 Zeliang Wei1†
Zeliang Wei1† Xicheng Chen1†
Xicheng Chen1† Jialu Huang2†Zhenyan Wang1Tianhua Yao1Chengcheng Gao1Haojia Wang1Pengpeng Li1Wei Ye1Yang Li1Ning Yao1Rui Zhang1Ning Tang3Fei Wang4
Jialu Huang2†Zhenyan Wang1Tianhua Yao1Chengcheng Gao1Haojia Wang1Pengpeng Li1Wei Ye1Yang Li1Ning Yao1Rui Zhang1Ning Tang3Fei Wang4 Jun Hu2*Dong Yi1*
Jun Hu2*Dong Yi1* Yazhou Wu1*
Yazhou Wu1*- 1Department of Health Statistics, College of Preventive Medicine, Army Medical University, Chongqing, China
- 2Department of Neurology, Southwest Hospital, Army Medical University, Chongqing, China
- 3Department of Medical Engineering, The 953 Hospital of the Chinese People’s Liberation Army, Shigatse, China
- 4Medical Big Data and Artificial Intelligence Center, Southwest Hospital, Army Medical University, Chongqing, China
Aim: The detection and segmentation of cerebral microbleeds (CMBs) images are the focus of clinical diagnosis and treatment. However, segmentation is difficult in clinical practice, and missed diagnosis may occur. Few related studies on the automated segmentation of CMB images have been performed, and we provide the most effective CMB segmentation to date using an automated segmentation system.
Materials and Methods: From a research perspective, we focused on the automated segmentation of CMB targets in susceptibility weighted imaging (SWI) for the first time and then constructed a deep learning network focused on the segmentation of micro-objects. We collected and marked clinical datasets and proposed a new medical micro-object cascade network (MMOC-Net). In the first stage, U-Net was utilized to select the region of interest (ROI). In the second stage, we utilized a full-resolution network (FRN) to complete fine segmentation. We also incorporated residual atrous spatial pyramid pooling (R-ASPP) and a new joint loss function.
Results: The most suitable segmentation result was achieved with a ROI size of 32 × 32. To verify the validity of each part of the method, ablation studies were performed, which showed that the best segmentation results were obtained when FRN, R-ASPP and the combined loss function were used simultaneously. Under these conditions, the obtained Dice similarity coefficient (DSC) value was 87.93% and the F2-score (F2) value was 90.69%. We also innovatively developed a visual clinical diagnosis system that can provide effective support for clinical diagnosis and treatment decisions.
Conclusions: We created the MMOC-Net method to perform the automated segmentation task of CMBs in an SWI and obtained better segmentation performance; hence, this pioneering method has research significance.
1 Introduction
Cerebral small vessel disease (CSVD) refers to a combination of clinical, imaging and pathological manifestations triggered by various types of small vessel and capillary lesions in the brain, with cerebral microbleeds (CMBs) being one of the main manifestations (Greenberg et al., 2009; Pantoni, 2010). CMBs have been proven to be a diagnostic indicator for a variety of cerebrovascular diseases, such as stroke, dysfunction, dementia and cognitive impairment. The number, distribution, and size of CMBs are important imaging-based indicators that are used for clinical diagnosis and treatment (Shuaib et al., 2019). For example, the lobar distribution of CMBs may be used to indicate the risk of cerebral amyloid angiopathy (Farid et al., 2017). For patients, improvements in CMB detection and segmentation accuracy are beneficial to reduce the psychological stress and economic burden caused by misdiagnosis. For physicians, the efficient detection and segmentation of CMBs can effectively improve efficiency, and it can help physicians fully grasp the optimal treatment time (Yakushiji, 2015). Automated segmentation of CMBs is beneficial to save the time of both physicians and patients, which in turn provides opportunities for monitoring and analysing numerous neurologic diseases.
CMBs are a type of brain parenchymal lesion that occur when small blood vessels and capillaries rupture. CMBs can appear as small ovoid (<10 mm in diameter) hypointense signals in susceptibility weighted imaging (SWI) sequences of magnetic resonance imaging (MRI) and are extremely representative clinical microlesions (Wardlaw et al., 2013; Smith et al., 2019). However, the automated segmentation of microlesions represented by CMBs is a more difficult and challenging clinical task because CMBs are widely distributed throughout the brain. They are not only extremely small but also share a high degree of visual similarity with CMB analogues (such as calcification, rust, and veins) (Myung et al., 2021). In addition, CMBs present a blooming effect on MRI images, meaning that the volume of CMBs increase with increasing echo time, and various acquisition settings may affect CMB sizes (Rashid et al., 2021). Therefore, there is a significant need to implement automated segmentation of CMBs in SWI sequences, which is difficult but possible. However, most of the previous studies are limited to CMB target detection (Dou et al., 2016; Liu et al., 2019; Al-masni et al., 2020; Li et al., 2021b; Myung et al., 2021; Rashid et al., 2021), and there is a lack of related research on the automatic segmentation of CMBs.
Aiming at the difficulty of automated segmentation of CMBs in SWI sequences, we proposed a new medical micro-object cascade network (MMOC-Net) to perform automated segmentation of CMBs. This network consists of two stages, which can consider global and local information, and can achieve better feature extraction accuracy (Hu et al., 2020). In the first stage, a modified U-Net module is used to segment the potential CMB regions. In the second stage, the final segmentation task is performed by using a full-resolution network (FRN) at each region of interest, and residual atrous spatial pyramid pooling (R-ASPP) is added to extract multiscale information.
The major contributions of our work are as follows:
1) Research perspective: Few related studies on the automated segmentation of CMBs have been performed thus far, and we provide a more reliable and effective automatic segmentation system for CMBs. Compared with previous studies, in this paper, millimetre performance enhancements are a point of focus. In addition, a new segmentation method for CMBs, which is of pioneering method with research significance, is proposed.
2) Research methods: We propose a new MMOC-Net method to perform segmentation. The FRN in the network can generate full-resolution features to boost the pixel-level segmentation performance. R-ASPP can extract multiscale image features based on the FRN to circumvent the risk of gradient explosion. The joint loss function can consider various evaluation metrics to ensure the best segmentation performance.
3) Evaluation metrics: We propose two evaluation indices, the Dice similarity coefficient (DSC) and the F2-score (F2), which are suitable for medical micro-objective segmentation. The DSC is the primary metric that is used to evaluate medical segmentation and can reflect the proportion of pixels correctly identified by the model. F2 can fully emphasize the importance of the sensitivity (SEN) on the premise of considering the precision (PRE). The research concept in this paper is in accordance with practical clinical needs and can be implemented to effectively reduce the rate of missed clinical diagnosis. The results of this study show that the method can perform well in terms of some important indices, such as DSC and F2.
4) Application value: Considering the lack of sufficient and available public datasets for CMB segmentation, we collect all available SWI images from 316 patients (625 pieces) with CMBs and use manual markers to obtain labels. To the best of our knowledge, this is currently the largest datasets used in automated CMB segmentation. It can also be applied to more segmentation tasks due to its good generalizability.
2 Related Works
The detection and segmentation of CMBs have always been the focus of clinical applications. The traditional CMB detection task needs to be visually performed with the aid of valid visual scoring scales, such as the microbleed anatomical rating scale (MARS) (Gregoire et al., 2009) or the brain observer microbleed scale (BOMBS) (Cordonnier et al., 2009). Traditional detection methods include technologies based on unified segmentation (Seghier et al., 2011), support vector machines (SVMs) (Barnes et al., 2011) or radial symmetry transformations (RSTs) (Bian et al., 2013; Kuijf et al., 2013). However, traditional methods suffer from low detection efficiency, poor accuracy, and high missed diagnosis rates and have been gradually replaced by deep learning methods.
In recent years, image processing methods based on deep learning techniques have been gradually proposed and promoted. Some studies on fully automated medical image detection and segmentation have been performed. Currently, the most traditional deep learning method is the convolutional neural network (CNN) (Havaei et al., 2017). CNN architectures use two paths to extract image features at various scales. The fully convolutional network (FCN), which is a tree-structured multitask network, was constructed with high efficiency for end-to-end network construction (Shelhamer et al., 2017). However, FCNs still suffer from difficulties in fine segmentation tasks. Ronneberger proposed a U-shaped convolutional network called U-Net, which performs well on various medical image segmentation tasks (Ronneberger et al., 2015). However, U-Net does not work well on medical micro target fine segmentation tasks.
There is a significant need to implement automated segmentation of CMBs in SWI sequences, which is difficult but possible. Myung et al. (2021) proposed a two-stage approach to conduct CMB detection based on the you only look once (YOLO) model, which achieved an SEN of 80.96%. Rashid et al. (2021) proposed DEEPMIR to detect CMBs and iron deposits, and an average SEN of between 84%–88% was achieved. Li et al. (2021b) used feature enhancement in CMB detection, and an SEN of 90.00% was achieved, suggesting that feature enhancement can be a helpful algorithm to enhance the deep learning model. Dou et al. (2016) performed CMB detection via 3D convolutional neural networks, and a sensitivity of 92.31% was achieved. Liu et al. (2019) presented a two-stage CMB detection framework that achieved a sensitivity of 93.50%. These studies demonstrate the potential of applying deep learning techniques for improving efficiency and accuracy in the diagnosis of CMB. However, these studies are mostly limited to target detection, and few relevant studies have been found to perform automatic CMB segmentation on SWI sequences.
3 Methodology
Medical image segmentation is a challenging task in the field of computer vision. Because the segmentation target of CMB lesions is small and the effect of the single-step segmentation method is limited, we adopt the two-stage segmentation model MMOC-Net, which consists of coarse to fine segments to improve the detection and segmentation effect of lesions, and its overall framework is shown in Figure 1.
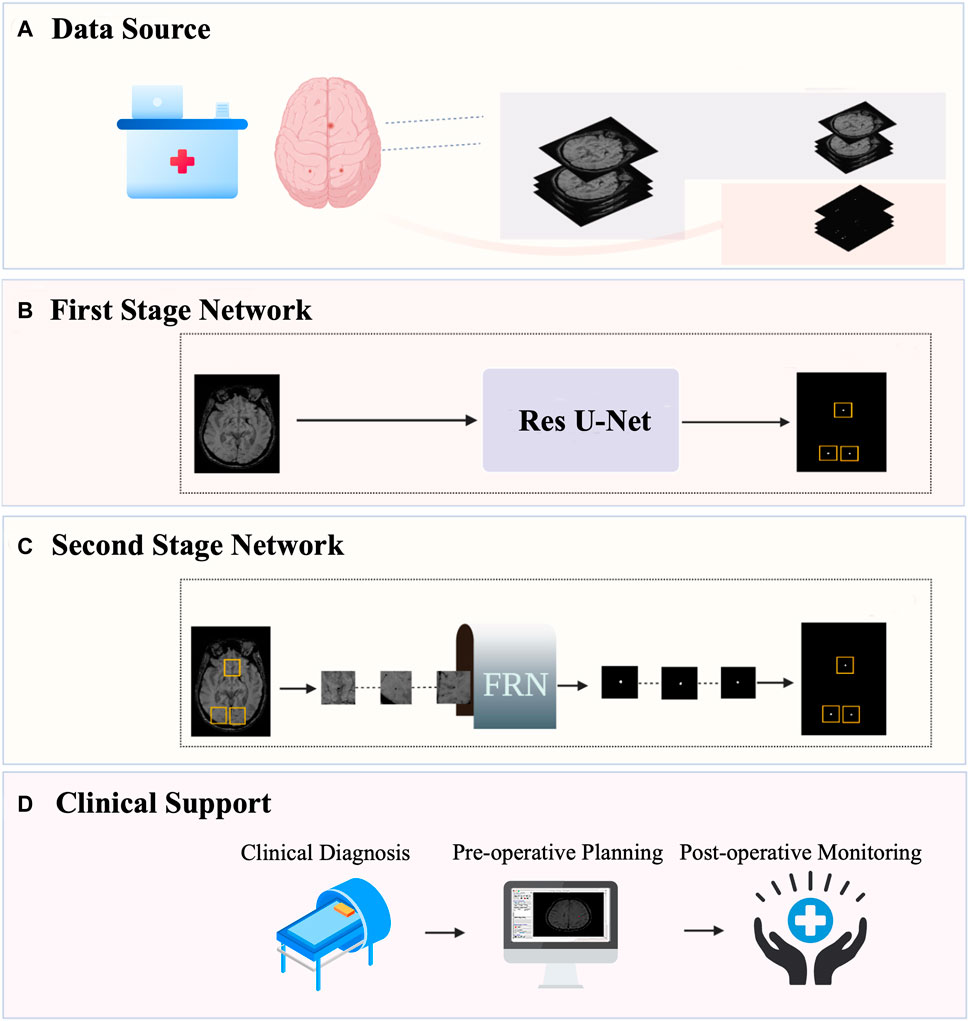
FIGURE 1. Overall framework of MMOC-Net. (A) Data collection and annotation process; (B) The first-stage coarse segmentation method uses Res U-Net to perform preliminary segmentation and identify the region of interest (ROI); (C) The second-stage fine segmentation method: FRN stands for full resolution network. The ROI regions are selected and input into the FRN to complete fine segmentation. (D) Automatic segmentation can obtain the distribution, quantity and size of lesions and support clinical decision-making.
The first stage is coarse segmentation, and we utilize the improved U-Net to segment a whole original image. The focus of this stage is not on the PRE value of lesion contour segmentation but on the SEN value of lesion detection to ensure the full detection of potential lesions. The second stage is fine segmentation in which ROI regions of a certain size are selected, centred on the lesions detected in the first stage (including sizes of 16 × 16, 32 × 32, 64 × 64, and 128 × 128) and input into the FRN for local fine segmentation. This process ensures that segmentation contours are accurate, excludes false positives and increases the overall PRE in micro-object segmentation.
3.1 Data Source
Our data were obtained from cranial MR images of 316 patients with CMBs at the Department of Neurology, Southwest Hospital, Army Medical University, Chongqing, China. The images of each patient were composed of the original image and the corresponding manually segmented mask. The imaging data of each patient contained MRI scans of the brain with various sequences, including T1, T2 and SWI, of which the SWI sequence was used. Segmentation masks for all patients were jointly annotated by two experienced clinicians, providing a binary image containing manual segmentation for each subject to ensure the accuracy of the training data.
Considering pertinence and accuracy and ensuring a sufficient sample size and diversity of the sample distribution, we selected 1–4 scans from the complete images of each patient, for a total of 625 scans. These data were divided into two subsets with a ratio of 4:1. In other words, there were 500 pieces of training data and 125 pieces of validation data. This study was reviewed and approved by the hospital ethics committee under ethics number (B) KY2021173.
The intensities of MR images are unnormalized data, so we adopted the min-max normalization method to process the images for intensity values. In addition, to improve data utilization and model generalization efficacy, several data augmentation strategies were used: 1) A random intensity translation and scaling were applied across each channel with standard deviation (−0.2∼0.2). 2) A random rotation with a 30% probability of rotation and a rotation degree limited to 180° were used. 3) Random horizontal and vertical flips were performed with a 30% probability. 4) Random noise was added.
3.2 Model Construction
3.2.1 First Stage Network
In the first stage, we use the improved U-Net model after pretraining to coarsely segment the CMB, as shown in Figure 2.
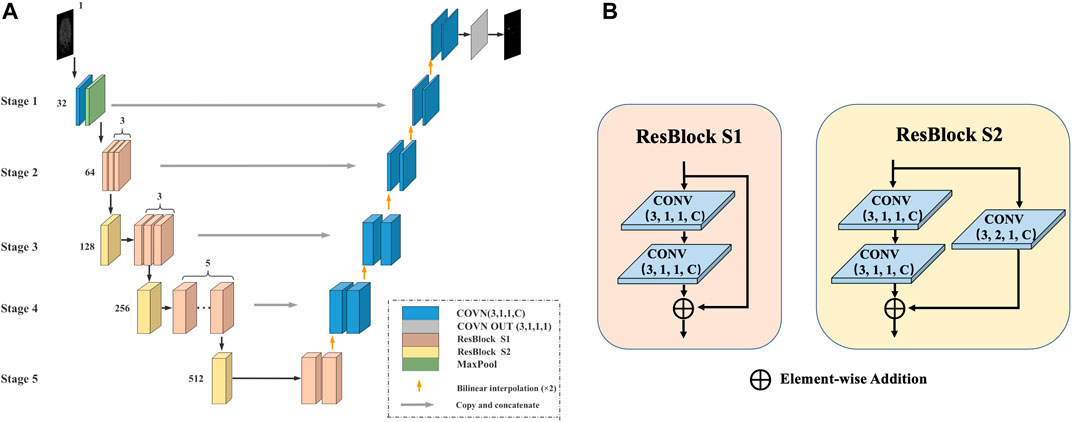
FIGURE 2. The first stage of the method. (A) U-Net model for coarse segmentation: The number represents the number of channels, the encoder is replaced with Res-Block during the encoding process, and the deconvolution is replaced with bilinear interpolation during the decoding process. (B) Res-Block S1/S2: The Res-Block S1 module contains two convolutional layers and uses shortcut connections to ensure the consistency of the gradient. The Res-Block S2 module adds a convolutional layer to the base of S1.
The U-Net model consists of an encoder (used for downsampling), a decoder (used for upsampling), and a skip connection and is divided into five stages. 1) Encoding process: The original encoder is replaced with a residual module (Res-Block), which can prevent the problem of vanishing/exploding gradients to provide a faster convergence rate and reduce the risk of overfitting. The output channel number of Stage 1 is 32. Stage 2 contains 3 Res-Block S1 modules, and the number of output channels is 64. Stage 3 contains 1 Res-Block S2 module and 3 Res-Block S1 modules, and the number of output channels is 128. Stage 5 contains 2 Res-Block S1 modules and 1 Res-Block S2 module, and the number of output channels is 512. 2) Decoding process: All deconvolutions are replaced with bilinear interpolation. The advantage is that no additional training parameters are needed, which can effectively reduce the model size and increase the running speed. 3) Skip connection: In each stage, a skip connection is used to fuse information in the encoding and decoding processes.
Our Res-Block is defined as:
where
Based on the above information, the learning characteristics from l to L can be obtained as:
Using the chain rule, the gradient of the reverse process can be found as:
Here, loss is the loss of the learning process, and
3.2.2 Second Stage Network
In the second stage, we propose an FRN and added the R-ASPP module using a fine segmentation method to obtain the final segmentation result, as shown in Figure 3.

FIGURE 3. The second stage of the network architecture. (A) FRN framework: This framework removes the downsampling structure and always extracts image features at the original input resolution to effectively prevent lesion information loss. (B) R-ASPP module: In the middle of the FRN, we innovatively add the R-ASPP module.
The FRN includes two convolutional layers, six residual modules and 1 R-ASPP module. We segment the target image patch centred on the region that is located by coarse segmentation. Then, we use the target image patch as the input of the FRN to focus on the precise segmentation of the target area without searching for the lesion on the entire image. After the target image patch is input to the first layer of convolution, a 32-channel feature map can be obtained, and then 3 Res-Block S1 modules are used to extract shallow features.
In the middle of the FRN, we innovatively add the R-ASPP module to extract multiscale features, the next 3 Res-Block S1 modules to extract deep features, and finally compress the features into one channel through CONV OUT to complete the result output. This module can perform parallel sampling of dilated convolutions with different sampling rates for a given input, and it can also prevent gradient disappearance or explosion.
In the R-ASPP module, feature maps are input into the dilated convolutions with dilation rates of 6, 8, 12, and 1 in the flat pooling layer. Their outputs are integrated and input into a convolution layer with a kernel size of 1 × 1 to obtain the number of channels consistent with that of the input feature map. The output of the previous convolutional layer and the input feature map are connected by shortcuts to obtain the result, and the output is
where ⊙ denotes the convolution operation, f0 is the input feature map, AP denotes the average pooling operation, K1 represents that the size of the convolution kernel is 1 × 1, Kdi represents that the size of the convolution kernel is 3 × 3, the dilation rate is di = (4,8,12), and h represents the identity mapping of the shortcut connection.
3.3 Modified Loss Function
Due to the imbalance between the pixels of CMBs and the background, binary cross entropy (BCE) loss and dice loss (DL) are taken as the loss functions. In addition, we creatively add the SEN loss function. The functions and advantages of each loss function are discussed below.
BCE is derived from the maximum likelihood function under the condition of a Bernoulli distribution and has been widely used in object classification and image pixel-level segmentation. BCE is used to measure the difference between two probability distributions of a given random variable or an event set. The smaller the value is, the smaller the difference between the two probability distributions. BCE can be defined as follows:
DL is more suitable for unbalanced tasks such as medical image segmentation. The DL loss value represents the predictive performance of the trained model. DL can be defined as:
In the CMB segmentation task, there is an imbalance between the foreground and the background. In terms of the clinical needs of the CMB segmentation task, an improvement in SEN is more important than an improvement in PRE. Therefore, we propose an SEN loss function whose value represents the missed diagnosis rate; it can be defined as:
Here,
In conclusion, BCE can improve the stability of model training, DL can make the model prediction results more closely resemble the expected value, and the SEN loss function can improve the SEN of model training. Therefore, we combine three types of loss functions to construct the total loss function as follows:
Here, the value of λ can affect the degree of the influence of the SEN loss value, and the larger the value is, the higher the weight of the influence of SEN. We determine the optimal value of λ after many pre-experiments. The focus of the coarse segmentation stage is to detect as many potential lesions as possible, so we set λ = 10. The focus of the fine segmentation stage is to balance SEN and PRE, so we set λ = 1. In model training, the total loss function value gradually decreases until it becomes stable, and the training model with the best prediction performance can be obtained.
3.4 Training Details
The training process is accelerated using a GPU, and the details of the running environment are shown in Table 1.

TABLE 1. Summary of the experimental environment.
In the coarse segmentation model training stage, all images are scaled to 352 × 448, and the input size of the ROIs in the fine segmentation model is 32 × 32 pixels. This design ensures that the lesion is of a detectable size while not exceeding the operating memory limit due to the image being too large. Both stages use the Adam optimizer to update the network weights, and the initial learning rate η is 0.0002.
During the training process, we also employ early stopping and cross-validation strategies, aiming to improve the persuasiveness of the experimental results and prevent the occurrence of overfitting during training. In each fold of the training set, we use early stopping and five-fold cross-validation strategies to select the number of epochs and the hyperparameters. We set the maximum number of data training iterations to 500 epochs and the patch size to 6. We also use the gradient checkpoint operation of PyTorch to reduce memory consumption.
3.5 Evaluation Metric
Confusion matrices are often used to evaluate the classification or segmentation tasks in deep learning, and
SEN and PRE are important measures of missed diagnosis and misdiagnosis, respectively. Missed diagnosis and misdiagnosis are pairs of contradictions, and it is often impossible to completely prevent them. In actual clinical diagnosis and treatment, the incidence of a missed diagnosis of CMBs is significantly higher than that of a misdiagnosis, and the consequences of a missed diagnosis are far greater than those of a misdiagnosis. The occurrence of a missed diagnosis may incur extremely high treatment risks and treatment costs, which cause irreversible clinical consequences. Even if a misdiagnosis occurs, subsequent diagnosis and treatment can be implemented, and serious consequences rarely occur. Therefore, it is more important to reduce the risk of missed diagnosis in CMB diagnosis. SEN and PRE can be expressed as:
The DSC is a mask similarity metric that measures how similar a predicted image is to the pixel spots of the ground truth. DSC describes the degree of similarity by evaluating the ratio of the area of the overlapping part of the two ensembles to the total area and is calculated as:
Here,
The F-score comprehensively weighs the PRE and SEN indicators. F2 is a special case of the F-score, and it focuses more on the SEN indicator. Our optimization principle ensures a high SEN value under the premise of ensuring that the PRE value is acceptable. This design is intended to reduce the clinical missed diagnosis rate as much as possible under the premise of ensuring a certain diagnostic accuracy rate. Therefore, the definition of F2 is more in line with the needs of this research and can be defined as:
We take the optimization of DSC and F2 as the primary goal and take DSC and F2 as the primary evaluation indices. To fully evaluate the effect of segmentation, we also introduce JSC and MCC as secondary evaluation indicators; they can be expressed as
The raincloud plot is a data visualization tool that provides more statistical information. It draws on the advantages of a variety of traditional statistical graphs and visualizes the original data, probability density and key statistical information (i.e., the median, average, and confidence interval) (Allen et al., 2019). From the term raincloud, “rain” represents the original data lattice, and “cloud” represents the data distribution. Box plots, central tendency information and error bar information are also added to the figure to further improve the statistical information. In a raincloud plot, redundant mirroring probability distributions are replaced with box plots and original data points and can provide important information such as data relationships and data distributions.
Medical datasets often have the problem of unbalanced categories, so we additionally choose the P-R curve to intuitively reflect the segmentation effect of the model. SEN and PRE can be used to draw precision-recall (P-R) curves, and the model performance can be better judged by the inclusion relationship of the P-R curve. The area under the P-R curve can be defined as the average PRE (AP) value. The higher this value is, the better the overall classification effect of the pixels.
4 Results
4.1 MMOC-Net Segmentation Results
In Table 2, the segmentation results are presented for the validation set using an ROI size of 32 × 32. An average DSC value of 87.93% for five-fold cross-validation and an average F2 value of 90.69% were achieved.

TABLE 2. Segmentation performance (%).
The total loss values and SEN changes at each epoch of the model are plotted and detailed in Figure 4. The results show that as the number of iterations increases, the total loss value decreases, the SEN value increases, and the convergence of our model is fast.
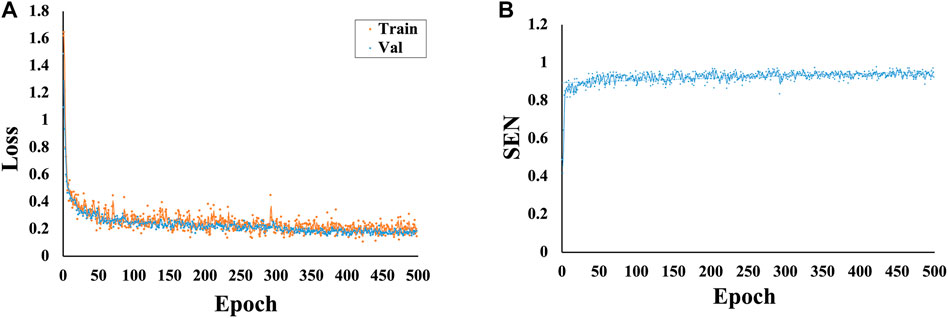
FIGURE 4. Variations in the loss and SEN values at different epochs. (A) Variations in the loss values at different epochs. (B) Variations in the SEN values at different epochs.
4.2 Effectiveness Comparison of Region of Interest Sizes
To investigate the effect of the ROI size on model performance, we compare the segmentation results of the four ROI sizes. The results show that the best segmentation results can be obtained when the size is 32 × 32. A DSC value of 87.93% and an F2 value of 90.69% were achieved under these conditions, as detailed in Table 3. Therefore, a size of 32 × 32 is adopted for each ablation combination in the later text.
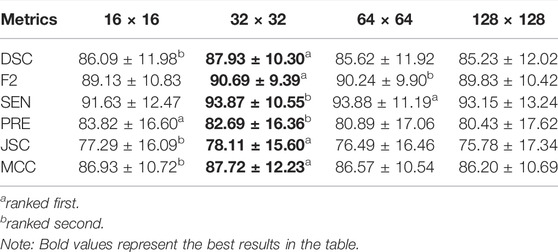
TABLE 3. Comparison of the four ROI size segmentation performance results (%).
The raincloud plots of DSC and F2 of the four ROI sizes are presented in Figures 5A,B; from these plots, we select the best ROI size. The results based on the raincloud plot for the 32 × 32 size have a better distribution of data, and the DSC and F2 values are closer to the high-score region. For the box plot, an overall segmentation accuracy improvement is evident with dimension a as well as the median and mean numbers of DSC and F2. Therefore, 32 × 32 is the optimal size for capturing image features with optimal segmentation and stability. The P-R curves of the four ROI sizes are presented in Figure 5C, and the results show that the inclusion relationship of the 32 × 32 size is significantly better than those of the other sizes, and the area under the curve is the largest (0.915).
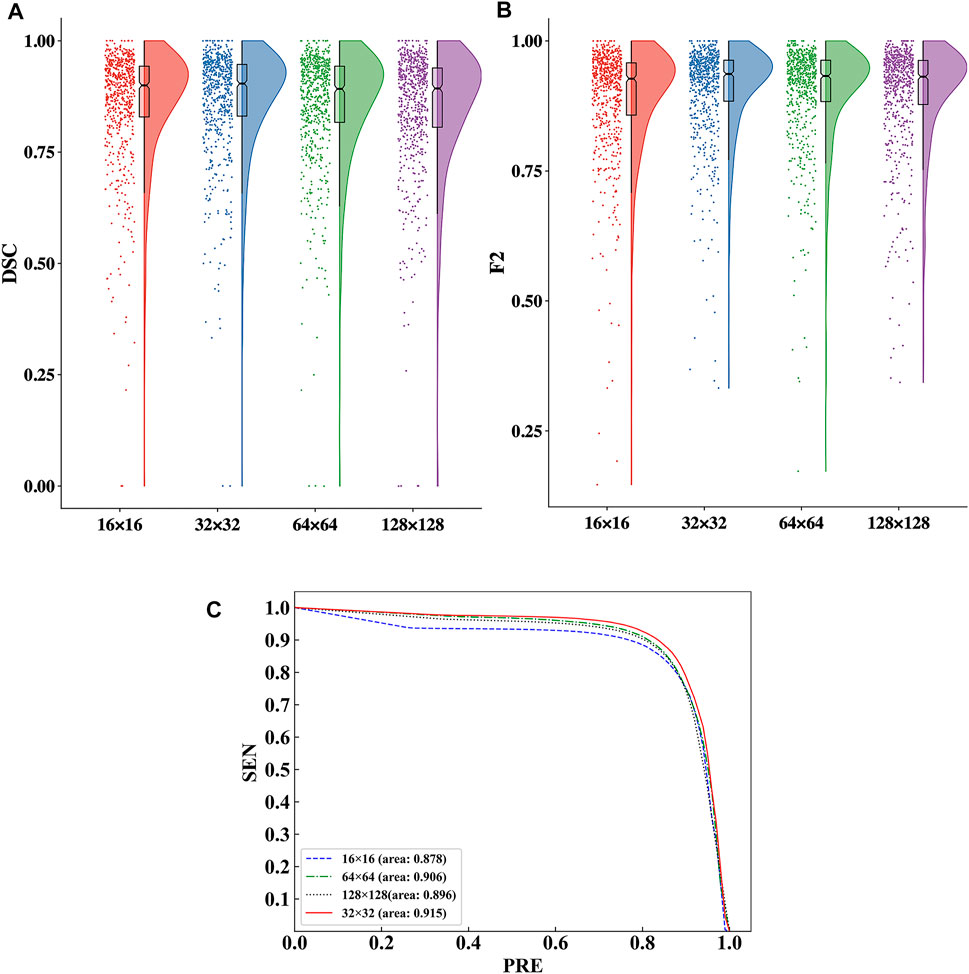
FIGURE 5. Comparison of the segmentation performance for the four ROI sizes. (A) Comparison of the DSC values in the raincloud plot for the four ROI sizes. (B) Comparison of the F2 values in the raincloud plot for the four ROI sizes. (C) Comparison of the P-R curves of the segmentation performance for the four ROI sizes.
We visually display the segmentation results of the four ROI sizes to contrast the segmentation effect of various ROI sizes, as shown in Figure 6. When the 32 × 32 size is utilized, the highest DSC value is achieved, and the segmentation details are closer to the ground truth than those of the other sizes. The apparent risks of missed diagnosis and misdiagnosis are lower and have the best segmentation performance.

FIGURE 6. Comparison of the masks for the four ROI sizes. The columns from left to right represent the original image, the ground truth, the 32 × 32 size (ours), the 16 × 16 size, the 64 × 64 size, and the 128 × 128 size; the rows from top to bottom represent case Nos. 1–4, respectively. In case 1, the lesion in the upper right corner was correctly predicted by using the 32 × 32 size, while using the other three sizes, the diagnosis was missed or a misdiagnosis was made. In case 2, the small lesion in the lower right corner was correctly predicted by using the 32 × 32 size, whereas using the other three sizes, the diagnosis was missed. In case 3, the number and distribution of the lesions were correctly predicted using the 32 × 32 size, whereas using the other three sizes, the diagnosis was missed. In case 4, the result using the 32 × 32 size was closest to the number and distribution of the ground truth, while using the other three sizes resulted in missed diagnoses or made misdiagnoses.
4.3 Effectiveness Comparison of Ablation Combinations
To verify the validity of the components implemented in our method, we compare the segmentation performance of different fusion combinations. The results are compared separately by removing each segment, and the results show that MMOC-Net achieves the best segmentation results, with a DSC value of 87.93% and an F2 value of 90.69%. Table 4 for details.

TABLE 4. Comparison of the effectiveness of the four ablation combinations (%).
We utilize raincloud plots to compare the effectiveness when the four ablation combinations are chosen and aim to retrieve the best ablation combination, as shown in Figures 7A,B. In the raincloud plot, the data distribution of DSC and F2 in MMOC-Net is significantly better than those of the other combinations, and most of them are distributed in high-score regions. In the boxplot, the overall effect of the full MMOC-Net is increased, for both the medians and means of DSC and F2. Therefore, using MMOC-Net, including FRN, R-ASPP and the joint loss function, a better segmentation effect and stability can be obtained. The P-R curves of the four ablation combinations are shown in Figure 7C. The results show that the inclusion relationship of MMOC-Net is significantly better than those of the other combinations and has the largest area under the curve (0.915).
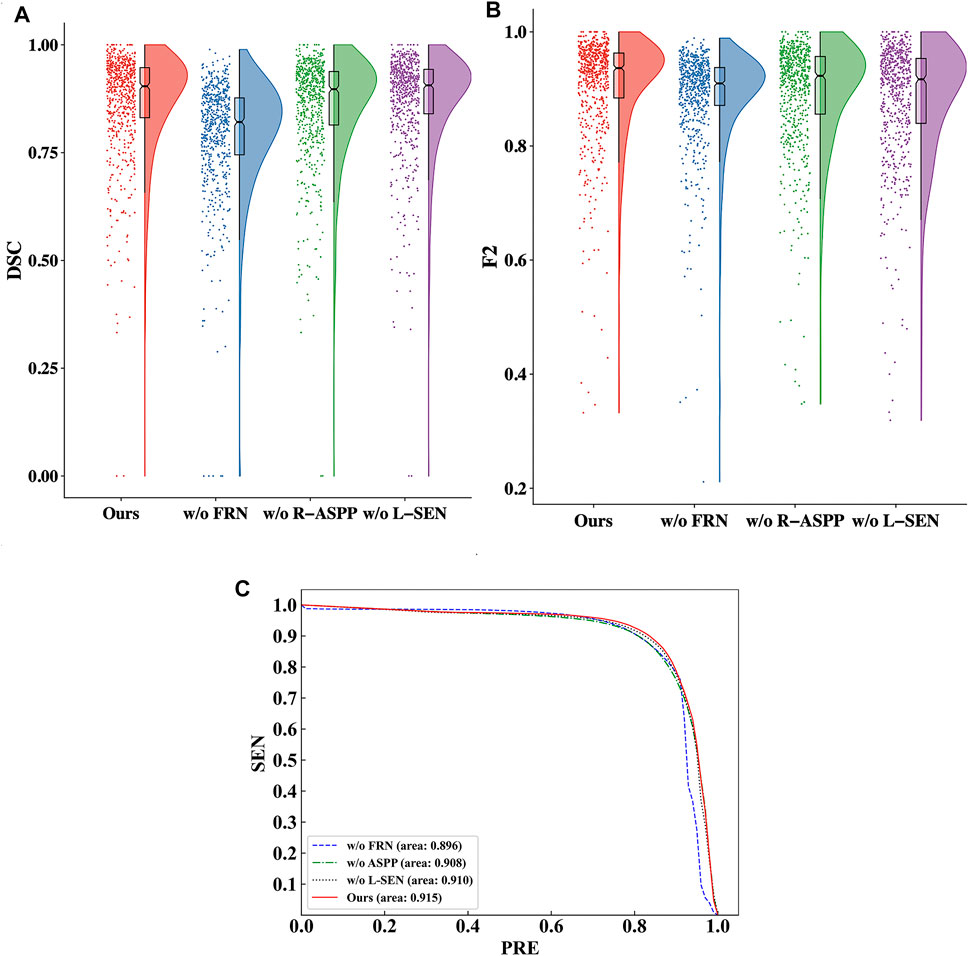
FIGURE 7. Comparison of the effectiveness of the four ablation combinations. (A) Comparison of the DSC values in the raincloud plot of the ablation combinations. (B) Comparison of the F2 values in the raincloud plot of the ablation combinations. (C) Comparison of the P-R curves of the segmentation performance results of the ablation combinations.
In this paper, the results of the four ablation combinations are demonstrated, and the segmentation performance results of the different methods are visually compared, as shown in Figure 8. The w/o FRN model has less effective segmentation performance, and more incorrect results are obtained. The w/o R-ASPP model has poor segmentation performance, and key lesion points are easily missed. The SEN value of w/o L-SEN is low, and leakage segmentation appears more frequently. Relative to other ablation combinations, the segmentation profile of MMOC-Net is the closest to the ground truth, indicating higher segmentation accuracy.
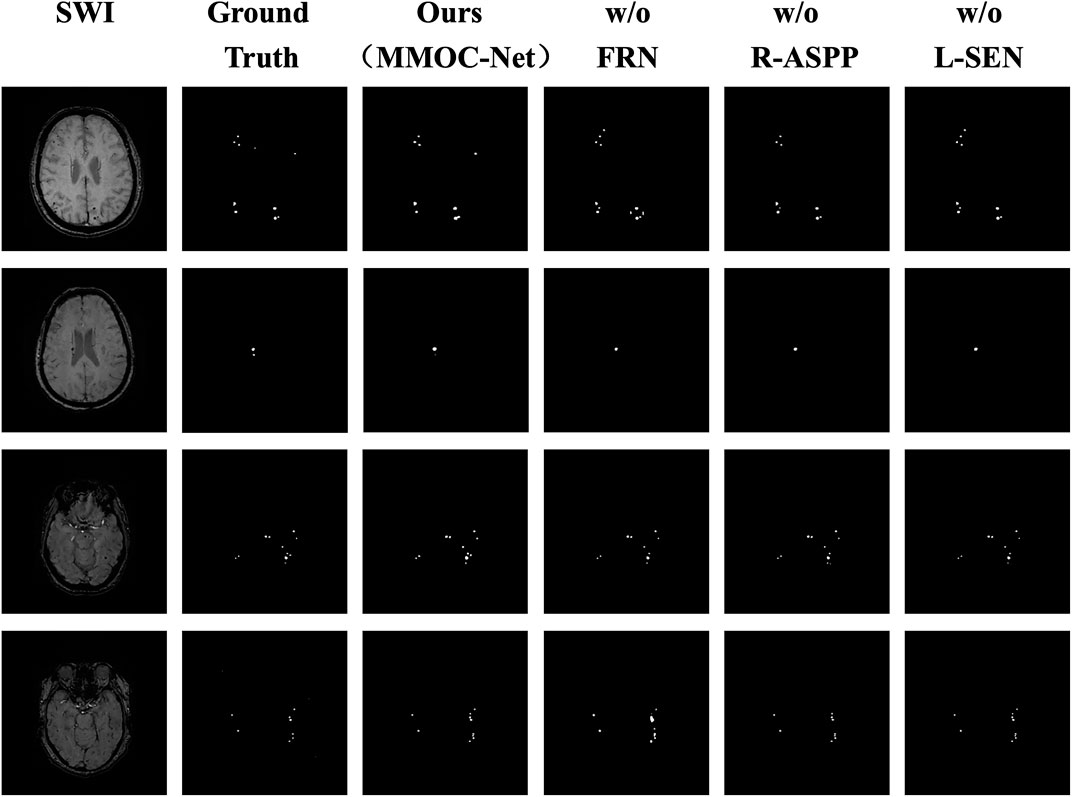
FIGURE 8. Comparison of the masks of the four ablation combinations. The columns from left to right represent the original image, the ground truth, the MMOC-Net model (ours), w/o FRN, w/o R-ASPP, and w/o L-SEN; the rows from top to bottom represent case Nos. 1–4, respectively. In case 1, the lesion in the upper right corner is correctly predicted by only MMOC-Net, while missed diagnoses and misdiagnoses were obtained using the other three models. In case 2, the small lesion in the lower right corner is correctly predicted only by MMOC-Net, while miss diagnoses occurred using the other three models. In case 3, the number and distribution of lesions are correctly predicted by MMOC-Net, while miss diagnoses occurred using the other three models. In case 4, MMOC-Net most closely approximates the number and distribution of the ground truth, whereas using the other three models obtain missed diagnoses and misdiagnoses.
4.4 Comparison With Previous Studies
Our method aims at the automatic segmentation of CMBs, and its comparison with previous studies can be divided into two aspects. On the one hand, our method is comparable to studies on CMB detection; on the other hand, our method is comparable to studies on segmentation of various objects in the brain.
In deep learning research on CMBs, most previous studies limited research to target detection, and there are few studies on the automatic segmentation of CMBs. Taking CMBs as the research object, we compare our segmentation research with previous detection research. The results show that for the same indicators, such as SEN, PRE, and FPavg, better results are achieved in this study than in previous studies, as shown in Table 5. Possible reasons for this discrepancy include differences in data sources, method construction, and mask types. Compared with target detection, the evaluation indicators of segmentation research are more comprehensive, and additional information such as lesion size, location, and volume can be obtained.
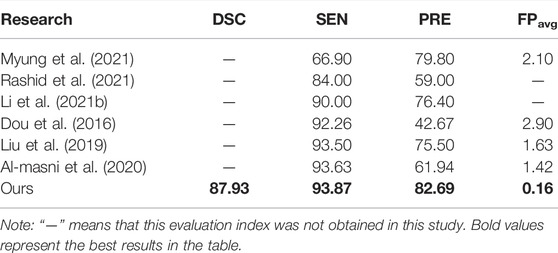
TABLE 5. Comparison of previous studies on the detection of CMBs and ours.
In a comparison of automated segmentation studies (Duan et al., 2020), implemented CMB segmentation in non-SWI sequences, but a DSC of only 50.30% was achieved. Fan et al. (2022) implemented 3D segmentation for CMBs, but a DSC of only 72.00% was achieved. There have also been studies on brain vessels (Dang et al., 2022), haemorrhage strokes (Li et al., 2021a) and white matter hyperintensities (Li et al., 2018). In our study, an excellent performance, with a DSC of 87.93%, is achieved for the automatic segmentation of CMBs, as shown in Table 6.
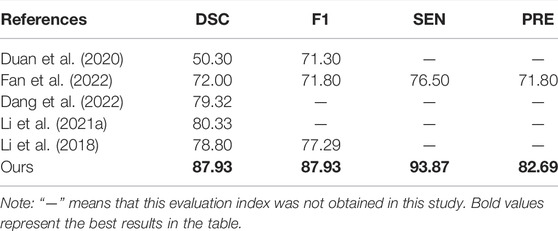
TABLE 6. Comparison of previous brain objects segmentation studies and ours.
4.5 Development of Visualization System
To improve the generalization ability of the method in this paper, we also innovatively developed visual automatic segmentation software, as shown in Figure 9. In practical applications, clinicians can efficiently and quickly obtain segmentation results based on deep learning, providing effective support for clinical diagnosis and treatment decisions. Our system has the advantages of convenience, speed and efficiency. After the operator selects the original image and segmentation method, the segmentation result can be automatically output. Using our system, the threshold for physician operation is lowered. As a result, this system can become more popular and may be applied in the majority of primary hospitals.
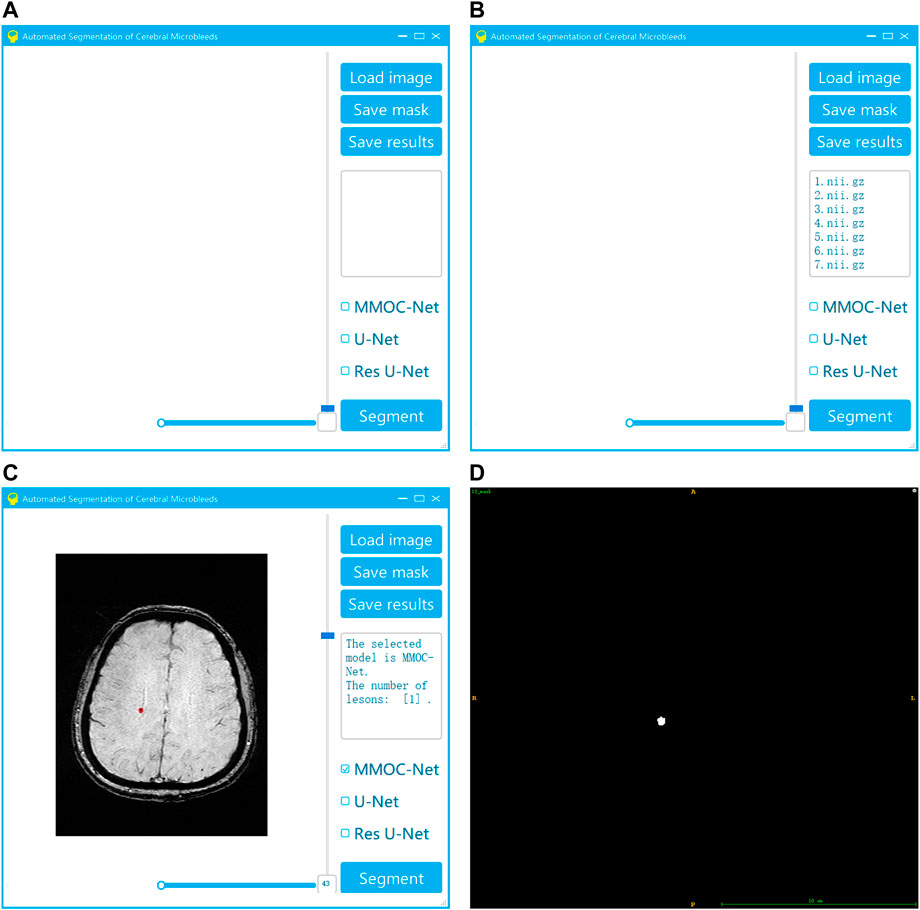
FIGURE 9. Visualization system for the automatic segmentation of medical small targets. (A) Interface of system startup; (B) Selection of the original image and segmentation method; (C) Running the segmentation to obtain the results; (D) Exporting the segmentation results.
5 Discussion
The segmentation of medical micro-objects is of great significance to the planning of clinical diagnosis and treatment, and it has become a popular issue in recent research. CMBs have been recognized as important biomarkers for the diagnosis of cerebrovascular diseases and the assessment of neurological dysfunction (Greenberg, 2021). However, in clinical practice, manual labelling of CMBs is laborious and diagnosis can easily be missed. There were few previous studies on automated image processing of CMBs, and they only focused on target detection. Few related studies on the automated segmentation of CMBs in SWI have been performed thus far. Automated segmentation of CMBs is beneficial to alleviate the work of physicians and improve the efficiency of diagnosis and treatment. The CMB automated segmentation task is performed for the first time in this study, which has seminal research significance and application prospects.
In this study, we construct a new MMOC-Net model that focuses on the segmentation of clinical microsamples and is implemented in a cascade. To the best of our knowledge, this is the first study to complete automated CMB segmentation in SWI sequence, which utilizes a new deep learning technique to efficiently analyze image information. In the cascade architecture, the first stage focuses on excluding background regions and screening potential candidate regions. We have developed a modified U-Net model for this stage, and the impact of the SEN in the modified loss function is valued. The second stage focuses on a small number of candidates and excludes false-positive regions with similar appearances to CMBs. At this stage, we employ FRN integrated with R-ASPP to identify CMBs. This results in higher SEN values and lower false-positive rates, which can better meet the requirements of accuracy.
In comparison with previous studies, the segmentation performance of MMOC-Net is excellent. This performance is better than the performance of similar studies of previous target detection and segmentation. The results of this study confirm that a properly trained MMOC-Net can achieve the accuracy of experienced clinicians and greatly improve the efficiency of diagnosis and treatment.
Compared with previous segmentation studies, the advantages of our method are as follows: 1) We adopt the implementation of coarse to fine segmentation, and FRN integrated with the R-ASPP module is beneficial for extracting full-resolution, multiscale image features, efficiently detecting CMB lesions. The above measures can consider global and local information and can achieve better feature extraction accuracy. 2) We propose a modified loss function, creatively add the optimization goal of sensitivity, and adopt different weight settings in the two-stage training, which is beneficial to reduce the missed diagnosis rate as much as possible on the premise of ensuring a certain precision. 3) In this paper, the ablation study is used to determine the optimal ROI size. With a size of 32 × 32, global and local information can be balanced well, and better feature extraction accuracy can be achieved.
Compared with previous research on object detection, there are several possible reasons as to why our method, which focuses on segmentation, can still achieve relative advantages: 1) Method: In our method, innovative improvements have been made in the network structure, parameter settings and objective function. 2) Label type: There are differences in annotations between detection and segmentation; detection uses bounding box labels, while segmentation uses fine-grained pixel-level labels. Compared with other detection methods, we use pixel-level accurate data for training and achieve better prediction results. 3) Information mining: The evaluation metrics for the accurate segmentation of CMBs generated by our method are more comprehensive and can provide more information, such as distribution, quantity, and size, which can be combined with relevant research on risk factors to provide effective support for clinical diagnosis and treatment decisions (Whitwell et al., 2015).
In practical applications, this method has high clinical significance. 1) Automation: In clinical screening and diagnosis, manual detection and segmentation of CMBs is an expensive, tedious and time-consuming task. Rapid and accurate automated CMB segmentation can alleviate the burden of clinicians so that they can focus on higher-level clinical decisions. 2) Effectiveness: CMB segmentation is highly skill- and experience-demanding for clinicians, and the labelling accuracy of different clinicians varies greatly. For example Duan et al. (2020), showed that the DSC of clinicians with many years of experience in manually segmenting CMBs is only 57.60%. In contrast, our method is an automated and standardized segmentation approach based on deep learning, which can effectively improve the segmentation accuracy and reduce the risk of missed diagnosis. 3) Visualization: We have also innovatively developed a visual automatic segmentation system, which has the advantages of convenience, speed and efficiency. Our system is conducive to lowering the threshold for physicians to operate. This can be popularized and applied in the majority of primary hospitals. 4) Generalizability: The existence of CMBs is related to a variety of cerebrovascular disease accidents and death risks. After acquiring CMB segmentation regions by the method in this paper, clinical information can be extracted from the distribution, quantity and size of CMBs to provide suggestions for further clinical interventions for patients.
Our study was well designed and rigorously implemented, but there were still some deficiencies and room for improvement. We envision future research directions as follows. 1) This study focuses on 2D image segmentation without utilizing 3D image features. In the future, we need to implement 3D layer segmentation to better utilize the spatialized, stereologic information of SWI images. In addition, the present study is a single-centre study with a relatively limited sample size, and it lacks validation on external datasets. In the future, we need to include more datasets with small medical micro-objects and perform studies with large sample sizes and multicentre validation. 2) There is still room to improve the segmentation performance of this method, and the generalization performance of the newly constructed MMOC-Net needs to be verified. In the future, we need to continue to optimize the relationship between the model structure and model parameters, improve the segmentation performance, and better apply the model in clinical diagnosis and treatment decisions.
6 Conclusion
In summary, we perform the automatic segmentation task of CMB images in SWI and create a brand-new segmentation method (MMOC-Net) with pioneering research implications. MMOC-Net can improve the diagnosis and treatment efficiency while reducing the missed diagnosis rate and can obtain a better segmentation performance (87.93% DSC and 90.69% F2). Our idea and method can realize the target detection and fine segmentation of medical micro-objects, which can make full use of image information to provide clinical decision support and has great application value and promotion prospects.
Data Availability Statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/qweiweili/MMOC-Net.
Ethics Statement
Written informed consent was not obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author Contributions
ZeW: conceptualization, data curation, resources, methodology, software, formal analysis, validation, investigation, writing—original draft. XC: methodology, software, formal analysis, validation, investigation, writing—original draft. JH: data curation, resources, software, formal analysis, writing—editing and polishing. ZhW and TY: investigation, resources, writing—polishing. CG, HW, and PL: Software, Validation, Investigation, Data curation. WY, YL, and NY: Validation, Resources. RZ, NT, and FW: Formal analysis, validation. JH and DY: conceptualization, investigation, validation, resources. YW: funding acquisition, conceptualisation, investigation, resources, methodology, writing—review and editing, project administration, supervision.
Funding
This work is supported by National Natural Science Foundation of China (Nos. 81872716, 82173621, 81873755), Natural Science Foundation of Chongqing (Cstc2020jcyj-zdxmX0017), National Key R&D Program of China under Grant (No. 2018YFC1311404).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Abbreviations
CMBs, cerebral microbleeds; CSVD, Cerebral small vessel disease; DSC, Dice similarity coefficient; F2, F2 score; FRN, full-resolution network; MMOC-Net, medical micro-object cascade network; PRE, precision; R-ASPP, atrous spatial pyramid pooling; SEN, sensitivity; SWI, susceptibility weighted imaging; ROI, region of interest.
References
Al-masni, M. A., Kim, W.-R., Kim, E. Y., Noh, Y., and Kim, D.-H. (2020). Automated Detection of Cerebral Microbleeds in MR Images: A Two-Stage Deep Learning Approach. NeuroImage Clin. 28, 102464. doi:10.1016/j.nicl.2020.102464
Allen, M., Poggiali, D., Whitaker, K., Marshall, T. R., and Kievit, R. A. (2019). Raincloud Plots: a Multi-Platform Tool for Robust Data Visualization. Wellcome Open Res. 4, 63. doi:10.12688/wellcomeopenres.15191.1
Barnes, S. R. S., Haacke, E. M., Ayaz, M., Boikov, A. S., Kirsch, W., and Kido, D. (2011). Semiautomated Detection of Cerebral Microbleeds in Magnetic Resonance Images. Magn. Reson. Imaging 29, 844–852. doi:10.1016/j.mri.2011.02.028
Bian, W., Hess, C. P., Chang, S. M., Nelson, S. J., and Lupo, J. M. (2013). Computer-aided Detection of Radiation-Induced Cerebral Microbleeds on Susceptibility-Weighted MR Images. NeuroImage Clin. 2, 282–290. doi:10.1016/j.nicl.2013.01.012
Cordonnier, C., Potter, G. M., Jackson, C. A., Doubal, F., Keir, S., Sudlow, C. L. M., et al. (2009). Improving Interrater Agreement about Brain Microbleeds: Development of the Brain Observer Microbleed Scale (BOMBS). Stroke 40, 94–99. doi:10.1161/strokeaha.108.526996
Dang, V. N., Galati, F., Cortese, R., Di Giacomo, G., Marconetto, V., Mathur, P., et al. (2022). Vessel-CAPTCHA: An Efficient Learning Framework for Vessel Annotation and Segmentation. Med. Image Anal. 75, 102263. doi:10.1016/j.media.2021.102263
Dou, Q., Chen, H., Yu, L., Zhao, L., Qin, J., Wang, D., et al. (2016). Automatic Detection of Cerebral Microbleeds from MR Images via 3D Convolutional Neural Networks. IEEE Trans. Med. Imaging 35, 1182–1195. doi:10.1109/tmi.2016.2528129
Duan, Y., Shan, W., Liu, L., Wang, Q., Wu, Z., Liu, P., et al. (2020). Primary Categorizing and Masking Cerebral Small Vessel Disease Based on "Deep Learning System". Front. Neuroinform. 14, 17. doi:10.3389/fninf.2020.00017
Fan, P., Shan, W., Yang, H., Zheng, Y., Wu, Z., Chan, S. W., et al. (2022). Cerebral Microbleed Automatic Detection System Based on the "Deep Learning". Front. Med. 9, 807443. doi:10.3389/fmed.2022.807443
Farid, K., Charidimou, A., and Baron, J.-C. (2017). Amyloid Positron Emission Tomography in Sporadic Cerebral Amyloid Angiopathy: A Systematic Critical Update. NeuroImage Clin. 15, 247–263. doi:10.1016/j.nicl.2017.05.002
Greenberg, S. M. (2021). Cerebral Microbleeds and Prediction of Intracranial Haemorrhage. Lancet Neurology 20, 252–254. doi:10.1016/s1474-4422(21)00065-x
Greenberg, S. M., Vernooij, M. W., Cordonnier, C., Viswanathan, A., Al-Shahi Salman, R., Warach, S., et al. (2009). Cerebral Microbleeds: a Guide to Detection and Interpretation. Lancet Neurology 8, 165–174. doi:10.1016/s1474-4422(09)70013-4
Gregoire, S. M., Chaudhary, U. J., Brown, M. M., Yousry, T. A., Kallis, C., Jager, H. R., et al. (2009). The Microbleed Anatomical Rating Scale (MARS): Reliability of a Tool to Map Brain Microbleeds. Neurology 73, 1759–1766. doi:10.1212/wnl.0b013e3181c34a7d
Havaei, M., Davy, A., Warde-Farley, D., Biard, A., Courville, A., Bengio, Y., et al. (2017). Brain Tumor Segmentation with Deep Neural Networks. Med. Image Anal. 35, 18–31. doi:10.1016/j.media.2016.05.004
Hu, H., Guan, Q., Chen, S., Ji, Z., and Lin, Y. (2020). Detection and Recognition for Life State of Cell Cancer Using Two-Stage Cascade CNNs. IEEE/ACM Trans. Comput. Biol. Bioinf. 17, 887–898. doi:10.1109/tcbb.2017.2780842
Kuijf, H. J., Brundel, M., de Bresser, J., van Veluw, S. J., Heringa, S. M., Viergever, M. A., et al. (2013). Semi-Automated Detection of Cerebral Microbleeds on 3.0 T MR Images. PLoS ONE 8, e66610. doi:10.1371/journal.pone.0066610
Li, H., Jiang, G., Zhang, J., Wang, R., Wang, Z., Zheng, W.-S., et al. (2018). Fully Convolutional Network Ensembles for White Matter Hyperintensities Segmentation in MR Images. NeuroImage 183, 650–665. doi:10.1016/j.neuroimage.2018.07.005
Li, L., Wei, M., Liu, B., Atchaneeyasakul, K., Zhou, F., Pan, Z., et al. (2021a). Deep Learning for Hemorrhagic Lesion Detection and Segmentation on Brain CT Images. IEEE J. Biomed. Health Inf. 25, 1646–1659. doi:10.1109/jbhi.2020.3028243
Li, T., Zou, Y., Bai, P., Li, S., Wang, H., Chen, X., et al. (2021b). Detecting Cerebral Microbleeds via Deep Learning with Features Enhancement by Reusing Ground Truth. Comput. Methods Programs Biomed. 204, 106051. doi:10.1016/j.cmpb.2021.106051
Liu, S., Utriainen, D., Chai, C., Chen, Y., Wang, L., Sethi, S. K., et al. (2019). Cerebral Microbleed Detection Using Susceptibility Weighted Imaging and Deep Learning. NeuroImage 198, 271–282. doi:10.1016/j.neuroimage.2019.05.046
Myung, M. J., Lee, K. M., Kim, H.-G., Oh, J., Lee, J. Y., Shin, I., et al. (2021). Novel Approaches to Detection of Cerebral Microbleeds: Single Deep Learning Model to Achieve a Balanced Performance. J. Stroke Cerebrovasc. Dis. 30, 105886. doi:10.1016/j.jstrokecerebrovasdis.2021.105886
Pantoni, L. (2010). Cerebral Small Vessel Disease: from Pathogenesis and Clinical Characteristics to Therapeutic Challenges. Lancet Neurology 9, 689–701. doi:10.1016/s1474-4422(10)70104-6
Rashid, T., Abdulkadir, A., Nasrallah, I. M., Ware, J. B., Liu, H., Spincemaille, P., et al. (2021). DEEPMIR: a Deep Neural Network for Differential Detection of Cerebral Microbleeds and Iron Deposits in MRI. Sci. Rep. 11, 14124. doi:10.1038/s41598-021-93427-x
Ronneberger, O., Fischer, P., and Brox, T. (2015). “U-net: Convolutional Networks for Biomedical Image Segmentation,” in Medical Image Computing And Computer-Assisted Intervention – MICCAI 2015 Lecture Notes in Computer Science. Editors N. Navab, J. Hornegger, W. M. Wells, and A. F. Frangi (Cham: Springer International Publishing), 234–241. doi:10.1007/978-3-319-24574-4_28
Seghier, M. L., Kolanko, M. A., Leff, A. P., Jäger, H. R., Gregoire, S. M., and Werring, D. J. (2011). Microbleed Detection Using Automated Segmentation (MIDAS): A New Method Applicable to Standard Clinical MR Images. PLoS ONE 6, e17547. doi:10.1371/journal.pone.0017547
Shelhamer, E., Long, J., and Darrell, T. (2017). Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39, 640–651. doi:10.1109/tpami.2016.2572683
Shuaib, A., Akhtar, N., Kamran, S., and Camicioli, R. (2019). Management of Cerebral Microbleeds in Clinical Practice. Transl. Stroke Res. 10, 449–457. doi:10.1007/s12975-018-0678-z
Smith, E. E., Biessels, G. J., De Guio, F., Leeuw, F. E., Duchesne, S., Düring, M., et al. (2019). Harmonizing Brain Magnetic Resonance Imaging Methods for Vascular Contributions to Neurodegeneration. Alzheimer's & Dement. Diagn. Assess. ; Dis. Monit. 11, 191–204. doi:10.1016/j.dadm.2019.01.002
Wardlaw, J. M., Smith, E. E., Biessels, G. J., Cordonnier, C., Fazekas, F., Frayne, R., et al. (2013). Neuroimaging Standards for Research into Small Vessel Disease and its Contribution to Ageing and Neurodegeneration. Lancet Neurology 12, 822–838. doi:10.1016/s1474-4422(13)70124-8
Whitwell, J. L., Kantarci, K., Weigand, S. D., Lundt, E. S., Gunter, J. L., Duffy, J. R., et al. (2015). Microbleeds in Atypical Presentations of Alzheimer's Disease: A Comparison to Dementia of the Alzheimer's Type. JAD 45, 1109–1117. doi:10.3233/jad-142628
Keywords: cerebral microbleed, medical micro-object, image segmentation, susceptibility weighted imaging, deep learning
Citation: Wei Z, Chen X, Huang J, Wang Z, Yao T, Gao C, Wang H, Li P, Ye W, Li Y, Yao N, Zhang R, Tang N, Wang F, Hu J, Yi D and Wu Y (2022) Construction of a Medical Micro-Object Cascade Network for Automated Segmentation of Cerebral Microbleeds in Susceptibility Weighted Imaging. Front. Bioeng. Biotechnol. 10:937314. doi: 10.3389/fbioe.2022.937314
Received: 06 May 2022; Accepted: 20 June 2022;
Published: 20 July 2022.
Edited by:
Zhiwei Ji, Nanjing Agricultural University, ChinaCopyright © 2022 Wei, Chen, Huang, Wang, Yao, Gao, Wang, Li, Ye, Li, Yao, Zhang, Tang, Wang, Hu, Yi and Wu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jun Hu, aHVqdW5jcUAxNjMuY29t; Dong Yi, eWRfaG91c2VAaG90bWFpbC5jb20=; Yazhou Wu, YXNpYXd1QHRtbXUuZWR1LmNu
†These authors have contributed equally to this work and share first authorship