 Sandra E. Fajardo Muñoz1*Anthony J. Freire Castro1Michael I. Mejía Garzón1
Sandra E. Fajardo Muñoz1*Anthony J. Freire Castro1Michael I. Mejía Garzón1 Galo J. Páez Fajardo2
Galo J. Páez Fajardo2 Galo J. Páez Gracia1
Galo J. Páez Gracia1- 1Facultad de Ingeniería Química, Universidad de Guayaquil, Guayaquil, Ecuador
- 2WMG, University of Warwick, Coventry, United Kingdom
Introduction: Excessive demand, environmental problems, and shortages in market-leader countries have led the citrus (essential) oil market price to drift to unprecedented high levels with negative implications for citrus oil-dependent secondary industries. However, the high price conditions have promoted market incentives for the incorporation of new small-scale suppliers as a short-term supply solution for the market. Essential oil chemical extraction via steam distillation is a valuable option for these new suppliers at a lab and small-scale production level. Nevertheless, mass-scaling production requires prediction tools for better large-scale control of outputs.
Methods: This study provides an intelligent model based on a multi-layer perceptron (MLP) artificial neural network (ANN) for developing a highly reliable numerical dependency between the chemical extraction output from essential oil steam distillation processes (output vector) and orange peel mass loading (input vector). In a data pool of 25 extraction experiments, 14 output–input pairs were the in training set, 6 in the testing set, and 5 cross-compared the model’s accuracy with traditional numerical approaches.
Results and Discussion: After varying the number of nodes in the hidden layer, a 1–9–1 MLP topology best optimizes the statistical parameters (coefficient of determination (R2) and mean square error) of the testing set, achieving a precision of nearly 97.6%. Our model can capture non-linearity behavior when scaling-up production output for mass production processes, thus providing a viable answer for the scalability issue with a state-of-the-art computational tool for planning, management, and mass production of citrus essential oils.
1 Introduction
The essential oil market is a well-established industry with interconnections with other industries, such as processed food, perfume fragrance, and strategic sectors (Maurya et al., 2021; Sharmeen et al., 2021; Israfi et al., 2022; Navarra et al., 2015; Bora et al., 2020). The world market has not yet recovered from the massive collapse of commerce during the COVID-19 pandemic and still shows signs of deceleration, with orange production dropping from the principal producers worldwide (Brazil, Florida, and Spain) (United States Department of Agriculture, 2022). Consequently, prices of citrus essential oils have reached unprecedented high levels (Technavio, 2022), making it attractive for newcomer producers to enter the market at least to cover local demand. The city of Las Naves in the Ecuadorian province of Bolivar is an attractive hub for citrus fruit production, with ambitious signs of expansion. Ecuador’s national institution for statistics and census (Instituto Nacional de Estadística y Censos—INEC) and the Ecuadorian minister’s office for agriculture and livestock farming (Ministerio de Agricultura y Ganadería—MAG) estimate a rise in orange production to 110.472 tons in upcoming years. At a local level (in other provinces in Ecuador), citrus fruit from Las Naves attracts high demand and consumption, guaranteeing a vast source of citrus waste that could ultimately serve in secondary product production.
Essential oils are organic compounds that provide the characteristic odor to citrus fruits and are a principal component of orange rind. The main component of citrus essential oil is limonene; its empirical formula (C10H16) is a monoterpene that exhibits two D- and L-limonene optical isomers and the racemic combination known as dipentene (González-Mas et al., 2019). Limonene is present in more than 49 volatile organic compounds (90% classified as terpenoid esters), with concentrations depending on the fruit variety: 30%–40% in bergamot, 40%–75% in lemon, and 68%–98% in sweet orange (Moufida and Marzouk, 2003). Most of its chemical and physical extraction processes rely on essential oil molecular volatility (Balboa Laura, 2011), although the quality and quantity of the essential oils in the fruit peel can impact the extraction efficiency levels independently of the extraction method (García, 2014). Microwave-assisted hydrodiffusion stands out because it is solvent-free and highly efficient with a short extraction time (Bustamante et al., 2016; Bora et al., 2020). However, for any extraction method, a highly accurate predictive model capable of determining extraction efficiency is very important for the optimization and design of scalable extraction pathways at various levels, such as in the laboratory or industry.
The wide set of variables and their non-linear and complex inter-relations make predicting the extraction yield of essential oil a challenging task. A lack of generality for mathematical models also contributes to this difficulty, with models being extraction technique-dependent (Berna et al., 2000; Sovová, 2005; Lainez-Cerón et al., 2022; El Ouaddari et al., 2022). A prediction model for steam distillation can even become obsolete with a variation in the essential oil source (Gawde et al., 2014). The inadequacy of a clear quality standard for a mathematical tool for predictions has led researchers to use polynomial, exponential, and logarithmic fitting tools to help at least with predictions in the locality (local space) of the data points (Zlatev and Shivacheva, 2018; Fakayode and Abobi, 2018). The local space of these basic fitting types comes at the expense of prediction capability away from the local domain—that is, extrapolation, a prediction feature required to enable the scalability of the extraction processes.
Artificial intelligence is a numerical approach that recognizes internal patterns in data to identify and classify data into larger sets. Artificial intelligent algorithms can then handle non-linearity and complexity in data structure and predict outputs of numerical processes (Meuwly, 2021). Given the complex nature of the variables in chemical processes, artificial intelligence is a suitable tool for formulating prediction models in this field. Steam distillation extraction models with artificial neural network algorithms have achieved remarkable accuracy in yield prediction of oil extraction from the soil (Daryasafar et al., 2014). Optimization of operating conditions in energy-intensive distillation processes can be explored via a machine learning-based predictive model concluding with recommendations for optimal steam flow that minimize energy consumption and maximize production yield (Park et al., 2022). We focus on developing an artificial intelligence model with a tool for steam distillation yield prediction of essential oil extraction from orange peel.
Using state-of-the-art artificial intelligence algorithms, this work introduces a technique-independent predictive neural network model for essential oil extraction from orange peel. We present a multi-layer perceptron (MLP) artificial neural network (ANN) with supervised learning. The model topological architecture achieves its best prediction via internal node adjusting of the model structure, while statistical error descriptors of the testing set are optimized. The MLP ANN handles input (orange peel mass) and output (essential oil mass) data from steam distillation experiments. Steam distillation is the most common technique at the laboratory level for essential oil extraction (Ferhat et al., 2006) and works on the principle that oil molecules diffuse when attached to water molecules in the vapor state (Chandler, 2002). The mean square error (MSE) and the coefficient of determination (R2) are the error descriptors of choice to guide network optimization, as used elsewhere (Park et al., 2022). A single hidden layer with nine neurons, back-propagation, and neural weights adjusted using the Levenberg–Marquardt algorithms optimizes the MSE and R2 of the oil extraction model. This model approach paves the way for planning and designing oil extraction processes at larger scales than in the laboratory.
2 Methodology
2.1 Sample collection
Local farmers from the Ecuadorian province of Bolívar in Las Naves city, 88 km northwest of Guaranda city, provided the Citrus sinensis L. raw peel material. This raw peel is waste from the production processes in the local citrus farms. The oranges used in production processes at local farms in Las Naves have a °Brix/Acidity index of 7. “°Brix” is a measure of the dissolved sugar in aqueous substances. One °Brix is traditionally defined as 1 g of sucrose in 100 g of water. “Acidity” is defined as titratable acidity, which measures the total acid concentration of food (also called total acidity). The reader can refer to Jayasena and Cameron (2008) for further reading. °Brix/Acidity is a classification step taken by local farmers before they use the oranges for food processing.
After we carefully transported the raw material to the city of Guayaquil, a visual inspection selected peel material with undamaged surfaces for the extraction experiments. We used cold water and a piece of soft tissue paper to wash off strange stains on the orange rind. The washed peel chunks went through a cut-down process to obtain smaller regular pieces of approximately 1.5 × 1.1 cm2 to facilitate essential oil extraction.
2.2 Steam distillation
The steam distillation equipment consisted of three main parts: a Clevenger-type apparatus, a heat source, and a glass spiral condenser. The glass tower consisted of two chambers: a lower chamber containing 1250 L of distilled water and a subsequent upper chamber containing the peel chunks. The bottom chamber served as a steam source under heat. We used five loading mass points (sample weight) of orange peel at 200, 300, 350, 400, and 500 g. Five steam distillation experimental repetitions per mass point were the statistical baseline of the artificial intelligence approach. This work performed a total of 25 distillation processes.
In each distillation experiment, the water vapor came from heating the 1250 L of distilled water in the lower chamber at 120°C. Vapor entered the upper chamber, separating the essential oil from the chunks, given the molecular volatility of the desired compounds. We later let it condense using the glass spiral condenser at 21°C in a mixture of water and essential oil molecules. An elapse time of 30 min for distillation proved optimal, based on previous hydro-distillation studies (Golmohammadi et al., 2018), to guarantee enough material after the first condensed drop. The Clevenger-type apparatus separated the resulting solution after condensation with the extracted essential oil at the top of a marked two-phase liquid given by the oil’s lower relative density.
2.3 Orange peel characterization
We followed the 930.15 method described by the Asociación de Químicos Analíticos Oficiales (AQAO, 2019) for humidity measurement. The underlying measurement principle was to detect the weight lost due to evaporation when exposing the sample to 70°C constant heating after a fixed amount of time. We used heating intervals of 2 h at a fixed 70°C and measured the mass of the washed peel pieces before and after the process. The mass value after the process is the total solid parameter (manual N° 925, 10, AOAC, 1997), and the mass difference with respect to the initial mass is the humidity measure.
Potentiometric pH measurements were used to probe the acidity of the peel samples (pH). The tried-and-tested 780 pH meter by Metrohm was employed. By comparing a known voltage with an unknown voltage according to the norm N° 981.12E, G, AOAC, 1997, the pH is calculated for the sample.
Spectrophotometry (PHARMACIA model Ultrospec 3000) measured the reducing sugar components of the orange peel in collaboration with UBA-laboratories (Uba Lab, 2022). The fundamentals of the principle can be found in Haldar et al. (2017).
2.4 Computational methods
A multi-layer perceptron (MLP) neural network algorithm is the artificial intelligence model of choice for our experiments due to its compatibility with our data structure. MLP is a supervised learning algorithm implemented and readily accessible in Matlab. A traditional model architecture consists of numerous hidden layers between the input and output layers, with some coded neurons per layer. We fixed the number of hidden layers to one with a sigmoid activation function between layers. The optimization process of the single hidden layer’s architecture consisted of varying the internal number of neurons to optimize a group of error descriptors: the MSE (minimization) and R2 (maximization) (Park et al., 2022)
respectively. At a given mass loading level, n is the number of data points in the mass loading set,
The model required a training and testing data set. The MLP algorithm processes the mass loading values as input and the essential oil extraction yield values as output. Of the 20 extraction experiments (5 per each 200, 300, 400, and 500 g mass loading point), data (mass loading and extraction yield) from 70% (14) of the experiments comprised the training data set. The remaining 30% (from the other six experiments) corresponded to the neural network testing set. We also used data from the testing set to compute the MSE and R2 descriptor in every iteration of the architectural restructuring. The 350 g set (data from five experiments are 350 g of mass loading) benchmarked the model’s predictive capabilities and compared it against traditional linear, logarithmic, and polynomial fitting curves.
2.5 Principal component analysis
Say we have a data matrix X, of n×p dimension, where the columns are the data features of interest, and the rows are the number of measurements for each feature. A principal component analysis focuses on determining a reduced number of features that encapsulate most of the information (variance) of the data set. We achieve this feature-dimensional-reducing property by computing the equation
where M is the reduced components representing most of the original information and V is the normalized eigenvector matrix of the variance matrix σ,
The matrix
For our data set, the entries in matrix X are the extracted essential oil percentages. The matrix is
where the columns are, from left to right, the orange peel mass loadings 200 g, 300 g, 350 g, 400 g, and 500 g. The rows are the five experiments we performed per mass loading.
After subtracting the average-extracted essential oil percentage for a given mass loading value from its corresponding column, we find that σ is
We introduce factor 106 to ease the matrix visualization for the reader. The eigenvalues of σ are 163.681, 13.934, 3.569, 0.012, and 0 with their respective eigenvectors.
•
•
•
•
•
We chose V to be a column vector with the normalized eigenvector for the eigenvalue 163.681, which is the first principal component.
With V defined, the matrix XTV reduced the number of measurements to the one representing the most data so that we could obtain a reliable representation of the data structure as a function of mass loading. We referred to the reduced measurement as the first component measurement.
3 Results and discussion
A homogeneous sample quality guaranteed enhanced statistical confidence in the data and thus improved the model’s prediction accuracy. We implemented a quality control scheme where, after the peel washing step described in Section 2, the regular peel chunks that fell within a 5% confidence interval relative to the standards in Table 1 were selected for the extraction experiments. High humidity was desirable so that an even molecular mixture (water + limonene oil molecules in the orange peel) would boil at lower boiling points than the separate liquids while steam flowed through the sample in the steam distillation experiments.
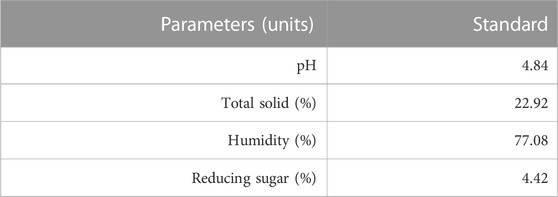
TABLE 1. Classification scheme to consistently spot similar peel features for oil extraction experiments.
Figure 1 and Table 2 summarize the experimental results at 200 g, 300 g, 350 g, 400 g, and 500 g mass loading levels with the washed regular chunks of orange rind after the extraction treatment. Yield figures are comparable with literature reports for steam distillation of essential oil from C. sinensis peel (Blanco Tirado et al., 1995; de Moraes Pultrini et al., 2006).
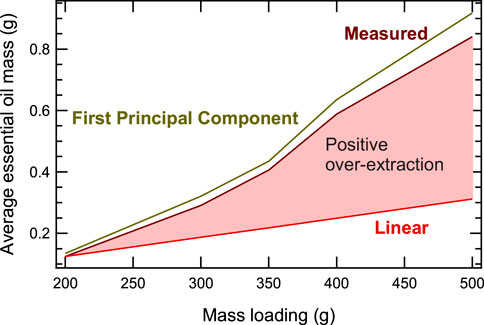
FIGURE 1. Extracted oil in terms of mass loading showing an extraction rate faster than expected. The extraction rate scales at a non-linear rate demonstrated by the first principal component in a PCA analysis.
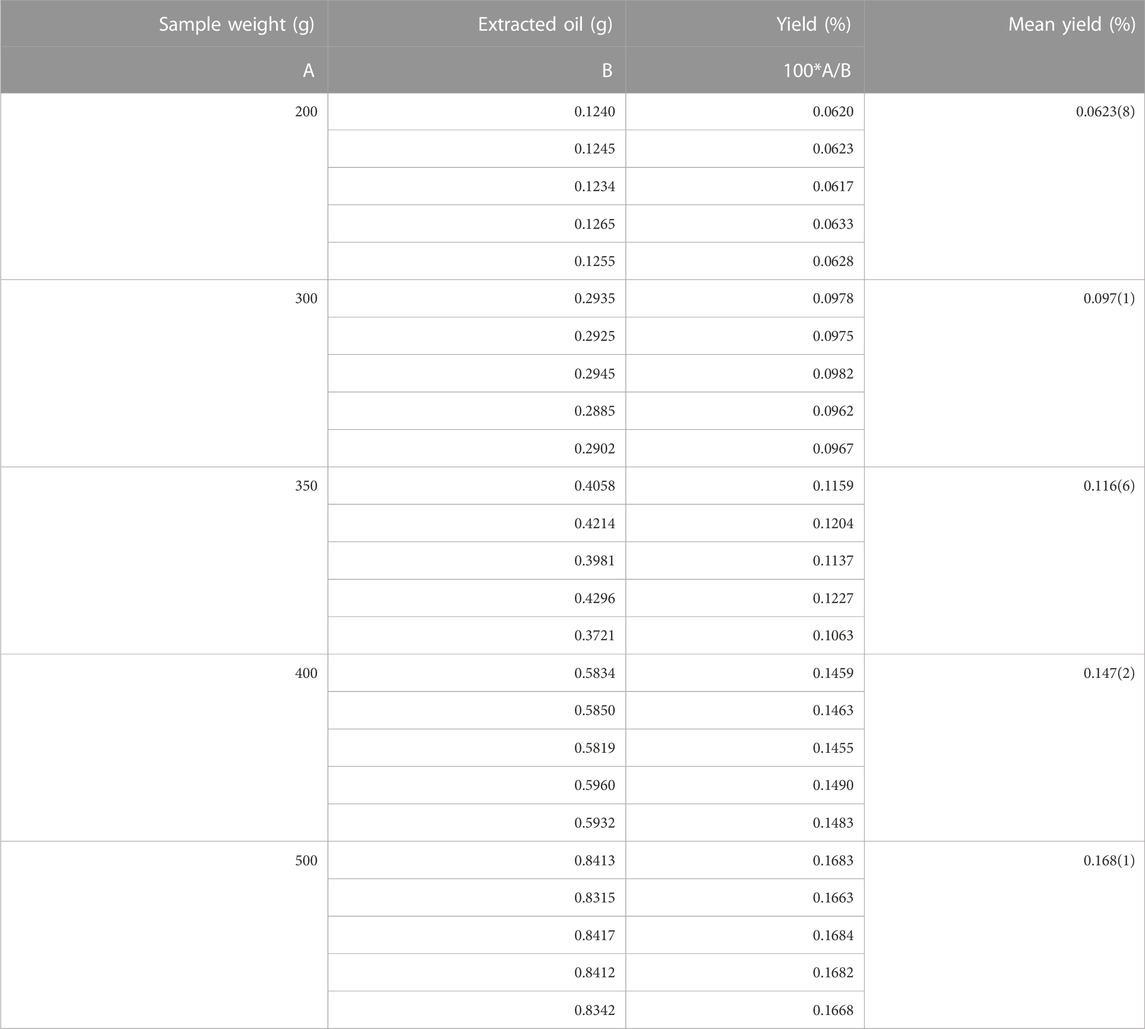
TABLE 2. Extraction yield of each mass loading with five repetitions per set. Values in parenthesis are part of the t-distribution confidence interval at the last significant figure.
As the mass loading increases, the extracted essential oil mass should linearly augment in the distillation process as depicted in Figure 1. However, the extraction yield scales up with the mass loading at a faster rate than the linear trend, rendering a positive over-extraction. This analysis is further supported by a principal analysis component developed in Section 2.5, with data increasing non-linearly with respect to the mass loading. This behavior makes the data structure ideal for non-linear numerical processes such as in the MLP algorithm. A t-distribution confidence interval analysis with 95% confidence and four degrees of freedom further supports the over-linear increase of the extraction yield. The t-distribution estimations (Column 4 in Table 2) suggest a more efficient extraction with sample weight.
Sun et al. (2017) also reported an over-linear dependency between the extraction yield and sample weight. Although the reason behind this dependency is beyond our current scope, we theorize that larger sample weights render an enhanced molecular diffusion across the orange peel–water interface. A larger loading mass occupies a larger space in the mass loading chamber, reducing the mixture’s boiling point (water vapor + essential oil molecules), thus promoting more material extraction. We will investigate this in more detail in subsequent research.
The MLP neural network shows promising results in Figure 2, predicting the extraction oil yield as a function of the neuron numbers for the 350-g sample set. Figure 2A shows the evolution of the error descriptors (MSE and R2) while the number of neurons increases in the network’s hidden layer. R2 stabilizes after six neurons, reaching a plateau afterward, while MSE bounces during the neuron number increment. Figure 2B describes the evolution of the predicted values from the network given a denser hidden layer.
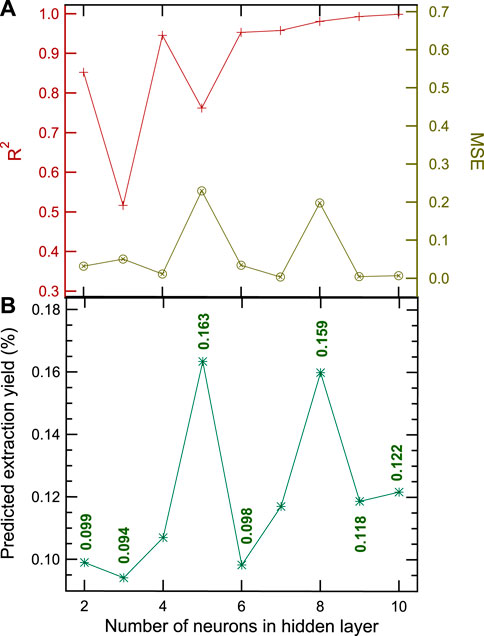
FIGURE 2. Results of the MLP neural network learning process with (A) the optimization process of the fitting parameters MSE and R2 for the testing set and (B) yield prediction for the verification set - 350 g.
We observe a clear correlation between the MLP’s predictions in Figure 2B and MSE in 2A. Numerical analysis demonstrates the MSE’s correlation with the model predictions stems from the MSE’s sensitivity to spiking values in the MLP model. We define a spiking value as mpred falling into the range of more than three sigma errors about
The predictive capacity of the network outperforms other more common mathematical models widely used in the literature (Zlatev and Shivacheva, 2018; Fakayode and Abobi, 2018), as observed in Table 3, with the highest R2 for the MLP neuron network. Our MLP model shows clear advantages over other models in accurately predicting the extraction yield for the 350-g mass loading set located in the vicinity of the sample weight range (from 200 to 500 g). With larger training sets, MLP should accurately predict the extraction values far from the training sample weight range. This feature is relevant for planning and designing scalable industrial extraction processes and is a valuable approach for initiating the leap from the laboratory to industrial scale-up.
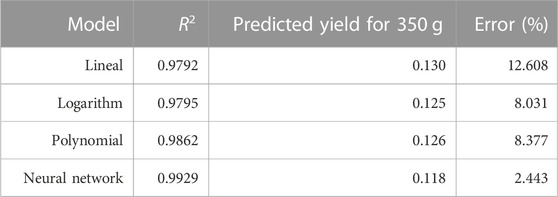
TABLE 3. Neuron network prediction capabilities against other common models.
4 Conclusion
We developed an innovative and alternative approach for an oil extraction yield predictor using state-of-the-art artificial intelligence algorithms. We use steam-distilled essential oil extraction data from orange peel to train a multi-layer perceptron (MLP) neural network in a supervised learning approach to achieve an accuracy beyond the standard predicting models in the literature. By simultaneously optimizing two fitting parameters (R2 and MSE), we demonstrate that the MLP neural network achieves its optimal architecture with one hidden layer and nine neurons, obtaining accuracy and predicting capabilities at R2 = 0.9929 and EMC% = 0.0040 for the validation sample set. The model developed in this work has the potential to unlock prediction capabilities in line with scalable design to bring lab-based production prototypes to an industrial level, thus being a viable path for a temporary solution for the citrus oil market.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author contributions
SF: supervision, writing—review and editing, project administration, and conceptualization. AF: writing—original draft, investigation, and formal analysis. MM: methodology. GPF: writing. GPG: validation, supervision, and writing—review and editing.
Acknowledgments
We acknowledge the support of the chemistry department at the Universidad de Guayaquil in allowing us to publish this work.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
AQAO (2019). The AOAC 21st edition of the official methods of analysis available at official methods of analysis. Rockville, Maryland: AOAC International.
Balboa Laura, M. H. (2011). Obtención experimental de aceite esencial y subproducto a partir de la cascara de naranja (citrus sinesis). La Paz, Bolivia: Bachelor’s thesis, Universidad Mayor de San Andrés.
Berna, A., Tárrega, A., Blasco, M., and Subirats, S. (2000). Supercritical CO2 extraction of essential oil from orange peel; effect of the height of the bed. J. Supercrit. Fluids 18, 227–237. doi:10.1016/S0896-8446(00)00082-6
Blanco Tirado, C., Stashenko, E., Combariza, M., and Martinez, J. (1995). Comparative study of colombian citrus oils by high-resolution gas chromatography and gas chromatography-mass spectrometry. J. Chromatogr. A 697, 501–513. doi:10.1016/0021-9673(94)00955-9
Bora, H., Kamle, M., Mahato, D. K., Tiwari, P., and Kumar, P. (2020). Citrus essential oils (CEOs) and their applications in food: An overview. Plants (Basel, Switz. 9, 357. doi:10.3390/plants9030357
Bustamante, J., van Stempvoort, S., García-Gallarreta, M., Houghton, J. A., Briers, H. K., Budarin, V. L., et al. (2016). Microwave assisted hydro-distillation of essential oils from wet citrus peel waste. J. Clean. Prod. 137, 598–605. doi:10.1016/j.jclepro.2016.07.108
Daryasafar, A., Ahadi, A., and Kharrat, R. (2014). Modeling of steam distillation mechanism during steam injection process using artificial intelligence. Sci. World J. 2014, 1–8. doi:10.1155/2014/246589
de Moraes Pultrini, A., Almeida Galindo, L., and Costa, M. (2006). Effects of the essential oil from citrus aurantium l. in experimental anxiety models in mice. Life Sci. 78, 1720–1725. doi:10.1016/j.lfs.2005.08.004
El Ouaddari, A., El Amrani, A., Jamal Eddine, J., and Antonio Cayuela-Sánchez, J. (2022). Rapid prediction of essential oils major components by vis/nirs models using compositional methods. Results Chem. 4, 100562. doi:10.1016/j.rechem.2022.100562
Fakayode, O. A., and Abobi, K. E. (2018). Optimization of oil and pectin extraction from orange (citrus sinensis) peels: A response surface approach. J. Anal. Sci. Technol. 9, 20. doi:10.1186/s40543-018-0151-3
Ferhat, M. A., Meklati, B. Y., Smadja, J., and Chemat, F. (2006). An improved microwave clevenger apparatus for distillation of essential oils from orange peel. J. Chromatogr. APlant Analysis 1112, 121–126. doi:10.1016/j.chroma.2005.12.030
García, R. T. (2014). Obtención de aceite esencial de citronela (cymbopogon winterianus) extraído por arrastre con vapor a escala piloto: Estudio de la influencia de variables en el rendimiento y la calidad del aceite. Master’s thesis, Universidad Tecnológica Nacional - Facultad Regional Resistencia.
Gawde, A., Cantrell, C. L., Zheljazkov, V. D., Astatkie, T., and Schlegel, V. (2014). Steam distillation extraction kinetics regression models to predict essential oil yield, composition, and bioactivity of chamomile oil. Industrial Crops Prod. 58, 61–67. doi:10.1016/j.indcrop.2014.04.001
Golmohammadi, M., Borghei, A., Zenouzi, A., Ashrafi, N., and Taherzadeh, M. J. (2018). Optimization of essential oil extraction from orange peels using steam explosion. Heliyon 4, e00893. doi:10.1016/j.heliyon.2018.e00893
González-Mas, M. C., Rambla, J. L., López-Gresa, M. P., Blázquez, M. A., and Granell, A. (2019). Volatile compounds in citrus essential oils: A comprehensive review. Front. Plant Sci. 10, 12. doi:10.3389/fpls.2019.00012
Haldar, D., Sen, D., and Gayen, K. (2017). Development of spectrophotometric method for the analysis of multi-component carbohydrate mixture of different moieties. Appl. Biochem. Biotechnol. 181, 1416–1434. doi:10.1007/s12010-016-2293-3
Israfi, N. A. M., Ali, M. I. A. M., Manickam, S., Sun, X., Goh, B. H., Tang, S. Y., et al. (2022). Essential oils and plant extracts for tropical fruits protection: From farm to table. Front. Plant Sci. 13, 999270. doi:10.3389/fpls.2022.999270
Jayasena, V., and Cameron, I. (2008). °Brix/Acid ratio as A predictor of consumer acceptability of crimson seedless table grapes. J. Food Qual. 31, 736–750. doi:10.1111/j.1745-4557.2008.00231.x
Lainez-Cerón, E., Ramírez-Corona, N., López-Malo, A., and Franco-Vega, A. (2022). An overview of mathematical modeling for conventional and intensified processes for extracting essential oils. Chem. Eng. Process. - Process Intensif. 178, 109032. doi:10.1016/j.cep.2022.109032
Levenberg, K. (1944). A method for the solution of certain non-linear problems in least squares. Q. Appl. Math. 2, 164–168. doi:10.1090/qam/10666
Marquardt, D. W. (1963). An algorithm for least-squares estimation of nonlinear parameters. J. Soc. Industrial Appl. Math. 11, 431–441. doi:10.1137/0111030
Maurya, A., Prasad, J., Das, S., and Dwivedy, A. K. (2021). Essential oils and their application in food safety. Front. Sustain. Food Syst. 5. doi:10.3389/fsufs.2021.653420
Meuwly, M. (2021). Machine learning for chemical reactions. Chem. Rev. 121, 10218–10239. doi:10.1021/acs.chemrev.1c00033
Moufida, S., and Marzouk, B. (2003). Biochemical characterization of blood orange, sweet orange, lemon, bergamot and bitter orange. Phytochemistry 62, 1283–1289. Reports on Structure Elucidation. doi:10.1016/S0031-9422(02)00631-3
Navarra, M., Mannucci, C., Delbò, M., and Calapai, G. (2015). Citrus bergamia essential oil: From basic research to clinical application. Front. Pharmacol. 6, 36. doi:10.3389/fphar.2015.00036
Park, H., Kwon, H., Cho, H., and Kim, J. (2022). A framework for energy optimization of distillation process using machine learning-based predictive model. Energy Sci. Eng. 10, 1913–1924. doi:10.1002/ese3.1134
Sharmeen, J. B., Mahomoodally, F. M., Zengin, G., and Maggi, F. (2021). Essential oils as natural sources of fragrance compounds for cosmetics and cosmeceuticals. Molecules 26, 666. doi:10.3390/molecules26030666
Sovová, H. (2005). Mathematical model for supercritical fluid extraction of natural products and extraction curve evaluation. J. Supercrit. Fluids 33, 35–52. doi:10.1016/j.supflu.2004.03.005
Sun, S.-H., Chai, G.-B., Li, P., Xie, J.-P., and Su, Y. (2017). Steam distillation/drop-by-drop extraction with gas chromatography–mass spectrometry for fast determination of volatile components in jujube (ziziphus jujuba mill.) extract. Chem. Central J. 11, 101. doi:10.1186/s13065-017-0329-6
Technavio (2022). Citrus oils market by application and geography - forecast and analysis 2022-2026. Elmhurst, IL, United States: Technavio.
Uba Lab (2022). Further information about uba-lab. Guayaquil, Ecuador: Analytical Laboratories Testing & Consulting. Available at: https://www.uba-lab.com/.
United States Department of Agriculture, (2022). Citrus: World markets and trade. Washington, United States: United States Department of Agriculture, Foreign Agricultural Service.
Keywords: multi-layer perceptron neural network, orange peels, citrus oil, steam distillation, optimization, extraction yield
Citation: Fajardo Muñoz SE, Freire Castro AJ, Mejía Garzón MI, Páez Fajardo GJ and Páez Gracia GJ (2023) Artificial intelligence models for yield efficiency optimization, prediction, and production scalability of essential oil extraction processes from citrus fruit exocarps. Front. Chem. Eng. 4:1055744. doi: 10.3389/fceng.2022.1055744
Received: 28 September 2022; Accepted: 14 December 2022;
Published: 10 January 2023.
Edited by:
Fausto Gallucci, Eindhoven University of Technology, NetherlandsReviewed by:
Anping Wang, Guizhou Normal University, ChinaJuan Gabriel Segovia Hernandez, University of Guanajuato, Mexico
Copyright © 2023 Fajardo Muñoz, Freire Castro, Mejía Garzón, Páez Fajardo and Páez Gracia. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Sandra E. Fajardo Muñoz , c2FuZHJhLmZhamFyZG9tQHVnLmVkdS5lYw==