 Philomina Princiya Mascarenhas1
Philomina Princiya Mascarenhas1 M. S. Sannidhan
M. S. Sannidhan Ancilla J. Pinto
Ancilla J. Pinto Dabis Camero
Dabis Camero Jason Elroy Martis
Jason Elroy Martis
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
BRIEF RESEARCH REPORT article
Front. Bioinform., 10 March 2025
Sec. Computational BioImaging
Volume 5 - 2025 | https://doi.org/10.3389/fbinf.2025.1485797
Teledermatology, a growing field of telemedicine, is widely used to diagnose skin conditions like acne, especially in young adults. Accurate diagnosis depends on clear images, but blurring is a common issue in most images. In particular, for acne images, it obscures acne spots and facial contours, leading to inaccurate diagnosis. Traditional methods to address blurring fail to recover fine details, making them unsuitable for teledermatology. To resolve this issue, the study proposes a framework based on generative networks. It comprises three main steps: the Contour Accentuation Technique, which outlines facial features to create a blurred sketch; a deblurring module, which enhances the sketch’s clarity; and an image translator, which converts the refined sketch into a color photo that effectively highlights acne spots. Tested on Acne Recognition Dataset, the framework achieved an SSIM of 0.83, a PSNR of 22.35 dB, and an FID score of 10.77, demonstrating its ability to produce clear images for accurate acne diagnosis. Further, the details of research can be found on the project homepage at: https://github.com/Princiya1990/CATDeblurring.
In digital image processing, clear images are essential for accurate analysis and decision-making in many areas (Bui et al., 2018). However, blurring caused by camera movement or focus problems can distort important details (Pan et al., 2019). This is especially problematic in teledermatology, where clear images are important for evaluating skin conditions, such as acne severity, to ensure accurate diagnoses, proper treatment, and avoid misunderstandings (Suha and Sanam, 2022). Considering this, there is a strong need for effective image processing methods to improve image clarity and retain fine details.
Straight forward approaches for deblurring, such as Wiener filtering and Richardson-Lucy deconvolution (Šroubek et al., 2019), rely on mathematical models to reverse blurring by estimating and correcting the distortion, aiming to minimize the mean square error between the restored and original images (Gnanasambandam et al., 2024). However, these methods struggle with complex blurring or unpredictable noise, often resulting in issues like ringing artifacts and amplified noise (Joshi and Sheetlani, 2019). These limitations underscore the need for more adaptive and reliable approaches, with studies highlighting GAN-based deblurring techniques as a promising solution to overcome these challenges by restoring image clarity (Mankotia et al., 2024; Song and Lam, 2021). However, some studies also revealed that GANs suffer to generate better quality of deblurred images due to the insufficient exposure of facial structure hiding the contours in the blurred images (Shi et al., 2024; Qi et al., 2021; Jung et al., 2022). This limitation is particularly significant in applications like acne assessments, where facial contours provide major context for understanding lesion distribution and texture (Samizadeh, 2022). One commonly used technique to address this issue is translating the image into a sketch, which helps to sharpen the image by emphasizing its contours. However, when applied to blurred images, this approach often fails to produce clear sketches due to the insufficient visibility of facial structures (Chen et al., 2024). To address these challenges, implementing an image processing algorithm or preprocessor that exposes contours before sketching can significantly improve the clarity of sketches. This approach ensures better visualization and more accurate results, particularly in applications like dermatological assessments, where clear contour details are essential for understanding conditions like acne (Dumitrescu et al., 2021).
Building on the observations discussed earlier, the proposed image deblurring framework is designed to overcome the limitations of existing systems through three main components. The first is an image preprocessor called the Contour Accentuation Technique (CAT), which extracts the contours of facial structures from a blurred input image, presenting them in the form of a sketch. Next, a deblurring module featuring DeblurGAN refines the sketch produced by CAT, removing blur and enhancing clarity. Finally, an image translator module, powered by a conditional GAN (cGAN), converts the clear sketch into a color photo image. Although the CAT component initially generates a blurry sketch, it effectively highlights the facial contours, providing structural information that aids the deblurring module in producing a higher-quality sketch. These refined sketches, when translated into photo images by the image translator module, result in images where acne spots are clearly visible, improving their overall diagnostic utility. Figure 1 provides an overview of this process, showing the progression from deblurred input photo to clear photo image as output.

Figure 1. Sample image showing the workflow of the proposed image deblurring framework.
The effectiveness of the proposed image deblurring framework is evaluated using the Acne Recognition Dataset (Kucev, 2023) as the primary benchmark, specifically designed for acne severity detection. For further validation, standard datasets: CUHK (Wang and Tang, 2008), AR (Cao et al., 2022), and XM2GTS derived from a subset XM2VTS dataset (Messer et al., 1999) are used.
This research work has the following research contributions:
1. Implementation of CAT to reveal facial structures through sketch generation based on contour extraction.
2. Utilization of DeblurGAN to specifically enhance the clarity of blurred sketches generated by CAT in order to highlight acne spots.
3. Development of an image translator module using cGAN to transform sketches into color photo images, enabling a realistic visual analysis of acne spots.
Vodrahalli et al. (2020) and Pan et al. (2019) emphasize that clear images are essential in teledermatology for accurate medical diagnoses. Meanwhile, Suha and Sanam (2022) point out that blurry images can easily cause misunderstandings when treating acne, leading to incorrect diagnoses. Straight forward methods such as Wiener filtering and Lucy-Richardson deconvolution (Šroubek et al., 2019; Joshi and Sheetlani, 2019) work well only in stable conditions, as noted by Gnanasambandam et al. (2024). Some works used GANs to fix blurry images because these methods can sharpen photos while keeping them looking natural (Kupyn et al., 2018; Kupyn et al., 2019; Xiong et al., 2024; Peng et al., 2023). Work by Zhai et al. (2022) and Wang et al. (2023) also showed that GANs are even capable of handling the challenge of deblurring facial images. However, keeping small facial details and highlighting contours continues to be a difficult task in face deblurring research (Shi et al., 2024; Qi et al., 2021). Also, works by Lee et al. (2020), Qi et al. (2021), and Jung et al. (2022) have shown that exposing contours remains a challenging task. Meanwhile, Collins et al. (2020) stressed the importance of minor facial feature information for producing the results of improved quality.
Recognizing the importance of clear images in teledermatology and the current challenges in GAN-based facial deblurring, this study focuses on improving these methods for acne imaging through contour accentuation and sketch-based transformations. Martis et al. (2024) and Capozzi et al. (2021) proved that clearly highlighting facial boundaries in training sketches can improve the quality of images produced by sketch-to-photo GANs. Likewise, Mankotia et al. (2024) reported that DeblurGAN performs better when the facial outline is clearly exposed. Building on these findings, Chen et al. (2023) demonstrated that using a preprocessor to expose contours early in the process leads to better deblurring performance. Motivated by this, we incorporated CAT as a preprocessor in this work to achieve better deblurring performance.
The proposed image deblurring framework consists of three primary components:1) Contour Accentuation Technique (CAT), 2) Deblurring Module, 3) Image Translator module. Figure 2 shows the entire workflow of our system and details of each process are elaborated in subsequent sections.
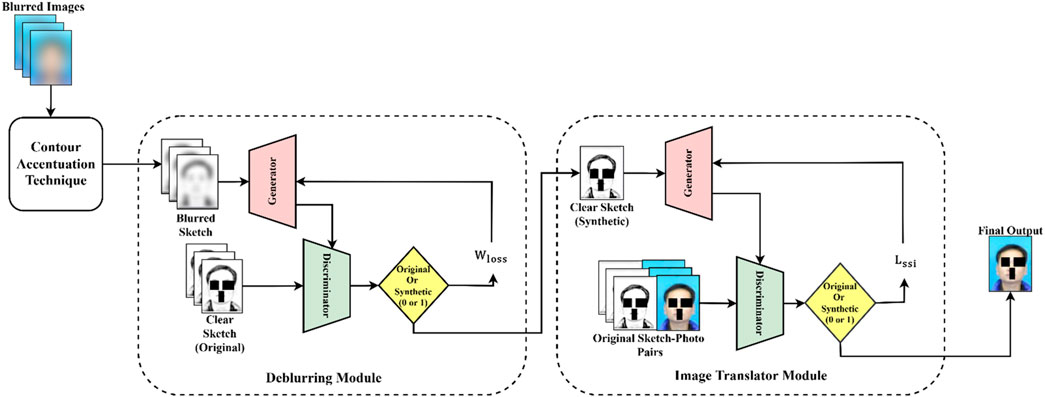
Figure 2. Overview of the proposed image deblurring framework with CAT.
This is a preprocessor used to transform the image into a sketch where important features, such as contours, are exposed in blurred image aiding to improve the quality of the image generation further. Figure 3 outlines the steps of CAT, including grayscale, blending, and contrast correction. These steps work together to refine the image, exposing the contours. Each step is discussed in detail in the following subsections.
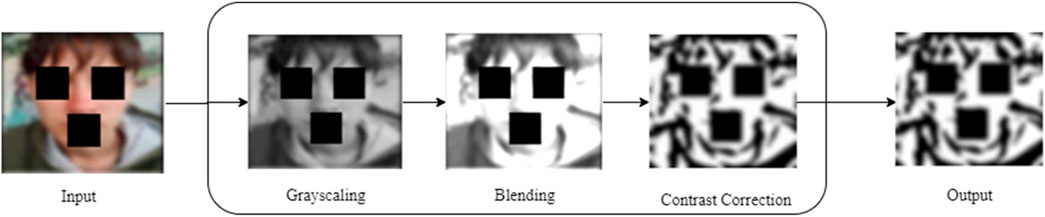
Figure 3. Illustration of proposed CAT process.
This step transforms the color image into a grayscale version. This method reduces color information targeting on exposing the facial boundary to reveal the face structure. This step is vital for sketch generation, as it exposes the structural features necessary for creating realistic sketches (Tani and Yamawaki, 2024). Equation 1 reveals the mathematical formulation for the grayscale conversion.
In the equation,
In this process, the transitions between light and dark areas in grayscale image is smoothened in order to preserve key details in the facial area (Zhang et al., 2020). Equation 2 explains the blending function used in CAT.
In this equation,
The parameter
At this stage, blended image is enhanced by adjusting brightness and tuning luminance. For dark images, a luminance value greater than 1 is used, and for light images, less than 1, ensuring realistic and consistent luminance (Chen and Chen, 2022). Additionally, the function adjusts contrast, essential for blending images with different exposures or color temperatures (Dang et al., 2024). Equation 4 demonstrates this process mathematically.
This equation shows how each pixel
The deblurring module takes blurred sketches produced by the CAT as input and outputs deblurred sketches. As shown in Figure 2, this module uses DeblurGAN (Kupyn et al., 2018), trained specifically on facial sketches, to achieve the deblurring process. DeblurGAN enhances blurred sketches by training GAN network that contains generator and discriminator components. The generator consists of a deep convolutional neural network that performs an end-to-end transformation from blurred to deblurred facial sketches. It starts with an initial convolutional layer with 64 filters, a
The discriminator module distinguishes between original and synthetic sketches. It employs four convolutional layers with filters 64, 128, 256 and 512 respectively, each using 4 × 4 kernel with step size of 2 (except for the last layer). To enhance training stability and feature extraction, LeakyReLU activation with
In Equation 5,
The generated sketch from the deblurring module is fed as input to this module. As depicted in Figure 2, thus module uses sketch-to-photo cGAN. Unlike the deblurring module, this module focuses on generating photo-realistic images preserving the structure obtained from the deblurring module. The generator architecture in this case begins with an initial convolutional layer of 64 filters with
The discriminator employs a patch-based structure with four convolutional layers with filters 64,128, 256 and 512 respectively using a
In the equation,
This section presents Algorithm 1: Deblurred_Sketch_To_Photo, which details an approach for converting blurred sketches into clear, color photos using GANs integrated with CAT.
Algorithm 1.Deblurred_Sketch_To_Photo.
Input: Blurred sketch.
Output: Color Photo with improved clarity.
1: Initialize DeblurGAN with generator
2: For every blurred image do
3:
4: do
5: Generate a deblurred image
6: Train
7: Update G using Wasserstein distance
8: Optimize both G and D using their respective objective functions:
9: For D, maximize:
10: For G, minimize the Wasserstein distance to adjust its parameters effectively
11: while (D fails to distinguish from original images)
12: for the deblurred training sketch samples, do
13: Sample batch of
14: Sample batch of images from the data
15: update discriminator functions
16: sample batch of m noise samples for image
17: update the generator using gradient functions.
18: end for
19: done
The CAT (Lines 3–5) sharpens blurred images by enhancing edges, converting to grayscale, blending to emphasize structures, and refining pixels for clearer sketches. DeblurGAN (Lines 8–14) employs a GAN framework to enhance sketch clarity, with a generator creating deblurred images and a discriminator refining accuracy by distinguishing them from sharp images. The Sketch_to_Photo_GAN (Lines 17–23) turns deblurred sketches into photorealistic images through iterative training, aligning outputs closely with input sketches.
This section outlines the outcomes achieved through the experimental investigation of our proposed image deblurring framework. The system was implemented on a high-performance setup with Dual NVIDIA Tesla P100 GPUs, each with 3584 cores and 18.7 Teraflops of power, and Dual Intel Xeon E5-2609V4 CPUs, with 8 cores at 1.7 GHz and 128 GB RAM. To evaluate the outcomes, the following referential metrics are used: SSIM, PSNR, DIQA SRCC, DIQA PLCC, and AE. Additionally, non-referential metrics such as NIQE, BRISQUE, FID, and IS are also employed (Sannidhan et al., 2019; Hu et al., 2023; Martis et al., 2024).
As previously mentioned, this study utilized photographic images from four datasets: 1) the Acne Recognition Dataset (Kucev, 2023), comprising 220 images, 2) the CUHK dataset (Wang and Tang, 2008), containing 188 images, 3) the AR dataset (Cao et al., 2022), featuring 200 images, and 4) the XM2GTS dataset (Messer et al., 1999), which includes 42 images. Using these images required sketches are generated through CAT. These datasets initially contained no blurred images. Therefore, Gaussian blur (Ai et al., 2023) was applied with kernel 5 × 5 to blur the images. The four datasets used in this study were consistently divided into training and testing sets with a split ratio of 70% for training, and 30% each for testing.
This section explores the impact of CAT on the DeBlurring Module applied to the datasets described in Section 5.1. The effectiveness of CAT in improving image quality is evaluated using the metrics discussed earlier, and the results are presented in Table 1.
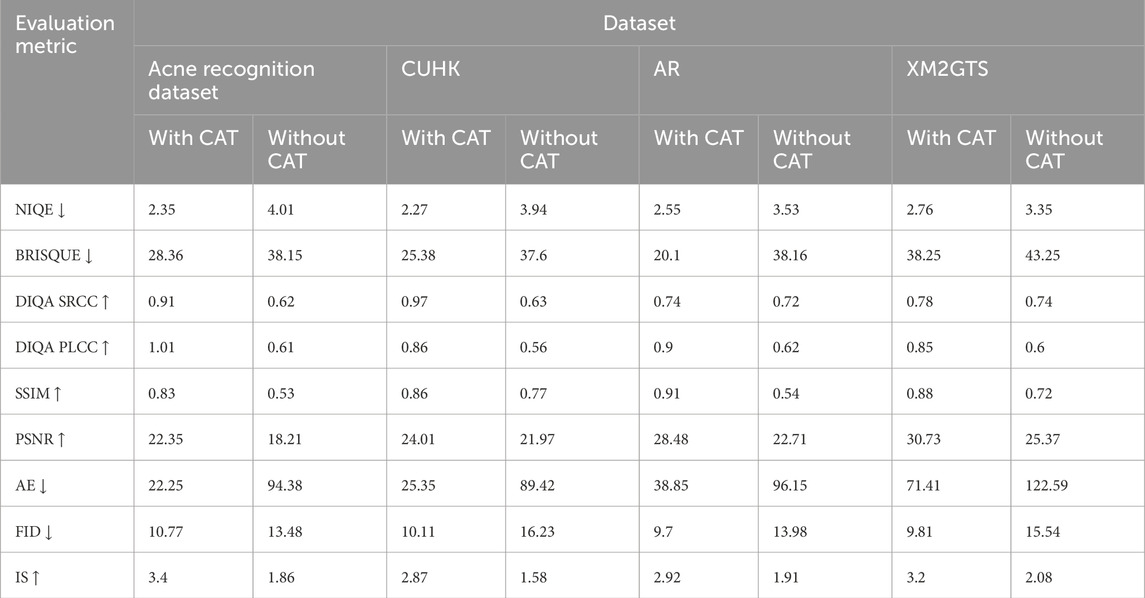
Table 1. Evaluation of CAT’s effectiveness on the deblurring module across datasets.
Table 1 demonstrates that the application of CAT leads to significant improvements across all metrics. Notably, the SSIM shows an average increase of 35% across all datasets. This improvement highlights CAT’s effectiveness in preserving critical structural details.
This section examines the impact of CAT on the image translator module in producing photo images from sketches. The evaluation utilizes sketches generated by the deblurring module, both with and without CAT, as input to the image translator module. Table 2 summarizes the findings, including both non-referential and referential metrics previously discussed, with the data reflecting average values across all datasets outlined in Section 5.1.

Table 2. Impact of CAT on image translator module.
The data in Table 2 shows significant improvements with CAT across all the metrics confirming the impact of CAT aiding the generation of better-quality photos.
This section presents a visual gallery depicting image synthesis evolution during training. Figure 4A illustrates the deblurring process across adopted datasets, transitioning from Ground images to Blurred inputs, blurred sketch produced by CAT and clear photo from image translator module. Further 4 b) presents visual analysis of deblurring using Wiener Filtering and Richardson-Lucy Deconvolution.

Figure 4. (A) Visualization of the proposed image deblurring framework (B) Visual comparison of deblurring results using Wiener Filtering and Richardson-Lucy deconvolution.
Table 3 presents a comparative analysis of the proposed image deblurring framework against existing image enhancement and GAN-based deblurring techniques. The results represent the average values obtained across the adopted datasets.
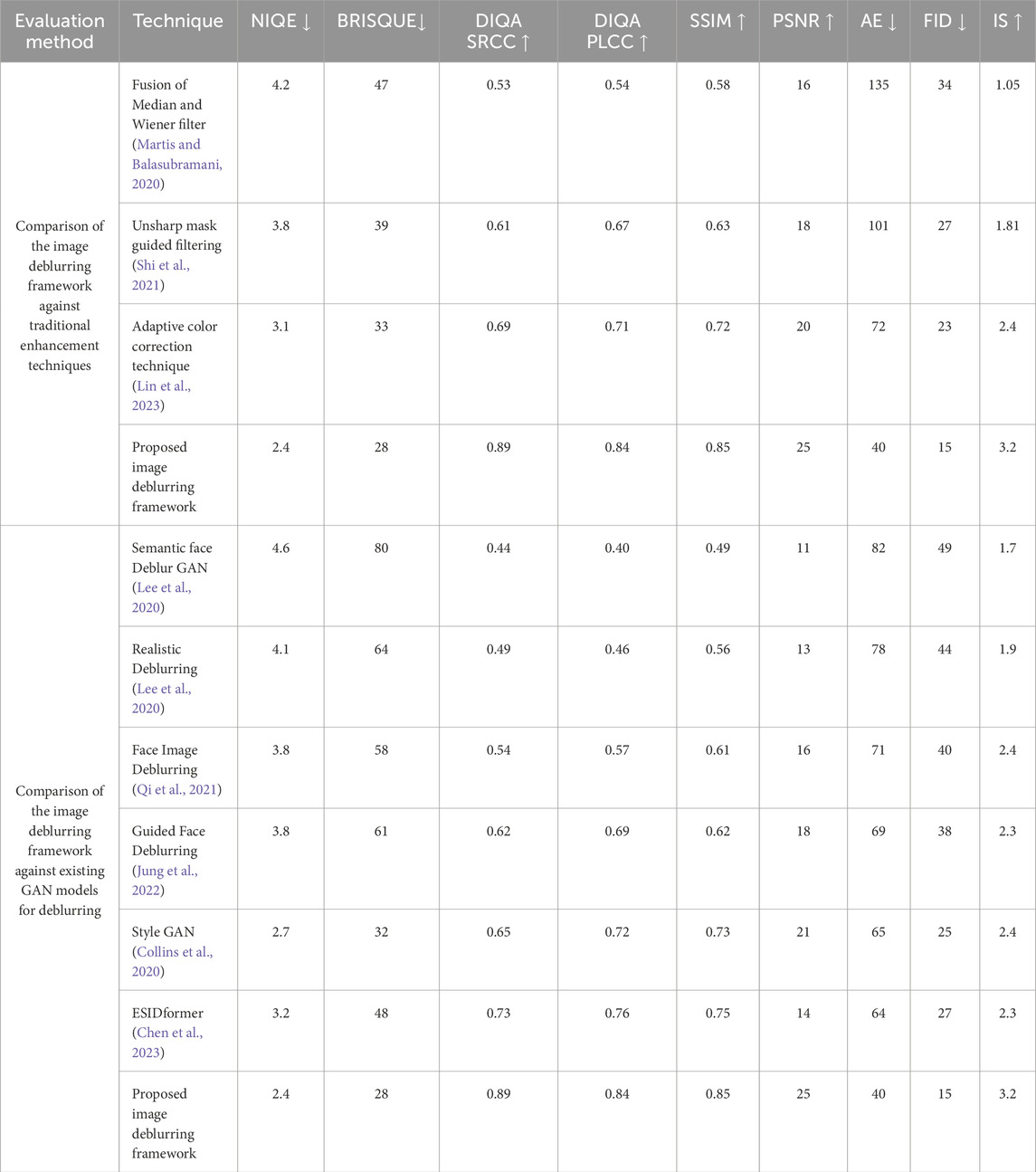
Table 3. Comparison of the proposed image deblurring framework with existing techniques.
In this paper, we propose an image deblurring framework to address blurring issues in teledermatology, with a particular focus on acne images. The framework is designed to deblur images and enhance their clarity through three core modules: the Contour Accentuation Technique (CAT), the deblurring module, and the image translator module. The CAT module forms the foundation of the framework, extracting facial contours from blurred images and generating a blurred sketch to aid the deblurring process in the next module. The deblurring module enhances the clarity of the sketch produced by the CAT module by removing blur. Finally, the image translator module transforms the refined sketch into a photo image, offering a realistic view. Experimental analysis shows that incorporating CAT significantly improves the quality of the generated photo images. The proposed image deblurring framework on comparison achieved notable results, demonstrating superior performance over existing methods. In future, this research work can be extended to support and automate the acne severity assessment, aiding dermatologists in making faster and more accurate diagnoses.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding authors.
PM: Conceptualization, Methodology, Writing–original draft. Sannidhan MS: Conceptualization, Methodology, Writing–original draft, Writing–review and editing. AP: Conceptualization, Funding acquisition, Methodology, Project administration, Writing–review and editing. DC: Formal Analysis, Funding acquisition, Resources, Writing–review and editing. JM: Writing–review and editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This is funded for open access publication upon acceptance by Manipal Institute of Technology, Manipal Academy of Higher Education, Manipal, 576104, India and NMAM Institute of Technology, Nitte Deemed to be University.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ai, X., Ni, G., and Zeng, T. (2023). Color image restoration with mixed Gaussian–Cauchy noise and blur. Comput. Appl. Math. 42 (8), 347. doi:10.1007/s40314-023-02461-0
Bui, T., Ribeiro, L., Ponti, M., and Collomosse, J. (2018). Sketching out the details: sketch-based image retrieval using convolutional neural networks with multi-stage regression. Comput. and Graph. 71, 77–87. doi:10.1016/j.cag.2017.12.006
Cao, B., Wang, N., Li, J., Hu, Q., and Gao, X. (2022). Face photo-sketch synthesis via full-scale identity supervision. Pattern Recognit. 124, 108446. doi:10.1016/j.patcog.2021.108446
Capozzi, L., Pinto, J. R., Cardoso, J. S., and Rebelo, A. (2021). “End-to-End deep sketch-to-photo matching enforcing realistic photo generation,” in Iberoamerican congress on pattern recognition (Cham: Springer International Publishing), 451–460.
Chen, L., and Chen, L. (2022). Adaptive image enhancement method based on gamma correction. Academic Journal of Computing & Information Science 5 (4), 65–70. doi:10.25236/AJCIS.2022.050412
Chen, M., Yi, S., Lan, Z., and Duan, Z. (2023). An efficient image deblurring network with a hybrid architecture. Sensors 23 (16), 7260. doi:10.3390/s23167260
Chen, Y., Wang, Y., Zhang, Y., Feng, R., Zhang, T., Lu, X., et al. (2024). “Fine-granularity face sketch synthesis,” in ICASSP 2024-2024 IEEE international conference on acoustics, speech and signal processing (ICASSP) (IEEE), 4035–4039.
Collins, E., Bala, R., Price, B., and Susstrunk, S. (2020). “Editing in style: uncovering the local semantics of gans,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5771–5780.
Dang, R., Liu, W., and Tan, H. (2024). Recommendations on the correlated color temperature of light sources for traditional Chinese paper relics in museums. LEUKOS 20 (1), 1–8. doi:10.1080/15502724.2022.2143370
Dumitrescu, C., Raboaca, M. S., and Felseghi, R. A. (2021). Methods for improving image quality for contour and textures analysis using new wavelet methods. Appl. Sci. 11 (9), 3895. doi:10.3390/app11093895
Gnanasambandam, A., Sanghvi, Y., and Chan, S. H. (2024). The secrets of non-blind Poisson deconvolution. IEEE Trans. Comput. Imaging 10, 343–356. doi:10.1109/tci.2024.3369414
Hu, B., Zhao, T., Zheng, J., Zhang, Y., Li, L., Li, W., et al. (2023). Blind image quality assessment with coarse-grained perception construction and fine-grained interaction learning. IEEE Trans. Broadcast. 70, 533–544. doi:10.1109/tbc.2023.3342696
Joshi, H., and Sheetlani, J. (2019). Image restoration and deblurring using lucy Richardson technique with wiener and regularized filter. J. Harmon. Res. Appl. Sci. 7 (2), 56–64. doi:10.30876/johr.7.2.2019.56-64
Jung, S. H., Lee, T. B., and Heo, Y. S. (2022). “Deep feature prior guided face deblurring,” in Proceedings of the IEEE/CVF winter conference on applications of computer vision, 3531–3540.
Kucev, R. (2023). Acne recognition dataset. Kaggle. Available at: https://www.kaggle.com/datasets/tapakah68/skin-problems-34-on-the-iga-scale/data.
Kupyn, O., Budzan, V., Mykhailych, M., Mishkin, D., and Matas, J. (2018). “Deblurgan: blind motion deblurring using conditional adversarial networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 8183–8192.
Kupyn, O., Martyniuk, T., Wu, J., and Wang, Z. (2019). “Deblurgan-v2: deblurring (orders-of-magnitude) faster and better,” in Proceedings of the IEEE/CVF international conference on computer vision, 8878–8887.
Lee, T. B., Jung, S. H., and Heo, Y. S. (2020). Progressive semantic face deblurring. IEEE Access 8, 223548–223561. doi:10.1109/access.2020.3033890
Lin, S., Li, Z., Zheng, F., Zhao, Q., and Li, S. (2023). Underwater image enhancement based on adaptive color correction and improved retinex algorithm. IEEE Access 11, 27620–27630. doi:10.1109/access.2023.3258698
Mankotia, P., Bansal, J., and Rai, H. (2024). “Leveraging generative adversarial networks (GANs) for image deblurring,” in 2024 IEEE recent advances in intelligent computational systems (RAICS) (IEEE), 1–5.
Martis, J. E., and Balasubramani, R. (2020). Reckoning of emotions through recognition of posture features. J. Appl. Secur. Res. 15 (2), 230–254. doi:10.1080/19361610.2019.1645530
Martis, J. E., Sannidhan, M. S., Pratheeksha Hegde, N., and Sadananda, L. (2024). Precision sketching with de-aging networks in forensics. Front. Signal Process. 4, 1355573. doi:10.3389/frsip.2024.1355573
Messer, K., Matas, J., Kittler, J., Luettin, J., and Maitre, G. (1999). XM2VTSDB: the extended M2VTS database. Second Int. Conf. audio video-based biometric person authentication 964, 965–966.
Osahor, U., Kazemi, H., Dabouei, A., and Nasrabadi, N. (2020). “Quality guided sketch-to-photo image synthesis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 820–821.
Pan, L., Dai, Y., and Liu, M. (2019). “Single image deblurring and camera motion estimation with depth map,” in 2019 IEEE winter conference on applications of computer vision (WACV) (IEEE), 2116–2125.
Peng, J., Guan, T., Liu, F., and Liang, J. (2023). “MND-GAN: a research on image deblurring algorithm based on generative adversarial network,” in 2023 42nd Chinese control conference (CCC) (IEEE), 7584–7589.
Qi, Q., Guo, J., Li, C., and Xiao, L. (2021). Blind face images deblurring with enhancement. Multimedia Tools Appl. 80, 2975–2995. doi:10.1007/s11042-020-09460-x
Samizadeh, S. (2022). Aesthetic assessment of the face. Non-Surgical Rejuvenation Asian Faces, 107–121. doi:10.1007/978-3-030-84099-0_8
Sannidhan, M. S., Prabhu, G. A., Robbins, D. E., and Shasky, C. (2019). Evaluating the performance of face sketch generation using generative adversarial networks. Pattern Recognit. Lett. 128, 452–458. doi:10.1016/j.patrec.2019.10.010
Shi, C., Zhang, X., Li, X., Mumtaz, I., and Lv, J. (2024). Face deblurring based on regularized structure and enhanced texture information. Complex and Intelligent Syst. 10 (2), 1769–1786. doi:10.1007/s40747-023-01234-w
Shi, Z., Chen, Y., Gavves, E., Mettes, P., and Snoek, C. G. (2021). Unsharp mask guided filtering. IEEE Trans. Image Process. 30, 7472–7485. doi:10.1109/tip.2021.3106812
Song, L., and Lam, E. Y. (2021). “MBD-GAN: model-based image deblurring with a generative adversarial network,” in 2020 25th international conference on pattern recognition (ICPR) (IEEE), 7306–7313.
Šroubek, F., Kerepecký, T., and Kamenický, J. (2019). “Iterative Wiener filtering for deconvolution with ringing artifact suppression,” in 2019 27th European signal processing conference (EUSIPCO) (IEEE), 1–5.
Suha, S. A., and Sanam, T. F. (2022). A deep convolutional neural network-based approach for detecting burn severity from skin burn images. Mach. Learn. Appl. 9, 100371. doi:10.1016/j.mlwa.2022.100371
Tani, H., and Yamawaki, A. (2024). Light-weight color image conversion like pencil drawing for high-level synthesized hardware. Artif. Life Robotics 29 (1), 29–36. doi:10.1007/s10015-023-00927-2
Vodrahalli, K., Daneshjou, R., Novoa, R. A., Chiou, A., Ko, J. M., and Zou, J. (2020). “TrueImage: a machine learning algorithm to improve the quality of telehealth photos,” in Biocomputing 2021: proceedings of the pacific symposium, 220–231.
Wang, J., Xiong, Z., Huang, X., Shi, H., and Wu, J. (2023). “Image deblurring using fusion transformer-based generative adversarial networks,” in International conference on mobile networks and management (Cham: Springer Nature Switzerland), 136–153.
Wang, X., and Tang, X. (2008). Face photo-sketch synthesis and recognition. IEEE Trans. pattern analysis Mach. Intell. 31 (11), 1955–1967. doi:10.1109/TPAMI.2008.222
Xiong, L., Hu, Y., and Zhang, D. (2024). “An improved image deblurring algorithm based on GAN,” in 2024 IEEE 3rd international conference on electrical engineering, big data and algorithms (EEBDA) (IEEE), 1226–1230.
Yu, S., Han, H., Shan, S., Dantcheva, A., and Chen, X. (2019). “Improving face sketch recognition via adversarial sketch-photo transformation,” in 2019 14th IEEE international conference on automatic face and gesture recognition (FG 2019) (IEEE), 1–8.
Zhai, L., Wang, Y., Cui, S., and Zhou, Y. (2022). “Enhancing underwater image using degradation adaptive adversarial network,” in 2022 IEEE International Conference on Image Processing (ICIP) (IEEE), 4093–4097.
Keywords: generative adversarial networks, image deblurring, contour accentuation technique, teledermatology, acne severity detection
Citation: Mascarenhas PP, Sannidhan MS, Pinto AJ, Camero D and Martis JE (2025) Improving acne severity detection: a GAN framework with contour accentuation for image deblurring. Front. Bioinform. 5:1485797. doi: 10.3389/fbinf.2025.1485797
Received: 24 August 2024; Accepted: 14 February 2025;
Published: 10 March 2025.
Edited by:
Steven Fernandes, Creighton University, United StatesReviewed by:
Luigi Di Biasi, University of Salerno, ItalyCopyright © 2025 Mascarenhas, Sannidhan, Pinto, Camero and Martis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: M. S. Sannidhan, c2FubmlkaGFuQG5pdHRlLmVkdS5pbg==; Ancilla J. Pinto, cGludG8uYW5jaWxsYWpAbWFuaXBhbC5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.