 Georgia Zellou
Georgia Zellou Mohamed Afkir
Mohamed Afkir Mohamed Lahrouchi
Mohamed Lahrouchi Karim Bensoukas3
Karim Bensoukas3
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Commun. , 18 March 2025
Sec. Language Communication
Volume 10 - 2025 | https://doi.org/10.3389/fcomm.2025.1518754
This study examines the acceptability of voweled and vowelless nonwords produced by a native speaker of Tashlhiyt (a Moroccan Amazigh language) across listeners from five different language groups: L1 Tashlhiyt, L1 Tarifit, L1 Moroccan Arabic, L1 English, and L1 Mandarin. The languages vary in the complexity of allowable word types, though only Tashlhiyt allows lexically vowelless word forms. Hyper- and hypo-speech forms of the items were also compared in order to explore the effect of speaking style on listeners’ phonological knowledge. Results show gradient cross-language effects of nonword acceptability: compared to the native Tashlhiyt listeners, L1 Tarifit and L1 Moroccan Arabic listeners did not differ in their wordlike judgments. In contrast, L1 English showed lower and sonority-based wordlikeness preferences; L1 Mandarin listeners provided the lowest ratings of Tashlhiyt nonwords and were not sensitive to sonority variations. In contrast to the language-specific effect of word phonotactics, the role of clear speech in enhancing wordlikeness judgments was equivalent in effect size across language backgrounds.
Speakers have productive knowledge of the patterns in their native language. An illustration of this comes from observations that listeners prefer non- (or pseudo-) word forms that follow the phonological patterns of the words in their language. For instance, native English listeners are more likely to accept blick as a potential word in their language, but not bnick, on the basis that the consonant sequence bl is found in many English words while a bn onset is not present in the lexicon (Chomsky and Halle, 1968). Nonword acceptability, then, provides a window into listeners’ abstract phonological knowledge about the words in their native language.
The phonological form of words, however, vary widely across and within languages of the world. Phonologically, languages differ in the allowable segment sequences that can occur within a word; some languages allow words with complex sequences of consonants, while other languages only have words with a simple coda or onset. Additionally, within a language, articulation can vary depending on speaking style: the same word can be pronounced differently across clear speech (i.e., hyperarticulation, which contains extreme segment variants) and reduced speech (i.e., hyperarticulation, which is produced with less articulatory effort) (Lindblom, 1990). Clarity-oriented speech variation appears to be a language-universal phenomenon, although the details on precisely which acoustic cues get enhanced in hyperspeech have been shown to vary across languages and phonological contrasts (e.g., Smiljanić and Bradlow, 2005).
In the current study, we focus on two types of variation in the forms of words in spoken language—phonotactic complexity and speech style—and we examine how they predict nonword acceptability for speakers across five languages. In particular, we present ‘voweled’ words (e.g., words with CVC structure) and ‘vowelless’ words (e.g., with CCC structure) produced in Clear and Reduced speech to listeners from a variety of native language backgrounds. The languages were selected to vary in their syllable structure allowances: ranging from a language with simple phonotactic preferences (here, Mandarin, which only allows simple onsets and codas) to languages that allow words with sonority-defying consonant sequences. For instance, in Amazigh languages of Morocco, words can contain consonant sequences that do not conform to cross-linguistic sonority sequencing preferences (e.g., onsets with non-rising sonority in words like [qbər] ‘before/accept’ in Tarifit) and even words without vowels (e.g., [zdʁ] ‘live in’ in Tashlhiyt). Our phonotactic prediction is that, consistent with a huge body of prior literature, phonotactic preferences of nonwords by listeners will follow their native language-specific patterns. On the other hand, there is much less prior work exploring the effect of speaking style on nonword acceptability. In contrast, we predict that the effect of speaking style on nonword acceptability will be consistent across the languages, since this is a cross linguistically universal type of variation.
In the current study, we focus on a typologically rare word form: vowelless words. Cross-linguistically, the most preferred syllable type is CV. Complex onsets or codas tend to be guided by sonority constraints on consonant sequencing such that less sonorous segments occupy peripheral syllable positions and more sonorous segments occur toward the syllable centers (Clements, 1990). Some languages contain words that defy these preferences. A notable example are vowelless words in Tashlhiyt, an Amazigh language spoken in Southern Morocco. In Tashlhiyt, words can contain consonant sequences that go against sonority sequencing preferences (e.g., [ʁdar] ‘at’) and words containing no lexical vowel are common (e.g., [sxf] ‘faint’).
A prior study explored the acceptability of Tashlhiyt-like nonwords and found that Tashlhiyt listeners show equal wordlikeness judgments of vowelless nonce words containing obstruents as they do for vowel- and sonorant-centered items (Zellou et al., 2024b). In contrast, native English-speaking listeners show decreasing preference for nonwords as the sonority value of the word nucleus decreases. An open question from this prior finding is whether native speakers of other languages that do not allow vowelless words will show the same patterns of dispreferring vowelless nonwords.
We address this question in the current study. We examine cross-linguistic perception of Tashlhiyt-like nonword items produced in clear and reduced speech across listeners from 5 distinct language backgrounds: (1) Listeners with the same native language background as the speaker (Tashlhiyt). (2) Listeners whose native language is also an Amazigh language, closely related to Tashlhiyt but mutually unintelligible. Here, the language is Tarifit, which contains similar, through more restrictive, phonotactics as Tashlhiyt; Tarifit does not have vowelless words (in their phonological analysis of Tarifit, Dell and Tangi (1992) argue that the preferred Tarifit syllable structure is CVC and schwa is inserted to break up underlying consonants sequences). (3) Listeners whose native language does not contain vowelless words yet are in contact with Amazigh languages. This language is Moroccan Arabic (in fact, distantly related to Amazigh languages through the Afro-Asiatic family) which has been phonologically analyzed as not allowing vowelless words (Dell and Elmedlaoui, 2012). (4) English-speaking listeners—a language with more restrictive phonological patterns than 1–3. (5) Mandarin-speaking listeners—a language with even more restrictions on syllable shapes. English and Mandarin are unrelated to Tashlhiyt and the listeners have no exposure to Tashlhiyt or an Amazigh language.
The syllable structure allowances of these 5 languages vary along a continuum. As mentioned above, Tashlhiyt has the most permissive syllable structure: words without vowels, including consonant sequences containing only obstruents, are allowed (and frequent) in the language. Our prior work has found that all our Tashlhiyt-like nonwords—including those containing obstruent-centers—are equally and highly accepted as possible words by L1 Tashlhiyt listeners (Zellou et al., 2024b). In contrast, Tarifit syllable structure has a strong preference for CVC, CV, V and VC syllables (Dell and Tangi, 1992). Other possible word forms in Tarifit are CVCC, CCVC, and VCC (McClelland, 1996). For words with more complex syllable structures, schwa is inserted (Mourigh and Kossmann, 2019). Since words without vowels are not phonologically allowable in Tarifit (Dell and Tangi, 1992), we predict L1 Tarifit listeners will show lower acceptance of vowelless nonwords than L1 Tashlhiyt listeners. The syllable structure of allowable words in Moroccan Arabic (also known as Darija) is more similar to the Amazigh languages than to Classical Arabic (Chtatou, 1997; Lahrouchi, 2018). For instance, words with complex, sonority-defying consonant clusters are permitted in Moroccan Arabic (Dell and Elmedlaoui, 2012; e.g., [ktəb] ‘he wrote’). Yet, vowelless words are not phonologically permitted in Moroccan Arabic; therefore, L1 Moroccan Arabic listeners could pattern like L1 Tarifit listeners, indicating acceptance of nonwords follows syllable structure patterns, not language relatedness.
We also note that in descriptive phonetic work with Tarifit speakers done by us, and also sometimes reported in phonological descriptions (Mourigh and Kossmann, 2019), we observe occasionally that some triconsonantal words with schwa are produced as phonetically vowelless under conditions of de-emphasis. (We have not examined this yet for Moroccan Arabic, but we also suspect this might be possible in that language, too.) So, while words in Tarifit must phonologically contain vowels, and vowelled words are the most commonly produced phonetic form of most lexical items, sometimes Tarifit speakers produce variants of CCəC words that do not contain vowels. So, this provides us with an alternative hypothesis, which is that since Tarifit speakers sometimes can produce phonetic variants of words that are vowelless, they will show acceptance of vowelless nonwords in Tashlhiyt as possible Tarifit words.
We also examine L1 Mandarin listeners’ perception of Tashlhiyt nonwords. Neither syllable-initial nor -final consonant clusters are permitted in Mandarin words (Complex onsets are allowed only if C2 is a glide), and only nasal codas are observed (Wu and Kenstowicz, 2015). Therefore, we predict the Tashlhiyt nonwords in the present study will be categorically rejected as possible Mandarin words by L1 Mandarin listeners.
Finally, our inclusion of L1 English listeners should also be highly informative about the role of language experience on vowelless word acceptability. For one, like Tarifit and Moroccan Arabic, English allows words with more complex syllable structures: English words can allow up to three consonants in the onset and up to four segments in the coda position (e.g., ‘string’ [strɪŋ] = CCCVC and ‘sixths’ [sɪksθs] CVCCCC). However, there are strong phonotactic constraints for complex clusters within words (e.g., /s/ must be one of the segments in complex clusters containing more than 2 segments; otherwise sonority sequencing preferences are followed). English can have syllabic sonorants, though not in stressed syllables. Thus, while some of our Tashlhiyt-like nonwords might be somewhat acceptable to L1 English listeners (e.g., words with syllabic sonorants), some should be unacceptable (e.g., words with obstruent centers). Thus, we predict gradient acceptance of Tashlhiyt-like nonwords by L1 English listeners, following sonority-based preferences.
We also examine how phonetic variation affects nonword acceptability. Natural speech is highly variable—a single word is never pronounced the same twice. We focus on one type of systematic acoustic variation, namely when a talker enunciates and speaks “clearly.” Talkers produce words containing hyperarticulated realization of segments when talking to someone who is hard of hearing or not a native speaker of the language, while more hypoarticulated speech contains shorter and reduced variants of sounds (Picheny et al., 1986; Krause and Braida, 2004; Zellou and Scarborough, 2019; Cohn et al., 2022). Clear speech enhancement is a cross-linguistic phenomenon and many studies report that hyperspeech enhances listeners’ perception of non-native sounds (e.g., Cho et al., 2020; Zeng et al., 2023).
How might clear vs. reduced speech forms of words affect nonword acceptability judgments for listeners with different language backgrounds? Clear speech has been shown to be better perceived by listeners, to enhance recognition memory and recall, and to improve speech segmentation (Smiljanić and Bradlow, 2011; Scarborough and Zellou, 2013; Guo and Smiljanic, 2021). Given that speakers across all languages routinely modify their speech during everyday communication in response to changing communicative demands, this is a type of variation that could enhance perceptibility of forms regardless of native language background. It is also possible that phonological knowledge is stable and not affected by differences in phonetic forms of words, such as when they are hyper- or hypo-articulated. If this is the case, the same patterns of nonword acceptability judgments should be observed in both clear and reduced speaking styles.
One stance we argue for in the current paper is the importance of considering speaking style when exploring listeners’ phonological knowledge. The role of acoustic variation on wordlikeness judgments is underexplored. Yet, there is much prior work showing that listeners’ processing and recall of lexical items is enhanced by clear speech: since spoken word recognition involves discrimination of stored lexical forms, utterances containing more distinctive and enhanced forms of segments will be better recognized than when there are reduced forms (Wright, 2004). We propose that the same patterns will hold for nonword acceptability by listeners, even when they are produced by a speaker in a non-native language.
The present study examines cross-language nonword acceptability judgments of tri-segmental nonwords that are either phonologically vowelless (CCC) or voweled (CVC), produced by a native speaker of Tashlhiyt in clear and reduced speech mode. We compare wordlikeness judgments by listeners from five different language backgrounds: L1 Tashlhiyt, L1 Tarifit, L1 Moroccan Arabic, L1 English, and L1 Mandarin. Nonword acceptability tasks require listeners to compare auditory stimuli to the characteristics of lexical items stored in memory. There is much prior work demonstrating that nonwords with greater lexical support are rated as more word-like than nonwords with less (Munson, 2001; Frisch et al., 2001). Thus, listeners from different language backgrounds show different nonword preferences, depending on the nonword’s similarity to other lexical forms within their native languages. We predict that even though Tashlhiyt is the only language in this set that allows vowelless words, wordlikeness judgments by listeners from other language backgrounds will vary gradiently based on the allowed complexity of syllable structures of each language. We also predict that the effect of speaking style will be similar regardless of listeners’ language background, given that clear speech provides more phonetically distinct forms of words.
The experiment consisted of a nonword acceptability judgment task with three-segment nonwords produced by a native Tashlhiyt speaker. The words varied in their sonority profile—either vowelless containing an obstruent consonant center, vowelless containing a sonorant consonant center, or containing a vowel nucleus. The nonce words were constructed to be possible Tashlhiyt nonce words containing commonly occurring word-initial sounds (f, r) and word-final sounds (r, n, m) in the language. The middle segment was set to vary in sonority value. To quantify the sonority value of the center segment, we adapted the sonority scale of Parker (2002), where integers are assigned to sounds: vowel = 7, liquid = 6, nasal = 5, voiced fricative = 4, voiceless fricative = 3, voiced stop = 2, voiceless stop = 1. The nonwords, and these assigned sonority values, are provided in Table 1.
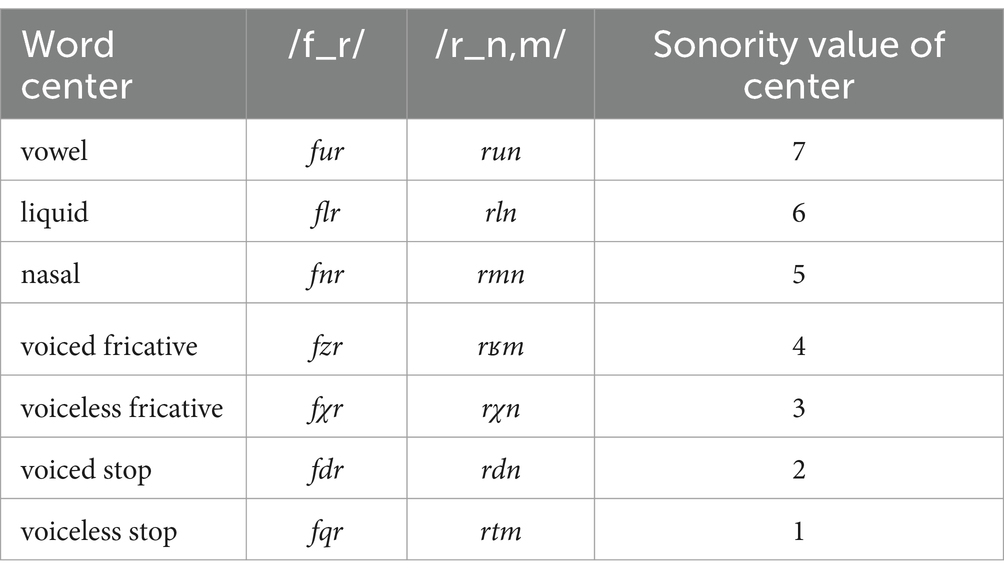
Table 1. Nonwords used in the current study.
To create the auditory stimuli, a native speaker of Tashlhiyt produced all the nonce word items in a sound-attenuated booth in two speaking styles. To elicit clear speech, the speaker was given instructions similar to those used to elicit clear speech in previous literature (e.g., Bradlow, 2002; Zellou et al., 2022): “In this condition, speak the words clearly to someone who is having a hard time understanding you.” The speaker produced the words in a fast speaking style with instructions: “now, speak the list as if you are talking to a friend or family member you have known for a long time who has no trouble understanding you, and speak quickly.” Recordings were made with an AT 8010 Audio-technica microphone and USB audio mixer (M-Audio Fast Track), digitized at a 44.1 kHz sampling rate. Each item was segmented and excised from the audio recording and amplitude normalized to 65 dB.
A total of 193 listeners completed the study. We recruited listeners from 5 different language backgrounds, depending on their reported first language: L1 Tashlhiyt, L1 Tarifit, L1 Moroccan Arabic, L1 English, and L1 Mandarin. Table 2 provides the demographic characteristics of the listeners in each language category.
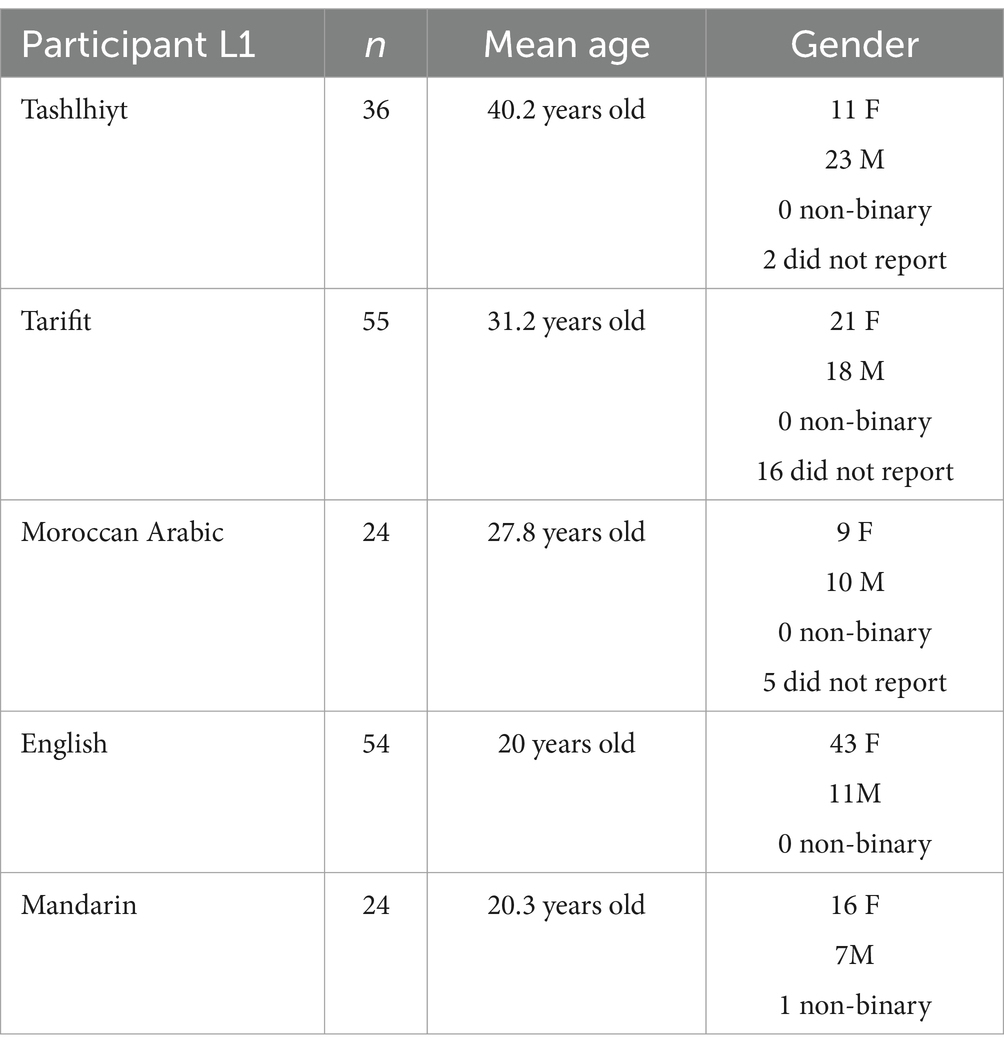
Table 2. Demographic characteristics of the listener participants across the five native languages.
The L1 Tashlhiyt, L1 Tarifit, and L1 Moroccan Arabic participants were recruited through email flyers. The Tashlhiyt listeners were the same set of participants reported in Zellou et al. (2024b). The Tashlhiyt participants reported that Tashlhiyt was their first language and that both parents speak Tashlhiyt. They also reported that they spoke French, and Arabic (Moroccan Arabic and Classical Arabic). Some reported to also speak additional languages (English, n = 22; Spanish, n = 1; Italian, n = 1; German, n = 1; Turkish, n = 1). Tashlhiyt listeners reported growing up in cities such as Agadir (n = 16), Marrakech (n = 1), Essaouira (n = 2), Tiznit (n = 4), or other towns and villages in Southern Morocco.
The L1 Tarifit speakers all reported that Tarifit was their first language. They all reported to speak Moroccan Arabic as a second language, as well as Classical Arabic. In addition, some of them reported speaking other languages as L2 (French, n = 36; English, n = 30; Spanish, n = 4; Dutch, n = 2; German, n = 1; Turkish, n = 1). All Tarifit participants reported that they were born in the Northern Moroccan region of Nador.
The L1 Moroccan Arabic participants recruited in this study were also from the Nador region. This was a convenience sample of L1 Moroccan Arabic speakers as we were collecting data in Nador. These speakers are all from Segangan and Nador center city. Half reported growing up in Nador (n = 12), though some reported growing up in other cities in Morocco and moving to Nador in adulthood (Oujda, n = 2; Tiferssit, n = 1; Berkane, n = 1; Guercif, n = 1; Errachidia, n = 1; Beni Mellal, n = 1; Khemissat, n = 1; Tinghir, n = 1; Meknes, n = 1; Kenitra, n = 1) or other towns in Eastern Morocco (n = 1). Some of the L1 Moroccan Arabic speakers reported speaking different languages as L2 (French, n = 14; English, n = 13; Spanish, n = 1; Dutch, n = 1; Italian, n = 1; Turkish, n = 1). In this part of Morocco, Moroccan Arabic L1 speakers have been in contact with Tarifit speakers for different periods of time, depending on the time they came to the city. It follows that their proficiency in Tarifit is very variable. Overall, they can understand the language to some extent but can barely speak it. While we would have preferred to collect data from Moroccan Arabic speakers with no exposure to Amazigh, this was our convenience sample. We discuss this issue further in the discussion.
The L1 English and L1 Mandarin participants were recruited from the UC Davis subjects’ pool. The L1 English speakers reported being native speakers of American English. Seven participants reported that they speak a language other than English in the home (Farsi, n = 1; Tagalog, n = 1; Telugu, n = 1; Hindi, n = 1; Arabic, n = 1; Mandarin n = 2). The L1 Mandarin listeners reported Mandarin as being their native language (they all spoke English as well and did not report other languages spoken). We asked the L1 English and L1 Mandarin participants if they spoke or had studied Tashlhiyt or any of the languages of North Africa; none reported that this was the case.
The study was approved by the UC Davis Institutional Review Board (IRB). All research was performed in accordance with guidelines and regulations of the IRB. All participants completed informed consent before participating. None of the listeners reported having a hearing or language impairment.
The experiment was conducted as an online survey via the Qualtrics platform. Participants were instructed to complete the experiment in a quiet room without distractions or noise, to silence their phones, and to wear headphones.
Each trial consisted of the auditory presentation of a nonword. Trial order was randomized for each participant. The trial played the audio file once with no option to repeat. Listeners were instructed to rate how likely the word they heard could become a word in their native language in the future. These general instructions were adapted from Daland et al. (2011): “Rate how likely you think this word could become a new word in English in the future.” The instructions were adapted for each participant group, i.e., the language was listed as Tashlhiyt for the Tashlhiyt participants, Tarifit for the L1 Tarifit participants, English for the L1 English participants, etc. Participants marked their ratings for each trial on a sliding scale from 0 (“not at all likely”) to 100 (“very likely”).
Nonword acceptability ratings of the nonword items were modeled as a continuous dependent variable (0–100; centered and scaled prior to model fitting) with a linear mixed effects model using the lme4 package (Bates, 2015) in R. Estimates for degrees of freedom, t-statistics, and p-values were computed using Satterthwaite approximation with the lmerTest package (Kuznetsova et al., 2017). The model included three fixed effects: Listener First Language (L1) (5 levels: Tashlhiyt [reference level], Tarifit, Moroccan Arabic, English, Mandarin; treatment coded), Speech Style (Clear, Fast [reference level]; sum coded), and Sonority value of the middle segment (a continuous predictor, centered and scaled prior to model fitting). In addition, the interaction between Listener L1 and Speech Style, as well as the interaction between Listener L1 and Sonority value were included in the model. The model random effects included by-listener and by-item random intercepts, as well as by-participant random slopes for Speech Style and Sonority Value.
The model output is provided in Table 3. The model revealed an effect of Listener L1: Tashlhiyt listeners provided the highest acceptability ratings of the nonwords (L1 Tashlhiyt mean = 54.1) and the English and Mandarin L1 listeners provided significantly lower acceptability ratings (L1 English mean = 28.4; L1 Mandarin mean = 17). The Tarifit listeners’ ratings were not significantly different from those of the Tashlhiyt listeners (L1 Tarifit mean = 49.6). The Moroccan Arabic listeners’ ratings were marginally lower than the Tashlhiyt listeners’ ratings (L1 Moroccan Arabic mean = 44.9).
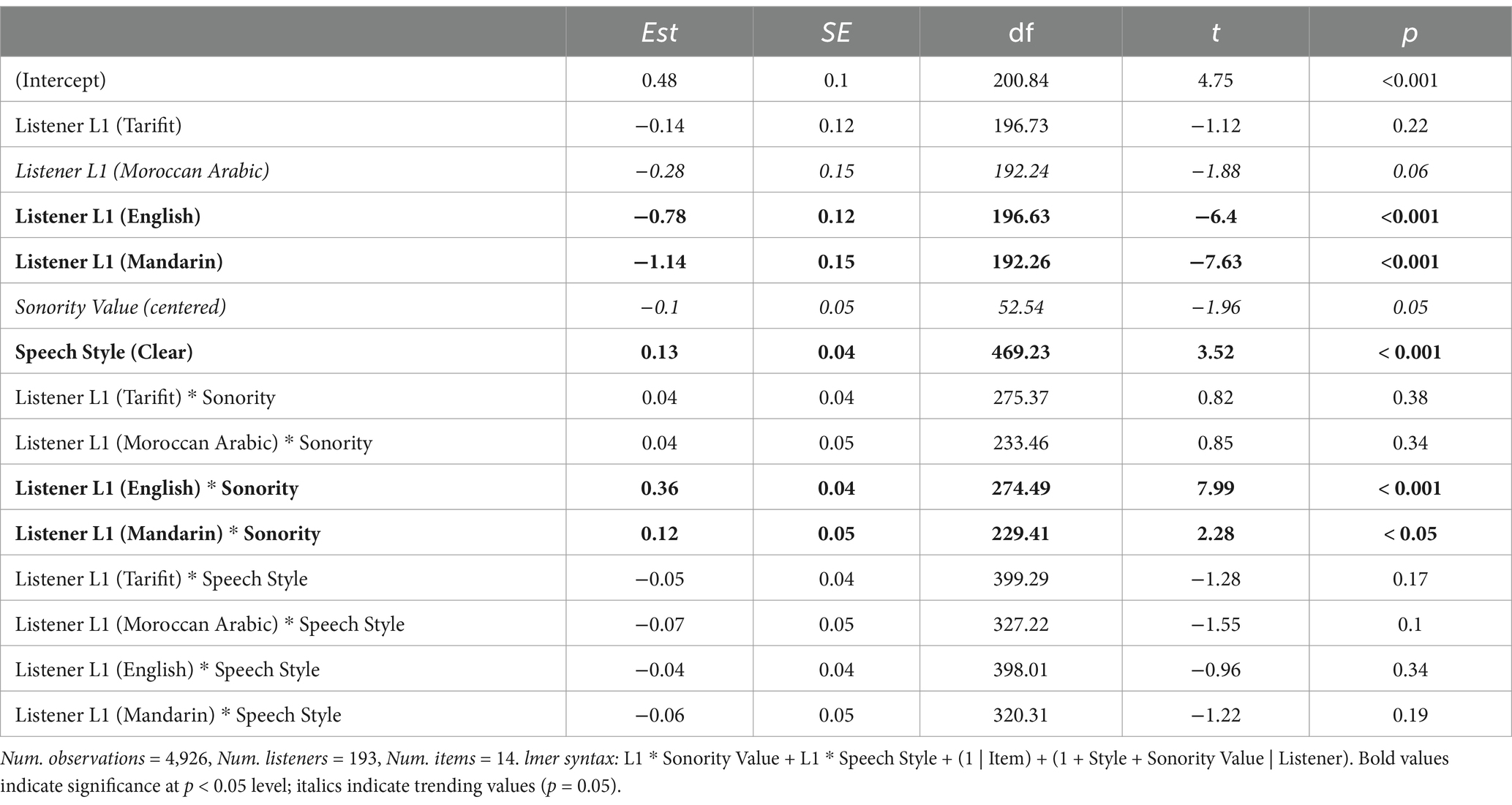
Table 3. Summary statistics for the lmer on nonword acceptability ratings.
We also ran models with the Language Background predictor releveled in order to make different L1 Listener group comparisons. A model with L1 Listener background releveled with English as the reference level revealed a significant difference for each of the languages: compared to the L1 English listeners, L1 Tashlhiyt, L1 Tarifit and L1 Moroccan Arabic listeners provided higher nonword judgments, while L1 Mandarin listeners gave lower nonword acceptability judgments (all p < 0.05). A model with L1 Moroccan Arabic listeners as the reference level did not show a significant difference between L1 Moroccan Arabic and L1 Tarifit listeners (p = 0.29).
Figure 1 shows mean acceptability ratings from each listener group across the two speaking styles. The model revealed a simple effect of Speech Style: nonwords produced in Clear speech have higher ratings (Clear = 40.4, Fast = 36.1). Yet, there was not an interaction between speaking style and listener language background; in other words, the effect of speaking style was consistent across listener L1s.

Figure 1. Mean nonword acceptability ratings for items produced in clear and fast speech styles across different listener language backgrounds.
The model revealed an interaction between Listener L1 and Sonority value of the middle segment. Figure 2 provides word acceptability ratings based on the sonority value of the nonword items for each listener L1 group. First, as seen in Figure 2, the height of the bars for nonwords varying in sonority are relatively flat for the Tashlhiyt, Tarifit, and Moroccan Arabic listener groups. Indeed, there was not a significant coefficient for sonority value for L1 Tarifit and L1 Moroccan Arabic listeners. In contrast, nonword acceptability ratings vary a lot based on sonority value for the English listeners: the significantly positive coefficient for sonority value for L1 English indicates that these participants were more likely to provide higher ratings for words with more sonorous centers. There was also a positive coefficient for the L1 Mandarin group, also revealing that acceptability of nonwords increased with higher sonority centers for those listeners. Yet, the coefficient value is smaller than those for the L1 English group.
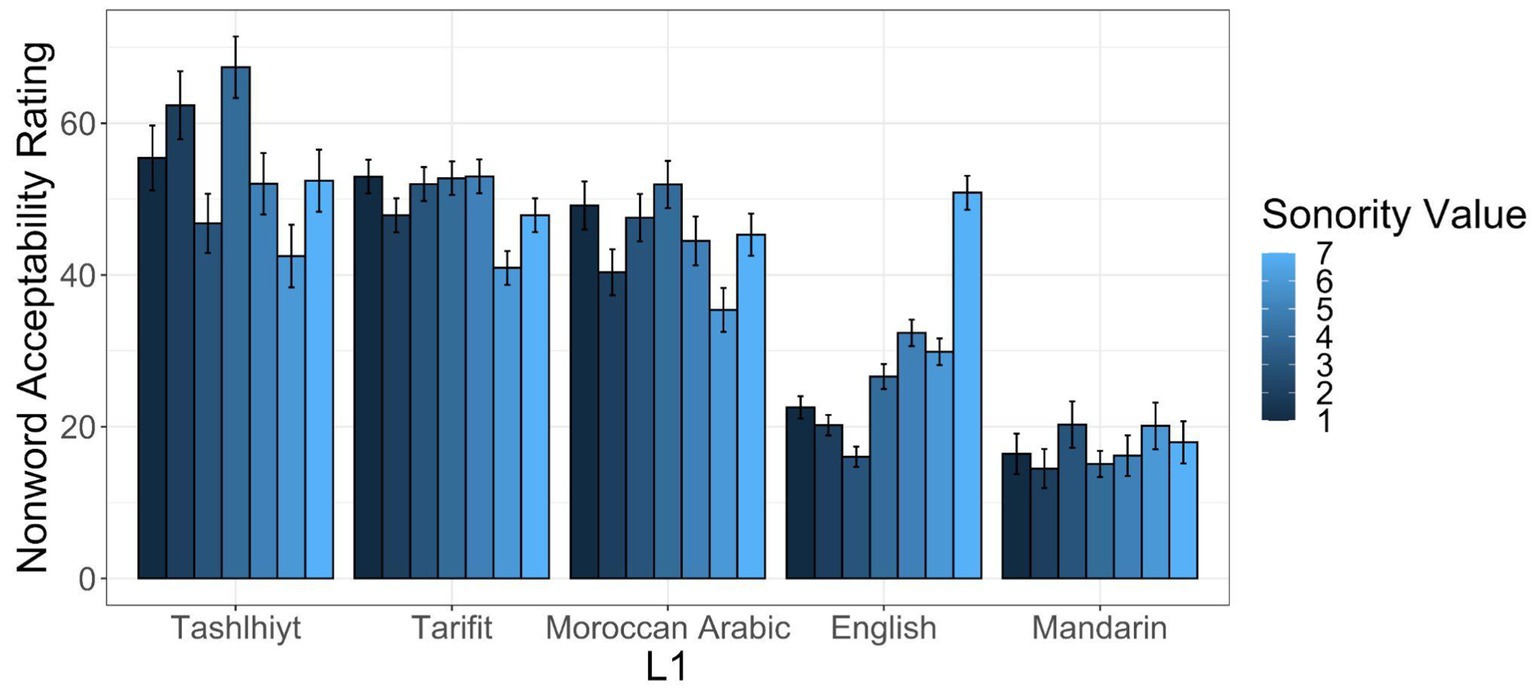
Figure 2. Mean nonword acceptability ratings based on the sonority value of the center segment for items, across different listener language backgrounds.
The present study investigated the perception of Tashlhiyt-like nonword items produced in clear and reduced speech styles by listeners with different native language backgrounds. Tashlhiyt is a language that permits highly complex syllable structures and our nonword items reflect variation in phonological structures present in the language. Indeed, numerically, the L1 Tashlhiyt listeners provided the highest acceptability ratings of our stimuli.
Meanwhile, the L1 Tarifit listeners showed similar word acceptability judgments of the nonword items as the L1 Tashlhiyt listeners. Tarifit is a language genetically related to Tashlhiyt and also permits words with highly complex syllable structures, though vowelless words are not allowed in Tarifit (and, there are other phonological differences across the languages, such as /l/ was lost in Tarifit due to a historical merger with /r/; Mourigh and Kossmann, 2019; Lafkioui, 2011). If the phonotactics of the Tashlhiyt and Tarifit are different, why do the Tarifit listeners show high acceptance of Tashlhiyt-like nonwords? One possible explanation for this is that the allowable sonority patterns are complex enough in Tarifit that vowelless words are taken as acceptable by listeners; Tarifit allows for complex consonant clusters of varied sonority profiles, similar to Tashlhiyt. If this is the case, this would mean that vowelless words are not categorically different in phonotactics than words with highly complex sequences of consonants. So, one way to interpret this finding is that language relatedness and structural similarity predicts high acceptance of Tashlhiyt-like nonwords. Even though Tarifit has a phonological restriction against vowelless words, listeners still show similar acceptance of them as native speakers, indicating that exposure to these words leads to acceptance of them in a nonword judgment task.
A second possibility is that, as we mentioned in the Introduction, phonetically vowelless variants of words are found in Tarifit and that could lead to acceptance of vowelless nonwords from Tashlhiyt. Our phonetic examination of CCəC words in Tarifit shows that occasionally they are produced with vowel deletion (about 5% of productions of words with this structure, according to our preliminary corpus). Thus, vowelless words are a phonetic variant of some words in Tarifit. This could explain why Tarifit speakers accept Tashlhiyt vowelless nonwords at high rate—they do align to a variant phonetic form of words in Tarifit.
We can also note that Tashlhiyt vowelless words are often produced with intrusive vocoids, especially before an /r/ and between voiced or hetero-organic consonant sequences (Ridouane and Cooper-Leavitt, 2019). This was the case with the nonword stimuli in our current study, as well; most were produced with a small transitional vocoid within the word as they contained the phonological context for schwa insertion. This could have also enhanced the acceptability of these words by Tarifit listeners.
Another possibility is that Tarifit listeners have some exposure to Tashlhiyt through language contact, for instance, via the media. In Morocco there is a national TV station (called “Tamazight” or the 8th) where shows, news, and other media content is broadcast in the different Amazigh varieties, including Tashlhiyt. So, Tarifit speakers could have been exposed to Tashlhiyt via this TV station, at least.
We also observe that L1 Moroccan Arabic speakers are not significantly different in vowelless nonword perception than L1 Tarifit speakers, and only marginally lower than the L1 Tashlhiyt listeners. Additionally, we do not observe the L1 Moroccan Arabic listeners’ word likeness ratings varying based on nonword sonority properties. Moroccan Arabic is not an Amazigh language; it is a dialectal variety of Arabic. However, vowel reduction processes in Moroccan Arabic words mean that the syllable structure in the language is closer to that of the Amazigh languages than some other varieties of Arabic (Chtatou, 1997). Through language contact with Amazigh, Moroccan Arabic lost short vowels from Classical Arabic and developed complex consonant clusters of varied sonority profiles (Dell and Elmedlaoui, 2012; Lahrouchi, 2018; Bensoukas and Boudlal, 2012a, 2012b). Thus, listeners whose L1s are similar to Tashlhiyt, through language contact, also show similar acceptance of vowelless words as native Tashlhiyt speakers.
We can also consider how a different group of Moroccan Arabic listeners might behave in this task. Moroccan Arabic contains a lot of regional and ethnic variation (e.g., Heath, 2002). In the current study, the L1 Moroccan Arabic speakers we recruited are from an Amazigh-dominant region. They could be influenced by hearing Tarifit, a language related to Tashlhiyt. This could explain why their nonword perceptual patterns were not different from the L1 Tarifit listeners. Prior work, for instance, has shown that language contact does affect listeners’ perceptual patterns of a language they do not speak: Lev-Ari and Peperkamp (2016) examined the perception of Spanish alveolar trill by monolingual American English listeners and found that individuals who simply lived in a geographic location with a high proportion of native Spanish speakers were more likely to accept an auditory stimulus item as containing the Spanish phoneme, compared to those who lived in a community with much fewer native Spanish speakers. They concluded that even community-based exposure to another language affects listeners’ expectations for word and sound shapes in a speech signal. Similar findings for other speech communities with languages in contact are reported by Panther et al. (2023) and Todd et al. (2023). This could also be an additional source of Tarifit listeners’ experience with, and thus acceptance of, Tashlhiyt word forms. Future work comparing L1 Moroccan Arabic speakers from other parts of Morocco—in particular, those who live in regions with fewer Amazigh speakers—could illuminate the role of language contact in the patterns of perception of Tashlhiyt.
We also acknowledge that some of our listener groups also had different age distributions (e.g., mean age was about 40 years old for the Tashlhiyt listeners vs. twenties for Moroccan Arabic, English, and Mandarin listeners). We are not aware of any literature or prior work proposing or finding evidence that adult age affects the perception or interpretation of nonwords. Though, this certainly is a possibility given that many aspects of the production and perception of speech change throughout the lifespan (e.g., Sankoff, 2018; Dubno, 2015). However, for our current results, given that our non-Tashlhiyt listener groups were most similar in ages, this is likely not a factor explaining differences in these non-native listeners groups.
In contrast, English and Mandarin are languages with categorically different syllable structure patterns than Tashlhiyt. Specifically, the L1 English and L1 Mandarin listeners in the present study provided much lower acceptability ratings of the Tashlhiyt nonwords than listeners from the other language backgrounds. Moreover, L1 Mandarin listeners provided even lower wordlikeness ratings than L1 English listeners. Thus, there is a gradient pattern of cross-language nonword acceptability ratings—L1 English listeners are more likely to accept Tashlhiyt nonwords than L1 Mandarin listeners.
Also, the phoneme inventories of Mandarin and English are not very similar to Tashlhiyt. Moroccan Arabic is similar to both Tarifit and Tashlhiyt in terms of phoneme inventory: all three languages have large consonant inventories containing consonants with guttural places of articulation, as well as alveolar sounds that contrast in pharyngealization. The overlap in phoneme inventories could also explain similar nonword rating patterns for the Tashlhiyt, Tarifit, and Moroccan Arabic, compared to the other two languages. Another shared phonological feature of these three languages is that they allow for highly complex syllable structures, including sonority-defying clusters. This raises the possibility that the overall complexity of syllable structure in a language will predict the acceptability of nonce words differing in the sonority of the syllable nucleus. This implies that it is not specifically the inventory of syllable nuclei that predicts judgments but rather some global measure of complexity across different parts of the syllable.
Moreover, English and Mandarin listeners displayed sensitivity to the sonority properties of the words: they were less likely to accept items containing low sonority word centers. This reflects the statistics of words in their native languages: neither English nor Mandarin permit vowelless words. However, syllable structure allowances are stricter in Mandarin than in English. Thus, the flatter slope of the sonority value effect for Mandarin listeners possibly reflects more categorically lower ratings for all the items, relative to the English listeners.
We also observed that all listeners provided higher wordlikeness ratings for items produced in clear speech, compared to fast/reduced speech productions. This was a consistent effect size across each listener group. In other words, language background does not affect the boost to wordlikeness that clear speech productions provide. Clear speech is known to enhance word and phoneme intelligibility for both native and non-native listeners (Smiljanić and Bradlow, 2011). It also has been shown to enhance other perceptual effects, such as memory (Keerstock and Smiljanic, 2019), learning (Zellou et al., 2024a), and discrimination (Zellou et al., 2024b). Here, we demonstrate that clear speech enhances wordlikeness for both native and non-native listeners. This finding is also consistent with recent work in neurolinguistics indicating that wordlikeness perception involves sensorimotor and acoustic processing mechanisms (Avcu et al., 2023). Perhaps because clear speech provides more acoustically distinct forms of items, listeners are more willing to accept hyperarticulated items as possible words regardless of their language background.
Thus, we find that, overall, word acceptability ratings across listeners with different language backgrounds patterns with the phonological similarity of the languages to Tashlhiyt, based on descriptions of syllable structure allowances across the languages. Thus, this study is consistent with prior work that nonword acceptability is gradient and based on language experience (e.g., Vitevitch et al., 1997; Hayes and Wilson, 2008; Zuraw, 2007; Myers and Tsay, 2005). We also extended this line of work to variation in acoustic-phonetic form. This is another type of variation in word phonotactics, except one that is common across all languages. Thus, our stable effect of speech style is also consistent with the role of language experience on nonword acceptability.
We believe that the results of the current study can also speak to larger theoretical issues on phonological typology and language evolution. Nonword acceptability judgments are a tool that can inform phonological theory (Frisch et al., 2000; Albright, 2009; Daland et al., 2011), particularly in probing listeners’ abstract knowledge about the patterns of word forms in their listeners native language. Could it also hold clues to language change and evolution? We find that even though Tarifit and Moroccan Arabic do not have phonologically vowelless words, speakers of those languages show similar acceptability of Tashlhiyt-like vowelless nonwords to native Tashlhiyt listeners (which contains many vowelless words). Yet, as mentioned, Tarifit speakers can occasionally produce phonetically vowelless forms of words. So, perhaps the presence of this variation in Tarifit allows for their acceptance of vowelless nonwords. This could be one pathway for the evolution of phonologically vowelless words—from phonetic variation, to phonologization of vowellessess.
The results of the current study can also speak to larger issues in Amazigh language studies. Amazigh languages are understudied in psycholinguistic research, yet they contain unique linguistic, social, and historical patterns. Linguistic research can benefit from investigations of these languages. Cross-Amazigh perception and communication is even more under-researched. There are movements to “standardize” Moroccan Amazigh for the purposes of teaching the language in schools, having a presence in official and governmental contexts, and creating a cohesive Amazigh cultural and linguistic entity. However, there is very little empirical work on perception by Amazigh speakers from different varieties. This is a ripe avenue for future research.
The present study finds both language-specific and universal influences on wordlikeness judgments of vowelless nonwords produced by a native speaker of Tashlhiyt. Listeners whose native languages were phonologically similar to Tashlhiyt showed similar wordlikeness judgments to L1 Tashlhiyt listeners. Our results indicate that language similarity supports the acceptance of vowelless nonwords. English allows more complex phonotactic structures than Mandarin, and we observe more gradient acceptance of Tashlhiyt nonwords by L1 English listeners but categorically lower ratings of Tashlhiyt nonwords by L1 Mandarin listeners. Thus, language-specific phonotactic patterns will lead to differences in acceptability of vowelless words. We also observed that the role of clear speech in enhancing wordlikeness judgments was equivalent in effect size across language backgrounds. Thus, in contrast to the language-specific effect of lexical-phonological statistics, speaking style appears to have a non-language-specific role in making speech forms more acceptable as words for listeners.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving humans were approved by UC Davis Institutional Review Board. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
GZ: Conceptualization, Formal analysis, Investigation, Visualization, Writing – original draft. MA: Conceptualization, Data curation, Investigation, Writing – original draft. ML: Conceptualization, Data curation, Writing – original draft. KB: Data curation, Writing – original draft.
The author(s) declare that no financial support was received for the research and/or publication of this article.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor AP declared a past collaboration with the author GZ.
The author(s) declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Albright, A. (2009). Feature-based generalisation as a source of gradient acceptability. Phonology 26, 9–41. doi: 10.1017/S0952675709001705
Avcu, E., Newman, O., Ahlfors, S. P., and Gow, D. W. Jr. (2023). Neural evidence suggests phonological acceptability judgments reflect similarity, not constraint evaluation. Cognition 230:105322. doi: 10.1016/j.cognition.2022.105322
Bates, D. M. (2015). lme4: mixed-effects modeling with R https.cran.r-project.org/web/packages/lme4/vignettes/lmer.pdf (Accessed January 1, 2024).
Bensoukas, K., and Boudlal, A. (2012a). “The prosody of Moroccan Amazigh and Moroccan Arabic: similarities in the phonology of schwa” in Prosody matters: Essays in honor of Lisa Selkirk. eds. J. J. McCarthy, T. Borowsky, S. Kawahara, T. Shinya, and M. Sugahara (London: Equinox), 3–42.
Bensoukas, K., and Boudlal, A. (2012b). An Amazigh substratum in Moroccan Arabic: the prosody of schwa. Lang. Lit. 22, 179–221. doi: 10.34874/PRSM.r2l-v22.37499
Bradlow, A. R. (2002). Confluent talker-and listener-oriented forces in clear speech production. Lab. Phonol. 7, 241–273. doi: 10.1515/9783110197105
Cho, S., Jongman, A., Wang, Y., and Sereno, J. A. (2020). Multi-modal cross-linguistic perception of fricatives in clear speech. J. Acoust. Soc. Am. 147, 2609–2624. doi: 10.1121/10.0001140
Chtatou, M. (1997). The influence of the Berber language on Moroccan Arabic. Int. J. Sociol. Lang. 123, 101–118. doi: 10.1515/ijsl.1997.123.101
Clements, G. N. (1990). “The role of the sonority cycle in core syllabification” in Papers in laboratory phonology I: Between the grammar and physics of speech. eds. J. Kingston and M. E. Beckman (Cambridge, CUP: Cambridge University Press), 283–333.
Cohn, M., Ferenc Segedin, B., and Zellou, G. (2022). Acoustic-phonetic properties of Siri-and human-directed speech. J. Phon. 90:101123:101123. doi: 10.1016/j.wocn.2021.101123
Daland, R., Hayes, B., White, J., Garellek, M., Davis, A., and Norrmann, I. (2011). Explaining sonority projection effects. Phonology 28, 197–234. doi: 10.1017/S0952675711000145
Dell, F., and Elmedlaoui, M. (2012). Syllables in Tashlhiyt Berber and in Moroccan Arabic (Vol. 2). Dordrecht: Springer Science & Business Media.
Dell, F., and Tangi, O. (1992). Syllabification and empty nuclei in Ath-Sidhar Rifian Berber. J. Afric. Lang. Linguist. 13, 125–162. doi: 10.1515/jall.1992.13.2.125
Dubno, J. R. (2015). Speech recognition across the life span: longitudinal changes from middle-age to older adults. Am. J. Audiol. 24, 84–87. doi: 10.1044/2015_AJA-14-0052
Frisch, S., Large, N., and Pisoni, D. (2000). Perception of wordlikeness: effects of segmental probability and length on the processing of nonwords. J. Mem. Lang. 42, 481–496. doi: 10.1006/jmla.1999.2692
Frisch, S. A., Large, N. R., Zawaydeh, B., and Pisoni, D. B. (2001). Emergent phonotactic generalizations in English and Arabic. Typol. Stud. Lang. 45, 159–180. doi: 10.1075/tsl.45.09fri
Guo, Z. C., and Smiljanic, R. (2021). Speaking clearly improves speech segmentation by statistical learning under optimal listening conditions. Lab. Phonol. 12:14. doi: 10.5334/labphon.310
Hayes, B., and Wilson, C. (2008). A maximum entropy model of phonotactics and phonotactic learning. Linguist. Inq. 39, 379–440. doi: 10.1162/ling.2008.39.3.379
Keerstock, S., and Smiljanic, R. (2019). Clear speech improves listeners' recall. J. Acoust. Soc. Am. 146, 4604–4610. doi: 10.1121/1.5141372
Krause, J. C., and Braida, L. D. (2004). Acoustic properties of naturally produced clear speech at normal speaking rates. J. Acoust. Soc. Am. 115, 362–378. doi: 10.1121/1.1635842
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. H. (2017). lmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26. doi: 10.18637/jss.v082.i13
Lafkioui, M. (2011). How system-internal linguistic factors indicate language change and diffusion. A geolinguistic analysis of Berber data. Dialectol. Geolinguist. 19, 62–80. doi: 10.1515/dig.2011.003
Lahrouchi, M. (2018). “Syllable structure and vowel-zero alternations in Moroccan Arabic and Berber” in The Routledge handbook of African linguistics. eds. A. Agwuele and A. Bodomo (Oxon, UK: Routledge), 168–180.
Lev-Ari, S., and Peperkamp, S. (2016). How the demographic makeup of our community influences speech perception. J. Acoust. Soc. Am. 139, 3076–3087. doi: 10.1121/1.4950811
Lindblom, B. (1990). Explaining phonetic variation: a sketch of the H& H theory. Speech Prod. Speech Model. 55, 403–439. doi: 10.1007/978-94-009-2037-8_16
McClelland, C. W. (1996). Interrelations of prosody, clause structure and discourse pragmatics in Tarifit Berber. Ph.D. Dissertation, The University of Texas at Arlington.
Mourigh, K., and Kossmann, M. G. (2019). An introduction to Tarifiyt Berber (Nador, Morocco). Münster: Ugarit-Verlag.
Munson, B. (2001). Phonological pattern frequency and speech production in adults and children. J. Speech Lang. Hear. Res. 44, 778–792. doi: 10.1044/1092-4388(2001/061)
Myers, J., and Tsay, J. (2005). “The processing of phonological acceptability judgments.” In Proceedings of symposium on 90–92 NSC projects. pp. 26–45.
Panther, F. A., Mattingley, W., Todd, S., Hay, J., King, J., and Panther, F. (2023). Proto-lexicon size and phonotactic knowledge are linked in non-Māori speaking New Zealand adults. Lab. Phonol. 14:7943. doi: 10.16995/labphon.7943
Parker, S. G. (2002). Quantifying the sonority hierarchy. Ph.D. Dissertation, University of Massachusetts Amherst.
Picheny, M. A., Durlach, N. I., and Braida, L. D. (1986). Speaking clearly for the hard of hearing II: acoustic characteristics of clear and conversational speech. J. Speech Lang. Hear. Res. 29, 434–446. doi: 10.1044/jshr.2904.434
Ridouane, R., and Cooper-Leavitt, J. (2019). A story of two schwas: a production study from Tashlhiyt. Phonology 36, 433–456. doi: 10.1017/S0952675719000216
Sankoff, G. (2018). Language change across the lifespan. Ann. Rev. Linguist. 4, 297–316. doi: 10.1146/annurev-linguistics-011817-045438
Scarborough, R., and Zellou, G. (2013). Clarity in communication: “clear” speech authenticity and lexical neighborhood density effects in speech production and perception. J. Acoust. Soc. Am. 134, 3793–3807. doi: 10.1121/1.4824120
Smiljanić, R., and Bradlow, A. R. (2005). Production and perception of clear speech in Croatian and English. J. Acoust. Soc. Am. 118, 1677–1688. doi: 10.1121/1.2000788
Smiljanić, R., and Bradlow, A. R. (2011). Bidirectional clear speech perception benefit for native and high-proficiency non-native talkers and listeners: intelligibility and accentedness. J. Acoust. Soc. Am. 130, 4020–4031. doi: 10.1121/1.3652882
Todd, S., Ben Youssef, C., and Vásquez-Aguilar, A. (2023). Language structure, attitudes, and learning from ambient exposure: lexical and phonotactic knowledge of Spanish among non-Spanish-speaking Californians and Texans. PLoS One 18:e0284919. doi: 10.1371/journal.pone.0284919
Vitevitch, M. S., Luce, P. A., Charles-Luce, J., and Kemmerer, D. (1997). Phonotactics and syllable stress: implications for the processing of spoken nonsense words. Lang. Speech 40, 47–62. doi: 10.1177/002383099704000103
Wright, R. (2004). A review of perceptual cues and cue robustness. Phonet. Based Phonol. 34:57. doi: 10.1017/CBO9780511486401.002
Wu, F., and Kenstowicz, M. (2015). Duration reflexes of syllable structure in mandarin. Lingua 164, 87–99. doi: 10.1016/j.lingua.2015.06.010
Zellou, G., Barreda, S., Lahrouchi, M., and Smiljanić, R. (2024a). Learning a language with vowelless words. Cognition 251:105909. doi: 10.1016/j.cognition.2024.105909
Zellou, G., Lahrouchi, M., and Bensoukas, K. (2022). Clear speech in Tashlhiyt Berber: the perception of typologically uncommon word-initial contrasts by native and naive listeners. J. Acoust. Soc. Am. 152, 3429–3443. doi: 10.1121/10.0016579
Zellou, G., Lahrouchi, M., and Bensoukas, K. (2024b). The perception of vowelless words in Tashlhiyt. Glossa 9, 1–41. doi: 10.16995/glossa.10438
Zellou, G., and Scarborough, R. (2019). Neighborhood-conditioned phonetic enhancement of an allophonic vowel split. J. Acoust. Soc. Am. 145, 3675–3685. doi: 10.1121/1.5113582
Zeng, Y., Leung, K. K., Jongman, A., Sereno, J. A., and Wang, Y. (2023). Multi-modal cross-linguistic perception of mandarin tones in clear speech. Front. Hum. Neurosci. 17:1247811. doi: 10.3389/fnhum.2023.1247811
Keywords: wordlikeness, speech perception, phonological theory, clear speech, Amazigh languages
Citation: Zellou G, Afkir M, Lahrouchi M and Bensoukas K (2025) Cross-language variation in the acceptability of vowelless nonwords. Front. Commun. 10:1518754. doi: 10.3389/fcomm.2025.1518754
Edited by:
Anne Pycha, University of Wisconsin–Milwaukee, United StatesReviewed by:
Evgeniya Gutova, University of Navarra, SpainCopyright © 2025 Zellou, Afkir, Lahrouchi and Bensoukas. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Georgia Zellou, Z3plbGxvdUB1Y2RhdmlzLmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.