as previously observed (Calvet et al., 2023), the critical region coincides with the highest performance. However, for b < 0, the region of optimal performance does not coincide with the critical region when the connectivity degree K is optimally selected. Instead, supplanting the disordered phase, a re-entrance of the critical region is observed, indicated by an increased attractor diversity, which surprisingly aligns with the best-performing region. This insight suggests that the attractor dynamics can be utilized to identify the region of interest for the design or reservoirs, and this also holds for b > 0 and its identified critical region (Calvet et al., 2023).
In terms of the interplay between b and the connectivity degree K, our research shows that a carefully selected K (K = 4) renders the sign of b irrelevant, as the optimal b becomes ±ϵ with ϵ very small. This suggests that the optimal balance is near, but not at, perfect symmetry, even though b → 0 results in zero performance. In statistical physics, it is well known that symmetry breaking induces critical phase transitions (Goldenfeld, 2018), and our findings suggest that symmetry breaking in the balance of excitatory-inhibitory synapses is crucial for achieving optimal performance. Refining initial literature (Bertschinger and Natschläger, 2004; Snyder et al., 2013; Burkow and Tufte, 2016; Echlin et al., 2018), the highest-performing region is characterized by a preponderance of irregular attractors within the disordered region.
To understand this, one can consider what happens when σ* tends to infinity. This can be achieved in two ways: first, when the standard deviation of the weight σ is fixed while the mean weights μ → 0, and second, when μ is fixed while σ → ∞. The first case has been covered in other works (Bertschinger and Natschläger, 2004; Büsing et al., 2010) and shows the importance of tuning the scaling of the input weights with the recurrent weight statistics (Burkow and Tufte, 2016). In the present work, however, the second option is considered, as the mean weights is fixed, and σ increases to higher values. As such, b approaches zero, which results in a symmetry between excitation and inhibition but with increasingly higher synaptic weights (in absolute value). Consequently, each neuron receives equal excitatory and inhibitory recurrent inputs, and since the input weights are kept constant, the external input becomes insignificant. Finally, since neurons have a zero threshold, they have a 50% probability of spiking, leading to a random spike train. Therefore, it is not surprising to observe a performance dip as σ → ∞ (b → 0) since the reservoir activity becomes independent of the input. However, what requires further investigation is the unexpected drastic performance increase when this symmetry is slightly broken as b = ±ϵ~0.03 (roughly corresponding to a 6% difference between excitatory and inhibitory synapses).
Regarding the impact of N on the performance, we show that K again plays a crucial role. First, the fine-tuning of K removes the asymmetry between b positive and negative. Second, in contrast to previous studies with network sizes below 1, 000 (Bertschinger and Natschläger, 2004; Büsing et al., 2010; Burkow and Tufte, 2016; Echlin et al., 2018), our results somewhat challenge the common wisdom that increasing N has an unconditional positive impact on performance. Indeed, we observe in the prediction task that K = 8 and K = 16 can provoke a non-monotonic relationship between the top performance and N. Surprisingly, it is possible to obtain networks of size 1, 000 that will outperform networks of size 10, 000, while networks of size 100 can be found to perform equivalently. However, this is only true when b > 0, and this effect is also dependent on the task difficulty. For instance, in line with Calvet et al. (2023), as one chooses N = 10, 000, both K = 16 and K = 8 give a performance that increases with the difficulty of the task, while for smaller network size, the relation is in the opposite direction. The reason behind this remarkably intricate relationship has yet to be uncovered. On the other hand, when b > 0, the results are comparable to the memory task, and the picture gets clearer as K is decreased to 4; the increase of the network size gives the best return on performance. This seems to align with the work of Bertschinger and Natschläger (2004) showing that when K = 4, RBN RC of sizes up to 1, 000 displays a linear relationship between performance and N. Lastly, reservoir-to-reservoir variability seems to decrease with network size, which seems to corroborate the findings of Echlin et al. (2018) for bigger N.
These findings highlight the critical role of K in determining other control parameters. Firstly, the optimal number of connections (K = 4) eliminates the performance asymmetry, significantly simplifying the parameter b selection. Secondly, consistent with previous studies, N generally enhances performance, but this is only true for optimal K = 4 values, particularly in the prediction task, where smaller reservoirs occasionally outperform larger ones. Additionally, the performance gain obtained by K is significant only when the reservoir size is sufficiently large. For instance, with reservoirs of size N = 100, K had close to no effect on the best performance. However, optimally choosing K becomes key to obtaining a gain in performance when increasing the network size.
Our work reveals a complex interplay between the topology and weights parameters, but assuming a reservoir of sufficient size (N≥1, 000), K acts as a pivotal control parameter by greatly simplifying the way parameters interact with each other. When K is optimal, then N must be maximized, and b can be chosen very close to zero but finite and of any sign.
5 Future work
Understanding the relationship between dynamics and performance is crucial for simplifying reservoir design (Bertschinger and Natschläger, 2004; Krauss et al., 2019a,b; Metzner and Krauss, 2022; Calvet et al., 2023). As corroborated by our findings and those of Calvet et al. (2023), the dynamics of the attractor may significantly correlate with performance, particularly in delineating the high-performing regions within the parameter space b. This insight is noteworthy as it suggests the possibility of limiting the scope of the parameter space through the analysis of the dynamics of free runs, thereby circumventing the need for numerous costly training simulations. While this observation aligns with previous studies that have demonstrated the role of attractors in memory retrieval (Wu et al., 2008; Zou et al., 2009) and information processing (Cabessa and Villa, 2018), it does raise intriguing questions. Specifically, the correlation of the re-entrant region of criticality, marked by a predominance of irregular attractors and a few cyclic ones with optimal performance, invites a more comprehensive examination. With its noisy dynamics, as evidenced by a high BiEntropy, this region challenges the conventional understanding that chaos is associated with super-critical regimes (Rubinov et al., 2011), and low input to state correlation (Metzner and Krauss, 2022). The question of how information is processed within the reservoir remains open. One potential avenue for exploration could be the classification of activity into more granular categories. Fortunately, the attractors of RBN can be fully categorized (Zou et al., 2009), including the enumeration of attractors and their sizes. This approach may illuminate the unique characteristics of attractors that contribute to performance. With a more nuanced comprehension of the relationship between attractor dynamics and performance, future research could leverage multiple attractor categories within a pool of multiple reservoirs, as demonstrated in Ma et al. (2023), using a block-diagonal weight matrix. This strategy could potentially enhance the computational capabilities while reducing the computational costs of RBN reservoirs.
Our study advances the quest for a clear methodology for the design of RBN reservoirs by revealing a certain hierarchy of importance in the choice of control parameters. Practically, this means that the first parameter that should be determined is K, which controls how other parameters will react to tasks. The fine-tuning of K is important to simplify the choice of the other parameters (N and b) and also because it drastically improves the performance. What we show in the memory and prediction task is that the optimal K is somewhat invariant but still sensitive to the difficulty of the task; in all our tests, the most difficult level showed a clear winner with K = 4, which is probably what most real-life situations will require. On the other hand, it would be of interest to validate that this value holds in other types of tasks, such as the classification of various input types (Embrechts et al., 2009). Next, the choice of the parameter N remains trivial as long as K is appropriately chosen. Taking into consideration our findings, one can only recommend using a network of size at least 10, 000, since below this, the gain in performance induced by the careful selection of K is very limited. Regarding the interest of choosing an even bigger network, future work could try to push the reservoirs into more difficult tasks, for example, by increasing δ, the shift in time between input and target, setting the difficulty of the task, and test the gain in performance with larger N.
Lastly, our findings reveal a more intricate relationship than anticipated for the link between K and b. Specifically, performance was found to be highly sensitive to symmetry breaking in the excitation-inhibition balance, while the metrics used to probe the dynamics were completely unaware of the symmetry. In practice, however, this unexpected link means a simpler design. This is because, in contrast to the study Calvet et al. (2023) performed on K = 16, when K = 4, the choice of b also becomes simple; it must be very close to zero, and the sign is not relevant anymore. Still, future research could investigate the relationship between the optimal balance and other dynamic-probing metrics, including spatial and temporal correlation (Metzner and Krauss, 2022), more specific attractor analysis (Wu et al., 2008; Zou et al., 2009), and possibly topology (Kinoshita et al., 2009; Masulli and Villa, 2016). For instance, it could be hypothesized that the longest neural pathways in the random graph become available for information transmission only at b = ±ϵ, which could explain why optimal performance necessitates a breaking of symmetry in the balance.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://zenodo.org/records/10247107.
Author contributions
EC: Methodology, Software, Writing – original draft. BR: Funding acquisition, Supervision, Writing – review & editing. JR: Funding acquisition, Supervision, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the CRSNG/NSERC (Discovery Grant RGPIN-2017-06218), the Canada Research Chair Program, NSERC, and CFREF.
Acknowledgments
The authors are grateful to Lucas Herranz for carefully reviewing the manuscript. They also want to thank their colleagues at NECOTIS for their helpful feedback and productive discussions during the research process.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncom.2024.1348138/full#supplementary-material
References
Aljadeff, J., Stern, M., and Sharpee, T. (2015). Transition to chaos in random networks with cell-type-specific connectivity. Phys. Rev. Lett. 114, 1–5. doi: 10.1103/PhysRevLett.114.088101
Arviv, O., Medvedovsky, M., Sheintuch, L., Goldstein, A., and Shriki, O. (2016). Deviations from critical dynamics in interictal epileptiform activity. J. Neurosci. 36, 12276–12292. doi: 10.1523/JNEUROSCI.0809-16.2016
Bertschinger, N., and Natschläger, T. (2004). Real-time computation at the edge of chaos in recurrent neural networks. Neural Comput. 16, 1413–1436. doi: 10.1162/089976604323057443
Bianchi, F. M., Livi, L., and Alippi, C. (2016). Investigating echo state networks dynamics by means of recurrence analysis. IEEE Transact. Neural Netw. Learn. Syst. 29, 427–439. doi: 10.1109/TNNLS.2016.2630802
Brunel, N. (2000). Dynamics of networks of randomly connected excitatory and inhibitory spiking neurons. J. Physiol. 94, 445–463. doi: 10.1016/S0928-4257(00)01084-6
Burkow, A. V., and Tufte, G. (2016). Exploring Physical Reservoir Computing using Random Boolean Networks (PhD thesis). Norwegian University of Science and Technology - NTNU. Available online at: http://hdl.handle.net/11250/2417596
Büsing, L., Schrauwen, B., and Legenstein, R. (2010). Connectivity, dynamics, and memory in reservoir computing with binary and analog neurons. Neural Comput. 22, 1272–1311. doi: 10.1162/neco.2009.01-09-947
Cabessa, J., and Villa, A. E. P. (2018). Attractor dynamics of a Boolean model of a brain circuit controlled by multiple parameters. Chaos 28:106318. doi: 10.1063/1.5042312
Calvet, E., Rouat, J., and Reulet, B. (2023). Excitatory/inhibitory balance emerges as a key factor for RBN performance, overriding attractor dynamics. Front. Comput. Neurosci. 17:1223258. doi: 10.3389/fncom.2023.1223258
Cattaneo, G., Finelli, M., and Margara, L. (1997). “Topological chaos for elementary cellular automata,” in Italian Conference on Algorithms and Complexity CIAC 1997, Vol. 1203 (Springer), 241–252. Availabla online at: http://link.springer.com/10.1007/3-540-62592-5_76
Cherupally, S. K. (2018). Hierarchical Random Boolean Network Reservoirs. Technical Report. Portland, OR: Portland State University. Available online at: https://archives.pdx.edu/ds/psu/25510
Cramer, B., Stöckel, D., Kreft, M., Wibral, M., Schemmel, J., Meier, K., et al. (2020). Control of criticality and computation in spiking neuromorphic networks with plasticity. Nat. Commun. 11:2853. doi: 10.1038/s41467-020-16548-3
Croll, G. J. (2014). “BiEntropy—the measurement and algebras of order and disorder in finite binary strings,” in Scientific Essays in Honor of H Pierre Noyes on the Occasion of His 90th Birthday, eds J. C. Amson, and L. H. Kauffman, 48–64. Available online at: http://www.worldscientific.com/doi/abs/10.1142/9789814579377_0004
Echlin, M., Aguilar, B., Notarangelo, M., Gibbs, D., and Shmulevich, I. (2018). Flexibility of Boolean network reservoir computers in approximating arbitrary recursive and non-recursive binary filters. Entropy 20:954. doi: 10.3390/e20120954
Ehsani, M., and Jost, J. (2022). Self-organized criticality in a mesoscopic model of excitatory-inhibitory neuronal populations by short-term and long-term synaptic plasticity. Front. Comput. Neurosci. 16:910735. doi: 10.3389/fncom.2022.910735
Embrechts, M. J., Alexandre, L. A., and Linton, J. D. (2009). “Reservoir computing for static pattern recognition,” in ESANN 2009, 17th European Symposium on Artificial Neural Networks (Bruges: ESANN).
Galera, E. F., and Kinouchi, O. (2020). Physics of psychophysics: large dynamic range in critical square lattices of spiking neurons. Phys. Rev. Res. 2:033057. doi: 10.1103/PhysRevResearch.2.033057
Gallicchio, C. (2020). “Sparsity in reservoir computing neural networks,” in 2020 International Conference on INnovations in Intelligent SysTems and Applications (INISTA) (IEEE), 1–7. Available online at: https://ieeexplore.ieee.org/document/9194611/
Glass, L., and Hill, C. (1998). Ordered and disordered dynamics in random networks. Europhys. Lett. 41, 599–604. doi: 10.1209/epl/i1998-00199-0
Goldenfeld, N. (2018). Lectures on Phase Transitions and the Renormalization Group. CRC Press. Available online at: https://www.taylorfrancis.com/books/9780429962042
Goudarzi, A., Banda, P., Lakin, M. R., Teuscher, C., and Stefanovic, D. (2014). A comparative study of reservoir computing for temporal signal processing. arXiv. 1–11. doi: 10.48550/arXiv.1401.2224
Hajnal, M. A., and Lőrincz, A. (2006). “Critical echo State networks,” in Artificial Neural Networks – ICANN 2006. ICANN 2006. Lecture Notes in Computer Science, Vol. 4131, eds. S. D. Kollias, A. Stafylopatis, W. Duch, and E. Oja (Berlin, Heidelberg: Springer). doi: 10.1007/11840817_69
Haluszczynski, A., and Räth, C. (2019). Good and bad predictions: assessing and improving the replication of chaotic attractors by means of reservoir computing. Chaos 29:5118725. doi: 10.1063/1.5118725
Jaeger, H. (2005). A Tutorial on Training Recurrent Neural Networks, Covering BPPT, RTRL, EKF and the “Echo State Network” Approach. ReVision 2002, 1–46. Available online at: http://www.mendeley.com/catalog/tutorial-training-recurrent-neural-networks-covering-bppt-rtrl-ekf-echo-state
Jalalvand, A., Demuynck, K., De Neve, W., and Martens, J. P. (2018). On the application of reservoir computing networks for noisy image recognition. Neurocomputing 277, 237–248. doi: 10.1016/j.neucom.2016.11.100
Kingma, D. P., and Ba, J. (2015). “Adam: a method for stochastic optimization,” in 3rd International Conference for Learning Representations (San Diego, CA: ICLR). Available online at: http://arxiv.org/abs/1412.6980
Kinoshita, S.-I., Iguchi, K., and Yamada, H. S. (2009). Intrinsic properties of Boolean dynamics in complex networks. J. Theor. Biol. 256, 351–369. doi: 10.1016/j.jtbi.2008.10.014
Krauss, P., Schuster, M., Dietrich, V., Schilling, A., Schulze, H., and Metzner, C. (2019a). Weight statistics controls dynamics in recurrent neural networks. PLoS ONE 14:e0214541. doi: 10.1371/journal.pone.0214541
Krauss, P., Zankl, A., Schilling, A., Schulze, H., and Metzner, C. (2019b). Analysis of structure and dynamics in three-neuron motifs. Front. Comput. Neurosci. 13:5. doi: 10.3389/fncom.2019.00005
Luque, B., and Solé, R. V. (2000). Lyapunov exponents in random Boolean networks. Phys. A Stat. Mech. Appl. 284, 33–45. doi: 10.1016/S0378-4371(00)00184-9
Ma, H., Prosperino, D., Haluszczynski, A., and Räth, C. (2023). Efficient forecasting of chaotic systems with block-diagonal and binary reservoir computing. Chaos 33:e0151290. doi: 10.1063/5.0151290
Maass, W., Natschläger, T., Markram, H., Maass, N., and Markram (2002). Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comp. 14, 2531–2560. doi: 10.1162/089976602760407955
Masulli, P., and Villa, A. E. P. (2016). The topology of the directed clique complex as a network invariant. Springerplus 5:388. doi: 10.1186/s40064-016-2022-y
Metzner, C., and Krauss, P. (2022). Dynamics and information import in recurrent neural networks. Front. Comput. Neurosci. 16:876315. doi: 10.3389/fncom.2022.876315
Natschläger, T., Bertschinger, N., and Legenstein, R. (2005). “At the edge of chaos: real-time computations and self-organized criticality in recurrent neural networks,” in Proceedings of the 17th International Conference on Neural Information Processing Systems (NIPS'04) (Cambridge, MA: MIT Press), 145–152.
Nelson, S. B., and Valakh, V. (2015). Excitatory/inhibitory balance and circuit homeostasis in autism spectrum disorders. Neuron 87, 684–698. doi: 10.1016/j.neuron.2015.07.033
Poil, S. S., Hardstone, R., Mansvelder, H. D., and Linkenkaer-Hansen, K. (2012). Critical-state dynamics of avalanches and oscillations jointly emerge from balanced excitation/inhibition in neuronal networks. J. Neurosci. 32, 9817–9823. doi: 10.1523/JNEUROSCI.5990-11.2012
Pontes-Filho, S., Lind, P., Yazidi, A., Zhang, J., Hammer, H., Mello, G. B., et al. (2020). A neuro-inspired general framework for the evolution of stochastic dynamical systems: Cellular automata, random Boolean networks and echo state networks towards criticality. Cogn. Neurodyn. 14, 657–674. doi: 10.1007/s11571-020-09600-x
Rubinov, M., Sporns, O., Thivierge, J.-P., and Breakspear, M. (2011). Neurobiologically realistic determinants of self-organized criticality in networks of spiking neurons. PLoS Comput. Biol. 7:e1002038. doi: 10.1371/journal.pcbi.1002038
Sandvig, I., and Fiskum, V. (2020). “Self-organized Criticality in engineered in vitro networks; A balance of excitation and inhibition” in Norwegian University of Science and Technology (Issue October). Faculty of Medicine and Health Sciences.
Sanzeni, A., Histed, M. H., and Brunel, N. (2022). Emergence of irregular activity in networks of strongly coupled conductance-based neurons. Phys. Rev. X 12, 1–65. doi: 10.1103/PhysRevX.12.011044
Snyder, D., Goudarzi, A., and Teuscher, C. (2012). “Finding optimal random Boolean Networks for reservoir computing,” in Artificial Life 13 (MIT Press), 259–266.
Snyder, D., Goudarzi, A., and Teuscher, C. (2013). Computational capabilities of random automata networks for reservoir computing. Phys. Rev. E 87:042808. doi: 10.1103/PhysRevE.87.042808
Sprekeler, H. (2017). Functional consequences of inhibitory plasticity: homeostasis, the excitation-inhibition balance and beyond. Curr. Opin. Neurobiol. 43, 198–203. doi: 10.1016/j.conb.2017.03.014
Steiner, P., Jalalvand, A., and Birkholz, P. (2023). Cluster-based input weight initialization for echo state networks. IEEE Transact. Neural Netw. Learn. Syst. 34, 7648–7659. doi: 10.1109/TNNLS.2022.3145565
Triefenbach, F., Jalalvand, A., Schrauwen, B., and Martens, J. P. (2010). “Phoneme recognition with large hierarchical reservoirs,” in Advances in Neural Information Processing Systems (Vol. 23), eds. J. Lafferty, C. Williams, J. Shawe-Taylor, R. Zemel, and A. Culotta (Curran Associates, Inc.). Available online at: https://proceedings.neurips.cc/paper_files/paper/2010/file/2ca65f58e35d9ad45bf7f3ae5cfd08f1-Paper.pdf
Van Vreeswijk, C., and Sompolinsky, H. (1996). Chaos in neuronal networks with balanced excitatory and inhibitory activity. Science 274, 1724–1726. doi: 10.1126/science.274.5293.1724
Van Vreeswijk, C., and Sompolinsky, H. (2005). “Irregular activity in large networks of neurons,” Methods and Models in Neurophysics, Volume LXXX: Lecture Notes of the Les Houches Summer School, eds. C. Chow, B. Gutkin, D. Hansel, C. Meunier, and J. Dalib (Elsevier), 341–406.
Wu, S., Hamaguchi, K., and Amari, S. I. (2008). Dynamics and computation of continuous attractors. Neural Comput. 20, 994–1025. doi: 10.1162/neco.2008.10-06-378
Yang, H., Shew, W. L., Roy, R., and Plenz, D. (2012). Maximal variability of phase synchrony in cortical networks with neuronal avalanches. J. Neurosci. 32, 1061–1072. doi: 10.1523/JNEUROSCI.2771-11.2012
Zhu, R., Hochstetter, J., Loeffler, A., Diaz-Alvarez, A., Nakayama, T., Lizier, J. T., et al. (2021). Information dynamics in neuromorphic nanowire networks. Sci. Rep. 11, 1–15. doi: 10.1038/s41598-021-92170-7
Keywords: reservoir computing, RBN, criticality, topology, memory, prediction
Citation: Calvet E, Reulet B and Rouat J (2024) The connectivity degree controls the difficulty in reservoir design of random boolean networks. Front. Comput. Neurosci. 18:1348138. doi: 10.3389/fncom.2024.1348138
Received: 01 December 2023; Accepted: 16 February 2024;
Published: 14 March 2024.
Edited by:
Guohe Zhang, Xi'an Jiaotong University, ChinaReviewed by:
Kazuki Nakada, Hiroshima City University, JapanAlessandro E. P. Villa, Neuro-heuristic Research Group (NHRG), Switzerland
Copyright © 2024 Calvet, Reulet and Rouat. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Emmanuel Calvet, ZW1tYW51ZWwuY2FsdmV0QHVzaGVyYnJvb2tlLmNh