 Angel Goñi-Moreno
Angel Goñi-Moreno Pablo I. Nikel
Pablo I. Nikel- 1School of Computing, Newcastle University, Newcastle upon Tyne, United Kingdom
- 2The Novo Nordisk Foundation Center for Biosustainability, Technical University of Denmark, Kongens Lyngby, Denmark
Biocomputing uses molecular biology parts as the hardware to implement computational devices. By following pre-defined rules, often hard-coded into biological systems, these devices are able to process inputs and return outputs—thus computing information. Key to the success of any biocomputing endeavor is the availability of a wealth of molecular tools and biological motifs from which functional devices can be assembled. Synthetic biology is a fabulous playground for such purpose, offering numerous genetic parts that allow for the rational engineering of genetic circuits that mimic the behavior of electronic functions, such as logic gates. A grand challenge, as far as biocomputing is concerned, is to expand the molecular hardware available beyond the realm of genetic parts by tapping into the host metabolism. This objective requires the formalization of the interplay of genetic constructs with the rest of the cellular machinery. Furthermore, the field of metabolic engineering has had little intersection with biocomputing thus far, which has led to a lack of definition of metabolic dynamics as computing basics. In this perspective article, we advocate the conceptualization of metabolism and its motifs as the way forward to achieve whole-cell biocomputations. The design of merged transcriptional and metabolic circuits will not only increase the amount and type of information being processed by a synthetic construct, but will also provide fundamental control mechanisms for increased reliability.
Biocomputing
Computation can be broadly defined as the formal procedure by which input information is processed according to pre-defined rules and turned into output data. Since this definition does not specify the type of information and rules involved in the process, it is applicable to electronic devices as well as to biological systems. In other words, biological systems do perform computations. While the computational ability of biological matter has been explicitly described a number of times along the twentieth century (Bennett, 1982), it was Leonard Adleman who showed the feasibility of implementing human-defined computations with molecular (i.e., genetic) hardware (Adleman, 1994). Although the discussion on what would be the equivalent of computer hardware and software in biological systems is still largely open (Danchin, 2009), the term hardware in this article identifies any physical, tangible component (e.g., nucleic acids or metabolites) in a cell. On this first example of biocomputation, Adleman physically encoded an instance of the Hamiltonian path problem (a well-known mathematical problem in graph theory) in DNA strands, and solved it in vitro by using routine molecular biology methods. A bacterial computer (i.e., an in vivo computer), would solve an instance of the same problem 15 years later (Baumgardner et al., 2009). By the end of last century, Weiss et al. (2002) showed that synthetic regulatory networks could be conceptualized in vivo as a series of Boolean logic gates–the key device of cellular computers. This novel conceptual framework set the start of a frantic wave of electronic-inspired bioengineering in synthetic biology. Additionally, these seminal works also shifted the inspiration within the biocomputing community drastically, from mathematics and computer science to electronic engineering.
Whole-Cell Biocomputations
Cells are able to process input information in many different and intricate ways. For the sake of clarity, in this article we propose to group the processing of information into two types of computing (i.e., genetic and metabolic) depending on the nature of the input and components thereof. To date, most of the biocomputing developments in synthetic biology dealt almost exclusively with genetic material and parts. This type of approach limits the scope of the potential synthetic biocomputations that can be executed, since a number of important resources are not being utilized. In a challenging paper entitled “It's the metabolism, stupid!,” de Lorenzo (2015) suggested that “the interplay of DNA and metabolism is […] akin to that of politics and economy. Both realms drive their own autonomous agendas and obviously influence each other.” In a similar fashion, the field of heterotic computing (Kendon et al., 2015) advocates the use of various types of computing that merge the strengths of individual types into more powerful, heterotic devices.
Synthetic Biology as an Active Biocomputing Field
Boolean logic is central to the field of computing. Therefore, the design and implementation of Boolean logic functions in cells—typically encoded into genetic material (Figure 1A)—is key to the development of synthetic biology approaches rooted on biocomputing (Amos and Goñi-Moreno, 2018). The engineering of a genetic toggle switch (Gardner et al., 2000) and an oscillator (Elowitz and Leibler, 2000) in Escherichia coli at the onset of the twenty-first century had set the start of what is a very active field nowadays. Over the last (almost) 20 years, a number of circuits have been successfully engineered in living cells, such as logic gates mentioned above (Wang et al., 2011), counters (Friedland et al., 2009), multiplexers (Moon et al., 2011), adders (Ausländer et al., 2012), and memories (Bonnet et al., 2013). Inspired by computer science, distributed computations have also been designed and build in multicellular systems by modifying cell-cell communication programmes (Goñi-Moreno et al., 2011, 2019; Regot et al., 2011). From solving relatively simple mathematical problems to compute intricate Boolean logic operations, biological systems have proved to be a powerful platform for tackling applications that are restricted to traditional “silicon-based” computer technologies, such as diagnosis, bioproduction, and bioremediation.
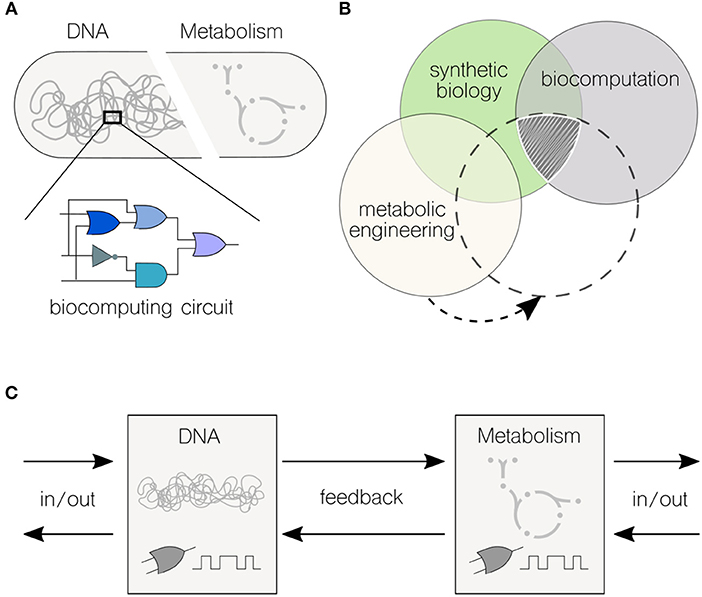
Figure 1. Interfacing genetic and metabolic processes for high-performance biocomputations. (A) Biocomputing circuits are typically encoded into genetic material. Synthetic biology provides an extensive toolkit of genetic parts and devices that are assembled to build combinatorial (and even sequential) logic circuits. The metabolic environment where the circuit runs is often overlooked when it comes to formalize logic motifs. (B) The expanding field of biocomputation intersects synthetic biology. Genetic logic circuits have been central to synthetic biology since the formal inception of the discipline. Thus, far, there is no obvious exploitation of this type of biocomputation for metabolic engineering–there is, however, enough synergy between the three disciplines to find an overlapping (sub)field. (C) Information processing flows in merged transcriptional and metabolic circuits. Both transcriptional and metabolic networks are able to sense external inputs and yield output responses; the feedback from one layer to the other can effectively communicate information.
Synthetic biocomputing circuits are growingly more complex and accurate every day, mostly due to endless efforts in improving the genetic toolkit (Silva-Rocha et al., 2013; Martínez-García et al., 2014; Durante-Rodríguez et al., 2018), mathematical methods (Church et al., 2014; Goñi-Moreno and Amos, 2015) and design procedures (Goñi-Moreno and Amos, 2012; McLaughlin et al., 2018) for the so-called design-build-test-learn synthetic biology cycle (Goñi-Moreno et al., 2016). There are, nevertheless, major challenges on the genetic computing front (Goñi-Moreno, 2014; Manzoni et al., 2016), such as the urgent need for standardization of components, measurements, and information (Myers et al., 2017; Fabre and Sonnenschein, 2019). As long as synthetic biology claims to be a true engineering discipline, such a standardization problem must be tackled without delay to enable bona fide modularity and predictability of genetic circuits (Vilanova et al., 2015). Altogether, the implementation of biocomputations using genetic material is driven by an excellent scientific momentum at the present time.
Metabolic Engineering as a Potential Biocomputing Field
While there is a phenomenal potential for development, the metabolic aspect of computation has not been explored to the same degree as it has been implemented via genetic circuits (Figure 1B). This fact arises from a still-limited knowledge on the complexity of metabolic networks even in the so-called “model” organisms (Benedetti et al., 2016; Calero and Nikel, 2019). Nielsen and Keasling (2016) have recently stressed the presence of metabolic networks with hard wired, tightly regulated lines of communication in virtually all living cells–which are inherently difficult to manipulate but, as the very definition implies, offer an unique opportunity for engineering multi-level computations. In the same way synthetic biology uses genetic parts and devices to build complex systems with pre-defined behaviors, metabolic networks are characterized by some (more or less conserved) principles that can be used for re-purposing biochemical nodes. The bowtie model of central metabolism indicates that the core biochemistry of the cell includes the biochemical transformations necessary for the synthesis of the 12 known essential biomass precursors (Noor et al., 2010). This architecture requires a high level of regulation, especially at the level of gene transcription (Kochanowski et al., 2017). Is precisely at this intersection between cellular processes that biocomputing could play a role in re-programming the metabolic machinery of cells.
High-Performance Biocomputing
Natural cellular pathways are rarely based on genetic or metabolic activities alone. Thus, the concept of heterotic computing (i.e., the coordination between different types of computing), is intrinsic to biological systems. However, synthetic circuits are not often exploiting the full computational power of the cellular machinery. Although the type of processes is very different, the cooperation between them could pave the way to a new generation of whole-cell circuits with enhanced abilities. This aspect is what we refer to as high-performance biocomputing.
Against this background, Figure 1C shows the flows of information in high-performance biocomputations. A first challenge would be to describe what in computing are called primitives, which are the simplest elements with which software programs are built upon. This will result in a set of well-characterized genetic and metabolic units (e.g., coding sequences and metabolic reactions) and motifs (e.g., oscillations and switches), including types of inputs and outputs for each computing end. Although current efforts are individually tackling this challenge in either the genetic (Nielsen et al., 2016) or metabolic (Sánchez-Pascuala et al., 2017) fronts, there is still the issue that genetic and metabolic units must be plugged together to allow information flow in both directions. This connectivity will enable the direct modification of genetic motifs by the action of their metabolic counterparts (and vice-versa). Depending on the specific process, and the type of information being computed, either of the two ends could return the desired output.
The increasing focus on the interplay between genetic and metabolic networks (Shlomi et al., 2007; Kumar et al., 2018) is resulting in a revolution of metabolic engineering driven by the core principles of synthetic biology. Not only molecular tools are actively being developed (Keasling, 2012; Nikel and de Lorenzo, 2018), but also control strategies to engineer genetic circuits are being increasingly exploited for the regulation of metabolism in a pre-defined fashion (Oyarzún and Stan, 2013; Chen and Liu, 2018; Moser et al., 2018). The foundations of high-performance biocomputing are therefore established and ready to benefit from the input of the computing community. Yet, a solid representation framework is needed to fully realize this purpose.
A Unified Representation Framework
Boolean logic is a way to abstract the underlying mechanistic details of a device into its high-level functional performance. By doing so, gene expression can be abstracted into ON/OFF states (i.e., either the gene is, or is not, being expressed under a given environmental condition) regardless of the particularities the gene of interest might have. Even in the case of radical analog fluctuations in gene expression, the ON/OFF abstraction still provides an useful conceptual framework (García-Betancur et al., 2017; Goñi-Moreno et al., 2017). However, when it comes to implementation, the Boolean abstraction needs to be complemented by a dynamical analysis of the components at stake. For example, the time-scales with which genetic and metabolic interactions occur can potentially be very different. Therefore, the dynamic analysis of individual reactions is as fundamental as the functional representation of the system as a whole.
To illustrate this point, we discuss a case of merged genetic and metabolic circuitry integration in a platform bacterium. Figure 2A shows a logic-gate representation of a simple merged transcriptional and metabolic circuit in the soil bacterium Pseudomonas putida KT2440. This device merges state-of-the-art DNA regulatory circuitry (Nielsen et al., 2016) with dynamics that are far beyond DNA reach: the metabolic ability of the cells to catabolize glycerol (Nikel et al., 2015). In this way, the circuit output depends not only in the upstream computation of typical genetic inputs (generic inputs A and B in the diagram) but also in the metabolic dynamics of glycerol uptake. The link that enables the functioning of the circuit is the transcriptional repressor GlpR, which somewhat encodes information about the metabolic state of the cell (the action of GlpR on the cognate glp gene cluster is relieved by the metabolite glycerol-3-phosphate, G3P) and acts on a specific promoter. Note that virtually any other signaling molecule or transcription factor that feeds the final genetic AND logic gate can be inserted downstream of this promoter. Moreover, any regulatory step in the circuit can be connected back to, e.g., the key enzyme GlpK (essential for glycerol processing) thus providing feedback control from the genetic to the metabolic side of the device. As a result, the combinatorial genetic logic circuit is now linked to the physiological state of the cell concerning the dynamics of carbon source uptake, which can be both read and controlled.
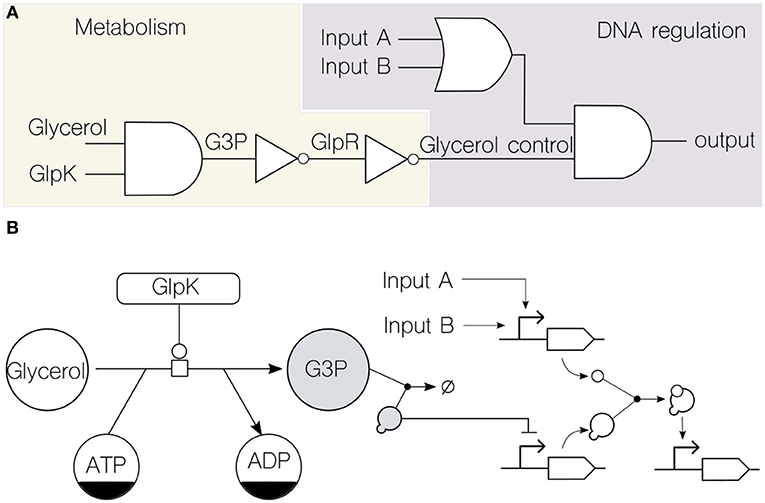
Figure 2. Formal representation of merged transcriptional and metabolic circuits. (A) Circuit formalization into Boolean functions (i.e., logic gates) assists the combination of metabolism and DNA regulation. Using the known transcriptional and metabolic network that rules glycerol consumption in the soil bacterium P. putida KT2440 (Nikel et al., 2014) as an example, the circuit depicts the role of glycerol as an input along with other signals (inputs A and B) typically used in transcriptional logic. Note that the flow of information is bidirectional, since the metabolic GlpK input (a key enzyme involved in glycerol consumption) can be modified by the genetic circuit. This top-level logic design enables the abstraction of details about the type of substrate used by providing a unified computing framework. (B) The same glycerol circuit is formalized through the adoption of existing representation standards: the Systems Biology Graphical Notation (SBGN) for metabolic networks and the Synthetic Biology Open Language (SBOL) visual for genetic circuits. The two shaded components, the key metabolite glycerol-3-phosphate (G3P) and the transcriptional repressor GlpR, constitute the physical link that merge both computing layers.
Using a lower, more specific, layer of representation, the Systems Biology Graphical Notation (SBGN) (Le Novère et al., 2009) and the Synthetic Biology Open Language (SBOL) (Galdzicki et al., 2014) were used to formalize the circuit (Figure 2B) for both metabolic and genetic parts, respectively. This helps identifying the link, which in this case is formed by the interaction between a metabolite (G3P) and a transcriptional repressor (GlpR)—thereby merging the metabolic and genetic layers of regulation in the bacterial cell (Figure 2B).
We recently coined the term metabolic widget to refer to such merged circuits (Chavarría et al., 2016). The metabolic machinery of the cell, often referred to as the context when focusing on genetic logic, offers powerful resources that can greatly improve current biocomputations. Far from trying to avoid the context, the framework proposed herein is taking full advantage of it, which can lead to widgets that assist more complex and accurate pre-defined processes of information. The adoption of such a configuration will have a double impact by providing essential information about both the metabolic and genetic wiring of the cell while taking full advantage of these interactions for re-programming core cellular functions.
From a broader perspective, evolution has shaped intricate cellular processes that merge both genetic and metabolic networks; yet, human-defined biocomputations rarely make use of both computing types. We advocate for taking this path into account in order to access and exploit the high-performance biocomputing power intrinsic to natural systems, empowering the design-build-test-learn cycle to entirely new directions.
Author Contributions
Both authors have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
This work was supported by the SynBio3D (UK-EPSRC-EP/R019002/1) project of the UK Engineering and Physical Sciences Research Council, and the BioRoboost (EU-H2020-BIOTEC-820699) Contract of the European Union to AG-M. This work was also supported by The Novo Nordisk Foundation (Grant NNF10CC1016517) and the Danish Council for Independent Research (SWEET, DFF-Research Project 8021-00039B) to PIN.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors wish to thank Prof. Víctor de Lorenzo (CNB-CSIC, Madrid, Spain) for inspiring discussions.
References
Adleman, L. M. (1994). Molecular computation of solutions to combinatorial problems. Science 266, 1021–1024. doi: 10.1126/science.7973651
Amos, M., and Goñi-Moreno, A. (2018). “Cellular computing and synthetic biology,” in Computational Matter, eds S. Stepney, S. Rasmussen, and M. Amos (Berlin: Springer) 93–110.
Ausländer, S., Ausländer, D., Müller, M., Wieland, M., and Fussenegger, M. (2012). Programmable single-cell mammalian biocomputers. Nature 487, 123–127. doi: 10.1038/nature11149
Baumgardner, J., Acker, K., Adefuye, O., Crowley, S. T., Deloache, W., Dickson, J. O., et al. (2009). Solving a Hamiltonian path problem with a bacterial computer. J. Biol. Eng. 3:11. doi: 10.1186/1754-1611-3-11
Benedetti, I., de Lorenzo, V., and Nikel, P. I. (2016). Genetic programming of catalytic Pseudomonas putida biofilms for boosting biodegradation of haloalkanes. Metab. Eng. 33, 109–118. doi: 10.1016/j.ymben.2015.11.004
Bennett, C. H. (1982). The thermodynamics of computation—a review. Int. J. Theor. Phys. 21, 905–940. doi: 10.1007/BF02084158
Bonnet, J., Yin, P., Ortiz, M. E., Subsoontorn, P., and Endy, D. (2013). Amplifying genetic logic gates. Science 340, 599–603. doi: 10.1126/science.1232758
Calero, P., and Nikel, P. I. (2019). Chasing bacterial chassis for metabolic engineering: a perspective review from classical to non-traditional microorganisms. Microb. Biotechnol. 12, 98–124. doi: 10.1111/1751-7915.13292
Chavarría, M., Goñi-Moreno, Á., de Lorenzo, V., and Nikel, P. I. (2016). A metabolic widget adjusts the phosphoenolpyruvate-dependent fructose influx in Pseudomonas putida. mSystems 1, e00154–e00116. doi: 10.1128/mSystems.00154-16
Chen, X., and Liu, L. (2018). Gene circuits for dynamically regulating metabolism. Trends Biotechnol. 36, 751–754. doi: 10.1016/j.tibtech.2017.12.007
Church, G. M., Elowitz, M. B., Smolke, C. D., Voigt, C. A., and Weiss, R. (2014). Realizing the potential of synthetic biology. Nat. Rev. Mol. Cell Biol. 15, 289–294. doi: 10.1038/nrm3767
Danchin, A. (2009). Bacteria as computers making computers. FEMS Microbiol. Rev. 33, 3–26. doi: 10.1111/j.1574-6976.2008.00137.x
de Lorenzo, V. (2015). It's the metabolism, stupid! Environ. Microbiol. Rep. 7, 18–19. doi: 10.1111/1758-2229.12223
Durante-Rodríguez, G., de Lorenzo, V., and Nikel, P. I. (2018). A post-translational metabolic switch enables complete decoupling of bacterial growth from biopolymer production in engineered Escherichia coli. ACS Synth. Biol. 7, 2686–2697. doi: 10.1021/acssynbio.8b00345
Elowitz, M. B., and Leibler, S. (2000). A synthetic oscillatory network of transcriptional regulators. Nature 403, 335–338. doi: 10.1038/35002125
Fabre, M. M., and Sonnenschein, N. (2019). Improving reproducibility in synthetic biology. Front. Biotechnol. Bioeng. 7:18. doi: 10.3389/fbioe.2019.00018
Friedland, A. E., Lu, T. K., Wang, X., Shi, D., Church, G., and Collins, J. J. (2009). Synthetic gene networks that count. Science 324, 1199–1202. doi: 10.1126/science.1172005
Galdzicki, M., Clancy, K. P., Oberortner, E., Pocock, M., Quinn, J. Y., Rodriguez, C. A., et al. (2014). The Synthetic Biology Open Language (SBOL) provides a community standard for communicating designs in synthetic biology. Nat. Biotechnol. 32, 545–550. doi: 10.1038/nbt.2891
García-Betancur, J. C., Goñi-Moreno, A., Horger, T., Schott, M., Sharan, M., Eikmeier, J., et al. (2017). Cell differentiation defines acute and chronic infection cell types in Staphylococcus aureus. eLife 6:e28023. doi: 10.7554/eLife.28023
Gardner, T. S., Cantor, C. R., and Collins, J. J. (2000). Construction of a genetic toggle switch in Escherichia coli. Nature 403, 339–342. doi: 10.1038/35002131
Goñi-Moreno, A. (2014). On genetic logic circuits: forcing digital electronics standards? Memetic Comput. 6, 149–155. doi: 10.1007/s12293-014-0136-8
Goñi-Moreno, A., and Amos, M. (2012). Continuous computation in engineered gene circuits. BioSystems 109, 52–56. doi: 10.1016/j.biosystems.2012.02.001
Goñi-Moreno, A., and Amos, M. (2015). “DiSCUS: a simulation platform for conjugation computing,” in International Conference on Unconventional Computation and Natural Computation, (Auckland), 181–191.
Goñi-Moreno, A., Benedetti, I., Kim, J., and de Lorenzo, V. (2017). Deconvolution of gene expression noise into spatial dynamics of transcription factor–promoter interplay. ACS Synth. Biol. 6, 1359–1369. doi: 10.1021/acssynbio.6b00397
Goñi-Moreno, A., Carcajona, M., Kim, J., Martínez-García, E., Amos, M., and de Lorenzo, V. (2016). An implementation-focused bio/algorithmic workflow for synthetic biology. ACS Synth. Biol. 5, 1127–1135. doi: 10.1021/acssynbio.6b00029
Goñi-Moreno, A., de la Cruz, F., Rodríguez-Patón, A., and Amos, M. (2019). Dynamical task switching in cellular computers. Life 9:E14. doi: 10.3390/life9010014
Goñi-Moreno, A., Redondo-Nieto, M., Arroyo, F., and Castellanos, J. (2011). Biocircuit design through engineering bacterial logic gates. Nat. Comput. 10, 119–127. doi: 10.1007/s11047-010-9184-2
Keasling, J. D. (2012). Synthetic biology and the development of tools for metabolic engineering. Metab. Eng. 14, 189–195. doi: 10.1016/j.ymben.2012.01.004
Kendon, V., Sebald, A., and Stepney, S. (2015). Heterotic computing: past, present and future. Philos. Trans. R. Soc. A 373:20140225. doi: 10.1098/rsta.2014.0225
Kochanowski, K., Gerosa, L., Brunner, S. F., Christodoulou, D., Nikolaev, Y. V., and Sauer, U. (2017). Few regulatory metabolites coordinate expression of central metabolic genes in Escherichia coli. Mol. Syst. Biol. 13:903. doi: 10.15252/msb.20167402
Kumar, S., Mahajan, S., and Jain, S. (2018). Feedbacks from the metabolic network to the genetic network reveal regulatory modules in E. coli and B. subtilis. PLoS ONE 13:e0203311. doi: 10.1371/journal.pone.0203311
Le Novère, N., Hucka, M., Mi, H., Moodie, S., Schreiber, F., Sorokin, A., et al. (2009). The systems biology graphical notation. Nat. Biotechnol. 27, 735–741. doi: 10.1038/nbt.1558
Manzoni, R., Urrios, A., Velázquez-García, S., de Nadal, E., and Posas, F. (2016). Synthetic biology: insights into biological computation. Integr. Biol. 8, 518–532. doi: 10.1039/C5IB00274E
Martínez-García, E., Aparicio, T., Goñi-Moreno, A., Fraile, S., and de Lorenzo, V. (2014). SEVA 2.0: an update of the Standard European Vector Architecture for de-/re-construction of bacterial functionalities. Nucleic Acids Res. 43, D1183–D1189. doi: 10.1093/nar/gku1114
McLaughlin, J. A., Myers, C. J., Zundel, Z., Misirli, G., Zhang, M., et al. (2018). SynBioHub: a standards-enabled design repository for synthetic biology. ACS Synth. Biol. 7, 682–688. doi: 10.1021/acssynbio.7b00403
Moon, T. S., Clarke, E. J., Groban, E. S., Tamsir, A., Clark, R. M., Eames, M., et al. (2011). Construction of a genetic multiplexer to toggle between chemosensory pathways in Escherichia coli. J. Mol. Biol. 406, 215–227. doi: 10.1016/j.jmb.2010.12.019
Moser, F., Espah Borujeni, A., Ghodasara, A. N., Cameron, E., Park, Y., and Voigt, C. A. (2018). Dynamic control of endogenous metabolism with combinatorial logic circuits. Mol. Syst. Biol. 14:e8605. doi: 10.15252/msb.20188605
Myers, C. J., Beal, J., Gorochowski, T. E., Kuwahara, H., Madsen, C., McLaughlin, J. A., et al. (2017). A standard-enabled workflow for synthetic biology. Biochem. Soc. Trans. 45, 793–803. doi: 10.1042/BST20160347
Nielsen, A. A., Der, B. S., Shin, J., Vaidyanathan, P., Paralanov, V., Strychalski, E. A., et al. (2016). Genetic circuit design automation. Science 352:aac7341. doi: 10.1126/science.aac7341
Nielsen, J., and Keasling, J. D. (2016). Engineering cellular metabolism. Cell 164, 1185–1197. doi: 10.1016/j.cell.2016.02.004
Nikel, P. I., and de Lorenzo, V. (2018). Pseudomonas putida as a functional chassis for industrial biocatalysis: from native biochemistry to trans-metabolism. Metab. Eng. 50, 142–155. doi: 10.1016/j.ymben.2018.05.005
Nikel, P. I., Kim, J., and de Lorenzo, V. (2014). Metabolic and regulatory rearrangements underlying glycerol metabolism in Pseudomonas putida KT2440. Environ. Microbiol. 16, 239–254. doi: 10.1111/1462-2920.12224
Nikel, P. I., Romero-Campero, F. J., Zeidman, J. A., Goñi-Moreno, A., and de Lorenzo, V. (2015). The glycerol-dependent metabolic persistence of Pseudomonas putida KT2440 reflects the regulatory logic of the GlpR repressor. mBio 6:e00340. doi: 10.1128/mBio.00340-15
Noor, E., Eden, E., Milo, R., and Alon, U. (2010). Central carbon metabolism as a minimal biochemical walk between precursors for biomass and energy. Mol. Cell 39, 809–820. doi: 10.1016/j.molcel.2010.08.031
Oyarzún, D. A., and Stan, G. B. V. (2013). Synthetic gene circuits for metabolic control: design trade-offs and constraints. J. R. Soc. Interface 10:20120671. doi: 10.1098/rsif.2012.0671
Regot, S., Macia, J., Conde, N., Furukawa, K., Kjellén, J., Peeters, T., et al. (2011). Distributed biological computation with multicellular engineered networks. Nature 469, 207–211. doi: 10.1038/nature09679
Sánchez-Pascuala, A., de Lorenzo, V., and Nikel, P. I. (2017). Refactoring the Embden–Meyerhof–Parnas pathway as a whole of portable GlucoBricks for implantation of glycolytic modules in Gram-negative bacteria. ACS Synth. Biol. 6, 793–805. doi: 10.1021/acssynbio.6b00230
Shlomi, T., Eisenberg, Y., Sharan, R., and Ruppin, E. (2007). A genome-scale computational study of the interplay between transcriptional regulation and metabolism. Mol. Syst. Biol. 3:101. doi: 10.1038/msb4100141
Silva-Rocha, R., Martínez-García, E., Calles, B., Chavarría, M., Arce-Rodríguez, A., de las Heras, A., et al. (2013). The Standard European Vector Architecture (SEVA): a coherent platform for the analysis and deployment of complex prokaryotic phenotypes. Nucleic Acids Res. 41, D666–D675. doi: 10.1093/nar/gks1119
Vilanova, C., Tanner, K., Dorado-Morales, P., Villaescusa, P., Chugani, D., Frías, A., et al. (2015). Standards not that standard. J. Biol. Eng. 9:17. doi: 10.1186/s13036-015-0017-9
Wang, B., Kitney, R. I., Joly, N., and Buck, M. (2011). Engineering modular and orthogonal genetic logic gates for robust digital-like synthetic biology. Nat. Commun. 2:508. doi: 10.1038/ncomms1516
Keywords: biocomputing, synthetic biology, metabolic engineering, boolean logic, genetic circuits, metabolic networks
Citation: Goñi-Moreno A and Nikel PI (2019) High-Performance Biocomputing in Synthetic Biology–Integrated Transcriptional and Metabolic Circuits. Front. Bioeng. Biotechnol. 7:40. doi: 10.3389/fbioe.2019.00040
Received: 14 December 2018; Accepted: 18 February 2019;
Published: 11 March 2019.
Edited by:
Pablo Carbonell, University of Manchester, United KingdomReviewed by:
Mario Andrea Marchisio, Tianjin University, ChinaJesus Picó, Universitat Politècnica de València, Spain
Copyright © 2019 Goñi-Moreno and Nikel. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Angel Goñi-Moreno, YW5nZWwuZ29uaS1tb3Jlbm9AbmV3Y2FzdGxlLmFjLnVr