 Elma Blom
Elma Blom Tessel Boerma
Tessel Boerma Figen Karaca
Figen Karaca Jan de Jong5
Jan de Jong5- 1Department of Education and Pedagogy, Utrecht University, Utrecht, Netherlands
- 2Department of Language and Culture, The Arctic University of Norway UiT, Tromsø, Norway
- 3Department of Literature, Languages, and Communication, Utrecht University, Utrecht, Netherlands
- 4Center for Language Studies, Radboud University, Nijmegen, Netherlands
- 5Department of Biological and Medical Psychology, University of Bergen, Bergen, Norway
- 6College of Social Sciences and Humanities, Koç University, Istanbul, Turkey
Introduction: To guarantee a reliable diagnosis of Developmental Language Disorder (DLD) in bilingual children, evaluating both languages is recommended. However, little is known about how DLD impacts the heritage language, and it is largely unknown whether bilingual children with DLD develop the heritage language at the same pace as their peers with typical development (TD).
Methods: For this longitudinal study that focused on children's grammatical development, we analyzed semi-spontaneous speech samples of 10 Turkish-Dutch children with DLD (bi-DLD) and 10 Turkish-Dutch children with typical development (bi-TD). Children were 5 or 6 years old at the first wave of data collection, and there were three waves of longitudinal data collection with 1-year intervals. In addition, data from 20 monolingual Dutch controls were analyzed (10 mono-DLD, 10 mono-TD).
Results and discussion: Results indicate that heritage language assessment can inform clinical diagnosis. In the case of Turkish spoken in the Netherlands, short sentences, the absence of the genitive suffix in simple constructions and avoidance of complex constructions that require possessive marking could potentially be clinical markers of DLD. Accusative case errors are also relatively frequent in bilingual Turkish-Dutch children with DLD, but these are less promising as a clinical marker because previous research suggests that omission and substitution of accusative case can be part of the input to Turkish heritage language learners. In Dutch, frequent omission of grammatical morphemes in the verbal domain coupled with a limited amount of overregularization errors could indicate that a child is at risk for DLD, both in bilingual and monolingual contexts. Cross-linguistic comparisons of error types in Turkish and Dutch confirm that, regardless of typological differences, children with DLD use short sentences, avoid complex structures, and omit grammatical morphemes. Longitudinal analyses revealed that children with DLD can develop the heritage language at the same pace as TD children, even if this language is not supported at school. Strong intergenerational transmission and heritage language maintenance among Turkish migrants in the Netherlands may be key.
Introduction
Developmental Language Disorder (DLD) is a congenital disorder that affects ~5–7% of the children (Tomblin et al., 1997; Norbury et al., 2016).1 Symptoms include a delayed onset of language development (Rice, 2013), and persistent difficulties in learning language, specifically grammar (Leonard, 2014). While most international research to date is concerned with DLD in monolingual children, it is generally believed that, worldwide, monolinguals are outnumbered by children learning more than one language (Bialystok et al., 2012). Consequently, the numbers of bilingual children on clinical caseloads are large. Bilingual children face the risk of misdiagnosis because appropriate instruments for assessing language proficiency in a bilingual context are lacking (Mennen and Stansfield, 2006; Kohnert, 2010). To guarantee a reliable diagnosis of DLD, assessment in both languages is recommended (American Speech-Language-Hearing Association, 2022).
To inform clinical practice as well as research on bilingual assessment, the current study investigated both languages of children with DLD who learn Turkish as a heritage language and Dutch as a societal language. DLD in Dutch has featured prominently in research, and there is a growing body of research on heritage Turkish. However, little is known about how DLD impacts heritage Turkish, and it is unknown if bilingual children with DLD develop heritage Turkish at the same pace as their peers with typical development (TD). In this longitudinal study, we investigated children's simultaneous grammatical development over the course of a 2-year period, to determine how DLD impacts both Turkish and Dutch development. Our primary aim was to establish how DLD impacts grammatical development in both languages and, specifically, their errors with grammatical morphemes. Secondarily, grammatical morpheme errors in Dutch of bilingual children with DLD were compared with monolingual Dutch control data to establish reliable and robust clinical markers for Dutch that are relevant in bilingual and monolingual contexts.
Language status and DLD
Heritage language learners are exposed to the language of the country that their parents or grandparents migrated from Valdés (2000). This language, that they inherit from their family, is “decisively not the language of the greater society” (Cabo, 2012; p. 451). It is confined to informal domains, such as use with family and friends, in contrast to the omnipresent societal language, which is used in informal and formal domains, such as work and education. Studies have shown that the societal language will inevitably become children's dominant language. Heritage language development is slower (Hoff, 2018), may come to a halt, may show signs of attrition (Montrul, 2008), or will not be used anymore by children. These effects are stronger in families where both parents speak the societal language (De Houwer, 2007) or when the heritage language does not receive systematic support at school (Restrepo et al., 2010).
With respect to Turkish in the Netherlands, recent research has indicated that children's Turkish development is under pressure (Akoğlu and Yağmur, 2016; Backus and Yağmur, 2017), despite strong intergenerational transmission of Turkish (Extra and Yağmur, 2010). Children's less proficient development in Turkish could be related to linguistic norms imposed by schools in the Netherlands. Dutch schools are not very welcoming to the language and culture of minority groups, and instruction in minority or heritage languages in public schools has been discontinued in 2004 (Kuiken and Van der Linden, 2013). That spending time in Dutch-speaking schools has a negative impact on children's Turkish development is supported by questionnaire data, showing that Turkish is often reported as children's dominant language at age 4–5 years while this shifts to Dutch from age 8–9 years (Extra et al., 2002). Results from a longitudinal study, in which children's vocabulary in Turkish and Dutch was measured, are in line with these survey data (Blom et al., 2014a). Blom et al. (2014a) showed that at age 5 years (i.e., after spending about 1 year in Dutch kindergarten), 40% of the Turkish-Dutch children obtained higher vocabulary scores in Turkish than Dutch, while 1 year later this percentage had dropped to 11%. These findings are, however, not in line with a cross-sectional study investigating a group of bilingual Turkish-Dutch children using a range of measures for Turkish and Dutch language proficiency (Verhoeven et al., 2012). Verhoeven et al. (2012) conclude that skills in both languages kept on growing. Children in all age groups (6–7 years, 8–9 years, 10–11 years) had, on average, higher scores in Turkish compared to Dutch. Interaction effects showed that the difference between Turkish and Dutch became smaller with age for phoneme discrimination and reproduction, and story comprehension. These findings suggest that, for most children, Turkish remained their dominant language throughout primary education. This seems hard to reconcile with the conclusion that heritage Turkish is under pressure, although the cross-sectional design of the study conducted by Verhoeven et al. (2012) limits conclusions about development.
The study of Verhoeven et al. included children with TD and DLD. In their study, no indications were found that heritage language development was different across the two groups, which contrasts with observations reported by Restrepo and Kruth (2000), who compared two 7-year-old bilingual Spanish-English girls with and without DLD with similar time of exposure to English (the societal language). Their findings suggest that the child with DLD showed more rapid loss of heritage Spanish, in line with the hypothesis that effects of limited input in and use of the heritage language could be amplified in the context of DLD (Blom et al., 2019). The reason for this amplifying effect is that children with DLD are found to have difficulties processing language input (Gillam et al., 2019), as evidenced in studies which show that children with DLD need more input than their peers with TD to reach the same language level (Rice et al., 1992; Gray, 2003; Weismer et al., 2013; MacRoy-Higgins and Dalton, 2015). Conceivably, input processing limitations, particularly when coupled with limited language input and use, will not only slow down language development but could also lead to faster erosion of the heritage language because the linguistic representations of children with DLD are less ingrained, less stable, and less robust than those of their TD peers.
In sum, although bilingual assessment is recommended, it is largely unknown whether and how bilingual assessment can contribute to a reliable diagnosis of DLD in the context of heritage language learners. In children with DLD, language skills in Turkish and Dutch will both be weak, and lower levels of input and use may disproportionally affect Turkish learned as a heritage language. However, Turkish may also be weakly developed in TD children, due to its status as heritage language, limiting the diagnostic potential. In that case, the status of the heritage language and the presence of DLD would create a confound. Research into the heritage language development of children with DLD as well as comparisons with their TD peers are needed to establish the potential contribution of heritage language assessment to a reliable diagnosis of DLD.
Language typology and DLD
In addition to language status, language typology is a factor which influences the way in which DLD impacts language development, particularly in the types of error children make (Leonard, 2014). For example, in Germanic languages, like Dutch and German, correct use of finite verbs poses a problem for children with DLD (Clahsen et al., 1997; Rice et al., 1997; de Jong, 1999; Wexler et al., 2004). In languages with extensive case systems, such as Hungarian or Finnish, case errors are frequent (Lukács et al., 2010; Leonard et al., 2014). In terms of grammatical morpheme production, children with DLD tend to frequently omit grammatical morphemes in Germanic languages (Rice and Wexler, 1996; Blom et al., 2014b), while making few overregularization errors (e.g., go–goed) (monolinguals: Oetting and Horohov, 1997; Redmond and Rice, 2001; Van der Lely and Ullman, 2001; bilinguals: Blom and Paradis, 2013). In morphologically rich languages, such as Hebrew or Hungarian, children with DLD substitute grammatical morphemes rather than omitting them (Dromi et al., 1999; Lukács et al., 2009). In these languages, if multiple features need to be encoded in an inflectional sequence, they tend to produce all but one feature correctly (Leonard, 2014), or substitute a form that carries more grammatical features with one that has fewer features (Dromi et al., 1999). As Turkish and Dutch differ strongly in the expression of case and in richness of morphology, it is expected that DLD in Turkish and Dutch is characterized by different types of grammatical morpheme errors. Below, we briefly describe some basic properties of Turkish (based on Kornfilt, 1997; Göksel and Kerslake, 2005; Topbaş and Yavas, 2010) and Dutch (based on Haeseryn et al., 1997; Booij, 2002), as well as characteristics of DLD in both languages.
Turkish
Turkish is an agglutinative language, meaning that a root can be followed by multiple morphemes. Derivational morphemes are closest to the root. The sequence of nominal inflections, which follows derivational morphemes, starts with plural, followed by agreement markers that express person and number of the possessor, and, lastly, case, as illustrated in (1).
(1) Kitap-lar-ın-da
book-PL-2POSS-LOC
“in your books.”
Nominative case is not marked overtly, while accusative case is used with definite objects only and not if the object is indefinite. Other cases are genitive, dative, locative, ablative and instrumental case. The sequence of verbal inflections is: voice (reciprocal, passive, causative), negation, mood (desiderative, necessitative, optative, possibility), tense (progressive, future, present/aorist, definite past, narrative past), and agreement, as illustrated in (2). Agreement in the nominal and verbal domain expresses person (1, 2, 3) and number (singular, plural). Third person singular verb agreement is not expressed overtly, and there is no gender agreement. Syntactically, the basic word order in Turkish is Subject-Object-Verb. As argument structure is reflected in case marking, word order variations are allowed, but these are typically associated with pragmatic and semantic distinctions.
(2) Gör-üş-me-yebil-ir-di-k
see-RECIP-NEG-POSSIBILITY-AOR-PST-1PL
“we could have not met.”
With respect to grammatical errors made by Turkish children with DLD, available research has focused on the word-level (morphology) rather than the sentence-level (syntax), which is not surprising given the agglutinative character of Turkish and its relatively free word order. Exploratory studies of Acarlar and Johnston (2006, 2011) with children with general developmental delays whose spontaneous speech was analyzed show that nominal morphology is more vulnerable than verbal morphology. Specifically, case marking and genitive-possessive constructions where the possessor bears the genitive case and the possessee an agreement marker, like evi in (3), were found to be problematic.
(3) Bir kız-ın evi
A-INDEF girl-GEN house-3PS.POSS
“a girl's house.”
Genitive-possessive constructions may also be used in complex sentence structures in Turkish. In certain types of embedded clauses, the finite sentence form is not preserved. The verb of the embedded clause is nominalized (VN) and marked with a possessive suffix while its subject is marked with genitive case, forming a genitive-possessive construction, as in (4). Case markers may, then, be attached to the whole embedded clause (American Speech-Language-Hearing Association, 2022). Such complex use of genitive case was argued to be a potential explanation for genitive case errors of Turkish children with atypical language development (Acarlar and Johnston, 2011).
(4) Sen-in kazan-acağ-ın-ı düşün-üyor-um.
You-GEN win-VN(future)-2SG.POSS-ACC think-PROG-1SG
“I think that you will win.”
More recent studies indicate that both noun and verb morphology are affected in Turkish children with DLD (Topbaş et al., 2016; Güven and Leonard, 2020, 2021). Güven and Leonard (2020, 2021) examined noun and verb morphology in spontaneous speech samples of 40 children with DLD between ages 4 and 7 years. Children with DLD were less accurate than age-matched and younger TD children on noun as well as verb morphology. The most frequent noun morphology error was the use of unmarked nominative case in contexts that required an overt suffix. The children with DLD had more difficulties using nouns with more than one suffix than the TD children did and tended to preserve the suffix closest to the stem (plural) while dropping more distant suffixes. Verb morphology errors were mostly incorrect bare stems, omitted suffixes, and substituted suffixes. Verbs requiring fewer suffixes were used with greater accuracy than verbs requiring more suffixes, indicating that length was an important factor. Errors in non-transparent irregular verbs were moreover relatively frequent (Güven and Leonard, 2021).
Two studies investigated children with DLD who learned Turkish as a heritage language. In their research with 20 bilingual Turkish-Dutch children with DLD, de Jong et al. (2010) observed more errors in the nominal than the verbal domain. Data in this study were collected with a sentence completion task, supplemented with data collected using a narrative task (Frog story). Studying spontaneous speech samples of two Turkish-German children with DLD, Rothweiler et al. (2010) found high accuracy in case marking, although the children with DLD produced more errors (15%) than three Turkish-German TD children (5.6%). Specifically, substitutions of accusative case for dative case distinguished DLD from TD, although such errors were found in only one of two children with DLD. The errors of the other child with DLD were limited to omission errors. Importantly, in the context of the Netherlands, children's errors with accusative case may reflect properties of their input: in Turkish multiword expressions, accusative case can be omitted or substituted under the influence of Dutch which has no case marking for the direct object (Doğruöz and Backus, 2009). Furthermore, the genitive-possessive construction [see (3)] is not frequently used by heritage speakers of Turkish or is prone to errors (drop of the genitive marker) (Boeschoten, 1990), which is reflected in child data collected in the Netherlands (de Jong et al., 2010) and Germany (Rothweiler et al., 2010).
Dutch
Dutch is a fusional language with sparse inflectional morphology, which is mostly concentrated around verbs. Finite verbs are marked for agreement (person, number) and tense. In the present tense singular, bare verb stems are used in first person context whereas second and third person are marked with a suffix (-t). In present tense plural and past tense contexts, number is expressed, and no person distinction is made. Non-finite verbs are selected by modal or tense auxiliaries, and formed with an-en suffix (infinitives, e.g., dans-en “to dance”) or circumfix (past participles, e.g., ge-dans-t “danced”). Nominal inflection is limited. Nouns can carry diminutive and number suffixes. Dutch has a hybrid gender system, distinguishing between common and neuter in the nominal system and distinguishing feminine, masculine and neuter in the pronominal system. Definite determiners are marked for gender (de and het “the” mark common and neuter gender, respectively), while the indefinite determiner (een “a”) is unmarked for gender. Attributive adjectives are typically inflected with a schwa (groen-∂), as in (5), unless the adjective appears in an indefinite phrase and modifies a singular neuter noun (6):
(5) Het groene dak
The-DEF.SG.NEUT green roof
“the green roof.”
(6) Een groen dak
A-INDEF.SG green roof
“a green roof.”
Syntactically, Dutch has a basic Subject-Object-Verb (SOV) word order with Verb Second in main clauses, resulting in placement of finite verbs in second position and inversion of subject and verb when a non-subject occupies the first position in a sentence. Non-finite verbs are placed in the sentence-final position.
Previous research has identified the verbal domain as the locus of errors in Dutch children with DLD (de Jong, 1999; Rispens and De Bree, 2014). One error that has received much attention in research on monolingual Dutch children with DLD are “root” or “optional” infinitives, i.e., utterances with an infinitive that lack a finite verb (Wexler et al., 2004). Children with DLD also omit finite suffixes, resulting in incorrect bare verb stems which are placed in finite (second) position in the sentence (Blom et al., 2014b). One study on bilingual children suggested that incorrect bare stems could be a clinical marker (Verhoeven et al., 2011), that is, a linguistic form or principle that is characteristic of children with DLD and that enables identification of the disorder (Rice and Wexler, 1996). Another study indicated that there is not one specific error that is typical for (bilingual) DLD (Blom et al., 2013). In the nominal domain, both monolingual and bilingual children with DLD drop determiners, substitute the neuter gender definite determiner het or neuter gender demonstratives dat/dit with the common gender definite determiner de or common gender demonstratives die/deze, respectively, and use inflected adjectives instead of unmarked adjectives (in (6) that would imply substitution of groene for groen) (Orgassa and Weerman, 2008; Blom et al., 2015; Marinis et al., 2017). However, gender marking is acquired relatively late in Dutch (Cornips and Hulk, 2008). Moreover, in Dutch ethnolects, gender marking is variable (Hinskens et al., 2021), reducing its potential as a clinical marker. Investigating noun plural and past participle morphology, Boerma, et al. (2017) conclude that the omission of participial affixes is characteristic of DLD in monolingual and bilingual contexts. Noun plural production did not adequately differentiate DLD from TD groups. On the sentence level, word order errors and omissions of obligatory argument structure elements are found (Bol and Kuiken, 1988; de Jong, 1999; Zwitserlood et al., 2015), but these findings are solely based on research with monolinguals.
In sum, while several studies have investigated the grammatical development of children with DLD in Dutch, research on DLD in heritage Turkish is limited. To obtain more clarity and inform clinical practice, a broad overview of different grammatical morpheme errors of bilingual Turkish-Dutch children in both languages is needed, because typological differences between the two languages will impact the error patterns. Furthermore, to establish reliable and robust clinical markers, DLD status is relevant, regardless of bilingualism and developmental changes. That is, linguistic structures with which monolingual and bilingual children with DLD make persistently more errors than their TD peers may help to identify DLD.
Present study
For the present study, we analyzed transcribed recordings of semi-naturalistic productions of Turkish and Dutch. Data in both languages of 10 bilingual children with DLD were compared with those of 10 bilinguals with TD to determine the effects of DLD on children's simultaneous grammatical development in the heritage language (Turkish) and the societal language (Dutch). For Dutch, available control data of 20 monolingual children, equally divided over DLD and TD groups, were analyzed to determine whether between-group differences are dependent on bilingualism. From each child, data were collected three times with 1-year intervals, allowing for longitudinal analyses that provide insight into the pace of grammatical development. This study focused primarily on grammatical morphemes, but because so little is known about DLD in the context of heritage language development, we also investigated grammatical development more broadly at the sentence-level. Three main research questions guided the study.
Research question 1: Effects of DLD on the heritage language (Turkish)
a. Does grammatical development in Turkish differ between bilingual Turkish-Dutch children with and without DLD?
b. Do the types of errors with grammatical morphemes in Turkish differ between bilingual Turkish-Dutch children with and without DLD?
Across languages, DLD has a persistent effect on children's grammatical development. Longitudinal research with monolingual children suggests that while the onset of development of children with DLD is delayed, they develop at the same rate as TD children (Rice, 2013). We therefore expected that bilingual children with DLD would produce shorter utterances in Turkish and that they would make more grammatical errors than bilingual children with TD throughout the course of the study. However, if DLD interacts with levels of language input and use, it could have a disproportional effect on heritage language development (Restrepo and Kruth, 2000; Blom et al., 2019), as input and use in the heritage language may be limited. This yields the expectation that Turkish language skills of TD children may develop at a faster pace than those of children with DLD (i.e., longer sentences and fewer errors over time) because of low levels of input in Turkish.
Regarding the types of errors, we expected that children with DLD and TD would make a variety of errors, but that children with DLD would make more errors (Güven and Leonard, 2020, 2021). Grammatical morpheme errors could occur in the nominal and verbal domain (Güven and Leonard, 2020, 2021). We expected that case errors and errors with genitive-possessive constructions would be frequent (Acarlar and Johnston, 2006, 2011; Rothweiler et al., 2010; Güven and Leonard, 2020). Because of this, it is possible that grammatical morpheme errors in the nominal domain are more frequent than grammatical morpheme errors in the verbal domain (Acarlar and Johnston, 2006; de Jong et al., 2010). Further, in children with DLD, omissions could be more frequent than substitutions (Güven and Leonard, 2020), although case substitutions could occur as well (Rothweiler et al., 2010).
Research question 2: Effects of DLD on the societal language (Dutch)
a. Does grammatical development in Dutch differ between bilingual Turkish-Dutch children with and without DLD?
b. Do the types of errors with grammatical morphemes in Dutch differ between bilingual Turkish-Dutch children with and without DLD?
We expected that bilingual children with DLD would produce shorter utterances in Dutch, and that they would make more grammatical errors than bilingual TD children. Furthermore, in Dutch, DLD and TD groups may be more likely to develop at the same pace than in Turkish, presuming that input levels in Dutch are relatively high due to schooling in Dutch.
Several studies have shown that children with DLD who are learning Dutch tend to make errors with grammatical morphemes in the verbal domain, and omit finite morphology (de Jong, 1999; Wexler et al., 2004; Verhoeven et al., 2011; Blom et al., 2013, 2014b) and participial affixes (Boerma, 2017). Regarding types of errors, we expected that these errors would also be more frequent in bilingual children with DLD compared to their TD peers. Overregularization, in contrast, may be infrequent in Dutch-speaking children with DLD, similar to what has been found for English (Oetting and Horohov, 1997; Redmond and Rice, 2001; Van der Lely and Ullman, 2001; Blom and Paradis, 2013), which is, like Dutch, a western Germanic language and typologically similar.
Research question 3: Comparisons with monolinguals in the societal language (Dutch)
a. Are the grammatical morpheme errors found for monolingual Dutch children with DLD similar to those found for the bilingual Turkish-Dutch children with DLD?
Reliable clinical markers must be independent of whether a child is exposed to one or more languages. To establish whether grammatical morpheme production in Dutch can be a reliable clinical marker, we compared the types of grammatical morpheme errors of bilinguals (RQ2) with that of monolinguals. Assuming that children's errors with grammatical morphemes are more impacted by DLD than by bilingualism (Blom and Boerma, 2016; Boerma, et al., 2017), we expected that similar patterns would emerge in DLD-TD comparisons in monolinguals and bilinguals. This comparison focused on Dutch because monolingual Turkish control data were not available, and because our study concerned bilingual Turkish-Dutch children growing up in the Netherlands.
Methods
Participants
The data analyzed for the purpose of this study were collected within a larger longitudinal project on the interaction of bilingualism and DLD (see Boerma, 2017). The bilingual DLD sample included 10 bilingual Turkish-Dutch children. From a larger database, this core group of 10 Turkish-Dutch children with DLD (bi-DLD) was matched on a subject-by-subject basis with 10 Turkish-Dutch children with TD (bi-TD), 10 monolingual Dutch children with DLD (mo-DLD), and 10 monolingual Dutch children with TD (mo-TD). For each bi-DLD child, we tried to find the closest match in terms of chronological age (established at wave 1) and nonverbal intelligence (NVIQ; measured with the Wechsler Nonverbal-NL at wave 1) in the other three groups. In the two bilingual groups, Dutch input before age 4 years and Dutch input at home at wave 1 were also included in the matching procedure as criteria. This information was gathered with the Parents of Bilingual Children Questionnaire (PaBiQ; Tuller, 2015). Table 1 summarizes the demographic characteristics of the four matched groups, also including information on sex and socioeconomic status (SES) which were not prioritized during the matching procedure. Individual data about the subject-by-subject matching can be found in the Supplementary material.
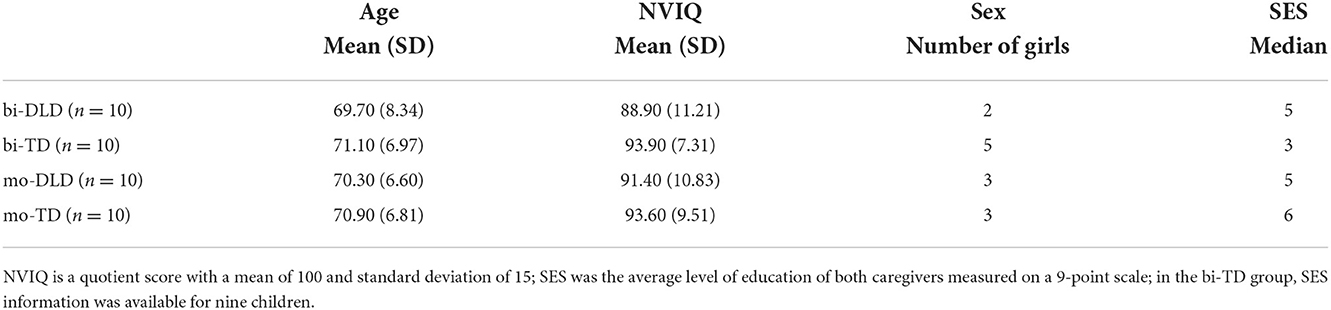
Table 1. Demographic characteristics of the four matched groups.
All children with DLD were recruited through two national organizations that provide education and care for children with language difficulties (Royal Auris Group, Royal Dutch Kentalis). They were diagnosed with DLD by a certified speech-language pathologist using official national guidelines (Stichting Siméa, 2014), which meant that they either (1) performed below 2 SD overall on a standardized test battery or (2) below 1.5 SD on two out of four subscales. Moreover, their nonverbal intelligence was 70 or above. We certified the latter for all children at wave 1 of the current study. In addition, their scores on a sentence repetition task (TAK Zinsvorming, part of the Taaltoets Alle Kinderen; Verhoeven and Vermeer, 2001) that was administered as part of our research, pointed to language difficulties. The TAK has norms for Dutch monolingual and bilingual children. Based on their scores, monolingual children are assigned to one of five level groups, where A is the highest level corresponding to the 25% highest scoring monolingual children in the population and E the lowest level corresponding to the 10% lowest scoring monolingual children. For comparisons with bilingual level groups, bilingual children are assigned to one of three level groups based on the performance of a bilingual norm group: low (1SD below the mean, corresponding to the 16th percentile or below), average (around the mean) or high (1SD above the mean, corresponding to the 84th percentile or above). All bi-DLD children scored in the low-level group for bilinguals. In the bi-TD group, 4 children scored in the low-level group, 3 in the average level group and 3 in the high-level group. Out of the 10 mo-DLD children, 8 scored within the 10th percentile (E), 1 in the 25th percentile (D), and 1 in the 50th percentile (C). Out of the 10 Mo-TD children, no child scored in the 10th percentile, and 1 in the 25th percentile (D); the other 9 scored in the 50th percentile or above (C, B, A).
All participating children were born in the Netherlands, but exposed to Turkish at home through their parents, who were all speakers of Turkish. In the DLD group, 3 bilingual children had parents who were both born in Turkey; the other 7 children had one parent who was born in Turkey and one parent who was born in the Netherlands. In the TD group, 6 children had parents who were both born in Turkey, 1 child had one parent who was born in Turkey and one parent who was born in the Netherlands, 3 children had parents who were both born in the Netherlands, and for 1 child this information was not available. At wave 1, information about input in Dutch and Turkish was collected. On average, 35% (bi-DLD) and 38% (bi-TD) of the total input before age 4 was in Dutch (the rest in Turkish). Of the total current input at home at wave 1, 35% (bi-DLD) and 44% (bi-TD) was in Dutch (the rest in Turkish). In the DLD group, 5 parents indicated that their child preferred to speak Turkish at home, 4 indicated that their child preferred to speak Dutch and for 1 child the parents indicated both languages as their preferred language. In the TD group, 2 parents indicated that their child preferred to speak Turkish at home, 3 indicated a preference for Dutch, 4 indicated that both languages were preferred, and for 1 child this information was not available. Children's preferences may have changed at Waves 2 and 3, but this was not verified.
Materials
Samples
Speech samples were recordings of a test session in which children produced (semi-)spontaneous speech during a narrative task, which was similarly elicited in Dutch and in Turkish. The narrative task alone did not always yield enough utterances per child to be able to calculate reliable measures. In addition to the stories, we therefore also transcribed an informal conversation with the children prior to the narrative task (in both languages) in which the children were asked about a range of accessible topics including their hobbies, birthday and/or favorite tv-show. This conversation allowed us to elicit more utterances, which benefited the reliability of the language measures. As part of the narrative task, children first listened to a model story told by the research assistant. After hearing a model story, the children were asked to tell a story based on a coherent sequence of six colored pictures either depicting a story about young goats or young birds (MAIN; Gagarina et al., 2012). Afterwards 10 questions about the story in the pictures were asked. The stories were designed for narrative analysis, but the data can also be analyzed for the purpose of studying grammatical development. Speech samples included the stories the children told as well as all the answers to the questions of the experimenter to increase the total number of utterances. All stories were transcribed using Codes for the Human Analysis of Transcripts (CHAT) transcription format, based on the audio recordings. As a general index of grammatical development, mean length of utterance (MLU) was calculated using Computerized Language Analysis (CLAN) (MacWhinney, 2000), measured in the number of words that children use in their utterances. The counts included unintelligible words (“xxx”), and excluded filled pauses and language switches, that is, in the Turkish data, switches to Dutch and in the Dutch data, switches to Turkish. In the Dutch data, there were only five instances of Turkish words, and < 1% of the words involved a language switch. In the Turkish data, 7.48% of the words involved a language switch to Dutch. For all bilingual children, except one, data on both Turkish and Dutch were available. One bi-DLD child hardly spoke during the Turkish test session at wave 1 and when she spoke, it was almost always in Dutch. Turkish data from waves 2 and 3 are available for this child.
Coding categories: Grammatical errors in Turkish
Codes relevant for the current study consist of four main categories, namely grammatical errors in the noun phrase (nominal domain), grammatical morpheme errors with verbs (verbal domain), word order errors, and sentence element errors. Uninterpretable/incomplete words and utterances were coded for exclusion. Lexical errors (e.g., using git “go” instead of gel “come”) along with other lexical categories (e.g., use of general-all-purpose words, onomatopoeia) were coded but not included in this study as they were not relevant to grammatical development. Language switches were coded as they are relevant for MLU calculations, as discussed earlier.
Nominal domain errors are comprised of grammatical morpheme errors with case markers, genitive-possessive suffixes and their agreement markers, derivational morphemes, plural marker, and order of suffixation. Verb errors are comprised of errors with tense, agreement, mood, voice, and order of suffixation. Note that derivational morpheme errors were observed in Turkish, but not in Dutch. Because there is no clear-cut distinction between derivation and inflection (Booij, 2006) and because derivational morphemes may be meaningful when describing grammatical markers of DLD, we decided to include the errors with derivational morphemes in Turkish.
Most grammatical morpheme errors in our data are omissions or substitutions of grammatical morphemes. Substitutions refer to the use of incorrect grammatical morphemes. Incorrect addition of a grammatical morpheme and duplication of third person singular possessive suffix were also encountered, though occurrence of the former was rare. In addition to grammatical morpheme errors, we coded errors related to word order and sentence elements. Since Turkish is a (relatively) free word order language, different orders of the verb and its arguments are not considered as an error. The word order errors only include the cases in which the ordering of words caused an ungrammaticality as in (7) where the adverb geri “back” should precede and modify the embedded verb almak “to take,” but instead it precedes and modifies the verb of the main clause.
(7) çünkü topunu almak geri istiyordu.
because ball-3PS.POSS-ACC take-VN back want-PROG-PST
“because he wanted to take his ball back.”
Sentence element errors include omissions of obligatory arguments, i.e., subject and object (but importantly, only if their omission was not licensed by the discourse), omission of obligatory sentence elements other than arguments (e.g., verb, subordinators) and incorrectly used sentence elements. The occurrence of word order and sentence element errors was limited.
A full version of the coding scheme, including examples, can be found at: https://osf.io/3z2sj/.
Coding categories: Grammatical errors in Dutch
As for Turkish, codes fall in one of four main categories and pertain to the grammatical morpheme errors in the noun phrase (nominal domain), grammatical morpheme errors with verbs (verbal domain), word order errors, and sentence element errors. Uninterpretable/incomplete and one-word utterances were coded for exclusion. Errors with prepositions were coded as such but were not included in this study as these were lexical errors (i.e., incorrect meaning, not form). A miscellaneous category included codes for other lexical categories (e.g., use of general-all-purpose words, onomatopoeia) and language switches. Lexical errors were not part of this study. Coding of language switches was relevant in order to exclude them in calculating MLU, as explained earlier.
Noun phrase errors are comprised of grammatical morpheme errors with determiners, pronouns, numerals, adjectival inflections, noun plurals, or diminutives. Verb errors include grammatical morpheme errors with tense and agreement (i.e., finite verbs), and non-finite verbs (i.e., participles, infinitives). Most grammatical morpheme errors are omissions or substitutions of grammatical morphemes. Substitutions refer to the use of incorrect grammatical morphemes. Overregularization errors were coded as a subtype of substitution errors, but they were not treated as grammatical errors in the analyses because they reflect the productive use of a morphological rule and do not indicate a grammatical problem. A third type of error concerns incorrect additions of grammatical morphemes. This was coded but the occurrence of such errors was limited.
In addition to codes about grammatical morphemes, we coded word order and sentence element errors. Word order errors include errors with subject-verb inversion, the absence of verb second in main clauses, and the use of verb second in embedded clause, in addition to a miscellaneous category with other word order errors that do not fall within one of these three subtypes. Sentence element errors include omission of obligatory arguments (i.e., subject, object), omission of obligatory sentence elements other than arguments (e.g., verb, complementizers), incorrectly used sentence elements, and incorrect addition of sentence elements.
A full version of the coding scheme, including examples, can be found at: https://osf.io/3z2sj/.
Inter-rater reliability
To calculate inter-rater reliability, about 20 percent of the Dutch and Turkish data were coded by two other, independent coders. To select a representative 20 percent of the errors, a Python script went over the data file in which the errors were coded and created an output file in which the following were listed: unique error categories per wave per group, overall unique errors, and tables for each wave showing the error counts per category per child. It was calculated how many errors needed to be included to select a representative 20 percent. Then, the tables showing errors per child were examined manually in Excel. For both Dutch and Turkish data, the children with the most diverse types of errors were selected. The error categories that did not appear in the selected children were detected, and children who made most of those errors were also included in the representative errors file. While selecting children with the most diverse types of errors, the percentage of errors that had to be selected was also considered.
For the Turkish data, the errors of 9 TD children (2 for wave 1, 4 for wave 2, and 3 for wave 3) and 8 DLD children (2 for wave 1, 3 for wave 2, 3 for wave 3) were selected for double coding. For the Dutch data, the errors of 12 TD children (4 different children per wave; some overlap between children across the three waves) and 12 DLD children (4 per wave; as above) were selected. For Dutch, more data were selected because the total sample was larger, including both bilingual and monolingual children.
See Table 2 for an overview of the results for Turkish and Dutch.
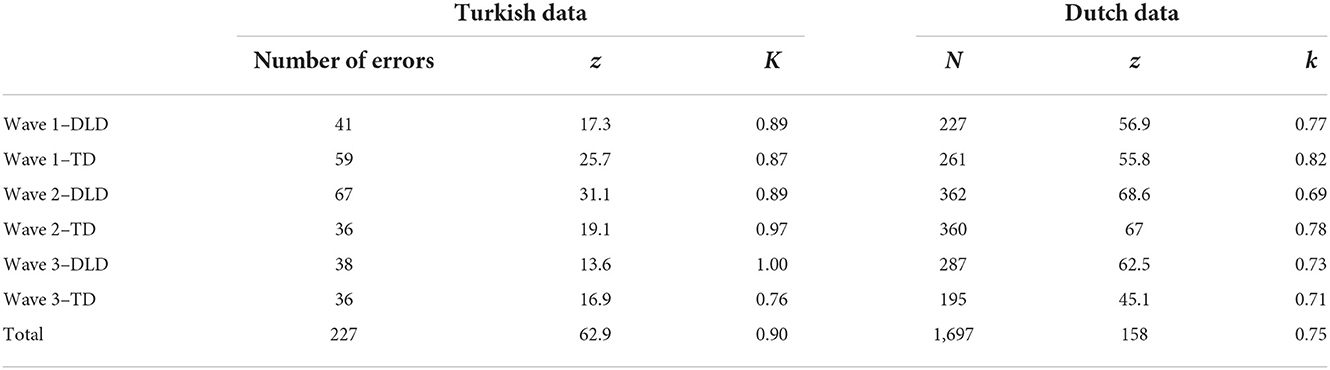
Table 2. Inter-rater reliability for Dutch and Turkish data.
For the Turkish data, the inter-rater reliability (kappa) was 0.818 based on 277 instances (z = 56.2). However, the second coder had misinterpreted the language mixing category, which is why their coding in this category was replaced with that of a third coder. The data set was otherwise kept the same. The kappa score, then, increased to 0.90 based on again 277 instances (z = 62.9). Inter-rater reliability was also calculated per wave per group. The final kappa scores per wave per group for Turkish ranged from moderate to perfect (0.76–1), and for Dutch from moderate to strong (0.69–0.82).
Procedure
The research was approved by The Standing Ethical Assessment Committee of the Faculty of Social and Behavioral Sciences at Utrecht University (#22-0098). Informed consent forms were signed by parents of participants. Children were individually tested in a quiet room at school. At each wave of data collection, there were two test sessions of ~ 1 h with an experimenter who was a native speaker of Dutch. For the bilingual children, there was also one session of ~1 h with a bilingual experimenter who was a native speaker of Turkish and Dutch. However, the experimenter only spoke Turkish with the child. The session in Turkish was on a different day than the Dutch sessions and was always the first session. The conversation and narrative task in Dutch was administered in the second Dutch session. To avoid any cross-over effects, a different picture sequence of the MAIN was used in the Turkish and in the Dutch session. Thus, if a child told a story about young birds in Turkish, the story about young goats would be used in the Dutch session.
Data-analysis strategy
To investigate the impact of DLD at the three waves, linear regression models were run for Turkish (RQ1) and Dutch (RQ2), using the lmer function of the lme4 package in R (Bates et al., 2015; R Core Team, 2016). First, we tested whether the inclusion of a random intercept for Child was justified. No further random structure was included because of the small sample size. Second, we ran a model that contained Group, Wave, and the interaction between Group and Wave as fixed-effects predictors, and a second model with only main effects of Group and Wave. Models were compared using a log likelihood ratio test. In the results section, only the optimal model (i.e., the most parsimonious and preferred model) was reported.
For both languages, several dependent variables were used: (1) Mean length of utterance (MLU). (2) Relative frequency of grammatical errors. Grammatical errors were errors with grammatical morphemes, word order or sentence elements. The number of grammatical errors was divided by the number of utterances (i.e., relative frequency) and thus controlled for length of the transcript. The denominator included all utterances, except for unintelligible utterances, and, in Dutch, one-word utterances. In Turkish, one-word utterances were not excluded because one-word utterances are common in Turkish because of the pro-drop/argument drop feature of the language (which contrasts with Dutch). Moreover, due to its agglutinative character, one-word utterances can create obligatory contexts for grammatical morphemes in Turkish. (3) Proportions of omitted and substituted grammatical morphemes. In Turkish, the proportion of omitted grammatical morphemes was the number of omission errors divided by the sum of grammatical morpheme errors, which included omission, substitution, addition, and duplication errors. The proportion of substitution errors was calculated in a similar way. In Dutch, nearly all grammatical morpheme errors could be captured by omissions and substitutions. Therefore, the proportion of omitted grammatical morphemes was the number of omission errors divided by the sum of omission and substitution errors; because the proportion of substitution errors is the counterpart, it was not necessary to calculate the proportion of substitutions separately. (4) Proportion of grammatical morpheme errors in the nominal domain. In both languages, the proportion of grammatical morpheme errors in the nominal domain was the number of errors in the nominal domain divided by the sum of errors in the nominal and verbal domain. The proportion of grammatical errors in the verbal domain is thus the counterpart of the proportion of errors in the nominal domain.
Overregularization was not included in the quantitative analyses because this type of error indicates that children can apply morphological rules rather than reflecting a lack of grammatical knowledge. Because DLD and TD may differ in overregularization, we did include overregularization in the qualitative analyses performed to address RQ1b and RQ2b. The qualitative analyses were aimed at identifying patterns in grammatical morpheme errors that characterized DLD (i.e., clinical markers). To be able to observe more robust patterns, data from the three waves were combined for the qualitative analyses. The availability of data from monolingual Dutch controls enabled us to compare errors with grammatical morphemes in Dutch across bilinguals and monolinguals (RQ3). In so doing, we aimed to establish the reliability and robustness of clinical markers of DLD.
Results
Below, we first present the quantitative and qualitative results for Turkish (RQ 1), then the quantitative and qualitative results for Dutch (RQ 2 and 3).
Turkish
Grammatical development in Turkish
Table 3 shows utterance length (MLU in words) and relative frequency of grammatical errors. The absolute numbers per error type (grammatical morphemes, word order, sentence elements) can be found in the Supplementary material. Errors with word order and sentence elements were infrequent.
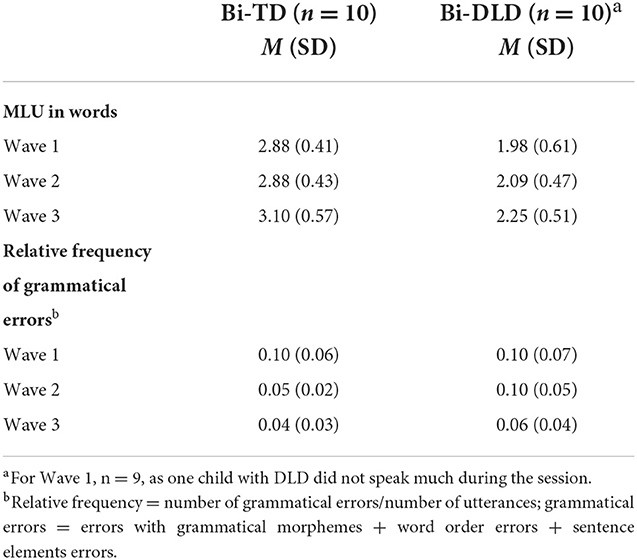
Table 3. Mean length of utterance (MLU) and relative frequency of grammatical errors in Turkish.
MLU in Turkish
The optimal model showed a significant main effect for Group (β = −0.85, SE = 0.17, p < 0.001), indicating that the bi-TD children produced longer utterances than the bi-DLD children. The difference in MLU between Waves 1 and 3 was marginally significant (β = 0.25, SE = 0.13, p = 0.05), whereas the difference between Waves 1 and 2 was not (β = 0.06, SE = 0.13, p = 0.63). An analysis with Wave 2 as the reference level showed that the difference between Waves 2 and 3 was also not significant (β = 0.20, SE = 0.12, p = 0.11). These results suggest that utterance length increased marginally between the first and third year across bi-TD and bi-DLD children.
Relative frequency of grammatical errors in Turkish
The optimal model revealed a marginally significant effect of Group (β = 0.02, SE = 0.01, p = 0.06), suggesting that the bi-DLD group made slightly more grammatical errors than the bi-TD children. The difference between Waves 1 and 3 in relative frequency of grammatical errors was significant (β = −0.05, SE = 0.02, p = 0.001), and both the difference between Waves 1 and 2 (β = −0.03, SE = 0.02, p = 0.09) and Waves 2 and 3 was not significant (β = −0.02, SE = 0.01, p = 0.10). These results suggest that relative frequency of grammatical errors across bi-TD and bi-DLD groups decreased over time between the first and third year of data collection.
Errors with grammatical morphemes in Turkish: Omission and substitution
Table 4 provides more detailed information about grammatical morpheme errors, specifically the proportions of omissions and substitutions of grammatical morpheme errors as well as the proportion of grammatical morpheme errors in the nominal domain. The denominators were always the sum of grammatical morpheme errors.

Table 4. Proportions of grammatical morpheme errors per type and domain in Turkish.
Regarding the proportion of omission errors, the optimal model with main effects of Wave and Group showed a significant effect of Group (β = 0.23, SE = 0.08, p = 0.01), suggesting that the bi-DLD children made more omission errors than bi-TD children. The difference between Wave 1, Wave 2 and Wave 3 was not significant. Regarding the proportion of substitution errors, the optimal model with main effects of Wave and Group showed no significant difference between bi-TD and bi-DLD children (β = −0.07, SE = 0.07, p = 0.33) and a significant difference only between Waves 2 and 3 (β = 0.17, SE = 0.08, p = 0.04), indicating that across bi-TD and bi-DLD groups, the substitution errors increased between Waves 2 and 3.
Errors with grammatical morphemes in Turkish: Nominal and verbal domain
The optimal model was a model with only main effects, but neither the effect of Wave nor the effect of Group reached statistical significance, indicating that the proportion of errors in the nominal domain relative to the verbal domain did not differ across the three waves and across the groups.
Types of errors with grammatical morphemes in Turkish
Most grammatical morpheme errors in Turkish were in the nominal domain, comprising 80% of the errors; 20% were in the verbal domain. Below, errors in the nominal and verbal domain will be described in greater detail. To illustrate how the distribution of errors is different between the bi-TD and bi-DLD groups, pie charts were created for the most prominent error categories. The pie charts demonstrate the percentage of types of errors (e.g., omission, substitution) with the encoding of a certain grammatical feature or aspect (e.g., accusative case).
Nominal domain in Turkish
Numerically, the number of errors with grammatical morphemes in the nominal domain was quite similar in the two groups (bi-TD: n = 144 vs. bi-DLD: n = 159), but the complexity and distribution of the errors differed across groups. In terms of complexity, the errors that involved an embedded noun clause structure, which is more complex than a simple noun clause structure, constituted 9% of the errors in the bi-TD group and 0.6% of the errors in the bi-DLD group. Pie charts were created for accusative and dative case (Figure 1) errors, and possessive suffix and genitive case (Figure 2) errors. Below, we will discuss the patterns for these two categories in greater detail.
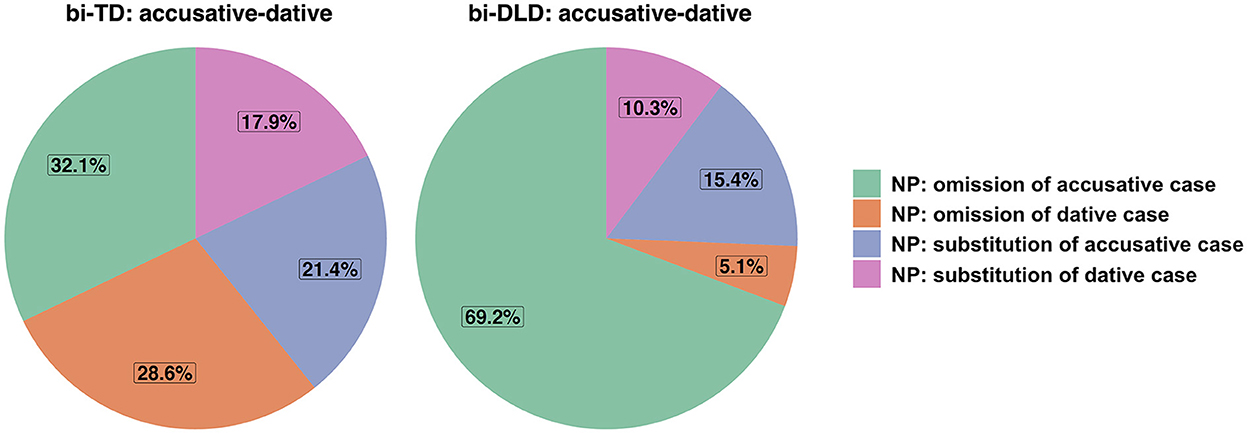
Figure 1. Distributions of accusative-dative errors in Turkish in the bi-TD and bi-DLD group.
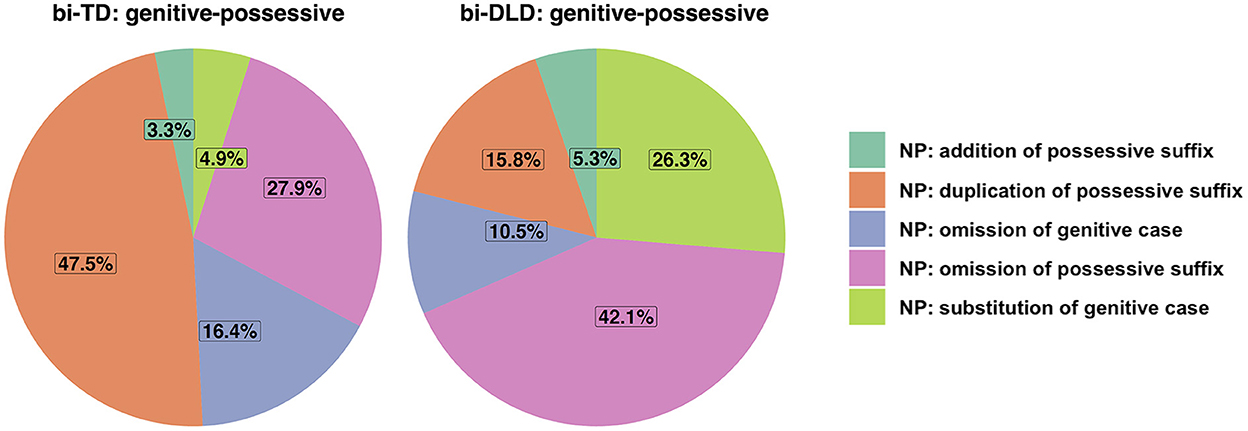
Figure 2. Distributions of genitive-possessive errors in Turkish in the bi-TD and bi-DLD group.
Accusative and dative case errors
The pie charts for case errors (Figure 1) include accusative and dative case since accusative case was mostly substituted with dative case (67%) and vice versa (71%). The bi-DLD children made more errors with accusative and dative cases (n = 78) than the bi-TD children (n =28). Figure 1 shows that while there was a similar distribution of omission and substitution of accusative and dative cases in the bi-TD group, omission of accusative case was relatively frequent in the bi-DLD group compared to bi-TD group. This pattern of findings suggests that bi-DLD children had most problems with using accusative case in obligatory contexts.
Accusative case was almost always substituted with dative case in the bi-TD group. In the bi-DLD group, accusative case was more diversely substituted with other case markers, but still mostly with dative case. The example in (8) below shows how accusative case was substituted with dative case by a bi-TD child in Wave 1. In (8), the direct object of the verb ye- “eat” was incorrectly marked with dative case instead of accusative case.
(8) kuşϕ ona [: onu] [*] yiyo(r).
bird-NOM it-DAT [: it-ACC] eat-PROG-3SG.
“The bird is eating it.”
When dative case was substituted in the bi-TD group, it was always substituted with accusative case. In the bi-DLD group, this was true for half of the substitutions. In the other cases, it was substituted with locative or instrumental case. Two of the five instances in the bi-TD group included substitution of dative case on the nominalized verb of the embedded noun clause. Since such errors involve case marking on a clause level, they are more complex than substitution of a case marker on a simple noun. In (9), the verb of the main clause yardım et- “help” requires the embedded noun clause to bear dative case, yet a bi-TD child at Wave 1 marked the embedded nominalized verb yüzme “swimming” with accusative case. No such errors were present in the bi-DLD group.
(9) sora anne kuzu yardım ediyo(r) yüzmesini [: yüzmesine] [*].
then mother lamb help make-PROG-3SG swim-VN-3SG.POSS-ACC [:swim-VN-3SG.POSS-DAT]
“The mother lamb is helping (her baby) swim.”
Possessive suffix and genitive case errors
Regarding genitive-possessive constructions, the bi-TD children made numerically more errors than the bi-DLD children (n = 61 vs. n = 38). As Figure 2 shows, duplication of possessive suffix accounted for almost half of the errors in the bi-TD group, whereas in the bi-DLD group omission of the possessive suffix held the highest percentage.
Omission of possessive suffix was numerically similar in the two groups (bi-TD: n = 17, bi-DLD: n = 16). However, in the bi-TD group, 7 of these errors were due to a missing 3rd person singular marker -(s)I in noun compound structures, while such cases were almost non-existent in the bi-DLD group (n = 1). In the example below, the target word was yarış arabası “race car,” which is a type of compound in Turkish that consists of two nouns. The first noun yarış “race” is in the bare form while the second noun araba-sı is marked with the 3rd person singular possessive suffix -(s)I. (10) illustrates a case in which a bi-TD child in Wave 1 omitted the possessive suffix in the second noun of this compound.
(10) yarış araba [: arabası] [*].
race car [: car-3SG.POSS]
“race car.”
This type of omission of the possessive suffix is different from omission of possessive suffix in regular genitive-possessive constructions, because in compound NPs it does not imply possession of one thing by another. Example (11) below illustrates omission of possessive suffix in a case where it signifies a possession. In (11), a bi-DLD child at Wave 2 says anne “mother” instead of annem “(my) mother”, omitting the 1st person singular possessive suffix –(I)m.
(11) anne [: annem] [*] yapıyo(r).
mother [: mother-1SG.POSS] make-PROG-3SG
“My mother is making it.”
Omission of genitive case was numerically higher in the bi-TD (n = 10) than in the bi-DLD (n = 4) group. In the bi-TD group, almost half of these errors involved an embedded noun clause, such that the genitive case was omitted on the embedded clause subject, whereas all omission of genitive case errors in bi-DLD were simple genitive-possessive construction errors. In example (12) below from a bi-TD child at Wave 2, fare “mouse” is the subject of the embedded clause, and it should have been marked with genitive case. The embedded clause is marked with parentheses in the sentence below.
(12) çünkü (fare [: farenin] [*] ondan kaçmıcanı [: kaçmayacağını]) düşünmüş.
because mouse [: mouse-GEN] he-ABL run-away-NEG-FUT-3SG.POSS-ACC think-PST-3SG
“Because he thought the mouse would not run away from him.”
Omission of genitive case in such cases points to a more complex type of error compared to omission of genitive case in simpler genitive-possessive constructions as shown in example (12) below, produced by a child with DLD at Wave 3. In (13), the child says o topu “he ball” instead of o-nun topu “his ball,” omitting the genitive case.
(13) çünkü [/] çünkü o [: onun] [*] topu suyun
içindeydi.
because [/] because he [: he-GEN] [*] ball-3SG.POSS water-GEN
inside-3SG.POSS-LOC-PST.
“Because his ball was in the water.”
Verbal domain in Turkish
The bi-DLD group made more errors (n = 49) than the bi-TD group (n = 29). Figure 3 shows the distribution of agreement and tense errors in the verbal domain in the two groups. Bi-TD children never omitted tense suffixes, while bi-DLD children did so in 18% of the cases shown in Figure 3. The percentage of omission of agreement was quite similar in the bi-TD and bi-DLD groups. While the percentage of substitution of agreement markers was higher in the bi-TD than in the bi-DLD group, the percentage of substitution of tense markers with another tense marker was higher in the bi-DLD than in the bi-TD group. The frequency of these errors is, however, low.
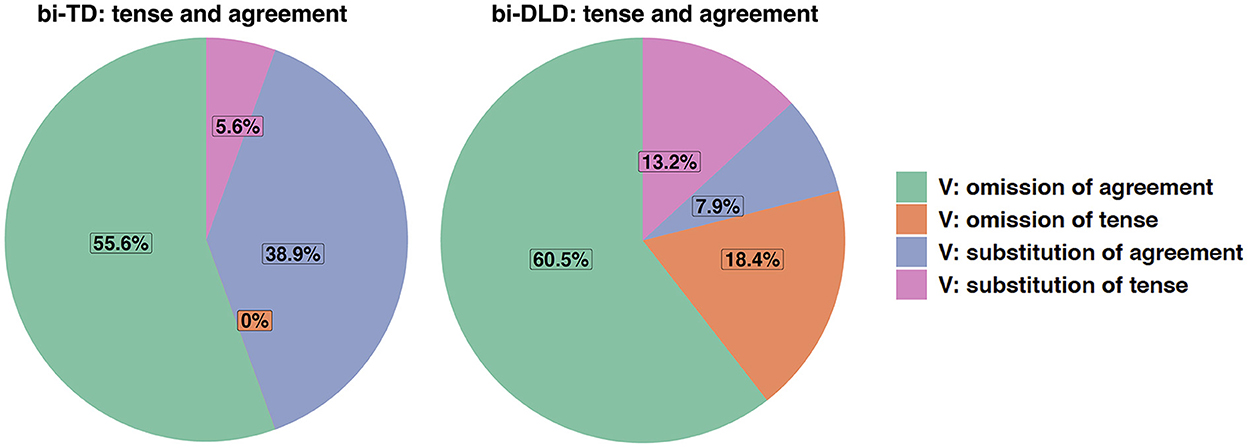
Figure 3. Distributions of tense and agreement errors in Turkish in the bi-TD and bi-DLD group.
Dutch
Grammatical development in Dutch
Table 5 shows utterance length (MLU in words) and relative frequency of grammatical errors. The absolute numbers per error type (grammatical morphemes, word order, sentence elements) can be found in the Supplementary material.
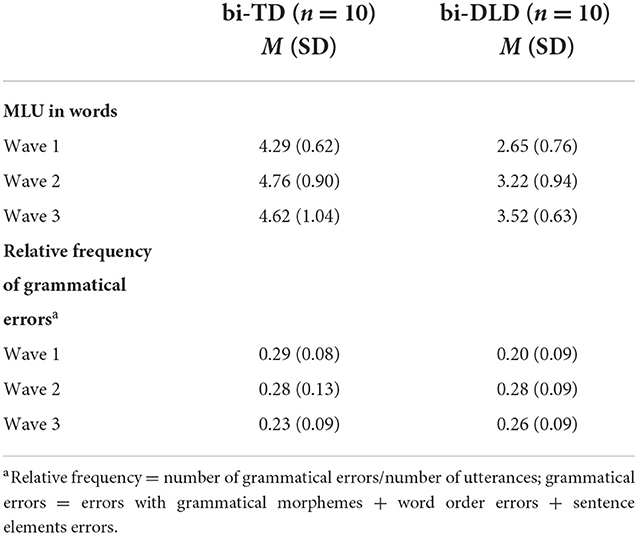
Table 5. Mean length of utterance (MLU) and relative frequency of grammatical errors in Dutch.
MLU in Dutch
The optimal model showed a significant effect of Group (β = −1.43, SE = 0.32, p < 0.001), indicating that Bi-DLD children used shorter utterances than Bi-TD children. Wave 3 differed significantly from Wave 2 (β = 0.52, SE = 0.17, p = 0.003) and Wave 1 (β = 0.60, SE = 0.17, p < 0.001). An analysis with Wave 2 as the reference level shows that there is no statistically significant increase of MLU between Waves 2 and 3. These results suggest that utterance length increased between the first and third year across the bi-TD and bi-DLD children.
Relative frequency of grammatical errors in Dutch
The interaction model turned out to be the optimal model, but showed no significant effects for Wave or Group, or a significant interaction effect.
Errors with grammatical morphemes in Dutch: Omissions and substitution
Table 6 provides more detailed information about grammatical morpheme errors, specifically the proportions of omissions of grammatical morphemes and proportion of grammatical morpheme errors in the nominal domain. The denominators are respectively the sum of omission and substitutions of grammatical morphemes, and the sum of grammatical morpheme errors in the nominal and verbal domain.
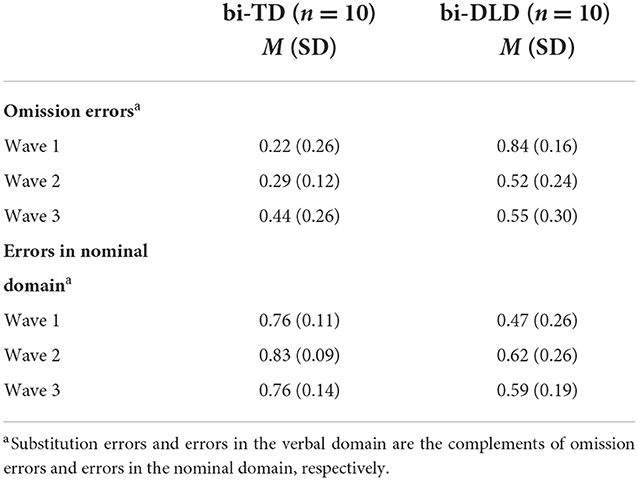
Table 6. Proportions of grammatical morpheme errors per type and domain in Dutch.
Regarding the proportion of omissions of grammatical morphemes, the optimal model showed a significant interaction between Group and Wave 2 (β = −0.39, SE = 0.15, p = 0.01) and between Group and Wave 3 (β = −0.51, SE = 0.15, p = 0.001), in addition to main effects of Group (β = 0.62, SE = 0.10, p < 0.001) and Wave 3 (β = 0.22, SE = 0.10, p = 0.04). Figure 4 illustrates the interaction effect showing that at Wave 1 (reference level), the proportion of omissions was higher for the bi-DLD group than the bi-TD group and that the difference between the two groups is smaller at Waves 2 and 3. Recall that the number of substitutions is the counterpart; consequently, the proportion of substitutions is higher for bi-TD than bi-DLD at Wave 1 and this difference is smaller at Waves 2 and 3.
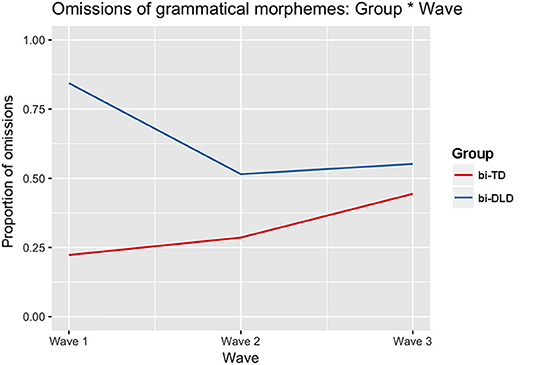
Figure 4. Interaction effect between Group and Wave on the omission of grammatical morphemes in Dutch.
Errors with grammatical morphemes in Dutch: Nominal and verbal domain
The optimal model showed a significant effect of Group: the bi-DLD group made more errors in the verbal domain, and, reversely, the bi-TD group made more errors in the nominal domain (β = −0.22, SE = 0.06, p < 0.001). In addition, the effect of Wave 2 reached statistical significance (β = 0.11, SE = 0.05, p = 0.03), suggesting that the proportion of grammatical morphemes errors in the nominal domain is larger at Wave 2 compared to Wave 1.
Types of grammatical morpheme errors in Dutch
In this section, types of errors with grammatical morphemes are discussed for bi-DLD and bi-TD (research question 2b), and compared with monolingual controls (mo-DLD, mo-TD) to determine whether error patterns depend on bilingualism (research question 3). Grammatical morpheme errors in Dutch were more frequent in the nominal domain compared to the verbal domain, comprising 60% and 40% of all grammatical morpheme errors, respectively. This pattern in the bilinguals resembled that in the monolingual controls, who had 65% of their grammatical morpheme errors in the nominal domain and 35% in the verbal domain. For the purpose of interpretation, it is relevant to mention that these percentages may not only represent a contrast between domains but also between free-standing and bound grammatical morphemes: in Dutch, in the nominal domain, grammatical morphemes are predominantly free-standing whereas in the verbal domain, bound grammatical morphemes predominate. This confound interferes with the cross-linguistic comparison as in Turkish, there is no such distinction.
Nominal domain in Dutch
Numerically, bi-TD children (n = 378) made more errors than bi-DLD children (n = 211). Most prominent were errors with determiners and pronouns, which are free-standing grammatical morphemes. In the bi-TD group, errors with determiners (48%) and pronouns (44%) accounted for 92% of the errors with grammatical morphemes in the nominal domain; in the bi-DLD group, this is also 92%, but errors with determiners (62%) were more frequent than pronoun errors (30%). To illustrate error distributions in the bi-TD and bi-DLD groups, pie charts were created for determiners (Figure 5) and pronouns (Figure 6). Numerically, mo-TD children (n = 211) made fewer errors than mo-DLD children (n = 242). In the mo-TD group, errors with determiners and pronouns accounted for 93% (determiners: 27%, pronouns: 66%) of the errors with grammatical morphemes in the nominal domain; in the mo-DLD group, this was 95% (determiners: 55%, pronouns: 40%).
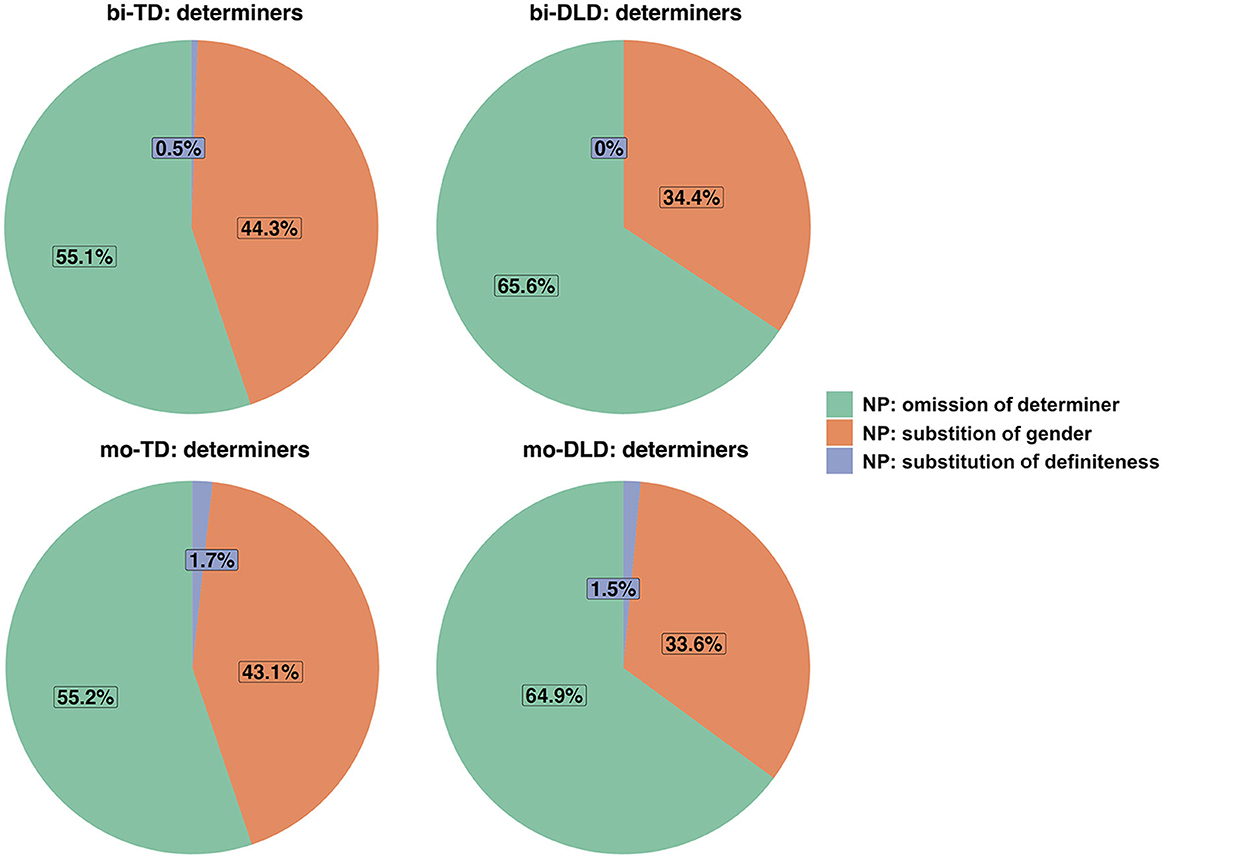
Figure 5. Distributions of determiner errors in Dutch in the bi-TD, bi-DLD, mo-TD, and mo-DLD group.
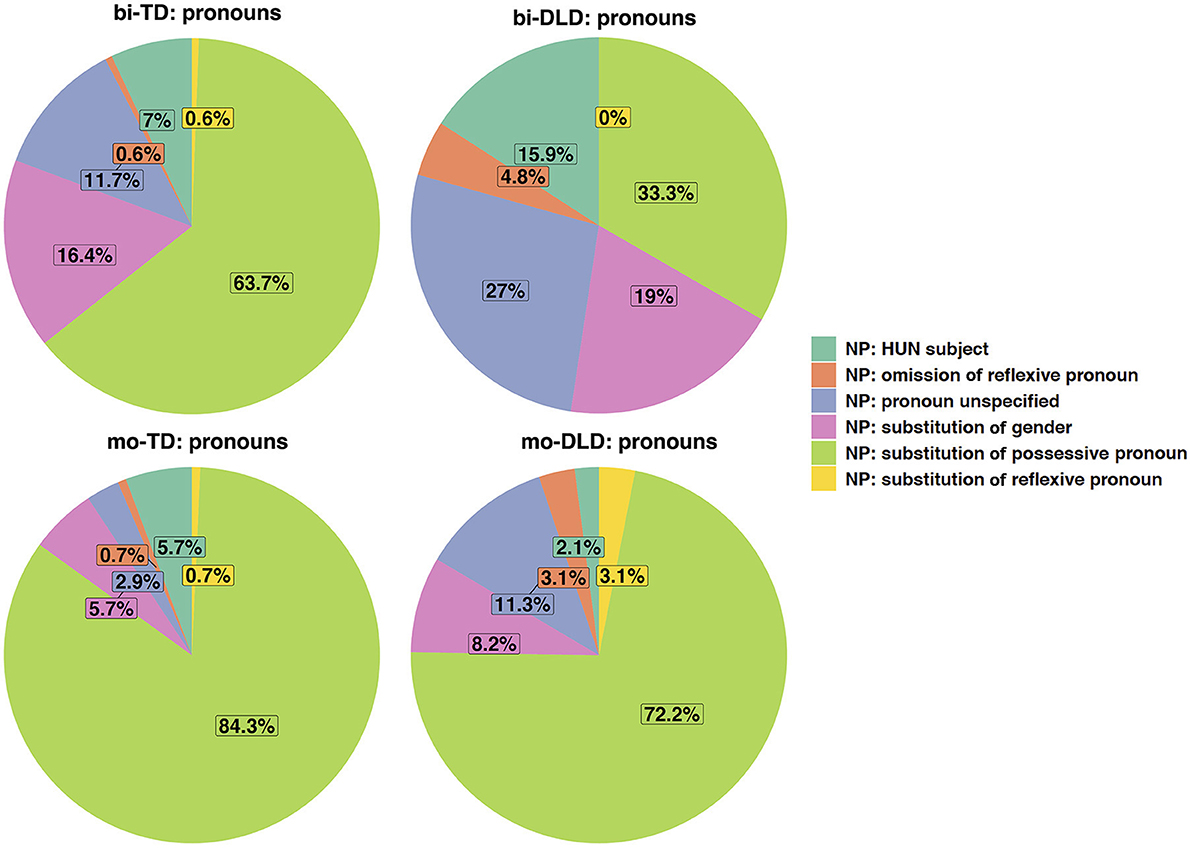
Figure 6. Distributions of pronoun errors in Dutch in the bi-TD, bi-DLD, mo-TD, and mo-DLD group.
Determiner errors
Figure 5 shows that the patterns of errors with determiners are quite similar for the bi-DLD and bi-TD children, although the former group may omit determiners slightly more often. Errors in both groups comprise missing and substituted determiners, i.e., use of the common gender definite determiner de or demonstrative die (bi-TD: n = 102, bi-DLD: n = 86) instead of the neuter gender definite determiner het or demonstrative dat (bi-TD: n = 82; bi-DLD: n = 45). Example (14), which is produced by a bilingual TD child at Wave 2 and contains a diminutivized noun (which is always neuter gender in Dutch), illustrates a substitution of the demonstrative. Substitution of definite determiners by indefinite determiners, and vice versa, hardly ever occurred. Patterns in the monolingual groups closely resemble those in the bilingual groups.
(14) en die [: dat] [*] koe+tje viel eraf.
and that-DEM.COM cow-DIM fall-PST it+from
“and the little cow fell from it.”
Pronoun errors
Children in the bi-TD and bi-DLD groups made a variety of errors with pronouns, as shown in Figure 6. The most prominent difference between the groups concerns the substitution of possessive pronouns such as mijn (“mine”) or zijn (“his”) by personal pronouns such as mij (“my”) or hem (“him”), as illustrated in example (15), which is produced by a bilingual TD child at Wave 1. These errors are not only numerically more frequent in the bi-TD group (n = 109) than in the bi-DLD group (n = 21), but they are also relatively more frequent. While the mo-TD and mo-DLD groups show in this respect the same pattern as the bi-TD group, there is no predominant error in the bi-DLD group. Also, in the bi-DLD group, the category “unspecified” (which contains a variety of errors that do not fit any of the other error categories) is relatively large. Use of hun “them” in subject position instead of the required nominative form zij or ze “they” is common in colloquial Dutch and may, therefore, not count as an error.
(15) omdat hij hem [: zijn] [*] bal terug heeft.
because he-3SG.ACC/DAT ball back have-3SG.PRES
“because he has his ball back.”
Verbal domain in Dutch
The bi-TD children made fewer errors (n = 167) than the bi-DLD children (n = 227). In the bi-TD group, errors with finite verbs and non-finite verbs accounted for, respectively, 89 and 10% of the errors with grammatical morphemes in the verbal domain; in the bi-DLD group, the percentages are 88 and 11%, respectively. Most errors with finite and non-finite verbs are substitutions and omissions of bound grammatical morphemes (i.e., affixes), and contrast in this respect with the determiner and pronoun errors in the nominal domain. To illustrate the distribution of errors in the bi-TD and bi-DLD groups, pie charts were created for finite verbs (Figure 7) and non-finite verbs (Figure 8). Below, we will discuss the patterns in greater detail, thereby again comparing bilinguals with monolingual controls to determine whether error patterns are dependent on bilingualism. Numerically, the mo-TD children (n = 61, finite verbs: 84%, non-finite verbs: 5%) made fewer errors with verbs than the mo-DLD children (n = 179, finite verbs: 93%, non-finite verbs: 8%).
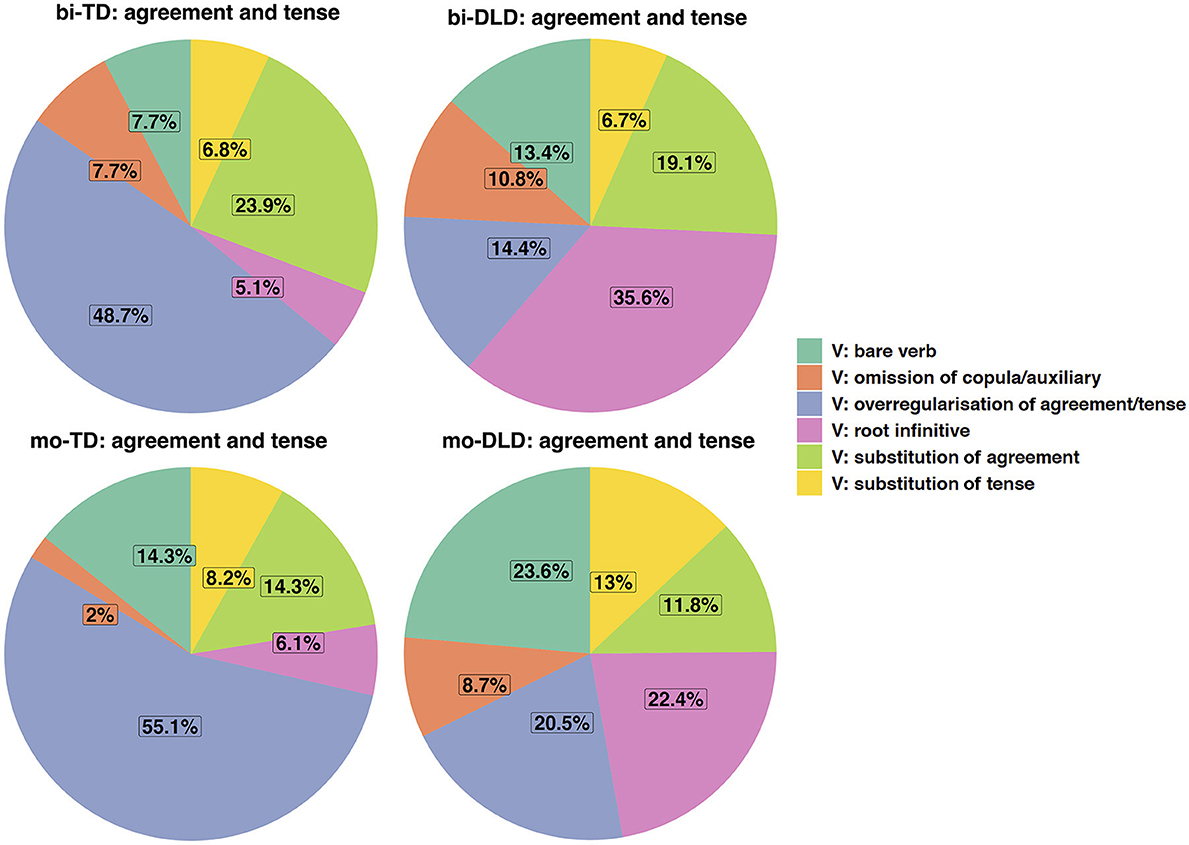
Figure 7. Distributions of agreement and tense errors in Dutch in the bi-TD, bi-DLD, mo-TD, and mo-DLD group.
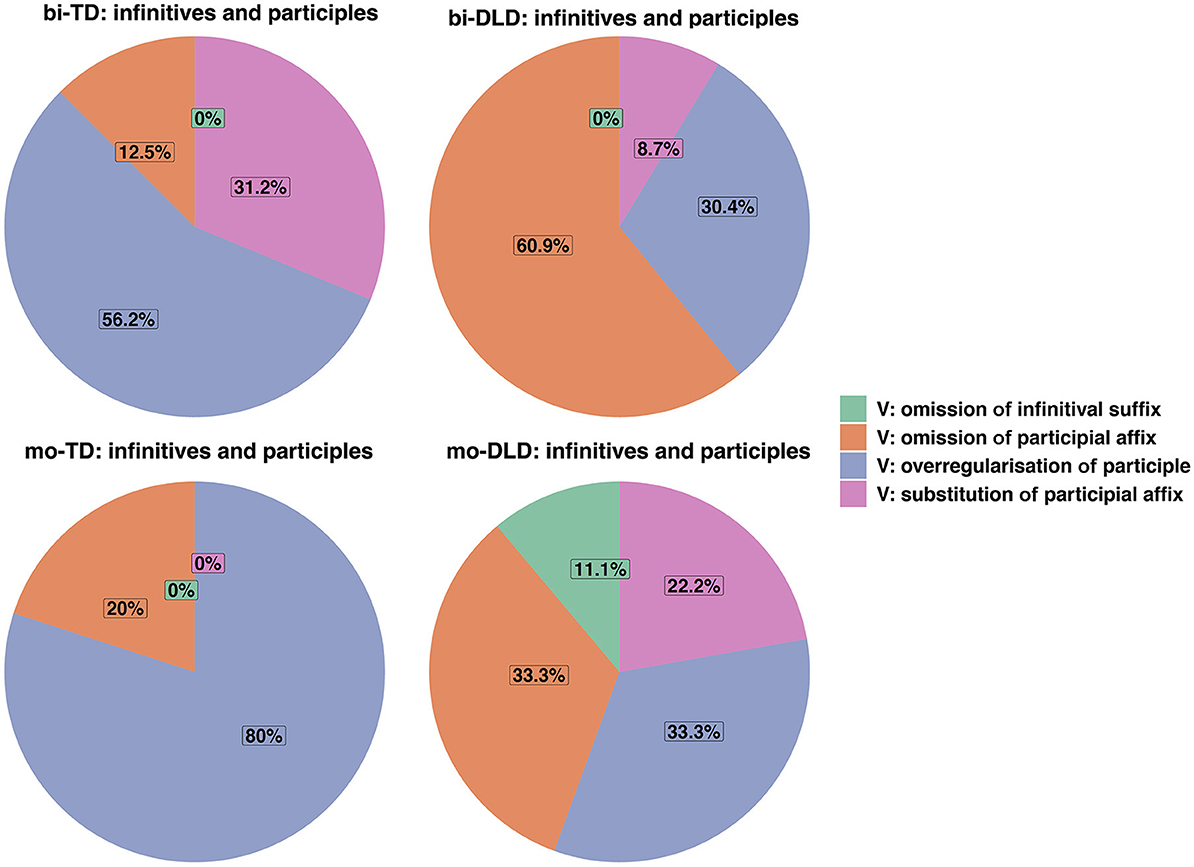
Figure 8. Distributions of infinitives and participles in Dutch in the bi-TD, bi-DLD, mo-TD, and mo-DLD group.
Agreement and tense errors
The bi-DLD children used root infinitives much more often (n = 69) than the bi-TD children (n = 6). A similar pattern can be seen in the mo-DLD children (n = 36) vs. the mo-TD children (n = 3). In example (16) below, a bi-DLD child at Wave 2 uses a root infinitive, which is defined by the lack of a finite verb in second position and presence of an infinitive (vasthouwe) following the direct object (feet).
(16) hij voete(n) vasthouwe [*].
he-NOM.3SG foot-PL hold-INF
“he holds feet.”
Like root infinitives, which have an infinitival suffix but lack agreement and tense marking, use of bare verbs reflects omission of obligatory agreement and tense marking. While in the bi-DLD group root infinitives are more frequent than bare verbs (n = 26), the two errors are about equally frequent in the mo-DLD group. Bare verbs are found less often in the bi-TD (n = 9) and mo-TD groups (n = 7) than in the two DLD groups, similar to root infinitives. However, in relative terms and as illustrated in the pie charts, bare verbs seem somewhat less typical of DLD than root infinitives. The example below shows a bi-DLD child at Wave 2 using the bare stem wil (instead of the inflected plural form willen).
(17) hun [: zij] [*] wil [: willen] [*] een worme [: worm] ete(n).
them want-STEM a worm eat-INF
“they want to eat a worm.”
Overregularizations, in contrast to root infinitives and bare verbs, were more frequent in the bi-TD group (n = 57) than in the bi-DLD group (n = 28), and account for quite a large portion of errors with finite verbs in both the bi-TD and mo-TD groups, as indicated in Figure 7. Overregularization occurred with irregular agreement and tense forms (where a regular inflectional suffix is added to the stem instead of using the target irregular form). Below in example (18), a bi-TD child at Wave 3 uses the regular past tense suffix -de with the stem klim “climb” instead of the target irregular form klom.
(18) de poes klimde [: klom] [*] op de boom
the cat climb-SG-PST on the tree
“the cat climbed in the tree.”
Errors with participles
Figure 8 shows errors with infinitives and participles. In Dutch, infinitives and participles are morphologically marked with, respectively, an infinitival suffix (-en) and a circumfix (ge_d/t, ge_en). The bi-DLD children showed relatively many omissions of participial affixes (n = 14) and they substituted participial affixes (n = 2) and overregularized irregular participles (n = 7) less often than the bi-TD children (omission: n = 2, substitution: n = 5, overregularization: n = 9). That TD children overregularize more than children with DLD can also be observed in monolinguals.
Omission of the participial suffix is illustrated below in (19), where a bi-DLD child at Wave 2 uses gekreeg (“received”) instead of gekregen, not using the suffix -en, while using the prefix ge- and changing the stem vowel to create an irregular form.
(19) en ik heb nog een kettings [: kettingen] [*] gekreeg [: gekregen] [*] voor m'n verjaardag.
and I have-1SG.PRES also a necklaces receive-PTC for my birthday
“and I have also been given a necklace for my birthday.”
Discussion and conclusion
In this longitudinal study, we investigated children's simultaneous grammatical development over the course of a 2-year period, to determine how DLD impacts on both the heritage language (Turkish) and societal language (Dutch). Below, we discuss the most important results of our study in relation to the three research questions that guided the study.
Effects of DLD on Turkish learned as a heritage language
Heritage language development can be at risk because of limited input and use at home and a lack of support in schools (De Houwer, 2007; Montrul, 2008; Restrepo et al., 2010; Hoff, 2018). The question arises how this specific and often challenging context of heritage language learning interacts with the limited language learning abilities of children with DLD. Because previous research on this group of language learners focused on the societal language, a complete picture of bilingual development in this group of language learners is lacking. If the heritage language is not well developed in both children with and without DLD, this would limit the diagnostic potential of heritage language assessment. Therefore, we wanted to know whether grammatical development in heritage Turkish differs between Turkish-Dutch children with and without DLD, both quantitatively and qualitatively.
In Turkish, the bi-DLD children in our study used shorter utterances than the bi-TD children and they also tended to make more grammatical errors, which were mostly errors with grammatical morphemes, and to a lesser extent, errors with sentence elements. Word order errors were infrequent in both bi-DLD and bi-TD groups, which is not surprising, given the relatively free word order in Turkish. Regarding grammatical morphemes, children in the bi-DLD group made more omission errors than children in the bi-TD group, whereas the groups did not differ in substitution of grammatical morphemes. Grammatical morpheme errors were made in both the nominal and verbal domain, but both groups made more errors in the nominal domain, as has been suggested in previous literature (Acarlar and Johnston, 2006, 2011). Like the bilingual children in our study, previous research showed that monolingual Turkish children with DLD tend to make omission errors (Güven and Leonard, 2020, 2021). In these respects, our study suggests that effects of DLD in heritage Turkish learned in the Netherlands resemble those in monolingual Turkish learned in Turkey.
The three-wave longitudinal design of the present study enabled us to investigate development across the bi-TD and bi-DLD groups. Longitudinal analyses revealed that the relative frequency of grammatical errors decreased over time, while the mean length of utterance showed some increase during the period that we investigated. Both findings support the same conclusion, namely that the children continued to develop their Turkish. Previous studies have indicated that children's Turkish development is under pressure (Akoğlu and Yağmur, 2016; Backus and Yağmur, 2017), and it is promising that the children in our study who are born and raised in the Netherlands, and who are second or third generation migrants, are still developing their Turkish skills even after spending some years in a Dutch-speaking school environment. In most bilingual families that participated, Turkish was spoken at home at least half of the time, and sometimes even more than 80% of the time. These percentages confirm earlier observations about Turkish migrant families in the Netherlands, which indicated strong intergenerational transmission and maintenance of Turkish (Extra and Yağmur, 2010). Most probably, frequent Turkish input at home contributed to the continuing Turkish development of the children who participated in our study. It remains to be seen whether children continue to develop their Turkish at the same rate at later ages, as pressure of Dutch will become stronger when children grow older. A third developmental finding was that the proportion of substitution errors increased. This increase of substitutions was observed between the second and third wave of data collection, which may be compatible with the idea that substitution errors reflect a later phase in development in which learners know that a grammatical position needs to be filled, but the feature specifications of the different grammatical morphemes are still unstable, and, perhaps, partly underspecified, resulting in mismatches and substitution errors (see, for an overview of relevant theoretical accounts: Ionin, 2013). Finally, no significant interactions were found, which indicates that developmental patterns did not differ between the bi-TD and bi-DLD children. We tentatively predicted that children with DLD may develop at a slower pace than their TD peers because of input processing limitations coupled with limited input and use. The absence of an interaction is not in line with this prediction and may indicate that Turkish input and use are sufficient for children whose ability to learn language is impaired. This could be related to high levels of heritage language maintenance in the Turkish community and does not necessarily generalize to heritage languages that are transmitted less and that have lower levels of maintenance. For example, in the Netherlands, heritage language maintenance is stronger among migrants from Turkish descent compared to migrants from Moroccan descent who speak Berber languages (Extra and Yağmur, 2010).
In addition to quantitative analyses, we performed qualitative analyses of grammatical morpheme errors. Children in both groups produced a variety of errors, in line with (Güven and Leonard, 2020, 2021) observations based on monolingual Turkish children with and without DLD. However, children also showed a large degree of interindividual variation, similar to what has been reported for child heritage learners of Turkish in Germany (Rothweiler et al., 2010). Like in other studies, investigating both monolingual and bilingual learners of Turkish, we found that accusative case was a locus of errors. Rothweiler et al. (2010) concluded that the Turkish-German bilingual children with DLD in their study omitted and substituted accusative case. While we found that substitutions (mostly with dative case) did occur in the bi-DLD children, relative frequency data revealed that omissions are more typical for the bi-DLD group, in line with studies on monolingual Turkish (Güven and Leonard, 2020). Although accusative case errors are also common in monolingual learners of Turkish, such errors must be interpreted with caution in the context of Turkish learned as a heritage language. Accusative case errors may be developmental in nature, but we cannot exclude the possibility that children are exposed to such “errors” because it is a characteristic of Turkish spoken in the Netherlands (Doğruöz and Backus, 2009). Focusing on accusative case errors to establish a DLD diagnosis in the context of Turkish as a heritage language could thus contribute to overdiagnosis.
The patterns of errors regarding the genitive-possessive construction were different across the two groups as well. The bi-DLD group tended to omit the possessive suffix, while the bi-TD group tended to duplicate the possessive suffix. Interestingly, when the genitive suffix was omitted by a bi-TD child, this often involved an embedded noun clause, such that the genitive case was omitted on the subject of the embedded clause. In contrast, all omissions of genitive case in the bi-DLD group involved simple genitive-possessive construction errors. In other words, omission errors in the bi-TD group may have surfaced because they attempted to utter complex constructions, and not because they have not mastered the genitive case per se. In a similar vein, unlike children in the bi-DLD group, children in the bi-TD group sometimes substituted dative case on the nominalized verb of the embedded noun clause. It may be the case that such errors were not found in the bi-DLD group because they do not use embedded noun clauses that require genitive case on the subject or case marking on the nominalized verb. The issue of complexity in relation to genitive marking in Turkish is also brought up by Acarlar and Johnston (2011), who found increased error rates with the genitive suffix in children with developmental delays. The observations in our study demonstrate the importance of considering the complexity of the construction if a suffix is obligatory: children with DLD may show a greater tendency to make errors with suffixes in simple constructions and avoid the more complex constructions altogether in comparison to their TD peers.
Effects of DLD on Dutch learned as the societal language
With this study, our aim was to enhance our understanding of the parallel development of Turkish learned as a heritage language and Dutch as a societal language. The second set of analyses was, therefore, focused on Dutch. Note that, in recent years, a handful of studies investigated the impact of DLD on Dutch grammatical development in bilingual children of Turkish descent (Orgassa and Weerman, 2008; Verhoeven et al., 2011; Blom et al., 2013; Marinis et al., 2017), and one study reported on both Turkish and Dutch language outcomes (Verhoeven et al., 2012), but none of these studies analyzed semi-spontaneous speech or performed longitudinal analyses. The results of the present study are not only insightful with respect to the dual language development of heritage language Turkish and societal language Dutch in children but are also important to determine whether results of previous research that were obtained using controlled and standardized procedures, are replicated in semi-spontaneous speech, and to establish developmental effects.
In Dutch, the bi-DLD children used shorter utterances than the bi-TD children, similar to what has been reported for comparisons of utterance length across younger monolingual Dutch children with and without DLD (Bol and Kuiken, 1988). Across the two groups, utterance length increased during the period of the study, pointing to an ongoing and steady development in Dutch. However, there was no statistical evidence indicating that the relative frequency of grammatical errors decreased over time. So, although sentence complexity increased, children did not appear to make fewer grammatical errors. Moreover, statistical analyses revealed no effect of group, suggesting that the relative frequency of grammatical errors did not differ across the bi-TD and bi-DLD group. While this seems surprising at first sight, and was not predicted beforehand, it is possible that the semi-spontaneous data that we analyzed may show less effect of DLD than data collected with standardized instruments and experimental materials (as used in previous research), because children with DLD may have avoided constructions that they find difficult to use, which to some extent concurs with what we suggested for the complex genitive-possessive constructions in Turkish. Moreover, the children with DLD used short utterances, reducing the possibility of making errors.
However, while these explanations may contribute to understanding the absence of a difference, they may not provide a full explanation, as in Turkish, the relative frequency of grammatical errors did differ between the bi-TD and bi-DLD groups, even though the same method of data collection was used and the utterances of bi-DLD children were short. In Turkish, however, grammatical morpheme errors, which were most of the grammatical errors, comprised bound morphology, while in Dutch, many of the errors were made with free-standing grammatical morphemes, specifically determiners. Such errors are not a typical characteristic of DLD in West Germanic languages (Leonard, 2014) and are known to be prone to influences of language contact (Hinskens et al., 2021), impacting on language use of both bilingual children with DLD and TD.
The proportion of omissions of grammatical morphemes was higher for the bi-DLD children than the bi-TD children and, reversely, the proportion of substitutions of grammatical morphemes was higher for the bi-TD than the bi-DLD group. A significant interaction effect revealed that the difference between the two groups in types of errors became smaller over the course of the study. The observation that children with DLD tend to omit grammatical morphemes in Dutch confirms patterns found in previous research on monolinguals (Blom et al., 2014b, 2015) and bilinguals (Verhoeven et al., 2011; Boerma, et al., 2017). Regarding the domain of errors with grammatical morphemes, the bi-DLD children made more errors in the verbal domain compared to the nominal domain, as expected and in line with previous research that identified verbs as a problem area in Dutch DLD (de Jong, 1999; Wexler et al., 2004).
In addition to quantitative analyses, we also analyzed errors with Dutch grammatical morphemes qualitatively, both comparing the bi-DLD and bi-TD groups with each other, as well as with monolingual Dutch control groups. In the nominal domain, children made most errors with determiners and pronouns, which are both free-standing grammatical morphemes in Dutch. In bilingual and monolingual contexts, no clear pattern emerged that distinguished the errors of children with DLD from those of children with TD. The verbal domain, in contrast, showed quite pronounced differences between the bi-DLD and bi-TD group, which may be related to the fact that there is more bound morphology in the verbal than in the nominal domain. Bi-DLD children used more utterances in which tense and agreement marking was absent and they omitted participial affixes more often compared to bi-TD children, which reflects grammatical limitations. A different picture emerged from the bi-TD sample, where overregularization of irregular agreement, tense and participles reflected productive knowledge of grammatical rules. Highly similar patterns were found when comparing the distribution of errors across the mo-DLD and mo-TD groups, indicating that the types of errors were more strongly impacted by DLD than bilingualism. Moreover, the patterns are consistent with previous research showing that, in Dutch, DLD is manifested in omission of agreement and tense (de Jong, 1999; Wexler et al., 2004; Verhoeven et al., 2011; Blom et al., 2013, 2014b) and participial affixes (Boerma, 2017). Limited overregularization in children with DLD has been reported previously for English (Oetting and Horohov, 1997; Redmond and Rice, 2001; Van der Lely and Ullman, 2001; Blom and Paradis, 2013). The results of our study indicate that this observation generalizes to Dutch.
Bilingual assessment and (semi-)spontaneous speech
Analysis of (semi-)spontaneous speech, as used in the current study, could be relevant in clinical practice in situations where no standardized instruments are available, as is often the case in bilingual assessment. Spontaneous speech samples provide rich and ecologically valid data and provide a broad insight into children's linguistic behavior. However, analyses are also limited by what children produce spontaneously. In the case of DLD specifically, utterance length can be short, children may use reduced, simple sentences and avoid more complex structures, reducing the presence of clinical markers, that is, constructions that are likely to yield a high proportion of errors in DLD (Rice and Wexler, 1996). Also, the focus on specific clinical markers may be less useful in spontaneous speech analysis because the open procedure results in a wide range of errors, which broadens and to some extent corrects the (limited) view offered by clinical marker analyses.
However, using the outcomes of analysis of (semi-)spontaneous speech, screening instruments and diagnostic instruments can be developed that target clinical markers. The outcomes of the current study support the claim that bound grammatical morphology in the nominal domain for Turkish and in the verbal domain for Dutch is a promising clinical marker that characterizes DLD, irrespective of bilingualism (Blom et al., 2015; Boerma, 2017). This insight could be used to improve existing language assessment instruments. For example, the Dutch sentence repetition task that is part of the Taaltoets Alle Kinderen “Language Assessment for All Children” (TAK; Verhoeven and Vermeer, 2001) focuses on children's correct repetition of specific free-standing grammatical morphemes and word order patterns. A focus on bound grammatical morphology could result in a more sensitive instrument. The word formation task that is part of the same language assessment battery focuses on bound regular and irregular grammatical morphology in the nominal and verbal domain. However, the outcomes of our study suggest that bound grammatical morphology in the nominal domain may have limited added value (see also: Boerma, 2017), and the same may be true for irregular forms, unless, perhaps, amount of overregularization is considered. In addition, the word formation task focuses on inherent morphology (plural marking on nouns, participle marking on verbs), while contextual morphology, in particular agreement marking in the verbal domain, constitutes an area of difficulty for children with DLD who are learning Dutch (de Jong, 1999; Verhoeven et al., 2011; Blom et al., 2013, 2014b).
Limitations of the study
The longitudinal design, matching of children on background variables, and combination of quantitative and qualitative analyses are important strengths of the study. The conclusions of this study are, however, also limited in several respects. The study would have benefitted from a monolingual Turkish control group to measure the difference between Turkish as a heritage language and a societal language. Moreover, one child with DLD hardly used any Turkish at the first wave. Finally, analysis of (semi-)spontaneous speech provides rich and ecologically valid data, but the speech samples in this study are brief. Larger corpora provide more reliable conclusions, but an increase of corpus size is costly. Automatic transcription and morphosyntactic coding could be solutions, but these options are not yet available for child language research. In addition, although spontaneous speech data are potentially rich, analyses can be limited by the tendency of children with DLD to produce short and simple sentences. The current study was focused on grammatical errors as potential clinical markers. For this reason, we restricted measures of grammatical complexity to MLU. However, because correctness and complexity are both relevant for DLD, future research should include several measures of grammatical complexity, beyond MLU (Tuller et al., 2012).
Conclusions
Cross-linguistic comparisons of error types in Turkish and Dutch confirm that, regardless of typological differences, children with DLD avoid complex constructions, use short sentences, and omit grammatical morphemes. Because complexity and omissions refer to different phenomena in the two languages, investigating the heritage language is of added value and can inform clinical diagnosis. In the case of Turkish spoken in the Netherlands, short sentences, and omission of possessive marking in simple genitive-possessive constructions could be markers of DLD. Although omission and substitution of accusative case are relatively frequent in bilingual Turkish-Dutch children with DLD, correct use of accusative case is less promising as a clinical marker because omission and substitution of accusative case can be part of the input to Turkish heritage language learners. In Dutch, frequent omission of grammatical morphemes in the verbal domain coupled with a limited amount of overregularization errors could indicate that a child is at risk of DLD, both in bilingual and monolingual contexts. These are also aspects that could inform assessment in only Dutch, if assessment in both languages is not possible. Longitudinal analyses revealed that children with DLD can develop the heritage language and do so at the same pace as children with typical development, even if this language is not supported at school. Strong intergenerational transmission and heritage language maintenance among Turkish migrants in the Netherlands may be key.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://osf.io/3z2sj/.
Ethics statement
The studies involving human participants were reviewed and approved by Ethics Review Board of the Faculty of Social and Behavioral Sciences (FERB) at Utrecht University. Written informed consent to participate in this study was provided by the participants' legal guardian/next of kin.
Author contributions
Conceptualization: EB, TB, and JJ. Writing—original draft and funding acquisition: EB. Writing—review and editing and methodology: EB, TB, JJ, FK, and AK. Investigation: TB. Formal analysis and visualization: EB and FK. All authors contributed to the article and approved the submitted version.
Funding
This work was supported by a Vidi Grant #276-70-023 awarded to EB by the Netherlands Organization for Scientific Research (NWO).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2022.1059427/full#supplementary-material
Footnotes
1. ^These often-cited prevalence data are based on English-speaking population samples. The current study is focused on bilingual Turkish-Dutch children in the Netherlands. Regarding DLD prevalence among Turkish-speaking children, Topbaş et al. (2019) estimate 5% prevalence in Turkey. Regarding DLD prevalence among Dutch-speaking children, it is relevant to note that there is no national registration of children with DLD in the Netherlands. Reep-van den Bergh et al. (1998) report prevalence data ranging from 2% to >20% in the Netherlands. This wide range is related to the use of different instruments, cutoff scores, and classification criteria.
References
Acarlar, F., and Johnston, J. R. (2006). Computer-based analysis of Turkish child language: clinical and research applications. J. Multiling. Commun. Disord. 4, 78–94. doi: 10.1080/14769670600704821
Acarlar, F., and Johnston, J. R. (2011). Acquisition of Turkish grammatical morphology by children with developmental disorders. Int. J. Lang. Commun. Disord. 46, 728–738. doi: 10.1111/j.1460-6984.2011.00035.x
Akoğlu, G., and Yağmur, K. (2016). First-language skills of bilingual Turkish immigrant children growing up in a Dutch submersion context. Int. J. Biling. Educ. Biling. 19, 706–721. doi: 10.1080/13670050.2016.1181605
American Speech-Language-Hearing Association (2022). Bilingual Service Delivery (Practice Portal). Available online at: https://www.asha.org/practice-portal/professional-issues/bilingual-service-delivery/#collapse_4 (accessed November 24, 2022).
Backus, A., and Yağmur, K. (2017). Differences in pragmatic skills between bilingual Turkish immigrant children in the Netherlands and monolingual peers. The International Journal of Bilingualism: Cross-Disciplinary, Cross-Linguistic Studies of Language Behavior. 23, 817–830. doi: 10.1177/1367006917703455
Bates, D., Maechler, M., Bolker, B., and Walker, S. (2015). Fitting linear mixed-effects models using lme4. J. Stat. Softw. 67, 1–48. doi: 10.18637/jss.v067.i01
Bialystok, E., Craik, F. I., and Luk, G. (2012). Bilingualism: consequences for mind and brain. Trends Cogn. Sci. 16, 240–250. doi: 10.1016/j.tics.2012.03.001
Blom, E., and Boerma, T. D. (2016). Effects of language impairment and bilingualism across domains: vocabulary, morphology and verbal memory. Linguist. Approaches Biling. 7, 2773200. doi: 10.1075/lab.15018.blo
Blom, E., Boerma, T. D., and de Jong, J. (2019). “First language attrition and developmental language disorder.” in The Oxford Handbook of Language Attrition, Eds, M. S. Schmid and B. Köpke (Oxford University Press), 108–120.
Blom, E., de Jong, J., Orgassa, A., Baker, A. E., and Weerman, F. P. (2013). Verb inflection in monolingual Dutch and sequential bilingual Turkish-Dutch children with and without SLI. Int. J. Lang. Commun. Disord. 48, 382–393. doi: 10.1111/1460-6984.12013
Blom, E., Küntay, A. C., Messer, M., Verhagen, J., and Leseman, P. (2014a). The benefits of being bilingual: working memory in bilingual Turkish–Dutch children. J. Exp. Child Psychol. 128, 105–119. doi: 10.1016/j.jecp.2014.06.007
Blom, E., and Paradis, J. (2013). Past tense production by English second language learners with and without language impairment. J. Speech Lang. Hear. Res. 56, 281–294. doi: 10.1044/1092-4388(2012/11-0112)
Blom, E., Vasić, N., and Baker, A. (2015). The pragmatics of articles in Dutch children with specific language impairment. Lingua. 155, 29–42. doi: 10.1016/j.lingua.2013.12.002
Blom, E., Vasić, N., and de Jong, J. (2014b). Production and processing of subject-verb agreement in monolingual Dutch children with specific language impairment. J. Speech Lang. Hear. Res. 57, 952–965. doi: 10.1044/2014_JSLHR-L-13-0104
Boerma, T. D. (2017). Profiles and paths: effects of language impairment and bilingualism on children's linguistic and cognitive development [Doctoral Dissertation, Utrecht University] Utrecht University Repository. Available online at: https://dspace.library.uu.nl/handle/1874/356269
Boerma, T. D., Wijnen, F., Leseman, P. P. M., and Blom, E. (2017). Grammatical morphology in monolingual and bilingual children with and without language impairment: the case of Dutch plurals and past participles. J. Speech Lang. Hear. Res. 60, 2064–2080. doi: 10.1044/2017_JSLHR-L-16-0351
Boeschoten, H. E. (1990). Acquisition of Turkish by immigrant children: a multiple case study of Turkish children in the Netherlands aged 4 to 6. [Doctoral Dissertation, Tilburg University] Tilburg University Research Portal. Available online at: https://research.tilburguniversity.edu/en/publications/acquisition-of-turkish-by-immigrant-children-a-multiple-case-stud
Bol, G. W., and Kuiken, F. (1988). Grammaticale analyse van taalontwikkelingsstoornissen (Publication No. 304236) [Doctoral Dissertation, University of Amsterdam].
Booij, G. E. (2006). “Inflection and derivation.” in: Encyclopedia of Language and Linguistics, Eds K. Brown (New York: Elsevier), 654–661. doi: 10.1016/B0-08-044854-2/00115-2
Cabo, D. P. Y. (2012). The (il)logical problem of heritage speaker bilingualism and incomplete acquisition. Appl. Linguist. 33, 450–455. doi: 10.1093/applin/ams037
Clahsen, H., Bartke, S., and Göllner, S. (1997). Formal features in impaired grammars: a comparison of English and German SLI children. J. Neurolinguistics. 10, 151–171. doi: 10.1016/S0911-6044(97)00006-7
Cornips, L., and Hulk, A. (2008). Factors of success and failure in the acquisition of grammatical gender in Dutch. Second Lang. Res. 24, 267–295. doi: 10.1177/0267658308090182
De Houwer, A. (2007). Parental language input patterns and children's bilingual use. Applied Psycholinguistics. 28, 411–424. doi: 10.1017/S0142716407070221
de Jong, J. (1999). Specific language impairment in Dutch: Inflectional morphology and argument structure. [Doctoral Dissertation, University of Groningen] University of Groningen research portal. Available online at: https://research.rug.nl/en/publications/specific-language-impairment-in-dutch-inflectional-morphology-and
de Jong, J., Çavus, N., and Baker, A. (2010). Language impairment in Turkish-Dutch bilingual children. Communication disorders in Turkish (Bristol: Multilingual Matters), 288–300. doi: 10.21832/9781847692474-018
Doğruöz, A. S., and Backus, A. (2009). Innovative constructions in Dutch Turkish: an assessment of ongoing contact-induced change. Bilingualism. 12, 41–63. doi: 10.1017/S1366728908003441
Dromi, E., Leonard, L. B., Adam, G., and Zadunaisky-Ehrlich, S. (1999). Verb agreement morphology in Hebrew-speaking children with specific language impairment. J. Speech Lang. Hear. Res. 42, 1414–1431. doi: 10.1044/jslhr.4206.1414
Extra, G., Aarts, R., van der Avoird, T., Broeder, P., and Yağmur, K. (2002). De andere talen van Nederland: thuis en op school. Coutinho.
Extra, G., and Yağmur, K. (2010). Language proficiency and socio-cultural orientation of Turkish and Moroccan youngsters in the Netherlands. Language and Education. 24, 117–132. doi: 10.1080/09500780903096561
Gagarina, N. V., Klop, D., Kunnari, S., Tantele, K., Välimaa, T., Balčiūnienė, I., et al. (2012). MAIN: Multilingual assessment instrument for narratives. Berlin: Zentrum für Allgemeine Sprachwissenschaft.
Gillam, R. B., Montgomery, J. W., Evans, J. L., and Gillam, S. L. (2019). Cognitive predictors of sentence comprehension in children with and without developmental language disorder: implications for assessment and treatment. Int. J. Speech Lang. Pathol. 21, 240–251. doi: 10.1080/17549507.2018.1559883
Göksel, A., and Kerslake, C. (2005). Turkish: A comprehensive grammar (1st ed.). London: Routledge. doi: 10.4324/9780203340769
Gray, S. (2003). Diagnostic accuracy and test–retest reliability of nonword repetition and digit span tasks administered to preschool children with specific language impairment. J. Commun. Disord. 36, 129–151. doi: 10.1016/S0021-9924(03)00003-0
Güven, S., and Leonard, L. B. (2020), Production of noun suffixes by Turkish-speaking children with developmental language disorder their typically developing peers. Int. J. Lang. Commun. Disord. 55, 387–400. doi: 10.1111/1460-6984.12525
Güven, S., and Leonard, L. B. (2021). Verb morphology in Turkish-speaking children with and without DLD: the role of morphophonology. Clin. Linguist. Phon. 1–25. doi: 10.1080/02699206.2021.2012836
Haeseryn, W., Romijn, K., Geerts, G., Rooij, J. D., and Van den Toorn, M. C. (1997). Algemene Nederlandse Spraakkunst 2. Groningen: Martinus Nijhoff.
Hinskens, F. L. M. P., van Hout, R., Muysken, P. C., and van Wijngaarden, R. P. A. (2021). Variation and change in grammatical gender marking: The case of Dutch ethnolects. Linguistics. 59, 75–100. doi: 10.1515/ling-2020-0265
Hoff, E. (2018). Bilingual development in children of immigrant families. Child Dev. Perspect. 12, 80–86. doi: 10.1111/cdep.12262
Ionin, T. (2013). “Morphosyntax.” in: The Cambridge Handbook of Second Language Acquisition, Cambridge Handbooks in Language and Linguistics, Eds. J. Herschensohn and M. Young-Scholten (Cambridge: Cambridge University Press, 505–528.
Kohnert, K. (2010). Bilingual children with primary language impairment: issues, evidence and implications for clinical actions. J. Commun. Disord. 43, 456–473. doi: 10.1016/j.jcomdis.2010.02.002
Kuiken, F., and Van der Linden, E. (2013). Language policy and language education in the Netherlands and Romania. Dutch J. Appl. Linguist. 2, 205–223. doi: 10.1075/dujal.2.2.06kui
Leonard, L. B. (2014). Specific language impairment across languages. Child Dev. Perspect. 8, 1–5. doi: 10.1111/cdep.12053
Leonard, L. B., Kunnari, S., Savinainen-Makkonen, T., Tolonen, A., Mäkinen, L., Luotonen, M., et al. (2014). Noun case suffix use by children with specific language impairment: an examination of Finnish. Appl. Psycholinguist. 35, 833–854. doi: 10.1017/S0142716412000598
Lukács, A., Leonard, L. B., and Kas, B. (2010). Use of noun morphology by children with language impairment: the case of Hungarian. Int. J. Lang. Commun. Disord. 45, 145–161. doi: 10.3109/13682820902781060
Lukács, A., Leonard, L. B., Kas, B., and Pleh, C. (2009). The use of tense and agreement by Hungarian-speaking children with language impairment. J. Speech Lang. Hear. Res. 52, 98–117. doi: 10.1044/1092-4388(2008/07-0183)
MacRoy-Higgins, M., and Dalton, K. P. (2015). The influence of phonotactic probability on nonword repetition and fast mapping in 3-year-olds with a history of expressive language delay. J. Speech Lang. Hear. Res. 58, 1773–1779. doi: 10.1044/2015_JSLHR-L-15-0079
Marinis, T., Chondrogianni, V., Vasic, N., Weerman, F., and Blom, E. (2017). The impact of transparency and morpho-phonological cues in the acquisition of grammatical gender in sequential bilingual children and children with specific language impairment: a cross-linguistic study. Cross-linguistic influence in bilingualism: In honor of Aafke Hulk. 153. doi: 10.1075/sibil.52.08mar
Mennen, I., and Stansfield, J. (2006). Speech and language therapy services to multilingual children in Scotland and England: a comparison of three cities. J. Multiling. Commun. Disord. 4, 23–44. doi: 10.1080/14769670500272689
Montrul, S. (2008). Second language acquisition welcomes the heritage language learner: opportunities of a new field. Second Lang. Res. 24, 487–506. doi: 10.1177/0267658308095738
Norbury, C. F., Gooch, D., Wray, C., Baird, G., Charman, T., Simonoff, E., et al. (2016). The impact of nonverbal ability on prevalence and clinical presentation of language disorder: evidence from a population study. J. Child Psychol. Psychiatry. 57, 1247–1257. doi: 10.1111/jcpp.12573
Oetting, J. B., and Horohov, J. E. (1997). Past-tense marking by children with and without specific language impairment. J. Speech Lang. Hear. Res. 40, 62–74. doi: 10.1044/jslhr.4001.62
Orgassa, A., and Weerman, F. (2008). Dutch gender in specific language impairment and second language acquisition. Second Lang. Res. 24, 333–364. doi: 10.1177/0267658308090184
R Core Team. (2016). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. Available online at: https://www.R-project.org/
Redmond, S. M., and Rice, M. L. (2001). Detection of irregular verb violations by children with and without SLI. J. Speech Lang. Hear. Res. 44, 655–669. doi: 10.1044/1092-4388(2001/053)
Reep-van den Bergh, C. M. M., de Koning, H. J., de Ridder-Sluiter, J. G., van de Lem, G. J., and van der Maas, P. J. (1998). Prevalentie van taalontwikkelingsstoornissen bij kinderen. Tijdschrift voor Gezondheidswetenschappen. 76, 311–317.
Restrepo, M. A., Castilla, A. P., Schwanenflugel, P. J., Neuharth-Pritchett, S., Hamilton, C. E., and Arboleda, A. (2010). Effects of a supplemental Spanish oral language program on sentence length, complexity, and grammaticality in Spanish-speaking children attending English-only preschools. Language, Speech and Hearing Services in Schools. 41, 3–13. doi: 10.1044/0161-1461(2009/06-0017)
Restrepo, M. A., and Kruth, K. (2000). Grammatical characteristics of a Spanish-English bilingual child with specific language impairment. Commun. Disord. Q. 21, 66–76. doi: 10.1177/152574010002100201
Rice, M. L. (2013). Language growth and genetics of specific language impairment. Int. J. Speech Lang. Pathol. 15, 223–233. doi: 10.3109/17549507.2013.783113
Rice, M. L., Buhr, J., and Oetting, J. B. (1992). Specific-language-impaired children's quick incidental learning of words: the effect of a pause. J. Speech Hear. Res. 35, 1040–1048. doi: 10.1044/jshr.3505.1040
Rice, M. L., Noll, K. R., and Grimm, H. (1997). An extended optional infinitive stage in german-speaking children with specific language impairment. Lang. Acquis. 6, 255–295. doi: 10.1207/s15327817la0604_1
Rice, M. L., and Wexler, K. (1996). Toward tense as a clinical marker of specific language impairment in English-speaking children. J. Speech Lang. Hear. Res. 39, 1239–1257. doi: 10.1044/jshr.3906.1239
Rispens, J. E., and De Bree, E. H. (2014). Past tense productivity in Dutch children with and without SLI: the role of morphophonology and frequency. J. Child Lang. 41, 200–225. doi: 10.1017/S0305000912000542
Rothweiler, M., Chilla, S., and Babur, E. (2010). Specific language impairment in Turkish: evidence from case morphology in Turkish-German successive bilinguals. Clin. Linguist. Phon. 24, 540–555. doi: 10.3109/02699200903545328
Stichting Siméa. (2014). Indicatiecriteria: auditief en/of communicatief beperkte leerlingen. Available online at: https://simea.nl/dossiers/passend-onderwijs/brochures-po/simea-brochure%20indicatiecriteria-juni-2014.pdf
Tomblin, J. B., Records, N. L., Buckwalter, P., Zhang, X., Smith, E., and O'Brien, M. (1997). Prevalence of specific language impairment in kindergarten children. J. Speech Lang. Hear. Res. 40, 1245–1260. doi: 10.1044/jslhr.4006.1245
Topbaş, S., Bulut, T., and Günhan, N. E. (2019). “Turkey.” in Managing Children with Developmental Language Disorder: Theory and Practice Across Europe and Beyond, Eds J. Law, C. McKean, C. A. Murphy and E. Thordardottir (London: Routledge), 365–377.
Topbaş, S., Güven, S., Uysal, A. A., and Kazanoglu, D. (2016). “Language impairment in Turkish-speaking children: the nature of morphological errors.” in The acquisition of Turkish in childhood, Eds B. Haznedar and N. Ketrez (Amsterdam/Philadelphia: Benjamins), 295–324. doi: 10.1075/tilar.20.13top
Topbaş, S., and Yavas, M. (2010). Communication disorders in Turkish (1st ed.). Bristol: Multilingual Matters. doi: 10.21832/9781847692474
Tuller, L. (2015). “Clinical use of parental questionnaires in multilingual contexts,” in Methods for Assessing Multilingual Children: Disentangling Bilingualism From Language Impairment, eds S. Armon-Lotem, J. de Jong, and N. Meir (Bristol: Multilingual Matters), 301–330.
Tuller, L., Henry, C., Sizaret, E., and Barthez, M.-A. (2012). Specific language impairment at adolescence: avoiding complexity. Appl. Psycholinguist. 33, 161–184. doi: 10.1017/S0142716411000312
Valdés, G. (2000). “The teaching of heritage languages: an introduction for Slavic-teaching professionals.” in The Learning and Teaching of Slavic Languages and Cultures: Toward the 21st Century, Eds O. Kagan, and B. Rifkin (Bloomington, IN: Slavica), 375–403.
Van der Lely, H. K. J., and Ullman, M. T. (2001). Past tense morphology in specifically language impaired and normally developing children. Lang. Cogn. Process. 16, 177–217. doi: 10.1080/01690960042000076
Verhoeven, L., Steenge, J., and van Balkom, H. (2012), Linguistic transfer in bilingual children with specific language impairment. Int. J. Lang. Commun. Disord. 47, 176–183. doi: 10.1111/j.1460-6984.2011.00092.x
Verhoeven, L. T. W., Steenge, J., and van Balkom, H. (2011). Verb morphology as clinical marker of specific language impairment: evidence from first and second language learners. Res. Dev. Disabil. 32, 1186–1193. doi: 10.1016/j.ridd.2011.01.001
Verhoeven, L. T. W., and Vermeer, A. (2001). Taaltoets alle kinderen. diagnostische toets voor de mondelinge vaardigheid Nederlands bij kinderen van groep 1 tot en met 4. Arhem: Citogroep.
Weismer, S. E., Venker, C. E., Evans, J. L., and Moyle, M. J. (2013). Fast mapping in late-talking toddlers. Appl. Psycholinguist. 34, 69–89. doi: 10.1017/S0142716411000610
Wexler, K., Schaeffer, J., and Bol, G. W. (2004). Verbal syntax and morphology in typically developing Dutch children and children with SLI: how developmental data can play an important role in morphological theory. Syntax. 7, 148–198. doi: 10.1111/j.1467-9612.2004.00006.x
Keywords: language impairment, bilingualism, heritage language, grammatical morphemes, cross-linguistic comparison, longitudinal design, error types, clinical markers
Citation: Blom E, Boerma T, Karaca F, de Jong J and Küntay AC (2022) Grammatical development in both languages of bilingual Turkish-Dutch children with and without Developmental Language Disorder. Front. Commun. 7:1059427. doi: 10.3389/fcomm.2022.1059427
Received: 01 October 2022; Accepted: 16 November 2022;
Published: 15 December 2022.
Edited by:
Natalia Meir, Bar-Ilan University, IsraelReviewed by:
Natalia Banasik-Jemielniak, The Maria Grzegorzewska University, PolandMaureen Scheidnes, Memorial University of Newfoundland, Canada
Copyright © 2022 Blom, Boerma, Karaca, de Jong and Küntay. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Elma Blom, dy5iLnQuYmxvbUB1dS5ubA==