 Takashi Matsubara
Takashi Matsubara- Computational Intelligence, Fundamentals of Computational Science, Department of Computational Science, Graduate School of System Informatics, Kobe University, Hyogo, Japan
Precise spike timing is considered to play a fundamental role in communications and signal processing in biological neural networks. Understanding the mechanism of spike timing adjustment would deepen our understanding of biological systems and enable advanced engineering applications such as efficient computational architectures. However, the biological mechanisms that adjust and maintain spike timing remain unclear. Existing algorithms adopt a supervised approach, which adjusts the axonal conduction delay and synaptic efficacy until the spike timings approximate the desired timings. This study proposes a spike timing-dependent learning model that adjusts the axonal conduction delay and synaptic efficacy in both unsupervised and supervised manners. The proposed learning algorithm approximates the Expectation-Maximization algorithm, and classifies the input data encoded into spatio-temporal spike patterns. Even in the supervised classification, the algorithm requires no external spikes indicating the desired spike timings unlike existing algorithms. Furthermore, because the algorithm is consistent with biological models and hypotheses found in existing biological studies, it could capture the mechanism underlying biological delay learning.
1. Introduction
As confirmed in biological studies, the precise timing of a neuronal spike plays a fundamental role in information processing in the central nervous system (Carr and Konishi, 1990; Middlebrooks et al., 1994; Seidl et al., 2010). In information coding called temporal coding, the timing of at least one generated spike represents an output. In contrast, in rate coding, spiking neural network (SNN) generates spikes repeatedly over a certain period and the number of generated spikes represents an output (Brader et al., 2007; Nessler et al., 2009; Beyeler et al., 2013; O'Connor et al., 2013; Diehl and Cook, 2015; Zambrano and Bohte, 2016). SNNs in rate coding are increasingly being investigated for efficient computational architectures in engineering applications. The SNN-based architectures consume less energy and require smaller hardware area than traditional artificial neural network architectures (Querlioz et al., 2013; Neftci et al., 2014; Cao et al., 2015). However, repeated spike generation increases the computational time (VanRullen and Thorpe, 2001). To improve the efficiency of SNN-based architectures, the SNN can be implemented in temporal coding rather than rate coding (Matsubara and Torikai, 2013, 2016).
When multiple pre-synaptic spikes simultaneously arrive at a post-synaptic neuron, they evoke a large excitatory post-synaptic potential (EPSP). In response, the post-synaptic neuron elicits a spike and thereby delivers the signal to the latter part of the SNN with a high probability (see Figure 1). In other words, a neuron behaves as a coincidence detector. As the membrane potential of the post-synaptic neuron increases rapidly with increasing efficacy of the projecting synapse, synaptic modification influences the post-synaptic spike timing. Many algorithms adjust the timing of post-synaptic spikes in a supervised manner by potentiating synapses that potentially evoke EPSPs at the desired timing, while depressing other synapses. Examples are the ReSuMe algorithm (Ponulak, 2005; Sporea and Grüning, 2013; Matsubara and Torikai, 2016), the Tempotron algorithm (Gütig and Sompolinsky, 2006; Yu et al., 2014), and algorithms proposed in Pfister et al. (2006) and Paugam-Moisy et al. (2008). A pre-synaptic spike arrives at a post-synaptic neuron through the axon of the pre-synaptic neuron. The delay incurred by traveling through the axon is called the axonal conduction delay (Waxman and Swadlow, 1976). Thus, temporal coding must consider the pre-synaptic spike timing plus the conduction delay (see left panel of Figure 1B). Izhikevich et al. (2004) and Izhikevich (2006b) demonstrated that even when the conduction delays are constant, an SNN with synaptic modification called spike timing-dependent plasticity (STDP) (Markram et al., 1997; Bi and Poo, 1998) self-organizes its characteristic responses to spatio-temporal spike patterns. In Gerstner et al. (1996), multiple pre-synaptic neurons driven by a single signal source deliver the signal to a post-synaptic neuron after various delays. Synaptic modification maintains the synapses that simultaneously evoke an EPSP by potentiating them and prunes other synapses by depressing them. SpikeProp (Bohte et al., 2002) models a similar process in a supervised manner. However, under the assumption of multiple connections, the SNN requires numerous unused paths for future development. Alternatively, the SNN accepts limited spatio-temporal spike patterns depending on the initial network connections and conduction delays. Fixing the delay time limits the flexibility and efficiency of the SNN (see right panel of Figure 1B).
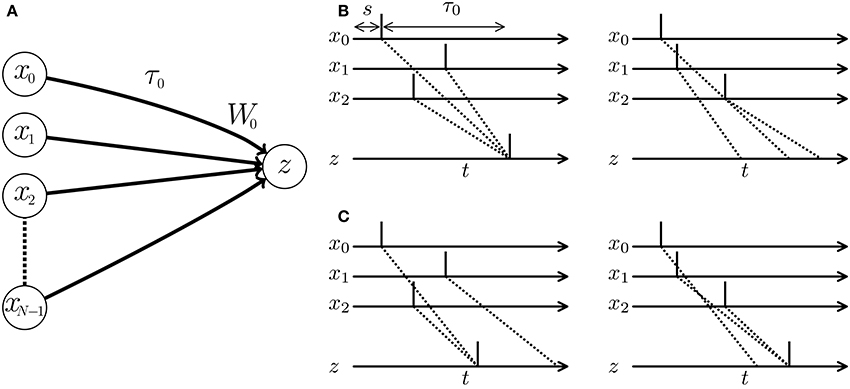
Figure 1. (A) Schematic of a spiking neural network (SNN) consisting of multiple pre-synaptic neurons xi and a post-synaptic neuron z. W0 denotes the weight of the synapse projecting from the pre-synaptic neuron x0 to the post-synaptic neuron z, and τ0 denotes the conduction delay of the axon corresponding to the synapse. (B,C) Post-synaptic spikes in response to spatio-temporal spike patterns. Each vertical line denotes a spike elicited by a neuron. Dotted lines show the transmission paths of the pre-synaptic spikes to the post-synaptic neuron z. (B) When the conduction delays are fixed, the post-synaptic neuron responds to the spatio-temporal pattern of pre-synaptic spikes and elicits a spike (left panel), but is unresponsive to a second pattern (right panel). (C) When the conduction delays are plastic, the optimized SNN generates post-synaptic spikes at times depending on the given spatio-temporal patterns of the pre-synaptic spikes.
As mentioned above, information processing in a neural circuit requires the synchronous arrival of spikes elicited by multiple pre-synaptic neurons, and thus optimal conduction delay in the axons is critical. Axons are surrounded by myelin, which works as an electrical insulator and reduces the conduction delay (Rushton, 1951). Myelination and demyelination of axons appear to depend on neuronal activity (Fields, 2005; Bakkum et al., 2008; Jamann et al., 2017). Fields (2015) and Baraban et al. (2016) hypothesized that synaptic modification occurs only after the arrival timings of the pre-synaptic spikes have been adjusted by activity-dependent myelination.
The adaptation of the conduction delay is called delay learning. Supervised delay learning algorithms such as the DL-ReSuMe algorithm (Taherkhani et al., 2015) directly adjust the conduction delay to suit the given spatio-temporal patterns of the pre- and post-synaptic spikes. After the adjustment, the SNN generates post-synaptic spikes at the desired timings (see Figure 1C). These algorithms answer the purpose to reproduce the spatio-temporal patterns, but are not suited for classification of the spatio-temporal patterns because the desired timings are generally unknown and should be manually adjusted with great care in the classification tasks. Hence, this approach reduces the flexibility in the context of machine learning and poorly represents biological systems that self-adapt to changing environments. In unsupervised delay learning, the SNN instead self-organizes in response to a given spike pattern (Hüning et al., 1998; Eurich et al., 1999, 2000). However, none of the unsupervised delay learning algorithms tackled practical tasks such as classification and reproduction of given spike patterns (see Table 1 for comparison). Thus, a delay learning algorithm that classifies given spike patterns in both unsupervised and supervised manners is greatly desired.
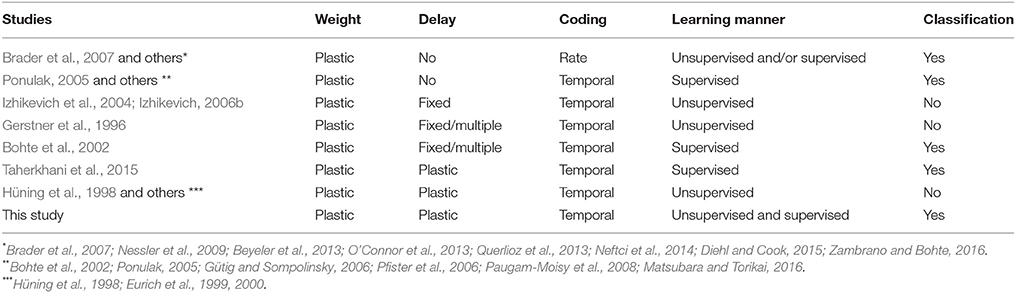
Table 1. Comparison of SNNs in different studies.
The present study proposes an unsupervised learning algorithm that adjusts the conduction delays and synaptic weights of an SNN. In a theoretical analysis, the proposed learning algorithm is confirmed to approximate the Expectation-Maximization (EM) algorithm. Optimization algorithms in probabilistic models including EM algorithm have been analyzed SNNs with no or fixed delay (e.g., Nessler et al., 2009; Kappel et al., 2014, 2015; Rezende and Gerstner, 2014). The proposed learning algorithm can be considered to extend the earlier methods to the conduction delay optimization. When evaluated on several practical classification tasks, the proposed algorithm successfully discriminated the given spatio-temporal spike patterns in an unsupervised manner. Furthermore, the algorithm was adaptable to supervised learning for improved classification accuracy. Remarkably, even in the supervised classification, the algorithm does give no external spikes indicating the timings at which the SNN should generate spikes. The adjustment of the synaptic weight in the proposed algorithm mimics that of STDP and occurs after the conduction delay was adjusted, supporting the hypothesis of Fields (2015) and Baraban et al. (2016). Therefore, the proposed learning algorithm presents as a good hypothetical model of biological delay learning, and might contribute to further investigations of SNNs in temporal coding. Preliminary and limited results of this study were presented in our conference paper (Matsubara, 2017).
2. Spike Timing-Dependent Conduction Delay Learning
2.1. Spiking Neural Network (SNN)
An SNN consists of multiple pre-synaptic neurons x0, …, xN−1 connected to a post-synaptic neuron z (see Figure 1A). Let T be an experimental time period and δ be the time step. The discrete times are denoted by t = 0, δ, 2δ, … (t < T). The binary variable xi,s is set to 1 when a pre-synaptic neuron xi generates a spike at time s and 0 otherwise. Owing to the discrete time, a spike has a width equal to the time step δ. Hence, each set x = {xis} represents a spatio-temporal spike pattern (see Figure 1B). The pre-synaptic neuron xi is connected to the post-synaptic neuron z via a synapse with a synaptic weight Wi ≥ 0 and a conduction delay τi ≥ 0. A pre-synaptic spike xis = 1 arrives at the post-synaptic neuron z after a conduction delay τi. After τi, the spike evokes an excitatory post-synaptic potential (EPSP) proportional to the synaptic weight Wi. The time course of the EPSP is expressed by a temporal relation function g(Δt) that depends on the temporal difference s−t and the conduction delay τi (namely, Δt = s + τi − t). For multiple pre-synaptic spikes, the EPSP is the linear sum of the EPSPs evoked by the pre-synaptic spikes. Then, the post-synaptic membrane potential vt at time t is then given by
The binary variable zt is set to 1 when the post-synaptic neuron z generates a spike at time t and 0 otherwise. For the parameters τ = {τi} and W = {Wi} and a given spatio-temporal spike pattern x = {xis}, the post-synaptic neuron z is assumed to generate a single spike within the experimental time period 0 ≤ t < T, i.e., . Such a constraint is important and is commonly applied in studies of temporal coding (e.g., Bohte et al., 2002) where the output of the SNN in temporal coding is defined as the timing of the post-synaptic spike. The present study initially follows the previous studies, but later proposed an alternative model without the constraint (see section 2.5). This study also assumes that for a spatio-temporal spike pattern x = {xis}, the probability of generating a post-synaptic spike zt = 1 at time t is exponentially proportional to the EPSP normalized by a constant as follows:
Note that p(zt = 1|x) > 0 at any time t. In other words, the post-synaptic neuron z can elicit a spike even before the first pre-synaptic spike arrives. In biological neural networks, such spikes are induced by physiological noise. Note also that the normalizing constant Z includes a term denoting the membrane potential at a future time t′ > t. Therefore, sampling the post-synaptic spike zt = 1 requires anti-causal information. The alternative model proposed in section 2.5 overcomes this limitation.
2.2. Multinoulli-Bernoulli Mixture Model
This subsection introduces the mixture probabilistic model. Let x be a set of visible binary random variables {xis}, each following a Bernoulli distribution, and z be a set of latent binary random variables {zt} following a Multinoulli distribution, i.e., . Also let ω = {ωt} denote the mixture weights, and π = {πist} denote the posterior probability of xis = 1 given zt = 1. The generative Multinoulli-Bernoulli mixture model p(z, x; ω, π) is then expressed as
Here, the posterior probability πist is substituted by sigm(Vist) using the sigmoid function sigm(u) = (1+exp(−u))−1. In addition, Vist is modeled by the function Wig(s + τi − t)−v where v is a bias parameter and the mixture weight wt is assumed to have a constant value eb. The log-probability is then rewritten as
When the experimental time period T is sufficiently long and the time t is sufficiently distant from the temporal boundaries (0 and T), is independent of the post-synaptic spike timing t; that is, . The posterior probability of zt = 1 given x = {xis} is then equivalent to Equation (2);
2.3. Learning Algorithm Based on the EM Algorithm
The SNN model Equation (2) can be optimized through optimization of the Multinoulli-Bernoulli mixture model Equation (4) under the certain constraints. Let θ be the parameter set and X be a dataset of spatio-temporal spike patterns x. In general, training a generative model involves maximizing the model evidence 𝔼x~X[log p(x; θ)] (Murphy, 2012). For an arbitrary distribution q(z), the evidence is expressed as
where the evidence lower bound equals 𝔼x~X𝔼z~q(z)[log p(z, x; θ)−log q(z)] and DKL(·) is the Kullback-Leibler divergence. The model evidence 𝔼x~X[log p(x; θ)] can be maximized by the Expectation-Maximization (EM) algorithm. In the E-step, q(z) is substituted by the posterior probability p(z|x; θold) of the mixture model with the currently estimated parameter set θold. The M-step updates the estimated parameter set θ to maximize the evidence lower bound . The present study employs a stochastic version of the EM algorithm (Sato, 1999; Nessler et al., 2009). Given a spatio-temporal spike pattern , the stochastic EM algorithm first generates a post-synaptic spike by Equation (2). This spike generation corresponds to the E-step of the EM algorithm. Next, the parameters θ = {W, τ} are updated to maximize the evidence lower bound using a gradient ascent algorithm. This parameter update corresponds to the M-step of the EM algorithm. From an SNN perspective, the parameter update corresponds to synaptic plasticity with delay learning. Note that, unlike the original EM algorithm, the M-step of the stochastic EM algorithm is not guaranteed to maximize the model evidence 𝔼x~X[log p(x; θ)] but at least maximizes the evidence lower bound .
Based on Equation (4), the gradients of the evidence lower bound w.r.t. the conduction delay τi and synaptic weight Wi are respectively given by;
As Equation (4) and the first term in Equation (5) are independent of the time step δ, the second term in Equation (5) (which does depend on δ) is multiplied by δ: This normalization makes Equation (5) robust to the size of the time step δ. The parameters θ are then updated as follows:
where η is a learning rate. The conditions are similar in a supervised manner, except that the post-synaptic spike is sourced externally.
2.4. Classification
A spatio-temporal spike pattern x is associated with one of the timings t = 0δ, 1δ, … depending on the timing t of the generated post-synaptic spike zt = 1. However, a given dataset X of spatio-temporal spike patterns x should be classifiable into smaller groups. In this study, the decision boundaries between N groups are defined as the n-th N-quantiles (n = 1, 2, …, N − 1) of the generated post-synaptic spike timings t for which zt = 1. For example, suppose that a dataset X contains 100 spatio-temporal spike patterns x falling into estimated two groups. The spatio-temporal spike patterns x are then sorted by the timings t of the post-synaptic spikes zt = 1. After sorting, patterns 1–50 are classified into group 1 and the remainder are classified into group 2.
2.5. Alternative Spiking Neural Network
In the SNN introduced above, the Multinoulli distribution p(z|x; τ, W) must be sampled over time t to generate a post-synaptic spike zt = 1. In other words, whether a post-synaptic spike zt = 1 is generated at time t anti-causally depends on the EPSP and post-synaptic spike at a future time t′ > t. To remove this unrealistic assumption, this subsection slightly modifies the SNN formulation. The new formulation replaces the Multinoulli distribution with multiple independent Bernoulli distributions and introduces the following Bernoulli–Bernoulli mixture model with posterior probability ρ = {ρist} of xis = 1 given zt = 0;
In this case, given a spatio-temporal spike pattern x, the posterior probabilities p(zt|x; ω, π, ρ) of the post-synaptic spikes zt = 1 at times t are completely independent. As described above, the prior probability ωt of zt = 1 is replaced with a time-independent term eb and the posterior probability πist of xis = 1 given zt = 1 is modeled as πist = sigm(Vist) = sigm(Wig(s + τi − t)−v). In addition, the posterior probability ρist is substituted by a constant sigm(v). The log-probability function becomes
where and . The prior probability ωt is replaced by an independent variable and a variable ĉ that depends on and v.
The posterior probability of zt = 1 given x is expressed as
where . The variable is replaced by a variable , which is treated as an independent parameter hereafter. The independent parameter b in the Bernoulli–Bernoulli mixture model is additional to the parameters in the Multinoulli-Bernoulli mixture model.
The evidence lower bound is given by 𝔼x~X𝔼zt~q(zt)[log p(zt, x; θ)−log q(zt)]]. The gradients of w.r.t. the parameters τi and Wi are, respectively given by
Equations (7) and (8) are equivalent to Equations (4) and (5) respectively, but are summed over time t (they sum the post-synaptic spikes zt = 1). Therefore, given a spatio-temporal spike pattern x and a single post-synaptic spike zt = 1, the parameters are updated as in the Multinoulli-Bernoulli mixture model.
Unlike the SNN based on the Multinoulli-Bernoulli mixture model, the above SNN is unconstrained by the number of post-synaptic spikes (i.e., ). To prevent an excessive number or the complete absence of post-synaptic spikes, this subsection introduces homeostatic plasticity (Turrigiano et al., 1999; Turrigiano and Nelson, 2000), a biological mechanism that presumably maintains the excitability of a neuron within a regular range (Van Rossum et al., 2000; Abraham, 2008; Watt and Desai, 2010; Matsubara and Uehara, 2016). The additional parameter in Equation (6) embodies the intrinsic excitability of the Bernoulli neuron z. The intrinsic excitability is adjusted after every receipt of the spatio-temporal spike pattern x. When post-synaptic neuron z generates at least one spike (i.e., ), its intrinsic excitability reduces by ; conversely if no spikes are generated (i.e., ), its intrinsic excitability increases by . Algorithmically, this conditional expression is given by
The spatio-temporal spike patterns x are classified as described in section 2.4, with an important difference; each post-synaptic spike zt = 1 is weighted by the inverse number of generated post-synaptic spikes, i.e., . In other words, a spatio-temporal spike pattern x is associated with a group by majority voting of multiple post-synaptic spikes zt = 1.
3. Experiments and Results
3.1. Windows of Plasticity
In this study, the temporal relation function g(Δt) was expressed as the following Gaussian function:
Here, the parameters μ and σ denote the mean and standard deviation of the distribution, respectively. Figure 2A plots the temporal relation function g(Δt) when μ = 1.5 ms and σ = 1 ms. The EPSP is commonly modeled by the double-exponential function (e.g., Shouval et al., 2010), which has zero gradient for all Δt < 0. As the proposed SNN is trained according to the gradient of the temporal relation function g(Δt), the double-exponential function is unsuitable for the purpose. In this study, the causality was preserved by clamping the temporal relation function g(s + τi − t) to 0 for all s − t < 0.
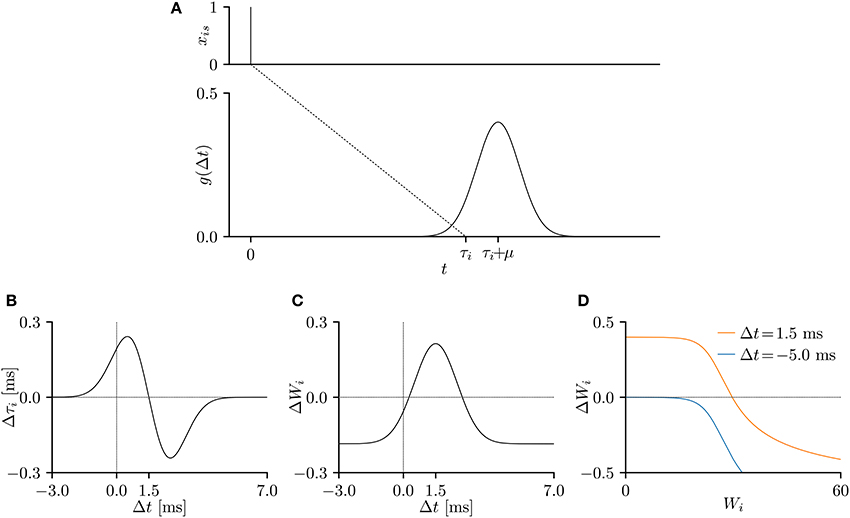
Figure 2. (A) A temporal relation function g(Δt), representing an excitatory post-synaptic potential (EPSP) or current (EPSC), when the pre-synaptic spike is elicited at s = 0 ms. The parameters were set to μ = 1.5 ms and σ = 1.0 ms and the conduction delay τi was set to τ = 10 ms. (B–D) The gradients of the lower bound of the model evidence 𝔼x~X[log p(x; θ)] with respect to the parameters Wi and τi. The time step δ was 0.05 ms, the experimental time period T was 50 ms, and the remaining parameters were set to v = 10, and η = 0.001. The gradient shapes depend on the shape of the temporal relation function g(Δt). (B) Temporal window of the delay learning, showing the relationship between the temporal difference Δt and the change Δτi in conduction delay τi, where Δt = s + τi − t. (C) Temporal window of the synaptic plasticity, showing the relationship between the temporal difference Δt and the change ΔWi in synaptic weight Wi. (D) The change ΔWi in synaptic weight Wi versus the current synaptic weight Wi for Δt = 1.5 ms (orange) and Δt = -5.0 ms (blue).
The experimental time period T was 50 ms, the time step δ was set to 0.05 ms. The remaining parameters were set to μ = 1.5 ms, σ = 1.0 ms, v = 10, and η = 0.001, unless otherwise stated. The gradients of the evidence lower bound w.r.t. the conduction delay τi and synaptic weight Wi were considered to be changes by the delay learning and synaptic plasticity, respectively. When plotted against the temporal difference Δt = s+τi−t, the gradients represent the temporal windows of the delay learning and synaptic plasticity. As shown in Figure 2B, the conduction delay τi increases (decreases) when the temporal difference Δt is smaller (larger) than 1.5 ms. The EPSP peaks at 1.5 ms, indicating that a post-synaptic spike xt = 1 attracts the nearby pre-synaptic spikes xis = 1. The temporal window of the synaptic weight Wi is similar to that of the STDP (Figure 2C). Specifically, the synapse is potentiated (depressed) when the temporal difference Δt is positive (negative), but is always depressed when the temporal difference Δt is large and positive, as noted in previous electrophysiological studies (Markram et al., 1997; Bi and Poo, 1998) and theoretical studies (Shouval et al., 2002; Wittenberg and Wang, 2006; Shouval et al., 2010). Figure 2D plots the amount of synaptic modification ΔWi versus the current synaptic weight Wi. The decreasing trend is again consistent with previous electrophysiological (Bi and Poo, 1998) and theoretical (Van Rossum et al., 2000; Gütig et al., 2003; Shouval et al., 2010; Matsubara and Uehara, 2016) studies.
3.2. Results for Toy Spike Patterns
First, the SNN and the proposed learning algorithm based on the Multinoulli-Bernoulli mixture model were evaluated on toy spike patterns generated by three pre-synaptic neurons. Figure 3A shows typical spatio-temporal spike patterns x. The pre-synaptic neurons x0, x1, and x2 elicited spikes at 1+ξ0, 5+ξ1, and 13+ξ2 ms respectively in spike pattern A, and at 13+ξ0, 9+ξ1, and 1+ξ2 ms, respectively in spike pattern B. Here, ξ0, ξ1, and ξ2 are the noise terms following a uniform distribution . Fifty samples from each of spike patterns A and B were extracted as the training dataset; other fifty samples were reserved as the test dataset. All synaptic weights Wi were uniformly initialized to 1, and the conduction delays τi (ms) were sampled from the uniform distribution . The post-synaptic neuron z was repeatedly fed with the spatio-temporal spike patterns x, and generated spikes zt = 1. The gray shaded areas in Figure 3A depicts the posterior probability p(zt = 1|x; W, τ) of spiking each millisecond. Figure 3B shows the probability distribution of post-synaptic spike timings zt = 1 for the test dataset before learning. The unlearned model cannot discriminate the spike patterns A and B using the post-synaptic spike timings zt = 1. Note that the proposed SNN is intrinsically probabilistic, meaning that a post-synaptic neuron can elicit a spike at an arbitrary time t. During the learning procedure, the synaptic weights Wi and the conduction delays τi were gradually changed by the proposed learning algorithm (Figure 3E). The conduction delays τi (ms) were clamped to the range 0–20 ms but never reached the limits. Figure 3F shows random samples of the post-synaptic spike timings zt = 1, separated into spike patterns A and B by the decision boundary (the solid black line). After sufficiently many samples, the spike patterns converged into limited temporal ranges and the two groups were clearly demarcated. The post-synaptic spike timings zt = 1 and their distributions after the learning procedure are exemplified in Figures 3C,D, respectively. In this trial, the classification accuracy of both the training and test datasets converged to 100 %. The average classification accuracy over 100 trials was 99.6 ± 2.6% for the training dataset and 99.6 ± 2.5% for the test dataset (Figure 3G). The results are summarized in Table 2.
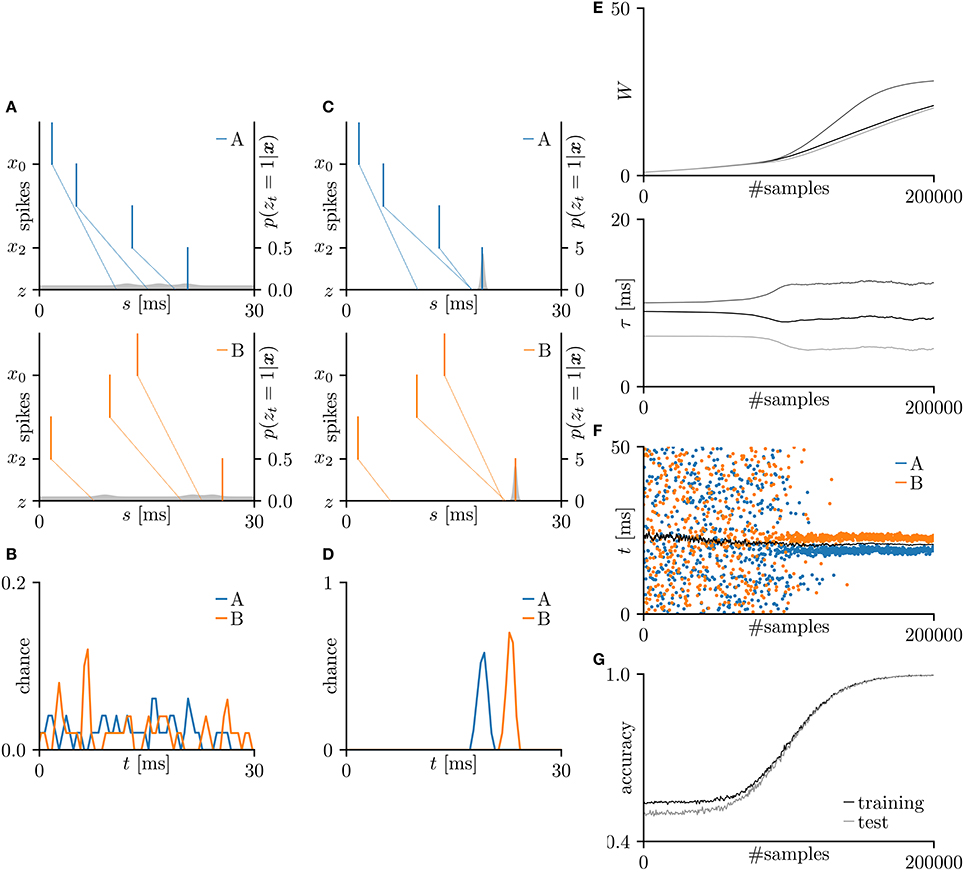
Figure 3. Results of SNN based on the Multinoulli-Bernoulli mixture model, evaluated on toy spike patterns. (A) Representative spatio-temporal spike patterns A (top panel) and B (bottom panel), and the post-synaptic spikes zt = 1 before the learning procedure. Vertical lines represent pre-synaptic spikes xis = 1 and post-synaptic spikes zt = 1 (the left vertical axes). Dotted lines denote transmission of the pre-synaptic spikes xis = 1 to the post-synaptic neuron z with conduction delays τi. Gray shaded areas denote the probability of eliciting a post-synaptic spikes zt = 1 per 1 ms (the right vertical axes). (B) Test distributions of the post-synaptic spike timings zt = 1 before learning. (C) Post-synaptic spike timings zt = 1 after learning, given the spatio-temporal spike patterns x in (A). (D) Test distributions of the post-synaptic spike timing zt = 1 after learning. (E) Trajectories of the synaptic weights Wi and conduction delays τi during the learning procedure. The darkest lines denote the values of the parameters W0 and τ0, and the lighter lines denote Wi and τi for i = 1, 2, … . (F) Random samples of the post-synaptic spike timings zt = 1. The black solid line marks the decision boundary between spike patterns A and B. (G) Classification accuracy in the training and test datasets, each averaged over 100 trials.
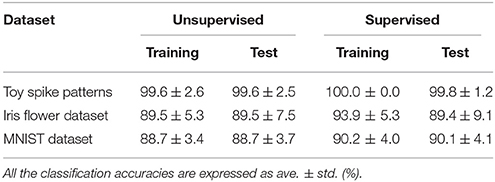
Table 2. Classification accuracy of the proposed SNN based on the Multinoulli-Bernoulli mixture model.
3.3. Results for the Iris Flower Dataset
Next, the proposed learning algorithm was evaluated on the iris flower dataset (Fisher, 1936), which consists of the data of three species (Setosa, Versicolor, and Virginica). The dataset of each species comprises 50 data points, and each data point consists of four features (the lengths and widths of the sepals and petals). Accordingly, the number N of pre-synaptic neurons was set to 4. The spike timing of each feature was normalized to the range 0–10 ms. As the sepal length k0 ranges from 4.3 to 7.9 cm, the pre-synaptic neuron x0 generated a single spike at ms. The generated post-synaptic spikes zt = 1 were then classified into three groups corresponding to the three species. Fifteen randomly chosen data points were assigned as the test set; the remainder were used as the training dataset. The other conditions were those described in section 3.2. The results are summarized in Figure 4. The average classification accuracy over 100 trials was 89.5 ± 5.3% for the training dataset and 89.5 ± 7.5% for the test dataset.
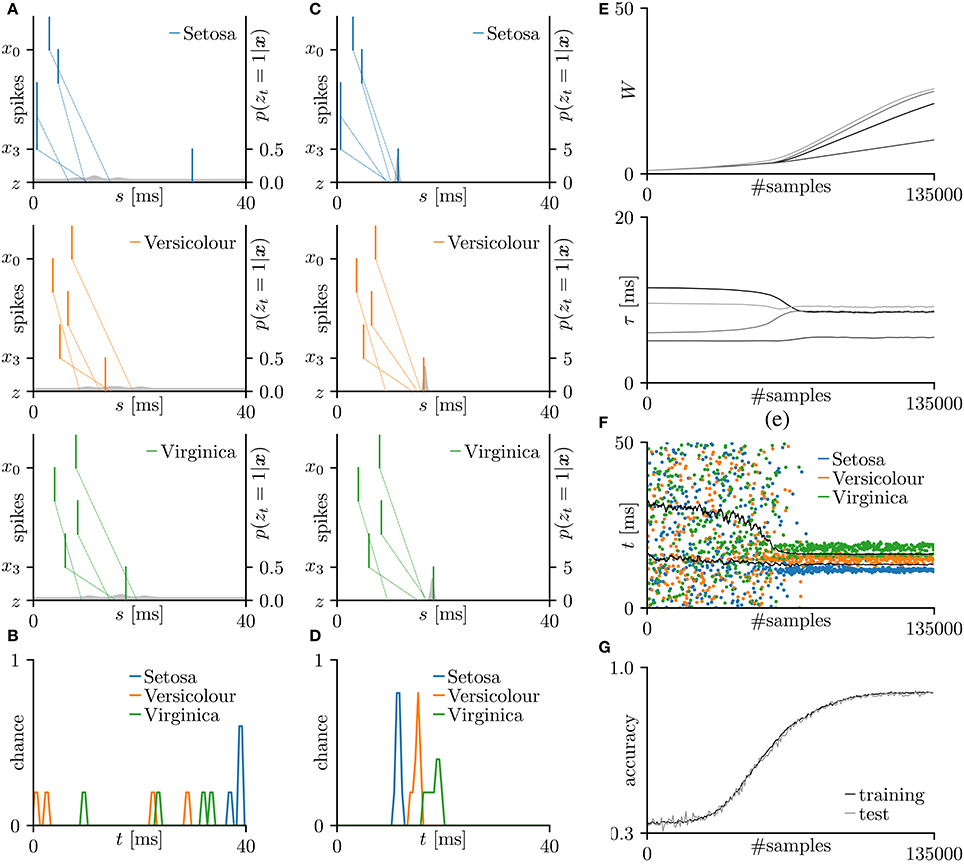
Figure 4. Results of SNN based on the Multinoulli-Bernoulli mixture model, evaluated on the iris flower dataset (Fisher, 1936). (A) Representative spatio-temporal spike patterns of Setosa (top panel), Versicolor (middle panel), and Virginica (bottom panel), and the post-synaptic spikes zt = 1 before learning. Vertical lines represent pre-synaptic spikes xis = 1 and post-synaptic spikes zt = 1 (the left vertical axes). Dotted lines denote transmission of the pre-synaptic spikes xis = 1 to the post-synaptic neuron z with conduction delays τi. Gray shaded areas denote the probability of eliciting a post-synaptic spikes zt = 1 per 1 ms (the right vertical axes). (B) Test distributions of the post-synaptic spike timings zt = 1 before learning. (C) Post-synaptic spike timings zt = 1 after learning, given the spatio-temporal spike patterns x in (A). (D) Test distributions of the post-synaptic spike timing zt = 1 after learning. (E) Trajectories of the synaptic weights Wi and conduction delays τi during the learning procedure. The darkest lines denote the values of the parameters W0 and τ0, and the lighter lines denote Wi and τi for i = 1, 2, … . (F) Random samples of the post-synaptic spike timings zt = 1. The black solid lines mark the decision boundaries between the three species. (G) Classification accuracy in the training and test datasets, each averaged over 100 trials.
For comparison, this subsection introduces the results of the multilayer ReSuMe algorithm (Sporea and Grüning, 2013), a supervised learning algorithm for multilayer SNNs in rate coding. The multilayer ReSuMe algorithm was also evaluated on the iris flower dataset. In this evaluation, a trial was deemed successful if the classification accuracy exceeded 95% on the training dataset. After weeding out the unsuccessful trials, the proposed learning algorithm and multilayer ReSuMe algorithm achieved a classification accuracy of 94.7 ± 6.5 and 94.0 ± 0.79% respectively, on the test dataset (see Table 3). Despite its single-layer architecture, the SNN trained by the proposed learning algorithm classified the iris flower dataset at least as accurately as the multilayer SNN trained by the multilayer ReSuMe algorithm.
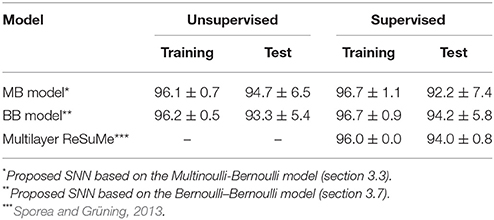
Table 3. Classification accuracies in the iris flower dataset after selection.
3.4. Results for the MNIST Dataset
In this subsection, the proposed learning algorithm was evaluated on the MNIST dataset (LeCun et al., 1998), which contains 28 × 28 grayscale images of 70,000 handwritten digits. In standard rate coding, the pixel intensities are represented by 28 × 28 = 784 pre-synaptic neurons (Nessler et al., 2009; Beyeler et al., 2013; O'Connor et al., 2013; Querlioz et al., 2013; Neftci et al., 2014; Diehl and Cook, 2015; Zambrano and Bohte, 2016). To emphasize the temporal coding, this study instead represented the rows and columns of the images by 28 pre-synaptic neurons and their 28 corresponding spike timings, respectively. When a pre-synaptic neuron xi generated a spike at time s, the intensity of the pixel in row i and column s of the image was considered to exceed 0.5 (see Figure 5A). For simplicity, only the digits 0 and 8 were included in the analysis. After removing the other digits, 13,728 images were available. This experiment employed a 10-fold cross-validation: 10 % of images were randomly chosen for the test set. The results are summarized in Figure 5. This experiment yielded much more pre-synaptic spikes xis = 1 than the previous two experiments. During transmission, the pre-synaptic spikes xis = 1 that largely contributed to the post-synaptic spike zt = 1 were emphasized. More specifically, if μ−1 < Δt = s+τi−t < μ+1 for the post-synaptic spike zt = 1, the pre-synaptic spikes xis = 1 was emphasized with a thick color line, whereas other pre-synaptic spikes xis = 1 were attenuated (see Figures 5A,C). According to Figure 5C, the C-shaped edges are heightened, indicating that the SNN selectively detects and responds to these edges. In general, the C-shaped edge appears on the left side of digit 0 and in the center of digit 8, so the post-synaptic spikes zt = 1 responded earlier to “0” than to “8”. In some trials, the SNN responded to reversed C-shaped edges (or to edges in digits such as “7”), and the post-synaptic spikes zt = 1 responded earlier to “8” than to “0” (see Figure 6). The average classification accuracy over 100 trials was 88.7 ± 3.4% for the training dataset and 88.7 ± 3.7% for the test dataset.
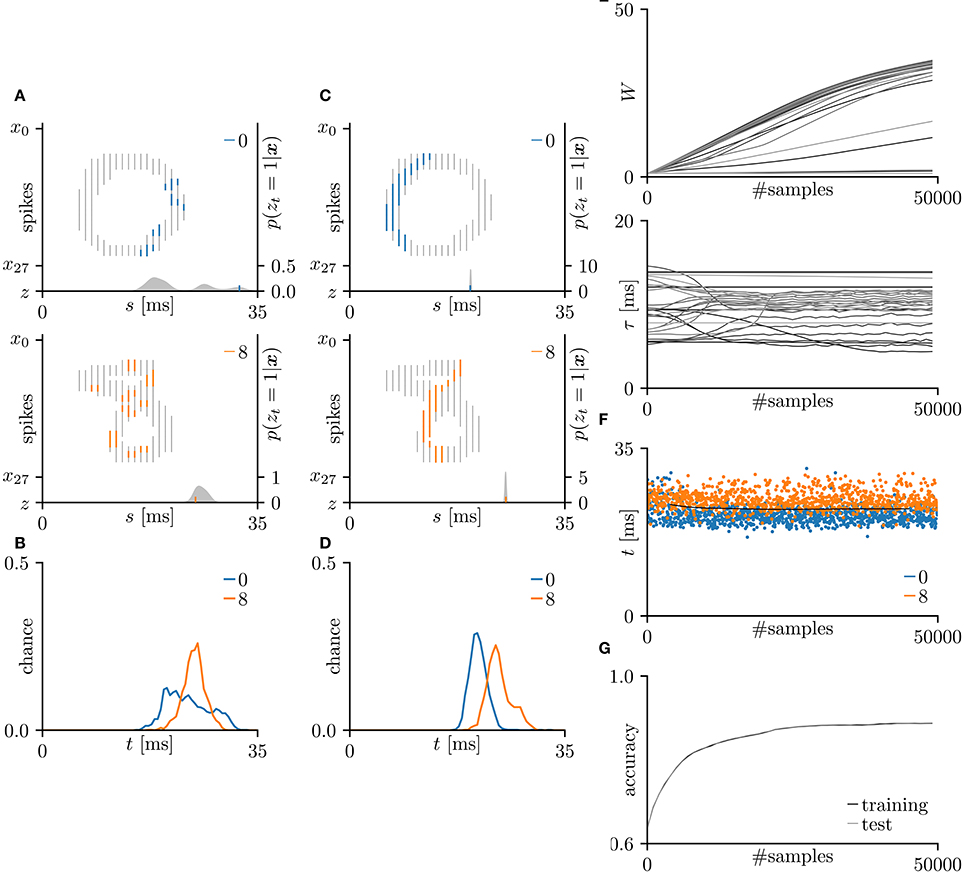
Figure 5. Results of SNN based on the Multinoulli-Bernoulli mixture model, evaluated on the hand-written digits 0 and 8 in the MNIST dataset (LeCun et al., 1998). (A) Representative spatio-temporal spike patterns of digit 0 (top panel) and digit 8 (bottom panel), and the post-synaptic spikes zt = 1 before learning. Thick colored lines indicate the pre-synaptic spikes xis = 1, elicited within μ − 1 < Δt = s + τi − t < μ + 1 for zt = 1; other pre-synaptic spikes xis are depicted as thin gray lines (the left vertical axes). Gray shaded areas denote the probability of eliciting a post-synaptic spikes zt = 1 per 1 ms (the right vertical axes). (B) Test distributions of the post-synaptic spike timings zt = 1 before learning. (C) Post-synaptic spike timings zt = 1 after learning, given the spatio-temporal spike patterns x in (A). (D) Test distributions of the post-synaptic spike timing zt = 1 after learning. (E) Trajectories of the synaptic weights Wi and conduction delays τi during the learning procedure. The darkest lines denote the values of the parameters W0 and τ0, and the lighter lines denote Wi and τi for i = 1, 2, … . (F) Random samples of the post-synaptic spike timings zt = 1. The black solid line marks the decision boundary between spike patterns the hand-written digits 0 and 8. (G) Classification accuracy in the training and test datasets, each averaged over 100 trials.
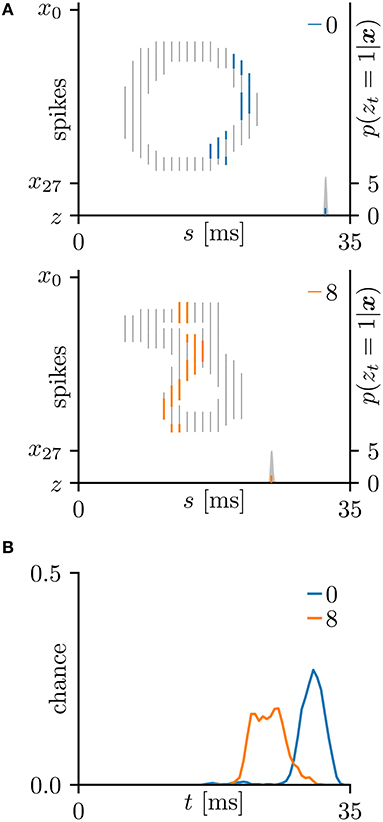
Figure 6. Other results on the hand-written digits 0 and 8 in the MNIST dataset (LeCun et al., 1998). (A) Representative spatio-temporal spike patterns of digit 0 (top panel) and digit 8 (bottom panel), and the post-synaptic spikes zt = 1 after the learning procedure as per Figure 5C. Thick colored lines indicate the pre-synaptic spikes xis = 1, elicited within μ − 1 < Δt = s + τi − t < μ+1 for zt = 1; other pre-synaptic spikes xis are depicted as thin gray lines (the left vertical axes). Gray shaded areas denote the probability of eliciting a post-synaptic spikes zt = 1 per 1 ms (the right vertical axes). (B) Test distributions of the post-synaptic spike timing zt = 1 after learning. The SNN selectively responds to the reversed C-shaped edges, so the post-synaptic spikes zt = 1 responding to “8” are earlier than those responding to “0” (in contrast to Figure 5).
3.5. Results without Delay Learning
The proposed learning algorithm was also evaluated without delay learning. More specifically, the synaptic weights Wi were updated by Equation (5), and the conduction delays τi were clamped to their initial values (i.e., were not updated by Equation 4). The other conditions were those described in previous subsections. All of the accuracies were drastically reduced (see Table 4).
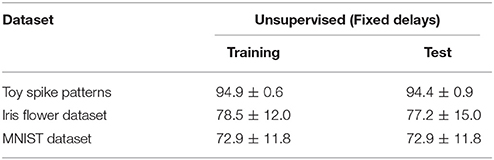
Table 4. Classification accuracy of the proposed SNN without delay learning.
3.6. Results with Supervised Learning
The proposed learning algorithm is adaptable to supervised learning, in which synaptic plasticity and delay learning are not self-driven by generated post-synaptic spikes, but are driven by external spikes generated at the desired timings (Bohte et al., 2002; Ponulak, 2005; Gütig and Sompolinsky, 2006; Pfister et al., 2006; Paugam-Moisy et al., 2008; Taherkhani et al., 2015; Matsubara and Torikai, 2016). However, the desired timings are generally unknown. In this study, the spatio-temporal spike patterns x are classified by whether the post-synaptic spike timing zt = 1 arrives earlier or later than the boundary decision. The group with the latest average post-synaptic spike timing should generate the most delayed post-synaptic spike. Therefore, the “late” group were given an external post-synaptic spike (where d > 0) after the generated post-synaptic spike zt = 1. Meanwhile, the “early” group were given a post-synaptic spike before the generated post-synaptic spike zt = 1. These post-synaptic spikes zt+d = 1 and zt−d = 1 tend to delay or advance the generated post-synaptic spike zt = 1, respectively. In this study, the time parameter d was set to δ = 0.05 ms. The results of supervised learning are summarized in Tables 2, 3. In almost every case, the classification accuracy was improved, confirming that the proposed learning algorithm can be adapted to supervised learning without manually adjusting the spike timings.
3.7. Results with Multiple Post-synaptic Spikes
This subsection evaluates the SNN based on the Bernoulli–Bernoulli mixture model described section 2.5. The homeostatic plasticity parameters were set to b+ = 0.01 and b− = 0.0001, indicating that, on average, one in every hundred spatio-temporal spike patterns induces no post-synaptic spike zt = 1. To determine the decision boundaries, the absence of the post-synaptic spike zt = 1 was considered to indicate an exceptionally late post-synaptic spike (e.g., zT = 1). As shown in Tables 3, 5, the classification accuracy was improved in the iris flower dataset but degraded in the MNIST dataset. As an example, Figure 7 shows the results of applying multiple post-synaptic spikes in the MNIST dataset.
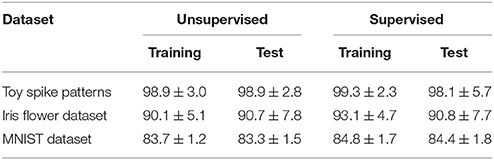
Table 5. Classification accuracy of the proposed SNN based on thle Bernoulli–Bernoulli mixture model.
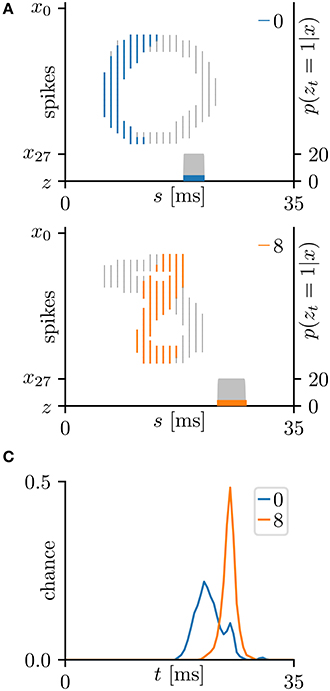
Figure 7. Results of SNN based on the Bernoulli–Bernoulli mixture model for the hand-written digits 0 and 8 in the MNIST dataset (LeCun et al., 1998). (A) Representative spatio-temporal spike patterns of digit 0 (top panel) and digit 8 (bottom panel), and the post-synaptic spikes zt = 1 after the learning procedure as per Figure 5C. Thick colored lines indicate the pre-synaptic spikes xis = 1, elicited within μ − 1 < Δt = s + τi − t < μ+1 for zt = 1; other pre-synaptic spikes xis are depicted as thin gray lines (the left vertical axes). Gray shaded areas denote the probability of eliciting a post-synaptic spikes zt = 1 per 1 ms (the right vertical axes). (B) Test distribution of mean timings of the post-synaptic spikes zt = 1 after learning. Like the Multinoulli-Bernoulli mixture model (see Figure 5), the SNN selectively responds to the C-shaped edges.
4. Discussion
Rate-coding SNNs have already succeeded in various unsupervised and supervised learning tasks (Brader et al., 2007; Nessler et al., 2009; Beyeler et al., 2013; O'Connor et al., 2013; Diehl and Cook, 2015; Zambrano and Bohte, 2016), and have provided the opportunity for efficient computational architectures (Querlioz et al., 2013; Neftci et al., 2014; Cao et al., 2015). However, rate coding requires repeated sampling of the generated spikes, which increases the computational time (VanRullen and Thorpe, 2001). The alternative approach is temporal coding, which encodes the information into a spatio-temporal spike pattern. Temporal coding requires the timing of at least one spike (Bohte et al., 2002; Ponulak, 2005; Gütig and Sompolinsky, 2006; Pfister et al., 2006; Paugam-Moisy et al., 2008; Yu et al., 2014; Taherkhani et al., 2015), potentially enabling more efficient computational architectures than those based on rate coding (Matsubara and Torikai, 2013, 2016). These studies computed gradients of spike timing or excitatory post-synaptic potential with respect to synaptic weight and/or conduction delay, and adjusted to them to elicit post-synaptic spikes at the desired timings. However, they focused exclusively on supervised learning algorithms, which always require teacher spikes at the desired timings. In general, the desired timings are unknown and require careful manual adjustment. Therefore, this approach limits the flexibility in the context of machine learning and poorly represents biological systems that self-adapt to changing environments. Unsupervised delay learning algorithms have received far less attention than supervised learning. The few studies published in this area have not approached practical tasks such as classification and reproduction of given spike patterns (Hüning et al., 1998; Eurich et al., 1999, 2000). In contrast, the proposed unsupervised learning algorithm approximates the EM algorithm (see section 2), and can therefore classify the given spatio-temporal spike patterns by inferring their hidden causes. Under the proposed learning algorithm, the SNN also detected frequent patterns in the given spatio-temporal spike patterns. In addition, the proposed learning algorithm can be adapted to supervised learning without the application of externally determined spike timings.
The proposed learning algorithm relates the synaptic weight modification ΔW to the temporal difference Δt and the current synaptic weight W (see section 3.1). When the temporal difference Δt is positive, the synapse is potentiated; when Δt is negative or largely positive, it is depressed. This relationship is consistent with previous electrophysiological studies (Markram et al., 1997; Bi and Poo, 1998) and has been discussed in theoretical studies (Shouval et al., 2002; Wittenberg and Wang, 2006; Shouval et al., 2010). The amount of synaptic modification ΔWi decreases with increasing current synaptic weight Wi. This relationship is also consistent with previous electrophysiological study (Bi and Poo, 1998) and is considered to maintain neuronal activity by suppressing excessive potentiation (Van Rossum et al., 2000; Gütig et al., 2003; Shouval et al., 2010; Matsubara and Uehara, 2016). The Results of the iris flower dataset (summarized in Figure 4) demonstrate that during the early learning phase, the pre-synaptic spikes are not simultaneously delivered to the post-synaptic neuron, and the synaptic weights and conduction delays change only gradually. After 50,000 samples, the conduction delays rapidly changed and almost converged to certain values before 60,000 samples. At that time, the pre-synaptic spikes arrived at the post-synaptic neuron simultaneously. Following the changing conduction delays, the synaptic weights increase, post-synaptic spikes become clustered, and the classification accuracy becomes higher (see Figures 4E–G). Similar time courses were observed for the toy spike patterns (see Figure 3). These results support Fields (2015) and Baraban et al. (2016), who hypothesized that conduction delay is adjusted for the synchronous arrival of multiple pre-synaptic spikes before the synaptic modification dominates. They also demonstrated that clustered post-synaptic spikes and accurate classification require the combined optimization of conduction delay and synaptic weight. Before the synaptic weights increase, the classification accuracy is poor. Therefore, delay learning and synaptic plasticity are inherently linked as mentioned by Jamann et al. (2017). Although, the detailed of biological delay learning (i.e., activity-dependent myelination) remains unclear, this study provides a good hypothetical explanation of the mechanism underlying this process.
With the MNIST dataset, the test accuracies of the proposed algorithm based on the Multinoulli-Bernoulli mixture model were almost equal to the corresponding train accuracies as summarized in Tables 2, 4. This could be because the MNIST has a limited number of local minima insensitively to the separation of the test dataset. Since the experiment employed a 10-fold cross-validation, the average test accuracy becomes equal to the average train accuracy if the proposed algorithm always converges to the same local minimum. Actually, in all the 100 trials, the proposed algorithm apparently converged to one of two local minima shown in Figures 5, 6.
When the conduction delays were fixed, the classification accuracy of the proposed learning algorithm drastically reduced (see Table 4). This occurred because the classification depends on the timing t of the post-synaptic spike zt = 1, which remained almost static the delay modification. This result demonstrates one advantage of the proposed learning algorithm over other temporal coding learning algorithm such as the ReSuMe algorithm (Ponulak, 2005; Sporea and Grüning, 2013) and the Tempotron algorithm (Gütig and Sompolinsky, 2006; Yu et al., 2014), which learn by synaptic modification only. Gerstner et al. (1996) and Bohte et al. (2002) assumed multiple paths from a single source to a post-synaptic neuron with various delays. In such a situation, synaptic modification can adjust the post-synaptic spike timing by pruning the inappropriate paths leaving the appropriate ones only. However, an SNN based on this approach either requires numerous unused paths for future development, or its flexibility is limited by the initial network connections and conduction delays. SNNs optimized by delay learning algorithms such as the proposed learning algorithm are more efficient and flexible. A performance comparison between the two learning approaches is outside the scope of this paper, but is a worthwhile future task.
Despite the single-layer architecture, the classification accuracy of the SNN trained by the proposed learning algorithm is comparable to (even slightly superior to) that of multilayer ReSuMe, a supervised learning algorithm designed for multilayer SNNs (Sporea and Grüning, 2013). Supervised learning algorithms such as variants of ReSuMe (Ponulak, 2005; Sporea and Grüning, 2013; Taherkhani et al., 2015) and Tempotron (Gütig and Sompolinsky, 2006; Yu et al., 2014) require the desired timings of post-synaptic spikes, which must be determined before the learning procedure. As the desired timings are generally unknown, they should be adjusted manually and carefully in classification tasks. On the other hand, the proposed learning algorithm automatically determines the desired timing from the given dataset and the initial parameter values, even during a supervised learning. The removal of the need for external timing is another advantage of the proposed learning algorithm.
In temporal coding, the proposed learning algorithm requires fewer parameters and fewer spikes than existing learning algorithms in rate coding. Single-layer SNN in rate coding required 4 pre-synaptic and 3 post-synaptic neurons with 15 parameters (4 weight parameters and a bias parameter for each group) for the iris flower dataset, and more than 784 neurons and parameters for 2 digits in the MNIST dataset (e.g., Nessler et al., 2009; Neftci et al., 2014). In these algorithms, each pre-synaptic neuron corresponds to a feature or a pixel, and each post-synaptic neuron corresponds to a group. As a single neuron represents multiple values by its spike timing in temporal coding, the proposed neural network requires 4 pre-synaptic neurons and 1 post-synaptic neuron with 10 parameters (4 synaptic weights Wi, 4 conduction delays τi, and 2 decision boundaries) for the iris flower dataset, and only 29 neurons and 57 parameters for 2 digits in the MNIST dataset. In addition, each feature is the iris flower dataset was encoded into a single spike timing with in the range 0–10 ms with a time step of δ = 0.05 ms. Therefore, the resolution of each feature was 200 stages. To achieve the same resolution in rate coding, the pre-synaptic spikes must be generated up to 200 times. The proposed learning algorithm requires far fewer pre-synaptic spikes. In future works, rate coding in the proposed and existing learning algorithms should be compared with similar numbers of parameters and spikes. Note that, as the proposed SNNs have only one post-synaptic neuron, they can classify two or three groups at most. To classify more groups, the proposed SNN must be generalized to multiple interacting post-synaptic neurons.
This study proposed two types of SNNs; one based on the Multinoulli-Bernoulli mixture model, the other on the Bernoulli–Bernoulli mixture model. The former takes a single post-synaptic spike from the temporal distribution, whereas the latter can independently elicit a post-synaptic spike at every time step and exhibits a burst-like behavior. The SNN based on the Bernoulli–Bernoulli mixture model classified the iris flower dataset more accurately, and the MNIST dataset less accurately, than the SNN based on the Multinoulli-Bernoulli mixture model. Owing to the multiple generations of post-synaptic spikes, there was little variation among trials in the iris flower dataset, and the learning proceeded more robustly than in the SNN based on the Multinoulli-Bernoulli mixture model. Consequently, the accuracy was improved in this dataset. Conversely, the number of pre-synaptic spikes representing a single image varied widely in the MNIST dataset, generating a widely varying number of post-synaptic spikes. The SNN based on the Bernoulli–Bernoulli mixture model sometimes detected too many edges similar to the template edge in various sub-regions, and sometimes detected no edge. Meanwhile, the SNN based on the Multinoulli-Bernoulli mixture model always detected the single edge that best fitted the template edge. Therefore, the learning of the SNN based on the Bernoulli–Bernoulli mixture model proceeded less robustly, lowering the classification accuracy of the MNIST dataset.
The SNN proposed in section 2.1 can also be implemented in continuous time. However, the number of pre-synaptic spikes xis = 1 is unlimited in this mode, and the joint probability p(x, z) of the Multinoulli-Bernoulli and Bernoulli–Bernoulli mixture models is difficult to define. For this reason, the SNN was implemented in discrete time. The EPSP of the proposed SNN is the linear sum of the EPSPs induced by multiple pre-synaptic spikes xis = 1, and the proposed learning algorithms in sections 2.3 and 2.5 were normalized by the time step δ. Hence, the proposed SNN is robust to the time step δ and can be approximated to continuous time as the time step δ approaches 0.
Note that Equation (4) and the first term in Equation (5) are independent of the time step δ but the second term in Equation (5) does depend on δ. When adjusting the time step δ,
In contrast, the behavior of dynamical spiking neurons described by an ordinary differential equation is sensitive to the time step and the numerical simulation algorithm (Hansel et al., 1998). A continuous-time SNN and its corresponding generative model will be explored in future work.
The Bernoulli–Bernoulli mixture model independently draws a post-synaptic spike zt = 1 at each time step. However, biological studies have confirmed that the intervals between the generated spikes do not follow a Poisson distribution, implying that the spikes in biological neural networks are not independently generated (Burns and Webb, 1976; Levine, 1991). When a dynamical neuron generates a spike, it enters the relative refractory period. During this time, the neuron becomes less sensitive to stimuli and is less likely to generate a spike. After the relative refractory period, the neuron returns to its resting state and resumes its usual chance of generating a spike (Izhikevich, 2006a, Chapter 8). Incorporated with these dynamics, the SNN based on the Bernoulli–Bernoulli mixture model would be purged of its burst-like behavior in the MNIST dataset (which degraded the classification accuracy), and would be rendered more computationally efficient and more biologically realistic. A dynamic version of the proposed SNN is a further opportunity for future work.
5. Conclusion
This study proposed an unsupervised learning algorithm that adjusts the conduction delays and synaptic weights in an SNN. The proposed learning algorithm approximates the Expectation-Maximization (EM) algorithm and was confirmed to classify the spatio-temporal spike patterns in several practical problems. In addition, the proposed learning algorithm is adjustable to supervised learning, which improves its classification accuracy. The formulation of the proposed learning algorithm is partially consistent with the synaptic plasticity demonstrated in previous biological and theoretical studies. Therefore, the proposed learning algorithm is a strong candidate model of biological delay learning and will contribute to further investigations of SNNs in temporal coding.
Author Contributions
The author confirms being the sole contributor of this work and approved it for publication.
Funding
This study was partially supported by the JSPS KAKENHI (16K12487), Kayamori Foundation of Information Science Advancement, The Nakajima Foundation, and SEI Group CSR Foundation.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The author would like to thank Prof. Kuniaki Uehara at Kobe University, and Dr. Ferdinand Peper and Dr. Hiromasa Takemura at CiNet for valuable discussions.
References
Abraham, W. C. (2008). Metaplasticity: tuning synapses and networks for plasticity. Nat. Rev. Neurosci. 9:387. doi: 10.1038/nrn2356
Bakkum, D. J., Chao, Z. C., and Potter, S. M. (2008). Long-term activity-dependent plasticity of action potential propagation delay and amplitude in cortical networks. PLOS ONE 3:e2088. doi: 10.1371/journal.pone.0002088
Baraban, M., Mensch, S., and Lyons, D. A. (2016). Adaptive myelination from fish to man. Brain Res. 1641, 149–161. doi: 10.1016/j.brainres.2015.10.026
Beyeler, M., Dutt, N. D., and Krichmar, J. L. (2013). Categorization and decision-making in a neurobiologically plausible spiking network using a STDP-like learning rule. Neural Netw. 48, 109–124. doi: 10.1016/j.neunet.2013.07.012
Bi, G.-Q., and Poo, M.-M. (1998). Synaptic modifications in cultured hippocampal neurons: dependence on spike timing, synaptic strength, and postsynaptic cell type. J. Neurosci. 18, 10464–10472.
Bohte, S. M., Kok, J. N., and La Poutré, H. (2002). Error-backpropagation in temporally encoded networks of spiking neurons. Neurocomputing 48, 17–37. doi: 10.1016/S0925-2312(01)00658-0
Brader, J. M., Senn, W., and Fusi, S. (2007). Learning real-world stimuli in a neural network with spike-driven synaptic dynamics. Neural Comput. 19, 2881–2912. doi: 10.1162/neco.2007.19.11.2881
Burns, B. D., and Webb, A. C. (1976). The spontaneous activity of neurones in the cat's cerebral cortex. Proc. R. Soc. Lond. Ser. B Biol. Sci. 194, 211–223. doi: 10.1098/rspb.1976.0074
Cao, Y., Chen, Y., and Khosla, D. (2015). Spiking deep convolutional neural networks for energy-efficient object recognition. Int. J. Comput. Vis. 113, 54–66. doi: 10.1007/s11263-014-0788-3
Carr, C. E., and Konishi, M. (1990). A circuit for detection of interaural time differences in the brain stem of the barn owl. J. Neurosci. 10, 3227–3246.
Diehl, P. U., and Cook, M. (2015). Unsupervised learning of digit recognition using spike-timing-dependent plasticity. Front. Comput. Neurosci. 52538, 1–6. doi: 10.3389/fncom.2015.00099
Eurich, C. W., Pawelzik, K., Ernst, U., Cowan, J. D., and Milton, J. G. (1999). Dynamics of self-organized delay adaptation. Phys. Rev. Lett. 82, 1594–1597. doi: 10.1103/PhysRevLett.82.1594
Eurich, C. W., Pawelzik, K., Ernst, U., Thiel, A., Cowan, J. D., and Milton, J. G. (2000). Delay adaptation in the nervous system. Neurocomputing 32–33, 741–748. doi: 10.1016/S0925-2312(00)00239-3
Fields, R. D. (2005). Myelination: an overlooked mechanism of synaptic plasticity? Neuroscientist 11, 528–531. doi: 10.1177/1073858405282304
Fields, R. D. (2015). A new mechanism of nervous system plasticity: activity-dependent myelination. Nat. Rev. Neurosci. 16, 756–767. doi: 10.1038/nrn4023
Fisher, R. A. (1936). The use of multiple measurements in taxonomic problems. Ann. Eugen. 7, 179–188. doi: 10.1017/CBO9781107415324.004
Gerstner, W., Kempter, R., van Hemmen, J. L., and Wagner, H. (1996). A neuronal learning rule for sub-millisecond temporal coding. Nature 383, 76–78. doi: 10.1038/383076a0
Gütig, R., Aharonov, R., Rotter, S., and Sompolinsky, H. (2003). Learning input correlations through nonlinear temporally asymmetric Hebbian plasticity. J. Neurosci. 23, 3697–3714.
Gütig, R., and Sompolinsky, H. (2006). The tempotron: a neuron that learns spike timing-based decisions. Nat. Neurosci. 9, 420–428. doi: 10.1038/nn1643
Hansel, D., Mato, G., Meunier, C., and Neltner, L. (1998). On numerical simulations of integrate-and-fire neural networks. Neural Comput. 10, 467–483. doi: 10.1162/089976698300017845
Hüning, H., Glünder, H., and Palm, G. (1998). Synaptic delay learning in pulse-coupled neurons. Neural Comput. 10, 555–565. doi: 10.1162/089976698300017665
Izhikevich, E. M. (2006a). Dynamical Systems in Neuroscience: The Geometry of Excitability and Bursting. The MIT Press.
Izhikevich, E. M. (2006b). Polychronization: computation with spikes. Neural Comput. 18, 245–282. doi: 10.1162/089976606775093882
Izhikevich, E. M., Gally, J. A., and Edelman, G. M. (2004). Spike-timing dynamics of neuronal groups. Cereb. Cortex 14, 933–944. doi: 10.1093/cercor/bhh053
Jamann, N., Jordan, M., and Engelhardt, M. (2017). Activity-dependent axonal plasticity in sensory systems. Neuroscience doi: 10.1016/j.neuroscience.2017.07.035. [Epub ahead of print].
Kappel, D., Habenschuss, S., Legenstein, R., and Maass, W. (2015). “Synaptic sampling: a Bayesian approach to neural network plasticity and rewiring,” in Advances in Neural Information Processing Systems (NIPS) (Montréal, QC), 370–378.
Kappel, D., Nessler, B., and Maass, W. (2014). STDP installs in winner-take-all circuits an online approximation to hidden Markov model learning. PLoS Comput. Biol. 10:e1003511. doi: 10.1371/journal.pcbi.1003511
LeCun, Y., Bottou, L., Bengio, Y., and Haffner, P. (1998). Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2323. doi: 10.1109/5.726791
Levine, M. W. (1991). The distribution of the intervals between neural impulses in the maintained discharges of retinal ganglion cells. Biol. Cybern. 65, 459–467.
Markram, H., Lübke, J., Frotscher, M., and Sakmann, B. (1997). Regulation of synaptic efficacy by coincidence of postsynaptic APs and EPSPs. Science 275, 213–215. doi: 10.1126/science.275.5297.213
Matsubara, T. (2017). “Spike timing-dependent conduction delay learning model classifying spatio-temporal spike patterns,” in The 2017 International Joint Conference on Neural Networks (IJCNN2017) (Anchorage: IEEE), 1831–1839.
Matsubara, T., and Torikai, H. (2013). Asynchronous cellular automaton-based neuron: theoretical analysis and on-FPGA learning. IEEE Trans. Neural Netw. Learn. Syst. 24, 736–748. doi: 10.1109/TNNLS.2012.2230643
Matsubara, T., and Torikai, H. (2016). An asynchronous recurrent network of cellular automaton-based neurons and its reproduction of spiking neural network activities. IEEE Trans. Neural Netw. Learn. Syst. 27, 836–852. doi: 10.1109/TNNLS.2015.2425893
Matsubara, T., and Uehara, K. (2016). Homeostatic plasticity achieved by incorporation of random fluctuations and soft-bounded hebbian plasticity in excitatory synapses. Front. Neural Circ. 10:42. doi: 10.3389/fncir.2016.00042
Middlebrooks, J. C., Clock, A. E., Xu, L., and Green, D. M. (1994). A panoramic code for sound localization by cortical neurons. Science 264, 842–844.
Neftci, E., Das, S., Pedroni, B., Kreutz-Delgado, K., and Cauwenberghs, G. (2014). Event-driven contrastive divergence for spiking neuromorphic systems. Front. Neurosci. 7:272. doi: 10.3389/fnins.2013.00272
Nessler, B., Pfeiffer, M., and Maass, W. (2009). “STDP enables spiking neurons to detect hidden causes of their inputs,” in Advances in Neural Information Processing Systems (NIPS) (Whistler, BC), 1357–1365.
O'Connor, P., Neil, D., Liu, S. C., Delbruck, T., and Pfeiffer, M. (2013). Real-time classification and sensor fusion with a spiking deep belief network. Front. Neurosci. 7:178. doi: 10.3389/fnins.2013.00178
Paugam-Moisy, H. H., Martinez, R., and Bengio, S. (2008). Delay learning and polychronization for reservoir computing. Neurocomputing 71, 1143–1158. doi: 10.1016/j.neucom.2007.12.027
Pfister, J.-P., Toyoizumi, T., Barber, D., and Gerstner, W. (2006). Optimal spike-timing-dependent plasticity for precise action potential firing in supervised learning. Neural Comput. 18, 1318–1348. doi: 10.1162/neco.2006.18.6.1318
Ponulak, F. (2005). ReSuMe-New Supervised Learning Method for Spiking Neural Networks. Poznan University, Institute of Control and Information Engineering, Vol. 22, 467–510.
Querlioz, D., Bichler, O., Dollfus, P., and Gamrat, C. (2013). Immunity to device variations in a spiking neural network with memristive nanodevices. IEEE Trans. Nanotechnol. 12, 288–295. doi: 10.1109/TNANO.2013.2250995
Rezende, J. D., and Gerstner, W. (2014). Stochastic variational learning in recurrent spiking networks. Front. Comput. Neurosci. 8:38. doi: 10.3389/fncom.2014.00038
Rushton, W. A. H. (1951). A theory of the effects of fibre size in medullated nerve. J. Physiol. 115, 101–122. doi: 10.1113/jphysiol.1951.sp004655
Sato, M.-A. (1999). Fast Learning of On-Line EM Algorithm. Rapport Technique, ATR Human Information Processing Research Laboratories.
Seidl, A. H., Rubel, E. W., and Harris, D. M. (2010). Mechanisms for adjusting interaural time differences to achieve binaural coincidence detection. J. Neurosci. 30, 70–80. doi: 10.1523/JNEUROSCI.3464-09.2010
Shouval, H. Z., Bear, M. F., and Cooper, L. N. (2002). A unified model of NMDA receptor-dependent bidirectional synaptic plasticity. Proc. Natl. Acad. Sci. U.S.A. 99, 10831–10836. doi: 10.1073/pnas.152343099
Shouval, H. Z., Wang, S. S.-H., and Wittenberg, G. M. (2010). Spike timing dependent plasticity: a consequence of more fundamental learning rules. Front. Comput. Neurosci. 4:19. doi: 10.3389/fncom.2010.00019
Sporea, I., and Grüning, A. (2013). Supervised learning in multilayer spiking neural networks. Neural Comput. 25, 473–509. doi: 10.1162/NECO_a_00396
Taherkhani, A., Belatreche, A., Li, Y., and Maguire, L. P. (2015). DL-ReSuMe: a delay learning-based remote supervised method for spiking neurons. IEEE Trans. Neural Netw. Learn. Syst. 26, 3137–3149. doi: 10.1109/TNNLS.2015.2404938
Turrigiano, G. G., Desai, N. S., and Rutherford, L. C. (1999). Plasticity in the intrinsic excitability of cortical pyramidal neurons. Nat. Neurosci. 2, 515–520. doi: 10.1038/9165
Turrigiano, G. G., and Nelson, S. B. (2000). Hebb and homeostasis in neuronal plasticity. Curr. Opin. Neurobiol. 10, 358–364. doi: 10.1016/S0959-4388(00)00091-X
Van Rossum, M. C. W., Bi, G.-Q. Q., and Turrigiano, G. G. (2000). Stable Hebbian learning from spike timing-dependent plasticity. J. Neurosci. 20, 8812–8821.
VanRullen, R., and Thorpe, S. J. (2001). Rate coding versus temporal order coding: what the retinal ganglion cells tell the visual cortex. Neural Comput. 13, 1255–1283. doi: 10.1162/08997660152002852
Watt, A. J., and Desai, N. S. (2010). Homeostatic plasticity and STDP: keeping a neuron's cool in a fluctuating world. Front. Synaptic Neurosci. 2:5. doi: 10.3389/fnsyn.2010.00005
Waxman, S. G., and Swadlow, H. A. (1976). Ultrastructure of visual callosal axons in the rabbit. Exp. Neurol. 53, 115–127. doi: 10.1016/0014-4886(76)90287-9
Wittenberg, G. M., and Wang, S. S.-H. (2006). Malleability of spike-timing-dependent plasticity at the CA3-CA1 synapse. J. Neurosci. 26, 6610–6617. doi: 10.1523/JNEUROSCI.5388-05.2006
Yu, Q., Tang, H., Tan, K. C., and Yu, H. (2014). A brain-inspired spiking neural network model with temporal encoding and learning. Neurocomputing 138, 3–13. doi: 10.1016/j.neucom.2013.06.052
Keywords: spiking neural network, temporal coding, delay learning, activity-dependent myelination, spike timing-dependent plasticity, unsupervised learning
Citation: Matsubara T (2017) Conduction Delay Learning Model for Unsupervised and Supervised Classification of Spatio-Temporal Spike Patterns. Front. Comput. Neurosci. 11:104. doi: 10.3389/fncom.2017.00104
Received: 31 May 2017; Accepted: 02 November 2017;
Published: 21 November 2017.
Edited by:
Florentin Wörgötter, University of Göttingen, GermanyReviewed by:
J. Michael Herrmann, University of Edinburgh, United KingdomChristian Leibold, Ludwig-Maximilians-Universität München, Germany
Copyright © 2017 Matsubara. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Takashi Matsubara, bWF0c3ViYXJhQHBob2VuaXgua29iZS11LmFjLmpw