
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Cell Dev. Biol., 22 July 2022
Sec. Molecular and Cellular Pathology
Volume 10 - 2022 | https://doi.org/10.3389/fcell.2022.906042
This article is part of the Research TopicAdvances in Platforms for Disease ModelingView all 7 articles
 Xing Wu1†
Xing Wu1† Di Xu2†Tong Ma2
Di Xu2†Tong Ma2 Zhao Hui Li1
Zhao Hui Li1 Zi Ye1
Zi Ye1 Fei Wang3
Fei Wang3 Xiang Yang Gao3Bin Wang2Yu Zhong Chen2Zhao Hui Wang4Ji Li Chen5Yun Tao Hu6Zong Yuan Ge2Da Jiang Wang1*
Xiang Yang Gao3Bin Wang2Yu Zhong Chen2Zhao Hui Wang4Ji Li Chen5Yun Tao Hu6Zong Yuan Ge2Da Jiang Wang1* Qiang Zeng3*
Qiang Zeng3*Background: Cataract is the leading cause of blindness worldwide. In order to achieve large-scale cataract screening and remarkable performance, several studies have applied artificial intelligence (AI) to cataract detection based on fundus images. However, the fundus images they used are original from normal optical circumstances, which is less impractical due to the existence of poor-quality fundus images for inappropriate optical conditions in actual scenarios. Furthermore, these poor-quality images are easily mistaken as cataracts because both show fuzzy imaging characteristics, which may decline the performance of cataract detection. Therefore, we aimed to develop and validate an antiinterference AI model for rapid and efficient diagnosis based on fundus images.
Materials and Methods: The datasets (including both cataract and noncataract labels) were derived from the Chinese PLA general hospital. The antiinterference AI model consisted of two AI submodules, a quality recognition model for cataract labeling and a convolutional neural networks-based model for cataract classification. The quality recognition model was performed to distinguish poor-quality images from normal-quality images and further generate the pseudo labels related to image quality for noncataract. Through this, the original binary-class label (cataract and noncataract) was adjusted to three categories (cataract, noncataract with normal-quality images, and noncataract with poor-quality images), which could be used to guide the model to distinguish cataract from suspected cataract fundus images. In the cataract classification stage, the convolutional-neural-network-based model was proposed to classify cataracts based on the label of the previous stage. The performance of the model was internally validated and externally tested in real-world settings, and the evaluation indicators included area under the receiver operating curve (AUC), accuracy (ACC), sensitivity (SEN), and specificity (SPE).
Results: In the internal and external validation, the antiinterference AI model showed robust performance in cataract diagnosis (three classifications with AUCs >91%, ACCs >84%, SENs >71%, and SPEs >89%). Compared with the model that was trained on the binary-class label, the antiinterference cataract model improved its performance by 10%.
Conclusion: We proposed an efficient antiinterference AI model for cataract diagnosis, which could achieve accurate cataract screening even with the interference of poor-quality images and help the government formulate a more accurate aid policy.
Cataracts are the leading cause of blindness worldwide (Flaxman et al., 2017). According to the etiological classification, the most common type is age-related cataracts (Tang et al., 2016). In China, the incidence rate of cataracts is as high as 80% in 60–89-year-old people and is almost 90% in the elderly over 90 years old (National Health Commission, 2020). With the acceleration of population aging, the prevalence of cataracts is expected to increase (Song et al., 2018). Early diagnosis and timely surgery can effectively treat cataracts to improve the vision and quality of life of patients (Limwattananon et al., 2018; Wu et al., 2019). However, due to the uneven distribution of medical resources, the shortage of ophthalmologists, and the increase in the number of cataract patients, many cataract patients cannot receive early diagnosis and effective treatment, particularly in the primary medical facilities of low- and middle-income countries (Ramke et al., 2017).
At present, slit lamp camera images are widely applied for cataract diagnosis due to their optical feature and legibility (Zhang et al., 2019). However, there are some limitations to a certain degree in rural areas, i.e., the nonportability of slit lamp devices and the shortage of medical device technicians. In comparison, fundus photographs have several advantages in their efficiency and their handleability. Meanwhile, with the universal application of artificial intelligence (AI) for disease diagnosis, some work focus on automatic cataract detection using AI technique (Patel et al., 2009; Castaneda et al., 2015; Harini and Bhanumathi, 2016; Long et al., 2017). Therefore, combining fundus images and AI-based methods is regarded as a more feasible scheme for automatic cataract detection in actual applications (Park et al., 2020).
Several studies work on AI-assisted diagnosis models of cataracts based on fundus images. Li et al. (2010) divided the fundus images into normal and abnormal, which was an earlier method to apply machine learning to fundus image classification. Xu et al. (2020) proposed a deep learning approach to integrate global and local cataract features to construct a hybrid global–local feature representation model. Ran et al. (2018) extracted the initial feature using deep convolutional neural networks (CNNs) and detected the level of cataracts through random forests. Yang et al. (2016) proposed an ensemble learning-based method to improve the accuracy of cataract diagnosis. Triyadi et al. (2022) processed the two-class cataract classification using VGG-19, Resnet-50, and Resnet-100, whereas several studies improved the cataract classification into four categories, including normal, immature, mature, and hyper mature using the hybrid model (Imran et al., 2020; Simanjuntak et al., 2022). In the study, 1239 fundus images were used to train the model, and three independent feature sets (i.e., wavelet-, sketch-, and texture-based features) were extracted from each fundus image. Two learning models were established, and then, the ensemble method combining the double models was used to classify the fundus image. The best performance of the ensemble method for cataract classification and four-level grading tasks was 93.2% and 84.5%, respectively. Zhang et al. (2019) proposed a six-level cataract grading method that focused on multifeature fusion based on stacking. They extracted two kinds of features that can distinguish the level of cataracts from 1352 fundus images and created a frame consisting of two supported vector machine classifiers and a fully connected neural network to grade cataracts. The average accuracy of the six-level grading model was 92.66%. Previous studies have focused on the use of AI for the identification and grading of age-related cataracts based on normal-quality fundus images, and they are less likely to consider the quality of fundus images (Gao et al., 2015; Guo et al., 2015; Dong et al., 2017).
However, for cataract detection, the issue of image quality must be considered in actual scenarios since the existence of poor-quality fundus images caused by inappropriate optical scenes in the real world is likely to be mistaken as cataract images, which may cause performance degradation and false positives of cataract diagnosis to some extent. Figure 1 showed the typical noncataract with poor-quality image, noncataract with normal-quality image, and cataract image, respectively. The figure shows that noncataract with poor-quality image is easily mistaken as cataract, which will bring some challenges to cataract identification. In the study, the criteria to distinguish normal and poor-quality noncataract images mainly depended on the lighting and exposure of fundus images. For normal noncataract images, they were under moderate exposure, in which the junction between the rim of the optic disk and the optic cup, the small blood vessels on the surface of the optic disk, and the normal retinal nerve fiber layer were clearly distinguishable as a reference. As for poor-quality noncataract images, there were two main manifestations, including underexposure and light leaking. The first type was that fundus images were generally blurred and dark due to underexposure. In addition, the other one showed a yellow edge, a light leakage-like edge, or a water drop-like reflective band of the surrounding area of the fundus image.
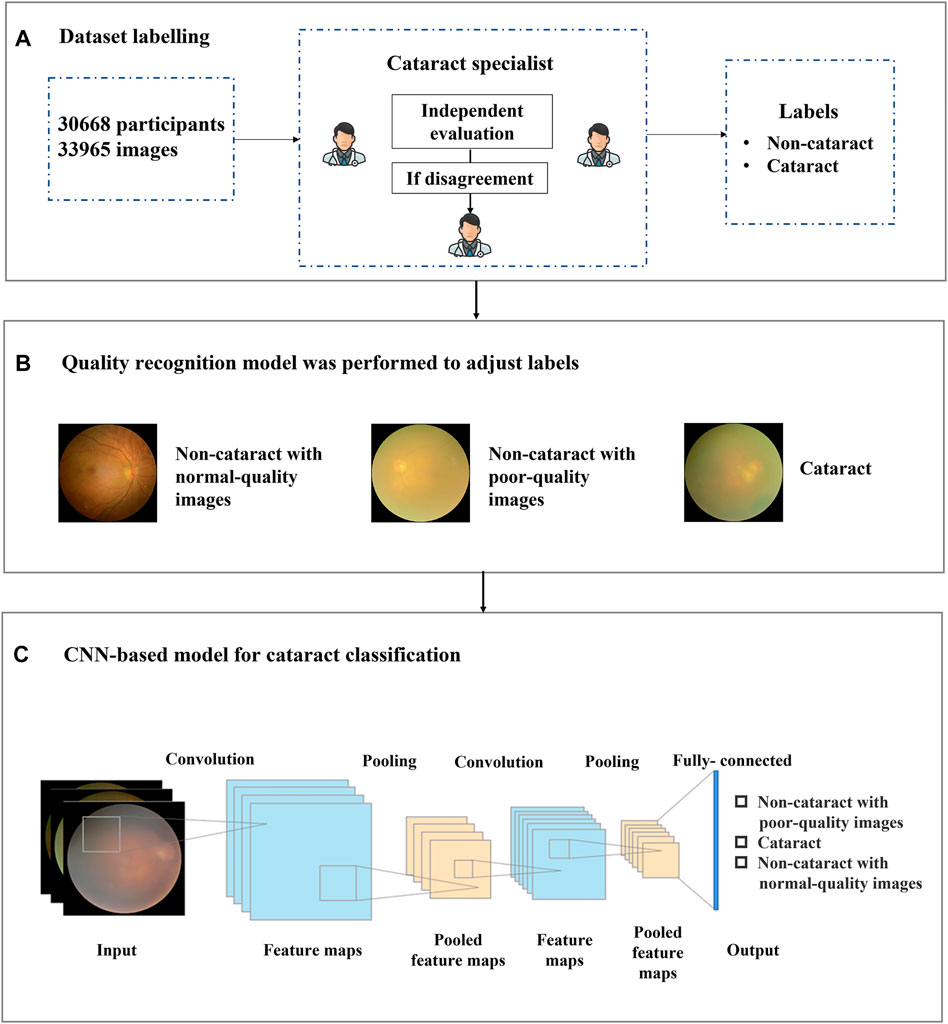
FIGURE 1. Overall training pipeline for the cataract artificial intelligence model. (A) the dataset included 33,965 images of 30,668 participants. Each image was independently labeled by two experienced ophthalmologists, and a third ophthalmologist was consulted if a disagreement arose between the initial ophthalmologists. (B) all 33,965 images with binary-class diagnosis labels were adjusted and reassigned to three categories of labels by the quality recognition model. (C) all 33,965 images were input to the convolutional neural networks-based model for training and validating the antiinterference cataract artificial intelligence classification model.
Therefore, in our study, to alleviate the issue of diagnostic performance degradation due to the interference of poor-quality fundus images, we proposed a hybrid structure based on a two-stage AI model to achieve accurate cataract image recognition with the distraction of image quality. The results show that our proposed method has increased the robustness of the model and achieved accurate cataract detection even with numerous interferences. Furthermore, it can assist doctors in cataract diagnosis more efficiently.
In the study, the dataset which included 14,820 participants and 16,200 fundus images of cataract and noncataract was retrospectively derived from the Chinese PLA general hospital from September 2018 to May 2021. The participants’ basic information (age, sex), brief medical history with related examinations such as slit lamp images, and fundus images were anonymized and acquired from the hospital information system. The fundus images were excluded from the study if the participants had congenital cataract, intraocular lens, aphakic eye, severe eye trauma, or corneal opacity. The 14,820 participants with fundus images and medical information were simply randomized into the development dataset (88%) and internal validation dataset (12%). The 16,200 fundus images were split randomly into mutually exclusive sets for training dataset (development dataset) and internal testing dataset (internal validation dataset) of the AI model at an 8:1 ratio. To validate the availability of the antiinterference AI model in a real-world scenario, 17,765 fundus images of 15,848 participants were prospectively collected (from June 2021 to December 2021) from three real-world settings (i.e., iKang Guobin Healthcare Group Co., Ltd., Shanghai Shibei Hospital of Jing’an District and Beijing Tsinghua Changgung Hospital) as external test dataset (Shown in Figure 2). In our study, three different nonmydriatic fundus cameras (Canon, Syseye, and Topcon) were used. All fundus images were macula and optic disk-centered 45-color fundus photographs.
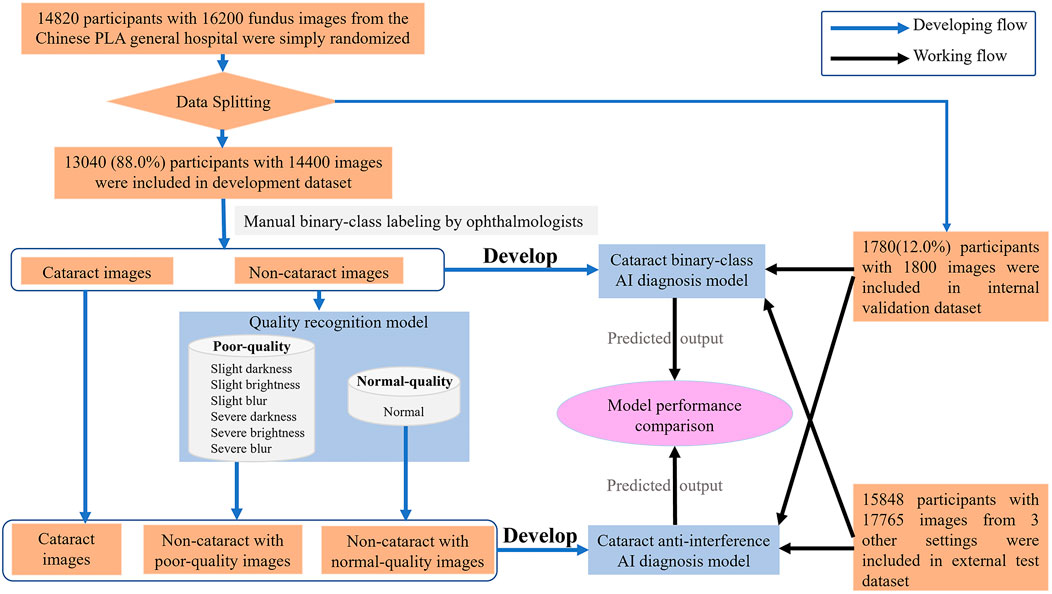
FIGURE 2. Flow chart describing the datasets and methods used for our artificial intelligence model.
Each image was independently evaluated and labeled by two experienced ophthalmologists, and a third ophthalmologist was consulted in case of disagreement (shown in Figure 1A). The medical information corresponding to each recruited fundus image was provided to the ophthalmologists to improve diagnostic accuracy. The fundus images were labeled into two categories, namely, cataract and noncataract.
For our model training stage, the model consisted of two AI submodules, a quality recognition model for cataract labeling and a CNN-based model for cataract classification, which were both trained on the development dataset. The AI model used in this study was based on deep neural network architecture. In order to obtain an effective model for real clinical usage, the whole model learning process needed to involve two steps, model training and model validation. In the model training stage, the goal was to train an AI model to fit the training data points and be competent for the specific problem. One common approach was to let the model learn with labeled data sets that were annotated by professionals. The labels were used as supervisory signals to guide models to have better capabilities to recognize cataracts. The validation stage aimed to predict the results of the input images and validate the performance of the model. During the validation stage, labels were not available during the prediction and were used to measure the performance after the model output its predictions. In our experiment, the model was tested in the internal and external validation dataset, and the results output by the AI model were then compared with the ground truth to evaluate the performance of the model.
In the practical scene, the performance of the cataract AI classification model could be largely affected by the image quality, especially when the cataract images are easily confused with poor-quality images of noncataract; thus, the correct distinction between the two is crucial for the performance of the following cataract AI recognition model. Therefore, in the first stage, we built a quality recognition model that aimed to assess the fundus images according to the image quality and generated the three-category cataract labeling for the next step.
Based on this situation, we proposed a label-based method to better distinguish cataract from noncataract with suspected fundus images using the quality recognition model. The quality recognition model was trained with a seven-category task, including normal, slight darkness, slight brightness, slight blur, severe darkness, severe brightness, and severe blur. This quality recognition model is the quality control tool for fundus images developed by Hu et al. (2021) in Airdoc company in 2019, which can be widely used in many retinal disease recognition tasks on fundus images. The model consists of two steps, the first one uses a generative adversarial network to determine whether the images are fundus images, and the second step is applied to output the probabilities of each quality grade (seven in total) of images. By combining the fundus image recognition model with the image quality classification network model, the overall accuracy can be improved by filtering out the interference from nonfundus images while obtaining a more accurate fundus image quality classification. The area under the curve (AUC) of the quality model was 99%, which was suitable for quality recognition of noncataract images; thus, we have applied this method to our work. Moreover, we employed the model to generate pseudo labels for noncataract, distinguishing between normal quality and poor quality. Therefore, by labeling the categories (slight darkness, slight brightness, slight blur, severe darkness, severe brightness, and severe blur) as poor-quality noncataract class, the original annotations were further refined into three categories (cataract, noncataract with normal-quality images, and noncataract with poor-quality images), which would give guidance to our cataract AI diagnosis model on the aspect of the label, so that the AI model could improve the performance of cataract classification (shown in Figure 1B).
The quality recognition model in our method was mainly based on Inception-Resnet pretrained on ImageNet. During training, the model was optimized with the cross-entropy loss, which was defined as follows.
Based on the quality recognition model, an antiinterference AI classification model with a CNN was trained to predict the label of images (cataract, noncataract with normal-quality images, and noncataract with poor-quality images).
CNN is a kind of feedforward neural network with depth structure and convolution calculation (Sun et al., 2019). It is one of the representative algorithms of deep learning. Because of its depth and massive layers, CNN has huge representation power to learn visual features of ophthalmic diseases and discriminate them effectively. The structure of the cataract AI classification model was mainly based on Inception-Resnet pretrained on ImageNet (Szegedy et al., 2017). As shown in Figure 1C, a CNN consisted of several convolution layers, a pooling layer, and a fully connected layer. The convolution and pooling layers cooperated to form multiple convolution groups, extract features layer by layer, and finally complete the classification through the fully connected layer. More specifically, random rotation, a data argumentation method, was applied in the data preprocessing stage, and then, each image was resized to
During the training stage, we used the fundus images from the development dataset as input to train the models. After one hundred training epochs, a cataract classification model can be obtained, and the accuracy and loss curve during the training process were shown in Figure 3. As for implementation details, we trained the network on our dataset for 100 epochs with a batch size of 24. Stochastic gradient descent with a momentum of 0.9 and a weight decay of
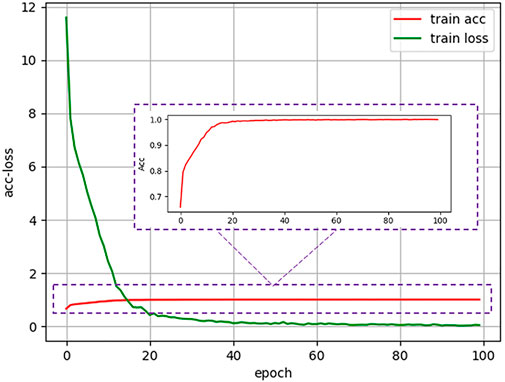
FIGURE 3. Accuracy and loss curve of antiinterference cataract artificial intelligence diagnosis model in the training process.
To verify the robustness of our proposed method, we set up a control experiment, in which the cataract diagnosis model was trained on the binary-class labels, including normal and cataract two categories. In addition, the setting of the control experiment was consistent with the proposed method. Then, we tested the performance of the cataract binary-class AI model in the control experiment and the antiinterference cataract AI diagnosis model concerning standard diagnosis based on ophthalmologists’ evaluation in the same dataset (internal validation set and external test dataset, which contained a certain amount of poor-quality fundus images). Furthermore, we tested the performance of the antiinterference model in the external test dataset.
The indices used for evaluation were calculated using the accuracy of the formula (ACC) = (TP + TN)/(TP + TN + FP + FN), sensitivity (SEN) = TP/(TP + FN), and specificity (SPE) = TN/(TN + FP), where TP is true positive, TN is true negative, FP is false positive, and FN is false negative. Asymptotic two-sided 95% CIs presented as the AUC and were calculated by using bootstrap analysis with 100,000 random seed sampling. Receiver operating characteristic curves were created using the R statistical package, V.3.2.4. To visualize the decision ways of the model, we applied the Grad-CAM to generate heatmaps.
A total of 30,668 participants with 33,965 fundus images were recruited for this study (Table 1). Among them, 15,804 (51.53%) are male and 14,864 (48.47%) are female. In the development, internal validation, and external test dataset, the participants in different sex groups were relatively evenly distributed, respectively.

TABLE 1. Characteristics of the development, internal validation, and external test dataset.
The diagnostic performance of the cataract AI diagnosis model in the control experiment on the internal validation dataset was shown in Table 2; Figure 4A, Figure5A. The model determined the diagnosis of cataracts with an AUC of 82.22% and an ACC of 64.33%. From the confusion matrix, shown in Figure 5A, we could see that there were many noncataract images were mistakenly classified as cataract due to the interference of poor-quality fundus images; thus, the performance of cataract recognition degraded to a certain degree.

TABLE 2. erformance of the two cataract artificial intelligence diagnosis models in the internal validation dataset.
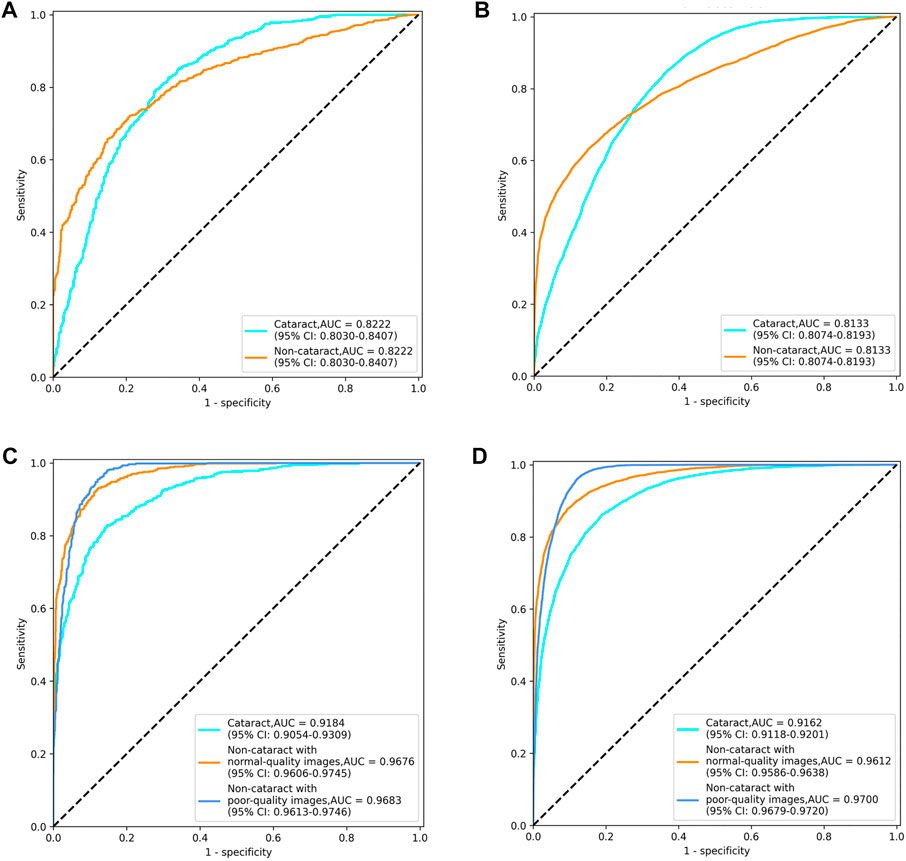
FIGURE 4. Receiver operating characteristic curves of the two cataract artificial intelligence diagnosis models. (A) binary-class model in the internal validation dataset. (B) binary-class model in the external test dataset. (C) antiinterference model in the internal validation dataset. (D) antiinterference model in the external test dataset.
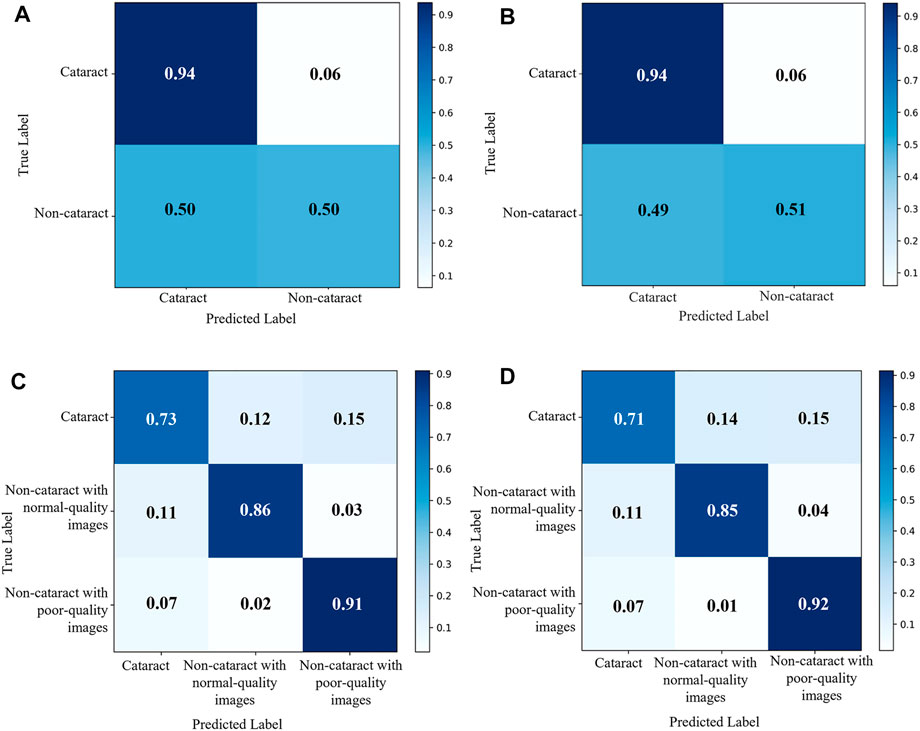
FIGURE 5. Confusion matrix of the two cataract artificial intelligence diagnosis models. (A) binary-class model in the internal validation dataset. (B) binary-class model in the external test dataset. (C) antiinterference model in the internal validation dataset. (D) Antiinterference model in the external test dataset.
For the results of the binary-class model in the external test dataset, the receiver operating characteristic curve and confusion matrix diagram were exhibited in Table 3; Figures 4B, 5B. The AUC and ACC in the external test dataset were 81.33% and 65.34%. In addition, similar to the performance in the internal validation dataset, the performance of the model was also affected to some extent by poor-quality images.

TABLE 3. erformance of the two cataract artificial intelligence diagnosis models in the external test dataset.
Receiver operating characteristic curves and confusion matrix diagrams of the antiinterference cataract AI diagnosis model was shown in Figures 4C,D; Figures 5C,D. The model determined diagnosis of cataract, noncataract with normal-quality images, or noncataract with poor-quality images with AUC of 91.84%, 96.76%, and 96.83% in the internal validation dataset, respectively (Table 2). Compared with the model that was trained on the binary-class label, the antiinterference cataract model improved its performance by 10%.
The model determined diagnosis of cataract, noncataract with normal-quality images, or noncataract with poor-quality images with AUCs of 91.62%, 96.12%, and 97.00% in the external test dataset, respectively (Table 3).
Figure 6 provided the visual feature map both in our proposed method and control experiment. We analyzed the heatmaps in two aspects. First, by comparing our approach with the control experiment, it could be seen that for the cataract and noncataract with normal-quality images, the attention regions of both methods were similar, with cataract focusing on the blurred areas, optic disk, and great vessels and noncataract with normal-quality image concerning the small and medium vessels (Figure 6A). However, for the noncataract with poor-quality images, our proposed method focused more on the important part, which showed a better ability to distinguish cataracts with the suspected cataract images. For instance, in Figure 6B, a noncataract with poor-quality images was misclassified by the control experiment as the cataract class because it expressed a similar yellow margin of the peripheral area with cataract images, which was due to the light leakage from the device. However, our method paid more attention to the light change and darker area rather than the blur and suspected cataract part. Second, comparing the attention area that our model focused on and the cataract criterion of professional doctors, they had the consistent regulations that were based on the blur degree of whole fundus images and the visibility of the vessels and optic disk to determine the cataract (Figure 6C). Therefore, through the visual analysis, it showed that our method had a better ability to diagnose cataracts than the control experiment.
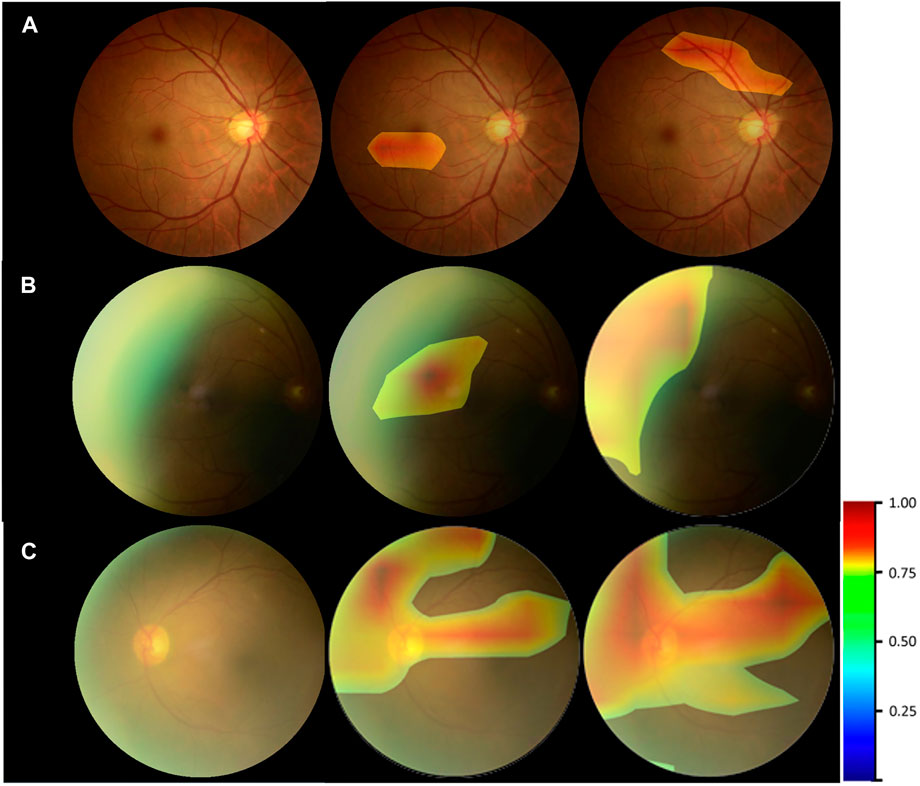
FIGURE 6. Heatmap visualization examples. Left column: the original fundus images; middle column: general heatmap of antiinterference method; right column: general heatmap of control experiment. (A) noncataract with normal-quality image. (B) noncataract with poor-quality image. (C) cataract.
Cataract is the most common cause of blindness worldwide with the characteristic of lenticular opacity. With the rapid development of AI in medicine, the AI model can effectively identify the details such as blood vessels in the fundus images, which makes it feasible for automatic diagnosis through the fundus images. Several studies have been reported using an AI model based on fundus images for cataract diagnosis. In the fundus images taken from subjects with mild cataracts, small retinal vessels are visible but slightly blurred. With the aggravation of cataracts, more structures will be invisible until nothing can be seen.
In the previous study, the cataract AI model developed from a single learning model to multiple learning models and improved the prediction accuracy substantially. Yang et al. (2013) built a neural network classifier that consists of three parts: preprocessing, feature extraction, and classifier construction. Imran et al. (2021) proposed a novel hybrid convolutional and recurrent neural network for cataract classification and increased an average accuracy of 97.39% for four-class cataract classification. Yadav and Yadav (2022) studied computer-aided cataract detection and grading by extracting and fusing features and integrating the predictions through machine learning methods, which achieved 96.25% four-class classification accuracy. The six-level classification of cataracts could enable ophthalmologists to accurately understand the patient’s condition, and the average accuracy of the six-grading model was up to 92.66%. However, all above this, the fundus images with good quality are the key points (Zhang et al., 2019). Here, we reported that the accuracy of the antiinterference model was approximately 83%, which is lower than that in the previous study. This may be due to our inclusion of fundus images with poor quality in the study, resulting in complicated interference.
Studies have shown that the fuzziness and scanning quality index of fundus images are related to cataract AI identification and grading (Xu et al., 2010; Chen et al., 2021). Poor-quality images can greatly affect the accuracy of the results (Zhang et al., 2019). The common limitation of previous studies is that there are high requirements for the quality of fundus images. However, in the actual cataract screening scenario, it is difficult to ensure that all of the fundus images meet the quality requirements because of the uneven technical level of operators and inadequate cooperation of patients. The interference of poor-quality images caused by shooting encountered in the research has not been solved.
In the study, we developed and validated an antiinterference cataract diagnosis model that can identify quality problems of fundus images to be better applied in the real world. The model that can achieve accurate cataract recognition mainly included a quality recognition model for adjusting cataract labels and a CNN-based model for cataract classification. The quality recognition model aimed to distinguish between cataract images and noncataract with poor-quality images that are easy to be misclassified by converting the original binary-class label into a triplet. Then, we trained cataract diagnosis models based on dichotomy and trichotomy respectively and compared their performance. According to the results of this study, we found that the antiinterference cataract model improved the performance by 10% compared with the model that was trained on the binary-class label; hence, the quality recognition model can enhance the robustness of the cataract AI diagnosis model.
In the primary medical facilities of low- and middle-income countries, a cataract cannot be diagnosed until it develops to an advanced stage and even the symptoms can be observed with the naked eye. Our cataract AI diagnosis model is helpful for the early detection of cataracts. If participants are diagnosed with cataracts using the AI model, they need to go to the hospital and follow the doctor’s advice for further examination, such as slit lamp and ophthalmic B-type ultrasound. If the output of the AI model is noncataract with poor-quality images, it would be best to retake new fundus images with normal quality or after mydriasis as early as possible. Assuming that the output of the AI model is noncataract with normal-quality images, the participants need to be retested in 12 months.
Considering that the dataset used for internal validation has similar characteristics to the dataset used for model training, it may lead to better accuracy and stability of the research results than the real situation. Therefore, further external validation was conducted, and our proposed model showed good performance. In the future, a larger sample size database will help to optimize the antiinterference cataract model (Chen et al., 2021).
In conclusion, we developed an AI model for antiinterference cataract automatic diagnosis based on fundus images. The antiinterference model achieved cataract diagnosis with high accuracy even in the presence of poor-quality image interference, allowing the model to provide cataract screening and help the government formulate a more accurate aid policy. In recent 10 years, the application of AI for cataract identification and grading based on fundus images has developed rapidly. To better achieve cataract classification, further research needs to be done to develop a cataract grading AI model based on our proposed method.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
The Ethical Committee of Chinese PLA General Hospital waived the need for informed consent from the participants. The study was conducted by the Declaration of Helsinki and approved by the ethics committee of the Chinese PLA General Hospital.
XW, YC, DW, and QZ contributed to the conception of the study. XW, DX, BW, ZG, and QZ contributed to study design and model training. XW, ZY, FW, XG, ZW, JC, YH, and ZL contributed to the acquisition of the data. XW, DX, TM, and ZL contributed to the analysis and interpretation of the data. XW, DX, and TM wrote the draft. DW and QZ revised the draft. All the authors read and approved the final manuscript.
The research was supported by the Natural Science Foundation of Beijing (7212092), Capital’s Funds for Health Improvement and Research (2022-2-5041), the Bigdata Project Foundation of PLA general hospital (2019MBD-037) Military Healthcare Program (19BJZ24), and the National Natural Science Foundation of China (81872920).
Authors DX, TM, BW, YC, and ZG were employed by the company Beijing Airdoc Technology Co., Ltd., China. Author ZW was employed by the company iKang Guobin Healthcare Group Co., Ltd., China.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as potential conflicts of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Castaneda, C., Nalley, K., Mannion, C., Bhattacharyya, P., Blake, P., Pecora, A., et al. (2015). Clinical Decision Support Systems for Improving Diagnostic Accuracy and Achieving Precision Medicine. J. Clin. Bioinform 5, 4. doi:10.1186/s13336-015-0019-3
Chen, S., Wang, k., and Wan, X. (2021). Artificial Intelligence in Diagnosis and Classification of Cataract. Int. Rev. Ophthalmol. 45, 231–236. doi:10.3760/cma.j.issn.1673-5803.2021.03.011
Dong, Y., Zhang, Q., Qiao, Z., and Yang, J.-J. (2017). “Classification of Cataract Fundus Image Based on Deep Learning,” in Proceeding of the 2017 IEEE International Conference on Imaging Systems and Techniques (IST), Beijing, China, 18-20 October 2017, 1–5. doi:10.1109/IST.2017.8261463
Flaxman, S. R., Bourne, R. R. A., Resnikoff, S., Ackland, P., Braithwaite, T., Cicinelli, M. V., et al. (2017). Global Causes of Blindness and Distance Vision Impairment 1990-2020: a Systematic Review and Meta-Analysis. Lancet Glob. Health 5, e1221–e1234. doi:10.1016/s2214-109x(17)30393-5
Gao, X., Lin, S., and Wong, T. Y. (2015). Automatic Feature Learning to Grade Nuclear Cataracts Based on Deep Learning. IEEE Trans. Biomed. Eng. 62, 2693–2701. doi:10.1109/TBME.2015.2444389
Guo, L., Yang, J.-J., Peng, L., Li, J., and Liang, Q. (2015). A Computer-Aided Healthcare System for Cataract Classification and Grading Based on Fundus Image Analysis. Comput. Industry 69, 72–80. doi:10.1016/j.compind.2014.09.005
Harini, V., and Bhanumathi, V. (2016). “Automatic Cataract Classification System,” in Proceedings of the 2016 International Conference on Communication and Signal Processing (ICCSP), Melmaruvathur, India, 06-08 April 2016, 0815–0819. doi:10.1109/ICCSP.2016.7754258
Hu, X., Zhao, X., He, C., and Zhang, D. (2021). Fundus Image Quality Control Method, Device, Electronic Equipment and Storage Medium. China patent application CN202110616409.6.
Huiqi Li, H., Joo Hwee Lim, J. H., Jiang Liu, J., Mitchell, P., Tan, A. G., Jie Jin Wang, J. J., et al. (2010). A Computer-Aided Diagnosis System of Nuclear Cataract. IEEE Trans. Biomed. Eng. 57, 1690–1698. doi:10.1109/TBME.2010.2041454
Imran, A., Li, J., Pei, Y., Akhtar, F., Mahmood, T., and Zhang, L. (2021). Fundus Image-Based Cataract Classification Using a Hybrid Convolutional and Recurrent Neural Network. Vis. Comput. 37 (8), 2407–2417. doi:10.1007/s00371-020-01994-3
Imran, A., Li, J., Pei, Y., Akhtar, F., Yang, J.-J., and Dang, Y. (2020). Automated Identification of Cataract Severity Using Retinal Fundus Images. Comput. Methods Biomechanics Biomed. Eng. Imaging & Vis. 8 (6), 691–698. doi:10.1080/21681163.2020.1806733
Limwattananon, C., Limwattananon, S., Tungthong, J., and Sirikomon, K. (2018). Association between a Centrally Reimbursed Fee Schedule Policy and Access to Cataract Surgery in the Universal Coverage Scheme in Thailand. JAMA Ophthalmol. 136, 796–802. doi:10.1001/jamaophthalmol.2018.1843
Long, E., Lin, H., Liu, Z., Wu, X., Wang, L., Jiang, J., et al. (2017). An Artificial Intelligence Platform for the Multihospital Collaborative Management of Congenital Cataracts. Nat. Biomed. Eng. 1, 0024. doi:10.1038/s41551-016-0024
Meimei Yang, M. M., Yang, J.-J., Qinyan Zhang, Q. Y., Yu Niu, Y., and Jianqiang Li, J. Q. (2013). “Classification of Retinal Image for Automatic Cataract Detection,” in Proceeding of the 2013 IEEE 15th International Conference on e-Health Networking, Applications and Services (Healthcom 2013), Linsbon, 09-12 October 2013, 674–679. doi:10.1109/HealthCom.2013.6720761
National Health Commission. (2020). The White Paper on Eye Health in china. Available at: https://www.nhc.gov.cn/xcs/s3574/202006/1f519d91873948d88a77a35a427c3944.shtml [Accesed Jan 13, 2022].
Park, S. J., Lee, E. J., Kim, S. I., Kong, S.-H., Jeong, C. W., and Kim, H. S. (2020). Clinical Desire for an Artificial Intelligence-Based Surgical Assistant System: Electronic Survey-Based Study. JMIR Med. Inf. 8, e17647. doi:10.2196/17647
Patel, V. L., Shortliffe, E. H., Stefanelli, M., Szolovits, P., Berthold, M. R., Bellazzi, R., et al. (2009). The Coming of Age of Artificial Intelligence in Medicine. Artif. Intell. Med. 46, 5–17. doi:10.1016/j.artmed.2008.07.017
Ramke, J., Zwi, A. B., Lee, A. C., Blignault, I., and Gilbert, C. E. (2017). Inequality in Cataract Blindness and Services: Moving beyond Unidimensional Analyses of Social Position. Br. J. Ophthalmol. 101, 395–400. doi:10.1136/bjophthalmol-2016-309691
Ran, J., Niu, K., He, Z., Zhang, H., and Song, H. (2018). “Cataract Detection and Grading Based on Combination of Deep Convolutional Neural Network and Random Forests,” in Proceeding of the 2018 International Conference on Network Infrastructure and Digital Content (IC-NIDC), Guiyang, China, 22-24 August 2018, 155–159. doi:10.1109/ICNIDC.2018.8525852
Simanjuntak, R. B. J., Fu’adah, Y., Magdalena, R., Saidah, S., Wiratama, A. B., and Ubaidah, I. D. W. S. (2022). Cataract Classification Based on Fundus Images Using Convolutional Neural Network. JOIV Int. J. Inf. Vis. 6 (1), 33–38. doi:10.30630/joiv.6.1.856
Song, P., Wang, H., Theodoratou, E., Chan, K. Y., and Rudan, I. (2018). The National and Subnational Prevalence of Cataract and Cataract Blindness in China: a Systematic Review and Meta-Analysis. J. Glob. Health 8, 010804. doi:10.7189/jogh.08-01080410.7189/jogh.08.010804
Sun, X., Li, Y., Kang, H., and Shen, Y. (2019). Automatic Document Classification Using Convolutional Neural Network. J. Phys. Conf. Ser. 1176, 032029. doi:10.1088/1742-6596/1176/3/032029
Szegedy, C., Ioffe, S., Vanhoucke, V., and Alemi, A. A. (2017). “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning,” in Proceeding of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, USA, February 04-09, 2017, 4278–4284.
Tang, Y., Wang, X., Wang, J., Huang, W., Gao, Y., Luo, Y., et al. (2016). Prevalence of Age-Related Cataract and Cataract Surgery in a Chinese Adult Population: The Taizhou Eye Study. Invest. Ophthalmol. Vis. Sci. 57, 1193–1200. doi:10.1167/iovs.15-18380
Triyadi, A. B., Bustamam, A., and Anki, P. (2022). “Deep Learning in Image Classification Using VGG-19 and Residual Networks for Cataract Detection,” in Proceeding of the 2022 2nd International Conference on Information Technology and Education (ICIT&E), Malang, Indonesia, 22-22 January 2022, 293–297. doi:10.1109/ICITE54466.2022.9759886
Wu, X., Huang, Y., Liu, Z., Lai, W., Long, E., Zhang, K., et al. (2019). Universal Artificial Intelligence Platform for Collaborative Management of Cataracts. Br. J. Ophthalmol. 103, 1553–1560. doi:10.1136/bjophthalmol-2019-314729
Xu, L., Yang, C., Yang, H., Wang, S., Shi, Y., and Song, X. (2010). The Study of Predicting the Visual Acuity after Phacoemulsification According to the Blur Level of Fundus Photography. Ophthalmol. CHN 19, 81–83.
Xu, X., Zhang, L., Li, J., Guan, Y., and Zhang, L. (2020). A Hybrid Global-Local Representation CNN Model for Automatic Cataract Grading. IEEE J. Biomed. Health Inf. 24, 556–567. doi:10.1109/JBHI.2019.2914690
Yadav, J. K. P. S., and Yadav, S. (2022). Computer-aided Diagnosis of Cataract Severity Using Retinal Fundus Images and Deep Learning. Comput. Intell. doi:10.1111/coin.12518
Yang, J.-J., Li, J., Shen, R., Zeng, Y., He, J., Bi, J., et al. (2016). Exploiting Ensemble Learning for Automatic Cataract Detection and Grading. Comput. Methods Programs Biomed. 124, 45–57. doi:10.1016/j.cmpb.2015.10.007
Keywords: cataract, artificial intelligence, auxiliary diagnosis, fundus image, convolution neural network
Citation: Wu X, Xu D, Ma T, Li ZH, Ye Z, Wang F, Gao XY, Wang B, Chen YZ, Wang ZH, Chen JL, Hu YT, Ge ZY, Wang DJ and Zeng Q (2022) Artificial Intelligence Model for Antiinterference Cataract Automatic Diagnosis: A Diagnostic Accuracy Study. Front. Cell Dev. Biol. 10:906042. doi: 10.3389/fcell.2022.906042
Received: 28 March 2022; Accepted: 21 June 2022;
Published: 22 July 2022.
Edited by:
Arjun Singh, Memorial Sloan Kettering Cancer Center, United StatesReviewed by:
Azhar Imran, Air University, PakistanCopyright © 2022 Wu, Xu, Ma, Li, Ye, Wang, Gao, Wang, Chen, Wang, Chen, Hu, Ge, Wang and Zeng. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Da Jiang Wang, V2FuZ2RhamlhbmczMDFAMTYzLmNvbQ==; Qiang Zeng, enEzMDFAMTI2LmNvbQ==
†These authors have contributed equally to this work and share the first authorship.
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.