 Emilia Ståhlbom
Emilia Ståhlbom Jesper Molin2
Jesper Molin2 Claes Lundström
Claes Lundström
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
PERSPECTIVE article
Front. Bioinform. , 29 March 2023
Sec. Data Visualization
Volume 3 - 2023 | https://doi.org/10.3389/fbinf.2023.1112649
This article is part of the Research Topic Expert Opinions in bioinformatics data visualization View all 4 articles
In this perspective article we discuss a certain type of research on visualization for bioinformatics data, namely, methods targeting clinical use. We argue that in this subarea additional complex challenges come into play, particularly so in genomics. We here describe four such challenge areas, elicited from a domain characterization effort in clinical genomics. We also list opportunities for visualization research to address clinical challenges in genomics that were uncovered in the case study. The findings are shown to have parallels with experiences from the diagnostic imaging domain.
Readers of this journal are likely to concur that research on visualization for bioinformatics data is both important and challenging. In this perspective article we will discuss a subarea where additional complex challenges come into play: visualization methods targeting clinical use. In our experience, these thorny complexities are particularly pertinent in genomics.
From several aspects, biomedical visualization research has been thoroughly mapped out. In terms of application areas, Garrison et al. (2022) provide a comprehensive overview. In terms of articulating the scientific discipline as such, Raidou et al. (2020) describe many key aspects. We argue, however, that the complexities of targeting clinical work constitute another fundamental but less recognized aspect of this discipline, complementary to visualization research targeting scientists.
A main contribution of this article is to articulate the challenge areas arising when visualization research in bioinformatics targets clinical use. The four challenge areas were identified through a case study, a domain characterization effort in clinical genomics. Another contribution is the agenda for visualization method development opportunities uncovered by the case study. Finally, we will put our findings in a greater context, where we find strong parallels with visualization for diagnostic imaging.
In this section we will briefly walk through the clinical workflows that constitute the background of this perspective article. Around the world, precision medicine initiatives are underway that can be expected to greatly increase the use of DNA sequencing in clinical routine, such as using broad panels as the norm for oncology patients.
DNA sequencing is performed by request from the patient’s treating physician. The output data from sequencing is interpreted by a variant analyst, who relates their findings in a report to the ordering physician. Interpreting the data entails finding variants that are relevant to the patient’s disease and relating said variants to previous knowledge. The variant analyst needs to navigate multiple gigabytes of data per case, and sort through an assortment of knowledge databases. Thus, the task of efficiently reaching insights through data-intensive analysis fully maps to the core value proposition of visualization methods.
The most common method for DNA sequencing is next-generation sequencing (NGS), where the sample DNA is broken into fragments before being sequenced (Figure 1A). The fragment sequences are then mapped to a reference genome based on similarity, to determine their most likely original coordinates. The vast amount of data is handled through use of callers, software algorithms that find suspected variants, calls, in the sequencing output data. Simply put, the work of the variant analyst is to review the calls and report conclusions relevant for treatment decisions to the physician (Figure 1B).
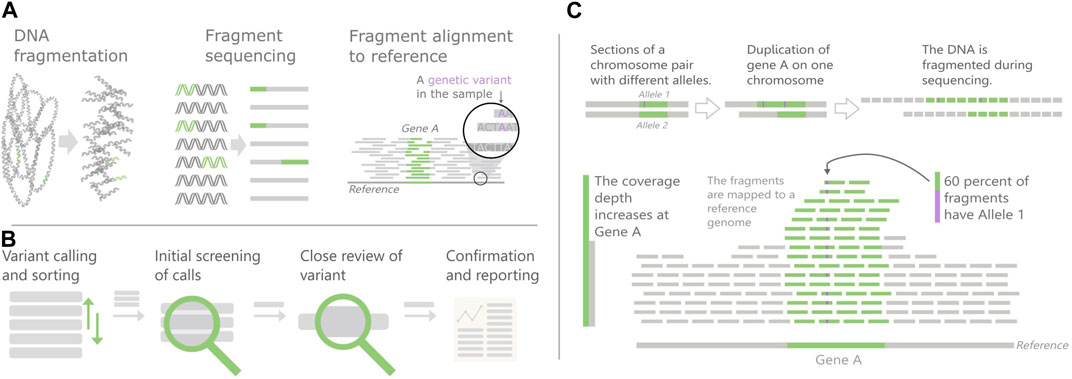
FIGURE 1. Overview of Next-generation sequencing (NGS) and Copy number variants (CNVs). (A) The NGS principles (B) Variant review pipeline, (C) CNV detection in NGS data. CNVs cause an increase in the number of fragments mapped to their area, which can skew the fraction of segments with different alleles.
This perspective article will use analysis of copy number variants (CNVs) as a case study. A CNV is an increase or decrease in the number of copies of a large section of the genome. Current research shows that CNVs are important in cancer development as well as for some hereditary diseases, but little is still known about their full impact. They are also complicated to find in NGS data since they are longer than the DNA fragments.
Challenges and opportunities relevant for visualization in clinical genomics has been discussed in previous work. Handling variants of unknown significance is one such challenge (Biesecker, 2012; Hellwig et al., 2019), as is other types of decision support design (Yaung and Pek, 2021; Kulchak Rahm et al., 2021). Effective reporting is another area in focus, both to ordering physician and to patients (Biesecker (2012); Wynn et al., 2018; Sanderson et al., 2019). Tools for collaboration and knowledge sharing between geneticists have also been studied (Liang, 2017).
A good entry point to NGS visualization methods is the survey and taxonomy presented by Nusrat et al. (2019), which was also the base for visualization framework efforts (L’Yi et al., 2022; Pandey et al., 2022; L’Yi and Gehlenborg, 2022). Other previous efforts have proposed methods targeting specific genomics analysis tasks (O’Brien et al., 2010; Ruddle et al., 2013; Ferstay et al., 2013; Reber et al., 2013). Some of these methods partially target an everyday clinical scenario, whereas some do not, but many components and ideas are nevertheless promising to include in future clinical solutions.
Efforts mainly residing in the bioinformatics research community often include tools to visualize genomics data as well. As our case study centers on CNV analysis, CNV visualization tools are the most relevant here (Tebel et al., 2017; Sante et al., 2014; Macnee et al., 2022; Chandramohan et al., 2021; Markham et al., 2019; Ramesh et al., 2022; Ma et al., 2015; Zhou et al., 2021; Chanwigoon et al., 2020). Many tools target cohort analysis and other types of research-only use. A common trait for the development of these tools is that the respective design process is tightly connected to the specific needs and requirements of the creator’s own organizations. Broader analyses of domain challenges and in-depth end-user evaluations are not in focus, making it difficult to draw conclusions on how well the tools would fit other scenarios and organizations.
The empirical examples of the challenge areas, discussed below, stem from a case study on CNV visualization needs. In the first phase of an ongoing research effort to design genomics visualizations for the clinic, based on a design study approach (Meyer and Dykes, 2020), we performed a domain characterization based on interviews. We conducted three in-depth semi-structured interviews with predetermined interview guides as scaffolds, with domain experts (bioinformaticians and geneticists) who work with analyzing NGS data for diagnosis of inherited disease. All three domain experts had experience from all steps in the variant review pipeline of Figure 1B. In addition, informal discussions were held with genomics laboratory personnel (including technicians, geneticists, and bioinformaticians) from both oncology and clinical laboratories. In total thirteen participants across four different hospitals were consulted. We focused on inherited disease as reviewing CNVs in clinical routine today mainly is done within that area in the hospitals we visited.
The structure of the deep interviews was as follows. After an introduction to the study, the participants were asked to describe the situations in which they do CNV analysis. The interview then moved to questions to drill down into details about analysis tasks, data, existing tools, reporting, and wish lists for the future. The participants were encouraged to explain through case walk-through, while speaking about the performed actions out loud. The final part consisted of getting feedback on paper sketches on visualization designs. The informal discussions followed shorter interview guides or were led primarily by the participant. We used transcriptions and thematic encoding (Braun and Clarke, 2006) to analyze the material, resulting in six themes summarized in Figure 2.
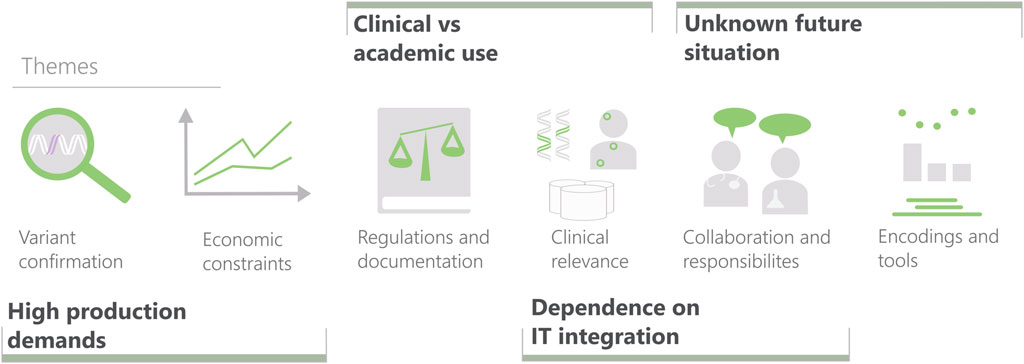
FIGURE 2. The six themes characterizing variant interpretation created from interview data and the four elicited challenge areas for visualization research in clinical settings (bold), including their relation to the themes. Themes, from left to right: Variant confirmation (mainly ruling out false positives). Effects of limited time and resources. Constraints imposed by laws and regulations (ranging from IT security to validation of laboratory processes). Evaluating the clinical relevance of a variant. The interplay between the professions involved in the diagnostic work. Encodings and tools used for displaying CNVs.
The focus of this perspective article is to outline generic challenges for clinical visualization research. With that objective, we analyzed the interview findings to regroup them into such challenge areas. The four areas elicited will be described next. For each area, a first paragraph articulates the respective visualization research challenge, which then is followed by underpinning examples from the genomics case study. The relations between themes and areas are given in Figure 2. The case study also uncovered distinct unmet needs that form an agenda for visualization method development in this domain, which is outlined in Section 4.5.
The first challenge area in clinical settings is the demand of high throughput. Economic pressure in healthcare is severe, leading to a mindset where any activities aside from those directly affecting patient management typically are discarded. In essence, the challenge here lies in giving the productivity demand a sufficiently dominant weight, which is in conflict with a visualization researcher’s natural ambitions to convey as much insights from the data as possible.
Several findings in the Variant confirmation and Economic constraints theme of the case study illustrate the challenges of clinical work being a high-production workflow. First and foremost, a recurring observation is: Time constraints limit the breadth of which calls to review and the depth of review for each variant called. Only some calls are investigated, where the trade-off is made between the risk of missing something essential and the waste of spending time on unnecessary analysis. The decision on how to limit breadth and depth leans heavily on the time available. Participants expressed a desire to focus their attention only on the most promising calls, and requested better methods for ranking the calls.
As further exemplified in the descriptions of variant confirmation work, a particularly important aspect is that the list of potential CNVs contains many false positives and is typically too long to go through thoroughly. To work effectively, the analysts rely on CNV caller methods for filtering and sorting the calls, but the quality of callers is a common source of frustration. One participant describes it as:
”Either you have very low sensitivity or […] you’re drowning in false positives”.
A related area is the difference between clinical and academic work, which includes more aspects than the difference in production pace discussed above. This is particularly articulated in genomics, an area characterized by academic operations being very influential on clinical use. This prerequisite poses a risk that visualization methods are inadvertently developed for a research setting, and that it can be difficult to realize what advances are needed to reach clinical effectiveness.
An overarching observation, essentially corresponding to the entire Clinical relevance theme, pinpoints this challenge area: Only findings that have clinical relevance for the patient’s symptoms are investigated and reported. In other words, work that is spent eliciting information that cannot be used to guide the patient’s treatment is considered as wasted time. This type of usefulness emphasis is represented also in other matters, including diverging opinions among the participants regarding whether whole-genome sequencing is worth the extra cost (including the additional review time).
Another area of contrast is represented by findings in the Regulations and documentation part of the case study. In clinical settings, the documentation of the review is dictated by regulatory demands. The responsibility is summarized as follows by one of the respondents:
”We have to make sure that it works from sample arrival until report submission.”
When asked about how documentation of the interpretation process was solved in practice, participant’s answers referred to manual activities such as keeping intermediary results in their heads or writing on paper what to follow up on later in the process.
The regulatory demands also refer to validation of both the sequencing and review process. While scientific rigor also requires good control of genomics operations, for clinical work, the moral and legal responsibility for the welfare of actual patients constitutes a higher bar. In some cases, the academically developed CNV detection methods are not validated for clinical use, which means that any findings must be verified with another technique.
Empirical evidence for successful visualization designs is typically gathered through user studies. In this respect, a challenge applicable to most visualization research is that a new tool will have an unfair disadvantage compared to the existing tool which is well known to the end user. The challenge is, however, much greater when future workflows are unknown and not even the end user knows what the future situation will be like.
The challenge area of designing visualizations for unknown future scenarios is highlighted by findings regarding roles and competence in the Collaboration and responsibilities theme. In several ways, participants expressed that current practices are in need of improvement. One sign of lacking maturity is that the competence mix and work practices were different across the sites. Moreover, one respondent highlighted the need for more and deeper collaboration across professions as genomic testing becomes more complex. However, the main finding pointing to the necessity of future changes to work descriptions and role responsibilities is that several respondents underlined the challenge of varying experience in the laboratory team.
Knowledge of laboratory procedures and understanding of the bioinformatics software creates an awareness of their limitations. For example, novice variant analysts might trust pathogenicity prediction software too much. One participant expressed concern regarding errors when designing the sequencing process or interpreting its results, that could be made by an analyst or physician with less experience.
Further illustration of this challenge area comes from the Encodings and tools theme. Several sites use result presentation conventions from microarray visualization, the previously predominant genomics testing method, to address varying levels of experience. For example, one site employs base pair binning to display copy number in scatterplots instead of the bar chart of coverage depth. While much detail is lost, it decreases the need for training personnel to work with a new data representation.
Thus, there is currently a disconnect between the competence of the roles in the process, and what at least the most competent users believe corresponds to high quality care. Time will tell what the situation will converge to (in terms of competence development, new roles, adapted workflows, etc.), but it is clear that a visualization researcher needs to target scenarios that are not fully in place today.
The fourth challenge area is the difficulty to isolate clinical tools from each other. The dependence on the integration with existing IT systems, such as the electronic health record or laboratory information system, will have great impact on the user experience of any visualization tool. Thus, a user evaluation of a novel visualization application in an isolated setup may be of little relevance for usefulness in an actual, integrated clinical setting.
IT integration aspects often appeared in the interviews. With regards to the Clinical relevance theme, several participants expressed that they needed to search in many different places to get a clear picture of current knowledge of their variant. Some sources are used to investigate the function of the gene, some contain variant occurrence frequency and pathogenicity, and others focus only on one variant type or disease. This is perhaps best summarized by the following statement:
”I have a thousand tabs open at the same time.”
Joint work across sites also adds IT complexity, as interviewees reported in the Collaboration and responsibilities theme. One site relies on another site for some of their bioinformatics, for example. The integration area also connects to the challenges of targeting an unknown future, as the respondents expressed desire to include further systems not yet available due to legal concerns about cloud services.
Apart from informing the challenge area descriptions, many of the domain characterization findings also describe current pain points that constitute opportunities for visualization research in terms of method and application development.
In the variant call screening step, the task of narrowing down the call list to a few candidates for further scrutiny is described as time-consuming if manual, or error-prone if automated. A visualization opportunity in this context is condensed glyphs or other representations to give pre-attentive cues to allow the analyst to skip irrelevant list entries, at subsecond pace.
The multiscale characteristic of variant review offers possibilities for tailored visualization methods. Semantic zoom concepts, where information items persist but become more granular when drilling down, appear as a promising approach. The large number of sources that needs to be involved in the variant review points towards linked views solutions, but at a particularly challenging level.
In several analytic steps, effective comparative visualization designs will be needed, as the genomic output needs to be compared to other individual cases, local cohorts, and larger populations. A research target would be to address this need by developing condensation methods for difference graphs. Another aspect that will need to permeate many visualization components is uncertainty awareness, a major factor for instance in determining clinical relevance.
With regards to the need for documentation, it would be interesting to study how well visualization provenance methods could tackle this, in combination with automatic summaries of key events. Along similar lines, an interesting research target would be methods for report generation that captures the necessary conclusions in the background without explicit user entries.
We have presented our insights on how an ambition to do visualization research targeting clinical needs will entail additional challenges. We hope that these perspectives can be useful for future efforts towards this, in our view, highly motivated type of medical visualization research. Insights from visualization researchers working with scientists from other domains were described by Beyer et al. (2020). Notably, in that context the challenge areas presented here are not brought up, again pointing to a distinct difference in working in the clinical setting compared to a scientific usage scenario.
The conclusions from our domain characterization in genomics are well aligned with our experiences from many years of similar work in radiology and pathology. High production demands were confirmed in our work to characterize visual analytics in radiology, where time pressure was seen by radiologists as the most challenging aspect of all (Lundström and Persson, 2011). This means that tools entailing even a minor additional workload are unlikely to be adopted even if there are other benefits. The current situation of rapid evolution of clinical genomics practices can be related to the digitization of pathology imaging, that for us posed the research challenge of designing visualizations for a not yet existing user group (Molin et al., 2015). The need to account for productivity demands and IT integration has been underlined also in the area of clinical decision support in tumor boards (Müller et al., 2021).
With regards to clinical vs. academic use, there is a parallel to the current focus of artificial intelligence (AI) implementation in diagnostic imaging. There is a disconnect between the isolated sandbox of typical AI studies and the actual clinical workflows (Adler-Milstein et al., 2021). Moreover, the performance evaluations during method development are not sufficient, and validation in the actual clinical environment is necessary (Daye et al., 2022). The final challenge area about the need for integration with existing systems also turns up in diagnostic imaging AI, as it is highlighted as a key success factor for clinical implementation (Daye et al., 2022).
The perspectives described in this article can also be put into a bigger picture. The traditional mindset for the process of making research impact in healthcare is to go from identifying knowledge gaps in medicine, carrying out basic research addressing them, then carrying out translational research efforts, followed by clinical implementation. The model for visualization research towards clinical use is a different one, that one could call healthcare-native research. Here, the clinical prerequisites do not come in only in a translational phase, but constitute the origin of the research agenda and permeates the method development throughout.
In conclusion, the complexities of visualization research for clinical settings are thorny—but challenges are also inspirational for making advances. We hope that many will agree with us that the many opportunities for visualization to have impact in the bioinformatics areas of healthcare should attract much scientific interest in years to come.
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding author.
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
ES conceived and carried out the domain characterization study, assisted by JM, AY, and CL. CL conceived the challenge areas. ES and CL wrote the first draft of the article, which all authors jointly finalized.
This research has been funded by the Swedish Foundation for Strategic Research, grant ID20-0092, and the Knut and Alice Wallenberg Foundation through Grant KAW 2019.0024.
We would like to thank all study participants for sharing their knowledge and limited time.
ES, JM, and CL are employed at Sectra AB.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Adler-Milstein, J., Chen, J. H., and Dhaliwal, G. (2021). Next-generation artificial intelligence for diagnosis: From predicting diagnostic labels to “wayfinding”. Jama 326, 2467–2468. doi:10.1001/jama.2021.22396
Beyer, J., Hansen, C., Hlawitschka, M., Hotz, I., Kozlikova, B., Scheuermann, G., et al. (2020). “Case studies for working with domain experts,” in Foundations of data visualization (Springer), 255–278.
Biesecker, L. G. (2012). Opportunities and challenges for the integration of massively parallel genomic sequencing into clinical practice: Lessons from the ClinSeq project. Genet. Med. 14, 393–398. Number: 4 Publisher: Nature Publishing Group. doi:10.1038/gim.2011.78
Braun, V., and Clarke, V. (2006). Using thematic analysis in psychology. Qual. Res. Psychol. 3, 77–101. doi:10.1191/1478088706qp063oa
Chandramohan, R., Kakkar, N., Roy, A., and Parsons, D. W. (2021). reconCNV: interactive visualization of copy number data from high-throughput sequencing. Bioinformatics 37, 1164–1167. doi:10.1093/bioinformatics/btaa746
Chanwigoon, S., Piwluang, S., and Wichadakul, D. (2020). inCNV: An integrated analysis tool for copy number variation on whole exome sequencing. Evol. Bioinforma. 16, 117693432095657. Publisher: SAGE Publications Ltd STM. doi:10.1177/1176934320956577
Daye, D., Wiggins, W. F., Lungren, M. P., Alkasab, T., Kottler, N., Allen, B., et al. (2022). Implementation of clinical artificial intelligence in radiology: Who decides and how? Radiology 305, 555–563. doi:10.1148/radiol.212151
Ferstay, J. A., Nielsen, C. B., and Munzner, T. (2013). “Variant view: Visualizing sequence variants in their gene context,” in IEEE transactions on visualization and computer graphics, 19, 2546–2555. doi:10.1109/TVCG.2013.214
Garrison, L. A., Kolesar, I., Viola, I., Hauser, H., and Bruckner, S. (2022). “Trends & opportunities in visualization for physiology: A multiscale overview,” in Computer graphics forum (Wiley Online Library), 41, 609–643.
Hellwig, L. D., Turner, C., and O’Neill, S. C. (2019). Patient-centered care and genomic medicine: A qualitative provider study in the military health system. J. Genet. Couns. 28, 940–949. doi:10.1002/jgc4.1144
Kulchak Rahm, A., Walton, N. A., Feldman, L. K., Jenkins, C., Jenkins, T., Person, T. N., et al. (2021). User testing of a diagnostic decision support system with machine-assisted chart review to facilitate clinical genomic diagnosis. BMJ Health & Care Inf. 28, e100331. doi:10.1136/bmjhci-2021-100331
Liang, W. H. (2017). User-centered design of a collaborative genetic variant interpretation tool. Master Thesis. University of Washington.
Lundström, C., and Persson, A. (2011). “Characterizing visual analytics in diagnostic imaging,” in EuroVA@ EuroVis.
L’Yi, S., and Gehlenborg, N. (2022). Multi-view design patterns and responsive visualization for genomics data (Open Science Framework). doi:10.31219/osf.io/pd7vq
L’Yi, S., Wang, Q., Lekschas, F., and Gehlenborg, N. (2022). Gosling: A grammar-based toolkit for scalable and interactive genomics data visualization. IEEE Trans. Vis. Comput. Graph. 28, 140–150. doi:10.1109/TVCG.2021.3114876
Ma, L., Qin, M., Liu, B., Hu, Q., Wei, L., Wang, J., et al. (2015). cnvCurator: an interactive visualization and editing tool for somatic copy number variations. BMC Bioinforma. 16, 331. doi:10.1186/s12859-015-0766-y
Macnee, M., Pérez-Palma, E., Brünger, T., Klöckner, C., Platzer, K., Stefanski, A., et al. (2022). CNV-ClinViewer: Enhancing the clinical interpretation of large copy-number variants online [Preprint]. doi:10.1101/2022.03.23.22272818
Markham, J. F., Yerneni, S., Ryland, G. L., Leong, H. S., Fellowes, A., Thompson, E. R., et al. (2019). CNspector: A web-based tool for visualisation and clinical diagnosis of copy number variation from next generation sequencing. Sci. Rep. 9, 6426. doi:10.1038/s41598-019-42858-8
Meyer, M., and Dykes, J. (2020). Criteria for rigor in visualization design study. IEEE Trans. Vis. Comput. Graph. 26, 1–97. doi:10.1109/TVCG.2019.2934539
Molin, J., Fjeld, M., Mello-Thoms, C., and Lundström, C. (2015). Slide navigation patterns among pathologists with long experience of digital review. Histopathology 67, 185–192. doi:10.1111/his.12629
Müller, J., Cypko, M., Oeser, A., Stoehr, M., Zebralla, V., Schreiber, S., et al. (2021). Visual assistance in clinical decision support. EuroVis 2021—Dirk Bartz Prize.
Nusrat, S., Harbig, T., and Gehlenborg, N. (2019). Tasks, techniques, and tools for genomic data visualization. Comput. Graph. Forum 38, 781–805. doi:10.1111/cgf.13727
O’Brien, T. M., Ritz, A. M., Raphael, B. J., and Laidlaw, D. H. (2010). Gremlin: An interactive visualization model for analyzing genomic rearrangements. IEEE Trans. Vis. Comput. Graph 16, 918–926. doi:10.1109/TVCG.2010.163
Pandey, A., L’Yi, S., Wang, Q., Borkin, M., and Gehlenborg, N. (2022). GenoREC: A recommendation system for interactive genomics data visualization. [Preprints]. doi:10.31219/osf.io/rscb4
Raidou, R., Kozlikova, B., Beyer, J., Ropinski, T., and Fujishiro, I. (2020). “NII Shonan meeting report no. 167: Formalizing biological and medical visualization,” in Formalizing Biological and Medical Visualization, February 24–27, 2020 (Chiyoda-Ku: National Institute of Informatics).
Ramesh, R. G., Bigdeli, A., Rushton, C., and Rosenbaum, J. N. (2022). CNViz: An R/Shiny application for interactive copy number variant visualization in cancer. J. Pathol. Inform. 13, 100089. doi:10.1016/j.jpi.2022.100089
Reber, S., Zhao, Y., Zhang, L., Orloff, M., and Eng, C. (2013). “Visual analysis of tracts of homozygosity in human genome,” in EuroVis Workshop on Visual Analytics, 5. ISBN: 9783905674552 Publisher: The Eurographics Association. doi:10.2312/PE.EUROVAST.EUROVA13.037-041
Ruddle, R. A., Fateen, W., Treanor, D., Sondergeld, P., and Quirke, P. (2013). “Leveraging wall-sized high-resolution displays for comparative genomics analyses of copy number variation,” in 2013 IEEE symposium on biological data visualization (BioVis) (IEEE), 89–96. doi:10.1109/BioVis.2013.6664351
Sanderson, S. C., Hill, M., Patch, C., Searle, B., Lewis, C., and Chitty, L. S. (2019). Delivering genome sequencing in clinical practice: An interview study with healthcare professionals involved in the 100 000 genomes project. BMJ Open 9, e029699. Publisher: British Medical Journal Publishing Group Section: Genetics and genomics. doi:10.1136/bmjopen-2019-029699
Sante, T., Vergult, S., Volders, P.-J., Kloosterman, W. P., Trooskens, G., Preter, K. D., et al. (2014). ViVar: A comprehensive platform for the analysis and visualization of structural genomic variation. PLoS ONE 9, e113800. Publisher: Public Library of Science. doi:10.1371/journal.pone.0113800
Tebel, K., Boldt, V., Steininger, A., Port, M., Ebert, G., and Ullmann, R. (2017). GenomeCAT: A versatile tool for the analysis and integrative visualization of DNA copy number variants. BMC Bioinform. 18 (1), 19. doi:10.1186/s12859-016-1430-x
Wynn, J., Lewis, K., Amendola, L. M., Bernhardt, B. A., Biswas, S., Joshi, M., et al. (2018). Clinical providers’ experiences with returning results from genomic sequencing: An interview study. BMC Med. Genomics 11, 45. doi:10.1186/s12920-018-0360-z
Yaung, S. J., and Pek, A. (2021). From information overload to actionable insights: Digital solutions for interpreting cancer variants from genomic testing. J. Mol. Pathology 2, 312–318. Number: 4 Publisher: Multidisciplinary Digital Publishing Institute. doi:10.3390/jmp2040027
Keywords: visualization, bioinformatics, genomics, next-generation sequencing, copy number variant (CNV), visual analytics (VA), cancer, rare diseases
Citation: Ståhlbom E, Molin J, Ynnerman A and Lundström C (2023) The thorny complexities of visualization research for clinical settings: A case study from genomics. Front. Bioinform. 3:1112649. doi: 10.3389/fbinf.2023.1112649
Received: 30 November 2022; Accepted: 13 March 2023;
Published: 29 March 2023.
Edited by:
Barbora Kozlikova, Masaryk University, CzechiaReviewed by:
Cagatay Turkay, University of Warwick, United KingdomCopyright © 2023 Ståhlbom, Molin, Ynnerman and Lundström. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Emilia Ståhlbom, ZW1pbGlhLnN0YWhsYm9tQGxpdS5zZQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.