 Pavlos S. Bouzinis
Pavlos S. Bouzinis Panagiotis D. Diamantoulakis
Panagiotis D. Diamantoulakis George K. Karagiannidis
George K. Karagiannidis- Department of Electrical and Computing Engineering, Wireless Communication and Information Processing Group (WCIP), Aristotle University of Thessaloniki, Thessaloniki, Greece
Federated Learning (FL) is a promising decentralized machine learning technique, which can be efficiently used to reduce the latency and deal with the data privacy in the next 6th generation (6G) of wireless networks. However, the finite computation and communication resources of the wireless devices, is a limiting factor for their very low latency requirements, while users need incentives for spending their constrained resources. In this direction, we propose an incentive mechanism for Wireless FL (WFL), which motivates users to utilize their available radio and computation resources, in order to achieve a fast global convergence of the WFL process. More specifically, we model the interaction among users and the server as a Stackelberg game, where users (followers) aim to maximize their utility/pay-off, while the server (leader) focuses on minimizing the global convergence time of the FL task. We analytically solve the Stackelberg game and derive the optimal strategies for both the server and the user set, corresponding to the Stackelberg equilibrium. Following that, we consider the presence of malicious users, who may attempt to mislead the server with false information throughout the game, aiming to further increase their utility. To alleviate this burden, we propose a deep learning-aided secure mechanism at the servers’ side, which detects malicious users and prevents them from participating into the WFL process. Simulations verify the effectiveness of the proposed method, which result in increased users’ utility and reduced global convergence time, compared with various baseline schemes. Finally, the proposed mechanism for detecting the users’ behavior seems to be very promising in increasing the security of WFL-based networks.
1 Introduction
The 6th generation (6G) of wireless networks, is envisioned to support ubiquitous artificial intelligence services and be the evolution of wireless networks from “connected things” to “intelligent things” Letaief et al. (2019). Conventional machine learning approaches are usually conducted in a centralized manner, where a central entity collects the generated data, and performs the training. However, the increasing computing capabilities of wireless devices as well as the sensitive data-privacy concerns have paved the way for a promising decentralized solution, the Federated Learning (FL) Konečnỳ et al. (2016), McMahan et al. (2017). The salient feature of FL lies in the retention of the locally generated data at the device, thus, each learner individually trains the model locally without uploading any raw data to the server. Hence, the learners collaboratively build a shared model with the aid of a server, whose role is to update and redistribute the global training parameters to the learners. In this manner, the user data privacy is preserved, while the communication traffic is reduced leading to low latency, due to the absence of raw and big volume data transfer Li et al. (2020). In accordance with the key requirements of 6G networks, it is evident that 6G could be empowered by FL for ensuring low-latency and privacy preserving intelligent services Bouzinis et al. (2022a), Bouzinis et al. (2022b).
1.1 Motivation and State-of-the-Art
In the context of wireless networks, several studies have investigated the improvement of FL, in terms of model accuracy, energy efficiency, and reduced latency. For instance, the authors in Chen et al. (2020b), Shi et al. (2020b), minimized the training loss under latency and energy requirements, by jointly optimizing the computation and radio resources, as well as the user scheduling. Moreover, in another wireless FL (WFL) setup, the users’ total energy consumption and/or latency minimization, have been investigated in Tran et al. (2019), Chen et al. (2020a), Yang et al. (2021).
Although, the aforementioned research works have contributed for the efficient deployment of FL in wireless networks, there is still an open challenge regarding users’ willingness to participate into the WFL process. In particular, the users should be motivated, in order to contribute in this process with their limited energy resources. Thus, incentive designs are requisite, in order to attract the clients to be involved in this resource-consuming procedure. The considered incentives, could be expressed as a reward provided by the task publisher. For example, in Kang et al. (2019) an incentive mechanism for reliable FL was proposed, based on the contract theory, while a reputation metric was introduced, in order to measure the data-wise reliability and trustworthiness of the clients. In similar direction, authors in Lim et al. (2020) proposed an hierarchical incentive mechanism for FL. In the first level, a contract theory approach was proposed to incentivize workers to provide high quality and quantity data, while in the second level, a coalitional game approach was adopted among the model owners. In Zhan et al. (2020), a deep-reinforcement learning incentive mechanism for FL has been constructed. More specifically, a Stackelberg game was formulated, in order to obtain the optimal pricing strategy of the task publisher and the optimal training strategies of the edge nodes, which constituted the client set. Moreover, in Sarikaya and Ercetin (2019), authors formulated a Stackelberg game among workers and the task publisher, aiming to minimize the latency of a FL communication round, while in Khan et al. (2020), a Stackelberg game was formulated for FL in edge networks. Finally, in the context of a crowdsourcing framework, authors in Pandey et al. (2020) proposed a Stackelberg game for motivating the FL users to generate high accuracy models, while the server focused on providing high global model accuracy side. However, none of the above works designed an incentive mechanism, by taking into account the minimization of the FL global convergence time, which can finally result in achieving decreased delay. It should be also highlighted, that the number of scheduled devices affects the convergence speed of the global model, and its effects have not been investigated. More specifically, the trade-off between the duration of a global WFL round and the number of total rounds until convergence, has not been well-studied in the context of incentive criteria. Finally, it should be noted that when examining clients’ strategies, all previous works did not consider the joint optimization of the communication and computation resources, which can further enhance the performance and head towards meeting the strict latency requirements of 6G networks.
Also, the modeling of the interaction among the server and the users becomes more complicated when some of the users are not legitimate, degrading the overall quality of experience. However, this issue has not been considered by the existing literature, despite the progress in the development of techniques that have the potential to mitigate similar threats, such as deep learning. Recently, the application of deep learning into wireless communications has sparked widespread interest Zappone et al. (2019), while it is expected to realize the vision of 6G, which will heavily rely on AI services. For instance, deep learning has been used for simplifying the physical layer operations, such as data detection, decoding, channel estimation, as well as for resource allocation tasks and efficient optimization Sun et al. (2017). Owing to its encouraging results, deep learning may be appropriate for ensuring an unimpeachable interaction among the users and the server, as implied by the incentive mechanism during the WFL procedure, by detecting abnormal or malicious users’ behaviors.
1.2 Contribution
Driven by the aforementioned considerations, we propose a novel incentive mechanism for WFL, by modeling the interaction among users and the server/task publisher during an WFL task, by using tools from game theory. In particular, users’ objective goal is to maximize their utility, which is subject to their individual completion time of the WFL task and the energy consumption for local training and parameter transmission, given a reward for the timely task completion and an energy cost, respectively. On the other hand, the server aims to minimize the global convergence time of the WFL process. The aforementioned interaction between the server/task publisher and the users corresponds to a Stackelberg game, where the server acts as the leader of the game and announces the delay tolerance, and the users/clients constitute the set of followers and receive their decisions based on the reward given by the server and the announced delay tolerance. The convergence time is a metric of paramount importance for providing low-latency intelligent services in 6G networks, while its minimization has not been examined in the aforementioned works. Therefore, one of the main goals of the proposed incentive mechanism is to accelerate the convergence of the WFL procedure. Moreover, the convergence time is highly related with the number of communication rounds between the users and the task publisher, which is a function of the number of participating users. Hence, during the Stackelberg game, we show that the task publisher should urge a certain number of users for participation, in order to achieve the minimum convergence speed. This fact highlights the significance of user scheduling during the game, which aims to mitigate the straggler effect, i.e., excluding clients who are responsible for the occurrence of long delays. To this end, we consider the scenario where malicious users are involved into the game, which may strive to misinform the server regarding their consumed resources and possibly benefit from this action. In order to avert such behaviors, we propose the use of a Deep Neural Network (DNN), which aims to classify the users’ identity, as honest or malicious, based on resource-related observations. Through this approach, we aim to guarantee an irreproachable interaction among the users and the server, and exclude clients with malicious actions from the FL process.
The contributions of this work can be summarized as follows:
1) We construct an incentive mechanism, for motivating users to utilize their resources during a FL task, through the improvement of their utility, while the task publisher aims to minimize the global convergence time of the WFL process.
2) We formulate and solve a Stackelberg game for the considered user-server interaction. In particular, we obtain the optimal strategy of the users for maximizing their utility, i.e., the optimal adjustment of both computation and communication resources. Furthermore, we obtain the task publisher’s optimal strategies for minimizing the global convergence time. This translates to the selection of the optimal delay tolerance during a WFL communication round, based on the number of scheduled users.
3) During the user-server interaction via the Stackelberg game, we assume that malicious users may announce false information regarding their utilized resources, aiming to mislead the server and increase their pay-off. To tackle with this issue, we construct a security mechanism at the servers’ side, whose role is to recognize false announcements and subsequently identify malicious users. Specifically, we construct and train a DNN to accurately detect malicious users. The training of the DNN is supervised and it is based on observations regarding the users’ consumed resources.
4) Simulations were conducted to evaluate the performance of the proposed approaches. The results verify the effectiveness of the solutions to the game, in comparison with various baseline schemes. Moreover, insights for the Stackelberg game and its effects to the convergence time of the FL task are provided. Furthermore, the joint optimization of radio and computation resources is shown to result in increased user utility. Finally, the considered DNN for detecting malicious users, presents a quite satisfactory classification accuracy, corroborating the effectiveness of this security mechanism.
2 System Model
2.1 WFL Model
We consider a WFL system, consisting of K clients/users indexed as
The local loss function on the whole data set Dk is defined as
where f (wk, xn,k, yn,k) is the loss function on the input-output pair {xn,k, yn,k} and captures the error of the model parameter wk for the considered input-output pair. Therefore, each user is interested in obtaining the wk which minimizes its loss function. For different FL tasks, the loss function also differs. For example, for a linear regression task the loss function is
i.e., to find
The training process consists of N rounds, denoted by i. Thus, the i-th round is described below
1) Firstly, the BS broadcasts the global parameter wi to all participating users during the considered round. We highlight that it is not mandatory that all users are participating into the process. Let
2) After receiving the global model parameter, each user
3) After receiving all the local parameters, the server aggregates them, in order to update the global model parameter, by applying
The whole procedure is repeated for N rounds, until a required accuracy is achieved. During the first round, the global parameter w0 is initialized by the server. The WFL model is depicted in Figure 1. Also, Table 1 summarizes the list of notations used in this article.
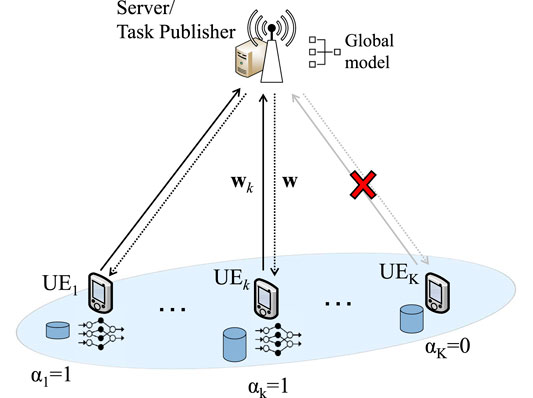
FIGURE 1. WFL system model.

TABLE 1. List of notations.
2.2 Computation Model
The computation resources for local model training, i.e., CPU cycle frequency, of the k-th user is denoted as fk. The number of CPU cycles for a user k to perform one sample of data in local model training is denoted by ck. Hence, the computation time dedicated for a local iteration, i.e., a step of the gradient descent method, is given as
where Dk is the data size of the dataset
where ζ is a constant parameter related to the hardware architecture of device k.
2.3 Communication Model
By using orthogonal frequency domain multiple access (OFDMA) to transmit a model update to the server/BS, the achievable transmission rate (bit/s) of user k can be written as
where B is the available bandwidth, N0 is the spectral power density and pk, gk denote the transmit power, and channel gain of user k, respectively. The channel gain is modeled as
where sk denotes the data size of the training parameters wk. Moreover, the consumed energy for the considered transmission, is given by
Following that, the total time that a user should dedicate for both computation and communication purposes, is given as
Since the transmit power of the BS is much higher than that of the users’, we ignore the delay of the server for broadcasting the global parameter to the users. Finally, the total energy consumption of the k-th user during a communication round, for executing local computations, and uploading the local training parameters, can be written as
3 User Utility and Convergence Time of the Global Model
In the considered system, the server should wait for all users to terminate the local parameter transmission and afterwards update the global model. Thus, users who present large τk are considered as stragglers, since they will be responsible for the occurrence of large delay during a communication round. More specifically, the total delay of a round is given by
3.1 User Utility Function
The utility function aims to quantify the incentive of a user for being involved into the FL process, in terms of a money-based reward, and it is a tool for facilitating the economic interaction among the users and the task publisher. In order to ensure low latency, we assume that the maximum delay tolerance that server requires during a communication round is
where q1 > 0 is a constant reward given by the server to the user, for a timely task completion. Thus, q1 is the price for a unit of time, received by the users. It is obvious that smaller task completion time τk, leads to higher earned reward. Moreover, q2 > 0, denotes the cost of energy consumption and ak is a binary variable, which indicates whether user k will participate in the process or not. We assume that user k will participate, i.e., ak = 1, only if the condition Uk > 0 is satisfied, otherwise user k will decide not to be involved. In essence, the utility function consists of a term which reflects the reward for the timely task completion, i.e.,
3.2 Global Convergence Time
The objective goal of the task publisher is to minimize the convergence time of the FL process, in order to extract the global training model. The convergence time can be expressed as
where Tmax is given by
and represents the total delay in a communication round, since it is determined by the slowest scheduled device, while N denotes the number of total communication rounds. As shown in Li et al. (2019), the total number of communication rounds to achieve a certain global accuracy, is on the order of
where the parameters θ and β can be determined through experiments to reflect data distribution characteristics. Moreover, this model can adopt both i.i.d. and non-i.i.d. data distributions among users Li et al. (2019). From (13) it is observed that by increasing the number of participating users, i.e., increasing
4 Stackelberg Game Formulation and Solution
4.1 Two-Stage Game Formulation
As discussed previously, each user is interested in maximizing its own utility function by optimally adjusting the available resources i.e., CPU clock speed fk, transmission time tk, transmit power pk, and finally decide whether he will participate in the training process or not, by adjusting ak. Moreover, the value of the utility function is being affected by the delay demand that the task publisher requires. On the other hand, the task publisher is willing to minimize the total convergence time of the FL process, by adjusting the maximum delay tolerance
Clients’ goal is to maximize their utility function, given a value of
where
C1 represents the data transmission constraint, while
On the other hand, the optimization problem at the side of the task publisher for minimizing the global convergence time, can be formulated as
where
while the left-hand-side of C1 represents the overall fee that the task publisher is paying to all participating clients and Q denotes the total budget that the task publisher posses. The server is responsible for optimally adjusting
To what follows, the definitions regarding the users’ and server’s optimal actions, as well as the SE, are provided Başar and Olsder (1998), Pawlick et al. (2019). The Stackelberg games are solved backwards in time, since the followers move after observing the leader’s action. The optimal actions for each follower, i.e., the optimal values of fk, pk, tk, ak that are denoted by
Based on the anticipated followers’ response, the leader chooses its optimal action T*, which satisfies
Then, by using the aforementioned definitions of the optimal actions for each player, the point
4.2 Proposed Solution of the Stackelberg Game
4.2.1 Users’ Utility Function Maximization
As stated previously, users are eager to participate only if their utility function is positive, otherwise they set ak = 0 and do not spend any of their available communication and computation resources. The optimization problem
The optimization problem in (21) is non-convex due to the coupling of tk and pk. However it can be easily proved that
where
It is obvious that
The problem is non-convex in its current formulation. However, it is easy to verify that the constraint C1 always hold with equality, since the selection of larger tk or pk will lead to the decrease of the objective function. Following that, it holds
and by substituting tk in (24), the optimization problem is equivalent to the following formulation
Although problem (26) is non-convex, it can be transformed and solved efficiently with the aid of fractional programming. By observing the objective function in (26), it can be expressed as
For a given λ, the function Z (pk) ≜Φ(pk) − λΨ(pk) is convex with respect to pk, since Φ(pk) is affine and Ψ(pk) is concave. Therefore, the optimal solution that minimizes Z (pk), can be easily derived by taking
Hence, the optimal
Algorithm 1. Dinkelbach’s Algorithm for solving (26), ∀k
1: Initialize:
2: repeat
3: n ← n + 1
4:
5:
6: until
7:
After obtaining the optimal
where
since the condition
4.2.2 Global Convergence Time Minimization
Next, we proceed to the minimization of the convergence time, which is executed by the task publisher. As discussed previously, the server is able to dynamically adjust the value of
where the constraint C1 has occur by manipulating the C1 in (16). In order to solve the problem in (31), the server will execute a search among the K possible values of
which implies that the number of scheduled users will be K − l, while the specific user participation is described by (30).
4.2.3 Stackeleberg Equilibrium
The whole procedure of the Stackelberg’s game is summarized in Algorithm 2. More specifically, in step 1, the server initializes the delay tolerance
Algorithm 2. Stackelberg equilibrium
1: Server initializes
2: Each user derive
3: Server calculates
4: Server selects
5: Users decide if they will participate, i.e., if
5 Detecting and Preventing Malicious Users From the FL Process
5.1 Malicious Users
During the considered interaction among users and the task publisher, a question that may arise is the following: What if users were malicious and announced false values of
Firstly, we assume that only one user is dishonest, e.g., the m-th user. In order to improve his utility, user m may select to announce
5.2 Deep Learning-Aided Malicious Users Detection
Driven by the aforementioned scenario, a secure mechanism which detects malicious/abnormal users’ behavior should be constructed, in order to ensure an irreproachable clients-task publisher interaction. Therefore, the servers’ aim is to recognize whether the users’ transmitted tuple
5.2.1 Deep Neural Network Structure
We consider a feed-forward DNN consisting of an input layer, an output layer and M − 1 fully connected hidden layers. All layers are indexed from 0 to M. We denote the number of nodes in the m-th layer as lm. For the hidden layers, the output of the i-th node in the m-th layer, is calculated as follows
where
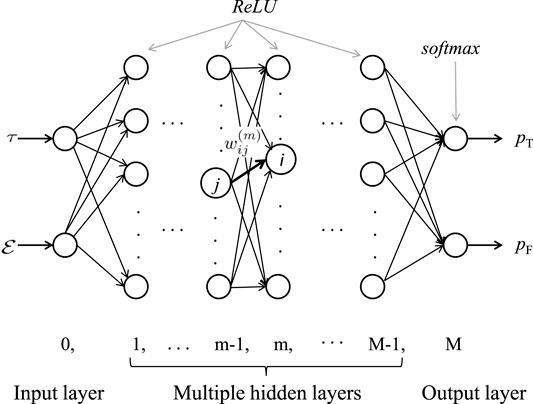
FIGURE 2. Deep neural network structure.
5.2.1.1 Data Generation
The data are generated in the following manner. The τ* and
5.2.1.2 Training Stage
The entire training data set
5.2.1.3 Testing Stage
In the testing stage, a test set is generated, in a similar manner with the training stage. Following that, the test set is passed through the trained neural network and the predictions are collected. The predicted label of a test sample is given by
Finally, the classification accuracy is evaluated, i.e., the ability of the neural network to detect in which user category, honest or dishonest, do the testing samples correspond.
6 Numerical Results and Performance Evaluation
We consider K = 20 uniformly distributed users in a circular cell with radius R = 500 m, while the BS is located at the center of the cell. The wireless bandwidth is B = 150 KHz, the noise power spectral density is N0 = −174 dBm/Hz, the maximum transmit power of the users is
Next, we set β = 27.773 and θ = 0.941 2 Shi et al. (2020a). These values correspond to a specific data distribution when the MNIST data set is used, which is a well-known handwritten digit dataset. In particular, according to Shi et al. (2020a), the considered values of β, θ reflect an i.i.d. data distribution among users. Furthermore, we also adopt the classification of the handwritten digits as the FL task. Following that, the user training data has been set as Dk = 1.6 Mbit, the size of the training parameters is sk = 1 Mbit and ck is uniformly distributed in the interval [10, 40] cycles/bit. It is noted that in the following figures, all results are averaged over 10,000 trials, by means of Monte Carlo.
In Figure 3 the impact of the number of scheduled users on the average global convergence time is demonstrated, for various values of the task publisher’s reward q1. Furthermore, we consider that users employ the optimal proposed strategy, in order to maximize their utility. As it can be observed, neither enforcing all users nor a small portion of them to participate, will lead to the average convergence time minimization. This phenomenon can be explained as follows. By scheduling a large amount of users to participate it is more likely that the latency during a communication round will be large, owing this to the straggler effect, while the convergence time will be negatively affected. On the contrary, by urging a small number of users to be involved, the required number of communication rounds to achieve global convergence will highly increase, deteriorating the convergence time. Moreover, it can be observed that higher reward q1 leads to smaller convergence time. This is reasonable, since when the reward is higher, users are motivated to spend their available resources for a fast local training and parameter transmission to the server, leading to a decreased delay during each communication round.
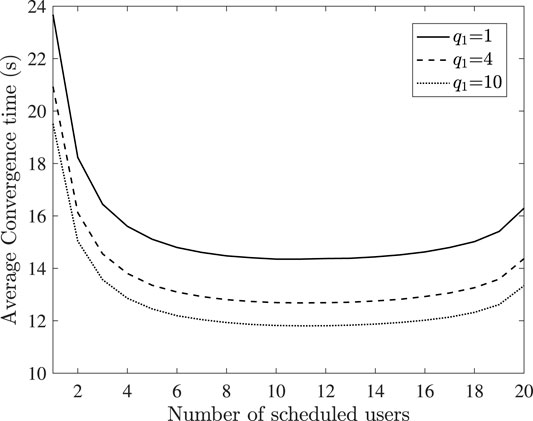
FIGURE 3. Impact of number of scheduled users on the average convergence time of the FL task.
Following that, in Figure 4, the average convergence time versus the reward q1 is depicted. We compare the proposed method with the following cases. Firstly, the server randomly selects the number of participating users and secondly, the server always schedules 10 users for participation. It can be seen that the proposed method outperforms the considered cases. Therefore, the importance of wisely selecting the delay tolerance
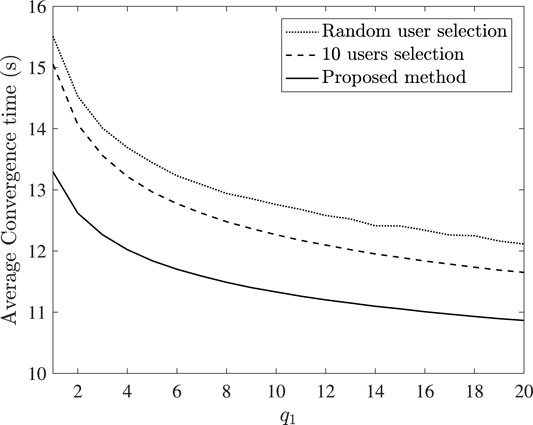
FIGURE 4. Average convergence time versus q1.
In the continue, Figure 5 exhibits the average utility of the users given that
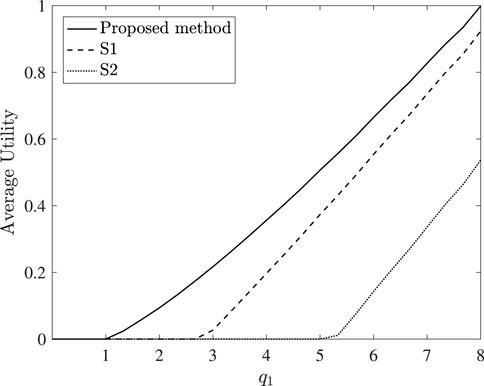
FIGURE 5. Average utility of users versus q1.
6.1 DNN Setup and Performance
The neural network consists of three hidden layers. The first hidden layer contains 200 neurons, while the rest two layers contain 80 neurons. The optimization algorithm we use for minimizing the loss function of the neural network is the RMSprop, which is an efficient implementation of the mini-batch stochastic gradient descent method. The decay rate has been set as 0.9. In order to select suitable values for the learning rate and the batch size, the validation set was used for the evaluation of the loss function. More specifically, in Figure 6 and Figure 7, the evolution of the loss function throughout the training epochs is demonstrated. It can been observed that when the learning rate is equal to 0.001, the smallest loss is achieved. Moreover, the batch size which achieves the smallest loss is 100, which is finally adopted. In addition, the number of training epochs has been set as 200, since at this point the loss function is relatively close to a steady level. For the training of the neural network 36,000 samples were generated, while the validation set consists of 4,000 samples. Also, we used 5,000 testing samples, in order to evaluate the accuracy of the neural network. We highlight that throughout the generation of the training, validation and testing set, the ratio of honest to dishonest users was 1:1. Moreover, throughout the generation of the training and validation set, we fix δ1 = 0.2 and δ2 = 1, which means that
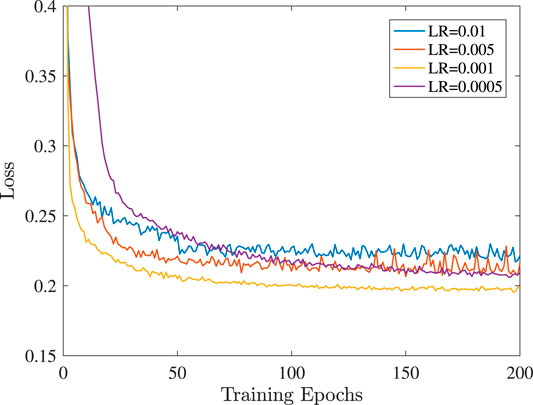
FIGURE 6. Learning rate selection.
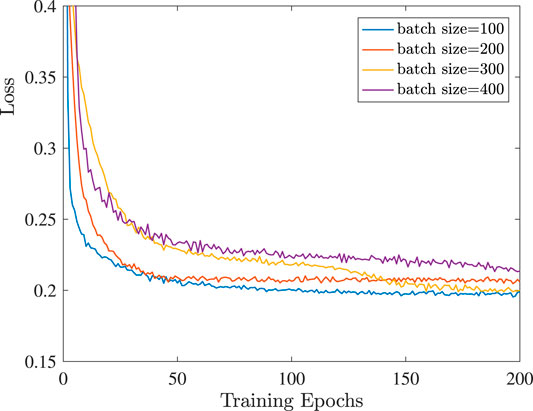
FIGURE 7. Batch size selection.

TABLE 2. DNN’s parameters.
In Figure 8, the testing accuracy is evaluated, after passing the testing set through the DNN. Various values of δ1 are considered, while we set δ2 = 1. This implies that the malicious users’ false declared energy consumption
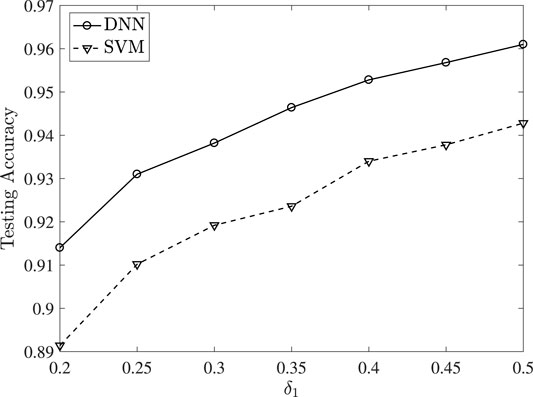
FIGURE 8. DNN’s testing accuracy.
7 Conclusion
In this paper, we propose a secure incentive mechanism for WFL in 6G networks. Specifically, we formulate a Stackelberg game between the clients and the server, where the clients aim to maximize their utility, while the server is focusing on minimizing the global convergence time of the FL task. The optimal solution to the game is obtained while the efficiency of the proposed solution is verified, leading to reduced latency, owing to the decreased global convergence time and increased user-utility. Moreover, we consider the presence of malicious users throughout the game, who may attempt to misinform the server regarding their utilized resources, aiming to further increase their profit. To prevent such behavior, we construct a deep neural network at the server’s side, which focuses on classifying the users’ identity, as malicious or honest. Simulation results validate the effectiveness of the proposed mechanism, as a promising solution for detecting malicious users. To this end, in order to further increase the incentive design efficiency, additional FL features may be taken into account. In this direction, an interesting future topic could be the consideration of the clients’ data quality and quantity throughout the construction of the incentive mechanism, as well as the investigation of their impact on the total convergence time of WFL.
Data Availability Statement
The datasets presented in this article are not readily available because they need to be converted in a presentable format. Requests to access the datasets should be directed to bXBvdXppbmlzQGF1dGguZ3I=.
Author Contributions
Conceptualization and Methodology, PB, PD, and GK. Formal Analysis, PB. Validations, PB and PD. Simulations and Visualization, PB. Writing-Review and Editing, PB, PD, and GK. Supervision, GK.
Funding
Part of the research leading to these results has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No. 957406. Also, part of this research has been co-financed by the European Regional Development Fund by the European Union and Greek national funds through the Operational Program Competitiveness, Entrepreneurship and Innovation, under the call: Special Actions: Aquaculture - Industrial Materials - Open Innovation in Culture (project code: T6YBP-00134).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bouzinis, P. S., Diamantoulakis, P. D., and Karagiannidis, G. K. (2022a). Wireless Federated Learning (WFL) for 6G Networks⁴Part I: Research Challenges and Future Trends. IEEE Commun. Lett. 26, 3–7. doi:10.1109/lcomm.2021.3121071
Bouzinis, P. S., Diamantoulakis, P. D., and Karagiannidis, G. K. (2022b). Wireless Federated Learning (WFL) for 6G Networks-Part II: The Compute-Then-Transmit NOMA Paradigm. IEEE Commun. Lett. 26, 8–12. doi:10.1109/lcomm.2021.3121067
Chen, M., Poor, H. V., Saad, W., and Cui, S. (2020a). “Convergence Time Minimization of Federated Learning over Wireless Networks,” in ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, June 2020 (IEEE), 1–6. doi:10.1109/icc40277.2020.9148815
Chen, M., Yang, Z., Saad, W., Yin, C., Poor, H. V., and Cui, S. (2020b). A Joint Learning and Communications Framework for Federated Learning over Wireless Networks. IEEE Trans. Wireless Commun. 20 (1), 263–283. doi:10.1109/TWC.2020.3024629
Dinkelbach, W. (1967). On Nonlinear Fractional Programming. Manage. Sci. 13, 492–498. doi:10.1287/mnsc.13.7.492
Kang, J., Xiong, Z., Niyato, D., Xie, S., and Zhang, J. (2019). Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining Reputation and Contract Theory. IEEE Internet Things J. 6, 10700–10714. doi:10.1109/jiot.2019.2940820
Khan, L. U., Pandey, S. R., Tran, N. H., Saad, W., Han, Z., Nguyen, M. N. H., et al. (2020). Federated Learning for Edge Networks: Resource Optimization and Incentive Mechanism. IEEE Commun. Mag. 58, 88–93. doi:10.1109/mcom.001.1900649
Konečnỳ, J., McMahan, H. B., Yu, F. X., Richtárik, P., Suresh, A. T., and Bacon, D. (2016). Federated Learning: Strategies for Improving Communication Efficiency. arXiv. [Preprint].
Letaief, K. B., Chen, W., Shi, Y., Zhang, J., and Zhang, Y.-J. A. (2019). The Roadmap to 6g: Ai Empowered Wireless Networks. IEEE Commun. Mag. 57, 84–90. doi:10.1109/mcom.2019.1900271
Li, X., Huang, K., Yang, W., Wang, S., and Zhang, Z. (2019). On the Convergence of Fedavg on Non-iid Data. arXiv. [Preprint].
Li, T., Sahu, A. K., Talwalkar, A., and Smith, V. (2020). Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal. Process. Mag. 37, 50–60. doi:10.1109/msp.2020.2975749
Lim, W. Y. B., Xiong, Z., Miao, C., Niyato, D., Yang, Q., Leung, C., et al. (2020). Hierarchical Incentive Mechanism Design for Federated Machine Learning in mobile Networks. IEEE Internet Things J. 7, 9575–9588. doi:10.1109/jiot.2020.2985694
McMahan, B., Moore, E., Ramage, D., Hampson, S., and y Arcas, B. A. (2017). “Communication-efficient Learning of Deep Networks from Decentralized Data,” in Artificial Intelligence and Statistics (PMLR), 1273–1282.
Pandey, S. R., Tran, N. H., Bennis, M., Tun, Y. K., Manzoor, A., and Hong, C. S. (2020). A Crowdsourcing Framework for On-Device Federated Learning. IEEE Trans. Wireless Commun. 19, 3241–3256. doi:10.1109/twc.2020.2971981
Pawlick, J., Colbert, E., and Zhu, Q. (2019). A Game-Theoretic Taxonomy and Survey of Defensive Deception for Cybersecurity and Privacy. ACM Comput. Surv. (Csur) 52, 1–28. doi:10.1145/3337772
Sarikaya, Y., and Ercetin, O. (2019). Motivating Workers in Federated Learning: A Stackelberg Game Perspective. IEEE Networking Lett. 2, 23–27. doi:10.1109/lnet.2019.2947144
Schaible, S. (1976). Fractional Programming. II, on Dinkelbach's Algorithm. Manage. Sci. 22, 868–873. doi:10.1287/mnsc.22.8.868
Shi, W., Zhou, S., and Niu, Z. (2020a). “Device Scheduling with Fast Convergence for Wireless Federated Learning,” in ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, June 2020 (IEEE), 1–6. doi:10.1109/icc40277.2020.9149138
Shi, W., Zhou, S., Niu, Z., Jiang, M., and Geng, L. (2020b). Joint Device Scheduling and Resource Allocation for Latency Constrained Wireless Federated Learning. IEEE Trans. Wireless Commun. 20, 453–467. doi:10.1109/twc.2020.3025446
Sun, H., Chen, X., Shi, Q., Hong, M., Fu, X., and Sidiropoulos, N. D. (2017). “Learning to Optimize: Training Deep Neural Networks for Wireless Resource Management,” in 2017 IEEE 18th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Sapporo, July 2017 (IEEE), 1–6. doi:10.1109/spawc.2017.8227766
Tran, N. H., Bao, W., Zomaya, A., Nguyen, M. N., and Hong, C. S. (2019). “Federated Learning over Wireless Networks: Optimization Model Design and Analysis,” in IEEE INFOCOM 2019-IEEE Conference on Computer Communications, Paris, April–May 2019 (IEEE), 1387–1395. doi:10.1109/infocom.2019.8737464
Yang, Z., Chen, M., Saad, W., Hong, C. S., and Shikh-Bahaei, M. (2021). Energy Efficient Federated Learning over Wireless Communication Networks. IEEE Trans. Wireless Commun. 20, 1935–1949. doi:10.1109/twc.2020.3037554
Zappone, A., Di Renzo, M., and Debbah, M. (2019). Wireless Networks Design in the Era of Deep Learning: Model-Based, Ai-Based, or Both? IEEE Trans. Commun. 67, 7331–7376. doi:10.1109/tcomm.2019.2924010
Keywords: wireles federated learning, incentive mechanism, stackelberg game, convergence time minimization, deep learning
Citation: Bouzinis PS, Diamantoulakis PD and Karagiannidis GK (2022) Incentive-Based Delay Minimization for 6G-Enabled Wireless Federated Learning. Front. Comms. Net 3:827105. doi: 10.3389/frcmn.2022.827105
Received: 01 December 2021; Accepted: 18 February 2022;
Published: 30 March 2022.
Edited by:
Adlen Ksentini, EURECOM, FranceReviewed by:
Zehui Xiong, Nanyang Technological University, SingaporeJianbo Du, Xi’an University of Posts and Telecommunications, China
Copyright © 2022 Bouzinis, Diamantoulakis and Karagiannidis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: George K. Karagiannidis, Z2Vva2FyYWdAYXV0aC5ncg==