
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Cell Dev. Biol. , 26 May 2021
Sec. Molecular and Cellular Pathology
Volume 9 - 2021 | https://doi.org/10.3389/fcell.2021.652848
This article is part of the Research Topic The Application of AI and Other Advanced Technology in Studying Eye Diseases and Visual Development View all 21 articles
 Ling Wei1,2,3†
Ling Wei1,2,3† Wenwen He1,2,3†Jinrui Wang4Keke Zhang1,2,3
Wenwen He1,2,3†Jinrui Wang4Keke Zhang1,2,3 Yu Du1,2,3Jiao Qi1,2,3
Yu Du1,2,3Jiao Qi1,2,3 Jiaqi Meng1,2,3Xiaodi Qiu1,2,3Lei Cai1,2,3Qi Fan1,2,3Zhennan Zhao1,2,3Yating Tang1,2,3Shuang Ni5Haike Guo5Yunxiao Song6
Jiaqi Meng1,2,3Xiaodi Qiu1,2,3Lei Cai1,2,3Qi Fan1,2,3Zhennan Zhao1,2,3Yating Tang1,2,3Shuang Ni5Haike Guo5Yunxiao Song6 Xixi He4Dayong Ding4
Xixi He4Dayong Ding4 Yi Lu1,2,3*
Yi Lu1,2,3* Xiangjia Zhu1,2,3*
Xiangjia Zhu1,2,3*Background: Due to complicated and variable fundus status of highly myopic eyes, their visual benefit from cataract surgery remains hard to be determined preoperatively. We therefore aimed to develop an optical coherence tomography (OCT)-based deep learning algorithms to predict the postoperative visual acuity of highly myopic eyes after cataract surgery.
Materials and Methods: The internal dataset consisted of 1,415 highly myopic eyes having cataract surgeries in our hospital. Another external dataset consisted of 161 highly myopic eyes from Heping Eye Hospital. Preoperative macular OCT images were set as the only feature. The best corrected visual acuity (BCVA) at 4 weeks after surgery was set as the ground truth. Five different deep learning algorithms, namely ResNet-18, ResNet-34, ResNet-50, ResNet-101, and Inception-v3, were used to develop the model aiming at predicting the postoperative BCVA, and an ensemble learning was further developed. The model was further evaluated in the internal and external test datasets.
Results: The ensemble learning showed the lowest mean absolute error (MAE) of 0.1566 logMAR and the lowest root mean square error (RMSE) of 0.2433 logMAR in the validation dataset. Promising outcomes in the internal and external test datasets were revealed with MAEs of 0.1524 and 0.1602 logMAR and RMSEs of 0.2612 and 0.2020 logMAR, respectively. Considerable sensitivity and precision were achieved in the BCVA < 0.30 logMAR group, with 90.32 and 75.34% in the internal test dataset and 81.75 and 89.60% in the external test dataset, respectively. The percentages of the prediction errors within ± 0.30 logMAR were 89.01% in the internal and 88.82% in the external test dataset.
Conclusion: Promising prediction outcomes of postoperative BCVA were achieved by the novel OCT-trained deep learning model, which will be helpful for the surgical planning of highly myopic cataract patients.
A predicted number of 938 million people of the world’s population may suffer from high myopia by the year 2050 (Holden et al., 2016), leading to a major worldwide concern. Eyes with high myopia were prone to early-onset and nuclear-type cataracts (Hoffer, 1980; Zhu et al., 2018). Yet, nowadays, surgery is the only effective therapeutic method for cataracts (Thompson and Lakhani, 2015). With the advancement of techniques, cataract surgery can now provide a promising visual outcome in nonmyopes (Liu et al., 2017). However, for highly myopic cataract patients, due to the more complicated fundus conditions such as foveoschisis, chorioretinal atrophy, or cicatrices from previous choroidal neovascularization (Chang et al., 2013; Todorich et al., 2013; Gohil et al., 2015; Lichtwitz et al., 2016; Li et al., 2018), their visual benefit from cataract surgery remains hard to be determined preoperatively.
With the wide application of optical coherence tomography (OCT), surgeons could assess the fundus status of highly myopic eyes on an anatomical scale (Huang et al., 2018; Li et al., 2018), but the morphological diagnoses were hard to be directly associated with the actual manifested visual acuity (VA). Therefore, difficulties might occur when surgeons want to predict the postoperative VA and explain the prognosis to the highly myopic patients during preoperative conversations, which might thereby affect the overall surgical planning and patients’ satisfaction with the surgery later.
Recently, deep learning was found promising in automated classification. Particularly, the ResNet and Inception algorithms have their advantages on medical image analysis (Gulshan et al., 2016; Fu et al., 2018; Grassmann et al., 2018). Such techniques have the potential to revolutionize the diagnosis and clinical prediction by rapidly reviewing large amounts of morphological features and by performing integrations difficult for human experts (Kermany et al., 2018). Hence, prediction of the clinical manifestation based on deep learning analysis of relevant morphological features is becoming possible and important (Chen et al., 2018; Rohm et al., 2018). However, due to the more complicated and variable morphological changes of the fundus, no appropriate deep learning model has been developed for highly myopic eyes currently.
In this study, on the basis of the OCT scans of highly myopic eyes, we aim to predict their postoperative VA of cataract surgery by developing and comparing five machine learning algorithms and consequently evaluating the model on real-world datasets.
The Institutional Review Board of the Eye and Ear, Nose, and Throat (ENT) Hospital of Fudan University (Shanghai, China) approved this study. The study adhered to the tenets of the Declaration of Helsinki and was registered at www.clinicaltrials.gov (accession number NCT03062085). Written consent was obtained from the patients and all private information was removed in advance.
An internal dataset including 1,415 highly myopic eyes from 1,415 patients was drawn from the database of the Shanghai High Myopia Study between 2015 and 2020 at the Eye and ENT Hospital of Fudan University (Shanghai, China). Eligible criteria were as follows: (1) cataract patients with axial length (AL) over 26.0 mm, (2) had reliable macular OCT measurements before cataract surgery, (3) underwent uneventful cataract surgeries, and (4) had credible postoperative best corrected visual acuity (BCVA) measured at 4 weeks after surgery. Exclusion criteria were eyes with (1) corneal opacity or other corneal diseases that may significantly influence the visual pathway, (2) congenital ocular abnormities, (3) neuropathies that may influence the visual acuity, (4) ocular trauma, and (5) other severe oculopathies that may affect the surgical outcomes. The OCT images in the internal dataset were taken from Spectrialis OCT (Heidelberg Engineering, Heidelberg, Germany) or Cirrus OCT (Carl Zeiss Meditec, Dublin, CA, United States).
Another external dataset consisted of 161 highly myopic eyes of 161 patients drawn from the database of the Heping Eye Hospital (Shanghai, China) with the same inclusion and exclusion criteria. The OCT images in this external dataset were taken from Spectrialis OCT (Heidelberg Engineering, Heidelberg, Germany).
The eligible internal database was randomly divided into a training dataset, a validation dataset, and an internal test dataset with a fixed ratio of 6:2:2. The eligible external database was all used as an external test dataset. The actual BCVAs at 4 weeks after cataract surgery were set as the ground truth. The Snellen VA was converted to its logarithm of minimal angle of resolution (logMAR) equivalent as previously described, with counting fingers being assigned a value of 1.9, hand motion 2.3, light perception 2.7, and no light perception 3.0 (Lange et al., 2009). Eyes with actual BCVAs < 0.30 logMAR (Snellen 6/12 or higher) were defined as the good VA group, while eyes with actual BCVAs ≥ 0.30 logMAR (Snellen 6/12 and lower) were defined as the poor VA group (Quek et al., 2011).
The e2e files from Spectrialis OCT or scan figures from Cirrus OCT were extracted and preprocessed. All OCT images were down-sized to 224 × 224 pixels, the default choice for deep learning-based image classification. In order to simulate more real-world situations and to improve model generalization ability, it was performed on the image by changing the brightness, saturation, and contrast with a factor uniformly sampled from [0, 2], respectively. After the color space normalization, the macular OCT images were set as model input.
In our study, to predict the BCVA after cataract surgery for highly myopic patients, we constructed an ensemble learning using five different deep convolutional neural networks (CNN) algorithms, including Deep Residual Learning for Image Recognition (ResNet, Microsoft Research) with 18, 34, 50, and 101 layers (ResNet-18, ResNet-34, ResNet-50, and ResNet-101) (He et al., 2016) and Inception-v3 (Szegedy et al., 2016). The postfix number of ResNet referred to diverse depths of ResNet networks that lead to different parameter scales. All five models were pretrained on the ImageNet dataset. For each model, the last fully connected layer which originally output 1,000 class was replaced to output a single value to suit our task. The parameters of this layer were randomly initialized.
Based on the training dataset, the model was optimized with a target of minimizing the mean square error (MSE) loss function using the Adam optimizer (Fu et al., 2018). The final output score was calculated as the mean value of the ensemble model. MSE loss was defined as:
where N indicates the number of input OCT images, indicates the actual BCVA, and yi indicates the predicted BCVA.
The maximal number of training epochs was set to be 80. We adopted an early stop strategy, which is the training procedure stops when there is no performance improvement on the validation dataset in 15 consecutive epochs. The initial learning rate was set to 0.001 and would be decayed by 0.1 every 30 epochs. Each CNN algorithm was trained five times repeatedly, and only the model with the best performance on the validation dataset was reserved for the ensemble learning.
The metrics used to show the differences in logMAR postoperative BCVA between the prediction and the ground truth were mean absolute error (MAE, calculated for the predictions of the algorithms compared to the ground truth) and the root mean square error (RMSE), which were defined as:
where N, , and yi were defined as above.
Furthermore, sensitivity is defined as the proportion of correctly predicted eyes with VA < 0.30 logMAR (or ≥0.30 logMAR) in the overall eyes having actual VA < 0.30 logMAR (or ≥0.30 logMAR). Precision is defined as the proportion of correctly predicted eyes with VA < 0.30 logMAR (or ≥0.30 logMAR) in the overall eyes having predicted VA < 0.30 logMAR (or ≥0.30 logMAR).
The ensemble learning of the five CNN models was adopted to develop the prediction model and then further evaluated using the internal and external test datasets, which contain data the model has not seen. The OCT reports in pdf format from both test datasets were adopted and evaluated. The prediction error was calculated by subtracting the predicted BCVA from the actual BCVA. The percentage of BCVA prediction errors within ± 0.30 logMAR (Snellen 6/12, Re0.30 logMAR) was then calculated (Gao et al., 2015), which was defined as:
where N, , and yi were defined as above. I(⋅) is the function which returns 1 if the ⋅ is true, else return 0.
In order to make the performance more comparable, fixed randomly generated seeds were used to shuffle the data and initialize the models’ parameter. To better visualize the prediction, gradient-weighted class activation mapping (Grad-CAM) was used to highlight the model’s interests in the OCT images in prediction VA (Selvaraju et al., 2020).
The illustration of the pipeline of our work is demonstrated in Figure 1.
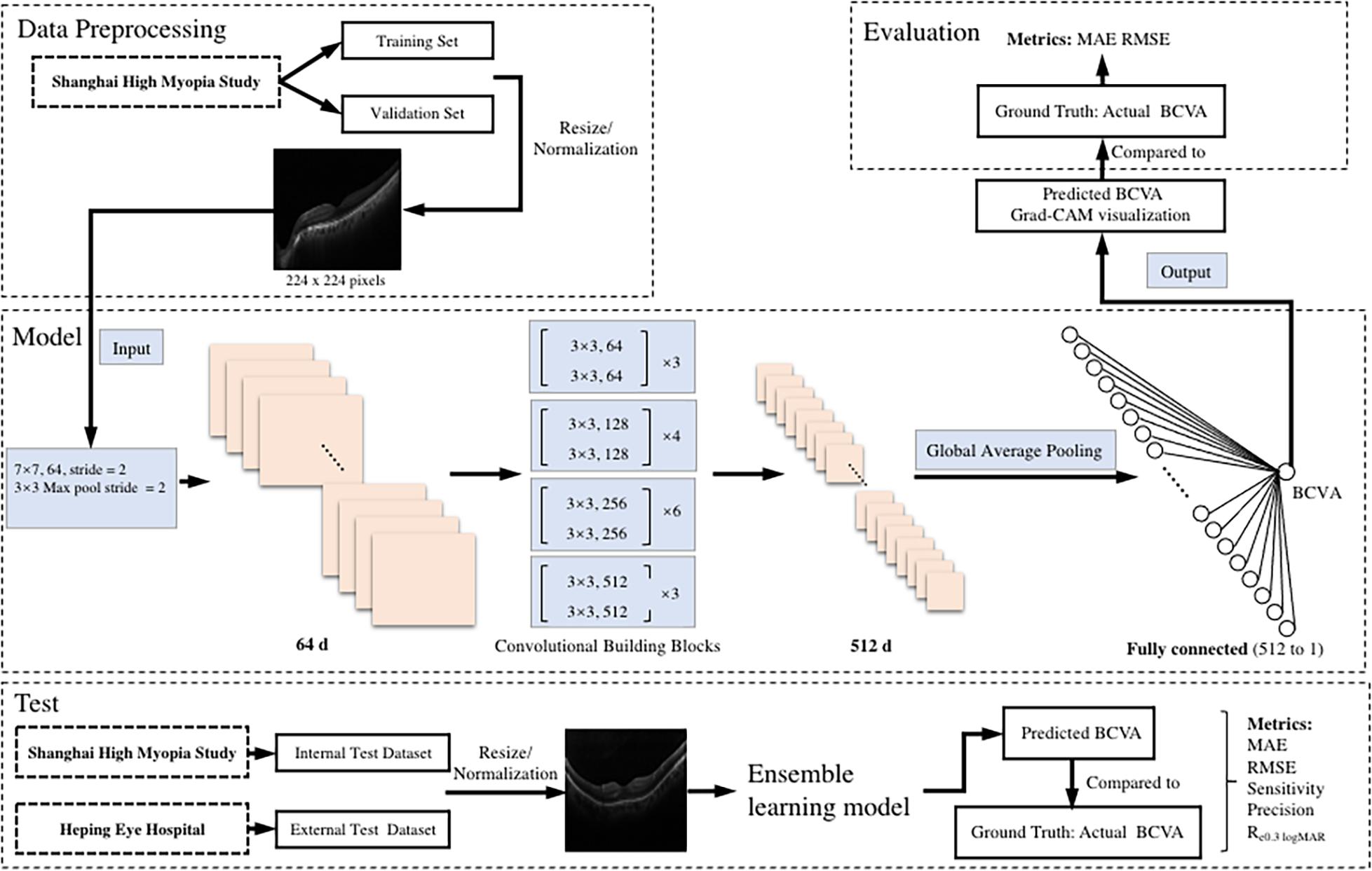
Figure 1. An illustration of the pipeline of the tasks. The preoperative b-scan OCT image is fed into the model. It eventually outputs the prediction of postoperative BCVA. BCVA, best corrected visual acuity; logMAR, logarithm of the minimum angle of resolution; MAE, mean absolute error; RMSE, root mean square error; Re0.30 logMAR, the percentage of BCVA prediction errors within ± 0.30 logMAR.
Continuous variables were described as the mean ± standard deviation. The Student’s t test or one-way ANOVA test followed by Tukey’s test was used to compare the continuous variables and the χ2 test was used to compare categorical variables. The alignment of the predicted BCVA and ground truth was demonstrated by scatter plots. Pearson correlation analysis was used to evaluate the relationship between the predicted outcome and the ground truth, and the Bland–Altman plot was used to assess the agreement between the predicted outcome and the ground truth. The information of the computer used in this study was as follows: Intel Xeon 4144 (2.20 GHz), 128 gigabytes of RAM, and three pieces of GeForce RTX 2080 Ti Ubuntu 18.04 LTS. Model development was performed by Python (version 3.7.5) with libraries of torch (version 1.4.0) and torchvision (version 0.4.0), and statistical analyses were performed with a commercially available statistical software package (SPSS Statistics 20.0; IBM, Armonk, NY).
The clinical characteristics of the patients are demonstrated in Table 1. No difference was found in age, sex, and mean actual postoperative BCVA among the training, validation, internal test, and external test datasets (p > 0.05).
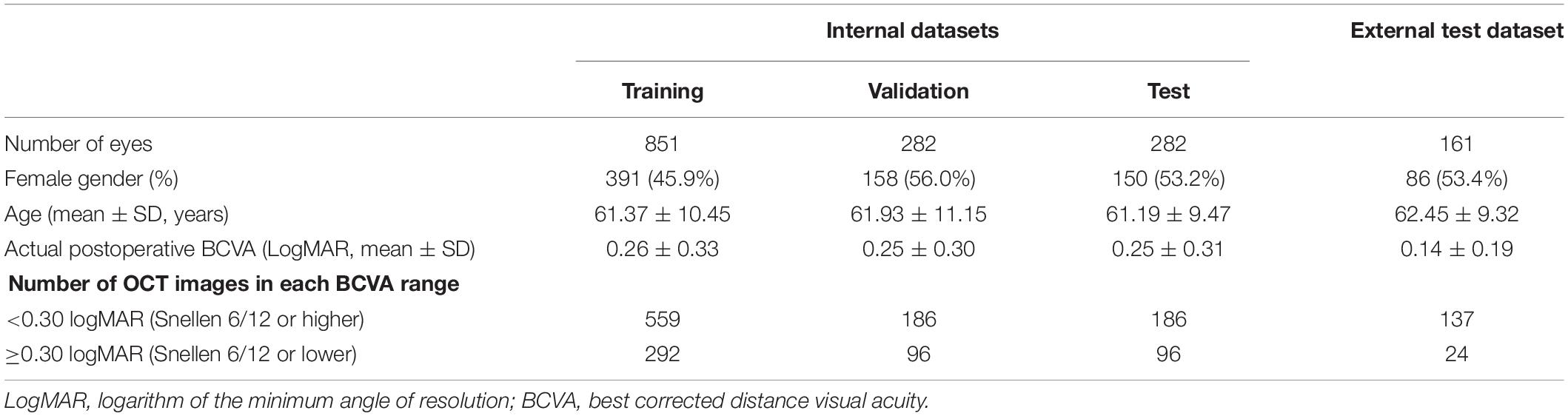
Table 1. Demographic and clinical characteristics.
The performances of all five CNN algorithms were compared after training and validating for five times. The average values of the five-time performances of the five models separately and the ensemble learning outcomes combining all models’ decisions using the validation dataset are presented in Table 2. Notably, the ensemble learning showed the lowest MAE (0.1566 logMAR) and the lowest RMSE (0.2433 logMAR). Therefore, the ensemble learning model with the most promising performance was then chosen for further development and evaluations.

Table 2. The performances of five algorithms and the ensemble learning using the validation dataset (n = 282).
The internal and external test datasets were used to determine the performance of our prediction model using the ensemble learning and to confirm the generalizability. As shown in Table 3, the prediction model demonstrated stably promising outcomes with MAEs of 0.1524 and 0.1602 logMAR and RMSEs of 0.2612 and 0.2020 logMAR in the internal and external test datasets, respectively. In the internal test dataset, the sensitivity of our model was 90.32% in the good VA group and 42.71% in the poor VA group; the precision was 75.34% in the good VA group and 69.49% in the poor VA group. In the external test dataset, the sensitivity of our model was 81.75% in the good VA group and 45.83% in the poor VA group; the precision was 89.60% in the good VA group and 30.55% in the poor VA group. The scatter plot of the predicted BCVA and the ground truth (actual BCVA) was demonstrated in the internal (Figure 2A) and external test datasets (Figure 2B). Pearson correlation analysis revealed the significant relationships between the predicted BCVA and the ground truth in the internal test dataset (r = 0.55; p < 0.001) and external test dataset (Pearson coefficients r = 0.50; p < 0.001). The Grad-CAM visualization was used for the CNN models. Representative cases in the good VA group (Figure 2C) and in the poor VA group (Figure 2D) were demonstrated, showing the highly discriminative region of OCT scans when predicting the VA.
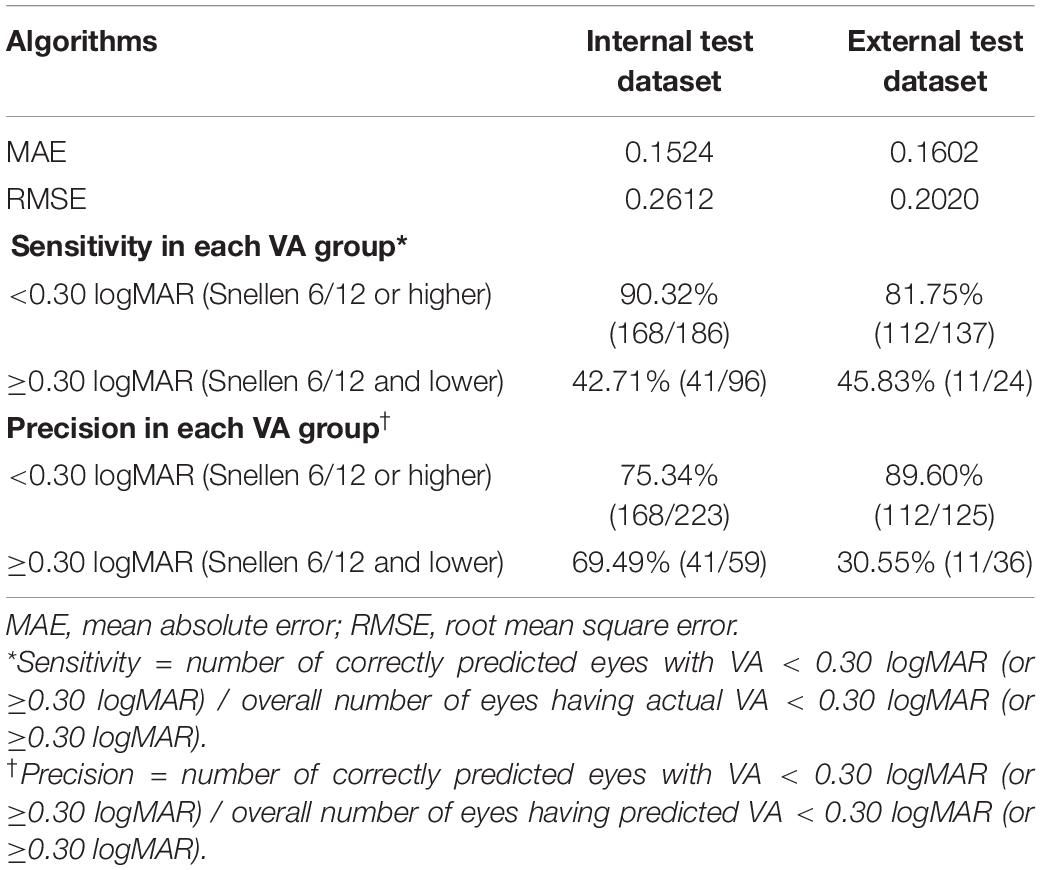
Table 3. The performances of the prediction model in the internal (n = 282) and external test datasets (n = 161).
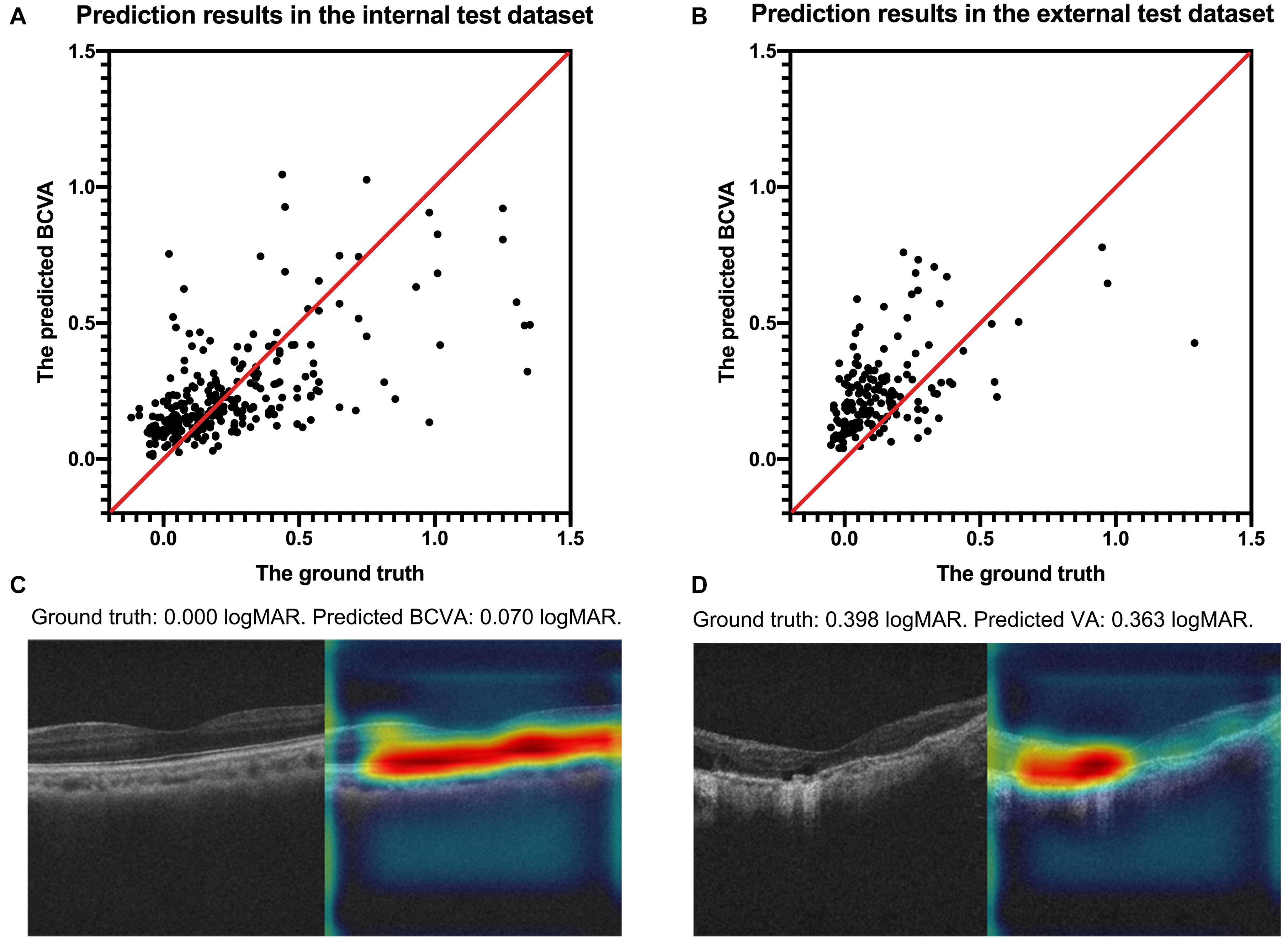
Figure 2. The scatter plots of the predicted BCVA and the actual BCVA (ground truth) in the internal (A) and external (B) test datasets. Representative cases of Grad-CAM visualization in the good VA group (C) and in the poor VA group (D). Red regions corresponds to highly discriminative areas of OCT scans when predicting the VA. All values were provided in logMAR units. BCVA, best corrected distance visual acuity; logMAR, logarithm of the minimum angle of resolution; Grad-CAM, gradient-weighted class activation mapping.
The Bland–Altman plots assessing the agreement between predictions and the ground truth are shown in Figure 3. The 95% confidence limits of agreement ranged from −0.52 to 0.50 logMAR in the internal test dataset and −0.22 to 0.44 logMAR in the external test dataset, while no statistically significant evidence of proportional bias was found (both p > 0.05). Figure 4 shows the distributions of the difference between the ground truth and the predicted BCVA in both test datasets. The percentages of the prediction errors within ± 0.30 logMAR were 89.01% in the internal test dataset and 88.82% in the external test dataset.
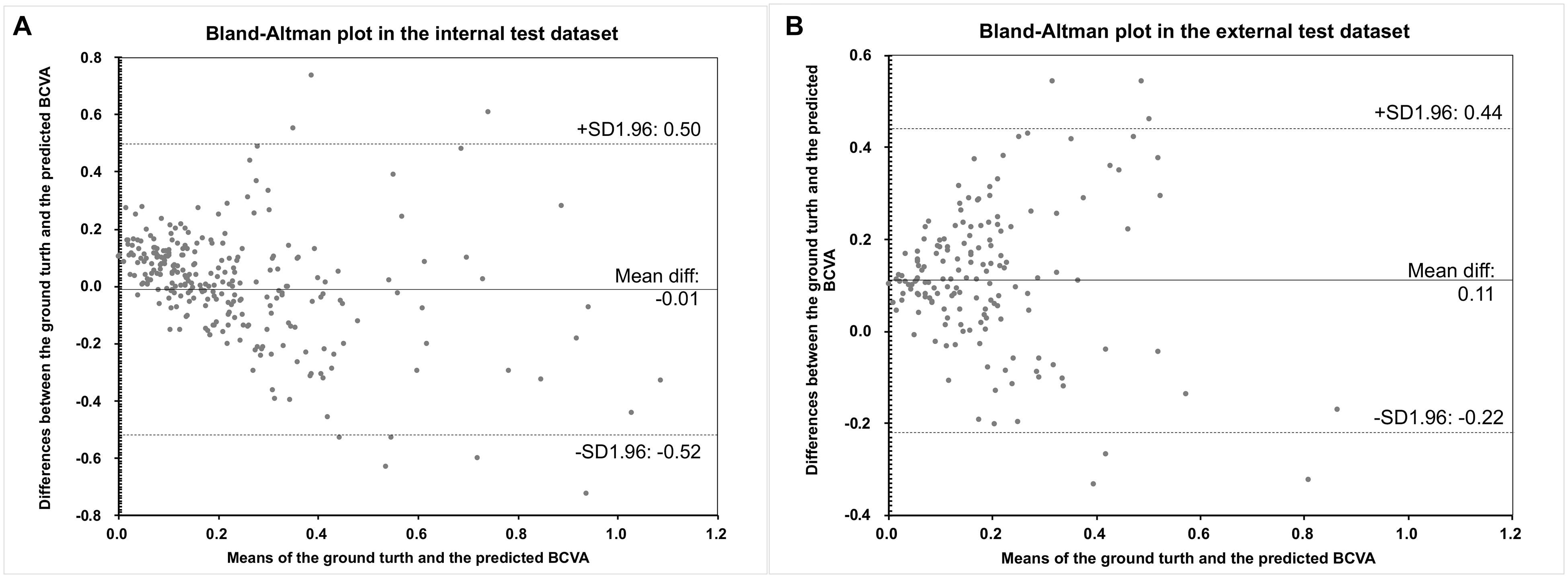
Figure 3. The Bland–Altman plots of the predicted BCVA and the actual BCVA (ground truth) in the internal (A) and external (B) test datasets. All values were provided in logMAR units. BCVA, best corrected distance visual acuity; logMAR, logarithm of the minimum angle of resolution.
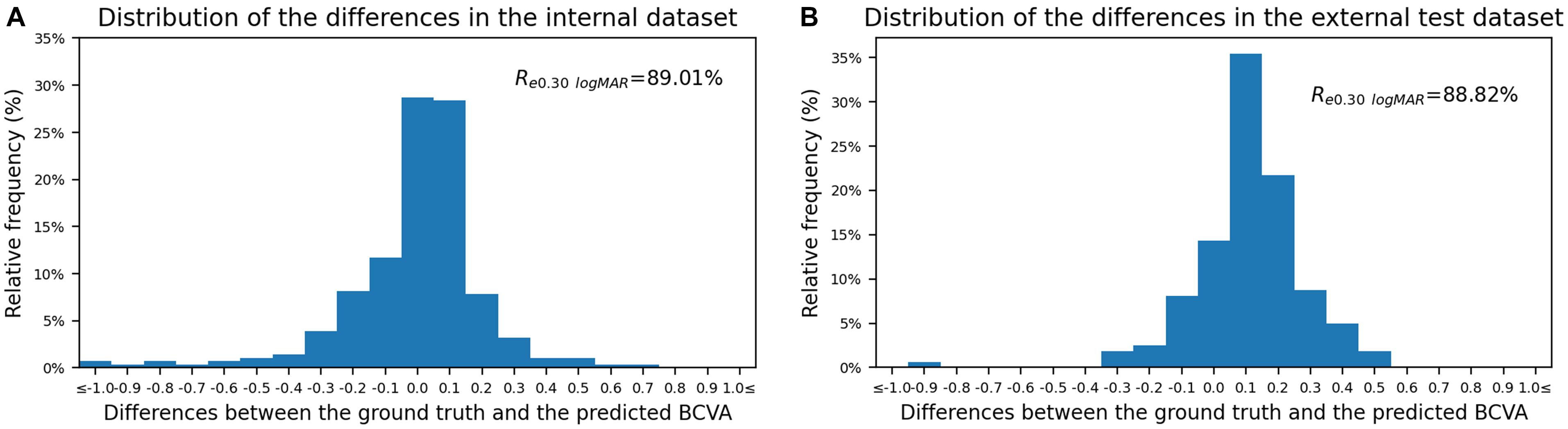
Figure 4. The distribution of the difference between the predicted BCVA and the actual BCVA (ground truth) in the internal (A) and external (B) test datasets. All values were provided in logMAR units. The vertical axis indicates the relative frequency of each BCVA delta value. BCVA, best corrected visual acuity; logMAR, logarithm of the minimum angle of resolution; Re0.30 logMAR, the percentage of BCVA prediction errors within ± 0.30 logMAR.
Further analysis was conducted on the falsely predicted cases in the test datasets. They can be divided into two groups: (1) underestimated cases: the ground truth < 0.30 logMAR (good VA) but the predicted VA ≥ 0.30 logMAR (poor VA), and (2) overestimated cases: the ground truth ≥ 0.30 logMAR (poor VA) but the predicted VA < 0.30 logMAR (good VA). Supplementary Table 1 shows the distribution of all falsely predicted cases. These cases can be attributed to the following four categories: (A) vague OCT images induced by extraordinarily cloudy cataract (under- or overestimated, 39.6%); (B) morphological changes on OCT scan exist but might have poor effect on VA (underestimated, 8.1%), e.g., changes located away from the macular, which were irregularly focused by the model; (C) morphological changes on OCT scan exist but might have unclear effect on VA (under- or overestimated VA, 46.8%), e.g., rough retinal pigment epithelium layer or irregular inner segment/outer segment layer; and (D) morphological changes on OCT scan exist which might have some effect on VA, but were presented as signal-deficient lesions and were accidentally ignored by the model (overestimated VA, 5.4%). Representative cases in the four categories with their Grad-CAM visualizations are presented in Supplementary Figure 1.
Highly myopic cataract patients usually inevitably have macular complications such as foveoschisis, chorioretinal atrophy, and cicatrices from previous choroidal neovascularization (Chang et al., 2013; Todorich et al., 2013; Gohil et al., 2015; Lichtwitz et al., 2016; Li et al., 2018), which could render the preoperative prediction of visual acuity after cataract surgery very difficult, even though an OCT scan can be used for morphological diagnosis (Jeon and Kim, 2011). In the present study, by using the preoperative OCT scans of macular as input, we developed and validated a deep learning algorithm to predict the postoperative BCVA of highly myopic eyes after cataract surgery and revealed that the ensemble model showed stably promising performance in both internal and external test datasets with MAEs of 0.1524 and 0.1602 logMAR and RMSEs of 0.2612 and 0.2020 logMAR, respectively.
Cataract patients usually expect a significant improvement of VA after removal of the cloudy lens (Zhu et al., 2017). However, those with high myopia are more concerned about their VA improvement during the surgical planning stage. Myopic maculopathies are the main source of the gap between the expected outcomes and the actual potentials their fundus have. Hence, a forecast model which could tell the patients their potential postoperative visual acuities might be helpful with their surgical decisions (Rönbeck et al., 2011). Nevertheless, the prediction of VA for highly myopic eyes has always been very difficult. Although high-resolution OCT may reveal morphological changes and thereby identify eyes at high risk of developing clinically significant macular complications affecting the postoperative visual outcomes (Hayashi et al., 2010), it is still hard for cataract surgeons to specifically determine the exact postoperative VA preoperatively.
In recent years, deep learning has been widely applied for its ability to process highly complex tasks through a neural network, which can be seen as a mathematical function composed of a large number of parameters provided by medical images. An OCT scan of macular could provide millions of morphological parameters affecting the VA (Abdolrahimzadeh et al., 2017; Chung et al., 2019). The neural network was able to identify the corresponding features and thereby automatically generate the target VA predictions. Therefore, using deep learning algorithms to predict the postoperative BCVA was practicable and meaningful. Compared with other types of neural networks, CNN can initially identify a few adjacent pixels as local lower-level features and then merge them into global higher-level features, and thus, it has been proven effective widely in the field of medical image analysis (Anwar et al., 2018). In the current study, when taking a preoperative OCT image as input, the ensemble learning showed the most promising performance, and the model automatically predicted the postoperative BCVA for highly myopic eyes having cataract surgeries with promising accuracies. With this model, surgeons only need to input an OCT image of macular, and a predicted postoperative BCVA together with a Grad-CAM visualization could be generated. The expectant surgical outcomes could be discussed between the surgeons and highly myopic patients before surgery. Patients might more thoroughly understand their macular status and how it might affect the visual outcome of cataract surgery. It might also help with surgical decisions such as whether to choose premium IOL implantations.
Previous reports about applying deep learning approaches to predict VA outcomes were mainly in the field of retinal or macular diseases, such as age-related macular degeneration, diabetic retinopathy, or retinopathy of prematurity (Chen et al., 2018; Rohm et al., 2018; Huang et al., 2020). The morphologies of featured lesions for these diseases were relatively simple or identifiable. Yet, there are rare studies about implementing the deep learning approach on high myopia due to its more complicated and variable fundus status (Zhu et al., 2020). It might be more valuable to predict the VA outcomes based on the diverse fundus morphologies for highly myopic eyes. Moreover, dozens of features from the patients’ medical history were adopted or annotated one by one to train their models (Chen et al., 2018; Rohm et al., 2018; Huang et al., 2020). It might be highly difficult to ensure that during applications, such many features from real-world patients were available simultaneously and completely. The data missing problem might be serious and may result in uncertain accuracies, thus restricting the generalizability of their models. Our study, mainly targeting VA prediction of highly myopic eyes, adopted the OCT scan as the only input feature, which examines almost every highly myopic patient before their cataract surgery. Hence, the data missing problem could be rare when clinically applying our model.
Notably, our model has shown considerable sensitivity and precision in the good VA group in both test datasets (all >75%), thus solving nearly 60% of the problems after cataract surgery according to a previous report (Barañano et al., 2008). As for the poor VA group, the model demonstrated relatively lower sensitivity and precision, which might due to the very complicated and changeable characteristic of the fundus status among these highly myopic patients. As for the falsely predicted cases in categories A and C, manually predicting the VA can still be tricky for experienced cataract surgeons. In the future, the accuracy could be further improved by the model training with larger sample sizes. As for the falsely predicted cases in categories B and D, they revealed less focus on the signal-deficient signs by the model intrinsically, but only made up very minimal proportions. This can be further improved by manual annotations of the signal-deficient lesions when more cases are included in model training in the future. Currently, as there are no perfect ways to accurately predict the surgical benefit of highly myopic patients with very poor fundus condition, our predictions by the deep learning model might still provide valuable references for preoperative communications and clinical decisions for this special population.
In conclusion, based on macular OCT images taken before cataract surgery, we are taking the lead to originally develop the deep learning prediction model for highly myopic eyes, which can provide promising predictions of postoperative BCVA for cataract patients with high myopia. Our model will be helpful for surgical planning and preoperative conversations with highly myopic cataract patients.
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
The studies involving human participants were reviewed and approved by The Institutional Review Board of the Eye and Ear, Nose, and Throat Hospital of Fudan University (Shanghai, China). The patients/participants provided their written informed consent to participate in this study.
LW and WH collected the data, performed the analyses, and wrote the manuscript. JW, XH, and DD programmed the model and performed the analyses. KZ, YD, JQ, and JM collected the data and performed the analyses. XQ, LC, QF, ZZ, YT, SN, and HG collected the data. YS performed the analyses. YL and XZ gained the fund and supervised the process. XZ revised the manuscript, gained the fund, and supervised the process. All authors contributed to the article and approved the submitted version.
The publication of this article was supported by research grants from the National Natural Science Foundation of China (Nos. 81870642, 81970780, and 81670835), the Outstanding Youth Medical Talents Program of Shanghai Health and Family Planning Commission (No. 2017YQ011), Science and Technology Innovation Action Plan of Shanghai Science and Technology Commission (No. 19441900700), National Key R&D Program of China (No. 2018YFC0116800), Clinical Research Plan of SHDC (No. SHDC12019X08), and WIT120 Research Project of Shanghai (No. 2018ZHYL0220).
JW, XH, and DD were employed by the company Visionary Intelligence Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcell.2021.652848/full#supplementary-material
Abdolrahimzadeh, S., Parisi, F., Plateroti, A. M., Evangelista, F., Fenicia, V., Scuderi, G., et al. (2017). Visual acuity, and macular and peripapillary thickness in high myopia. Curr. Eye Res. 42, 1468–1473. doi: 10.1080/02713683.2017.1347692
Anwar, S. M., Majid, M., Qayyum, A., Awais, M., Alnowami, M., and Khan, M. K. (2018). Medical image analysis using convolutional neural networks: a review. J. Med. Syst. 42:226.
Barañano, A. E., Wu, J., Mazhar, K., Azen, S. P., and Varma, R. (2008). Visual acuity outcomes after cataract extraction in adult latinos. The Los Angeles latino eye study. Ophthalmology 115, 815–821. doi: 10.1016/j.ophtha.2007.05.052
Chang, L., Pan, C. W., Ohno-Matsui, K., Lin, X., Cheung, G. C., Gazzard, G., et al. (2013). Myopia-related fundus changes in Singapore adults with high myopia. Am. J. Ophthalmol. 155, 991–999.e1.
Chen, S. C., Chiu, H. W., Chen, C. C., Woung, L. C., and Lo, C. M. (2018). A novel machine learning algorithm to automatically predict visual outcomes in intravitreal ranibizumab-treated patients with diabetic macular edema. J. Clin. Med. 7:475. doi: 10.3390/jcm7120475
Chung, Y. W., Choi, M. Y., Kim, J. S., and Kwon, J. W. (2019). The association between macular thickness and axial length in myopic eyes. Biomed. Res. Int. 2019:8913582.
Fu, H., Cheng, J., Xu, Y., Zhang, C., Wong, D. W. K., Liu, J., et al. (2018). Disc-aware ensemble network for glaucoma screening from fundus image. IEEE Trans. Med. Imaging 37, 2493–2501. doi: 10.1109/tmi.2018.2837012
Gao, X., Lin, S., and Wong, T. Y. (2015). Automatic feature learning to grade nuclear cataracts based on deep learning. IEEE Trans. Biomed. Eng. 62, 2693–2701. doi: 10.1109/tbme.2015.2444389
Gohil, R., Sivaprasad, S., Han, L. T., Mathew, R., Kiousis, G., and Yang, Y. (2015). Myopic foveoschisis: a clinical review. Eye (Lond.) 29, 593–601. doi: 10.1038/eye.2014.311
Grassmann, F., Mengelkamp, J., Brandl, C., Harsch, S., Zimmermann, M. E., Linkohr, B., et al. (2018). Deep learning algorithm for prediction of age-related eye disease study severity scale for age-related macular degeneration from color fundus photography. Ophthalmology 125, 1410–1420. doi: 10.1016/j.ophtha.2018.02.037
Gulshan, V., Peng, L., Coram, M., Stumpe, M. C., Wu, D., Narayanaswamy, A., et al. (2016). Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA 316, 2402–2410. doi: 10.1001/jama.2016.17216
Hayashi, K., Ohno-Matsui, K., Shimada, N., Moriyama, M., Kojima, A., Hayashi, W., et al. (2010). Long-term pattern of progression of myopic maculopathy: a natural history study. Ophthalmology 117, 1595–1611, 1611.e1591–e1594.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Identity mappings in deep residual networks,” in Computer Vision – Eccv 2016, Part IV, Vol. 9908, eds B. Leibe, J. Matas, N. Sebe, and M. Welling (Cham: Springer), 630–645. doi: 10.1007/978-3-319-46493-0_38
Hoffer, K. J. (1980). Biometry of 7,500 cataractous eyes. Am. J. Ophthalmol. 90, 360–368. doi: 10.1016/s0002-9394(14)74917-7
Holden, B. A., Fricke, T. R., Wilson, D. A., Jong, M., Naidoo, K. S., Sankaridurg, P., et al. (2016). Global prevalence of myopia and high myopia and temporal trends from 2000 through 2050. Ophthalmology 123, 1036–1042. doi: 10.1016/j.ophtha.2016.01.006
Huang, C. Y., Kuo, R. J., Li, C. H., Ting, D. S., Kang, E. Y., Lai, C. C., et al. (2020). Prediction of visual outcomes by an artificial neural network following intravitreal injection and laser therapy for retinopathy of prematurity. Br. J. Ophthalmol. 104, 1277–1282.
Huang, X., Zhang, Z., Wang, J., Meng, X., Chen, T., and Wu, Z. (2018). Macular assessment of preoperative optical coherence tomography in ageing Chinese undergoing routine cataract surgery. Sci. Rep. 8:5103.
Jeon, S., and Kim, H. S. (2011). Clinical characteristics and outcomes of cataract surgery in highly myopic Koreans. Korean J. Ophthalmol. 25, 84–89. doi: 10.3341/kjo.2011.25.2.84
Kermany, D. S., Goldbaum, M., Cai, W., Valentim, C. C. S., Liang, H., Baxter, S. L., et al. (2018). Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 172, 1122–1131.e9.
Lange, C., Feltgen, N., Junker, B., Schulze-Bonsel, K., and Bach, M. (2009). Resolving the clinical acuity categories “hand motion” and “counting fingers” using the Freiburg Visual Acuity Test (FrACT). Graefes Arch. Clin. Exp. Ophthalmol. 247, 137–142. doi: 10.1007/s00417-008-0926-0
Li, T., Wang, X., Zhou, Y., Feng, T., Xiao, M., Wang, F., et al. (2018). Paravascular abnormalities observed by spectral domain optical coherence tomography are risk factors for retinoschisis in eyes with high myopia. Acta Ophthalmol. 96, e515–e523.
Lichtwitz, O., Boissonnot, M., Mercié, M., Ingrand, P., and Leveziel, N. (2016). Prevalence of macular complications associated with high myopia by multimodal imaging. J. Fr. Ophtalmol. 39, 355–363. doi: 10.1016/j.jfo.2015.11.005
Liu, Y. C., Wilkins, M., Kim, T., Malyugin, B., and Mehta, J. S. (2017). Cataracts. Lancet 390, 600–612.
Quek, D. T., Jap, A., and Chee, S. P. (2011). Risk factors for poor visual outcome following cataract surgery in Vogt-Koyanagi-Harada disease. Br. J. Ophthalmol. 95, 1542–1546. doi: 10.1136/bjo.2010.184796
Rohm, M., Tresp, V., Müller, M., Kern, C., Manakov, I., Weiss, M., et al. (2018). Predicting visual acuity by using machine learning in patients treated for neovascular age-related macular degeneration. Ophthalmology 125, 1028–1036. doi: 10.1016/j.ophtha.2017.12.034
Rönbeck, M., Lundström, M., and Kugelberg, M. (2011). Study of possible predictors associated with self-assessed visual function after cataract surgery. Ophthalmology 118, 1732–1738. doi: 10.1016/j.ophtha.2011.04.013
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., and Batra, D. (2020). Grad-CAM: visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 128, 336–359. doi: 10.1007/s11263-019-01228-7
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. (2016). “Rethinking the inception architecture for computer vision,” in Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, (Las Vegas, NV: IEEE), 2818–2826.
Todorich, B., Scott, I. U., Flynn, H. W. Jr., and Chang, S. (2013). Macular retinoschisis associated with pathologic myopia. Retina 33, 678–683. doi: 10.1097/iae.0b013e318285d0a3
Zhu, X., Li, D., Du, Y., He, W., and Lu, Y. (2018). DNA hypermethylation-mediated downregulation of antioxidant genes contributes to the early onset of cataracts in highly myopic eyes. Redox Biol. 19, 179–189. doi: 10.1016/j.redox.2018.08.012
Zhu, X., Meng, J., Wei, L., Zhang, K., He, W., and Lu, Y. (2020). Cilioretinal arteries and macular vasculature in highly myopic eyes. Ophthalmol. Retina 4, 965–972. doi: 10.1016/j.oret.2020.05.014
Keywords: machine learning, visual acuity, high myopia, cataract, optical coherence tomography
Citation: Wei L, He W, Wang J, Zhang K, Du Y, Qi J, Meng J, Qiu X, Cai L, Fan Q, Zhao Z, Tang Y, Ni S, Guo H, Song Y, He X, Ding D, Lu Y and Zhu X (2021) An Optical Coherence Tomography-Based Deep Learning Algorithm for Visual Acuity Prediction of Highly Myopic Eyes After Cataract Surgery. Front. Cell Dev. Biol. 9:652848. doi: 10.3389/fcell.2021.652848
Received: 13 January 2021; Accepted: 19 April 2021;
Published: 26 May 2021.
Edited by:
Haotian Lin, Sun Yat-sen University, ChinaCopyright © 2021 Wei, He, Wang, Zhang, Du, Qi, Meng, Qiu, Cai, Fan, Zhao, Tang, Ni, Guo, Song, He, Ding, Lu and Zhu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiangjia Zhu, emh1eGlhbmdqaWExOTgyQDEyNi5jb20=; Yi Lu, bHV5aWVlbnRAMTYzLmNvbQ==
†These authors have contributed equally to this work
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.