 Martijn Gösgens
Martijn Gösgens Remco van der Hofstad
Remco van der Hofstad Nelly Litvak
Nelly Litvak
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
METHODS article
Front. Complex Syst. , 26 February 2024
Sec. Complex Networks
Volume 2 - 2024 | https://doi.org/10.3389/fcpxs.2024.1331320
This article is part of the Research Topic Insights in Complex Networks View all 5 articles
We present the class of projection methods for community detection that generalizes many popular community detection methods. In this framework, we represent each clustering (partition) by a vector on a high-dimensional hypersphere. A community detection method is a projection method if it can be described by the following two-step approach: 1) the graph is mapped to a query vector on the hypersphere; and 2) the query vector is projected on the set of clustering vectors. This last projection step is performed by minimizing the distance between the query vector and the clustering vector, over the set of clusterings. We prove that optimizing Markov stability, modularity, the likelihood of planted partition models and correlation clustering fit this framework. A consequence of this equivalence is that algorithms for each of these methods can be modified to perform the projection step in our framework. In addition, we show that these different methods suffer from the same granularity problem: they have parameters that control the granularity of the resulting clustering, but choosing these to obtain clusterings of the desired granularity is nontrivial. We provide a general heuristic to address this granularity problem, which can be applied to any projection method. Finally, we show how, given a generator of graphs with community structure, we can optimize a projection method for this generator in order to obtain a community detection method that performs well on this generator.
In complex networks, there often are groups of nodes that are better connected internally than to the rest of the network. In network science, these groups are referred to as communities. These communities often have a natural interpretation: they correspond to friend groups in social networks, subject areas in citation networks, or industries in trade networks. Community detection is the task of finding these groups of nodes in a network. This is typically done by partitioning the nodes, so that each node is assigned to exactly one community. There are many different methods for community detection (Fortunato, 2010; Fortunato and Hric, 2016; Rosvall et al., 2019). Yet, it is not easy to say which method is preferable in a given setting.
Most existing methods in network science detect communities by maximizing a quality function that measures how well a clustering into communities fits the network at hand. One of the most widely-used quality functions is modularity (Newman and Girvan, 2004), which measures the fraction of edges that are inside communities, and compares this to the fraction that one would expect in a random graph without community structure. One of the main advantages of modularity maximization is that it does not require one to specify the number of communities that one wishes to detect. However, this does not mean that modularity automatically detects the desired number of communities: it is known that in large networks, modularity maximization is unable to detect communities below or above a given size (Fortunato and Barthélemy, 2007). This problem is often referred to as the resolution limit, or the granularity problem, of modularity maximization. This problem is often ameliorated by introducing a resolution parameter (Reichardt and Bornholdt, 2006; Traag et al., 2011), which allows one to control the range of community sizes that modularity maximization is able to detect.
One of the most popular algorithms for modularity maximization is the Louvain algorithm (Blondel et al., 2008). This algorithm performs a greedy maximization and is able to find a local maximum of modularity in linear time (empirically) in the number of network edges.
Community detection is closely related to the more general machine learning task of data clustering, as we essentially cluster the nodes based on network topology. In data clustering, the objects to be clustered are typically represented by vectors, and one uses methods like k-means (Jain, 2010) or spectral clustering (Von Luxburg, 2007) to find a spatial clustering of these vectors so that nearby vectors are assigned to the same cluster. Community detection can be considered as an instance of clustering, where the elements to be clustered are network nodes.
In this study, we unify several popular community detection and clustering methods into a single geometric framework. We do so by describing a metric space of clusterings, where we represent each clustering C by a binary vector b(C) indexed over the node pairs, i.e.,
It turns out that many community detection methods fit this framework. In Gösgens et al. (2023a), we prove that modularity maximization is a projection method. In this work, we additionally show that several other popular community detection methods are projection methods. In Section 3, we show that Correlation Clustering (Bansal et al., 2004), the maximization of Markov stability (Delvenne et al., 2010; Lambiotte et al., 2014) and likelihood maximization for several generative models (Avrachenkov et al., 2020) are projection methods. We emphasize that in this paper, we establish equivalences between community detection methods in the strictest mathematical sense. As such, our analytical results are much stronger than merely pointing out that methods are similar or related. Specifically, when we say that two methods are equivalent, we mean that their quality functions f1 and f2 define the exact same rankings of clusterings, so that for all clusterings C1, C2, f1(C1) ≥ f1(C2) holds if and only if f2(C1) ≥ f2(C2).
Some relations between existing community detection methods were already known (Veldt et al., 2018; Newman, 2016). The novelty of this work is that we unify many community detection methods into a single class of projection methods, and uncover the geometric structure that is baked into each of these methods. Furthermore, we demonstrate the following advantages of this geometric perspective.
Firstly, we show that any community detection method that maximizes or minimizes a weighted sum over pairs of vertices is a projection method. This unifies many well-known methods [Correlation Clustering (Bansal et al., 2004), Markov Stability (Delvenne et al., 2010), modularity maximization (Newman and Girvan, 2004), likelihood maximization (Avrachenkov et al., 2020)], and any other current or future method that can be presented in this form. Importantly, the hyperspherical geometry comes with natural measures for clustering granularity (the latitude) and the similarity between clusterings (the correlation distance). These measures are additionally related to the quality function (the angular distance) by the hyperspherical law of cosines, as we explain in Section 2.
Secondly, this geometric framework yields understanding that all community detection methods that are generalized by the projection method, suffer from the same granularity problem. That is, these methods require parameter tuning to produce communities of the desired granularity. In Section 5.2 we use the hyperspherical geometry to derive a general heuristic that addresses this problem. We demonstrate that this heuristic, obtained in our earlier work Gösgens et al. (2023b), can be applied to any projection method.
Thirdly, projection methods can be combined by taking linear combinations of their query vectors. In Section 5.3, we demonstrate how we can efficiently find a linear combination that performs well in a given setting.
As a side remark, we note that in network science, the term “clustering” is also used to refer to the abundance of triangles in real-world networks, which is often quantified by the clustering coefficient (Watts and Strogatz, 1998; Newman, 2003). The presence of communities usually goes hand in hand with an abundance of triangles (Peixoto, 2022). We emphasize that in the present work, we use the term “clustering” to refer to data clustering, and not to the clustering coefficient. Nevertheless, the global clustering coefficient can be expressed in terms of our hyperspherical geometry (Gösgens et al., 2023a).
The remainder of the paper is organized as follows: in Section 2, we describe the projection method and the hyperspherical geometry of clusterings. In Section 3, we prove that several popular community detection methods are projection methods and discuss the implications of these equivalences. In Section 4, we discuss algorithms that can be used to perform the projection step in the projection method. Finally, Section 5 presents methodology for choosing a suitable projection method in given settings. In particular, Section 5.2 discusses how to modify a query mapping in order to obtain a projection method that detects communities of desired granularity, while Section 5.3 demonstrates how we can perform hyperparameter tuning within the projection method. Our implementation of the projection method and the experiments of Section 5 is available on Github1.
This paper discusses the relations between several different community detection methods, that each come with their own notations. We aim to keep notation as consistent as possible, and here we list the most common notation that we will use throughout the paper.
We represent a graph by an n × n adjacency matrix A with node set [n] = {1, … , n} and m edges. We denote the degree of node i by di. We write ∑i<j to denote a sum over all node pairs i, j ∈ [n] with i < j. We denote the number of node pairs by
In this section, we describe the hyperspherical geometry that the projection method relies on. For more details, we refer to Gösgens et al. (2023b). We consider a graph with n nodes and define a clustering as a partition of these nodes. For a clustering C, we define the clustering vector b(C) as the binary vector indexed by the node-pairs, given by
Note that the dimension of this vector is
The vector representation b(C), together with the angular distance, defines a hyperspherical geometry of clusterings.
The clustering into a single community corresponds to the all-one vector b(C) = 1, while the clustering into n singleton communities corresponds to b(C) = −1. These two vectors form opposite poles on the hypersphere. The extent to which a clustering resembles the former or latter is referred to as its granularity: fine-grained clusterings consist of many small communities, while coarse-grained clusterings consist of few and large communities. We measure clustering granularity by the latitude of the clustering vector. For
Thus, quantifying clustering granularity by the latitude is equivalent to quantifying it by the sum of squared cluster sizes.
Borrowing more terminology from geography, for λ ∈ [0, π], we define the parallel
Similarly, we define the meridian of x as the one-dimensional line
For three vectors x, y, r, we can measure the angle on the surface of the hypersphere that the line from x to r makes with the line from y to r. This angle ∠(x, r, z) is given by the hyperspherical variant of the law of cosines:
In particular, when we take r = −1, this angle corresponds to the angle between the meridians of x and y. This angle turns out to have an interesting interpretation, as stated in Theorem 1:
Theorem 1. (Gösgens et al., 2023a). For two vectors x and y that are not multiples of 1, the angle that their meridians make is equal to the arccosine of the Pearson correlation between x and y.
Because of Theorem 1, we call this angle the correlation distance between x and y. Note that da (x, − 1) = ℓ(x), so that the correlation distance is given by
and the Pearson correlation between vectors x and y is thus given by cos dρ(x, y). The correlation coefficient between two clustering vectors b(C), b(T) turns out to be a useful quantity for measuring the similarity between clusterings C and T (Gösgens et al., 2021). There exist many measures to quantify the similarity between two clusterings, but most of these measures suffer from the defect that they are biased towards either coarse- or fine-grained clusterings (Vinh et al., 2009; Lei et al., 2017). The Pearson correlation between two clustering vectors does not suffer from this bias, and additionally satisfies many other desirable properties (Gösgens et al., 2021). Because of that, we will use the Pearson correlation to measure the similarity between clusterings. For clusterings C and T, the Pearson correlation is given by
where mC = |Intra(C)|, mT = |Intra(T)| and mCT = |Intra(C) ∩Intra(T)|. In cases where C and T correspond to the detected and planted (i.e., ground-truth) clusterings, we use ρ(C, T) as a measure of the performance of the community detection.
Above, we have defined the hyperspherical geometry of clusterings. This geometry comes with natural measures for clustering granularity (the latitude ℓ) and similarity between clusterings (the correlation ρ). The idea behind the projection method is that we map a graph to a point in this same geometry, and then find the clustering vector that is closest to that point. For a graph with adjacency matrix A, we denote the vector that it is mapped to by
Definition 1. A community detection method is a projection method if it can be described by the following two-step approach: (1) the graph with adjacency matrix A is first mapped to a query vector q(A); and (2) the query vector is projected to the set of clustering vectors by minimizing da(q(A), b(C)) over the set of clusterings C.
There exist infinitely many ways to map graphs to query vectors. One of the simplest ways is to simply turn the adjacency matrix into a vector like
The vector v (Ar) counts the number of paths of length r between each pair of vertices. In particular,
There are many more ways in which we can construct a query vector based on A. For example, the entry q(A)ij can also depend on the degrees of i and j or even the length of the shortest path between i and j.
Finally, because we are minimizing the angular distance, the length of q(A) is not relevant. It may be natural to normalize all vectors to a Euclidean length
In summary, the hyperspherical geometry comes with three key measures: firstly, the angular distance da (q(A), b(C)) is the quality measure that we minimize in order to detect communities. Secondly, the latitude measures the granularity of a clustering. That is, ℓ(b(T)) measures the granularity of the planted clustering, while ℓ(b(C)) measures the granularity of the detected clustering. Thirdly, the correlation distance between the planted and detected communities dρ(b(C), b(T)) [or its cosine, ρ(C, T) = cos dρ(b(C), b(T))] measures the performance of the detection. In Section 5.2, we will additionally see that dρ(q(A), b(T)) is a useful measure. The angular distance, correlation distance and latitude are related by the hyperspherical law of cosines, given in (4).
In this section, we will prove that the class of projection methods generalizes several community detection methods. We prove that the class of projection methods is equivalent to correlation clustering, and we prove that the remaining methods are subclasses of the class of projection methods. For each of the related clustering and community detection methods, we will provide the query mapping of the corresponding projection method. The relations between the methods that are discussed here are illustrated in Figure 1.
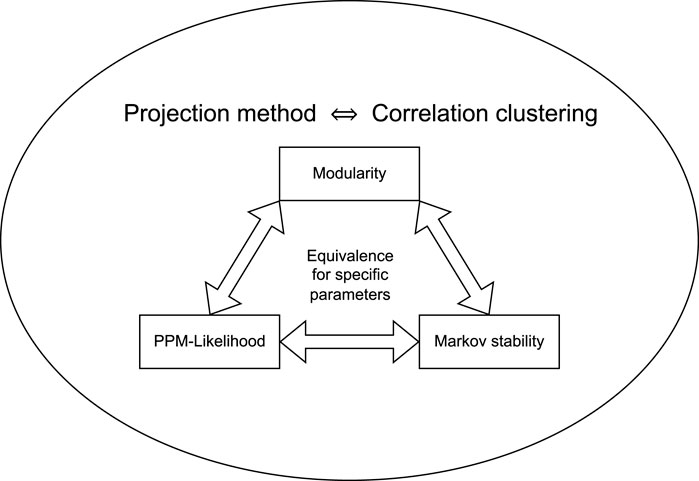
FIGURE 1. A schematic overview of the equivalences between the community detection and clustering methods that are described in Section 3. The projection method is completely equivalent to correlation clustering, while modularity, PPM-likelihood and Markov stability are subsets. For certain parameter choices, these latter three methods are equivalent.
Correlation clustering (Bansal et al., 2004) is a framework for clustering where pairwise similarity and dissimilarity values
Correlation clustering solves the maximization problem
Equivalently, one can express the disagreement of a clustering C with weights
Then (6) can be stated as a minimization problem
Somewhat counter-intuitively, the equivalent formulations (6) and (7) lead to different approximation results. Indeed, for minimization problems (7), an α-approximation guarantee means that for a given α > 1, an optimization algorithm
where C* solves (7). On the other hand, for the maximization problem (6), a β-approximation guarantee means that for a given β < 1, the optimization algorithm
Now, suppose, we have found an α-approximation in (8). Then
which gives some approximation guarantee for the maximization problem, but not of the same multiplicative form as (9).
The motivation for correlation clustering originates from the setting where we are given a noisy classifier that, for each pair of objects, predicts whether they should be clustered together or apart (Bansal et al., 2004). This leads to the simple ±1 version of correlation clustering, where
For the general case where the weights are unconstrained, it is known that maximizing agreement is APX-hard (Charikar et al., 2005), which means that any constant-factor approximation is NP-hard. The same authors do provide a 0.7666-approximation algorithm by rounding the semi-definite programming solution. Note that this does not contradict the APX-hardness result, as semi-definite programming is also NP-hard.
We now prove that correlation clustering corresponds to a projection method:
Lemma 1. Correlation clustering with similarity and dissimilarity values
Proof. Minimizing da (q(CC), b(C)) is equivalent to maximizing
The last term does not depend on C, so we obtain that indeed maximizing ⟨q(CC), b(C)⟩ is equivalent to maximizing CorClustmax (C; w+, w−), as required.□
It is easy to see that any query vector q can also be turned into a correlation clustering objective by taking
The equivalence between correlation clustering and projection methods gives a new interpretation for correlation clustering in terms of hyperspherical geometry, and allows one to transfer hardness results from correlation clustering to projection methods.
While the fields of community detection and correlation clustering are similar, the focus of the two fields is notably different: correlation clustering studies clustering from an algorithmic viewpoint, where the goal is to design algorithms with provable optimization guarantees with respect to the correlation clustering quality function. In contrast, community detection focuses mainly on the choice of the quality function, with the aim to obtain a meaningful clustering into communities. In this context, ‘meaningful’ can mean either statistically significant, or similar to some ground truth clustering. In summary, community detection asks “What quality function to optimize?” while correlation clustering asks “What algorithm is best for optimizing the correlation clustering quality function?.”
Veldt et al. (2018) introduced an interesting variant of correlation clustering methods known as LambdaCC, and showed that it is related to Sparsest Cut, Normalized Cut and Cluster Deletion. They additionally introduce a degree-corrected variant of LambdaCC and prove that it is equivalent to CL-modularity, which we discuss in Section 3.3.
The Markov stability (Delvenne et al., 2010) of a clustering with respect to a network quantifies how likely a random walker is to find itself in the same community at the beginning and end of some time interval. When communities are clearly present in a network, then a random walker will tend to stay inside communities for long time periods and travel between communities infrequently. Markov stability can be defined for various types of discrete- or continuous-time random walks (Lambiotte et al., 2014). Let P(t)ij be the probability that the random walker is at node j at time t if it was at node i at time 0, and denote by
Formally, let C be a clustering and let the clusters be numbered 1, 2, … , k, where k is the number of clusters in C. We denote by H(C) the n × k indicator matrix of the clustering C, where H(C)ia = 1 if node i belongs to the a-th cluster, and H(C)ia = 0 otherwise. Markov stability is defined as
For more details on the definition of Markov stability and its variants, we refer to Delvenne et al. (2010) and Lambiotte and Schaub (2021). We show that maximizing Markov stability is a projection method with respect to the query vector
where
Lemma 2. For any matrix
over the set of all clusterings C is equivalent to minimizing
Proof. The trace is written as
We write
Now, note that H(C)iaH(C)ja = 1 whenever i and j are both in community a, and H(C)iaH(C)ja = 0 otherwise. Therefore, summing over a, we get ∑aH(C)iaH(C)ja = 1 if ij ∈ Intra(C), ji ∈ Intra(C) or i = j. Hence,
Note that the sum ∑i∈[n]Xii does not depend on C, so that omitting it will not affect the optimization. In addition, we can subtract
To conclude, trace maximization is equivalent to maximizing ⟨v(X), b(C)⟩, which is equivalent to minimizing da (v(X), b(C)) over the set of clusterings C. □
It is known (Delvenne et al., 2010) that for a discrete-time Markov chain and t = 1, Markov stability is equivalent to CL-modularity maximization with γ = 1, which we define in Section 3.3. The time parameter t controls the granularity of the detected communities. When t = 0, we get communities of size 1, because P0 = I, so that
Note that the vector and matrix representations of clusterings are related by b(C) = 2v (H(C)H(C)⊤) − 1. This relation makes it possible to re-define the hyperspherical geometry from Section 2 entirely in terms of n × n matrices instead of
The vector representation has the advantage that it omits these unimportant values, which is why we use query vectors instead of query matrices. Nevertheless, the matrix representation allows for an easier analysis in some settings. For example, in Liu and Barahona (2018), the spectral properties of Markov stability are leveraged to create an optimization algorithm.
Modularity maximization is one of the most widely-used community detection methods (Newman and Girvan, 2004). Modularity measures the excess of edges inside communities, compared to a null model; a random graph model without community structure. This null model is usually either the Erdős-Rényi (ER) model or the Chung-Lu [CL, Chung and Lu (2001)] model. Modularity comes with a resolution parameter that controls the granularity of the detected clustering. For the ER and CL null models, modularity is given by
where we recall that di is the degree of node i,
In Gösgens et al. (2023b), we have proven that modularity maximization is a projection method. In addition, the equivalence between modularity maximization and correlation clustering was already proven by Veldt et al. (2018). Hence, Lemma 1, too, establishes that modularity maximization is a projection method. Finally, Newman (2006) shows that modularity can be written in a similar trace-maximization form as (12), which additionally allows one to use Lemma 2 to prove that modularity maximization is a projection method. Either way, we get the following query vectors:
where v(A) is the adjacency vector (the half-vectorization of the adjacency matrix); m is the number of edges; and
The vector
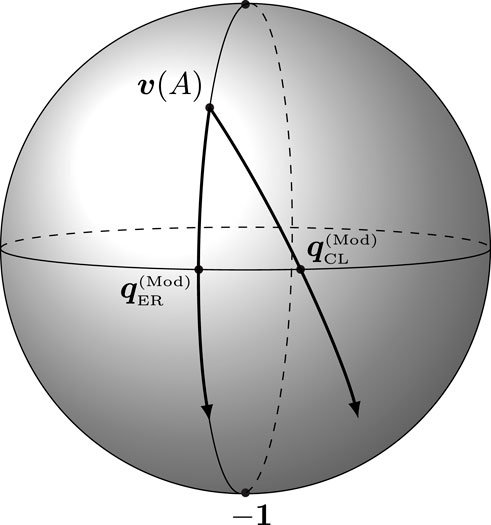
FIGURE 2. Illustration of the geodesics formed by varying the resolution parameter of the modularity vector for a fixed null model. The ER-modularity vectors lie on a single meridian, in contrast to the CL-modularity vectors.
It is well-known that modularity maximization is unable to detect communities that are either too large or too small (Fortunato and Barthélemy, 2007). This behavior is often demonstrated by the ring of cliques, a graph consisting of k cliques of size s each, where each clique is connected to the next one by a single edge. Let us denote the adjacency matrix of this ring of cliques by Ak,s, and let Tk,s denote its natural clustering into k cliques. For fixed γ and s and sufficiently large k, modularity-maximizing algorithms will merge neighboring cliques. Geometrically, this problem can be understood as follows: because N = Θ(k2) and m = Θ(k), (14) tells us that
Note that half of the hypersphere lies within a distance
Note that by (14), the latitude of the ER-modularity vector is a monotone function of the resolution parameter γ. Thus, choosing the resolution parameter is equivalent to setting the latitude of the query vector
Minimizing
In terms of the resolution parameter γ, both these approaches yield γ = Θ(k). Moreover, it can be shown that for both of these approaches, merging neighboring cliques does not decrease
While these two approaches effectively address the granularity problem of modularity for this ring of cliques network, they do not work well in general. We provide a better and more universal approach in Section 5.2.
The Planted Partition Model (PPM) is one of the simplest random graph models that incorporates community structure. In this model, we assume there is some planted clustering into communities (the ground truth partition) and that nodes of the same community are connected with probability pin, while nodes of different communities are connected with probability pout < pin. The likelihood of the PPM was derived in Holland et al. (1983). For an adjacency matrix A, the likelihood that it was generated by a PPM with clustering C, is given by
In this standard PPM, we see that the adjacency matrix has binary entries. In Avrachenkov et al. (2020), the PPM is generalized to allow for pairwise interactions in any measurable set
After taking the logarithm, it is easy to see that this is equal to the maximization variant of correlation clustering with
The standard binary PPM is recovered for
It has been observed that likelihood maximization methods for community detection have a bias towards communities of sizes close to log n (Zhang and Peixoto, 2020; Peixoto, 2021; Gösgens et al., 2023b). This can be understood by linking likelihood maximization to Bayesian inference (Peixoto, 2021): Bayesian community detection methods (Peixoto, 2019) assume a prior distribution over the set of clusterings and then find the clustering with the highest posterior probability. Bayes’ rule reads
Note that the denominator is constant w.r.t. C. If we were to assume a uniform prior, i.e., Prior(C) ∝ 1, then we get Posterior (C|A) ≡Likelihood (A|C). This tells us that likelihood maximization is equivalent to Bayesian inference under the assumption of a uniform prior. The uniform distribution over clusterings has been studied in the field of combinatorics for decades (Harper, 1967; Sachkov, 1997). For example, it is known that, asymptotically as n → ∞, almost all clusters will have sizes close to log n. This explains why likelihood maximization methods have a bias towards clusterings of this granularity.
Not every community detection method fits our hyperspherical framework of community detection. A community detection method is not a projection method if the quality function cannot be monotonously transformed to a sum over intra-cluster pairs. Also, in projection methods, the contribution of a node-pair ij to the sum may depend on the input data (e.g., the graph), but not on the clustering C. In this section, we give a few examples of methods that do not fit this framework.
In Section 3.4 we saw that some likelihood methods fit our hyperspherical framework. However, not all inferential methods are projection methods. For example, suppose we take a PPM where the intra-community density is such that each node has λ intra-community neighbors in expectation. Then, if i and j are in a community of size s, they should be connected with probability λ/(s − 1). Hence, the likelihood function fin in (15) would depend on s, which requires the query vector q(PPM) to depend on C. Our hyperspherical framework does not allow for this. Similarly, the Bayesian stochastic blockmodeling inference from Peixoto (2019) does not fit our hyperspherical framework because the contribution of each node pair ij depends on the size (and label) of the communities of i and j in an intricate way that cannot be captured by a query vector.
The k-means algorithm is arguably the oldest and most well-studied clustering method (Jain, 2010). The aim of k-means is to divide given vectors
where
Therefore, the contribution of each community is again normalized by its size, which is not allowed in our hyperspherical framework.
Another clustering method closely related to k-means is spectral clustering (Von Luxburg, 2007). In spectral clustering, we are given an affinity matrix
The previous section shows that many community detection methods fit our definition of projection methods. A consequence of this is that the same optimization algorithms can be used for each of them. However, it is known that this optimization is NP-hard, and in some forms even APX-hard.
The general problem of correlation clustering (Bansal et al., 2004) and the subproblem of maximizing modularity (Brandes et al., 2007; Meeks and Skerman, 2020) are known to be NP-complete. However, modularity maximization is known to be Fixed-Parameter Tractable (FPT) when parametrized by the size of the minimum vertex cover of the graph (Meeks and Skerman, 2020). Nevertheless, it has been shown that modularity maximization (Dinh et al., 2015) and the maximization variant of correlation clustering (Charikar et al., 2005) are APX-hard, meaning that approximating it to any constant factor is NP-hard. This tells us that for large graphs, it may be prohibitively expensive to compute the clustering that minimizes da (q, b(C)) over the set of clusterings C, for a general query vector q.
Nevertheless, there are some approaches that are able to optimize some of the objectives from Section 3 with surprising efficiency. In particular, the Bayan algorithm (Aref et al., 2022) for modularity maximization is able to find the exact modularity maximum in graphs of up to several thousands nodes within hours. This approach relies on an Integer Linear Programming (ILP) formulation. Similar ILP formulations exist for the general problem of correlation clustering (Bansal et al., 2004). These can be converted to the following general ILP formulation of the projection method: in the projection step, we maximize
subject to b(C)ij ∈ {−1, 1} for all i < j and the constraints
for all i, j, k ∈ [n].
There are many approximate maximization algorithms that are able to quickly find clusterings with high modularity. The Louvain (Blondel et al., 2008) and Leiden (Traag et al., 2019) algorithms are perhaps the most well-known heuristics for modularity maximization. These algorithms iterate over the nodes and make use of the network sparsity to find the greedy relabeling of a node. For a node i, finding this greedy relabeling has complexity
The algorithms proposed in the field of correlation clustering come with theoretical approximation guarantees. Due to the equivalence established in Lemma 1, these algorithms can be applied to modularity maximization. Conversely, modularity maximization algorithms like the Louvain algorithm can be applied to the correlation clustering quality function, allowing for comparisons between these algorithms. Interestingly, while there exist no optimization guarantees for the Louvain algorithm, it does seem to outperform correlation clustering algorithms in such comparisons (Veldt et al., 2018). The Louvain algorithm can be modified to minimize da (q, b(C)) with similar performance. However, the computational complexity may depend on the particular query vector q (Gösgens et al., 2023a). More precisely, our modification of Louvain assumes a query vector of the form q = v (S + L), where
We denote by
The modularity landscape is known to be glassy (Good et al., 2010), which means that there are many local maxima with values close to the global maximum. It is likely that for a general query vector q, the landscape of da (q, b(C)) suffers from a similar glassiness, which explains why its exact minimization is computationally expensive, while its approximate minimization is computationally cheap.
However, the ultimate goal of community detection is not to minimize the distance to some query vector, but to obtain a meaningful clustering of the network nodes. In settings where we have a generative model, like the PPM, the popular LFR benchmark (Lancichinetti et al., 2008), or the more recent ABCD benchmark (Kamiński et al., 2021), a meaningful clustering is a clustering that is similar to the planted clustering. However, there is no guarantee that the planted clustering corresponds to the global (or even a local) optimum. Most prominently, in sparse network models, it is highly unlikely that a locally optimal clustering corresponds to the planted clustering. A simple argument for this is that a sparse network model contains isolated nodes with high probability, and these nodes will not be assigned to their true community in any locally optimal clustering.
Moreover, when applying the Louvain algorithm to graphs from generators, it has been observed that the obtained modularity often exceeds the modularity of the planted clustering. This tells us that simple greedy optimization algorithms like Louvain already result in a clustering vector
In the experiments for this paper, we have applied the Louvain algorithm 4,150 times for different combinations of query mappings and networks. In most of these cases, we chose a query vector using a heuristic, which will be explained in Section 5.2, that is designed to ensure
The important conclusion from these observations is that better optimization algorithms do not necessarily result in more meaningful clusterings. Instead, it seems more important to choose the query vector so minimizers of da (q, b(C)) are close to the ground truth clustering vector b(T).
In the previous section, we have seen that the choice of the quality function (or equivalently, the query vector) may have a bigger impact on the performance of a community detection method than the choice of the optimization algorithm.
Choosing a quality function is difficult because it is hard to compare two quality functions in a meaningful way. However, when restricting to the set of projection methods, the hyperspheric geometry provides us with additional tools to compare the query vectors: for example, we can compute the latitude of the query vector and distances between query vectors. This provides us with some information about the relative position of the query vectors. In addition, these query vectors define a vector space, so that linear combinations of query vectors also correspond to community detection methods. In this section, we discuss several ways to choose a query mapping, which maps graphs to a query vectors q.
We assume that we are given some generator, which produces a tuple (A, T) of an adjacency matrix and a planted clustering (the ground truth). This generator defines a joint distribution on (A, T). In our experiments, we make use of several different generators:
The standard (not generalized) PPM from Section 3.4 is the simplest random graph model with community structure. In this model, there is a planted clustering (partition) of the nodes, and nodes of the same community are more likely to connect to each other than nodes of different communities. We discuss three different variants of the PPM. The first one is a random graph model with homogeneity in both the degree and the community size distribution. We consider k equally sized communities of size n/k (assuming k divides n), and assume that each node has (in expectation) the same number of neighbors inside and outside its community, given by λin and λout, respectively. We then set the connection probabilities as
This way, each node’s degree follows the same distribution, which is a sum of two binomially distributed random variables, which can be approximated by a Poisson distribution with mean λin + λout.
The second variant of the PPM has homogeneous degrees (again, approximately Poisson distributed), but has heterogeneity in the community-size distribution. We draw k community sizes from a power-law distribution with some power-law exponent δ, meaning that the probability of obtaining a size s decays as s−δ. We make sure that each node has on average λin intra-community neighbors and λout neighbors outside of its community, by setting
for nodes in communities of size s, and
where mT is the number of intra-community pairs in the planted clustering T.
To obtain a graph generator with degree heterogeneity and homogeneous community sizes, we assign a weight θi > 0 to each node and use the PPM parametrization that was proposed in Prokhorenkova and Tikhonov (2019). We consider k equally-sized communities of size n/k (again, assuming k divides n). We denote the sum of weights inside the a-th community by Θa and denote the total weight by
and nodes from different communities are connected with probability
With these parameters, a node has on average approximately λin neighbors inside its community and λout neighbors outside its community. In addition, the expected degree of a node i is approximately equal to its weight θi. To obtain a degree distribution with power-law exponent τ, we draw the weights from a distribution with this same power-law exponent.
The Artificial Benchmark for Community Detection (ABCD) is a graph generator that incorporates heterogeneity in both the degree and community-size distribution in order to generate graphs that resemble real-world networks (Kamiński et al., 2021). This is done by generating a sequence of community sizes and degrees with power-law exponents δ and τ. Then, it performs a matching process to assign degrees to nodes inside communities. The generator has a parameter ξ that controls the fraction of edges that are inter-community edges.
We set the parameters of the graph generators as follows: we consider graphs with n = 1,000 nodes and mean degree λin + λout = 8. We choose the parameters of these generators so that each node has (in expectation) λout = 2 neighbors outside its community. For DCPPM and ABCD, we set the power-law exponent of the degree distribution to τ = 2.5. We generate the planted partitions as follows: For PPM and DCPPM, we consider k = 50 communities of size s = 20 each. For ABCD, we set
Modularity and Markov stability both have a parameter that controls the granularity of the detected clusterings. Modularity comes with a resolution parameter γ, and increasing γ typically results in detecting communities of smaller sizes. However, it is unclear how this resolution parameter should be chosen in order to detect clusterings of the desired granularity. With ‘desired’, we mean that the granularity of the detected clustering is similar to the granularity of the planted clustering in cases where the graph is drawn from a graph generator. For ER-modularity, there is a particular value of γ(pin, pout) for which maximizing ER-modularity is equivalent to maximizing the likelihood of a PPM with parameters pin, pout. However, as mentioned in Section 3.4, it is known that maximizing this likelihood is biased towards communities of logarithmic size. Markov stability comes with a time parameter t which controls the granularity of the detected clustering. Increasing t results in detecting larger communities. Again, it is unclear how this time should be chosen in order to detect communities of the desired granularity.
Within the framework of projection methods, a natural measure of the granularity of a clustering C is the latitude ℓ(b(C)) of the corresponding clustering vector. Hence, in cases where the graph is drawn from a generator with a planted clustering T, a clustering with ‘desired’ granularity is a clustering C with ℓ(b(C)) ≈ ℓ(b(T)). In turn, the desired ℓ(b(C)) can be obtained by choosing the right latitude of a query vector. How to make this choice is the topic of the remainder of this Section 5.2.
The simplest way to change a query vector in order to detect clusterings of coarser granularity, is to add a multiple of 1. That is, a new query vector q′ = q + c ⋅1 for some c > 0. The vectors q′ and q lie on the same meridian, i.e., dρ(q, q′) = 0, while q′ is further away from −1, so that ℓ(q′) > ℓ(q). Hence, adding c ⋅1 is equivalent to projecting the vector q to a different latitude, i.e.,
In Gösgens et al. (2023a), we proposed a general heuristic that prescribes this latitude as a function of λT = ℓ(b(T)) and θ = dρ(q, b(T)). This granularity heuristic prescribes
We denote the query vector obtained by applying the granularity heuristic, by
We briefly illustrate how solving da (q*, b(T)) = θ leads to (17): we use (4) to express cos θ in terms of λT, λ* and da (q*, b(T)) like
Squaring both sides and making the substitutions cos da (q*, b(T)) = cos θ and sin2λ* = 1 − cos2λ* yields
This can be rewritten to the following quadratic equation in cos λ*:
which has solutions
This gives two possible solutions for λ*, one of which corresponds to (17). We refer to Gösgens et al. (2023b) for the remaining details of the derivation and the experimental validation of this heuristic.
Note that cos θ is the Pearson correlation coefficient between q and b(T), and can be considered a measure of how much information q carries of the clustering T. As a special case, note that cos θ = 1 implies that q and b(T) lie on the same meridian, and we can see that λ*(λT, 0) = λT, so that q* = b(T). In the other extreme, where q is not correlated with b(T) (i.e., θ = π/2), we have λ*(λT, π/2) = π/2, so that the resulting query vector lies on the equator (just like the modularity vector for γ = 1). For θ ∈ (0, π/2), the heuristic latitude λ*(λT, θ) is between λT and π/2.
To compute the heuristic latitude choice in (17), we need estimates of λT and θ, which requires some knowledge of the planted clustering T. It might seem that requiring this knowledge of the planted clustering defeats the purpose of community detection. However, requiring partial knowledge of the planted clustering is not uncommon in other community detection methods, such as likelihood-based methods (Newman, 2016; Prokhorenkova and Tikhonov, 2019). Moreover, when we have access to the graph generator, we can use this to estimate the means of λT and θ, and use these estimates in (17).
In Gösgens et al. (2023a), we have shown that this granularity heuristic works well for several query vectors q, including modularity vectors. In this section, we demonstrate that this heuristic also works well for Markov stability vectors. For t ∈ {1, … , 5}, we consider the projection method with query mapping
To quantify the quality of the approximation ℓ(b(C)) ≈ ℓ(b(T)), we define the relative granularity error as ℓ(b(C))/ℓ(b(T)) − 1, which we want to be close to 0. Positive values indicate that the detected clustering is more coarse-grained than the planted clustering, while negative values indicate that the detected clustering is too fine-grained. We measure the similarity between the detected and planted communities by the correlation coefficient ρ(C, T) = cos dρ(b(C), b(T)). Values close to 1 indicate that the clusterings are highly similar, while values close to zero indicate that C is not more similar to T than a random relabeling of C.
For the PPM, HPPM, DCPPM and ABCD graph generators, the results are shown in Figures 3–6. For each generator, we generate 50 graphs and show boxplots of the outcomes for each of the query mappings.
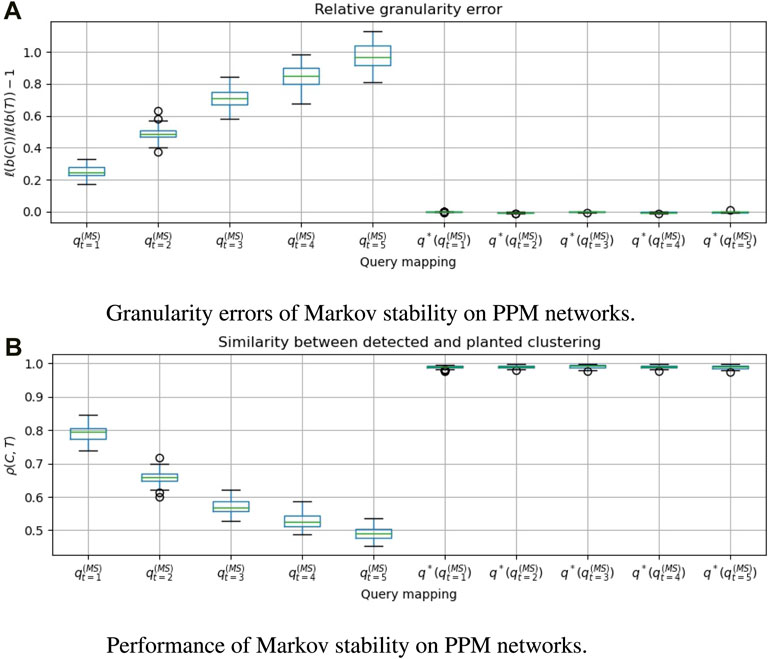
FIGURE 3. For 50 graphs drawn from the Planted Partition Model (PPM), we evaluate Markov stability with time t ∈ [5], and compare the clusterings that are obtained with and without applying the granularity heuristic. q*(⋅) denotes the heuristic. A positive granularity error indicates that the detected clustering is coarser than the planted clustering. ρ(C, T) = cos dρ(b(C), b(T)) is the Pearson correlation between the clustering vectors, which we wish to make close to 1. We see that
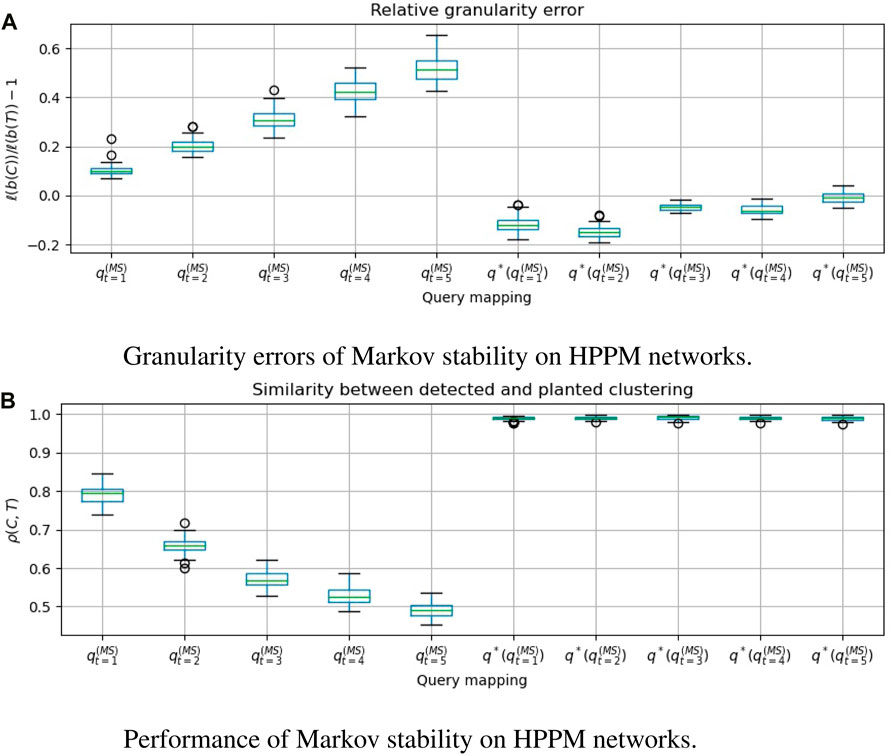
FIGURE 4. For 50 graphs drawn from a Heterogeneously-sized Planted Partition Model (HPPM), we evaluate Markov stability with time t ∈ [5], and compare the clusterings that are obtained with and without applying the granularity heuristic. q*(⋅) denotes the heuristic. A positive granularity error indicates that the detected clustering is coarser than the planted clustering. ρ(C, T) = cos dρ(b(C), b(T)) is the Pearson correlation between the clustering vectors, which we wish to make close to 1. We see that
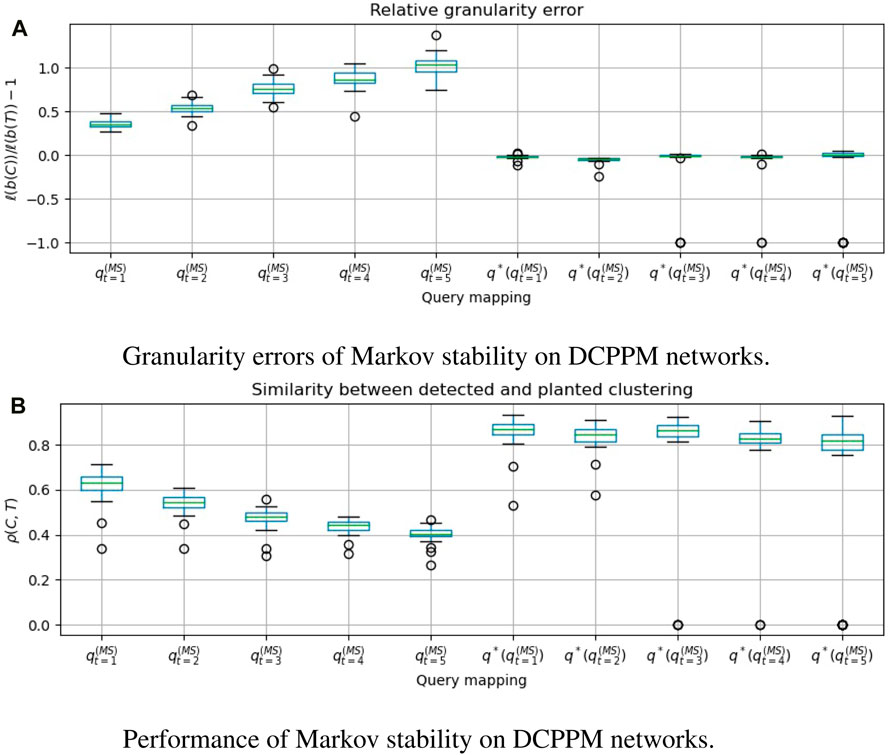
FIGURE 5. For 50 graphs drawn from the Degree-Corrected Planted Partition Model (DCPPM), we evaluate Markov stability with time t ∈ [5], and compare the clusterings that are obtained with and without applying the granularity heuristic. q*(⋅) denotes the heuristic. A positive granularity error indicates that the detected clustering is coarser than the planted clustering. ρ(C, T) = cos dρ(b(C), b(T)) is the Pearson correlation between the clustering vectors, which we wish to make close to 1. We see that
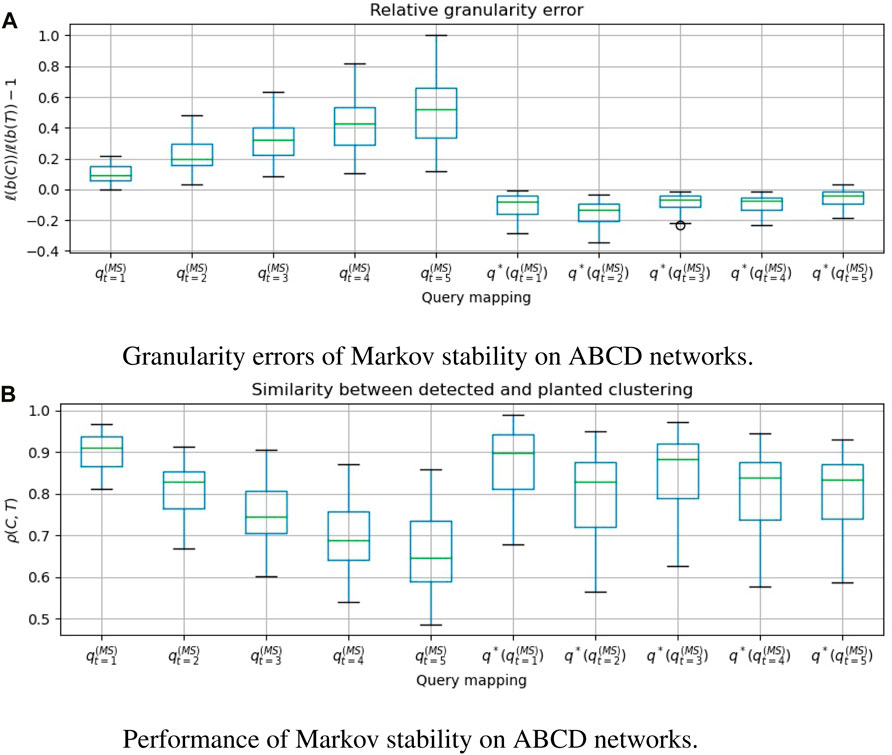
FIGURE 6. For 50 graphs drawn from the Artificial Benchmark for Community Detection (ABCD), we evaluate Markov stability with time t ∈ [5], and compare the clusterings that are obtained with and without applying the granularity heuristic. q*(⋅) denotes the heuristic. A positive granularity error indicates that the detected clustering is coarser than the planted clustering. ρ(C, T) = cos dρ(b(C), b(T)) is the Pearson correlation between the clustering vectors, which we wish to make close to 1. We see that
In Figures 3a, 4a, 5a, 6a, we see that the granularity heuristic indeed leads to detecting clusterings with granularity closer to the granularity of the planted clustering. For almost all cases, we see that the median relative granularity error after applying the heuristic is closer to zero than before applying the heuristic. The only exception is t = 1 for the HPPM generator. We see that overall, the granularity heuristic results in clusterings that are slightly more fine-grained than the planted clustering.
In addition, Figures 3b, 4b, 5b, 6b show that the granularity heuristic typically leads to an increased similarity to the planted clustering. The only two exceptions are HPPM and ABCD for t = 1, where the granularity heuristic results in slightly lower performance. For the PPM generator, Figure 3B shows that for each of the values of t, the detection is near-perfect (all similarities are higher than ρ = 0.97). For the HPPM and DCPPM generators, Figures 4B, 5B show that the heterogeneity in the community sizes and degrees result in slightly lower performance on these generators.
Figures 3a, 4a, 5a, 6a show that for the query vector
Note that the running time of the Louvain algorithm for Markov Stability vectors depends on the sparsity of the transition matrix P(t). To illustrate: for t = 1, the transition matrix has the same number of positive entries as the adjacency matrix, and (our implementation of) the Louvain algorithm runs in around 5 s. In contrast, for t = 5, we have P (5)ij > 0 for each pair of nodes that is connected by a path of length 5, which leads to a much denser matrix, and the Louvain algorithm takes roughly 200 s per instance. While the continuous-time variant of Markov stability may be able to detect clusterings of finer granularity, the corresponding transition matrix satisfies P(t)ij > 0 whenever i and j are connected by any path. This leads to a much denser matrix, so that the Louvain algorithm will take even more time.
In Section 3, we have seen that the class of projection methods contains many interesting community detection methods. A further advantage of projection methods is that we can combine different community detection methods by taking linear combinations of their query mappings. On the one hand, this yields infinitely many community detection methods, and gives a lot of flexibility. On the other hand, this begs the question how to choose a suitable query mapping for a task at hand. For instance, are there preferable choices for a particular graph generator? In this section, we will partially address this question by showing how one can tune a projection method to a graph generator, in order to maximize the performance on graphs sampled from this generator.
We assume that we are given a generator that produces graphs with their community assignments. We consider linear combinations of a few query mappings and perform a grid search to find the coefficients that yield the best query vector. A grid search is a standard approach for hyperparameter tuning, where we discretize each of the parameter intervals and evaluate all possible combinations. To avoid overfitting, one usually generates two different sets of graphs: a training set and a validation set. The training set is used to find the best hyperparameter combination, while the validation set is used to get an unbiased estimate of the performance of the obtained hyperparameters values.
To demonstrate this method, we show how we can optimize a projection method for the ABCD graph generator from the previous section. To allow for comparison with this previous section, we consider the same 50 ABCD graphs as the validation set. For the training set, we generate 15 new ABCD graphs from this same generator.
We consider query vectors that are linear combinations of four vectors: the constant vector 1 (to control granularity), the adjacency vector v(A), the degree-product vector d(A) and the Jaccard vector j(A). The latter is defined as follows: let N(i) denote the neighborhood of i. We follow the convention that i ∈ N(i) for all i ∈ [n]. Then j(A)ij is the Jaccard similarity between the neighborhoods of i and j:
We consider query vectors that are linear combinations of these four vectors, q = c1 ⋅1 + cA ⋅v(A) + cd ⋅d(A) + cj ⋅j(A). Since in the hyperspherical geometry, the length of the query vector does not affect the detected clustering, we can reduce the number of hyperparameters by one. Assuming that the best combination has cA > 0, we set cA = 1, thereby making the grid search more efficient. Moreover, for most values of the coefficient c1, the detection method will result in clusterings of a wrong granularity. Thus, instead of fitting c1, we use the granularity heuristic from Section 5.2. Then we are left with the following parametrization of query vectors:
This leaves two hyperparameters to be tuned by the grid search. Note that the vector d(A) is a correction term for the degrees. Because of that, the best performance is likely to be found for cd ≤ 0. We choose the interval cd ∈ [−6, 0], which we discretize in steps of
The results are shown in Figure 7. We see that there is a large region where the method performs well. In particular, the best-performing coefficients are
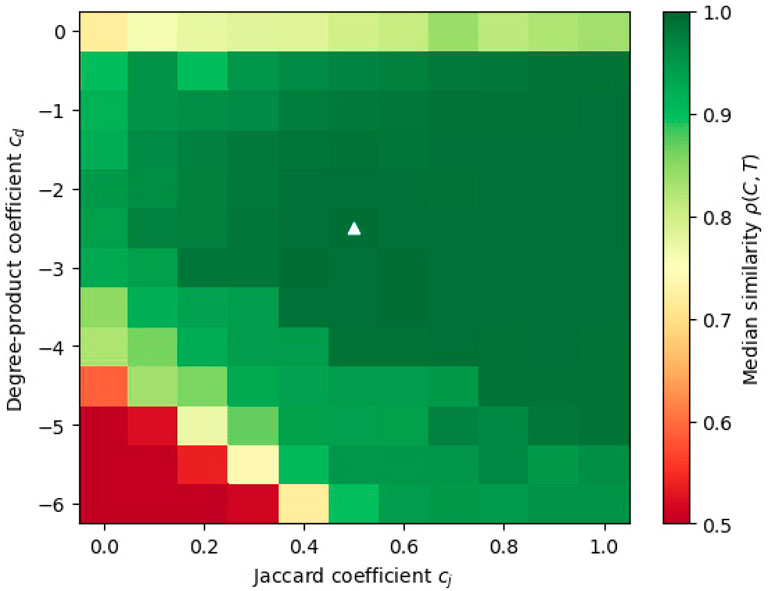
FIGURE 7. A heatmap of the median performance (similarity between the detected and planted clusterings, as measured by ρ(C, T)) for different linear combinations of query mappings. The medians are computed over 10 samples of ABCD graphs, with the same parameters as in the experiments of Section 5.2. The best performance is marked with a white triangle.
Table 1 compares the performance of the trained projection method to other projection methods. We see that Markov stability with time t = 1 performs best among Markov stability methods (without the granularity heuristic), and also outperforms PPM- and DCPPM-likelihood maximization (Newman, 2016). Note that Markov stability with t = 1 is equivalent to CL-modularity maximization with γ = 1. This query mapping achieved a median performance of ρ = 0.912, which is good, but significantly lower than the performance of our optimized query mapping. In addition, we see that the optimized projection method outperforms the other projection methods in terms of latitude error due to the latitude heuristic. This is despite the fact that the likelihood-based methods require comparable knowledge about the generative process as our latitude heuristic.

TABLE 1. The performance of several projection methods on a set of 50 ABCD graphs (the same set of graphs as in Figure 6).
In this demonstration, we have kept the setup relatively simple by taking combinations of only 4 vectors, reducing this to two coefficients. We did this for simplicity and so that we can visualize the performance on the training set by a two-dimensional heatmap. This already led to strong performance. It is likely that we can improve performance even further by including a larger number of query vectors, and using a grid search instead of the granularity heuristics to determine the coefficient c1. The obvious downside is that optimization for a larger number of parameters becomes computationally more demanding, and one must increase the size of the training set to avoid overfitting.
To conclude, we have shown that the class of projection methods unifies many popular community detection methods and is expressive enough to fit realistic benchmark generators like ABCD. This work paves the way to many follow-up research. On the one hand, there are many algorithmic questions: what projection algorithms work well for what query vectors? Are there sets of query vectors for which the minimization of da (q, b(C)) is not NP-hard? On the other hand, there are also several methodological questions: how do the best-performing coefficients of the linear combination depend on the network properties? For example, how does the best-performing coefficient cd depend on the mean and variance of the degree distribution?
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/MartijnGosgens/hyperspherical_community_detection.
MG: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Software, Validation, Writing–original draft, Writing–review and editing. RvdH: Conceptualization, Methodology, Supervision, Writing–review and editing, Formal Analysis, Funding acquisition. NL: Conceptualization, Investigation, Methodology, Supervision, Writing–review and editing, Formal Analysis, Funding acquisition.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Netherlands Organisation for Scientific Research (NWO) through the Gravitation NETWORKS grant no. 024.002.003.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declared that they were an editorial board member of Frontiers, at the time of submission. This had no impact on the peer review process and the final decision.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
1The code is available at https://github.com/MartijnGosgens/hyperspherical_community_detection.
2There are four combinations of coefficients that achieve this exact same median performance. We choose this one as it has the highest mean performance.
Aref, S., Chheda, H., and Mostajabdaveh, M. (2022). The bayan algorithm: detecting communities in networks through exact and approximate optimization of modularity. arXiv preprint arXiv:2209.04562.
Aref, S., Mostajabdaveh, M., and Chheda, H. (2023). Heuristic modularity maximization algorithms for community detection rarely return an optimal partition or anything similar. arXiv preprint arXiv:2302.14698.
Avrachenkov, K., Dreveton, M., and Leskelä, L. (2020). Community recovery in non-binary and temporal stochastic block models. arXiv preprint arXiv:2008.04790.
Bansal, N., Blum, A., and Chawla, S. (2004). Correlation clustering. Mach. Learn. 56, 89–113. doi:10.1023/b:mach.0000033116.57574.95
Blondel, V. D., Guillaume, J.-L., Lambiotte, R., and Lefebvre, E. (2008). Fast unfolding of communities in large networks. J. Stat. Mech. theory Exp. 2008, P10008. doi:10.1088/1742-5468/2008/10/p10008
Brandes, U., Delling, D., Gaertler, M., Gorke, R., Hoefer, M., Nikoloski, Z., et al. (2008). On modularity clustering. IEEE Trans. Knowl. data Eng. 20, 172–188. doi:10.1109/tkde.2007.190689
Charikar, M., Guruswami, V., and Wirth, A. (2005). Clustering with qualitative information. J. Comput. Syst. Sci. 71, 360–383. doi:10.1016/j.jcss.2004.10.012
Chawla, S., Makarychev, K., Schramm, T., and Yaroslavtsev, G. (2015). “Near optimal lp rounding algorithm for correlationclustering on complete and complete k-partite graphs,” in Proceedings of the forty-seventh annual ACM symposium on Theory of computing, 219–228.
Chung, F., and Lu, L. (2001). The diameter of sparse random graphs. Adv. Appl. Math. 26, 257–279. doi:10.1006/aama.2001.0720
Delvenne, J.-C., Yaliraki, S. N., and Barahona, M. (2010). Stability of graph communities across time scales. Proc. Natl. Acad. Sci. 107, 12755–12760. doi:10.1073/pnas.0903215107
Dhillon, I. S., Guan, Y., and Kulis, B. (2004). “Kernel k-means: spectral clustering and normalized cuts,” in Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, 551–556.
Dinh, T. N., Li, X., and Thai, M. T. (2015). “Network clustering via maximizing modularity: approximation algorithms and theoretical limits,” in 2015 IEEE International Conference on Data Mining (IEEE), 101–110.
Fortunato, S. (2010). Community detection in graphs. Phys. Rep. 486, 75–174. doi:10.1016/j.physrep.2009.11.002
Fortunato, S., and Barthélemy, M. (2007). Resolution limit in community detection. Proc. Natl. Acad. Sci. 104, 36–41. doi:10.1073/pnas.0605965104
Fortunato, S., and Hric, D. (2016). Community detection in networks: a user guide. Phys. Rep. 659, 1–44. doi:10.1016/j.physrep.2016.09.002
Good, B. H., De Montjoye, Y.-A., and Clauset, A. (2010). Performance of modularity maximization in practical contexts. Phys. Rev. E 81, 046106. doi:10.1103/physreve.81.046106
Gösgens, M., van der Hofstad, R., and Litvak, N. (2023a). “Correcting for granularity bias in modularity-based community detection methods,” in Proceedings Algorithms and Models for the Web Graph: 18th International Workshop, WAW 2023, Toronto, ON, Canada, May 23–26, 2023 (Springer), 1–18.
Gösgens, M., van der Hofstad, R., and Litvak, N. (2023b). The hyperspherical geometry of community detection: modularity as a distance. J. Mach. Learn. Res. 24, 1–36.
Gösgens, M. M., Tikhonov, A., and Prokhorenkova, L. (2021). “Systematic analysis of cluster similarity indices: how to validate validation measures,” in International Conference on Machine Learning, Cambridge, Massachusetts, USA (PMLR), 3799–3808.
Harper, L. (1967). Stirling behavior is asymptotically normal. Ann. Math. Statistics 38, 410–414. doi:10.1214/aoms/1177698956
Holland, P. W., Laskey, K. B., and Leinhardt, S. (1983). Stochastic blockmodels: first steps. Soc. Netw. 5, 109–137. doi:10.1016/0378-8733(83)90021-7
Jain, A. K. (2010). Data clustering: 50 years beyond k-means. Pattern Recognit. Lett. 31, 651–666. doi:10.1016/j.patrec.2009.09.011
Kamiński, B., Prałat, P., and Théberge, F. (2021). Artificial benchmark for community detection (abcd)—fast random graph model with community structure. Netw. Sci. 9, 153–178. doi:10.1017/nws.2020.45
Lambiotte, R., Delvenne, J.-C., and Barahona, M. (2014). Random walks, markov processes and the multiscale modular organization of complex networks. IEEE Trans. Netw. Sci. Eng. 1, 76–90. doi:10.1109/tnse.2015.2391998
Lambiotte, R., and Schaub, M. T. (2021). Modularity and dynamics on complex networks. Cambridge University Press.
Lancichinetti, A., Fortunato, S., and Radicchi, F. (2008). Benchmark graphs for testing community detection algorithms. Phys. Rev. E 78, 046110. doi:10.1103/physreve.78.046110
Lei, Y., Bezdek, J. C., Romano, S., Vinh, N. X., Chan, J., and Bailey, J. (2017). Ground truth bias in external cluster validity indices. Pattern Recognit. 65, 58–70. doi:10.1016/j.patcog.2016.12.003
Liu, Z., and Barahona, M. (2018). Geometric multiscale community detection: markov stability and vector partitioning. J. Complex Netw. 6, 157–172. doi:10.1093/comnet/cnx028
Meeks, K., and Skerman, F. (2020). The parameterised complexity of computing the maximum modularity of a graph. Algorithmica 82, 2174–2199. doi:10.1007/s00453-019-00649-7
Newman, M. E. (2003). Properties of highly clustered networks. Phys. Rev. E 68, 026121. doi:10.1103/physreve.68.026121
Newman, M. E. (2006). Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E 74, 036104. doi:10.1103/physreve.74.036104
Newman, M. E. (2016). Equivalence between modularity optimization and maximum likelihood methods for community detection. Phys. Rev. E 94, 052315. doi:10.1103/physreve.94.052315
Newman, M. E., and Girvan, M. (2004). Finding and evaluating community structure in networks. Phys. Rev. E 69, 026113. doi:10.1103/physreve.69.026113
Peixoto, T. P. (2019). Bayesian stochastic blockmodeling. Adv. Netw. Clust. blockmodeling, 289–332. doi:10.1002/9781119483298.ch11
Peixoto, T. P. (2021). Descriptive vs. inferential community detection: pitfalls, myths and half-truths arXiv preprint arXiv:2112.00183.
Peixoto, T. P. (2022). Disentangling homophily, community structure, and triadic closure in networks. Phys. Rev. X 12, 011004. doi:10.1103/physrevx.12.011004
Prokhorenkova, L., and Tikhonov, A. (2019). “Community detection through likelihood optimization: in search of a sound model,” in The World Wide Web Conference, 1498–1508.
Reichardt, J., and Bornholdt, S. (2006). Statistical mechanics of community detection. Phys. Rev. E 74, 016110. doi:10.1103/physreve.74.016110
Rosvall, M., Delvenne, J.-C., Schaub, M. T., and Lambiotte, R. (2019). Different approaches to community detection. Adv. Netw. Clust. blockmodeling 105–119, 105–119. doi:10.1002/9781119483298.ch4
Sachkov, V. N. (1997). Probabilistic methods in combinatorial analysis, 56. Cambridge University Press.
Traag, V. A., Van Dooren, P., and Nesterov, Y. (2011). Narrow scope for resolution-limit-free community detection. Phys. Rev. E 84, 016114. doi:10.1103/physreve.84.016114
Traag, V. A., Waltman, L., and Van Eck, N. J. (2019). From louvain to leiden: guaranteeing well-connected communities. Sci. Rep. 9, 5233. doi:10.1038/s41598-019-41695-z
Veldt, N., Gleich, D. F., and Wirth, A. (2018). A correlation clustering framework for community detection. Proceedings of the 2018 World Wide Web Conference, 439–448.
Vinh, N. X., Epps, J., and Bailey, J. (2009). “Information theoretic measures for clusterings comparison: is a correction for chance necessary?,” in Proceedings of the 26th annual international conference on machine learning, 1073–1080.
Von Luxburg, U. (2007). A tutorial on spectral clustering. Statistics Comput. 17, 395–416. doi:10.1007/s11222-007-9033-z
Watts, D. J., and Strogatz, S. H. (1998). Collective dynamics of ‘small-world’networks. Nature 393, 440–442. doi:10.1038/30918
Keywords: community detection, clustering, modularity, Markov stability, Correlation clustering, granularity
Citation: Gösgens M, van der Hofstad R and Litvak N (2024) The projection method: a unified formalism for community detection. Front. Complex Syst. 2:1331320. doi: 10.3389/fcpxs.2024.1331320
Received: 31 October 2023; Accepted: 05 February 2024;
Published: 26 February 2024.
Edited by:
Claudio Castellano, Istituto dei Sistemi Complessi (ISC-CNR), ItalyReviewed by:
Sadamori Kojaku, Binghamton University, United StatesCopyright © 2024 Gösgens, van der Hofstad and Litvak. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Martijn Gösgens, cmVzZWFyY2hAbWFydGlqbmdvc2dlbnMubmw=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.