 Rollyn Labuguen1*
Rollyn Labuguen1* Jumpei Matsumoto2*
Jumpei Matsumoto2* Salvador Blanco Negrete1
Salvador Blanco Negrete1 Hiroshi Nishimaru2
Hiroshi Nishimaru2 Hisao Nishijo2
Hisao Nishijo2 Masahiko Takada3Yasuhiro Go4,5
Masahiko Takada3Yasuhiro Go4,5 Ken-ichi Inoue3
Ken-ichi Inoue3 Tomohiro Shibata1*
Tomohiro Shibata1*- 1Department of Human Intelligence Systems, Graduate School of Life Science and Systems Engineering, Kyushu Institute of Technology, Kitakyushu, Japan
- 2Systems Emotional Science, University of Toyama, Toyama, Japan
- 3Systems Neuroscience Section, Department of Neuroscience, Primate Research Institute, Kyoto University, Inuyama, Japan
- 4Cognitive Genomics Research Group, Exploratory Research Center on Life and Living Systems (ExCELLS) National Institutes of Natural Sciences, Okazaki, Japan
- 5Department of System Neuroscience, National Institute for Physiological Sciences, Okazaki, Japan
Video-based markerless motion capture permits quantification of an animal's pose and motion, with a high spatiotemporal resolution in a naturalistic context, and is a powerful tool for analyzing the relationship between the animal's behaviors and its brain functions. Macaque monkeys are excellent non-human primate models, especially for studying neuroscience. Due to the lack of a dataset allowing training of a deep neural network for the macaque's markerless motion capture in the naturalistic context, it has been challenging to apply this technology for macaques-based studies. In this study, we created MacaquePose, a novel open dataset with manually labeled body part positions (keypoints) for macaques in naturalistic scenes, consisting of >13,000 images. We also validated the application of the dataset by training and evaluating an artificial neural network with the dataset. The results indicated that the keypoint estimation performance of the trained network was close to that of a human-level. The dataset will be instrumental to train/test the neural networks for markerless motion capture of the macaques and developments of the algorithms for the networks, contributing establishment of an innovative platform for behavior analysis for non-human primates for neuroscience and medicine, as well as other fields using macaques as a model organism.
Introduction
Behavior analyses are fundamental for understanding brain functions and malfunctions (Datta et al., 2019). Motion capture technologies allow the quantification of animal's pose and motion with a high spatiotemporal resolution enabling the study of the relationship between various brain functions and behaviors (Vargas-Irwin et al., 2008; Nagasaka et al., 2011; Mathis and Mathis, 2020). However, attaching the physical markers for the motion capture is often not practical for animal studies, as the markers themselves disturb/change the subject's behavior (Nakamura et al., 2016; Mathis et al., 2018; Berger et al., 2020). Thanks to recent advances in machine vision using deep learning, the video-based markerless motion capture has been developed to a level permitting practical use (Mathis and Mathis, 2020), in which an artificial neural network predicts the location of body parts in a video without the requirement for physical markers, and enabled successful behavioral studies in rodents (e.g., Cregg et al., 2020; Dooley et al., 2020; Mathis and Mathis, 2020). Macaque monkeys are an important non-human primate model, particularly in the field of neuroscience (Kalin and Shelton, 2006; Capitanio and Emborg, 2008; Nelson and Winslow, 2008; Watson and Platt, 2012). The robust markerless motion capture using deep learning will allow studying various complex naturalistic behaviors in detail, and permit investigation of relationship between naturalistic behaviors and brain functions (Datta et al., 2019; Mathis and Mathis, 2020). Analyzing naturalistic behavior is crucial in brain-science, since the brain evolved from natural behaviors, and various behaviors, such as complex social behaviors, can be observed only in the natural situations (Datta et al., 2019; Mathis and Mathis, 2020). The deep neural networks usually require manually labeled body parts positions in thousands of pictures to learn prediction of the body parts positions in an arbitrary picture. However, such a large labeled dataset for macaque monkeys in the naturalistic scene has not been developed. The lack of this dataset limits the markerless motion capture technology applications for macaque studies (Bala et al., 2020; Berger et al., 2020).
To overcome this limitation, we created a novel open dataset of the manually labeled body part positions (keypoints) for macaques in naturalistic scenes, consisting of >13,000 pictures. We also validated the usefulness of the dataset by training and evaluating an artificial neural network with the dataset. The results revealed that the keypoint estimation performance of the trained network was close to that of a human level. Our dataset will provide basis for markerless motion capture on the naturalistic behaviors.
Materials and Methods
Image Data Collection
A total of 13,083 images of macaque monkeys were obtained from the internet or were captured in zoos or the Primate Research Institute of Kyoto University. Images on the internet were obtained through Google Open Images (https://storage.googleapis.com/openimages/web/index.html) by searching for images with a “macaque” tag. Pictures zoos were acquired from the outside of the breeding areas, with granted permission provided by the zoos. Images in the Primate Research Institute of Kyoto University were taken in the breeding fields without causing any specific interventions to the monkeys. The photo capturing in the institute was approved by the Animal Welfare and Animal Care Committee of the Primate Research Institute of Kyoto University and conducted in accordance with the Guidelines for the Care and Use of Animals of the Primate Research Institute, Kyoto University.
Image Data Annotation
The positions of 17 keypoints (nose and left and right ears, eyes, shoulders, elbows, wrists, hips, knees, and ankles) and instance segmentation for each monkey in each of the pictures were first annotated by non-researchers employed by Baobab Inc. (Chiyoda-ku, Japan). As further expertise was required for high-quality monkey annotation, the keypoint labels were then further refined with eight researchers working with macaques at Kyoto University and the University of Toyama, using a custom-made Python script. The keypoints were labeled according to the following guidelines: (1) The keypoints of the limbs (shoulder, elbow, wrist, hip, knee, and ankle) should be located at the center of the joint rotation. (2) Ear, eye, and nose keypoints should be located at the entrance of the ear canal, the center of eye ball, in the middle position between the entrances of the two nostrils, respectively. (3) A keypoint was annotated, if its position was predictable despite being occluded, except for ears, eyes, and nose facing the back side of the picture. The resultant labels were compatible with the Microsoft COCO Keypoint Dataset (Lin et al., 2014).
Performance Evaluation of an Artificial Neural Network Trained With the Present Dataset
To validate the present dataset, we trained an artificial neural network estimating keypoint positions by using the DeepLabCut algorithm proposed for markerless pose estimation in animals (Mathis et al., 2018). Briefly, DeepLabCut is a versatile and straightforward algorithm in which the 50-layer ResNet pre-trained for the ImageNet object recognition task (He et al., 2016) is transferred for the keypoint estimation by replacing the classification layer at the output of the ResNet with the deconvolutional layers (see Supplementary Figure 1 for the network architecture of the DeepLabCut). The utilization of transfer learning allows DeepLabCut algorithm to require a relatively small number of training data (Nath et al., 2019). The accuracy of keypoint prediction with the DeepLabCut algorithm has been shown to be comparable or superior to similar algorithms recently suggested for the animal pose estimation (Graving et al., 2019). DeepLabCut is a widely used algorithm in the field of neuroscience, because of its user-friendly interface and documentations, and a well-established community, as well as its good performance. Due to DeepLabCut (version 2.1.6) currently not supporting the estimation of keypoints in multiple animals in a picture, we first generated single monkey images by masking the monkeys in the images except for one monkey and used these masked images as the input. Some monkey images in the dataset were excluded due to technical reasons (e.g., a keypoint of one monkey is covered by the mask of the other monkeys). Then, the images were resized to adjust the length to 640 pixels while maintaining the images aspect ratio, before inputting it into the network. In total, 15,476 single monkey images were generated. Among the images, 14,697 single monkey images were used to train the network and the rest (779 images) were used to evaluate the trained network. The network model was implemented using Python scripts with Tensorflow support. The network is trained up to a million iterations. The training took 20 h to complete on a Nvidia GTX 1080 Ti graphics processing unit workstation.
The keypoint prediction by the trained network was evaluated. A predicted keypoint with confidence level > 0.4 was defined to be detected. First, minor cases showing the keypoint(s) detected outside the monkey segment were eliminated. True positive, true negative, false positive, and false negative detections were counted. A keypoint was defined as a correct detection by the network (true positive detection) if there was the corresponding ground truth keypoint in the same image, regardless of its location in the image. For true positive cases, the Euclidean distance between the predicted and ground truth position was calculated as the error of position estimation. The error value represented the normalized value with respect to the length of the monkey's bounding box due to variations in the size of the monkey in the images. To check the accuracy of the predicted pose, the root-mean-square error (RMSE) was also calculated with all keypoints in each image (Mathis et al., 2018). To evaluate the error values of the keypoint position predictions, we investigated human variability by calculating the errors between the keypoint positions annotated by two humans. Finally, among the true positive cases, numbers of limb keypoints misattributed as the homologous keypoint on another limb (e.g., left wrist misattributed as right wrist, left ankle, or right ankle) are also counted. Specifically, i-th keypoint were defined as being misattributed to a homologous j-th keypoint on another limb, if the keypoint satisfies both of the following two conditions: (1) the normalized position error of the i-th keypoint was >20%; (2) the ground truth positions of j-th keypoint was closest to the predicted position of i-th keypoint among the ground truth positions of homologous keypoints. Note that these keypoint predictions obtained with the trained network were evaluated on set of test images which are not included during training of the network.
Results
In total, the present data set contains keypoints and instance segmentation of 16,393 monkeys in 13,083 pictures. Each picture captures 1–5 monkeys; 10,630 pictures with a single monkey and 2,453 pictures with multiple monkeys (Figure 1).

Figure 1. Examples of pictures and labels in the present dataset.
To validate the dataset, we trained an artificial network with 14,697 single monkey images in the dataset using the DeepLabCut algorithm (Mathis et al., 2018). The performance of the keypoint prediction of the trained network was evaluated on 779 test images unseen during training. Figure 2 shows examples of the keypoint predictions (see Supplementary Video 1 for keypoint prediction for movies). Among 779 images, 24 images had keypoint(s) detected outside the target monkey. Most of them (17 images) were due to imperfect masks of the other monkeys in the picture (Supplementary Figure 2). The “out of monkey” cases were removed from the analysis.

Figure 2. Examples of test image predictions. Test images (left), the ground truth keypoint positions (center) and the position predicted by the artificial neural network trained with the present dataset using the DeepLabCut algorithm (right; a–h). The inset (top right corner) shows color codes of the keypoints. Red arrows in (h) indicate a misattribution error.
We investigated the performance of keypoint detection (judging whether a keypoint exists anywhere in the picture or not) of the trained network (Supplementary Table 1). Both precision and recall of the keypoint detection were approximately 90% in most of the keypoints, suggesting good detection performance.
To further investigate the accuracy of the detected keypoints, the error of predicted position was calculated for each keypoint (Figure 3, gray bar). The prediction's RMSE values (6.02 ± 0.18%; mean ± s.e.m) were comparable to those between the positions manually labeled by two different people (5.74 ± 0.16%; p = 0.250, student's t-test), suggesting that the trained network's performance in the keypoint position estimation was close to the human level. The effect of the label refinement by researchers was also examined. The error values for the dataset before the refinement were calculated as previously mentioned. The analyses revealed that the averaged RMSE values after the refinement (6.02 ± 0.18%) were significantly smaller than the one before the refinement (7.83 ± 0.23%; p = 9.13 × 10−10, Student's t-test; see Supplementary Figure 3 for the error value of each keypoint). The result suggests that the network trained with the dataset refined by the researchers predicted the keypoint more consistently.
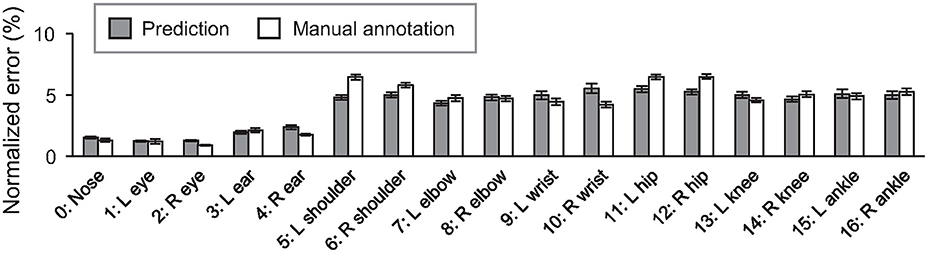
Figure 3. Averaged error of predicted (gray) and manual labeled (white) positions of each keypoint comparing with the ground truth positions. Error bars represent standard error of the mean (s.e.m).
In some cases, we observed that the predicted positions of monkey's keypoints on a limb were located on homologous keypoints on another limb (Figure 2h, see also Supplementary Video 1).
We then quantified the frequency of such misattribution errors (Table 2). The misattribution errors were relatively frequent in the distal keypoints (elbow, knee, wrist, and ankle), especially on the hind limbs. The total number of images having at least one misattribution error was 114 (15%). The result shows that there is still room for improvement, although the RMSE indicates human-level performance.
Discussions
In this study, we created a novel large dataset of labeled keypoints of macaque monkeys (Figure 1, Table 1). The keypoint estimation performance of the neural network trained with the dataset was close to that of human level (Figures 2, 3; Supplementary Video 1), demonstrating the usefulness of the present dataset. We also found a significant improvement of the network prediction after the label refinement by researchers using macaques (Supplementary Figure 3), suggesting that the refinement successfully enhanced the quality of the dataset. Although we tested only single monkey images due to the limitation of the algorithm, the present dataset should be useful to train/test the network for multi-animal motion capture. The label formats in the present dataset are compatible with those used in the COCO dataset for humans (Lin et al., 2014), allowing users to try a direct application of algorithms developed for human motion capture. A recent study also proposed a similarly sized labeled dataset of rhesus monkeys (Bala et al., 2020). In the study, they captured freely moving monkeys in a 2.5 m cubic cage with 62 cameras surrounding the cage. The multi-camera system allows to reconstruct 3D pose after manually labeling images simultaneously captured from 3 to 4 views. Interestingly, the reconstructed 3D pose is projected to the other around 60 views and enables automatically labeling the images from all the views. This cross-view data augmentation allowed them to get labels of around 200,000 monkey images with 33,192 images labeled manually. The critical difference between the two datasets is that pictures in their dataset were taken in a single laboratory environment, our dataset consists of pictures taken in many different naturalistic environments. Thanks to the “in-the-wild” aspect of the collected pictures, the present data set has rich variations in pose, body shape, lighting, and background in naturalistic contexts. The rich variation will help to train and test artificial neural networks with high generalizability (Mathis et al., 2019). Thus, the two datasets will compensate each other to train or test better neural networks in future studies. As the dataset formats (i.e., which keypoints are labeled) were slightly different among the two datasets, some additional efforts are necessary to combine or compare these two datasets directly.
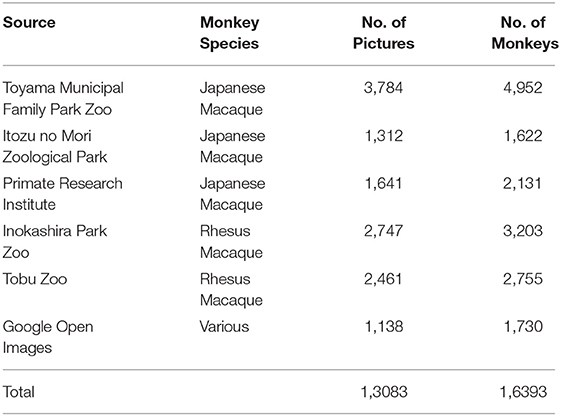
Table 1. The number of pictures and monkeys in the present dataset from each source.
To understand how the brain generates our behavior, analyzing naturalistic behaviors is crucial. The brain evolved from natural behaviors, and various behaviors, such as complex social behaviors, can be observed only in the natural situations (Datta et al., 2019; Mathis and Mathis, 2020). The high-resolution spatiotemporal data obtained with the markerless motion capture will also aid in understanding brain dynamics underlying the behavior (Berger et al., 2020). Specific posture and motion are informative for studying animals' emotions and intension (Nakamura et al., 2016), and the motor functions (Berger et al., 2020). Furthermore, the automatic and long-term analyses of naturalistic behavior from a large number of subjects permit new data-driven approaches to find unusual behaviors, personalities and, underlying genetic and neural mechanisms (Vogelstein et al., 2014; De Chaumont et al., 2019). For instance, the recently discovered autistic traits exhibited by macaque monkeys (Yoshida et al., 2016) was identified by such a behavioral observation. Thus, the markerless motion capture for macaque monkeys developed based on the present dataset will be of great use for many neuroscience studies.
The performance evaluation of the network trained with the present dataset revealed that there is still room for improvement regarding the misattribution of the limb keypoints (Figure 2h, Table 2), although the RMSE indicates the human-level performance (Figure 3). The DeepLabCut algorithm (Mathis et al., 2018) used in the present evaluation does not explicitly utilize the prior knowledge about the animal's body, whereas the other algorithms were suggested to use the connection between keypoints (Insafutdinov et al., 2016; Cao et al., 2017) or 3D shape of the subject (Biggs et al., 2018; Zuffi et al., 2019). Such utilization of the prior knowledge may help to improve the estimation. However, even the state-of-the-art human motion capture algorithms also have difficulties in analyzing the pictures with severe occlusion or crowded people (Mathis and Mathis, 2020). Due to severe occlusions more frequently being observed in naturalistic behaviors in monkeys than in humans, better algorithms may be required in the future. An alternative approach for the improvement will be enriching the dataset itself. Although we tried to capture many different poses in various contexts, the sampling was biased to the frequently observed poses. Adding data selectively for the rarely observed poses may improve the performance of the trained network. Combining with the other monkey datasets made for laboratory environments (Bala et al., 2020; Berger et al., 2020) or transfer learning of the network trained with the human dataset (Sanakoyeu et al., 2020) are also interesting approaches. Nevertheless, in practice, the performance of the network shown in the present study may be sufficient for many applications, after appropriate temporal filtering of the motion data (Berman et al., 2014; Nath et al., 2019) and additional training with the labels made on the pictures in the target experiment (Mathis et al., 2019).
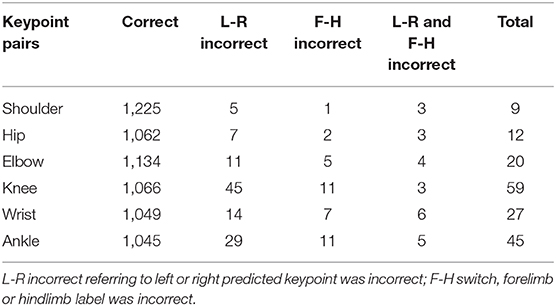
Table 2. Number of the misattribution errors.
In the present study, we evaluated the keypoint estimation in 2D images by the neural network. However, for the next step of behavior analysis, the researchers would need to reconstruct the 3D pose and motion of the animals (Nath et al., 2019; Bala et al., 2020) then label the behaviors that the animals are exhibiting based on the estimated pose and motion (Datta et al., 2019). The post-processing methods for converting the high-dimensional motion data into meaningful and interpretable behavioral events and parameters of a single animal or interacting animals are still under active developments (Berman et al., 2014; Datta et al., 2019; Dviwedi et al., 2020). The present dataset will permit simple access to motion data of macaques in various environments, and this could accelerate the development of post-processing method by accumulating the motion data associated with various natural behaviors. It is also interesting to add labels of monkey behavior (e.g., running, eating, sleeping, grooming, fighting, etc.) engaged in each picture in the present dataset, for the development of the behavioral event detection methods.
Conclusion
We created a novel large open dataset of keypoint labels of macaques in naturalistic scenes. The dataset will be instrumental to train/test the neural networks for markerless motion capture of the macaques and developments of the algorithms for the networks, contributing to the establishment of an innovative platform of behavior analysis for non-human primates for neuroscience and medicine, as well as the other fields using macaques (Carlsson et al., 2004).
Data Availability Statement
The dataset for this study is publicly available on the website of Primate Research Institute, Kyoto University (http://www.pri.kyoto-u.ac.jp/datasets/). The trained network model described in the present paper is readily available through DeepLabCut Model Zoo (http://www.mousemotorlab.org/dlc-modelzoo). The other raw data supporting the conclusions of this article will be made available by the authors upon request.
Ethics Statement
The animal study was reviewed and approved by Animal Welfare and Animal Care Committee of the Primate Research Institute of Kyoto University.
Author Contributions
RL, TS, JM, KI, YG, HNishij, and HNishim designed this research. JM, KI, TS, RL, and MT created the dataset. RL, SBN, JM, and TS evaluated the performance of the neural network trained with the dataset. All the authors discussed the results and commented on the manuscript, read and approved the final manuscript.
Funding
This work was supported by the Cooperative Research Program of Primate Research Institute, Kyoto University, the Grant-in-Aid for Scientific Research from Japan Society for the Promotion of Science (Nos. 16H06534, 19H04984, and 19H05467), and the grant of Joint Research by the National Institutes of Natural Sciences (NINS) (NINS Program No. 01111901).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We would like to thank Yu Yang, Yang Meng, Kei Kimura, Yukiko Otsuka, Andi Zheng, Jungmin Oh, Gaoge Yan, and Yuki Kinoshita for manually labeling and refining the keypoints.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnbeh.2020.581154/full#supplementary-material
References
Bala, P. C., Eisenreich, B. R., Yoo, S. B. M., Hayden, B. Y., Park, H. S., and Zimmermann, J. (2020). Automated markerless pose estimation in freely moving macaques with OpenMonkeyStudio. Nat. Commun. 11:4560. doi: 10.1038/s41467-020-18441-5
Berger, M., Agha, N. S., and Gail, A. (2020). Wireless recording from unrestrained monkeys reveals motor goal encoding beyond immediate reach in frontoparietal cortex. Elife 9:e51322. doi: 10.7554/eLife.51322
Berman, G. J., Choi, D. M., Bialek, W., and Haevitz, J. W. (2014). Mapping the stereotyped behaviour of freely-moving fruit flies. J. R. Soc. Interface 11:20140672. doi: 10.1098/rsif.2014.0672
Biggs, B., Roddick, T., Fitzgibbon, A., and Cipolla, R. (2018). “Creatures great and SMAL: recovering the shape and motion of animals from video,” in ACCV 2018: 14th Asian Conference on Computer Vision (Perth, WA), 3–19.
Cao, Z., Simon, T., Wei, S. E., and Sheikh, Y. (2017). “Realtime multi-person 2d pose estimation using part affinity fields,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Honolulu, HI), 7291–7299.
Capitanio, J. P., and Emborg, M. E. (2008). Contributions of non-human primates to neuroscience research. Lancet 371, 1126–1135. doi: 10.1016/S0140-6736(08)60489-4
Carlsson, H. E., Schapiro, S. J., Farah, I., and Hau, J. (2004). Use of primates in research: a global overview. Am. J. Primatol. 63, 225–237. doi: 10.1002/ajp.20054
Cregg, J. M., Leiras, R., Montalant, A., Wanken, P., Wickersham, I. R., and Kiehn, O. (2020). Brainstem neurons that command mammalian locomotor asymmetries. Nat. Neurosci. 23, 730–740. doi: 10.1038/s41593-020-0633-7
Datta, S. R., Anderson, D. J., Branson, K., Perona, P., and Leifer, A. (2019). Computational neuroethology: a call to action. Neuron 104, 11–24. doi: 10.1016/j.neuron.2019.09.038
De Chaumont, F., Ey, E., Torquet, N., Lagache, T., Dallongeville, S., Imbert, A., et al. (2019). Live mouse tracker: real-time behavioral analysis of groups of mice. Nat. Biomed. Eng. 3, 930–942. doi: 10.1038/s41551-019-0396-1
Dooley, J. C., Glanz, R. M., Sokoloff, G., and Blumberg, M. S. (2020). Self-generated whisker movements drive state-dependent sensory input to developing barrel cortex. Curr. Biol. 30, 2404–2410.e4. doi: 10.1016/j.cub.2020.04.045
Dviwedi, S. K., Ngeo, J. G., and Shibata, T. (2020). Extraction of Nonlinear synergies for proportional and simultaneous estimation of finger kinematics. IEEE Trans. Biomed. Eng. 67, 2646–2658. doi: 10.1109/tbme.2020.2967154
Graving, J. M., Chae, D., Naik, H., Li, L., Koger, B., Costelloe, B. R., et al. (2019). DeepPoseKit, a software toolkit for fast and robust animal pose estimation using deep learning. Elife 8:e47994. doi: 10.7554/eLife.47994.sa2
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for imagerecognition,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Piscataway, NJ: IEEE), 770–778.
Insafutdinov, E., Pishchulin, L., Andres, B., Andriluka, M., and Schiele, B. (2016). “DeeperCut: a deeper, stronger, and faster multi-person pose estimation model,” in European Conference on Computer Vision (New York, NY: Springer), 34–50.
Kalin, N. H., and Shelton, S. E. (2006). Nonhuman primate models to study anxiety, emotion regulation, and psychopathology. Ann. N.Y. Acad. Sci. 1008, 189–200. doi: 10.1196/annals.1301.021
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., et al. (2014). “Microsoft coco: common objects in context,” in European Conference on Computer Vision (Zurich: Springer), 740–755.
Mathis, A., Mamidanna, P., Cury, K. M., Abe, T., Murthy, V. N., Mathis, M. W., et al. (2018). DeepLabCut: markerless pose estimation of user-defined body parts with deep learning. Nat. Neurosci. 21, 1281–1289. doi: 10.1038/s41593-018-0209-y
Mathis, A., Yüksekgönül, M., Rogers, B., Bethge, M., and Mathis, M. W. (2019). Pretraining Boosts Out-of-Domain Robustness for Pose Estimation. Available online at: http://arxiv.org/abs/1909.11229 (accessed November 12, 2020).
Mathis, M. W., and Mathis, A. (2020). Deep learning tools for the measurement of animal behavior in neuroscience. Curr. Opin. Neurobiol. 60, 1–11. doi: 10.1016/j.conb.2019.10.008
Nagasaka, Y., Shimoda, K., and Fujii, N. (2011). Multidimensional recording (MDR) and data sharing: an ecological open research and educational platform for neuroscience. PLoS ONE 6:e22561. doi: 10.1371/journal.pone.0022561
Nakamura, T., Matsumoto, J., Nishimaru, H., Bretas, R. V., Takamura, Y., Hori, E., et al. (2016). A markerless 3D computerized motion capture system incorporating a skeleton model for monkeys. PLoS ONE. 11:e0166154. doi: 10.1371/journal.pone.0166154
Nath, T., Mathis, A., Chen, A. C., Patel, A., Bethge, M., and Mathis, M. W. (2019). Using DeepLabCut for 3D markerless pose estimation across species and behaviors. Nat. Protoc. 14, 2152–2176. doi: 10.1038/s41596-019-0176-0
Nelson, E. E., and Winslow, J. T. (2008). Non-human primates: model animals for developmental psychopathology. Neuropsychopharmacology 34, 90–105. doi: 10.1038/npp.2008.150
Sanakoyeu, A., Khalidov, V., McCarthy, M. S., Vedaldi, A., and Neverova, N. (2020). “Transferring dense pose to proximal animal classes,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Seattle, WA), 5232–5241.
Vargas-Irwin, C. E., Shakhnarovich, G., Yadollahpour, P., Mislow, J. M., Black, M. J., and Donoghue, J. P. (2008). Decoding complete reach and grasp actions from local primary motor cortex populations. J. Neurosci. 30, 9659–9669. doi: 10.1523/JNEUROSCI.5443-09.2010
Vogelstein, J. T., Park, Y., Ohyama, T., Kerr, R. A., Truman, J. W., Priebe, C. E., et al. (2014). Discovery of brainwide neural-behavioral maps via multiscale unsupervised structure learning. Science 344, 386–92. doi: 10.1126/science.1250298
Watson, K. K., and Platt, M. L. (2012). Of mice and monkeys: using non-human primate models to bridge mouse- and human-based investigations of autism spectrum disorders. J. Neurodev. Disord. 4:21. doi: 10.1186/1866-1955-4-21
Yoshida, K., Go, Y., Kushima, I., Toyoda, A., Fujiyama, A., Imai, H., et al. (2016). Single-neuron and genetic correlates of autistic behavior in macaque. Sci. Adv. 2:e1600558. doi: 10.1126/sciadv.1600558
Keywords: non-human primate, deep learning, pose estimation, large-scale dataset, behavior analysis
Citation: Labuguen R, Matsumoto J, Negrete SB, Nishimaru H, Nishijo H, Takada M, Go Y, Inoue K and Shibata T (2021) MacaquePose: A Novel “In the Wild” Macaque Monkey Pose Dataset for Markerless Motion Capture. Front. Behav. Neurosci. 14:581154. doi: 10.3389/fnbeh.2020.581154
Received: 08 July 2020; Accepted: 15 December 2020;
Published: 18 January 2021.
Edited by:
Gernot Riedel, University of Aberdeen, United KingdomReviewed by:
Joshua C. Brumberg, Queens College (CUNY), United StatesValeria Manera, University of Nice Sophia Antipolis, France
Copyright © 2021 Labuguen, Matsumoto, Negrete, Nishimaru, Nishijo, Takada, Go, Inoue and Shibata. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rollyn Labuguen, bGFidWd1ZW4tcm9sbHluQGVkdS5icmFpbi5reXV0ZWNoLmFjLmpw; Jumpei Matsumoto, am1AbWVkLnUtdG95YW1hLmFjLmpw; Tomohiro Shibata, dG9tQGJyYWluLmt5dXRlY2guYWMuanA=