 Saad M. Alshahrani
Saad M. Alshahrani Hadil Faris Alotaibi2
Hadil Faris Alotaibi2- 1Department of Pharmaceutics, College of Pharmacy, Prince Sattam Bin Abdulaziz University, Al-Kharj, Saudi Arabia
- 2Department of Pharmaceutical Sciences, College of Pharmacy, Princess Nourah Bint AbdulRahman University, Riyadh, Saudi Arabia
- 3Department of Pharmaceutical chemistry, College of Pharmacy, Taif University, Taif, Saudi Arabia
This paper presents a thorough examination for drug release from a polymeric matrix to improve understanding of drug release behavior for tissue regeneration. A comprehensive model was developed utilizing mass transfer and machine learning (ML). In the machine learning section, three distinct regression models, namely, Decision Tree Regression (DTR), Passive Aggressive Regression (PAR), and Quadratic Polynomial Regression (QPR) applied to a comprehensive dataset of drug release. The dataset includes r(m) and z(m) inputs, with corresponding concentration of solute in the matrix (C) as response. The primary objective is to assess and compare the predictive performance of these models in finding the correlation between input parameters and chemical concentrations. The hyper-parameter optimization process is executed using Sequential Model-Based Optimization (SMBO), ensuring the robustness of the models in handling the complexity of the controlled drug release. The Decision Tree Regression model exhibits outstanding predictive accuracy, with an R2 score of 0.99887, RMSE of 9.0092E-06, MAE of 3.51486E-06, and a Max Error of 6.87000E-05. This exceptional performance underscores the model’s capability to discern intricate patterns within the drug release dataset. The Passive Aggressive Regression model, while displaying a slightly lower R2 score of 0.94652, demonstrates commendable predictive capabilities with an RMSE of 6.0438E-05, MAE of 4.82782E-05, and a Max Error of 2.36600E-04. The model’s effectiveness in capturing non-linear relationships within the dataset is evident. The Quadratic Polynomial Regression model, designed to accommodate quadratic relationships, yields a noteworthy R2 score of 0.95382, along with an RMSE of 5.6655E-05, MAE of 4.49198E-05, and a Max Error of 1.86375E-04. These results affirm the model’s proficiency in capturing the inherent complexities of the drug release system.
1 Introduction
Efficient delivery of therapeutic agents to the desired site has been a subject of research owing to the importance of this method in cancer treatment. Drugs might reach other tissues and damage them, while low dosage of drug could reach the cancer cells for treatment. Therefore, the design of targeted drug delivery systems would be of fundamental importance for cancer effective treatment (Kandula et al., 2023; Chen et al., 2024; Lu et al., 2024; Sameer Khan et al., 2024). Drug can be loaded into various carriers such as polymeric nanoparticles and reach the target cells, while its release can be triggered by various means such as pH or temperature change (Ali et al., 2023).
Modeling and computation of drug release from carriers can be utilized for design and optimization of drug delivery systems based on polymeric carriers. Some mathematical models have been developed to simulate mass transfer in polymeric-based drug release (González-Garcinuño et al., 2023; Kubinski et al., 2023; Carr and Pontrelli, 2024). Usually, molecular diffusion is the main mechanism that happens in polymeric-based drug delivery systems where the drug molecules diffuse through the porous structure of polymeric carrier. Some parameters such as pore structure of carrier, molecular interaction, temperature, and pH can affect the release rate of drug molecules. On the other hand, machine learning models can be used for simulation of drug release from polymeric carriers. The method is based upon collection of datasets and building models via appropriate algorithms. This method is indeed fast and possesses higher performance in terms of fitting accuracy.
Machine learning (ML) techniques have shown great potential in the field of drug development by enabling accurate forecasting of drug solubility and density (Abdelbasset et al., 2022; Almehizia et al., 2023). These techniques have the capability to evaluate large amounts of data and extract meaningful patterns and relationships that can be utilized for predictions (Jovel and Greiner, 2021). This paper provides a thorough analysis of three distinct regression models, namely, Decision Tree Regression (DTR), Passive Aggressive Regression (PAR), and Quadratic Polynomial Regression (QPR). These models were carefully evaluated using a comprehensive dataset in the field of drug release from a porous polymeric carrier. The hyper-parameter optimization process is executed using Sequential Model-Based Optimization (SMBO).
Decision Tree Regression is a versatile algorithm that can be utilized in a wide range of regression tasks. Careful tuning of hyperparameters is essential to prevent overfitting and ensure optimal model performance (Talekar and Agrawal, 2020). Passive Aggressive Regression offers a flexible and adaptive approach to regression tasks, particularly in situations where data arrives sequentially or in a streaming fashion (Crammer et al., 2006). Also, Quadratic Polynomial Regression is a valuable tool for capturing quadratic relationships in the data. Careful consideration of model complexity and potential overfitting is crucial for obtaining reliable and meaningful results (Yao and Müller, 2010).
By systematically evaluating Decision Tree Regression (DTR), Passive Aggressive Regression (PAR), and Quadratic Polynomial Regression (QPR) models on a dataset comprising over 15,000 data samples, the study provides valuable insights into the strengths and limitations of each model. The incorporation of Sequential Model-Based Optimization (SMBO) for hyper-parameter tuning enhances the robustness of the models, highlighting the significance of thoughtful parameter optimization.
2 Problem statement
This research dataset consists of more than 15,000 data points, incorporating three key variables: r measured in meters, z also in meters, and chemical concentration C expressed in mol/m3. The data have been collected from a CFD (Computational Fluid Dynamics) simulation of drug-loaded polymeric matrix. The CFD was utilized to numerically solve time-dependent mass balance per species (COMSOL, 2008) and the generated data was used for building the machine learning models. The correlation heatmap between variables is shown in Figure 1. This step was done as the preliminary data visualization to see how data vary in the domain of drug delivery system.
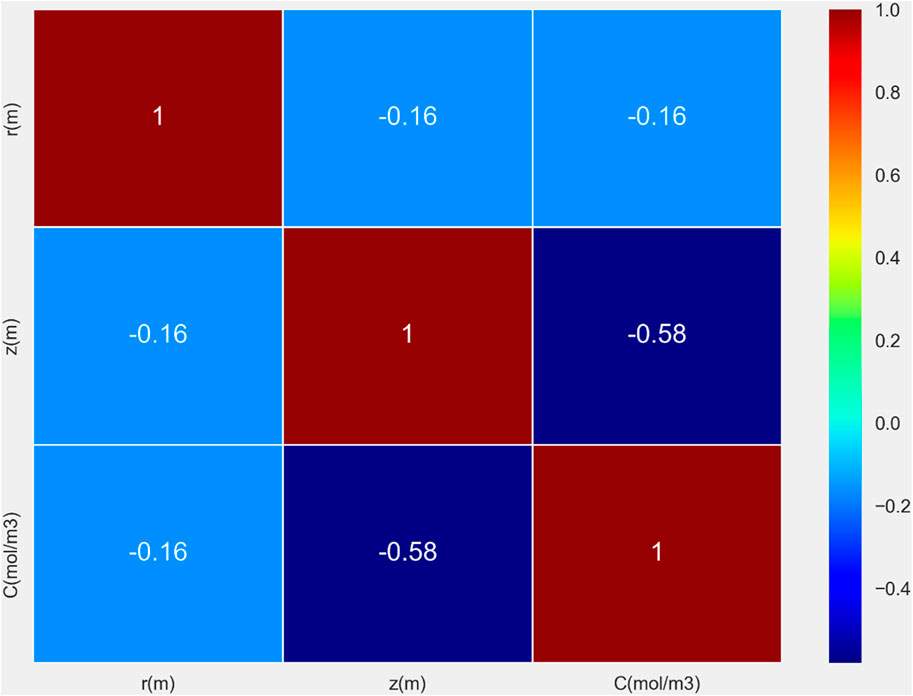
Figure 1. Correlation heatmap for drug release dataset.
The z-score, or standard score, is a statistical measure widely employed for outlier detection in various studies, including the present research. When conducting outlier analysis, the z-score is a useful metric that provides a standardized representation of the deviation of a data point from the mean of the dataset. It measures the distance from a data point to the mean in standard deviation units.
The expression for determining the z-score of a data point X within a dataset having a mean of μ and a standard deviation of σ is articulated as follows (Anusha et al., 2019):
In this context, Z signifies the z-score of the data point, X represents the individual data value, μ is indicative of the mean within the dataset, and σ denotes the standard deviation.
A high absolute z-score indicates that the data point is far from the mean and is considered a potential outlier. The threshold for identifying outliers using z-scores is often set empirically; commonly, a z-score beyond 2 or 3 standard deviations is considered indicative of an outlier.
In the specific context of this study, the z-score method has been employed for outlier detection. By calculating z-scores for the relevant variables or features, the study aims to identify data points that exhibit significant deviations from the norm, facilitating a robust analysis of the dataset and ensuring the reliability of the research findings. The result of z-score analyses is shown in Figure 2.
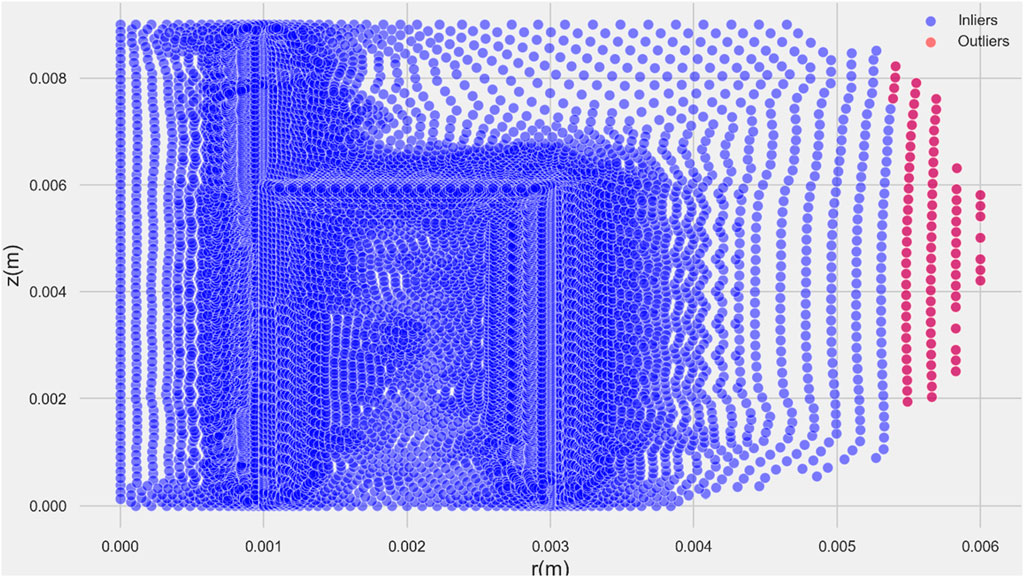
Figure 2. Z-Score plot analysis.
3 Method of computing
3.1 Sequential Model-Based Optimization (SMBO)
Sequential Model-Based Optimization (SMBO) emerges as a powerful strategy for optimizing hyperparameters within the domain of machine learning. It seamlessly integrates elements of Bayesian optimization and model-driven reasoning to systematically navigate the hyperparameter landscape, identifying optimal configurations for a given machine learning model (Croppi, 2021).
Hyperparameters, distinct from model parameters learned during training, constitute pre-defined configuration settings governing a model’s behavior and performance. The paramount goal of hyperparameter tuning is to pinpoint the most favorable values for these settings, significantly influencing the overall performance of the model.
SMBO is a technique that utilizes Bayesian optimization principles to optimize a given objective function. The core idea behind SMBO is to iteratively assess and update a surrogate model, which approximates the true objective function. This surrogate model guides the optimization process by estimating the objective function based on evaluated hyperparameter configurations (Lacoste et al., 2014).
At each iteration, SMBO selects the subsequent hyperparameter configuration for evaluation, striking a balance between exploration and exploitation. This decision is informed by an acquisition function denoted as a(x), gauging the utility of evaluating a specific configuration x based on predictions from the surrogate model. The acquisition function incorporates both the predicted performance
Here,
To establish the surrogate model, SMBO initiates with a random sample of hyperparameter configurations, refining and updating them iteratively based on the acquisition function until a stopping criterion is met.
SMBO’s merits in hyperparameter tuning include its efficiency in exploring hyperparameter space, capacity to capture intricate interactions between hyperparameters, automated configuration process, and adaptability to diverse hyperparameters and machine learning algorithms.
3.2 Decision Tree Regression model (DTR)
Decision Tree Regression (DTR) stands out as a potent tool in the realm of machine learning, serving the purpose of predictive modeling and regression analysis. Differing from its classification equivalent, Decision Tree Classification, DTR has a distinct focus on forecasting continuous values. Its operation involves the iterative division of the dataset into subsets based on the features’ values, leading to the formation of a tree-like arrangement of decision nodes (Kotsiantis, 2013).
Consider X as the input feature matrix comprising n samples and m features, while y represents the corresponding target variable. The Decision Tree Regression model can be expressed as (Rokach et al., 2005; Olson et al., 2020):
Here,
The objective of the model is to identify optimal values for the parameters
The structure of DTR model is displayed in Figure 3. In the training procedure, the dataset undergoes iterative division into subsets by leveraging feature thresholds. The algorithm meticulously picks the feature and its associated threshold, aiming to minimize the mean squared error (MSE) concerning predictions within each subset. The recursive partitioning persists until a predetermined stopping condition is met, whether it involves reaching a maximum tree depth or satisfying a minimum threshold of samples per leaf (Quinlan, 1986; Suthaharan et al., 2016). Advantages of Decision Tree Regression can be summarized in following items (Bertsimas et al., 2017):
1. Non-linearity Handling: DTR excels in taking complicated non-linear associations between input parameters and the response variable, rendering it well-suited for handling complex datasets.
2. Interpretability: Decision trees are inherently interpretable, allowing users to easily understand and visualize the decision-making process.
3. Robustness to Outliers: DTR is robust to outliers as it makes decisions based on splits, rather than relying on the mean or median.

Figure 3. Structure of DTR model.
3.3 Passive Aggressive Regression (PAR)
Passive Aggressive Regression (PAR) is a type of online learning algorithm used for regression tasks. It is particularly suitable for scenarios where data streams in real-time, and the model needs to adapt and update its parameters continuously. The “Passive Aggressive” name stems from its aggressive updating strategy when making incorrect predictions and passive behavior when predictions are correct (Salas et al., 2015).
The Passive Aggressive Regression model is defined by the following update rule (Crammer et al., 2006):
Here w indicates the weight vector,
3.4 Quadratic Polynomial Regression model (QPR)
QPR has been known as a polynomial regressive technique that extends the linear regression technique to find quadratic correlations between the input features and the response parameters. Unlike simple linear models which consider a linear relationship, QPR accommodates more complex curvilinear patterns in the data (Heiberger and Neuwirth, 2009; Yao and Müller, 2010; Almehizia et al., 2023).
Let X represent the input feature matrix with n data points and m features, and y be the corresponding target variable. The QPR model is defined by the equation (Yao and Müller, 2010; Almehizia et al., 2023):
Where,
4 Results and discussion
The evaluation of the Decision Tree Regression (DTR), Passive Aggressive Regression (PAR), and Quadratic Polynomial Regression (QPR) models was conducted on a dataset comprising more than 15,000 data points, with input parameters represented by r(m) and z(m) coordinates, and the output parameter denoted by concentration (C) in mol/m³. The models underwent hyper-parameter optimization using Sequential Model-Based Optimization (SMBO). Table 1 presents a summary of the numeric results obtained from the assessment conducted. This table provides a concise overview of the key metrics and performance measures obtained from the evaluation of the regression models.
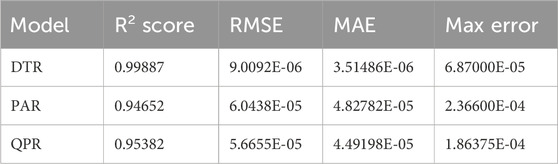
Table 1. Final metrics of the optimized models.
The DTR model demonstrates outstanding predictive accuracy, reflected in an impressive R2 score of 0.99887, underscoring its capability to discern intricate patterns within the dataset. The negligible RMSE, MAE, and Max Error values further emphasize the precision and reliability of the model in predicting chemical concentrations. Figure 4 showcases a visual comparison between the model predicted values and the true values using the Decision Tree Regression (DTR) model.
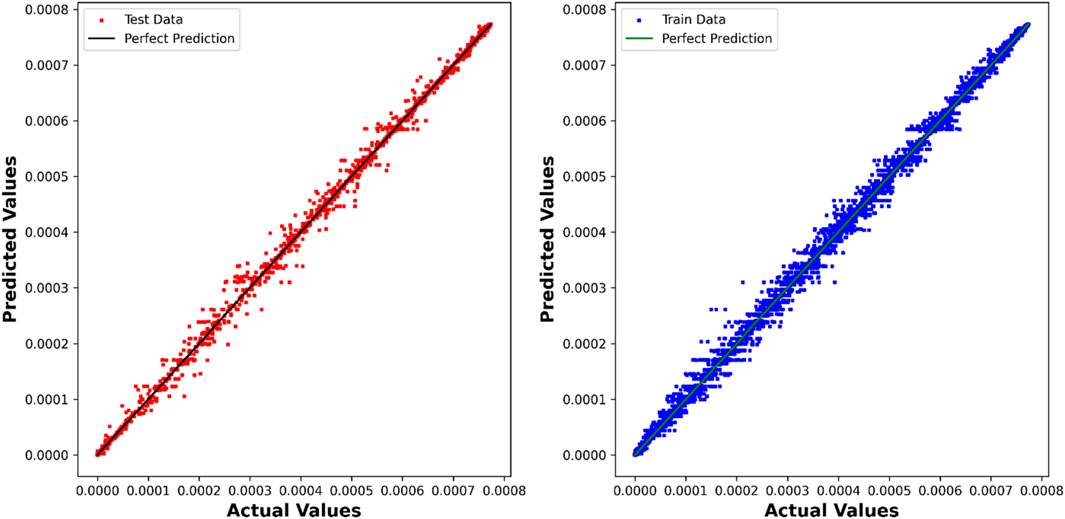
Figure 4. DTR model: Predicted values compared to True values.
While the PAR model demonstrates a slightly lower R2 score of 0.94652, its performance remains commendable, with competitive RMSE, MAE, and Max Error values. This indicates the model’s effectiveness in capturing relationships within the dataset, albeit with a nuanced trade-off between accuracy and complexity. In Figure 5, a visual comparison is presented, illustrating the disparities between the values predicted by the PAR model and the actual values.
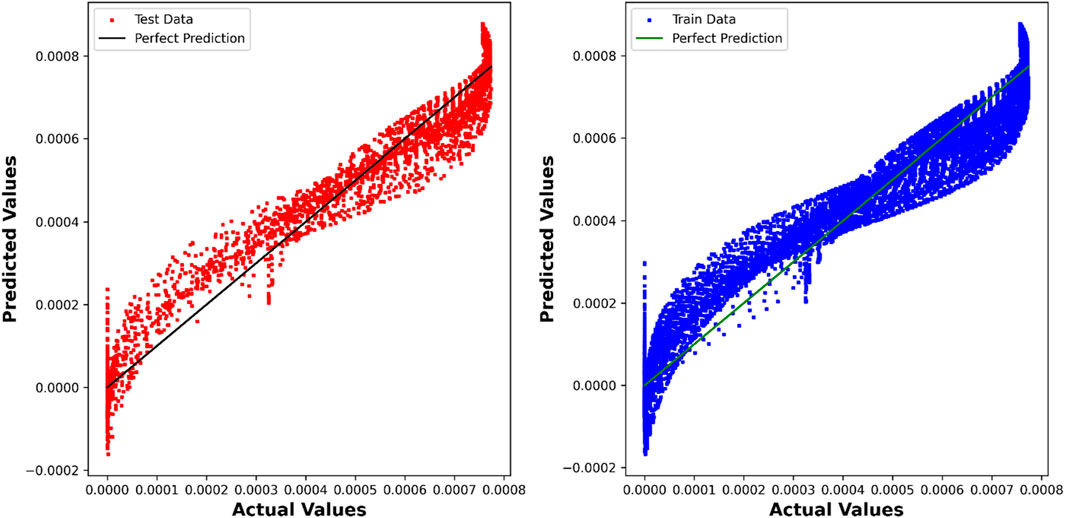
Figure 5. PAR model: Predicted values compared to True values.
The QPR model, designed to capture non-linear relationships, achieves a noteworthy R2 score of 0.95382. The model’s competitive RMSE, MAE, and Max Error values underscore its proficiency in accommodating the inherent complexities of the chemical engineering dataset. Figure 6 provides a visual representation, demonstrating the distinctions between the values forecasted by the QPR model and the factual values.

Figure 6. QPR model: Predicted values compared to True values.
Figures 7–9 present three-dimensional representations of concentration in relation to the variables r(m) and z(m), utilizing the three regression models. These visualizations offer a comprehensive view of how concentration varies across different values of r(m) and z(m) for each model. The change in drug concentration which has been obtained by the model could be attributed to the molecular diffusion occurring indie the polymeric matrix. Although both convective and diffusional mass transfer have been considered in the mass transfer model, the contribution of diffusion is significant and controls the release of drug from the carrier.
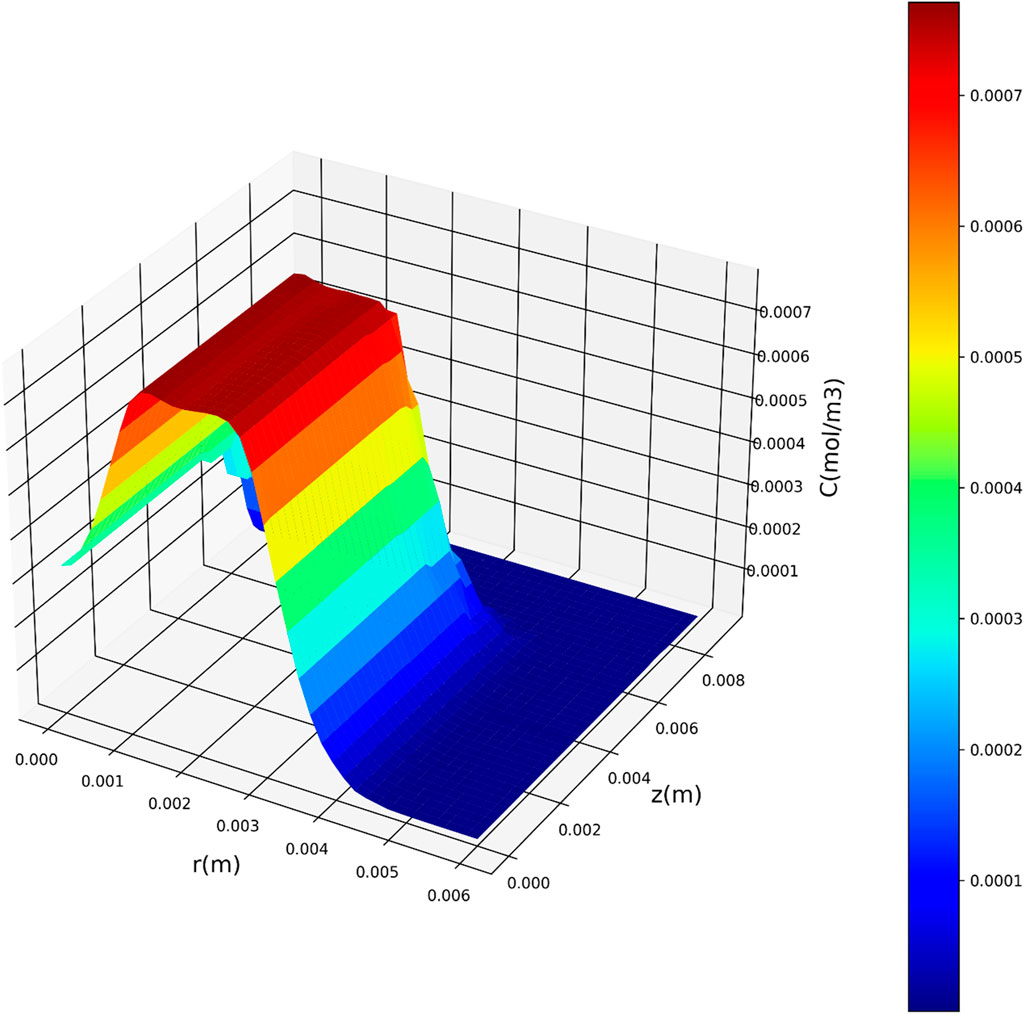
Figure 7. Three-dimensional representation of concentration with respect to r(m) and z(m) utilizing the DTR model.

Figure 8. Three-dimensional representation of concentration with respect to r(m) and z(m) utilizing the PAR model.
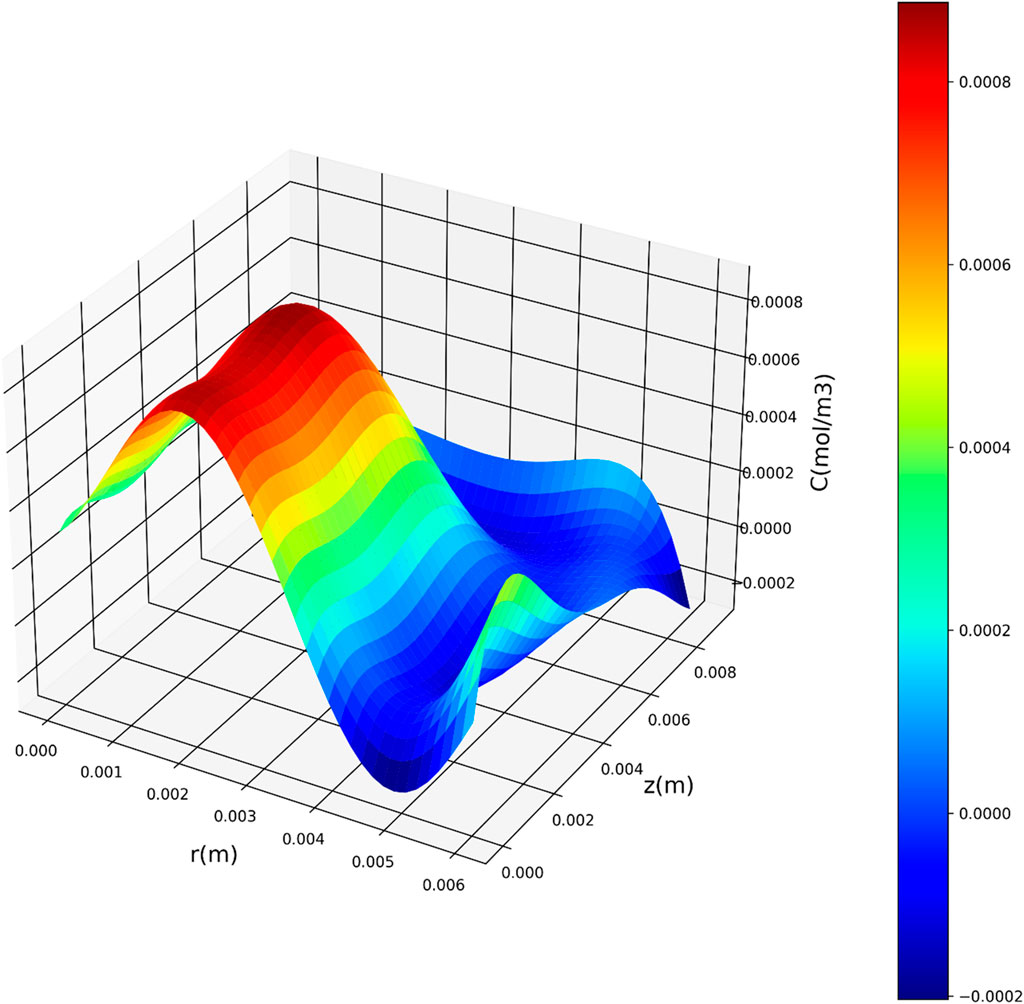
Figure 9. Three-dimensional representation of concentration with respect to r(m) and z(m) utilizing the QPR model.
Leveraging the DTR model, acknowledged as the top-performing model in this investigation, Figures 10, 11 depict the partial dependency of concentration on the variables r(m) and z(m), respectively. These visualizations provide insights into how changes in r(m) and z(m) influence the drug concentration, while keeping the other variable constant at multiple levels. This visualization provides a comprehensive representation of how the concentration varies across different combinations of the input variables, r(m) and z(m). The center of geometry is the drug where its concentration is the highest, while concentration declines beyond the center due to the diffusion as well as chemical reactions.
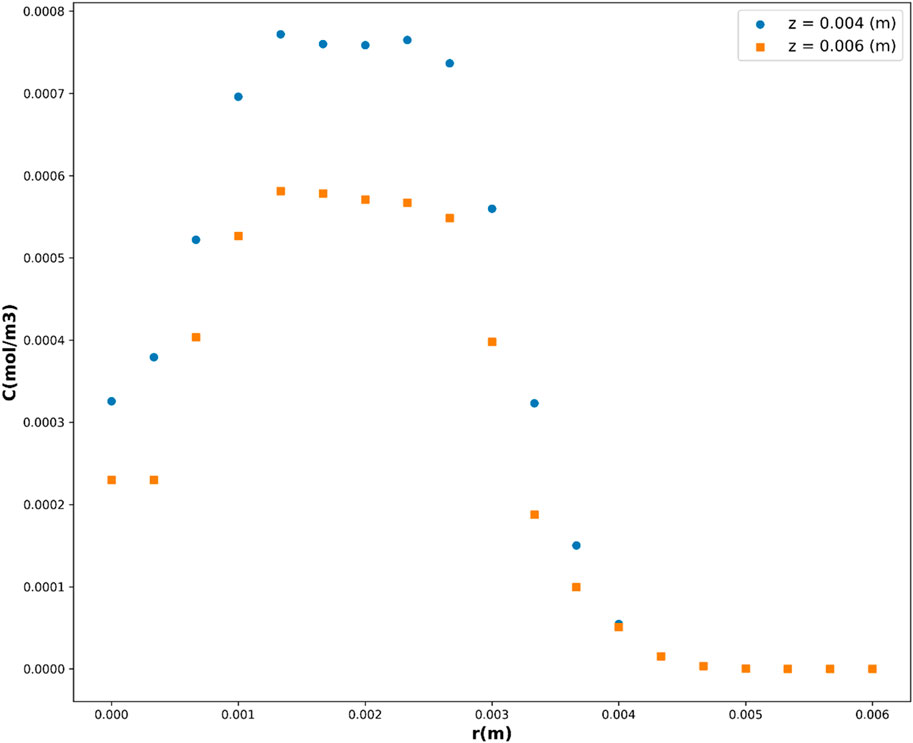
Figure 10. Concentration’s dependency on r.
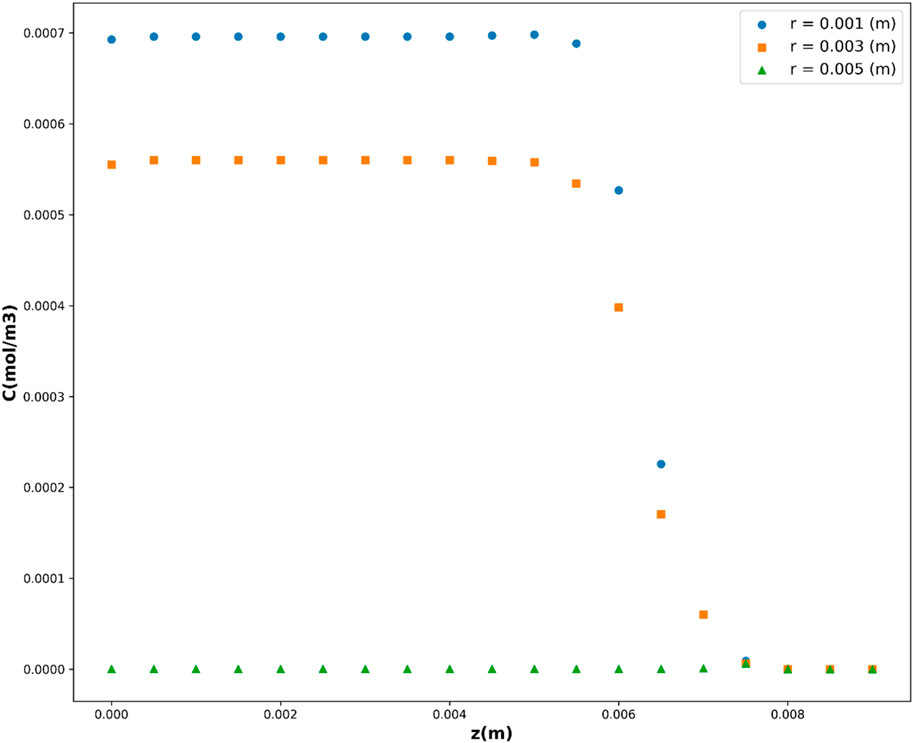
Figure 11. Concentration’s dependency on z.
5 Conclusion
In conclusion, this paper has presented a rigorous evaluation of three distinct regression models, namely, Decision Tree Regression (DTR), Passive Aggressive Regression (PAR), and Quadratic Polynomial Regression (QPR), within the context of a dataset containing more than 15,000 data points. The dataset has been obtained from mass transfer simulation of drug release from a porous polymeric carrier. The input parameters, r(m) and z(m), were utilized to predict the output concentration (C) in mol/m³. The models underwent hyper-parameter optimization through Sequential Model-Based Optimization (SMBO), ensuring a meticulous exploration of the parameter space.
The results showcase the exceptional predictive capabilities of the Decision Tree Regression model, evidenced by a significant R2 score of 0.99887, a negligible RMSE of 9.0092E-06, a minute MAE of 3.51486E-06, and a maximum error of 6.87000E-05. Despite a slightly lower R2 score, the Passive Aggressive Regression model demonstrated commendable performance, while the Quadratic Polynomial Regression model showcased proficiency in capturing non-linear relationships within the dataset.
This comparative analysis not only provides valuable insights into the specific strengths and limitations of each regression model but also serves as a guide for practitioners in selecting an appropriate model tailored to the complexities of chemical engineering datasets. The incorporation of SMBO contributes to the robustness of the models, highlighting the significance of thoughtful hyper-parameter tuning in enhancing predictive accuracy. Overall, this research contributes to the ongoing discourse on regression model selection and optimization techniques in the domain of drug delivery, offering a foundation for further exploration and refinement in predictive modeling methodologies for design of advanced drug delivery systems.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
SA: Conceptualization, Data curation, Formal Analysis, Resources, Writing–original draft. HA: Funding acquisition, Methodology, Project administration, Software, Visualization, Writing–original draft, Writing–review and editing. MA: Conceptualization, Data curation, Investigation, Methodology, Resources, Validation, Writing–original draft.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by Princess Nourah bint Abdulrahman University researchers supporting project number (PNURSP2024R205), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Acknowledgments
The authors extend their appreciation to Prince Sattam bin Abdulaziz University for funding this research work through the project number (PSAU/2023/03/26726). The authors extend their appreciation to Princess Nourah Bint AbdulRahman University, Riyadh, Saudi Arabia for funding this work under researcher supporting project number PNURSP2024R205.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abdelbasset, W. K., Elsayed, S. H., Alshehri, S., Huwaimel, B., Alobaida, A., Alsubaiyel, A. M., et al. (2022). Development of GBRT model as a novel and robust mathematical model to predict and optimize the solubility of decitabine as an anti-cancer drug. Molecules 27 (17), 5676. doi:10.3390/molecules27175676
Ali, A., Javed, R., Farhangi, S., Shah, T., Ullah, S., ul Ain, N., et al. (2023). Metal phenolic networks (MPNs)-based pH-sensitive stimulus responsive nanosystems for drug delivery in tumor microenvironment. J. Drug Deliv. Sci. Technol. 84, 104536. doi:10.1016/j.jddst.2023.104536
Almehizia, A. A., Naglah, A. M., Alkahtani, H. M., Hani, U., and Ghazwani, M. (2023). Numerical optimization of drug solubility inside the supercritical carbon dioxide system using different machine learning models. J. Mol. Liq. 392, 123466. doi:10.1016/j.molliq.2023.123466
Anusha, P. V., Anuradha, C., Chandra Murty, D. P. S., and Chebrolu, D. S. K. (2019). Detecting outliers in high dimensional data sets using Z-score methodology. Int. J. Innovative Technol. Explor. Eng. 9 (1), 48–53. doi:10.35940/ijitee.a3910.119119
Bertsimas, D., Dunn, J., and Paschalidis, A. (2017). “Regression and classification using optimal decision trees,” in 2017 IEEE MIT undergraduate research technology conference (URTC), Cambridge, MA, USA, 03-05 November 2017 (IEEE).
Carr, E. J., and Pontrelli, G. (2024). Modelling functionalized drug release for a spherical capsule. Int. J. Heat Mass Transf. 222, 125065. doi:10.1016/j.ijheatmasstransfer.2023.125065
Chen, W., Shi, K., Yu, Y., Yang, P., Bei, Z., Mo, D., et al. (2024). Drug delivery systems for colorectal cancer chemotherapy. Chin. Chem. Lett. 35 (2), 109159. doi:10.1016/j.cclet.2023.109159
Crammer, K., Dekel, O., Keshet, J., Shalev-Shwartz, S., and Singer, Y. (2006). Online passive aggressive algorithms. J. Mach. Learn. Res. 7, 551–585.
González-Garcinuño, Á., Baldino, L., Tabernero, A., Guastaferro, M., Cardea, S., Reverchon, E., et al. (2023). Validation of a compartmental model to predict drug release from porous structures produced by ScCO2 techniques. Eur. J. Pharm. Sci. 180, 106325. doi:10.1016/j.ejps.2022.106325
Heiberger, R. M., and Neuwirth, E. (2009) Polynomial regression. R through excel: a spreadsheet interface for statistics, data analysis, and graphics, 269–284.
Jovel, J., and Greiner, R. (2021). An introduction to machine learning approaches for biomedical research. Front. Med. 8, 771607. doi:10.3389/fmed.2021.771607
Kandula, S., Singh, P. K., Kaur, G. A., and Tiwari, A. (2023). Trends in smart drug delivery systems for targeting cancer cells. Mater. Sci. Eng. B 297, 116816. doi:10.1016/j.mseb.2023.116816
Kotsiantis, S. B. (2013). Decision trees: a recent overview. Artif. Intell. Rev. 39, 261–283. doi:10.1007/s10462-011-9272-4
Kubinski, A. M., Shivkumar, G., Georgi, R. A., George, S., Reynolds, J., Sosa, R. D., et al. (2023). Predictive drug release modeling across dissolution apparatuses I and II using computational Fluid Dynamics. J. Pharm. Sci. 112 (3), 808–819. doi:10.1016/j.xphs.2022.10.027
Lacoste, A., Larochelle, H., Laviolette, F., and Marchand, M. (2014) Sequential model-based ensemble optimization. arXiv preprint arXiv:1402.0796.
Lu, S., Zhang, C., Wang, J., and Zhao, L. (2024). Research progress in nano-drug delivery systems based on the characteristics of the liver cancer microenvironment. Biomed. Pharmacother. 170, 116059. doi:10.1016/j.biopha.2023.116059
Olson, D. L. (2020). “Regression tree models,” in Predictive data mining models. Editors D. L. Olson, and D. Wu (Springer), 57–77.
Rokach, L., and Maimon, O. (2005). “Decision trees,” in Data mining and knowledge discovery handbook. Editors O. Maimon, and L. Rokach (Springer Science and Business Media), 165–192.
Salas, A., Roberts, S. J., and Osborne, M. A. (2015) A variational Bayesian state-space approach to online passive-aggressive regression. arXiv preprint arXiv:1509.02438.
Sameer Khan, M., Jaswanth Gowda, B., Hasan, N., Gupta, G., Singh, T., Md, S., et al. (2024). Carbon nanotube-mediated platinum-based drug delivery for the treatment of cancer: advancements and future perspectives. Eur. Polym. J. 206, 112800. doi:10.1016/j.eurpolymj.2024.112800
Suthaharan, S., and Suthaharan, S. (2016). “Decision tree learning,” in Machine learning models and algorithms for big data classification: thinking with examples for effective learning. Editor S. Suthaharan (Springer), 237–269.
Talekar, B., and Agrawal, S. (2020). A detailed review on decision tree and random forest. Biosci. Biotechnol. Res. Commun. 13 (14), 245–248. doi:10.21786/bbrc/13.14/57
Tran, A., Tran, M., and Wang, Y. (2019). Constrained mixed-integer Gaussian mixture Bayesian optimization and its applications in designing fractal and auxetic metamaterials. Struct. Multidiscip. Optim. 59 (6), 2131–2154. doi:10.1007/s00158-018-2182-1
Keywords: durg delivery, decision tree regression, passive aggressive regression, quadratic polynomial regression, modeling
Citation: Alshahrani SM, Alotaibi HF and Alqarni M (2024) Modeling and validation of drug release kinetics using hybrid method for prediction of drug efficiency and novel formulations. Front. Chem. 12:1395359. doi: 10.3389/fchem.2024.1395359
Received: 03 March 2024; Accepted: 23 May 2024;
Published: 21 June 2024.
Edited by:
Phanish Suryanarayana, Georgia Institute of Technology, United StatesReviewed by:
Pengfei Jia, Guangxi University, ChinaJesus Alfredo Rosas Rodríguez, University of Sonora, Mexico
Copyright © 2024 Alshahrani, Alotaibi and Alqarni. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Saad M. Alshahrani, U20uQWxzaGFocmFuaUBwc2F1LmVkdS5zYQ==