 Fabian Schubert
Fabian Schubert Claudius Gros
Claudius Gros
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Comput. Neurosci. , 24 February 2021
Volume 15 - 2021 | https://doi.org/10.3389/fncom.2021.587721
This article is part of the Research Topic Modeling Synaptic Transmission View all 8 articles
Recurrent cortical networks provide reservoirs of states that are thought to play a crucial role for sequential information processing in the brain. However, classical reservoir computing requires manual adjustments of global network parameters, particularly of the spectral radius of the recurrent synaptic weight matrix. It is hence not clear if the spectral radius is accessible to biological neural networks. Using random matrix theory, we show that the spectral radius is related to local properties of the neuronal dynamics whenever the overall dynamical state is only weakly correlated. This result allows us to introduce two local homeostatic synaptic scaling mechanisms, termed flow control and variance control, that implicitly drive the spectral radius toward the desired value. For both mechanisms the spectral radius is autonomously adapted while the network receives and processes inputs under working conditions. We demonstrate the effectiveness of the two adaptation mechanisms under different external input protocols. Moreover, we evaluated the network performance after adaptation by training the network to perform a time-delayed XOR operation on binary sequences. As our main result, we found that flow control reliably regulates the spectral radius for different types of input statistics. Precise tuning is however negatively affected when interneural correlations are substantial. Furthermore, we found a consistent task performance over a wide range of input strengths/variances. Variance control did however not yield the desired spectral radii with the same precision, being less consistent across different input strengths. Given the effectiveness and remarkably simple mathematical form of flow control, we conclude that self-consistent local control of the spectral radius via an implicit adaptation scheme is an interesting and biological plausible alternative to conventional methods using set point homeostatic feedback controls of neural firing.
Cortical networks are highly recurrent, a property that is considered to be crucial for processing and storing temporal information. For recurrent networks to remain stable and functioning, the neuronal firing activity has to be kept within a certain range by autonomously active homeostatic mechanisms. It is hence important to study homeostatic mechanisms on the level of single neurons, as well as the more theoretic question of characterizing the dynamic state that is to be attained on a global network level. It is common to roughly divide adaptation mechanisms into intrinsic homeostasis, synaptic homeostasis, and metaplasticity.
Synaptic scaling was identified as a mechanism that can postsynaptically regulate neural firing by adjusting synaptic efficacies in a proportional, multiplicative way. This finding has led to numerous studies investigating the role of synaptic scaling in controlling neural network activity (Turrigiano et al., 1998; Turrigiano and Nelson, 2000; Turrigiano, 2008) and in stabilizing other plasticity mechanisms (van Rossum et al., 2000; Stellwagen and Malenka, 2006; Tetzlaff, 2011; Toyoizumi et al., 2014). Indeed, synaptic scaling has proven successful in stabilizing activity in recurrent neural networks (Lazar et al., 2009; Remme and Wadman, 2012; Zenke et al., 2013; Effenberger and Jost, 2015; Miner and Triesch, 2016). However, these studies either used synaptic scaling as the sole homeostatic mechanism (Remme and Wadman, 2012; Zenke et al., 2013) or resorted to a variant of synaptic scaling where the scaling is not dynamically determined through a control loop using a particular target activity, but rather by a fixed multiplicative normalization rule (Lazar et al., 2009; Effenberger and Jost, 2015; Miner and Triesch, 2016). Therefore, these homeostatic models cannot account for higher moments of temporal activity patterns, i.e., their variance, as this would require at least the tuning of two parameters (Cannon and Miller, 2017).
Within more abstract models of rate encoding neurons, intrinsic homeostasis and synaptic scaling essentially correspond to adjusting a bias and gain factor on the input entering a nonlinear transfer function. Within this framework, multiple dual-homeostatic adaptation rules have been investigated concerning their effect on network performance. In this framework, the adaptation of the bias acts as an intrinsic plasticity mechanism for the control of the internal excitability of a neuron (Franklin et al., 1992; Abbott and LeMasson, 1993; Borde et al., 1995), while the gain factors functionally correspond to a synaptic scaling of the recurrent weights. Learning rules for these types of models were usually derived by defining a target output distribution that each neuron attempts to reproduce by changing neural gains and biases (Steil, 2007; Triesch, 2007; Schrauwen et al., 2008; Boedecker et al., 2009), or were directly derived from an information-theoretic measure (Bell and Sejnowski, 1995).
While these studies did indeed show performance improvements by optimizing local information transmission measures, apparently, optimal performance can effectively be traced back to a global parameter, the spectral radius of the recurrent weight matrix (Schrauwen et al., 2008). Interestingly, to our knowledge, theoretical studies on spiking neural networks did not explicitly consider the spectral radius as a parameter affecting network dynamics. Still, the theory of balanced states in spiking recurrent networks established the idea that synaptic strengths should scale with , where k is the average number of afferent connections (Van Vreeswijk and Sompolinsky, 1998). According to the circular law of random matrix theory, this scaling rule simply implies that the spectral radius of the recurrent weight matrix remains finite as the number of neurons N increases. More recent experiments on cortical cultures confirm this scaling (Barral and D'Reyes, 2016).
In the present study, we investigated whether the spectral radius of the weight matrix in a random recurrent network can be regulated by a combination of intrinsic homeostasis and synaptic scaling. Following the standard echo-state framework, we used rate encoding tanh-neurons as the model of choice. However, aside from their applications as efficient machine learning algorithms, echo state networks are potentially relevant as models of information processing in the brain (Nikolić et al., 2009; Hinaut et al., 2015; Enel et al., 2016). Note in this context that extensions to layered ESN architectures have been presented by Gallicchio and Micheli (2017), which bears a somewhat greater resemblance to the hierarchical structure of cortical networks than the usual shallow ESN architecture. This line of research illustrates the importance of examining whether local and biological plausible principles exist that would allow to tune the properties of the neural reservoir to the “edge of chaos” (Livi et al., 2018), particularly when a continuous stream of inputs is present. The rule has to be independent of both the network topology, which is not locally accessible information, and the distribution of synaptic weights.
We propose and compare two unsupervised homeostatic mechanisms, which we denote by flow control and variance control. Both regulate the mean and variance of neuronal firing such that the network works in an optimal regime concerning sequence learning tasks. The mechanisms act on two sets of node-specific parameters, the biases bi, and the neural gain factors ai. We restricted ourselves to biologically plausible adaptation mechanisms, viz adaptation rules for which the dynamics of all variables are local, i.e., bound to a specific neuron. Additional variables enter only when locally accessible. In a strict sense, this implies that local dynamics are determined exclusively by the neuron's dynamical variables and by information about the activity of afferent neurons. Being less restrictive, one could claim that it should also be possible to access aggregate or mean-field quantities that average a variable of interest over the population. For example, nitric oxide is a diffusive neurotransmitter that can act as a measure for the population average of neural firing rates (Sweeney et al., 2015).
Following a general description of the network model, we introduce both adaptation rules and evaluate their effectiveness in tuning the spectral radius in sections 2.4 and 2.5. We assess the performance of networks that were subject to adaptation in section 2.7, using a nonlinear sequential memory task. Finally, we discuss the influence of node-to-node cross-correlations within the population in section 2.8.
A full description of the network model and parameters can be found in the methods section. We briefly introduce the network dynamics as
Each neuron's membrane potential xi consists of a recurrent contribution xr,i(t) and an external input Ii(t). The biases bi are subject to the following homeostatic adaptation:
Here, μt defines a target for the average activity and ϵb is the adaptation rate.
The local parameters ai act as scaling factors on the recurrent weights. We considered two different forms of update rules. Loosely speaking, both drive the network toward a certain dynamical state which corresponds to the desired spectral radius. The difference between them lies in the variables characterizing this state: While flow control defines a relation between the variance of neural activity and the variance of the total recurrent synaptic current, variance control does so by a more complex relation between the variance of neural activity and the variance of the synaptic current from the external input.
The first adaptation rule, flow control, is given by
The parameter Rt is the desired target spectral radius and ϵa the adaptation rate of the scaling factor. The dynamical variables and have been defined before in Equations (1) and (2). We also considered an alternative global update rule where ΔRi(t) is given by
where || · || denotes the Euclidean vector norm. However, since this is a non-local rule, it only served as a comparative model to Equation (5) when we investigated the effectiveness of the adaptation mechanism. Three key assumptions enter flow control, Equation (5):
• Represented by xr,i(t), we assume that there is a physical separation between the recurrent input that a neuron receives and its external inputs. This is necessary because xr,i(t) is explicitly used in the update rule of the synaptic scaling factors.
• Synaptic scaling only affects the weights of recurrent connections. However, this assumption is not crucial for the effectiveness of our plasticity rule, as we were mostly concerned with achieving a preset spectral radius for the recurrent weight matrix. If instead the scaling factors acted on both the recurrent and external inputs, this would lead to an “effective” external input . However, ai only affecting the recurrent input facilitated the parameterization of the external input by means of its variance (see section 2.7), a choice of convenience.
• For (5) to function, neurons need to able to represent and store squared neural activities.
Whether these three preconditions are satisfied by biological neurons needs to be addressed in future studies.
The second adaptation rule, variance control, has the form
Equation (7) drives the average variance of each neuron toward a desired target variance at an adaptation rate ϵa by calculating the momentary squared difference between the local activity yi(t) and its trailing average . Equation (8) calculates the target variance as a function of the target spectral radius Rt, the current local square activity and a trailing average of the local variance of the external input signal. When all ai(t) reach a steady state, the average neural variance equals the target given by (8). According to a mean-field approach that is described in section 5.6, reaching this state then results in a spectral radius Ra that is equal to the target Rt entering (8). Intuitively, it is to be expected that is a function of both the spectral radius and the external driving variance: The amount of fluctuations in the network activity is determined by the dynamic interplay between the strength of the external input as well as the recurrent coupling.
A full description of the auxiliary equations and variables used to calculate and can be found in section 5.1.
Similar to flow control, we also considered a non-local version for comparative reasons, where (8) is replaced with
Again, ||·|| denotes the Euclidean norm. Before proceeding to the results, we discuss the mathematical background of the proposed adaptation rules in some detail.
There are some interesting aspects to the theoretical framework at the basis of the here proposed regulatory scaling mechanisms.
The circular law of random matrix theory states that the eigenvalues λj are distributed uniformly on the complex unit disc if the elements of a real N × N matrix are drawn from distributions having zero mean and standard deviation (Tao and Vu, 2008). Given that the internal weight matrix ( denoting matrices) with entries Wij has prN non-zero elements per row (pr is the connection probability), the circular law implies that the spectral radius of aiWij, the maximum of |λj|, is unity when the synaptic scaling factors ai are set uniformly to 1/σw, where σw is the standard deviation of Wij. Our goal is to investigate adaptation rules for the synaptic scaling factors that are based on dynamic quantities, which includes the membrane potential xi, the neural activity yi and the input Ii.
The circular law, i.e., a N × N matrix with i.i.d. entries with zero mean and 1/N variance approaching a spectral radius of one as N → ∞, can be generalized. Rajan and Abbott (2006) investigated the case where the statistics of the columns of the matrix differ in their means and variances: given row-wise E-I balance for the recurrent weights, the square of the spectral radius of a random N × N matrix whose columns have variances is for N → ∞. Since the eigenvalues are invariant under transposition, this result also holds for row-wise variations of variances and column-wise E-I balance. While the latter is not explicitly enforced in our case, deviations from this balance are expected to tend to zero for large N given the statistical assumptions that we made about the matrix elements Wij. Therefore, the result can be applied to our model, where node-specific gain factors ai are applied to each row of the recurrent weight matrix. Thus, the spectral radius Ra of the effective random matrix with entries aiWij [as entering (2)] is
for large N, when assuming that the distribution underlying the bare weight matrix with entries Wij has zero mean. Note that can be expressed alternatively in terms of the Frobenius norm , via
We numerically tested Equation (10) for N = 500 and heterogeneous random sets of ai drawn from a uniform [0, 1]-distribution and found a very close match to the actual spectral radii (1–2% relative error). Given that the Ra,i can be interpreted as per-site estimates for the spectral radius, one can use the generalized circular law (10) to regulate Ra on the basis of local adaptation rules, one for every ai.
For the case of flow control, the adaptation rule is derived using a comparison between the variance of neural activity that is present in the network with the recurrent contribution to the membrane potential. A detailed explanation is presented in sections 2.6, 5.5. In short, we propose that
where xr,i is the recurrent contribution to the membrane potential xi. This stationarity condition leads to the adaptation rule given in Equation (5). An analysis of the dynamics of this adaptation mechanisms can be found in section 5.5.
Instead of directly imposing Equation (12) via an appropriate adaptation mechanism, we also considered the possibility of transferring this condition into a set point for the variance of neural activities as a function the external driving. To do so, we used a mean-field approach to describe the effect of recurrent input onto the resulting neural activity variance. An in-depth discussion is given in section 5.6. This led to the update rule given by Equations (7) and (8) for variance control.
We used several types of input protocols for testing the here proposed adaptation mechanisms, as well as for assessing the task performance discussed in section 2.7. The first two variants concern distinct biological scenarios:
• Binary. Binary input sequences correspond to a situation when a neural ensemble receives input dominantly from a singular source, which itself has only two states, being either active or inactive. Using binary input sequences during learning is furthermore consistent with the non-linear performance test considered here for the echo-state network as a whole, the delayed XOR-task. See section 2.7. For symmetric binary inputs, as used, the source signal u(t) is drawn from ±1.
• Gaussian. Alternatively one can consider the situation that a large number of essentially uncorrelated input streams are integrated. This implies random Gaussian inputs signals. Neurons receive in this case zero-mean independent Gaussian noise.
Another categorical dimension concerns the distribution of the afferent synaptic weights. Do all neurons receive inputs with the same strength, or not? As a quantifier for the individual external input strengths, the variances of the local external input currents where taken into account. We distinguished two cases
• Heterogeneous. In the first case, the are quenched random variables. This means that each neuron is assigned a random value before the start of the simulation, as drawn from a half-normal distribution parameterized by σ = σext. This ensures that the expected average variance is given by .
• Homogeneous. In the second case, all are assigned the identical global value .
Overall, pairing “binary” vs. “Gaussian” and “heterogeneous” vs. “homogeneous,” leads to a total of four different input protocols, i.e., “heterogeneous binary,” “homogeneous binary,” “heterogeneous Gaussian,” and “homogeneous Gaussian.” If not otherwise stated, numerical simulations were done using networks with N = 500 sites and a connection probability pr = 0.1.
In Figure 1, we present a simulation using flow control for heterogeneous Gaussian input with an adaptation rate . The standard deviation of the external driving was set to σext = 0.5. The spectral radius of Ra of was tuned to the target Rt = 1 with high precision, even though the local, row-wise estimates Ra,i showed substantial deviations from the target.
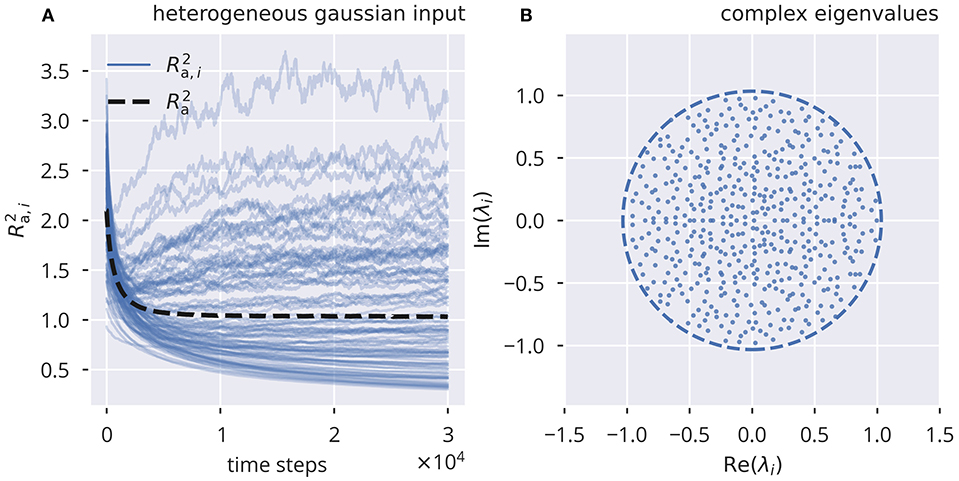
Figure 1. Online spectral radius regulation using flow control. The spectral radius Ra and the respective local estimates Ra,i as defined by (10). For the input protocol see section 5.3. (A) Dynamics of and , in the presence of heterogeneous independent Gaussian inputs. Local adaptation. (B) Distribution of eigenvalues of the corresponding effective synaptic matrix , after adaptation. The circle denotes the spectral radius.
We further tested the adaptation with other input protocols (see section 2.3 and Supplementary Figure 1). We found that flow control robustly led to the desired spectral radius Rt under all Gaussian input protocols, while binary input caused Ra to converge to higher values than Rt. However, when using global adaptation, as given by Equation (6), all input protocols resulted in the correctly tuned spectral radius (see Supplementary Figure 2).
Numerically, we found that the time needed to converge to the stationary states depended substantially on Rt, slowing down when the spectral radius becomes small. It is then advantageous, as we have done, to scale the adaptation rate ϵa inversely with the trailing average of , viz as . An exemplary plot showing the effect of this scaling is shown in Figure 7 (see section 5.2 for further details).
To evaluate the amount of deviation from the target spectral radius under different input strengths and protocols, we plotted the difference between the resulting spectral radius and the target spectral radius for a range of external input strength, quantified by their standard deviation σext. Results for different input protocols are shown in Supplementary Figure 5. For correlated binary input, increasing the input strength resulted in stronger deviations from the target spectral radius. On the other hand, uncorrelated Gaussian inputs resulted in perfect alignment for the entire range of input strengths that we tested.
In comparison, variance control, shown in Figure 2, Supplementary Figure 3, resulted in notable deviations from Rt, for both uncorrelated Gaussian and correlated binary input. As for flow control, we also calculated the deviations from Rt as a function of σext (see Supplementary Figure 6). For heterogeneous binary input, deviations from the target spectral radius did not increase monotonically as a function of the input strength (Supplementary Figure 6A), reaching a peak at σext ≈ 0.4 for target spectral radii larger than 1. For homogeneous binary input, we observed a substantial negative mismatch of the spectral radius for strong external inputs (see Supplementary Figure 6C).
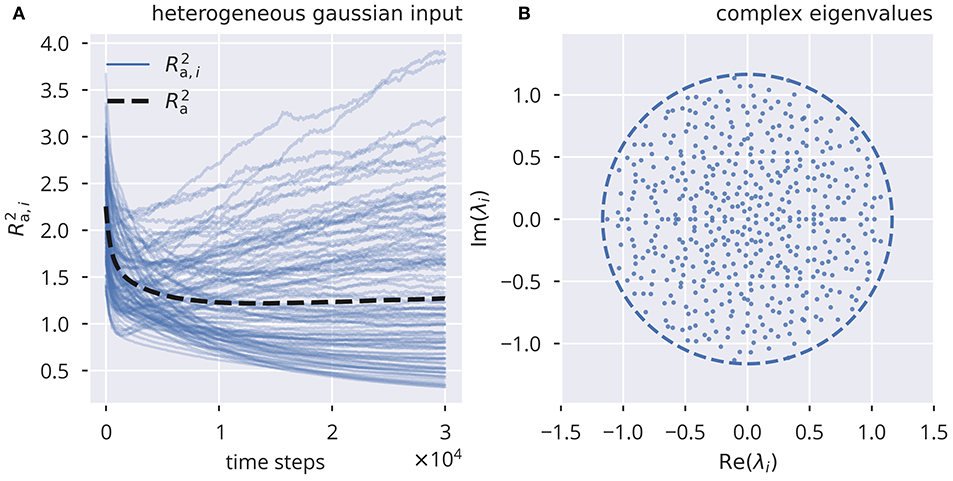
Figure 2. Online spectral radius regulation using variance control. The spectral radius Ra and the respective local estimates Ra,i as defined by (10). For the input protocol see section 5.3. (A) Dynamics of and , in the presence of heterogeneous independent Gaussian inputs. Local adaptation. (B) Distribution of eigenvalues of the corresponding effective synaptic matrix . The circles denote the respective spectral radius.
Overall, we found that variance control did not exhibit the same level of consistency in tuning the system toward a desired spectral radius, even though it did perform better in some particular cases (compare Supplementary Figure 5A for large σext with Supplementary Figure 6). Moreover, variance control exhibited deviations from the target (shown in Supplementary Figure 4) even when a global adaptation rule was used, as defined in (9). This is in contrast to the global variant of flow control, which, as stated in the previous section, robustly tuned the spectral radius to the desired value even in the presence of strongly correlated inputs.
Apart from the spectral radius Ra of the matrix , one may consider the relation between the adaptation dynamics and the respective singular values σi of . We recall that the spectrum of is given by the squared singular values, , and that the relation holds. Now, assume that the time-averaged projection of neural activity y = y(t) onto all eigenvectors of Ûa is approximately the same, that is, there is no preferred direction of neural activity in phase space. From this idealized case, it follows that the time average of the recurrent contribution to the membrane potential can be expressed with
as the rescaled average of the . For the second equation, we used the fact that the equals the sum of all matrix elements squared (Sengupta and Mitra, 1999; Shen, 2001). With (10), one finds that (13) is equivalent to and hence to the flow condition (12). This result can be generalized, as done in section 5.5, to the case that the neural activities have inhomogeneous variances, while still being uncorrelated with zero mean. We have thus shown that the stationarity condition leads to a spectral radius of (approximately) unity.
It is worthwhile to note that the singular values of do exceed unity when Ra = 1. More precisely, for a random matrix with i.i.d. entries, one finds in the limit of large N that the largest singular value is given by σmax = 2Ra, in accordance with the Marchenko-Pastur law for random matrices (Marčenko and Pastur, 1967). Consequently, directions in phase space exist in which the norm of the phase space vector is elongated by factors greater than one. Still, this does not contradict the fact that a unit spectral radius coincides with the transition to chaos for the non-driven case. The reason is that the global Lyapunov exponents are given by
which eventually converge to ln ∥λi∥, see Supplementary Figure 7 and Wernecke et al. (2019), where λi is the ith eigenvalue of . The largest singular value of the nth power of a random matrix with a spectral radius Ra scales like in the limit of large powers n. The global Lyapunov exponent goes to zero as a consequence when Ra → 1.
To this point, we presented results regarding the effectiveness of the introduced adaptation rules. However, we did not account for their effects onto a given learning task. Therefore, we tested the performance of locally adapted networks under the delayed XOR task, which evaluates the memory capacity of the echo state network in combination with a non-linear operation. For the task, the XOR operation is to be taken with respect to a delayed pair of two consecutive binary inputs signals, u(t−τ) and u(t−τ−1), where τ is a fixed time delay. The readout layer is given by a single unit, which has the task of reproducing
where XOR[u, u′] is 0/1 if u and u′ are identical/not identical.
The readout vector wout is trained with respect to the mean squared output error,
using ridge regression on a sample batch of Tbatch = 10N time steps, here for N = 500, and a regularization factor of α = 0.01. The batch matrix , of size Tbatch × (N + 1), holds the neural activities as well as one node with constant activity serving as a potential bias. Similarly, the readout (column) vector wout is of size (N + 1). The Tbatch entries of fτ are the fτ (t), viz the target values of the XOR problem. Minimizing (16) leads to
The learning procedure was repeated independently for each time delay τ. We quantified the performance by the total memory capacity, MCXOR, as
This is a simple extension of the usual definition of short term memory in the echo state literature (Jaeger, 2002). The activity of the readout unit is compared in (19) with the XOR prediction task, with the additional neuron, yN+1 = 1, corresponding to the bias of the readout unit. Depending on the mean level of the target signal, this offset might actually be unnecessary. However, since it is a standard practice to use an intercept variable in linear regression models, we decided to include it into the readout variable yout. The variance and covariance are calculated with respect to the batch size Tbatch.
The results for flow control presented in Figure 3 correspond to two input protocols, heterogeneous Gaussian and binary inputs. Shown are sweeps over a range of σext and Rt. The update rule (5) was applied to the network for each pair of parameters until the ai values converged to a stable configuration. We then measured the task performance as described above. Note that in the case of Gaussian input, this protocol was only used during the adaptation phases. Due to the nature of the XOR task, binary inputs with the corresponding variances are to be used during performance testing. See Supplementary Figure 8 for a performance sweep using the homogeneous binary and Gaussian input protocol. Optimal performance was generally attained around the Ra ≈ 1 line. A spectral radius Ra slightly smaller than unity was optimal when using Gaussian input, but not for binary input signals. In this case the measured spectral radius Ra deviated linearly from the target Rt, with increasing strength of the input, as parameterized by the standard deviation σext. Still, the locus of optimal performance was essentially independent of the input strength, with maximal performance attained roughly at Rt ≈ 0.55. Note that the line Ra = 1 joins Rt = 1 in the limit σext → 0.
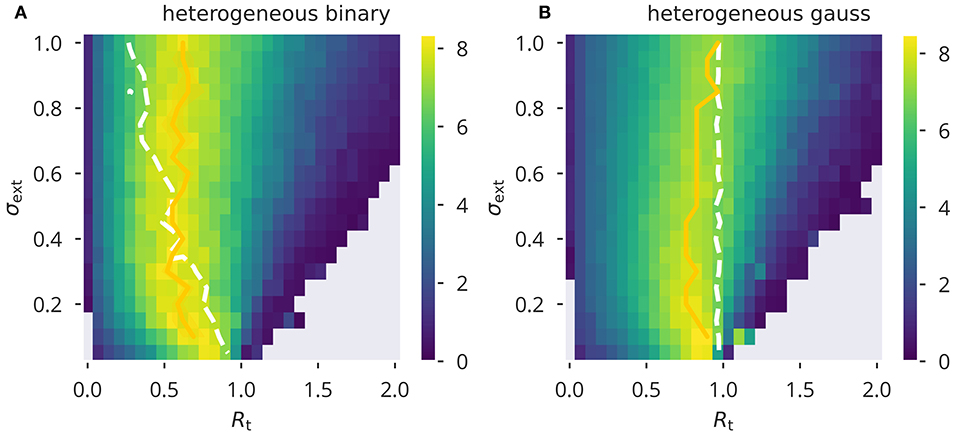
Figure 3. XOR performance for flow control. Color-coded performance sweeps for the XOR-performance (18) after adaptation using flow control. Averaged over five trials. The input has variance and the target for the spectral radius is Rt. (A,B) Heterogeneous binary/Gaussian input protocols. Optimal performance for a given σext was estimated as a trial average (yellow solid line) and found to be generally close to criticality, Ra = 1, as measured (white dashed lines).
Comparing these results to variance control, as shown in Figure 4, we found that variance control led to an overall lower performance. To our surprise, for external input with a large variance, Gaussian input caused stronger deviations from the desired spectral radius as compared to binary input. Therefore, in a sense, it appeared to behave opposite to what we found for flow control. However, similar to flow control, the value of Rt giving optimal performance under a given σext remained relatively stable over the range of external input strength measured. On the other hand, using homogeneous input (see Supplementary Figure 9), did cause substantial deviations from the target spectral radius when using binary input.
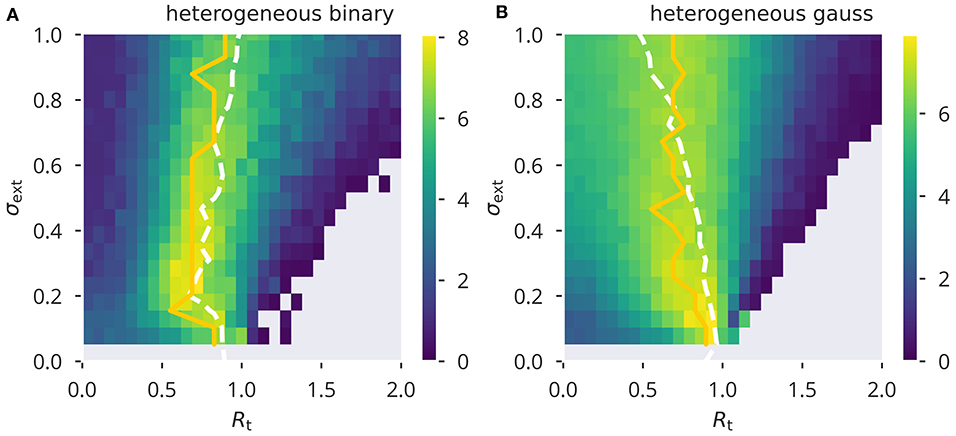
Figure 4. XOR performance for variance control. Color-coded performance sweeps for the XOR-performance (18) after adaptation using variance control. Averaged over five trials. The input has variance and the target for the spectral radius Rt. (A,B) Heterogeneous binary/Gaussian input protocols. Optimal performance (yellow solid line) is in general close to criticality, Ra = 1, as measured (white dashed lines).
A crucial assumption leading to the proposed adaptation rules is the statistical independence of neural activity for describing the statistical properties of the bare recurrent contribution to the membrane potential, . In particular, the variance of xbare enters the mean-field approach described in section 5.6. Assuming statistical independence across the population for yi(t), it is simply given by , where
is the variance of the sum of the bare afferent synaptic weights (see also section 5.1). Being a crucial element of the proposed rules, deviations from the prediction of would also negatively affect the precision of tuning the spectral radius. In Figure 5, a comparison of the deviations is presented for the four input protocols introduced in section 5.3. For the Gaussian protocols, for which neurons receive statistically uncorrelated external signals, one observes that in the thermodynamic limit N → ∞ via a power law, which is to be expected when the presynaptic neural activities are decorrelated. On the other side, binary 0/1 inputs act synchronous on all sites, either with site-dependent or site-independent strengths (heterogeneous/homogeneous). Corresponding activity correlations are induced and a finite and only weakly size-dependent difference between and shows up. Substantial corrections to the analytic theory are to be expected in this case. To this extend we measured the cross-correlation C(yi, yj), defined as
with the covariance given by Cov(yi, yj) = 〈(yi − 〈yi〉t)(yj − 〈yj〉t)〉t. For a system of N = 500 neurons the results for the averaged absolute correlation are presented in Figure 6 (see Supplementary Figure 10 for homogeneous input protocols). Autonomous echo-state layers are in chaotic states when supporting a finite activity level, which implies that correlations vanish in the thermodynamic limit N → ∞. The case σext = 0, as included in Figure 6, serves consequently as a yardstick for the magnitude of correlations that are due to the finite number of neurons.
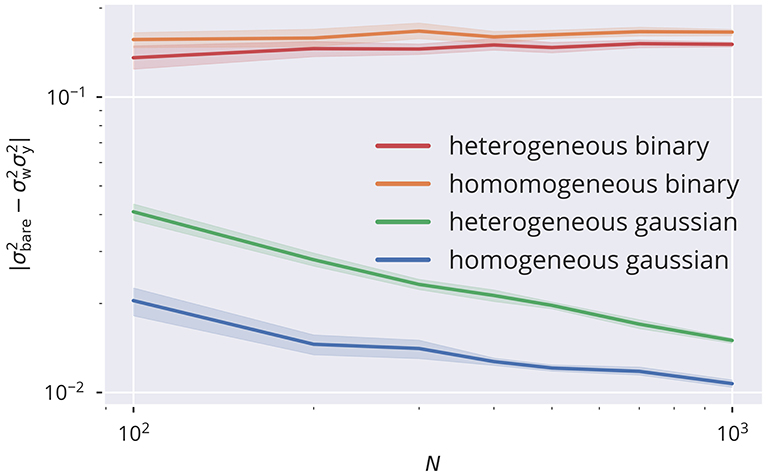
Figure 5. Size dependence of correlation. Comparison between the variance of the bare recurrent input with . Equality is given when the presynaptic activities are statistically independent. This can be observed in the limit of large network sizes N for uncorrelated input data streams (homogeneous and heterogeneous Gaussian input protocols), but not for correlated inputs (homogeneous and heterogeneous binary input protocols). Compare section 5.3 for the input protocols. Parameters are σext = 0.5, Ra = 1, and μt = 0.05.
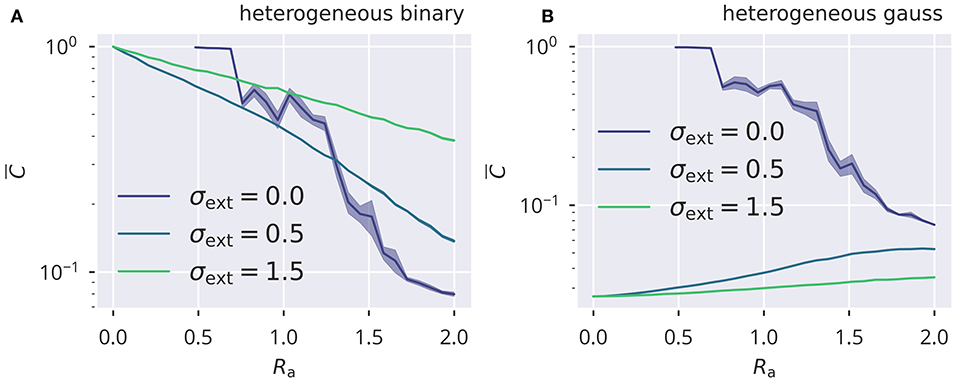
Figure 6. Input induced activity correlations. For heterogeneous binary and Gaussian inputs (A,B), the dependency of mean activity cross correlations (see Equation 21). is shown as a function of the spectral radius Ra. Results are obtained for N = 500 sites by averaging over five trials, with shadows indicating the standard error across trials. Correlations are due to finite-size effect for the autonomous case σext = 0.
Input correlations were substantially above the autonomous case for correlated binary inputs, with the magnitude of decreasing when the relative contribution of the recurrent activity increased. This was the case for increasing Ra. The effect was opposite for the Gaussian protocol, for which the input did not induce correlations, but contributed to decorrelating neural activity. In this case, the mean absolute correlation was suppressed when the internal activity became small in the limit Ra → 0. For larger Ra, the recurrent input gained more impact on neural activity relative to the external drive and thus drove toward an amount of correlation that would be expected in the autonomous case.
The mechanisms for tuning the spectral radius via a local homeostatic adaptation rule introduced in the present study require neurons to have the ability to distinguish and locally measure both external and recurrent input contributions. For flow control, neurons need to be able to compare the recurrent membrane potential with their own activity, as assumed in section 2.2. On the other hand, variance control directly measures the variance of the external input and derives the activity target variance accordingly. The limiting factor to a successful spectral radius control is the amount of cross-correlation induced by external driving statistics. As such, the functionality and validity of the proposed mechanisms depended on the ratio between external input, i.e., feed-forward or feedback connections, with respect to recurrent, or lateral connections. In general, it is not straightforward to directly connect experimental evidence regarding the ratio between recurrent and feed-forward contributions to the effects observed in the model. It is, however, worthwhile to note that the fraction of synapses associated with interlaminar loops and intralaminar lateral connections are estimated to make up roughly 50% (Binzegger et al., 2004). Relating this to our model, it implies that the significant interneural correlations that we observed when external input strengths were of the same order of magnitude as the recurrent inputs, can not generally be considered an artifact of biologically implausible parameter choices. Synchronization (Echeveste and Gros, 2016) is in fact a widely observed phenomenon in the brain (Usrey and Reid, 1999), with possible relevance for information processing (Salinas and Sejnowski, 2001).
On the other hand, correlations due to shared input reduces the amount of information that can be stored in the neural ensemble (Bell and Sejnowski, 1995). Maximal information is achieved if neural activities or spikes trains form an orthogonal ensemble (Földiak, 1990; Bell and Sejnowski, 1995; Tetzlaff et al., 2012). Furthermore, neural firing in cortical microcircuits was found to be decorrelated across neurons, even if common external input was present (Ecker et al., 2010), that is, under a common orientation tuning. Therefore, the correlation we observed in our network due to shared input might be significantly reduced by possible modifications/extensions of our model: First, a strict separation between inhibitory and excitatory nodes according to Dale's law might help actively decorrelating neural activity (Tetzlaff et al., 2012; Bernacchia and Wang, 2013). Second, if higher dimensional input was used, a combination of plasticity mechanisms in the recurrent and feed-forward connections could lead to the formation of an orthogonal representation of the input (Földiak, 1990; Bell and Sejnowski, 1995; Wick et al., 2010), leading to richer, “higher dimensional” activity patterns, i.e., a less dominant largest principal component. Ultimately, if these measures helped in reducing neural cross-correlations in the model, we thus would expect them to also increase the accuracy of the presented adaptation mechanisms. We leave these modifications to possible future research.
Overall, we found flow control to be generally more robust than variance control in the sense that, while still being affected by the amount of correlations within the neural reservoir, the task performance was less so prone to changes in the external input strength. Comparatively stable network performance could be observed, in spite of certain deviations from the desired spectral radius (see Figure 3). A possible explanation may be that flow control uses a distribution of samples from only a restricted part of phase space, that is, from the phase space regions that are actually visited or “used” for a given input. Therefore, while a spectral radius of unity ensures—statistically speaking—the desired scaling properties in all phase-space directions, it seem to be enough to control the correct scaling for the subspace of activities that is actually used for a given set of input patters. Variance control, on the other hand, relies more strictly on the assumptions that neural activities are statistical independent. In consequence, the desired results could only be achieved under a rather narrow set of input statistics (independent Gaussian input with small variance). In addition, the approximate expression derived for the nonlinear transformation appearing in the mean field approximation adds another layer of potential source of systematic error to the control mechanism. This aspect also speaks in favor of flow control, since its rules are mathematically more simple. In contrast to variance control, the stationarity condition stated in Equation (12) is independent of the actual nonlinear activation function used and could easily be adopted in a modified neuron model. It should be noted, however, that the actual target Rt giving optimal performance might then also be affected.
Interestingly, flow control distinguishes itself from a conventional local activity-target perspective of synaptic homeostasis: There is no predefined set point in Equation (5). This allows heterogeneities of variances of neural activity to develop across the network, while retaining the average neural activity at a fixed predefined level.
We would like to point out that, for all the results presented here, only stationary processes were used for generating the input sequences. Therefore, it might be worth considering the potential effects of non-stationary, yet bounded, inputs on the results in future work. It should be noted, however, that the temporal domain enters both adaptation mechanisms only in the form of trailing averages of first and second moments. As a consequence, we expect the issue of non-stationarity of external inputs to present itself simply as a trade-off between slower adaptation, i.e., longer averaging time scales, and the mitigation of the effects of non-stationarities. Slow adaptation is, however, completely in line with experimental results on the dynamics of synaptic scaling, which is taking place on the time scale of hours to days (Turrigiano et al., 1998; Turrigiano, 2008).
Apart from being relevant from a theoretical perspective, we propose that the separability of recurrent and external contributions to the membrane potential is an aspect that is potentially relevant for the understanding of local homeostasis in biological networks. While homeostasis in neural compartments has been a subject of experimental research (Chen et al., 2008), to our knowledge, it has not yet been further investigated on a theoretical basis, although it has been hypothesized that the functional segregation within the dendritic structure might also affect (among other intraneural dynamical processes) homeostasis (Narayanan and Johnston, 2012). The neural network model used in this study lacks certain features characterizing biological neural networks, like strict positivity of the neural firing rate or Dale's law, viz E-I balance (Trapp et al., 2018). Future research should therefore investigate whether the here presented framework of local flow control can be implemented within more realistic biological neural network models. A particular concern regarding our findings is that biological neurons are spiking. The concept of an underlying instantaneous firing rate is, strictly speaking, a theoretical construct, let alone the definition of higher moments, such as the “variance of neural activity.” It is however acknowledged that the variability of the neural activity is central for statistical inference (Echeveste et al., 2020). It is also important to note that real-world biological control mechanisms, e.g., of the activity, rely on physical quantities that serve as measurable correlates. A well-known example is the intracellular calcium concentration, which is essentially a linearly filtered version of the neural spike train (Turrigiano, 2008). On a theoretical level, Cannon and Miller showed that dual homeostasis can successfully control the mean and variance of this type of spike-averaging physical quantities (Cannon and Miller, 2017). An extension of the flow control to filtered spike trains of spiking neurons could be an interesting subject of further investigations. However, using spiking neuron models would have shifted the focus of our research toward the theory of liquid state machines (Maass et al., 2002; Maass and Markram, 2004), exceeding the scope of this publication. We therefore leave the extension to more realistic network/neuron models to future work.
We implemented an echo state network with N neurons, receiving Din inputs. The neural activity is yi ∈ [−1, 1], xi the membrane potential, ui the input activities, Wij the internal synaptic weights and Ii the external input received. The output layer will be specified later. The dynamics
is discrete in time, where the input Ii is treated instantaneously. A tanh-sigmoidal has been used as a nonlinear activation function.
The synaptic renormalization factor ai in (22) can be thought of as a synaptic scaling parameter that neurons use to regulate the overall strength of the recurrent inputs. The strength of the inputs Ii is unaffected, which is biologically plausible if external and recurrent signals arrive at separate branches of the dendritic tree (Spruston, 2008).
The Wij are the bare synaptic weights, with aiWij being the components of the effective weight matrix . Key to our approach is that the propagation of activity is determined by , which implies that the spectral radius of the effective, and not of the bare weight matrix needs to be regulated.
The bare synaptic matrix Wij is sparse, with a connection probability pr = 0.1. The non-zero elements are drawn from a Gaussian with standard deviation
and vanishing mean μ. Here Npr corresponds to the mean number of afferent internal synapses, with the scaling enforcing size-consistent synaptic-weight variances. As discussed in the results section, we applied the following adaptation mechanisms:
for the thresholds bi.
• adaptation of gains, using flow control:
• adaptation of gains, with variance control:
Note that Equations (28)–(30) have the same mathematical form
since they only serve as trailing averages that are used in the two main Equations (26) and (27).
For a summary of all model parameters (see Table 1).

Table 1. Standard values for model parameters.
For small values of Rt and weak external input, the average square activities and membrane potentials and can become very small. As a consequence, their difference entering ΔRi(t) in (25) also becomes small in absolute value, slowing down the convergence process. To eliminate this effect, we decided to rescale the learning rate by a trailing average of the squared recurrent membrane potential, i.e., . The effect of this renormalization is shown in Figure 7. Rescaling the learning rate effectively removes the significant rise of convergence times for small σext and small Rt.
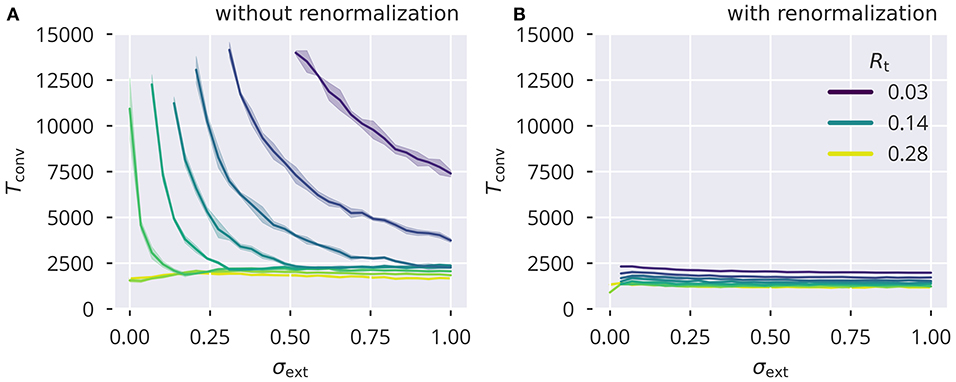
Figure 7. Convergence time with and without adaptation rate renormalization Number of time steps Tconv needed for to fall below 10−3. Shown are results using heterogeneous Gaussian input without and with, (A) and respectively (B), a renormalization of the learning rate . Note that, due to computational complexity, an estimate of Ra given by (10) was used. An initial offset of 0.5 from the target Rt was used for all runs. Color coding of Rt is the same in both panels.
Overall, we examined four distinct input protocols.
• Homogeneous Gaussian. Nodes receive inputs Ii(t) that are drawn individually from a Gaussian with vanishing mean and standard deviation σext.
• Heterogeneous Gaussian. Nodes receive stochastically independent inputs Ii(t) that are drawn from Gaussian distributions with vanishing mean and node specific standard deviations σi, ext. The individual σi, ext are normal distributed, as drawn from the positive part of a Gaussian with mean zero and variance .
• Homogeneous binary. Sites receive identical inputs Ii(t) = σextu(t), where u(t) = ±1 is a binary input sequence.
• Heterogeneous binary. We define with
the afferent synaptic weight vector , which connects the binary input sequence u(t) to the network. All are drawn independently from a Gaussian with mean zero and standard deviation σext.
The Gaussian input variant simulates external noise. We used it in particular to test predictions of the theory developed in section 5.6. In order to test the performance of the echo state network with respect to the delayed XOR task, the binary input protocols are employed. A generalization of the here defined protocols to the case of higher-dimensional input signals would be straightforward.
For an understanding of the spectral radius adaptation dynamics of flow control, it is of interest to examine the effect of using the global adaptation constraint
in (5). The spectral radius condition (12) is then enforced directly, with the consequence that (32) is stable and precise even in the presence of correlated neural activities (see Supplementary Figures 5A–C). This rule, while not biologically plausible, provides an opportunity to examine the dynamical flow, besides the resulting state. There are two dynamic variables, a = ai ∀ i, where, for the sake of simplicity, we assumed that all ai are homogeneous, and the activity variance . The evolution of resulting from the global rule (6) is shown in Figure 8. For the flow, Δa = a(t + 1) − a(t) and , the approximation
is obtained. For the scaling factor a, this leads to a fixed point of Rt/σw. We used the mean-field approximation for neural variances that is derived in section 5.6. The analytic flow compares well with numerics, as shown in Figure 8. For a subcritical rescaling factor a and σext = 0, the system flows toward a line of fixpoints defined by a vanishing and a finite a ∈ [0, 1] (see Figure 8A). When starting with a > 0, the fixpoint is instead . The situation changes qualitatively for finite external inputs, viz when σext > 0, as shown in Figures 8B–D. The nullcline is now continuous and the system flows to the fixed point, as shown in Figures 8B–D, with the value of being determined by the intersection of the two nullclines. In addition, we also varied the target spectral radius (see Figures 8B,C). This caused a slight mismatch between the flow of the simulated systems and the analytic flow. It should be noted, however, that this is to be expected anyhow since we used an approximation for the neural variances, again (see section 5.6).
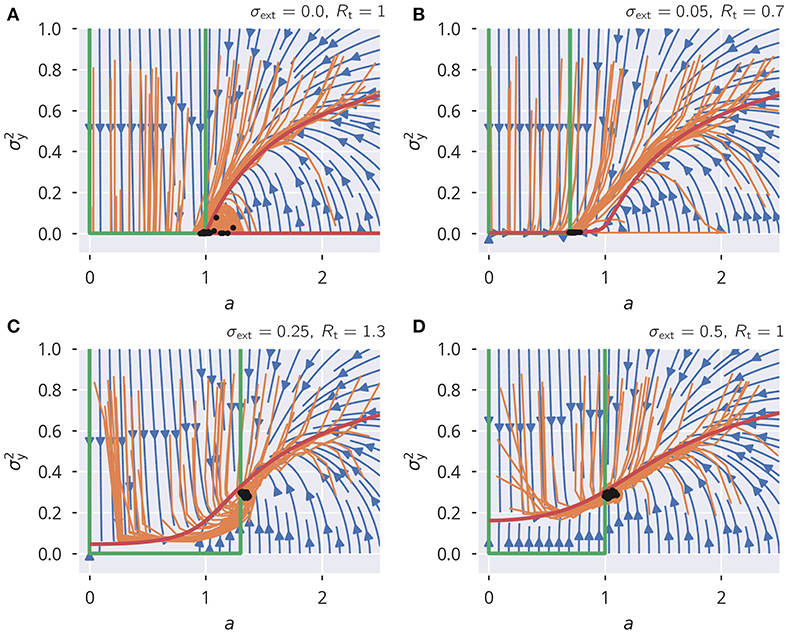
Figure 8. Spectral radius adaptation dynamics. The dynamics of the synaptic rescaling factor a and the squared activity (orange), as given by (6). Also shown is the analytic approximation to the flow (blue), see (33) and (34), and the respective nullclines Δa = 0 (green) and (red). For the input, the heterogeneous binary protocol is used. (A–D) Correspond to different combinations of external input strengths and target spectral radii. The black dots show the stead-state configurations of the simulated systems. ϵa = 0.1.
This analysis shows that external input is necessary for a robust flow toward the desired spectral weight, the reason being that the dynamics dies out before the spectral weight can be adapted when the isolated systems starts in the subcritical regime.
We would like to show that the stationarity condition in Equation (12) results in the correct spectral radius, under the special case of independently identically distributed neural activities with zero mean.
We start with Equation (12) as a stationarity condition for a given Rt:
We can express the left side of the equation as
We define with being the set of eigenvalues, which are also the squared singular values of , and {uk} the respective set of orthonormal (column) eigenvectors. We insert the identity and find
Given zero mean neural activity, is the covariance matrix of neural activities. is a diagonal matrix holding the and is a unitary matrix whose columns are {uk}. is expressing in the diagonal basis of .
Including the right hand side of (35), we get
However, since the trace is invariant under a change of basis, we find
Defining , we get
If we assume that the node activities are independently identically distributed with zero mean, we get . In this case, which was also laid out in section 2.6, the equation reduces to
The Frobenius norm of a square Matrix is given by . Furthermore, the Frobenius norm is linked to the singular values via (Sengupta and Mitra, 1999; Shen, 2001). This allows us to state
which, by using (10), gives
A slightly less restrictive case is that of uncorrelated but inhomogeneous activity, that is . The statistical properties of the diagonal elements then determine to which degree one can still claim that Equation (44) leads to Equation (45). Supplementary Figure 11 shows an example of a randomly generated realization of and the resulting diagonal elements of , where the corresponding orthonormal basis was generated from the SVD of a random Gaussian matrix. As one can see, the basis transformation has a strong smoothing effect on the diagonal entries, while the mean over the diagonal elements is preserved. Note that this effect was not disturbed by introducing random row-wise multiplications to the random matrix from which the orthonormal basis was derived. The smoothing of the diagonal entries allows us to state that is a very good approximation in the case considered, which therefore reduces (44) to the homogeneous case previously described. We can conclude that the adaptation mechanism also gives the desired spectral radius under uncorrelated inhomogeneous activity.
In the most general case, we can still state that if and are uncorrelated, for large N, Equation (44) will tend toward
which would also lead to Equation (45). However, we can not generally guarantee statistical independence since the recurrent contribution on neural activities and the resulting entries of and thus also are linked to and , being the SVD of the recurrent weight matrix.
In the following, we deduce analytic expressions allowing to examine the state of echo-state layers subject to a continuous timeline of inputs. Our approach is similar to the one presented by Massar and Massar (2013).
The recurrent part of the input xi received by a neuron is a superposition of Npr terms, which are assumed here to be uncorrelated. Given this assumption, the self-consistency equations
determine the properties of the stationary state. We recall that σw parameterizes the distribution of bare synaptic weights via (23). The general expressions (49) and (50) hold for all neurons, with the site-dependency entering exclusively via ai, bi, σext, i and μext, i, as in (51), with the latter characterizing the standard deviation and the mean of the input. Here, is the variance of the recurrent contribution to the membrane potential, x, and σ2 the respective total variance. The membrane potential is Gaussian distributed, as Nμ, σ(x), with mean μ and variance σ2, which are both to be determined self-consistently. Variances are additive for stochastically independent processes, which has been assumed in (51) to be the case for recurrent activities and the external inputs. The average value for the mean neural activity is μi.
For a given set of ai, σext, i, and bi, the means and variances of neural activities, and μy, i, follow implicitly.
We compared the numerically determined solutions of (49) and (50) against full network simulations using, as throughout this study, N = 500, pr = 0.1, σw = 1, μt = 0.05. In Figure 9, the spectral radius Ra is given for the four input protocols defined in section 5.3. The identical ensemble of input standard deviations σext, i enters both theory and simulations. Theory and simulations are in good accordance for vanishing input. Here, the reason is that finite activity levels are sustained in an autonomous random neural network when the ongoing dynamics is chaotic and hence decorrelated. For reduced activity levels, viz for small variances , the convergence of the network dynamics is comparatively slow, which leads to a certain discrepancy with the analytic prediction (see Figure 9).
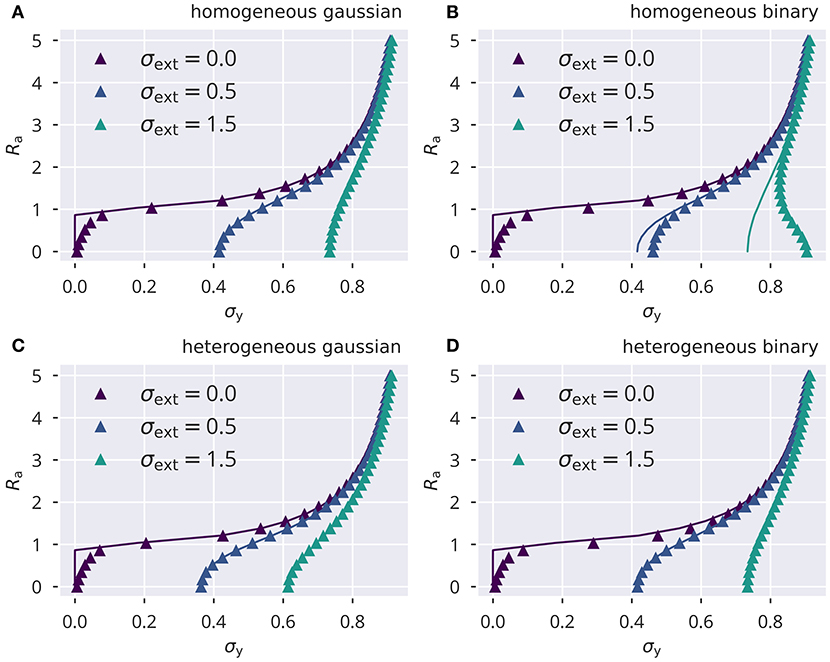
Figure 9. Variance control for the spectral radius. The spectral radius Ra, given by the approximation , for the four input protocols defined in section 5.3. Lines show the numerical self-consistency solution of (49), symbols the full network simulations. Note the instability for small σy and σext. (A) Homogeneous independent Gaussian input. (B) Homogeneous identical binary input. (C) Heterogeneous independent Gaussian input. (D) Heterogeneous identical binary input.
The integral occurring in the self-consistency condition (49) can be evaluated explicitly when a tractable approximation to the squared transfer function tanh2() is available. A polynomial approximation would capture the leading behavior close to the origin, however without accounting for the fact that tanh2() converges to unity for large absolute values of the membrane potential. Alternatively, an approximation incorporating both conditions, the correct second-order scaling for small, and the correct convergence for large arguments, is given by the Gaussian approximation
With this approximation the integral in (49) can be evaluated explicitly. The result is
Assuming that μ ≈ 0 and μy ≈ 0, inverting the first equation yields a relatively simple analytic approximation for the variance self-consistency equation:
This equation was then used for the approximate update rule in (8) and (34).
Alternatively, we can write (54) as a self- consistency equation between , , describing a phase transition at Ra = 1:
See Figure 10 for solutions of (55) for different values of . Note that for vanishing external driving and values of Ra above but close to the critical point, the standard deviation σy scales with , which is the typical critical exponent for the order parameter in classical Landau theory of second-order phase transitions (Gros, 2008, p. 169). If combined with a slow homeostatic process, flow or variance control in our case, this constitutes a system with an absorbing phase transition (Gros, 2008, p. 182–183), settling at the critical point Ra = 1. This phase transition can also be observed in Figure 9 for σext = 0 as a sharp onset in σy.
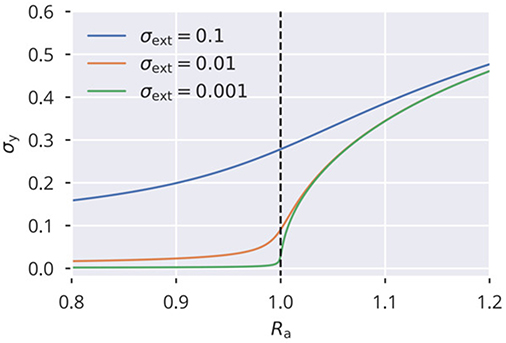
Figure 10. Phase transition of activity variance Shown are solutions of the analytical approximation given in (55), capturing the onset of activity (characterized by its variance ) at the critical point Ra = 1.
Publicly available datasets were analyzed in this study. This data can be found here: The datasets generated for this study can be found at: https://itp.uni-frankfurt.de/~fschubert/data_esn_frontiers. Simulation and plotting code is available at: https://github.com/FabianSchubert/ESN_Frontiers.
FS and CG contributed equally to the writing and review of the manuscript. FS provided the code, ran the simulations, and prepared the figures. All authors contributed to the article and approved the submitted version.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors acknowledge the financial support of the German research foundation (DFG) and discussions with R. Echeveste. This manuscript was published as a pre-print on biorxiv (Schubert and Gros, 2020).
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fncom.2021.587721/full#supplementary-material
Abbott, L. F., and LeMasson, G. (1993). Analysis of neuron models with dynamically regulated conductances. Neural Comput. 5, 823–842. doi: 10.1162/neco.1993.5.6.823
Barral, J., and D'Reyes, A. (2016). Synaptic scaling rule preserves excitatory-inhibitory balance and salient neuronal network dynamics. Nat. Neurosci. 19, 1690–1696. doi: 10.1038/nn.4415
Bell, A. J., and Sejnowski, T. J. (1995). An Information-maximisation approach to blind separation and blind deconvolution. Neural Comput. 7, 1129–1159. doi: 10.1162/neco.1995.7.6.1129
Bernacchia, A., and Wang, X. J. (2013). Decorrelation by recurrent inhibition in heterogeneous neural circuits. Neural Comput. 25, 1732–1767. doi: 10.1162/NECO_a_00451
Binzegger, T., Douglas, R. J., and Martin, K. A. (2004). A quantitative map of the circuit of cat primary visual cortex. J. Neurosci. 24, 8441–8453. doi: 10.1523/JNEUROSCI.1400-04.2004
Boedecker, J., Obst, O., Mayer, N. M., and Asada, M. (2009). Initialization and self-organized optimization of recurrent neural network connectivity. HFSP J. 3, 340–349. doi: 10.2976/1.3240502
Borde, M., Cazalets, J. R., and Buno, W. (1995). Activity-dependent response depression in rat hippocampal CA1 pyramidal neurons in vitro. J. Neurophysiol. 74, 1714–1729. doi: 10.1152/jn.1995.74.4.1714
Cannon, J., and Miller, P. (2017). Stable control of firing rate mean and variance by dual homeostatic mechanisms. J. Math. Neurosci. 7:1. doi: 10.1186/s13408-017-0043-7
Chen, N., Chen, X., and Wang, J. H. (2008). Homeostasis established by coordination of subcellular compartment plasticity improves spike encoding. J. Cell Sci. 121, 2961–2971. doi: 10.1242/jcs.022368
Echeveste, R., Aitchison, L., Hennequin, G., and Lengyel, M. (2020). Cortical-like dynamics in recurrent circuits optimized for sampling-based probabilistic inference. Nat. Neurosci. 1138–1149. doi: 10.1038/s41593-020-0671-1
Echeveste, R., and Gros, C. (2016). Drifting states and synchronization induced chaos in autonomous networks of excitable neurons. Front. Comput. Neurosci. 10:98. doi: 10.3389/fncom.2016.00098
Ecker, A. S., Berens, P., Keliris, G. A., Bethge, M., Logothetis, N. K., and Tolias, A. S. (2010). Decorrelated neuronal firing in cortical microcircuits. Science 327, 584–587. doi: 10.1126/science.1179867
Effenberger, F., and Jost, J. (2015). Self-organization in balanced state networks by STDP and homeostatic plasticity. PLoS Comput. Biol. 11:1004420. doi: 10.1371/journal.pcbi.1004420
Enel, P., Procyk, E., Quilodran, R., and Dominey, P. F. (2016). Reservoir computing properties of neural dynamics in prefrontal cortex. PLOS Comput. Biol. 12:e1004967. doi: 10.1371/journal.pcbi.1004967
Földiak, P. (1990). Forming sparse representations by local anti-Hebbian learning. Biol. Cybern. 64, 165–170. doi: 10.1007/BF02331346
Franklin, J. L., Fickbohm, D. J., and Willard, A. L. (1992). Long-term regulation of neuronal calcium currents by prolonged changes of membrane potential. J. Neurosci. 12, 1726–1735. doi: 10.1523/JNEUROSCI.12-05-01726.1992
Gallicchio, C., and Micheli, A. (2017). Echo state property of deep reservoir computing networks. Cogn. Comput. 9, 337–350. doi: 10.1007/s12559-017-9461-9
Gros, C. (2008). Complex and Adaptive Dynamical Systems, a Primer. Berlin; Heidelberg: Springer. doi: 10.1007/978-3-540-71874-1
Hinaut, X., Lance, F., Droin, C., Petit, M., Pointeau, G., and Dominey, P. F. (2015). Corticostriatal response selection in sentence production: insights from neural network simulation with reservoir computing. Brain Lang. 150, 54–68. doi: 10.1016/j.bandl.2015.08.002
Jaeger, H. (2002). Short Term Memory in Echo State Networks. Technical report, Fraunhofer Institute for Autonomous Intelligent Systems.
Lazar, A., Pipa, G., and Triesch, J. (2009). SORN: a self-organizing recurrent neural network. Front. Comput. Neurosci. 3:2009. doi: 10.3389/neuro.10.023.2009
Livi, L., Bianchi, F. M., and Alippi, C. (2018). Determination of the edge of criticality in echo state networks through Fisher information maximization. IEEE Trans. Neural Netw. Learn. Syst. 29, 706–717. doi: 10.1109/TNNLS.2016.2644268
Maass, W., and Markram, H. (2004). On the computational power of circuits of spiking neurons. J. Comput. Syst. Sci. 69, 593–616. doi: 10.1016/j.jcss.2004.04.001
Maass, W., Natschläger, T., and Markram, H. (2002). Real-time computing without stable states: a new framework for neural computation based on perturbations. Neural Comput. 14, 2531–2560. doi: 10.1162/089976602760407955
Marčenko, V. A., and Pastur, L. A. (1967). Distribution of eigenvalues for some sets of random matrices. Math. USSR-Sbornik 1, 457–483. doi: 10.1070/SM1967v001n04ABEH001994
Massar, M., and Massar, S. (2013). Mean-field theory of echo state networks. Phys. Rev. E 87:42809. doi: 10.1103/PhysRevE.87.042809
Miner, D., and Triesch, J. (2016). Plasticity-driven self-organization under topological constraints accounts for non-random features of cortical synaptic wiring. PLoS Comput. Biol. 12:e1004759. doi: 10.1371/journal.pcbi.1004759
Narayanan, R., and Johnston, D. (2012). Functional maps within a single neuron. J. Neurophysiol. 108, 2343–2351. doi: 10.1152/jn.00530.2012
Nikolić, D., Häusler, S., Singer, W., and Maass, W. (2009). Distributed fading memory for stimulus properties in the primary visual cortex. PLoS Biol. 7:e1000260. doi: 10.1371/journal.pbio.1000260
Rajan, K., and Abbott, L. F. (2006). Eigenvalue spectra of random matrices for neural networks. Phys. Rev. Lett. 97:188104. doi: 10.1103/PhysRevLett.97.188104
Remme, M. W., and Wadman, W. J. (2012). Homeostatic scaling of excitability in recurrent neural networks. PLoS Comput. Biol. 8:1002494. doi: 10.1371/journal.pcbi.1002494
Salinas, E., and Sejnowski, T. J. (2001). Correlated neuronal activity and the flow of neural information. Nat. Rev. Neurosci. 2, 539–550. doi: 10.1038/35086012
Schrauwen, B., Wardermann, M., Verstraeten, D., Steil, J. J., and Stroobandt, D. (2008). Improving reservoirs using intrinsic plasticity. Neurocomputing 71, 1159–1171. doi: 10.1016/j.neucom.2007.12.020
Schubert, F., and Gros, C. (2020). Local homeostatic regulation of the spectral radius of echo-state networks. bioRxiv [Preprint]. doi: 10.1101/2020.07.21.213660
Sengupta, A. M., and Mitra, P. P. (1999). Distributions of singular values for some random matrices. Phys. Rev. E 60:3389. doi: 10.1103/PhysRevE.60.3389
Shen, J. (2001). On the singular values of Gaussian random matrices. Linear Algeb. Appl. 326, 1–14. doi: 10.1016/S0024-3795(00)00322-0
Spruston, N. (2008). Pyramidal neurons: dendritic structure and synaptic integration. Nat. Rev. Neurosci. 9, 206–221. doi: 10.1038/nrn2286
Steil, J. J. (2007). Online reservoir adaptation by intrinsic plasticity for backpropagation-decorrelation and echo state learning. Neural Netw. 20, 353–364. doi: 10.1016/j.neunet.2007.04.011
Stellwagen, D., and Malenka, R. C. (2006). Synaptic scaling mediated by glial TNF-α. Nature 440, 1054–1059. doi: 10.1038/nature04671
Sweeney, Y., Hellgren Kotaleski, J., and Hennig, M. H. (2015). A diffusive homeostatic signal maintains neural heterogeneity and responsiveness in cortical networks. PLoS Comput. Biol. 11:e1004389. doi: 10.1371/journal.pcbi.1004389
Tao, T., and Vu, V. (2008). Random matrices: the circular law. Commun. Contemp. Math. 10, 261–307. doi: 10.1142/S0219199708002788
Tetzlaff, C. (2011). Synaptic scaling in combination with many generic plasticity mechanisms stabilizes circuit connectivity. Front. Comput. Neurosci. 5:47. doi: 10.3389/fncom.2011.00047
Tetzlaff, T., Helias, M., Einevoll, G. T., and Diesmann, M. (2012). Decorrelation of neural-network activity by inhibitory feedback. PLoS Comput. Biol. 8:1002596. doi: 10.1371/journal.pcbi.1002596
Toyoizumi, T., Kaneko, M., Stryker, M. P., and Miller, K. D. (2014). Modeling the dynamic interaction of hebbian and homeostatic plasticity. Neuron 84, 497–510. doi: 10.1016/j.neuron.2014.09.036
Trapp, P., Echeveste, R., and Gros, C. (2018). Ei balance emerges naturally from continuous hebbian learning in autonomous neural networks. Sci. Rep. 8, 1–12. doi: 10.1038/s41598-018-27099-5
Triesch, J. (2007). Synergies between intrinsic and synaptic plasticity mechanisms. Neural Comput. 19, 885–909. doi: 10.1162/neco.2007.19.4.885
Turrigiano, G. G. (2008). The self-tuning neuron: synaptic scaling of excitatory synapses. Cell 135, 422–435. doi: 10.1016/j.cell.2008.10.008
Turrigiano, G. G., Leslie, K. R., Desai, N. S., Rutherford, L. C., and Nelson, S. B. (1998). Activity-dependent scaling of quantal amplitude in neocortical neurons. Nature 391, 892–896. doi: 10.1038/36103
Turrigiano, G. G., and Nelson, S. B. (2000). Hebb and homeostasis in neuronal plasticity. Curr. Opin. Neurobiol. 10, 358–364. doi: 10.1016/S0959-4388(00)00091-X
Usrey, W. M., and Reid, R. C. (1999). Synchronous activity in the visual system. Annu. Rev. Physiol. 61, 435–456. doi: 10.1146/annurev.physiol.61.1.435
van Rossum, M. C. W., Bi, G. Q., and Turrigiano, G. G. (2000). Stable hebbian learning from spike timing-dependent plasticity. J. Neurosci. 20, 8812–8821. doi: 10.1523/JNEUROSCI.20-23-08812.2000
Van Vreeswijk, C., and Sompolinsky, H. (1998). Chaotic balanced state in a model of cortical circuits. Neural Comput. 10, 1321–1371. doi: 10.1162/089976698300017214
Wernecke, H., Sándor, B., and Gros, C. (2019). Chaos in time delay systems, an educational review. arXiv preprint arXiv:1901.04826. doi: 10.1016/j.physrep.2019.08.001
Wick, S. D., Wiechert, M. T., Friedrich, R. W., and Riecke, H. (2010). Pattern orthogonalization via channel decorrelation by adaptive networks. J. Comput. Neurosci. 28, 29–45. doi: 10.1007/s10827-009-0183-1
Keywords: recurrent networks, homeostasis, synaptic scaling, echo-state networks, reservoir computing, spectral radius
Citation: Schubert F and Gros C (2021) Local Homeostatic Regulation of the Spectral Radius of Echo-State Networks. Front. Comput. Neurosci. 15:587721. doi: 10.3389/fncom.2021.587721
Received: 27 July 2020; Accepted: 25 January 2020;
Published: 24 February 2021.
Edited by:
Florentin Wörgötter, University of Göttingen, GermanyReviewed by:
Christian Tetzlaff, University of Göttingen, GermanyCopyright © 2021 Schubert and Gros. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fabian Schubert, ZnNjaHViZXJ0QGl0cC51bmktZnJhbmtmdXJ0LmRl
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.