 Chieh-Tsai Wu1,2
Chieh-Tsai Wu1,2 Yau-Zen Chang
Yau-Zen Chang
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Bioeng. Biotechnol., 11 December 2023
Sec. Biomaterials
Volume 11 - 2023 | https://doi.org/10.3389/fbioe.2023.1297933
This article is part of the Research TopicHighlights from Conference of Biomaterials International 2023View all 8 articles
Creating a personalized implant for cranioplasty can be costly and aesthetically challenging, particularly for comminuted fractures that affect a wide area. Despite significant advances in deep learning techniques for 2D image completion, generating a 3D shape inpainting remains challenging due to the higher dimensionality and computational demands for 3D skull models. Here, we present a practical deep-learning approach to generate implant geometry from defective 3D skull models created from CT scans. Our proposed 3D reconstruction system comprises two neural networks that produce high-quality implant models suitable for clinical use while reducing training time. The first network repairs low-resolution defective models, while the second network enhances the volumetric resolution of the repaired model. We have tested our method in simulations and real-life surgical practices, producing implants that fit naturally and precisely match defect boundaries, particularly for skull defects above the Frankfort horizontal plane.
Skull defects can arise from various causes, including trauma, congenital malformations, infections, and iatrogenic treatments such as decompressive craniectomy, plastic surgery, and tumor resection. Recent studies (Yeap et al., 2019; Alkhaibary et al., 2020) have demonstrated that reconstructing extensive skull defects can significantly improve patients’ physiological and neurological processes by restoring cerebrospinal fluid dynamics and motor and cognitive functions. However, designing a customized implant for cranioplasty is complex and expensive, especially in cases with comminuted fractures.
Advances in medical imaging and computational modeling have enabled the creation of custom-made implants using computer-aided design software. The design process typically involves intensive human-machine interaction using specialized software and requires medical expertise. For example (Lee et al., 2009; Chen et al., 2017), have used mirrored geometry as a starting point for developing an implant model. However, since most human skulls are asymmetric to the sagittal plane, a unilateral defect may still require significant modification to fit the defect boundary after the mirroring operation, let alone defects spanning both sides.
Significant progress has been made in deep learning-based 2D image restoration. For instance (Yang et al., 2017), proposed a multi-scale convolutional neural network to provide high-frequency details for defect reconstruction. The image inpainting schemes of (Pathak et al., 2016; Iizuka et al., 2017) used an encoder-decoder network structure (Hinton and Salakhutdinov, 2006; Baldi, 2011; Dai et al., 2017) for adversarial loss training based on the Generative Adversarial Networks scheme (Goodfellow et al., 2014; Li et al., 2017). Yan and coauthors (Yan et al., 2018) also introduced a shift connection layer in the U-Net architecture (Ronneberger et al., 2015) for repairing defective images with fine details.
While deep learning techniques have made noteworthy progress in 2D image completion, 3D shape inpainting remains challenging due to the higher dimensionality and computational requirements to process 3D data (Maturana and Scherer, 2015). Among the early studies, Morais and coauthors in (Morais et al., 2019) conducted a pioneering study using an encoder-decoder network to reconstruct defective skull models at a volumetric resolution of up to 120 × 120 × 120 by integrating eight equally sized voxel grids of size 60 × 60 × 60.
In (Mahdi, 2021), a U-net (Ronneberger et al., 2015) scheme was developed to predict complete skulls, where the cropped skull modes were down-sampled and rescaled to a voxel resolution of 192 × 256 × 128. This investigation also demonstrates the importance of the quantity and diversity of datasets to ensure the quality and robustness of network predictions (Li et al., 2021a). proposed a patch-based training strategy for 3D shape completion by assembling an encoder-decoder network and a U-net on 128 × 128 × 128 patches cropped from defective skull models. This approach alleviates the memory and computational power requirements. However, when the size of the defect is close to the patch size, the reconstruction performance significantly worsens. Besides, as observed in (Li et al., 2021b), merging patches can easily lead to uneven surfaces.
In (Ellis and Aizenberg, 2020), four 3D U-Net (Ronneberger et al., 2015) models with the same architecture were trained separately in an ensemble. All four models were used to predict complete skulls with a volume resolution of 176 × 224 × 144, and the results were averaged as the final output. The paper reported the loss of edge voxels at the corners of implants. Matzkin and coauthors in (Matzkin et al., 2020a) also used the U-Net architecture for 3D skull model reconstruction and concluded that estimating the implant directly may produce less noise. In a follow-up work by Matzkin and coauthors in (Matzkin et al., 2020b), a shape constructed by averaging healthy head CT images is concatenated with the input to provide complementary information to facilitate the robustness of the model predictions.
Besides, the Statistical Shape Modeling technique (SSM) (Fuessinger et al., 2019; Xiao et al., 2021) can model 3D shapes explicitly from a collection of datasets. This method is inherently insensitive to defect size and shape and can potentially reconstruct skull defects (Li et al., 2022). demonstrated its application to substantial and complex defects, but this approach performed worse on medium-sized synthetic defects than deep learning-based methods.
More recently, Wu and coauthors (Wu et al., 2022) successfully developed a dilated U-Net for 3D skull model reconstruction with a volumetric resolution of 112 × 112 × 40. However, the repairable defect area was limited to the upper parts of skulls, and the voxel resolution was insufficient for direct use in implant fabrication. Building on this work, we propose a new approach to advance the 3D skull model inpainting technique in this paper. Our approach can reconstruct skull models with a higher volumetric resolution of 512 × 512 × 384, meeting the needs of cranial implant design.
Figure 1 illustrates the use of our proposed deep learning system for cranioplasty. The system inputs a normalized defective 3D skull model derived from a set of CT-scanned images. Using this defective model, our system automatically reconstructs the skull model. A 3D implant model is then obtained by subtracting the original defective model from the completed model. Once a validated implant model is ready, technicians can use manufacturing processes such as 3D printing and molding (Lee et al., 2009; Wu et al., 2021) to convert raw materials into an implant for surgical treatment.
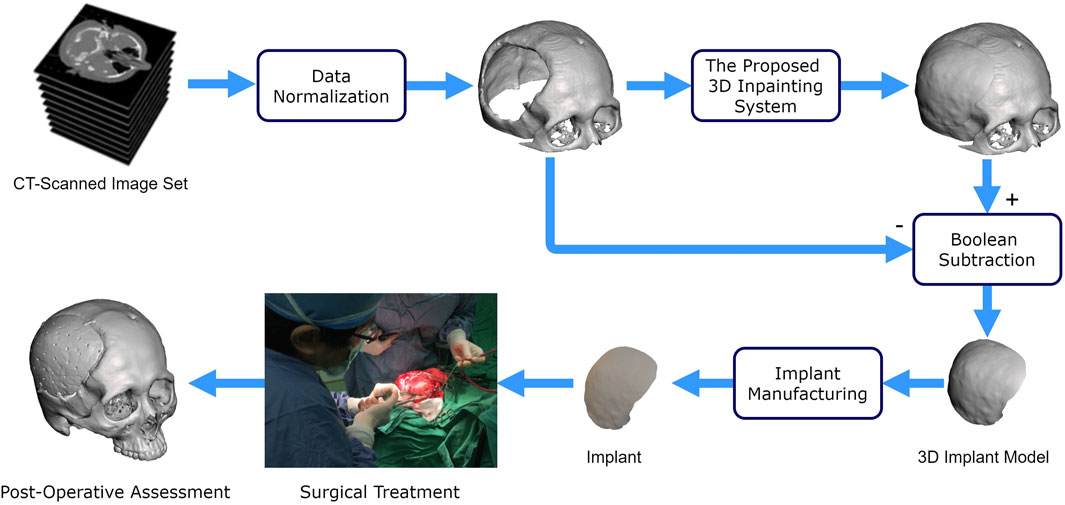
FIGURE 1. Flowchart of cranial restoration using the proposed deep learning technique.
The effectiveness of a deep learning system relies on several factors, including the quality of training data, the network architecture, and training strategies. In this section, we delve into these aspects in detail.
We collected and curated a dataset of skull models to train and evaluate neural networks. This dataset includes pairs of intact and defective skull models, with the defective models created by applying 3D masks to the intact ones. These skull models were carefully selected from three datasets described below.
The binary datasets, SkullFix (Li and Egger, 2020; Kodym et al., 2021) and SkullBreak (Li and Egger, 2020), were derived from an open-source collection of head-CT images known as the CQ500 dataset (Chilamkurthy et al., 2018). The SkullFix dataset was released for the first MICCAI AutoImplant Grand Challenge (Li and Egger, 2020) in 2020, while the SkullBreak dataset was provided for the second MICCAI AutoImplant Challenge (Li and Egger, 2020) in 2021.
In these datasets, defective models were created by masking certain areas of intact 3D skull models. SkullFix defects are circular or rectangular, while SkullBreak defects are more irregular to mimic traumatic skull fractures. In this study, we selected only 92 intact models from these two datasets.
The Department of Neurosurgery, Chang Gung Memorial Hospital, Taiwan, gathered a dataset over the last 12 years. To ensure confidentiality, the Institutional Review Board, Chang Gung Medical Foundation, Taiwan, under the number 202002439B0, approved removing sensitive information about individuals. Out of the 343 sets of collected data, only 75 datasets were used in this study due to incompleteness or the presence of bone screws. Since image acquisition conditions vary, the bone density of each patient is also different, which necessitated setting the intensity threshold for extracting bone tissue individually, generally within the Hounsfield scale interval [1200, 1817].
During our research, we simplified the skull models we had gathered to reduce memory usage. This was accomplished by removing the bone tissue below the Frankfort horizontal plane (Pittayapat et al., 2018). Besides, although CT images typically have a planar resolution of 512 × 512 pixels, the slice interval can vary from 0.3 to 1.25 mm. To ensure a consistent volumetric resolution of 512 × 512 × 384 voxels, we used the Lanczos interpolation method (Mottola et al., 2021) to resample the skull datasets in the craniocaudal direction. As a result, the cranial models had a typical voxel size of 0.45 mm × 0.45 mm × 0.8 mm.
As shown in Figure 2, defects were created on complete skull models using elliptical-cylindrical or ellipsoidal 3D masks to produce a diverse training dataset with different sizes and shapes of defects. The masks were applied randomly to various positions on the skull model, ranging from 60 to 120 mm in diameter. Twenty-five defect variations were injected into each complete skull model.
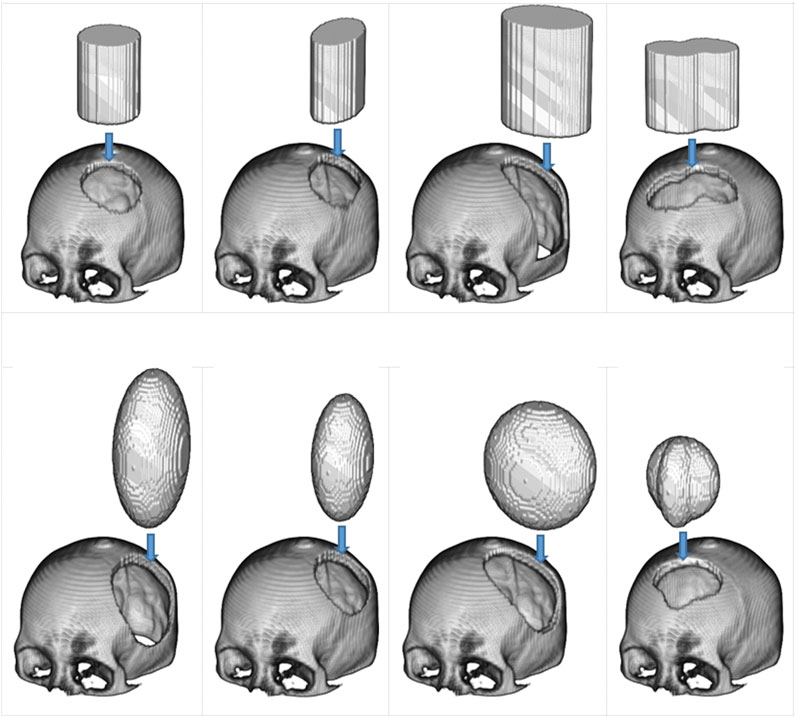
FIGURE 2. The use of 3D masks to generate simulated defects on cranial models. In the top row are two types of masks: the elliptical cylinder and the mixed elliptical cylinder. The bottom row, on the other hand, has two different mask types: the ellipsoid and the hybrid ellipsoid.
We employed a data augmentation technique (Shorten and Khoshgoftaar, 2019) to expand the skull dataset by rotating the skull models along the craniocaudal axis. The rotation interval was set at 2°, resulting in seven variants for each skull model. Notably, three variants were generated on one side.
Eventually, we collected 25,930 datasets of paired skull models after removing models with out-of-range defects. Each dataset comprises two intact skull models and two defective ones, which were normalized to two volumetric resolutions: 512 × 512 × 384 and 128 × 128 × 96. The lower-resolution model was down-sampled from the corresponding higher-resolution model. Our final skull data was divided into three groups: training data comprising 21,600 datasets, validation data of 2,400 datasets, and test data of 1,930 datasets.
We developed two deep-learning networks to predict complete skull models from incomplete ones. As shown in Figure 3, the first is a 10-layer 3D completion network, and the second is a 14-layer resolution enhancement network. Both networks were trained using a supervised learning approach on the training dataset of two different volumetric resolutions.

FIGURE 3. Overview of the proposed 3D inpainting system. The system comprises two networks: a 3D completion network and a resolution enhancement network. The 3D completion network completes the defective skull model with a volume resolution of 128 × 128×96. The resolution enhancement network uses both the completed model of 128 × 128 × 96 and the defective model of 512 × 512 × 384 to generate a 512 × 512 × 384 completed skull model.
A defective skull model is first normalized to a volume resolution of 512 × 512 × 384 to prepare input for the networks, retaining only the bone tissue above the Frankfort horizontal plane (Pittayapat et al., 2018). This normalized model is then transformed into a low-resolution defective cranial model with a resolution of 128 × 128 × 96, which becomes the input for the 3D completion network. The network predicts a 128 × 128 × 96 completed skull model. By downsampling the 3D skull model, the computational resources required to process the data are reduced. Finally, the 3D resolution enhancement network uses both the 128 × 128 × 96 completed skull model and the original 512 × 512 × 384 defective skull model as inputs to generate a 512 × 512 × 384 completed skull model.
This network uses a 3D U-Net (Ronneberger et al., 2015) with 3D dilations at the bottleneck section, as illustrated in Figure 4 and Table 1. The network employs 3 × 3 × 3 kernels in all convolutional layers, including basic convolutions and dilated convolutions, with a dilation rate of 2 for all dilated convolutions. Additionally, all max-pooling operators are of size 2 × 2 × 2.
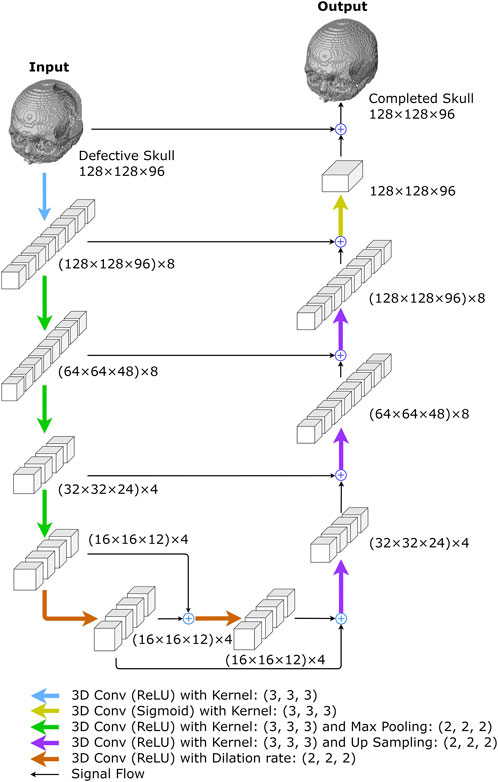
FIGURE 4. The proposed 3D completion network. The network was created to reconstruct low-resolution skull models. The numbers represent the size of I/O data or feature maps, i.e., the outputs of convolutional layers. For example, (128 × 128 × 96) x 8 describes an 8-channel tensor of size 128 × 128 × 96 in each channel.
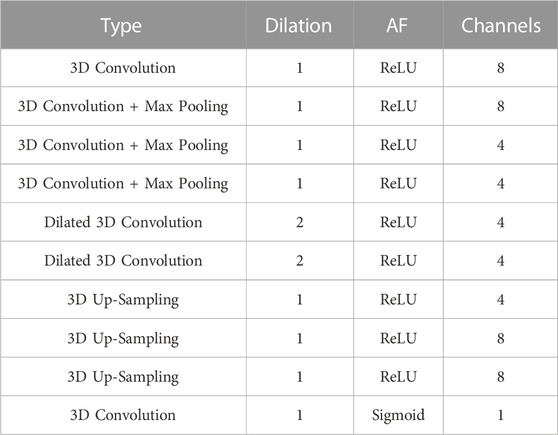
TABLE 1. The architecture of the 10-layer 3D completion network. “AF” is the activation function succeeding a convolutional layer and “Channels” depicts the filter number of a convolutional layer. All convolutional kernels in the network are of size 3 × 3×3 with stride = 1.
The network begins with a convolution layer and rectified linear unit (ReLU) activations (Agarap, 2018), generating an 8-channel feature map. The down-sampling section on the left side of the network repeatedly performs three convolutions, followed by ReLU activations and max-pooling operations. After each convolution operation, the size of feature maps is halved, while the number of channels remains at 8, 4, and 4, respectively. The bottleneck comprises two dilated convolutional layers with four filters, each connected by skip-connections (Alkhaibary et al., 2020) and followed by ReLU activations (Agarap, 2018).
In the up-sampling section, there are more up-convolutions followed by ReLU activations, and the corresponding feature maps from the down-sampling section are added in. We used nearest-neighbor interpolation upsampling (Kolarik et al., 2019) for the up-convolutions, which assigns the grayscale value from the nearest original voxel to each new voxel.
After that, a convolution layer with sigmoid activation functions is applied to the feature maps from the up-sampling path. The final network output is obtained by adding the result to the original network input. The 3D completion network is made up of 8,269 trainable parameters.
The network predicts a high-resolution completed skull model using a low-resolution completed model and a high-resolution defective model. As shown in Figure 5 and Table 2, the network combines a 3D completion network and a shallower U-Net (Ronneberger et al., 2015). The 3D completion architecture provides a geometric abstraction of the complete low-resolution model to enhance the high-resolution defective model. All convolutional filter kernels and max-pooling operators in the network are 3 × 3 × 3 and 2 × 2 × 2, respectively, similar to the 3D completion network.
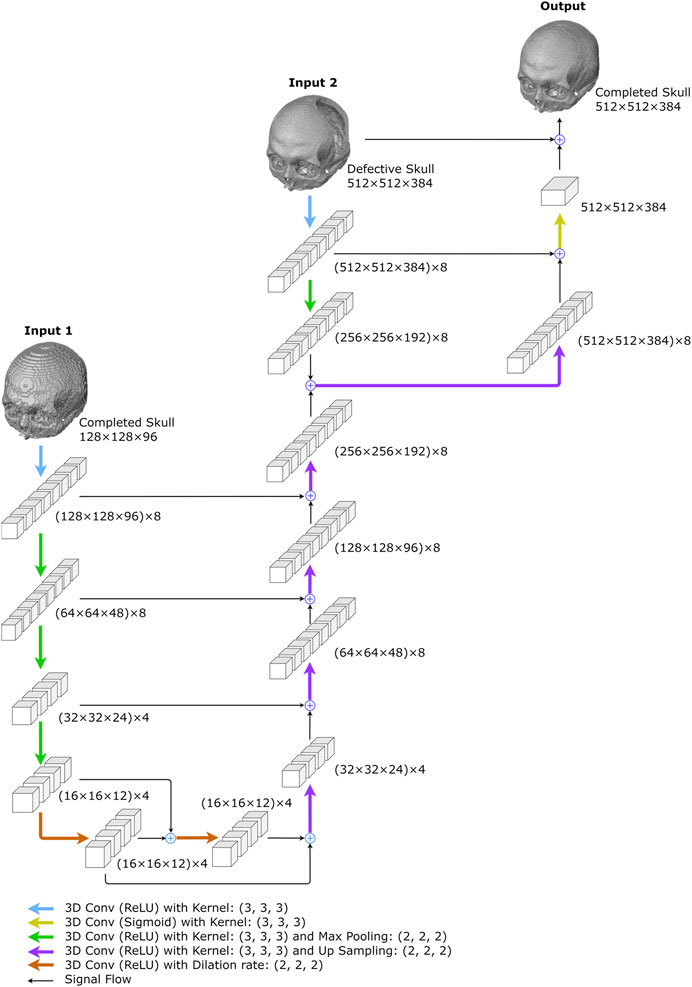
FIGURE 5. The proposed resolution enhancement network. The network was created to predict high-resolution completed skull models. Two inputs are required: the low-resolution completed skull model created in the first stage and the original high-resolution defective model.
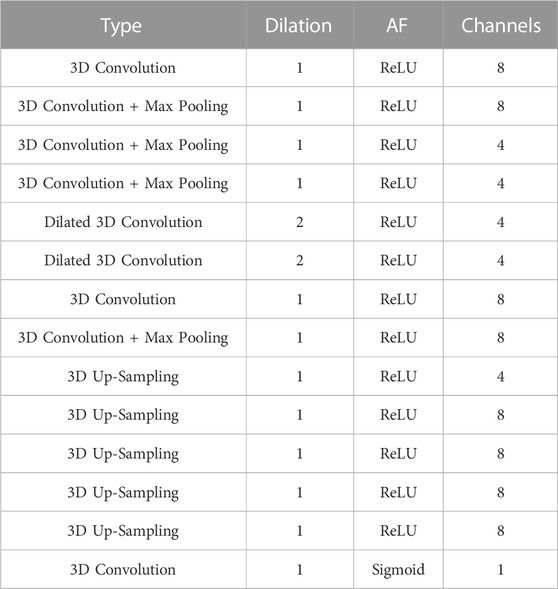
TABLE 2. The architecture of the 14-layer resolution enhancement network. “AF” is the activation function succeeding a convolutional layer and “Channels” depicts the filter number of a convolutional layer. All convolutional kernels in the network are of size 3 × 3×3 with stride = 1.
As illustrated in Figure 5, the 3D completion network output is followed by an up-sampling convolution layer and ReLU activations in the upper middle. The high-resolution defect model acts as the second input and undergoes a down-sampling convolution layer, followed by ReLU activations and max pooling operations. The two inputs are added up and go through an up-sampling convolution layer with ReLU activations, as depicted on the upper right side of Figure 5. Another decoder section follows, which encompasses an addition operation with the corresponding feature maps from the down-sampling section. The bottleneck of the shallower U-Net does not have dilated convolution.
The output is generated by a convolutional layer normalized to the range [0, 1] using sigmoid activation functions. Finally, the predicted voxel values are thresholded at 0.45 to transform the resultant models into binary values. The network has a total of 11,741 trainable parameters.
While training the 3D completion network and the resolution enhancement network, we utilized binary cross-entropy (Liu and Qi, 2017) as the loss function and Adadelta (Zeiler, 2012) as the optimizer. The binary cross-entropy (Liu and Qi, 2017) evaluates the proximity of the predicted probability of voxel values to the target values, where 1 or 0 represent the presence or absence of bone tissue, respectively. Adadelta (Zeiler, 2012) is an adaptive stochastic gradient descent algorithm that adjusts the learning rate without needing a parameter setting. All trainable parameters were randomly initialized (Skolnick et al., 2015).
We utilized 21,600 datasets consisting of 128 × 128 × 96 skull models to train the 3D completion network. In addition, we employed 5,800 datasets of 128 × 128 × 96 and 512 × 512 × 384 skull models to train the resolution enhancement network. During the network training phase, we used 2,400 datasets for the 3D completion network validation and 600 for the resolution enhancement network validation. These validation datasets were independent of the training datasets. All skull models were saved as uint8, where the file size of a 128 × 128 × 96 skull model was between 127 and 268 kB, and the file size of a 512 × 512 × 384 skull model was between 5.1 and 7.1 MB.
The calculations for network training and usage were performed on a personal computer that had an Intel Core i9-9900K 3.6 GHz CPU, 128 GB DDR4 memory, and an NVIDIA GeForce RTX A6000 graphics card with 48 GB GDDR6 GPU memory. To accommodate the GPU memory limitations, we used a batch size of 10 during the 3D completion network training and 4 during the resolution enhancement network training.
We shuffled the datasets at the beginning of each epoch to improve data order independence and prevent the optimizer from getting stuck in a local minimum of the loss function. The 3D completion network was trained for 1,200 epochs over 12.5 days, while the resolution enhancement network was trained for 20 epochs over 45 days. After training, we selected the networks that achieved the best loss values in the validation dataset for the reconstruction and resolution enhancement tasks.
Following the training, it took only 4.9 s to obtain a completed 128 × 128 × 96 skull model using the 3D completion network and 7.2 s to get a 512 × 512 × 384 high-resolution skull model using the resolution enhancement network. In summary, using the proposed approach, it takes less than 10 min to create an implant model ready for manufacturing once a defective skull model is available for design. This is a significant improvement over the manual restoration method, which takes more than 1 h. This is in addition to the improvement in geometric quality.
Further details regarding the hardware and software setup for training and evaluation, training history, and additional case studies are available in the Supplementary Material linked to this article.
To demonstrate the performance of our proposed 3D cranial inpainting system, both numerical studies and surgical practice are presented in this section, highlighting its quantitative and qualitative capabilities.
We created defects on numerical models by applying various 3D masks to intact skull models for study. The removed parts are considered ground truth (ideal) implants for quantitative investigations. The implants generated by the proposed system are compared to the ground truth implant models using the Sørensen-Dice index (Dice, 1945; Carass et al., 2020) and Hausdorff Distance (Morain-Nicolier et al., 2007) metrics.
In this study, skull models were converted to a voxel-based representation. Each voxel value is treated as a Boolean, with 1 representing bone tissue and 0 representing otherwise. The Sørensen-Dice index (SDI) (Dice, 1945; Carass et al., 2020) is defined and calculated as follows:
In Eq. 1, NTP denotes the number of true positives, NFP represents the number of false positives, and NFN is the number of false negatives. In the second expression of Eq. 1, P is a skull model predicted by the proposed approach, and G is its corresponding ground-truth model. The 1-norm calculates the number of 1’s in a voxel-based model.
In addition, the Hausdorff Distance (HD) (Morain-Nicolier et al., 2007) measures the distance between two sets of voxels, P and G, in this study. It is defined as the most significant distance from the center of any bone-tissue voxel in the set P to the closest center of any bone-tissue voxel in the set G. The HD between G and P is calculated as:
In Eq. 2, gB and pB represent bone-tissue voxels (with value 1) in G and P, respectively. The distance between the centers of two voxels is calculated using the L2 norm (the Euclidean norm). For a skull model of voxels measuring 0.45 mm × 0.45 mm × 0.8 mm, one HD unit is equivalent to a distance between 0.45 mm and 1.0223 mm, serving as a quantitative measurement.
The proposed approach generates implants in two stages, as detailed in the Materials and Methods section. The first stage produces low-resolution implant modes, while the second generates high-resolution ones. Figure 6 illustrates four case studies with simulated defects. The first row displays the defective skull models in an isometric view. The ground-truth implants are shown in the second row for comparison. The third and fourth rows present the low and high-resolution implants produced by the proposed system in the first and second stages, respectively.
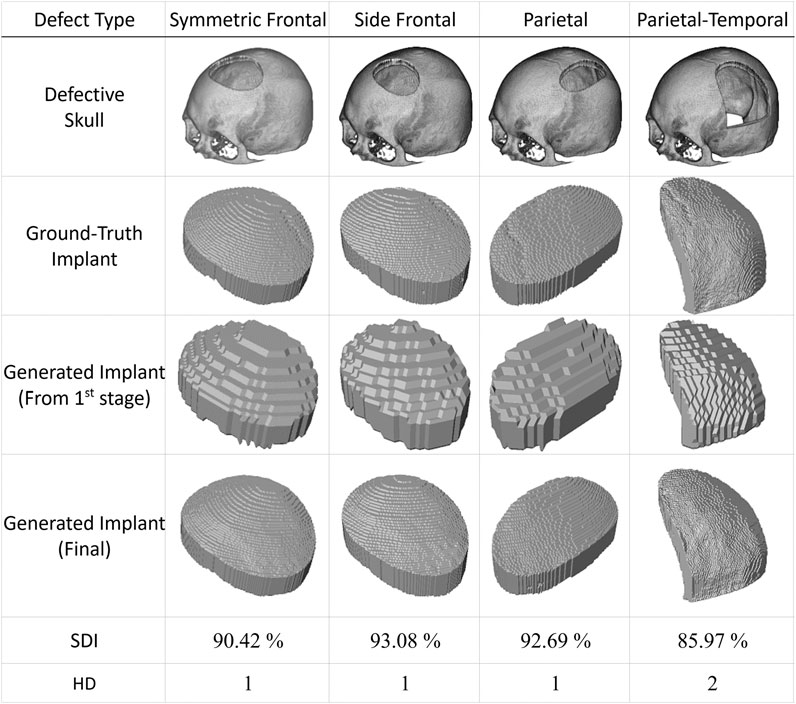
FIGURE 6. Automatic generation of implants for simulated defects using the proposed method. The first row shows skull models with simulated defects derived by subtracting 3D masks from an intact skull model using Boolean operations. The second row displays the ground-truth implants. The automatic generation of implants using the proposed approach requires two stages. The third row shows the outputs of the first stage, while the fourth row presents the results of the final stage. It is important to note that there is no cranial suture pattern on the resulting implant models and that the test datasets have never been used in training.. (All implant models, including the ground-truth implants, are enlarged to facilitate visual inspection).
The last two rows of Figure 6 present the quantitative performance of the proposed deep learning scheme. The case in the last column, with a significant defect denoted as type Parietal-Temporal, has an HD index of 2, while the rest have HD values of 1. The last column also has a smaller SDI value of 85.97%, while the SDI values for the remaining columns are all above 90%.
This simulation study shows that the suggested system can produce implants that closely resemble actual lost tissue based on defective skull models. The first stage generates implants with a lower resolution, while the second stage significantly enhances their resolution. Please note that cranial suture patterns are not restored, which does not hinder practical usage.
Figure 7 presents two additional case studies demonstrating the proposed networks’ ability to reconstruct and improve the resolution of large-area defects. These two extreme cases illustrate the potential of the proposed system to reconstruct defects more significant than one-third of the upper part of the skull.
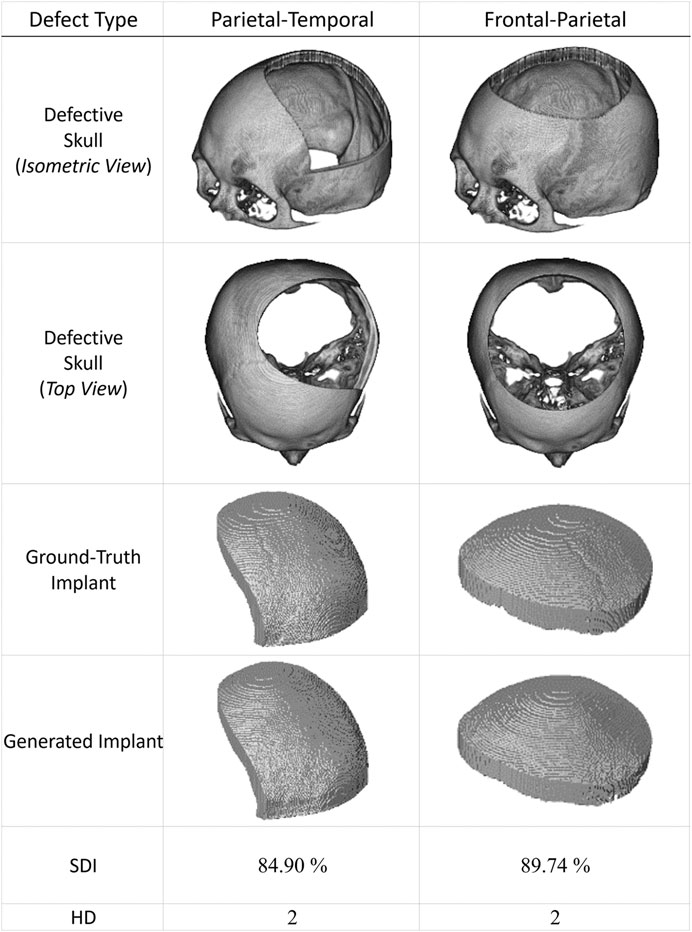
FIGURE 7. Two extreme cranial reconstruction examples with large-area defects. The first two rows display skull models from different viewpoints with defects more significant than one-third of the upper skull. The third row shows the ground-truth implant modes, while the fourth row presents the final implant models generated by the proposed scheme. (The ground-truth and generated implants have been magnified for visual inspection. Also, these two defective datasets have never been used in training).
Recently, several publicly available datasets have been released for cranial reconstruction studies. We collected several cases from (Li and Egger, 2020) and present four representative results in Figure 8. The defect in the first column is made of a cubic mask. In contrast, the defects in the other three columns are irregularly shaped. The first row displays the defective skulls, while the second row shows how the generated implants fit into them. The ground-truth and generated implants are shown in the third and fourth rows. The last two rows demonstrate the quantitative performance of the proposed system in these simulated cases.
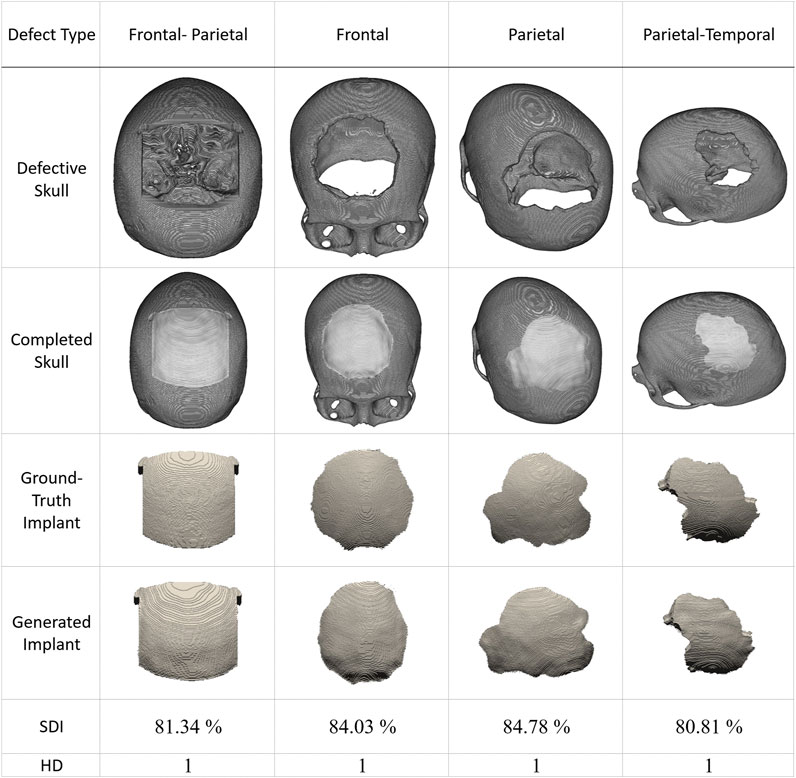
FIGURE 8. Inpainting performance of the proposed approach using cases collected from (Li and Egger, 2020). The first row shows defective skull models. The second row shows the generated implants placed on the defective models, demonstrating their compatibility with the defects. The third row displays the ground-truth implant modes, while the fourth row presents the final implant models generated by the proposed scheme.. (The implants are magnified in the third and fourth rows to facilitate visual inspection. These defective data sets have never been used in training).
Based on the results presented in Figure 8, we can conclude that the reconstruction performance of the proposed system degrades for irregular defects. However, HD values remain at 1, and all SDI values are above 80%.
Further analysis of the reconstruction performance of our approach is available in the Supplementary Material, which is linked to this article. These studies include comparisons with manually repaired cases stored in a database known as MUG500+ (Li et al., 2021c). One of the examples in the Supplementary Material, Supplementary Figure S11, demonstrates four cases with significant and irregular defects that were reconstructed using our method. The frontal-orbital implants have lower SDI values of 78.28% and 79.67% compared to the frontal-parietal implants, which have SDI values of 79.83% and 83.76%. This difference in performance may be due to the lack of frontal-orbital defective cases in the training dataset. However, implants created for these challenging cases are still useful for treatment purposes with minor modifications, even though the HD values go up to 2.
The proposed deep learning system has been utilized in cranial surgeries, along with retrospective numerical studies presented in the last section. These studies have been registered on ClinicalTrials.gov with Protocol ID 202201082B0 and ClinicalTrials.gov ID NCT05603949. Additionally, the study has been approved by the Institutional Review Board of Chang Gung Medical Foundation in Taiwan under IRB 202002439B0. Here, we demonstrate a surgical application outcome of our proposed system.
A young man, aged 24, has a significant craniofacial deformity and was seeking surgery to restore the structure of his skull. Seven years ago, the patient fell from a height of 5 m, resulting in a severely comminuted fracture and intracranial hemorrhage. These injuries were treated with an extensive craniectomy, but the skull has remained open, as shown in Figure 9A.
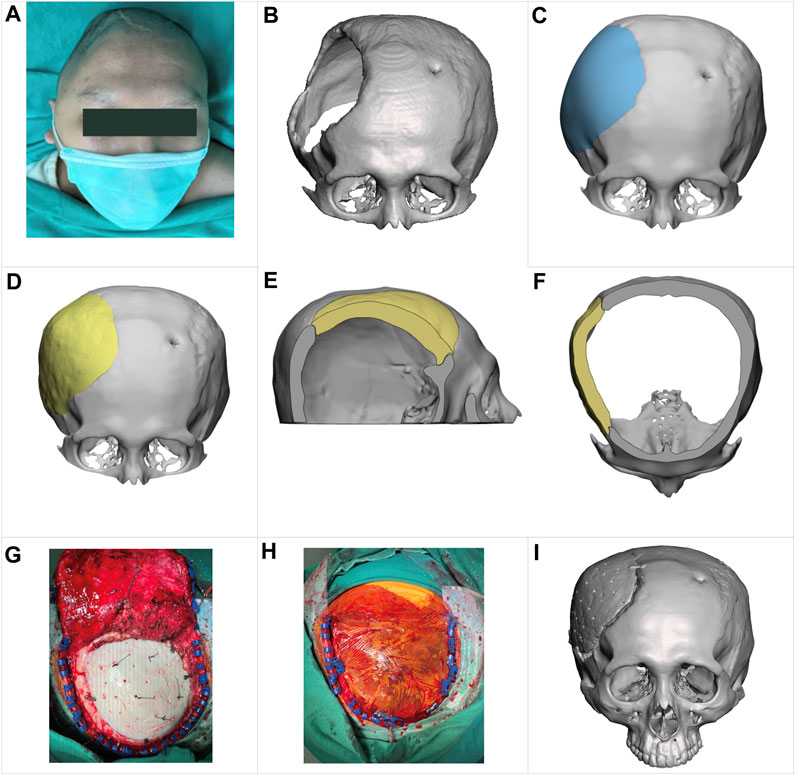
FIGURE 9. Clinical reconstruction of a skull defect with an implant designed by the proposed approach. (A) a preoperative photograph of the patient. (B) a 3D skull image based on a CT scan. (C) a skull model reconstructed by a technician using CAD software, showing the appearance of a typical hand-designed implant (depicted in blue for clarity). (D–F) illustrate the shape of the implant (in yellow) generated by the proposed approach and how it fits into the defective skull in the front view, sagittal cross-section view, and transversal cross-section view, respectively. (G, H) are intraoperative photographs. (I) a postoperative 3D image based on CT scanning, showing the patient’s cranial status 1 week after the surgery.
As depicted in the 3D image from a CT scan in Figure 9B, this cranial opening spanned the parietal, frontal, and temporal bones and measured up to 114 mm at its widest point. The edge of the opening was covered by scar tissue due to a prolonged ossification process. Additionally, there was a small hole in the left frontal bone to place an external ventricular drain.
Figures 4E, F, 9D show the shape of an implant generated by the proposed method and how it fits into the defective skull. For comparison, Figure 9C shows a reconstructed skull model created by a technician using CAD software to demonstrate what a typical hand-designed implant would look like. The implant produced by the proposed method fits the defect well and has a more natural appearance despite being asymmetrical to the left side of the skull. Additionally, a small patch covering the hole drilled for the ventriculostomy drainage system was removed, as placing an implant of that size was unnecessary.
To quantitatively assess the reconstruction performance, we compared the reconstructed 3D skull models generated by the proposed deep-learning approach with that designed manually using the cranial vault asymmetry index (CVAI) (Yin et al., 2015), originally used to evaluate the symmetry of positional plagiocephaly.
The CVAI index is calculated using a measurement plane. Figure 10 shows that this plane intersects the implant the most and is parallel to the Frankfort horizontal plane. Additionally, the figure provides top views of the reconstructed skulls, where lines AC and BD are diagonal lines drawn 60° from the Y-axis. Points A, B, C, and D are located on the measurement plane, and point O is at the intersection of lines AC, BD, and the Y-axis.
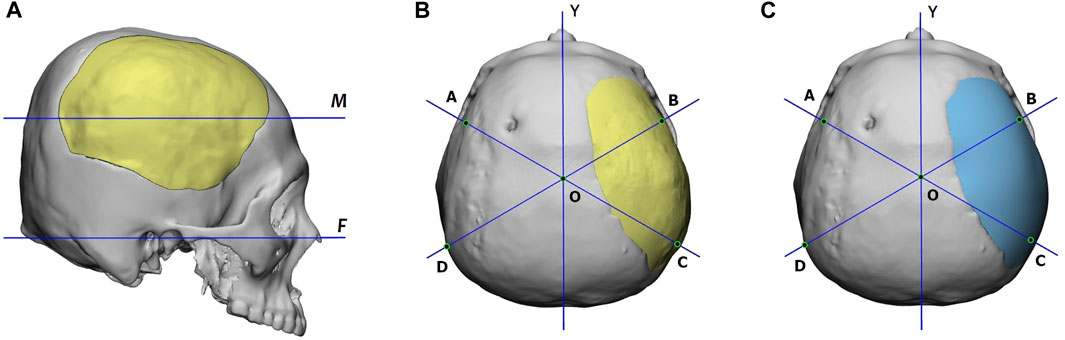
FIGURE 10. (A) Definition of the measurement plane, denoted as M, for the CVAI index. Plane M intersects the implant the most and is parallel to the Frankfort horizontal plane, marked as F. (B) and (C) are the reconstructed skulls’ top views, which display the diagonal lines for CVAI. Lines AC and BD are drawn 60° from the Y-axis in each diagram, and points A, B, C, and D are located on the measurement plane. The point o is located at the intersection of lines AC, BD, and the Y-axis. The implant of (B) is generated by the proposed deep-learning approach, while that of (C) is designed manually.
Based on the length of these lines, we define the anterior cranial vault asymmetry index (ACVAI) and the posterior cranial vault asymmetry index (PCVAI) in Eqs 3, 4.
The ACVAI evaluates the degree of asymmetry in the front part of the skull based on the intact side, while the PCVAI evaluates the back part of the skull. A perfectly symmetrical reconstructed skull will receive a score of 0% for both ACVAI and PCVAI.
Table 3 summarizes the ACVAI and PCVAI values of the two design approaches. The proposed deep-learning approach yielded ACVAI and PCVAI values of 2.22% and 2.14%, respectively. On the other hand, the manual design approach resulted in ACVAI and PCVAI values of 2.05% and 6.03%, respectively. The deep-learning approach produced more symmetric geometry in the back part of the skull, while the difference in the front part of the skull was insignificant for both approaches.

TABLE 3. Comparison of implant design quality using ACVAI (the anterior cranial vault asymmetry index) and PCVAI (the posterior cranial vault asymmetry index). Lengths of lines AO, BO, CO, and DO are measured in millimeters.
The implant fabrication process began with creating a 3D-printed template using the implant model generated by the proposed deep learning system. Silicone rubber was then used to make a mold that captured the geometric details of the implant. The implant was created through casting and molding, with most of the manufacturing in the operating room to ensure cleanliness and sterilization. In this surgery, the implant was made of polymethylmethacrylate (PMMA) (Yeap et al., 2019) bone cement. We have chosen this material for skull patches for over 15 years (Wu et al., 2021) and found it satisfactory in healing, duration, and providing protection. Excluding 3D printing, the casting and molding process took less than 30 min.
As shown in the intraoperative photograph in Figure 9G, we made 30 holes in the implant with a diameter of 2 mm for dural tenting (Przepiórka et al., 2019). In our experience with cranioplasty, this arrangement facilitates interstitial fluid circulation and exudate absorption during healing. Figure 9I shows a 3D image based on a CT scan taken 1 week after the surgery. The patient has been followed up for over 6 months and has no postoperative complications.
According to (Li et al., 2021b), craniotomy defects typically have uneven borders due to manual cutting during the procedure. Our first-hand experience aligns with this observation. As a result, our study did not utilize synthetic defects with straight borders, as provided in, e.g., (Gall et al., 2019; Li et al., 2021d), to train and demonstrate the reconstruction capabilities of our proposed system.
As materials engineering advances, neurosurgeons explore using alloplastic materials (Yeap et al., 2019; Alkhaibary et al., 2020) for long-term skull reconstruction. Various options, such as polymethylmethacrylate (PMMA), polyetheretherketone (PEEK), polyethylene, titanium alloy, and calcium phosphate-based bone cement, have been used for cranioplasty materials. PEEK and titanium alloys offer excellent biomechanical properties, allowing for a significant reduction in implant thickness to reduce loading while providing support (PEEK’s tensile strength: 90 MPa; Ti6Al4V Grade 5: 862 MPa). To facilitate this, surgeons must be able to determine the thickness of an implant according to their requirements.
To adjust the thickness of an implant model, one can utilize software tools like Autodesk® Meshmixer to extract the outer surface. Extending the surface to a specified thickness, the final implant model can be produced. Figure 11 demonstrates this thickness-modification procedure using the defective cranial model described in Figure 9 with a 2 mm thickness for the new implant. Additionally, Ellis and coauthors in (Ellis et al., 2021) emphasized the importance of creating implants with smooth transitions and complete defect coverage without excess material. This example reveals that the updated design still fulfills these requirements, despite the change in thickness.
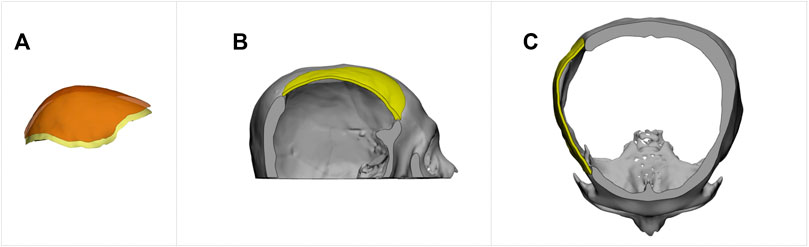
FIGURE 11. The creation of an implant with a specified thickness for cranial restoration. The implant model was generated by extracting the outer surface of the implant generated by the proposed method, shown in Figure 9D, and extending it by 2 mm in the inner direction. (A). Surface extraction. (B). Sagittal view. (C). Transverse view.
Our proposed system greatly minimizes the need for post-processing thanks to the remarkable similarity between the reconstructed and defective models. However, in line with the recommendation in (Li et al., 2021a), incorporating morphological openness and connected component analysis (CCA) (Gazagnes and Wilkinson, 2021) proves helpful in achieving the final implant geometry. Morphological openings, which involve erosion and dilation of the model, can eliminate small or thin noises attached to it and isolated noises. Also, verifying the final implant design using a 3D-printed model (Lee et al., 2009; He et al., 2016) before proceeding with cranioplasty is essential.
In clinical practice, allowing for larger tolerances when fitting a cranial implant may be necessary. One effective method to achieve this is to scale up the defective skull model to 102% before performing a Boolean subtraction with the reconstructed skull model. This approach provides a more tolerant fit and helps eliminate noise from mismatches between the reconstructed and defective models outside the defect area.
The training of the 3D completion network requires 1,200 epochs and 21,600 pairs of skull models, while that of the resolution enhancement network only needs 20 epochs and 5,800 pairs of skull models. This difference in data requirements and training epochs is due to the more significant challenge faced by the first network in reconstructing skulls with defects of varying sizes, positions, and types compared to that of the second network in raising the resolution of various skull models.
The proposed neural networks are based on the U-net (Ronneberger et al., 2015) architecture. The 3D completion network is a direct extension of the work presented in (Wu et al., 2022) and was constructed by increasing the resolution of each layer. The resolution enhancement network is created by merging two U-nets. This innovative architecture allows the network to effectively utilize the high-resolution geometry from the defective model and the low-resolution framework from the reconstructed model.
U-nets (Ronneberger et al., 2015) are autoencoders (Hinton and Salakhutdinov, 2006; Baldi, 2011; Dai et al., 2017) that feature skip connections (He et al., 2016). In a U-net, feature maps in the encoder section are combined with the corresponding feature maps in the decoder section. This makes the U-Net utilize features extracted in the encoder section to reconstruct a 3D model in the decoder part (Li et al., 2021a). showed the importance of skip connections (He et al., 2016) in encoder-decoder networks for reconstructing a defective skull.
We observed that the encoder-decoder network’s ability to fill holes decreased when skip connections were used. However, incorporating dilated convolutions (Yu and Koltun, 2016) compensates for this weakness and leads to stable convergence during training. This observation is consistent with the findings reported in (Jiang et al., 2020), which showed that dilation layers could enhance the performance of 2D image inpainting. Dilated convolutions allow kernels to expand their operating range on the input and gather contextual information from multiple scales. These features facilitate the completion of missing structures in the entire skull model.
Unlike the approach in (Devalla et al., 2018), which used dilated convolutions throughout, we applied dilated convolutions only to the bottleneck section in our proposed networks. We did not use batch normalization, as we did not observe accuracy benefits during network training, given memory and computing constraints limiting our batch size. We implement skip connections via summation (He et al., 2016) rather than concatenation (Gao Huang et al., 2017), as we found the summation operations more suitable for the voxel-based architecture to enable stable end-to-end training.
Through analysis of the training history and performance evaluations, we determined that removing batch normalization and restricting dilated convolutions simplifies the network, reduces computational overhead, and facilitates efficient training and inference while retaining accuracy. Specifically, attempting dilated convolutions throughout increased model capacity but resulted in instability during training and intractable execution time that hindered hyperparameter tuning. The arrangement of our architecture is tuned for the voxel input modality and tailored hardware constraints to enhance execution efficiency without sacrificing model performance.
In addition, the number of filters in the convolutional layers affects the stability and accuracy of the network. Increasing the filters can enhance capability but also prolongs costly 3D network training. Given our computational constraints, we optimized the filter numbers to balance performance and efficiency. Through experimentation, we found that 4-8 filters per layer provided adequate representational power while minimizing overhead.
While these choices are based on trial-and-error tuning, future ablation studies would provide a better understanding of each factor’s impact. Our current architecture modifications reduce parameters to facilitate efficient training under constraints. Further analysis can methodically validate the contribution of individual components like filter numbers to identify optimal accuracy-efficiency trade-offs based on available resources quantitatively.
A well-designed cranial implant improves aesthetic outcomes and minimizes operative duration, blood loss, and the risk of infection. This paper introduces an approach for automatically generating implant geometry using a deep learning system.
Our deep-learning approach’s success depends on two factors: the quality of the training data and the effectiveness of the neural network architectures. With our method, we can produce skull models with a volumetric resolution of 512 × 512 × 384 in two stages, which meets most clinical requirements for implant fabrication. In the first stage, the 3D completion network reconstructs defective skull models at a resolution of 128 × 128 × 96. In the second stage, another network known as the resolution enhancement network increases the reconstructed skull models’ resolution to 512 × 512 × 384.
Our numerical studies and clinical implementation have demonstrated the effectiveness of our proposed approach in creating personalized cranial implant designs for various clinical scenarios. The implants produced by the system were well-matched to the defects’ location and could significantly reduce surgery time. In a representative case study, our approach significantly produced more symmetric reconstruction than a manual design. This can lead to fewer postoperative complications and result in higher patient satisfaction.
Our research and clinical trials have demonstrated the effectiveness of our personalized cranial implant designs, which are tailored to different clinical scenarios. The implants generated by our system were accurately matched to the location of the defects, thereby significantly reducing surgery time. In a case study, our proposed approach produced more symmetric reconstructed geometry than manual design, leading to fewer postoperative complications and higher patient satisfaction.
This paper showcases the effectiveness of our proposed deep learning system for neurosurgery. However, we do acknowledge that our system has limitations. The process must be divided into two stages to reduce computational overhead during training, and the input needs to be normalized into two files with volume resolutions of 128 × 128 × 96 and 512 × 512 × 384. These limitations increase the amount of labor required and limit the range of deficiencies that can be addressed. In cases where defective skull models include even lower parts, designing implants using deep learning techniques may be more challenging or impossible due to individual differences in Zygomatic and Maxilla geometry.
We plan to further our research by developing a user-friendly system that is more computationally efficient, can recover a broader range of defect types and extents, and can accept datasets with varying patient poses and different slice intervals. To achieve these goals, we are exploring alternative deep learning networks based on other representations of 3D shapes, including polygon meshes (Hanocka et al., 2019), point clouds (Charles et al., 2017; Qi et al., 2017; Xie et al., 2021), and octree-based data (Tatarchenko et al., 2017; Wang et al., 2017; Wang et al., 2018; Wang et al., 2020). This could lead to more advanced and effective solutions than the volumetric data types used in our current work.
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
The studies involving humans were approved by The Institutional Review Board (IRB) of Chang Gung Medical Foundation, Taiwan. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
C-TW: Data curation, Formal Analysis, Investigation, Supervision, Validation, Writing–review and editing. Y-HY: Data curation, Methodology, Software, Visualization, Writing–review and editing. Y-ZC: Conceptualization, Funding acquisition, Investigation, Methodology, Resources, Supervision, Validation, Visualization, Writing–original draft, Writing–review and editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. We gratefully acknowledge funding from the National Science and Technology Council, Taiwan, under Grant Nos. NSTC 111-2221-E-182-057, MOST 110-2221-E-182-034, MOST 109-2221-E-182-025, and MOST 108-2221-E-182-061, and Chang Gung Memorial Hospital, Taiwan, under Grant Nos. CMRPG3L1181, CORPD2J0041, and CORPD2J0042.
Author Y-HY was employed by ADLINK Technology, Inc.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fbioe.2023.1297933/full#supplementary-material
Agarap, A. F. (2018). Deep learning using rectified linear units (relu). arXiv:1803.08375. doi:10.48550/arXiv.1803.08375
Alkhaibary, A., Alharbi, A., Alnefaie, N., Almubarak, A. O., Aloraidi, A., and Khairy, S. (2020). Cranioplasty: a comprehensive review of the history, materials, surgical aspects, and complications. World Neurosurg. 139, 445–452. doi:10.1016/j.wneu.2020.04.211
Baldi, P. (2011). Autoencoders, unsupervised learning, and deep architectures. Proc. ICML Workshop Unsupervised Transf. Learn 27, 37–50. doi:10.5555/3045796.3045801
Carass, A., Roy, S., Gherman, A., Reinhold, J. C., Jesson, A., Arbel, T., et al. (2020). Evaluating white matter lesion segmentations with refined sørensen-dice analysis. Sci. Rep. 10, 8242. doi:10.1038/s41598-020-64803-w
Charles, R. Q., Su, H., Kaichun, M., and Guibas, L. J. (2017). “PointNet: deep learning on point sets for 3D classification and segmentation,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR 2017) (IEEE). Honolulu, Hawaii, United States, July 21–26, 77–85. doi:10.1109/CVPR.2017.16
Chen, X., Xu, L., Li, X., and Egger, J. (2017). Computer-aided implant design for the restoration of cranial defects. Sci. Rep. 23, 4199. doi:10.1038/s41598-017-04454-6
Chilamkurthy, S., Ghosh, R., Tanamala, S., Mustafa Biviji, M., Campeau, N. G., Venugopal, V. K., et al. (2018). Deep learning algorithms for detection of critical findings in head CT scans: a retrospective study. Lancet 392 (10162), 2388–2396. doi:10.1016/S0140-6736(18)31645-3
Dai, A., Qi, C. R., and Niebner, M. (2017). “Shape Completion using 3D-encoder-predictor CNNs and shape synthesis,” in Proc. Computer Vision and Pattern Recognition (CVPR 2017) (IEEE). Honolulu, Hawaii, United States, July 21–26, 6545–6554. doi:10.1109/CVPR.2017.693
Devalla, S. K., Renukanand, P. K., Sreedhar, B. K., Subramanian, G., Zhang, L., Perera, S., et al. (2018). DRUNET: a dilated-residual U-Net deep learning network to segment optic nerve head tissues in optical coherence tomography images. Biomed. Opt. Express. 9 (7), 3244–3265. doi:10.1364/BOE.9.003244
Dice, L. R. (1945). Measures of the amount of ecologic association between species. Ecology 26 (3), 297–302. doi:10.2307/1932409
Ellis, D. G., and Aizenberg, M. R. (2020). “Deep learning using augmentation via registration: 1st place solution to the AutoImplant 2020 challenge,” in Lecture notes in computer science, LNCS (Springer), 47–55. doi:10.1007/978-3-030-64327-0_6
Ellis, D. G., Alvarez, C. M., and Aizenberg, M. R. (2021). “Qualitative criteria for feasible cranial implant designs,” in Towards the automatization of cranial implant design in cranioplasty II, LNCS 13123. Editors J. Li, and J. Egger (Spinger). doi:10.1007/978-3-030-92652-6_2
Fuessinger, M. A., Schwarz, S., Neubauer, J., Cornelius, C.-P., Gass, M., Poxleitner, P., et al. (2019). Virtual reconstruction of bilateral midfacial defects by using statistical shape modeling. J. Craniomaxillofac. Surg. 47 (7), 1054–1059. doi:10.1016/j.jcms.2019.03.027
Gall, M., Tax, A., Li, X., Chen, X., Schmalstieg, D., Schäfer, U., et al. (2019). Cranial defect datasets. Figshare. doi:10.6084/m9.figshare.4659565.v6 https://figshare.com/articles/dataset/Cranial_Defect_Datasets/4659565/6.
Gao Huang, G., Zhuang Liu, Z., and Maaten, L. V. (2017). “Densely connected convolutional networks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR 2017) (IEEE). Honolulu, Hawaii, United States, July 21–26, 2261–2269. doi:10.1109/CVPR.2017.243
Gazagnes, S., and Wilkinson, M. H. F. (2021). Distributed Connected component filtering and analysis in 2D and 3D tera-scale data Sets. IEEE Trans. Image Process. 30, 3664–3675. doi:10.1109/TIP.2021.3064223
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). Generative adversarial networks. arxiv. doi:10.48550/arXiv.1406.2661
Hanocka, R., Hertz, A., Fish, N., Giryes, R., Fleishman, S., and Cohen-Or, D. (2019). MeshCNN: a network with an edge. ACM Trans. Graph. 38 (90), 1–12. doi:10.1145/3306346.3322959
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR 2016), Las Vegas, NV, USA, 27-30 June 2016 (IEEE), 770–778. doi:10.1109/CVPR.2016.90
Hinton, G. E., and Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. Science 313 (5786), 504–507. doi:10.1126/science.1127647
Iizuka, S., Simo-Serra, E., and Ishikawa, H. (2017). Globally and locally consistent image completion. ACM Trans. Graph. 36 (4), 1–14. doi:10.1145/3072959.3073659
Jiang, Y., Xu, J., Yang, B., Xu, J., and Zhu, J. (2020). Image inpainting based on generative adversarial networks. IEEE Access 8, 22884–22892. doi:10.1109/ACCESS.2020.2970169
Kodym, O., Li, J., Pepe, A., Gsaxner, C., Chilamkurthy, S., Egger, J., et al. (2021). SkullBreak/SkullFix – dataset for automatic cranial implant design and a benchmark for volumetric shape learning tasks. Data Brief 35, 106902. doi:10.1016/j.dib.2021.106902
Kolarik, M., Burget, R., and Riha, K. (2019). “Upsampling algorithms for autoencoder segmentation neural networks: a comparison study,” in Proc. 2019 11th International Congress on Ultra Modern Telecommunications and Control Systems and Workshops (ICUMT), Dublin, Ireland, 28-30 October 2019 (IEEE). doi:10.1109/ICUMT48472.2019.8970918
Lee, S. C., Wu, C. T., Lee, S. T., and Chen, P. J. (2009). Cranioplasty using polymethyl methacrylate prostheses. J. Clin. Neurosci. 16, 56–63. doi:10.1016/j.jocn.2008.04.001
Li, J., and Egger, J. (2020). Towards the automatization of cranial implant design in cranioplasty I. Springer International. doi:10.1007/978-3-030-92652-6
Li, J., Ellis, D. G., Pepe, A., Gsaxner, C., Aizenberg, M., Kleesiek, J., et al. (2022). Back to the Roots: reconstructing large and complex cranial defects using an image-based statistical shape model. arXiv. doi:10.48550/arXiv.2204.05703
Li, J., Gsaxner, C., Pepe, A., Morais, A., Alves, V., Campe, G. V., et al. (2021d). Synthetic skull bone defects for automatic patient-specific craniofacial implant design. Sci. Data 8, 36. doi:10.1038/s41597-021-00806-0
Li, J., Krall, M., Trummer, F., Memon, A. R., Pepe, A., Gsaxner, C., et al. (2021c). MUG500+: database of 500 high-resolution healthy human skulls and 29 craniotomy skulls and implants. Data Brief. 39, 107524. doi:10.1016/j.dib.2021.107524
Li, J., Pimentel, P., Szengel, A., Ehlke, M., Lamecker, H., Zachow, S., et al. (2021b). AutoImplant 2020-First MICCAI challenge on automatic cranial implant design. IEEE Trans. Med. Imaging. 40, 2329–2342. doi:10.1109/TMI.2021.3077047
Li, J., von Campe, G., Pepe, A., Gsaxner, C., Wang, E., Chen, X., et al. (2021a). Automatic skull defect restoration and cranial implant generation for cranioplasty. Med. Image Anal. 73, 102171. doi:10.1016/j.media.2021.102171
Li, Y., Liu, S., Yang, J., and Yang, M.-H. (2017). “Generative face completion,” in Proc. Computer Vision and Pattern Recognition (CVPR 2017), Karamay, China, 27 May 2022, 3911–3919. doi:10.1109/CVPR.2017.624
Liu, L., and Qi, H. (2017). “Learning effective binary descriptors via cross entropy,” in Proc. 2017 IEEE Winter Conf. Appl. Comput. Vis. (WACV), Santa Rosa, CA, USA, 24-31 March 2017 (IEEE), 1251–1258. doi:10.1109/WACV.2017.144
Mahdi, H. (2021). “A U-Net based system for cranial implant design with pre-processing and learned implant filtering,” in Towards the automatization of cranial implant design in cranioplasty IILNCS, 13123 (Springer), 63–79. doi:10.1007/978-3-030-92652-6_6
Maturana, D., and Scherer, S. (2015). “VoxNet: a 3D convolutional neural network for real-time object recognition,” in Proc. IEEE/RSJ Int. Conf. Intell. Robots and Syst, Hamburg, Germany, 28 September 2015 - 02 October 2015 (IEEE), 922–928. doi:10.1109/IROS.2015.7353481
Matzkin, F., Newcombe, V., Glocker, B., and Ferrante, E. (2020b). “Cranial implant design via virtual craniectomy with shape priors,” in Towards the automatization of cranial implant design in cranioplasty, lecture notes in computer science, LNCS 12439 (Cham: Springer). doi:10.1007/978-3-030-64327-0_5
Matzkin, F., Newcombe, V., Stevenson, S., Khetani, A., Newman, T., Digby, R., et al. (2020a). “Self-supervised skull reconstruction in brain CT Images with decompressive craniectomy,” in Med. Image. Comput. Comput. Assist. Interv., lecture notes in computer science, LNCS 12262 (Springer), 390–399. doi:10.1007/978-3-030-59713-9_38
Morain-Nicolier, F., Lebonvallet, S., Baudrier, E., and Ruan, S. (2007). Hausdorff distance based 3D quantification of brain tumor evolution from MRI images. Proc. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2007, 5597–5600. doi:10.1109/IEMBS.2007.4353615
Morais, A., Egger, J., and Alves, V. (2019). “Automated computer-aided design of cranial implants using a deep volumetric convolutional denoising autoencoder,” in Proc. The world conf. Inf. Syst. And technol. (WorldCIST'19 2019) (Springer), 151–160. doi:10.1007/978-3-030-16187-3_15
Mottola, M., Ursprung, S., Rundo, L., Sanchez, L. E., Klatte, T., Mendichovszky, I., et al. (2021). Reproducibility of CT-based radiomic features against image resampling and perturbations for tumour and healthy kidney in renal cancer patients. Sci. Rep. 11, 11542. doi:10.1038/s41598-021-90985-y
Pathak, D., Krähenbühl, P., Donahue, J., Darrell, T., and Efros, A. A. (2016). “Context encoders: feature learning by inpainting,” in Proc. Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27-30 June 2016 (IEEE). doi:10.1109/CVPR.2016.278
Pittayapat, P., Jacobs, R., Bornstein, M. M., Odri, G. A., Lambrichts, I., Willems, G., et al. (2018). Three-dimensional Frankfort horizontal plane for 3D cephalometry: a comparative assessment of conventional versus novel landmarks and horizontal planes. Eur. J. Orth. 40 (3), 239–248. doi:10.1093/ejo/cjx066
Przepiórka, L., Kunert, P., Żyłkowski, J., Fortuniak, J., Larysz, P., Szczepanek, D., et al. (2019). Necessity of dural tenting sutures in modern neurosurgery: protocol for a systematic review. BMJ Open 9 (2), e027904. doi:10.1136/bmjopen-2018-027904
Qi, C. R., Yi, L., Su, H., and Guibas, L. J. (2017). “PointNet++: deep hierarchical feature learning on point sets in a metric space,” in Proc. 31st int. Conf. Neural inf. Process. Syst. (NIPS 2017) (Spinger), 5105–5114. doi:10.5555/3295222.3295263
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-Net: convolutional networks for biomedical image segmentation,” in Int. Conf. Medical imag. Comput. And comput.-assisted intervention (MICCAI 2015), LNCS 9351 (Springer), 234–241. doi:10.1007/978-3-319-24574-4_28
Shorten, C., and Khoshgoftaar, T. M. (2019). A survey on image data augmentation for deep learning. J. Big Data 6, 60. doi:10.1186/s40537-019-0197-0
Skolnick, G. B., Naidoo, S. D., Nguyen, D. C., Patel, K. B., and Woo, A. S. (2015). Comparison of direct and digital measures of cranial vault asymmetry for assessment of plagiocephaly. J. Craniofac. Surg. 26 (6), 1900–1903. doi:10.1097/SCS.0000000000002019
Tatarchenko, M., Dosovitskiy, A., and Brox, T. (2017). “Octree generating networks: efficient convolutional architectures for high-resolution 3D outputs,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV) (IEEE). Venice, Italy, October 22–29, 2107–2115. doi:10.1109/ICCV.2017.230
Wang, P. S., Liu, Y., Guo, Y. X., Sun, C. Y., and Tong, X. (2017). O-CNN: octree-based convolutional neural networks for 3D shape analysis. ACM Trans. Graph. 36 (4), 1–11. doi:10.1145/3072959.3073608
Wang, P. S., Liu, Y., and Tong, X. (2020). “Deep octree-based CNNs with output-guided skip connections for 3D shape and scene completion,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Seattle, WA, USA, 14-19 June 2020 (IEEE), 1074–1081. doi:10.1109/CVPRW50498.2020.00141
Wang, P. S., Sun, C. Y., Liu, Y., and Tong, X. (2018). Adaptive O-CNN: a patch-based deep representation of 3D shapes. ACM Trans. Graph. 37 (6), 1–11. doi:10.1145/3272127.3275050
Wu, C. T., Lu, T. C., Chan, C. S., and Lin, T. C. (2021). Patient-specific three-dimensional printing guide for single-stage skull bone tumor surgery: novel software workflow with manufacturing of prefabricated jigs for bone resection and reconstruction. World Neurosurg. 147, e416–e427. doi:10.1016/j.wneu.2020.12.072
Wu, C. T., Yang, Y. H., and Chang, Y. Z. (2022). Three-dimensional deep learning to automatically generate cranial implant geometry. Sci. Rep. 12, 2683. doi:10.1038/s41598-022-06606-9
Xiao, D., Lian, C., Wang, L., Deng, H., Lin, H.-Y., Thung, K.-H., et al. (2021). Estimating reference shape model for personalized surgical reconstruction of craniomaxillofacial defects. IEEE Trans. Biomed. Eng. 68, 362–373. doi:10.1109/TBME.2020.2990586
Xie, J., Xu, Y., Zheng, Z., Zhu, S. C., and Wu, Y. N. (2021). “Generative PointNet: deep energy-based learning on unordered point sets for 3D generation, reconstruction and classification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., CVPR 2021 (IEEE) June 19–25, 14976–14984. doi:10.1109/CVPR46437.2021.01473 (Due to the COVID-19 pandemic, CVPR 2021 was moving to a virtual event).
Yan, Z., Li, X., Li, M., Zuo, W., and Shan, S. (2018). “Shift-Net: image inpainting via deep feature rearrangement,” in Computer vision – ECCV 2018, lecture notes in computer science, LNCS 11218. Editors V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss (Springer). doi:10.1007/978-3-030-01264-9_1
Yang, C., Lu, X., Lin, Z., Shechtman, E., Wang, O., and Li, H. (2017). “High-resolution image inpainting using multi-scale neural patch synthesis,” in Proc. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21-26 July 2017 (IEEE). doi:10.1109/CVPR.2017.434
Yeap, M. C., Tu, P. H., Liu, Z. H., Hsieh, P. C., Liu, Y. T., Lee, C. Y., et al. (2019). Long-term complications of cranioplasty using stored autologous bone graft, three-dimensional polymethyl methacrylate, or titanium mesh after decompressive craniectomy: a single-center experience after 596 procedures. World Neurosurg. 128, e841–e850. doi:10.1016/j.wneu.2019.05.005
Yin, H., Dong, X., and Yang, B. (2015). A new three-dimensional measurement in evaluating the cranial asymmetry caused by craniosynostosis. Surg. Radiol. Anat. 37, 989–995. doi:10.1007/s00276-015-1430-y
Yu, F., and Koltun, V. (2016). “Multi-scale context aggregation by dilated convolutions,” in Proc. 4th int. Conf. Learn. Rep. (ICLR 2016) (Spinger). doi:10.48550/arXiv.1511.07122 https://www.vis.xyz/pub/dilation/.
Keywords: cranioplasty, cranial implant, deep learning, defective skull models, volumetric resolution, 3D inpainting
Citation: Wu C-T, Yang Y-H and Chang Y-Z (2023) Creating high-resolution 3D cranial implant geometry using deep learning techniques. Front. Bioeng. Biotechnol. 11:1297933. doi: 10.3389/fbioe.2023.1297933
Received: 20 September 2023; Accepted: 22 November 2023;
Published: 11 December 2023.
Edited by:
Takao Hanawa, Tokyo Medical and Dental University, JapanReviewed by:
Shireen Y. Elhabian, The University of Utah, United StatesCopyright © 2023 Wu, Yang and Chang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yau-Zen Chang, emVuQGNndS5lZHUudHc=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.