 Xianli Liu
Xianli Liu Guo Zhou2*
Guo Zhou2* Yongquan Zhou
Yongquan Zhou- 1College of Artificial Intelligence, Guangxi University for Nationalities, Nanning, China
- 2Department of Science and Technology Teaching, China University of Political Science and Law, Beijing, China
- 3Xiangsihu College of Gunagxi University for Nationalities, Nanning, Guangxi, China
- 4Guangxi Key Laboratories of Hybrid Computation and IC Design Analysis, Nanning, China
Introduction: Extreme learning machine (ELM) is a training algorithm for single hidden layer feedforward neural network (SLFN), which converges much faster than traditional methods and yields promising performance. However, the ELM also has some shortcomings, such as structure selection, overfitting and low generalization performance.
Methods: This article a new functional neuron (FN) model is proposed, we takes functional neurons as the basic unit, and uses functional equation solving theory to guide the modeling process of FELM, a new functional extreme learning machine (FELM) model theory is proposed.
Results: The FELM implements learning by adjusting the coefficients of the basis function in neurons. At the same time, a simple, iterative-free and high-precision fast parameter learning algorithm is proposed.
Discussion: The standard data sets UCI and StatLib are selected for regression problems, and compared with the ELM, support vector machine (SVM) and other algorithms, the experimental results show that the FELM achieves better performance.
1. Introduction
Artificial neural network (ANN) is a parallel computing system which simulates human brain activity by using widely interconnected neuron structure and certain learning rules. Because of its strong self-learning, associative memory, adaptive and fault-tolerant ability, it can easily detect the complex nonlinear relationship between the dependent variable and the independent variables, and has large-scale parallel computing ability. Therefore, it has become a popular and useful model for classification, clustering, pattern recognition and prediction in many disciplines, and is a powerful tool to solve problems that cannot be solved by many traditional methods (Abiodun et al., 2018).
Artificial neural network (ANN) has gone through four stages of development, and hundreds of models have been established so far. It has achieved great success in applied research fields such as handwriting recognition (Baldominos et al., 2018), image annotation (Afridi et al., 2018) and speech recognition (Gautam and Sharma, 2019), et al. However, most ANNs are only simple simulation of biological networks, so they often appear inadequate in dealing with big data and complex tasks, and cannot be satisfactory in both processing speed and calculation accuracy. Among the hundreds of neural network models, traditional training algorithms are usually gradient-based, such as back-propagation neural network (BP) (Werbos, 1974). BP algorithm has been widely used in many fields because of its easy understanding and implementation. However, that gradient-based algorithm is easy to converge to the local minimum and cannot obtain the global optimal solution, because the solution it obtains is sensitive to the initial parameters and depends on the complexity of the feature space, and the iterative learning of the BP algorithm makes the convergence speed too slow. In recent years, Huang et al. proposed for the first time a single hidden layer feedforward neural network learning algorithm called Extreme Learning Machine (ELM) (Huang et al., 2006), which breaks through the commonly used feedforward neural network learning theories and methods. Compared with support vector machine (SVM) (Cortes and Vapnik, 1995), ELM tends to achieve higher classification accuracy with lower computational complexity (Li et al., 2019). Since ELM has the advantages of high learning accuracy, easy to use, easy to implement, and fast learning speed, it has been applied widely in ELM self-encoder (Yimin Yang and Jonathan, 2018), handwriting recognition (Tang et al., 2016), regression and classification (Huang et al., 2012), big data analysis (Sun et al., 2017), and many improved algorithms of ELM (Zong et al., 2013; Geng et al., 2017; Sattar et al., 2019; Gong et al., 2021; Kardani et al., 2021) have also emerged to deal with specific problems. Studies have shown that ELM, especially in some applications, has the advantages of simple structure, short training times, and high calculation accuracy compared with popular deep learning, and the obtained solution is the only optimal solution, which ensures the generalization performance of the network.
The extreme learning machine (ELM) theory has attracted extensive attention by scholars all over the world since it was proposed (Huang et al., 2012; Tang et al., 2016; Sun et al., 2017; Yimin Yang and Jonathan, 2018), and a lot of achievements have been made in its theoretical and applied research. Kärkkäinen (2019) proposed an ELM which conducts ridge regression using a distance-based, the experimental results show that the over-learning with the distance-based basis is avoided in the classification problem. Atiquzzaman and Kandasamy (2018) successfully used ELM for hydrological flow series prediction. Golestaneh et al. (2018) presented a fuzzy wavelet ELM, and its performance is better than ELM. Yaseen et al. (2019) used the enhanced extreme learning machine for river flow forecasting. Pacheco et al. (2018) used restricted Boltzmann machine to determine the input weights of ELM, which greatly optimized the performance of ELM. Christou et al. (2018) proposed a hybrid ELM method for neural networks, which is applied to a series of regression and classification problems. Murli et al. (2018) applied extreme learning machine to microgrid protection under wind speed intermittency. Artem and Stefan (2017) applied ELM to the credit evaluation of user credit cards, indicating that it is a valuable alternative to other credit risk modeling methods. Henríquez and Ruz (2019) used ELM to reduce the noise of near-infrared spectroscopy data, which was successfully applied. Mohammed et al. (2018) proposed an improved ELM based on competitive group optimization and applied it to medical diagnosis. Lima et al. (2017) proposed a variable complexity online sequential ELM, which was successfully used for streamflow prediction. Paolo and Roberto (2017) applied ELM to inverse reactor kinetics, and the experimental results show that ELM application has great potential. Ozgur and Meysam (2018) compared the performance of wavelet ELM and wavelet neural networks. Vikas and Balaji (2020) proposed a PIELM and successfully applied it to solve partial differential equations; Peter and Israel (2020) proposed a new morphological/linear perceptron ELM and implemented fast classification problems.
So far, the ELM has been widely used in industry, agriculture, military, medicine and other fields. Although the research on ELM has made a lot of achievements, from the classification of achievements, there are many application achievements and few theoretical achievements, which greatly limit the application scope of ELM. In particular, there are still the following shortcomings in the ELM theory:
(1) The weights randomly determined by hidden layer neurons have a great impact on the classification performance of the network, and the number of hidden layer neurons cannot be calculated by an effective algorithm. Although some researchers have proposed some optimization algorithms about ELM, these algorithms transform the steps to determine the number of hidden layer neurons into optimization problems, which are cumbersome and time-consuming.
(2) In the learning and training of ELM, the regularization coefficient plays an important role, which requires people to manually determine the size before classification and recognition. However, there is no effective parameter selection method at present. In most cases, people use trial and error method to select the size of the regular coefficient.
(3) Because the ELM has the defect of randomly giving the left weight and the hidden layer threshold, the regression model is prone to have low generalization performance and poor stability, which is crucial to classification problems.
Aiming at the shortcomings of the above ELM theory, this article takes the functional neuron (FN) model (Castillo, 1998; Guo et al., 2019) as the basic unit, intends to use the functional equation solving theory to guide the modeling process of extreme learning machine, and proposes a new type of functional extreme learning machine (FELM) theory. The functional neurons of the learning machine are not fixed, and they are usually linear combinations of linearly independent base functions. In FELM, network learning can be achieved by adjusting the coefficients of base functions in neurons. For the parameters (coefficients) selection method, one simple, iterative-free and high-precision parameter fast learning algorithm is proposed. Finally, through simulation experiments on the regression problems of real standard test data sets, compared with the traditional extreme learning machine (ELM) and support vector regression (SVR), the approximation ability, parameter learning speed, generalization performance and stability of the proposed FELM are experimentally tested.
The rest of the article is organized as follows: in Section “2. Functional extreme learning machine (FELM)”, we describe the FELM modeling theory, parameter learning algorithm and the feasibility analysis of the modeling theory in detail. Section “3. Experimental results and analysis” conducts regression experiments to evaluate the performance of the proposed technology. Finally, we summarize and future work in Section “4. Conclusions and future works”.
2. Functional extreme learning machine (FELM)
Taking the FN model as the basic unit, a kind of learning machine with better performance is designed based on the functional equation solving theory, which is called Functional Extreme Learning Machine (FELM). The model is different from the traditional extreme learning machine. The type and quantity of hidden layer activation function in the structure of FELM are not fixed and can be adjusted. Figure 1A is the functional neuron model, and Figure 1B is the M-P neuron model. Comparing Figure 1A and Figure 1B, it can be seen that compared with artificial neurons, functional neurons lack the weight information on the connection line and can have multiple outputs. The output of functional neurons is:

Figure 1. (A) Functional neuron model. (B) M-P neuron model.
Functional neuron f can be a linear combination of arbitrary nonlinear correlation base functions:
where {φj(x1, x2, …, xk) | j = 1,2,…,n} is any given base functions, which can be learned. According to specific problems and data, different functions can be selected, such as trigonometric basis function and Fourier basis function; {aj|j = 1, 2, …, n} is a parameter set, which can also be learned. It can be used to infinitely approximate the expected accuracy of functional neuron function f(x1, x2, …, xk).
2.1. FELM model
With functional neuron as the basic unit (Figure 1A), the definition of general FELM is established:
Definition 1: Any FELM is a binary ordered pair: FELM = < X, U >, where X is a node set, U = { < Yi, Fi, Zi > |i = 1, 2, …, n} is a functional neuron set on the node set X and satisfies: For any node Xi ∈ X, it is an input node or an output node and at least one functional neuron belongs to the node set U.
According to the definition of FELM, the components of general FELM include:
(1) Several layers of storage units: one layer input unit; one layer output unit; some intermediate units are used to store the information generated by functional neurons in the intermediate layer; all are represented by solid circles with corresponding names (i.e., {xi, yi, zi, …} in Figure 2).
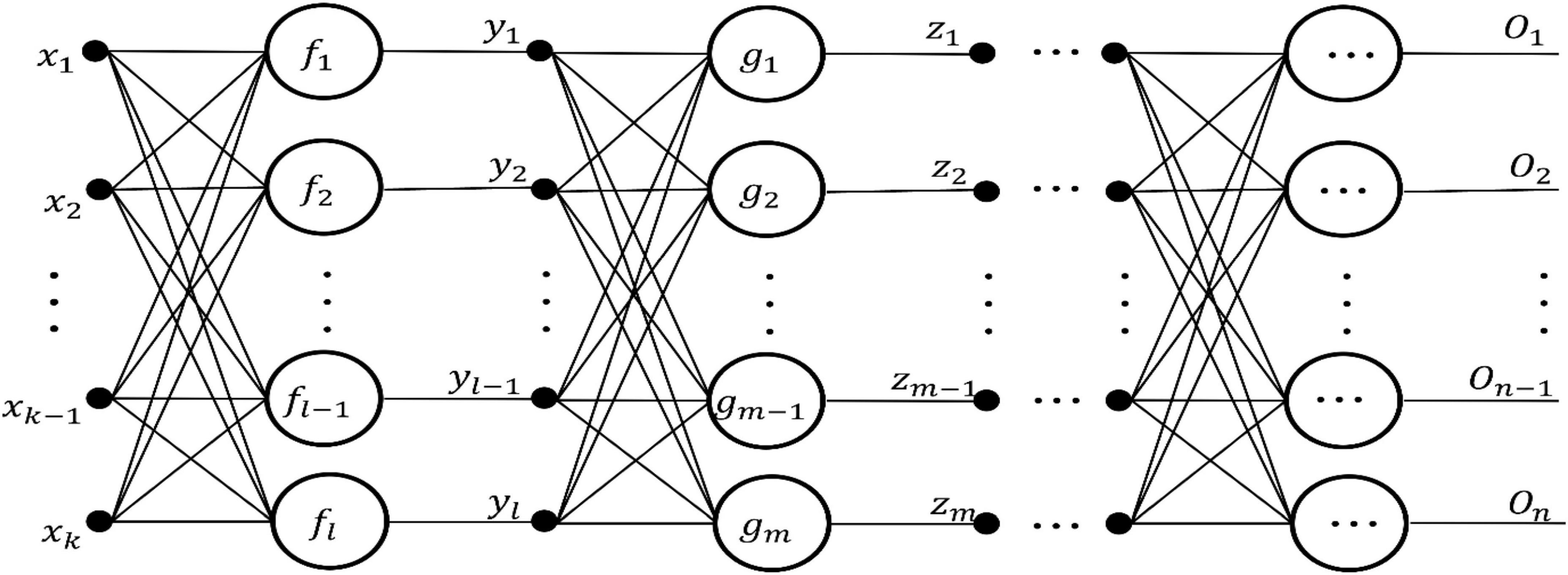
Figure 2. Topological structure of general FELM.
(2) One layer or several layers of processing units: A processing unit is a functional neuron, which handles a set of input values from the previous layer of functional neurons or input units, and provides a set of input data for the next layer of functional neurons or output units. (i.e., {fi, gi, …} in Figure 2).
(3) Directional connection lines: it connects the storage unit and the processing unit, and the arrow indicates the flow direction of information.
All these elements together constitute the structure of the FELM, and determine the generalization ability of the FELM.
We based on the above definition and components of FELM, it is easy to design a general FELM. The network topology is shown in Figure 2:
The output expression of FELM in Figure 2 is:
The Figure 2 shows the general FELM model, and the output expression (3) of the network is essentially a functional equation group. In turn, any functional equations can draw the corresponding functional learning machine. Therefore, it is concluded that any FELM establishes a one-to-one correspondence with the functional equation (group). Based on the correspondence between FELM and functional equation (group), the functional equation theory is used to guide the modeling process of FELM. The steps are as follows:
Step 1. Based on the characteristics of the undetermined problem and the definition of FELM, the initial FELM model for solving the undetermined problem is established.
Step 2. Obtain the output expression of the initial FELM; this expression corresponds to a functional equation group;
Step 3. Using the method of solving functional equations, the general solution expression is given.
Step 4. Based on the general solution expression of functional equations, the corresponding FELM is redrawn by using its one-to-one correspondence with FELM.
Step 5. Output the simplified FELM.
In this way, according to the above modeling steps of FELM, any type of FELM can be drawn, and the model establishes one-to-one correspondence with functional equation (group). Moreover, the functional equations are used to simplify and obtain any optimal FELM. The theoretical basis of the definition is based on the mathematical model of “binary ordered pairs” in discrete mathematics. Its physical meaning is similar to the layout structure of a printed circuit board (PCB). In the practical application of FELM modeling theory, based on the characteristics and data of the problem to be solved, the FELM (initial structure) of any problem to be solved can be obtained according to the above definition of general FELM and the theoretical guidance of modeling process by solving functional equation.
Based on the definition and constituent elements of FELM, any type of FELM can be drawn, and one-to-one correspondence with functional equation (group) can be established. Therefore, using functional equation solving theory to guide the design process of FELM is supported by mathematical theory, which is correct and easy to operate. The unique structure of FELM fundamentally overcomes the shortcomings of the current extreme learning machine that the weights randomly determined by hidden layer neurons have a great impact on the classification performance of the network, and the number of hidden layer neurons cannot be obtained by an effective algorithm.
2.2. FELM learning algorithm
The FELM is based on the problem-driven modeling, without weight and threshold concepts. Its learning essence is to learn the network structure and parameters. Aiming at the parameter (coefficient) selection method, based on the parameter error cost function evaluation criterion, a simple, no iteration and high precision fast parameter learning algorithm is designed by using the theory of linear equations. The learning process of FELM is shown in Figure 3.
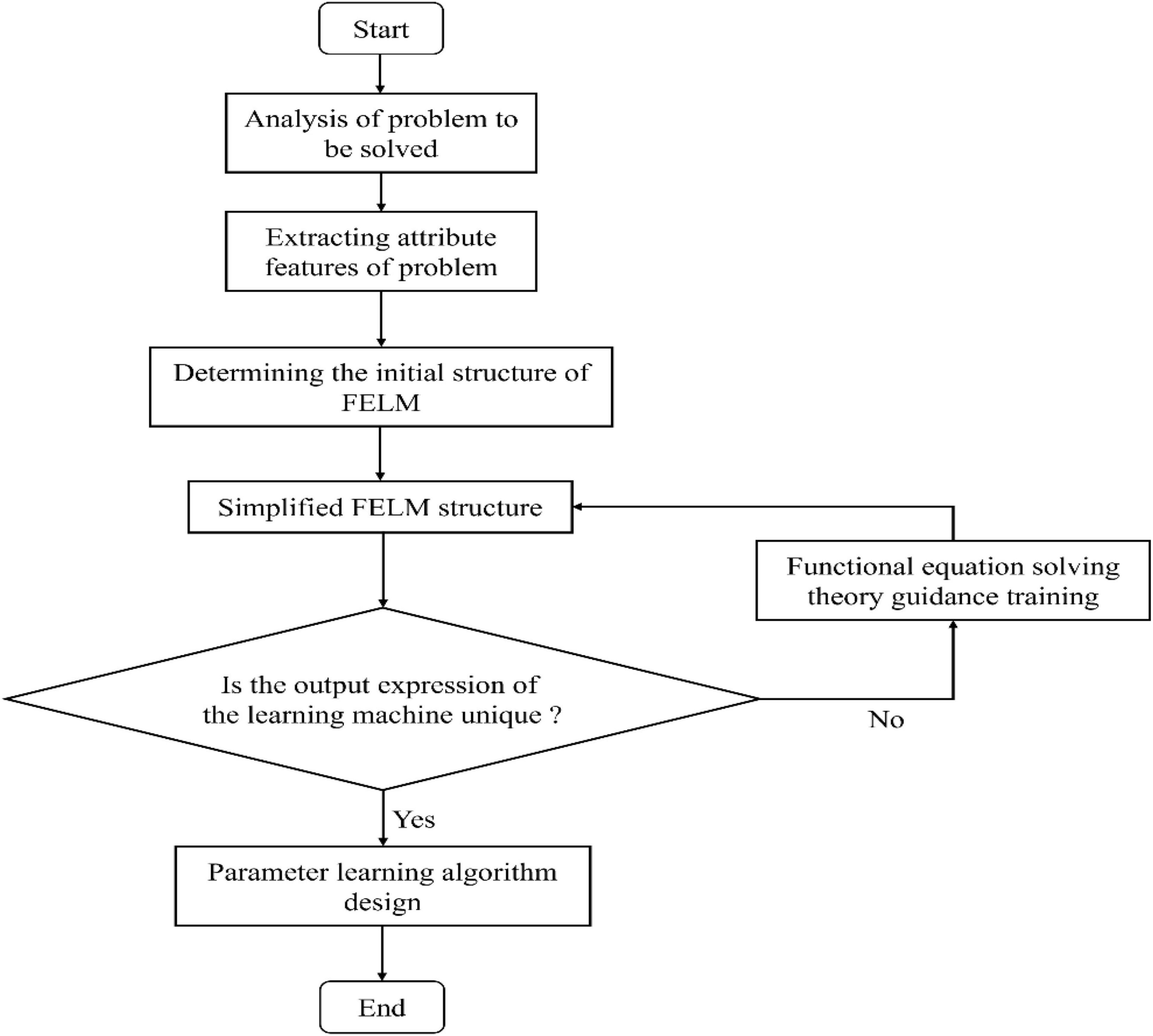
Figure 3. General FELM learning process diagram.
The learning process of FELM in Figure 5 is illustrated by a specific example:
Set a disease d with three basic symptoms: x: fever, y: dry cough; z: fatigue. How to build a FELM to implement its prediction so that: d = D(x, y, z).
(1) Determine the initial structure of FELM. According to the knowledge and information (known data, prior knowledge of the problem and some characteristics of the function, etc.) of the problem, the initial structure of FELM is designed. In the process of diagnosing a disease with three characteristics, the order of symptoms asked by doctors is different, and three cases of the initial structure are shown as in Figures 4A–C:
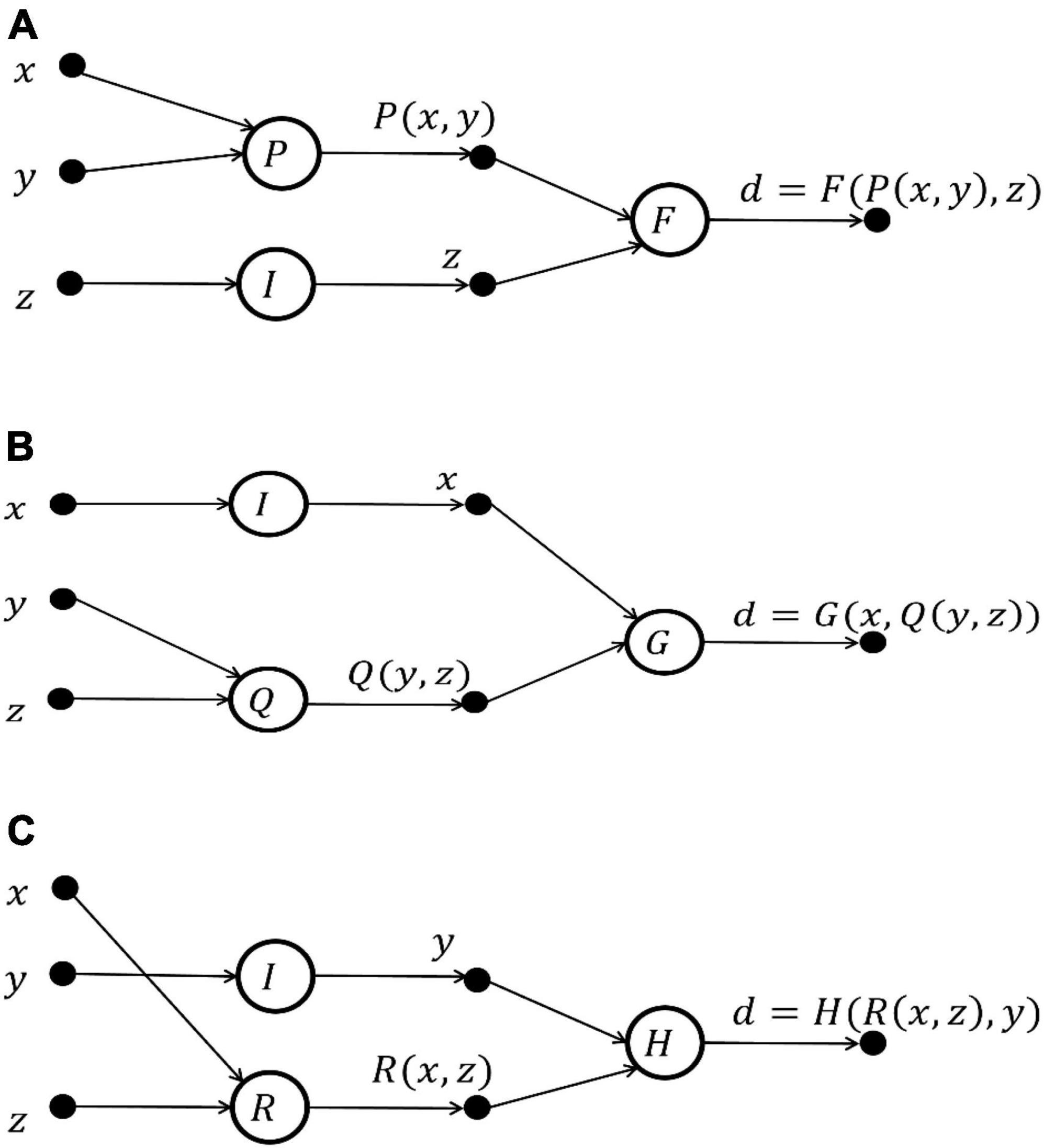
Figure 4. Initial structure of FELM for predicting disease d = D(x, y, z). (A) Diagnostic order: x → y → z. (B) Diagnostic order: y → z → x. (C) Diagnostic order: x → z → y.
(2) Simplifying the initial structure of FELM. Since each initial network structure corresponds to a functional equation group, the FELMs equivalent to the initial network structure is found by using the characteristics of the solution of the functional equation, and the simple and optimal FELM equivalent to the initial network structure is selected.
The above examples in Figure 4 are essentially independent of the diagnostic order, which meet functional equation.
The general solution of Eq. 4 is:
The FELM equivalent to functional Eq. 5 is shown in Figure 5.
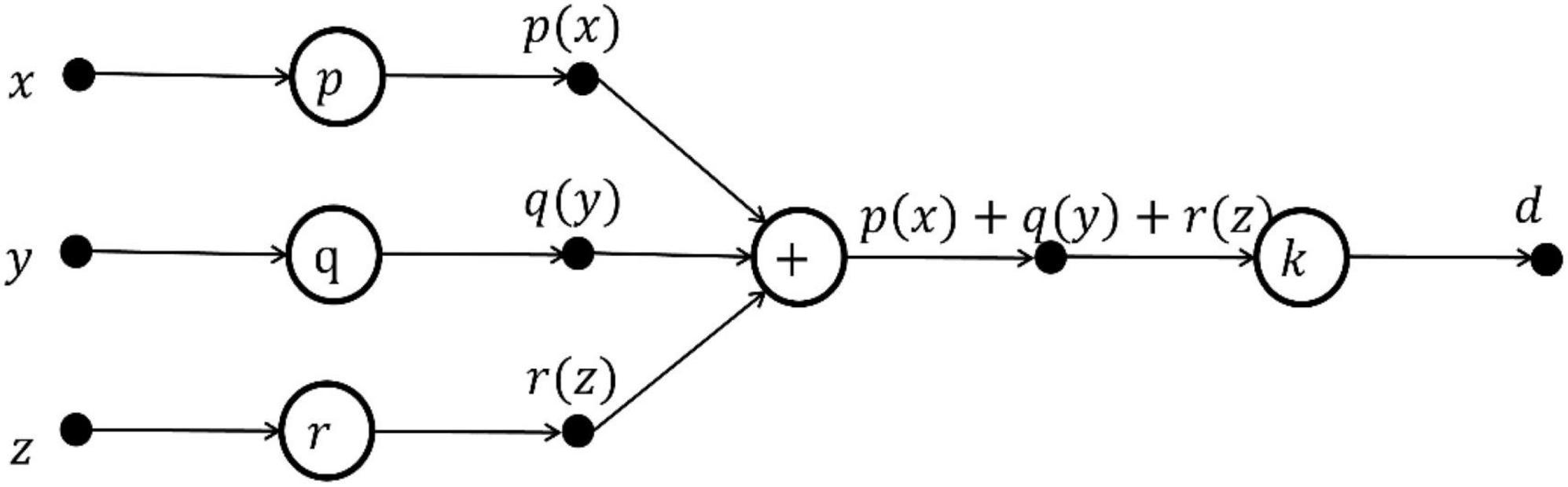
Figure 5. The FELM structure equivalent to Figure 4.
In this way, the design network can be simplified by using the solution theory of functional equations, and the equivalent, a simple and optimal FELM can be obtained.
(3) Uniqueness of output expression of functional extreme machine. Before FELM learning, ensure the uniqueness of output expression. It is proved theoretically that for a given FELM, under the same initial conditions, the FELM has the same output value for any input value.
The above example is still used to prove the equivalence of FELMs in Figures 4, 5. It is assumed that there are two functional neuron function sets: {k1, p1, q1, r1} and {k2, p2, q2, r2}, so that
For any variable x, y, z, let , the solution of the functional equation is:
Such uniqueness is proved.
(4) Parameter learning algorithm design for FELM. In the general FELM in Figure 4, a multi-input single-output single-hidden layer FELM is selected as an example. Its network structure is shown in Figure 6:
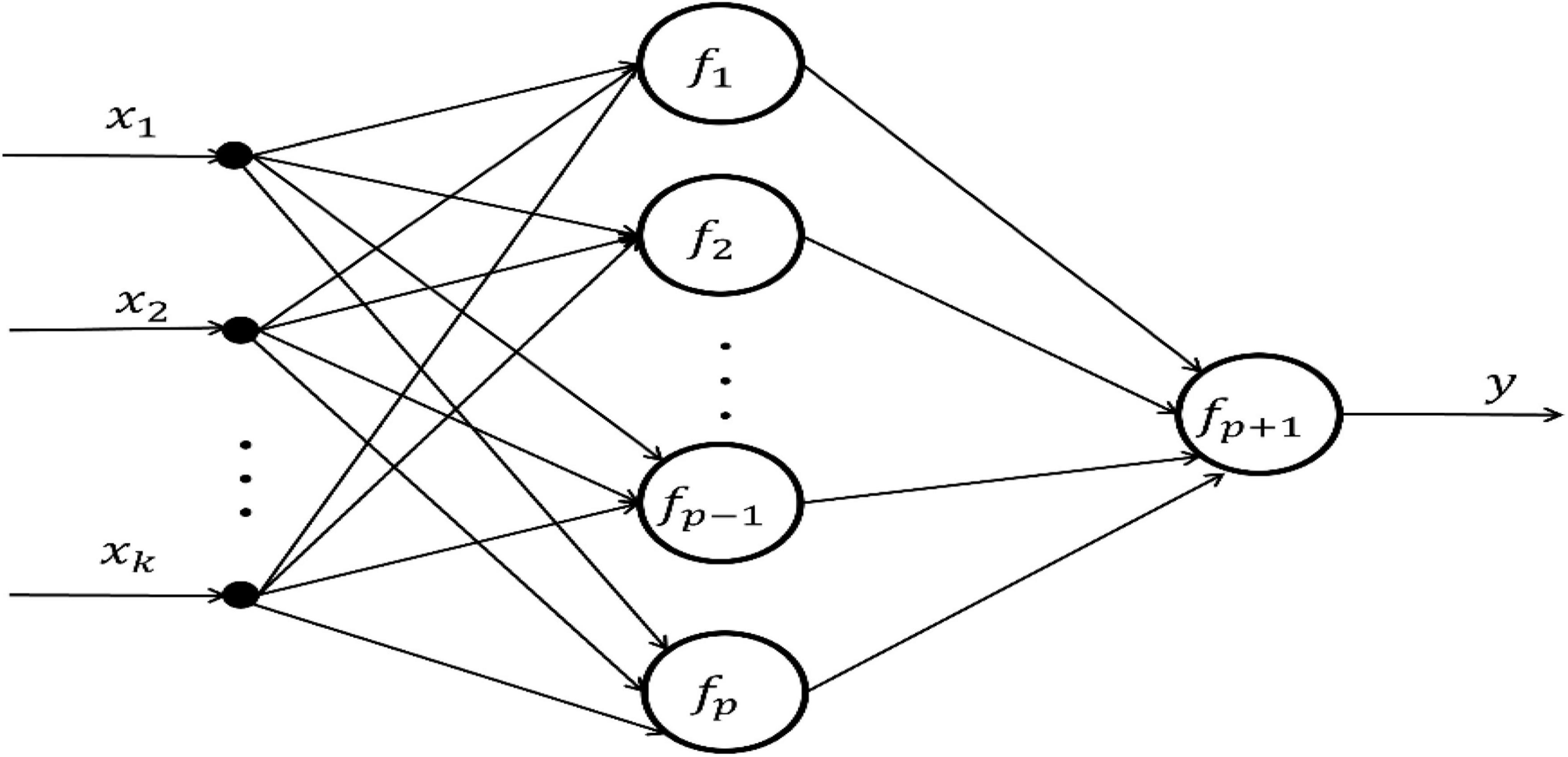
Figure 6. Multi-input single-output single-hidden layer FELM.
Let input X = [x1, x2, …, xk] and output y; each neuron function in the hidden layer fi, i = 1, 2, …, p is a linear combination of any nonlinear correlation base functions, that is,
where m is the number of functional neuron base functions. For the convenience of matrix representation. Let si = X ● ωi, ωi = [1, 1, …, 1]T. Then Eq. 8 can be written:
when the function of output neuron has inverse function, it can also be expressed as a linear combination of base functions:
The output of the FELM in Figure 6 is:
Let the sample data be (Xr, yr) and the error cost is:
where sri = Xrωi.
If there are n groups of sample data, the sum of squares of error of the FELM model is:
By changing the value of the base function coefficient aij, E is minimized.
If fp+1 is a reversible function, the error sum of the FELM model can be expressed as:
where sr,p + 1 = yr.
2.2.1. Parameter learning algorithm
The optimal value of parameter coefficient aij can be obtained by solving (15):
where t = 1, 2, …, p + 1; s = 1, 2, …, m.
The Eq. 15 is a linear equation group, which is easy to solve. Expand Eq. 15, such as Eq. 16:
In matrix form, Eq. 16 can be written as:
Let P = [a11, a12, ⋯, a1m, a21, ⋯, a2m, ⋯, ap+1,1, ⋯, ap+1,m]. So B can be written as . So Eq. 17 is:
In Eq. 18, the vector P is the desired parameter coefficients, but it will not be unique. In order to solve this problem, initial constraint conditions need to be given. Suppose the given constraints are as follows.
where s0 = X0ωi, i = 1,2,…, P and s0 = y0, i = P + 1; βi is any real constant. Therefore, by using the Lagrange multipliers technique, the following auxiliary function can be established.
The minimum model error sum of squares corresponds to.
where t = 1, 2, …, p + 1; s = 1, 2, …, m.
Let
In matrix form, Eq. 21 can be written as:
It is very simple to use Eq. 22 to solve the parameters. This parameter learning algorithm is simple, iterative-free, and has good approximation effect.
2.2.2. FELM parameter learning algorithm analysis
The FELM is based on problem-driven, learning network structure and parameters. Its each step in the learning process is operable and realizable, and the learning process is suitable for any FELM. At the same time, the theoretical basis and mathematical derivation of learning algorithms of FELM are given. The parameter learning algorithm is simple, no iteration and high precision, which is convenient for engineers to use.
The learning process of FELM is completely different from that of the ELM, for its structure have no weight values and the threshold value of neurons. In the ELM, the input layer weights and hidden neuron thresholds of the network are randomly selected, but people can only choose the size of the regularization coefficient by trial and error method, because there is no effective parameter selection method. The characteristics of FELM structure and the process of parameter learning make the problem fundamentally solved. Based on some simple examples, the above shows the learning process of the structure and parameters of the FELM, and its research ideas can be extended to general situations.
3. Experimental results and analysis
In this section, the performance of the proposed FELM is compared with feedforward neural network algorithms such as the ELM and support vector regression (SVR) on approximating two artificial datasets and 16 benchmark real problems. For comparison, three variant algorithms of ELM (OP-ELM) (Miche et al., 2010), inverse-free ELM (Li et al., 2016), OS-RELM (Shao and Er, 2016) and the variant algorithm of SVR (LSSVR) are also added. Simulations of all algorithms are performed in the MATLAB 2019b environment running on an 11th Gen Intel(R) Core(TM) i5-11320H @ 3.20GHz and 16GB RAM.
The SVR, LSSVR, ELM, and OP-ELM source codes used in this experiment were downloaded from www.csie.ntu.edu.tw/cjlin/libsvm/,www.esat.kuleuven.be/sista/lssvmlab/;www.ntu.edu.sg/home/egbhuang/; and www.cis.hut.fi/projects/tsp/index.php?page=OPELM, respectively. We use the radial basis function as the kernel function for SVR and LSSVR. In SVR, two parameters are mainly optimized. For each problem we use different combinations of the cost parameter C and the kernel parameter γ to estimate the generalized accuracy (Huang and Zhao, 2018): C = [212, 211, …, 2−1, 2−2] and γ = [24, 23, …, 2−9, 2−10] (Huang et al., 2006). Therefore, on SVR, for each problem we try 15 × 15 = 225 (C,γ) parameter combinations, 50 trials for each combination, then calculate the root mean square error (RMSE) of the 50 results of the combination, take the combination with the smallest root mean square error among the 225 combinations as the best parameter combination, and the parameter optimization process of LSSVR is the same. LSSVR mainly optimizes the regularization parameter (C) and the kernel parameter (kp), and the adopted ranges are the same as C and γ of SVR, respectively. The activation functions of ELM and its variants and the base functions of FELM will be set according to the following specific problems to be solved.
3.1. Artificial datasets
3.1.1. Artificial case 1: f1 (x) = x cos(4x)
In the interval [−1.0, 1.5], 101 training samples (xi, fi) were obtained by sampling at 0.025 intervals. In addition, with 0.025 as the interval, nine data points are obtained in the unlearned interval [1.505, 1.705] as the prediction points. In this example, FELM uses the base functions: {sin (x), sin (2x), sin (3x), sin (4x), sin (5x), sin (6x)}. The optimal combination parameter of SVR is (C, γ) = (212, 20), the optimal combination parameter of LSSVR: (C, kp) = (212, 2−10). ELM, OP-ELM and inverse-free ELM use the sig function as the activation function, and the activation function of OS-RELM is triangular basis function, because the commonly used sig function cannot obtain a feasible solution to this problem in a reasonable time. Trigonometrically-Activated Fourier Neural Networks (Zhang et al., 2009a) (hereinafter referred to as TAFNN) will also be added for performance comparison. The definition error of function as follows.
where expectt is the expected output, and predictt represents the actual network output, N is the number of sample points. And E/N is the average error.
As shown in Table 1, the parts in bold are the optimal data, FELM has a competitive advantage in training time, and the total training error and the average training error are less than 6 compared algorithms (especially hundreds of thousands of times smaller than ELM, inverse-free ELM and OS-RELM, Figure 7 shows that the training results obtained by the above three algorithms are not satisfactory), but slightly worse than OP-ELM. However, the training time of FELM is more than 200 times faster than OP-ELM, and its hidden layer has only 6 parameters, so its model complexity is much lower than OP-ELM. Figure 7 shows the testing of 8 algorithms. It can be seen that the testing results of FELM are good, and the error between its output and the target output is small. The testing results of ELM, inverse-free ELM and OS-RELM are different from the target output. In terms of prediction accuracy, FELM obtains the smallest total prediction error and average prediction error which shows that it has good generalization performance. A more intuitive comparison of predictions is shown in Figure 8. Therefore, compared with other comparison algorithms, FELM can obtain the highest prediction accuracy in the shortest time under the smallest network model.
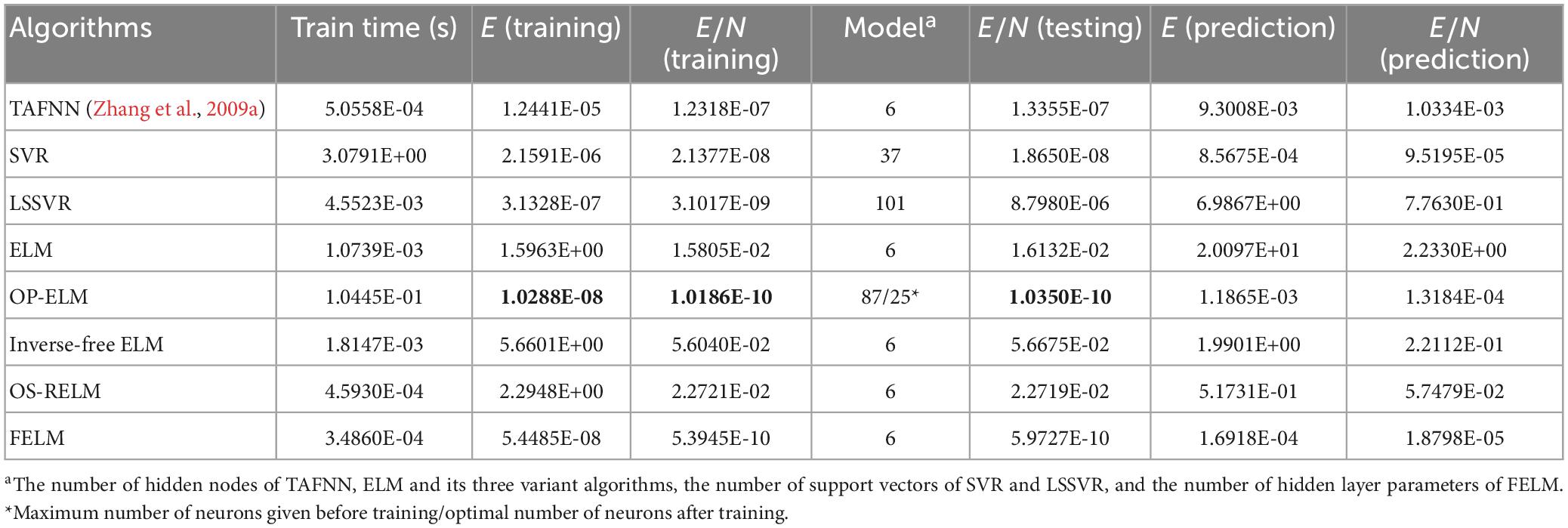
Table 1. Comparison of simulation and prediction on the f1(x).
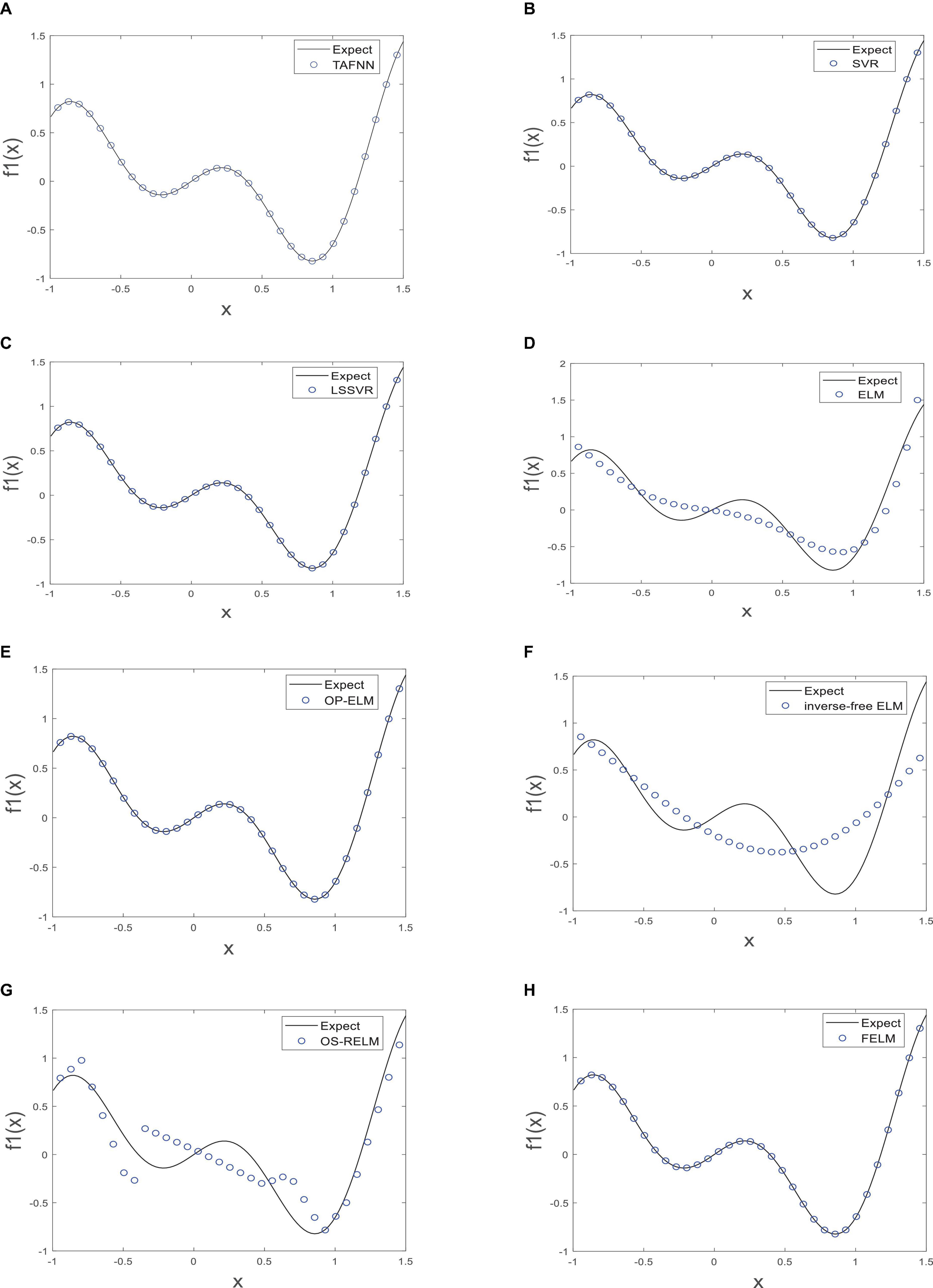
Figure 7. The test of each algorithm [(A) TAFNN, (B) SVR, (C) LSSVR, (D) ELM, (E) OP-ELM, (F) Inverse-free ELM, (G) OS-RELM, and (H) FELM] on f1(x).
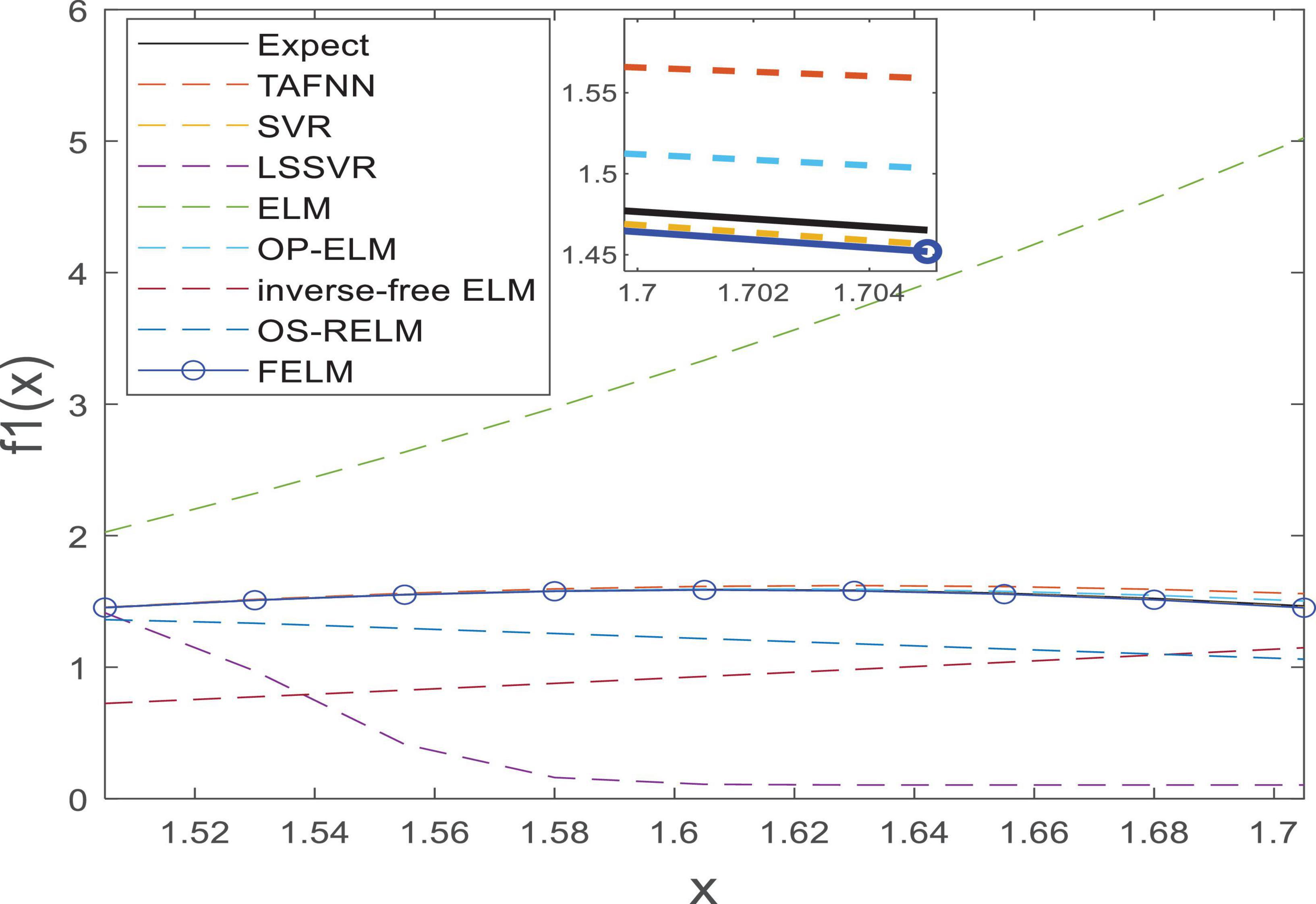
Figure 8. The prediction on f1(x).
3.1.2. Artificial case 2: f2 (x) = ex cos (6πx) /3 sin (x)
In the interval [−1, 1], 201 training samples are obtained at 0.01 sampling interval. The following simulation is carried out to determine the optimal number of hidden neurons corresponding to four different expectation average error(Eexpect = 10−2, 10−3, 10−4, 10−5), the evaluation metric is Eq. 23. The FELM uses {1, x, x2, x3, …, x24} as the base functions in this example. For different expected mean errors, the best parameters of SVR (C, γ) = (2−1, 24), (21, 24), (24, 24), (25, 24). The best parameters of LSSVR (C, kp) = (2−2, 2−10), (20, 2−10), (22, 2−10), (24, 2−10). OP-ELM uses the commonly used activation function sig function, and the activation function of ELM, inverse-free ELM and OS-RELM is triangular basis function. The Legendre neural network (Zhang et al., 2009b) (hereinafter referred to as Legendre) will also be used for comparison.
As shown in Table 2, the parts in bold are the optimal data, except for the first Eexp ect, under the other three Eexp ect, the structural complexity of FELM is the lowest with the Legendre, because they use similar hidden layer functions. It can be seen from the table that the time required for the FELM optimization process is short, indicating that of its learning speed is fast. Table 2 shows that the higher the required precision, the network complexity of ELM, inverse-free ELM and OS-RELM increase exponentially, while the model complexity of SVR has always been relatively large, and the structural complexity of LSSVR remains unchanged because all training samples have been used all the time. In contrast to FELM, its structural complexity will not increase significantly due to high precision requirements, but will increase slowly. Figure 9 shows the approximation of FELM under four different required accuracies.
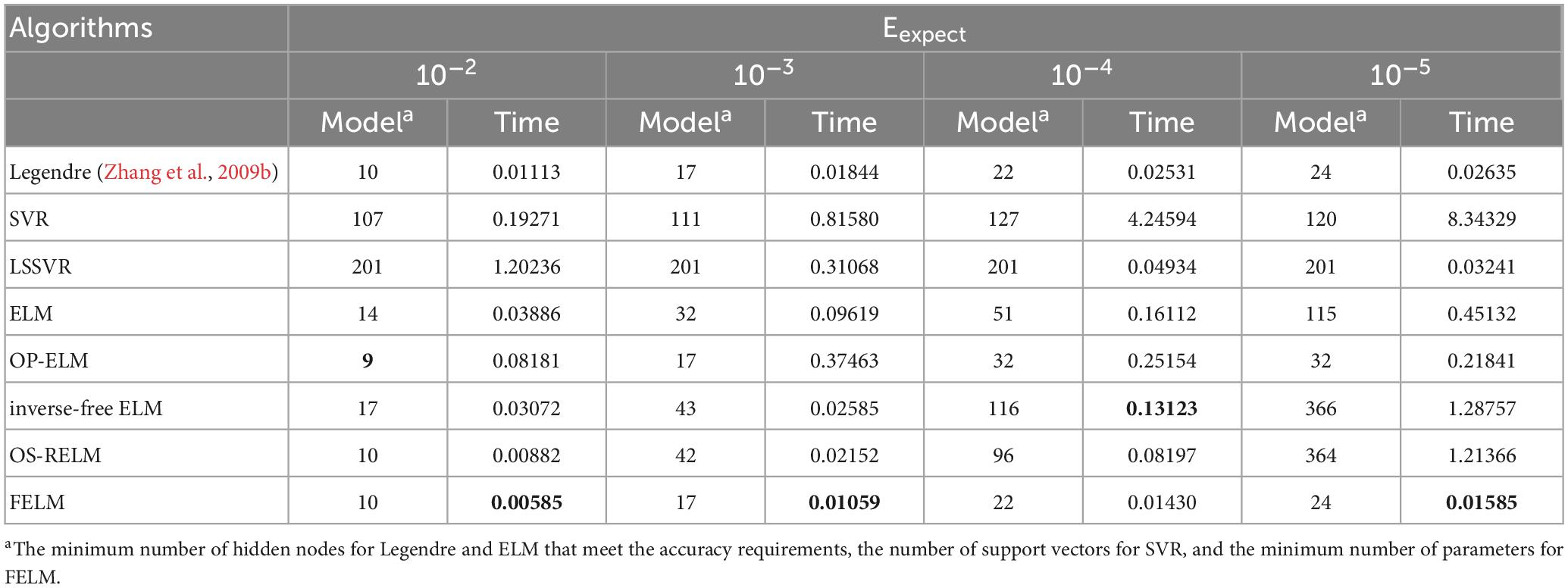
Table 2. Comparison of the simplest network structure and running time for approximating f2(x) at four precisions.
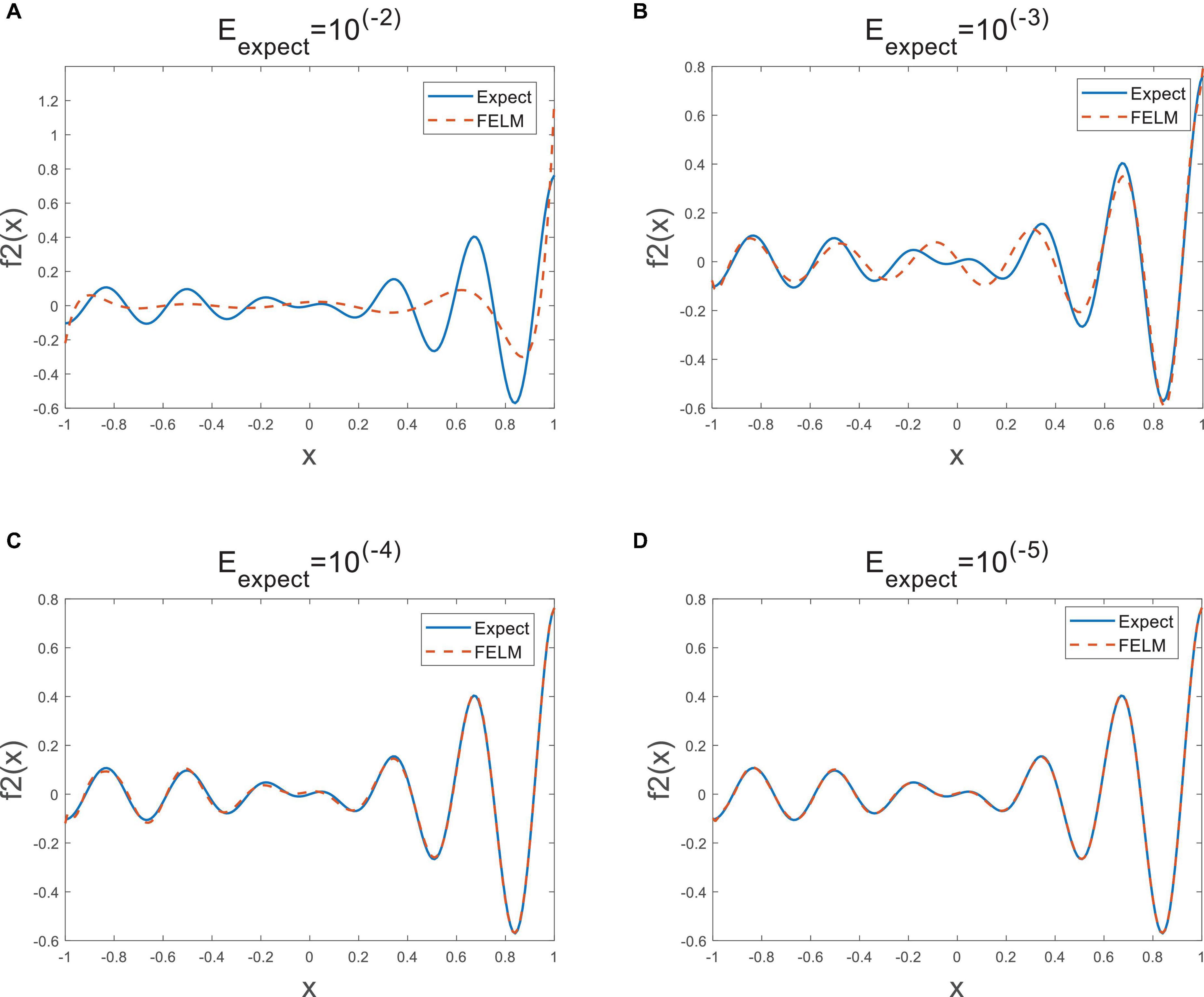
Figure 9. The approximation error [(A–D) 10−2∼10−5] of FELM.
3.2. Realistic regression problem
3.2.1. Data sets and experimental settings
The 16 real benchmark datasets are selected because they cover various fields, and the data size and dimension are different. They are mainly obtained from the data archives of UCI Machine Learning (Asuncion and Newman, 2007) and StatLib (StatLib DataSets Archive, 2021). Table 3 lists the specifications of these datasets. In practical applications, the distribution of these datasets is unknown, and most datasets are not noise-free. For these 7 algorithms, 50 independent simulation trials are performed on each dataset, and the training and test data are randomly regenerated from their entire dataset, two-thirds training and one-third testing. Additionally, in our experiments, all inputs (attributes) and outputs (targets) are normalized to the range [−1, 1].
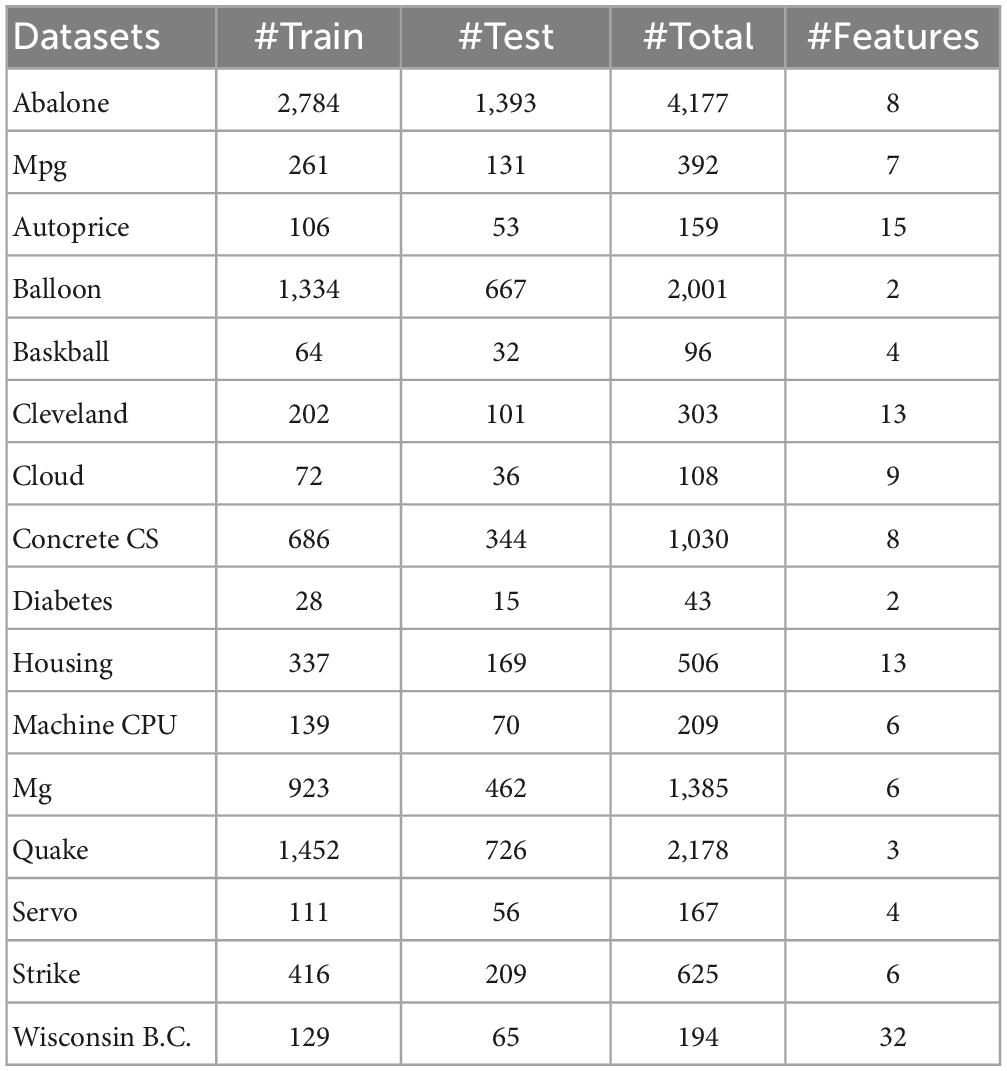
Table 3. Examples of actual regression.
The ELM uses the sig function as the activation function, OP-ELM uses Gaussian kernel, and the proposed algorithm uses two different types of base functions: φ1 = {1, x, x2, x3} and φ1 = {sin(x), sin(2x), sin(3x)}, the rest of the comparison algorithms use the RBF kernel. The network complexity comparison of FELM, ELM and SVR is shown in Table 4, where FELM and ELM adopt the same network complexity on the same problem, it can be seen that in most cases, FELM is more compact than SVR. It should be noted that, for fairness, the network complexity of OP-ELM, inverse-free ELM and OS-RELM is also the same as ELM, and will not be repeated in the table. Finally, on the baskball, cloud and diabetes problems, the maximum number of neurons for OP-ELM is pre-specified as 62, 70 and 26, respectively, because they have fewer training sets, and the remaining data sets are used a maximum number of 100 neurons.
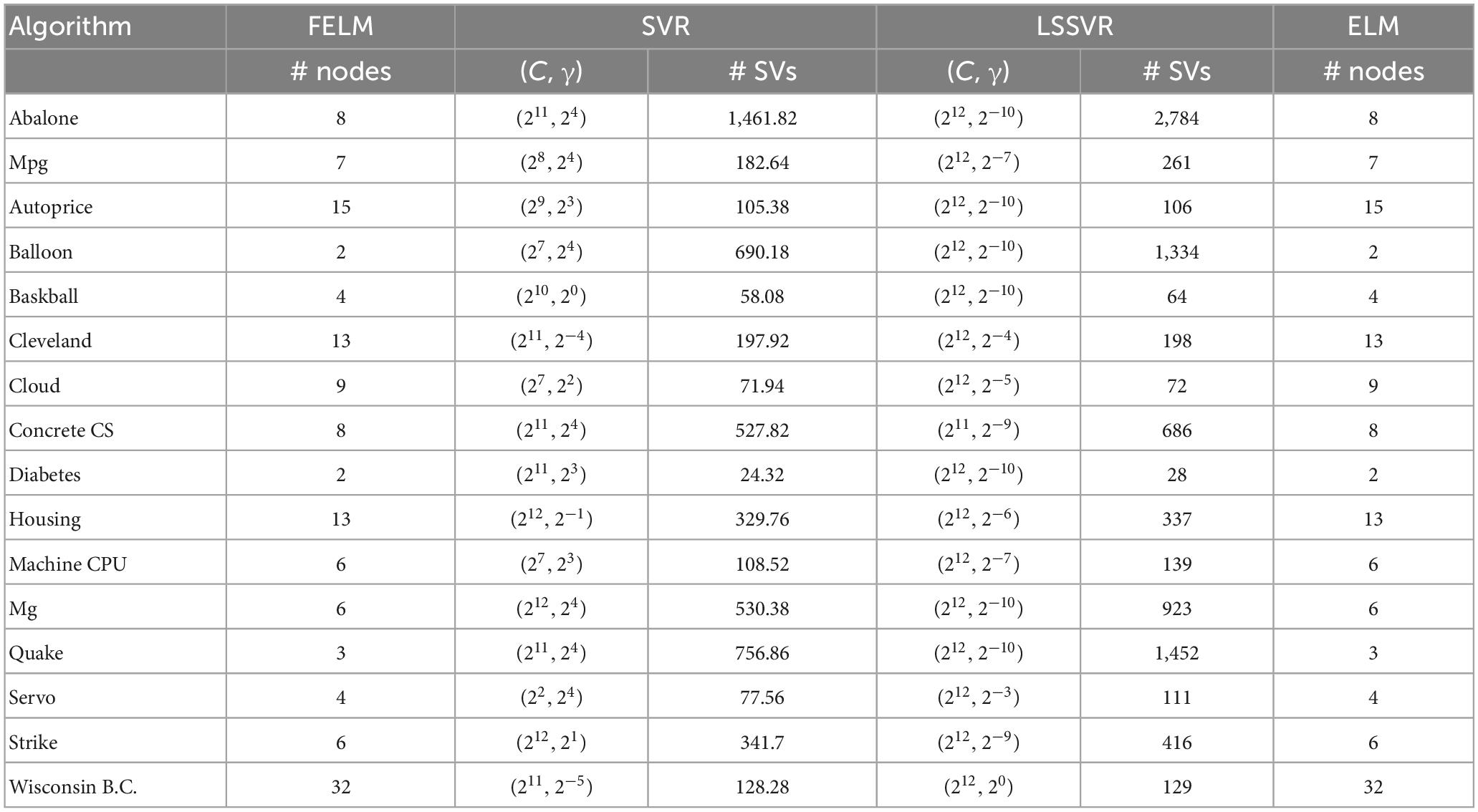
Table 4. Comparison of network complexity.
3.2.2. Evaluation criteria
On the above 13 benchmark regression problems, the evaluation criteria of FELM, ELM and SVR adopt root mean square error:
3.2.3. Evaluation and analysis of experimental results
The FELM is compared with other algorithms to test RMSE under two different types of base functions, and the winners are shown in Tables 5, 6 in bold. As can be seen from Tables 5, 6, FELM achieves higher generalization performance than the other 6 algorithms on all problems. Except on the Wisconsin B.C. problem, the average test RMSE of FELM is 1 order of magnitude higher than the other algorithms on the other 15 problems. It is worth noting that in Table 6, LSSVR achieves the best training results, but on most problems, its test and training RMSE are 3 orders of magnitude different, while the training and test RMSE of FELM are of the same order of magnitude or only one order of magnitude worse. Figures 10–13 shows that whether FELM uses φ1 or φ2, on Balloon, the curve of FELM and SVR are at the same level and below, which shows that although they obtain similar results, they are better than other algorithms. In Wisconsin B.C., The comparison curves of FELM, SVR and OP-ELM are also similar. But for other 14 problems, it can be seen from the figure that the curves of FELM are all at the bottom, and the fluctuations are gentler, while other algorithms have large fluctuations, indicating that compared with other algorithms, it not only obtains the highest accuracy, but also the network outputs of each independent trial are very close to the expected value, and the error is very small.
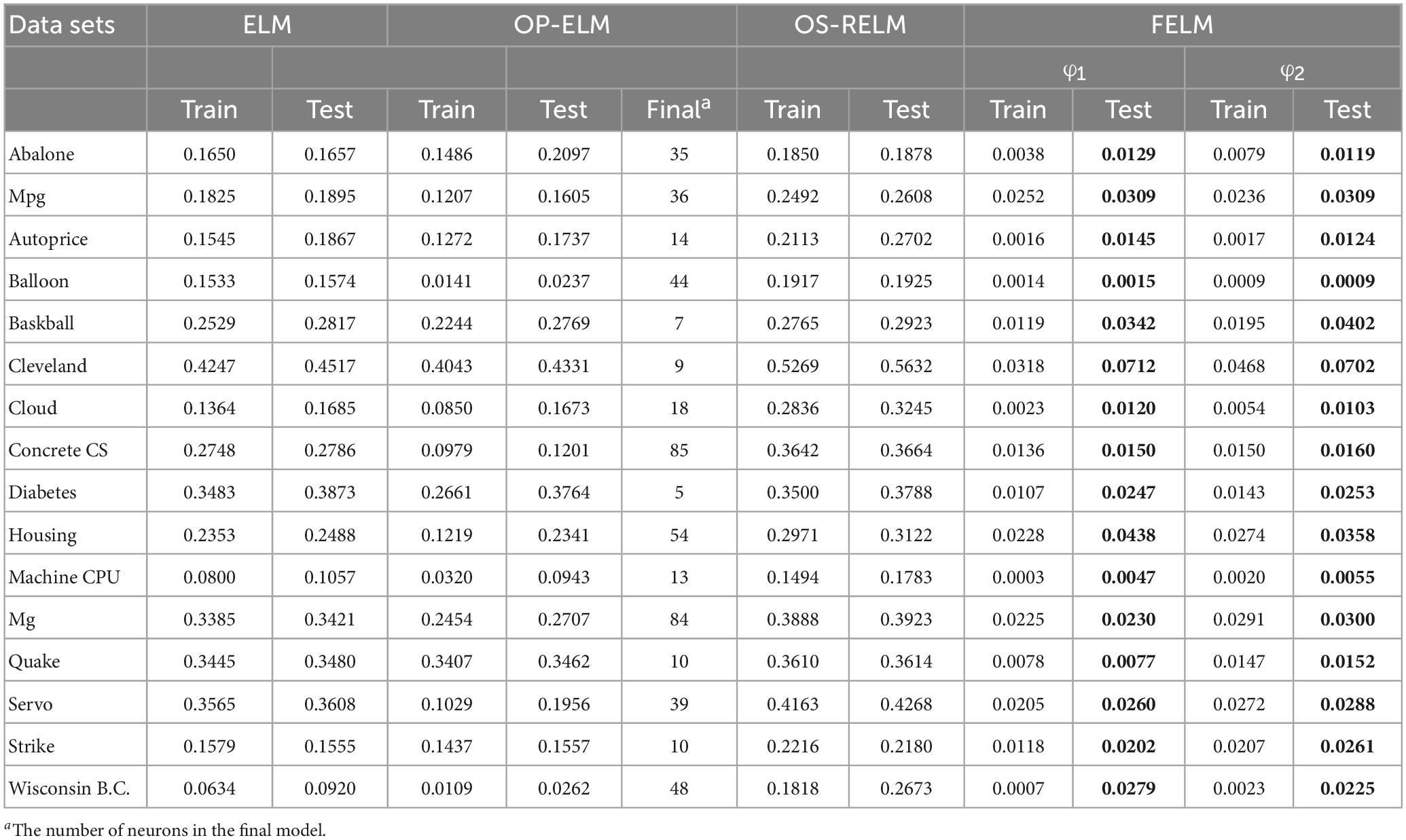
Table 5. Comparison of training and testing RMSE.
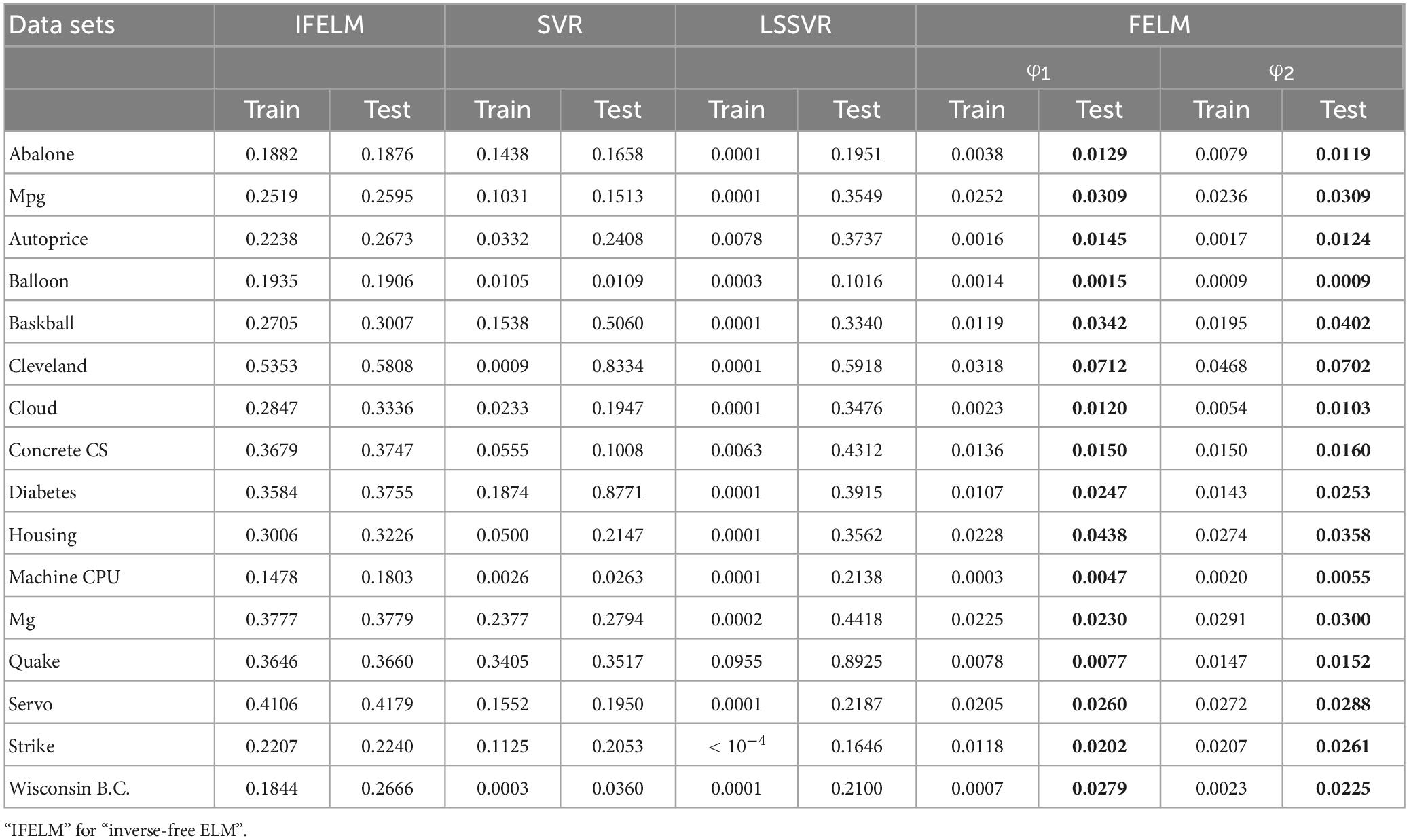
Table 6. Comparison of training and testing RMSE.
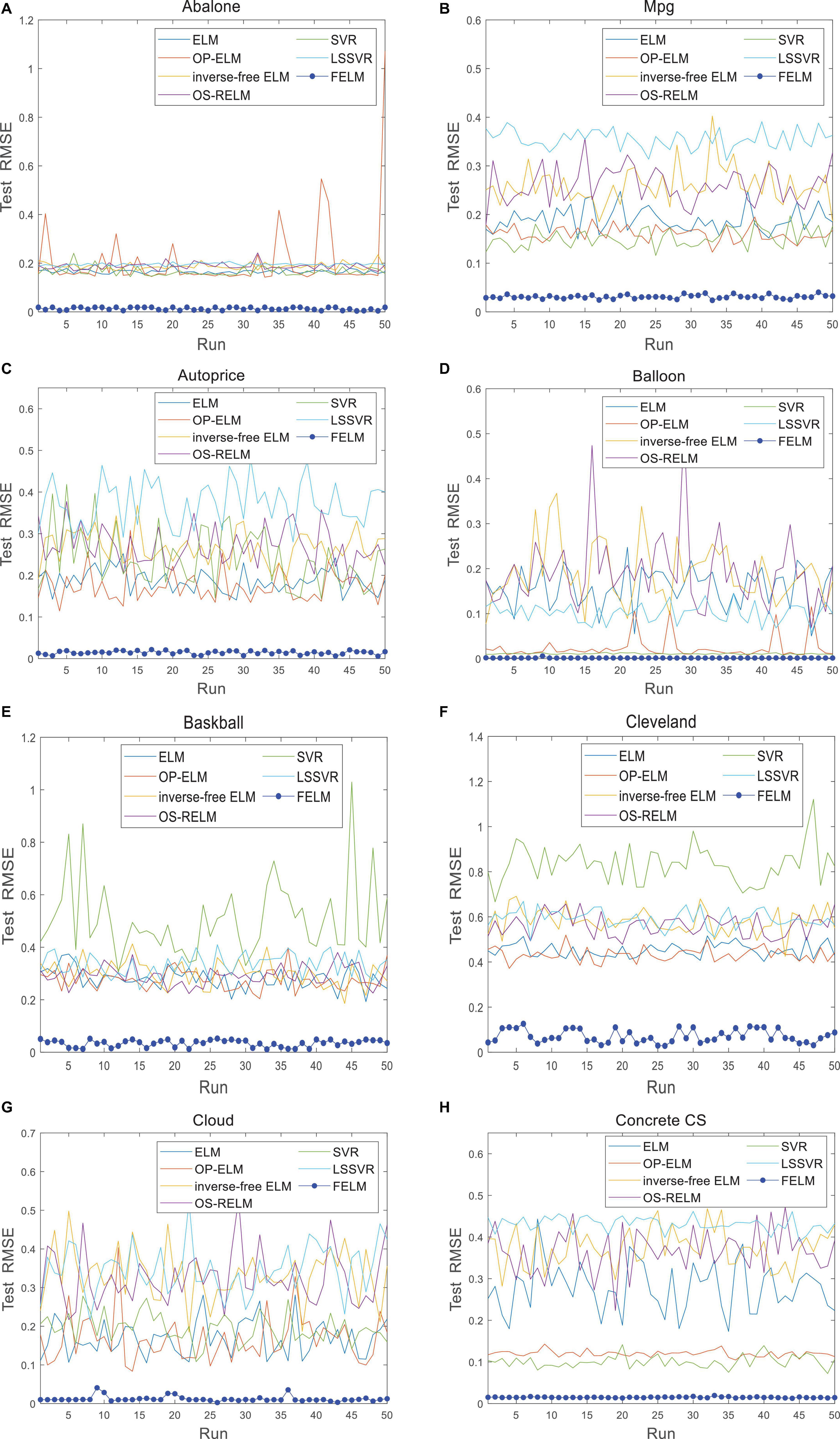
Figure 10. Comparison of test RMSE on the first 8 datasets when FELM uses φ1. (A) Abalone data set, (B) Mpg data set, (C) autoprice data set, (D) balloon data set, (E) baskball data set, (F) cleveland data set, (G) cloud data set, and (H) concrete CS data set.
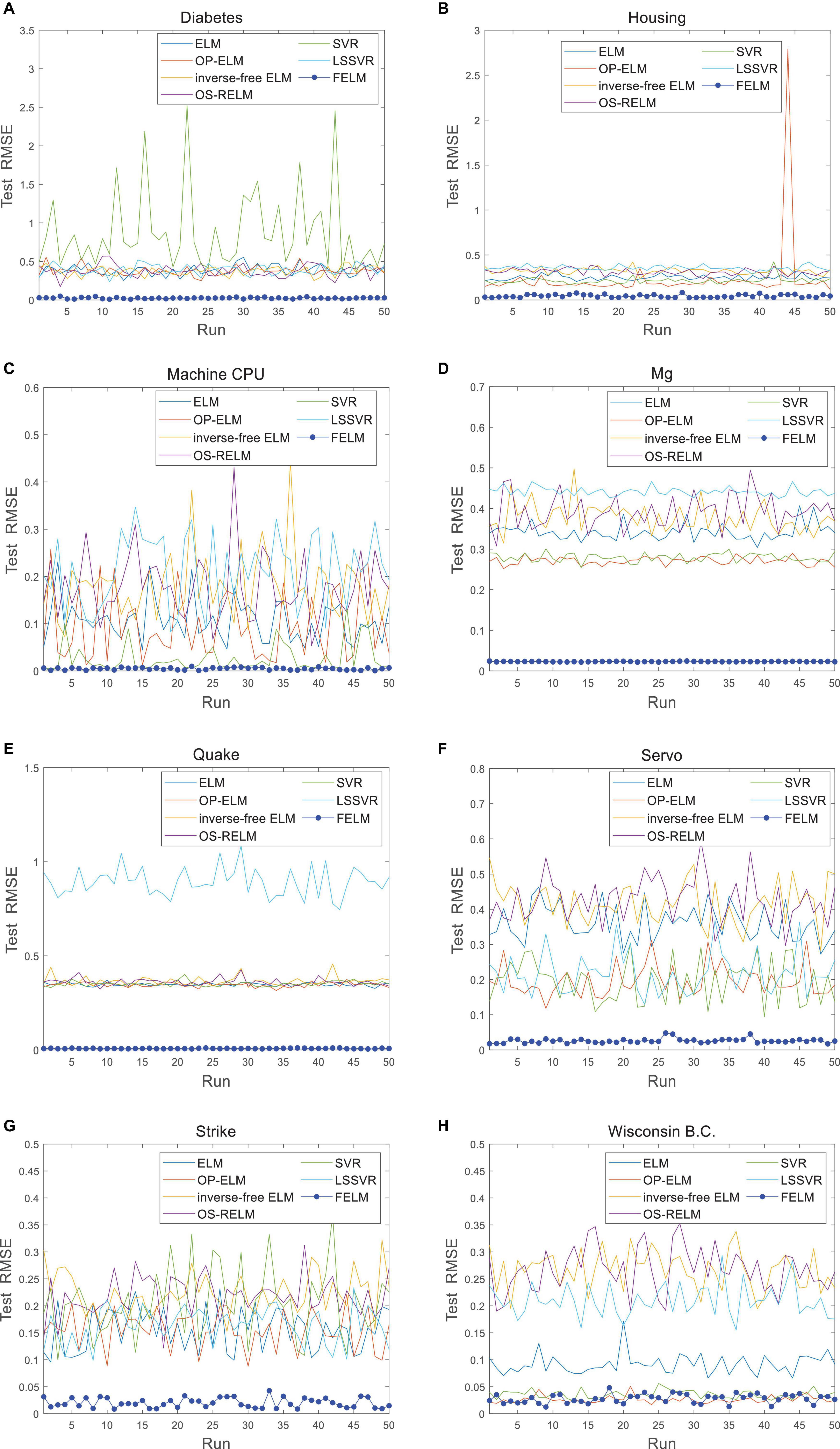
Figure 11. Comparison of test RMSE on the last 8 datasets when FELM uses φ1. (A) Diabetes data set, (B) housing data set, (C) machine CPU data set, (D) Mg data set, (E) quake data set, (F) servo data set, (G) strike data set, and (H) wisconsin B.C. data set.
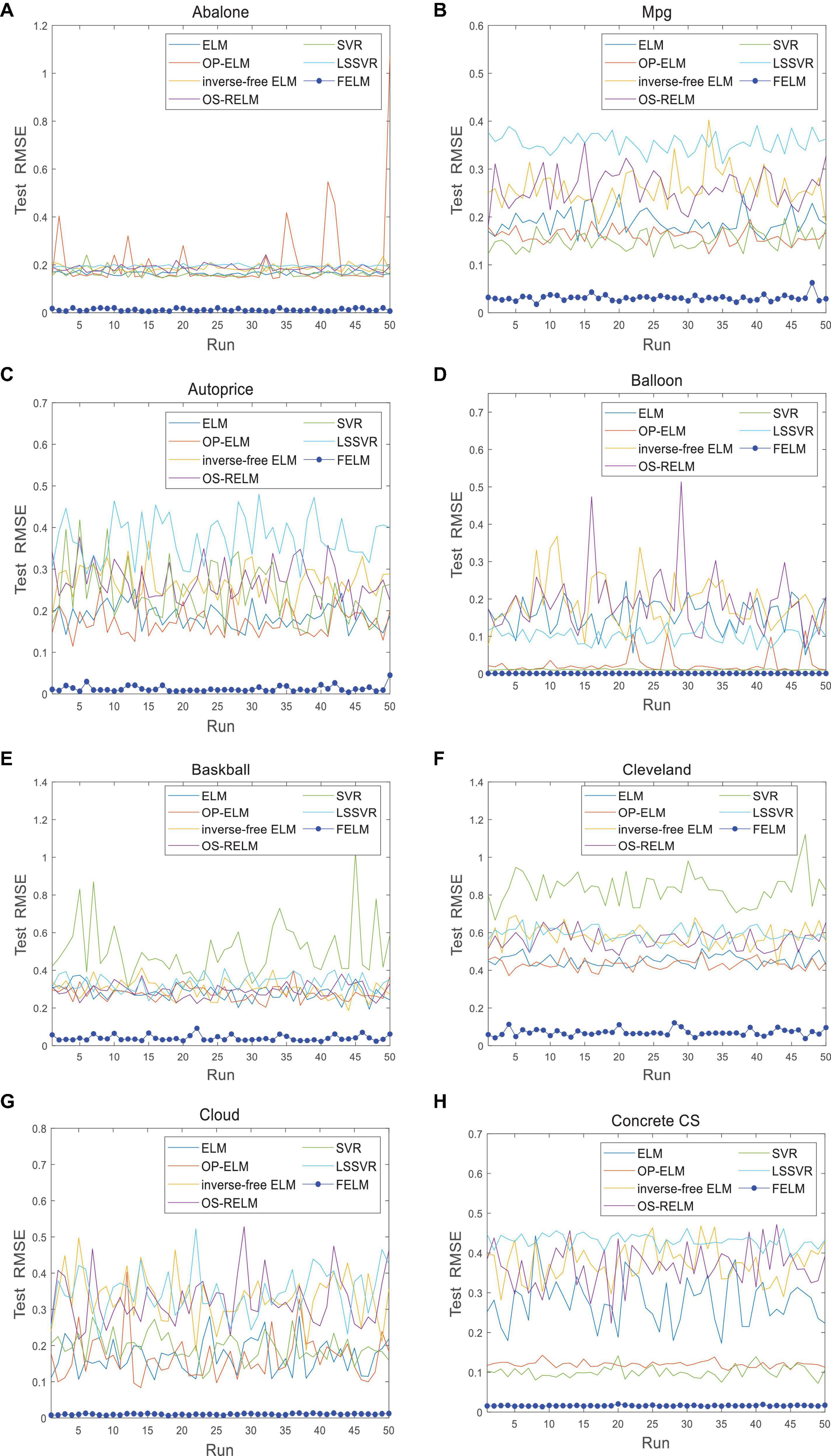
Figure 12. Comparison of test RMSE on the first 8 datasets when FELM uses φ2. (A) Abalone data set, (B) Mpg data set, (C) autoprice data set, (D) balloon data set, (E) baskball data set, (F) cleveland data set, (G) cloud data set, and (H) concrete CS data set.
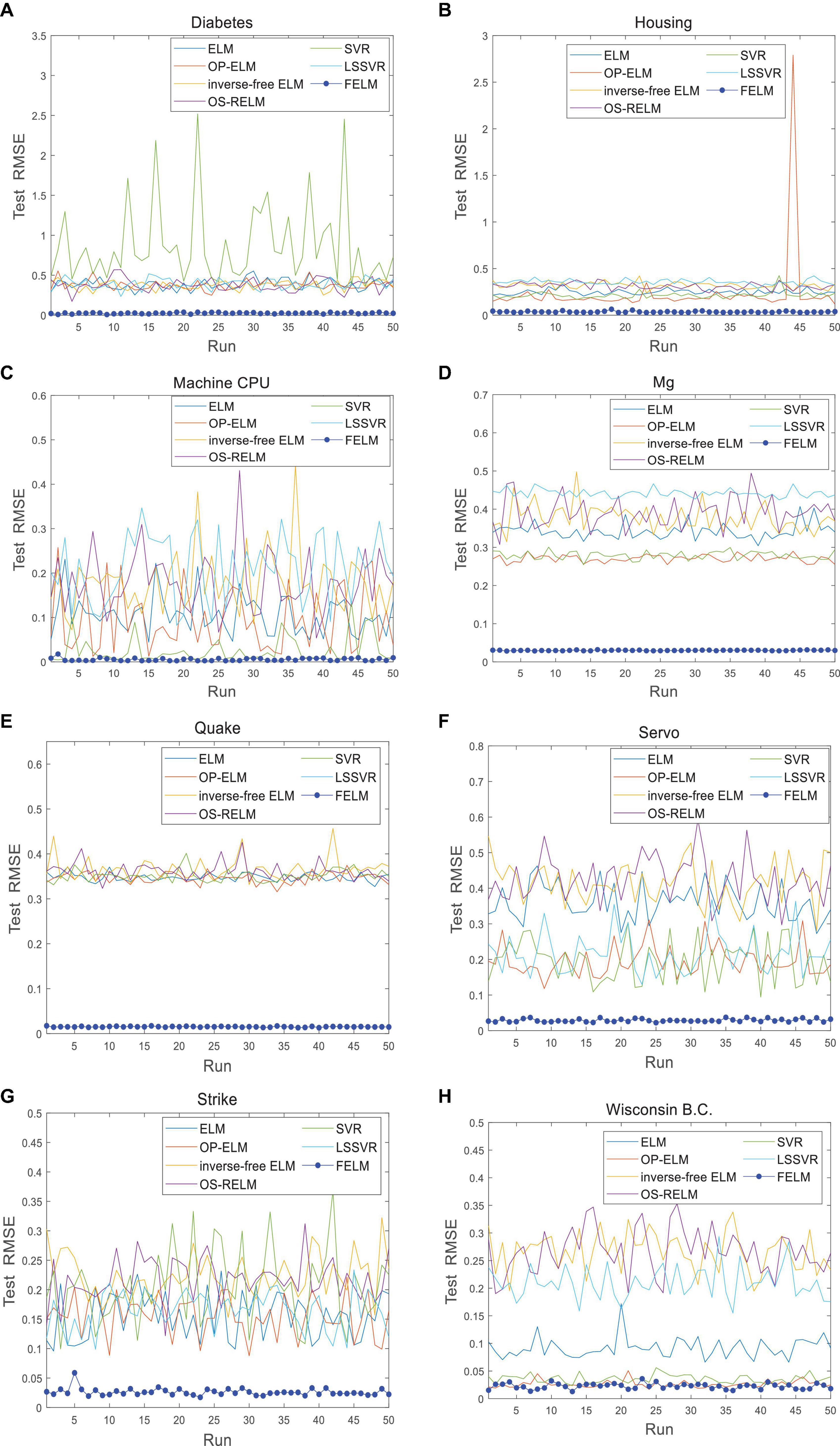
Figure 13. Comparison of test RMSE on the last 8 datasets when FELM uses φ2. (A) Diabetes data set, (B) housing data set, (C) machine CPU data set, (D) Mg data set, (E) quake data set, (F) servo data set, (G) strike data set, and (H) wisconsin B.C. data set.
Figure 14 shows the average time comparison of 7 algorithms on 16 datasets, where FELM−φ1 and FELM−φ2 use φ1 and φ2 base functions for FELM, respectively. Tables 7, 8 and Figure 14 show that the average training time of FELM on the two different types of base functions is close, and it is also similar to ELM, inverse-free ELM and OS-RELM in learning speed and test time. But it is obvious from Figure 14 that FELM learns ten times or even more than a hundred times faster than OP-ELM, SVR and LSSVR on most problems.
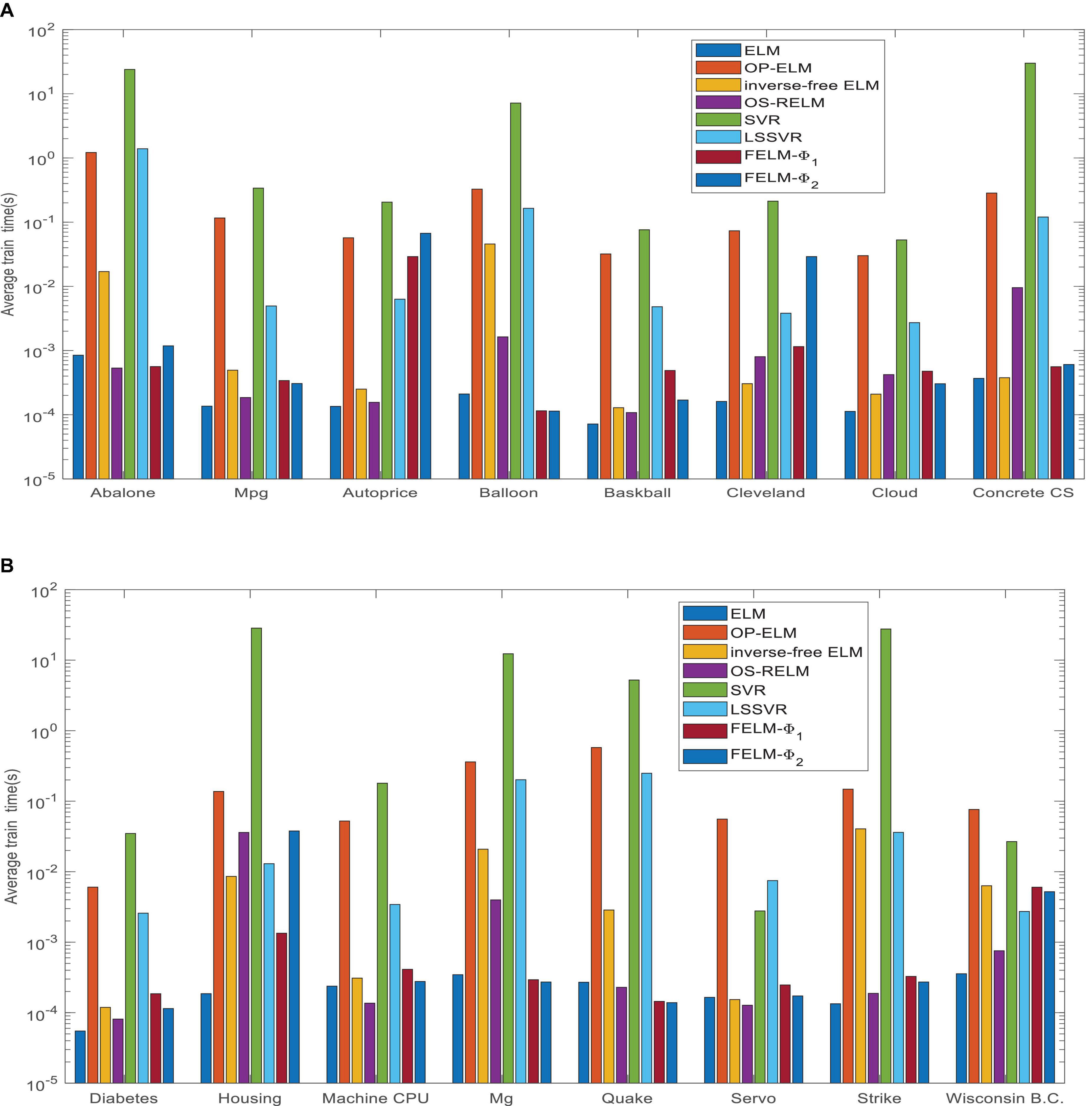
Figure 14. Comparison of eight algorithms training time. (A) Eight data sets average training time and (B) eight data sets average test time.
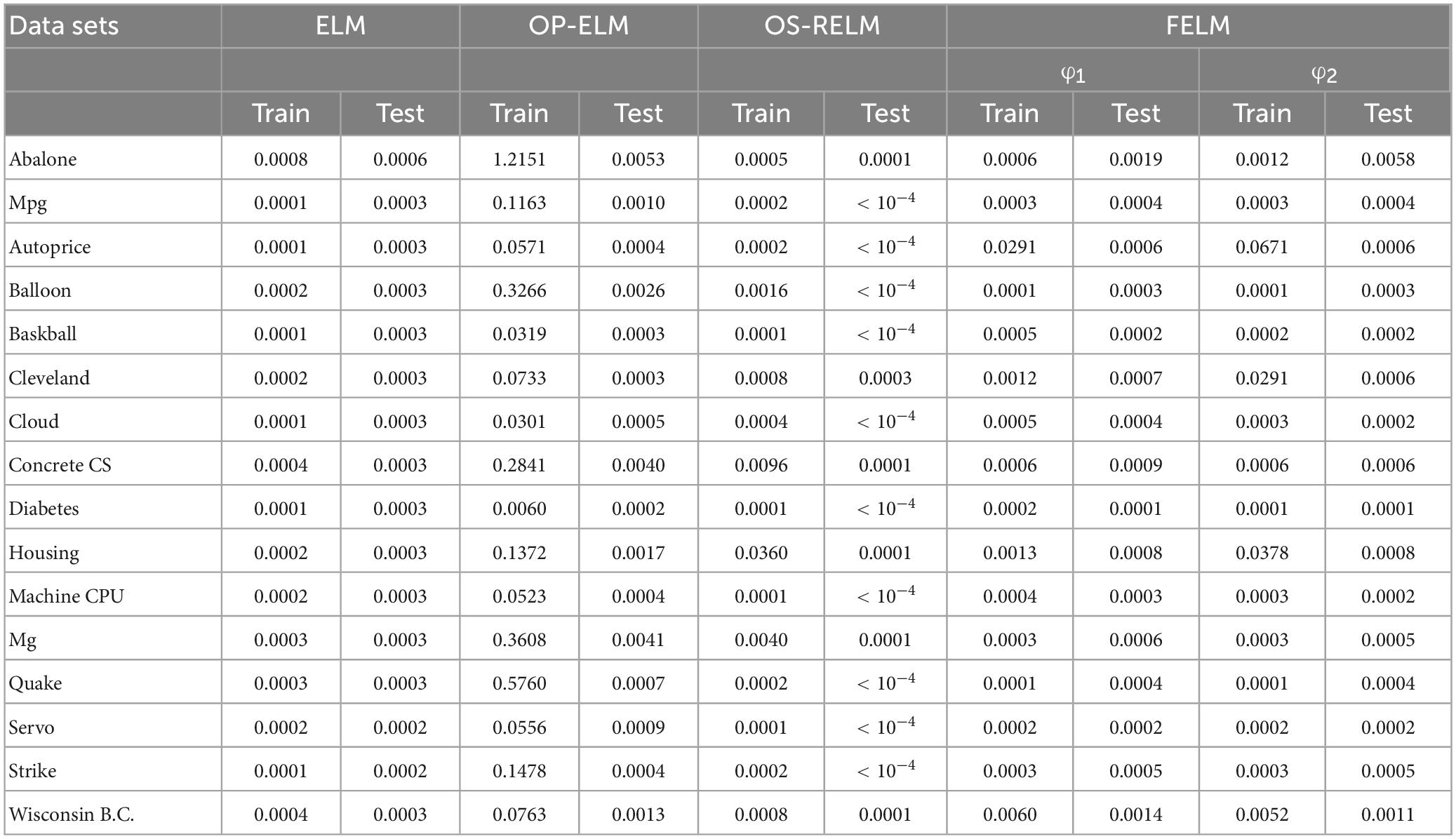
Table 7. Comparison of training and testing time.
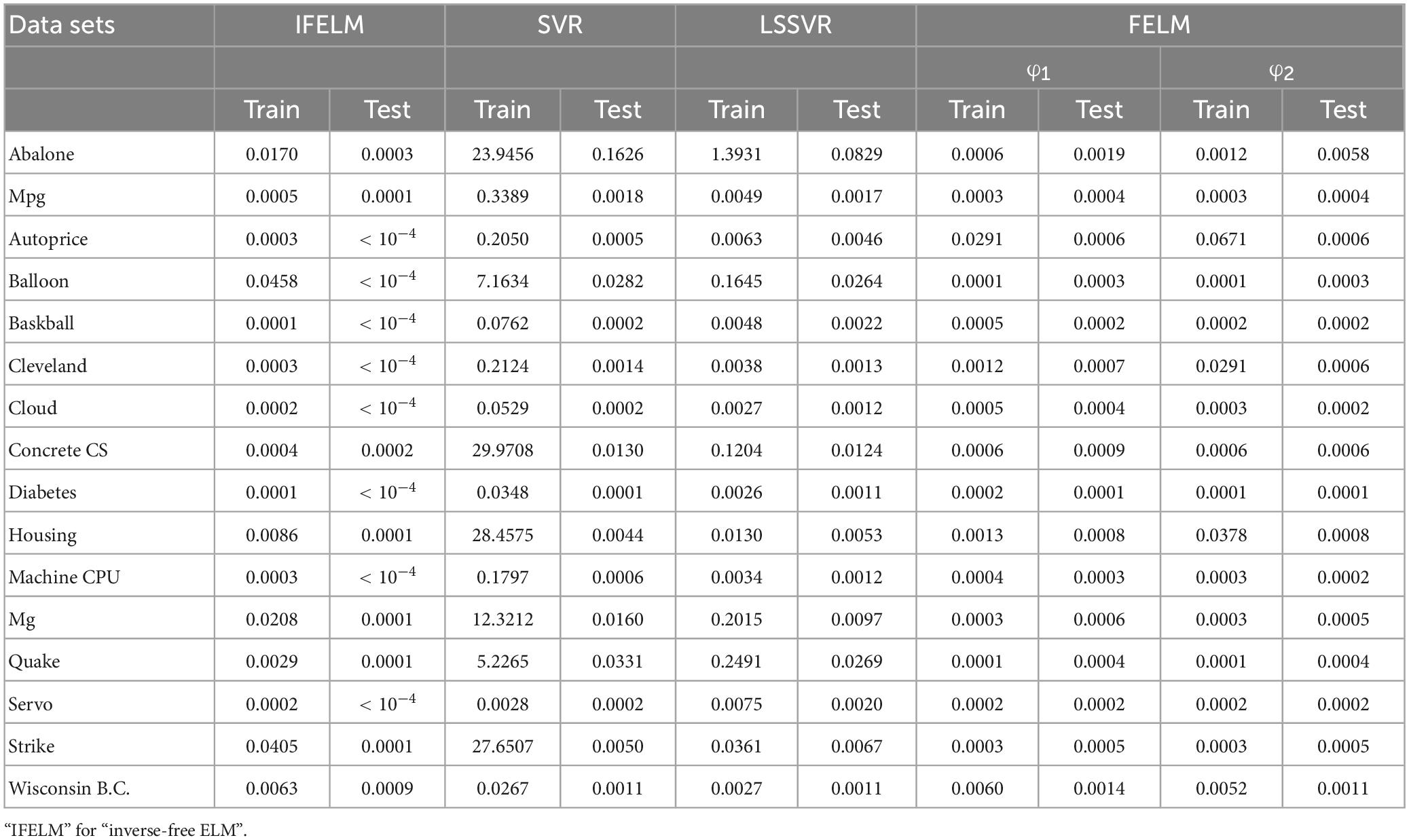
Table 8. Comparison of training and testing time.
In fact, according to the above experiments, it is obvious that FELM has better generalization performance than other comparison algorithms; at the same time, the RMSE of FELM changes milder or less, which means that FELM has stronger robustness. In addition, ELM has the advantage of fast learning speed, and the algorithm proposed in this article has been shown to not only generalize well, but also compete with ELM in learning speed.
4. Conclusions and future works
This article proposes a new type of functional extreme learning machine theory, the parameter learning algorithm without iteration makes the learning speed of FELM very fast. In our simulations, for many problems, the learning stage of FELM can be completed in less than a few seconds. Although the purpose of this article is not to compare functional extreme learning machine with ELM, SVR and their improved algorithms, we also make a simple comparison between FELM and six algorithms in the simulations. The results show that the learning speed of FELM can not only compete with ELM and its improved algorithms, but also be dozens or hundreds of times faster than SVR. As our experimental results show, FELM has higher test accuracy under the same network complexity as ELM and its variants. Because SVR usually generates more support vectors (computing units), LSSVR uses all training data, and functional extreme learning machine just needs few hidden layer nodes (computing units) in the same application. In applications requiring fast prediction and response capability, SVR algorithm may take several hours, so it is not suitable for real-time prediction, and the performance of FELM in this article seems to prove that it is suitable for this application. Compared with popular learning technologies, the proposed FELM has several important characteristics. (1) The training speed of FELM is very fast; (2) Fast parameter learning algorithm without iteration and with high precision; (3) Different function families can be selected according to specific problems, such as trigonometric function bases, Fourier basis functions, etc. In this article, we have proved that FELM is very useful in many practical regression problems, but the following two aspects can be studied in the future: under the actual engineering error, the purpose of optimizing the network is achieved by reducing the network complexity. The network parameters are obtained by matrix pseudo inverse method.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
Author contributions
XL carried out the FELM algorithm studies, participated in the drafted manuscript. GZ carried out the review and editing. YZ carried out the review and editing. QL carried out the design algorithm model. All authors read and approved the final manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, Grant number 62066005, U21A20464.
Acknowledgments
The authors express great thanks to the financial support from the National Natural Science Foundation of China.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abiodun, O. I., Jantan, A., Omolara, A. E., Dada, K. V., Mohamed, N. A., and Arshad, H. (2018). State-of-the-art in artificial neural network applications: A survey. Heliyon 4:e00938. doi: 10.1016/j.heliyon.2018.e00938
Afridi, M. J., Ross, A., and Shapiro, E. M. (2018). Recent advances in convolutional neural networks. Pattern Recogn. 77, 354–377. doi: 10.1016/j.patcog.2017.10.013
Artem, B., and Stefan, L. (2017). Extreme learning machines for credit scoring: An empirical evaluation. Exp. Syst. Appl. 86, 42–53. doi: 10.1016/j.eswa.2017.05.050
Asuncion, A., and Newman, D. J. (2007). U machine learning repository, School of Information and Computer Science. Irvine, CA: University of California.
Atiquzzaman, M., and Kandasamy, J. (2018). Robustness of Extreme Learning Machine in the prediction of hydrological flow series. Comput. Geosci. 120, 105–114. doi: 10.1016/j.cageo.2018.08.003
Baldominos, A., Saez, Y., and Isasi, P. (2018). Evolutionary convolutional neural networks: An application to handwriting recognition. Neurocomputing 283, 38–52. doi: 10.1016/j.neucom.2017.12.049
Castillo, E. (1998). Functional networks. Neural Process. Lett. 7, 151–159. doi: 10.1023/A:1009656525752
Christou, V., Tsipouras, M. G., Giannakeas, N., and Tzallas, A. T. (2018). Hybrid extreme learning machine approach for homogeneous neural networks. Neurocomputing 311, 397–412. doi: 10.1016/j.neucom.2018.05.064
Cortes, C., and Vapnik, V. (1995). Support-vector networks. Mach. Learn. 20, 273–297. doi: 10.1007/BF00994018
Gautam, R., and Sharma, M. (2019). Speech recognition using deep neural networks: A systematic review. IEEE Access 7, 19143–19165. doi: 10.1109/ACCESS.2019.2896880
Geng, Z. Q., Dong, J. G., Chen, J., and Han, Y. (2017). A new self-organizing extreme learning machine soft sensor model and its applications in complicated chemical processes. Eng. Appl. Artif. Intell. 62, 38–50. doi: 10.1016/j.engappai.2017.03.011
Golestaneh, P., Zekri, M., and Sheikholeslam, F. (2018). Fuzzy wavelet extreme learning machine. Fuzzy Sets Syst. 342, 90–108. doi: 10.1016/j.fss.2017.12.006
Gong, D., Hao, W., Gao, L., Feng, Y., and Cui, N. (2021). Extreme learning machine for reference crop evapotranspiration estimation: Model optimization and spatiotemporal assessment across different climates in China. Comput. Electron. Agric. 187:106294. doi: 10.1016/j.compag.2021.106294
Guo, Z., Yongquan, Z., Huajuan, H., and Zhonghua, T. (2019). Functional networks and applications: A survey. Neurocomputing 335, 384–399. doi: 10.1016/j.neucom.2018.04.085
Henríquez, P. A., and Ruz, G. A. (2019). Noise reduction for near-infrared spectroscopy data using extreme learning machines. Eng. Appl. Artif. Intell. 79, 13–22. doi: 10.1016/j.engappai.2018.12.005
Huang, G., Zhou, H., Ding, X., and Zhang, R. (2012). Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. 42, 513–529. doi: 10.1109/TSMCB.2011.2168604
Huang, G. B., Zhu, Q. Y., and Siew, C. K. (2006). Extreme learning machine: Theory and applications. Neurocomputing 70, 489–501. doi: 10.1016/j.neucom.2005.12.126
Huang, Y., and Zhao, L. (2018). Review on landslide susceptibility mapping using support vector machines. Catena 165, 520–529. doi: 10.1016/j.catena.2018.03.003
Kardani, N., Bardhan, A., Samui, P., Nazem, M., Zhou, A., and Armaghani, D. J. (2021). A novel technique based on the improved firefly algorithm coupled with extreme learning machine (ELM-IFF) for predicting the thermal conductivity of soil. Eng. Comput. 38, 3321–3340. doi: 10.1007/s00366-021-01329-3
Kärkkäinen, T. (2019). Extreme minimal learning machine: Ridge regression with distance-based basis. Neurocomputing 342, 33–48. doi: 10.1016/j.neucom.2018.12.078
Li, H. T., Chou, C. Y., Chen, Y. T., Wang, S., and Wu, A. (2019). Robust and lightweight ensemble extreme learning machine engine based on eigenspace domain for compressed learning. IEEE Trans. Circ. Syst. 66, 4699–4712. doi: 10.1109/TCSI.2019.2940642
Li, S., You, Z., Guo, H., Luo, X., and Zhao, Z. (2016). Inverse-free extreme learning machine with optimal information updating. IEEE Trans. Cybern. 46, 1229–1241. doi: 10.1109/TCYB.2015.2434841
Lima, A. R., Hsieh, W. W., and Cannon, A. J. (2017). Variable complexity online sequential extreme learning machine, with applications to streamflow prediction. J. Hydrol. 555, 983–994. doi: 10.1016/j.jhydrol.2017.10.037
Miche, Y., Sorjamaa, A., Bas, P., Simula, O., Jutten, C., and Lendasse, A. (2010). OP-ELM: Optimally pruned extreme learning machine. IEEE Trans. Neural Netw. 21, 158–162. doi: 10.1109/TNN.2009.2036259
Mohammed, E., Hossam, F., and Nadim, O. (2018). Improving Extreme Learning Machine by Competitive Swarm Optimization and its application for medical diagnosis problems. Exp. Syst. Appl. 104, 134–152. doi: 10.1016/j.eswa.2018.03.024
Murli, M., Ebha, K., and Subhojit, G. (2018). Microgrid protection under wind speed intermittency using extreme learning machine. Comput. Electr. Eng. 72, 369–382. doi: 10.1016/j.compeleceng.2018.10.005
Ozgur, K., and Meysam, A. (2018). Modelling reference evapotranspiration using a new wavelet conjunction heuristic method: Wavelet extreme learning machine vs wavelet neural networks. Agric. For. Meteorol. 263, 41–48. doi: 10.1016/j.agrformet.2018.08.007
Pacheco, A. G. C., Krohling, R. A., and Da Silva, C. A. S. (2018). Restricted Boltzmann machine to determine the input weights for extreme learning machines. Exp. Syst. Appl. 96, 77–85. doi: 10.1016/j.eswa.2017.11.054
Paolo, P., and Roberto, F. (2017). Application of extreme learning machines to inverse neutron kinetics. Ann. Nuclear Energy 100, 1–8. doi: 10.1016/j.anucene.2016.08.031
Peter, S., and Israel, C. (2020). Extreme learning machine for a new hybrid morphological/linear perceptron. Neural Netw. 123, 288–298. doi: 10.1016/j.neunet.2019.12.003
Sattar, A., Ertuğrul, ÖF., Gharabaghi, B., McBean, E. A., and Cao, J. (2019). Extreme learning machine model for water network management. Neural Comput. Appl. 31, 157–169. doi: 10.1007/s00521-017-2987-7
Shao, Z., and Er, M. J. (2016). An online sequential learning algorithm for regularized extreme learning machine. Neurocomputing 173, 778–788. doi: 10.1016/j.neucom.2015.08.029
StatLib DataSets Archive, (2021). StatLib DataSets Archive. Available online at: https://www.causeweb.org/cause/resources/library/r12673
Sun, H., Jia, J., Goparaju, B., Huang, G., Sourina, O., Bianchi, M., et al. (2017). Large-scale automated sleep staging. Sleep 40:zsx139. doi: 10.1093/sleep/zsx139
Tang, J., Deng, C., and Huang, G. B. (2016). Extreme learning machine for multilayer perceptron. IEEE Trans. Neural Netw. Learn. Syst. 27, 809–821. doi: 10.1109/TNNLS.2015.2424995
Vikas, D., and Balaji, S. (2020). Physics informed extreme learning machine (PIELM)–A rapid method for the numerical solution of partial differential equations. Neurocomputing 391, 96–118. doi: 10.1016/j.neucom.2019.12.099
Werbos, P. (1974). New tools for prediction and analysis in the behavioral sciences. Ph. D. thesis. Cambridge, MA: Harvard University.
Yaseen, Z. M., Sulaiman, S. O., Deo, R. C., and Chau, W. K. (2019). An enhanced extreme learning machine model for river flow forecasting: State-of-the-art, practical applications in water resource engineering area and future research direction. J. Hydrol. 569, 387–408. doi: 10.1016/j.jhydrol.2018.11.069
Yimin Yang, Q. M., and Jonathan, W. (2018). Autoencoder with invertible functions for dimension reduction and image reconstruction. IEEE Trans. Syst. Man Cybern. 48, 1065–1079. doi: 10.1109/TSMC.2016.2637279
Zhang, Y., Kuang, Z., and Xiao, X. (2009a). A direct-weight-determination method for trigonometrically- activated fourier neural networks. Comput. Eng. Sci. 31, 112–115.
Zhang, Y., Liu, W., and Cai, B. (2009b). Number determination of hidden-layer neurons in weights-directly-determined Legendre neural network. J. Chin. Comp. Syst. 30, 1298–1301.
Keywords: FN, ELM, functional equation, parameter learning algorithm, FELM
Citation: Liu X, Zhou G, Zhou Y and Luo Q (2023) Functional extreme learning machine. Front. Comput. Neurosci. 17:1209372. doi: 10.3389/fncom.2023.1209372
Received: 20 April 2023; Accepted: 20 June 2023;
Published: 11 July 2023.
Edited by:
Yu-Jun Zheng, Hangzhou Normal University, ChinaReviewed by:
Huiling Chen, Wenzhou University, ChinaHuayue Chen, China West Normal University, China
Huimin Zhao, Civil Aviation University of China, China
Copyright © 2023 Liu, Zhou, Zhou and Luo. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guo Zhou, emhvdWd1b0BjdXBsLmVkdS5jbg==; Yongquan Zhou, emhvdXlvbmdxdWFuQGd4dW4uZWR1LmNu