 Johannes Burdack1
Johannes Burdack1 Fabian Horst1*
Fabian Horst1* Sven Giesselbach2,3
Sven Giesselbach2,3 Ibrahim Hassan1,4
Ibrahim Hassan1,4 Sabrina Daffner5
Sabrina Daffner5 Wolfgang I. Schöllhorn1,6
Wolfgang I. Schöllhorn1,6- 1Department of Training and Movement Science, Institute of Sport Science, Johannes Gutenberg-University, Mainz, Germany
- 2Knowledge Discovery, Fraunhofer-Institute of Intelligent Analysis and Information Systems (IAIS), Sankt Augustin, Germany
- 3Competence Center Machine Learning Rhine-Ruhr (ML2R), Dortmund, Germany
- 4Faculty of Physical Education, Zagazig University, Zagazig, Egypt
- 5Qimoto, Doctors‘ Surgery for Sport Medicine and Orthopedics, Wiesbaden, Germany
- 6Department of Wushu, School of Martial Arts, Shanghai University of Sport, Shanghai, China
Human movements are characterized by highly non-linear and multi-dimensional interactions within the motor system. Therefore, the future of human movement analysis requires procedures that enhance the classification of movement patterns into relevant groups and support practitioners in their decisions. In this regard, the use of data-driven techniques seems to be particularly suitable to generate classification models. Recently, an increasing emphasis on machine-learning applications has led to a significant contribution, e.g., in increasing the classification performance. In order to ensure the generalizability of the machine-learning models, different data preprocessing steps are usually carried out to process the measured raw data before the classifications. In the past, various methods have been used for each of these preprocessing steps. However, there are hardly any standard procedures or rather systematic comparisons of these different methods and their impact on the classification performance. Therefore, the aim of this analysis is to compare different combinations of commonly applied data preprocessing steps and test their effects on the classification performance of gait patterns. A publicly available dataset on intra-individual changes of gait patterns was used for this analysis. Forty-two healthy participants performed 6 sessions of 15 gait trials for 1 day. For each trial, two force plates recorded the three-dimensional ground reaction forces (GRFs). The data was preprocessed with the following steps: GRF filtering, time derivative, time normalization, data reduction, weight normalization and data scaling. Subsequently, combinations of all methods from each preprocessing step were analyzed by comparing their prediction performance in a six-session classification using Support Vector Machines, Random Forest Classifiers, Multi-Layer Perceptrons, and Convolutional Neural Networks. The results indicate that filtering GRF data and a supervised data reduction (e.g., using Principal Components Analysis) lead to increased prediction performance of the machine-learning classifiers. Interestingly, the weight normalization and the number of data points (above a certain minimum) in the time normalization does not have a substantial effect. In conclusion, the present results provide first domain-specific recommendations for commonly applied data preprocessing methods and might help to build more comparable and more robust classification models based on machine learning that are suitable for a practical application.
Introduction
Human movements are characterized by highly non-linear and multi-dimensional interactions within the motor system (Chau, 2001a; Wolf et al., 2006). In this regard, the use of data-driven techniques seems to be particularly suitable to generate predictive and classification models. In recent years, different approaches based on machine-learning techniques such as Artificial Neural Networks (ANNs), Support Vector Machines (SVMs) or Random Forest Classifiers (RFCs) have been suggested in order to support the decision making of practitioners in the field of human movement analysis, e.g., in classifying movement patterns into relevant groups (Schöllhorn, 2004; Figueiredo et al., 2018). Most machine-learning applications in human movements are found in human gait using biomechanical data (Schöllhorn, 2004; Ferber et al., 2016; Figueiredo et al., 2018; Halilaj et al., 2018; Phinyomark et al., 2018). Although it is generally striking that there are more and more promising applications of machine learning in the field of human movement analysis, the applications are very diverse and differ in their objectives, samples and classification tasks. In order to fulfill the application requirements and to ensure the generalizability of the results, a number of stages are usually carried out to process the raw data in classifications using machine learning. Typically, machine-learning classifications of gait patterns consist of a preprocessing and a classification stage (Figueiredo et al., 2018). The preprocessing stage can be distinguished in feature extraction, feature normalization, and feature selection. The classification stage includes cross validation, model building and validation, as well as evaluation. Different methods have been used for each stage and there is no clear consensus on how to proceed in each of these stages. This is particularly the case for the preprocessing stages of the measured raw data before the classification stage, where there are hardly any recommendations, standard procedures or systematic comparisons of different steps within the preprocessing stage and their impact on the classification accuracy (Slijepcevic et al., 2020). The following six steps, for example, can be derived from the preprocessing stage: (1) Ground reaction force (GRF) filtering, (2) time derivative, (3) time normalization, (4) data reduction, (5) weight normalization, and (6) data scaling.
(1) There are a number of possible noise sources in the recording of biomechanical data. Noise can be reduced by careful experimental procedures, however, cannot be completely removed (Challis, 1999). So far there is less known about optimal filter-cut-off frequencies in biomechanical gait analysis (Schreven et al., 2015). Apart from a limited certainty about an optimal range of filter cut-off frequencies of the individual GRF components, the effect of GRF filtering on the prediction performance of machine-learning classifications has not been reported.
(2) In the majority of cases, time-continuous waveforms or time-discrete gait variables are measured and used for the classification (Schöllhorn, 2004; Figueiredo et al., 2018). Although, some authors also used time derivatives or data in the frequency or frequency-time domain from time-continuous waveforms (Schöllhorn, 2004; Figueiredo et al., 2018). A transformation, which has barely been applied so far, is the first-time derivative of the acceleration, also known as jerk (ΔtGRF) (Flash and Hogan, 1985). However, ΔtGRF might describe human gait more precisely than velocity and acceleration, especially when the GRF is measured. ΔtGRF can be determined directly by calculating the first-time derivative of the GRF measured by force plates.
(3) Feature normalization has been applied in order to achieve more robust classification models (Figueiredo et al., 2018). A normalization in time is commonly applied to normalize the biomechanical waveforms as percentage of the step, stride or stance phase (Kaczmarczyk et al., 2009; Alaqtash et al., 2011a,b; Eskofier et al., 2013; Zhang et al., 2014). It is differentiated among other things between 101 points in time (Eskofier et al., 2013), 1000 points in time (Slijepcevic et al., 2017) or the percentage occurrence per step cycle (Su and Wu, 2000).
(4) The purpose of data reduction is to reduce the amount of data to the most relevant features. A dimensionally reduction is often performed in order to determine which data is to be retained and which can be discarded. The use of dimension reduction can speed up computing time or reduce storage costs for data analysis. However, it should be noted that these feature selection approaches can not only reduce computation costs, but could also improve the classification accuracy (Phinyomark et al., 2018). Beside the unsupervised selection of single time-discrete gait variables (Schöllhorn, 2004; Begg and Kamruzzaman, 2005), typical methods for reducing the dimensionality of the data is, for example, the Principal Component Analysis (Deluzio and Astephen, 2007; Lee et al., 2009; Eskofier et al., 2013; Badesa et al., 2014).
(5) Another way of feature normalization is weight or height normalization. Weight and height normalizations in amplitude are a frequently used method to control for inter-individual differences in kinetic and kinematic variables (Wannop et al., 2012). To what extent the multiplication by a constant factor influences the classification has not yet been investigated to the best of our knowledge.
(6) A third way of feature normalization is data scaling. Data scaling is often performed to normalize the amplitude of one or different variable time courses (Mao et al., 2008; Laroche et al., 2014). The z-score method is mainly used (Begg and Kamruzzaman, 2005; Begg et al., 2005). In machine learning, scaling to a variable or variable waveform the interval [0, 1] or [-1, 1] is common in order to minimize amplitude-related weightings when training the classifiers (Hsu et al., 2003). To the best of our knowledge, it has not yet been investigated whether it makes a difference to scale over a single gait trial or over all trials of one subject in one session.
In summary, there is a lack of domain-specific standard procedures and recommendations, especially for the various data preprocessing steps commonly applied before machine-learning classifications. Therefore, the aim of this analysis is to compare different commonly applied data preprocessing steps and examine their effect on the classification performance using different machine-learning classifiers (ANN, SVM, RFC). A systematic comparison is of particular interest for deriving domain-specific recommendations, finding best practice models and the optimization of machine-learning classifications of human gait data. The analysis is based on the classification problem described by Horst et al. (2017), who investigated intra-individual gait patterns across different time-scales over 1 day.
Materials and Methods
Sample and Experimental Protocol
The publicly available dataset on intra-individual changes of gait patterns by Horst et al. (2017, 2019a) and two unpublished datasets (Daffner, 2018; Hassan, 2019) following the same experimental protocol were used for this analysis. In total, the joint dataset consisted of 42 physically active participants (22 females, 20 males; 25.6 ± 6.1 years; 1.72 ± 0.09 m; 66.9 ± 10.7 kg) without gait pathology and free of lower extremity injuries. The study was conducted in accordance with the Declaration of Helsinki and all participants were informed of the experimental protocol and provided their written consent. The approval of the ethics committee of the Rhineland-Palatinate Medical Association in Mainz has been received.
As presented in Figure 1, the participants performed 6 sessions (S1–S6) of 15 gait trials in each session, while there was no intervention between the sessions. After the first, third and fifth session, the participants had a break of 10 min until the beginning of the subsequent session. Between S2 and S3 was a break of 30 min and between S4 and S5 the break was 90 min. The participants were instructed to walk a 10 m-long path at a self-selected speed barefooted. For each trial, three-dimensional GRFs were recorded by means of two Kistler force plates of type 9287CA (Kistler, Switzerland) at a frequency of 1,000 Hz. The Qualisys Track Manager 2.7 software (Qualisys AB, Sweden) managed the recording. During the investigation, the laboratory environment was kept constant and each subject was analyzed by the same assessor only. Before the first session, each participant carried out 20 familiarization trials to get used to the experimental setup and to determine a starting point for a walk across the force plates. Before each of the following sessions, five familiarization trials were carried out to take into account an effect of practice and to control the individual starting position. In addition, the participants were instructed to look toward a neutral symbol (smiley) on the opposite wall of the laboratory to direct their attention away from targeting the force plates and ensure a natural gait with upright posture. The description of the experimental procedure can be found as well in the original study (Horst et al., 2017).
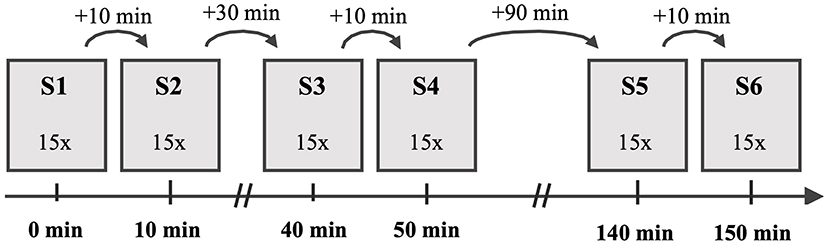
Figure 1. Experimental procedure with the chronological order of the six sessions (S1–S6) and the duration of the rest periods between subsequent sessions.
Data Preprocessing
The stance phase of the right and left foot was determined using a vertical GRF threshold of 20 Newton. Different combinations of commonly used data preprocessing steps, which typically precede machine-learning classifications of biomechanical gait patterns have been compared (Figure 2). Within the introduced stage of preprocessing, the following six data preprocessing steps were investigated: (1. GRF filtering) comparing filtered and unfiltered GRF data. The method described by Challis (1999) was used to determine the optimal cut-off frequencies (fc) for the respective gait trials. The optimal filter frequencies were calculated for each foot and each of the three dimensions in each gait trial separetly. (2. Time derivative) comparing the recorded GRF and ΔtGRF, the first-time derivative of the GRF. ΔtGRF was calculated by temporally derivating the GRF for each time interval. (3. Time normalization) comparing the number of time points for the time normalization to the stance phase. Each variable was time normalized to 11, 101 and 1,001 data points, respectively. (4. Data reduction) comparing non-reduced, time-continuous waveforms (TC), time-discrete gait variables (TD) and principle components by a reduction using Principal Component Analysis (PCA) applied to the time-continuous waveforms. The PCA (Hotelling, 1933) is a statistical procedure that uses an orthogonal transformation from a set of observations of potentially correlated variables into a set of values of linearly uncorrelated variables, the so called “principal components.” In this transformation, the first principal component explains the largest possible part of the variance. Each subsequent principal component again explains the largest part of the remaining variance, with the restriction that subsequent principal components are orthogonal to the preceding principal components. In our experiment, the resulting features, i.e., the principle components explaining 98% of the total variance, were used as input feature vectors for the classification. The time-discrete gait variables of the fore-aft and medio-lateral shear force were the minimum and the the maximum values as well as their occurrence during the stance phase, and of the vertical force the minimum and the two local maxima values as well as their occurrence during the stance phase. This resulted in 28 time-discrete gait variables for GRF data and 24 time-discrete gait variables for ΔtGRF data. (5. Weight normalization) comparing whether weight normalization to the body weight of every session was performed or not. The normalization to the body weight before every season would exclude the impact of any changes in the body mass during the investigation. (6. Data scaling) comparing different data scaling techniques. Scaling is a common procedure for data processing prior to classifications of gait data (Chau, 2001a,b). It was carried out to ensure an equal contribution of all variabilities to the prediction performance and to avoid dominance of variables with greater numeric range (Hsu et al., 2003). On the one hand, this involved a z-transformation over all trials and one over each single trial combined with a scaling to the range of [−1, 1] (Hsu et al., 2003), determined over all trials or over each single trial. The combination of these amplitude normalization methods result in four different scaling methods.
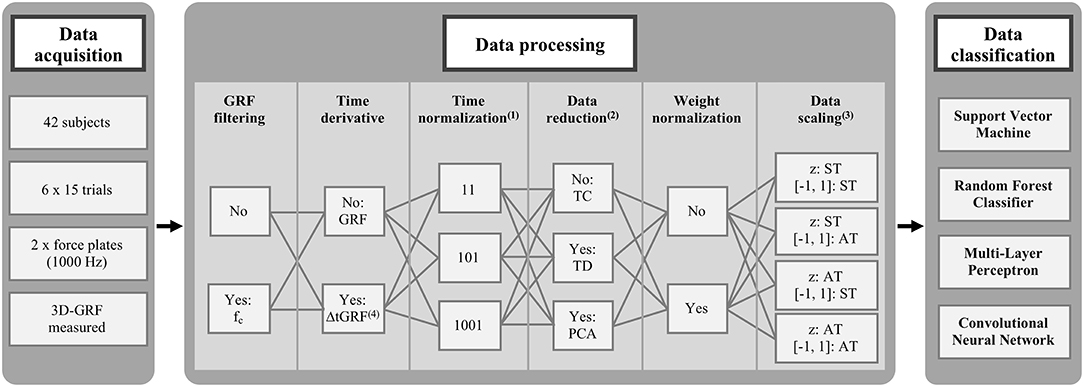
Figure 2. Combinations of commonly used data preprocessing steps before machine-learning classifications. (1) Data points per foot and dimension. (2) Time-continuous waveforms without reduction (TC), time-discrete gait variables by an unsupervised reduction (TD), and principle components by a supervised reduction using Principal Component Analysis (PCA). (3) Z-transformation combined with scaling from [−1, 1] over single trials (ST) or all trials (AT). fc: individual optimal filter cut-off frequency. (4) ΔtGRF: first-time derivative of GRF.
The data preprocessing was managed within Matlab R2017b (MathWorks, USA) and all combinations of each methods of each data preprocessing and classification step were performed in the current analysis in the order described in Figure 2. In total, the analysis included 1,152 different combinations of data preprocessing and classification step methods (1,152 = 2 GRF filtering * 2 Time derivative * 3 Time normalization * 3 Data reduction * 2 Weight normalization * 4 Data scaling * 4 Classifier). In the two methods TD and PCA for data reduction, the data scaling could not be applied for all methods. In many cases, all values of a time-discrete gait variable or a principle component were identical [Figure 2: Data Scaling z: ST or [−1, 1]: ST] and thus no variance occurred, which is necessary for the calculation of the data scaling. Only, the data scaling over all trials from one subject [Figure 2: Data scaling: z: AT, [−1, 1]: AT] could be performed for all three methods of data reduction. In order to keep the number of considered combinations the same for all methods of a data preprocessing step, only the data scaling of all attempts of one subject [Figure 2: Data scaling: z: AT, [−1, 1]: AT] was considered for the descriptive and statistical analysis in the results section. This scaling also led to by far the best performance scores. Consequently, 288 different combinations of data preprocessing and classification step methods (288 = 2 GRF filtering * 2 Time derivative * 3 Time normalization * 3 Data reduction * 2 Weight normalization * 1 Data scaling * 4 Classifier) were compared quantitatively with each other on basis of the performance scores.
Data Classification
The intra-individual classification of gait patterns was based on the 90 gait trials (90 = 6 sessions × 15 trials) of each participant. For each trial, a concatenated vector of the three-dimensional variables of both force plates was used for the classification. Due to the different time normalization and data reduction methods, the resulting length of the input feature vectors differed (Table 1).
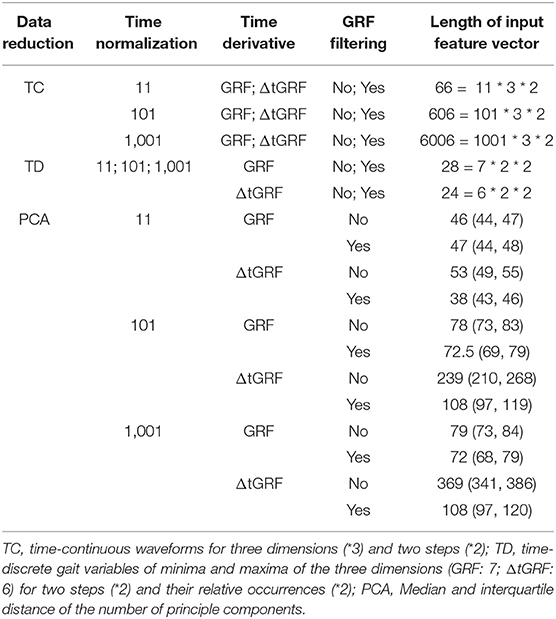
Table 1. Length of the resulting input feature vectors depending on different combinations of preprocessing methods.
The classification based on the following four supervised machine-learning classifiers with an exhaustive hyper-parameter search: (1) Support Vector Machines (SVMs) (Boser et al., 1992; Cortes and Vapnik, 1995; Müller et al., 2001; Schölkopf and Smola, 2002) using a linear kernel and a grid search to determine the best cost parameter C = 2−5, 2−4.75, …, 215. (2) Random Forest Classifiers (RFCs) (Breiman, 2001) with the Gini coefficient as decision criterion. Different numbers of trees (n_estimators = 200, 225, …, 350) and maximal tree depth (n_depth = 4, 5, …, 8) were determined empirically via grid search. (3) Multi-Layer Perceptrons (MLPs) (Bishop, 1995) with one hidden layer of size 26 (= 64 neurons) and 2,000 iterations with the weight optimization algorithm Adam (β1 = 0.9, β2 = 0.999, ε = 10−8). The learning rate regularization parameter α (= 10−1, 10−2, …, 10−7) was determined via grid search in the cross-validation. (4) Convolutional Neural Networks (CNNs) (LeCun et al., 2015) consisting of three convolutional layers and one fully connected layer. The first convolutional layers contained 24 filters with a kernel size of 8, a stride of 2 and a padding of 4. The second contained 32 filters with a kernel size of 8, a stride of 2 and a padding of 4. The third convolutional layer contained 48 filters with a kernel size of 6, a stride of 3 and a padding of 3. After each convolutional layer a ReLU activation was performed and after a fully connected layer a SoftMax was used to obtain probability of each of the classes. This architecture follows CNNs previously used for the classification of GRF data (Horst et al., 2019b). The ability to distinguish gait patterns of one test session from gait patterns of other test sessions was investigated in a multi-class classification (six-session classification) setting. For the evaluation of the prediction performance, the F1-, precision- and recall-scores were calculated over a stratified 15-fold cross validation configuration. 78 of 90 parts of the data were used for training, 6 of 90 parts were used as a validation set and the remaining 6 of 90 parts was reserved for testing. The 6 samples per test split were evenly distributed across all session partitions and are excluded from the complete training and validation process. Only 6 samples were selected for the test split because we wanted to guarantee as much training data as possible. In order to get meaningful results, the Training Validation Test splitting was stratified repeated 15 times so that each of the 90 gait trials was exactly once in the test set. The classification was performed within Python 3.6.3 (Python Software Foundation, USA) using the scikit-learn toolbox (0.19.2) (Pedregosa et al., 2011) and PyTorch (1.2.0) (Paszke et al., 2019).
The evaluation was carried out by calculating the performance indicators (accuracy, F1-score, precision and recall) defined by the number of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN):
Please note that since this is a balanced data set for multi-class classification, the accuracy corresponds exactly to the recall.
Statistical Analysis
For the comparison of the different combinations of the described preprocessing steps, the mean performance scores were compared statistically. Each mean value combined all combinations of preprocessing steps where the preprocessing method was part of. The Shapiro-Wilk test showed that none of the examined variables violated the normal distribution assumption (p ≥ 0.109). For the comparison of all combinations of the preprocessing methods, paired-samples t-test and repeated-measures ANOVAs were calculated for the variables of time derivative, GRF filtering and weight normalization. For the ANOVAs post hoc Bonferroni corrected paired-samples t-tests were calculated for the variables of time normalization, data reduction and classifier. Furthermore, the effect sizes d and were calculated; d and are considered a small effect for |d| = 0.2 and < 0.06, a medium effect for |d| = 0.5 and 0.06 < < 0.14 and a large effect for |d| = 0.8 and > 0.14 (Cohen, 1988). The p-value at which research is considered worth to be continued (Fisher, 1922) has been set to p = 0.05. To determine a best practice model, all combinations of data preprocessing methods were ranked according to their mean performance scores over 15-fold cross validation and the rank sum was calculated.
Results
Average Performance of Different Data Preprocessing Methods
The analysis compares 288 different combinations of data preprocessing methods based on the resulting F1-score. Table 2 displays the mean F1-score for each individual participant over the 15-fold cross validation (Supplementary Tables S1, S2 show the mean precision and recall values).
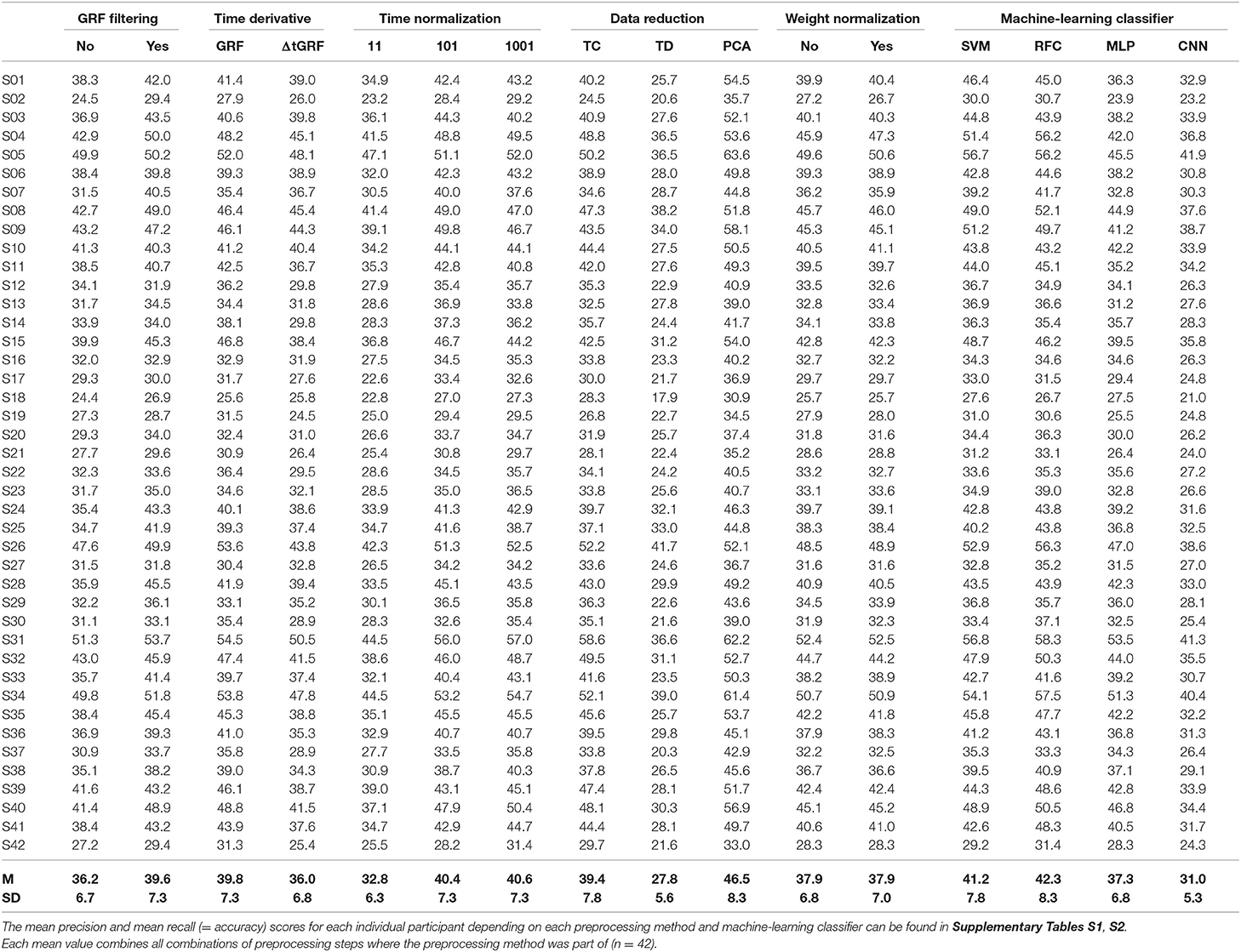
Table 2. Mean F1-score for each individual participant depending on each preprocessing method and machine-learning classifier.
Figure 3 shows the mean F1-scores over all participants. It is noticeable that the highest mean F1-scores were achieved using PCA, while the normalization to 101 and 1,001 data points or the weighting has only a minor effect on the F1-score. The time normalization to only 11 data points and the reduction to time-discrete gait variables gave particularly low mean classification scores. Concerning the machine-learning classifiers, the RFCs achieved the highest mean F1-scores followed by the SVMs, MLPs, and CNNs.
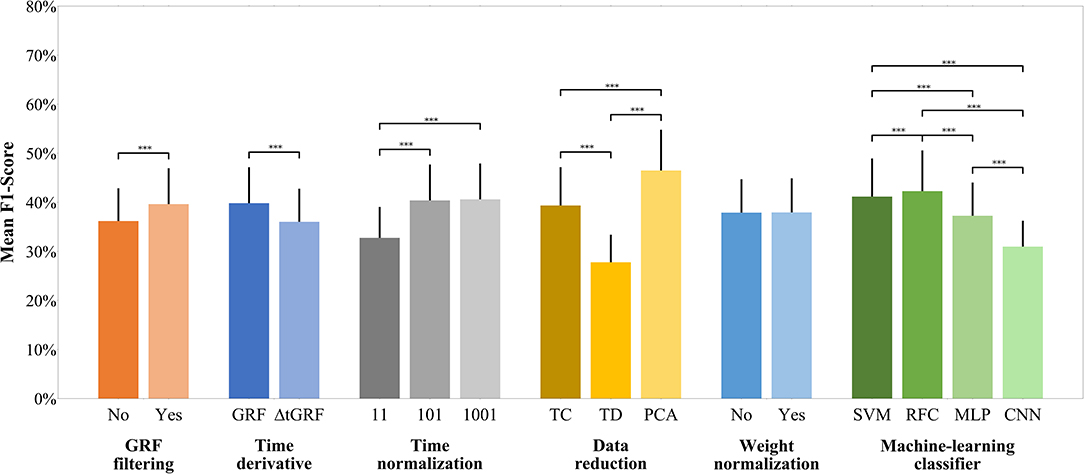
Figure 3. F1-score of each preprocessing step across all participants. The y-axis shows the mean F1-score achieved. The bar charts show the mean value and the standard deviation depending on the respective preprocessing step. The parentheses show a statistically significant effect. Random Baseline = 16.7%; ***p ≤ 0.001.
GRF Filtering
A paired-samples t-test was performed to determine if there were differences in F1-score in unfiltered GRF data compared to fc–filtered GRF data across all participants. The mean F1-score of the filtered GRF data (M = 39.6%, SD = 7.3%) was significantly higher than that of the unfiltered GRF data (M = 36.2%, SD = 6.7%). The effect size, however, was small [t(41) = 8.200, p < 0.001, |d| = 0.492].
Time Derivative
A paired-samples t-test was conducted to compare the F1-score of GRF and ΔtGRF across all participants. The mean F1-score of GRF (M = 39.8%, SD = 7.3%) was significantly higher than that of ΔtGRF (M = 36.0%, SD = 6.8%) and showed a medium effect size [t(41) = 8.162, p < 0.001, |d| = 0.540].
Time Normalization
A repeated-measures ANOVA determined that there is a significant global effect with large effect size of F1-score between time normalization to 11, 101 and 1,001 data points [F(2.000, 82.000) = 367.115, p < 0.001, = 0.900]. Post hoc paired-samples t-test with Bonferroni correction revealed that there is no significant difference [t(41) = −0.741, p = 0.463, |d| = 0.031] between a time normalization to 101 (M = 40.4%, SD = 7.3%) data points and 1,001 data points (M = 40.6%, SD = 7.3%). However, the time normalization to 101 data points performed significantly better [t(41) = 22.397, p < 0.001, |d| = 1.118] than time normalized to 11 data points (M = 32.8%, SD = 6.3%). Also the time normalization to 1,001 data points performed significantly better than to 11 data points [t(41) = 21.789 p < 0.001, |d| = 1.150]. Both effect sizes are considered as large.
Data Reduction
A one-way repeated-measures ANOVA was conducted to compare the F1-scores of PCA (M = 54.9%, SD = 8.5%), TC (M = 50.9%, SD = 8.8%), and TD (M = 37.5%, SD = 6.5%). The Huynh-Feldt corrected results showed a highly significant main effect with a large effect size [F(1.594, 65.365) = 378.372, p < 0.001, = 0.902]. Bonferroni corrected post hoc paired-samples t-tests showed that PCA performed significantly better than TC [t(41) = 14.540, p < 0.001, |d| = 0.884] and TD [t(41) = 22.658, p < 0.001, |d| = 2.635]. The effect size for both comparisons is considered as large. Furthermore, TC performed also significantly better than TD with a large effect size [t(41) = 16.516, p < 0.001, |d| = 1.701].
Weight Normalization
A paired-samples t-test was conducted to compare the F1-scores of weight-normalized and non-weight-normalized data across all participants. There was no significant difference [t(41) = −0.644, p = 0.523, |d| = 0.006] in the F1-scores for non-weight-normalized data (M = 37.9%, SD = 6.8%) and weight-normalized data (M = 37.9%, SD = 7.0%).
Machine-Learning Classifier
A repeated-measures ANOVA with Huynh-Feldt correction showed a highly significantly global effect with large effect size [F(1.130, 103.478) = 240.138, p < 0.001, = 0.854] between the predicted F1-scores by the SVMs (M = 41.2%, SD = 7.8%), RFCs (M = 42.3%, SD = 8.3%), MLPs (M = 37.3%, SD = 6.8%), and CNNs (M = 31.0%, SD = 5.3%). Post hoc Bonferroni corrected paired-samples t-test revealed that the RFCs performed significantly better, with a small effect size, than the SVMs [t(41) = 3.531, p = 0.001, |d| = 0.140], with a medium effect size than the MLPs [t(41) = 9.459, p < 0.001, |d| = 0.664] and with a large effect size than the CNNs [t(41) = 20.780, p < 0.001, |d| = 1.625]. Also the SVMs performed significantly better than the MLPs with a medium effect [t(41) = 8.115, p < 0.001, |d| = 0.534] and significantly better than the CNNs with a large effect [t(41) = 23.811, p < 0.001, |d| = 1.530]. Furthermore, the MLPs performed significantly better than the CNNs with a large effect [t(41) = 13.725, p < 0.001, |d| = 1.035].
Best Practice Combinations of Different Data Preprocessing Methods
In addition to the mean F1-scores for each method of all preprocessing and classification steps, Table 3 shows the 30 combinations with the highest overall F1-scores, including precision and recall (the complete list including precision and recall can be found in Supplementary Table S3). It is particularly noticeable that the first 18 ranks were all achieved using PCA for data reduction. Furthermore, the first eight ranked combinations used GRF data. The first twelve ranked combinations were classified with SVMs, while the highest F1-score was 13th with MLP, 27th with RFC and 57th with CNN.
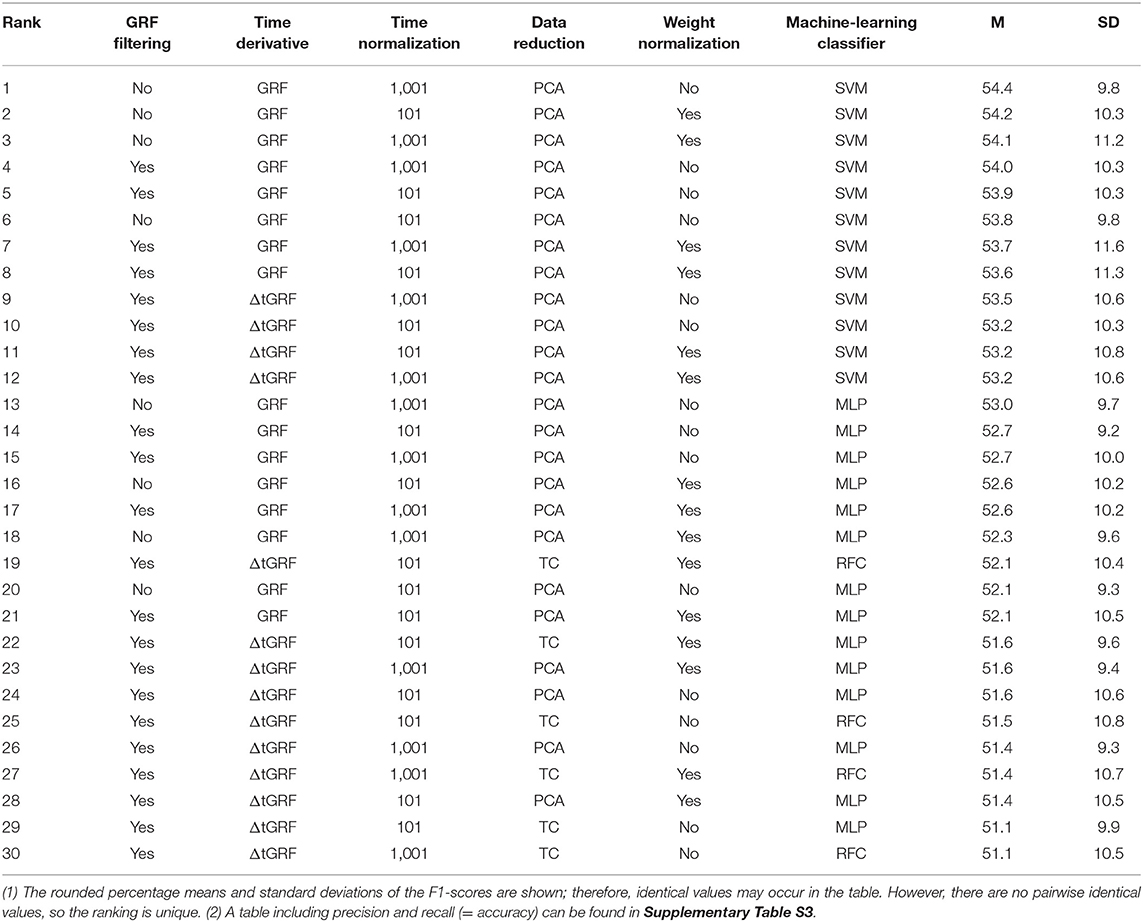
Table 3. Top 30 combinations of preprocessing methods, ranked by the mean F1-score over the 15-fold cross validation (n = 42).
Table 4 shows the rank scores of all classifications performed for the 288 combinations of the different preprocessing steps according to the F1-scores (Supplementary Tables S4, S5 display the rank score depending on precision and recall). The PCA achieved a particularly high rank score with 87.5% of the maximum achievable rank score. In addition, the GRF with 73.9% and the GRF filtering with 73.4% finished with high rank scores. Again, there are no or only minor differences within the weight normalization and the time normalization to 101 and 1,001 data points. Among the classifiers, the RFCs achieved the highest rank score, just ahead of the SVMs and MLPs and quite far in advance of CNNs.

Table 4. Rank scores of all combinations of preprocessing methods depending on their mean F1-score over the 15-fold cross validation (n = 42).
Discussion
A growing number of promising machine-learning applications could be found in the field of human movement analysis. However, these approaches differ in terms of objectives, samples, and classification tasks. Furthermore, there is a lack of standard procedures and recommendations within the different methodological approaches, especially with respect to data preprocessing steps usually performed prior to machine-learning classification. In this regard, the current analysis comprised a systematic comparison of different preprocessing steps and their effects on the prediction performance of different machine-learning classifiers. The results revealed first domain-specific recommendations for the preprocessing of GRF data prior to machine-learning classifications. This includes, for example, benefits of filtering GRF data and supervised data reduction techniques (e.g., PCA) compared to non-reduced (time-continuous waveforms) or unsupervised data reduction techniques (time-discrete gait variables). On the other hand, the results indicate that the normalization to a constant factor (weight normalization) and the number of data points (above a certain minimum) used during time normalization seem to have little influence on the prediction performance. Furthermore, the first-time derivative (ΔtGRF) could not achieve advantages over the GRF in terms of prediction performance.
In general, the present results can help to find domain-specific standard procedures for the preprocessing of data that may enable to improve machine-learning classifications in human movement analysis make different approaches better comparable in the future. It should be noted, however, that the results presented are based solely on prediction performance and do not provide information about the effects on the trained models.
GRF Filtering
The present results indicate that the filtered GRF data led to significantly higher mean F1-scores and rank scores than the unfiltered GRF data. The results were especially striking for the classifications of ΔtGRF data. While no clear trend could be derived for the best-ranked combinations of GRF data, most of the best-ranked combinations of ΔtGRF data were filtered. To our knowledge, this analysis was the first that investigated whether a filter (using an optimal filter cut-off frequency) affects the prediction performance of GRF data in human gait (Schreven et al., 2015). The present findings suggest that machine-learning classification should use filtered GRF data. However, it should be noted that the estimation of the optimal filter cut-off frequency using the method described by Challis (1999) is only one out of several possibilities to set a cut-off frequency. Because the individual filter cut-off frequencies were separately calculated for trial and each variable, so it is not yet possible to recommend a generally valid unique cut-off frequency.
Time Derivative
With respect to the feature extraction using the first-time derivative, our analysis revealed that the GRF achieved significantly higher F1-scores compared to the ΔtGRF. In addition, the highest prediction F1-scors were also achieved with the GRF. However, it needs to be noted that the highest F1-score using ΔtGRF data were <1% lower than the highest F1-score using GRF data. Because the time derivative alone did not increase the prediction performance, it might be helpful to aggregate different feature extraction methods to improve classification models (Slijepcevic et al., 2020).
Time Normalization
The time normalization to 101 and 1,001 data points was significantly better than that to only 11 data points. These results are in line with current research, where 101 and 1,001 values are commonly used (Eskofier et al., 2013; Slijepcevic et al., 2017). Three of the four best ranks were achieved using the time normalization to 1,001 data points, but these were only slightly higher than those time normalized to 101 data points. In both methods, the best prediction performances where achieved in combination with PCA. In terms of computational costs, it is advisable to weigh up to what extent relatively small improvements in the prediction performance justify the additional time required for classification. Furthermore, if computational cost is an important factor, a time normalization to fewer data points (above a certain minimum) could also be useful, since the results showed only little influence on the prediction performance.
Data Reduction
This analysis showed that PCA, which is frequently used in research (Figueiredo et al., 2018; Halilaj et al., 2018; Phinyomark et al., 2018), also achieves the highest F1-scores and ranks, compared with time-continuous waveforms and time-discrete gait variables. The highest F1-score of a machine-learning model based on time-continuous waveforms was 2.3% lower than that of PCA. Machine-learning models solely according to time-discrete characteristics is not recommended based on these analysis results. In line with Phinyomark et al. (2018), reducing the amount of data to the relevant characteristics is not only a cost-reducing method, but can also improve machine-learning classifications.
Weight Normalization
While weight normalization is necessary in inter-individual comparisons (Mao et al., 2008; Laroche et al., 2014), there have been no recommendations regarding intra-personal comparisons so far. The results of this analysis suggest that performing or not performing weight normalization leads to almost the same results and therefore shows no difference in prediction performance. Consequently, multiplication by a constant factor seems to play no role in the machine-learning classifications. This could be particularly interesting if different datasets are combined.
Machine-Learning Classifier
Four commonly used machine-learning classifiers (SVM, RFC, MLP, and CNN) were compared in this analysis. The RFCs achieved significantly higher mean F1-scores across all data preprocessing methods than the SVMs, MLPs, and CNNs. Compared to the other classifiers, the RFC seems to be most robust in case of a strong reduction of data (i.e., the time normalization to 11 data points or the unsupervised data reduction using the selection of time-discrete gait variables). However, the highest performance scores were achieved by SVMs followed by MLPs, RFCs, and CNNs. For gait data the SVM seems to be a powerful machine-learning classifier as often described in the literature (Figueiredo et al., 2018). The MLPs provided only mediocre prediction performances, which could be due to the fact that the total amount of data is simply too small for ANNs (Chau, 2001b; Begg and Kamruzzaman, 2005; Begg et al., 2005; Lai et al., 2008). This impression is reinforced by the even lower prediction performances of the CNNs as “deep” ANN architecture. In addition, the MLPs and CNNs required a lot of computation time for the classification, while the classification based on SVM and RFC was much more timesaving. Based on the presented results, using linear SVMs for the classification of gait data can be recommended. Furthermore, in line with recent research (Slijepcevic et al., 2020), a majority vote could possibly provide an even better classification. However, it should be noted that only a small selection of classifiers and architectures were examined in this analysis.
Conclusion
Based on a systematic comparison, the results provide first domain-specific recommendations for commonly used preprocessing methods prior to classifications using machine learning. However, caution is advised here, as the present findings may be limited to the classification task examined (six-session classification of intra-individual gait patterns) or even to the dataset. Furthermore, the derived recommendations are based exclusively on the prediction scores of the models. Therefore, no information can be obtained about the actual impact of the preprocessing methods and their combinations on the training process and the class representations of the trained models. Overall, it can be concluded that preprocessing has a crucial influence on machine-learning classifications of biomechanical gait data. Nevertheless, further research on this topic is necessary to find out general implications for domain-specific standard procedures.
Data Availability Statement
The dataset analyzed during the current study is available in the Mendely Data Repository (Burdack et al., 2020) (http://dx.doi.org/10.17632/y55wfcsrhz.1).
Ethics Statement
The studies involving human participants were reviewed and approved by the ethical committee of the medical association Rhineland-Palatinate in Mainz (Germany). The participants provided their written informed consent to participate in this study.
Author Contributions
FH, SD, and IH recorded the data. JB, FH, and WS conceived the presented idea. JB, FH, and SG performed the data analysis and designed the figures. JB and FH wrote the manuscript. JB, FH, SG, SD, IH, and WS reviewed and approved the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank John Henry Challis for providing his Matlab files to determine the optimal filter cut-off frequency and Djodje Slijepcevic for supporting us with his code for the PCA. This research has been partially funded by the German Federal Ministry of Education and Research (Grant No. 01S18038B).
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fbioe.2020.00260/full#supplementary-material
References
Alaqtash, M., Sarkodie-Gyan, T., Yu, H., Fuentes, O., Brower, R., and Abdelgawad, A. (2011a). Automatic classification of pathological gait patterns using ground reaction forces and machine learning algorithms. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2011, 453–457. doi: 10.1109/IEMBS.2011.6090063
Alaqtash, M., Yu, H., Brower, R., Abdelgawad, A., and Sarkodie-Gyan, T. (2011b). Application of wearable sensors for human gait analysis using fuzzy computational algorithm. Eng. Appl. Artif. Intell. 24, 1018–1025. doi: 10.1016/j.engappai.2011.04.010
Badesa, F. J., Morales, R., Garcia-Aracil, N., Sabater, J. M., Casals, A., and Zollo, L. (2014). Auto-adaptive robot-aided therapy using machine learning techniques. Comput. Methods Programs Biomed. 116, 123–130. doi: 10.1016/j.cmpb.2013.09.011
Begg, R. K., and Kamruzzaman, J. (2005). A machine learning approach for automated recognition of movement patterns using basic, kinetic and kinematic gait data. J. Biomech. 38, 401–408. doi: 10.1016/j.jbiomech.2004.05.002
Begg, R. K., Palaniswami, M., and Owen, B. (2005). Support vector machines for automated gait classification. IEEE Trans. Biomed. Eng. 52, 828–838. doi: 10.1109/TBME.2005.845241
Boser, B. E., Guyon, I. M., and Vapnik, V. N. (1992). “A training algorithm for optimal margin classifiers,” in Proceedings of the Fifth Annual Workshop on Computational Learning Theory - COLT '92 (New York, NY: ACM), 144–152. doi: 10.1145/130385.130401
Burdack, J., Horst, F., Giesselbach, S., Hassan, I., Daffner, S., and Schöllhorn, W. I. (2020). A public dataset of overground walking kinetics in healthy adult individuals on different sessions within one day. Mendeley Data, v1. doi: 10.17632/y55wfcsrhz.1
Challis, J. H. (1999). A procedure for the automatic determination of filter cutoff frequency of the processing of biomechanical data. J. Appl. Biomech. 15, 304–3017. doi: 10.1123/jab.15.3.303
Chau, T. (2001a). A review of analytical techniques for gait data. part 1: fuzzy, statistical and fractal methods. Gait Posture 13, 49–66. doi: 10.1016/S0966-6362(00)00094-1
Chau, T. (2001b). A review of analytical techniques for gait data. Part 2: neural network and wavelet methods. Gait Posture 13, 102–120. doi: 10.1016/S0966-6362(00)00095-3
Cohen, J. (1988). Statistical Power Analysis for the Behavioral Sciences. New York, NY: Academic Press.
Cortes, C., and Vapnik, V. (1995). Support-vector networks. Mach. Learn. 20, 273–297. doi: 10.1007/BF00994018
Daffner, S. (2018). Individualität und variablität der kinematischen und dynamischen gangmuster bei zwillingen (Master's thesis). Johannes Gutenberg-University, Mainz, Germany.
Deluzio, K. J., and Astephen, J. L. (2007). Biomechanical features of gait waveform data associated with knee osteoarthritis: an application of principal component analysis. Gait Posture 25, 86–93. doi: 10.1016/j.gaitpost.2006.01.007
Eskofier, B. M., Federolf, P., Kugler, P. F., and Nigg, B. M. (2013). Marker-based classification of young–elderly gait pattern differences via direct PCA feature extraction and SVMs. Comput. Methods Biomech. Biomed. Engin. 16, 435–442. doi: 10.1080/10255842.2011.624515
Ferber, R., Osis, S. T., Hicks, J. L., and Delp, S. L. (2016). Gait biomechanics in the era of data science. J. Biomech. 49, 3759–3761. doi: 10.1016/j.jbiomech.2016.10.033
Figueiredo, J., Santos, C. P., and Moreno, J. C. (2018). Automatic recognition of gait patterns in human motor disorders using machine learning : a review. Med. Eng. Phys. 53, 1–12. doi: 10.1016/j.medengphy.2017.12.006
Fisher, R. A. (1922). On the mathematical foundations of theoretical statistics. Philos. Trans. R. Soc. A 222, 309–368. doi: 10.1098/rsta.1922.0009
Flash, T., and Hogan, N. (1985). The coordination of arm movements: an experimentally confirmed mathematical model. J. Neurosci. 5, 1688–1703. doi: 10.1523/JNEUROSCI.05-07-01688.1985
Halilaj, E., Rajagopal, A., Fiterau, M., Hicks, J. L., Hastie, T. J., and Delp, S. L. (2018). Machine learning in human movement biomechanics: best practices, common pitfalls, and new opportunities. J. Biomech. 81, 1–11. doi: 10.1016/j.jbiomech.2018.09.009
Hassan, I. (2019). A dataset of overground walking kinetics in healthy adult individuals on different sessions within one day (Dataset thesis). Johannes Gutenberg-University, Mainz, Germany.
Horst, F., Eekhoff, A., Newell, K. M., and Schöllhorn, W. I. (2017). Intra-individual gait patterns across different time-scales as revealed by means of a supervised learning model using kernel-based discriminant regression. PLoS ONE 12:e0179738. doi: 10.1371/journal.pone.0179738
Horst, F., Eekhoff, A., Newell, K. M., and Schöllhorn, W. I. (2019a). A public dataset of overground walking kinetics and lower-body kinematics in healthy adult individuals on different sessions within one day. Mendeley Data, v1. doi: 10.17632/b48n46bfry.1
Horst, F., Lapuschkin, S., Samek, W., Müller, K. R., and Schöllhorn, W. I. (2019b). Explaining the unique nature of individual gait patterns with deep learning. Sci. Rep. 9:2391. doi: 10.1038/s41598-019-38748-8
Hotelling, H. (1933). Analysis of a complex of statistical variables into principal components. J. Educ. Psychol. 24, 417–441. doi: 10.1037/h0071325
Hsu, C., Chang, C., and Lin, C. (2003). A Practical Guide to Support Vector Classification. Technical report, National Taiwan University. Retrieved from: https://www.csie.ntu.edu.tw/cjlin/papers/guide/guide.pdf (accessed March 24, 2020).
Kaczmarczyk, K., Wit, A., Krawczyk, M., and Zaborski, J. (2009). Gait classification in post-stroke patients using artificial neural networks. Gait Posture 30, 207–210. doi: 10.1016/j.gaitpost.2009.04.010
Lai, D. T. H., Begg, R. K., Taylor, S., and Palaniswami, M. (2008). Detection of tripping gait patterns in the elderly using autoregressive features and support vector machines. J. Biomech. 41, 1762–1772. doi: 10.1016/j.jbiomech.2008.02.037
Laroche, D., Tolambiya, A., Morisset, C., Maillefert, J. F., French, R. M., Ornetti, P., et al. (2014). A classification study of kinematic gait trajectories in hip osteoarthritis. Comput. Biol. Med. 55, 42–48. doi: 10.1016/j.compbiomed.2014.09.012
LeCun, Y., Bengio, Y., and Hinton, G. (2015). Deep learning. Nature 521, 436–444. doi: 10.1038/nature14539
Lee, M., Roan, M., and Smith, B. (2009). An application of principal component analysis for lower body kinematics between loaded and unloaded walking. J. Biomech. 42, 2226–2230. doi: 10.1016/j.jbiomech.2009.06.052
Mao, Y., Saito, M., Kanno, T., Wei, D., and Muroi, H. (2008). “Walking pattern analysis and SVM classification based on simulated gaits,” in Proceedings of the 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (Vancouver, BC), 5069–5072. doi: 10.1109/IEMBS.2008.4650353
Müller, K. R., Mika, S., Rätsch, G., Tsuda, K., and Schölkopf, B. (2001). An introduction to kernel-based learning algorithms. IEEE Trans. Neural Netw. 12, 181–201. doi: 10.1109/72.914517
Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., et al. (2019). “PyTorch: an imperative style, high-performance deep learning library,” in Advances in Neural Information Processing Systems 32, eds H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Vancouver, BC: Curran Associates, Inc.), 8026–8037.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in Python. J. Mach. Learn. Res. 12, 2825–2830. Retrieved from: http://www.jmlr.org/papers/v12/pedregosa11a.html (accessed March 24, 2020).
Phinyomark, A., Petri, G., Ibáñez-Marcelo, E., Osis, S. T., and Ferber, R. (2018). Analysis of big data in gait biomechanics: current trends and future directions. J. Med. Biol. Eng. 38, 244–260. doi: 10.1007/s40846-017-0297-2
Schölkopf, B., and Smola, A. J. (2002). Learning With Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. Cambridge, MA: The MIT Press.
Schöllhorn, W. I. (2004). Applications of artificial neural nets in clinical biomechanics. Clin. Biomech. 19, 876–898. doi: 10.1016/j.clinbiomech.2004.04.005
Schreven, S., Beek, P. J., and Smeets, J. B. J. (2015). Optimising filtering parameters for a 3D motion analysis system. J. Electromyogr. Kinesiol. 25, 808–814. doi: 10.1016/j.jelekin.2015.06.004
Slijepcevic, D., Zeppelzauer, M., Gorgas, A. M., Schwab, C., Schuller, M., Baca, A., et al. (2017). Automatic classification of functional gait disorders. IEEE J. Biomed. Health Inform. 22, 1653–1661. doi: 10.1109/JBHI.2017.2785682
Slijepcevic, D., Zeppelzauer, M., Schwab, C., Raberger, A. M., Breiteneder, C., and Horsak, B. (2020). Input representations and classification strategies for automated human gait analysis. Gait Posture 76, 198–203. doi: 10.1016/j.gaitpost.2019.10.021
Su, F. C., and Wu, W. L. (2000). Design and testing of a genetic algorithm neural network in the assessment of gait patterns. Med. Eng. Phys. 22, 67–74. doi: 10.1016/S1350-4533(00)00011-4
Wannop, J. W., Worobets, J. T., and Stefanyshyn, D. J. (2012). Normalization of ground reaction forces, joint moments, and free moments in human locomotion. J. Appl. Biomech. 28, 665–676. doi: 10.1123/jab.28.6.665
Wolf, S., Loose, T., Schablowski, M., Döderlein, L., Rupp, R., Gerner, H. J., et al. (2006). Automated feature assessment in instrumented gait analysis. Gait Posture 23, 331–338. doi: 10.1016/j.gaitpost.2005.04.004
Keywords: gait classification, data selection, data processing, ground reaction force, multi-layer perceptron, convolutional neural network, support vector machine, random forest classifier
Citation: Burdack J, Horst F, Giesselbach S, Hassan I, Daffner S and Schöllhorn WI (2020) Systematic Comparison of the Influence of Different Data Preprocessing Methods on the Performance of Gait Classifications Using Machine Learning. Front. Bioeng. Biotechnol. 8:260. doi: 10.3389/fbioe.2020.00260
Received: 25 October 2019; Accepted: 12 March 2020;
Published: 15 April 2020.
Edited by:
Peter A. Federolf, University of Innsbruck, AustriaReviewed by:
João Paulo Morais Ferreira, Superior Institute of Engineering of Coimbra (ISEC), PortugalChi-Wen Lung, Asia University, Taiwan
Copyright © 2020 Burdack, Horst, Giesselbach, Hassan, Daffner and Schöllhorn. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Fabian Horst, aG9yc3RAdW5pLW1haW56LmRl