 Junpei Zhong
Junpei Zhong Angelo Cangelosi
Angelo Cangelosi Stefan Wermter
Stefan Wermter- 1Department of Computer Science, University of Hamburg, Hamburg, Germany
- 2School of Computer Science, University of Hertfordshire, Hatfield, UK
- 3School of Computing and Mathematics, University of Plymouth, Plymouth, UK
The acquisition of symbolic and linguistic representations of sensorimotor behavior is a cognitive process performed by an agent when it is executing and/or observing own and others' actions. According to Piaget's theory of cognitive development, these representations develop during the sensorimotor stage and the pre-operational stage. We propose a model that relates the conceptualization of the higher-level information from visual stimuli to the development of ventral/dorsal visual streams. This model employs neural network architecture incorporating a predictive sensory module based on an RNNPB (Recurrent Neural Network with Parametric Biases) and a horizontal product model. We exemplify this model through a robot passively observing an object to learn its features and movements. During the learning process of observing sensorimotor primitives, i.e., observing a set of trajectories of arm movements and its oriented object features, the pre-symbolic representation is self-organized in the parametric units. These representational units act as bifurcation parameters, guiding the robot to recognize and predict various learned sensorimotor primitives. The pre-symbolic representation also accounts for the learning of sensorimotor primitives in a latent learning context.
1. Introduction
Although infants are not supposed to acquire the symbolic representational system at the sensorimotor stage, based on Piaget's definition of infant development, the preparation of language development, such as a pre-symbolic representation for conceptualization, has been set at the time when the infant starts babbling (Mandler, 1999). Experiments have shown that infants have established the concept of animate and inanimate objects, even if they have not yet seen the objects before (Gelman and Spelke, 1981). Similar phenomena also include the conceptualization of object affordances such as the conceptualization of containment (Bonniec, 1985). This conceptualization mechanism is developed at the sensorimotor stage to represent sensorimotor primitives and other object-affordance related properties.
During an infants' development at the sensorimotor stage, one way to learn affordances is to interact with objects using tactile perception, observe the object from visual perception and thus learn the causality relation between the visual features, affordance and movements as well as to conceptualize them. This learning starts with the basic ability to move an arm toward the visual-fixated objects in new-born infants (Von Hofsten, 1982), continues through object-directed reaching at the age of 4 months (Streri et al., 1993; Corbetta and Snapp-Childs, 2009), and can also be found during the object exploration of older infants (c.f. Ruff, 1984; Mandler, 1992). From these interactions leading to visual and tactile percepts, infants gain experience through the instantiated “bottom-up” knowledge about object affordances and sensorimotor primitives. Building on this, infants at the age of around 8–12 months gradually expand the concept of object features, affordances and the possible causal movements in the sensorimotor context (Gibson, 1988; Newman et al., 2001; Rocha et al., 2006). For instance, they realize that it is possible to pull a string that is tied to a toy car to fetch it instead of crawling toward it. An associative rule has also been built that connects conceptualized visual feature inputs, object affordance and the corresponding frequent auditory inputs of words, across various contexts (Romberg and Saffran, 2010). At this stage, categories of object features are particularly learned in different contexts due to their affordance-invariance (Bloom et al., 1993).
Therefore the integrated learning process of the object's features, movements according to the affordances, and other knowledge is a globally conceptualized process through visual and tactile perception. This conceptualized learning is a precursor of a pre-symbolic representation of language development. This learning is the process to form an abstract and simplified representation for information exchange and sharing1. To conceptualize from visual perception, it usually includes a planning process: first the speaker receives and segments visual knowledge in the perceptual flow into a number of states on the basis of different criteria, then the speaker selects essential elements, such as the units to be verbalized, and last the speaker constructs certain temporal perspectives when the events have to be anchored and linked (c.f. Habel and Tappe, 1999; von Stutterheim and Nuse, 2003). Assuming this planning process is distributed between ventral and dorsal streams, the conceptualization process should also emerge from the visual information that is perceived in each stream, associating the distributed information in both streams. As a result, the candidate concepts of visual information are statistically associated with the input stimuli. For instance, they may represent a particular visual feature with a particular class of label (e.g., a particular visual stimuli with an auditory wording “circle”) (Chemla et al., 2009). Furthermore, the establishment of such links also strengthens the high-order associations that generate predictions and generalize to novel visual stimuli (Yu, 2008). Once the infants have learned a sufficient number of words, they begin to detect a particular conceptualized cue with a specific kind of wording. At this stage, infants begin to use their own conceptualized visual “database” of known words to identify a novel meaning class and possibly to extend their wording vocabulary (Smith et al., 2002). Thus, this associative learning process enables the acquisition and the extension of the concepts of domain-specific information (e.g., features and movements in our experiments) with the visual stimuli.
This conceptualization will further result in a pre-symbolic way for infants to communicate when they encounter a conceptualized object and intend to execute a correspondingly conceptualized well-practised sensorimotor action toward that object. For example, behavioral studies showed that when 8-to-11-month-old infants are unable to reach and pick up an empty cup, they may point it out to the parents and execute an arm movement intending to bring it to their lips. The conceptualized shape of a cup reminds infants of its affordance and thus they can communicate in a pre-symbolic way. Thus, the emergence from the conceptualized visual stimuli to the pre-symbolic communication also gives further rise to the different periods of learning nouns and verbs in infancy development (c.f. Gentner, 1982; Tardif, 1996; Bassano, 2000). This evidence supports that the production of verbs and nouns are not correlated to the same modality in sensory perception: experiments performed by Kersten (1998) suggest that nouns are more related to the movement orientation caused by the intrinsic properties of an object, while verbs are more related to the trajectories of an object. Thus we argue that such differences of acquisitions in lexical classes also relate to the conceptualized visual ventral and dorsal streams. The finding is consistent with Damasio and Tranel (1993)'s hypothesis that verb generation is modulated by the perception of conceptualization of movement and its spatio-temporal relationship.
For this reason, we propose that the conceptualized visual information, which is a prerequisite for the pre-symbolic communication, is also modulated by perception in two visual streams. Although there have been studies of modeling the functional modularity in the development of ventral and dorsal streams (e.g., Jacobs et al., 1991; Mareschal et al., 1999), the bilinear models of visual routing (e.g., Olshausen et al., 1993; Memisevic and Hinton, 2007; Bergmann and von der Malsburg, 2011), in which a set of control neurons dynamically modifies the weights of the “what” pathway on a short time scale, or transform-invariance models (e.g., Földiák, 1991; Wiskott and Sejnowski, 2002) by encouraging the neurons to fire invariantly while transformations are performed in their input stimuli. However, a model that explains the development of conceptualization from both streams and results in an explicit representation of conceptualization of both streams while the visual stimuli is presented is still missing in the literature. This conceptualization should be able to encode the same category for information flows in both ventral and dorsal streams like “object files” in the visual understanding (Fields, 2011) so that they could be discriminated in different contexts during language development.
On the other hand, this conceptualized representation that is distributed in two visual streams is also able to predict the tendency of appearance of an action-oriented object in the visual field, which causes some sensorimotor phenomena such as object permanence (Tomasello and Farrar, 1986) showing the infants' attention usually is driven by the object's features and movements. For instance, when infants are observing the movement of the object, recording showed an increase of the looking times when the visual information after occlusion is violated in either surface features or location (Mareschal and Johnson, 2003). Also the words and sounds play a top–down role in the early infants' visual attention (Sloutsky and Robinson, 2008). This could hint at the different development stages of the ventral and dorsal streams and their effect on the conceptualized prediction mechanism in the infant's consciousness. Accordingly, the model we propose about the conceptualized visual information should also be able to explain the emergence of a predictive function in the sensorimotor system, e.g., the ventral stream attempts to track the object and the dorsal stream processes and predicts the object's spatial location, when the sensorimotor system is involved in an object interaction. We have been aware of that this build-in predictive function in a forward sensorimotor system is essential: neuroimaging research has revealed the existence of internal forward models in the parietal lobe and the cerebellum that predict sensory consequences from efference copies of motor commands (Kawato et al., 2003) and supports fast motor reactions (e.g., Hollerbach, 1982). Since the probable position and the movement pattern of the action should be predicted on a short time scale, sensory feedback produced by a forward model with negligible delay is necessary in this sensorimotor loop.
Particularly, the predictive sensorimotor model we propose is suitable to work as one of the building modules that takes into account the predictive object movement in a forward sensorimotor system to deal with object interaction from visual stimuli input as Figure 1 shows. This system is similar to Wolpert et al. (1995)'s sensorimotor integration, but it includes an additional sensory estimator (the lower brown block) which takes into account the visual stimuli from the object so that it is able to predict the dynamics of both the end-effector (which is accomplished by the upper brown block) and the sensory input of the object. This object-predictive module is essential in a sensorimotor system to generate sensorimotor actions like tracking and avoiding when dealing with fast-moving objects, e.g., in ball sports. We also assert that the additional inclusion of forward models in the visual perception of the objects can explain some predictive developmental sensorimotor phenomena, such as object permanence.
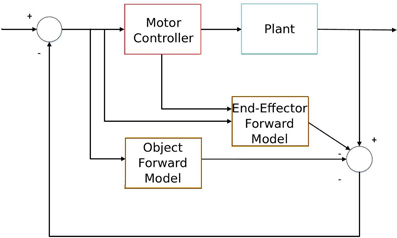
Figure 1. Diagram of sensorimotor integration with the object interaction. The lower forward model predicts the object movement, while the upper forward model extracts the end-effector movement from sensory information in order to accomplish a certain task (e.g., object interaction).
In summary, we propose a model that establishes links between the development of ventral/dorsal visual streams and the emergence of the conceptualization in visual streams, which further leads to the predictive function of a sensorimotor system. To validate this proof-of-concept model, we also conducted experiments in a simplified robotics scenario. Two NAO robots were employed in the experiments: one of them was used as a “presenter” and moved its arm along pre-programmed trajectories as motion primitives. A ball was attached at the end of the arm so that another robot could obtain the movement by tracking the ball. Our neural network was trained and run on the other NAO, which was called the “observer”. In this way, the observer robot perceived the object movement from its vision passively, so that its network took the object's visual features and the movements into account. Though we could also use one robot and a human presenter to run the same tasks, we used two identical robots, due to the following reasons: (1) the object movement trajectories can be done by a pre-programmed machinery so that the types and parameters of it can be adjusted; (2) the use of two identical robots allows to interchange the roles of the presenter and observer in an easier manner. As other humanoid robots, a sensorimotor cycle that is composed of cameras and motors also exists in NAO robots. Although its physical configurations and parameters of sensory and motor systems are different from those in human beings' or other biological systems, our model only handles the pre-processed information extracted from visual stimuli. Therefore it is sufficient to serve as a neural model that is running in a robot CPU to explain the language development in the cortical areas.
2. Materials and Methods
2.1. Network Model
A similar forward model exhibiting sensory prediction for visual object perception has been proposed in our recently published work (Zhong et al., 2012b) where we suggested an RNN implementation of the sensory forward model. Together with a CACLA trained multi-layer network as a controller model, the forward model embodied in a robot receiving visual landmark percepts enabled a smooth and robust robot behavior. However, one drawback of this work was its inability to store multiple sets of spatial-temporal input–output mappings, i.e., the learning did not converge if there appeared several spatial-temporal mapping sequences in the training. Consequently, a simple RNN network was not able to predict different sensory percepts for different reward-driven tasks. Another problem was that it assumed only one visual feature appeared in the robot's visual field, and that was the only visual cue it could learn during development. To solve the first problem, we further augment the RNN with parametric bias (PB) units. They are connected like ordinary biases, but the internal values are also updated through back-propagation. Comparing to the generic RNN, the additional PB units in this network act as bifurcation parameters for the non-linear dynamics. According to Cuijpers et al. (2009), a trained RNNPB can successfully retrieve and recognize different types of pre-learned, non-linear oscillation dynamics. Thus, this bifurcation function can be regarded as an expansion of the storage capability of working-memory within the sensory system. Furthermore, it adds the generalization ability of the PB units, in terms of recognizing and generating non-linear dynamics. To tackle the second problem, in order to realize sensorimotor prediction behaviors such as object permanence, the model should be able to learn objects' features and object movements separately in the ventral and dorsal visual streams, as we have shown in Zhong et al. (2012a).
Merging these two ideas, in the context of sensorimotor integration in hand-object interaction, the PB units can be considered as a small set of high-level conceptualized units that describe various types of non-linear dynamics of visual percepts, such as features and movements. This representation is more related to the “natural prototypes” from visual perception, for instance, than a specific language representation (Rosch, 1973).
The development of PB units can also be seen as the pre-symbolic communication that emerges during sensorimotor learning. The conceptualization, on the other hand, could also result in the prediction of future visual percepts of moving objects in sensorimotor integration.
In this model (Figure 2), we propose a three-layer, horizontal product Elman network with PB units. Similar to the original RNNPB model, the network is capable of being executed under three running modes, according to the pre-known conditions of inputs and outputs: learning, recognition and prediction. In learning mode, the representation of object features and movements are first encoded in the weights of both streams, while the bifurcation parameters with a smaller number of dimensions are encoded in the PB units. This is consistent with the emergence of the conceptualization at the sensorimotor stage of infant development.
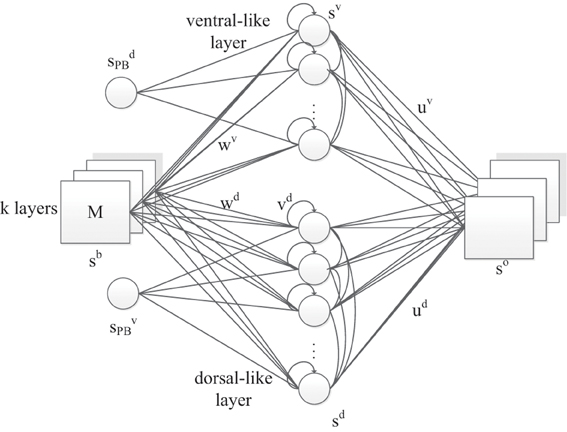
Figure 2. The RNNPB-horizontal network architecture, where k layers represent k different types of features. Size of M indicates the transitional information of the object.
Apart from the PB units, another novelty in the network is that the visual object information is encoded in two neural streams and is further conceptualized in PB units. Two streams share the same set of input neurons, where the coordinates of the object in the visual field are used as identities of the perceived images. The appearance of values in different layers represents different visual features: in our experiment, the color of the object detected by the yellow filter appears in the first layer whereas the color detected by the green filter appears in the second layer; the other layer remains zero. For instance, the input ((0,0),(x, y)) represents a green object at (x, y) coordinates in the visual field. The hidden layer contains two independent sets of units representing dorsal-like “d” and ventral-like “v” neurons, respectively. These two sets of neurons are inspired by the functional properties of dorsal and ventral streams: (1) fast responding dorsal-like units predict object position and hence encode movements; (2) slow responding ventral-like units represent object features. The recurrent connection in the hidden layers also helps to predict movements in layer d and to maintain a persistent representation of an object's feature in layer v. The horizontal product brings both pathways together again in the output layer with one-step ahead predictions. Let us denote the output layer's input from layer d and layer v as xd and xv, respectively. The network output so is obtained via the horizontal product as
where ⊙ indicates element-wise multiplication, so each pixel is defined by the product of two independent parts, i.e., for output unit k it is sok = xdk · xvk.
2.2. Neural Dynamics
We use sb(t) to represent the activation and PBd/v(t) to represent the activation of the dorsal/ventral PB units at the time-step t. In some of the following equations, the time-index t is omitted if all activations are from the same time-step. The inputs to the hidden units yvj in the ventral stream and ydj in the dorsal stream are defined as
where wdli, wvji represent the weighting matrices between dorsal/ventral layers and the input layer, wdli, wvji represent the weighting matrices between PB units and the two hidden layers, and vdll' and vvjj' indicate the recurrent weighting matrices within the hidden layers.
The transfer functions in both hidden layers and the PB units all employ the sigmoid function recommended by LeCun et al. (1998),
where ρd/v represent the internal values of the PB units.
The terms of the horizontal products of both pathways can be presented as follows:
The output of the two streams composes a horizontal product for the network output as we defined in Equation (1).
2.2.1. Learning mode
The training progress is basically determined by the cost function:
where sbi(t + 1) is the one-step ahead input (as well as the desired output), sok(t) is the current output, T is the total number of available time-step samples in a complete sensorimotor sequence and N is the number of output nodes, which is equal to the number of input nodes. Following gradient descent, each weight update in the network is proportional to the negative gradient of the cost with respect to the specific weight w that will be updated:
where ηij is the adaptive learning rate of the weights between neuron i and j, which is adjusted in every epoch (Kleesiek et al., 2013). To determine whether the learning rate has to be increased or decreased, we compute the changes of the weight wi,j in consecutive epochs:
The update of the learning rate is
where ξ+ > 1 and ξ− < 1 represent the increasing/decreasing rate of the adaptive learning rates, with ηmin and ηmax as lower and upper bounds, respectively. Thus, the learning rate of a particular weight increases by ξ+ to speed up the learning when the changes of that weight from two consecutive epochs have the same sign, and vice versa.
Besides the usual weight update according to back-propagation through time, the accumulated error over the whole time-series also contributes to the update of the PB units. The update for the i-th unit in the PB vector for a time-series of length T is defined as:
where δPB is the error back-propagated to the PB units, e is eth time-step in the whole time-series (e.g., epoch), γi is PB units' adaptive updating rate which is proportional to the absolute mean value of the back-propagation error at the i-th PB node over the complete time-series of length T:
The reason for applying the adaptive technique is that it was realized that the PB units converge with difficulty. Usually a smaller learning rate is used in the generic version of RNNPB to ensure the convergence of the network. However, this results in a trade-off in convergence speed. The adaptive learning rate is an efficient technique to overcome this trade-off (Kleesiek et al., 2013).
2.2.2. Recognition mode
The recognition mode is executed with a similar information flow as the learning mode: given a set of the spatio-temporal sequences, the error between the target and the real output is back-propagated through the network to the PB units. However, the synaptic weights remain constant and only the PB units will be updated, so that the PB units are self-organized as the pre-trained values after certain epochs. Assuming the length of the observed sequence is a, the update rule is defined as:
where δPB is the error back-propagated from a certain sensory information sequence to the PB units and γ is the updating rate of PB units in recognition mode, which should be larger than the adaptive rate γi at the learning mode.
2.2.3. Prediction mode
The values of the PB units can also be manually set or obtained from recognition, so that the network can generate the upcoming sequence with one-step prediction.
3. Results
In this experiment, as we introduced, we examined this network by implementing it on two NAO robots. They were placed face-to-face in a rectangle box of 61.5 cm × 19.2 cm as shown in Figure 3. These distances were carefully adjusted so that the observer was able to keep track of movement trajectories in its visual field during all experiments using the images from the lower camera. The NAO robot has two cameras. We use the lower one to capture the images because its installation angle is more suitable to track the balls when they are held in the other NAO's hand.

Figure 3. Experimental Scenario: two NAOs are standing face-to-face with in a rectangle box.
Two 3.8 cm diameter balls with yellow/green color were used for the following experiments. The presenter consecutively held each of the balls to present the object interaction. The original image, received from the lower camera of the observer, was pre-processed with thresholding in HSV color-space and the coordinates of its centroid in the image moment were calculated. Here we only considered two different colors as the only feature to be encoded in the ventral stream, as well as two sets of movement trajectories encoded in the dorsal stream. Although we have only tested a few categories of trajectories and features, we believe the results can be extrapolated to multiple categories in future applications.
3.1. Learning
The two different trajectories are defined as below,
The cosine curve,
and the square curve,
where the 3-dimension tuple (x, y, z) are the coordinates (centimeters) of the ball w.r.t the torso frame of the NAO presenter. t loops between (−π, π]. In each loop, we calculated 20 data points to construct trajectories with 4 s sleeping time between every two data points. Note that although we have defined the optimal desired trajectories, the arm movement was not ideally identical to the optimal trajectories due to the noisy position control of the end-effector of the robot. On the observer side, the (x, y) coordinates of the color-filtered moment of the ball in the visual field were recorded to form a trajectory with sampling time of 0.2 s. Five trajectories, in the form of tuple (x, y, z) w.r.t the torso frame of the NAO observer were recorded with each color and each curve, so total 20 trajectories were available for training.
In each training epoch, these trajectories, in the form of tuples, were fed into the input layer one after another for training, with the tuples of the next time-step serving as a training target. The parameters are listed in Table 1. The final PB values were examined after the training was done, and the values were shown in Figure 4. It can be seen that the first PB unit, along with the dorsal stream, was approximately self-organized with the color information, while the second PB unit, along with the ventral stream, was self-organized with the movement information.

Table 1. Network parameters.
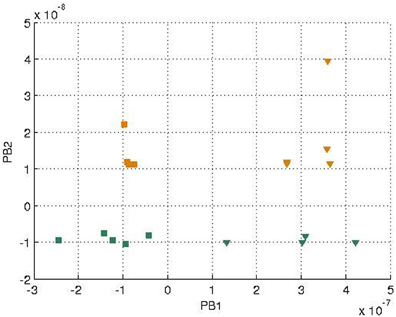
Figure 4. Values of two sets of PB units in the two streams after training. The square markers represent those PB units after the square curves training and the triangle markers represent those of the cosine curves training. The colors of the markers, yellow and green, represent the colors of the balls used for training.
3.2. Recognition
Another four trajectories were presented in the recognition experiment, in which the length of the sliding-window is equal to the length of the whole time-series, i.e., T = a in Equation (12). The update of the PB units were shown in Figure 5. Although we used the complete time-series sequence for the recognition, it should also be possible to use only part of the sequence, e.g., through the sliding-window approach with a smaller number of a to fulfil the real-time requirement in the future.
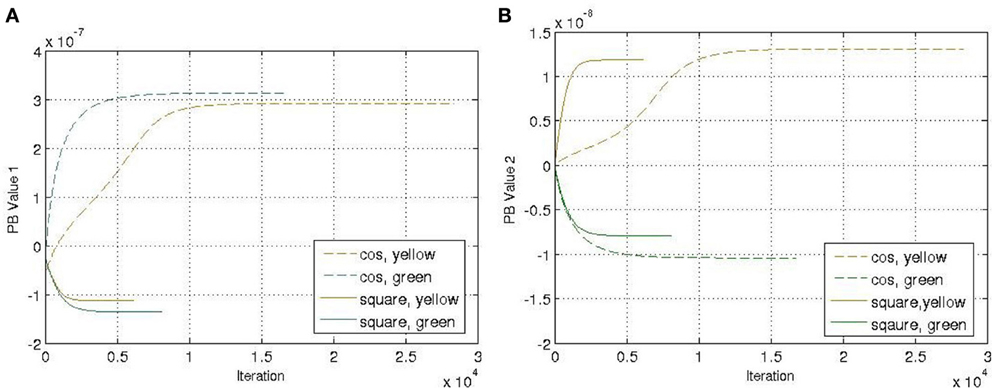
Figure 5. Update of the PB values while executing the recognition mode. (A) PB value 1. (B) PB value 2.
3.3. Prediction
In this simulation, the obtained PB units from the previous recognition experiment were used to generate the predicted movements using the prior knowledge of a specific object. Then, the one-step prediction from the output units were again applied to the input at the next time-step, so that the whole time-series corresponding to the object's movements and features were obtained. Figure 6 presents the comparisons between the true values (the same as used in recognition) and the predicted ones.
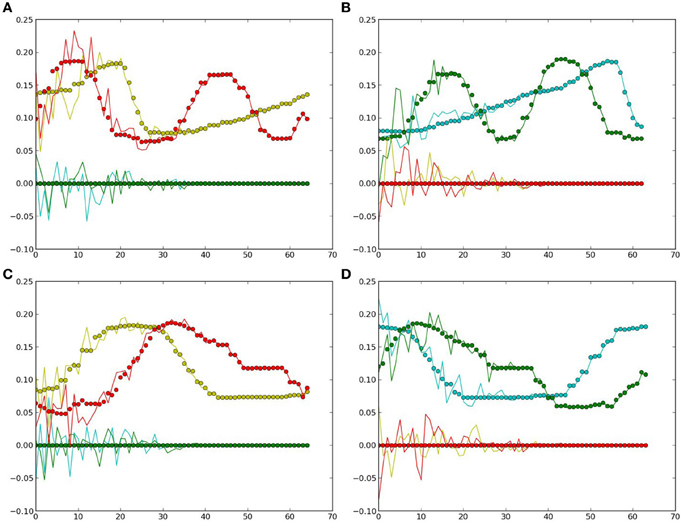
Figure 6. Generated values: the dots denote the true values for comparison, curves show the estimated ones. Yellow and red colors represent the values of the two neurons in the first layer (yellow), the colors green and clan represent those in the second layer (green). (A) Cosine curve, yellow ball. (B) Cosine curve, green ball. (C) Square curve, yellow ball. (D) Square curve, green ball.
From Figure 6 and Table 2, it can be observed that the estimation was biased quite largely to the true value within the first few time-steps, as the RNN needs to accumulate enough input values to access its short-term memory. However, the error became smaller and it kept track of the true value in the following time-steps. Considering that the curves are automatically generated given the PB units and the values at the first time-step, the error between the true values and the estimated ones are acceptable. Moreover, this result show clearly that the conceptualization affects the (predictive) visual perception.
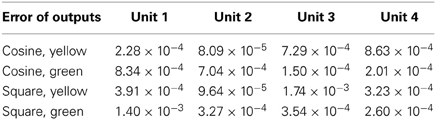
Table 2. Prediction error.
3.4. Generalization in Recognition
To testify whether our new computational model has the generalization ability as Cuijpers et al. (2009) proposed, we recorded another set of sequences of a circle trajectory. The trajectory is defined as:
The yellow and green balls were still used. We ran the recognition experiment again with the weight previously trained. The update of the PB units were shown in Figure 7. Comparing to Figure 4, we can observe that the positive and negative signs of PB values are similar as the square trajectory. This is probably because the visual perception of circle and square movements have more similarities than those between circle and cosine movements.
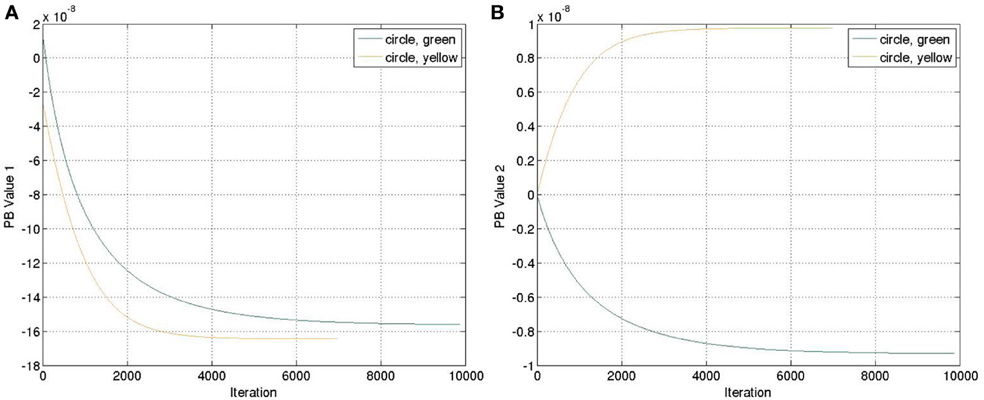
Figure 7. Update of the PB values while executing the recognition mode with an untrained feature (circle). (A) PB value 1. (B) PB value 2.
3.5. PB Representation with Different Speeds
We further generated 20 trajectories with the same data functions (Equations 13–18) but with a slower sampling time. In other words, the movement of the balls seemed to be faster with robot's observation. The final PB values after training were shown in Figure 8.
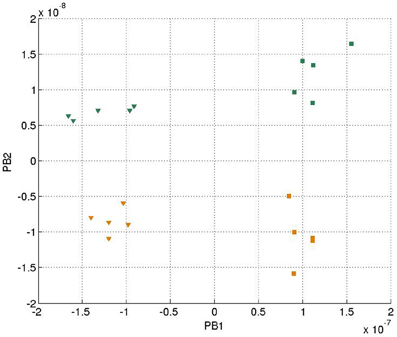
Figure 8. Values of two sets of PB units in the two streams after training with faster speed. The representation of the markers is the same as Figure 4.
It can be seen that generally the PB values were smaller comparing to Figure 4, which was probably because there was less error being propagated during training. Moreover, the corresponding PB values corresponding to colors (green and yellow) and movements (cosine and square) were interchanged within the same PB unit (i.e., along the same axis) due to the difference of random initial parameters of the network. But the PB unit along with the dorsal stream still encoded color information, while the PB unit along with ventral stream encoded movement information. The network was still able to show properties of spatio-temporal sequences data in the PB units' representation.
4. Discussion
4.1. Neural Dynamics
An advancement of the HP-RNN model is that it can learn and encode the “what” and “where” information separately in two streams (more specifically, in two hidden layers). Both streams are connected through horizontal products, which means fewer connections than full multiplication (as the conventional bilinear model) (Zhong et al., 2012a). In this paper, we further augmented the HP-RNN with the PB units. One set of units, connecting to one visual stream, reflects the dynamics of sequences in the other stream. This is an interesting result since it shows the neural dynamics in the hybrid combination of the RNNPB units and the horizontal product model. Taking the dorsal-like hidden layer for example, the error of the attached PB units is
where g'(·) and f'(·) are the derivatives of the linear and sigmoid transfer functions. Since we have the linear output, according to the definition of the horizontal product, the equation becomes,
The update of the internal values of the PB units becomes
where the xvk(t) term refers to the contribution of the weighted summation from the ventral-like layer at time t. Note that the term f'(ρvn2(t)) is actually constant within one epoch and it is only updated after each epoch with a relatively small updating rate. Therefore, from the experimental perspective, given the same object movement but different object features, the difference of the PB values mostly reflects the dynamic changes in the hidden layer of the ventral stream. The same holds for the PB units attached to the ventral-like layer. This brief analysis shows the PB units for one modularity in RNNPB networks with horizontal product connections, effectively accumulating the non-linear dynamics of other modularities.
4.2. Conceptualization in Visual Perception
The visual conceptualization and perception are intertwined processes. As experiments from Schyns and Oliva (1999) show, when the visual observation is not clear, the brain automatically extrapolates the visual percept and updates the categorization labels on various levels according to what has been gained from the visual field. On the other hand, this conceptualization also affects the immediate visual perception in a top–down predictive manner. For instance, the identity conceptualization of a human face predictively spreads conceptualizations in other levels (e.g., face emotion). This top–down process propagates from object identity to other local conceptualizations, such as object affordance, motion, edge detection and other processes at the early stages of visual processing. This can be tested by classic illusions, such as “the goblet illusion,” where perception depends largely on top–down knowledge derived from past experiences rather than direct observation. This kind of illusion may be explained by the error in the first few time steps of the prediction experiment of our model. Therefore, our model to some extent also demonstrates the integrated process between the conceptualization and the spatio-temporal visual perception. This top–down predictive perception may also arouse other visual based predictive behaviors such as object permanence.
Particularly, the PB units act as a high-level conceptualization representation, which is continuously updated with the partial sensory information perceived in a short-time scale. The prediction process of the RNNPB is assisted by the conceptualized PB units of visual perception, which is identical to the integration conceptualization and (predictive) visual perception. This is the reason why PB units were not processed as a binary representation, as Ogata et al. (2007) did for human-robot-interaction; the original values of PB units are more accurate in generating the prediction of the next time-step and performing generalization tasks. As we mentioned, this model is merely a proof-of-concept model that bridges conceptualized visual streams and sensorimotor prediction. For more complex tasks, besides expanding of the network size as we mentioned, more complex networks that are capable of extracting and predicting higher-level spatio-temporal structures (e.g., predictive recurrent networks owning large learning capacity by Tani and colleagues: Yamashita and Tani, 2008; Murata et al., 2013) can be also applied. It should be interesting to further investigate the functional modularity representation of these network models when they are interconnected with horizontal product too.
Furthermore, the neuroscience basis that supports this paper, in the context of the mirror neuron system based on object-oriented-actions (grasping), can be stated as the “data-driven” models such as MNS (Oztop and Arbib, 2002) and MNS2 (Bonaiuto et al., 2007; Bonaiuto and Arbib, 2010), although the main hypothesis in our model is not taken from the mirror neuron system theory. In the MNS review paper by Oztop et al. (2006), the action generation mode of the RNNPB model was considered to be excessive as there has no evidence yet to show that the mirror neuron system participates in action generation. However, in our model the generation mode has a key role of conceptualized PB units in the sensorimotor integration of object interaction. Nevertheless, the similar network architecture (RNNPB) used in modeling mirror neurons (Tani et al., 2004) and our pre-symbolic sensorimotor integration models may imply a close relationship between language (pre-symbolic) development, object-oriented actions, and the mirror neuron theory.
5. Conclusion
In this paper a recurrent network architecture integrating the RNNPB model and the horizontal product model has been presented, which sheds light on the feasibility of linking the conceptualization of ventral/dorsal visual streams, the emergence of pre-symbol communication, and the predictive sensorimotor system.
Based on the horizontal product model, here the information in the dorsal and ventral streams is separately encoded in two network streams and the predictions of both streams are brought together via the horizontal product while the PB units act as a conceptualization of both streams. These PB units allow for storing multiple sensory sequences. After training, the network is able to recognize the pre-learned conceptualized information and to predict the up-coming visual perception. The network also shows robustness and generalization abilities. Therefore, our approach offers preliminary concepts for a similar development of conceptualized language in pre-symbolic communication and further in infants' sensorimotor-stage learning.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors thank Sven Magg, Cornelius Weber, Katja Kösters as well as reviewers (Matthew Schlesinger, Stefano Nolfi) for improvement of the paper, Erik Strahl for technical support and NAO assistance in Hamburg and Torbjorn Dahl for the generous allowance to use the NAOs in Plymouth.
Funding
This research has been partly supported by the EU projects RobotDoC under grand agreement 235065 ROBOT-DOC, KSERA under grant agreement n° 2010-248085, POETICON++ under grant agreement 288382, ALIZ-E under grant agreement 248116 and UK EPSRC project BABEL.
Footnotes
1. ^For comparison of conceptualization between engineering and language perspectives, see (Gruber and Olsen, 1994; Bowerman and Levinson, 2001).
References
Bassano, D. (2000). Early development of nouns and verbs in french: exploring the interface between lexicon and grammar. J. Child Lang. 27, 521–559. doi: 10.1017/S0305000900004396
Bergmann, U., and von der Malsburg, C. (2011). Self-organization of topographic bilinear networks for invariant recognition. Neural Comput. 23, 2770–2797. doi: 10.1162/NECO_a_00195
Bloom, L., Tinker, E., and Margulis, C. (1993). The words children learn: evidence against a noun bias in early vocabularies. Cogn. Dev. 8, 431–450. doi: 10.1016/S0885-2014(05)80003-6
Bonaiuto, J., and Arbib, M. (2010). Extending the mirror neuron system model, II: what did I just do? A new role for mirror neurons. Biol. Cybern. 102, 341–359. doi: 10.1007/s00422-010-0371-0
Bonaiuto, J., Rosta, E., and Arbib, M. (2007). Extending the mirror neuron system model, I. Biol. Cybern. 96, 9–38. doi: 10.1007/s00422-006-0110-8
Bonniec, P. (1985). From visual-motor anticipation to conceptualization: reaction to solid and hollow objects and knowledge of the function of containment. Infant Behav. Dev. 8, 413–424. doi: 10.1016/0163-6383(85)90005-0
Bowerman, M., and Levinson, S. (2001). Language Acquisition and Conceptual Development, Vol. 3. Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511620669
Chemla, E., Mintz, T., Bernal, S., and Christophe, A. (2009). Categorizing words using “frequent frames”: what cross-linguistic analyses reveal about distributional acquisition strategies. Dev. Sci. 12, 396–406. doi: 10.1111/j.1467-7687.2009.00825.x
Corbetta, D., and Snapp-Childs, W. (2009). Seeing and touching: the role of sensory-motor experience on the development of infant reaching. Infant Behav. Dev. 32, 44–58. doi: 10.1016/j.infbeh.2008.10.004
Cuijpers, R., Stuijt, F., and Sprinkhuizen-Kuyper, I. (2009). “Generalisation of action sequences in RNNPB networks with mirror properties,” in Proceedings of the European Symposium on Neural Networks (ESANN) (Bruges, Belgium).
Damasio, A. R., and Tranel, D. (1993). Nouns and verbs are retrieved with differently distributed neural systems. Proc. Natl. Acad. Sci. U.S.A. 90, 4957–4960. doi: 10.1073/pnas.90.11.4957
Fields, C. (2011). Trajectory recognition as the basis for object individuation: a functional model of object file instantiation and object-token encoding. Front. Psychol. 2:49. doi: 10.3389/fpsyg.2011.00049
Földiák, P. (1991). Learning invariance from transformation sequences. Neural Comput. 3, 194–200. doi: 10.1162/neco.1991.3.2.194
Gelman, R., and Spelke, E. (1981). “The development of thoughts about animate and inanimate objects: implications for research on social cognition,” in Social Cognitive Development: Frontiers and Possible Futures, eds J. H. Flavell and L. Ross (Cambridge: Cambridge University Press), 43–66.
Gentner, D. (1982). “Why nouns are learned before verbs: linguistic relativity versus natural partitioning,” in Language Development, Vol. 2, ed S. Kuczaj (Hillsdale, NJ: Lawrence Eribaum), 301–334.
Gibson, E. (1988). Exploratory behavior in the development of perceiving, acting, and the acquiring of knowledge. Annu. Rev. Psychol. 39, 1–42. doi: 10.1146/annurev.ps.39.020188.000245
Gruber, T., and Olsen, G. (1994). An ontology for engineering mathematics. Knowl. Represent. Reason. 94, 258–269.
Habel, C., and Tappe, H. (1999). “Processes of segmentation and linearization in describing events,” in Representations and Processes in Language Production, eds C. von Stutterheim and R. Klabunde (Wiesbaden: Deutscher Universitaetsverlag), 43–66.
Hollerbach, J. M. (1982). Computers, brains and the control of movement. Trends Neurosci. 5, 189–192. doi: 10.1016/0166-2236(82)90111-4
Jacobs, R., Jordan, M., and Barto, A. (1991). Task decomposition through competition in a modular connectionist architecture: the what and where vision tasks. Cogn. Sci. 15, 219–250. doi: 10.1207/s15516709cog1502_2
Kawato, M., Kuroda, T., Imamizu, H., Nakano, E., Miyauchi, S., and Yoshioka, T. (2003). Internal forward models in the cerebellum: fMRI study on grip force and load force coupling. Prog. Brain Res. 142, 171–188. doi: 10.1016/S0079-6123(03)42013-X
Kersten, A. W. (1998). An examination of the distinction between nouns and verbs: associations with two different kinds of motion. Mem. Cogn. 26, 1214–1232. doi: 10.3758/BF03201196
Kleesiek, J., Badde, S., Wermter, S., and Engel, A. K. (2013). “Action-driven perception for a humanoid,” in Agents and Artificial Intelligence, eds J. Filipe and A. Fred (Berlin: Springer), 83–99. doi: 10.1007/978-3-642-36907-0_6
LeCun, Y., Bottou, L., Orr, G. B., and Müller, K. (1998). “Efficient backprop,” in Neural Networks: Tricks of the Trade, eds G. B. Orr and K.-R. Müller (Berlin: Springer), 9–50. doi: 10.1007/3-540-49430-8_2
Mandler, J. M. (1992). The foundations of conceptual thought in infancy. Cogn. Dev. 7, 273–285. doi: 10.1016/0885-2014(92)90016-K
Mandler, J. M. (1999). “Preverbal representation and language,” in Language and Space, eds P. Bloom, M. A. Peterson, L. Nadel, M. F. Garrett (Cambridge, MA: The MIT Press), 365.
Mareschal, D., and Johnson, M. H. (2003). The what and where of object representations in infancy. Cognition 88, 259–276. doi: 10.1016/S0010-0277(03)00039-8
Mareschal, D., Plunkett, K., and Harris, P. (1999). A computational and neuropsychological account of object-oriented behaviours in infancy. Dev. Sci. 2, 306–317. doi: 10.1111/1467-7687.00076
Memisevic, R., and Hinton, G. (2007). “Unsupervised learning of image transformations,” in 2007 IEEE Conference on Computer Vision and Pattern Recognition (Minneapolis, MN), 1–8. doi: 10.1109/CVPR.2007.383036
Murata, S., Namikawa, J., Arie, H., Sugano, S., and Tani, J. (2013). Learning to reproduce fluctuating time series by inferring their time-dependent stochastic properties: application in robot learning via tutoring. IEEE Trans. Auton. Ment. Dev. 5, 298–310. doi: 10.1109/TAMD.2013.2258019
Newman, C., Atkinson, J., and Braddick, O. (2001). The development of reaching and looking preferences in infants to objects of different sizes. Dev. Psychol. 37, 561. doi: 10.1037/0012-1649.37.4.561
Ogata, T., Matsumoto, S., Tani, J., Komatani, K., and Okuno, H. (2007). “Human-robot cooperation using quasi-symbols generated by RNNPB model,” in 2007 IEEE International Conference on Robotics and Automation (Roma), 2156–2161. doi: 10.1109/ROBOT.2007.363640
Olshausen, B., Anderson, C., and Van Essen, D. (1993). A neurobiological model of visual attention and invariant pattern recognition based on dynamic routing of information. J. Neurosci. 13, 4700–4719.
Oztop, E., and Arbib, M. (2002). Schema design and implementation of the grasp-related mirror neuron system. Biol. Cybernet. 87, 116–140. doi: 10.1007/s00422-002-0318-1
Oztop, E., Kawato, M., and Arbib, M. (2006). Mirror neurons and imitation: a computationally guided review. Neural Netw. 19, 254–271. doi: 10.1016/j.neunet.2006.02.002
Rocha, N., Silva, F., and Tudella, E. (2006). The impact of object size and rigidity on infant reaching. Infant Behav. Dev. 29, 251–261. doi: 10.1016/j.infbeh.2005.12.007
Romberg, A., and Saffran, J. (2010). Statistical learning and language acquisition. Wiley Interdiscip. Rev. Cogn. Sci. 1, 906–914. doi: 10.1002/wcs.78
Ruff, H. A. (1984). Infants' manipulative exploration of objects: effects of age and object characteristics. Dev. Psychol. 20, 9. doi: 10.1037/0012-1649.20.1.9
Schyns, P. G., and Oliva, A. (1999). Dr. Angry and Mr. Smile: when categorization flexibly modifies the perception of faces in rapid visual presentations. Cognition 69, 243–265. doi: 10.1016/S0010-0277(98)00069-9
Sloutsky, V. M., and Robinson, C. W. (2008). The role of words and sounds in infants' visual processing: from overshadowing to attentional tuning. Cogn. Sci. 32, 342–365. doi: 10.1080/03640210701863495
Smith, L., Jones, S., Landau, B., Gershkoff-Stowe, L., and Samuelson, L. (2002). Object name learning provides on-the-job training for attention. Psychol. Sci. 13, 13–19. doi: 10.1111/1467-9280.00403
Streri, A., Pownall, T., and Kingerlee, S. (1993). Seeing, Reaching, Touching: The Relations Between Vision and Touch in Infancy. Oxford: Harvester Wheatsheaf.
Tani, J., Ito, M., and Sugita, Y. (2004). Self-organization of distributedly represented multiple behavior schemata in a mirror system: reviews of robot experiments using RNNPB. Neural Netw. 17, 1273–1289. doi: 10.1016/j.neunet.2004.05.007
Tardif, T. (1996). Nouns are not always learned before verbs: evidence from mandarin speakers' early vocabularies. Dev. Psychol. 32, 492. doi: 10.1037/0012-1649.32.3.492
Tomasello, M., and Farrar, M. J. (1986). Object permanence and relational words: a lexical training study. J. Child Lang. 13, 495–505. doi: 10.1017/S030500090000684X
Von Hofsten, C. (1982). Eye–hand coordination in the newborn. Dev. Psychol. 18, 450. doi: 10.1037/0012-1649.18.3.450
von Stutterheim, C., and Nuse, R. (2003). Processes of conceptualization in language production: language-specific perspectives and event construal. Linguistics 41, 851–882. doi: 10.1515/ling.2003.028
Wiskott, L., and Sejnowski, T. (2002). Slow feature analysis: unsupervised learning of invariances. Neural Comput. 14, 715–770. doi: 10.1162/089976602317318938
Wolpert, D., Ghahramani, Z., and Jordan, M. I. (1995). An internal model for sensorimotor integration. Science 269, 1880–1882. doi: 10.1126/science.7569931
Yamashita, Y., and Tani, J. (2008). Emergence of functional hierarchy in a multiple timescale neural network model: a humanoid robot experiment. PLoS Comput. Biol. 4:e1000220. doi: 10.1371/journal.pcbi.1000220
Yu, C. (2008). A statistical associative account of vocabulary growth in early word learning. Lang. Learn. Dev. 4, 32–62. doi: 10.1080/15475440701739353
Zhong, J., Weber, C., and Wermter, S. (2012a). “Learning features and predictive transformation encoding based on a horizontal product model,” in Artificial Neural Networks and Machine Learning, ICANN, eds A. E. P. Villa, W. Duch, P. Érdi, F. Masulli, and G. Palm (Berlin: Springer), 539–546.
Keywords: pre-symbolic communication, sensorimotor integration, recurrent neural networks, parametric biases, horizontal product
Citation: Zhong J, Cangelosi A and Wermter S (2014) Toward a self-organizing pre-symbolic neural model representing sensorimotor primitives. Front. Behav. Neurosci. 8:22. doi: 10.3389/fnbeh.2014.00022
Received: 15 July 2013; Accepted: 14 January 2014;
Published online: 04 February 2014.
Edited by:
Leonid Perlovsky, Harvard University and Air Force Research Laboratory, USAReviewed by:
Matthew Schlesinger, Southern Illinois University, USAStefano Nolfi, Institute of Cognitive Sciences and Technologies CNR, Italy
Copyright © 2014 Zhong, Cangelosi and Wermter. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Junpei Zhong, Department of Computer Science, Knowledge Technology, University of Hamburg, Vogt-Kölln-Straße 30, 22527 Hamburg, Germany e-mail:emhvbmdAaW5mb3JtYXRpay51bmktaGFtYnVyZy5kZQ==