 Bahareh Yousefzadeh
Bahareh Yousefzadeh Gary Libben
Gary Libben Sidney J. Segalowitz2
Sidney J. Segalowitz2- 1Department of Applied Linguistics, Brock University, St. Catharines, ON, Canada
- 2Department of Psychology, Brock University, St. Catharines, ON, Canada
Compound words exhibit properties of both single words and phrases, raising the question of the extent to which compounds are processed as single units or as word combinations. Most studies have addressed this in Germanic languages (English, German and Dutch) which have the similar compound structure of modifier-head ordering. To see whether this limits our understanding of compound word processing and to examine compound decomposition in another language, we presented Persian stimuli auditorily in a paradigm involving typing out stimuli. We examined the effects of semantic transparency, modifier-head ordering and the potential differences between attached compounds written without spaces and those with a space between the constituents. We report the inter-keystroke-interval times, yielding letter-by-letter production of compound structures produced by 31 native speakers of Persian. Results analyzed in a linear mixed-model regression analysis suggested that, for all compounds, typing speed is slowed at the boundary between the constituents of Persian compound words. These effects, which we interpret to be evidence of morphological decomposition, were present for both semantically transparent and opaque compounds, for both head-initial and head-final compounds, and for both attached and spaced compounds. We observed greater morphological decomposition effects in semantically transparent (versus opaque) compounds. We also observed that the way transparency influences the degree of decomposition is moderated by headedness. Thus, this first report for the written production of compound words confirms previous observations of significant decomposition at morphological boundaries in English compounds, but with variation specific to Persian.
Introduction
Although compound words such as whiteboard and hot dog are common in English and indeed across the world’s languages, their structure contains paradoxes that have proven valuable to the advancement of our understanding of language representation and processing. Compounding can be seen as a type of word formation process in which new words are created through the combination of existing lexical elements which are often, themselves, free existing words in the language (e.g., white and board, hot and dog). This essential property of compound words raises two fundamental questions that have been noted since antiquity (Libben et al., 2021):
1. Are compound words best seen as single words, or rather combinations of words (as phrases are), or both?
2. Are the constituents of compound words themselves treated as words, or rather as morphological constituents (as prefixes and suffixes are), or both?
At present, evidence suggests that the answer to both questions (1) and (2) is “both.” There seems little doubt that compound words must be seen as having the properties of words, both linguistically and psycholinguistically. Perhaps the most compelling reason for this concerns the notion of semantic transparency. This relation between the meaning of a compound word as a whole and the extent to which that whole-word meaning is related to the meanings of a compound’s constituents has been the subject of considerable attention in both theoretical approaches to word structure (e.g., Anderson, 1992; Lieber and Stekauer, 2009; Rainer et al., 2014) and psycholinguistic approaches to compound representation and processing (Sandra, 1990; Libben and Weber, 2014; Gagné et al., 2016; Smolka and Libben, 2017; Günther et al., 2020; Günther and Marelli, 2023).
As a concrete illustration of the issue of semantic transparency, consider the compound word whiteboard. Although it might seem that the meaning of the compound as a whole is related straightforwardly to the meanings of the constituents white and board, it is exceedingly unlikely that its meaning as “a hard smooth white surface used for writing or drawing on with markers” (Merriam Webster, online) could be calculated from its two constituents alone. Rather, it seems evident that for a speaker of English to know the meaning of the word, it had to have been learned as a word in an appropriate context.
An even lower degree of semantic transparency is evident in the compound hot dog. Here, it would seem that, particularly because the compound is written with a space between the two constituents, that the individual meanings of hot and dog would be accentuated and the “wordness” of the full compound would be diminished. In fact, however, if a language user did not know the meaning of the whole compound as a word, it would be highly improbable that its meaning could be determined from the meanings of its parts (Libben, 2022).
The considerations above present evidence in support of the view that compound words must be seen as having a dual nature. They are both single words and combinations of lexical representations. This perspective is supported by masked constituent priming experiments such as those conducted by Fiorentino and Fund-Reznicek (2009) as well as overt constituent priming experiments (e.g., Libben et al., 2003) and overt semantic priming experiments such as those carried out by Sandra (1990) in which it was found that compounds such as whiteboard are facilitated by prior presentation of words (e.g., wood) that are semantically associated with one of their constituents (e.g., board) but which are not associated to the meaning of the whole compound (e.g., whiteboard).
The status of the constituent board in a compound such as whiteboard is at the core of Question 2. Libben has claimed that compound constituents must be seen as positionally bound morphological elements, presenting evidence that the morphological constituent -board, is neither the same as the independent word board nor the same as the compound modifier board- that would be found in the compound boardroom (Libben, 2019; Libben et al., 2021).
This observation that the mental representation of a compound constituent is related to its position brings to the foreground the issue of distinguishing between the position of a constituent and its morphological role in a compound. Traditionally, the term morphological head has referred to the element of a word that typically determines the lexical category of a multi-morphemic word and its semantic characteristics (Lieber, 1980; Selkirk, 1981; Williams, 1981; Di Sciullo and Williams, 1987). In English, it is the final element of a compound word that serves as its morphological head. Thus, the compound word boardroom is typically understood to be a type of room and interpreted as a noun, because the word room is a noun. For this reason, in English, it is not possible to separate the effects of morphological headedness in compound processing from the effects of position. In Persian, however, morphological heads can occur in both compound-initial position and in compound-final position.
In summary, we have seen that the paradoxes associated with compound word structure provide a valuable window to human lexical language processing. We have highlighted three factors in compounding that could bear on the interplay between constituent and compound word activation:
a. the semantic transparency of the constituents,
b. the information conveyed through morphological headedness,
c. the salience of compound constituency made possible by orthographic spacing.
The present study is motivated by the fact that the Persian language allows for the manipulation of all three of these factors, whereas most of the work on compounds has been in languages that only allow variation of the first factor. As we discuss below, Persian compounds show a range of semantic transparency. Importantly, Persian compounds differ from Germanic compounds in that they can be both head-initial and head-final, allowing for morphological headedness to be manipulated as a factor. Finally, like English to some extent, but unlike other languages such as German, both spaced and attached compounds in Persian are common. Details concerning the structure of Persian compounds with reference to these characteristics, in particular, are treated below.
A key feature of the present study is that it targets the issue of and degree of compound decomposition through a cross-modal written production experiment. We consider this technique to be sensitive to morphological and semantic characteristics of compound representation and processing as well as allowing us to examine the effects of the specific characteristics of the Persian language and writing system. The task, which we consider to be a “lexical dictation task” is one in which participants hear a word or compound spoken and then must type it as quickly and accurately as possible. Key dependent variables are typing accuracy and inter-keystroke interval (IKI) latency. The typing technique has been used to study lexical processing in European languages (Torrance et al., 2018), including English (Will et al., 2001) and German (Will et al., 2006). The auditory-to-typing cross-modal manipulation, however, has not been widely implemented (see Delattre et al., 2006) and, to the best of our knowledge, this is the first report of the use of typing in the study of Persian lexical representation and processing and in the study of compounds.
Persian compounding: a testing ground for compound representation and processing
Previous psycholinguistic research on Persian compounds
The processing of Persian compounds has been examined with respect to the factor of transparency for some time, especially with respect to verb compounds. While these studies have not addressed the issue of the size of morphological decomposition in production as we address here, verb compounds merit investigation because they are very highly productive in Persian in ways not available to other languages. See for example, Momenian et al. (2021a,b), Purmohammad et al. (2022), and Shabani-Jadidi (2012, 2014, 2016) for linguistic and psycholinguistic explorations of Persian verb compounds. For example, Shabani-Jadidi (2012) showed that with transparent verb compounds, priming the initial (noun) component speeds up lexical decision of the full compound more than priming the second (verb) component, but this was not the case when it is opaque. This suggests that transparent verb compounds decompose more than opaque ones. With respect to the current context, however, it is important to note that verb compounds do not permit variations in spacing or headedness, and therefore we cannot see whether morphological decomposition is affected by these factors in verb compounds. As indicated below (see section on Stimuli), we have not included verb compounds in the analyses of the current report for these reasons.
Some recent work has been done with Persian noun-noun compounds, reporting that headedness affects how priming influences reading speed, suggesting that initial and final headed compounds are processed differently (Torshizi, 2020).
Orthographic properties of Persian compounds
Like English, Persian is an Indo-European language. It is written from right to left using a script that is derived from Arabic (with the addition of four Persian consonants that Arabic does not possess). The Persian writing system has only one script style for both print and handwritten material, with slight differences between them for some letters. In Persian, some letters have different forms depending on their location in the word (at the beginning, middle, or end). For example, the letter /ه/ (which corresponds to h in English) offers all three types / ههه/. In addition, because the writing system is cursive in nature, some letters are able to be connected to letters on the right or left if their neighboring letters permit attachment (whereas in English all print letters are detached). For example, the Persian /د / cannot be attached to the left, but can be attached to the right, as in the word “بیدار,” for awake.
Morphological and semantic properties of Persian compounds
Productivity and composition of compounds
Compounding is highly productive in Persian. In fact, compounding is the most frequent word formation process, comprising 70% of the words generated by the Persian Language Academy as equivalents for new words (i.e., loanwords) (Tabatabaei, 2016). Compounding is particularly common for verbs, but Persian uses constituents from various lexical categories, including nouns, verb stems, adjectives, and adverbs. In a compound, each of these can serve as either the modifier or head. Examples of such constructions include the noun-noun compound “کتابخانه,” “book-house” for library, the noun-adjective compound “پیازداغ,” “onion-hot” for fried onion, and the noun-verb compound “بالگرد,” “wing-circle” for helicopter. The preceding examples represent the major patterns of compounding combination in Persian. Other combinations such as Adjective-Adjective (e.g., “نازک نارنجی,” “thin + orange-colored” for touchy) do occur, but are rare.
Free and bound constituents
Persian compounds are typically composed of two stems that can themselves be self-standing words (as in English). However, there are compounds that contain a bound form as their second constituent. For example, in a compound such as “دماسنج,” “temperature-measure” for thermometer, the second constituent “-measure” is a verb stem that does not appear independently, and is thus a bound morpheme. In order for these constituents to be used in various contexts, they must either be suffixed by [−esh] to produce the noun “سنجش” ([measure-] + [−esh] for measurement), or be inflected for tense and subject (e.g., “میسنجم,” [(mi-sanj-am), (incomplete aspect prefix + measure (stem) + first-person singular, respectively)]).
The presence of compound-internal morphosyntactic elements
One of the major reasons that compound words are regarded as compounds is the extent to which the constituents are fused with each other to turn a sequence of morphemes into a single word (e.g., into a biconstituent compound). Such attachment does not typically allow any morphosyntactic elements to influence constituents individually. For instance, in Persian, neither the initial nor the final constituent is inflected by the plural marker. However, the plural marker is applied to the compound word as a whole. All the compound words used in our study are of this sort.
The “Ezafe” construction
Persian has a within-phrase morphosyntactic element that, although not used in the present study, is worthy of note. A Persian phrase corresponding to the English sequence “big house” would be in reverse order in Persian and include the morphosyntactic element known as Ezafe (/e/ or /y/ between the noun and adjective). As a result, the English phrase “big house” becomes “خانهی بزرگ,” house-Ez big in Persian. The Ezafe element also acts as a linker in a possessive relation (e.g., “خانهی مادر,” house-Ez mother, for mother’s house).
Morphological headedness
A key difference between compounding in Persian and compounding in English concerns what has been described in the linguistic literature as “morphological headedness” (Arcodia, 2012). In English, compound words are morphologically head-final. Therefore, a compound constituent’s position in a compound and its morphological and semantic roles in that compound are very much related. It follows from this that if speakers of English are presented with the compound chicken dog for the first time, some might interpret it (on the model of turkey dog) to be a sausage made of chicken. Others might interpret it (on the model of bulldog or bird dog) to be a dog that is somehow chicken-like or perhaps bred to herd or chase chickens. It is very unlikely, however, that any speaker of English will interpret the compound chicken dog to be a type of chicken. The reason for this is that, in English, the initial element of a two-constituent compound typically functions as a modifier and the final constituent typically functions as the grammatical and semantic head. Thus, the combination of the adjective white and the noun board will result in a noun and not an adjective. It will also be interpreted as being literally, functionally, or metaphorically a type of board, not a type of white. This is not the case in Persian. Some Persian compounds are head initial and some are head final. Thus, Persian speakers who are presented with the novel compound chicken dog (مرغ سگ) could legitimately guess that it is a type of dog or that it is a type of chicken. In Persian, therefore, the role of a compound constituent cannot be deduced from its position in the word. For instance, in the compound maahi ghermez (“fish red”, for gold fish) the head “fish” is initial. However, in the similar compound, “are maahi” (“saw fish”, for sawfish), the head is final.
It is important to note that some Romance languages such as Italian also show variation in the modifier-head ordering of compound words and can therefore be considered to be similar to Persian in this respect. The manner in which this modifier-head order affects compound word recognition and reading in Italian was investigated by Marelli and Luzzatti (2012) using both a lexical decision task and an eye tracking paradigm. They report that how greater frequency of a constituent influences response time depends on an interaction of transparency and headedness. Thus, their findings support the view that, in addition to constituents being accessed during the processing of compounds, morphological structuring and semantic transparency interact in reading compounds. Their findings from both lexical decision and eye-tracking point to a processing advantage of semantically transparent compounds over less transparent ones. They also found processing advantages of head-final compounds as compared to head-initial ones. The authors note that the finding of a head-final advantage shows the headedness effect to be position-specific, mainly emerging for the rightmost constituent in the processing of Italian compounds.
While the lexical decision and eye-tracking results of the Marelli and Luzzatti (2012) do not target word-internal processing as does the typing task that we employ in the current study, their results demonstrate that constituent characteristics such as transparency and headedness can act together in complex ways to influence compound word visual processing.
Semantic transparency
Persian compound words vary in their semantic transparency -- the extent to which the meanings of lexical elements as compound constituents corresponds to their meanings as independent words. Some compounds can be considered to be fully semantically transparent (e.g., “ماهی قرمز,” “fish-red” for the English gold fish) while others (e.g., “گلابی,” “flower-blue” for pear) are considerably more semantically opaque. As in other languages, compounds vary in semantic transparency: Persian has fully transparent compounds (TT) such as “آبمیوه,” “water-fruit” for juice; partially transparent, transparent-opaque (TO) such as “وطن فروش,” “homeland-sell” for traitor; opaque-transparent (OT) such as “دست فروش,” “hand-sell” for street seller; and opaque-opaque (OO) such as “ریش سفید,” “white-beard” for a mediator.
Methodological considerations
The present research brings a “language production perspective” to the issue of morphological decomposition that, in our view, adds to the insights that can be obtained through studies of lexical recognition. The notion of morphological decomposition has been central to understanding how complex and compound words are represented and processed in the mind. Traditionally, it has referred to the extent to which whole-word processing involves the activation of sublexical constituents such as affixes or stems. It is important to note that, in a production paradigm such as the one that is employed in the present study, the term decomposition has a somewhat different focus. We assume that, in production, the finding of effects of morphological structure indicates that the morphological structure is part of a word’s mental representation. Thus, when a person types a word that they know, they are drawing on their stored knowledge of that word. As a result, the finding of decomposition effects in the production of a word such as bedroom, for example, suggests that (a) the mental representation for the compound word contains knowledge that it possesses the constituents bed and room, in addition to (b) that this knowledge enables lexical production to include sublexical motor sequences (the first motor sequence for bed, and the second motor sequence for room). Such an account would result in the observation of elevated IKIs exactly at the constituent boundary (i.e., at the end of one motor plan and at the beginning of the next one). In this way, the production paradigm with auditory stimulus presentation differs from the recognition paradigms such as lexical decision in that it specifically targets the nature of the stored mental representations for complex and compound words. For decomposition effects to be found in our paradigm, it is required that morphological constituency be part of a word’s mental representation.
We thus considered increased IKI duration at the compound constituent boundary to be an indicator of morphological decomposition (in the sense described above) and investigated the extent to which it is influenced by differences in the factors of transparency, headedness and spacing. We expected opaque and transparent compounds to differ in their decomposition, noting that in English, there are multiple reports that transparent compounds show greater decomposition than opaque compounds which nonetheless show some decomposition (Sandra, 2020; Libben et al., 2021; Creemers and Embick, 2022). For example, although OO compounds are similar to a single word because they both refer to a single notion, OO compounds are not as homogenized as single words. For this reason, we expect there to be a larger gap between morphemes of an OO compound (at the morpheme boundary) in comparison to a very small constant gap between letters of a word. As an example, in English, we can expect the word “bedroom” in English should produce a longer IKI between the letters “d” and “r” than between other letters, such as the letter “e” and the letter “d” within a single word or between “r” and “o” in the second constituent. From the results of the studies in English, we would expect that this constituent boundary gap would be yet larger for transparent compounds, as shown by Libben and Weber (2014) in a typing study. According to their findings, there was always a longer time to start the second constituent compared to the time to type the letter finishing the first morpheme whether the compound was transparent such as “blackboard” or opaque such as “deadline”. However, this increased typing time after the constituent boundary was larger for TT compounds than for OO compounds. This recognition of the constituent characteristics could be due to the compound being stored in the mental lexicon as a double-item, due to it being decomposed as it is being retrieved, or due to it being decomposed as it is being produced.
Hypotheses and predictions
The focus of this study is on the time between constituents within compounds (as measured by letter typing times) as it relates to different transparency, headedness, and spacing conditions. The key feature of the present study is that we examine all these factors together in a single language. Thus, our study of compound word production in Persian enables us to address the dynamics among semantic, morphological, and orthographic factors in word production.
We hypothesize that both semantically transparent and opaque compounds should show decomposition effects, but the effects should be larger for semantically transparent compounds. This expectation is grounded in the view that semantic opacity in both constituents makes the constituents less salient because they do not contribute semantically to the overall meaning of the compound word. It is important to note that although semantic transparency has been shown to have an effect across languages (Sandra, 2020), there are also language-specific factors that may need to be taken into consideration.
Although across languages there may seem no reason to expect processing advantages associated with headedness, in Persian, head-final compounds are the default and are the more productive form (Kahnemuyipour, 2014).
With respect to spacing, spaced compounds would seem intuitively to be more likely to be decomposed since they have a visual representation as separate constituents, perhaps even in a paradigm where the compound is presented auditorily.
Finally, our design enables us to explore whether these factors are purely additive or, in fact, are subject to interaction effects.
Method
Participants
We recruited 33 native Persian speakers aged between 17 to 50 years old who are used to typing texts with keyboards and reside in North America. Of these, two were using keyboards not compatible with our software resulting in our data set representing 31 participants. Most of these participants (28 of 31) indicated they are currently students, and the remaining three have completed post-graduate degrees. The task took almost 30 min for which each person was compensated $7.50CAD.
Stimuli
Stimuli consisted of 157 Persian compound words mostly selected from the Bijankhan et al. (2017) database. An additional 25 monomorphemic non-compound words were included in order to reduce expectations that all stimuli would be compounds, chosen to have words completely different from constituents in the compound combinations. See Appendix A for the stimulus set.
The entire stimulus set consists of 182 audio recordings set up in 4 blocks containing two blocks of 45 and two blocks of 46 stimuli. The compound stimuli included in the analyses averaged 1,022 ms in length (SD = 196 ms) with a range of 611 to 1,677 ms. Our stimuli included 79 TT and 55 OO compounds, 11 TO and 12 OT compounds. However, because compounds containing verb forms are always head-final, these were omitted from analyses as they would present a confound in any comparison involving headedness, resulting in a final set of 51 TT and 31 OO compounds. The analyses were restricted to TT and OO compounds due to an insufficient number of TO and OT compounds from which to select. In order to reduce repetition effects, no constituent appeared more than twice in either initial or final position in the stimulus set.
Procedure
We used the PsychoPy and Pavlovia platforms for creating and running online experiments in psycholinguistics (Peirce et al., 2019). Compounds were pseudorandomized within blocks with no repetitions of types in the trial sequence. To avoid repetition effects, every compound with a specific verb constituent was included only once.
The session began with two initial tasks. In the first task, participants were required to type a paragraph so that we could make sure that their keyboard had letter mapping consistent with our scoring program. A note explaining step-by-step what they should expect appeared for them to read. This was followed by another task presenting five words auditorily for them to type as a warm-up. Immediately after that, participants began the actual test by pressing the Enter/Return key. A 200 ms fixation marker “+” appeared in the middle of the screen followed by the auditory stimulus. Participants typed the compound right after they heard it. Having completed the word, indicated by pressing the Enter key, they saw the fixation cross and the next stimulus was played for them. They heard each compound only once. The stimuli were re-randomized for each participant.
The position of the compound that appeared on the screen was marked by “<<<” as illustrated in Figure 1. Participants were instructed that they could correct typos by hitting the Backspace key and retyping the letter. The latencies of all keystrokes are recorded by the system to be analyzed. Trials with any errors (including those with backspace corrections) were not included in the analysis and only keystrokes with latencies below 2000 ms were kept for the analyses.
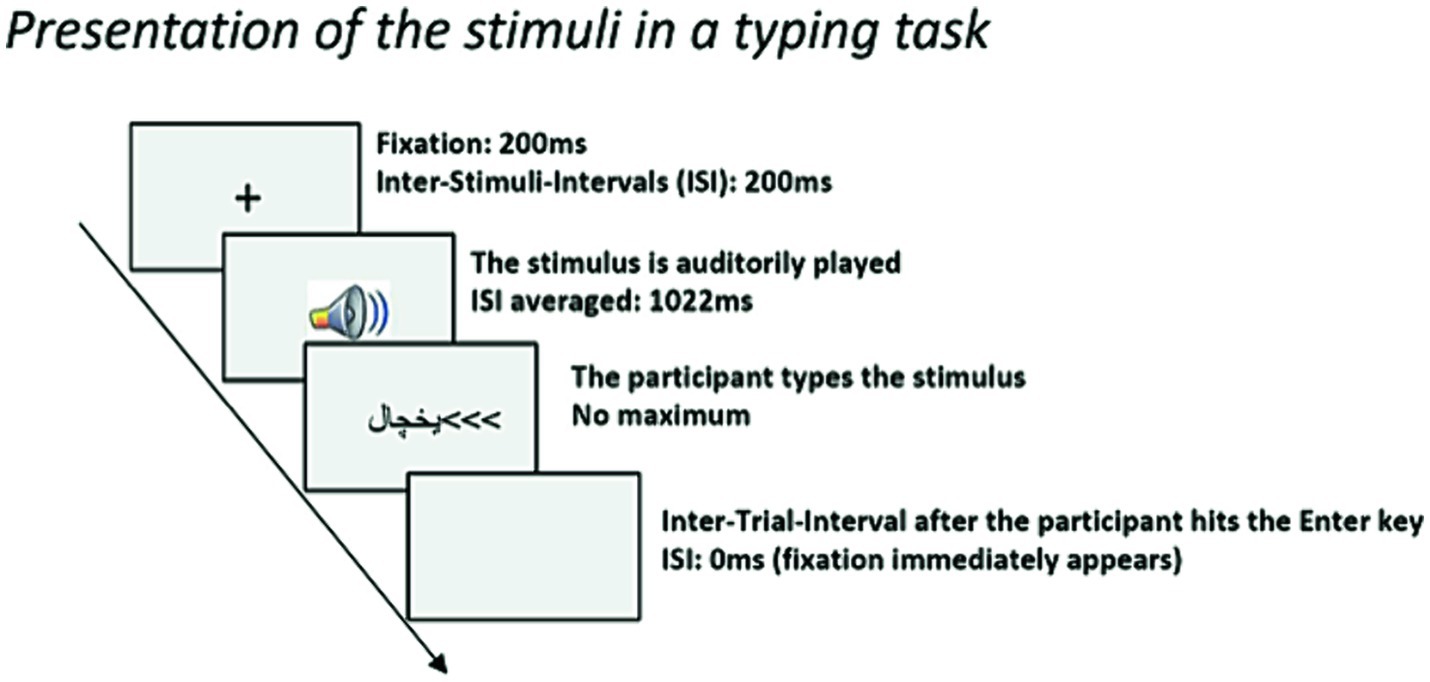
Figure 1. Task design.
Results
The focus of our response time analysis was typing latency at the morphological constituent boundary. This was operationalized as the time elapsed before the first letter of the second constituent of the compound word was typed after completion of the previous keystroke. To take English compound words as examples, the morphological constituent boundary latency for the compound keyboard would be calculated as the time elapsed between the pressing of the “y” key and the pressing of the “b” key. For a spaced compound (equivalent to an English example of hot dog), it would be calculated as the time elapsed between the pressing of the “space” key and the pressing of the “d” key. These constituent boundary latencies were compared to the latency of the immediately following letter, the latency of second letter of the second constituent (e.g., the time elapsed between the “b” and “o” in keyboard and the “d” and “o” in hot dog). This approach is based on the analyses presented by Libben et al. (2021), in which the boundary letter latency was compared to the latency of the immediately preceding letter as well as the latency of the immediately following letter. Our modification to use only the latency of the immediately following letter was required to accommodate the fact that, for spaced compounds, the immediately preceding letter is always a space (and the last letter of the first constituent is not immediately preceding). Using the immediately following letter, therefore, allowed us to “level the playing field” for attached and spaced compounds. We thus considered the boundary effect to be the extent to which the time taken to press the boundary letter was greater than the times taken to press the immediately following letter.
Typing times were analyzed in a linear mixed-effects model using R (R Core Team, 2021). Typing patterns for attached and spaced compounds were analyzed together in the same model. In our analyses, we considered a compound to be attached if no space was typed between the two constituents.1
In the linear mixed-effects regression models, sum-to-zero (−0.5/0.5) contrast coding was used for the four key predictor variables, each of which had two levels. The variable “position” (boundary, post-boundary) was interpreted to indicate degree of decomposition. It was expected that degree of decomposition would be related to the extent to which the typing latency of the boundary letter was greater than the typing latency of the following letter. Thus, at the core of our analysis, was the examination of the extent to which this variable interacted with the other key predictor variables. These were “transparency” (opaque, transparent), “headedness” (initial, final) and spacing (spaced, attached). In addition, two control variables were included. One variable concerned lexical frequency (the natural log frequency of the compound word in Persian). The other concerned the mechanics of keyboard typing (whether or not typing the letter required a switch of hands from the previous letter). The random effects variables were the participant, compound word, and the specific key being pressed. All random slopes were tried, but led to non-convergence. The summary of the model output is presented in Table 1.

Table 1. Linear fixed effects for per letter typing times at the constituent boundary and post-boundary positions in Persian compound words.
Main effects
Main effect of the boundary
Our results from a linear mixed-model analysis indicate that compounds as an overall group elicit decomposition, indicated by an increase in typing latency for the boundary letter as compared with the second letter of the second constituent. Overall, therefore, we interpret the pattern of data to show evidence of morphological effects for all compound types taken together.
In addition, there was a significant main effect of hand changing. Typing latencies were decreased when participants would change hands in moving from one letter to the next.
Measures of corpus frequency (Bijankhan et al., 2017) and Google frequency were obtained for each compound word. However, neither of these variables were found to play a significant role in any of the regression models and were therefore removed from the analyses.
Two-way interactions
Two-way interactions with position
There was a significant interaction between transparency and position such that transparent compounds (TTs) showed a greater difference between the boundary letter and the post-boundary letter than did the opaque compounds (OOs). There was also a significant interaction between spacing and position such that attached compounds (i.e., those without a space between the two constituents) showed a greater difference between the boundary letter and the post-boundary letter, as compared to spaced compounds (see Figure 2). There was no interaction between headedness and position.
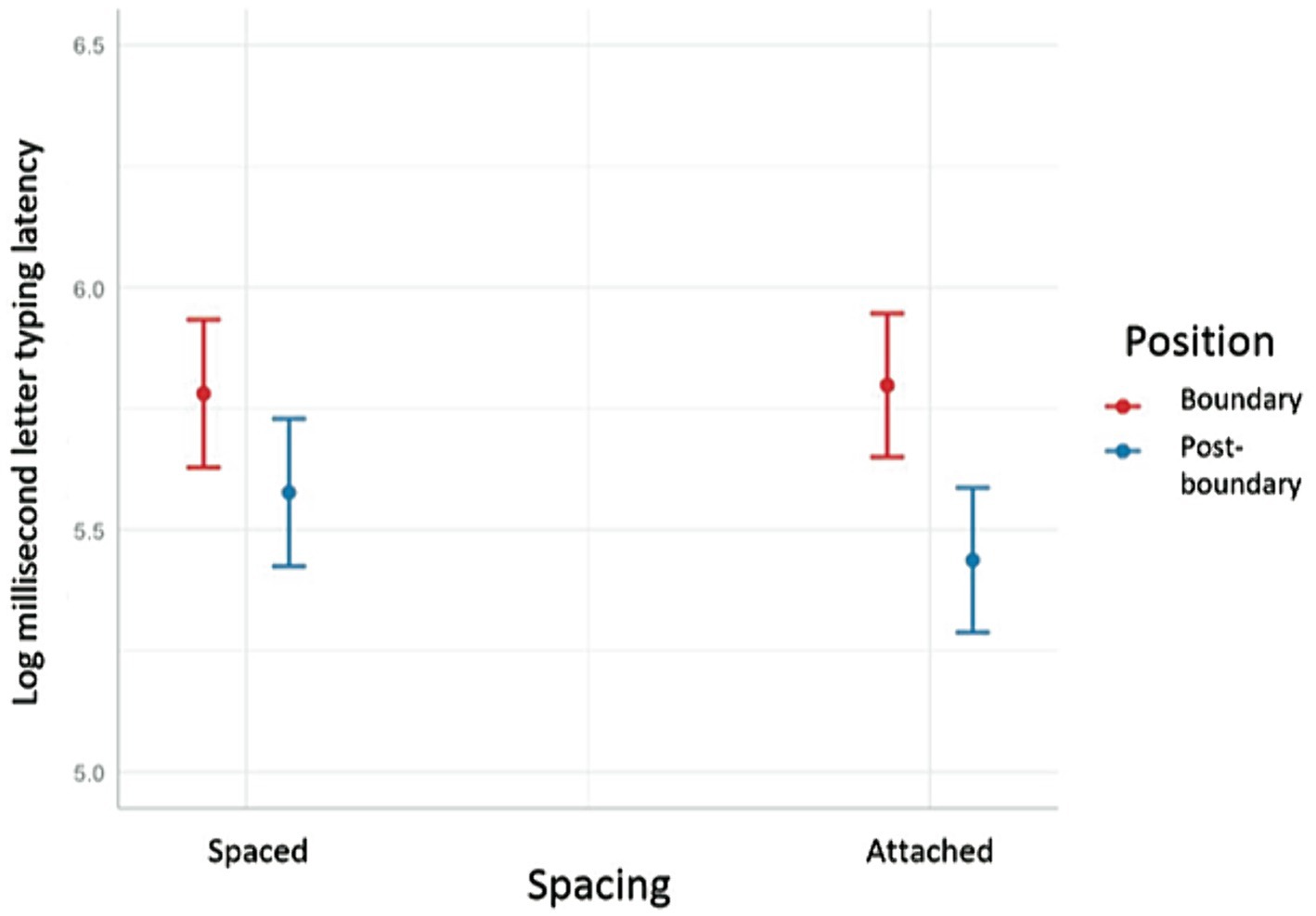
Figure 2. Spacing X Position interaction.
Other two-way interactions with spacing
There was a significant interaction between transparency and spacing such that transparent compounds (TTs) that were attached showed shorter typing latencies. There was also a significant interaction between headedness and spacing such that head final compounds that were attached compounds (i.e., those without a space between the two constituents) showed longer typing latency.
Three-way interaction
There was one significant three-way interaction between transparency, headedness and position. The TT compounds showed a larger decomposition effect than OO compounds but only for the head-initial compounds. This supercedes the above two-way interaction between transparency and position, whereby the TT compounds in general demonstrated a larger position effect than did the OO compounds. This three-way interaction is shown in Figure 3.
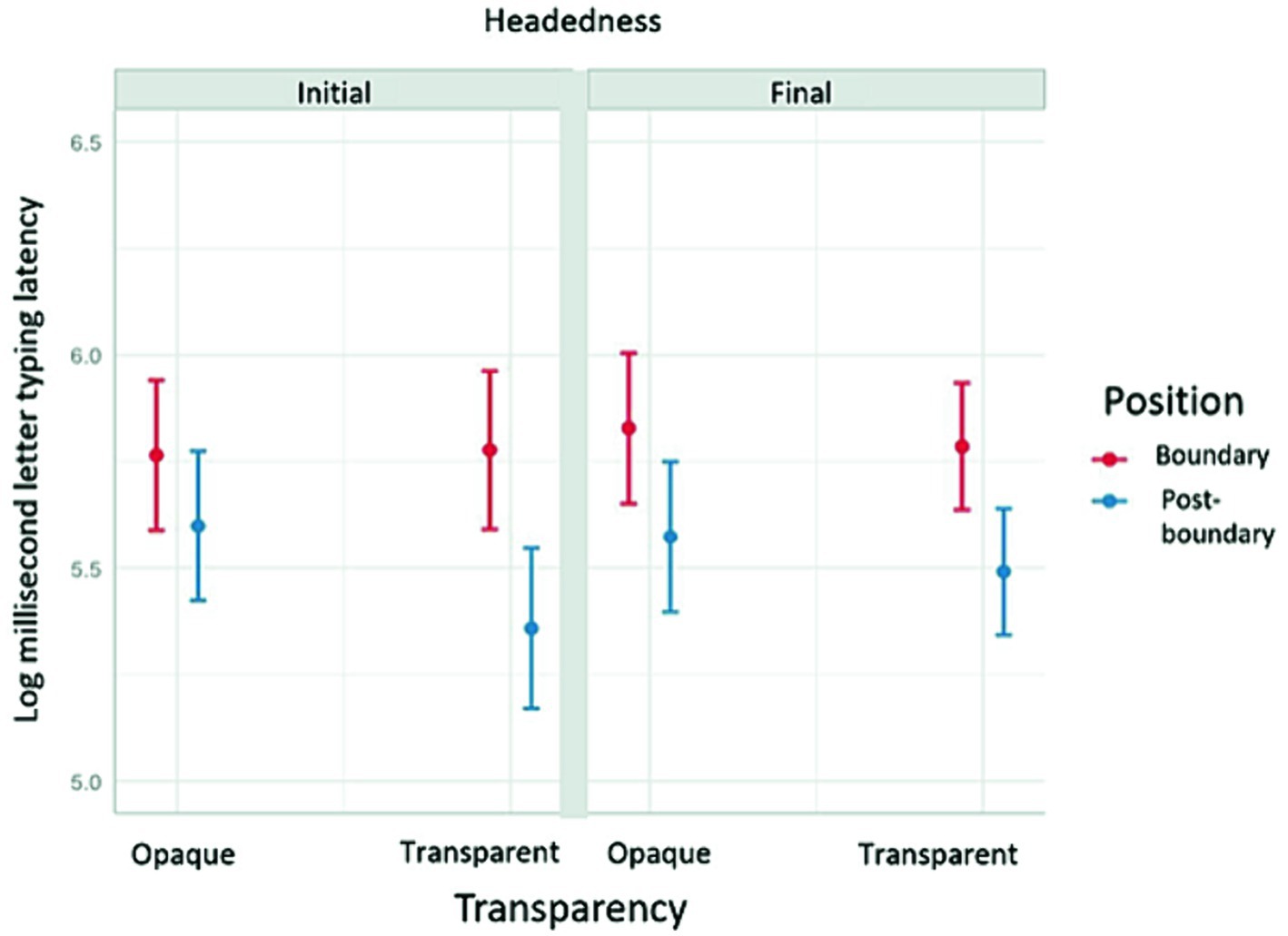
Figure 3. Transparency X Headedness X Position interaction.
In summary, our results show an overall decomposition effect in which typing latencies at the boundary letter are significantly longer than those at the non-boundary position. We found that this boundary effect is greater for transparent compounds than for opaque compounds, that it is greater for attached compounds than for spaced compounds. Finally, as can be seen in Figure 3, the transparency effect was greater for head-initial compounds.
Discussion
With this study we sought to address fundamental issues in the nature of compound word processing by investigating the written production of compound words in Persian. Previous work has reliably shown that when reading compound words in English, Dutch and German, fluent readers automatically access aspects of the constituents comprising the compound, as shown in various recognition tasks, most often requiring lexical decision following semantic or lexical priming. In addition, compounds in which the constituent meanings are transparent tend to show more such decomposition than those that are semantically opaque (Libben et al., 2020; Sandra, 2020). In these studies, semantic priming demonstrates that the meaning of the constituents influences lexical decision response times, even when the constituent meaning is independent of its apparent semantics within the compound. In terms of timing, the constituent word meaning affects even very early aspects of event-related potentials associated with the visual word form area in the visual cortex (Davis et al., 2019). Such ERP studies demonstrate that access to semantic information in the mental lexicon is available within the earliest processes of word decoding, as has been reported in a variety of paradigms (Segalowitz and Zheng, 2009; Hafer et al., 2022). However, other work shows that such access differences may be influenced by other factors in more complex ways by examining languages other than the Germanic ones in which most of the early research has been done. For example, Marelli and Luzzatti (2012) demonstrate that in Italian, which is more flexible with respect to headedness, there is a transparency-by-headedness interaction influencing how constituent characteristics (such as frequency and word length) affect lexical decision response time, suggesting a complex relation may be present.
Thus, questions remain as to what extent this pattern of compound decomposition can be generalized to languages whose morphology is not as regimented as in these Germanic languages. In the current study, we took advantage of the fact that Persian, also an Indo-European language, does not restrict the morphological head of compounds to being in the final position, nor generally having the constituents contiguous (Kahnemuyipour, 2014; Ahmadi-Torshizi, 2020). In fact, in our stimulus set, the majority of compounds employed a space between the constituents.
Our use of the typing paradigm enabled us to examine the temporal characteristics of morphological processing as it unfolds over the word of typewritten word production. We presented participants with the stimuli auditorily to which they responded by typing them on their home computer. The online data gathering program registered each key press and its timing, from which we derived which compounds were typed correctly and the time between each key press, i.e., the inter-key interval (IKI). We focused on IKI changes in the transition from the first to the second constituent (i.e., the time elapsed to press the first key of the second constituent compared to the time to press the second key). We interpreted the difference between this boundary latency and the latency to type the following letter to reflect morphological structuring in production. We refer to this as the boundary effect.
Our results supported the classic findings, but with a twist once we examined this with respect to the morphological factors that are available to us in Persian: (i) An increased IKI at the initiation of the second constituent generally supports the notion of decomposition; (ii) The boundary effect was also affected by whether the compound involved spacing: contrary to our expectations, attached compounds showed a larger boundary effect than did spaced compounds; and (iii) while there was no general effect of initial versus final headedness, headedness did moderate the general transparency effect whereby it was statistically more reliable for head-initial compounds and virtually absent in our data for head-final compounds.
These findings suggest there are several more avenues of research when considering lexical retrieval and production of compounds. First, we must take into account how languages differ in the morphological flexibility of compounds, and how these differences may influence our conclusions about work access and production. Second, we may need to consider that there is more than one “species” of compounds, and that these may differ in access and production properties. Third, the variety of practical psycholinguistic tools available to examine compound processing may reflect different aspects of access of production, not all relating in the same way to constituent decomposition. Fourth, the use of our typing production task makes apparent a number of methodological advantages as well as challenges.
Theoretical implications
Semantics and morphology in the mental lexicon
We used the typing methodology to investigate whether, across compound subtypes, we see evidence of morphological structuring in typewritten output. We also probed the extent to which such morphological structuring could be influenced by the semantic and morphological properties of compound words. In our study the semantic properties corresponded to differences in semantic transparency of the constituents and the morphological properties corresponded to differences in modifier–head orderings. We see such effects to have potential theoretical implications. For example, if we were to find that the processing and production challenges of typing head-initial compounds departs dramatically from those of typing head-final compounds, we may want to consider whether we should be classifying the two types as having dissimilar mental lexicon characteristics.
The headedness factor interacts with transparency in determining the extent of decomposition. We found that, for Persian head-initial compounds, TTs demonstrated a larger decomposition than OO compounds. This finding that transparency, which is a semantic property, and headedness, which is a morphological property, interact in modulating typing times between the constituents of compounds suggests that they interface at the level of words, especially considering that our word stimuli were presented in isolation and not in sentences or phrases. Such a finding of an interaction is also supported by the study of Malaia and Newman (2015), who investigated the neural bases of syntax-semantics interface processing in an EEG experiment involving participant comprehension while reading sentences. They manipulated the verb telicity (the syntactic factor) and the noun animacy (the semantic factor), in addition to some other combinations of syntactic and semantic components. The word-by-word EEG recording analysis indicated that these two factors interact within 100–200 ms from the onset of the target word.
Methodological and analytic considerations
The first general methodological question addressed in the current study concerned whether the paradigms employed for the study of compound processing can be expanded to not only typing production, but also to online data collection in a non-Latin script written right-to-left, given current available software. This was easily answered in the affirmative, and now immediately expands potential data collection to other languages using fonts related to Arabic script, in addition to Persian, and by extension is capable of including Hebrew, Hindi and other Asian alphabetic scripts. Of course, this also expands the potential participant pool to one beyond access to a laboratory setting.
In both the design and analysis phases of the present research, it was evident that the typing paradigm brings with it both methodological advantages and challenges. Chief among the advantages, in our view, is its ecological validity. In the typing paradigm, participants are engaged in an activity that is not unfamiliar to them and accords closely with their normal everyday language use. For the researchers, the typing technique brings with it the considerable advantage of making it possible to gather information at many points along the path of word production. This was essential to the focus of the present research, which had as its goal the understanding of the processing dynamics associated with the time elapsed through the medial sections of a compound word.
From our perspective, the ethological advantages of the typing paradigm far outweigh the disadvantages. Those disadvantages center on the inherent freedom that the paradigm creates for experimental participants. This includes their freedom to make errors. If, as was the case in our study, only correct typewritten responses are analyzed (i.e., produced correctly without self-correction), then much data will be lost due to performance errors (having to do with spelling uncertainty, anticipation errors, slips of the finger, etc.). Another extremely important consideration that emerged in the analysis of the data in this study was that the freedom of the typing paradigm uncovered linguistic and orthographic variations in Persian that we did not anticipate. For example, not all attached compounds were typed without spaces between constituents and not all spaced compounds were typed with spaces between their constituents. Although this created an analytic challenge in our own study (see Endnote 1 for how we handled this), it could emerge as an advantage in other studies that have examination of orthographic variation within words as a domain of focus.
An important methodological feature of the current study is its cross-modal nature. Participants were told that they would hear a word auditorily and then be required to type it as quickly and as accurately as possible. In this way, the task that we used was similar to a traditional dictation task but without semantic context. In our view, the task carries with it the advantage of being able to target central mental representations because it requires cross model translation (in this case from auditory input to manual output). It is noteworthy that, in the applied linguistics literature, the dictation task has been long considered to be an integrative task, in that it brings together multiple aspects of language ability (Oller, 1973; Irvine et al., 1974; Li, 2020). In the case of the current study, our design considerations included the desire to ensure that the morphological structuring that a participant exhibited emanated from his or her own lexical system rather than properties of stimulus presentation. The cross-model design that we employed supported this approach while also minimizing the effect of orthographic factors in the input. In this way, for example, we could be relatively confident that participants’ choices to write a word as either an attached or spaced compound reflected their internal lexical representations, rather than any visual properties of the stimulus presentation.
Orthographic properties of compound words
Our analyses needed to take into consideration that typing is a psycholinguistic activity that may involve many levels of cognitive and motor interaction. It is noteworthy that factors such as hand switching (i.e., involving whether a sequence of letters is produced by the same hand or the opposite hand) was highly significant in our analysis. Similarly, including the letter typed (i.e., actual key pressed on the keyboard) as a random factor in our analyses, improved model performance, but yielded similar final results.
Against the background of such typing and orthographic dynamics, we focussed on the presence or absence of a space within a compound word to be important to our analysis and our understanding of compound processing in Persian. First, it seems intuitively obvious that a compound that has a space separating the two constituents in written form should prompt the user to decompose it to a greater extent than compounds in which there is no space. Yet, paradoxically it appears from our results that the boundary gap is larger for the attached compounds (see Figure 2).
In considering how the typing of the space key might affect the typing time for the subsequent letters, we considered three possibilities. The simplest is that pressing the space key is an automated process during which no linguistic analysis happens of what is to come in the second constituent. A second possibility is that since the space key is pressed right before the second constituent begins, the time during the pressing of the space key may permit some planning of the second constituent. This planning information could include both linguistic processing needed for the initial letter of the second constituent (e.g., morphological and semantic information) and the actions required for pressing the space key itself. In this case, the initial letter of the second constituent would be typed faster than it would had there not been any space to be typed. This last possibility could lead to a masking of a boundary effect in compounds with a space.
A third possibility is that pressing the space key between constituents is actually a source of distraction, thus potentially increasing the time required to initiate the second constituent. In this case, the first letter of the second constituent would appear after a greater latency for spaced compounds compared to attached compounds. However, we can probably eliminate this possibility as our findings were the reverse of this situation, with spaced compounds showing a smaller boundary effect. This suggests that spaced compounds either have a reduced decomposition compared to attached compounds or that there is some processing that occurs during the pressing of the space bar, but that spaced compounds do not have the greatly increased decomposition that one’s intuition may suggest.
Comparison with previous studies in Germanic languages
The previous work with English, Dutch and German to a large extent reports a greater decomposition for transparent compounds over those that are more opaque. Of course, these are languages in which compounds are attached and head-final. Our Persian head-final attached compounds do not entirely support this conclusion. However, most earlier studies are based primarily on semantic priming tasks where the dependent variable is lexical decision time, not on processing time at the boundary as is the case in our typing task. Therefore, there may be different processes being addressed because of the task requirements, i.e., orthographic priming in the lexical decision tasks versus production planning in our typing task. Of course, there may also be language differences, for which we need replication to adjudicate. However, it would be fascinating to compare the orthographic priming and production planning differences in the same language, preferably with the same participants, such as can be done in English, Dutch and German. This may address more directly whether the two empirical approaches pertain to the same constituent decomposition of compounds.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by Brock University Research Ethics Board. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
BY: Writing – original draft, Writing – review & editing. GL: Writing – original draft, Writing – review & editing. SS: Writing – original draft, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This research was supported by the Social Sciences and Humanities Research Council of Canada Partnership Grant 895-2016-1008 (“Words in the World”).
Acknowledgments
The authors thank Jordan Gallant whose design and coding work was essential to the development of this research and its implementation in PsychPy. We thank Dr. Hamed Abdi for his invaluable comments. We thank Dr. Mahmood Bijankhan for sharing his database and supplementary data information.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2024.1293401/full#supplementary-material
Footnotes
1. ^Because participants occasionally inserted a space between constituents where standard spelling does not require one, and occasionally omitted them where it does, we ran analyses twice, once with standard spelling required and once with the spacing as the participants judged to be appropriate. The results of the two sets agreed with each other but the model was cleaner with the latter, which of course had more acceptable trials, and so the results of the larger model are presented.
References
Ahmadi-Torshizi, N. (2020). The structure and processing of Persian compound words in the mental lexicon: Experimental studies on compound word processing in Persian (Doctoral dissertation), McMaster University, Hamilton, Ontario, Canada.
Arcodia, G. F. (2012). Constructions and headedness in derivation and compounding. Morphology 22, 365–397. doi: 10.1007/s11525-011-9189-2
Bijankhan, M., Shojai, R., and Mirzababai, A., (2017). Building a corpus for named entity recognition and co-referent words systems using news texts register: project final report. ICT Research Institute, Project code 901962820. Communication and Information Technology Research Institute, Tehran, Iran.
Creemers, A., and Embick, D. (2022). The role of semantic transparency in the processing of spoken compound words. J. Exp. Psychol. Learn. Mem. Cogn. 48, 734–751. doi: 10.1037/xlm0001132
Davis, C. P., Libben, G., and Segalowitz, S. J. (2019). Compounding matters: event-related potential evidence for early semantic access to compound words. Cognition 184, 44–52. doi: 10.1016/j.cognition.2018.12.006
Delattre, M., Bonin, P., and Barry, C. (2006). Written spelling to dictation: sound-to-spelling regularity affects both writing latencies and durations. J. Exp. Psychol. Learn. Mem. Cogn. 32, 1330–1340. doi: 10.1037/0278-7393.32.6.1330
Di Sciullo, A.-M., and Williams, E. (1987). On the definition of word. Linguistic Monographs 14. Cambridge, MA: MIT Press.
Fiorentino, R., and Fund-Reznicek, E. (2009). Masked morphological priming of compound constituents. Ment. Lexicon 4, 159–193. doi: 10.1075/ml.4.2.01fio
Gagné, C. L., Spalding, T. L., and Nisbet, K. A. (2016). Processing English compounds: investigating semantic transparency. SKASE J. Theor. Linguist. 13. 1–22.
Günther, F., and Marelli, M. (2023). CAOSS and transcendence: modeling role-dependent constituent meanings in compounds. Morphology 33, 409–432. doi: 10.1007/s11525-021-09386-6
Günther, F., Marelli, M., and Bölte, J. (2020). Semantic transparency effects in German compounds: a large dataset and multiple-task investigation. Behav. Res. Methods 52, 1208–1224. doi: 10.3758/s13428-019-01311-4
Hafer, C. L., Weissflog, M., Drolet, C. E., and Segalowitz, S. J. (2022). The relation between belief in a just world and early processing of deserved and undeserved outcomes: an ERP study. Soc. Neurosci. 17, 95–116. doi: 10.1080/17470919.2022.2038262
Irvine, P., Atai, P., and Oller, J. W.Jr. (1974). Cloze, dictation, and the test of English as a foreign language. Lang. Learn. 24, 245–252. doi: 10.1111/j.1467-1770.1974.tb00506.x
Kahnemuyipour, A. (2014). Revisiting the Persian ezafe construction: a roll-up movement analysis. Lingua 150, 1–24. doi: 10.1016/j.lingua.2014.07.012
Libben, G. (2022). From lexicon to Flexicon: the principles of morphological transcendence and lexical Superstates in the characterization of words in the mind. Front. Artif. Intell. 4:788430. doi: 10.3389/frai.2021.788430
Libben, G. (2019). “Words as action: consequences for the monolingual and bilingual lexicon” in The description, measurement and pedagogy of words. eds. A. Tsedryk and C. Doe (Newcastle upon Tyne, UK: Cambridge Scholars Publishing), 14–33.
Libben, G., Gagné, C. L., and Dressler, W. U. (2020). The representation and processing of compounds words. Word Knowl. Word Usage 337, 336–352. doi: 10.1515/9783110440577-009
Libben, G., Gallant, J., and Dressler, W. U. (2021). Textual effects in compound processing: a window on words in the world. Front. Commun. 6:646454. doi: 10.3389/fcomm.2021.646454
Libben, G., Gibson, M., Yoon, Y. B., and Sandra, D. (2003). Compound fracture: The role of semantic transparency and morphological headedness. Brain and language, 84, 50–64.
Libben, G., and Weber, S. (2014). “Semantic transparency, compounding, and the nature of independent variables” in Morphology and meaning. eds. F. Rainer, W. U. Dressler, F. Gardani, and H. C. Luschützky (Amsterdam: Benjamins).
Lieber, R. (1980). On the organization of the lexicon. Cambridge, Mass., USA.: Doctoral dissertation, Massachusetts Institute of Technology).
Lieber, R., and Stekauer, P. (2009). “Introduction: status and definition of compounding” in The Oxford handbook of compounding. eds. R. Lieber and P. Stekauer (Oxford: Oxford University Press), 3–18.
Li, L. (2020). Exploring the effectiveness of a Reading-dictation task in promoting Chinese learning as a second language. High. Educ. Stud. 10, 100–108. doi: 10.5539/hes.v10n1p100
Malaia, E., and Newman, S. (2015). Neural bases of syntax–semantics interface processing. Cogn. Neurodyn. 9, 317–329. doi: 10.1007/s11571-015-9328-2
Marelli, M., and Luzzatti, C. (2012). Frequency effects in the processing of Italian nominal compounds: modulation of headedness and semantic transparency. J. Mem. Lang. 66, 644–664. doi: 10.1016/j.jml.2012.01.003
Momenian, M., Cham, S. K., Amini, J. M., Radman, N., and Weekes, B. (2021a). Capturing the effects of semantic transparency in word recognition: a cross-linguistic study on Cantonese and Persian. Lang. Cogn. Neurosci. 36, 612–624. doi: 10.1080/23273798.2020.1862878
Momenian, M., Radman, N., Rafipoor, H., Barzegar, M., and Weekes, B. (2021b). Compound words are decomposed regardless of semantic transparency and grammatical class: an fMRI study in Persian. Lingua 259:103120. doi: 10.1016/j.lingua.2021.103120
Oller, JR., J. W. (1973). Discrete-point tests versus tests of integrative skills in Focus on the Learner: Pragmatic Perspectives for the Language Teacher. Eds. J. W. Oller, Jr., and J. C. Richards. Rowley, MA: Newbury House.
Peirce, J. W., Gray, J. R., Simpson, S., MacAskill, M. R., Höchenberger, R., Sogo, H., et al. (2019). PsychoPy2: experiments in behavior made easy. Behav. Res. Methods 51, 195–203. doi: 10.3758/s13428-018-01193-y
Purmohammad, M., Vorwerg, C., and Abutalebi, J. (2022). The processing of bilingual (switched) compound verbs: competition of words from different categories for lexical selection. Biling. Lang. Congn. 25, 755–767. doi: 10.1017/S1366728921001103
Rainer, F., Dressler, W. U., Gardani, F., and Luschützky, H. C. (2014). “Morphology and meaning: an overview” in Morphology and meaning. eds. F. Rainer, W. U. Dressler, F. Gardani, and H. C. Luschützky (Amsterdam: Benjamins), 4–46.
R Core Team (2021). R: A language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing Available at: https://www.R-project.org/.
Sandra, D. (1990). On the representation and processing of compound words: automatic access to constituent morphemes does not occur. Q. J. Exp. Psychol. A 42, 529–567. doi: 10.1080/14640749008401236
Sandra, D. (2020). Morphological units: a theoretical and psycholinguistic perspective in Oxford research encyclopedia of linguistics. Oxford: Oxford UP.
Segalowitz, S. J., and Zheng, X. (2009). An ERP study of category priming: evidence of early lexical semantic access. Biol. Psychol. 80, 122–129. doi: 10.1016/j.biopsycho.2008.04.009
Selkirk, E. O. (1981). English compounding and the theory of word structure in The scope of lexical rules, Ed. Michael Moortgat. New York: Foris Publications USA. 229–277.
Shabani-Jadidi, P. (2012). Processing compound verbs in Persian. University of Ottawa: Canada. Ph.D. Dissertation.
Shabani-Jadidi, P. (2014). Processing compound verbs in Persian: a psycholinguistic approach to complex predicates. Ottawa, Ontario, Canada: Amsterdam University Press.
Shabani-Jadidi, P. (2016). Compound verb processing in second language speakers of Persian. Iran. Stud. 49, 137–158. doi: 10.1080/00210862.2015.1047644
Smolka, E., and Libben, G. (2017). Semantic transparency and compounding. Lang. Cogn. Neurosci. 32, 514–531. doi: 10.1080/23273798.2016.1256492
Torrance, M., Nottbusch, G., Alves, R. A., Arfé, B., Chanquoy, L., Chukharev-Hudilainen, E., et al. (2018). Timed written picture naming in 14 European languages. Behav. Res. Methods 50, 744–758. doi: 10.3758/s13428-017-0902-x
Torshizi, N. (2020). The structure and processing of Persian compound words in the mental lexicon: Experimental studies on compound word processing in Persian. Unpublished Ph.D. Dissertation, McMaster University, Hamilton, Canada. Available at: https://macsphere.mcmaster.ca/handle/11375/25862.
Williams, E. (1981). On the notions “lexically related”, and “head of a word”. Linguist. Inq. 12, 245–274,
Will, U., Nottbusch, G., and Weingarten, R. (2006). Linguistic units in word typing: effects of word presentation modes and typing delay. Writ. Lang. Lit. 9, 153–176. doi: 10.1075/wll.9.1.10wil
Keywords: Persian, compounds, psycholinguistics, typing, headedness, semantic transparency, spacing, language production
Citation: Yousefzadeh B, Libben G and Segalowitz SJ (2024) Persian compounds in the mental lexicon. Front. Commun. 9:1293401. doi: 10.3389/fcomm.2024.1293401
Edited by:
Gordana Hrzica, University of Zagreb, CroatiaReviewed by:
Pouneh Shabani-Jadidi, The University of Chicago, United StatesJoão Veríssimo, University of Lisbon, Portugal
Copyright © 2024 Yousefzadeh, Libben and Segalowitz. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Bahareh Yousefzadeh, YmFoYXJleW91c2VmemFkZUBnbWFpbC5jb20=