 Rodrigo Becerra
Rodrigo Becerra Jorge Osorio
Jorge Osorio Ítalo Cantarutti
Ítalo Cantarutti Gabriel Llanquinao4
Gabriel Llanquinao4- 1Department of Linguistics, University of Alberta, Edmonton, AB, Canada
- 2Departamento de Didáctica, Universidad Católica de la Santísima Concepción, Concepción, Chile
- 3Independent Researcher, Temuco, Chile
- 4Departamento de Infancia y Educación Básica, Universidad Católica de Temuco, Temuco, Chile
We compare the motion lexicalization patterns produced by L1 and L2 speakers of Mapudungun, an indigenous minority language spoken in Chile and Argentina. According to previous descriptions, the patterns of motion expression in Mapudungun have some characteristics of an equipollently-framed language, which contrast with the usual motion expression in Spanish. The data comprise oral narratives of the picture storybook “Frog, where are you?”, collected from 10 Mapudungun native speakers and 9 Spanish native speakers who are late bilinguals of Mapudungun. We report the general results (comparison of total clauses, translational clauses, types, and tokens) and analyze three general conflation patterns: the encoding of the semantic components of Path and Manner, the conflation of various components into serial verb constructions, and the encoding of Ground. The results show that L2 speakers encoded a significantly lower proportion of Manner verbs and a higher proportion of Path verbs than L1 speakers, used a significantly less diverse inventory of Path and Manner verb types, a significantly lower number of motion serial verb constructions, and a significantly higher number of plus-Ground clauses than L1 speakers, suggesting cross-linguistic influence from Spanish.
Introduction
The lexicalization patterns of motion in an L1 language can influence the way people encode motion in an L2, especially when both languages differ in their most frequent form-meaning mappings (e.g., Filipović and Vidaković, 2010; Hijazo-Gascón, 2018; Lewandowski and Özçalişkan, 2021). Until now, this effect has been recognized for learners of Indo-European and other major languages (e.g., Cadierno, 2004; Navarro and Nicoladis, 2005; Cadierno and Ruiz, 2006; Wu, 2011; Nozaki, 2019; Aktan-Erciyes, 2020), while learners of minority languages are still to be studied.
The investigation of cognitive effects related to the acquisition of minority languages is not only important for numerical reasons—around 85% of the world languages have <100,000 speakers and 50% of the languages have <5,000 speakers (Harrison, 2007; Romaine, 2007)1 —but also for theoretical and ethical reasons. First, adult learners of indigenous minority languages need to overcome multiple political and sociological barriers, which range from the lack of public policies promoting these languages and the reduced contexts where the L2 is spoken, to the stigma and discrimination against minority languages and the scarcity of learning materials. This way, we are dealing with contexts in which the L1 influence is unescapable, and it can be hypothesized that the influence of the L1, the majority language, on the L2 is strong. Second, most of minority languages are endangered and, according to optimistic estimates, around 50% of the world languages can be lost by 2100 (Austin and Sallabank, 2011). As Crevels (2012) puts it, the “clock is ticking” and researchers need to take action. In the same vein, a social justice turn is emerging in multilingualism research, advocating for a more active role of academia (Ortega, 2017, 2019). In this context, studies like this illustrate the distance between different thinking-for-speaking patterns and have the potential to serve for future pedagogical interventions (e.g., Cadierno, 2008).
In this paper, we compare the motion lexicalization patterns produced by adult native speakers of Mapudungun, an isolate indigenous minority language spoken in Chile and Argentina, with the patterns produced by adult Spanish speakers who are late bilinguals of Mapudungun. We focus on translational motion, defined as an event in which “an object's basic location shifts from one point to another in space” (Talmy, 2000, p. 35), as opposed to self-contained motion, in which an object maintains its position in relation to the Ground. According to previous descriptions, the motion expression patterns in Mapudungun have some characteristics of an equipollently-framed language, such as the frequent encoding of both Path and Manner in the main verb and the use of serial verb constructions (SVCs) (Becerra, 2017). Both patterns contrast with the usual motion expression in Spanish.
Three sets of form-meaning mappings are analyzed in both L1 and L2 speakers' production: the encoding of the semantic components of Path and Manner, the conflation of motion semantic components in SVCs, and the encoding of the Ground in adpositional phrases or other linguistic units. This study allows us to observe if L2 speakers are carrying over Spanish lexicalization patterns when speaking Mapudungun and, if so, regarding to what components of motion they are doing it and to what extent. Therefore, the present study sheds light on some aspects of Mapudungun expression of motion events that might be hard for Spanish speaking learners and, accordingly, should receive extra attention when studying and teaching the language.
Background
Motion Events Typologies and Inter-typological Differences
Since they were first put forth by Talmy (1985), motion events typologies have allowed researchers to compare the expression and conceptualization of motion events across languages. This endeavor has been made possible by the early recognition of motion as a universal cognitive domain, whose verbal expression relies on a language-specific packaging of universally attested semantic components (Talmy, 1985, 1991, 2000). In particular, Talmy (1985) identified four central semantic components of a motion event: Motion, referring to the presence of motion itself; Figure, the moving entity; Ground, the entity with respect to which the Figure moves; and Path, that is, the trajectory the Figure follows. All four components are deemed regularly or at least usually present in the expression of motion events. In addition, two other secondary components, Manner and Cause, were identified, although they were later redefined as relations the co-event bears to the main event (Talmy, 1991, 2000). While Manner is understood as an additional activity of the Figure that characterizes the way in which the motion unfolds, Cause refers to the force or specific action that incites or causes the movement.
Based on the mapping of the Path component onto linguistic forms, Talmy (1991, 2000) distinguished two different language types: verb-framed languages (or V-languages), which encode Path in the main verb root [e.g., in Spanish, El niño salió de la habitación (corriendo) ‘The boy went (running) out of the room’], and satellite-framed languages (or S-languages), which encode Path in a satellite, usually a particle or affix (e.g., in English, The boy ran out of the room). As shown in these examples, Spanish and English are considered, respectively, paradigmatic cases of verb-framed and satellite-framed languages (e.g., Talmy, 1991, 2000; Berman and Slobin, 1994; Slobin, 1996a, 2000, 2004). Importantly, S-languages tend to encode the co-event—either Manner, Cause, or other relations—in the verb, whereas V-languages tend to encode the co-event only optionally in an adverbial, gerund-like element, or other construction.
Behind this binary classification lies the assumption that the main verb and its satellites form the verb complex, a required constituent in the clause, which is asymmetric in nature. Thus, according to this model, there is one and only one (main) verb root, whereas there can be more than one satellite. In addition, according to this typology, languages tend to lexicalize either Path or Manner in the main verb root.2 This assumption has the important consequence that any semantic components expressed by the verb complex are backgrounded, that is, are made less attentionally salient and more readily expressed by the speaker compared to their expression in open-class elements outside the verb complex (Talmy, 2000). In turn, since most V-languages do not encode Manner in satellites,3 they lexicalize this component in an open class category, which would make it foregrounded and more cognitively demanding for the speakers.
Importantly, the meaning-to-form mapping distinction between S- and V-languages has implications at the level of discourse. Compared to speakers of V-languages, narratives of S-language speakers tend to use Manner verbs much more frequently, both in terms of number of tokens and amount of verb types; describe the Ground more frequently; identify more Path segments inside a single trajectory; and dispense with static descriptions, which are usually left to inference (Berman and Slobin, 1994; Slobin, 1996a, 2000, 2004). According to Slobin (2004, P. 223), these differences emerge from a combination of different “accessibility of means of expression” and cultural practices.
Although the binary Talmian typology has been inspiring and fruitful, its two-way distinction was questioned as the lexicalization patterns of more and more languages started to be described (e.g., Zlatev and David, 2003; Slobin, 2004; Zlatev and Yangklang, 2004). This led to the proposal of a third type, the so-called “equipollently-framed languages” or E-languages (Slobin, 2004, p. 249). The E-type is intended to cover cases in which Path and Manner are expressed through equivalent grammatical forms as in serial verb languages (e.g., Mandarin), in which Path and Manner verbs can have equal status; bipartite verb languages, where the verb has two morphemes with the same status, one expressing Manner and the other Path (e.g., Hokan and Klamath-Takelma languages); and functional or generic verb languages, which feature a general verb and several Manner and Path preverbs (e.g., Jaminjung). Expanded typologies (non-binary and non-tripartite) have also been put forward (e.g., Croft, 2003; Huang and Tanangkingsing, 2005; Croft et al., 2010; Fortis and Vittrant, 2011), however, all of them consider a symmetric type, equivalent to the equipollent framing by Slobin (2004).
E-language narratives have been described as somewhat intermediate between those of S- and V-languages. On the one hand, V- and E-languages are similar in their frequent and colloquial use of Path verbs, and in their low usage of Ground phrases per translational clause. On the other hand, E-language narratives resemble S-language descriptions in their frequent use of Manner verbs, the absence of verb selection restrictions in boundary crossing scenes, and the high granularity with which they segmentate complex trajectories (Zlatev and Yangklang, 2004; Chen and Guo, 2008; Ameka and Essegby, 2013).
Motion Events in Spanish and Mapudungun
As was mentioned above, Spanish has been characterized as a prototypical V-language (Talmy, 1991, 2000; Berman and Slobin, 1994; Slobin, 1996a, 2000, 2004). As such, Spanish tends to conflate Motion and Path in the verb root while Manner is usually optionally encoded in an adverbial phrase or gerund (1).

Accordingly, the description of motion events in Spanish tends to make colloquial and frequent use of Path verbs (e.g., ir ‘go’, venir ‘come’, entrar ‘enter’, salir ‘exit’, subir ‘ascend’, bajar ‘descend’), which are preferred in 65–82% of motion event descriptions (Slobin, 2004, p. 230–231). Moreover, the use of Path verbs along with state verbs (e.g., estar ‘be’, haber ‘there be’, tener ‘have’) is a frequent strategy of adult speakers. While state verbs set the stage, Path verbs indicate a change in location (Berman and Slobin, 1994). Manner verbs can also head clauses encoding translational motion events, but they are not the most frequent selection made by the speakers. Furthermore, in Spanish there is a “boundary crossing constraint” (Slobin, 2004, p. 225, see also Aske, 1989) at work that prevents most Manner verbs from being used as the main verb when the Figure moves into or out of a location conceptualized as an enclosed area or container.4
Spanish speakers also differ from S-language speakers regarding the amount of attention given to the encoding of the Ground, which has been operationalized, for example, as the absolute number of Ground phrases per verb or as the proportion of translational clauses with and without Ground phrases (Slobin, 1996a, 1997, 2004; Ibarretxe-Antuñano, 2009).5 These Ground elements are typically encoded in Spanish as adverbials or prepositional phrases (e.g., abajo ‘downwards’, al río ‘to the river’). Overall, Spanish speakers tend to mention a lower proportion of clauses containing Ground elements than S-language speakers do. Spanish speakers produced 63% of plus-Ground clauses in frog stories and 81% in novels, compared to an 82% of plus-Ground clauses produced by English speakers in frog stories and 96% in novels (Slobin, 1996a). Moreover, when Spanish speakers encode Ground elements in the clause, the vast majority of them include only one element (73%) and rarely two (8%), while more than one third of the descriptions made by English speakers (37%) encode 2, 3 or more Ground elements (Slobin, 1996a).
In turn, Mapudungun has been described as a non-prototypical equipollently-framed language, having both similarities and differences with other previously studied E-languages (Becerra, 2017). As other E-languages, Mapudungun allows SVCs that include two or more verb roots into a single polysynthetic word, unlike the multiword SVCs that are built in other E-languages.6 As a result, SVCs in Mapudungun can contain both a Path and a Manner verb root with equal grammatical status, so that speakers do not need to choose either one to the exclusion of the other, as is shown in (2).

Mapudungun also resembles E-languages in three other ways. First, it does not obey the boundary-crossing restriction, typical of V-languages; second, Mapudungun speakers produce a large number of Manner verb types, which produces a Manner/Path verb type ratio near 2 to 1; and third, Mapudungun has a big inventory of Path verbs, which are used twice as frequently as Manner verbs, despite the big number of Manner types available (Becerra, 2017). The first two characteristics are shared by E- and S-languages, while the last one renders E-languages closer to V-languages (Zlatev and David, 2003; Zlatev and Yangklang, 2004; Ameka and Essegby, 2013).
However, Mapudungun also differs from other E-languages. Importantly, Mapudungun presents a low specification of Ground elements per clause, which is not only lower than some previously described E-languages, such as Mandarin (Chen and Guo, 2008), Thai (Zlatev and Yangklang, 2004), Ewe, and Akan (Ameka and Essegby, 2013), but also lower than V-languages such as Spanish (Becerra, 2017). What is more, unlike multiword serial verb languages such as Mandarin, Thai, Ewe, and Akan, Mapudungun does not allow more than one Ground per clause, being in this regard more restrictive than both prototypical E-languages and Spanish.
The encoding of the Ground in Mapudungun is made mainly through the use of adpositional phrases. There are two sets of adpositions: one set of postpositions with very general meanings and one set of prepositions (also, adverbials) with specific meanings (Lizarralde and Becerra, 2017). However, none of them encode a specific directionality (e.g., equivalent to to or from). This way, the interpretation of a given landmark as a source, medium, or goal depends, in the first place, on the semantics of the verb and, in the second place, on a contextual interpretation.
Cross-Linguistic Influence in Second Language Acquisition
Inter-language variation has important consequences for our work. The recognition of these differences has allowed researchers to better understand the narrative patterns followed by speakers of different languages. These rhetorical styles are the result of various factors, among which we must consider linguistic structure (the morphosyntactic constructions and lexicon available), online processing (related to factors such as ease of access and heaviness of construction), and cultural practices (e.g., cultural attention to spatial orientation and cultural differences in textual organization) (Berthele, 2004; Slobin, 2004, 2017; Wilkins, 2004; Ibarretxe-Antuñano, 2009; Beavers et al., 2010). Consequently, languages differ in rhetorical style, which represents a challenge for language learners.
When faced to the task of acquiring a second language, people must learn not only the new linguistic forms but must also adapt themselves to the extent to which the second language encodes each one of the motion semantic components. However, the learner's first language may shape the learning process in various ways. In general, cross-linguistic influence, or transfer, can be defined as “the influence of a person's knowledge of one language on that person's knowledge or use of another language” (Jarvis and Pavlenko, 2008, p. 1). According to these scholars, cross-linguistic influence can occur at two cognitive levels: linguistic and conceptual, both of which are relevant to this research. While the former involves transfer from a person's linguistic knowledge and usage over forms, structures, or rules in another language, the latter emerges from “the ways a person has learned—as a speaker of a particular language and as a member of a particular discourse community—to attend to, perceive, interpret, construe, conceptualize, categorize and refer to experience” (Jarvis, 2017, p. 21).
As a result, the acquisition of target-like patterns is not straightforward since lexicalization patterns of motion in an L1 can be transferred to an L2 language, at least to some extent (Cadierno, 2004; Navarro and Nicoladis, 2005; Cadierno and Ruiz, 2006; Donoso and Bylund, 2015; Hijazo-Gascón, 2018, 2021; Nozaki, 2019). For example, native speakers of Danish tend to exhibit a higher degree of elaboration of Path in their Spanish L2 narratives than Spanish native speakers do. This effect was found both in the proportion of translational clauses containing Ground adjuncts and in the satellization of Spanish locative elements, used by Danish L1 speakers to encode Path, as in (3).

In (3), a Spanish L2 speaker uses the non-directional verb mover ‘move’ plus the adverbial abajo ‘underneath, below’ as a Path particle, mimicking a Danish conflation pattern. First, the speaker uses the non-directional verb mover ‘moves’ and not a Path verb (such as bajar ‘descend’), which are frequently used by Spanish speakers in other contexts, nor a verb conflating Cause (such as tirar or arrojar ‘throw’), which would be the preferred choice made by Spanish native speakers in scenes like the one described in (3). Second, the adverbial abajo ‘underneath, below’, although primarily locative, can have a directional interpretation when used with a Path verb (Aske, 1989; Mateu and Rigau, 2010), especially when it appears forming a construction with either a preposition (para abajo ‘down’) or with some nouns encoding the Ground (e.g., cerro abajo ‘down the hill’), which is not the case in (3). All in all, the whole Danish pattern (non-Path motion verb + directional satellite') is deployed in (3).8
Similar effects were not observed in narratives by Italian learners of Spanish (Cadierno and Ruiz, 2006). Although it is tempting to attribute the L1 transfers to broad typological differences (being Italian and Spanish usually described as V-languages, different from Danish, an S-language), this kind of transfers have not only been found between typologically different languages but also between pair of languages that can be characterized as belonging to the same type, as long as their most frequent form-meaning mappings differ (e.g., Filipović and Vidaković, 2010; Hijazo-Gascón, 2018, 2021; Lewandowski and Özçalişkan, 2021).
The challenges of acquiring an L2 rhetorical style can be better understood considering the cognitive correlates of linguistic types and linguistic structure. According to Slobin (1987, 1996b, 2004), the conceptualizations that are mobilized for communication can be studied as a special form of thought, which he calls “thinking for speaking”. Slobin claims that a “highly codable domain plays a major role in thinking for speaking, with possible consequences for mental representation” (Slobin, 2004, p. 237) because “frequent use of forms directs attention to their functions, perhaps even making those functions (semantic and discursive) especially salient on the conceptual level” (Berman and Slobin, 1994, p. 640). Therefore, typologically different lexicalization patterns may have an impact on the conceptualization of experience, at least when it is accompanied by verbalization, directing the attention of speakers of different languages in different ways. Thus, acquiring a second language may demand a new way of thinking for speaking (Cadierno, 2004).9
Until now, cross-linguistic effects in the lexicalization of motion events have been studied and recognized for learners of Indo-European and other major languages, such as Hungarian (e.g., Mano et al., 2018), Korean (e.g., Choi and Lantolf, 2008), and Japanese (e.g., Nozaki, 2019; Iwasaki and Yoshioka, 2020). Most of the studies have considered different combinations of V- and S-languages, while Mandarin is the only E-language tested so far. In particular, cross-linguistic effects have been investigated for Mandarin speakers learning S- or V-languages (Brown, 2015; Chui et al., 2015), and for French and English speakers learning Mandarin (Wu, 2011; Arslangul, 2015; Tang et al., 2021).
On the one hand, Chui et al. (2015) report cross-linguistic influence of Mandarin into Russian. In particular, L1 Mandarin speakers who are elementary learners of Russian produce less clauses containing two or more Path elements than Russian native speakers. Alternatively, focusing on the elaboration of Manner, Brown (2015) claims that the low production of this component by Mandarin L1-English L2 bilinguals (compared to both L1 Mandarin and L1 English speakers) is not attributable to cross-linguistic influences but to a general effect on bilinguals' development, related to lexical knowledge and/or processing demands. On the other hand, being most V-languages low-Manner-salient languages and Mandarin a high-Manner-salient language, shifting from a L1 V-language to Mandarin as a L2 should be more challenging than the other way around. Accordingly, while the expression of Manner by Mandarin learners of Spanish does not seem to be affected by their L1 (Chui et al., 2015), French learners of Mandarin seem to experience L1 effects when producing motion events (Arslangul, 2015). Notably, French learners of Mandarin produce more Path verbs but less Path satellites, less Manner expressions, and less expressions encoding two or more semantic components than Mandarin native speakers (Arslangul, 2015).
Relevant cross-linguistic effects on Mandarin learners' have been studied when they produce and interpret SVCs. For example, English-speaking learners of Mandarin produce significantly less motion SVCs than Mandarin L1 speakers (Wu, 2011).10

Although the performance of Mandarin learners improves with simple SVCs and at advanced levels of proficiency, native speakers differed significantly from Mandarin learners at all levels. In addition, English-speaking learners of Mandarin judge the subevents codified in a SVC as more distant in time than Mandarin native speakers do, what has been explained as a cross-linguistic influence from English on the conceptualization of events in Mandarin (Tang et al., 2021).
In general, two sources of conceptual transfer are relevant for the study. First, cross-linguistic effects are common when the L2 encodes a semantic component more prominently or with higher specificity than the L1, so that learners need to tune their rhetorical style to increase the encoding of that component (Brown and Gullberg, 2008; Cadierno and Robinson, 2009; Cadierno, 2010; Arslangul, 2015; Alonso, 2019; Muñoz and Cadierno, 2019). Second, cross-linguistic effects have also been consistently reported when the L2 encodes a semantic component less prominently than the L1 but using the same kind of structures found in the L1. This way, L2 speakers can be tempted to overuse the familiar structures. This type of effect has been reported, for example, from Danish and German L1 speakers who are learners of Spanish. Both groups tend to produce more clauses containing Ground adjuncts than Spanish native speakers (Cadierno, 2004; Cadierno and Ruiz, 2006; Hijazo-Gascón, 2018, 2021).
The Present Study
In the context of the theoretical issues described above, the present study tests some implications of the thinking-for-speaking hypothesis for the lexicalization patterns produced by adult learners of a language typologically different from their L1. In particular, this study expands our knowledge about cross-linguistic effects by focusing on the possible influence between an understudied language pair, namely from a V- to an E-language. It is not known yet whether similar effects to those described by Arslangul (2015) from an L1 V-language to an L2 E-language can be replicated and, what is more, found for different languages, specifically, from Spanish to an L2 E-language that builds single-word serial verbs, such as Mapudungun. By analyzing the learners' L2 behavior and comparing it to L1 performance, we are testing one kind of evidence for cross-linguistic effects (Jarvis, 2000).
We asked two research questions:
(i) At the semantic level, to what extent do L1 and L2 Mapudungun speakers differ in the degree of attention they pay to Path, Manner, and Ground when producing motion events?
(ii) At the construction level, to what extent L1 and L2 Mapudungun speakers produce an equivalent number of SVCs when describing motion events?
Based on previous studies, we hypothesized that:
- L1 thinking-for-speaking patterns would be the starting point for learners of Mapudungun and, accordingly, these learners are expected to produce less Manner of motion expressions but more Path encodings and more Ground elements than Mapudungun native speakers.
- At the construction level, Mapudungun learners are expected to produce less SVCs and a less varied inventory of SVCs than native speakers, since learners would rely primarily on L1 rhetorical styles and constructions, in which SVCs are not found. Consequently, Mapudungun learners are expected to follow the tendency of choosing either a Path or a Manner main verb, what can also impact the frequency of the Path and Manner encoding in their narratives.
Methodology
Participants
Two participant groups took part in this study: 10 Mapudungun native speakers (8 male, 2 female) with a mean age of 46.1 (range 32–67), and 12 learners of Mapudungun who are native speakers of Spanish (9 male, 3 female) with a mean age of 32.3 (range 21–60).11 The selection of the participants was made using a combination of purposive and snowball sampling. Probability sampling was impractical due to context and the populations under study (low number of people, geographic dispersion, and a history of power imbalance and social stigmatization that makes people distrust institutions, including academia, and avoid exposure and participation), all of them common factors that can prevent probability sampling (Parker et al., 2019). We thus highlight the relevance of non-probability sampling in some contexts. As Kerlinger and Lee (2000, p. 178) state, “probability sampling does not guarantee more representative samples of the universe under study. […] With non-probability sampling the emphasis relies on the person doing the sampling […they] must be knowledgeable of the population to be studied and the phenomena under study.”
The Mapudungun native speakers are all Mapudungun-Spanish bilinguals who have learned Spanish during their childhood and use Mapudungun in a daily basis. There are very few Mapudungun monolinguals and none of them participated in this work. There were individual differences among participants both in terms of age and context of acquisition of Spanish as an L2 (whether at home or at school), and in terms of the contexts in which they use the L1. We did not consider these differences for participant selection and, as it will be discussed below, we claim that this did not impact on the validity of the results.
Regarding the L2 Mapudungun participants, their proficiency is comparable to a range from mid intermediate to advanced proficiency levels in the ACTFL guidelines (American Council on the Teaching of Foreign Languages, 2012). Given that there is no standardized language proficiency assessment for Mapudungun, we used a language background questionnaire and complemented it with our observation of their performance.12 The language background questionnaire surveyed their biographical information, language usage, and self-reported proficiency. All the participants started to study Mapudungun as young adults (mean 22.6, SD 4.1), either at high school, University courses, or non-formal education initiatives, and none of them participated in interactions in Mapudungun during their childhood. As a result, this group had been studying Mapudungun for an average of 8.5 years (SD 3.9). Based on this questionnaire, each participant was assigned a score in a 10-point ordinal scale, calculated by summing up points awarded for each answer. Five questions were scored: (i) number of years studying the language; (ii) frequency of language usage; (iii) diversity of contexts and interactions; (iv) diversity of topics spoken in the L2; and (v) self-reported proficiency. Questions (b) to (d) were included following previous surveys about bilingualism in the Mapudungun context (Zúñiga, 2007; Zúñiga and Olate, 2017). The categories provided for each question and their scores are shown in Table 1.
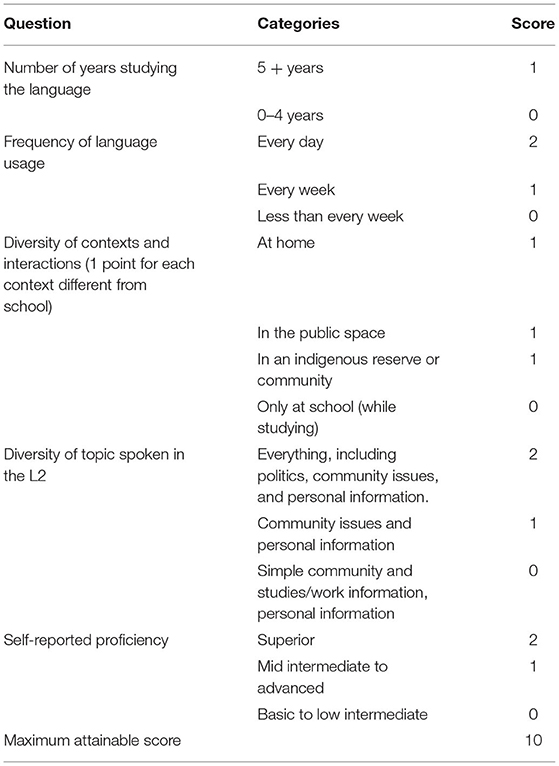
Table 1. Questions and scores of the language background questionnaire.
From the questionnaire, the L2 participants' proficiency was categorized as basic (0–4), intermediate to advanced (5–8) or superior (9–10). No participant got a score equal or higher than 9, whereas four participants obtained a score of 4. The questionnaire assessment was followed by a qualitative assessment during the interview in Mapudungun (see Section Materials below). Three of these participants (who ranked lowest in the questionnaire) had noticeable difficulties to tell the story, due to long and frequent pauses, and sometimes decided to skip a scene. Therefore, they were excluded from the study, so that the final sample was composed by 10 native speakers and 9 learners.
Materials
The data for the study was collected using the wordless picture storybook “Frog, where are you?” (Mayer, 1969), which the participants narrated orally in Mapudungun. All the participants were recruited and explained the task in Spanish, but communication was switched to Mapudungun during the interview in order to minimize any cross-linguistic effects. Participants were asked to familiarize first with the story and solve any questions or doubts before the interview started. During the interview, the participants went over the pages while they narrated the story, so that memory would not interfere with the results. Due to pandemic restrictions, L2 speakers were not interviewed in person, as the L1 Mapudungun speakers were. Thus, all L2 speakers were contacted and met with the investigators online (through video conference).
All interviews were recorded, transcribed, and segmented by clauses according to Berman and Slobin's (1994) transcription conventions. Following this procedure, each clause was transcribed on a different textline. We also followed Berman and Slobin's recommendations to annotate unclear cases (e.g., non-finite verbs, ellipsis, and center-embedded clauses) and included markup conventions to code some conversational features (e.g., pauses, lengthening, and intonation).
Annotations and Analysis
Every clause was annotated regarding the motion information it encodes. We focused in four semantic components: Motion, Path, Ground, and Manner. All translational clauses were counted and reserved for further analysis. From this sample, we added up all clauses encoding the semantic components under analysis, considering the various formal devices at use in the language. Translational clauses are headed by verbs encoding just Motion or conflating Motion and Path, Motion and Manner, or Motion, Path, and Manner.13 We also identified all serial verbs encoding motion, either in any of the verb roots or in a suffix. The different types of SVCs were distinguished and counted.
We also calculated the number of verb tokens and verb types encoding motion. First, the number of motion verb tokens is roughly equal to the number of translational clauses. There is a small difference between the two tallies, which derives from the few non-finite verb modifiers in some clauses. Second, two tallies of motion verb types were calculated: one for verb roots and another for verb stems. While the first one represents the diversity of indivisible verbal units used by the speakers, the second one represents the complete set of lexical units used by the speakers, including those formed by derivation and serialization from the verb roots. Then, the mean of motion verb types was calculated for each group, averaging the number of types produced by each speaker of a given group. Third, proportions of tokens of each relevant verb class (Path and Manner) to the total number of translational clauses were also calculated per speaker. These proportions give a good indicator of the relative attention paid by each participant to each verb class because, unlike the counts of tokens and types per speaker, proportions minimize the effects of different levels of proficiency, reflecting more directly possible L1 effects.
A data frame was created with all the data and inferential statistics was applied to it. In particular, the non-parametric Mann-Whitney U test (equivalent to Wilcoxon rank-sum test) was used to find if there is a difference in the observations of a quantitative variable in one group compared to the observations in the other group, specifically between the group of native speakers and the group of learners. The Mann-Whitney test is used for small samples and non-normal distributions, which was tested using the Shapiro-Wilk's method. This was tested for the different dependent variables under study. The statistical test was implemented in R program language (R Core Team, 2021) by using the coin (Hothorn et al., 2006) and rcompanion (Mangiafico, 2021) packages.
In order to answer our research questions, we analyzed three sets of form-meaning mappings from the narratives: the encoding of the semantic components Path and Manner in finite and non-finite verbs and other elements; the conflation of Path and Manner as well as other combinations of semantic components in SVCs; and the encoding of the Ground in noun, adpositional, or adverbial phrases. We calculated the percentage of Path verbs from the total of Path + Manner verbs and from the total of clauses produced by each participant, the percentage of Manner verbs out of the same totals, and the percentage of Ground phrases out of the total of translational clauses.
Results
We first present an analysis of the general expression of motion by L1 and L2 Mapudungun speakers and then turn to the encoding of the different semantic components in motion constructions, including the conflation of Path and Manner in SVCs.
General Expression of Motion
Overall, Mapudungun native speakers produced larger narratives and more motion predicates than Mapudungun learners. As can be seen from the total number of clauses and translational clauses in Table 2, L1 speakers produced narratives that are in average about twice as long as those produced by L2 speakers and contain more than twice the number of translational clauses than those found in L2 narratives. The number of translational clauses is roughly equal to the number of tokens of motion verb stems. Since there are 9 tokens of non-finite motion verbs functioning as Manner adjuncts (8 in L1 narratives and 1 in L2 narratives), the exact number of motion verb tokens is 583 in L1 and 237 in L2 narratives, as shown in Table 2.
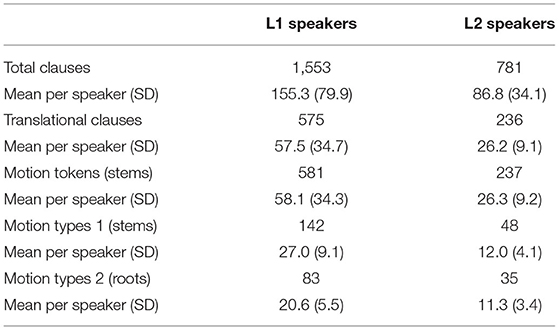
Table 2. Number of clauses, and motion tokens and types in Mapudungun narratives.
The difference between the two groups is found to be significant for the total number of clauses (p = 0.0301, Z = 2.16, r = 0.50) and for the number of translational clauses (p = 0.0079, Z = 2.65, r = 0.61). Additionally, the difference between the two groups in token, root type, and stem type production turned out to be significant, with L1 speakers producing significantly more motion tokens (p = 0.0042, Z = 2.86, r = 0.66), more root types (p = 0.0008, Z = 3.36, r = 0.77), and more stem types (p = 0.0004, Z = 3.52, r = 0.80).
The numerical difference between roots and stems derives from the suffixation of causative affixes to derive transitive stems and from the frequent usage of SVCs, which produce complex stems (5). In contrast, Mapudungun learners produced 238 verb tokens, 52 verbal stem types, and 39 verbal root types.

In (5a), we find the simple stem nag ‘descend’ that coincides with the verb root nag. In contrast, the stem naküm ‘take something down’ is found in (5b), formed by derivation from the root nag and the causative suffix -üm with the concurrence of morphophonemic processes. Similarly, the serial stem ütrünag is found in (5c), from the roots ütrü ‘fall’ and nag ‘descend’ (more about serial stems in Section Usage of SVCs below).
Most of the verb forms constructed by Mapudungun learners are target-like. However, two non-target-like verbs were wide-spread among Mapudungun learners and are relevant to our work. It is the case of some tokens of the verb roots tran ‘fall from a standing position’ and trana ‘lie down’. Specifically, in scenes of falling, while native speakers tend to produce a serial verb such as ütrünagi ‘[he/she] fell down’ (see 5c) or others similar to it, the majority of Mapudungun learners use a single verb construction, formed from the verb roots tran or trana, as in (6).

In (6a), the verb trani ‘fall from a standing position’ is used instead of ütrünagi ‘fall down’. However, trani is used for people or things (e.g., trees, chairs, tables) that are in a standing position before they fall, not for events such as the falling of the beehive in the story. Similarly, in (6b) another speaker uses the verb tranai ‘lie down’ by itself with the intended meaning of “the dog fell down from the window”. However, this verb communicates that the dog lies down, which is inconsistent with the fact that a source of a movement is mentioned. Therefore, other verbs would be expected instead of tranai.
These grammatical errors are likely related to the mismatch between the existence of a Spanish basic verb to indicate an event of falling, namely caer ‘fall down’, and the inexistence of a simple Mapudungun stem with an equivalent meaning. On the contrary, the underived stem tran does not cover the entire semantic field of falling, being restricted to entities that were standing before they fall, while trana encodes posture and not an event of falling. In contrast, the most common verb stem used in this case in Mapudungun, ütrünag, is formed by serialization. Other verbs also exist in Mapudungun, such as lar ‘tumble down’ and llangkü ‘fall off (e.g., leaves)’ but are used more restrictively, as well as many serial verbs indicating posture or position, such as müllengnag ('fall down face downwards'). Thus, the usage of tran and trana is an example of overgeneralization originated in a conceptual transfer from Spanish.
Expression of Path and Manner
Four classes of motion verb roots were recognized in the two groups of narratives: (i) Neutral verbs, which encode only Motion, with no conflation of any other semantic components; (ii) Path verbs, which conflate Motion and Path; (iii) Manner verbs, which conflate Motion and Manner; and (iv) Path + Manner verbs, which conflate Motion, Path, and Manner in a single root. Neutral and Path + Manner verbs are the smallest classes. One verb root type was classified as neutral: miyaw ‘move oneself around’, while three verb stems were classified as Path + Manner, namely lefmaw ‘run away’, the loanword aranka ‘run away’, and tran ‘fall from a standing position’ when is overgeneralized by L2 speakers with the meaning of ‘fall down’. A translational clause may be headed by a verb of any of the four classes with no derivation or serialization, be it a Path + Manner verb, as shown in (6a), a neutral verb (7a), a Path verb (7b), or a Manner verb (7c).

Non-finite verbs and adverbs functioning as Manner modifiers of the main verb were also identified. In consequence, the total number of translational clauses encoding Manner were the sum of the clauses with Manner verbs and those with Manner modifiers. As for Path, this component is necessarily encoded in the verb, even if there is a Ground modifier (e.g., an adpositional phrase). This way, the number of translational clauses encoding Path in the verb necessarily equals the number of clauses encoding Path in the verb.
Additionally, two groups of suffixes were identified in the sample that, inside a verbal construction, can turn a non-motion verb root into a stem encoding Motion: (i) a couple of directional suffixes (the cislocative suffix -pa and the translocative suffix -pu), which encode Path, and (ii) the perambulative suffix -(ki)yaw, which only encodes the semantic component Motion. Two cases are relevant for the analysis. First, some non-Motion verb roots and stems when appearing with any of these Motion suffixes are turned into a Manner-like event, such as the constructions awkantu-yaw “move around playing” and tritrangnamün-kiyaw “move around barefoot”. This kind of stems encodes a concomitant activity or a spatial configuration of the Figure that is perceived as Manner of motion and are classified as Manner-like in this paper. Second, other cases of non-Motion verb roots or stems appearing with Motion suffixes do not encode a concomitant activity or state but other relations of the co-event to the Motion event, for example, a concurrent result or a subsequent action (see Talmy, 2000). For example, this is the case of the root pe ‘see’ in the construction pepa ‘come to see’. These cases are counted as part of translational clauses, but the verb roots involved are not considered for token and type counts and analyses.
In Table 3, we present the mean of verb tokens per speaker and the total number of verb types of different classes produced by L1 and L2 speakers.
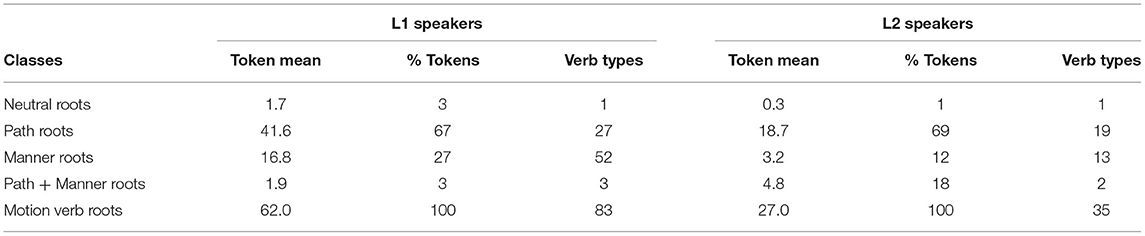
Table 3. Different verb classes in L1 and L2 narratives.
In general, L1 narratives are richer both in terms of the overall production of motion verbs, calculated as a mean of verb tokens, and in terms of the diversity of verb roots used in translational predicates, calculated as the total number of verb types. This is valid not only for motion verbs as a whole but also for the specific classes of Path and Manner verbs. While in terms of overall production L1 speakers used in average twice as many Path verb tokens and five times as many Manner verb tokens as L2 speakers, in terms of lexical diversity L1 speakers produced in average 6 more Path types and more than three times the number of Manner types produced by L2 speakers.
Inferential statistics was used to test the statistical significance of the inter-group difference in the proportions of Path and Manner tokens to the total number of translational clauses. As shown by the Mann-Whitney test, L1 speakers encode a significantly higher proportion of tokens of Manner verb roots than L2 speakers (p = 0.0012, Z = 3.22, r = 0.74), whereas no significant inter-group difference was found related to the proportion of Path tokens (p = 0.3902, Z = 0.85, r = 0.20). However, if the proportion of Path roots is calculated with respect to the sum of Path and Manner roots only, a significant inter-group difference is found, with L1 speakers producing significantly less Path roots (p = 0.0005, Z = −3.48, r = −0.80) than L2 speakers. In addition, L1 speakers produce a significantly higher number of Path types (p = 0.0024, Z = 3.03, r = 0.70) and especially Manner types (p = 0.0002, Z = 3.69, r = 0.85) than L1 speakers.
These results are noteworthy considering the inter-typological differences between Spanish and Mapudungun. Spanish has been described as a low-Manner-salient language (Slobin, 2004), while Mapudungun speakers pay special attention to Manner of motion, with a high proportion of Manner types (Becerra, 2017) and the encoding of fine-grained distinctions. This way, although differences in proficiency levels between L1 and L2 speakers can be a factor in the results, cross-linguistic effects related to inter-typological differences also seem to play a role, given that the difference between the two groups is bigger for Manner than it is for Path verbs.
Expression of Ground
Translational clauses were classified into “minus-Ground” and “plus-Ground” clauses. While the first type lacks any explicit reference to the Ground, the second type incorporate an element encoding the source, the medium, or the goal. As will be explained below, translational clauses are more likely to lack any Ground specification in both groups of narratives, and any verb type can appear with or without a Ground element, as can be seen from the comparison of (8) and (9).
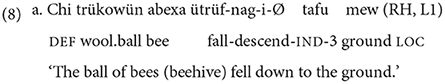

Whereas, (8) presents a plus-Ground clause, which encodes an adpositional phrase headed by the general locative postposition mew, (9c) presents a minus-Ground clause, more specifically, a bare verb. In this case, the goal of (9c) is inferred from the text since enough context had been provided in the previous clauses (9a-b).
Regarding the linguistic elements used to encode Ground, most of them are adpositional phrases, although noun phrases, adverbials, headless relative clauses, and a few instances of verb roots referring to the Ground are also used, as shown in Table 4. Results are presented as token means per speaker, averaged by group.
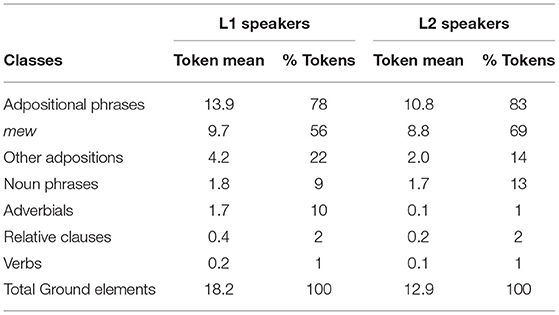
Table 4. Different devices used to encode Ground in L1 and L2 narratives.
We can see from Table 4 that both groups of participants produced a wide variety of devices, but a closer inspection shows that L1 speakers used a more diverse inventory of elements encoding Ground. This way, L2 speakers relied more heavily on the usage of adposition phrases and specially in the usage of one adposition, the general locative postposition mew, which does not encode any specific spatial configuration. On the contrary, L1 speakers proportionally favored the usage of other adpositions and adverbials, compared to L1 speakers. The two groups also differ in terms of the overall production of Ground elements. Table 5 shows the mean of Ground elements per speaker and the percentage of plus-Ground translational clauses in L1 and L2 narratives.
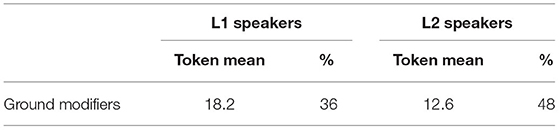
Table 5. Ground modifiers in L1 and L2 narratives.
Overall, L1 speakers produced more ground modifiers than L2 speakers. However, since L1 narratives are longer and have more translational clauses than L1 narratives, the proportion of translational clauses with Ground elements in L1 narratives is significantly smaller than in L2 narratives (p = 0.0328, Z = −2.13, r = −0.49). This inter-group difference is interesting in light of inter-typological differences. Mapudungun native speakers produce almost half of plus-Ground clauses compared to the L1 behavior found in some Spanish narratives (Slobin, 1996a). If one assumes that the Spanish lexicalization patterns of the group of L2 speakers does not strongly deviate from the previous Spanish descriptions, we could interpret that they have adapted their performance to the Mapudungun rhetorical style, but without making it completely target-like.
Usage of SVCs
The following four classes of SVCs are found in the data: (i) Path root + Path root, as in amu-tripa ‘escape’ (lit. ‘go-exit’); (ii) Manner root + Path root, such as in ringkü-tripa ‘jump out’ (lit. ‘jump-exit’); (iii) Ground root + Path root, as in longkon-tuku ‘put in the head’, from longko ‘head’ and tuku ‘put, insert’; and (iv) Path root encoding orientation of the Figure + Perception root, as in nag-kintu ‘look downwards’ (lit. ‘descend-look’). This last class of SVC can function as part of a motion predicate in the presence of a Motion suffix. In terms of frequency, the first two classes (Path + Path and Manner + Path) are the most common in the data, while the last two are marginal. Examples are provided for Path + Path and Manner + Path in (10a) and (10b), respectively. Other examples of SVCs have been already provided in (2), (5c), (8), and (9c).

Despite most of the tokens of SVCs in L2 narratives are target-like, some of them deviate from L1 use, both formally and semantically. For example, in (11a) the speaker uses the serial verb witra-püra ‘stand up’ (lit. ‘stand-ascend’) without the necessary mood, person, and number suffixes, and with an encoded meaning that differs from the intended meaning. In turn, in (11b) the speaker produces the serial verb trana-künu ‘leaving (something) lying down’ (lit. ‘lie.down-leave’), formally correct but semantically deviant.

Table 6 presents the overall frequency, token mean per speaker, and total number of SVC types in each group of narratives. L1 speakers produced in average six times more tokens of SVCs than L1 speakers, and a much more diverse set of SVCs (almost 5 times) in term of stem types. Although the production of SVCs by the group of native speakers surpassed the learners' group in all four classes, the bulk of the difference can be explained by the two first classes of SVCs, namely Path + Path and, especially, Manner + Path constructions.
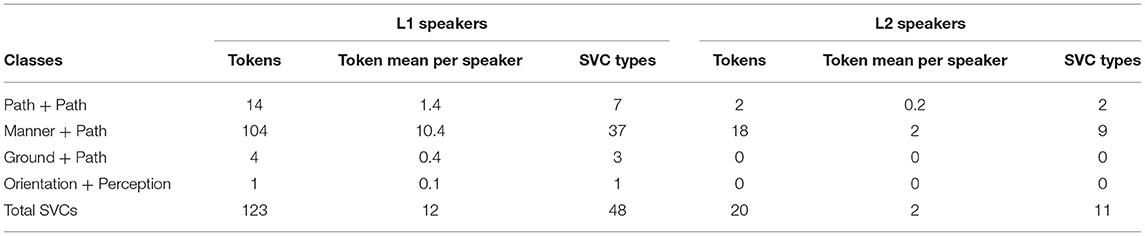
Table 6. Different classes of SVCs in L1 and L2 narratives.
The punctual action verb root künu ‘leave something’ appear in a few SVCs, either instead of the Path verb root or postposed as a third root, as in rupa-künu ‘have passed something’ (lit. ‘pass-leave something’), wechu-künu ‘put oneself on the top’ (lit. ‘reach the top-leave something’), and ütrüf-tuku-künu (lit. ‘throw-put-leave something’). For the sake of simplicity, these constructions were considered as part of the most related classes. Namely, there is one Path + künu serial verb in the data (L1 narratives), which is counted together with the Path + Path class. There are two Manner + Path + künu stems, one in each group of narratives, which are considered together with Manner + Path verbs. Finally, there are two tokens of Ground + künu verbs in L1 narratives, counted as part of the Ground + Path class.
A Mann-Whitney test was used to examine whether the difference in frequency of use, operationalized as the proportion of SVCs to translational clauses per speaker, and number of serial stem types between the two groups is statistically significant. As a result, we found that L1 speakers produced a significantly higher proportion of both motion SVCs (p = 0.0053, Z = 2.78, r = 0.64) and, specifically, Manner + Path SVCs (p = 0.0097, Z = 2.59, r = 0.59), and produced a significantly more varied set of serial verb stems (p = 0.0006, Z = 3.41, r = 0.78) than L2 speakers.
This result is likely to be linked to both language proficiency and L1 effects. One the one hand, SVCs are more complex than single verb constructions both formally and semantically, and their usage is certainly harder for L2 speakers. However, one can see from the data that L2 intermediate to advanced speakers have already started to use them, although only a restricted inventory. It would be thus useful for pedagogical purposes to study the first serial constructions Mapudungun learners produce and those still to be mastered. On the other hand, the usage of most SVCs requires L2 speakers to focus their attention and familiarize with a bigger inventory of Manner verbs and its interaction with Path verbs inside serial constructions. However, Mapudungun learners are more prone to produce Path tokens than Manner tokens (as also shown in Table 3), which can be related to typological differences between V- and E-languages.
Discussion
The present study reports the results of an investigation about the lexicalization of motion in narratives elicited by L1 Mapudungun speakers and Mapudungun learners who are Spanish native speakers. Since Spanish and Mapudungun differ typologically and rhetorically in the lexicalization of motion, we have hypothesized that L1 thinking-for-speaking patterns would be the cognitive point of departure for learners and, therefore, that Spanish may influence the way learners narrate motion events in Mapudungun.
After examining general inter-group differences in narratives (number of clauses, tokens, and types), we compared three main semantic mappings: the encoding of Path and Manner in different elements; the production of SVCs to encode Path, Manner, and other semantic components; and the encoding of the Ground. The findings shed light on our knowledge about cross-linguistic influence on the expression of motion events in L2, specifically, for an understudied combination of languages (L1 V-language and L2 E-language) in a context of speakers learning a minority language. The results show that Mapudungun learners produced significantly shorter narratives, containing less translational clauses, and less motion verb tokens. These results are probably dependent on levels of proficiency and on rhetorical styles that seem to favor detailed static descriptions in Mapudungun, what remains to be investigated.
As hypothesized, L2 speakers encoded a significantly lower proportion of Manner verb tokens and types, and a lower proportion of Path types than L1 speakers. Also related to the number of Manner types, L2 speakers encoded significantly less motion types overall compared to L1 speakers. Regarding Path tokens, the results are less conclusive. L2 speakers encoded a significantly higher proportion of Path tokens than L1 speakers if the proportion is based on the sum of Path + Manner tokens only, but no significant inter-group difference if it is calculated on the basis of all motion tokens. In addition, as expected, L2 speakers produced significantly less serial motion constructions, less SVCs encoding Manner + Path, and a smaller number of serial verb stems than L1 speakers. These findings are similar to those reported in previous studies for a L2 equipollently-framed language (Arslangul, 2015), being compatible with cross-linguistic influence from the L1. If Spanish motion conflation patterns are the cognitive starting point of adult learners, as late bilinguals they need to restructure their attentional patterns and linguistic behavior in tandem. On the one hand, they need to pay more attention to Manner of motion than they do in Spanish and, on the other hand, they need to expand the inventory of Manner types and learn to use a higher proportion of translational clauses encoding Manner, even when those clauses encode a source or a goal.
However, learning a new way of thinking for speaking could be more challenging than it sounds if we think about it solely as a matter of number of types and overall frequency. It would necessarily imply a restructuring in the way Path and Manner verbs are used. Importantly, given that Path verbs are required in Mapudungun to encode a landmark as a source or a goal, Spanish-speaking learners could rely on their native conflation patterns, which in these contexts tend to favor Path verbs—due to, among other factors, the boundary-crossing constraint—and they precisely seem to follow those patterns. However, not only there is no such boundary constraint in Mapudungun, but SVCs provide speakers with a frequent means to encode both Path and Manner as backgrounded components in those situations. As a consequence, the choice of Path verbs plus an underuse of SVCs would make the encoding of Manner by learners more cognitively demanding and, thus, less frequent.
Additionally, L2 narratives contain a significantly larger proportion of Ground elements compared to L1 narratives. This pattern points to the same direction, that is to say, to the existence of thinking-of-speaking effects on L2 narratives. Moreover, Ground is encoded by similar structures (mainly, adpositional phrases) in both languages but, unlike Manner, is encoded less frequently in the L2 compared to the L1. This suggests that Mapudungun learners seem to be overusing plus-Ground clauses, mimicking their native rhetorical patterns.
All together, these results suggest that the L2 performance of Mapudungun learners is influenced by thinking-of-speaking patterns from the L1. However, we cannot discard an effect of different proficiency levels between L1 speakers and the group of intermediate to advanced L2 speakers, which can be concurrent with cross-linguistic effects. In order to better test the conceptualization effects linked to the different thinking-for-speaking patterns of both languages, we need to compare the learners' performance with their performance in Spanish (the L1), which remains to be tested. This way, although we have found “intra-L1-group homogeneity” (Jarvis, 2000, p. 253), with Mapudungun learners behaving similarly to each other in some respects (e.g., encoding of Manner, Path, and usage of SVCs), we are still to find “intra-L1-group congruity” between the learners' L1 and L2 narratives. We leave this endeavor for future research direction.
Still other questions are raised. First, it would be worthwhile to test possible cross-linguistic effects of Mapudungun on the Spanish conflating patterns among the L1 speakers.15 Although most L1 participants are early Spanish bilinguals, one can hypothesize some degree of conceptual transfer to Spanish, at least in a sub-population of speakers. Second, for future work it would be interesting to compare different groups of L1 and L2 Mapudungun speakers based on age and context of acquisition and/or usage of the language. Fine-grain distinctions in this regard could shed light not only on the degree of conceptual transfer that late Mapudungun bilinguals experience at different levels of proficiency but also on possible transfer from Spanish to Mapudungun among L1 speakers and those who can be characterized as heritage speakers (e.g., Montrul, 2016). There is evidence that bilinguals can exhibit bidirectional cross-linguistic transfer even at intermediate levels of proficiency in the L2 (Brown and Gullberg, 2008) and, even more, can converge with native speakers of their L2 with respect to some patterns (Bylund, 2011). Both age of onset of L2 acquisition and length of residence in the L2 environment have been found to influence the likelihood of reverse transfer (from the L2 to the L1) (Donoso, 2017) and, given that the vast majority of Mapudungun speakers are bilingual, such an influence on the indigenous language might be inescapable. In the current context of political movement and revitalization efforts of the Mapudungun language, this kind of information could better inform future teaching materials.
In the Section Methodology we claim that our sample did not impact negatively on the validity of the results. What is more, we hypothesize that larger differences may exist between native Mapudungun speakers and late bilinguals if we select a sub-population of L1 speakers with a late age of Spanish acquisition and who use this language less frequently. One cannot discard that future researchers could get probabilistic samples in specific contexts but, if that continues to be impractical, replicating the study with different samples would help to overcome the possible weaknesses of non-random sampling (Kerlinger and Lee, 2000).
Finally, our findings show the relevance of an expanded typology of motion events, be it tripartite (e.g., Slobin, 2004) or broader (e.g., Croft et al., 2010). Since E-languages lexicalize Path in the verb, a binary typology usually classifies them as V-languages. However, some of the cross-linguistic effects found in this study are linked to the divergent lexicalization of Manner in E- compared to V-languages. Whereas E- languages tend to lexicalize Manner in the verb—a backgrounded form—most V-languages need to do it in an open class category outside the verb complex—implying higher cognitive demand. Moreover, we advocate for an expanded and nuanced typology that allows for variation (e.g., Lewandowski, 2021). As mentioned in this article, Mapudungun exhibits a much lower specification of Ground per clause than other E-languages (Zlatev and Yangklang, 2004; Chen and Guo, 2008; Ameka and Essegby, 2013), which is likely connected to morphosyntactic patterns (importantly, Mapudungun builds single word serial verbs, unlike the multiword verbs of other E-languages). Intra-type variation in E-languages is an open field for future research.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Ethics Statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their informed consent to participate in this study.
Author Contributions
RB: formulation of problem, collection of data, transcription, analysis, writing of the article, and discussion. JO: writing of the article. ÍC: sample design, transcription checking, and analysis of data. GL: sample design and revision of work. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We acknowledge the Mapudungun elders (Rosendo Huisca, Octavio Huaiquillan, WN, and MC), young native speakers [Olga Nahuel, José María (Küntremañ) Pereira Canio, CP, PS, JC, and AP], and learners (Daniel, Israel, Patricio, Lilen, Alejandra, Contulmo, Mañke, Antonio, Ana, Iván, and Alejandro) who trusted us and dedicated their time and knowledge to this study. Big thanks go as well to Fresia Mellico for collaborating with the authors to better understand the Mapudungun texts. Finally, we greatly appreciate the reviewers' comments and acknowledge their contribution to the final form of this paper.
Footnotes
1. ^In addition, according to Ethnologue, endangered languages represent the 42% of world languages and up to 92.5% of the world languages are not institutional (Eberhard et al., 2021). Thus, minority languages being the bulk of the languages of the world, they are clearly underrepresented in cognitive studies.
2. ^This is a simplification. Firstly, when speaking about the co-event, one may consider not only Manner, but also Cause and other relations (e.g., Precursion, Concomitance, and Subsequence) borne out by the co-event to the main event (Talmy, 1991, 2000). Among these, Manner is the most studied co-event relation in the literature and is the most important co-event relation in our work. Secondly, some languages such as Thai have a separate class of verbs that lexicalize both Path and Manner (Zlatev and Yangklang, 2004). However, those classes do not seem to represent the main lexicalization pattern in any language. Thirdly, Talmy (1985, 1991, 2000, 2005) has postulated two complementary ways of classifying languages. On the one hand, as was mentioned above, the binary divide between S- and V-languages is based on the mapping of Path on different morphosyntactic elements. Alternatively, if one classifies languages according to what semantic elements are mapped onto the verb, a triple classification emerges: (i) languages that lexicalize Path in the verb, labeled as V-languages in the first classification; (ii) those that lexicalize the co-event in the verb, that is, the majority of S-languages; and (iii) those that lexicalize the Figure in the verb, an example of which is Atsugewi (Talmy, 1985, 2000). This last group of languages would also be classified as satellite-framed, since they encode the Path in a satellite.
3. ^According to Talmy (2000), Nez Perce would be an exception since it attaches a Manner prefix to a verb root encoding Path. However, the affixal character of the Manner morpheme has been debated. For example, Croft (2003) considers the Manner morpheme a root and the overall pattern an example of compounding, thus, it would not be an example of verbal nor of satellite framing.
4. ^Spanish Manner verbs tend to follow this principle, but there is some discussion around it. Directional phrases headed by a “to” and hacia “toward” are generally accepted with Manner verbs and can lead to a pragmatic inference of the boundary being crossed, especially with verbs that encode a manner of motion prototypically performed to produce a displacement and reach a goal (e.g., Fábregas, 2007; Beavers et al., 2010; Lewandowski and Mateu, 2020).
5. ^However, intra-typological variation exists and has been largely recognized (Berthele, 2004, 2013; Ibarretxe-Antuñano, 2009; Ibarretxe-Antuñano and Hijazo-Gascón, 2012; Ibarretxe-Antuñano et al., 2017). Following the traditional interpretation, we are considering English as an exemplar, but not all satellite-framed languages encode Manner and Path to the same degree (see also Slobin, 2004, 2006, 2017; Ibarretxe-Antuñano, 2009; Lewandowski, 2021).
6. ^Despite its synthetic character, these constructions are SVCs according to the cross-linguistic definitions by Aikhenvald (2006) and Haspelmath (2016). In particular, they follow the five criteria identified by Haspelmath (2016, p. 296): construction, monoclausal, independent verbs, no linking element, and no predicate-argument relation between the verbs. Sometimes also called compounds (e.g., Zúñiga, 2017), they correspond to the one-word construction type in Aikhenvald (2006), characterized as “tightly knit SVCs” by Haspelmath (2016, p. 309).
7. ^The following glosses are used: 3: 3rd person; APRF, anti-perfect (Hasler, 2009); CAUS, causative; DEF, definite; DIR, directional (cislocative); DUB, dubitative; IND, indicative; LOC, locative; LK, linking element; NMLZ, nominalizer; PERF, perfective; POSS, possessive; PROG, progressive; RE, reversive or iterative.
8. ^We thank one of the reviewers for drawing our attention to the nuances of the Spanish verb + (locative/directional) adverbial construction.
9. ^According to Jarvis (2010, 2017), conceptual transfer covers the various phenomena studied by the thinking-for-speaking hypothesis and, more broadly, linguistic relativity. Interestingly, relativistic effects related to the conceptual domain of motion have not only been found in verbal behavior (as in thinking-for-speaking effects) but also in non-linguistic tasks. For example, both Spanish monolinguals and English-Spanish bilinguals tested in Spanish are significantly more likely to judge the similarity of motion events based on the Path of motion, compared to both English monolinguals and English-Spanish bilinguals tested in English (Lai et al., 2014). Moreover, the effect is higher for late bilinguals than it is for early bilinguals. In partial contradiction with this finding, Ji (2017) reported that both Mandarin and English monolinguals made more similarity judgments based on Path and less based on Manner of motion. However, in a second task, English monolinguals reacted significantly faster than Chinese monolinguals when selecting scenes matched by Manner, while Mandarin speakers took about the same time to select scenes based on Manner or Path. Additionally, at the neural level English and Spanish speakers have been reported to show different expectancies for the expression of motion. Specifically, “Spanish speakers showed higher expectancies for motion verbs to encode path and English speakers showed higher expectancies for motion verbs to encode manner followed by a secondary path expression” (Emerson et al., 2020, p. 1).
10. ^Unlike Slobin (2006), Wu (2011) considers this type of constructions as directional complement constructions (DCC) and not SVCs. According to Wu (2011), a DCC has a main verb followed by one or more Path or Deictic complements, such as jin “into” or lai “hither”. Wu (2011) claims that although these directional elements can function as full verbs in some sentences, they are completely grammaticalized in a DCC, such as (4). Whether these constructions are to be considered SVCs or DCCs, the argument presented does not change.
11. ^The high proportion of male to female participants was due to chance and/or unstudied social dynamics.
12. ^For a discussion about proficiency assessments using self-report, see De Bruin (2019).
13. ^A few tokens conflating Ground were also recognized (see Section Usage of SVCs below).
14. ^Examples from our data indicate, first, the participants' initials and, second, the status of the participant as an L1 or L2 speaker.
15. ^Many thanks to one of the reviewers for having identified this line of research.
References
Aikhenvald, A. (2006). “Serial verb constructions in typological perspective,” in Serial Verb Constructions. A Cross-Linguistic Typology, eds A. Aikhenvald and R. Dixon (New York, NY: Oxford University Press), 1–68.
Aktan-Erciyes, A. (2020). Effects of second language on motion event lexicalization: comparison of bilingual and monolingual children's frog story narratives. J. Lang. Linguist. Stud. 16, 1127–1145. doi: 10.17263/jlls.803576
Alonso, R. (2019). Boundary-crossing events across languages. A study on English speakers, Spanish speakers and second language learners. Rev. Cogn. Linguist. 18, 316–349. doi: 10.1075/rcl.00062.alo
Ameka, F., and Essegby, J. (2013). Serialising languages: satellite-framed, verb-framed, or neither. Ghana J. Linguist. 2.1, 19–38.
American Council on the Teaching of Foreign Languages, ACTFL (2012). ACTFL Proficiency Guidelines 2012. Available online at: https://www.actfl.org/sites/default/files/guidelines/ACTFLProficiencyGuidelines2012.pdf (accessed April 17, 2022).
Arslangul, A. (2015). “How French learners of Chinese L2 express motion events in narratives,” in Space and Quantification in Languages of China, eds D. Xu and J. Fu (New York, NY: Springer), 165–187.
Aske, J. (1989). “Path predicates in English and Spanish: a closer look,” in Proceedings of the 15th Annual Meeting of the Berkeley Linguistics Society, 1–14.
Austin, P. K., and Sallabank, J. (2011). “Introduction,” in The Cambridge Handbook of Endangered Languages, eds P. K. Austin and J. Sallabank (Cambridge: Cambridge University Press), 1–24.
Beavers, J., Levin, B., and Tham, S.-W. (2010). The typology of motion expressions revisited. J. Linguist. 46, 331–377. doi: 10.1017/S0022226709990272
Becerra, R. (2017). Mapudungun y tipología de los eventos de movimiento. Lenguas y Literaturas Indoamericanas 19, 118–140.
Berman, R., and Slobin, D. I. (1994). Relating Events in Narrative: A Crosslinguistic Developmental Study. Hillsdale, NY: Lawrence Erlbaum Associates.
Berthele, R. (2004). “The typology of motion and posture verbs: a variationist account,” in Dialectology Meets Typology. Dialect Grammar from a Cross-Linguistic Perspective, ed B. Kortmann (Berlin/New York, NY: Mouton de Gruyter), 93–126.
Berthele, R. (2013). “Disentangling manner and path: evidence from varieties of German and Romance,” in Variation and Change in the Coding of Motion Events, eds J. Goschler and A. Stefanowitsch (Amsterdam: John Benjamins), 55–75.
Brown, A. (2015). Universal development and L1-L2 convergence in bilingual construal of Manner in speech and gesture in Mandarin, Japanese, and English. Modern Lang. J. 99, 66–82. doi: 10.1111/j.1540-4781.2015.12179.x
Brown, A., and Gullberg, M. (2008). Bidirectional crosslinguistic influence in L1-L2 encoding of manner in speech and gesture. A study of Japanese speakers of English. Stud. Second Lang. Acquis. 30, 225–251. doi: 10.1017/S0272263108080327
Bylund, E. (2011). Segmentation and temporal structuring of events in early Spanish–Swedish bilinguals. Int. J. Bilingual. 15, 56–84. doi: 10.1177/1367006910379259
Cadierno, T. (2004). “Expressing motion events in a second language: a cognitive typological perspective,” in Cognitive Linguistics, Second Language Acquisition, and Foreign Language Teaching, eds M. Achard and S. Niemeier (Berlin: Mouton de Gruyter), 13–49.
Cadierno, T. (2008). “Motion events in Danish and Spanish: a focus on form pedagogical approach,” in Cognitive Approaches to Pedagogical Grammar, eds S. De Knop and T. De Rycker (Berlin/New York, NY: Mouton de Gruyter), 259–294.
Cadierno, T. (2010). “Motion in Danish as a second language: does the Learner's L1 make a difference?”, in Linguistic Relativity in SLA. Thinking for Speaking, eds Z. Han and T. Cadierno (Bristol: Multilingual Matters), 1–33.
Cadierno, T., and Robinson, P. (2009). Language typology, task complexity and the development of L2 lexicalization patterns for describing motion events. Ann. Rev. Cognit. Linguist. 7, 245–276. doi: 10.1075/arcl.7.10cad
Cadierno, T., and Ruiz, L. (2006). Motion events in Spanish L2 acquisition. Ann. Rev. Cognit. Linguist. 4, 183–216. doi: 10.1075/arcl.4.08cad
Chen, L., and Guo, J. (2008). Motion events in Chinese novels: evidence for an equipollently-framed language. J. Pragmat. 41, 1749–1766. doi: 10.1016/j.pragma.2008.10.015
Choi, S., and Lantolf, J. (2008). Representation and embodiment of meaning in L2 communication. Motion events in the speech and gesture of advanced L2 Korean and L2 English speakers. Stud. Second Lang. Acquisit. 30, 191–224. doi: 10.1017/S0272263108080315
Chui, K., Yeh, H., Lan, W.-C., and Cheng, Y.-H. (2015). Clausal-packaging of path of motion in Mandarin learners' acquisition of Russian and Spanish. Taiwan J. Linguist. 13, 1–23. doi: 10.6519/TJL.2015.13(1).1
Crevels, M. (2012). “Language endangerment in South America: the clock is ticking,” in The Indigenous Languages of South America: A Comprehensive Guide, L. Campbell and V. Grondona (Berlin/Boston, MA: Walter de Gruyter), 167–233.
Croft, W., Barðdal, J., Hollmann, W., Sotirova, V., and Taoka, C. (2010). “Revising Talmy's typological classification of complex event constructions,” in Contrastive Studies in Construction Grammar, ed H. Boas (Amsterdam: John Benjamins), 201–235.
De Bruin, A. (2019). Not all bilinguals are the same: a call for more detailed assessments and descriptions of bilingual experiences. Behav. Sci. 9, 33. doi: 10.3390/bs9030033
Donoso, A. (2017). Camino, Base y Manera en bilingües de español y sueco: efectos de una segunda lengua en los patrones de expresión del movimiento de una primera lengua. Onomázein 36, 198–231. doi: 10.7764/onomazein.36.01
Donoso, A., and Bylund, E. (2015). “The construal of goal-oriented motion events by Swedish speakers of L2 Spanish: encoding of motion endpoint and manner of motion,” in The Acquisition of Spanish in Understudied Language Pairings, eds T. Judy and S. Perpiñán (Amsterdam: John Benjamins), 233–254.
Eberhard, D. M., Simons, G. F., and Fennig, C. D. (2021). Ethnologue: Languages of the World. 24th Edn, eds. Dallas, TX: SIL International. Available online at: http://www.ethnologue.com (accessed November 15, 2021).
Emerson, S. N., Conway, C. M., and Özçaliskan, S. (2020). Semantic P600—but not N400—effects index crosslinguistic variability in speakers' expectancies for expression of motion. Neuropsychologia 149, 107638. doi: 10.1016/j.neuropsychologia.2020.107638
Fábregas, A. (2007). “The exhaustive lexicalisation principle,” in Tromsø Working Papers on Language and Linguistics: Nordlyd 34.2, Special Issue on Space, Motion, and Result, eds M. Bašić, M. Pantcheva, M. Son and P. Svenonius (Tromsø: CASTL), 165–199.
Filipović, L., and Vidaković, I. (2010). “Typology in the L2 classroom: Second language acquisition from a typological perspective,” in Cognitive Processing in Second Language Acquisition: Inside the Learner's Mind, eds M. Pütz and L. Sicola (Amsterdam: John Benjamins), 269–91.
Fortis, J.-M., and Vittrant, A. (2011). L'organisation syntaxique de l'expression de la trajectoire: Vers une typologie des constructions. Faits de Langues 38, 71–98. doi: 10.1163/19589514-038-02-900000006
Harrison, K. D. (2007). When Languages Die. The Extinction of the World's Languages and the Erosion of Human Knowledge. Oxford: Oxford University Press.
Hasler, F. (2009). El morfema –fu- del mapudungun como un marcador de antiperfecto: La marcación gramatical de la no vigencia en el momento de habla. (Undergraduate thesis, Universidad de Chile). Repositorio académico de la Universidad de Chile. Available online at: https://repositorio.uchile.cl/handle/2250/109816 (accessed November 18, 2021).
Haspelmath, M. (2016). The serial verb construction: comparative concept and cross-linguistic generalizations. Lang. Linguist. 17, 291–319. doi: 10.1177/2397002215626895
Hijazo-Gascón, A. (2018). Acquisition of motion events in L2 Spanish by German, French and Italian speakers. Lang. Learn. J. 46, 241–262. doi: 10.1080/09571736.2015.1046085
Hijazo-Gascón, A. (2021). Moving Across Languages. Motion Events in Spanish as a Second Language. Berlin/Boston, MA: Walter de Gruyter.
Hothorn, T., Hornik, K., van de Wiel, M. A., and Zeileis, A. (2006). A Lego system for conditional inference. Am. Statist. 60, 257–263. doi: 10.1198/000313006X118430
Huang, S., and Tanangkingsing, M. (2005). Reference to motion events in six Western Austronesian languages: toward a semantic typology. Oceanic Linguist. 44, 307–340. doi: 10.1353/ol.2005.0035
Ibarretxe-Antuñano, I. (2009). “Path salience in motion events,” in Crosslinguistic Approaches to the Psychology of Language: Research in the Tradition of Dan I. Slobin, eds J. Guo, E. Lieven, N. Budwig, S. Ervin-Tripp, K. Nakamura and S. Ozçalişkan (New York, NY: Psychology Press), 403–414.
Ibarretxe-Antuñano, I., and Hijazo-Gascón, A. (2012). “Variation in motion events. Theory and applications,” in Space and Time in Languages and Cultures. Linguistic Diversity, eds L. Filipović and K. M. Jaszczolt (Amsterdam/Philadelphia, PA: John Benjamins), 349–371.
Ibarretxe-Antuñano, I., Hijazo-Gascón, A., and Moret-Oliver, M. T. (2017). “The importance of minority languages in motion event typology. The case of Aragonese and Catalan,” in Motion and Space Across Languages: Theory and Applications, eds I. Ibarretxe-Antuñano (Amsterdam: John Benjamins), 123–149.
Iwasaki, N., and Yoshioka, K. (2020). Thinking-for-speaking to describe motion events. English-Japanese bilinguals' L1 English and L2 Japanese speech and gesture. Ca' Foscari Japan. Stud. 13, 71–97. doi: 10.30687/978-88-6969-428-8/004
Jarvis, S. (2000). Methodological rigor in the study of transfer. Identifying L1 influence in the interlanguage lexicon. Lang. Learn. 50, 245–309. doi: 10.1111/0023-8333.00118
Jarvis, S. (2010). Conceptual transfer: crosslinguistic effects in categorization and construal. Bilingual. Lang. Cogn. 14, 1–8. doi: 10.1017/S1366728910000155
Jarvis, S. (2017). “Transfer: an overview with an expanded scope,” in Crosslinguistic Influence and Distinctive Patterns of Language Learning: Findings and Insights from a Learner Corpus, eds A. Golden, S. Jarvis and K. Tenfjord (Bristol, Blue Ridge Summit: Multilingual Matters), 12–28.
Jarvis, S., and Pavlenko, A. (2008). Crosslinguistic Influence in Language and Cognition. New York, NY; London: Routledge.
Ji, Y. (2017). Motion event similarity judgments in one or two languages: an exploration of monolingual speakers of English and Chinese vs. L2 learners of English. Front. Psychol. 8, 909. doi: 10.3389/fpsyg.2017.00909
Kerlinger, F. N., and Lee, H. B. (2000). Foundations of Behavioral Research, 4th Edn. Fort Worth, TX: Harcourt College.
Lai, V. T., Garrido Rodriguez, G., and Narasimhan, B. (2014). Thinking-for-speaking in early and late bilinguals. Bilingual. Lang. Cogn. 17, 139–152. doi: 10.1017/S1366728913000151
Lewandowski, W. (2021). Variable motion event encoding within languages and language types: a usage-based perspective. Lang. Cogn. 13, 34–65. doi: 10.1017/langcog.2020.25
Lewandowski, W., and Mateu, J. (2020). Motion events again: delimiting constructional patterns. Lingua 247, 102956. doi: 10.1016/j.lingua.2020.102956
Lewandowski, W., and Özçalişkan, S. (2021). How language type influences patterns of motion expression in bilingual speakers. Second Lang. Res. 37, 27–49. doi: 10.1177/0267658319877214
Lizarralde, D., and Becerra, R. (2017). “Chew müley chi narki? Dónde está el gato? Localización de entidades en mapudungun,” in Mapun kimün. Relaciones mapunche entre persona, tiempo y espacio, eds R. Becerra and G. Llanquinao (Santiago: Ocholibros), 189–211.
Mangiafico, S. (2021). Rcompanion: Functions to Support Extension Education Program Evaluation. R package version 2.4.6. Available online at: https://CRAN.R-project.org/package=rcompanion (accessed December 21, 2021).
Mano, M., Yoshinari, Y., and Eguchi, K. (2018). “The effects of the first language on the description of motion events: focusing on L2 Japanese learners of English and Hungarian,” in New Perspectives on the Development of Communicative and Related Competence in Foreign Language Education, eds I. Walker, D. K. G. Chan, M. Nagami and C. Bourguignon (Boston, MA/Berlin: Walter de Gruyter), 125–156.
Mateu, J., and Rigau, G. (2010). Verb-particle constructions in Romance: a lexical-syntactic account. Probus 22, 241–269. doi: 10.1515/prbs.2010.009
Muñoz, M., and Cadierno, T. (2019). Mr Bean exits the garage driving or does he drive out of the garage? Bidirectional transfer in the expression of Path. IRAL Int. Rev. Appl. Linguist. Lang. Teach. 57, 45–69. doi: 10.1515/iral-2018-2006
Navarro, S., and Nicoladis, E. (2005). “Describing motion events in adult L2 Spanish narratives,” in Selected Proceedings of the 6th Conference on the Acquisition of Spanish and Portuguese as First and Second Languages, eds D. Eddington (Somerville, MA: Cascadilla Proceedings Project), 102–107.
Nozaki, S. (2019). Japanese lexicalization patterns of motion events and its acquisition by advanced-level English-speaking learners of Japanese. (Doctoral Dissertation, The Ohio State University). Available online at: https://etd.ohiolink.edu/apexprod/rws_olink/r/1501/ (accessed April 24, 2021).
Ortega, L. (2017). New CALL-SLA research interfaces for the 21st century: towards equitable multilingualism. CALICO J. 34, 283–231. doi: 10.1558/cj.33855
Ortega, L. (2019). SLA and the study of equitable multilingualism. Modern Lang. J. 103, 23–38. doi: 10.1111/modl.12525
Parker, C., Scott, S., and Geddes, A. (2019). “Snowball sampling,” in SAGE Research Methods Foundations, eds P. Atkinson, S. Delamont, A. Cernat, J. W. Sakshaug and R. A. Williams (London: SAGE Publications).
R Core Team. (2021). R: A Language and Environment for Statistical Computing. Vienna: R Foundation for Statistical Computing. Available online at: https://www.R-project.org/ (accessed December 18, 2021).
Romaine, S. (2007). Preserving Endangered Languages. Lang. Linguist. Compass 1, 115–132. doi: 10.1111/j.1749-818X.2007.00004.x
Slobin, D. I. (1987). “Thinking for speaking,” in Proceedings of the Thirteenth Annual Meeting of the Berkeley Linguistics Society, 435–445.
Slobin, D. I. (1996a). Two ways to travel: Verbs of motion in English and Spanish. In M. Shibatani and S. A. Thompson (Eds.), Grammatical constructions: Their form and meaning (pp. 195-220). Oxford: Clarendon Press.
Slobin, D. I. (1996b). “From “thought and language” to “thinking for speaking”,” in Rethinking Linguistic Relativity, eds J. Gumperz and S. Levinson (Cambridge: Cambridge University Press), 70–96.
Slobin, D. I. (1997). “Mind, code, and text,” in Essays on Language Function and Language Type: Dedicated to T. Givón, eds J. Bybee, J. Haiman, and S. A. Thompson (Amsterdam/Philadelphia, PA: John Benjamins), 437–467.
Slobin, D. I. (2000). “Verbalized events: a dynamic approach to linguistic relativity and determinism,” in Evidence for Linguistic Relativity, eds S. Niemeier and R. Dirven (Amsterdam/Philadelphia, PA: John Benjamins), 107–138.
Slobin, D. I. (2004). “The many ways to search for a frog: Linguistic typology and the expression of motion events,” in Relating Events in Narrative: Typological and Contextual Perspectives, eds S. Strömqvist and L. Verhoeven (Mahwah, NJ: Lawrence Erlbaum Associates), 219–257.
Slobin, D. I. (2006). “What makes manner of motion salient? Explorations in linguistic typology, discourse, and cognition,” in Space in Languages: Linguistic Systems and Cognitive Categories, eds M. Hickmann and S. Robert (Amsterdam; Philadelphia, PA: John Benjamins), 59–81.
Slobin, D. I. (2017). “Afterword. Typologies and language use,” in Motion and Space Across Languages: Theory and Applications, eds. I. Ibarretxe-Antuñano (Amsterdam: John Benjamins), 419–445.
Talmy, L. (1985). “Lexicalization patterns: semantic structure in lexical forms,” in Language Typology and Syntactic Description. Grammatical Categories and the Lexicon, V.3, eds T. Shopen (Cambridge: Cambridge University Press), 57–149.
Talmy, L. (1991). “Path to realization: a typology of event conflation,” in Proceedings of the 17th Annual Meeting of the Berkeley Linguistic Society. Berkeley, CA: Berkeley Linguistics Society, 480–519.
Talmy, L. (2000). Toward a cognitive semantics, in Vol. II: Typology and Process in Concept Structuring. Cambridge, MA: MIT Press. Available online at: https://psycnet.apa.org/record/2000-00903-000
Talmy, L. (2005). Interview: a windowing onto conceptual structure and language. Part 1: lexicalization and typology. Ann. Rev. Cogn. Linguist. 3, 325–347. doi: 10.1075/arcl.3.17iba
Tang, M., Vanek, N., and Roberts, L. (2021). Crosslinguistic influence on English and Chinese L2 speakers' conceptualization of event series. Int. J. Bilingualism 25, 205–223. doi: 10.1177/1367006920947174
Wilkins, D. (2004). “The verbalization of motion events in Arrernte,” in Relating Events in Narrative: Typological and Contextual Perspectives, eds S. Strömqvist and L. Verhoeven (Mahwah, NJ: Lawrence Erlbaum associates), 143–157.
Wu, S.-L. (2011). “Learning to express motion events in an L2: the case of Chinese directional complements,” Lang. Learn. 61, 414–454. doi: 10.1111/j.1467-9922.2010.00614.x
Zlatev, J., and David, C. (2003). Motion events constructions in Swedish, French and Thai: Three different language types? Manusya J. Human. 6, 18–42. doi: 10.1163/26659077-00604002
Zlatev, J., and Yangklang, P. (2004). “A third way to travel: the place of Thai and serial verb languages in motion event typology,” in Relating Events in Narrative: Typological and Contextual Perspectives, eds S. Strömqvist and L. Verhoeven (Mahwah, NJ: Lawrence Erlbaum Associates), 159–190.
Zúñiga, F. (2007). Mapudunguwelaymi am? ‘¿Acaso ya no hablas mapudungun?’ Acerca del estado actual de la lengua mapuche. Estudios Públicos 105, 532. doi: 10.38178/cep.vi105.532
Zúñiga, F. (2017). “Mapudungun,” in The Oxford Handbook of Polysynthesis, M. Fortescue, M. Mithun and N. Evans (Oxford: Oxford University Press), 696–712. doi: 10.1093/oxfordhb/9780199683208.013.40
Keywords: motion verbs, semantic typology, thinking for speaking, cross-linguistic effects, equipollently-framed, Mapudungun
Citation: Becerra R, Osorio J, Cantarutti Í and Llanquinao G (2022) Motion Events in L1 and L2 Mapudungun Narratives: Typology and Cross-Linguistic Influence. Front. Commun. 7:853988. doi: 10.3389/fcomm.2022.853988
Received: 13 January 2022; Accepted: 27 April 2022;
Published: 13 June 2022.
Edited by:
Alberto Hijazo-Gascón, University of East Anglia, United KingdomReviewed by:
Wojciech Lewandowski, Leipzig University, GermanyAlejandra Donoso, Linnaeus University, Sweden
Copyright © 2022 Becerra, Osorio, Cantarutti and Llanquinao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rodrigo Becerra, cmJlY2VycmFAdWFsYmVydGEuY2E=