 Aleksandr Zaitcev
Aleksandr Zaitcev Mohammad R. Eissa
Mohammad R. Eissa Zheng Hui1
Zheng Hui1 Mohammed Benaissa
Mohammed Benaissa- 1Department of Electronic and Electrical Engineering, University of Sheffield, Sheffield, United Kingdom
- 2Department of Oncology and Metabolism, University of Sheffield, Sheffield, United Kingdom
- 3Department of Diabetes and Endocrinology, Sheffield Teaching Hospitals NHS FT, Sheffield, United Kingdom
Background: Hypoglycemia is the most common adverse consequence of treating diabetes, and is often due to suboptimal patient self-care. Behavioral interventions by health professionals and self-care education helps avoid recurrent hypoglycemic episodes by targeting problematic patient behaviors. This relies on time-consuming investigation of reasons behind the observed episodes, which involves manual interpretation of personal diabetes diaries and communication with patients. Therefore, there is a clear motivation to automate this process using a supervised machine learning paradigm. This manuscript presents a feasibility study of automatic identification of hypoglycemia causes.
Methods: Reasons for 1885 hypoglycemia events were labeled by 54 participants with type 1 diabetes over a 21 months period. A broad range of possible predictors were extracted describing a hypoglycemic episode and the subject’s general self-care from participants’ routinely collected data on the Glucollector, their diabetes management platform. Thereafter, the possible hypoglycemia reasons were categorized for two major analysis sections - statistical analysis of relationships between the data features of self-care and hypoglycemia reasons, and classification analysis investigating the design of an automated system to determine the reason for hypoglycemia.
Results: Physical activity contributed to 45% of hypoglycemia reasons on the real world collected data. The statistical analysis provided a number of interpretable predictors of different hypoglycemia reasons based on self-care behaviors. The classification analysis showed the performance of a reasoning system in practical settings with different objectives under F1-score, recall and precision metrics.
Conclusion: The data acquisition characterized the incidence distribution of the various hypoglycemia reasons. The analyses highlighted many interpretable predictors of the various hypoglycemia types. Also, the feasibility study presented a number of concerns valuable in the design of the decision support system for automatic hypoglycemia reason classification. Therefore, automating the identification of the causes of hypoglycemia may help objectively to target behavioral and therapeutic changes in patients' care.
1 Introduction
The general goal of type 1 diabetes (T1D) care is maintenance of near normal levels of blood glucose (BG) (1). Avoidance of higher than normal BG (hyperglycemia) reduces the risk of long-term complications, such as eye, kidney or nerve damage (2). Whilst avoidance of low BGs (hypoglycemia) reduces the risk of cognitive impairment and accidents. Successful T1D management largely depends on patient self-care, which requires education and frequent decision making including regular blood glucose (BG) monitoring, insulin intake and its dose adjustment, carbohydrate counting, and planning for dose adjustments due to physical activity (3).
In conventional diabetes care BG levels and food/medication intake are registered by patients in individual diabetes diaries and are examined by clinicians at personal appointments generally occurring once every 3-6 months (4). However, with current and projected advances in sensing and communication technologies, diabetes care is progressively becoming more data-driven and patient-centered, focused on e-learning, decision support and remote supervision of self-care practices based on multimodal data acquisition (5–9). A novel developed Glucollector system (Figure 1) follows this approach. This data acquisition and management suite facilitates the collection, management and visualization of self-monitored blood glucose (SMBG) measurements, continuous glucose monitoring (CGM) data, carbohydrate and insulin intake, and provides a platform for clinician-patient communication and e-learning. Glucollector has been deployed in the DAFNEplus (Dose Adjustment for Normal Eating) Randomized Controlled Trial (RCT) (10).
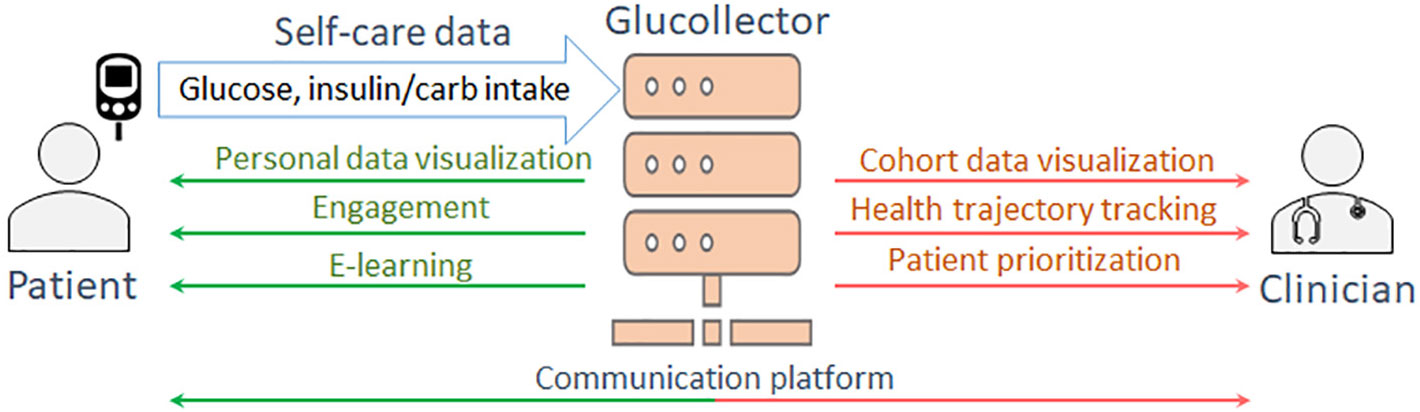
Figure 1 The functionality of Glucollector.
In both personal appointments and remote monitoring, the clinicians supervisory role is to detect problematic self-care patterns in diabetes diaries, to clarify the context of the abnormal pattern with the patient to identify the underlying reason, and to suggest changes to self-care routines to avoid such patterns reoccurring. Such manual interpretation of every episode is problematic considering the time lags between personal appointments and the amounts of data aggregated between them. This process is more feasible in a day-to-day patient supervision paradigm facilitated by the diabetes data management system, such as the Glucollector, where clinicians can examine the remotely collected self-care data in a convenient form. However, this process still becomes a tedious routine for clinicians often supervising tens or hundreds of patients, and therefore, there is a clear motivation to automate such BG pattern interpretation and provide clinical decision support driven by artificial intelligence (AI) and machine learning technology.
The modern diabetes treatment is associated with large amounts of data generated from health records, food/medication diaries and various smart monitoring devices. Taking this into account and that hypoglycemia represents a major adverse consequence of diabetes treatment, substantial research effort was committed to design data-driven tools based on machine learning that would provide assistance in clinical practice and personal day-to-day hypoglycemia prevention. A number of recent systematic reviews outline these research efforts (11–14). However, from these studies it is evident that in context of hypoglycemia prevention the pattern recognition and machine learning research mainly focuses on hypoglycemic event prediction, while the retrospective data-driven interpretation of reasons behind such events (automated hypoglycemia cause classification), that is needed for behavioral intervention, remains understudied.
This manuscript aims to fill this gap by conducting a feasibility study aiming to determine the practicality and limitations of automated hypoglycemia reason classification from patterns of T1D self-care data, collected by the modern diabetes management software. The key objectives of this study are to design indicative predictor variables from time series of self-care data, assess their statistical relationship with reasons behind hypoglycemic events, design an automated system for hypoglycemia cause classification and assess its practicality.
2 Materials and methods
2.1 Data acquisition
Data was collected between March 2018 and December 2019 from a cohort of 54 Glucollector users who were also patients of Sheffield Teaching Hospitals (STH) NHS Foundation Trust taking part in the DAFNEplus RCT, for details refer to the protocol paper of the trial (10). Ethics approvals were granted under REC ref: 16/NW/0573 and 18/SW/0100. For the purpose of data collection, the 10 most common reasons behind hypoglycemia episodes, defined as < 4mmol/L SMBG measurements, were identified by the diabetes specialists based on their clinical practice and patient interviews.
These reasons were presented to the participating people with type 1 diabetes who were asked to label their recent hypoglycemia episodes from the preceding two weeks on their Glucollector diabetes diary interface. For every episode, they were allowed to select up to two possible reasons with a confidence level of 1 to 5 for every answer with 5 being the highest confidence.
The 54 participants were 36 female (18 male), and the average age was 46.8± 15.2 years. These participants labeled a total of 1885 hypoglycemia observations which were obtained during the data collection period. Episodes that did not belong to class “Other” or “Don’t know” and which were labeled with confidence levels 4-5 were included into the analysis dataset, yielding a total of 821 observations. Figure 2 shows the class distribution of the collected dataset. Considering the vast disbalance in class observations the cases were grouped into the three general categories of hypoglycemia causes for statistical and predictive analysis: physical activity, mistakes in food intake, mistakes in medication dosage selection. It can be noted that cases related to physical activity constitute about 45% of the dataset. The second most prominent category of episodes is associated with carbohydrate counting and food intake (≈33%). Cases related to insulin dosage selection and intake comprise the third most common category with ≈15%. These three groups are used as possible class labels in the classification analysis section, i.e. the proposed machine learning system aims to “guess” the cause of hypoglycemic event from patterns of self-care data around the event.
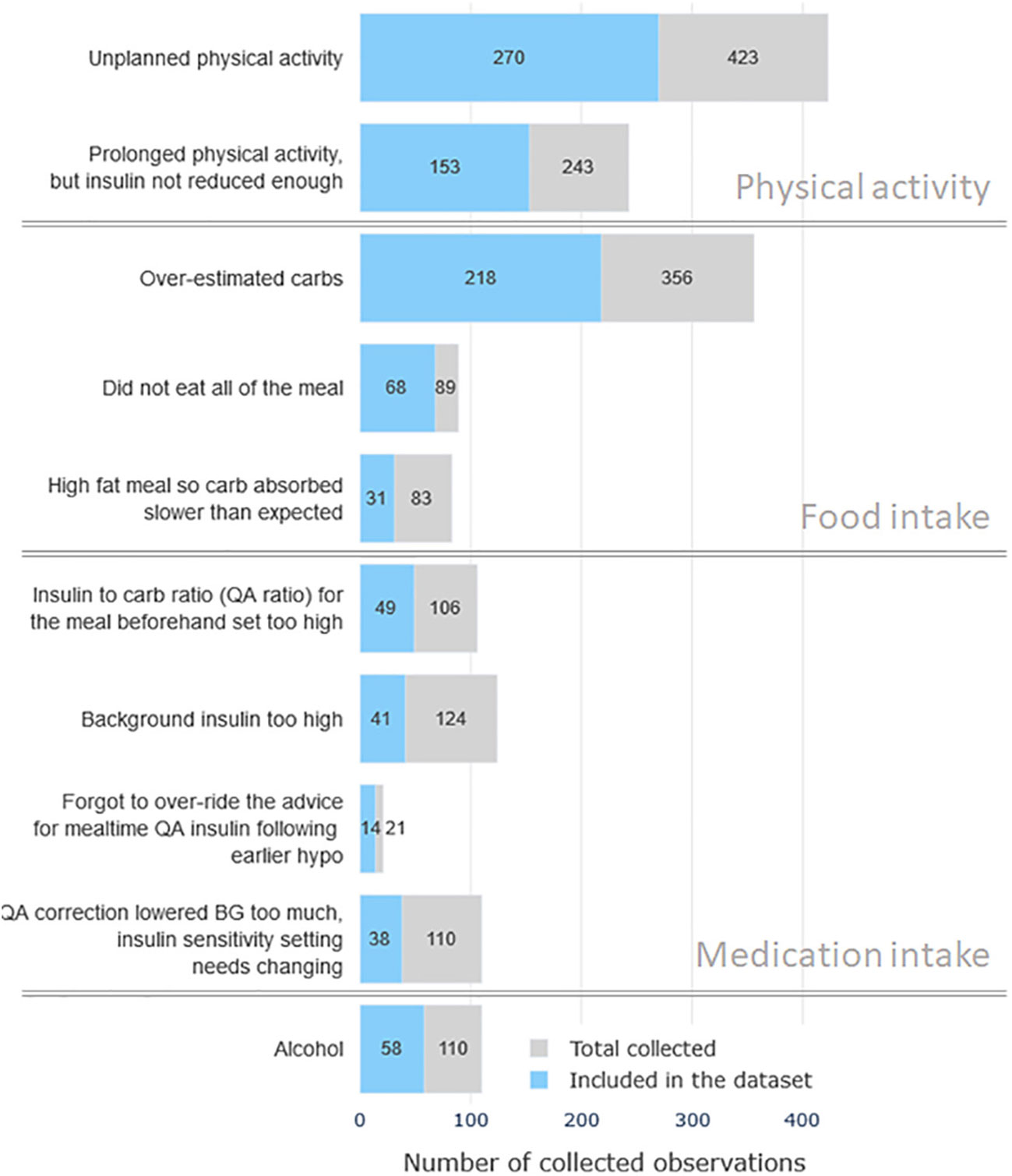
Figure 2 The distribution of the observed hypoglycemia cases by reasons. Gray color bars mark the total number of collected cases and the blue color bars denote the number of high-confidence cases included in the analysis dataset.
2.2 Event representation
For purposes of statistical and classification analyses discussed in the further sections, each labeled hypoglycemic case was represented as a set of predictor variables or “features” that describe the context of the observed hypoglycemia. These features were extracted from a variety of data sources in the Glucollector: static subject demographics from health records, user-uploaded self-care data (BG, insulin intake, carbohydrate intake), and Glucollector website usage statistics.
One of the key stages of the proposed analysis is to identify factors in data that are indicative of a particular hypoglycemia episode. To the best of our knowledge no such analyses have been conducted before, therefore, a broad range of possible predictors describing both the episode and the subject’s general self-care were considered. Table 1 lists the extracted features by categories, gives their description and short encodings. Each hypoglycemic case was represented by a total of 83numerical variables. Features that are not self-explanatory are further detailed below.
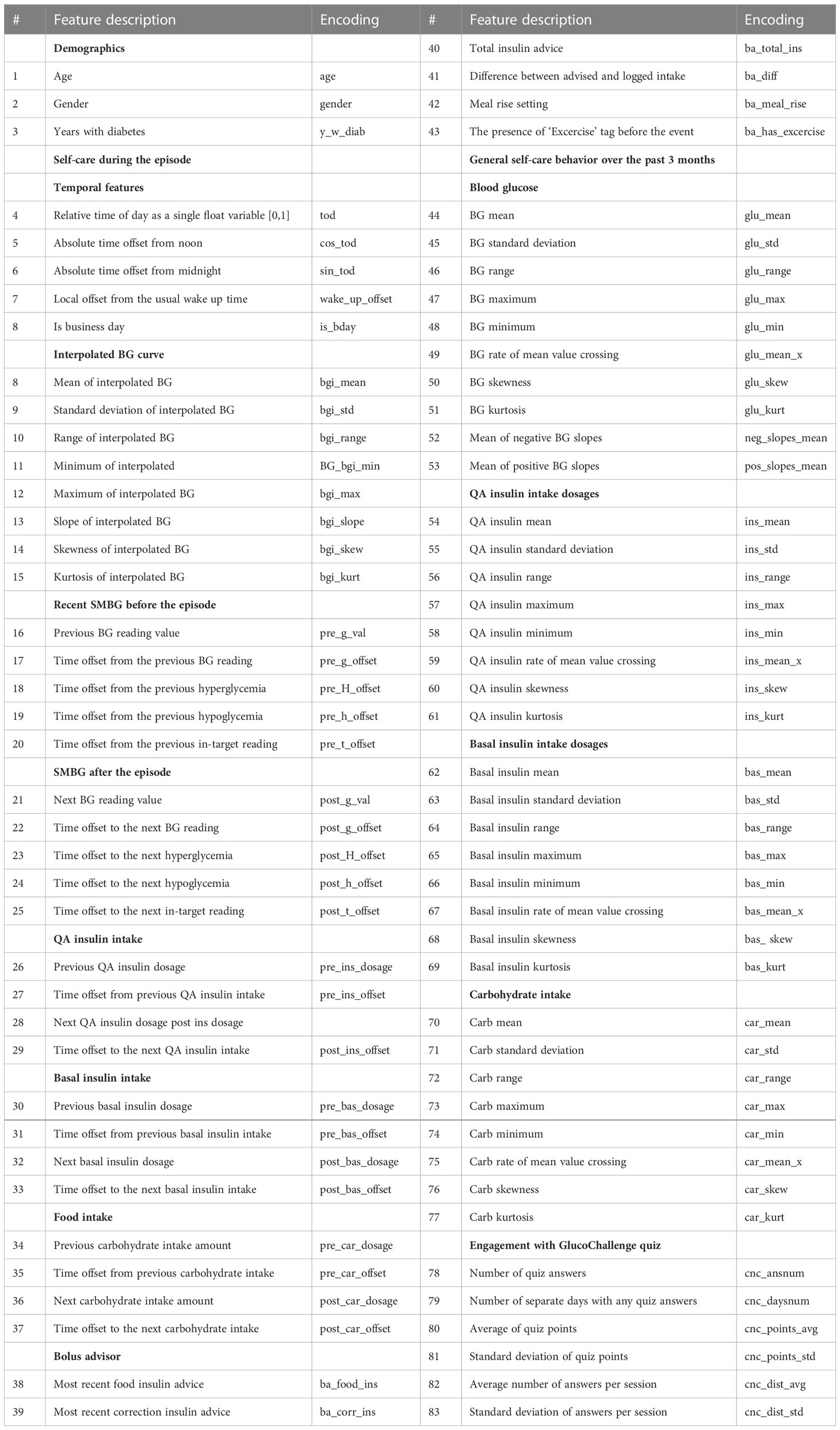
Table 1 Considered predictor variables.
The temporal features section contains the absolute time offsets in hours from noon and midnight to alleviate the boundary issue of a single float time representation (tod feature), e.g. 23:55 and 00:05 being represented by a very large and a very small value respectively, while being just 10 minutes apart. The wake_up_offset feature is extracted as a difference between the 3 month median time of day’s first BG reading (after 4:30) and the episode day’s first BG reading time. This feature was included to describe the discrepancy from subject’s usual day schedule. All time offsets (features 5-7, 17-20, 22-25, 27, 29, 31, 33, 35, 37) were expressed in hours.
Features 8-15 in Table 1 encode the BG trajectory around the hypoglycemic episode. To obtain them, SMBG readings from the 6 hours long time segment around each episode were interpolated using the piecewise cubic Hermite interpolating polynomial (PCHIP) (15) and summarized using a number of commonly used statistical functionals.
Features 26, 28, 30, 32, 34, 36 describing the most recent and the next intakes of food/medication were centered using the subject-specific means in order to take into account subjects’ physiological differences and their general food/medication intake amounts. For example, with being the average QA (quick acting) insulin dosage for subject k (feature 54), and being their most recent QA insulin intake dosage in a particular episode, the feature 26 was expressed as a difference .
Features 38-43 were extracted from patient personal Bolus Advisor devices which were used for QA insulin dosage calculation shortly before episodes.
The general self-care features 44-83 describe the overall statistics of BG, food and medication intake over the 3 months preceding the episode. In addition to that, each case included features of engagement with one of the Glucollector’s e-learning tools GlucoChallenge, which reflects the subject ability to estimate carbohydrate amount.
2.3 Statistical analysis
The aim of this analysis is to characterize the patterns of self-care during the different categories of causes of hypoglycemia. More specifically, the aim is to identify statistically significant relationships between the considered predictors and the target class labels. This analysis was conducted by fitting statistical models with binary outputs separately for each considered class of hypoglycemia.
The dataset is characterized by the three important qualities, which define the applicable types of such analysis: the observations are clustered by subjects, the considered predictors have different distributions and a high degree of collinearity. The former arises from the fact that each subject has provided multiple observations, which violates the observation independence assumption of the majority of statistical modeling tools. Therefore, Mixed Effect Generalized Linear Models (MEGLM) (16) and Generalized Estimating Equations (17) were considered, as they are capable of dealing with panel data and have no assumptions about the variable distributions.
The multicollinearity means that many of the considered data features are correlated. While there are no formal orthogonality assumptions in MEGLM and GEE methods, statistical significance of effect size estimates and model stability are deteriorated in the presence of highly collinear features (18). In the selected dataset the collinearity is mainly intrinsic and arises from how the predictors are defined, for example the predictor insulin range naturally correlates with both predictors minimum insulin value and maximum insulin value. Figure 3 shows the correlation matrix of the highly collinear non-binary features (Pearson ρ≥ 0.7 with any other feature).
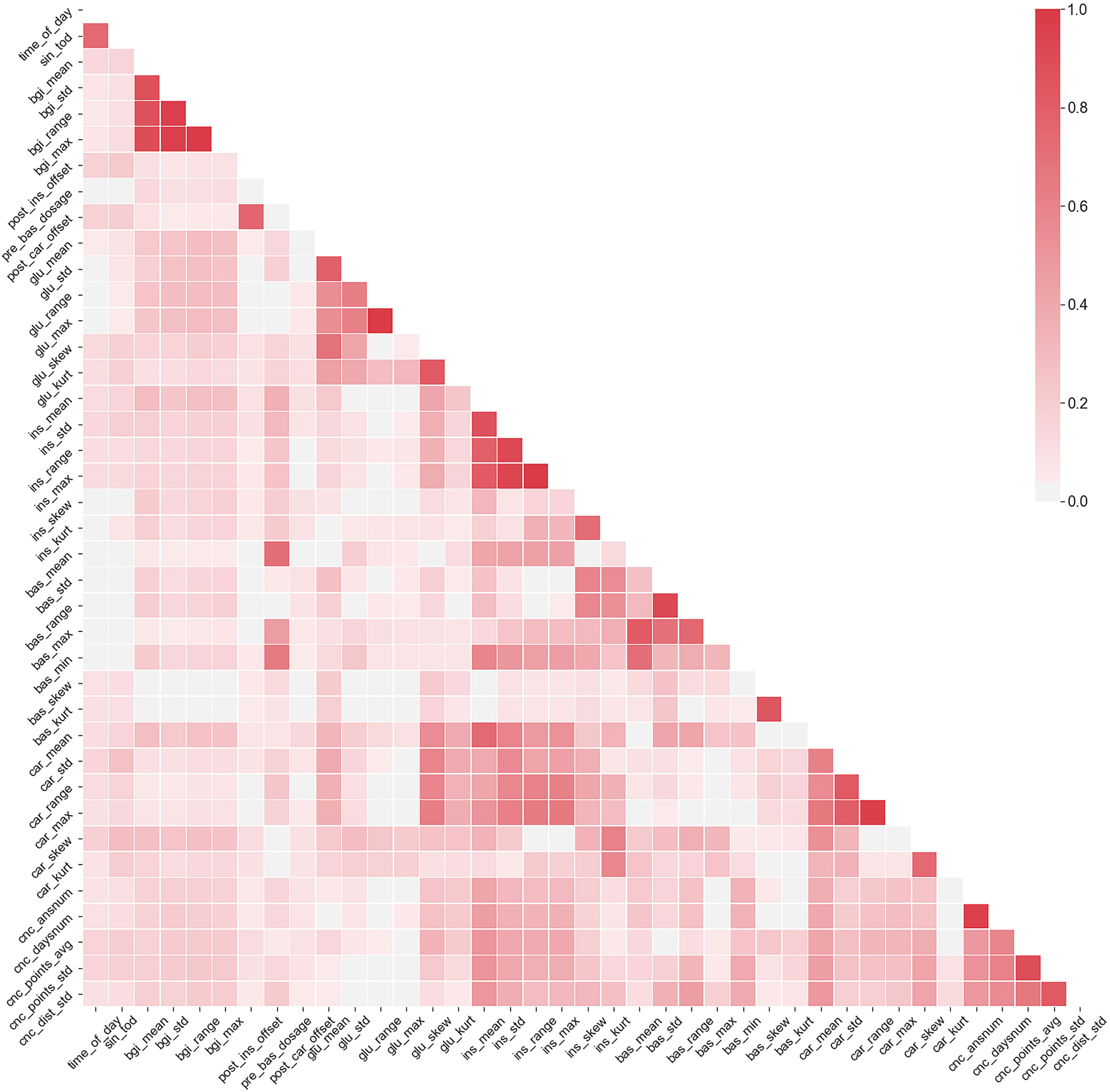
Figure 3 The correlation matrix of features that have exhibited ρ≥0.7 with at least one other feature. Color scale denotes the correlation between the variables.
The statistical significance of the relationships between the considered predictors and the target class labels were analyzed by fitting statistical models with binary outputs for each considered class of hypoglycemia. Not all of the considered features were available in some of the episode observations, especially the ones related to Bolus Advisor settings as they were often not provided by the users. This significantly reduces the dataset size in multiple regression analysis. Therefore, two types of regression were employed - single variable regression, allowing for a larger sample size, and multiple regression, allowing for a better model fit.
MEGLM models with binary output, logit link and random subject-specific intercepts were used in both single-variable and multiple regressions. This method was chosen over GEE due to the improved convergence stability. The generalized form of a MEGLM model is defined as follows:
where g is the link function, μ is n-by-1 vector of conditional probability of the outcome given the random effect b with n denoting the number of observations (events). X is n-by-f design matrix of predictor variables from Table 1 with f denoting the number of features. β is the f-by-1 fixed effects vector. Z is n-by-q random effect design matrix and b is the random effects q-by-1 vector with q denoting the number of participants. δ is the model offset vector.
With logit link function, subject id i, observation (event) j, hypoglycemia category k, single predictor variable x from Table 1, equation (1) takes the following form:
where pijk is the probability of event j from subject i belonging to category k. β0 denotes the model bias and β1 is the fixed effect coefficient of variable x. bi is the random-effect intercept for each subject i which accounts for behavioral and physiological variability. is the model fit error.
Beta coefficient β1 is the main product of this single variable association strength analysis. Term p/(1−p) is known as odds, hence the obtained beta coefficient can be interpreted as follows: increase in predictor variable x by 1 leads to an increase by β1 in the logarithm of odds, that the observed event belongs to category k. As explained before, not all predictor variables were available for each observed event, hence the single variable analysis allowed to employ more data. The beta coefficients obtained separately for each predictor from Table 1 are given in the left half of Table 2, with z-statistic from Wald test in parentheses.
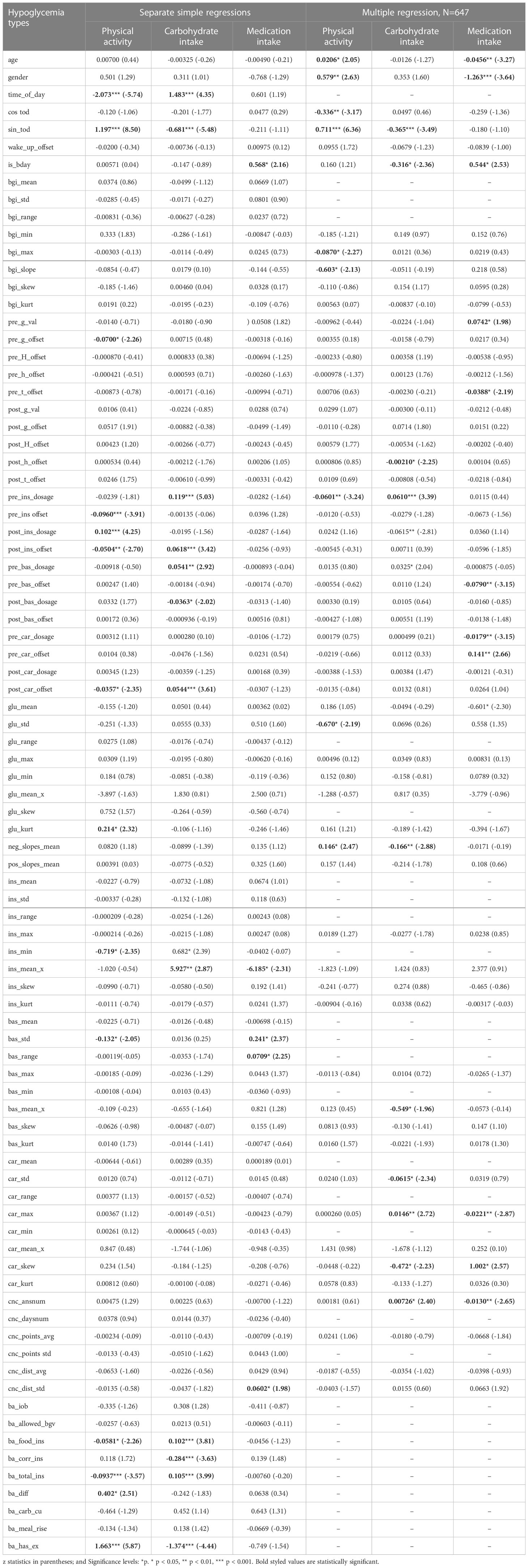
Table 2 Regression analysis.
When considering multiple predictors simultaneously it is first necessary to select the subset of variables leading to the best model fit. To obtain more reliable effect size estimates from multiple regression analysis only the most indicative predictors were preserved. The feature quality was tested by fitting a separate MEGLM model for each individual feature and calculating the resulting Bayesian information criterion (BIC) (19), which measures the goodness of fit. After selecting a subset for every prediction target, further filtering was done by calculating the Variance Inflation Factor (VIF) (20) for every feature, and discarding those with VIF ≥ 10, thus reducing the collinearity of features. Predictors related to Bolus Advisor settings and outputs were discarded from the multiple regression analysis to increase the sample size. Prior to the analyses the dataset was centered, but not scaled.
In case of multiple regression, equation (1) takes the following form:
The obtained beta coefficients from multiple regression analysis are given in the right half of Table 1 z-statistic from Wald test in parentheses. The different levels of statistical significance are marked by asterisk (* for p< 0.05, ** for p< 0.01, *** for p< 0.001). The statistical significance was defined as p< 0.05. The further interpretation of the obtained beta coefficients is given in the Results section. Data preparation was conducted in Python and statistical models were fit using STATA software.
2.4 Classification analysis
The aim of this analysis is to design machine learning models for automatic hypoglycemia classification and assess their performance. This system aims to automatically select one of the three categories of hypoglycemia causes - physical activity, food intake, medication intake (see Figure 2). The practical motivation is to design a decision support system, which would retrospectively analyze patient self-care data and highlight the possible problems in self-care to the clinician.
Two classification scenarios were investigated: binary one-vs-rest classification done separately for each class and exclusive 3-class classification. This analysis has utilized the same dataset as in multiple regression, with the Bolus Advisor features excluded to maximize the sample size.
The analysis sequence of all investigated scenarios is illustrated in Figure 4. It follows the conventional supervised learning scheme consisting of feature extraction the acquired data which were represented as explained in section 2.1, feature subset selection, classifier model training and validation (21).

Figure 4 Feature selection and classifier evaluation sequence.
First the dataset was split 10 times to obtain multiple training and validation samples for the 10-fold cross-validation (CV) procedure. During the split the data was grouped by subjects to make sure that the observations from the same subject were not simultaneously present in both training and validation sets. Within each CV fold a separate feature selection procedure was applied to obtain a subset of features yielding the best classification performance. Considering the strong collinearity in the dataset, the Sequential Forward Floating Selection (SFFS) (22) algorithm was used, as it was found to be especially efficient in such settings. This algorithm iteratively adds features to the selected subset and continuously attempts to reduce the set at every iteration, while monitoring for the classification performance increase. At each iteration the performance was measured by training and validating a separate ensemble classifier in a nested 5-fold CV procedure involving only the training sample of the outer CV fold. The nested CV was also set to respect the grouping by subjects.
The SFFS algorithm is computationally expensive, therefore Extremely Randomized Tree ensemble classifier (23) was used in the SFFS procedure, since it is computationally cheap, performs well in the presence of collinear features and requires less hyperparameter fine-tuning. The final classification performance in each CV fold was assessed by training a neural network classifier (24, 25), on the selected feature subset from the training CV sample and validating it on the same subset from the validation sample. This model, consisting of 3 fully connected layers with dropout regularization, required hyperparameter optimization, was more computationally expensive to train, but has consistently outperformed the other considered classification methods in our settings. The model output consists of a single unit in binary classifiers and 3 units with softmax activation in a multi-class model, each returning the one-vs-rest probability for the corresponding class. The dropout rate was set to 60% and the number of units in each hidden layer was set equal to the number of features in the selected subset, which was decided in a separate grid search prior to the analysis. In both, SFFS procedure and neural network training steps, the observations were weighted to account for the class disbalance in the dataset. Weights for observations of class i were calculated as , where Nobs is the dataset size, Ncl is the number of classes and Nobsi is the number of samples of class i.
Considering the strong feature collinearity, the same analysis was also conducted on predictors obtained from principal component analysis (PCA) (26) applied to the design matrix of all considered features. In this scenario the SFFS has selected generally smaller sets of orthogonal components with higher individual classification power.
The presented classification analysis has been conducted in Python using scikit-learn (27) and tensor flow (28) libraries.
2.4.1 Evaluation metrics
Due to this class disbalance in each classification scenario, the simple categorical accuracy did not adequately describe classification performance, therefore Matthews correlation coefficient (MCC) (29), precision, recall and F1-score, which is the harmonic mean of the latter two, were the chosen performance metrics. The SFFS procedure aimed to maximize the mean F1-score of the classifier cross-validation. And by changing the optimization target between recall, precision and F1-score in the neural network training step it was possible to obtain different classification performance profiles, potentially suitable in the various practical settings, for example, when a certain class recall is favored over classification precision or vice-versa. By definition the chosen performance metrics are calculated for individual classes, so in the multi-class classification analysis the class-average F1-score, recall and precision were used as neural network optimization targets.
3 Results
3.1 Statistical analysis
This analysis has highlighted a number of interpretable predictors of different hypoglycemia types. For example, as the statistical significance of multiple regression predictors suggests, episodes related to physical activity generally happened during daytime, were associated with lower QA insulin intake prior to event, were more common in men, in subjects with lower glycemic variability and slower BG fall in general. Episodes related to food intake had a higher probability to occur in mornings, evenings and on weekends, were associated with higher relative QA insulin dosages before the event and lower dosages after, were more commonly observed in subjects with slower general BG decline, frequent changes in basal insulin dosages and more frequent consumption of large amounts of food. Hypoglycemic episodes related to mistakes in medication dosage selection were more common in women, subjects with lower average BG levels, more frequent consumption of small amounts of food and less activity in the GlucoChallenge quiz; occurred more frequently during the business days and generally later after the food intake.
Simple regression scenarios show that the features extracted from Bolus Advisor settings, tags and most recent advice prior to the episodes are strong predictors of activity- and food-related hypoglycemia classes, however they were available in only 328 cases.
3.2 Classification analysis
The results of classification analysis are detailed in Table 3. The SFFS procedure aimed to maximize the mean F1-score of the classifier cross-validation. And by changing the optimization target between recall, precision and F1-score in the neural network training step it was possible to obtain different classification performance profiles, potentially suitable in the various practical settings, for example, when a certain class recall is favored over classification precision or vice-versa. By definition the chosen performance metrics are calculated for individual classes, so in the multi-class classification analysis the class-average F1-score, recall and precision were used as neural network optimization targets. The classification analysis was also conducted on predictors obtained from PCA applied to the design matrix of all considered features. The results of the described CV analyses are combined in Table 3, which contains the average performance metrics from CV with standard deviations.
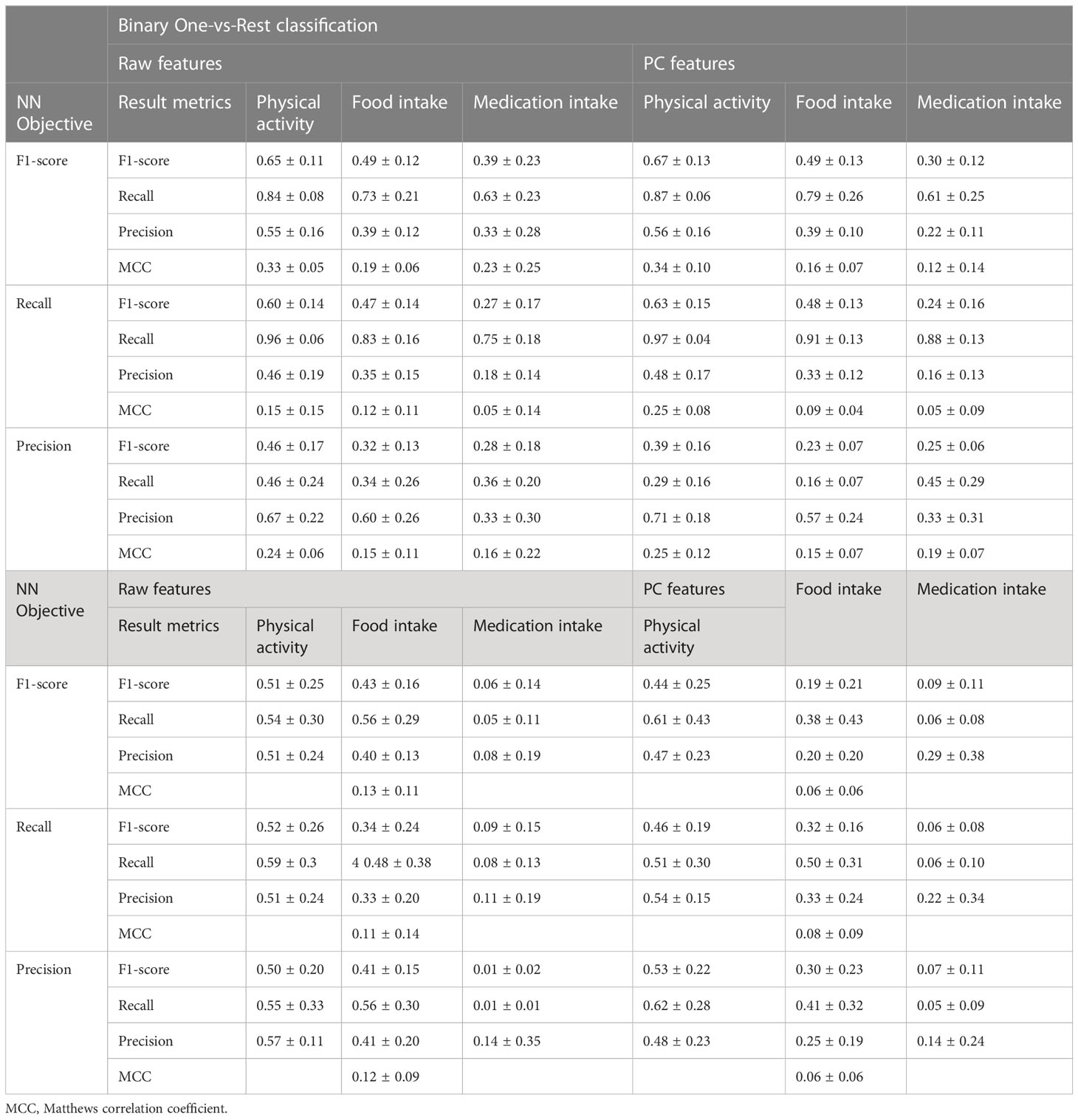
Table 3 Classification analysis results.
According to the results in Table 3, in all classification scenarios the accuracy metrics were proportionate to the corresponding class support. The highest F1-score for the most common class of activity-related episode was 0.67 ± 0.13 and 0.51 ± 0.25 in binary and multiclass classification scenarios respectively; 0.49 ± 0.12 and 0.43 ± 0.16 for a less represented class of food intake related episodes; 0.39 ± 0.23 and 0.6 ± 0.14 for the least common class of episodes related to medication intake. Despite the sampling weighting, detection of insulin-related episodes was rarely possible in the multiclass classification scenario.
The different performance profiles were successfully produced by changing the ANN training objective between F1-score, recall and precision. It can be speculated that for practical implementation in a decision support system, the F1-score and precision are more suitable choices of the target performance metric.
PCA transformation of the raw handcrafted features was especially beneficial in one-vs-rest classification scenario. Besides, it has significantly sped up the exhaustive SFFS procedure. Thus, the application of other PCA variations and dimensionality reduction methods is also of interest.
4 Discussion
The conducted feasibility study has outlined a number of concerns valuable in the design of the decision support system for automatic hypoglycemia reason classification. Firstly, our data acquisition has characterized the incidence distribution of the various hypoglycemia reasons with more than 45% of the collected cases being related to physical activity.
Secondly, the conducted statistical and classification analyses have highlighted many interpretable predictors of the various hypoglycemia types. These predictors were designed manually to describe the subject self-care around the observed episodes, as well as their general self-care habits. Although a relatively large number of predictors was considered, the further search for optimal data features based on clinical domain knowledge can potentially improve the performance of the desirable reasoning system. Besides that, deep learning (24) could be applied to this problem to automatically design features directly from the raw collected data, however such features would not be human-interpretable.
Thirdly, the classification analysis has characterized the potential performance and limitations of the proposed system in the current settings, where reasoning relies on data manually entered by subjects. As it currently stands, practical application of automatic hypoglycemia cause inference is questionable, due to the lack of self-care and physiological data. Statistical analysis results and manual visual assessment of subject self-care records show that food intake data is often omitted from personal diaries, especially snacks and food intake to correct hypoglycemia. This hinders the understanding and modeling of BG dynamics, and consequently, the classification performance.
While the objective unobtrusive measurement of food intake is problematic, continuous physical activity tracking in users via the commercially available wearable sensors is viable. Even though it was not measured in our experimental settings, classification analysis results show that activity-related episodes were the easiest to detect (Table 3), partially due to the amount of relevant cases in the dataset. It can be speculated that the introduction of activity tracking in subjects would significantly increase the rate and accuracy of this hypoglycemia class detection, which in turn would also reduce the uncertainty about other classes. Therefore it can be stated that the addition of physical activity tracking in Glucollector and other BG decision support systems is the key necessary element to make this type of reasoning feasible and beneficial in clinical practice.
Data availability statement
The datasets presented in this article are not readily available because the data is only available to the researchers of DAFNEplus. Requests to access the datasets should be directed to ME, bS5laXNzYUBzaGVmZmllbGQuYWMudWs=.
Ethics statement
The studies involving human participants were reviewed and approved by National Health Service Research Ethics Committee (REC ref: 16/WS/0230 and 18/SW/0100). The patients/participants provided their written informed consent to participate in this study.
Author contributions
ME, ZH, and TG designed the visual interfaces and collected the data. AZ, ME, and ZH analyzed the data and AZ performed the experiment. JE and MB verified the outcomes. AZ and ME prepared the manuscript with the help and review of all authors. All authors contributed to the article and approved the submitted version.
Funding
This study is funded by the National Institute for Health Research (NIHR) [Programme Grants for Applied Research (RP-PG-0514-20013) DAFNEplus]. This article was also supported by University of Sheffield Institutional Open Access Fund.
Conflict of interest
JE has served on advisory boards and/or received speaker fees for Abbott, DEXCOM, Eli Lily, Insulet, NovoNordisk, and Sanofi S.A.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Author disclaimer
The views expressed are those of the author(s) and not necessarily those of the NIHR or the Department of Health and Social Care.
References
1. Eissa MR, Benaissa M, Good T, Hui Z, Gianfrancesco C, Ferguson C, et al. Analysis of real-world capillary blood glucose data to help reduce hba1c and hypoglycaemia in type 1 diabetes: Evidence in favour of using the percentage of readings in target and coefficient of variation. Diabetic Med (2023) 40:e14972. doi: 10.1111/dme.14972
2. Control D, Group CTR. The effect of intensive treatment of diabetes on the development and progression of long-term complications in insulin-dependent diabetes mellitus. New Engl J Med (1993) 329:977–86. doi: 10.1056/NEJM199309303291401
3. Committee ADAPP. 6. glycemic targets: standards of medical care in diabetes–2022. Diabetes Care (2021) 45:S83–96. doi: 10.2337/dc22-S006
4. Mamykina L, Levine ME, Davidson PG, Smaldone AM, Elhadad N, Albers DJ. Data-driven health management: reasoning about personally generated data in diabetes with information technologies. J Am Med Inf Assoiciation (2016) 23:526–31. doi: 10.1093/jamia/ocv187
5. Eissa MR, Good T, Elliott J, Benaissa M. Intelligent data-driven model for diabetes diurnal patterns analysis. IEEE J Biomed Health Inf (2020) 24:2984–92. doi: 10.1109/JBHI.2020.2975927
6. Liang B, Koye DN, Hachem M, Zafari N, Braat S, Ekinci EI. Efficacy of flash glucose monitoring in type 1 and type 2 diabetes: A systematic review and meta-analysis of randomised controlled trials. Front Clin Diabetes Healthcare (2022) 3. doi: 10.3389/fcdhc.2022.849725
7. Dritsas E, Trigka M. Data-driven machine-learning methods for diabetes risk prediction. Sensors (2022) 22:5304. doi: 10.3390/s22145304
8. Nemat H, Khadem H, Eissa MR, Elliott J, Benaissa M. Blood glucose level prediction: advanced deep-ensemble learning approach. IEEE J Biomed Health Inf (2022) 26:2758–69. doi: 10.1109/JBHI.2022.3144870
9. Zaitcev A, Eissa MR, Hui Z, Good T, Elliott J, Benaissa M. A deep neural network application for improved prediction of HbA1c in type 1 diabetes. IEEE J Biomed Health Inf (2020) 24:2932–41. doi: 10.1109/JBHI.2020.2967546
10. Coates E, Amiel S, Baird W, Benaissa M, Brennan A, Campbell MJ, et al. Protocol for a cluster randomised controlled trial of the dafneplus (dose adjustment for normal eating) intervention compared with 5x1 dafne: a lifelong approach to promote effective self-management in adults with type 1 diabetes. BMJ Open (2021) 11:e040438. doi: 10.1136/bmjopen-2020-040438
11. Woldaregay AZ, Årsand E, Botsis T, Albers D, Mamykina L, Hartvigsen G. Data-driven blood glucose pattern classification and anomalies detection: machine-learning applications in type 1 diabetes. J Med Internet Res (2019) 21:e11030. doi: 10.2196/11030
12. Makroum MA, Adda M, Bouzouane A, Ibrahim H. Machine learning and smart devices for diabetes management: Systematic review. Sensors (2022) 22:1843. doi: 10.3390/s22051843
13. Kodama S, Fujihara K, Shiozaki H, Horikawa C, Yamada MH, Sato T, et al. Ability of current machine learning algorithms to predict and detect hypoglycemia in patients with diabetes mellitus: meta-analysis. JMIR Diabetes (2021) 6:e22458. doi: 10.2196/22458
14. Zhu T, Li K, Herrero P, Georgiou P. Deep learning for diabetes: a systematic review. IEEE J Biomed Health Inf (2020) 25:2744–57. doi: 10.1109/JBHI.2020.3040225
15. Fritsch FN, Carlson RE. Monotone piecewise cubic interpolation. SIAM J Numerical Anal (1980) 17:238–46. doi: 10.1137/0717021
16. McCulloch CE, Searle SR. Generalized, linear, and mixed models. Hoboken, New Jersey: John Wiley & Sons (2004).
17. Hardin JW, Hilbe JM. Generalized estimating equations. Boca Raton, Fla: Chapman and Hall/CRC (2002).
18. Dormann CF, Elith J, Bacher S, Buchmann C, Carl G, Carré G, et al. Collinearity: a review of methods to deal with it and a simulation study evaluating their performance. Ecography (2013) 36:27–46. doi: 10.1111/j.1600-0587.2012.07348.x
19. Schwarz G. Estimating the dimension of a model. Ann Stat (1978) 6:461–4. doi: 10.1214/aos/1176344136
20. Hair J, Black WC, Babin BJ, Anderson RE, Tatham RL. Multivariate data analysis. Seventh edition. Edinburgh Gate, Harlow, Essex, England; Pearson (2014).
21. Bishop CM, Nasrabadi NM. Pattern recognition and machine learning Vol. 4. New York: Springer (2006).
22. Pudil P, Novovičová J, Kittler J. Floating search methods in feature selection. Pattern Recognition Lett (1994) 15:1119–25. doi: 10.1016/0167-8655(94)90127-9
23. Geurts P, Ernst D, Wehenkel L. Extremely randomized trees. Mach Learn (2006) 63:3–42. doi: 10.1007/s10994-006-6226-1
25. Srivastava N, Hinton G, Krizhevsky A, Sutskever I, Salakhutdinov R. Dropout: a simple way to prevent neural networks from overfitting. J Mach Learn Res (2014) 15:1929–58.
26. Wold S, Esbensen K, Geladi P. Principal component analysis. Chemometrics Intelligent Lab Syst (1987) 2:37–52. doi: 10.1016/0169-7439(87)80084-9
27. Buitinck L, Louppe G, Blondel M, Pedregosa F, Mueller A, Grisel O, et al. Api design for machine learning software: experiences from the scikit-learn project. ECML PKDD Workshop: Languages for Data Mining and Machine Learning (2013) p. 108–22. arXiv.1309.0238.
28. Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, et al. Tensorflow: large-scale machine learning on heterogeneous systems. arXiv preprint (2016). arXiv:1603.04467.
Keywords: biomedical informatics, classification algorithms, machine learning, medical expert systems, statistical analysis, hypoglycemia, exercise, physical activity
Citation: Zaitcev A, Eissa MR, Hui Z, Good T, Elliott J and Benaissa M (2023) Automatic inference of hypoglycemia causes in type 1 diabetes: a feasibility study. Front. Clin. Diabetes Healthc. 4:1095859. doi: 10.3389/fcdhc.2023.1095859
Received: 11 November 2022; Accepted: 16 March 2023;
Published: 17 April 2023.
Edited by:
Petra Hanson, University of Warwick, United KingdomReviewed by:
Eleonora M. Aiello, University of Trento, ItalyAndrea M P Romani, Case Western Reserve University, United States
Copyright © 2023 Zaitcev, Eissa, Hui, Good, Elliott and Benaissa. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mohammad R. Eissa, bS5laXNzYUBzaGVmZmllbGQuYWMudWs=