 Hector Zenil
Hector Zenil James A. R. Marshall
James A. R. Marshall Jesper Tegnér
Jesper Tegnér
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Comput. Neurosci. , 24 January 2023
Volume 16 - 2022 | https://doi.org/10.3389/fncom.2022.956074
This article is part of the Research Topic Complex Network Dynamics in Consciousness View all 7 articles
Being able to objectively characterize the intrinsic complexity of behavioral patterns resulting from human or animal decisions is fundamental for deconvolving cognition and designing autonomous artificial intelligence systems. Yet complexity is difficult in practice, particularly when strings are short. By numerically approximating algorithmic (Kolmogorov) complexity (K), we establish an objective tool to characterize behavioral complexity. Next, we approximate structural (Bennett’s Logical Depth) complexity (LD) to assess the amount of computation required for generating a behavioral string. We apply our toolbox to three landmark studies of animal behavior of increasing sophistication and degree of environmental influence, including studies of foraging communication by ants, flight patterns of fruit flies, and tactical deception and competition (e.g., predator-prey) strategies. We find that ants harness the environmental condition in their internal decision process, modulating their behavioral complexity accordingly. Our analysis of flight (fruit flies) invalidated the common hypothesis that animals navigating in an environment devoid of stimuli adopt a random strategy. Fruit flies exposed to a featureless environment deviated the most from Levy flight, suggesting an algorithmic bias in their attempt to devise a useful (navigation) strategy. Similarly, a logical depth analysis of rats revealed that the structural complexity of the rat always ends up matching the structural complexity of the competitor, with the rats’ behavior simulating algorithmic randomness. Finally, we discuss how experiments on how humans perceive randomness suggest the existence of an algorithmic bias in our reasoning and decision processes, in line with our analysis of the animal experiments. This contrasts with the view of the mind as performing faulty computations when presented with randomized items. In summary, our formal toolbox objectively characterizes external constraints on putative models of the “internal” decision process in humans and animals.
To unravel the essence of the machinery enabling human and animal decisions is fundamental not only for understanding cognition but, by extension, when aiming to design advanced autonomous artificial intelligence systems. Recent progress in cognitive science suggests a Bayesian view of cognition as constituting a predictive system (Fahlman et al., 1983; Rao and Ballard, 1999; Friston and Stephan, 2007; Friston, 2010). Such a view is succinctly captured in Shakespeare’s in Macbeth, when Banquo asks the witches whether they can “……… look into the seeds of time, and say which grain will grow and which will not.” At the core of this view is the notion that our cognitive apparatus incorporates a model of the world, serving as a basis for making decisions (Ha and Schmidhuber, 2018; Friston et al., 2021). Thus, the Bayesian brain hypothesis suggests that underlying our behavior there is an inherent cognitive structure for making decisions based on predictions, which are derived in turn from a real-world model.
Therefore in some sense, cognitive systems for decision making in animals and humans hinge upon the capacity to handle probabilities under a Bayesian model. Such probabilities are thought to be central to the decision process. Here we propose to reformulate the challenge of dealing with “internal” probabilities using the concept of complexity, since we then can objectively ask how random or non-random particular instances of observable “external” behavior are. From such a viewpoint, we can potentially discover strong objective “external” regularizations constraining our models and analysis of the “internal” decision process, Bayesian or not. Since the emergence of the Bayesian predictive paradigm in cognitive science referred to above, researchers have expressed the need for a formal account of ‘complexity’ to, for example, enable objective characterization of animal experiments (e.g., Rushen, 1991; Manor and Lipsitz, 2012). There has, however, been a struggle to provide formal, normative, non-ad hoc, and universal accounts of features in behavioral sequences that are more advanced than probabilistic tools.
Previous work has introduced some measures of fractality (spatial and temporal) and Shannon Entropy in applications of relevance to human and animal welfare (Sabatini, 2000; Costa et al., 2002; Manor and Lipsitz, 2012). Yet, little has been numerically attempted toward a systematic animal behavioral analysis using quantitative measures of algorithmic content. Relying primarily upon heuristic analysis of animal and human behavioral data, different ideas have been proposed regarding the nature of decisions, behavior, probabilities, world models, and cognition which are thought to jointly account for behavioral data. For example, organisms exposed to a featureless environment have been thought to resort to a behavioral strategy close to a random walk, characterized by isotropic step lengths and following a heavy-tailed Levy distribution. Yet, without a proper formal analysis of “complexity,” we risk misinterpreting behavioral data from animals and humans.
Here we build on earlier work (Gauvrit et al., 2014a,b, 2015, 2017a,b; Zenil, 2017, Zenil et al., 2020) to show how algorithmic information theory provides measures for the high-order characterization of processes produced by deterministic choices (Zenil et al., 2018, 2019). Importantly, we target cases where such processes display no statistical regularities or rankings of ordered versus random-looking sequences in terms of their information content. Our objective in responding to this challenge is to use algorithmic information theory to develop a quantitative toolbox for complexity, and to validate our tools using well-known landmark studies of animal behavior. This task entails developing tools that can handle limited amounts of data in the behavioral sciences, i.e., estimating complexity for short strings. One problem for a decision system is how to build a prior under several partly competing constraints. For example, how do we meet the criteria for neutrality, making a minimal number of assumptions (Ockham’s razor), while also taking into account all possible scenarios (Epicurus’ Principle of Multiple Explanations) and moreover being sufficiently informative beyond statistical uniformity (Gauvrit et al., 2015).
To this end, we introduce Kolmogorov complexity (K) as a coherent formalism, which has been developed to incorporate all these principles. Kolmogorov complexity quantifies simplicity versus randomness and enables a distinction between correlation and causation in data. Its Kolmogorov complexity quantifies the complexity of an object by the length of its shortest possible description. For example, low K means that digits in a sequence can be deterministically generated— each bit is causally connected by a common generating source. However, that a sequence has a large Shannon Entropy means that its digits do not look statistically similar, not that they are necessarily causally disconnected. Thus far, statistical lossless compression algorithms have been used to approximate Kolmogorov complexity. However, they are based on statistical properties of sequences that are used to encode regularities, and as such they are, in fact, Shannon Entropy rate estimators (Zenil, 2020). Here we use an alternative method to approximate K based on Algorithmic Probability (Delahaye and Zenil, 2012; Soler-Toscano et al., 2014). In contrast to lossless compression, we can also deal with short sequences typically encountered in the behavioral sciences.
In addition, we also target what is referred to as the structural complexity, i.e., the amount of computation performed by a human or animal in decision-making. Since such a distinction between structural complexity and randomness cannot be accomplished using Kolmogorov complexity, we make use of the notion of Logical Depth (LD) (Bennett, 1988). Importantly, our approximation technique for short sequences also allow an estimation of LD based upon and motivated by Logical Depth (Zenil et al., 2012c,2020).
The algorithmic information theory provides a formal framework for verifying intuitive notions of complexity. For example, the algorithmic probability of a sequence s is the probability that a randomly chosen program running on a Universal (prefix-free) Turing Machine will produce s and halt. Since Turing Machines are conjectured to be able to perform any algorithmically specified computation, this corresponds to the probability that a random computation will produce s. It therefore serves as a natural formal definition of a prior distribution for Bayesian applications. Also, as we will see in the next section, the algorithmic probability of a string s is negatively linked to its (Kolmogorov–Chaitin) algorithmic complexity, defined as the length of the shortest program that produces s and then halts (Kolmogorov, 1965; Chaitin, 1969).
One important drawback of algorithmic complexity (which we will denote by K) is that it is not computable. Or, more precisely, K is lower-semi-computable, meaning that it cannot be computed with absolute certainty but can be arbitrarily approximated from above. Indeed, statistical lossless compression algorithms have been used to approximate K. However, new methods more deeply rooted in and motivated by algorithmic information theory can potentially provide alternative estimations of algorithmic probability (Delahaye and Zenil, 2012), and thus K, of strings of any length, especially short ones (c.f. next section), which has spurred a renewed interest in exact and objective numerical approximations of behavioral sequences. One feature that has been the basis of a criticism of applications of K is that K assigns the greatest complexity to random sequences. The notion of “sophistication” is useful to broaden the analysis of behavioral sequences. It assesses the structure of the sequence and assigns low complexity to randomness, since the measure introduces computational time. One such measure derives from Charles Bennett’s seminal contribution, based on Kolmogorov complexity, and is referred to as Logical Depth. Here we also use a measure based upon or motivated by Logical Depth (Zenil et al., 2012c) to quantify the complexity of behavioral sequences because it can provide further insight into another important aspect of animal behavior beyond randomness, namely, the “computational effort” that an animal may invest in behaving in a particular way.
One long-standing and widely used method for assessing Kolmogorov–Chaitin complexity is lossless compression, epitomized by the Lempel–Ziv algorithm. This tool, together with classical Shannon Entropy (Wang et al., 2014), has been used recently in neuropsychology to investigate the complexity of electroencephalogram data (EEG) or Functional Magnetic Resonance Imaging (fMRI) data (Mullally and Maguire, 2014). The size of a compressed file indicates its algorithmic complexity, and the size is, in fact, an upper bound of the true algorithmic complexity. However, compression methods have a basic flaw: they can only recognize statistical regularities, and are therefore implementations of variations of entropic measures, only assessing the rate of entropic convergence based on repetitions of strings of fixed sliding-window size. If statistical lossless compression algorithms work for approximating Kolmogorov complexity, they do so because compression is a sufficient test for non-randomness. Yet, statistical lossless compression fails in the other direction, unable to tell whether something is the result of or is produced by an algorithmic process (such as the digits of the mathematical constant π). That is, they cannot detect structure outside of simple repetition.
Popular compression methods are also inappropriate for short strings (of, say, less than a few hundred symbols). For short strings, lossless compression algorithms often yield files that are longer than the strings themselves, providing very unstable results that are difficult, if not impossible, to interpret (see Table 1). In cognitive and behavioral science, however, researchers usually deal with short strings of a few tens of symbols, for which compression methods are useless. This is one of the reasons behavioral scientists have long relied on tailor-made measures of complexity instead, because the factors mentioned above limit the applicability of lossless compression techniques for approximating complexity in behavioral sequences.
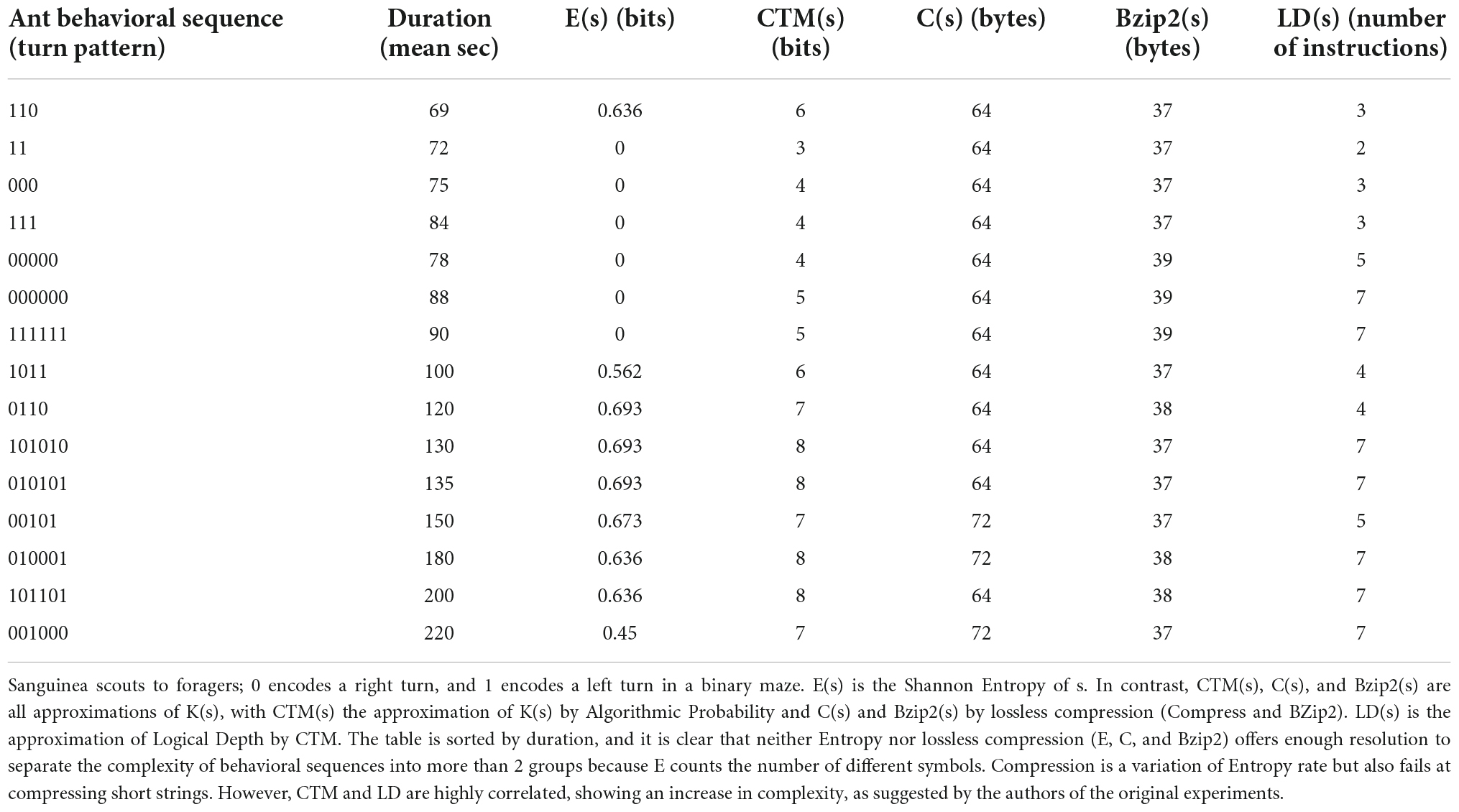
Table 1. Movement and duration [as reported by Reznikova and Ryabko (2012)] of information transmission from F.
The Coding theorem method (Delahaye and Zenil, 2012; Soler-Toscano et al., 2013) has been specifically designed to address this challenge. Thanks to this method, researchers have defined “Algorithmic Complexity for Short Strings” (ACSS). This is a concrete approximation of algorithmic complexity (Gauvrit et al., 2015), usable with very short strings. ACSS is available freely as an R-package (Gauvrit et al., 2015) and through an online complexity calculator1.
The idea at the root of ACSS is the use of algorithmic probability as a means to capture algorithmic complexity. The algorithmic probability of a string s is defined as the probability that a universal prefix-free reference Turing machine U will produce s and halt. Formally (Levin, 1974),
The algorithmic complexity of a string s is defined as the length of the shortest program p that, running on a reference universal prefix-free Turing machine U, will produce s and then halt. Formally (Kolmogorov, 1965; Chaitin, 1969),
K(s) and m(s) both depend on the choice of the Turing machine U. Thus, the expression “the algorithmic complexity of s” is, in itself, a shortcut. For long strings, this dependency is relatively small. Indeed, the invariance theorem states that for any two universal prefix-free Turing machines U and U’, there exists a constant c independent of s such that (Solomonoff, 1964; Kolmogorov, 1965; Chaitin, 1969).
The constant c can be arbitrarily large. If one would like to approximate the algorithmic complexity of short strings, the choice of U is thus relevant.
To partially overcome this inconvenience, we can take advantage of a formal link established between algorithmic probability and algorithmic complexity. The algorithmic coding theorem reads (Levin, 1974).
This theorem can be used to approximate a KU(s) through an estimation of mU(s), where KU and mU are approximations of K and m obtained by using a “reference” universal Turing machine U. Instead of choosing a particular “reference” universal Turing machine and feeding it with programs, Delahaye and Zenil (2007, 2012) used a huge sample of Turing machines running on blank tapes. By doing so, they built an experimental distribution approaching m(s) more smoothly, averaging over many Turing machines. ACSS(s) was then defined as –log2(m(s)) by the algorithmic Coding theorem (Eq. 4). ACSS(s) approximates an average KU(s). To validate the method, researchers have studied how ACSS varies under different conditions. It has been found that ACSS, as computed with different samples of small Turing machines, remains stable (Gauvrit et al., 2014). Also, several descriptions of Turing machines did not alter ACSS (Zenil et al., 2012a). For example, Zenil et al. (2012a) showed that ACSS remained relatively stable when using cellular automata instead of Turing machines. On a more practical level, ACSS is also validated by experimental results. For instance, as we will see in the following sections, ACSS is linked to human complexity perception. Moreover, the transition between using ACSS and lossless compression algorithms is smooth, with the two behaving similarly when the scope of string lengths overlap.
As noted in the Section “Introduction,” a measure of the “sophistication” of a sequence can be arrived at by combining the notions of algorithmic complexity and computational time. According to the concept of Logical Depth (Bennett, 1988), the complexity of a string is best defined by the time that an unfolding process takes to reproduce the string from its shortest description. The longer it takes, the more complex the string. Hence, complex objects can be seen as “containing internal evidence of a non-trivial causal history” (Bennett, 1988).
Unlike algorithmic complexity, which assigns a high complexity to random and highly organized objects, placing them at the same level, Bennett’s Logical Depth assigns a low complexity to both random and trivial objects. It is thus more in keeping with our intuitive sense of the complexity of physical objects, because trivial and random objects are intuitively easy to produce, lack a lengthy history, and unfold quickly. Bennett’s main motivation was to provide a reasonable means for measuring the physical complexity of real-world objects. Bennett provides a careful development (Bennett, 1988) of the notion of logical depth, taking into account the near-shortest programs, not merely the shortest one, to arrive at a robust measure. For finite strings, one of Bennett’s formal approaches to the logical depth of a string is defined as follows:
Let s be a string and d a significance parameter. A string’s depth at some significance d, is given by
where T(p) is the number of steps in the computation U(p) = s, and | p′| is the length of the shortest program for s, [thus | p′| is the Kolmogorov complexity K(s)]. In other words, LDd(s) is the least time T required to compute s from a d-incompressible program p on a Turing machine U, that is, a program that cannot be compressed by more than a fixed (small) number of bits d (Bennett, 1988). For algorithmic complexity, the choice of a universal Turing machine is bounded by an additive constant (as shown by the Invariance theorem described in the previous section). In contrast, Logical Depth is bounded by a multiplicative factor (Bennett, 1988). The simplicity of Bennett’s first definition of Logical Depth (Bennett, 1988), independent of size significance, makes it more suitable for applications (Delahaye and Zenil, 2012), serving as a practical approximation to this measure via the decompression times of compressed strings. To this end, it uses lossless compression algorithms, whose deviation from perfect compression is unknown (and cannot generally be known due to uncomputability results), to calculate size significance. This is because where LD is concerned, it is more relevant to consider the shortest time vis-à-vis a set of near-smallest programs rather than just a single, perhaps unrepresentative, time required by the shortest program alone. We will denote by LD(s) a measure approximating the Logical Depth of a string s, with no recourse to the significance parameter, and approximated by a powerful method, an alternative to lossless compression, explained in the next section.
We use the concept of algorithmic probability for the calculation of K (and LD) by application of the algorithmic Coding theorem. First, a sample of 2,836⋅109 random Turing machines are selected from a reduced enumeration of all 5-state 2-symbol Turing machines (Soler-Toscano et al., 2013), using the standard Turing machine formalism of the ‘Busy Beaver’ problem (Radó, 1962; Brady, 1983). The sample output returns the string produced by the halting machines, their runtimes, and the instructions used by each Turing machine. All the necessary information to estimate both the algorithmic probability measure and Logical Depth by finding the smallest machine (for this Turing machine formalism) producing s before halting is presented in Figure 1.
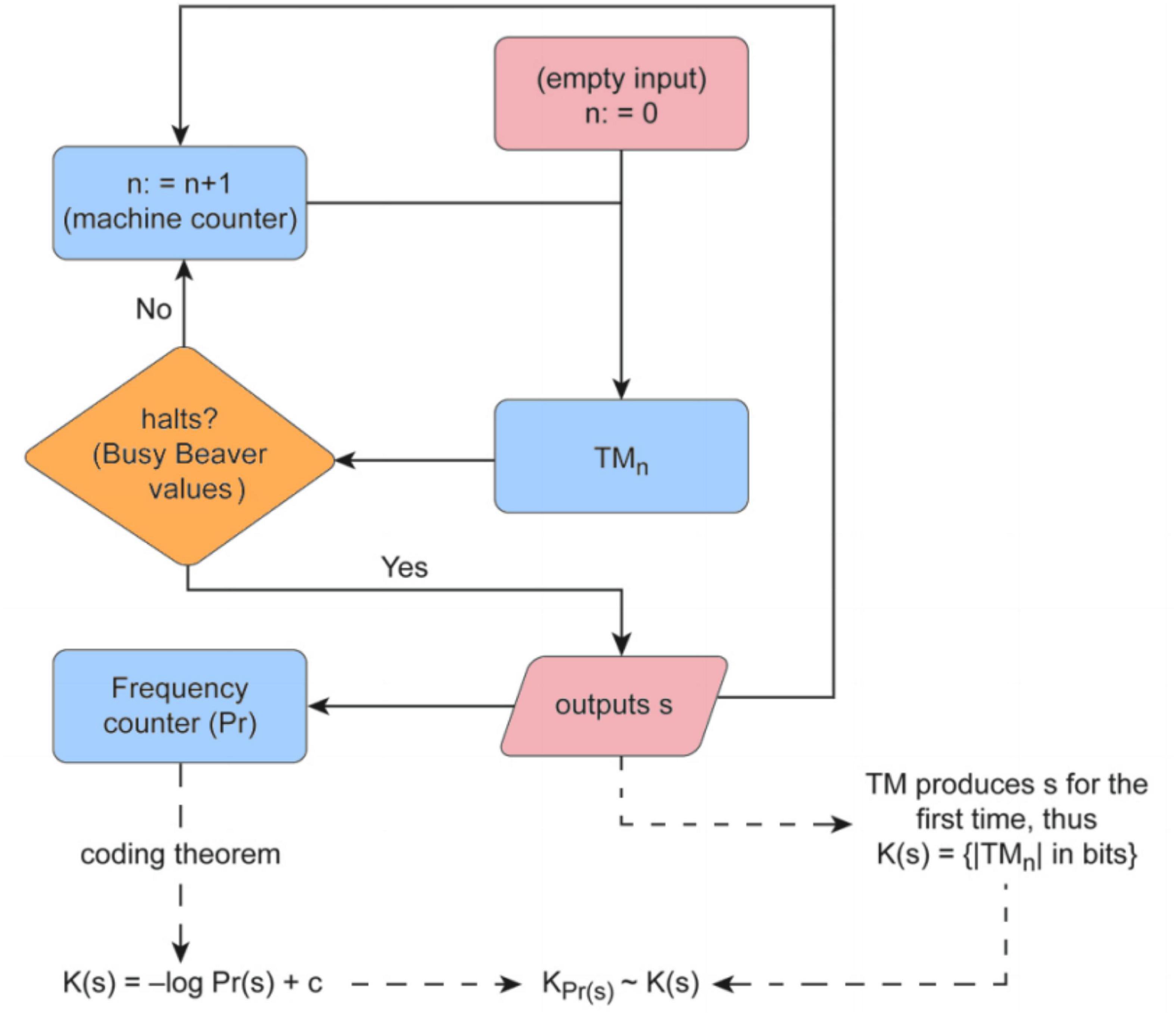
Figure 1. Flow chart of the Coding Theorem Method (CTM) and its implementation Algorithmic Complexity for Short Strings (ACSS), available as a package for the R programming language, shows how K and LD are approximated by way of an Algorithmic Probability-based measure upon application of the algorithmic Coding theorem. The method consists in running an enumeration of Turing machines from smaller to larger (by number of states) and determining whether the machine halts or not for a large set of small Turing machines for which either their halting time can be decided (with the so-called Busy Beaver functions) or an educated theoretical and numerical guess made. The algorithm counts the number of times a sequence is produced, which is a lower bound on its algorithmic probability, and then is transformed to an upper bound of the sequence’s Kolmogorov complexity using the so-called algorithmic Coding theorem (Bottom Left). The same algorithm also finds the shortest, fastest Turing machine that produces the same sequence, hence providing an estimation of its Logical Depth (Bottom Right). An online tool that provides estimations of CTM, and soon will include BDM too, can be found at http://www.complexity-calculator.com.
The Block Decomposition Method (Zenil et al., 2014) is used to estimate an algorithmic probability of longer sequences based on the concept of algorithmic probability, the calculation of which is computationally infeasible, given the number of Turing machines that it would be necessary to run in order to have a statistically significant frequency value, and ultimately impossible because of incomputability results. However, unlike traditional statistical lossless compression algorithms used to estimate K, the Block Decomposition Method (BDM) can deal with short sequences and has been successfully applied to human cognition before (Gauvrit et al., 2014b; Kempe et al., 2015b), as well as to algebraic and topological characterizations of graph theory and complex networks (Zenil et al., 2014), and offers an alternative to the use of statistical measures, including popular compression algorithms such as LZW that are mostly entropy estimators (Zenil, 2020).
The method consists in decomposing a long sequence into shorter, optionally overlapping sub-sequences, the Kolmogorov complexity of which can be estimated by running a large set of random computer programs in order to estimate their algorithmic probability. For example, the sequence “123123456” can yield, with a 6-symbol window with a 3-symbol overlap, the two subsequences “123123” and “123456,” i.e., what is known as k-mers, in this case 6-mers, all substrings of length 6. BDM then takes advantage of possible repetitions by applying the following formula:
where the sum ranges over the different subsequences p, np is the number of occurrences of each p, and K(p) is the complexity of p as approximated by CTM implemented in ACSS. As the formula shows, the Block decomposition method (BDM) takes into account both the local complexity of the subsequence and remote regularities by repetition of the same substring in the original sequence.
The BDM is a greedy divide-and-conquer algorithm that extends the power of the algorithmic Coding Theorem Method (see Figure 1), which is computationally intractable in a sound information-theoretical fashion, given classical information theory. We know we can encode the complexity of an object repeated n times with the complexity of the object and only log2(n) bits for the number of repetitions, thus helping to find tighter upper bounds to K. Unlike lossless compression algorithms used to approximate K, CTM, with BDM, constitutes a more deeply-rooted algorithmic approach to K, rather than merely statistical ones (such as LZW and cognates), which are more suitable for estimating Entropy rate than algorithmic (Kolmogorov) complexity. This is because, unlike statistical lossless compression (e.g., LZW), CTM can find the computer programs that produce certain non-statistical algorithmic patterns, such as subsequences of the decimal expansion of the mathematical constant π, that will merely look random to a popular statistical lossless compression algorithm.
To test the usefulness of algorithmic probability and logical depth for capturing intuitive notions of behavioral complexity, we applied these techniques to several experimental datasets for which complexity arguments are either lacking or have only been informally advanced. These datasets come from studies of the foraging behavior of Formica ants in binary mazes (e.g., Reznikova and Ryabko, 2012), and of the flight behavior of Drosophila flies in virtual arenas (e.g., Maye et al., 2007).
In a series of experiments surveyed in Reznikova and Ryabko (2012), red-blood ant scouts (Formica sanguinea) and red wood ants (Formica rufa) were placed in a binary maze with food (sugar syrup) at randomly selected endpoints. Scout ants were allowed to return through the maze once they had found the food to communicate instructions to a foraging team from the colony; scout ants were claimed to translate sensorimotor experiences into numerical or logical prescriptions transmitted to conspecifics in the form of sequences of branches (left or right) to follow to find the food successfully. 335 scout ants and their foraging teams took part in all the experiments with the binary tree mazes, and each scout took part in 10 or more trials. 338 trials were carried out using mazes with 2, 3, 4, 5, and 6 forks. The scout ants were observed to take progressively longer to communicate paths in deeper mazes (with more turns); that is, they transmitted more information. Informal results suggested that algorithmically simpler instructions of “right” and “left” movements toward the food patches were communicated faster and more effectively than more Kolmogorov complex (random-looking) behavioral sequences, thus suggesting that when strings are of the same length but transmitted at different rates, ants are capable of compressing the simpler sequences, unlike the more complex ones that are harder to compress or are uncompressible. This was not formalized, however. When conducting the ant experiment, the researchers also found that almost all naive foragers were able to find food on their own but that the time they spent was 10–15 times longer than the time spent by those ants that entered the maze after contact with a successful scout bearing information about the location of the food (Ryabko and Reznikova, 2009). Ryabko and Reznikova (2009), Reznikova and Ryabko, 2011, 2012, and other researchers Li and Vitányi (2008) were not able to numerically validate the relationship between complexity and communication times suggested by the results of the ant experiment. We applied our techniques for approximating algorithmic probability and logical depth (Delahaye and Zenil, 2012; Soler-Toscano et al., 2013; Zenil et al., 2020) to these extant data.
Experiments with Drosophila examined the behavior of tethered flies in a flight simulator consisting of a cylindrical arena homogeneously illuminated from behind (Maye et al., 2007). A fly’s tendency to perform left or right turns (yaw torque) was measured continuously and fed into a computer. The flies were divided into three groups: the ‘openloop’ group flew in a completely featureless white panorama (i.e., without feedback from the uniform environment–open loop). In addition to the open-loop group, data from two control groups were analyzed. These groups flew in an arena with either a single stripe (‘onestripe’ group) or in a uniformly dashed arena (‘uniform’ group). The ‘onestripe’ group’s environment contained a single black stripe as a visual landmark (pattern) that allowed for straight flight in closed-loop control since the fly could translate its visual input into a yaw torque to control the angular position of the stripe. The ‘uniform’ group flew in a uniformly textured environment otherwise free of singularities. This environment was closed-loop in the same sense as that provided for the ‘onestripe’ group, since the fly could use its yaw torque to control the angular position of the uniform textured environment. Maye et al. (2007) concluded that in the featureless environment, fly behavior was non-random, with the distribution of yaw directions produced by flies in the ‘open-loop’ group significantly deviating from the null Poisson distribution.
A virtual competitive setting was designed as described in Tervo et al. (2014). Here, the algorithm played the role of a virtual competitor (that can also be seen as a predator) against a rat. The algorithm was programmed to predict which hole the rat would choose against three increasingly complex predictive competitors. The rat had to choose a hole that it thought would not be chosen by the competitor in order to be rewarded. The task is therefore a prediction task, where the more successful the rat is at predicting the competitor’s behavior, the better it can avoid it and be rewarded. The first competitor consisted of an algorithm based on a binomial test able to react to significant bias. For example, if a rat had a clear preference for choosing either the left or right hole, Competitor 1 would correspondingly predict the hole with statistical bias. Competitor 2 reacted to any bias based on a binomial test. Competitor 3, however, displayed a diverse range of features and therefore constituted a greater challenge to the rat, because rats were rewarded with food if their competitors did not predict their hole choice. Each “environment” consisted of a long sequential list of trials for every competitor against 12 fresh individuals (rats). Competitors 1 and 2 used conditional prevalence of the left and right choices, given a particular history pattern of up to three prior steps, to inform their prediction. The optimal deterministic strategy consisted thus in keeping track of every pattern up to that length and ensuring that the conditional prevalence of going left or right was 0.5 (Tervo et al., 2014). The authors quantified how different the observed behavior was from this optimal strategy by calculating the Kullback–Leibler divergence from the optimal – a variation of Shannon Entropy – of the observed distribution of conditional prevalences, given all small sequences of lengths n = 1, 2, and 3. Their results, backed by clinical results tracking the engagement of the anterior cingulate cortex, an area of the brain related to decision-making, showed that when rats are faced with competitors that they cannot outsmart, they switch from strategic counter prediction behavior to a stochastic mode.
Competitor 1 only looked for biases toward Left or Right. For example, if the rat had chosen the Left hole with probability 0.6, then Competitor 1 would have predicted that the rat would choose Left, which would have resulted in no reward for the rat. The rat would then switch to more complicated strategies, maximizing Left and Right probability near 0.5 but following a deterministic bias in favor of itself. Thus, these animals were eventually able to model aspects of the underlying prediction algorithm and used that knowledge to anticipate the opponent’s predictions. Virtual Competitor 1 did not display the brain’s full capacity for generating behavioral variability, as it represented no challenge to the animals. Competitor 2 used the same prediction algorithm as Competitor 1, except that it removed the requirement that the bias in favor of one side or the other reach a predetermined threshold before competitive pressure was applied [see details in Tervo et al. (2014)] and was therefore slightly more challenging for the rats. Competitor 3, however, used a more sophisticated machine-learning strategy that learned to generate a strong prediction based on a set of weak trends in the data [details are given in Friedman et al. (2000)]. The rationale of the original experiment was that a stronger competitor would detect some of the patterns that a weaker competitor missed, leading to a correct prediction of the choices made by the animal – and thus to withholding of the reward. So, Competitor 2 looked for biases on moves up to three times back, which maked it more complicated. Competitor 3 used a much more sophisticated learning algorithm. As can be seen from the plots, the complexity of the reward (prediction) is almost equal and, in some cases, greater than the complexity of the animal choices, unlike the cases involving Competitors 1 and 2, where the reward is not only greater but diverges asymptotically from the rat’s complexity, indicating that the rat found an optimal behavioral strategy tending toward infinite reward vis-à-vis these competitors’ learning strategies. The rat seemed to have a short learning period which it spent matching the complexity of the competitor’s behavior before finding out that the competitor was highly predictable. This behavior allowed the rat to reduce its complexity and receive increasing rewards for lower behavioral complexity by fooling the competitor, e.g., with simple repetitions of LRR or RLL where the competitor expected L and R, respectively, as the last choice after LR and RL.
Here, we compare different ways of estimating LD and K by running a large set of enumerated standard Turing machines of increasing size (Zenil et al., 2020). We computed the correlation between approximations to K and LD utilizing lossless compression and CTM for all 212 bit strings up to length 12. To quantify the analysis, we use a non-linear least-squares regression model. We used the computed data and curve fitting of Compression and CTM estimations of K against CTM estimations of LD. Here we find the best fit using a quadratic function 14.76 + 0.0077x − 6.4⋅10–7x2. We find that CTM displays lower LD values for low and high K values. This demonstrates that only CTM conforms to the theoretical expectation where both Kolmogorov simple and Kolmogorov random strings are assigned lower Logical Depth. In contrast, lossless compression, instantiated using both Compress and BZip2 algorithms, displayed a trivial correlation with LD. This demonstrates that approximating K by traditional lossless compression algorithms, such as LZW and cognates, does not conform to the theoretical expectation of low LD for the lowest and highest K values. Moreover, nor can they be usefully applied to short behavioral sequences (Delahaye and Zenil, 2012; Soler-Toscano et al., 2014), such as the ones from a well-known behavioral experiment with ants (Table 1) and in more recent studies of the behavior of fruit flies and rats. This is because random sequences, like trivial ones, do not result from a sophisticated computation of their shortest descriptions. Indeed, if a sequence is random, its shortest description is of about the same length as the sequence itself, and therefore the decompression instructions are very short or non-existent. And if a sequence is trivially compressible, then the instructions for decompressing it may also be expected to be very simple. Right between these extremes, we find high sophistication or logical depth.
Here we demonstrate, in three different case-studies, that applying the algorithmic Coding theorem and numerical estimations based upon or motivated by Algorithmic Probability and Logical Depth, provides objective quantification of animal behavioral sequences (Zenil et al., 2020).
Interestingly, the order in which Reznikova and Ryabko (2012) informally sorted ants’ behavioral sequences, it turns out, corresponds to an order of increasing Kolmogorov complexity, as approximated by our methods motivated by and based upon algorithmic probability (Zenil et al., 2020). Table 1 shows the main results, comparing sequence complexity and scout-forager communication times.
The (Pearson) correlations found among the values reported in Table 1 and plotted in Figure 2 are as shown in Table 2.
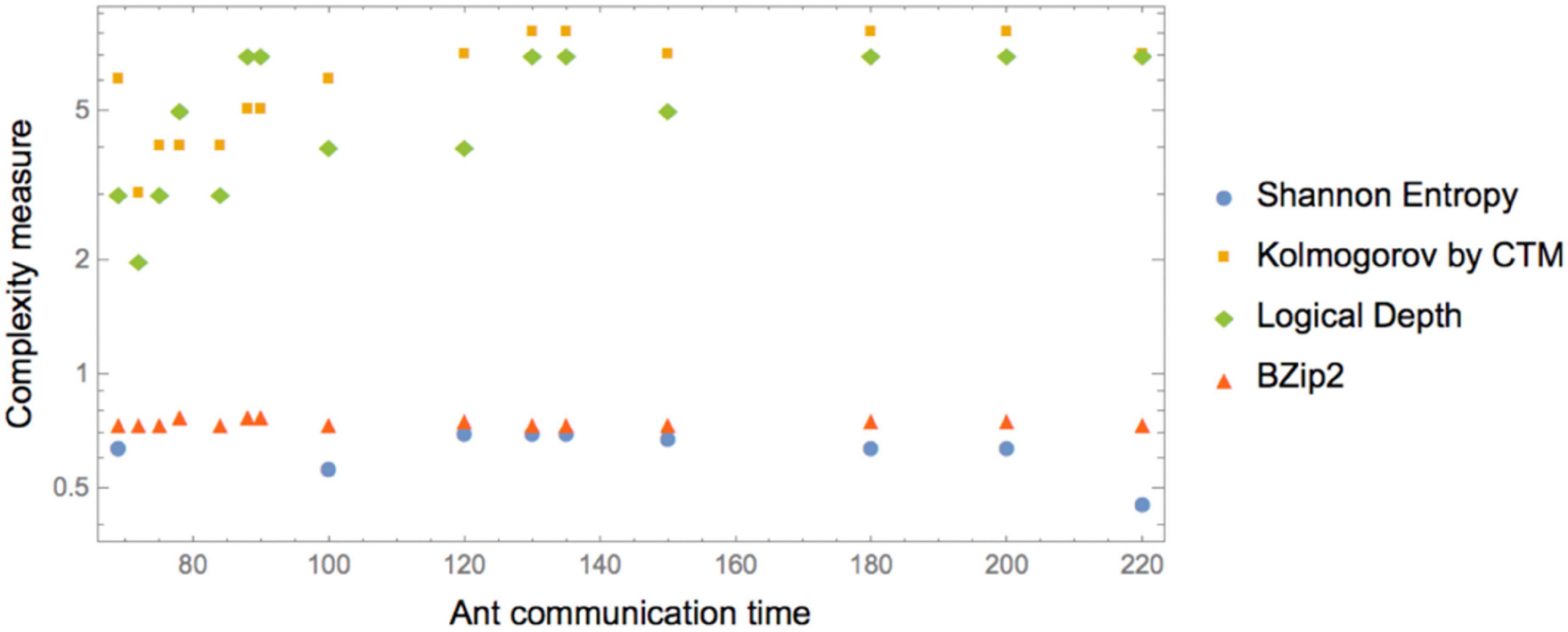
Figure 2. Log correlation between normalized (by a common constant) complexity measures and ant communication time. Kolmogorov complexity (employing an Algorithmic Probability based CTM measure) and Logical Depth (also measured by BDM) display the greatest correlation, with longer times for more complex K and LD. Shannon Entropy and lossless compression display no sensitivity to differences in the sequence. Compress behaves like Entropy.
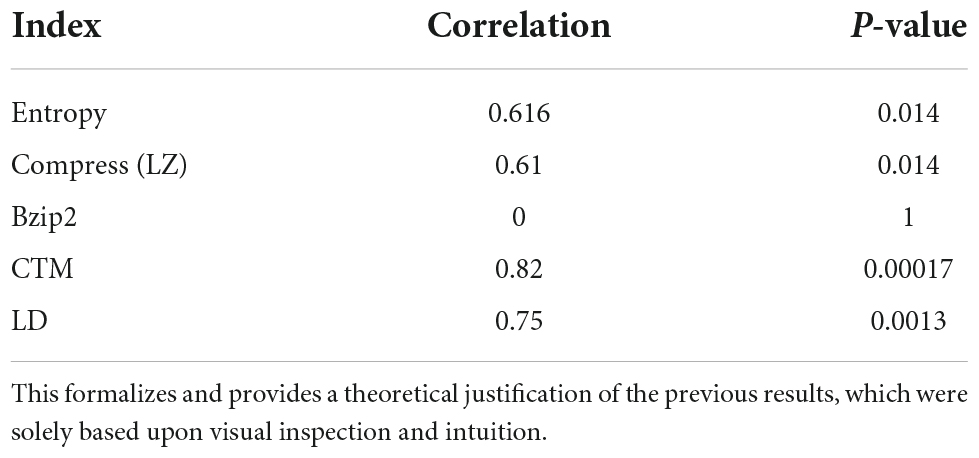
Table 2. CTM and Logical Depth found the best correlation—with high significance—between duration and Kolmogorov complexity (Figure 2).
More precisely, ant communication is correlated to the complexity of the instructions, i.e., instructions that take less time to communicate have low Kolmogorov complexity, while less efficiently communicated instructions have higher K and higher LD.
In the Drosophila experiments (Maye et al., 2007), yaw torque binary (right or left directions) behavioral sequences for tethered flies in a virtual reality flight arena were recorded in three environments for up to 30 min (see section “Materials and methods”).
As shown in Figure 3, the series of fruit fly torque spikes for the three groups of fruit flies had different Kolmogorov complexities, with the open-loop group being the furthest removed from algorithmic randomness and high in logical depth, suggesting an algorithmic source. This strengthens the authors’ (Maye et al., 2007) conclusion that the open-loop group had the largest distance to randomness. It suggests that fly brains are more than just input/output systems and that the uniform group came closest to a characteristic Levy flight. This observation amounts to a falsification of the alternative hypothesis that flies behave randomly in the absence of stimuli, as their neurons would only fire erratically, displaying no pattern. Here, however, the results suggest that in the absence of stimuli, the flies are even more challenged to find different flight strategies, perhaps seeking stimuli that would provide feedback on their whereabouts. Moreover, as shown in Figure 3, by measuring the subtle differences in complexity along the various sequences, the variance provides another dimension for analysis – of how different flies reacted to the same environment. As shown by Zenil et al. (2012b), if the environment is predictable, the cost of information processing is low. Still, this result also suggests that if the environment is not predictable, the cost of information processing quantified by logical depth is low if the stochastic behavior strategy is adopted, providing an evolutionary advantage (Zenil et al., 2012b). This strengthens their conclusion that environmental complexity drives the organism’s biological and cognitive complexity.
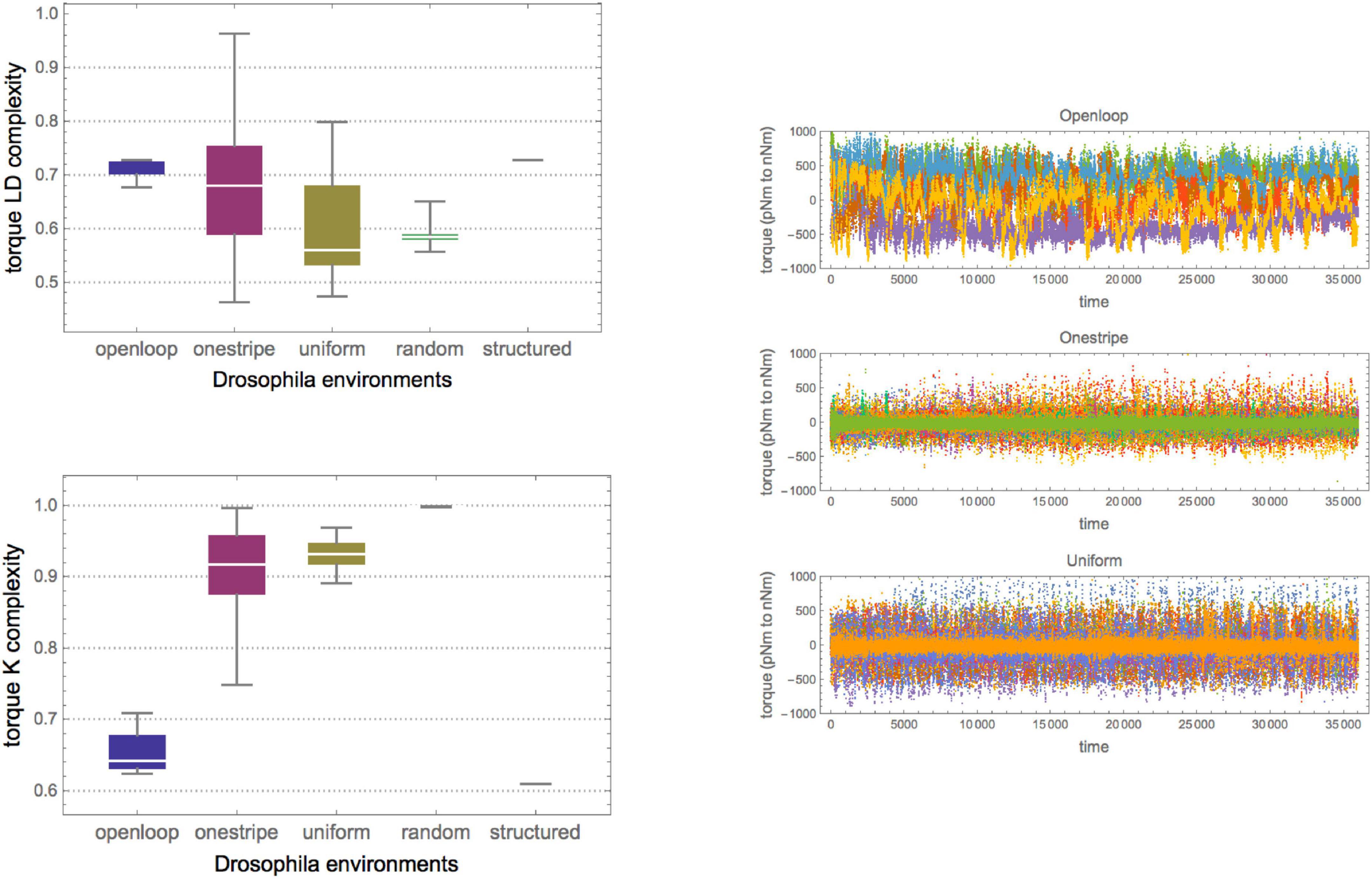
Figure 3. (Top Left) Raw yaw torque series of the three fruit fly groups (about 38,000 data points from a 30-min recorded flying period). (Right Top) Box plot of the series Kolmogorov complexity as measured by CTM over all flies in the three groups (6, 18, and 13). Each replicate was given a different color. (Right) In agreement with the results of Maye et al. (2007) the median complexity of the open-loop group is the most removed from (algorithmic) randomness. The values were normalized by maximum K complexity according to CTM (as compared to the substrings of greatest complexity as calculated from CTM). (Bottom Left) Box plot of the series’ Logical Depth complexity as measured by CTM over all flies in the three groups. The results suggest that the open-loop group has the highest significant median structural complexity (Logical Depth), hence suggesting greater causal history or calculation and a greater remove from randomness. In contrast, the other two groups are closer to pseudo-randomly generated sequences using a log uniform PNRG. This supports the original authors’ findings but adds that uniform stimuli seem to have a lower effect than no stimulus, and that the absence of stimuli also leads to different behavior, perhaps as a strategy to elicit environmental feedback. In both plots, all values were normalized by maximum LD complexity to have them between 0 and 1. In both box plots, the trivial sequences consist of 1 s, and therefore are maximally removed from randomness for Kolmogorov complexity (but are closer to randomness in the LD plot).
To the experimental data of Tervo et al. (2014) (binary behavioral sequences representing L for Left and R for right depending on the choice of the animal and the prediction of a virtual competitor), we applied lossless compression, BDM and BDM LD. BDM and compression showed the expected complexity for each set environment (see Figures 4, 5). The first one (Competitor 1) displays the lowest randomness for both the animal and the competitor/reward sequences [the competitor’s behavior is a Boolean function of the reward sequence given by (choice and reward) or (∼choice and ∼reward)]. The reward sequence encodes whether or not the competitor predicted the animal’s choice and whether it was given a droplet – when avoiding the competitor’s choice – or not. The goal of the rats is to outsmart the competitor’s behavior. Yet, that does not necessarily mean an increase in a rat’s behavioral Kolmogorov complexity (randomness), because it can fool the competitor with a simple strategy, as is the case for Competitors 1 and 2, and by switching to random-looking behavior in the case of Competitor 3. This variation of animal complexity over time, going from high to lower complexity, can be observed in Figure 4 and in Table 3, where a ranking of learning capabilities per rat for every environment is reported. In the environment with Competitor 1, a simple 3-tuple behavioral strategy outsmarts the competitor’s behavior with a strategy of low complexity by keeping the frequency of R and L choices at about 0.5 but following elementary patterns that the competitor does not follow (the alternation of LLR and RRL or RLL and LRR). On the other hand, logical depth shows that the structural complexity of the animal always ends up matching the structural complexity of the competitor and is never more or less than is required to outsmart it. From BDM and compression, it is also clear that the 3rd environment is of lower structural complexity. It’s consistent with the conclusion of the clinical experiment that rats switched to stochastic behavior when they could not outsmart the competitor, even though the mean is very similar when BDM and Compress are of lower complexity. This is not a surprise because the behavior of the competitor is not algorithmically random; it only appears random to the rat, which in turn tries to behave randomly. But it does so not with greater complexity than the competitor but only by matching the complexity of the competitor. After all, it is unlikely that the rat is behaving in an algorithmically random fashion, but rather simulating random behavior. Importantly, the difference is that it is performing some computation tracking its immediate history so as not to repeat movements, given that probabilistically, statistical randomness would allow a long list of L or R, which is not optimal. Hence it has to go beyond probabilities and truly try to simulate algorithmic randomness, thus increasing the required computation to reproduce the desired random-looking behavior and, therefore, its logical depth.
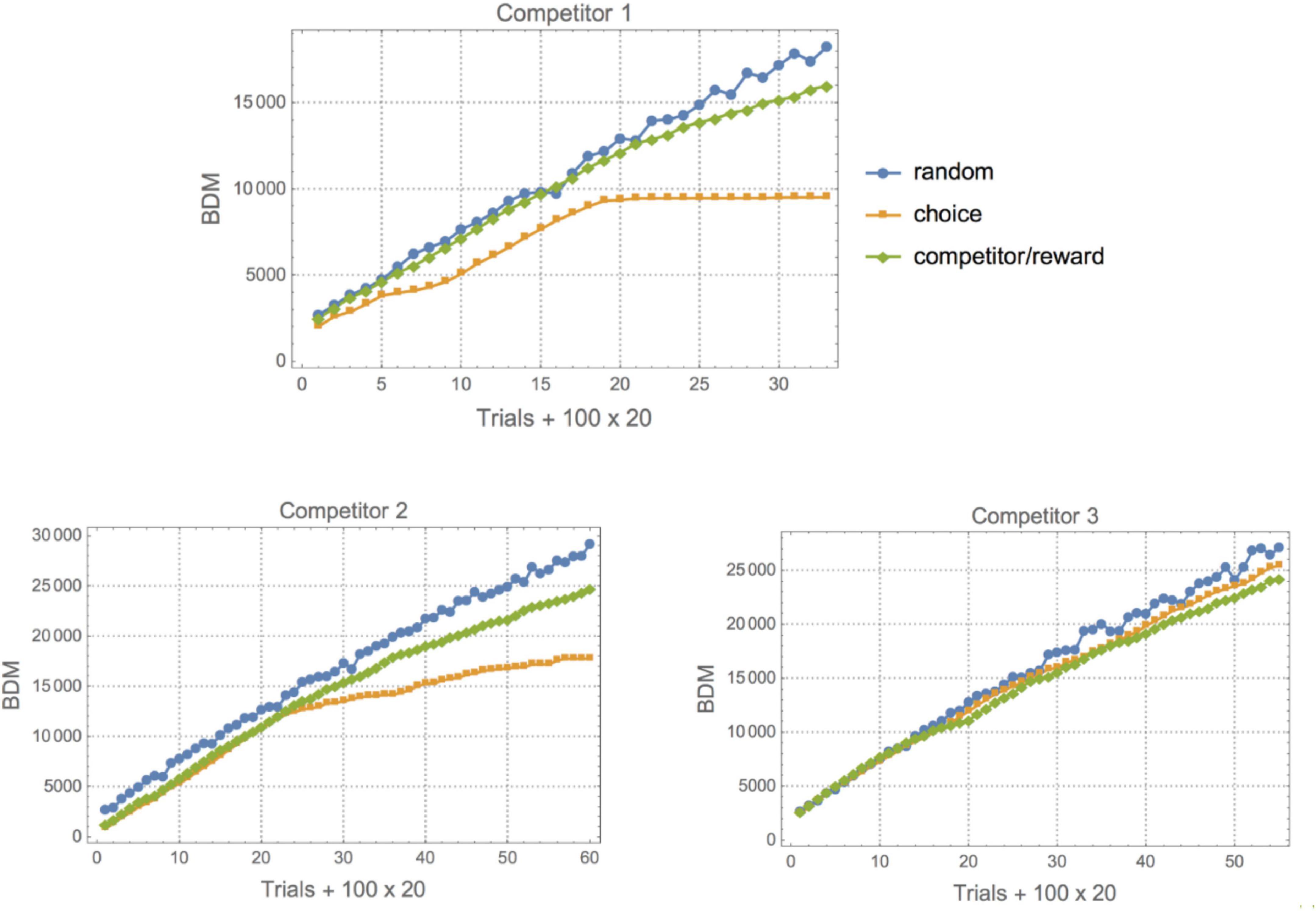
Figure 4. (Top) The same rat number 6 in the three different environments with different virtual competitors. With Competitor 1 this particular rat shows two kinds of “phase transitions”, leading to a decrease in its behavioral complexity. The standard strategy appears to be to start off by displaying random behavior to test the competitor’s prediction capabilities, switching between different patterns up to a point where the rat settles on a successful strategy that allows it to simply repeat the same behavior and yet receive the maximum reward after fooling the competitor. This phase comes later for Competitor 2 (Bottom Left), given that this new virtual competitor is slightly more sophisticated. For Competitor 3 (Bottom Right), the rat is unable to outsmart it because it implements a more sophisticated predictive algorithm. The rat either cannot settle on a single strategy and keeps performing a random search or decides to switch to or remain in a particular mode after finding itself outsmarted by the virtual competitor.
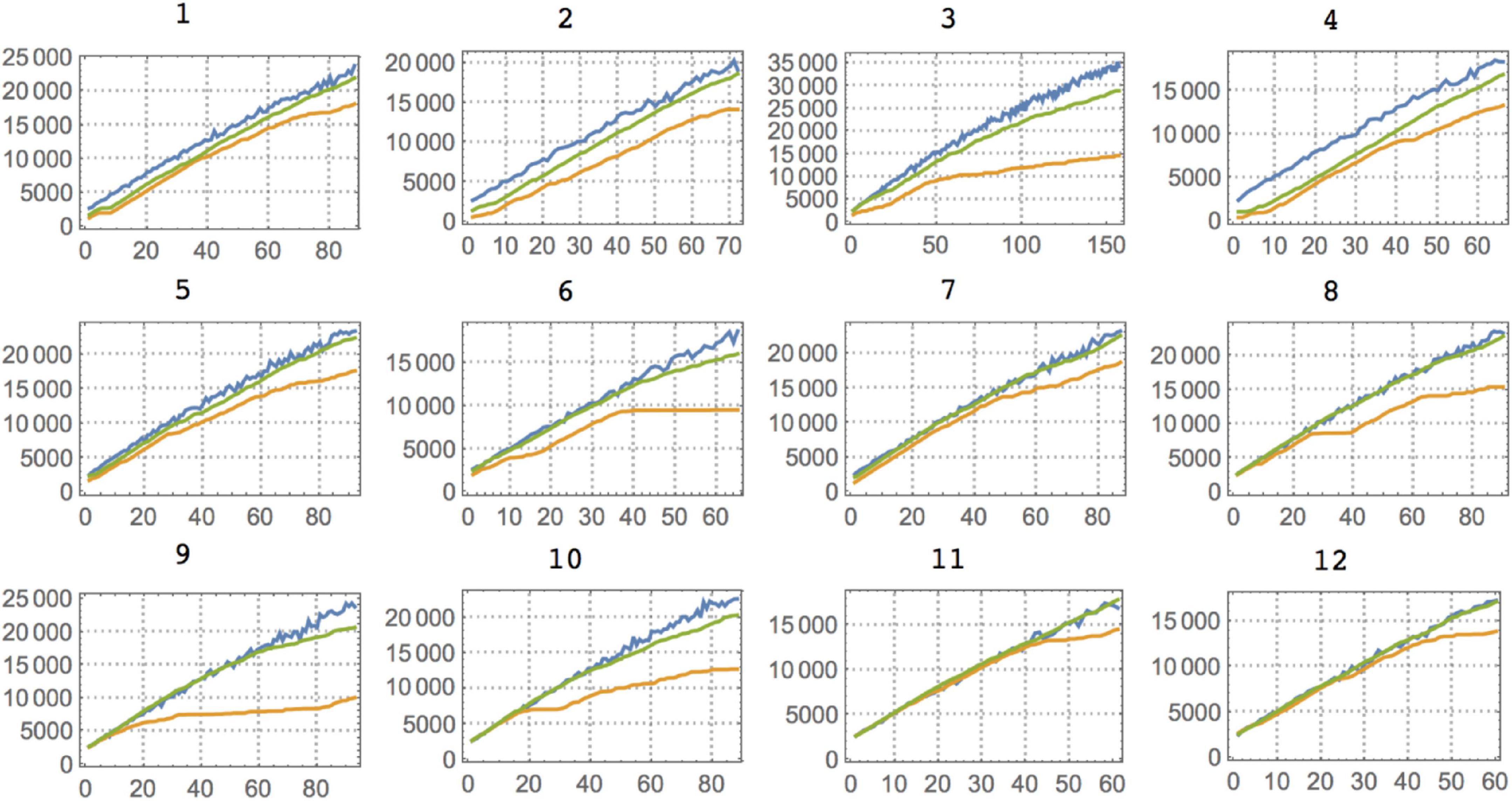
Figure 5. Complexity (BDM) plots for all 12 individuals (rats) against Competitor 1. For Competitors 2 and 3, the most salient feature is that against Competitor 1 the rats show a quick decrease in complexity that allows them to keep the maximal reward (in all three cases. The rats were close to the maximal possible reward except for Competitor 3, where they continued to act randomly, either as a strategy or because they remained in the exploratory transition that is displayed at the beginning of every experiment). Color legends and axis labels are the same as in Figure 4.
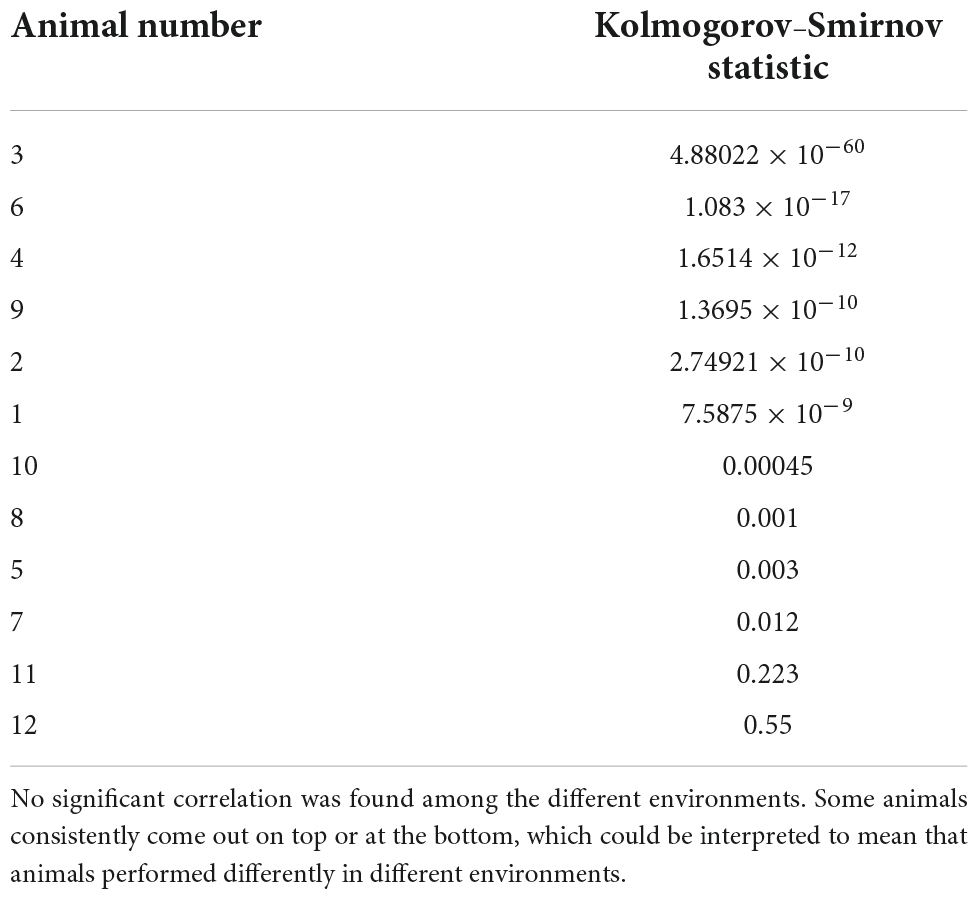
Table 3. A Kolmogorov–Smirnov comparison of the animal’s choice and the competitor’s complexity curves may provide a ranking of intelligence in a given environment, with the smallest values where the curves are at the greatest remove from each other and therefore signifying the fastest the animal has potentially settled on a successful strategy.
Figures 4, 5 show that these results suggest that the rats either switch to random behavior on purpose or continue in the random mode they started as a testing strategy to gauge the competitor’s capabilities. However, as shown by the clinical experiments, the rats seem to eventually suspend brain activity, seemingly after finding that they cannot devise an effective strategy (Tervo et al., 2014). But the results here build upon the previously reported conclusions that the rats seem to start with a high (random) complexity strategy in the first trials before settling on a single specific strategy if any. As shown in Figures 4, 5, against Competitor 1, rats quickly decide on an optimal strategy of low complexity that keeps rewarding them, thanks to the poor predictive capabilities of the virtual competitor. But as Figure 4 shows a representative case (and not a special one for Competitors 2 and 3), we see that animals make the transition later (Competitor 2) or never make it (Competitor 3).
The Spearman ranking tests among BDM and BDM LD in the three environments suggest, however, that intelligence can only be defined by task or environment in this experiment and for this set of animals. This is because no significant correlation was found in the ranking for different competitor experiments after a Kolmogorov–Smirnov test to determine the separation between animal and competitor behavioral complexity. There are two ways of outsmarting the virtual competitors that are confounded in the complexity curve. Either the animal learns fast and maximizes gain (keeps the competitor’s behavior complex), or minimizes effort (reflected in the decrease in its complexity). Hence the curves diverge.
Figure 6 shows how the structural complexity of the animal’s behavior matches that of the competitor, as suggested in Zenil et al. (2012b) (this seems to indicate, however, that the match is with Logical Depth complexity and not Kolmogorov complexity). That estimation based upon or motivated by Logical Depth, a measure of sophistication, is greater in the second experiment means that indeed both the algorithm and the animal behavior require more computational resources than in the 1st and 3rd experiments, where there is less consideration given to behavioral history, as the original paper reporting the clinical experiment claims. This also agrees with what we found by applying both lossless and BDM compression (Figure 4).
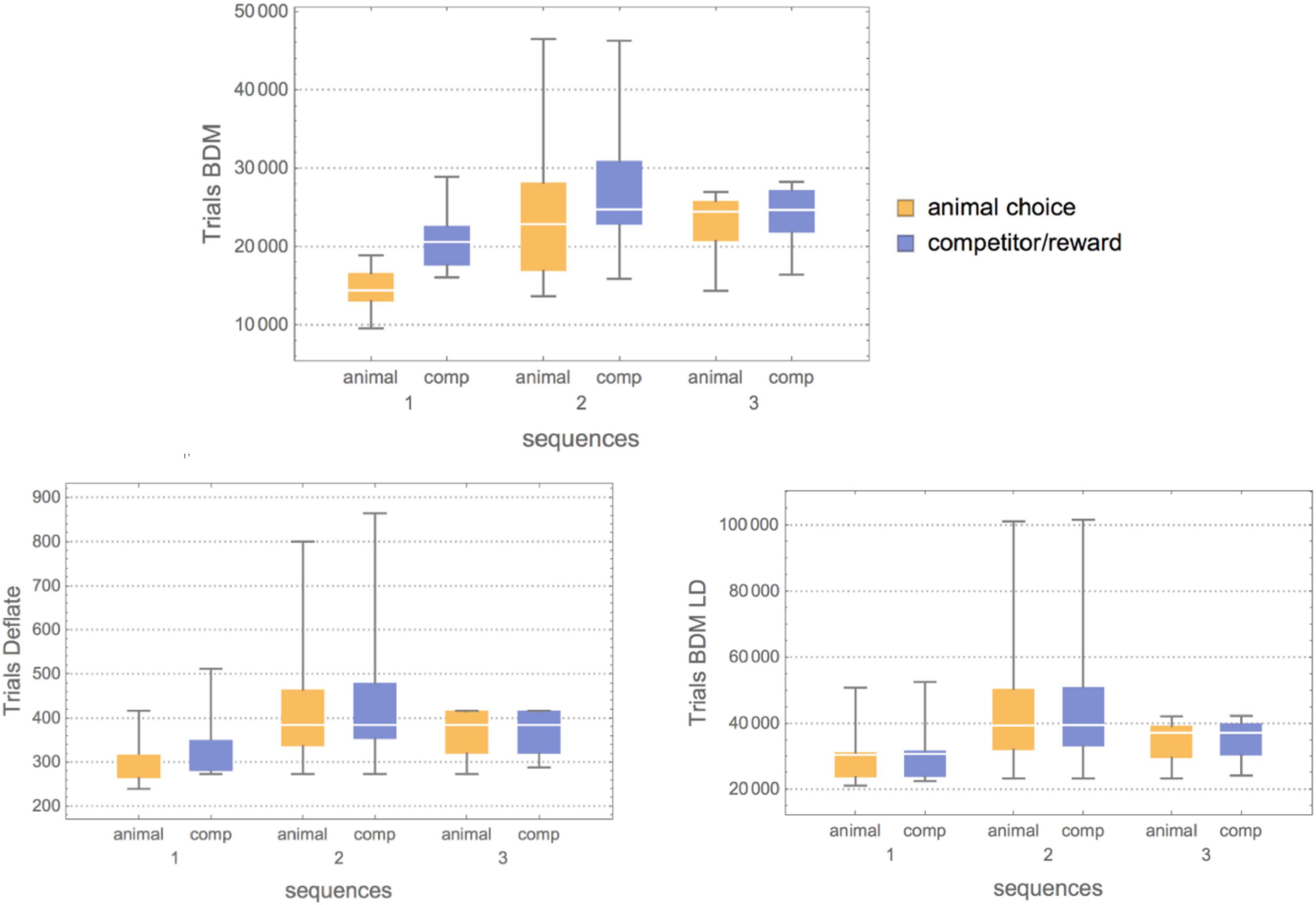
Figure 6. (Top) Box plots showing the results of three algorithmic information-theoretic complexity measures applied to the behavioral sequences for both animals and competitors (comp) in all three environments of increasing complexity (more powerful virtual competitor predictive capabilities). For BDM (Top), for Competitor 1, the complexity of both the animal and the competitor is low. Still, the gap between medians is extensive, meaning that the animal quickly outsmarted the competitor. For Competitor 2, however, not only is an increase in Kolmogorov complexity shown, but the median gap between the animal’s behavioral complexity and the competitor’s is smaller. Furthermore, the variance is greater, meaning that the animal explored more strategies of different complexity, and finally for Competitor 3 the medians match at higher Kolmogorov complexity (random-looking behavior). (Bottom) Compress (implementing the Deflate lossless compression algorithm) confirmed the BDM results but showed less fine granularity than BDM allowed, likely due to the fact that lossless compression finds it difficult to detect small patterns that both the animals and these simple competitors rely so much upon. BDM LD confirmed the nature of the strategy against Competitor 3, where there is a decrease in structural complexity as compared to the interaction with Competitor 2, hence suggesting that the animal remained in a stochastic mode of low Logical Depth but high Kolmogorov complexity.
It is also interesting to look at the asymptotic behavior of both the animal and the competitor (see Figure 5), as it indicates a period of training before the rats start overtaking the competitor with an optimally rewarding strategy. Indeed, for the experiment with Competitor 1, the training period is very short; on average between 100 and 300 trials are needed before the curves start to diverge, indicating that the animal has outsmarted the competitor. This can be advanced as a potential objective measure for animal intelligence, and one can see that subjects 3 and 6, for example, are among the fastest learners, the quickest at finding a good strategy, while subjects 11 and 12 are slow, a ranking based on a Kolmogorov–Smirnov test provided in Table 3. Against Competitor 2 (see Figure 4), the rat has a training period where it matches the virtual competitor’s behavior before outsmarting it. The gap indicates that there is a reward even in the face of lower animal complexity, which means it has cracked the competitor’s behavioral code. Against Competitor 3 (see Figure 4), however, the animal is truly challenged and chooses to behave randomly, to which the learning algorithm reacts accordingly. Thus, the two match in manifesting high Kolmogorov complexity as compared to the previous cases.
For Competitor 2, the estimation motivated by Logical Depth increases because both the animal and the virtual competitor are engaged in a computation that requires slightly more computing power and time than when the animal is pitted against Competitor 1. However, for Competitor 3, the Logical Depth decreases, again as an indication of either greater simplicity or randomness, which in this case, agrees with the experiment. And taking into consideration the result with BDM, it is randomness that is introduced in the animal’s choice of behavior against Competitor 3, which is in full agreement with the results reported in the independent study (Tervo et al., 2014) and in accordance with the clinical experiments measuring cortical feedback to quantify brain activity during the performance of the tasks.
To recap, we first demonstrated the validity of our numerical approximation of algorithmic and structural complexity. These techniques are broadly useful as they provide the community with an objective tool to characterize “complexity” in behavioral experiments. Furthermore, the notion of structural complexity lets us glimpse the amount of computation that, generically, a system requires to perform a particular decision leading to a behavioral sequence.
Next, we assessed the applicability and the insights the notions of algorithmic and structural complexity could bring to well-known studies of animal behavior involving ants, fruit flies, and rats. Importantly, these studies tax the animal to different degrees when it comes to environmental influence. One shared insight suggested by these studies, in light of our analysis, is that animals have some as yet unknown, mechanism(s) with which to perceive and cope appropriately with different degrees of complexity in their environment. In addition, beyond coping, it appears they can harness and utilize the environment in their internal decision process and in how they generate sequences of behavior. For example, the less efficiently communicated instructions to ants have higher complexity, yielding longer communication time, resulting in more complex behavioral sequences. Here the K and LD metric provides a formal justification of the heuristic analysis performed by Reznikova and Ryabko (2012) in the original study. Hence, behavioral complexity matches environmental complexity. Furthermore, one common idea in the literature (e.g., Auger-Méthé et al., 2016) has been that animals navigating in an environment devoid of structural stimuli will adopt a random strategy. Our re-analysis, with formal complexity measures, of the fruit fly study suggests that flies are even more challenged to find different navigation strategies. The uniform group, having a uniform striped environment, was closed to an isotropic navigation strategy, closest to randomness or what is commonly referred to as Levy flight. In contrast, the group with a featureless environment was the most non-random group, high in logical depth, suggesting an algorithmic source for their decision process. Notably, this derived result aligns with the authors’ (Maye et al., 2007) suggestion that the open-loop group appeared to be at the greatest remove from e randomness. Thus, in this case, a “simple” environment drives the animal toward an algorithmic bias in their attempt to devise a useful (navigation) strategy. Lastly, our analysis of the rats suggested a behavioral switch toward randomness in the face of environments with increasing complexity. Here, several interesting competitive situations were investigated. For example, our logical depth analysis revealed that the structural complexity of the rat always ends up matching the structural complexity of the competitor. In contrast, if the rat could not outsmart the competitor, it switched to random behavior. Here the rat has to try to simulate algorithmic randomness to reproduce a random-looking behavior. In the context of learning, deciding, and predicting, complexity measures captured subtle differences hinting at the mapping between an animal’s environment, its sensory inputs, and its reactions. In all cases, we have seen animals react or adjust to the different scenarios, from communicating faster instructions to locate food to implementing deterministic and stochastic strategies against unknown environments and competitors. We have seen that animals can switch between a wide range of complex strategies, from behaving randomly against a competitor they cannot outsmart to behaving in a very structured fashion even in the absence of external stimuli, validating the results of Tervo et al. (2014).
In summary, we have shown that animal behavioral experiments can be analyzed with novel and powerful tools drawn, based upon, or motivated by (algorithmic) information theory. Correlations in complexity can be established that are in agreement with and that elaborate on the conclusions of behavioral science researchers. We also report that a stronger correlation was consistently found between the behavioral sequences considered and their Kolmogorov complexity and Logical Depth than between these sequences and their Shannon Entropy. To the authors’ knowledge, this is the first application of these tools to the field of animal behavior and behavioral sequences.
Finally, we now turn to how these new results may translate to the understanding and analysis of human decision systems. Here we narrow the discussion on how to reinterpret experiments of how humans perceive randomness. Earlier pioneering studies by Kahneman et al. (1982) investigated how people reason and make decisions when confronted with uncertain and noisy information sources. Humans tend to report that a sequence of heads or tails, “HTTHTHHHTT,” is more likely to appear than the series “HHHHHTTTTT” when a coin is tossed. However, the probability of each string is 1/210, exactly the same, as indeed it is for all strings of the same length. In the “heuristics and bias” approach advocated and pioneered by Kahneman et al. (1982), these systematic errors were interpreted as biases inherent to human psychology or as the result of faulty heuristics. For instance, it was conjectured that people tended to say that “HHHHHTTTTT” was less random than “HTTHTHHHTT” because a so-called representativeness heuristic influenced them, according to which a string is more random the better it conforms to prototypical examples of random strings.
Given these purportedly faulty heuristics, human reasoning was interpreted as suggesting that humans had minds similar to a faulty computer. Considering recent work (Tervo et al., 2014), these behavioral biases can be accounted for by powerful complexity measures that point toward an algorithmic basis for behavior. This suggestion accords with the results reported from animal studies (Maye et al., 2007; Ryabko and Reznikova, 2009). In Zenil et al. (2012b) it was shown – albeit in an oversimplified setting – how animals would need to cope with environments of different complexity in order to survive and how this would require – and possibly explain – the evolution of information storage and the process of learning. In many ways, animal behavior (notably, human behavior) suggests that the brain often acts as a compression device. For instance, despite our very limited memory, we can retain long strings if they have low algorithmic complexity (Gauvrit et al., 2014). For the most part, cognitive and behavioral science deals with small sequences, often barely exceeding a few tens of values. For such short sequences, estimating the algorithmic complexity is a challenge. Indeed, prior to recent developments, the behavioral sciences relied largely on a subjective and intuitive account of complexity. While irreducibility is a pervasive challenge for the application of computation in data analysis (Zenil et al., 2012c), the Coding Theorem method allows some experimental explorations based upon algorithmic complexity even on very short strings (Soler-Toscano et al., 2014) and objects in the context of an evolutionary process using the same tools (Hernández-Orozco et al., 2018). We suggest that these results align with our analysis of the animal experiments, that experiments on how humans perceive randomness suggests the existence of an algorithmic bias in our reasoning and decision processes. This contrasts with the view of the mind as performing faulty computations or random Levy flight computations when presented with items with some degree of randomness. It suggests that the brain has an algorithmic component. The “new paradigm” in cognitive science suggests that the human (and animal) mind is not a faulty machine but a probabilistic one, which estimates and constantly revises probabilities of events in the world, taking into account previous information and computing possible models of the future (Fahlman et al., 1983; Rao and Ballard, 1999; Friston and Stephan, 2007; Friston, 2010).
While the construction of an internal mental model that effectively discerns the workings of a competitor could generate a successful counter-predictive strategy, apparently random behavior might be favored in situations in which the prediction of one’s actions by a competitor or predator has adverse consequences (Nash, 1950; Maynard Smith and Harper, 1988). Notice how two of the experiments we considered in this paper, the rat experiment and that involving fruit flies, also relate to new developments in Integrated Information Theory (IIT), having to do with an approach to consciousness that proceeds via a mathematical formulation (Tononi, 2008). According to this theory, consciousness necessarily entails an internal experience. Here one indication of such an experience is the internal computation necessary to filter out or adopt non-random strategies in the absence of stimuli. Our results seem to support this view and provide further evidence of this hypothesis in line with IIT. Another is how the apparent randomness of a rat’s behavior may actually result in the rat engaging in a sophisticated computation, even while ignoring sensory input from the competitor or predator, as suggested in the clinical experiments. High Logical Depth indicates a causal history that requires more than simple feedforward calculations connecting sensors to actions. All this is also along the lines of more recent results where special predicting neurons, as distinct from mirror neurons, were found in monkeys. These neurons specialized in predicting an opponent’s actions (Haroush and Williams, 2015).
In summary, the perspective brought to bear by our formal characterization of complexity in the animal and human domain may, in turn, find application in designing cognitive strategies and measures in robotics and artificial intelligence (Zenil et al., 2015). The approach introduced here, based on algorithmic complexity measures, may help interpret data with tools complementary to the classical ones drawn from traditional statistics. For an animal to exploit the environmental deviation from equilibrium, animals must go beyond probabilities, i.e., beyond merely calculating the frequency of moves and beyond trivial entanglement with the environment. Animals clearly distinguish between environments of different complexity, reacting accordingly. The tools introduced here could contribute to modeling animal behavior, discovering fundamental mechanisms, and also to the computational modeling of disease (Tegnér et al., 2009).
Behavioral sequences consist of a finite number of actions or decisions combined in various spatial and temporal patterns that can be analyzed using mathematical tools. Understanding the mechanisms underlying complex human and animal behavior is key to understanding biological and cognitive causality. In the past, mathematical tools for studying behavioral sequences were largely drawn from classical probability theory and traditional information theory. Our work here represents an advance in introducing powerful mathematical tools drawn from complexity science and information theory to study and quantify behavioral sequences’ randomness, simplicity, and structure. In addition, the tools and concepts introduced here offer new and alternative means for behavioral analysis, interpretation, and hypothesis testing.
The original contributions presented in this study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
There were no additional studies or experiments with animals, all data was pulled from other publicly available studies from primary source cited.
HZ led, wrote, and developed the methods, performed the experiments, the data analysis, and wrote the manuscript. JT and JM reviewed the manuscript and contributed with pointers to current behavioral research data. All authors reviewed the manuscript.
HZ was employed by Oxford Immune Algorithmics Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Auger-Méthé, M., Derocher, A., Demars, C., Plank, M., Codling, E., and Lewis, M. (2016). Evaluating random search strategies in three mammals from distinct feeding guilds. J. Anim. Ecol. 85, 1411–1421. doi: 10.1111/1365-2656.12562
Bennett, C. (1988). “Logical depth and physical complexity,” in The universal turing machine–a half-century survey, ed. R. Herken (Oxford: Oxford University Press), 227–257.
Brady, A. (1983). The determination of the value of Rado’s noncomputable function Sigma(k) for four-state Turing machines. Math. Comput. 40, 647–665. doi: 10.1090/S0025-5718-1983-0689479-6
Chaitin, G. (1969). On the length of programs for computing finite binary sequences: Statistical considerations. J. ACM 16, 145–159. doi: 10.1145/321495.321506
Costa, M., Goldberger, A., and Peng, C. (2002). Multiscale entropy analysis of complex physiologic time series. Phys. Rev. Lett. 89:068102. doi: 10.1103/PhysRevLett.89.068102
Delahaye, J.-P., and Zenil, H. (2007). “On the Kolmogorov-Chaitin complexity for short sequences,” in Randomness and Complexity, ed. C. Calude (Leibnitz: World Scientific).
Delahaye, J.-P., and Zenil, H. (2012). Numerical evaluation of algorithmic complexity for short strings: A glance into the innermost structure of randomness. Appl. Math. Comput. 219, 63–77. doi: 10.1016/j.amc.2011.10.006
Fahlman, S. E., Hinton, G. E., and Sejnowski, T. J. (1983). “Massively parallel architectures for A.I.: Netl, thistle, and boltzmann machines,” in Proceedings of the National Conference on Artificial Intelligence, (Washington DC).
Friedman, J., Hastie, T., and Tibshirani, R. (2000). Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 28, 337–407. doi: 10.1214/aos/1016218223
Friston, K. (2010). The free-energy principle: A unified brain theory? Nat. Rev. Neurosci. 11, 127–138. doi: 10.1038/nrn2787
Friston, K., and Stephan, K. (2007). Free energy and the brain. Synthese 159, 417–458. doi: 10.1007/s11229-007-9237-y
Friston, K., Moran, R. J., Nagai, Y., Taniguchi, T., Gomie, H., and Tenenbaum, J. (2021). World model learning and inference. Neural Netw. 144, 573–590. doi: 10.1016/j.neunet.2021.09.011
Gauvrit, N., Singmann, H., and Soler-Toscano, F. (2015). Algorithmic complexity for psychology: A user-friendly implementation of the coding theorem method. Behav. Res. Methods 48, 314–329. doi: 10.3758/s13428-015-0574-3
Gauvrit, N., Soler-Toscano, F., and Zenil, H. (2014). Natural scene statistics mediate the perception of image complexity. Vis. Cogn. 22, 1084–1091.
Gauvrit, N., Soler-Toscano, F., and Zenil, H. (2014b). Natural scene statistics mediate the perception of image complexity. Vis. Cogn. 22, 1084–1091.
Gauvrit, N., Zenil, H., and Tegnér, J. (2017a). “The Information-theoretic and algorithmic approach to human, animal and artificial cognition, forthcoming,” in Representation and reality: Humans, animals and machines, eds G. Dodig-Crnkovic and R. Giovagnoli (Berlin: Springer Verlag), 117–139. doi: 10.1007/978-3-319-43784-2_7
Gauvrit, N., Zenil, H., Soler-Toscano, F., and Delahaye, J. (2014a). Algorithmic complexity for short binary strings applied to psychology: A primer. Behav. Res. Methods 46, 732–744. doi: 10.3758/s13428-013-0416-0
Gauvrit, N., Zenil, H., Soler-Toscano, F., Delahaye, J., and Brugger, P. (2017b). Human behavioral complexity peaks at age 25. PLoS Comput. Biol. 13:e1005408. doi: 10.1371/journal.pcbi.1005408
Haroush, K., and Williams, Z. (2015). Neuronal prediction of opponent’s behavior during cooperative social interchange in primates. Cell 160, 1233–1245. doi: 10.1016/j.cell.2015.01.045
Hernández-Orozco, S., Kiani, N., and Zenil, H. (2018). Algorithmically probable mutations reproduce aspects of evolution, such as convergence rate, genetic memory and modularity. R. Soc. Open Sci. 5:180399. doi: 10.1098/rsos.180399
Kahneman, D., Slovic, P., and Tversky, A. (1982). Judgment under uncertainty: Heuristics and biases. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511809477
Kempe, V., Gauvrit, N., and Forsyth, D. (2015b). Structure emerges faster during cultural transmission in children than in adults. Cognition 136, 247–254. doi: 10.1016/j.cognition.2014.11.038
Kolmogorov, A. (1965). Three approaches to the quantitative definition of information. Problems Inform. Transm. 1, 1–7.
Levin, L. (1974). Laws of information conservation (non-growth) and aspects of the foundation of probability theory, Problems in Form. Transmission 10, 206–210.
Li, M., and Vitányi, P. (2008). An Introduction to kolmogorov complexity and its applications. Berlin: Springer. doi: 10.1007/978-0-387-49820-1
Manor, B., and Lipsitz, L. (2012). Physiologic complexity and aging: Implications for physical function and rehabilitation. Prog. Neuro Psychopharmacol. Biol. Psychiatry 45, 287–293. doi: 10.1016/j.pnpbp.2012.08.020
Maye, A., Hsieh, C-h, Sugihara, G., and Brembs, B. (2007). Order in spontaneous behavior. PLoS One 2:e443. doi: 10.1371/journal.pone.0000443
Maynard Smith, J., and Harper, D. (1988). The evolution of aggression: Can selection generate variability? Philos. Trans. R. Soc. Lond. B Biol. Sci. 319, 557–570. doi: 10.1098/rstb.1988.0065
Mullally, S. L., and Maguire, E. A. (2014). Learning to remember: The early ontogeny of episodic memory. Dev. Cogn. Neurosci. 9, 12–29. doi: 10.1016/j.dcn.2013.12.006
Nash, J. (1950). Equilibrium points in n-person games. Proc. Natl. Acad. Sci. U.S.A. 36, 48–49. doi: 10.1073/pnas.36.1.48
Radó, T. (1962). On non-computable functions. Bell Syst. Tech. J. 41, 877–884. doi: 10.1002/j.1538-7305.1962.tb00480.x
Rao, R. P. N., and Ballard, D. H. (1999). Predictive coding in the visual cortex: A functional interpretation of some extra-classical receptive-field effects. Nat. Neurosci. 2, 79–87. doi: 10.1038/4580
Reznikova, Z., and Ryabko, B. (2011). Numerical competence in animals, with an insight from ants. Behaviour 148, 405–434. doi: 10.1163/000579511X568562
Reznikova, Z., and Ryabko, B. (2012). “Ants and Bits,” in IEEE information theory society, newsletter, (Saint Petersburg: IEEE).
Rushen, J. (1991). Problems associated with the interpretation of physiological data in the assessment of animal welfare. Appl. Anim. Behav. Sci. 28, 381–386. doi: 10.1016/0168-1591(91)90170-3
Ryabko, B., and Reznikova, Z. (2009). The use of ideas of information theory for studying “Language” and intelligence in ants. Entropy 11, 836–853. doi: 10.3390/e11040836
Sabatini, A. (2000). Analysis of postural sway using entropy measures of signal complexity. Med. Biol. Eng. Comput. 38, 617–624. doi: 10.1007/BF02344866
Soler-Toscano, F., Zenil, H., Delahaye, J., and Gauvrit, N. (2013). Correspondence and independence of numerical evaluations of algorithmic information measures. Computability 2, 125–140. doi: 10.3233/COM-13019
Soler-Toscano, F., Zenil, H., Delahaye, J.-P., and Gauvrit, N. (2014). Calculating Kolmogorov complexity from the output frequency distributions of small turing machines. PLoS One 9:e96223.
Solomonoff, R. (1964). A formal theory of inductive inference: Parts 1 and 2. Inform. Control 7, 1–22. doi: 10.1016/S0019-9958(64)90223-2
Tegnér, J., Compte, A., Auffray, C., An, G., Cedersund, G., Clermont, G., et al. (2009). Computational disease modeling – fact or fiction? BMC Syst. Biol. 3:56. doi: 10.1186/1752-0509-3-56
Tervo, D., Proskurin, M., Manakov, M., Kabra, M., Vollmer, A., Branson, K., et al. (2014). Behavioral variability through stochastic choice and its gating by anterior cingulate cortex. Cell 159, 21–32. doi: 10.1016/j.cell.2014.08.037
Tononi, G. (2008). Consciousness as integrated information: A provisional manifesto. Biol. Bullet. 215, 216–242. doi: 10.2307/25470707
Wang, Z., Li, Y., Childress, A., and Detre, J. (2014). Brain entropy mapping using fMRI. PLoS One 9:e89948. doi: 10.1371/journal.pone.0089948
Zenil, H. (2017). “Cognition and the algorithmic nature of the mind,” in Encyclopedia of complexity and systems science, 2nd. Edn, ed. R. A. Meyers (Berlin: Springer).
Zenil, H. (2020). A review of methods for estimating algorithmic complexity: Options. challenges, and new directions. Entropy 22:612. doi: 10.3390/e22060612
Zenil, H., Delahaye, J.-P., and Gaucherel, C. (2012a). Image information content characterization and classification by physical complexity. Complexity 1, 26–42. doi: 10.1002/cplx.20388
Zenil, H., Gershenson, C., Marshall, J., and Rosenblueth, D. (2012b). Life as thermodynamic evidence of algorithmic structure in natural environments. Entropy 14, 2173–2191. doi: 10.3390/e14112173
Zenil, H., Kiani, N., and Tegnér, J. (2018). A review of graph and network complexity from an algorithmic information perspective. Entropy 20:55. doi: 10.3390/e20080551
Zenil, H., Kiani, N., and Tegnér, J. (2020). Methods and applications of algorithmic complexity, 1st Edn. Berlin: Springer.
Zenil, H., Kiani, N., Zea, A., and Tegnér, J. (2019). Causal deconvolution by algorithmic generative models. Nat. Mach. Intell. 1, 58–66. doi: 10.1038/s42256-018-0005-0
Zenil, H., Soler-Toscano, F., and Joosten, J. (2012c). Empirical encounters with computational irreducibility and unpredictability. Minds Mach. 22, 149–165. doi: 10.1007/s11023-011-9262-y
Zenil, H., Soler-Toscano, F., Delahaye, J., and Gauvrit, N. (2015). Two-dimensional Kolmogorov complexity and validation of the coding theorem method by compressibility. PeerJ Comput. Sci. 1:e23. doi: 10.7717/peerj-cs.23
Keywords: behavioral biases, ant behavior, behavioral sequences, communication complexity, tradeoffs of complexity measures, Shannon Entropy
Citation: Zenil H, Marshall JAR and Tegnér J (2023) Approximations of algorithmic and structural complexity validate cognitive-behavioral experimental results. Front. Comput. Neurosci. 16:956074. doi: 10.3389/fncom.2022.956074
Received: 29 May 2022; Accepted: 29 November 2022;
Published: 24 January 2023.
Edited by:
Sergio Iglesias-Parro, University of Jaén, SpainReviewed by:
Fabíola Keesen, Federal University of Rio de Janeiro, BrazilCopyright © 2023 Zenil, Marshall and Tegnér. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hector Zenil, aGVjdG9yLnplbmlsQGNzLm94LmFjLnVr
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.