 Nan Tang
Nan Tang Chunmei Qi
Chunmei Qi
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Cardiovasc. Med. , 22 October 2024
Sec. General Cardiovascular Medicine
Volume 11 - 2024 | https://doi.org/10.3389/fcvm.2024.1419551
This article is part of the Research Topic The Role of Artificial Intelligence Technologies in Revolutionizing and Aiding Cardiovascular Medicine View all 10 articles
Introduction: Accurate in-hospital mortality prediction following percutaneous coronary intervention (PCI) is crucial for clinical decision-making. Machine Learning (ML) and Data Mining methods have shown promise in improving medical prognosis accuracy.
Methods: We analyzed a dataset of 4,677 patients from the Regional Vascular Center of Primorsky Regional Clinical Hospital No. 1 in Vladivostok, collected between 2015 and 2021. We utilized Extreme Gradient Boosting, Histogram Gradient Boosting, Light Gradient Boosting, and Stochastic Gradient Boosting for mortality risk prediction after primary PCI in patients with acute ST-elevation myocardial infarction. Model selection was performed using Monte Carlo Cross-validation. Feature selection was enhanced through Recursive Feature Elimination (RFE) and Shapley Additive Explanations (SHAP). We further developed hybrid models using Augmented Grey Wolf Optimizer (AGWO), Bald Eagle Search Optimization (BES), Golden Jackal Optimizer (GJO), and Puma Optimizer (PO), integrating features selected by these methods with the traditional GRACE score.
Results: The hybrid models demonstrated superior prediction accuracy. In scenario (1), utilizing GRACE scale features, the Light Gradient Boosting Machine (LGBM) and Extreme Gradient Boosting (XGB) models optimized with BES achieved Recall values of 0.944 and 0.954, respectively. In scenarios (2) and (3), employing SHAP and RFE-selected features, the LGB models attained Recall values of 0.963 and 0.977, while the XGB models achieved 0.978 and 0.99.
Discussion: The study indicates that ML models, particularly the XGB optimized with BES, can outperform the conventional GRACE score in predicting in-hospital mortality. The hybrid models' enhanced accuracy presents a significant step forward in risk assessment for patients post-PCI, offering a potential alternative to existing clinical tools. These findings underscore the potential of ML in optimizing patient care and outcomes in cardiovascular medicine.
Cardiovascular disease (CVD) constitutes a dominant global health challenge, particularly accentuated within low- and middle-income countries (LMICs). The growing prevalence of CVD risk factors within these regions obviously increases the burden of mortality associated with this disease (1–3). Myocardial infarction (MI) is a severe medical condition stemming from a sudden reduction in blood flow to the heart, resulting in tissue damage. Clinical manifestations typically include chest pain, shortness of breath, and weakness (4, 5). Preventative measures mostly contain lifestyle changes and pharmacological interventions (6). Treatment modalities include the management of beta-blockers, diuretics, ACE inhibitors, calcium channel blockers, and nitrates.
The effective management of ST-segment elevation myocardial infarction (STEMI) is considered important in inpatient care, a fact emphasized by the guidance provided in the 2012 and 2017 ESC Guidelines. These guidelines prioritize early reperfusion therapy, particularly through main percutaneous coronary intervention (PCI), for optimal STEMI treatment. The diagnosis of STEMI poses challenges due to its potential to represent conditions, requiring careful consideration of various clinical factors during electrocardiogram interpretation (7, 8). Furthermore, STEMI rises as a complication of infective endocarditis, associated with a distinguished 30-day mortality rate (9). Timely diagnosis and immediate restoration of blood flow, preferably through primary PCI, are key steps in reducing myocardial damage and preventing complications following STEMI (10).
Despite the developments in PCI technologies, the in-hospital mortality (IHM) subsequent to PCI in emergency cases persists at a remarkably high rate. A study conducted by Moroni (11) clarified that IHM often correlates with pre-existing serious cardiovascular conditions, with procedural complications attributing to a minority of cases. This suggests an imperative for enhanced treatment modalities for severe cardiovascular situations, particularly in addressing cardiogenic shock. However, the utility of procalcitonin (PCT) as a prognostic indicator in these conditions remains controversial. Covino et al. (12) observed that early assessment of PCT in patients with intra-abdominal infection (IAI) did not yield a significant impact on IHM, while Dutta et al. (13) highlighted the potential of PCT levels in predicting mortality in disapprovingly ill surgical patients. Within the spectrum of STEMI, Dawson et al. (14) reported a lack of substantial reduction in IHM despite changes in technical characteristics. These findings emphasize the demand for further research activities and targeted interventions aimed at justifying IHM following PCI in emergency scenarios.
In contemporary clinical practice, a multitude of risk grading tools are employed to assess the risk of IHM among patients. Notable among these are the History, Electrocardiogram, Age, Risk factors, initial Troponin (HEART) score, the Thrombolysis in Myocardial Infarction (TIMI) score, and the Global Registry of Acute Coronary Events (GRACE) score, as identified by Liu (15). Nevertheless, the efficacy of these tools can fluctuate across diverse patient populations, with certain instruments demonstrating suboptimal performance in present-day practice (16). Within main care backgrounds, there is an observable trend toward utilizing routine healthcare data for risk grading. However, comprehensive documentation regarding the specific tools applied and their performance remains lacking (17). Additionally, within the intensive care situation, there is incredulity regarding the relevance and reliability of scales employed to measure job stressors. This underscores the imperative for further investigation and scholarly inquiry in this domain (18).
Regarding the GRACE scale, despite advancements in treatment approaches, it continues to be a critical tool for evaluating the risk of adverse outcomes in cases of serious coronary syndromes (19). Continuous monitoring of mortality rates in coronary care elements using the GRACE score indicates that while it generally performs adequately, there are still areas where improvements can be made (20). Additionally, research has shown that the GRACE score is effective in predicting major cardiac events in patients presenting with chest pain and suspected acute coronary syndrome (21). Moreover, a modified version of the GRACE score, identified as the angiographic GRACE score, has been developed and validated as a beneficial tool for predicting IHM, specifically in Japanese patients with acute myocardial infarction (22).
Over the past few decades, Data Mining (DM) and Machine Learning (ML) have emerged as influential tools in medicine, particularly in predicting and diagnosing cognitive diseases (23). These methods have been applied to a wide variety of medical conditions, including type 2 diabetes, hypertension, cardiovascular disease, renal diseases, liver diseases, mental illness, and child health (24). The usage of ML in medical informatics has seen a significant increase, with Support Vector Machine (SVM) and Random Forest (RF) being the most popular algorithms for classification problems (25). However, there is no single algorithm that is universally suitable for diagnosing or predicting diseases, and the combination of different processes often yields the greatest results (26).
ML models have shown potential in predicting IHM following PCI in patients with serious STEMI. Studies conducted by Li (27) and Yang (28) employed data from the Chinese Acute Myocardial Infarction (CAMI) registry to develop prediction models, achieving both high performance and interpretability. Moreover, Deng (29) applied a RF algorithm to forecast both no-reflow and IHM in STEMI patients undergoing key PCI, demonstrating superior discrimination. Falcao (30) identified predictors of IHM in patients with STEMI undergoing pharmacoinvasive treatment, including age, comorbidities, and practical success. Additionally, Tanık (31) found that the PRECISE-DAPT score, a predictive tool for bleeding risk, was independently associated with IHM in STEMI patients undergoing primary PCI. Furthermore, Bai (32) compared the performance of various ML models in predicting 1-year mortality in STEMI patients with hyperuricemia, with the CatBoost model showing the highest accuracy. To validate the accuracy of ML models, particularly the XGBoost model, in predicting 1-year mortality in patients with anterior STEMI, Li (33) conducted further research. Collectively, these studies highlight the significant potential of ML in improving risk prediction for STEMI patients post-PCI, offering valuable insights into prognosis and treatment strategies. However, there is a gap in existing literature related to ML prediction model development based on imperative features of patients rather than those four parameters leading to GRACE score development. Also, integrating currently developed optimization algorithms for enhanced prediction accuracy by hybrid and ensemble approaches are the innovative methods which their absence is strongly felt in the literature review.
This study aims to introduce a new approach to investigate the risk factors contributing to IHM in patients with MI following PCI, applying advanced ML techniques. The research methodology involved gathering datasets related to various features of patients to assess their impact on the mortality risk of patients utilizing classifiers like Extreme Gradient Boosting (XGB), Light Gradient Boosting (LGB), Stochastic Gradient Boosting (SGB), and Histogram Gradient Boosting (HGB). Monte Carlo Cross-Validation (MCCV) was used to select the best prediction models based on their Accuracy. Techniques, for instance, Recursive Feature Elimination (RFE) and Shapley Additive Explanations (SHAP), were employed to identify important features for classification. Three different scenarios were designed to predict the risk of IHM within 30 days to provide clinicians with an estimate of patient survivability or mortality likelihood pre-treatment. The first scenario studies the efficacy of the traditional GRACE scale system (including Age, patient age, heart rate (HR), systolic blood pressure (SBP), and acute heart failure (AHF) class), widely entrenched within hospital protocols. The second and third scenarios employ a subclass of features selected via the Shapley Additive explanations (SHAP) and Recursive Feature Elimination (RFE) methods, respectively. All analysis conducted in Python programming software. By comparing the prediction performance of base single models and their hybrid framework (optimized with meta-heuristic algorithms such as Augmented Gray Wolf Optimizer (AGWO), Bald Eagle Search Optimization (BES), Golden Jackal Optimizer (GJO), and Puma Optimizer (PO)) utilizing these scenarios, the study aims to give valuable insights to enhance risk assessment strategies and patient care paradigms for MI patients undergoing PCI intervention.
The boosting approach involves utilizing a “weak” or “base” learning algorithm repeatedly, each time with a different subset of training examples (or a varied distribution or weighting over the examples). In each iteration, the base learning algorithm generates a new weak prediction rule. After numerous rounds, the boosting algorithm combines these weak rules into a single prediction rule, aiming for a substantially improved level of accuracy compared to any individual weak rule (Figure 1). This iterative process enhances the overall predictive power of the model (34).
Figure 1. Boosting approach in ML.
The Extreme Gradient Boost Classifier (XGBC) represents a sophisticated implementation of the gradient boosting technique, employing an ensemble approach to combine multiple sets of base learners (trees) to establish a strong model capable of making significant predictions (35). XGBC offers various advantages, including the ability to leverage parallel processing for improved computational efficiency, providing flexibility in setting objectives, incorporating built-in cross-validation, and effectively addressing splits in the presence of negative loss. With these advantages, XGBC emerges as a highly suitable choice for analyzing classification data. Applying a tree-based methodology, XGBC constructs decision trees to classify training data, facilitating the achievement of specific target outcomes (36).
The gradient boosting procedure encompasses the subsequent sequential steps:
• The initialization of the boosting algorithm involves the description of the function (Equation 1):
• The iterative calculation includes the derivation of the gradient of the loss function (Equation 2):
Where α is the learning rate.
• Subsequently, each is fitted based on the gradient developed at each iterative step:
• The purpose of the multiplicative factor for each terminal node is executed, and subsequently, the boosted model is formulated (Equation 3):
LGB is a rapid training outline that blends decision tree algorithms with boosting methods. It prioritizes speed, using histogram-based techniques to accelerate training and conserve memory (37). Different from traditional trees, LGB employs leaf-wise tree growth, efficiently identifying high-branching gain leaves to optimize performance (38, 39).
The calculation procedures of LGB, delineated step by step in (40), involve finding a projected function that approximates the function based on the given training dataset . The primary objective is to minimize the expected values of specific loss functions, signified as (Equation 4).
In the process of approximating the final model, LGB will integrate a combination of multiple regression trees, represented as (Equation 5).
The regression trees signified as , denote decision rules, where N is the number of leaves in each tree. q signifies the decision rule, and w is a vector representing the weights of the leaf nodes. The model is incrementally trained at step t in an additive manner.
The Newton's method is employed to rapidly estimate the objective function, and (Equation 6) is simplified by eliminating the constant term:
In the given equation, and denote the first- and second-order gradient statistics of the loss functions. If the sample set for leaf j is denoted as , then (Equation 7) can be transformed into (Equation 8):
Equations 9, 10 are employed to calculate the optimal leaf weights and the extreme values of concerning the tree structure :
The term signifies the weight function assessing the effectiveness of the tree structure . Ultimately, the objective function is derived by consolidating the splits.
The objective function is defined as the sum of the splits with and representing the samples in the left and right branches, respectively (Equation 11).
Histograms are valuable tools for visualizing data distribution and frequency, especially with repetitive data. Grouping input data into bins, as in histograms, enhances model flexibility. Combining histogram-based methods with gradient boosting leads to strong ML ensembles, yielding high-performance models (41). HGBoost employs numeral-based data structures like histograms instead of sorted continuous values during tree-building, enabling it to capture complex nonlinear relationships in datasets effectively. This integration of gradient boosting with histogram-based techniques allows HGBoost to excel in modeling and optimizing feature connections (42).
Histogram-based Gradient Boosting Classification (HGBC) represents a difficult iteration of gradient boosting, employing decision trees as fundamental models and leveraging histograms to achieve outstanding improvements in computational efficiency. Observed remarks show that this methodology yields superior outcomes, diminishes ensemble size, and expedites inference, rendering it an attractive proposition for tackling intricate datasets within academic investigations (43).
Friedman (44) proposed Stochastic Gradient Boosting Machines (SGB), a method extensively employed in both classification and regression tasks. Decision stumps or regression trees serve as common choices for weak classifiers within SGB. The main aim of SGB is to train weak learners to minimize loss functions, such as mean square errors, with subsequent weak learners benefiting from the residuals of preceding ones for training.
Consequently, there is a reduction in the value of the loss function for the present weak learners. Employing the bagging technique serves to mitigate correlation among these learners, with each undergoing training on subsets sampled without replacement from the entirety of the dataset. The final prediction is then derived through the amalgamation of predictions generated by this cohort of weak learners (45).
Numerous methods, such as the Akaike information criterion (46) and statistics (47), tackle the task of model selection. Nevertheless, cross validation (CV) emerges as a standout approach (48–51), arranging a predictive perspective in this process. In CV, upon selecting a model (), the n samples (referred to as ) undergo a division.
The initial component, identified as the calibration set (), consists of samples applied for fitting the model, represented by the submatrix and sub-vector . The subsequent section termed the validation set (), comprises samples dedicated to model validation, depicted by the submatrix and sub-vector . This arrangement leads to a total of possible sample divisions. In each division, the model is fitted using the samples from the standardization set , resulting in the estimation . Treating the samples in the validation set as if they were future data points, the fitted model predicts the response vector (Equation 12).
The Accuracy across all samples in the validation set is considered by (Equation 13):
The formula involves calculating the Euclidean norm of a vector within a framework where a set S is comprised of elements from various validation sets, each corresponding to different sample splits denoted as . In this framework, the CV standard is defined by excluding a specific number of samples for validation, providing a method for systematically evaluating models on subsets of data.
For each , the computation of is conducted. (Equation 14) serves as an estimate for Accuracy within the constraints of finite samples. The CV criterion is focused on identifying the optimal that maximizes values across all for . As a result, the model is characterized by variables indexed by the integers in is chosen.
The widely used leave-one-out Cross-Validation (LOO-CV), where , is extensively applied in chemometrics. However, research findings have shown that models selected through LOO-CV can be inaccurately asymptotic. Although LOO-CV can choose a model with a bias that approaches infinity encompassing all non-zero elements in , it tends to include unnecessary additional variables in the model (52). This suggests that the model's dimension is not optimally concise, potentially leading to overfitting concerns.
It has been established that, in general, CV, under the conditions and (53), the likelihood of selecting the model with the best predictive capability tends toward unity when samples are reserved for validation. Consequently, the benchmark (Equation 14) shows asymptotic consistency. Yet, practically computing with a large is infeasible due to its exponential computational complexity. To tackle this issue, MCCV offers a simple and efficient solution. For a given α, the samples are randomly split into two sets: (of size ) and (of size ). This process is repeated N times, defining the repeated MCCV criterion as follows (Equation 15):
Employing the Monte Carlo method greatly decreases computational complexity. Theoretically, decreasing the number of samples for model calibration requires increasing the number of repetitions. Typically, it is deemed adequate to set to ensure that achieves similar performance to traditional (54).
In this study, 70% of the samples were considered for the fitting (training) of the prediction models, 30% were allocated for the validation process (testing), and finally, two LGBM and XGBC models with an accuracy of 0.97 and 0.98 have been selected, and in the following, only these two models will be examined in their hybrid version.
The study used data from patients treated at the Regional Vascular Center of Primorsky Regional Clinical Hospital in Vladivostok from 2015 to 2021. Patients were selected for inclusion in the STEMI and PCI study based on criteria confirmed upon their admission to the hospital. Exclusion criteria comprised non-ST elevation myocardial infarction, unconfirmed STEMI, or the absence of an indication for PCI. Finally, 4,677 patients were included in the study, from which 4,359 patients were in the “Alive” group who did not die within 30 days of the study after PCI, and 318 patients were in the “Die” group who died in hospital. The “Die” group comprised patients who passed away at any point during these 30 days, including those who did not survive to undergo post-PCI assessments. Conversely, the “Alive” group consisted of patients who survived the entire 30-day period and were monitored in the hospital throughout. It is important to note that patients with missing data were excluded from the dataset of those patients with no risk of death due to the abundance of information (the number of samples decreased to 2,709). For 318 patients who experienced IHM after PCI, the Multiple Imputation by Chained Equations (MICE) method was used to handle missing data. MICE achieves multiple imputation by creating multiple complete datasets, analyzing each dataset separately, and then combining the results to reduce the bias that a single imputation method might introduce (55). This method fully considers the uncertainty of the data when dealing with missing data, especially suitable for the complex multivariate data structure in this study. Compared with single imputation, MICE can provide more reliable statistical inference when dealing with a large amount of missing data. Ultimately, a cleaned dataset of 3,027 patients with 41 features, as described below in related categories, was chosen for the prediction task:
SPAP (Systolic Pulmonary Arterial Pressure), LVRMI (Left Ventricular Regional Motion Index), EF LV (Left Ventricular Ejection Fraction), ESV (End-Systolic Volume), LVRWTI (Left Ventricular Relative Wall Thickness Index), La1 (Left Atrial Diameter), Ra2 (Right Atrial Diameter), Ra1 (Right Atrium Pressure), PI (Pulsatility Index), EDV (End-Diastolic Volume), La2 (Left Atrial Pressure), SBP (Systolic Blood Pressure), DBP (Diastolic Blood Pressure).
NEUT (Neutrophils), EOS (Eosinophils), WBC (White Blood Cell count), Hb (Hemoglobin), RBC (Red Blood Cell count), PLT (Platelet count), LYM (Lymphocyte count).
TT (Thrombin Time), INR (International Normalized Ratio), APTT (Activated Partial Thromboplastin Time), PCT (Plateletcrit).
Urea [Blood Urea Nitrogen (BUN)], Glu (Glucose), Cr (Creatinine).
Age (Patient's Age), Weight (Patient's Weight), Height (Patient's Height), BMI (Body Mass Index).
Killip class [Killip Classification (classification of heart failure severity)], Form STEMI (STEMI Diagnosis), CKD (chronic kidney disease), AFib (Atrial Fibrillation), Diabetes (Diabetes Mellitus), COPD (Chronic Obstructive Pulmonary Disease), aMI (Acute Myocardial Infarction) And Sex (Patient's Gender).
SHAP, a method for attributing features additively, draws from both game theory and local explanations (56). The Shapley value has gained popularity as a method for providing interpretable feature attribution in ML models (57). SHAP simplifies inputs by transforming the original inputs x into a simplified representation z through a mapping function . This simplification enables the approximation of the original model using a linear function of binary variables based on (Equation 16):
is a binary vector with M elements representing input features, denotes the attribution value of the model when z is all zeros, calculated as , and represents the attribution value of the feature (Equations 17, 18).
SHAP stands out due to its three core properties: local accuracy, consistency, and proficiency in handling missing data. It uses the SHAP value as a unified metric for additive feature attributions. In the SHAP framework, F represents the subset of non-zero inputs in z, while S indicates the subset of F obtained by excluding the feature (58). Known for its model-agnostic nature, SHAP shows impressive adaptability across various ML and DL models, effectively determining the relative importance of individual input features within additive feature attribution methodologies (59). Table 1 reports SHAP values obtained for each feature in the dataset based on each base models and selected features.
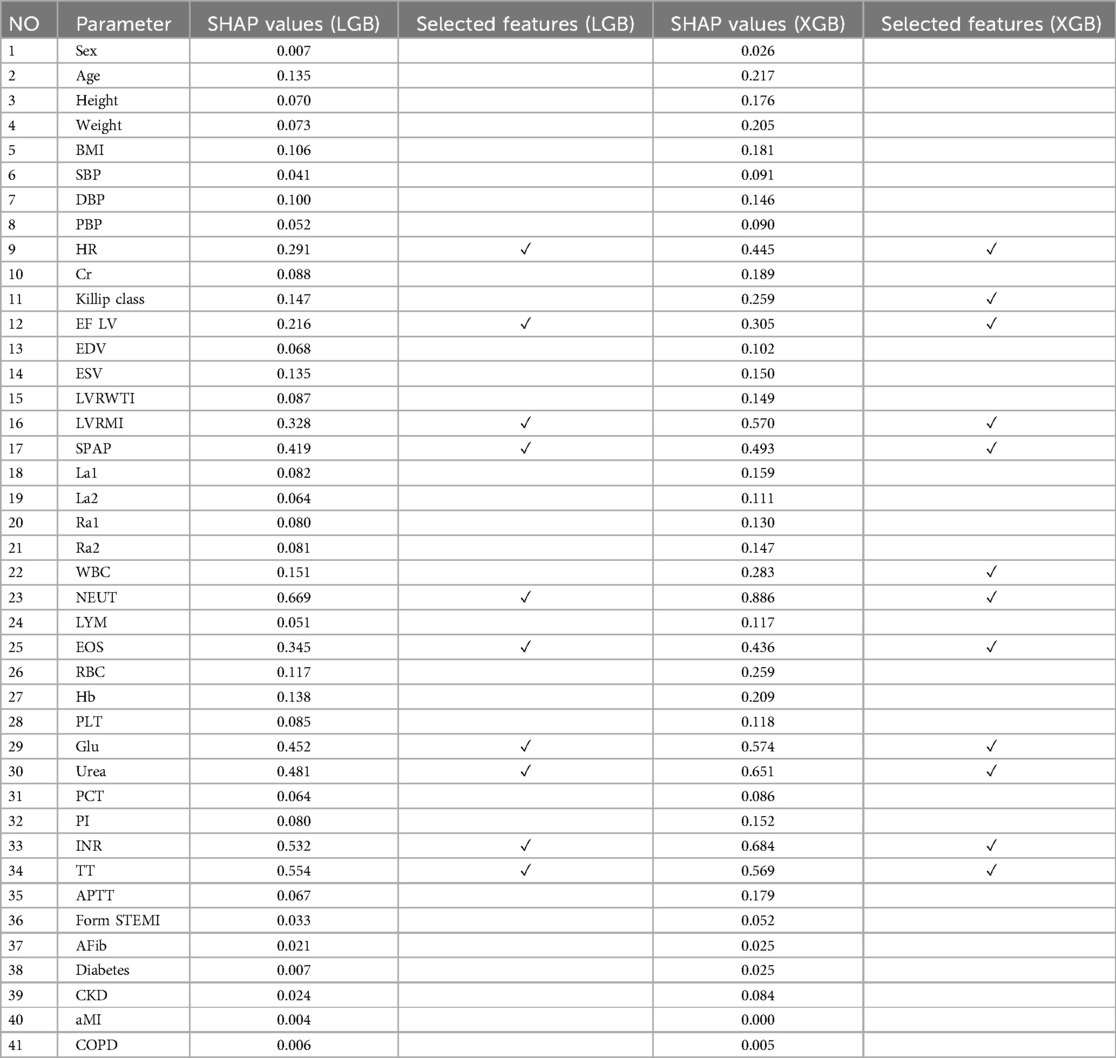
Table 1. SHAP values and selected features from the dataset based on each base model (scenario 2).
Figure 2 illustrates the features identified by the SHAP method for the LGB model, while Figure 3 shows the selected features for the XGB model. In the LGB model, ten features were recognized as essential factors in modeling and forecasting, while the XGB model identified 13 features. After a comprehensive examination of the relationships, it becomes apparent that the correlation between systolic pulmonary arterial pressure and heart rate, along with the correlation between neutrophils and glucose, is direct. Conversely, the relationship between neutrophils and eosinophils shows an inverse trend.
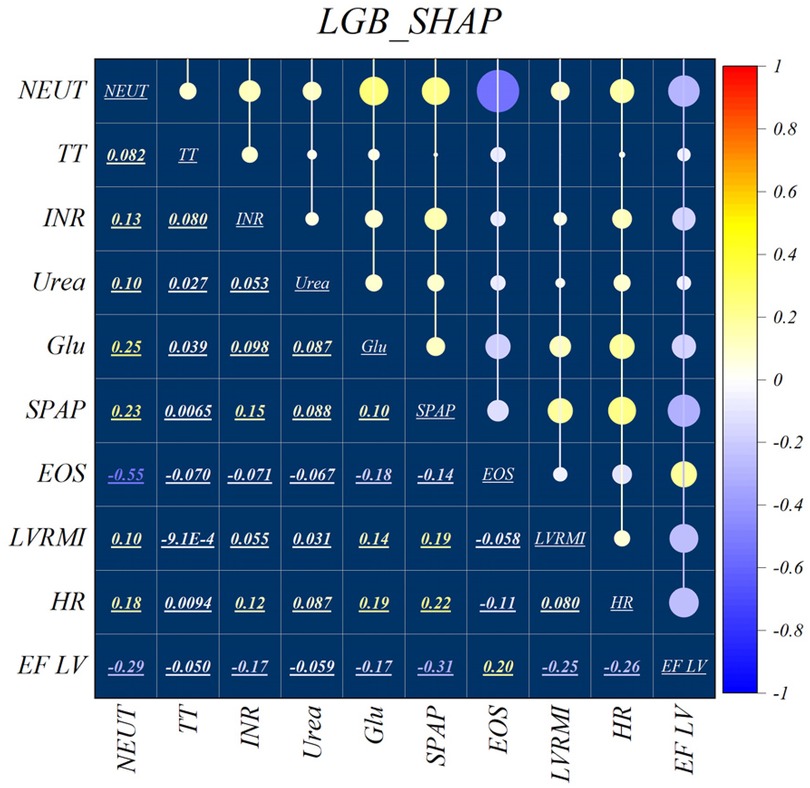
Figure 2. Feature selection and SHAP analysis for LGB.
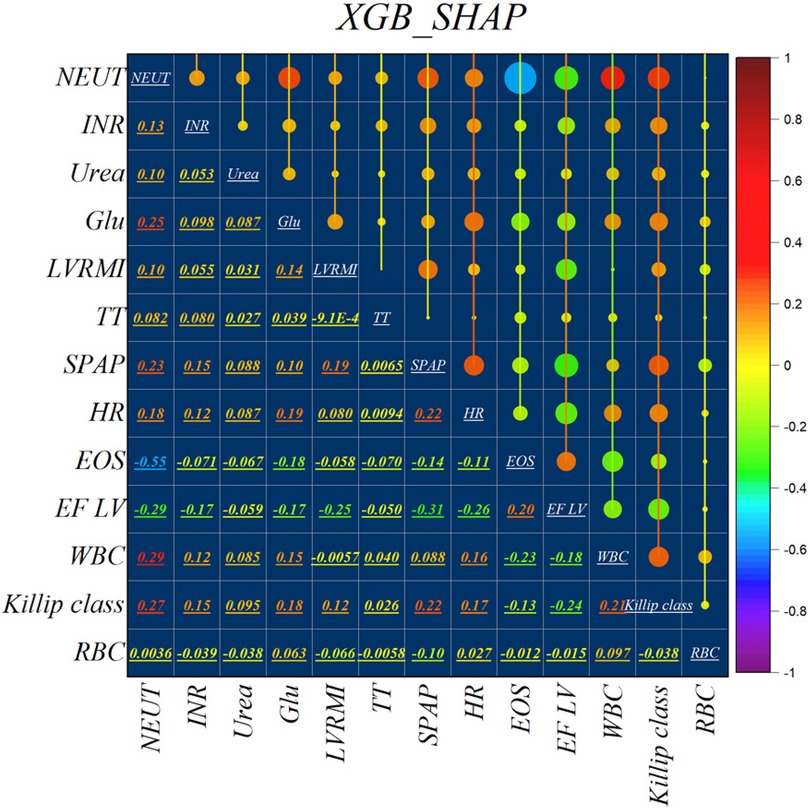
Figure 3. Feature selection and SHAP analysis for XGB.
The Recursive Feature Elimination (RFE) selection method (60) fundamentally operates through a recursive procedure wherein features are systematically ranked based on a specified measure of their significance.
A feature ranking criterion that performs well for individual features may not be suitable for assessing feature subsets effectively. Metrics such as or measure the impact of removing single features on the objective function but may struggle when removing multiple features simultaneously, which is crucial for obtaining a concise subset. To overcome this limitation, RFE employs an iterative approach to systematically remove the least relevant features in each iteration. RFE considers potential changes in feature importance across various feature subsets, particularly for highly correlated features. The order of feature elimination determines the final ranking, and the top n features are selected from this ranking for the feature selection process (61). Train the classifier, compute the ranking criterion for all features, and then remove the feature with the smallest ranking criterion.
When features are eliminated one by one, they are correspondingly ranked. However, the features ranked highest (eliminated last) may not necessarily be individually the most relevant. The optimal subset is determined by considering features collectively rather than individually. It is important to note that RFE does not affect correlation methods, as the ranking criterion is computed based solely on information from individual features. Table 2 reports the RFE ranking obtained for each feature in the dataset based on each base models and selected features.
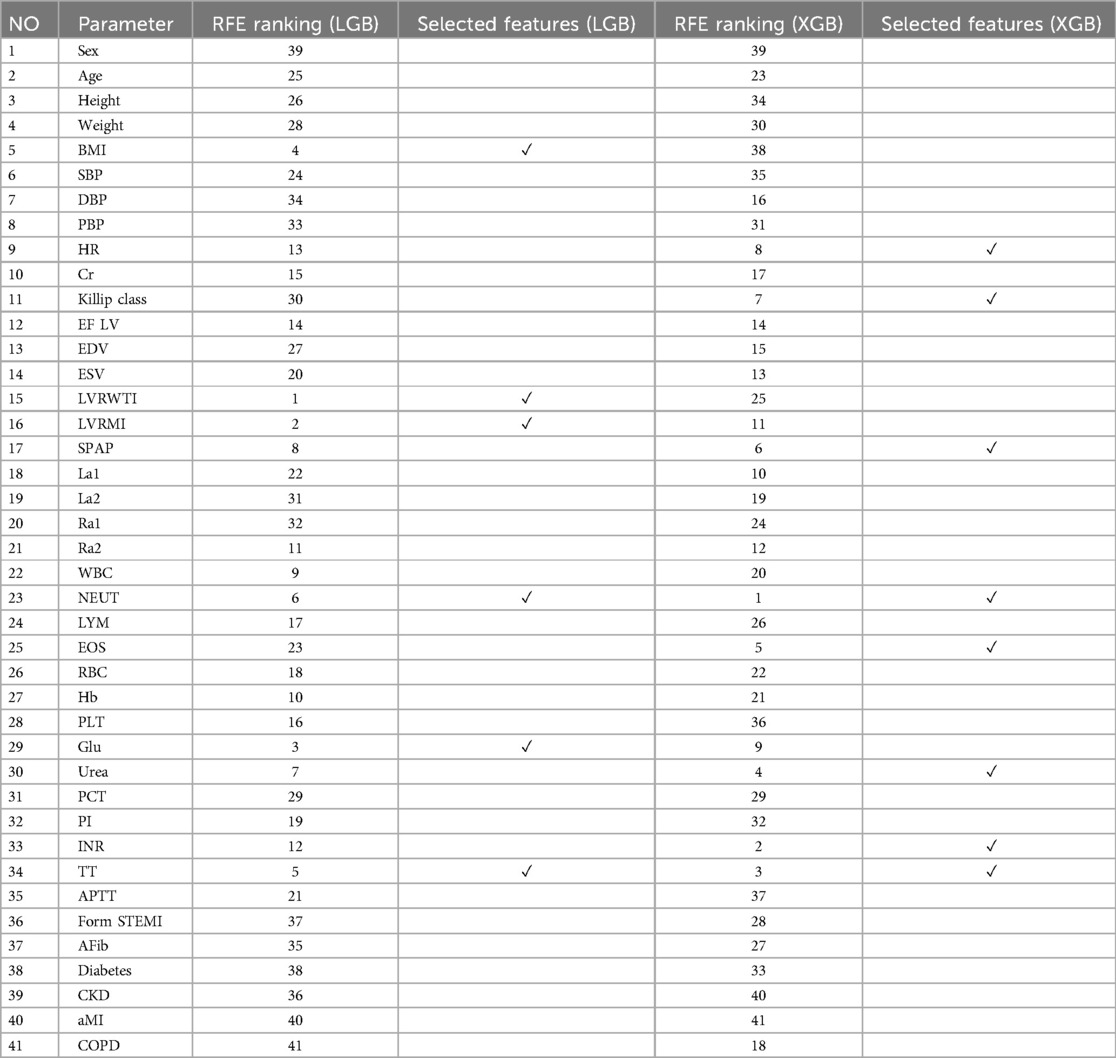
Table 2. RFE ranking and selected features from the dataset based on each base model (scenario 3).
The features selected using RFE for the LGB and XGB models are visually depicted in Figures 4, 5, respectively. The selected features consist of 6 parameters for the LGB model and 8 for the XGB model. Upon scrutiny of the presented matrix, it becomes apparent that the left ventricular regional motion index and the left ventricular relative wall thickness index, both cardiovascular parameters, display a direct relationship with each other. Additionally, it is remarkable that neutrophils demonstrate a strong correlation with heart rate, systolic pulmonary arterial pressure, and Killip classification. Conversely, thrombin time shows no significant relationship with other selected parameters.
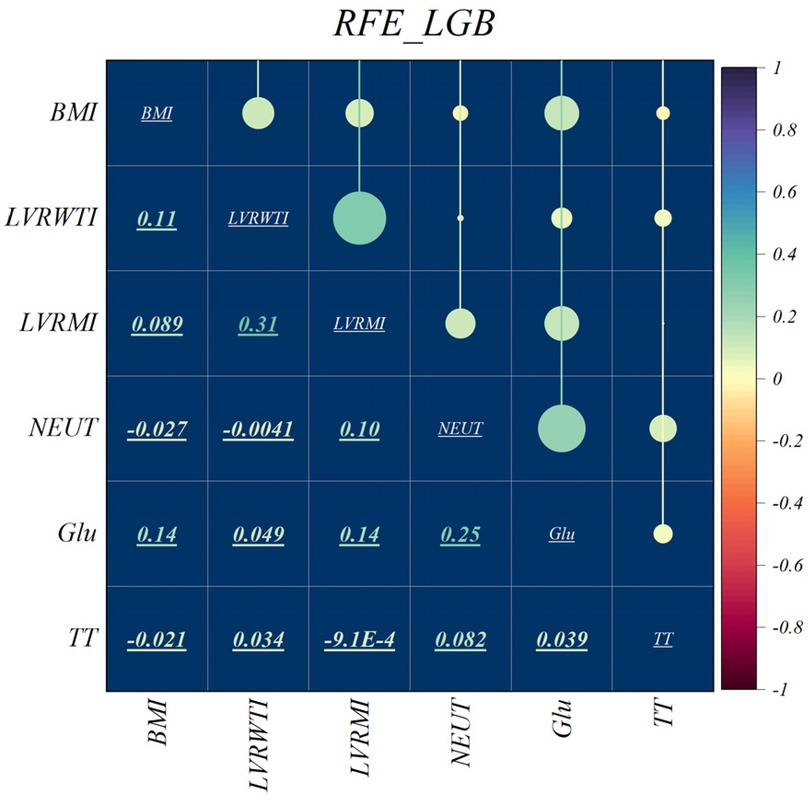
Figure 4. Feature selection and RFE analysis for LGB.

Figure 5. Feature selection and RFE analysis for XGB.
In this study, NEUT, TT, BUN, Glu, and SPAP were identified as key factors for the risk of IHM after PCI in patients with STEMI through the above-mentioned feature selection methods. NEUT play a central role in infection and inflammation, and their high levels in MI may indicate inflammatory processes associated with myocardial damage (62). Inflammation not only promotes atherosclerosis but may also lead to plaque rupture, increasing the risk of cardiac events (63). TT is an indicator for assessing the coagulation cascade, and its prolongation may suggest abnormal coagulation factor activity, increasing the risk of thrombosis after myocardial infarction (64). Additionally, prolonged TT may be associated with the use of anticoagulant drugs, which is common in the management of heart diseases. BUN reflects renal insufficiency in heart diseases, which may affect fluid and electrolyte balance, activate the renin-angiotensin-aldosterone system, leading to increased blood pressure and cardiac load, affecting cardiac function and clinical outcomes (65). High blood glucose is an independent risk factor for cardiovascular diseases, and chronic hyperglycemia promotes oxidative stress and inflammatory responses, leading to abnormal vascular endothelial function and accelerated atherosclerosis, exacerbating myocardial injury and the risk of cardiovascular events (66). Elevated SPAP is associated with changes in cardiac structure and function, and after myocardial infarction, it may indicate increased right ventricular load, leading to dysfunction, affecting the heart's pumping ability, increasing the risk of heart failure and death (67). These characteristics affect patient outcomes through various biological pathways, and a deeper understanding of these mechanisms can help better understand the disease development process and develop targeted treatment strategies.
In this study, we combined four metaheuristic algorithms: the Augmented Grey Wolf Optimizer (AGWO), Bald Eagle Search Optimization (BES), Golden Jackal Optimizer (GJO), and Puma Optimizer (PO). These algorithms, each mimicking unique behaviors in nature, possess different search strategies that effectively avoid local optima and demonstrate efficient search capabilities and robustness in complex decision spaces. To optimize model performance, we employed grid search and cross-validation methods to fine-tune hyperparameters. Grid search systematically iterates through predefined hyperparameter values and evaluates each combination using cross-validation. Cross-validation divides the dataset into multiple subsets, using one subset as a test set and the rest as training sets, to assess the model's generalization ability. This study specifically utilized the Monte Carlo Cross-Validation (MCCV) method, which evaluates the performance of optimizers under different hyperparameter settings through random sampling to determine the optimal parameter combination, thereby maximizing the model's predictive accuracy.
The AGWO algorithm emphasizes the search parameter (), fluctuating the global Grey Wolf Optimization (GWO). It matches gray wolves’ hunting behavior, where a leader, , directs the pack, supported by secondary wolves, , aiding in decision-making. represents the estimated outcomes targeted at resolving the research issue (68). The hunting process is categorized into four different sections as follows (69):
Exploring prey locations is enabled through the divergence of search agents, a condition satisfied when surpasses 1. Parameter A, essential in balancing exploration and exploitation, is primarily contingent upon parameter a as described in (Equation 19):
The parameter a randomly and nonlinearly transitions from 2 to 1 as the iteration increases, while and represent consistently dispersed random vectors ranging between 0 and 1 (Equations 20, 21). This process continues until it reaches the maximum iteration.
The mathematical formulation relating to the encirclement of prey is described as follows (Equations 22, 23):
represents the vector indicating the location of the grey wolf, while signifies the vector demonstrating the location of the prey.
In the proposed AGWO algorithm (Algorithm 1), the strategy for hunting is determined exclusively by the parameters and , which are defined in (Equations 24–26).
The coordinated efforts of search agents may aid in the process of preying on a target; this investigation is conducted when the magnitude of set A is less than one.

Algorithm 1. Pseudocode outlining the AGWO.
Alsattar et al. introduced the Bald Eagle Search (BES) algorithm, drawing inspiration from the discerning hunting strategy observed in bald eagles (70). This algorithm is arranged around three sequential phases reflective of the bald eagle's hunting behavior. Initially, the algorithm identifies spatial domains characterized by a delicate presence of potential targets. Subsequently, within these delineated spaces, extensive exploration is conducted to determine optimal solutions. Finally, similar to the decisive swooping action of the bald eagle, the algorithm strategically converges towards superior solutions (71). Through this emulation of the bald eagle's hunting strategy, the BES algorithm demonstrates a deliberate and efficient approach to optimization problem-solving (72).
During this phase, bald eagles strive to select a search area abundant with food, aiming for optimal conditions. Here is the mathematical representation of this stage (Equation 27):
control's location changes; r is a random number between 0 and 1. is a new position, is the best position found, is the average position of all eagles and is the current eagle's position.
During this stage, the bald eagle conducts a methodical search across various directions within the designated space to locate potential prey. It strategically assesses optimal hunting positions and plans its swooping maneuvers accordingly. This stage can be succinctly described in mathematical terms as (Equations 28–34):
quantifies the total number of search attempts, while denotes the angle delineating the direction of the search. The term encompasses a numerical value within the inclusive range of 0 to 1.
In the final phase, each bald eagle begins a swinging motion from a superior location toward its predefined prey. The mathematical definition of this behavior in this phase is presented as follows (Equations 35–41):
.
The comprehensive depiction of the BES algorithm is accessible through the subsequent pseudocode (Algorithm 2), and the flowchart of BES is illustrated in Figure 6.

Algorithm 2. Pseudocode outlining the Bald Eagle Search Optimization.
Figure 6. The flowchart of BES.
The Golden Jackal Optimizer (GJO) represents a recent advancement in swarm-based optimization methodologies strategically developed to optimize diverse engineering systems and processes (73). Drawing inspiration from the collaborative hunting tactics observed in golden jackals, the GJO includes three important subprocesses: Prey Exploration, Surrounding, and Attacking (74, 75). Within this section, the mathematical formulation of the GJO is clarified.
At the beginning of the optimization process, the generation of a set of prey location matrices is initiated, achieved via the randomization method described in (Equation 42):
The method that the golden jackal hunts, where the E value is greater than 1, is illustrated numerically. N is the number of prey populations at this stage, and n is the total number of variables.
In the given equation, t represents the iteration number, and denote the positions of male and female golden jackals, respectively, while represents the prey's position vector. The updated positions of the golden jackals are and , respectively. The variable E signifies the prey's evading energy, calculated using a specific formula (Equations 45, 46):
The equation assesses the ability of prey to avoid predators, considering several aspects. Firstly, a random value within the range of −1 to 1, denoted as , represents the prey's starting energy level. The parameter T signifies the maximum number of iterations, while is a constant value typically set to 1.5. indicates how quickly the prey's energy decreases over time.(Equations 47, 48) apply the distance between the golden jackal and the prey, expressed as , where denotes a vector of random numbers resulting from the Levy flight function.
The calculation uses random values for u and v that fall between 0 and 1, and it also includes a constant b that is often set to 1.5 by default.
The formula calculates the prey's updated location, , based on the positions of the male and female golden jackals.
The reduced capability of the prey to evade emerges when it faces violence from the golden jackals. This mathematical expression illustrates a decline in evading energy when is less than or equal to 1.
The comprehensive depiction of the GJO algorithm is outlined in the pseudocode provided below (Algorithm 3) and Figure 7 illustrates the flowchart of GJO.

Algorithm 3. Pseudocode delineation of the Golden Jackal Optimizer.
Figure 7. The flowchart of GJO.
The Puma algorithm was subjected to review by Abdollah Zadeh et al. (76), and its description is as follows:
The Puma, also called cougar or mountain lion, is a large American feline found across a vast range from the Andes to Canada. It is known for its adaptability, nocturnal nature, and ambush hunting style, preying on deer, rodents, and occasionally domestic animals (77–79). Pumas prefer dense scrub and rocky habitats, establish large territories, and display typical territorial behavior (80). They typically capture large prey every two weeks, relocating it for feeding over several days. Pumas are solitary, except for mothers and cubs, and rarely encounter each other except to share prey or in small communities centered around a dominant male's territory (81).
This section presents the PO algorithm, which draws inspiration from the hunting behaviors of pumas. Different from conventional meta-heuristic optimizers, PO introduces a unique mechanism for transitioning between the exploration and exploitation phases. It conceptualizes the best solution as a male puma and views the entire optimization space as a puma's territory, with other solutions representing female pumas. Purposeful and intelligent phase selection guides solutions through exploration or exploitation in each iteration. Drawing from puma behavior, diverse optimization approaches are employed in each phase, enhancing the algorithm's efficiency.
The algorithm, inspired by puma behavior, features an exploitation phase for revisiting known hunting grounds and an exploration phase for discovering new territories. It incorporates a sophisticated mechanism resembling an advanced hyper-heuristic algorithm, integrating diversity and intensification components for scoring. The phase transition section adopts two approaches inspired by puma intelligence: inexperienced pumas explore new territories while targeting promising areas for ambush.
In its early stages, the puma lacks experience and often engages in exploration activities simultaneously due to its unfamiliarity with its environment and lack of awareness of hunting locations within its territory. Conversely, it seeks hunting opportunities in favorable areas. In the Puma algorithm, during the initial three iterations, both exploration and exploitation operations are carried out concurrently until initialization is completed in the phase transition phase. In this section, as the exploitation and exploration phases are selected in each iteration, only two functions ( and ) are applied and calculated using (Equations 52–55):
The values of , associated with both exploitation and exploration phases, are determined using (Equations 52–55), while remains constant at 1. and , parameters with predetermined values, are used to prioritize the functions and during the optimization process.
In Equations 56, 61, the term represents the cost of the initial optimal solution generated during the initialization phase. Additionally, six variables, namely , , , , , and , denote the costs associated with the best solutions obtained from the exploitation and exploration phases across three repetitions (Equations 57–60).
After evaluating the functions and following the third iteration, a decision is made to exclusively pursue either exploration or exploitation phases. The positive experiences of other Pumas influence this choice. To determine which phase to prioritize, the coordinates of both the exploitation and exploration points are computed by applying (Equations 62, 63):
After computing and using (Equations 62, 63), the system determines whether to proceed with the exploration or exploitation phase based on their values. If , the exploitation stage is entered; otherwise, the exploration step is chosen. However, a serious consideration arises at the end of the third iteration: each step independently generates solutions exceeding the total population size. To address this, the total cost of solutions from both phases is calculated at the end of the third iteration. Only the best solutions from the entire pool are retained, ensuring that the population size remains constant by replacing the current solutions.
After three generational iterations, the Pumas acquire a satisfactory level of experience to opt for a singular optimization phase for subsequent iterations. Within this phase, three distinct scoring functions, namely , , and , are applied. The main function, , prioritizes either the exploration or exploitation phase based on their comparative performance, with a particular emphasis on the exploration phase. This function is determined using (Equation 52).
Equations 64, 65 define and for the exploitation and exploration phases at iteration t. and are costs before and after improving the current selection, while and indicate unselected iterations. , set between 0 and 1, determines the importance of the first function: advanced values prioritize it.
The second function gives preference to the phase that outperforms the other, focusing on resonance. It assesses good performances sequentially, aiding in the selection of the exploitation phase. (Equations 66, 67) are employed to calculate this function.
Equations 66, 67 introduce functions for exploration and exploitation in an optimization process, with costs representing solution performance. Updates to solution costs are tracked across current and past selections. Iteration counts capture unselected iterations between selections. The parameter influences the effectiveness of the exploration-exploitation balance. Overall, these elements form a framework for optimizing strategies.
The third function in the selection mechanism emphasizes diversity by increasing in value when its priority rises and decreasing when it declines. It ensures that less frequently selected phases still have a chance to be chosen, preventing the algorithm from getting trapped in local optima. This function is depicted in (Equations 68, 69).
Equations 68, 69 define functions and separately, representing the third function in exploitation and exploration stages over iterations signified by t. (Equation 54) specifies that if a stage is not chosen, the value of its corresponding third function increases by a parameter in each iteration; otherwise, it is set to zero. is a user-adjustable parameter ranging between 0 and 1, determining the likelihood of selecting a stage. A higher increases the chances of selecting the stage with a lower score and vice versa. (Equations 70, 71) compute the cost associated with changing stages.
Equations 70, 71 determine final costs for exploitation and exploration phases, with parameters a and d varying based on phase results, prioritizing diversity. (Equation 73) penalizes parameter a of the phase with higher cost, adjusting it linearly by 0.01. This approach, as discussed in (82), relies on , representing non-zero cost differences between exploitation and exploration phases (Equation 72).
In the exploration phase, inspired by the behavior of pumas searching for food, a random search is conducted within the territory. Pumas either explore new areas or approach other pumas to potentially share prey. Initially, the entire population is sorted in ascending order, and then each puma refines its solutions using (Equations 74, 75).
Equations 76, 77 involves randomly generating numbers within specified bounds and dimensions for problem-solving. Depending on certain conditions, one of two equations is selected to produce a new solution. This solution is then used to improve the current solution (Equations 78–81).
In the exploitation stage, the PO algorithm employs two operators inspired by puma behaviors: ambush hunting and sprinting. Pumas, in nature, typically ambush prey from concealed positions or chase them down in open spaces. (Equation 82) simulates the behavior of chasing prey, reflecting one of these hunting strategies.
Equation 82 in the PO algorithm embodies two strategies inspired by puma behaviors: fast running and ambush hunting. During exploitation, if a randomly generated number exceeds 0.5, the fast-running strategy is applied; otherwise, the ambush strategy is chosen. These strategies involve different movements towards prey, with various parameters and random factors influencing the process.
The Puma optimizer stands out for its higher implementation complexity compared to other optimizers due to its multiple phases and operations involved in creating intelligent systems. In each iteration, the cost function is applied only once for each search agent, ensuring acceptable computational complexity, as detailed in the relevant section.
AGWO, BES, GJO, and PO optimizers integrated with base models to supplement the efficacy of the selected models. As presented in Tables 3, 4, the fine tunned hyperparameters in the hybridization process for LGBC and XGBC are reported. For instance, the hyperparameters n_estimators, max_depth, and learning_rate are crucial for optimizing ensemble methods like Gradient Boosting Machines. n_estimators define the number of trees in the ensemble, with more trees generally improving performance but increasing computational cost and overfitting risk. max_depth limits the depth of each tree, balancing the ability to capture complex patterns with the risk of overfitting; deeper trees can capture more details but may overfit, while shallower trees might underfit. learning_rate, specific to boosting algorithms, scales the contribution of each tree, with lower rates enhancing robustness and preventing overfitting but requiring more iterations.
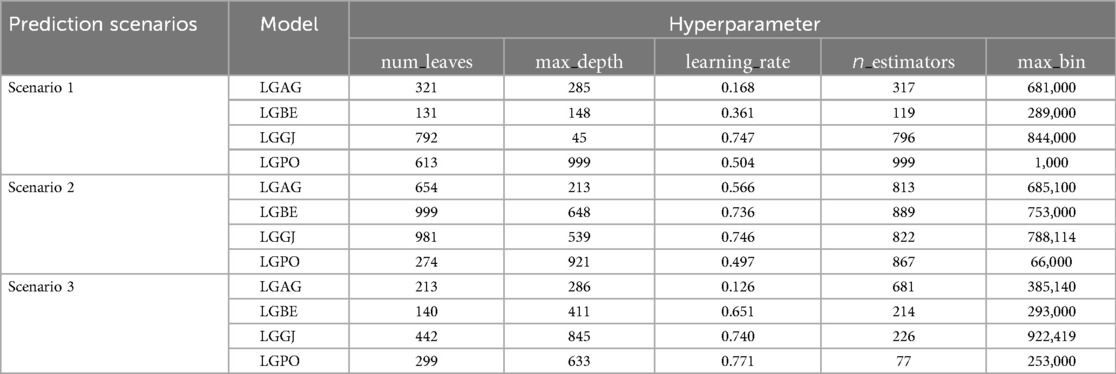
Table 3. The results of hyperparameters tunning in LGBC-based hybrid models development.
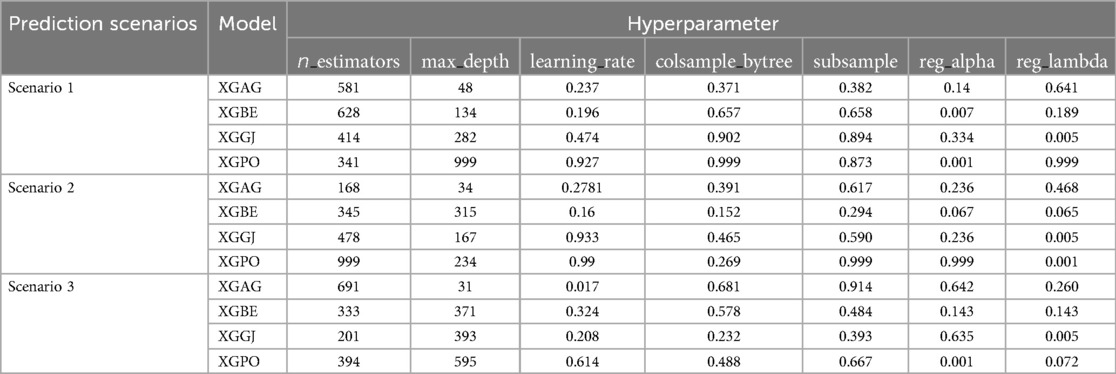
Table 4. The results of hyperparameters tunning in XGBC-based hybrid models development.
Furthermore, Figure 8 illustrates the convergence of hybrid models based on LGB across all three scenarios over 200 iterations. In the second scenario, the initial iterations for the hybrid models commence with a modest Accuracy of approximately 0.5, whereas in the third scenario, they begin with a higher Accuracy of around 0.6. Remarkably, the LGBE (S3) model achieves a remarkable accuracy of 0.97 within approximately 140 iterations. The convergence patterns of XGB-based hybrid models are depicted in Figure 9. Initially, the models display an accuracy of approximately 0.6. The XGBE (S3) model attains an Accuracy of nearly one after 125 iterations. Furthermore, the XGAG (S1) model achieves an Accuracy of 0.91 by the 110th iteration, indicating the weakest performance of features in scenario (1) in training hybrid models.
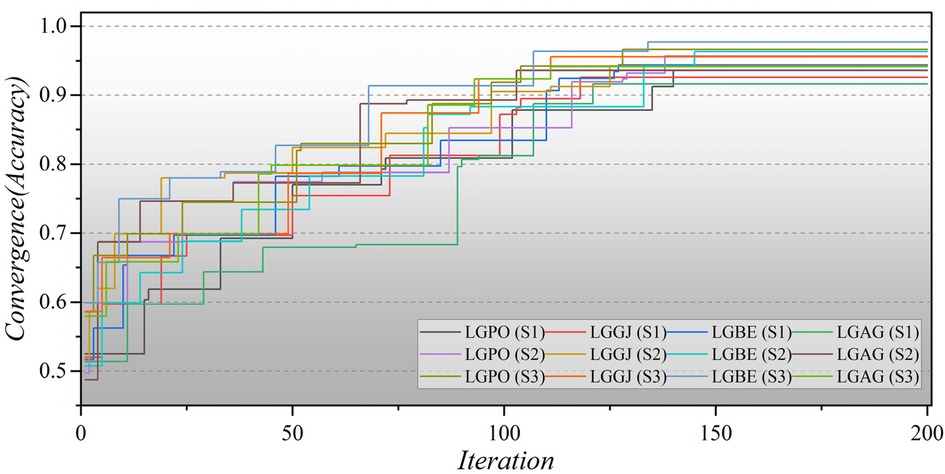
Figure 8. The convergence plot of LGB-based hybrid models in all three scenarios.
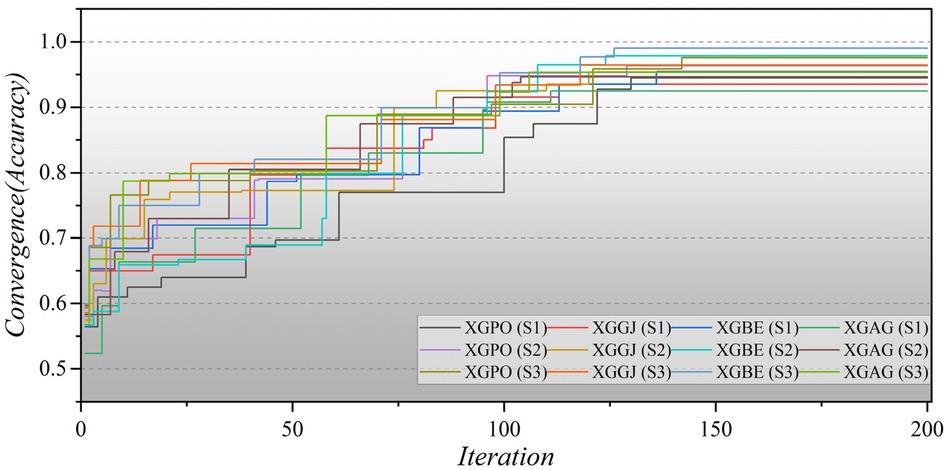
Figure 9. The convergence plot of XGB-based hybrid models in all three scenarios.
The importance of performance evaluation criteria in assessing ML algorithms is highlighted in the article, emphasizing the need to select metrics tailored to the specific problem. For comprehensive comparative analysis in classification tasks, widely recognized measures such as Accuracy, Precision, Recall, F1-Score, Correlation Coefficient (MCC), and Heidke Skill Score (HSS) are employed.
Accuracy serves as the primary metric for evaluating the accuracy of predictions. Precision, Recall, and F1-Score complement Accuracy, especially in scenarios with imbalanced data distributions. Precision measures the Accuracy of positive predictions, while Recall identifies all relevant instances within a class. The F1-Score combines both Precision and Recall to provide a balanced assessment. The MCC evaluates the reliability of binary classifications by considering true positives, true negatives, false positives, and false negatives. Higher MCC scores indicate more accurate predictions. MCC is particularly useful for assessing classifiers, especially in cases of unbalanced datasets, as it treats both positive and negative samples equally. These metrics, defined by (Equations 83–87):
represents the number of true positives, stands for the total of true negatives, indicates the number of false positives, and denotes the count of false negatives.
The HSS is a statistical metric devised by meteorologist Paul Heidke to evaluate the accuracy of categorical forecasts, primarily in meteorology (83). It involves comparing observed and forecasted categorical outcomes, taking into account hits, correct rejections, false alarms, and misses. The HSS formula provides a comprehensive assessment of predictive skills (Equation 88).
HSS is a metric used in meteorology to assess the accuracy of categorical weather forecasts. It compares observed and forecasted events. A score of 1 indicates perfect agreement, and 0 suggests performance equivalent to random chance.
The results are presented across three scenarios. In the first scenario, the GRACE Scale was applied, incorporating four parameters: HR, Age, SBP, and Killip Class, which are traditionally employed in hospitals (84). Table 5 provides a comprehensive comparison of performance metrics, encompassing Accuracy, Precision, Recall, F1-Score, MCC, and HSS, for the LGBM model alongside its hybrid models (LGAG, LGBE, LGGJ, and LGPO) and the XGBC model with its hybrid versions (XGAG, XGBE, XGGJ, and XGPO) across scenario (1) during both training and testing phases and for all data. Especially, the XGBE model displayed remarkable performance, achieving an Accuracy of 0.954, outperforming other models. Close behind, the LGBE and XGPO models each attained an Accuracy of 0.944. Particular significance was the superior performance demonstrated by the BES optimizer.
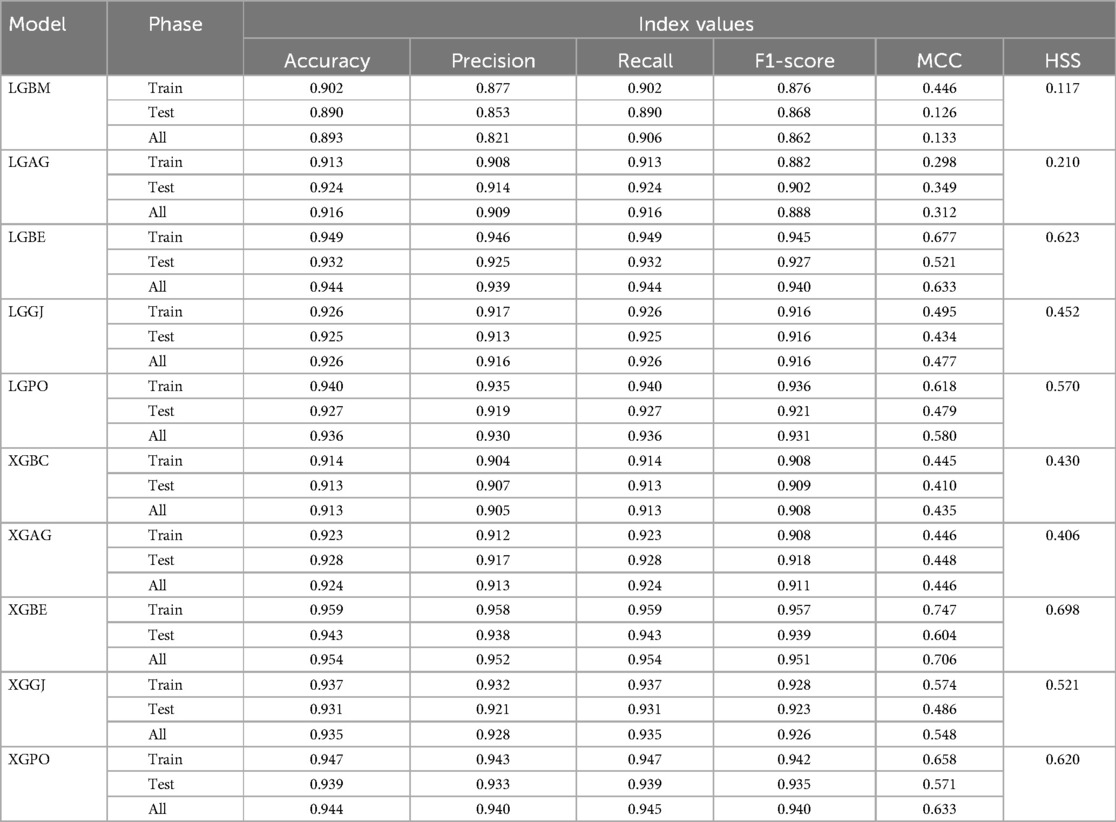
Table 5. Estimation metrics results for models’ prediction performance based on scenario (1).
In the second scenario, the features selected by SHAP were used, which included ten parameters for the LGBM model and 13 parameters for the XGBC model. Table 6 presents the results of evaluation metrics for the two mentioned single models and their hybrid versions based on scenario (2). The LGBM model was characterized by its relatively lower performance, evidenced by an Accuracy score of 0.921. Conversely, the LGBE model emerged as a standout performer within the domain of LGBM hybrid models, showing notable efficacy with an Accuracy score of 0.963. Especially, the XGBC model displayed the highest level of performance, boasting an impressive Accuracy value of 0.978, thereby establishing itself as the benchmark against which all other models are measured.
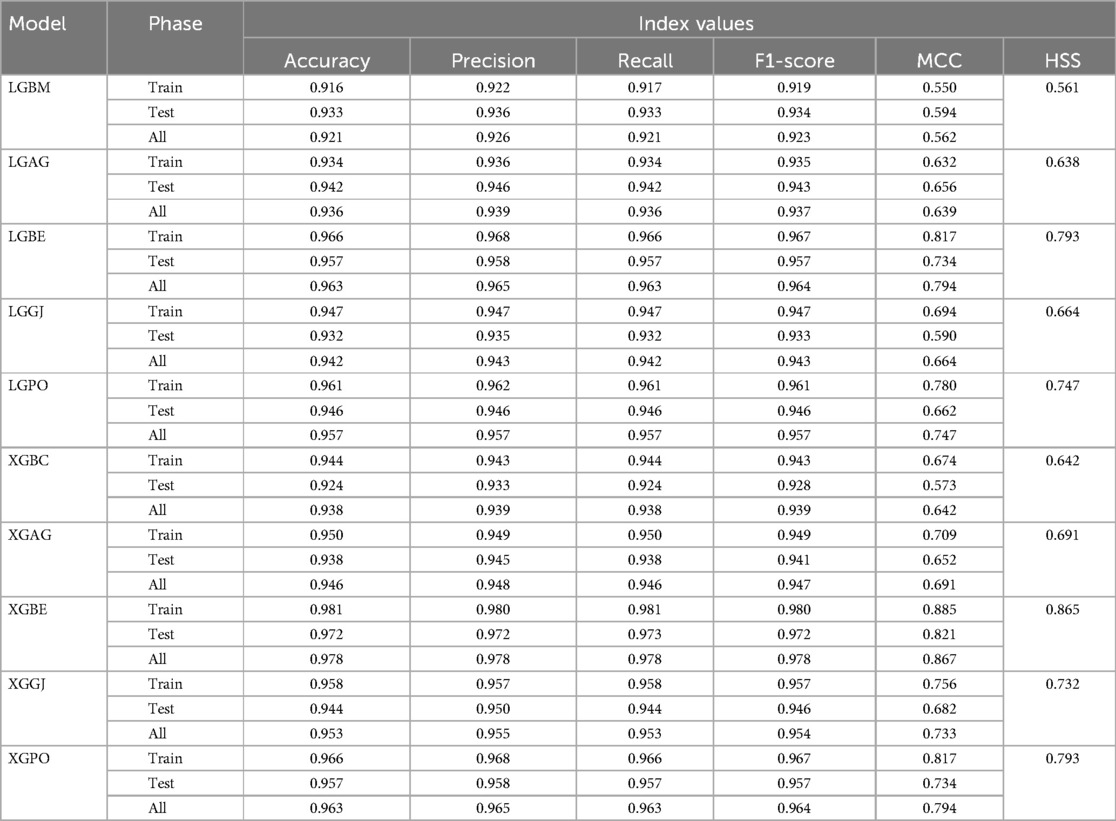
Table 6. Estimation metrics results for models’ prediction performance based on scenario (2).
The features selected by RFE were applied in the third scenario, comprising six features in the LGBM-based models and eight features in the XGBC-based model. According to Table 7, the XGBE model was the peak performer, boasting an exceptional Accuracy score of 0.990. Following closely, the LGBE model secured the second position with a commendable Accuracy of 0.977, while the XGPO model secured the third rank with an Accuracy score of 0.975. In contrast, the LGBM simple model presented the least impressive performance among the models under analysis.
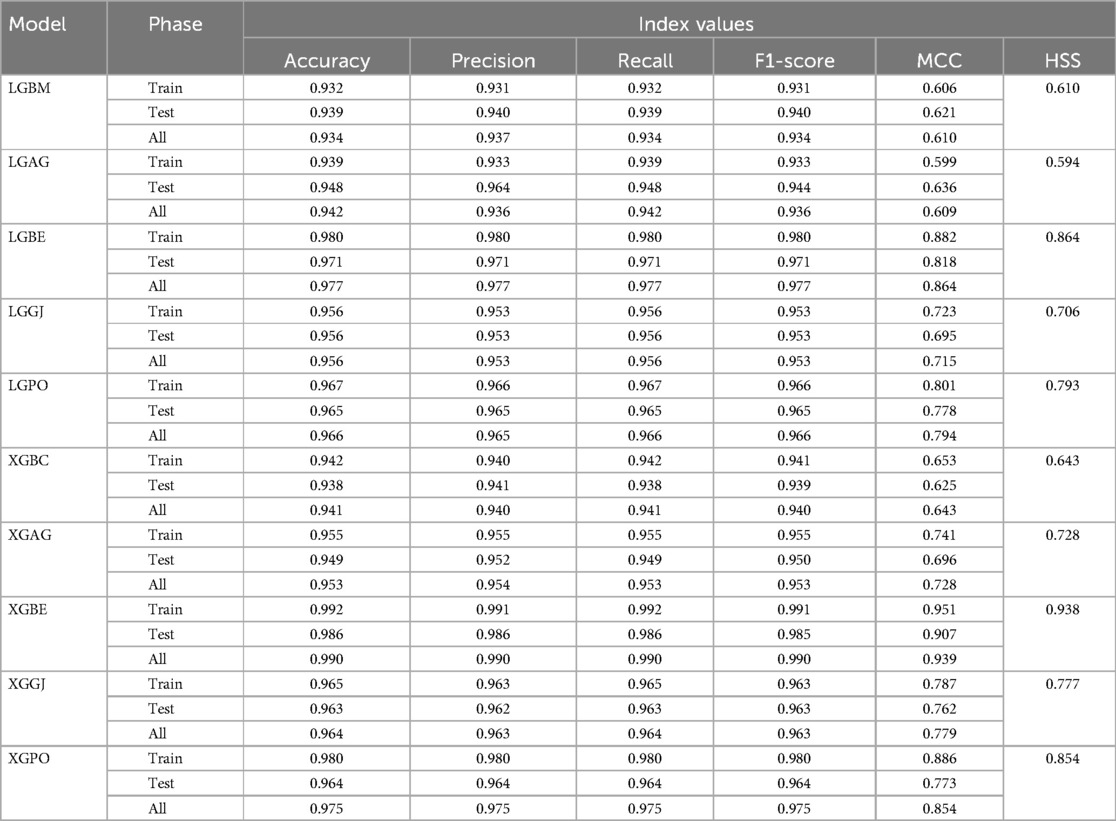
Table 7. Estimation metrics results for models’ prediction performance based on scenario (3).
In general, based on the comparative representations presented in Figures 10–14, it is evident that the models from the third scenario outperform those from the first and second scenarios according to the metrics of Accuracy, Precision, Recall, F1-Score, and MCC.
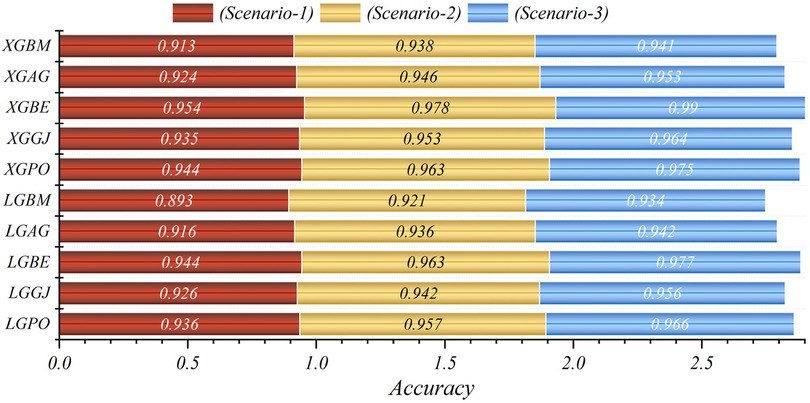
Figure 10. Graphical comparison of accuracy metric for the three scenarios in prediction models.
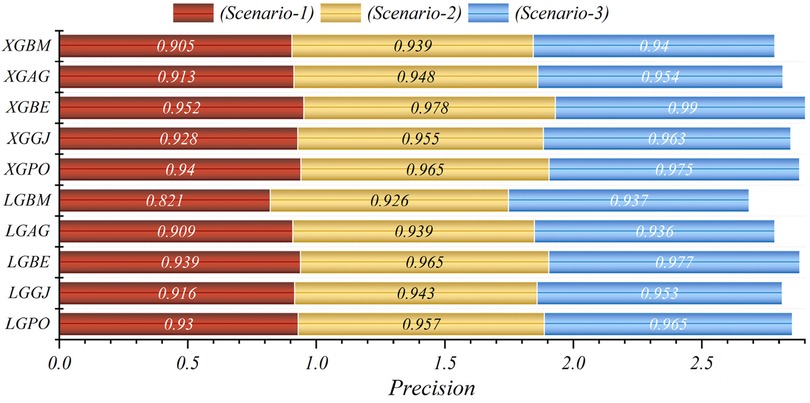
Figure 11. Graphical comparison of precision metric for the three scenarios in prediction models.
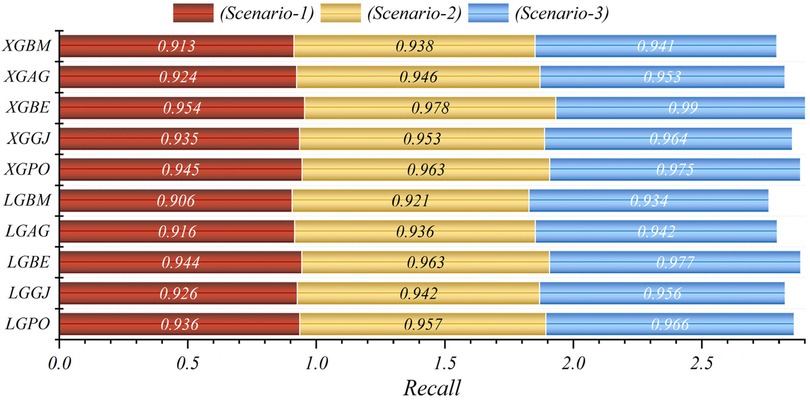
Figure 12. Graphical comparison of recall metric for the three scenarios in prediction models.
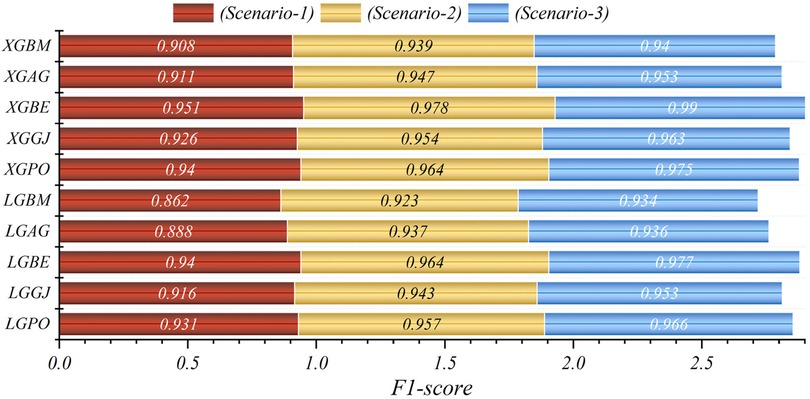
Figure 13. Graphical comparison of F1-score metric for the three scenarios in prediction models.

Figure 14. Graphical comparison of MCC metric for the three scenarios in prediction models.
Table 8 displays the evaluation criteria values used to assess the effectiveness of the models in distinguishing between the Alive and Die classes for the first scenario, while Tables 9, 10 present these metric values for the second and third scenarios, respectively.
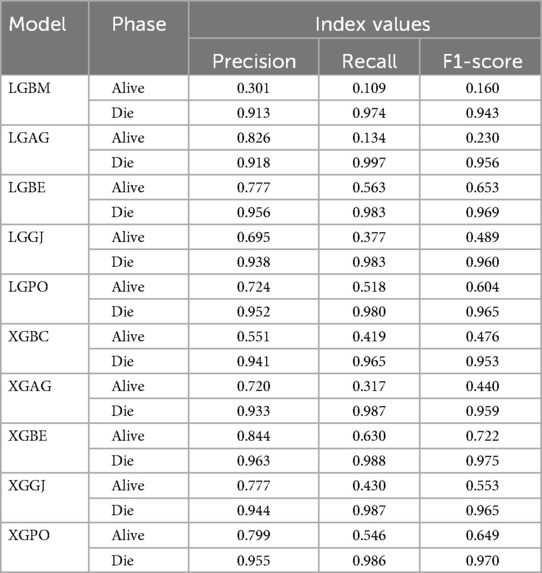
Table 8. The results of the evaluation criteria for assessing the effectiveness of the constructed models in classifying patients in scenario (1).
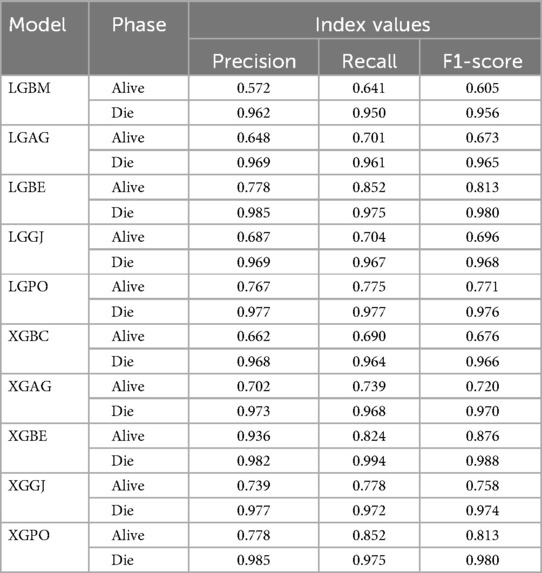
Table 9. The results of the evaluation criteria for assessing the effectiveness of the constructed models in classifying patients in scenario (2).
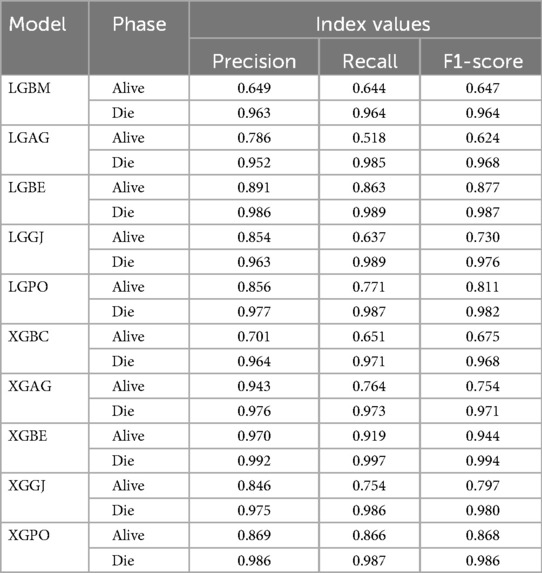
Table 10. The results of the evaluation criteria for assessing the effectiveness of the constructed models in classifying patients in scenario (3).
In all three scenarios, the models demonstrated higher accuracy in predicting and classifying patients in the Die class compared to the Alive class. Comparing the performance of the models in the Alive class in the first scenario, the XGBE model displayed superior performance with a Precision of 0.844, representing a 12.36% decrease compared to its Precision in the Die class. Conversely, the LGBE model outperformed the LGPO model with a Precision of 0.777. Moving to the second and third scenarios, the XGBE model achieved Precision values of 0.936 and 0.970, respectively, showing improved performance by 9.83% and 12.99% compared to the first scenario. Furthermore, the LGBE model maintains consistent performance in the second scenario, with a marginal difference of 0.13%, while in the third scenario, it demonstrated superior performance with a 12.79% increase.
In the first scenario, the XGBE model achieved the maximum performance in the Die class with a Precision of 0.963, while the LGBE, XGPO, and LGPO models displayed nearly identical performance in this class, with Precision values of 0.956, 0.955, and 0.952, respectively. Moving to the second scenario, the XGPO model demonstrated superior performance in classifying patients in the Die class with a Precision of 0.985, while the XGBE model ranked third with a slight difference of 0.31%. Lastly, in the third scenario, the XGBE model surpassed all others with an impressive Precision of 0.992 in the Die class, securing the top position. The LGBE model followed closely behind with a Precision of 0.986, earning the second rank.
Figure 15 presents a visual comparison of the models introduced in this research across scenarios (1), (2), and (3), using Precision, Recall, and F1-score metrics. In the LGBM and XGBC basic models, the Recall values are lower than those of other hybrid models in the Alive class, with values of 0.109 and 0.419 for the first scenario, 0.641 and 0.690 for the second scenario, and 0.644 and 0.651 for the third scenario, respectively. The lowest Recall value is attributed to the LGBM model in scenario (1) for the classification of Alive patients, while the highest value is recorded for the XGBE model in the third scenario and LGAG in the first scenario in the Die class, both with a value of 0.997.
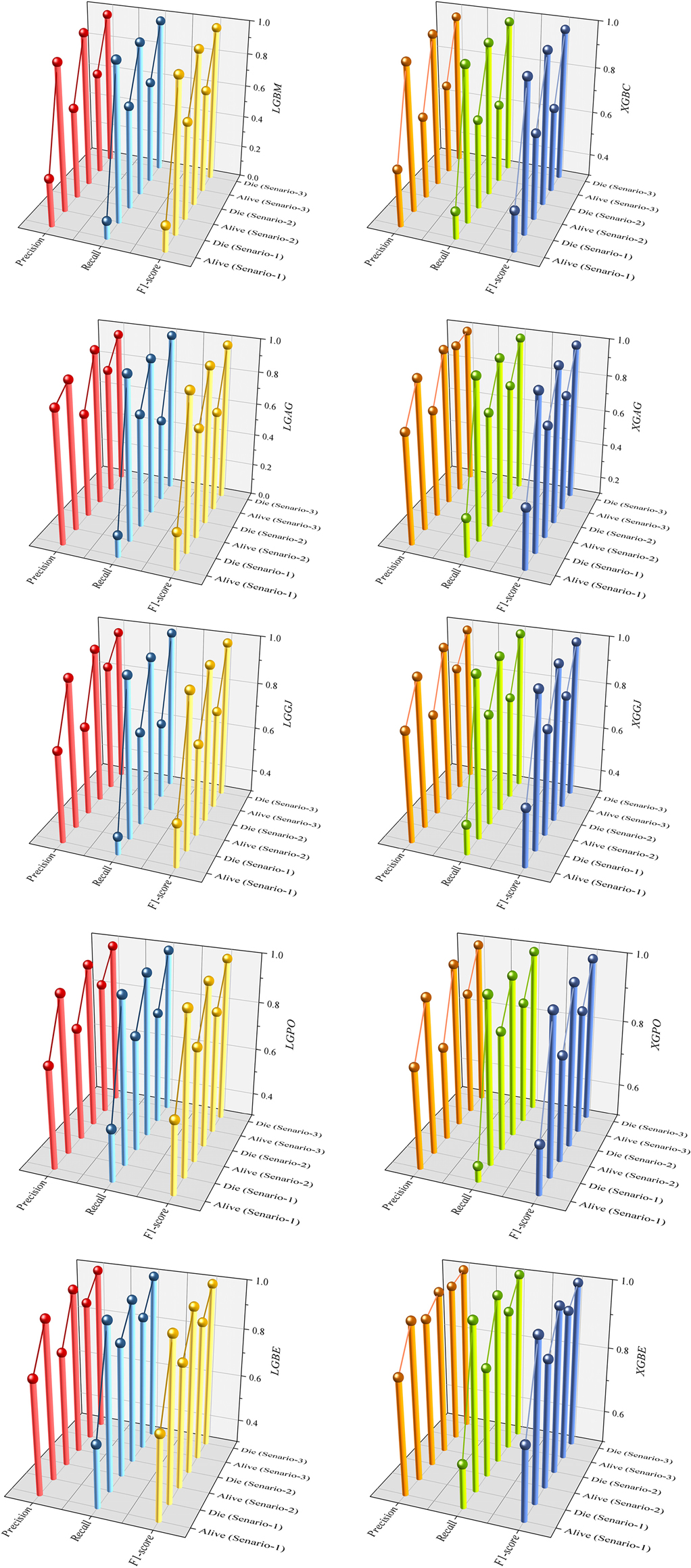
Figure 15. Comparative visual display of evaluation metrics for models across three scenarios in the Die and alive classes.
Figure 16 displays the confusion matrix depicting the classification performance in scenario (1), using the four features introduced by the GRACE Scale. This visual representation offers insights into the model's classification outcomes across various diagnostic categories. The LGBM model showed the highest error rate in misclassifying individuals from the Alive class into the Die group, with 253 patients misclassified. Following closely, the LGAG model ranked next, committing a similar error with 246 misclassified patients. Conversely, the LGAG model demonstrated the lowest error rate, misclassifying only eight deceased patients into the Alive class.
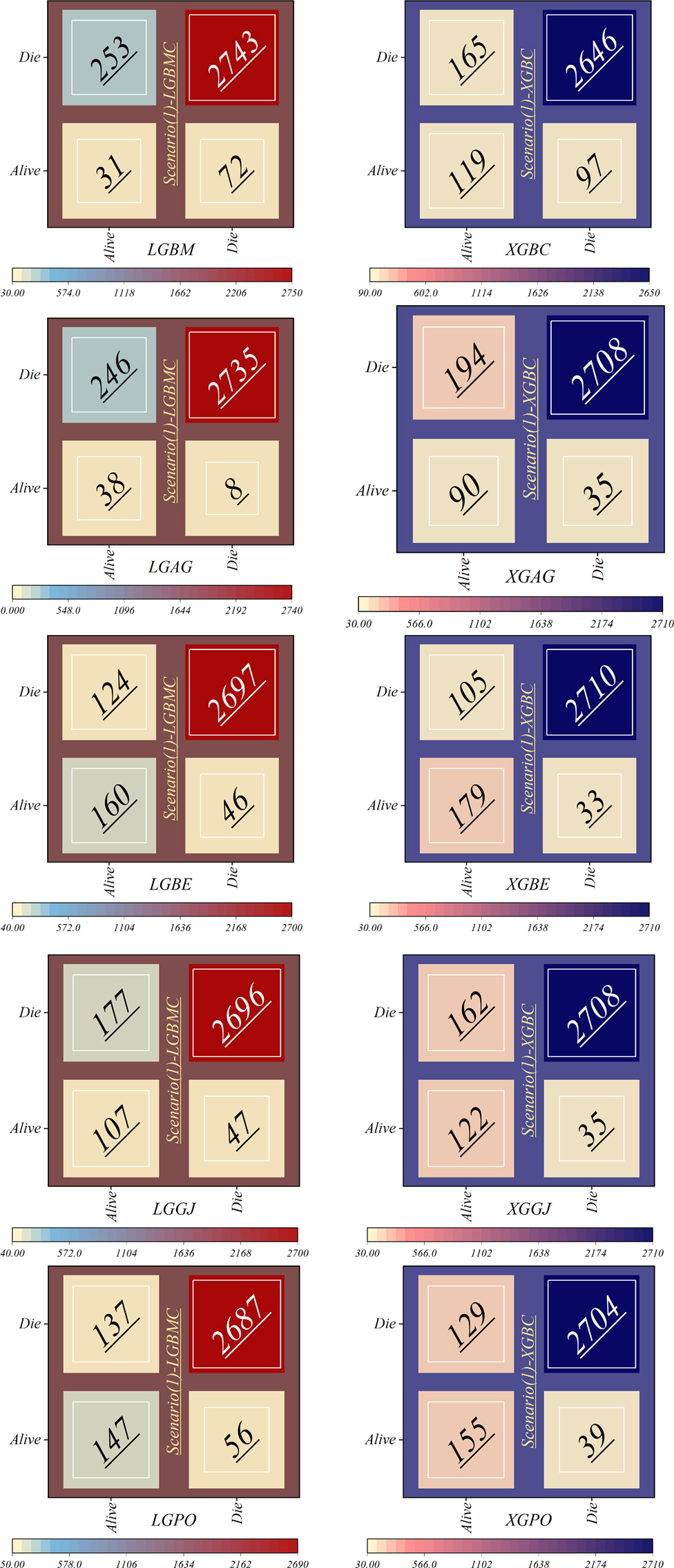
Figure 16. Confusion matrices depicting the accuracy of individual models within scenario (1).
Additionally, the XGBC model incorrectly classified 97 dead patients into the Alive group. In contrast, the LGBE model showcased superior performance compared to other hybrid models based on LGBM, with 124 and 46 misclassifications in the Alive and Die classes, respectively. Similarly, the XGBE model exhibited the lowest misclassification rate compared to other XGBC-based hybrid models.
Figure 17 depicts the correct and incorrect classification results of the models based on scenario (2), while Figure 18 represents those based on scenario (3). In the second scenario, SHAP was employed to identify effective features in modeling, whereas the third scenario employed RFE, resulting in an obvious increase in model accuracy. In scenario (2), as illustrated in Figure 17, the LGBM model continued to display the highest misclassification rate in the Alive class, speciously placing 102 patients in the Die class; however, it had enhanced its performance by 59.68% in correctly classifying the group of living patients. Conversely, the LGBE and XGPO models demonstrated the lowest errors in classifying living patients, misclassifying only 42 patients while correctly classifying 242 patients. The XGBE model excelled in classifying dead individuals, accurately classifying 2,727 patients while misclassifying only 16 patients.
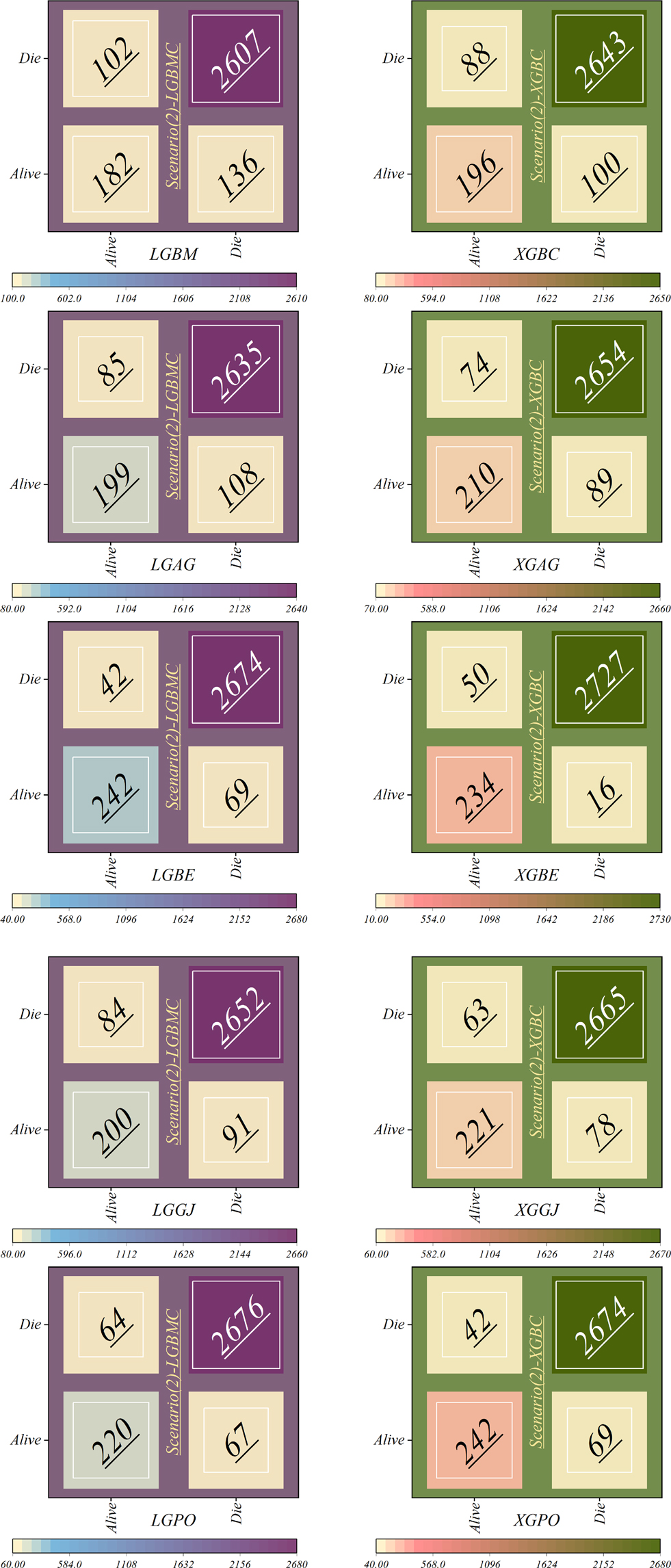
Figure 17. Confusion matrices depicting the accuracy of individual models within scenario (2).
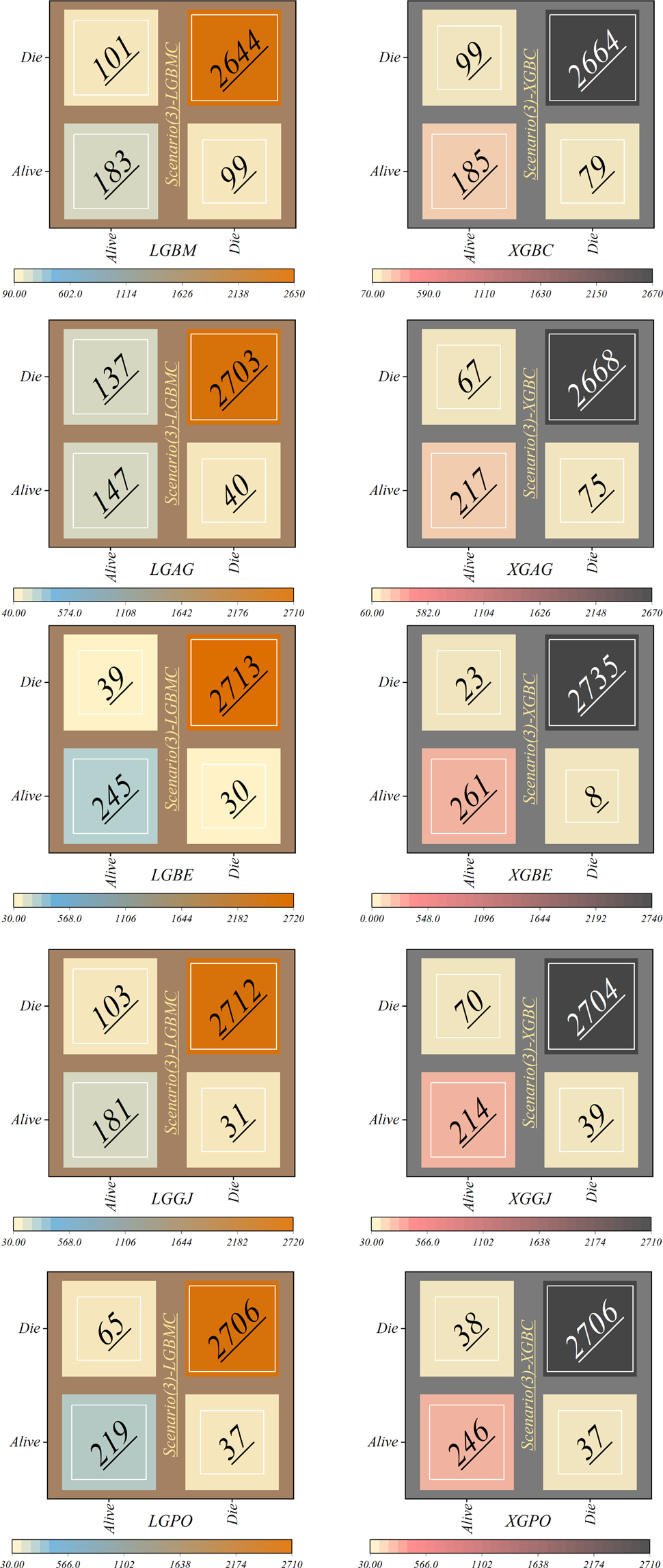
Figure 18. Confusion matrices depicting the accuracy of individual models within scenario (3).
In scenario (3), as delineated in Figure 18, notable discrepancies appear in the classification of alive patients. Specifically, the LGAG model shows a significant degree of error, misclassifying 137 patients. Similarly, the LGBM model demonstrates a considerable level of misclassification, with 99 patients incorrectly assigned to the Alive class. Contrarily, the XGBE model displays admirable performance, achieving 261 correct classifications and 23 misclassifications within the Alive group. Impressively, the XGBE model makes minimum errors, with only eight deceased patients erroneously categorized as Alive.
In general, the models in scenario (1) show the weakest performance, while the highest performance is observed in the third scenario. The application of scenario (1) in hospitals entails a high risk, as it relies only on four features: HR, Age, SBP, and Killip Class. Conversely, in scenario (2), the models employ ten features for LGBM and 13 features for XGB, leading to significantly higher accuracy compared to predictions based on the GRACE score. In scenario (3), the efficiency of the models surpasses that of scenarios (1) and 2 despite using fewer features 6 for the LGBM model and 8 for the XGB model. It is noteworthy that despite the reduced number of parameters, higher accuracy has been achieved. Upon comparing the two models, it can be concluded that the XGBE model offered the highest accuracy with eight features. This level of accuracy allows hospitals and healthcare professionals to predict the probability of survival more accurately, thereby reducing in-hospital mortality rates and tailoring treatments accordingly.
On the other hand, scenario (3) demanded a diminished set of parameters in comparison to scenario (2), thereby reducing the time required for testing. Such efficiency is particularly admirable in the context of patients’ serious conditions, where timely intervention is paramount. Moreover, the efficient testing regimen of scenario three not only hastens decision-making but also mitigates financial burdens. The decreased number of requisite tests translates to lower costs incurred by both patients and healthcare facilities, emphasizing the compelling value proposition of the model's heightened accuracy.
Figures 19, 20 depict HSS values for models based on LGBM and XGBC, respectively, to assess the accuracy of the predictions. In Figure 19, the mean HSS value for the third scenario approximates 0.7, while for the second scenario, it is around 0.65. Notably, the overall mean HSS value for the first scenario is approximately 0.4. This delineates that in scenario (1), the predictive accuracy stands at roughly 40%, which deviates from acceptable performance standards. Conversely, as depicted in Figure 20, the mean HSS value is about 0.5, highlighting the models’ lack of precision in scenario one concerning patient prediction and classification accuracy. Moreover, the mean HSS value for XGBC-based models in scenarios (2) and (3) averages approximately 0.67 and 0.71, respectively. Collectively, these findings prove the superior performance of models in scenario (3), revealing their exceptional forecasting capabilities and optimal operational efficiency.
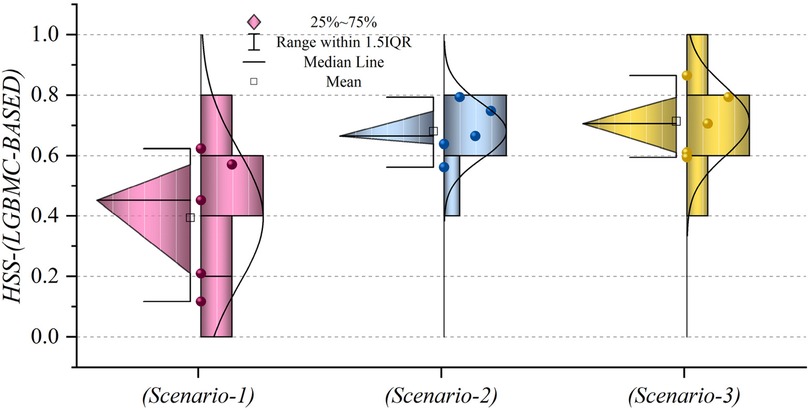
Figure 19. The chart illustrates the HSS values of LGBM models across three scenarios.
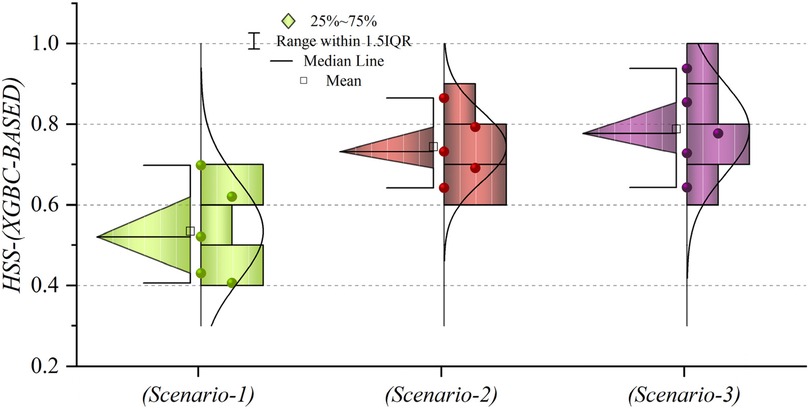
Figure 20. The chart illustrates the HSS values of XGBC models across three scenarios.
In this section, for comparing the Accuracy of predictions conducted by the best developed model (XGBE in the third scenario) in the study by those models in existing literature, the metric results are reported in Table 11. The results reveal that the Accuracy, Precision, and F1-score of the XGBE were 3% to 5% higher than the developed Catboost in the previous study.

Table 11. Comparison results between the accuracy of the best developed model with models in existing literature.
Cardiovascular disease presents a significant global health challenge, especially in low-income countries, contributing to increased mortality rates. Myocardial infarction (MI) arises from reduced blood flow to the heart, leading to tissue damage and symptoms like chest pain and shortness of breath. Effective management of ST-segment elevation myocardial infarction (STEMI) was critical, with early reperfusion therapy, particularly through percutaneous coronary intervention (PCI), prioritized for optimal care. This study employed advanced machine learning (ML) techniques to investigate risk factors influencing in-hospital mortality (IHM) in MI patients following PCI. Many ML classifiers, such as Extreme Gradient Boosting (XGB), Light Gradient Boosting (LGB), Stochastic Gradient Boosting (SGB), and Histogram Gradient Boosting (HGB), were used, and Monte Carlo cross-validation (MCCV) assisted in selecting top-performing models. Three scenarios were designed to evaluate forecast accuracy, one of which (scenario 1) was based on the traditional GRACE scaling system which can be calculated using online calculators available on medical websites or through electronic health record systems. The objective of this study was to provide insights to improve risk assessment and patient care strategies for MI patients undergoing PCI by using more imperative features of the patients rather than those utilized in traditional methods (GRACE score), which are extracted by feature selection methods. Additionally, meta-heuristic algorithms, including Gray Wolf Optimizer (AGWO), Bald Eagle Search Optimization (BES), Golden Jackal Optimizer (GJO), and Puma Optimizer (PO), were employed to enhance prediction accuracy.
In the evaluation of scenario (1) using the F1-Score standard, the LGBE and XGBE models demonstrated superior performance with values of 0.940 and 0.951, respectively. In the second scenario, these values increased to 0.964 and 0.978, indicating an improvement of 2.4% and 2.76% in model performance. Moreover, in scenario (3), these models showed further performance enhancements, with F1-score values increasing by 3.79% and 3.9%. The MCC value for the LGBE and XGBE models in the third scenario reached the highest level, with scores of 0.864 and 0.939, respectively. Despite scenario (1)'s reliance on only four features and its consequent weak performance, scenarios (2) and (3) demonstrate improved accuracy by applying more parameters. Especially, scenario (3) surpasses the others in efficiency despite employing fewer features, with the XGB model achieving the highest accuracy using eight features. This improved accuracy enables hospitals to predict survival probabilities more precisely, thereby reducing in-hospital mortality rates and permitting tailored treatments. Scenario (3)'s streamlined parameter testing process makes it the preferred choice, offering swift decision-making and cost reductions while ensuring accurate forecasts, particularly critical in serious patient conditions. Furthermore, the model constructed in this study can be integrated into clinical decision support systems, such as electronic health record (EHR) systems, to automatically provide risk scores when assessing STEMI patients, assisting doctors in considering the patient's IHM risk when choosing treatment strategies. Thus, a personalized treatment plan can be developed based on the patient's IHM risk level. For example, in high-risk patients, more proactive preventive treatment measures, such as early cardiac rehabilitation programs or intensified medication therapy, can be considered. At the same time, the predictive results of the model can serve as a basis for discussion among multidisciplinary teams, promoting communication and collaboration among medical personnel with different professional backgrounds, and jointly developing the best treatment plan for the patient.
The main limitation of this study is the single-center nature of the data source, which may limit the assessment of the model's generalizability. Additionally, although we have established an effective predictive model, we have not conducted detailed analyses on different patient subgroups, which may affect the model's applicability within specific subgroups. Future studies will address these limitations by collecting multicenter data and performing subgroup analyses to improve the model's generalizability and accuracy.
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author.
NT: Conceptualization, Writing – original draft, Data curation, Formal Analysis, Investigation, Methodology. SL: Data curation, Formal Analysis, Investigation, Writing – review & editing. KL: Data curation, Formal Analysis, Investigation, Writing – review & editing. QiaZ: Data curation, Formal Analysis, Investigation, Writing – review & editing. YD: Data curation, Formal Analysis, Investigation, Writing – review & editing. HS: Data curation, Formal Analysis, Funding acquisition, Investigation, Writing – review & editing. QinZ: Data curation, Formal Analysis, Investigation, Writing – review & editing. JH: Funding acquisition, Writing – review & editing. CQ: Funding acquisition, Writing – review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. This work was supported by the Xuzhou Medical University Affiliated Hospital of Science and Technology Development Excellent Talent Fund Project (Grant No. XYFY202249).
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcvm.2024.1419551/full#supplementary-material
1. Kelly BB, Narula J, Fuster V. Recognizing global burden of cardiovascular disease and related chronic diseases. Mt Sinai J Med. (2012) 79(6):632–40. doi: 10.1002/msj.21345
2. Wurie HR, Cappuccio FP. Cardiovascular disease in low- and middle-income countries: an urgent priority. Ethn Health. (2012) 17(6):543–50. doi: 10.1080/13557858.2012.778642
3. Roth GA, Huffman MD, Moran AE, Feigin V, Mensah GA, Naghavi M, et al. Global and regional patterns in cardiovascular mortality from 1990 to 2013. Circulation. (2015) 132(17):1667–78. doi: 10.1161/CIRCULATIONAHA.114.008720
4. Murphy A, Goldberg S. Mechanical complications of myocardial infarction. Am J Med. (2022) 135(12):1401–9. doi: 10.1016/j.amjmed.2022.08.017
5. Salari N, Morddarvanjoghi F, Abdolmaleki A, Rasoulpoor S, Khaleghi AA, Hezarkhani LA, et al. The global prevalence of myocardial infarction: a systematic review and meta-analysis. BMC Cardiovasc Disord. (2023) 23(1):206. doi: 10.1186/s12872-023-03231-w
6. Wei Q, Xiao Y, Du L, Li Y. Advances in nanoparticles in the prevention and treatment of myocardial infarction. Molecules. (2024) 29(11):2415. doi: 10.3390/molecules29112415
7. Ibanez B, James S, Agewall S, Antunes MJ, Bucciarelli-Ducci C, Bueno H, et al. 2017 ESC guidelines for the management of acute myocardial infarction in patients presenting with ST-segment elevation: the task force for the management of acute myocardial infarction in patients presenting with ST-segment elevation of the European Society of Cardiology (ESC). Eur Heart J. (2018) 39(2):119–77. doi: 10.1093/eurheartj/ehx393
8. Contessotto P, Spelat R, Ferro F, Vysockas V, Krivickienė A, Jin C, et al. Reproducing extracellular matrix adverse remodelling of non-ST myocardial infarction in a large animal model. Nat Commun. (2023) 14(1):995. doi: 10.1038/s41467-023-36350-1
9. Nazir S, Elgin E, Loynd R, Zaman M, Donato A. ST-elevation myocardial infarction associated with infective endocarditis. Am J Cardiol. (2019) 123(8):1239–43. doi: 10.1016/j.amjcard.2019.01.033
10. Mitsis A, Gragnano F. Myocardial infarction with and without ST-segment elevation: a contemporary reappraisal of similarities and differences. Curr Cardiol Rev. (2021) 17(4):e230421189013. doi: 10.2174/1573403X16999201210195702
11. Moroni F, Gurm HS, Gertz Z, Abbate A, Azzalini L. In-hospital death among patients undergoing percutaneous coronary intervention: a root-cause analysis. Cardiovasc Revasc Med. (2022) 40:8–13. doi: 10.1016/j.carrev.2022.01.021
12. Covino M, Fransvea P, Rosa F, Cozza V, Quero G, Simeoni B, et al. Early procalcitonin assessment in the emergency department in patients with intra-abdominal infection: an excess or a need? Surg Infect (Larchmt). (2021) 22(8):787–96. doi: 10.1089/sur.2020.373
13. Nazer R, Albarrati A, Ullah A, Alamro S, Kashour T. Intra-abdominal hypertension in obese patients undergoing coronary surgery: a prospective observational study. Surgery. (2019) 166(6):1128–34. doi: 10.1016/j.surg.2019.05.038
14. Dawson LP, Warren J, Mundisugih J, Nainani V, Chan W, Stub D, et al. Trends and clinical outcomes in patients undergoing primary percutaneous revascularisation for ST-elevation myocardial infarction: a single centre experience. Heart Lung Circ. (2018) 27(6):683–92. doi: 10.1016/j.hlc.2017.06.722
15. O'Rielly CM, Harrison TG, Andruchow JE, Ronksley PE, Sajobi T, Robertson HL, et al. Risk scores for clinical risk stratification of emergency department patients with chest pain but No acute myocardial infarction: a systematic review. Can J Cardiol. (2023) 39(3):304–10. doi: 10.1016/j.cjca.2022.12.028
16. Gerber Y, Weston SA, Enriquez-Sarano M, Jaffe AS, Manemann SM, Jiang R, et al. Contemporary risk stratification after myocardial infarction in the community: performance of scores and incremental value of soluble suppression of tumorigenicity-2. J Am Heart Assoc. (2017) 6(10):e005958. doi: 10.1161/JAHA.117.005958
17. Girwar SM, Jabroer R, Fiocco M, Sutch SP, Numans ME, Bruijnzeels MA. A systematic review of risk stratification tools internationally used in primary care settings. Health Sci Rep. (2021) 4(3):e329. doi: 10.1002/hsr2.329
18. Laurent A, Lheureux F, Genet M, Martin Delgado MC, Bocci MG, Prestifilippo A, et al. Scales used to measure job stressors in intensive care units: are they relevant and reliable? A systematic review. Front Psychol. (2020) 11:245. doi: 10.3389/fpsyg.2020.00245
19. Shuvy M, Beeri G, Klein E, Cohen T, Shlomo N, Minha S, et al. Accuracy of the global registry of acute coronary events (GRACE) risk score in contemporary treatment of patients with acute coronary syndrome. Can J Cardiol. (2018) 34(12):1613–7. doi: 10.1016/j.cjca.2018.09.015
20. Ciambrone G, Higa CC, Gambarte J, Novo F, Nogues I, Borracci RA. Continuous monitoring of coronary care mortality using the global registry for acute coronary events (GRACE) score. Crit Pathw Cardiol. (2020) 19(3):126–30. doi: 10.1097/HPC.0000000000000208
21. Chen J, Cazenave A, Dahle C, Llovel W, Panet I, Pfeffer J, et al. Applications and challenges of GRACE and GRACE follow-on satellite gravimetry. Surv Geophys. (2022) 43(1):305–45. doi: 10.1007/s10712-021-09685-x
22. Mitarai T, Tanabe Y, Akashi YJ, Maeda A, Ako J, Ikari Y, et al. A novel risk stratification system “angiographic GRACE score” for predicting in-hospital mortality of patients with acute myocardial infarction: data from the K-ACTIVE registry. J Cardiol. (2021) 77(2):179–85. doi: 10.1016/j.jjcc.2020.08.010
23. Bratić B, Kurbalija V, Ivanović M, Oder I, Bosnić Z. Machine learning for predicting cognitive diseases: methods, data sources and risk factors. J Med Syst. (2018) 42(12):243. doi: 10.1007/s10916-018-1071-x
24. Saberi-Karimian M, Khorasanchi Z, Ghazizadeh H, Tayefi M, Saffar S, Ferns GA, et al. Potential value and impact of data mining and machine learning in clinical diagnostics. Crit Rev Clin Lab Sci. (2021) 58(4):275–96. doi: 10.1080/10408363.2020.1857681
25. Aromolaran O, Aromolaran D, Isewon I, Oyelade J. Machine learning approach to gene essentiality prediction: a review. Brief Bioinform. (2021) 22(5):bbab128. doi: 10.1093/bib/bbab128
26. Subrahmanya SVG, Shetty DK, Patil V, Hameed BMZ, Paul R, Smriti K, et al. The role of data science in healthcare advancements: applications, benefits, and future prospects. Ir J Med Sci. (2022) 191(4):1473–83. doi: 10.1007/s11845-021-02730-z
27. Zhao J, Zhao P, Li C, Hou Y. Optimized machine learning models to predict in-hospital mortality for patients with ST-segment elevation myocardial infarction. Ther Clin Risk Manag. (2021) 17:951–61. doi: 10.2147/TCRM.S321799
28. Yang J, Li Y, Li X, Tao S, Zhang Y, Chen T, et al. A machine learning model for predicting in-hospital mortality in Chinese patients with ST-segment elevation myocardial infarction: findings from the China myocardial infarction registry. J Med Internet Res. (2024) 26:e50067. doi: 10.2196/50067
29. Deng L, Zhao X, Su X, Zhou M, Huang D, Zeng X. Machine learning to predict no reflow and in-hospital mortality in patients with ST-segment elevation myocardial infarction that underwent primary percutaneous coronary intervention. BMC Med Inform Decis Mak. (2022) 22(1):109. doi: 10.1186/s12911-022-01853-2
30. Falcão FJ, Alves CM, Barbosa AH, Caixeta A, Sousa JM, Souza JA, et al. Predictors of in-hospital mortality in patients with ST-segment elevation myocardial infarction undergoing pharmacoinvasive treatment. Clinics (Sao Paulo). (2013) 68(12):1516–20. doi: 10.6061/clinics/2013(12)07
31. Tanik VO, Cinar T, Arugaslan E, Karabag Y, Hayiroglu MI, Cagdas M, et al. The predictive value of PRECISE-DAPT score for in-hospital mortality in patients with ST-elevation myocardial infarction undergoing primary percutaneous coronary intervention. Angiology. (2019) 70(5):440–7. doi: 10.1177/0003319718807057
32. Bai Z, Lu J, Li T, Ma Y, Liu Z, Zhao R, et al. Clinical feature-based machine learning model for 1-year mortality risk prediction of ST-segment elevation myocardial infarction in patients with hyperuricemia: a retrospective study. Comput Math Methods Med. (2021) 2021:7252280. doi: 10.1155/2021/7252280
33. Li YM, Jiang LC, He JJ, Jia KY, Peng Y, Chen M. Machine learning to predict the 1-year mortality rate after acute anterior myocardial infarction in Chinese patients. Ther Clin Risk Manag. (2020) 16:1–6. doi: 10.2147/TCRM.S236498
34. Wojciechowski S, Majchrzak-Górecka M, Biernat P, Odrzywołek K, Pruss Ł, Zych K, et al. Machine learning on the road to unlocking microbiota’s potential for boosting immune checkpoint therapy. Int J Med Microbiol. (2022) 312(7):151560. doi: 10.1016/j.ijmm.2022.151560
35. Li S, Song S, Huang G. Prediction reweighting for domain adaptation. IEEE Trans Neural Netw Learn Syst. (2017) 28(7):1682–95. doi: 10.1109/TNNLS.2016.2538282
36. Li Y, Li M, Li C, Liu Z. Forest aboveground biomass estimation using landsat 8 and sentinel-1A data with machine learning algorithms. Sci Rep. (2020) 10(1):9952. doi: 10.1038/s41598-020-67024-3
37. Kobayashi Y, Yoshida K. Quantitative structure-property relationships for the calculation of the soil adsorption coefficient using machine learning algorithms with calculated chemical properties from open-source software. Environ Res. (2021) 196:110363. doi: 10.1016/j.envres.2020.110363
38. Anjum M, Khan K, Ahmad W, Ahmad A, Amin MN, Nafees A. New SHapley additive ExPlanations (SHAP) approach to evaluate the raw materials interactions of steel-fiber-reinforced concrete. Materials (Basel). (2022) 15(18):6261. doi: 10.3390/ma15186261
39. Hu X, Yin S, Zhang X, Menon C, Fang C, Chen Z, et al. Blood pressure stratification using photoplethysmography and light gradient boosting machine. Front Physiol. (2023) 14:1072273. doi: 10.3389/fphys.2023.1072273
40. Liao H, Zhang X, Zhao C, Chen Y, Zeng X, Li H. LightGBM: an efficient and accurate method for predicting pregnancy diseases. J Obstet Gynaecol. (2022) 42(4):620–9. doi: 10.1080/01443615.2021.1945006
41. Nematollahi MA, Jahangiri S, Asadollahi A, Salimi M, Dehghan A, Mashayekh M, et al. Body composition predicts hypertension using machine learning methods: a cohort study. Sci Rep. (2023) 13(1):6885. doi: 10.1038/s41598-023-34127-6
42. Xue T, Zhu T, Peng W, Guan T, Zhang S, Zheng Y, et al. Clean air actions in China, PM2.5 exposure, and household medical expenditures: a quasi-experimental study. PLoS Med. (2021) 18(1):e1003480. doi: 10.1371/journal.pmed.1003480
43. Huo S, Nelde A, Meisel C, Scheibe F, Meisel A, Endres M, et al. A supervised, externally validated machine learning model for artifact and drainage detection in high-resolution intracranial pressure monitoring data. J Neurosurg. (2024) 141(2):509–17. doi: 10.3171/2023.12.JNS231670
44. Su X, Bai M. Stochastic gradient boosting frequency-severity model of insurance claims. PLoS One. (2020) 15(8):e0238000. doi: 10.1371/journal.pone.0238000
45. Nakapraves S, Warzecha M, Mustoe CL, Srirambhatla V, Florence AJ. Prediction of mefenamic acid crystal shape by random forest classification. Pharm Res. (2022) 39(12):3099–111. doi: 10.1007/s11095-022-03450-4
46. Willis L, Lee E, Reynolds KJ, Klik KA. The theory of planned behavior and the social identity approach: a new look at group processes and social norms in the context of student binge drinking. Eur J Psychol. (2020) 16(3):357–83. doi: 10.5964/ejop.v16i3.1900
47. GBD 2015 Disease and Injury Incidence and Prevalence Collaborators. Global, regional, and national incidence, prevalence, and years lived with disability for 310 diseases and injuries, 1990–2015: a systematic analysis for the global burden of disease study 2015. Lancet. (2016) 388(10053):1545–602. doi: 10.1016/S0140-6736(16)31678-6
48. Ranalli MG, Salvati N, Petrella L, Pantalone F. M-quantile regression shrinkage and selection via the lasso and elastic net to assess the effect of meteorology and traffic on air quality. Biom J. (2023) 65(8):e2100355. doi: 10.1002/bimj.202100355
49. Li L, Feng CX, Qiu S. Estimating cross-validatory predictive p-values with integrated importance sampling for disease mapping models. Stat Med. (2017) 36(14):2220–36. doi: 10.1002/sim.7278
50. Bell G. Fluctuating selection: the perpetual renewal of adaptation in variable environments. Philos Trans R Soc Lond B Biol Sci. (2010) 365(1537):87–97. doi: 10.1098/rstb.2009.0150
51. Heard NA, Holmes CC, Stephens DA, Hand DJ, Dimopoulos G. Bayesian coclustering of anopheles gene expression time series: study of immune defense response to multiple experimental challenges. Proc Natl Acad Sci U S A. (2005) 102(47):16939–44. doi: 10.1073/pnas.0408393102
52. Shan G. Monte carlo cross-validation for a study with binary outcome and limited sample size. BMC Med Inform Decis Mak. (2022) 22(1):270. doi: 10.1186/s12911-022-02016-z
53. Li L, Chow SC, Smith W. Cross-validation for linear model with unequal variances in genomic analysis. J Biopharm Stat. (2004) 14(3):723–39. doi: 10.1081/BIP-200025679
54. Cao Y, Lin H, Wu TZ, Yu Y. Penalized spline estimation for functional coefficient regression models. Comput Stat Data Anal. (2010) 54(4):891–905. doi: 10.1016/j.csda.2009.09.036
55. Slade E, Naylor MG. A fair comparison of tree-based and parametric methods in multiple imputation by chained equations. Stat Med. (2020) 39(8):1156–66. doi: 10.1002/sim.8468
56. Meyers RL, Maibach R, Hiyama E, Häberle B, Krailo M, Rangaswami A, et al. Risk-stratified staging in paediatric hepatoblastoma: a unified analysis from the children’s hepatic tumors international collaboration. Lancet Oncol. (2017) 18(1):122–31. doi: 10.1016/S1470-2045(16)30598-8
57. Bloch L, Friedrich CM, Alzheimer’s Disease Neuroimaging Initiative. Data analysis with shapley values for automatic subject selection in Alzheimer’s disease data sets using interpretable machine learning. Alzheimers Res Ther. (2021) 13(1):155. doi: 10.1186/s13195-021-00879-4
58. Kim D, Handayani MP, Lee S, Lee J. Feature attribution analysis to quantify the impact of oceanographic and maneuverability factors on vessel shaft power using explainable tree-based model. Sensors (Basel). (2023) 23(3):1072. doi: 10.3390/s23031072
59. Yi F, Yang H, Chen D, Qin Y, Han H, Cui J, et al. XGBoost-SHAP-based interpretable diagnostic framework for Alzheimer’s disease. BMC Med Inform Decis Mak. (2023) 23(1):137. doi: 10.1186/s12911-023-02238-9
60. Darst BF, Malecki KC, Engelman CD. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. (2018) 19(Suppl 1):65. doi: 10.1186/s12863-018-0633-8
61. Alanni R, Hou J, Azzawi H, Xiang Y. A novel gene selection algorithm for cancer classification using microarray datasets. BMC Med Genomics. (2019) 12(1):10. doi: 10.1186/s12920-018-0447-6
62. Arruda-Olson AM, Reeder GS, Bell MR, Weston SA, Roger VL. Neutrophilia predicts death and heart failure after myocardial infarction: a community-based study. Circ Cardiovasc Qual Outcomes. (2009) 2(6):656–62. doi: 10.1161/CIRCOUTCOMES.108.831024
63. Han YC, Yang TH, Kim DI, Jin HY, Chung SR, Seo JS, et al. Neutrophil to lymphocyte ratio predicts long-term clinical outcomes in patients with ST-segment elevation myocardial infarction undergoing primary percutaneous coronary intervention. Korean Circ J. (2013) 43(2):93–9. doi: 10.4070/kcj.2013.43.2.93
64. Shin HC, Jang JS, Jin HY, Seo JS, Yang TH, Kim DK, et al. Combined use of neutrophil to lymphocyte ratio and C-reactive protein level to predict clinical outcomes in acute myocardial infarction patients undergoing percutaneous coronary intervention. Korean Circ J. (2017) 47(3):383–91. doi: 10.4070/kcj.2016.0327
65. Mhurchu CN, Rodgers A, Pan WH, Gu DF, Woodward M, Asia Pacific Cohort Studies Collaboration. Body mass index and cardiovascular disease in the Asia-pacific region: an overview of 33 cohorts involving 310000 participants. Int J Epidemiol. (2004) 33(4):751–8. doi: 10.1093/ije/dyh163
66. Mehta L, Devlin W, McCullough PA, O'Neill WW, Skelding KA, Stone GW, et al. Impact of body mass index on outcomes after percutaneous coronary intervention in patients with acute myocardial infarction. Am J Cardiol. (2007) 99(7):906–10. doi: 10.1016/j.amjcard.2006.11.038
67. Bucholz EM, Rathore SS, Reid KJ, Jones PG, Chan PS, Rich MW, et al. Body mass index and mortality in acute myocardial infarction patients. Am J Med. (2012) 125(8):796–803. doi: 10.1016/j.amjmed.2012.01.018
68. Saberi S, Rezaie B. Robust adaptive direct speed control of PMSG-based airborne wind energy system using FCS-MPC method. ISA Trans. (2022) 131:43–60. doi: 10.1016/j.isatra.2022.04.035
69. Premkumar M, Sinha G, Ramasamy MD, Sahu S, Subramanyam CB, Sowmya R, et al. Augmented weighted K-means grey wolf optimizer: an enhanced metaheuristic algorithm for data clustering problems. Sci Rep. (2024) 14(1):5434. doi: 10.1038/s41598-024-55619-z
70. Abou El Ela AA, El-Sehiemy RA, Shaheen AM, Shalaby AS, Mouafi MT. Reliability constrained dynamic generation expansion planning using honey badger algorithm. Sci Rep. (2023) 13(1):16765. doi: 10.1038/s41598-023-43622-9
71. Lakshmi GVN, Jayalaxmi A, Veeramsetty V. Optimal placement of distributed generation based on DISCO’s financial benefit with loss and emission reduction using hybrid Jaya-Red Deer optimizer. Electr Eng (Berl). (2023) 105(2):965–77. doi: 10.1007/s00202-022-01709-y
72. Sayed GI, Soliman MM, Hassanien AE. A novel melanoma prediction model for imbalanced data using optimized SqueezeNet by bald eagle search optimization. Comput Biol Med. (2021) 136:104712. doi: 10.1016/j.compbiomed.2021.104712
73. Wang Z, Mo Y, Cui M, Hu J, Lyu Y. An improved golden jackal optimization for multilevel thresholding image segmentation. PLoS One. (2023) 18(5):e0285211. doi: 10.1371/journal.pone.0285211
74. Liu W, Liu T, Liu Z, Luo H, Pei H. A novel deep learning ensemble model based on two-stage feature selection and intelligent optimization for water quality prediction. Environ Res. (2023) 224:115560. doi: 10.1016/j.envres.2023.115560
75. Jiang S, Yue Y, Chen C, Chen Y, Cao L. A multi-objective optimization problem solving method based on improved golden jackal optimization algorithm and its application. Biomimetics (Basel). (2024) 9(5):270. doi: 10.3390/biomimetics9050270
76. Karim FK, Khafaga DS, Eid MM, Towfek SK, Alkahtani HK. A novel bio-inspired optimization algorithm design for wind power engineering applications time-series forecasting. Biomimetics (Basel). (2023) 8(3):321. doi: 10.3390/biomimetics8030321
77. Ruprecht J, Eriksson CE, Forrester TD, Spitz DB, Clark DA, Wisdom MJ, et al. Variable strategies to solve risk-reward tradeoffs in carnivore communities. Proc Natl Acad Sci U S A. (2021) 118(35):e2101614118. doi: 10.1073/pnas.2101614118
78. Engebretsen KN, Beckmann JP, Lackey CW, Andreasen A, Schroeder C, Jackson P, et al. Recolonizing carnivores: is cougar predation behaviorally mediated by bears? Ecol Evol. (2021) 11(10):5331–43. doi: 10.1002/ece3.7424
79. Iriarte JA, Franklin WL, Johnson WE, Redford KH. Biogeographic variation of food habits and body size of the America puma. Oecologia. (1990) 85(2):185–90. doi: 10.1007/BF00319400
80. Wu ZS, Fu WP, Xue R. Nonlinear inertia weighted teaching-learning-based optimization for solving global optimization problem. Comput Intell Neurosci. (2015) 2015:292576. doi: 10.1155/2015/292576
82. Spicher N, Kukuk M. Delineation of electrocardiograms using multiscale parameter estimation. IEEE J Biomed Health Inform. (2020) 24(8):2216–29. doi: 10.1109/JBHI.2019.2963786
83. Lang Z, Wen QH, Yu B, Sang L, Wang Y. Forecast of winter precipitation type based on machine learning method. Entropy (Basel). (2023) 25(1):138. doi: 10.3390/e25010138
84. Shakhgeldyan KI, Kuksin NS, Domzhalov IG, Rublev VY, Geltser BI. Interpretable machine learning for in-hospital mortality risk prediction in patients with ST-elevation myocardial infarction after percutaneous coronary interventions. Comput Biol Med. (2024) 170:107953. doi: 10.1016/j.compbiomed.2024.107953
Keywords: in-hospital mortality, percutaneous coronary intervention, ST-elevation myocardial infarction, global registry of acute coronary events, machine learning prediction, feature selection
Citation: Tang N, Liu S, Li K, Zhou Q, Dai Y, Sun H, Zhang Q, Hao J and Qi C (2024) Prediction of in-hospital mortality risk for patients with acute ST-elevation myocardial infarction after primary PCI based on predictors selected by GRACE score and two feature selection methods. Front. Cardiovasc. Med. 11:1419551. doi: 10.3389/fcvm.2024.1419551
Received: 18 April 2024; Accepted: 4 October 2024;
Published: 22 October 2024.
Edited by:
Omneya Attallah, Technology and Maritime Transport (AASTMT), EgyptReviewed by:
Karthik Seetharam, West Virginia State University, United StatesCopyright: © 2024 Tang, Liu, Li, Zhou, Dai, Sun, Zhang, Hao and Qi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chunmei Qi, d3d0Z3kxMjU4MUAxNjMuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.