 Adam Kříž
Adam Kříž Denisa Bordag
Denisa Bordag- 1Institute of Czech Language and Theory of Communication, Faculty of Arts, Charles University, Prague, Czechia
- 2Herder Institute, Faculty of Philology, Leipzig University, Leipzig, Germany
This study explores how Czech-German late bilinguals process German (L2) noun-noun compounds. Using a lexical decision task combined with translation constituent priming, we investigated two factors potentially influencing the L2 compound processing: (a) the compound translation corresponds to one derived noun (e.g., Abendstern—večernice, ‘evening star') or to an adjective + noun phrase (e.g., Weizenmehl—pšeničná mouka, ‘wheat flour'); and (b) the compound translation entails translations of compound constituents (L1 translation of Abendstern, večernice, includes only first constituent, i.e. modifier, Abend = večer, ‘evening'; L1 translation of Weizenmehl, pšeničná mouka, includes both constituents, Weizen = pšenice, ‘wheat', Mehl = mouka, ‘flour'). Two experiments were conducted; one focussing on head priming, the other on modifier priming. The results are in line with non-selective bilingual access and decomposition of L2 compounds. They reveal no influence of factor (a), while (b) affects processing.
1. Introduction
The study builds on recent research exploring how bilinguals process compound words. Compounds typically consist of two or more word bases, e.g., moonlight, where the constituent light (referred to as the head) determines the lexical category and core meaning of the compound, and the constituent moon (the modifier) specifies the basic meaning. The research on bilingual compound processing deals mainly with morphological decomposition and often relates this to the issue of the interaction between the native and non-native language systems. The question of whether compounds are decomposed or accessed as full forms is central to the area of compound processing (for L2 research see e.g., Hasenäcker and Schroeder, 2019; for L2 research see e.g., De Cat et al., 2015; for both L1 and L2 research see e.g., Uygun and Gürel, 2017). In most current work, there is agreement that morphological structure does affect word recognition, at least to a certain degree (De Cat et al., 2015; Li et al., 2017; Libben et al., 2021; Creemers and Embick, 2022).
As for bilingual processing more generally, the predominant view is that lexical access is language non-selective (De Groot, 2011, p. 3). Support for this assumption comes, for example, from translation priming studies. Such work has reported that the recognition of a given word is facilitated when preceded by its translation equivalent in the non-target language, compared to when the word is preceded by an unrelated non-target language word (e.g., Meade et al., 2018). The studies examining the influence of L1 features on L2 compound processing and vice versa deliver further evidence for the non-selective hypothesis of bilingual processing. In particular, Bertram and Kuperman (2020) demonstrated that the correspondences/discrepancies in spelling between L1 compounds and their L2 translation equivalents (presented as spaced or concatenated forms) modulate reading speed of L1 compounds. In addition, Uygun and Gürel (2020) showed that L1 compound processing in Turkish-English bilinguals systematically differs from that of Turkish monolinguals.
Regarding the direction from L1 to L2, De Cat et al. (2015) showed that the headedness of L1 compounds influences the processing of L2 compounds. Further, Levy et al. (2006) cited sources that reported processing advantages for compounds which share morphological structure with their respective translations over compounds whose translation is a single word. Similarly, both Wang et al. (2010) and Ko et al. (2011) provided evidence that supported the claim that the processing of an L2 compound is affected by whether or not the L1 translation equivalents of both its constituents form an existing L1 compound (the so-called lexicality condition). The employed method in both studies was a simple lexical decision task (with no priming). Ko et al. (2011) tested advanced Korean (L1) learners of English (L2), whereas Wang et al. (2010) concentrated on Chinese (L1) learners of English (L2). Notably, an interaction of lexicality with frequency of the second constituent was observed. The processing advantage (higher accuracy rates in Ko et al., 2011; shorter reaction times in Wang et al., 2010) for L2 compounds with real L1 compound translations over L2 compounds with non-existing L1 compound translations was stronger in the case of compounds which had a high-frequency second constituent, compared to those with a low-frequency second constituent.
Similar questions were examined in Hebrew (L1)-English (L2) bilinguals by Libben et al. (2017). The authors used cross language constituent priming with targets (both in Hebrew and English) as either real compounds or non-existing compounds (elsewhere Libben et al., 2018, claim that primes in such tasks represent free-standing words formally identical with compound constituents rather than compound constituents themselves). The authors observed significant cross language priming effects for both constituents in both language directions. Further, in the analysis of real compounds, they did not find any processing advantage for words whose translation in the other language is a compound with identical constituents (this is in contrast to Wang et al., 2010; Ko et al., 2011, who found such an advantage). However, it was revealed that non-existing compounds whose translated constituents form a word in the other language were responded to more slowly and with higher error rates. The results are interpreted in relation to the hypothesis of morphological integration, claiming that lexical and morphological elements of bilingual lexical systems are interconnected and coactivated. The authors explain the absence of a processing advantage for real compounds with morphologically identical translations by the existence of just a small number of such compound pairs, which does not enable speakers to develop appropriate connections between them.
The goal of the current study is to investigate the possible impact of other formal relations between an L2 (noun-noun) compound and its L1 translation on L2 compound processing. The study thus contributes to the discussion on the morphological and formal sensitivity of bilinguals to translation equivalents in their languages. The languages explored are L2 German and L1 Czech. German is well known as a language with frequent, very productive and morphologically complex compounding (Libben et al., 2002). In contrast, Czech, a West-Slavic language, exploits compounding to a lesser extent (Bozděchová and Wagner, 2017). In both language systems, compound heads represent the last compound constituent. German noun-noun compounds can be translated into Czech in multiple ways. We focus on (a) “adjective + noun” translations, e.g., Weizenmehl = pšeničná mouka (‘wheat flour'); the adjective pšeničná is a derivation from the noun which corresponds to the translation of the first L2 compound constituent Weizen(= pšenice), the noun mouka is the translation of the second constituent Mehl; we will refer to these compounds as adjectival compounds (seen from the perspective of the structure of the Czech translation) - and (b) single noun translations which are derivations from the translation of the first L2 constituent, e.g., Abendstern = večernice(< večer = Abend) (‘evening star'), the translation of the second constituent (Stern = hvězda) is completely absent in the translation of the compound; we will refer to these as noun-based compounds. This material facilitates an examination of two aspects of form relations. The first is whether the L1 translation of an L2 compound corresponds to a non-compound word (a compound with single noun translation - noun-based compound), or to a two-word phrase (a compound with adjective + noun translation - adjectival compound) (structural condition). The second aspect of form relations is whether or not the L1 translation of L2 compound constituents occurs in the L1 translation of the whole L2 compound (overlap condition or just formal condition). These factors were tested in two experiments using the visual lexical decision task combined with translation constituent priming, where targets were L2 compounds and primes were L1 translations of their constituents. Experiment 1 focussed on head priming (e.g., mouka—Weizenmehl), whereas Experiment 2 focussed on modifier priming (pšenice—Weizenmehl).
The priming effect would point to language non-selective bilingual access. Moreover, if the structure of the translation (one word vs. two words) plays a key role, as predicted by the hypothesis of morphological integration, we would expect stronger priming effects in adjectival compounds in both experiments and faster processing for adjectival compounds in priming unrelated conditions, due to the one-to-one correspondence between L1 translation equivalents of L2 compounds and the compound constituents. However, if the formal overlap between the L2 compound and its translation plays a decisive role, we would expect a weaker priming effect in noun-based compounds in head priming (Experiment 1) and no difference in priming between noun-based compounds and adjectival compounds in modifier priming (Experiment 2), because the translation of the noun-based compound head does not appear in the translation of the whole L2 compound, whereas translations of modifiers in both noun-based compounds and adjectival compounds occur in the translation of L2 compounds.
2. Material and method
2.1. Participants
Thirty participants (6 males), mostly university students, took part in Experiment 1 which was conducted in the Czech Republic. The age of the participants ranged from 19 to 35 (mean = 23.93; median = 23). They learned and used German mainly in the Czech environment, with five participants not having been to a German-speaking country at all. The participant (aged 35) with the longest stay in a German-speaking country lived in Germany for 4 years.
Twenty-seven participants (6 males) took part in Experiment 2, none of whom were tested in Experiment 1. Their age ranged from 18 to 41 (mean = 28.26; median = 28). Ten participants who were currently staying/living in Germany completed the experiment in Germany, while the rest of the sessions took place in the Czech Republic. The longest stay in a German-speaking country in this group corresponded to 10 years (a female aged 41 who participated in the experiment in Germany). In contrast, three participants reported that they had never been to a German-speaking country.
The native language of all participants was Czech; they started to learn German with 14.7 (7; 22) years on average and their German proficiency was at B2/C1 level as assessed by two tests. The Goethe Test which evaluated mainly grammatical knowledge and DIALANG which focussed on vocabulary measures.
Prior to testing, participants gave informed consent and were told that all data would be anonymized. Participants received financial remuneration for their participation.
2.2. Materials
Fifty-two German compounds were selected from the list of German noun-noun compounds created by Schulte im Walde et al. (2016). To control for effects of variables other than the translation structure of the compounds, we aimed to include an equal number of adjectival compounds and noun-based compounds in our sample and to ensure that the two groups were comparable and counter-balanced in terms of key word properties.
Therefore, the chosen compounds were organized into 26 pairs, such that each pair consisted of one compound usually translated into Czech as adjective + noun and one compound translated into Czech as modifier-derived single noun.
The members of each compound pair were matched for length of both first and second constituents, compound frequency and frequency domination (is the head or the modifier more frequent?). The frequency counts were taken directly from Schulte im Walde et al.'s (2016) database.
We further avoided opaque compounds and compounds containing interfixes, and compounds containing cognates, complex words or abstract expressions. A few exceptions were made. They include four pairs of compounds with interfixes (Aschenbecher—Sonnenstrahl, Ameisenbär—Besuchstag, Lippenstift—Firmenwagen, Blumentopf—Liebeslied), two pairs of compounds differing by one letter in the length of the first constituent (Spielplatz—Windmühle, Schuhschrank—Silberbesteck), a compound containing an identical cognate (Firma in Firmenwagen) and six abstract compounds (Besuchstag, Hausarbeit, Hungerstreik, Pilgerfahrt, Probezeit, Sommerurlaub). Importantly, none of the listed exceptions affected the general pattern of results presented in the next sections. Analyses performed without them yielded similar results as the analyses reported containing them.
Each constituent was present only in one compound. The Czech translation of the second constituent (Experiment 1) or of the first constituent (Experiment 2) of each German compound was presented as a related prime. The unrelated prime was matched with the related prime for word class, gender, number of letters and syllables, and corpus frequency (based on corpus syn v7 of the Czech National Corpus; Hnátková et al., 2014; Křen et al., 2018). The critical stimuli are provided in the Appendix.
In addition to the critical trials, there were also filler prime-target pairs. The targets consisted of 50 German compounds (mainly of a different type to the experimental items), 45 non-compound words (e.g., Krähe—vrána /‘crow’/), 45 pseudowords (e.g., Liet) and 102 noun-noun pseudocompounds (with types “word+pseudoword”, “pseudoword+word”, “pseudoword+pseudoword”). Pseudocompounds and pseudowords were created from existing German words employing the Wuggy generator (Keuleers and Brysbaert, 2010).
Related and unrelated conditions were evenly presented, so that half of the targets were preceded by a related prime and the other half by an unrelated prime. Two lists of items were used that differ based on whether the experimental target had a related vs. unrelated prime. In one list, the target had an unrelated prime; in the second list the same target had a related prime. Lists were ascribed to participants randomly and evenly across the whole sample.
Sixteen practice items exhibiting all possible types of stimuli were also included.
2.3. Procedure
The lexical decision task was conducted using E-Prime software 2.0 (Schneider et al., 2007). The stimuli were presented on a computer screen in two blocks with a break in between. The experiment started with 16 practice items followed by 294 experimental trials. Each trial started with a fixation cross in the form of a “+” situated in the center of the screen for 500 milliseconds (ms). It was immediately followed by a prime appearing for 250 ms. Then the screen went blank for 100 ms, after which a target word appeared. The target word remained on screen until the response was registered or until a timeout of 1,600 ms. Participants were asked to respond as quickly and accurately as possible. If they did not respond within the time limit, the feedback “schneller” (‘faster') appeared on screen. Responses were executed by pressing the corresponding JA/NEIN button on the keyboard. Both primes and targets were presented centrally in Courier New font, bold, size 30 with primes in lowercase and targets in uppercase.
The stimuli were pseudorandomized for each participant, with a maximum of three items sharing word vs. non-word status or compoundness following in succession.
Following the lexical decision task, questionnaires relating to the level of participants' German language proficiency and their sociodemographic profile were administered. The last task was to translate all critical stimuli (compounds) into Czech and to assess their familiarity on a 5-point scale.
3. Results
In Experiment 2, two pairs of compounds were discarded from the subsequent analyses, because the modifier translation of one pair did not correspond to the equivalent that appeared in the conventional translation of the whole compound. For both experiments, the data were processed to remove inaccurate responses and responses to filler items. Across both experiments, 12% of responses to the experimental stimuli were not accurate. Then, separately and specifically for each participant, data points lying beyond two standard deviations from the mean were removed (6% of observations in Experiment 1 and 7% of observations in Experiment 2). In the next step, items assessed as unfamiliar by a participant (i.e. words that they reported never to have encountered) were excluded. The same holds for stimuli that participants did not translate or translated in a way that deviated from the intended equivalent. Lack of sufficient knowledge of the experimental compounds led to the exclusion of 23% of responses across both experiments (although it was our intention to include compounds known to the majority of speakers with B2 level of German, certain stimuli appeared to have a lower prevalence than originally expected).
The reaction time values according to main conditions are reported in Table 1.
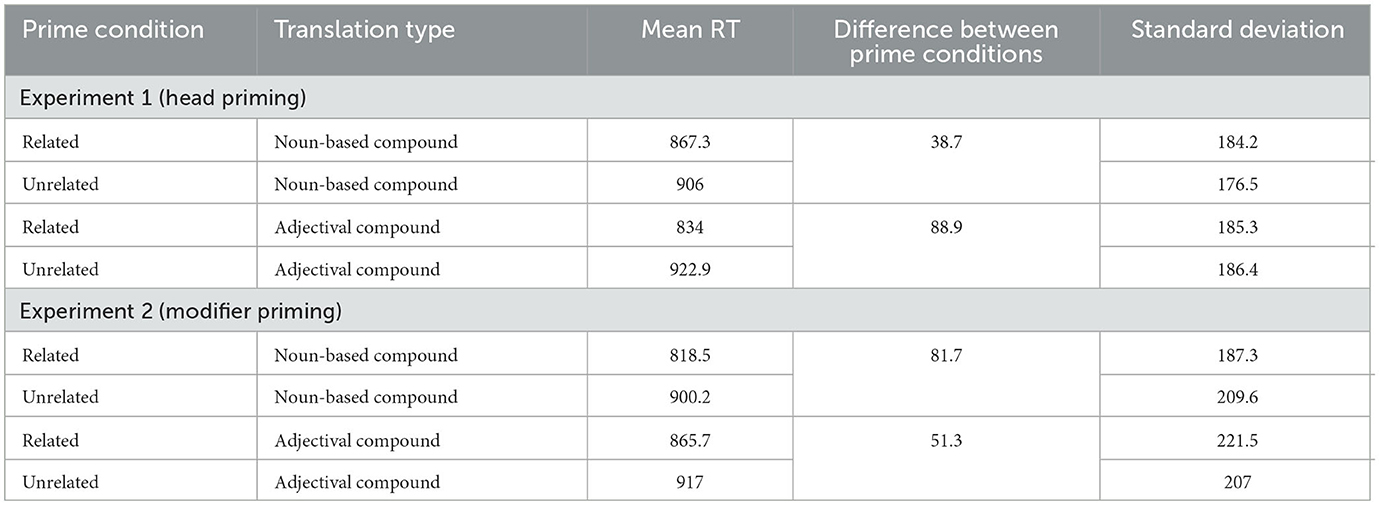
Table 1. Reaction times to the main experimental conditions (in milliseconds).
The subsequent analyses were performed in R (R Core Team, 2017). To test the effects of our predictor variables on reaction times, linear-mixed models were run using the lmerTest and pbkrtest packages (Kuznetsova et al., 2017). The Kenward-Roger approximation for the degrees of freedom was used. Participants and targets (compounds) were modeled as crossed random effects; random slopes for compound type were also used for the participant random effect. In the main analyses, fixed effects were the prime condition and the compound type (i.e. noun-based compound– one vs. adjectival compound—two). The results are summarized in Table 2.
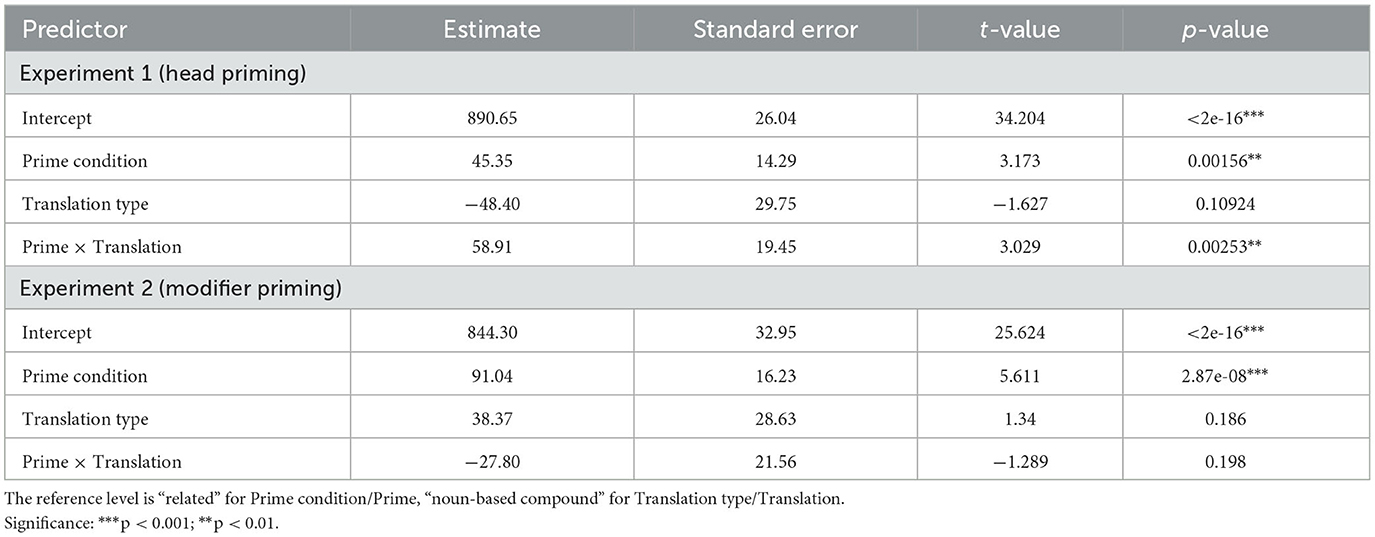
Table 2. Fixed effects of the variables predicting response latencies (in milliseconds).
The analyses revealed a significant priming effect in both experiments, but while there was a significant interaction between prime type and compound type in Experiment 1, no such interaction was observed in Experiment 2. This is not to say, however, that a priming effect was absent in one of the compound conditions. The separate follow-up analyses showed a significant priming effect for compounds with both types of translation in both experiments. Regarding Experiment 1, the interaction and separate analyses thus reveal that priming is more effective if the prime is a head in an adjectival compound (88.9 ms) than in a noun-based compound (38.7 ms).
The conclusion about the higher priming effectiveness in adjectival compounds vs. noun-based compounds when priming the head, but not the modifier is corroborated by the analysis covering both experiments as a specific predictor. The analysis showed a significant three-way interaction between prime type (related vs. unrelated), translation type (adjectival compound vs. noun-based compound) and experiment (Experiment 1 focused on head priming vs. Experiment 2 focused on modifier priming). See Table 3 for more detail.
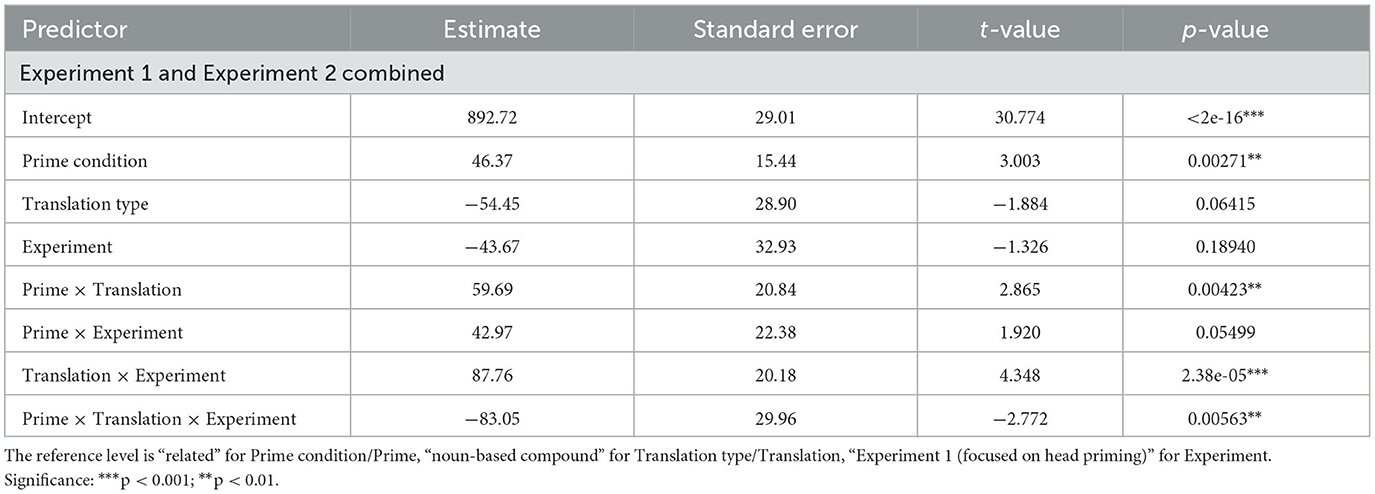
Table 3. Fixed effects of the variables predicting response latencies (in milliseconds) in both experiments.
The interaction remains significant even after the inclusion of compound frequency, first constituent frequency and second constituent frequency as additional predictors into the final model. All three frequency variables were log-transformed. The result of the model demonstrates that compound frequency has a facilitatory effect on the participants' responses (see Table 4), which is in line with Smolka and Libben's (2017) results, among others.
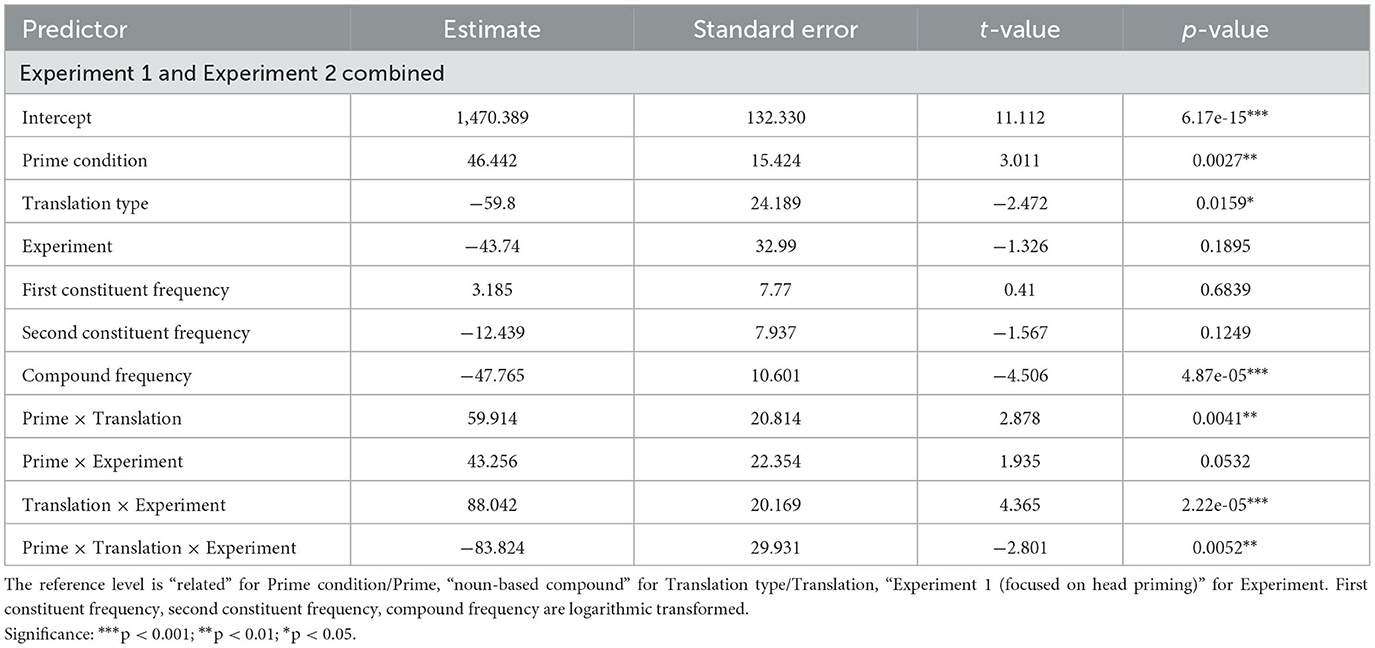
Table 4. Fixed effects of the variables predicting response latencies (in milliseconds) in both experiments, including frequency variables.
4. Discussion
The priming effects observed in all conditions in both experiments support the view of language non-selective bilingual access and decomposition of L2 compounds. However, the priming effects for the two types of stimuli (adjectival compounds vs. noun-based compounds) were not the same in all conditions. The priming effect for noun-based compounds was weaker than the effect for adjectival compounds when priming heads. Taken together, these results lead to the interpretation that the structure of the translation (L1 translation with one word vs. two words) does not affect the processing of German (L2) noun-noun compounds. If such a factor played a role, we would expect stronger priming effects for adjectival compounds in modifier priming as well. This is also supported by the results from the unrelated prime condition. In the case of the decisive role of the translation structure, adjectival compounds compared to noun-based compounds would have displayed faster processing times given the one-to-one correspondence between the L1 translation equivalent of L2 compounds and the compound constituents in these types of compounds. A similar interpretation with observed processing differences between two types of stimuli can be found in Wang et al. (2010) and Ko et al. (2011). However, in contrast to their studies, our study has not revealed any significant differences between processing compounds with structurally different translations.
Hence, the pattern of priming effects can be explained rather by the overlap between the form of the L2 compound and its translation. It is striking that the difference in priming effects was observed only in the condition where one of the compound types (namely noun-based compounds) does not have a translation containing the translation of a primed constituent. Therefore, it seems plausible that the L2 compound recognition rests on the mechanism of checking the L1 equivalent, which is stimulated by the experimental design. Priming effects such as these can be explained by two possible sources. First, a Czech prime (e.g., večer) activates the corresponding L1 entry, which then activates its L2 German translation equivalent (e.g., Abend). The preactivation of one of the L2 compound constituents speeds up compound (Abendstern) decomposition and its processing (as shown by priming being observed in all conditions). Second, the activation of the L1 entry through a Czech prime also helps the processing of the L1 representation of L2 compound equivalents (e.g., večernice), activated by the target L2 compound. When the translation of the L2 compound does not share the form with the prime form (i.e. the translation of one constituent; e.g., the form večernice, does not overlap with the translation of the second L2 compound constituent Stern/= hvězda/), no such help is provided (i.e. reduced head priming in noun-based compounds). We assume that the relevance of the L1 representation of an L2 compound for the L2 compound processing is based on the morphological analysis of the L1 compound equivalent. The parts of morphologically analyzed compound translations can boost the activation to the corresponding constituents of L2 compounds in a processing circle (e.g., večernice, activated by the L2 target Abendstern, is morphologically analyzed to večer + nice, root + affix, and the part večer sends additional activation to the constituent Abend in the L2 compound Abendstern).
In sum, our study indicates that L2 compound processing involves morphological analysis of both the L2 compound and its L1 translation equivalent and that it is affected by the form overlap between the two. On the other hand, L2 compound processing does not seem to be affected by the structural correspondence (one word vs. two words) between the L2 compound and its L1 translation. While this is the point which shows that our results are not fully compatible with the hypothesis of morphological integration, cross language constituent priming effects (and indicated parallel morphological analysis in both languages) points to the interconnectedness of morphological elements in the bilingual lexicon, which deserves more attention in future research.
Data availability statement
The transcripts of the audio recordings supporting the conclusion of this article can be made available by the authors upon request.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author contributions
Authors contributed equally to all aspects of the research, except for data collection (only AK). All authors contributed to the article and approved the submitted version.
Funding
AK: The work was supported by the European Regional Development Fund-Project “Creativity and Adaptability as Conditions of the Success of Europe in an Interrelated World” (No. CZ.02.1.01/0.0/0.0/16_019/0000734) and the Czech-German Fund for the Future. DB: The publication was funded by the Open Access Publishing Fund of Leipzig University supported by the German Research Foundation within the program Open Access Publication Funding.
Acknowledgments
The authors acknowledge support from the German Research Foundation (DFG) and Universität Leipzig within the program of Open Access Publishing.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2023.1133927/full#supplementary-material
References
Bertram, R., and Kuperman, V. (2020). The English disease in Finnish compound processing: backward transfer effects in Finnish–English bilinguals. Bilingualism Lang. Cogn. 23, 579–590. doi: 10.1017/S1366728919000312
Bozděchová, I., and Wagner, R. (2017). Kompozitum. In: Karlík, P., Nekula, M., and Pleskalová, J., editors. CzechEncy - Nový encyklopedický slovník češtiny. Available online at: https://www.czechency.org/slovnik/KOMPOZITUM (accessed June 20, 2022).
Creemers, A., and Embick, D. (2022). The role of semantic transparency in the processing of spoken compound words. J. Exp. Psychol. Learn. Memory Cogn. 48, 734–751. doi: 10.1037/xlm0001132
De Cat, C., Klepousniotou, E., and Baayen, R. H. (2015). Representational deficit or processing effect? An electrophysiological study of noun-noun compound processing by very advanced L2 speakers of English. Front. Psychol. 6, 77. doi: 10.3389/fpsyg.2015.00077
De Groot, A. M. B. (2011). Language and Cognition in Bilinguals and Multilinguals: An Introduction. New York, NY; Hove: Psychology Press. doi: 10.4324/9780203841228
Hasenäcker, J., and Schroeder, S. (2019). Compound reading in German: effects of constituent frequency and whole-word frequency in children and adults. J. Experiment. Psychol. Learn. Memory Cogn. 45, 920–933. doi: 10.1037/xlm0000623
Hnátková, M., Kren, M., Procházka, P., and Skoumalová, H. (2014). The SYN-series corpora of written Czech. In: eds. Calzolari, N., Choukri, K., Declerck, T., Loftsson, H., Maegaard, B., Mariani, J., et al., editos. Proceedings of the 9th International Conference on Language Resources and Evaluation (LREC). Reykjavik: European Language Resources Association. p. 160–164.
Keuleers, E., and Brysbaert, M. (2010). Wuggy: a multilingual pseudoword generator. Behav. Res. Methods 42, 627–633. doi: 10.3758/BRM.42.3.627
Ko, I. Y., Wang, M., and Kim, S. Y. (2011). Bilingual reading of compound words. J. Psycholinguistic Res. 40, 49–73. doi: 10.1007/s10936-010-9155-x
Křen, M., Cvrček, V., Čapka, T., Čermáková, A., Hnátková, M., Chlumská, et al (2018). Korpus SYN, verze 7 z 29. 11. 2018 [‘Corpus SYN, version 7 from 29 November 2018′]. Ústav Ceského národního korpusu FF UK. Available online at: http://www.korpus.cz (accessed June 20, 2022).
Kuznetsova, A., Brockhoff, P. B., and Christensen, R. H. B. (2017). LmerTest package: tests in linear mixed effects models. J. Stat. Softw. 82, 1–26. doi: 10.18637/jss.v082.i13
Levy, E. S., Goral, M., and Obler, L. K. (2006). Doghouse/Chien-maison/Niche: approaches to the understanding of compound processing in bilinguals. In: Libben, G., and Jarema, G., editors. The Representation and Processing of Compound Words. Oxford: Oxford University Press. p. 125–144. doi: 10.1093/acprof:oso/9780199228911.003.0006
Li, M., Jiang, N., and Gor, K. (2017). L1 and L2 processing of compound words: evidence from masked priming experiments in English. Bilingualism Lang. Cogn. 20, 384–402. doi: 10.1017/S1366728915000681
Libben, G., Gallant, J., and Dressler, W. U. (2021). Textual effects in compound processing: a window on words in the world. Front. Commun. 6, 646454. doi: 10.3389/fcomm.2021.646454
Libben, G., Goral, M., and Baayen, H. (2017). Morphological integration and the bilingual lexicon. In: Libben, M., Goral, M., and Libben, G., editors. Bilingualism: A Framework for Understanding the Mental Lexicon. Amsterdam: John Benjamins. p. 197–216. doi: 10.1075/bpa.6.09lib
Libben, G., Goral, M., and Baayen, H. (2018). What does constituent priming mean in the investigation of compound processing? Ment. Lexicon 13, 269–284. doi: 10.1075/ml.00001.lib
Libben, G., Jarema, G., Dressler, W., Stark, J., and Pons, C. (2002). Triangulating the effects of interfixation in the processing of German compounds. Folia Linguistica 36, 23–44. doi: 10.1515/flin.2002.36.1-2.23
Meade, G., Midgley, K. J., and Holcomb, P. J. (2018). An ERP investigation of L2–L1 translation priming in adult learners. Front. Psychol. 9, 986. doi: 10.3389/fpsyg.2018.00986
R Core Team (2017). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Available online at: https://www.R-project.org/ (accessed June 20, 2022).
Schneider, W., Eschman, A., and Zuccolotto, A. (2007). E-Prime: Getting Started Guide. Sharpsburg: Psychology Software Tools, Inc.
Schulte im Walde, S., Hätty, A., Bott, S., and Khvtisavrishvili, N. (2016). Ghost-NN: A representative gold standard of German noun-noun compounds. In: Calzolari, N., Choukri, K., Declerck, T., Goggi, S., Grobelnik, M., Maegaard, B., et al. Proceedings of the 10th Conference on Language Resources and Evaluation (LREC). Portoroz: European Language Resources Association. p. 2285–2292.
Smolka, E., and Libben, G. (2017). ‘Can you wash off the hogwash?' – semantic transparency of first and second constituents in the processing of German compounds. Lang. Cogn. Neurosci. 32, 514–531. doi: 10.1080/23273798.2016.1256492
Uygun, S., and Gürel, A. (2017). Compound processing in second language acquisition of English. J. Eur. Second Lang. Assoc. 1, 90–101. doi: 10.22599/jesla.21
Uygun, S., and Gürel, A. (2020). Does the processing of first language compounds change in late bilinguals? In: Schlechtweg, M., editors. The Learnability of Complex Constructions: A Cross-linguistic Perspective. Berlin: De Gruyter Mouton. p. 63–90. doi: 10.1515/9783110695113-004
Keywords: compound processing, bilingual processing, translation constituent priming, German, Czech
Citation: Kříž A and Bordag D (2023) The role of L1 translation form in L2 compound processing: the case of native Czech speakers processing German noun-noun compounds. Front. Commun. 8:1133927. doi: 10.3389/fcomm.2023.1133927
Received: 29 December 2022; Accepted: 19 June 2023;
Published: 10 July 2023.
Edited by:
Gary Libben, Brock University, CanadaReviewed by:
Katharina Korecky-Kröll, University of Vienna, AustriaGonia Jarema, Montreal University, Canada
Copyright © 2023 Kříž and Bordag. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Denisa Bordag, ZGVuaXNhdkB1bmktbGVpcHppZy5kZQ==