 Xuewu Song1,2,†Yitong Tong3Yi Luo1,2Huan Chang1,2Guangjie Gao1,2Ziyi Dong1,2
Xuewu Song1,2,†Yitong Tong3Yi Luo1,2Huan Chang1,2Guangjie Gao1,2Ziyi Dong1,2 Xingwei Wu1,2*
Xingwei Wu1,2* Rongsheng Tong1,2*
Rongsheng Tong1,2*
- 1Department of Pharmacy, Sichuan Provincial People’s Hospital, University of Electronic Science and Technology of China, Chengdu, China
- 2Chinese Academy of Sciences Sichuan Translational Medicine Research Hospital, Chengdu, China
- 3Chengdu Second People’s Hospital, Chengdu, China
Background: Short-term unplanned readmission is always neglected, especially for elderly patients with coronary heart disease (CHD). However, tools to predict unplanned readmission are lacking. This study aimed to establish the most effective predictive model for the unplanned 7-day readmission in elderly CHD patients using machine learning (ML) algorithms.
Methods: The detailed clinical data of elderly CHD patients were collected retrospectively. Five ML algorithms, including extreme gradient boosting (XGB), random forest, multilayer perceptron, categorical boosting, and logistic regression, were used to establish predictive models. We used the area under the receiver operating characteristic curve (AUC), accuracy, precision, recall, the F1 value, the Brier score, the area under the precision-recall curve (AUPRC), and the calibration curve to evaluate the performance of ML models. The SHapley Additive exPlanations (SHAP) value was used to interpret the best model.
Results: The final study included 834 elderly CHD patients, whose average age was 73.5 ± 8.4 years, among whom 426 (51.08%) were men and 139 had 7-day unplanned readmissions. The XGB model had the best performance, exhibiting the highest AUC (0.9729), accuracy (0.9173), F1 value (0.9134), and AUPRC (0.9766). The Brier score of the XGB model was 0.08. The calibration curve of the XGB model showed good performance. The SHAP method showed that fracture, hypertension, length of stay, aspirin, and D-dimer were the most important indicators for the risk of 7-day unplanned readmissions. The top 10 variables were used to build a compact XGB, which also showed good predictive performance.
Conclusions: In this study, five ML algorithms were used to predict 7-day unplanned readmissions in elderly patients with CHD. The XGB model had the best predictive performance and potential clinical application perspective.
1. Introduction
Coronary heart disease (CHD) is a common noncommunicable chronic cardiovascular disease in the elderly (1). Many elderly CHD patients require repeated hospitalizations due to poor disease control. Readmission refers to the patient returning to the hospital for the same or related treatment within a certain period after discharge (2). Readmission rates have become an important hospital performance measure for healthcare efficiency and quality improvement because unplanned readmission often means the failure of the initial intervention, especially for short-term readmission patients (3). Because of impaired mobility in elderly patients, repeated readmissions may be a difficult experience for patients and their families (4). In addition, frequent readmissions can increase the financial burden of patients, reduce their quality of life, and cause excessive consumption of medical resources. Therefore, it is of great significance to reduce the readmission of elderly CHD patients.
To that end, screening tools already exist to identify patients who may be readmitted to the hospital (4–7). However, these screening tools were developed primarily from data of 30-day or 1-year readmitted patients, which limited the accuracy of these tools in assessing patients’ 7-day unplanned readmission. Studies have shown that 84% of 7-day readmissions are avoidable (8). Therefore, developing a predictive model to assess the risk of readmission is the key to reducing 7-day unplanned readmission. Further, predicting the high risk of 7-day readmission may help avoid short-term unplanned readmission by targeted interventions. However, to our knowledge, there have been no established protocols for 7-day unplanned readmission in elderly patients with CHD.
A careful evaluation of the rehospitalization risk of elderly CHD patients plays a fundamental role in the clinical management of each patient. In recent years, the application of machine learning (ML) algorithms to predict clinical events has been actively conducted (9–11), and the development of a complicated and reliable classification tool has become possible. Therefore, we hypothesized that combining ML algorithms with patients’ basic information might make it possible to produce reliable prediction models to predict the 7-day unplanned readmission of elderly CHD patients. The purpose of this study was to collect patients’ basic information from the electronic medical record (EMR) system to establish an ML model for the prediction of unplanned readmission within 7 days of discharge in elderly patients with CHD.
2. Materials and methods
2.1. Study population and data source
We retrospectively collected the data of elderly CHD patients who underwent 7-day readmission in Sichuan Provincial People’s Hospital from July 2018 to June 2020. Also, we matched the non-readmission patients to the 7-day readmission patients by the ratio of 5:1. CHD, as a principal diagnosis, was confirmed by using the International Classification of Disease (ICD-10) codes (I20–I25). The patients aged <60 years, transferred to other hospitals, or readmitted by some specific treatments such as hemodialysis or radiation therapy will be excluded. We also excluded the patients with missing severe data or who died in the hospital. We collected the general information, records of diagnoses, medications, and comorbidities of the patients (7). For multiple laboratory results, we selected the last results of patients before discharge. This study was approved by the Ethics Committee of the Sichuan Academy of Medical Sciences and Sichuan Provincial People’s Hospital. Due to the retrospective nature of the study, informed consent was waived. Also, we hid the patients’ personal information during the study.
2.2. Data preprocessing
First, all variables were blinded to eliminate subjective influence. Then, categorical variables were represented by 0 and 1, continuous variables were standardized using the Z-score, and laboratory examinations were represented by 1, 2, and 3 (1, below the normal range; 2, within the normal range; and 3, above the normal range). The variables with missing data >90%, a single value occupying >90%, or the coefficient of variation <0.1 were deleted. Finally, we used random forest (RF) to replace the missing value, and Lasso was used for variable selection.
2.3. Machine learning algorithms
To establish the best prediction model, we used five representative ML algorithms, including extreme gradient boosting (XGB), RF, multilayer perceptron (MLP), categorical boosting (CB), and logistic regression (LR), as prediction model-based algorithms.
XGB is an ensemble classifier based on regression tree, which has the characteristics of short training time and high precision (12). XGB uses residuals to improve the model and adds an internal regularization to prevent overfitting and enhance the robustness of the model.
RF is also an ensemble classifier composed of hundreds to thousands of decision trees (13). The final classification result is determined by the mode of the output result by each tree. Moreover, this classifier has strong stability and robustness for small amounts of noise and outliers.
MLP is an ML algorithm developed by feedforward neural networks, which are composed of ordered layers comparable to human neuron processing (14). Structurally, the MLP model comprises an input layer, an output layer, and one or more hidden layers (15).
CB is an ML classification technique based on oblivious trees, which can deal with classification problems efficiently and reasonably (16). CB solves the problem of gradient bias and prediction shift to reduce the overfitting risk and improve the accuracy and generalization ability of the algorithm.
An LR model describes and estimates the relationship between one or more independent variables and one binary dependent variable (17). LR is used to compute the probability of an occurrence of binary outcomes (18). It has a powerful interpretation and has been widely used in diverse areas of medical research.
2.4. Model establishment
XGB, MLP, RF, LR, and CB were used to build the prediction models. The model establishment was as follows. All patients were randomly divided into a training set and a test set in the proportion of 8:2. The training set was used to build the classification models, and the test set was used to evaluate the predictive performance. Moreover, the borderline synthetic minority oversampling technique (SMOTE) (19) was used to solve the issues associated with the imbalanced data in the training set. Borderline SMOTE is an improved oversampling algorithm over SMOTE. Also, borderline SMOTE can generate new data from borderline data, thereby improving the category distribution of samples. Meanwhile, we trained the ML models on original data and evaluated their predictive performance on the test set.
2.5. Model evaluation
To evaluate the predictive performance of the ML models, we calculated five representative performance evaluation measures, including area under the receiver operating characteristic curve (AUC), accuracy, precision, recall, and F1 value. Meanwhile, as precision and recall are more meaningful in clinical practice, we also computed the area under the precision-recall curve (AUPRC) to assess the model performance. The model’s calibration was evaluated by the Brier score and calibration plot. The model was considered to have favorable calibration when the Brier score was ≤0.25 (20). SHapley Additive exPlanations (SHAP) values were used to measure the contribution of each variable to the best model.
2.6. Sample size assessment
We chose a repeated bootstrapping method to evaluate the appropriateness of sample size. First, we randomly selected 10%, 20%, and 30%–100% subsets from the training set by 100 times, respectively. Then, these subsets were used to establish prediction models combined with the best ML algorithm selected by model evaluation. Finally, we calculated the AUC of the test set based on the established models to assess the sample size.
2.7. Statistical analysis
Chi-square tests were used to analyze categorical variables expressed as counts and percentages. Continuous variables were expressed as means ± standard deviations or medians with first to third quartiles (median, Q1–Q3). We used the t-test or Mann–Whitney test to analyze the statistical significance. P-values <0.05 were considered statistically significant. Statistical analyses were performed by using SPSS software version 25 (IBM SPSS Statistics, IBM Corporation, Armonk, NY, United States). Model building was implemented using the stats and sklearn packages in Python (Version 3.8).
3. Results
3.1. Study population
We enrolled 139 patients who underwent 7-day unplanned readmission and matched the non-readmission patients (695) by a ratio of 5:1 in this study. A total of 834 elderly CHD patients were included, of which 426 (51.1%) were men and 408 (48.9%) were women. The average age was 73.5 ± 8.4 years, and the length of stay was 6 (3, 11) days. The general information of the patients is presented in Table 1. The whole process of the study is shown in Figure 1.
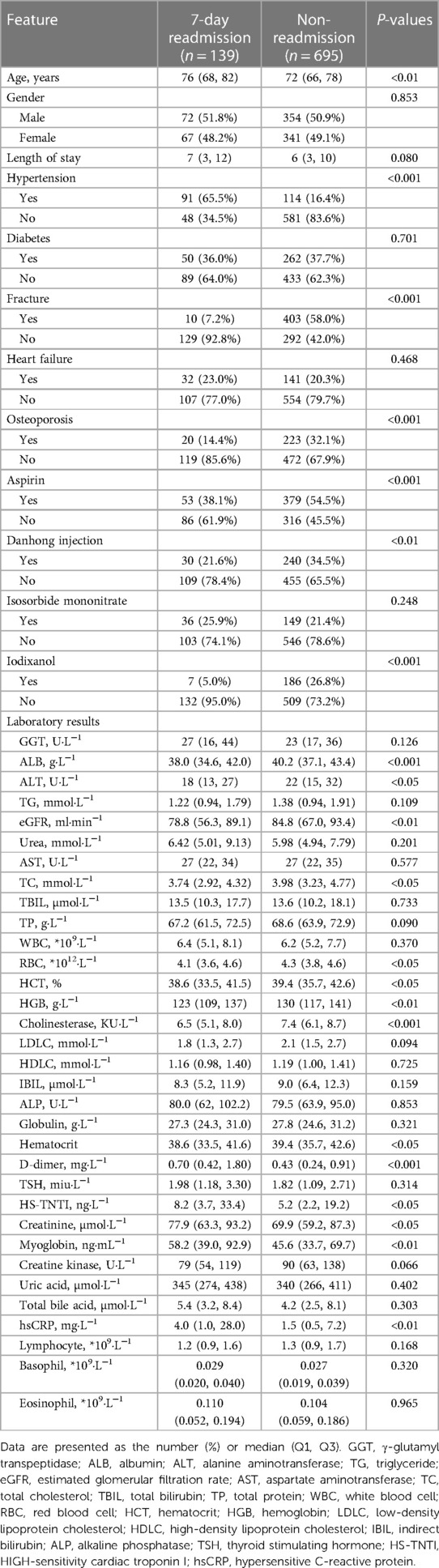
Table 1. Baseline characteristics of 7-day readmission vs. non-readmission patients.
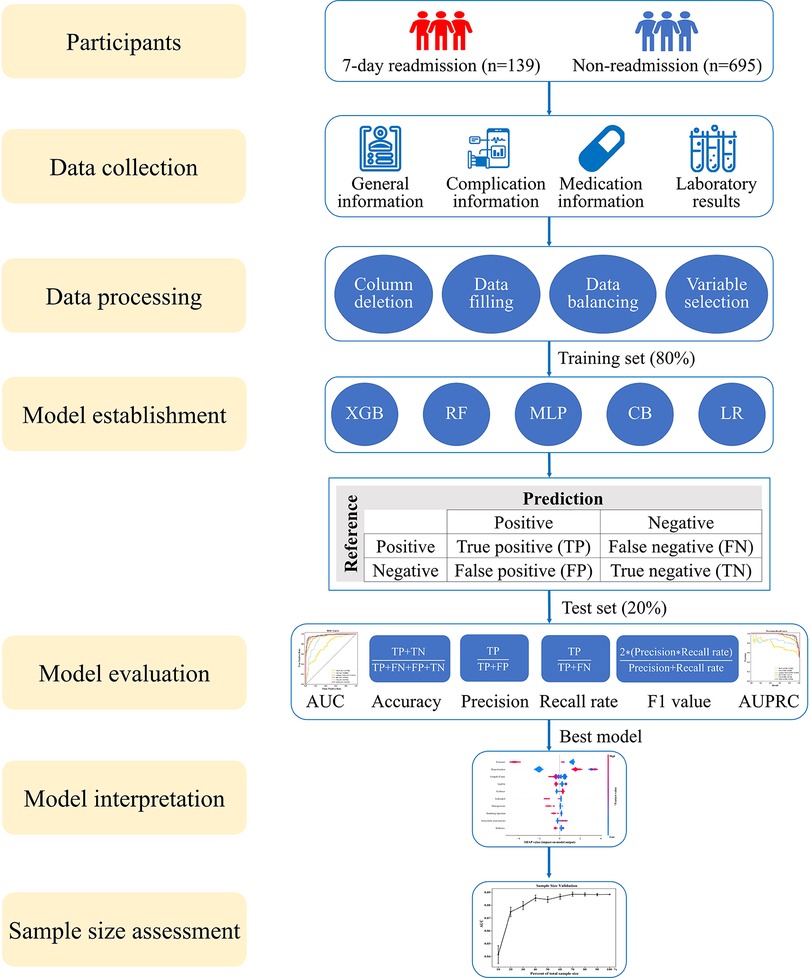
Figure 1. Research roadmap of the study. XGB, extreme gradient boosting; RF, random forest; MLP, multilayer perceptron; CB, categorical boosting; LR, logistic regression; AUC, area under the receiver operating characteristic curve; AUPRC, area under the precision-recall curve.
3.2. Data processing and variable selection
A total of 178 variables were collected, and the variables assignment results are shown in Supplementary Table S1. These variables included three general information (X1–X3), 15 comorbidities (X4–X18), 32 medications (X19–X50), and 128 laboratory tests (X51–X178). Sixty-five variables with missing value >90%, a single value occupying >90%, and a coefficient of variation <0.1 were deleted (Supplementary Table S2). Lasso was used for variable selection of the rest 113 variables, and 83 variables remained in the subsequent study (Supplementary Table S2).
3.3. Establishment and evaluation of the model
XGB, MLP, RF, LR, and CB were combined with 83 variables to establish ML models to predict 7-day unplanned readmission in elderly patients with CHD in the training set. The predictive performance of the ML models was checked in the test set. Table 2 presents the AUC, accuracy, precision, recall, and F1 value of the models. Among the models, XGB had the best performance, showing the highest AUC (0.9729), accuracy (0.9173), and F1 value (0.9134). To improve the clinical application of the model, a compact XGB model was applied by the top 10 variables according to the mean absolute SHAP value, which indicates their importance for prediction. The AUC, accuracy, precision, recall, and F1 value of the compact XGB model were 0.9474, 0.8630, 0.9015, 0.8151, and 0.8561, respectively (Table 2). Moreover, the receiver operating characteristic (ROC) curves of the ML models are shown in Figure 2A. In the ML models trained on original data, the CB model had the highest AUC (0.9149). The AUC, accuracy, precision, recall, and F1 value of the XGB model were 0.8446, 0.8443, 0.7500, 0.3529, and 0.4800, respectively (Supplementary Table S3). The ROC curves of the ML models trained on original data are shown in Supplementary Figure S1A.
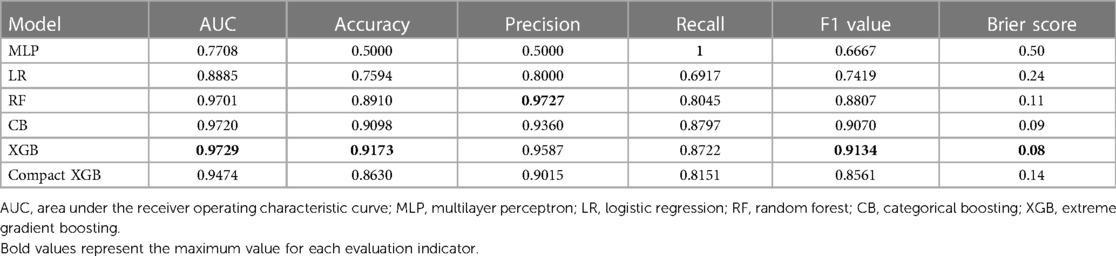
Table 2. Predictive performance of machine learning models on the test set.
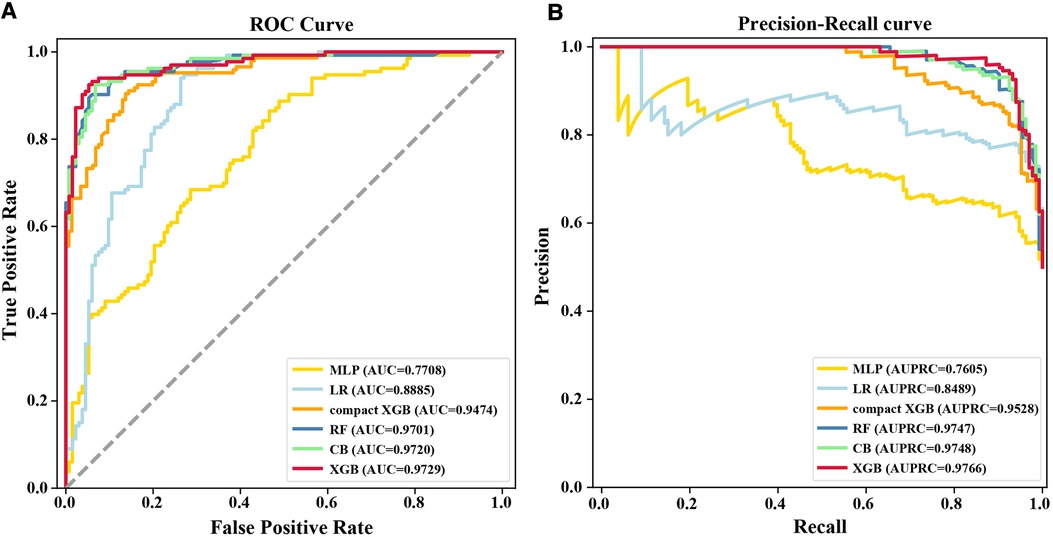
Figure 2. (A) ROC curves and (B) precision–recall curves for the six ML models on the test set. MLP, multilayer perceptron; AUC, area under the receiver operating characteristic curve; LR, logistic regression; RF, random forest; CB, categorical boosting; XGB, extreme gradient boosting; AUPRC, area under the precision-recall curve.
Recall was defined as the proportion of 7-day unplanned readmission patients who are correctly identified, and precision was defined as the proportion of actual readmission within the predicted readmission patients. For patients and doctors, precision and recall are perhaps clinically more meaningful for the prediction of 7-day unplanned readmission. Therefore, we also used precision-recall curves to evaluate the ML models’ predictive performance (Figure 2B). The result shows that the XGB model had the highest AUPRC (0.9766), and the AUPRC of the compact XGB model was 0.9528. The precision–recall curves of the ML models trained on original data are shown in Supplementary Figure S1B. Meanwhile, we used calibration curves to analyze the calibration ability. The calibration curves of the XGB and compact XGB models showed good calibration performance (Figure 3). The calibration curves of other ML models are shown in Supplementary Figure S2. Furthermore, the Brier score is an index to evaluate both calibration and discrimination of the model. The Brier scores of XGB and compact XGB models were 0.08 and 0.14, respectively (Table 2).
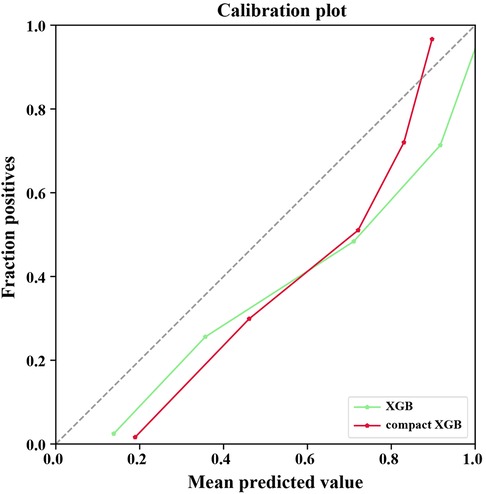
Figure 3. Calibration plot for the XGB and compact XGB models. XGB, extreme gradient boosting.
3.4. Model interpretation
In Figure 4, the top 10 variables in the XGB model are listed in descending order by the mean absolute SHAP value. The most important 10 variables contributing to the model were fracture, hypertension, length of stay, aspirin, D-dimer, iodixanol, osteoporosis, danhong injection (a traditional Chinese medicine injection used to treat cardiovascular diseases), isosorbide mononitrate, and diabetes. Meanwhile, the 10 variables were used to develop a compact XGB model.
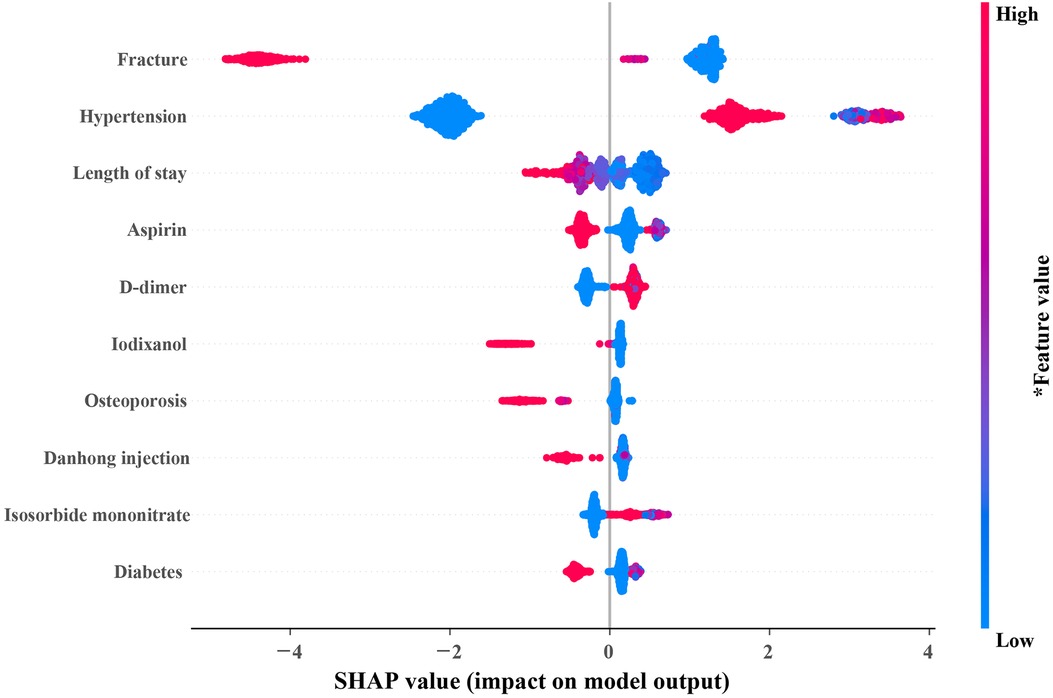
Figure 4. SHAP summary plot of the 10 most important variables of the XGB model. In the SHAP plot, the horizontal axis symbolizes the contribution of variables to the outcome, and the color of the dot represents the value of the variables. Red represents higher variable values, and blue represents lower variable values. SHAP, SHapley additive exPlanations; XGB, extreme gradient boosting.
3.5. Sample size assessment
The repeated bootstrapping method was used to assess the adequacy of the sample size, and the result is shown in Figure 5. As the percentage of sample size increased, AUC gradually increased and the fluctuation of the AUC decreased gradually. When the sample size reached 70%, the predictive performance of the model tended to be stable, indicating that a sufficient sample size was included in this study.
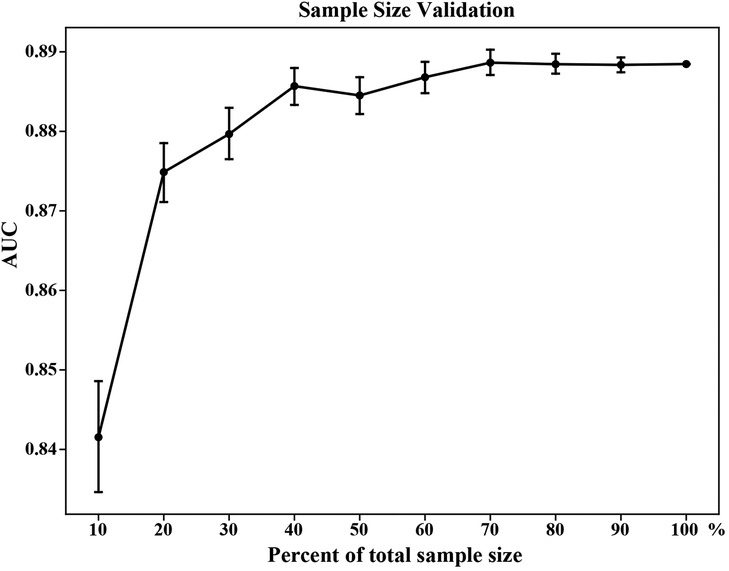
Figure 5. Sample size validation for the XGB model. The vertical bars represent the 95% confidence interval of AUC. XGB, extreme gradient boosting; AUC, area under the receiver operating characteristic curve.
4. Discussion
In this study, we used XGB, RF, MLP, CB, and LR algorithms, combined with detailed clinical data to establish ML models to predict 7-day unplanned readmission in elderly patients with CHD. We chose XGB as the model with the best fit owing to several factors because it had the highest AUC, accuracy, and F1 value. Although the recall of the MLP model was slightly higher than that of the XGB model, the low accuracy and precision of the MLP model made it difficult to be accepted clinically. In addition, the XGB model had good calibration capability, the best AUPRC, and the best Brier score. Meanwhile, to improve the clinical utility of the model, we used the 10 most important factors to develop a compact XGB model, which also showed a good predictive performance.
Several studies have assessed 30-day or 1-year all-cause readmissions after cardiovascular events (6, 21, 22), but to our knowledge, none focused on 7-day unplanned readmissions in elderly CHD patients. Okere et al. (21) used decision tree algorithms to predict 30-day hospital readmissions of 346,390 hospitalized patients (≥40 years) with a primary diagnosis of ischemic heart disease. The accuracy, precision, recall, and AUC of the model were all above 0.95. However, this study lacked the evaluation of model calibration ability. Gupta and colleagues (6) used 6 ML algorithms, including LR, naïve Bayes, support vector machine, deep neural network, RF, and gradient boosting, to build predictive models of 30-day readmission, but the best C statistic of the model was only 0.641. In China, 30-day readmission is an important indicator to measure the medical quality of third-class hospitals. Some Chinese researchers (22) established nine ML models to predict the risk of 30-day unplanned all-cause hospital readmissions with the AUC in the range of 0.681–0.720. These models could not be used to predict 7-day unplanned readmissions. In fact, 7-day readmission is always neglected, especially for elderly patients with chronic diseases. Therefore, we developed predictive models to accurately identify the elderly CHD patients more likely to be readmitted to the hospital within 7 days.
It is worth noting that the classification model may have a prediction bias. This is because 7-day unplanned readmission is rare and model discrimination is driven by patients without readmission. As a consequence, it is necessary to compare calibration with discrimination simultaneously. In this connection, the Brier score provides a more comprehensive assessment of model performance, combining model discrimination and calibration (23). The Brier score represents the mean square error between the predicted and observed results. Therefore, when two models are compared, the smaller the Brier score, the better the model performance. In our study, the Brier scores of the XGB model were all lower than those of other ML models, which showed that the XGB model had a good calibration ability in predicting 7-day unplanned readmission in elderly patients with CHD.
ML model, called black box frequently, one reason is that it can only offer risk estimates but cannot explain the sources of the risk (24). In recent years, SHAP has been widely used in model interpretation (25, 26). Using the SHAP summary plot, we identified the top contributors to the risk of 7-day unplanned readmission for individual patients. The results of SHAP showed that patients with fractures are unlikely to be readmitted to the hospital in the short term after discharge. Elderly CHD patients with hypertension had higher rehospitalization may due to poor blood pressure control. Moreover, the length of stay has been proven to be an important predictor of readmission of patients with cardiovascular diseases (21, 27, 28), which is consistent with the results of our study. Guidelines routinely recommend aspirin for CHD patients (29). In our study, elderly patients with CHD who did not use aspirin had a higher risk of readmission. This proves that aspirin improves prognosis in elderly patients with CHD. Furthermore, those elderly CHD patients with higher D-dimer had a higher risk of 7-day unplanned readmission because a higher D-dimer meant a higher risk of pulmonary thromboembolism (30, 31).
This study has limitations. First, although we collected the comorbidities of the elderly CHD patients from the EMR, relevant information, such as the severity of the disease and the duration of comorbidities, was not captured in our study and was, therefore, not included in the evaluation. Second, this study was a single-center study, and we were unable to evaluate the performance of the ML models in other medical institutions. Third, due to the retrospective nature of the study, we only collected the basic clinical features. Other features such as socioeconomic factors and health literacy, which may improve the readmission risk assessment, should be validated in further studies. Then, the recall and F1 value declined while the ML models were trained on original data, indicating that a larger sample size is needed to further optimize the model in the future. Finally, a prospective study is needed before the model implements in clinical practice.
5. Conclusions
In conclusion, we established ML models to predict 7-day unplanned readmission in elderly patients with CHD using ML algorithms. The XGB model showed the best predictive performance and had good calibration. In addition, the compact XGB model, developed by the top 10 important indicators, can predict 7-day unplanned readmission conveniently. This study showed that an ML-based approach is feasible and effective with a potential clinical application perspective on the reduction of 7-day readmission and the improvement of quality of care to elderly CHD patients.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors without undue reservation.
Ethics statement
The studies involving human participants were reviewed and approved by the Ethics Committee of the Sichuan Academy of Medical Sciences and Sichuan Provincial People’s Hospital. Written informed consent for participation was not required for this study in accordance with the national legislation and the institutional requirements.
Author contributions
XS, YT, XW, and RT contributed to the conception and design of the study. XS, YL, and ZD contributed to the collection of data. HC, GG, and XW performed the model development. XS and XW performed the statistical analysis. XS and YT wrote the first draft of the manuscript. XS, YT, XW, and RT contributed to reviewing the manuscript. All authors contributed to the article and approved the submitted version.
Funding
This study was funded by the National Natural Science Foundation of China (grant number 72174038) and the Bethune Foundation (grant number 2021HX019).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcvm.2023.1190038/full#supplementary-material
References
1. Niu YN, Li R, Zhao P, He P, Li YL, Wang Y. Quantitative and qualitative research on management strategies for dyspnoea in elderly patients with coronary heart disease complicated with chronic heart failure. J Multidiscip Healthc. (2022) 15:2007–13. doi: 10.2147/jmdh.S378379
2. HealthCare.gov. Hospital readmissions. Available at: https://www.healthcare.gov/glossary/hospital-readmissions/ (Accessed October 10, 2022).
3. Coatsworth-Puspoky R, Duggleby W, Dahlke S, Hunter K. Unplanned readmission for older persons: a concept analysis. J Adv Nurs. (2021) 77:4291–305. doi: 10.1111/jan.14893
4. Rajaguru V, Kim TH, Han W, Shin J, Lee SG. LACE index to predict the high risk of 30-day readmission in patients with acute myocardial infarction at a university affiliated hospital. Front Cardiovasc Med. (2022) 9:925965. doi: 10.3389/fcvm.2022.925965
5. Matheny ME, Ricket I, Goodrich CA, Shah RU, Stabler ME, Perkins AM, et al. Development of electronic health record-based prediction models for 30-day readmission risk among patients hospitalized for acute myocardial infarction. JAMA Netw Open. (2021) 4:e2035782. doi: 10.1001/jamanetworkopen.2020.35782
6. Gupta S, Ko DT, Azizi P, Bouadjenek MR, Koh M, Chong A, et al. Evaluation of machine learning algorithms for predicting readmission after acute myocardial infarction using routinely collected clinical data. Can J Cardiol. (2020) 36:878–85. doi: 10.1016/j.cjca.2019.10.023
7. Zhao P, Yoo I, Naqvi SH. Early prediction of unplanned 30-day hospital readmission: model development and retrospective data analysis. JMIR Med Inform. (2021) 9:e16306. doi: 10.2196/16306
8. MedPAC. Chapter 5: Payment policy for inpatient readmissions (June 2007 report). (Accessed October 10, 2022).
9. Castela Forte J, Yeshmagambetova G, van der Grinten ML, Scheeren TWL, Nijsten MWN, Mariani MA, et al. Comparison of machine learning models including preoperative. Intraoperative, and postoperative data and mortality after cardiac surgery. JAMA Netw Open. (2022) 5:e2237970. doi: 10.1001/jamanetworkopen.2022.37970
10. Sherman E, Alejo D, Wood-Doughty Z, Sussman M, Schena S, Ong CS, et al. Leveraging machine learning to predict 30-day hospital readmission after cardiac surgery. Ann Thorac Surg. (2022) 114:2173–79. doi: 10.1016/j.athoracsur.2021.11.011
11. Huang Y, Talwar A, Lin Y, Aparasu RR. Machine learning methods to predict 30-day hospital readmission outcome among US adults with pneumonia: analysis of the national readmission database. BMC Med Inform Decis Mak. (2022) 22:288. doi: 10.1186/s12911-022-01995-3
12. Yuan G, Lv B, Du X, Zhang H, Zhao M, Liu Y, et al. Prediction model for missed abortion of patients treated with IVF-ET based on XGBoost: a retrospective study. PeerJ. (2023) 11:e14762. doi: 10.7717/peerj.14762
13. Chen X, Ishwaran H. Random forests for genomic data analysis. Genomics. (2012) 99:323–29. doi: 10.1016/j.ygeno.2012.04.003
14. Abiodun OI, Jantan A, Omolara AE, Dada KV, Mohamed NA, Arshad H. State-of-the-art in artificial neural network applications: a survey. Heliyon. (2018) 4:e00938. doi: 10.1016/j.heliyon.2018.e00938
15. Mohammadi F, Dehbozorgi L, Akbari-Hasanjani HR, Joz Abbasalian Z, Akbari-Hasanjani R, Sabbaghi-Nadooshan R, et al. Evaluation of effective features in the diagnosis of COVID−19 infection from routine blood tests with multilayer perceptron neural network: a cross-sectional study. Health Sci Rep. (2023) 6:e1048. doi: 10.1002/hsr2.1048
16. Prokhorenkova L, Gusev G, Vorobev A, Dorogush AV, Gulin A. CatBoost: unbiased boosting with categorical features. arXiv preprint arXiv:1706.09516 (2017). (2017).
17. Zabor EC, Reddy CA, Tendulkar RD, Patil S. Logistic regression in clinical studies. Int J Radiat Oncol Biol Phys. (2022) 112:271–77. doi: 10.1016/j.ijrobp.2021.08.007
18. Abe D, Inaji M, Hase T, Takahashi S, Sakai R, Ayabe F, et al. A prehospital triage system to detect traumatic intracranial hemorrhage using machine learning algorithms. JAMA Netw Open. (2022) 5:e2216393. doi: 10.1001/jamanetworkopen.2022.16393
19. Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE: synthetic minority over-sampling technique. J Artif Intell Res. (2002) 16:321–57. doi: 10.1613/jair.953
20. Lin J, Yin M, Liu L, Gao J, Yu C, Liu X, et al. The development of a prediction model based on random survival forest for the postoperative prognosis of pancreatic cancer: a SEER-based study. Cancers (Basel). (2022) 14:4667. doi: 10.3390/cancers14194667
21. Okere AN, Sanogo V, Alqhtani H, Diaby V. Identification of risk factors of 30-day readmission and 180-day in-hospital mortality, and its corresponding relative importance in patients with ischemic heart disease: a machine learning approach. Expert Rev Pharmacoecon Outcomes Res. (2021) 21:1043–48. doi: 10.1080/14737167.2021.1842200
22. Zhang Z, Qiu H, Li W, Chen Y. A stacking-based model for predicting 30-day all-cause hospital readmissions of patients with acute myocardial infarction. BMC Med Inform Decis Mak. (2020) 20:335. doi: 10.1186/s12911-020-01358-w
23. Khera R, Haimovich J, Hurley NC, McNamara R, Spertus JA, Desai N, et al. Use of machine learning models to predict death after acute myocardial infarction. JAMA Cardiol. (2021) 6:633–41. doi: 10.1001/jamacardio.2021.0122
24. The Lancet Respiratory Medicine. Opening the black box of machine learning. Lancet Respir Med. (2018) 6:801. doi: 10.1016/s2213-2600(18)30425-9
25. Hyland SL, Faltys M, Hüser M, Lyu X, Gumbsch T, Esteban C, et al. Early prediction of circulatory failure in the intensive care unit using machine learning. Nat Med. (2020) 26:364–73. doi: 10.1038/s41591-020-0789-4
26. Lundberg SM, Nair B, Vavilala MS, Horibe M, Eisses MJ, Adams T, et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat Biomed Eng. (2018) 2:749–60. doi: 10.1038/s41551-018-0304-0
27. Miñana G, Bosch MJ, Núñez E, Mollar A, Santas E, Valero E, et al. Length of stay and risk of very early readmission in acute heart failure. Eur J Intern Med. (2017) 42:61–6. doi: 10.1016/j.ejim.2017.04.003
28. Reynolds K, Butler MG, Kimes TM, Rosales AG, Chan W, Nichols GA. Relation of acute heart failure hospital length of stay to subsequent readmission and all-cause mortality. Am J Cardiol. (2015) 116:400–5. doi: 10.1016/j.amjcard.2015.04.052
29. Levine GN, Bates ER, Bittl JA, Brindis RG, Fihn SD, Fleisher LA, et al. 2016 ACC/AHA guideline focused update on duration of dual antiplatelet therapy in patients with coronary artery disease: a report of the American College of Cardiology/American Heart Association task force on clinical practice guidelines. J Thorac Cardiovasc Surg. (2016) 152:1243–75. doi: 10.1016/j.jtcvs.2016.07.044
30. Bai Z, Huang Y, Song C, Liu H, Chen Y, Zhang H, et al. Clinical application of the innovance D-dimer assay in the diagnosis of acute pulmonary thromboembolism. Exp Ther Med. (2017) 13:3543–48. doi: 10.3892/etm.2017.4400
Keywords: readmission, machine learning, coronary heart disease, elderly, predict
Citation: Song X, Tong Y, Luo Y, Chang H, Gao G, Dong Z, Wu X and Tong R (2023) Predicting 7-day unplanned readmission in elderly patients with coronary heart disease using machine learning. Front. Cardiovasc. Med. 10:1190038. doi: 10.3389/fcvm.2023.1190038
Received: 20 March 2023; Accepted: 24 July 2023;
Published: 8 August 2023.
Edited by:
Massimo Bonacchi, University of Florence, ItalyReviewed by:
Kareen Teo, Independent researcher, Selangor, MalaysiaPeng Zhao, Liberty Mutual Insurance, United States
© 2023 Song, Tong, Luo, Chang, Gao, Dong, Wu and Tong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xingwei Wu NzE5MDE3NUB1ZXN0Yy5lZHUuY24= Rongsheng Tong MzE4MDA0MDMxQHFxLmNvbQ==
†ORCID Xuewu Song orcid.org/0000-0003-4750-7151