 Christina Hastings Blow
Christina Hastings Blow Lijun Qian
Lijun Qian Camille Gibson2
Camille Gibson2 Pamela Obiomon
Pamela Obiomon
95% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell. , 19 March 2025
Sec. Machine Learning and Artificial Intelligence
Volume 8 - 2025 | https://doi.org/10.3389/frai.2025.1530397
Introduction: AI fairness seeks to improve the transparency and explainability of AI systems by ensuring that their outcomes genuinely reflect the best interests of users. Data augmentation, which involves generating synthetic data from existing datasets, has gained significant attention as a solution to data scarcity. In particular, diffusion models have become a powerful technique for generating synthetic data, especially in fields like computer vision.
Methods: This paper explores the potential of diffusion models to generate synthetic tabular data to improve AI fairness. The Tabular Denoising Diffusion Probabilistic Model (Tab-DDPM), a diffusion model adaptable to any tabular dataset and capable of handling various feature types, was utilized with different amounts of generated data for data augmentation. Additionally, reweighting samples from AIF360 was employed to further enhance AI fairness. Five traditional machine learning models—Decision Tree (DT), Gaussian Naive Bayes (GNB), K-Nearest Neighbors (KNN), Logistic Regression (LR), and Random Forest (RF)—were used to validate the proposed approach.
Results and discussion: Experimental results demonstrate that the synthetic data generated by Tab-DDPM improves fairness in binary classification.
In our rapidly evolving society, artificial intelligence (AI) has become a ubiquitous presence, influencing everyday activities like online banking and digital assistants. However, how can we ensure the fairness of AI-generated outcomes? AI fairness seeks to enhance the transparency and explainability of AI systems (Li et al., 2023a). It scrutinizes the results to determine if they genuinely consider the users' best interests. Additionally, guidelines are being established to ensure the safety of both corporations and consumers. Various fairness tools have been developed to address the growing need to mitigate AI biases (Richardson and Gilbert, 2021). For example, AIF360 (Bellamy et al., 2019) offers a comprehensive set of fairness metrics for datasets and models, explanations for these metrics, and algorithms to reduce bias in datasets and models concerning protected attributes such as sex and race.
Data augmentation (Ding et al., 2019) aims to generate synthetic data from existing datasets to enlarge the training data to enhance the machine learning performance (Bansal et al., 2022). This technique increases both the quantity and variety of data available for training and testing models, eliminating the need for new data collection. Data augmentation can be achieved by either learning a generator, such as through GAN networks (Alqahtani et al., 2021), to create data from scratch, or by learning a set of transformations to apply to existing training set samples (Cubuk et al., 2019). Both approaches enhance the performance of deep learning models by providing a more diverse and abundant dataset.
In recent years, diffusion models (Yang et al., 2023) have emerged as a powerful technique for generating synthetic data to address data scarcity. For example, Villaizán-Vallelado et al. (2024) proposed a diffusion model for generating synthetic tabular data with three key enhancements: a conditioning attention mechanism, an encoder-decoder transformer as the denoising network, and dynamic masking. Nguyen et al. (2024) introduced a novel method for generating pixel-level semantic segmentation labels using the text-to-image generative model Stable Diffusion (SD), which incorporates uncertainty regions into the segmentation to account for imperfections in the pseudo-labels. Additionally, Hu et al. (2024) developed a novel diffusion GNN model called Syngand, capable of generating ligand and pharmacokinetic data end-to-end, providing a methodology for sampling pharmacokinetic data for existing ligands using this model.
In the context of tabular data augmentation (Cui et al., 2024), GANs (Goodfellow et al., 2020), and Variational Autoencoders (VAEs) (Kingma et al., 2019) offer distinct methodologies. GANs excel at capturing complex data distributions, making them highly effective for generating realistic tabular data. However, their training process is often unstable due to the adversarial setup, requiring meticulous tuning. In contrast, VAEs provide stable training through their probabilistic framework and are adept at learning latent representations, enabling data interpolation and exploration. Despite these advantages, VAEs tend to generate less sharp or realistic data compared to GANs, and balancing reconstruction loss with regularization remains a challenge. Diffusion models, compared to GANs and VAEs, present a promising alternative. They leverage a robust theoretical foundation for stable training to deliver high-quality generated data, addressing some of the limitations of GANs and VAEs. However, this advantage comes at the cost of higher computational requirements. Therefore, this study utilized diffusion model-based methods for tabular data augmentation to investigate enhancements in AI fairness.
This paper aims to investigate whether diffusion models can generate synthetic data to enhance AI fairness as well as machine learning performance. Tabular Denoising Diffusion Probabilistic Model (TabDDPM) (Kotelnikov et al., 2023) is a diffusion model that can be universally applied to any tabular dataset, handling all feature types. It uses multinomial diffusion for categorical and binary features, and Gaussian diffusion for numerical ones. Tab-DDPM effectively manages mixed data types and consistently generates high-quality synthetic data. It is used to conduct different increments of generated data samples, specifically 20,000, 100,000, and 150,000 samples. To further mitigate bias, reweighting samples was employed to recalibrate the data. This involves adjusting the significance or contribution of individual samples within the training dataset, making it possible to remove discrimination concerning sensitive attributes without altering existing labels (Calders et al., 2009). We used techniques from AIF360 (Bellamy et al., 2019) to determine these weights, based on the frequency counts associated with the sensitive attribute. To validate the proposed method, five traditional machine learning models were applied: Decision Tree (DT), Gaussian Naive Bayes (GNB), K Nearest Neighbor (KNN), Logistic Regression (LR), and Random Forest (RF). Experimental results indicate that the synthetic data generated by Tab-DDPM enhances the fairness of binary classification. For instance, both RF performance in binary classification and fairness evaluated by five evaluation metrics has been improved when enlarging the training data with the generated data.
The contributions of this paper can be summarized as:
1. Introduction of generative AI techniques for generating synthetic data to enhance AI fairness as well as machine learning performance.
2. Extensive experiments demonstrating that the fairness of different machine learning models can be improved with respect to various protected attributes.
This paper aims to examine the effectiveness of Tab-DDPM and sample reweighting in enhancing the fairness of traditional machine learning algorithms on classification tasks, focusing on two key AI techniques: diffusion models and sample reweighting.
TabDDPM (Kotelnikov et al., 2023) is a generative model for tabular data, an area of active research. Tabular datasets are often limited in size due to privacy concerns during data collection. Generative AI, like Tab-DDPM, can create new synthetic data without these privacy issues. It is a newly developed model capable of effectively generating new data from tabular datasets. In detail, the DDPM process consists of three main components: the forward process, the backward process, and the sampling procedure (Chang et al., 2023). The forward process adds noise to the training data. The reverse process trains denoising networks to iteratively remove noise, differing from generative adversarial networks (GANs) by removing noise over two timesteps instead of one. The sampling procedure uses the optimized denoising network to generate novel data. It uses a Gaussian diffusion model for numerical data and a Multinomial diffusion model for categorical and binary features. Hyperparameters play a crucial role in TabDDPM, significantly influencing the model's effectiveness. The general framework of TabDDPM is shown as Figure 1.
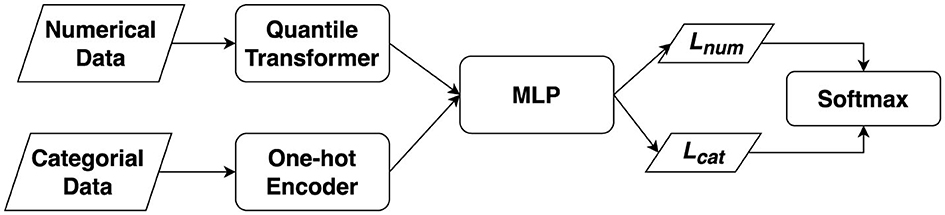
Figure 1. Tab-DDPM framework.
The numerical and categorical data were represented through two branches: quantile transformer for numerical data and one-hot encoding for categorical data. These new data representations were then fed into a DDPM process utilizing multilayer perceptrons (MLP) to minimize two types of losses Lnum and Lcat using softmax function.
Reweighting samples is a preprocessing technique that adjusts the significance or contribution of samples within a training dataset. Weights are strategically assigned making it possible to render datasets free from discrimination pertaining to sensitive attributes without altering existing labels. One such approach is by based on the frequency counts associated with the sensitive attribute (Calders et al., 2009).
This paper utilized the reweighting sample technique from the AIF360 toolbox for reweighting during the preprocessing phase. The contribution of the reweighting process comprises the training dataset with generated data of different increments with these samples containing attributes (including a sensitive attribute) and labels along with the specification of the sensitive attribute. The result being a transformed dataset where sample weights are adjusted for the sensitive attributes, mitigating potential classification bias. Throughout the reweighting process, an analysis of the allocation of the sensitive attributes within various groups is conducted. This analysis informs the calculation of reweighting coefficients, which, in turn, amends the sample weights to encourage a more uniform distribution across groups (Blow et al., 2024). For instance, given a sensitive (protected) attribute, the privileged group of these samples includes the samples with the positive sensitive attribute while the unprivileged group of samples includes the samples with the negative sensitive attribute.
The flow of the proposed method is depicted in Figure 2. The process begins with the random sampling of data, which serves as input to TabDDPM to generate synthetic tabular data. This synthetic data is then combined with the original training data to create a comprehensive dataset for training the ML model. In addition, reweighting samples from AIF360 is employ to adjust weights of different categories of samples to enhance fairness. Finally, the trained ML model is evaluated using test data, with performance assessed through multiple evaluation metrics, including various fairness metrics.
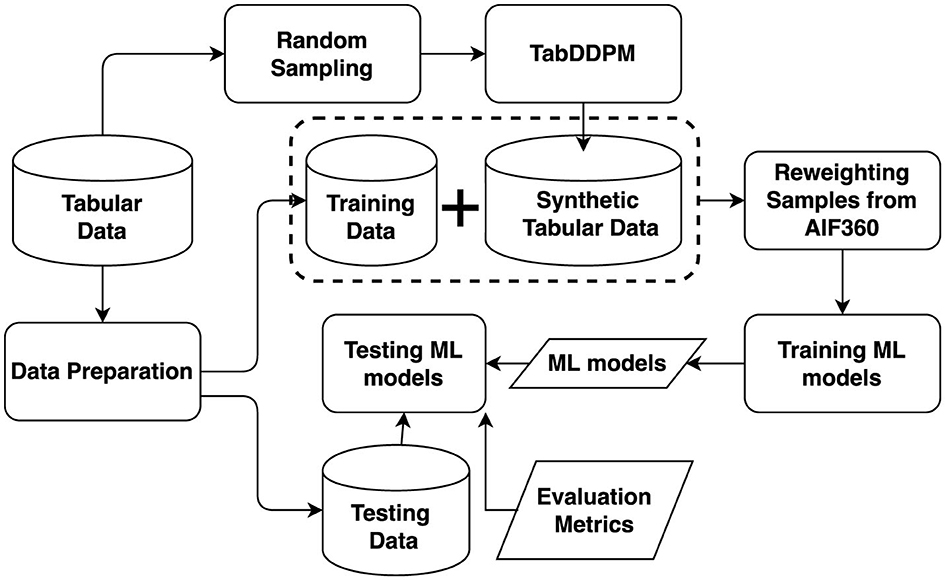
Figure 2. Flow of the proposed method.
TabDDPM processes numerical and categorical features using Gaussian diffusion and Multinomial diffusion, respectively. For instance, a tabular data sample x = < xnum1, ..., xnumN, xc1, ..., xcN> consists of numN numerical features and cN categorical features. Specifically, TabDDPM applies a Gaussian quantile transformation to process each categorical feature through a separate forward diffusion process, where noise components for all features are sampled independently. The reverse diffusion step in TabDDPM is executed by a multi-layer neural network, which produces an output with the same dimensionality as the input.
Reweighting samples involves adjusting the weights of four categories: wpp (weight of positive privileged samples), wpup (weight of positive unprivileged samples), wnp (weight of negative privileged samples), and wnup (weight of negative unprivileged samples), as outlined below.
where
Np: the number of samples in the privileged group.
Npp: the number of samples with the positive class in the privileged group.
Nnp: the number of samples with the negative class in the privileged group.
Nup: the number of samples in the unprivileged group.
Npup: the number of samples with the positive class in the unprivileged group.
Nnup: the number of samples with the negative class in the unprivileged group.
Npos: the number of samples with the positive class.
Nneg: the number of samples with the negative class.
Ntotal: the number of samples.
This study utilized the Adult Income and the COMPAS datasets and applied TabDDPM to generate new synthetic data, aiming to assess the combined effectiveness of data augmentation and sample reweighting in mitigating fairness issues.
Adult income dataset: The dataset consists of 48, 842 samples with 14 attributes, designed to predict whether an individual's income exceeds $50K/year based on census data (Becker and Kohavi, 1996). It was divided into training (28, 048 samples), testing (16, 281 samples), and validation (6, 513 samples) sets. The attributes were categorized into 8 categorical and 6 numerical features.
COMPAS dataset: The dataset consists of 7, 214 samples with 53 attributes, 18 attributes were used for generating data, which was used to determine whether a person would recidivate after two years. It was divided into training (4, 311 samples), testing (1, 724 samples), and validation (1, 150 samples) sets. The attributes were categorized into 211 categorical and 13 numerical features.
Synthetic dataset: TabDDPM was employed to generate synthetic samples to implement data augmentation, enhancing both AI fairness and classification performance. Synthetic data was added the Adult Income training set in sample sizes of 20, 000, 100, 000, and 150, 000. Similarly, synthetic data was added the COMPAS training set in sample sizes 2, 500, 8, 000, and 12, 000. As show in Figure 3, the distributions of synthetic data closely resemble the original data across sample sizes. Furthermore, the synthetic data is free of missing values, improving overall data quality. These observations suggest that synthetic data is a promising way for data augmentation, particularly in terms of maintaining data quality.
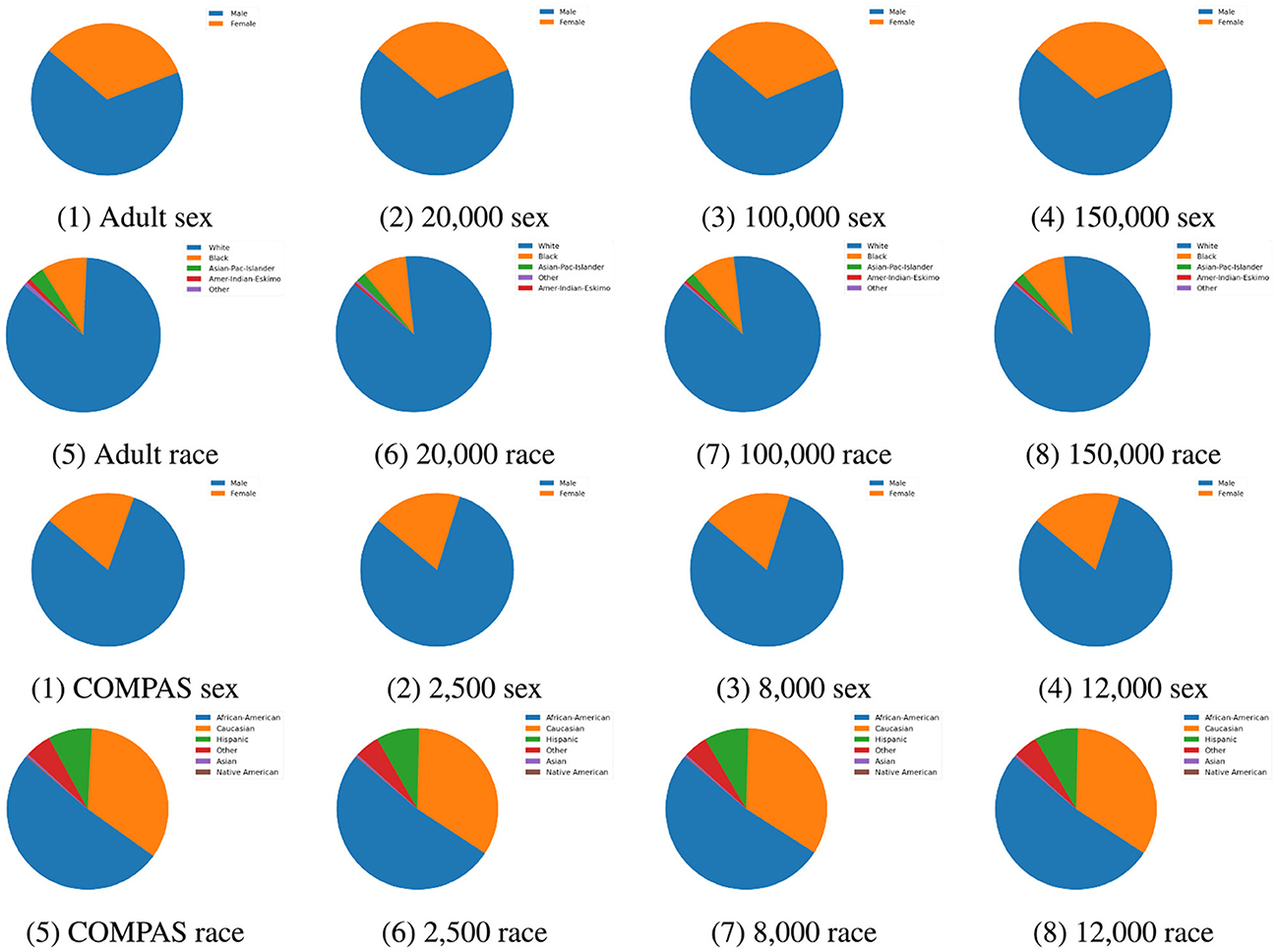
Figure 3. Attribute distribution comparison between original data and synthetic data for Adult Income and COMPAS datasets. The attributes sex and race for both datasets were compared.
This paper utilized five evaluation metrics to determine the effectiveness of reweighting samples for mitigating bias.
Disparate Impact (DI) refers to the unintentional bias that can occur when predictions result in varying error rates or outcomes across different demographic groups, where certain attributes like race, sex, religion, and age are considered protected. This bias may arise from training models on biased data or from the model itself being discriminatory. In this study, Disparate Impact is defined as the differential effects on prediction outcomes.
where ppup presents the prediction probability for unprivileged samples with positive predictions, while ppp denotes the prediction probability for privileged samples with positive predictions. A disparate impact value approaching 0 indicates bias in favor of the privileged group, while a value >1 indicates bias in favor of the unprivileged group. A value of 1 reflects perfect fairness in the predictions (Feldman et al., 2015).
Average odds difference (AOD) measures the average difference in false positive rates (FPR) and true positive rates (TPR) between unprivileged and privileged groups. It is calculated as:
where FPRup and FPRp represent the False Positive Rates for unprivileged and privileged samples, respectively, while TPRup and TPRp represent the True Positive Rates for unprivileged and privileged samples. An AOD value of 0 indicates perfect fairness. A positive AOD suggests bias in favor of the unprivileged group, while a negative AOD indicates bias in favor of the privileged group.
Statistical parity difference (SPD) is to calculate the difference between the ratio of favorable outcomes in unprivileged and privileged groups. It is defined by
A score below 0 suggests benefits for the unprivileged group, while a score above 0 implies benefits for the privileged group. A score of 0 indicates that both groups receive equal benefits.
Equal opportunity difference (EOD) assesses whether all groups have an equal chance of benefiting from predictions. EOD focuses on the True Positive Rate (TPR), which reflects the model's ability to correctly identify positives in both unprivileged and privileged groups. It is defined as follows:
A value of 0 signifies perfect fairness. A positive value indicates bias in favor of the unprivileged group, while a negative value indicates bias in favor of the privileged group.
Theil index (TI) is also called the entropy index which measures both the group and individual fairness. It is defined by
where and μ is the average of bi. A lower absolute value of TI value in this context would indicate a more equitable distribution of classification outcomes, while a higher absolute value suggests greater disparity.
Table 1 presents the fairness ranges and levels of various evaluation metrics. If the values of evaluation metrics fall into these ranges, it indicates that the machine learning models perform classification without bias. For the DI, the commonly accepted fairness range is [0.8, 1.25]. If the selection rate for the protected group is at least 80% of the selection rate for the unprotected group, the disparity is generally considered fair. Conversely, a DI >1.25 indicates a reverse disparity, potentially disadvantaging the unprotected group. For AOD, the range is the same as that of SPD and EOD. AOD = 0 signifies no difference in TPR (True Positive Rate) or FPR (False Positive Rate) between groups, indicating perfect fairness. The acceptable fairness range for AOD is typically [−0.1, 0.1], where AOD >0.1 indicates bias in favor of the protected group. AOD < −0.1 indicates bias in favor of the unprotected group. For the TI, higher values indicate greater unfairness, while TI = 0 represents perfect fairness.
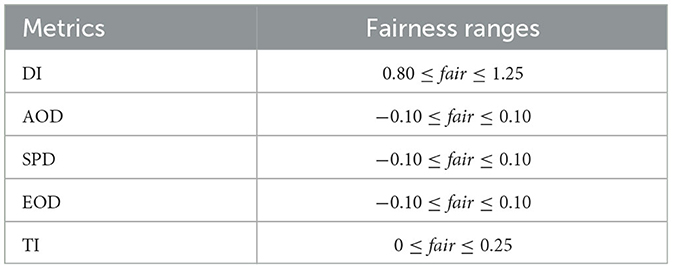
Table 1. Fairness ranges of various evaluation metrics.
To comprehensively validate the proposed method, we conduct extensive experiments in that regard of two protect attributes, namely Race and Sex, to examine the effectiveness of bias mitigation.
Race: Table 2 presents a performance comparison across all outputs before reweighting samples, using one classification metric, BA, and five fairness metrics–SPD, AOD, DI, EOD, and TI–on the Adult Income dataset, focusing on the protected attribute of Race. Generally, before reweighting samples to mitigate bias, augmenting the training data does not appear to effectively reduce bias. For example, the SPD value for GNB increases with the addition of synthetic samples, indicating that synthetic data may actually exacerbate bias. Additionally, the performance of LR in terms of classification and bias mitigation remains relatively unchanged, as reflected in the BA, AOD, and TI values. However, it is observed that the fairness of KNN is improved regarding the changes of values of PSD, AOD, DI, EOD, and TI.
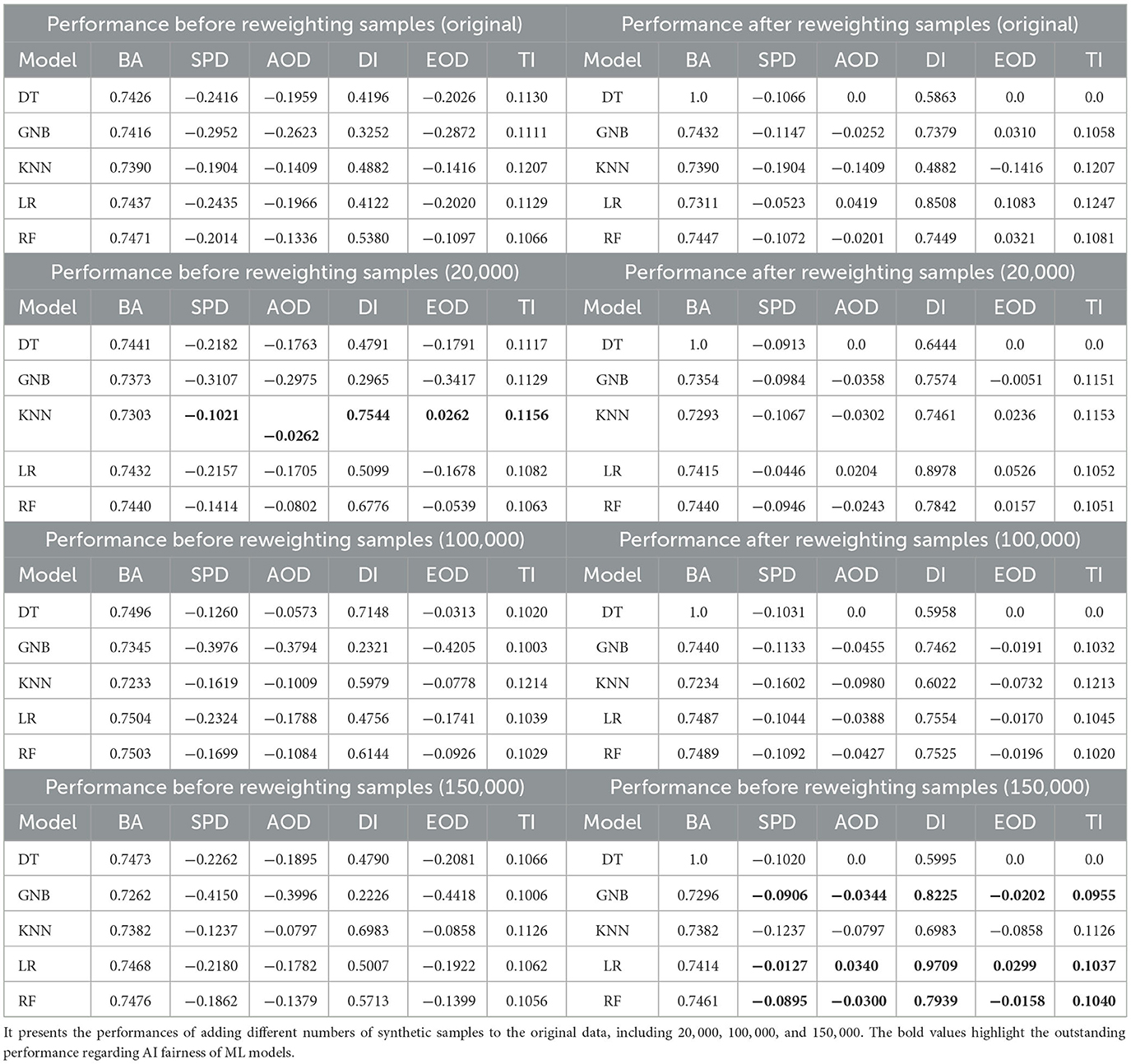
Table 2. Performance comparison between all outputs before and after reweighting through one classification metric BA and fairness metrics including SPD, AOD, DI, EOD, and TI on Adult income dataset regarding the protected attribute Race.
On the other hand, after reweighting the samples, bias is mitigated for most ML models, as indicated by improvements in SPD, AOD, and TI values. For instance, the bias in LR significantly decreases across all fairness metrics–SPD, AOD, DI, EOD, and TI. Similar trends are observed for other models like DT, GNB, and RF. Moreover, when more synthetic samples are added to the original training data, bias is further reduced, particularly in the case of the (150, 000) sample size, as shown in the improved performance of LR and RF.
Sex: Table 3 presents a performance comparison of all outputs before reweighting samples, using one classification metric (BA) and five fairness metrics (SPD, AOD, DI, EOD, and TI) on the Adult Income dataset, focusing on the protected attribute Sex. Before reweighting samples to address bias, similar patterns are observed: augmenting the training data does not effectively reduce bias, as shown consistently across ML models like KNN and LR, particularly in fairness metrics such as SPD and AOD for the cases of the (150, 000) sample size.
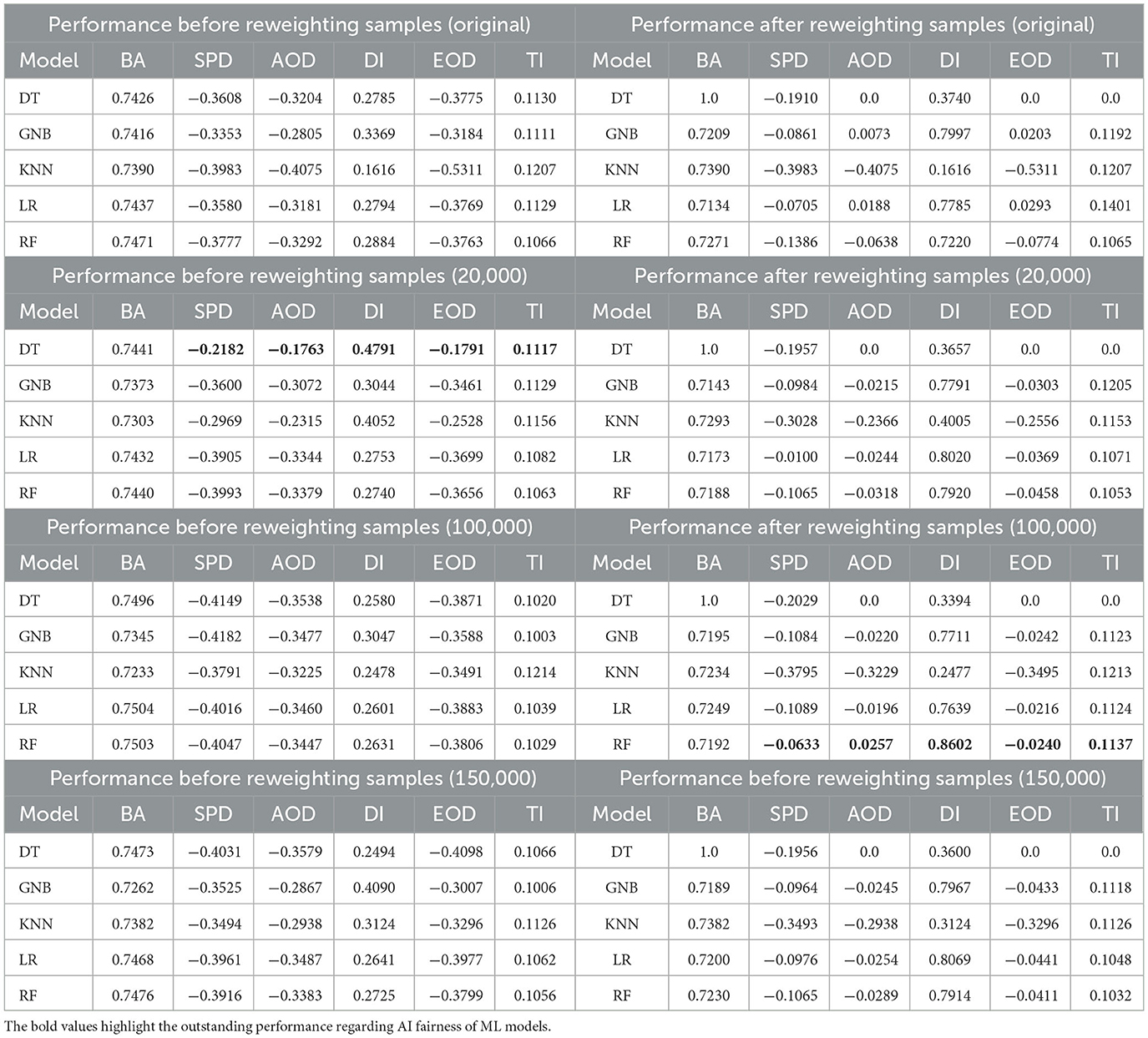
Table 3. Performance comparison between all outputs before and after reweighting through one classification metric BA and fairness metrics including SPD, AOD, DI, EOD, and TI on Adult income dataset regarding the protected attribute Sex.
However, after reweighting the samples, bias is reduced in most ML models, as indicated by improvements in SPD, AOD, and TI. For example, significant bias reductions are observed across all fairness metrics–SPD, AOD, DI, EOD, and TI–for models like LR, GNB, DT, and RF. Moreover, when additional synthetic samples are added to the original training data, bias is further mitigated, particularly in the case of GNB at the (150, 000) sample size.
Furthermore, to address the trade-off between BA and fairness metrics such as DI, AOD, SPD, EOD, and TI, we introduce the composite score defined below,
where the weights wBA, wSPD, wAOD, wEOD, wTI, and wDI are adjusted depending on the scenario. In this study, we set wBA = 0.5, while the other weights are equally set to 0.1. Additionally, all metric values are normalized, and a higher ScoreCS indicates better model performance. Figure 4 illustrates an example of navigating the trade-off by calculating the composite score across all models. Figures 4A, B are based on the results of performance before reweighting samples (20,000) and after reweighting samples (100,000) for the protected attribute Race. Similarly, Figures 4C, D are based on the results of performance before reweighting samples (20,000) and after reweighting samples (150,000) for the protected attribute Race. The results reveal that for the protected attribute Race, RF and LR generally outperformed other models in terms of ScoreCS, as shown in Figures 4A, B, respectively. In the case of the protected attribute Sex, DT demonstrated better performance compared to the other models.
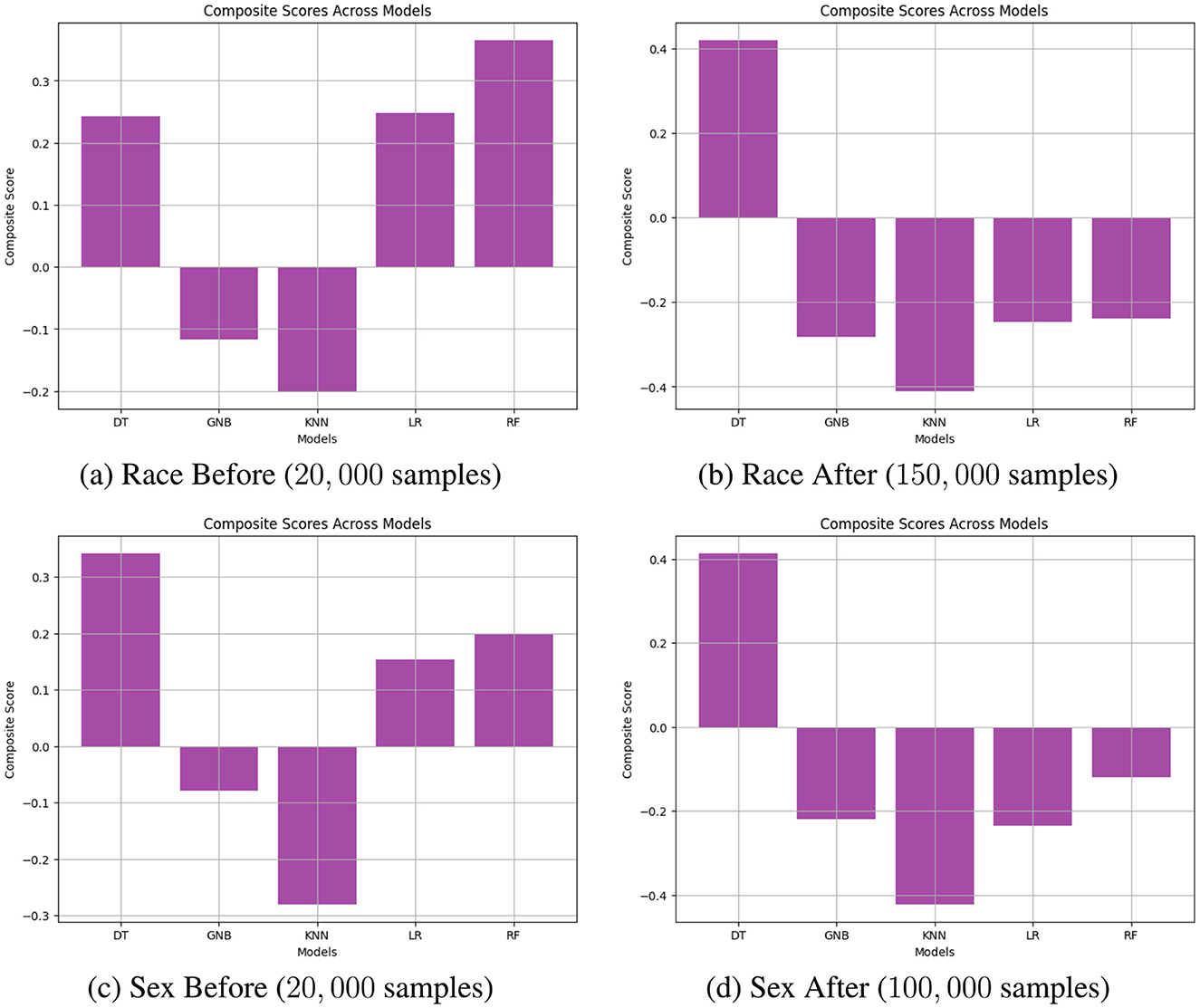
Figure 4. Navigating trade-off between BA and fairness metrics on Adult Income datasets including DI, AOD, SPD, EOD, and TI across all models through calculating composite scores. (A) Race Before (20, 000 samples). (B) Race After (150, 000 samples). (C) Sex Before (20, 000 samples). (D) Sex After (100, 000 samples).
Finally, Figures 5, 6 illustrate the impact of synthetic data on model fairness and accuracy by comparing the performance of models trained on the original data to those trained on augmented datasets incorporating synthetic samples. In Figures 5A, C show performance comparisons between the original training data and the augmented data (with 150, 000 synthetic samples) before reweighting. The results reveal that adding 150, 000 synthetic samples improves the stability of LR fairness, particularly evident in the stable AOD values near the optimal trade-off point, marked by the green box in Figure 5B. Notably, this augmentation does not significantly affect BA values.
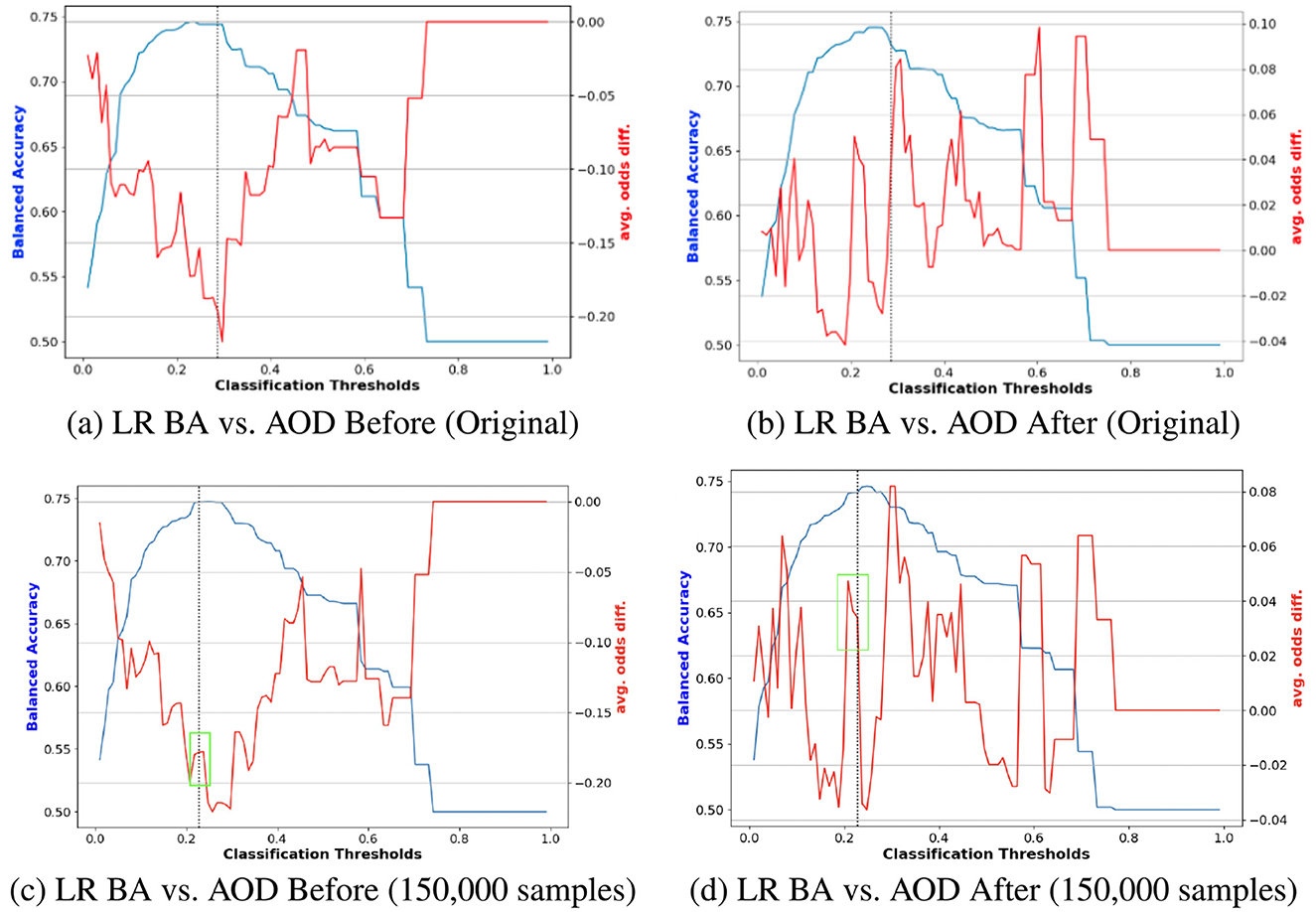
Figure 5. Performance comparison of BA and AOD in augmenting training data with 150, 000 synthetic samples on the Adult Income dataset, considering the protected attribute Race for LR. Subfigures (A) and (C) illustrate the performance comparison between the original training data and the augmented training data (with 150, 000 synthetic samples) before reweighting the samples. In contrast, Subfigures (B) and (D) present the comparison after reweighting the samples. (A) LR BA vs. AOD Before (Original). (B) LR BA vs. AOD After (Original). (C) LR BA vs. AOD Before (150,000 samples). (D) LR BA vs. AOD After (150,000 samples).
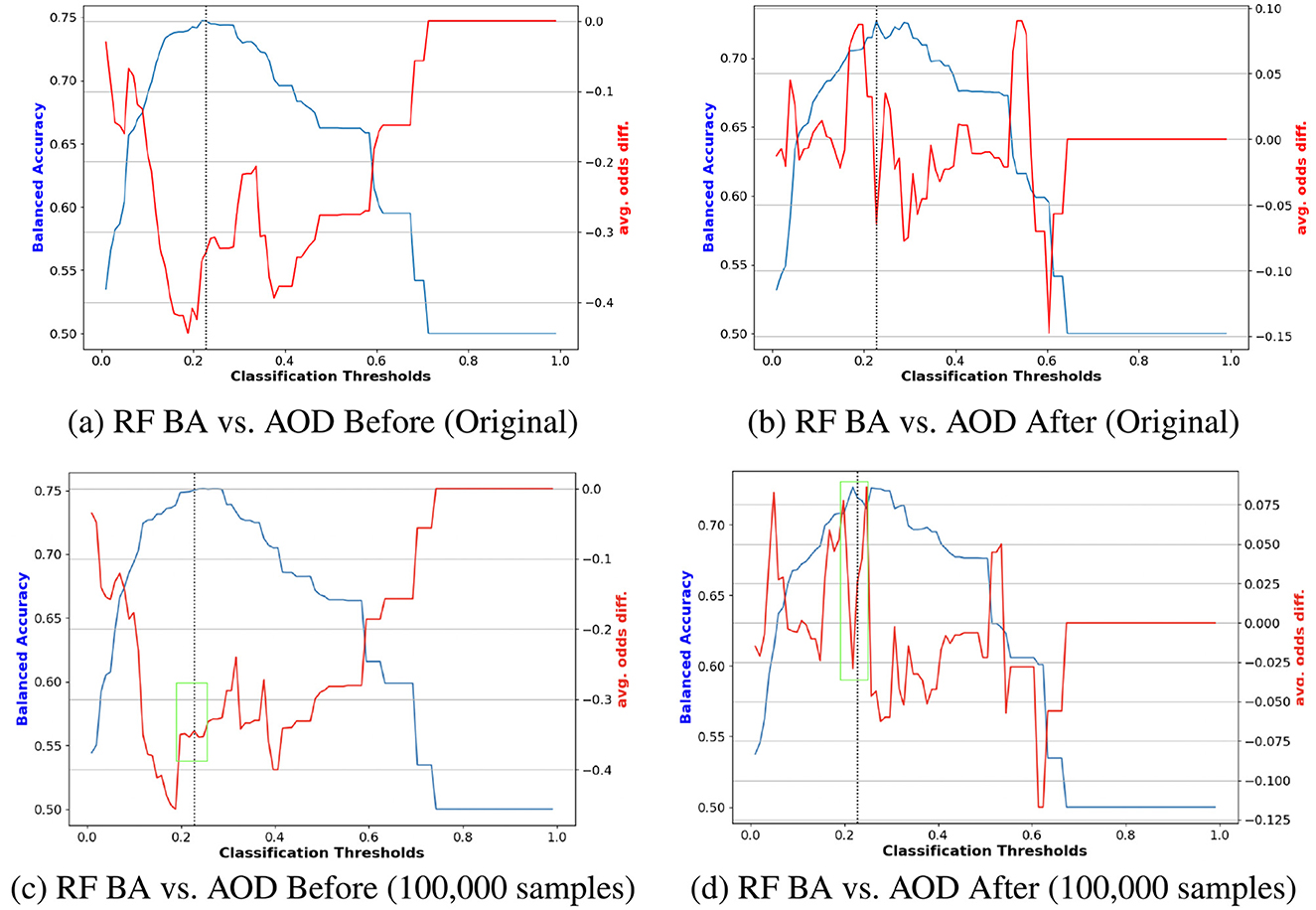
Figure 6. Performance comparison of BA and AOD in augmenting training data with 100, 000 synthetic samples on the Adult Income dataset, considering the protected attribute Sex for RF. Subfigures (A) and (C) illustrate the performance comparison between the original training data and the augmented training data (with 100, 000 synthetic samples) before reweighting the samples. In contrast, Subfigures (B) and (D) present the comparison after reweighting the samples. (A) RF BA vs. AOD Before (Original). (B) RF BA vs. AOD After (Original). (C) RF BA vs. AOD Before (100,000 samples). (D) RF BA vs. AOD After (100,000 samples).
Conversely, Figures 5B, D demonstrate the effects of reweighting on the augmented training data. Reweighting further emphasizes the benefits of synthetic augmentation by narrowing the range of absolute AOD values from [–0.25, 0] to [–0.04, 0.08]. Near the optimal trade-off point highlighted in the green box of Figures 5D, the augmented data exhibits greater stability, as evidenced by the less pronounced changes in AOD values.
A similar trend is observed in Figure 6. Figures 6A, C compare the original data and the augmented data (with 100, 000 synthetic samples) before reweighting. The stable AOD values in the green box of Figure 6C suggest that the augmented data enhances fairness stability for RF. Figures 6B, D reveal that reweighting further improves fairness, as indicated by the reduced range of absolute AOD values, reinforcing the notion that combining reweighting with data augmentation effectively enhances model fairness.
Race: Table 4 presents a performance comparison on the COMPAS dataset, focusing on the protected attribute Race. Prior to reweighting, adding 12, 000 synthetic samples to the training set significantly enhanced the fairness of RF in terms of fairness metrics such as SPD and DI, albeit at the cost of BA performance. After reweighting, the inclusion of synthetic samples further improved the fairness of multiple models in the training dataset.
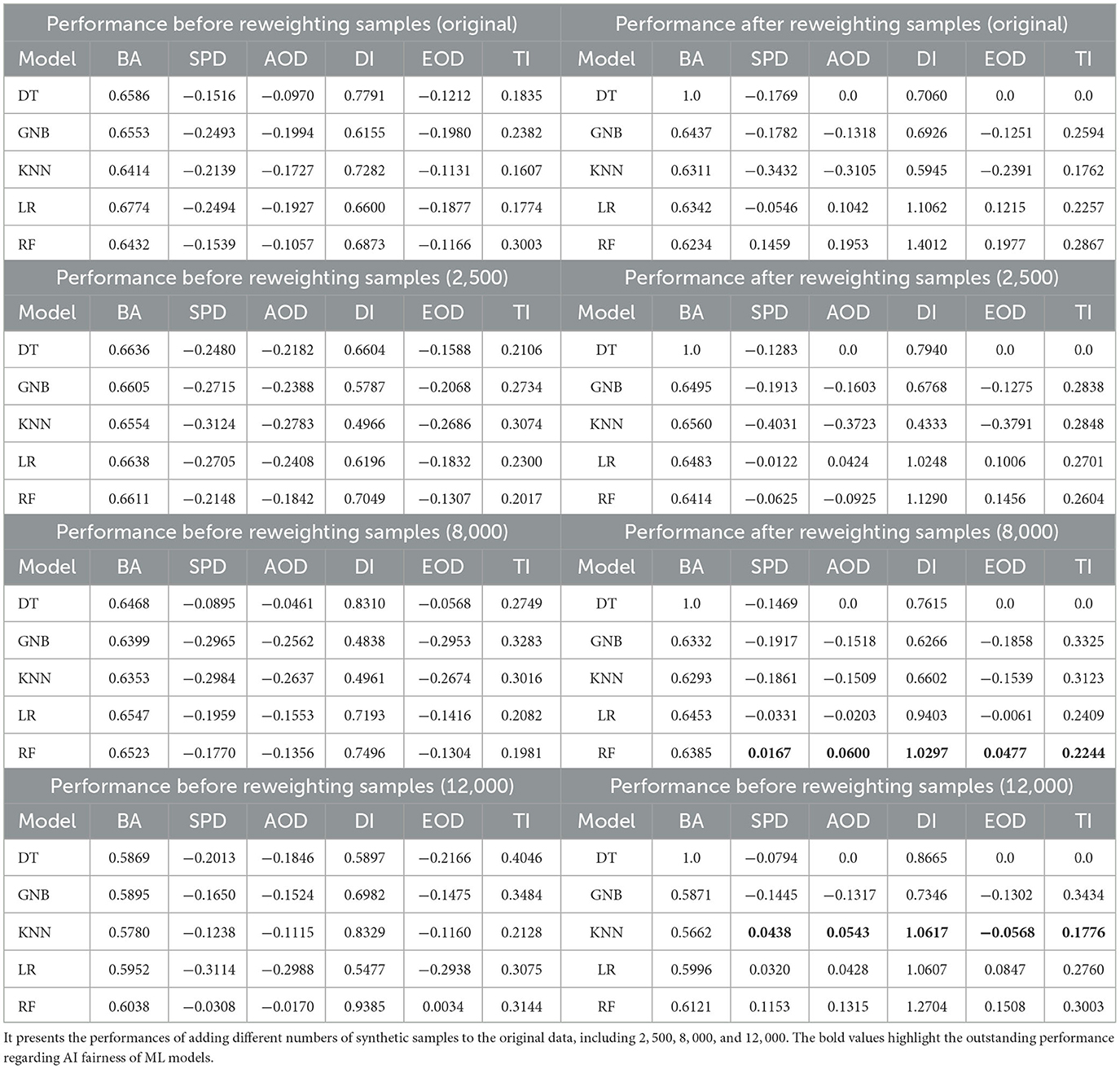
Table 4. Performance comparison between all outputs before and after reweighting through one classification metric BA and fairness metrics including SPD, AOD, DI, EOD, and TI on COMPAS dataset regarding the protected attribute Race.
Sex: Table 5 presents a performance comparison on the COMPAS dataset, focusing on the protected attribute Sex. Adding synthetic samples to the training set alone does not appear to improve model fairness. However, combining reweighting with synthetic sample augmentation proves effective in enhancing fairness.
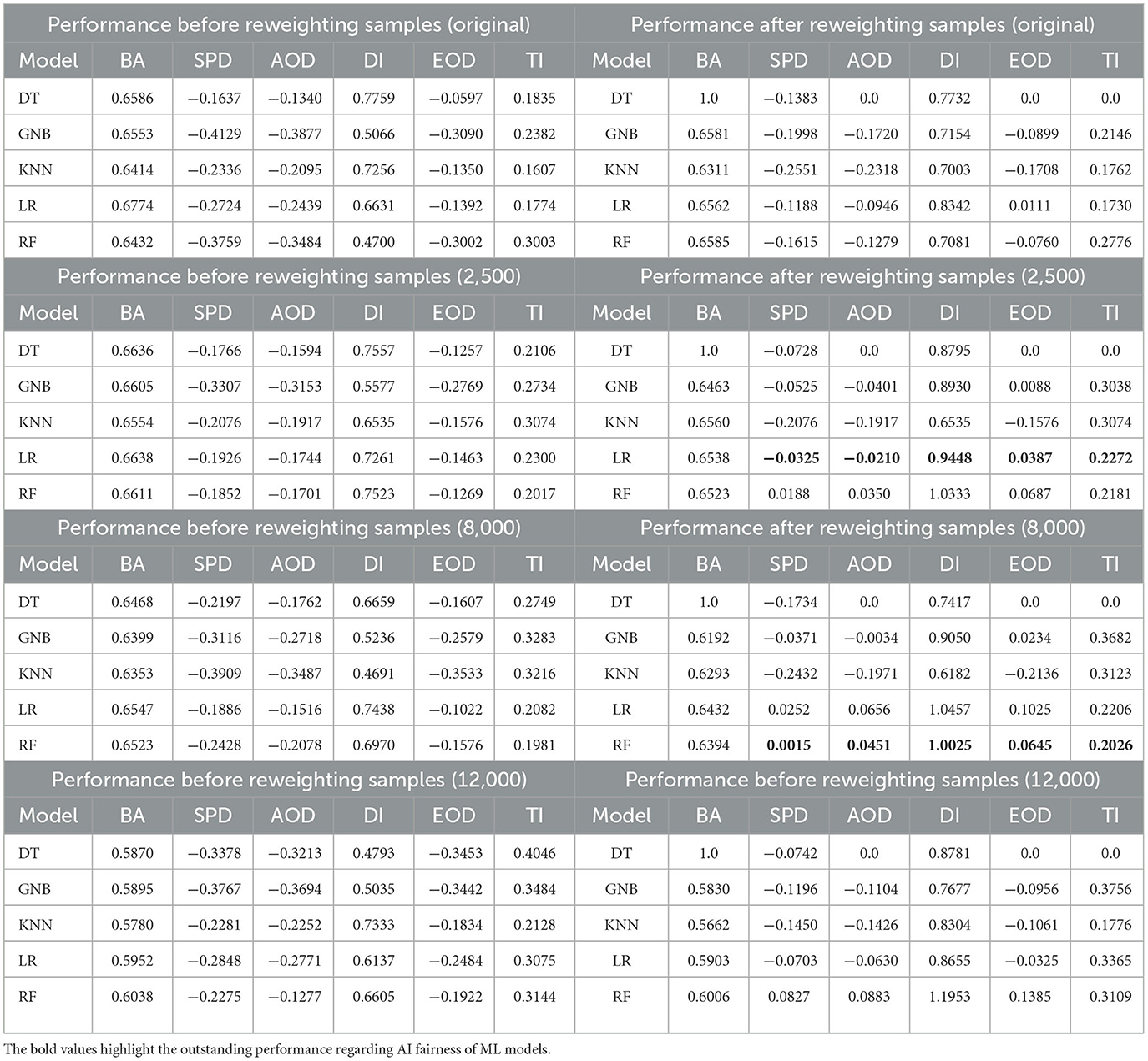
Table 5. Performance comparison between all outputs before and after reweighting through one classification metric BA and fairness metrics including SPD, AOD, DI, EOD and TI on COMPAS dataset regarding the protected attribute Sex.
Figure 7 illustrates an example of navigating the trade-off by computing the composite score across all models. Figures 7A, B depict performance results for the protected attribute Race before reweighting with 12,000 samples and after reweighting with 8,000 samples, respectively. Similarly, Figures 7C, D present results before reweighting with 8,000 samples and after reweighting with 80,000 samples for Race. The findings indicate that, prior to reweighting, RF outperformed other models, whereas DT achieved the highest ScoreCS after reweighting, as shown in Figures 7A, B. For the protected attribute Sex, LR exhibited superior performance before reweighting, while DT performed best after reweighting.
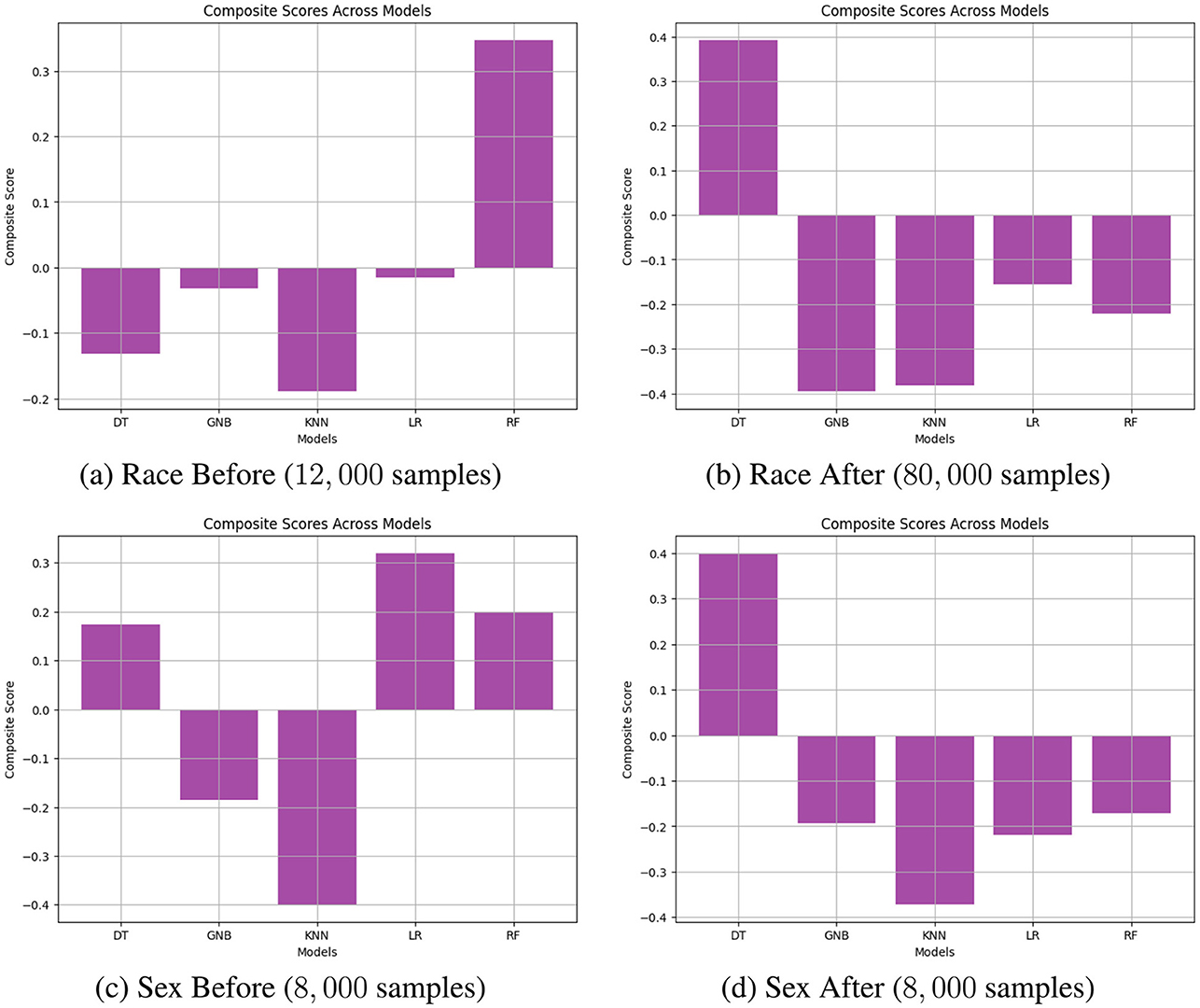
Figure 7. Navigating trade-off between BA and fairness metrics on COMPAS datasets including DI, AOD, SPD, EOD, and TI across all models through calculating composite scores. (A) Race Before (12, 000 samples). (B) Race After (80, 000 samples). (C) Sex Before (8, 000 samples). (D) Sex After (8, 000 samples).
Figures 8, 9 compare the original outputs for RF vs the data augmented outputs for 8, 000 for race and sex. Reweighting samples further amplifies the benefits of synthetic augmentation by reducing the variability in fairness metric values. Near the optimal trade-off point, highlighted in the green box, the augmented data demonstrates greater stability, as reflected in the smaller fluctuations.
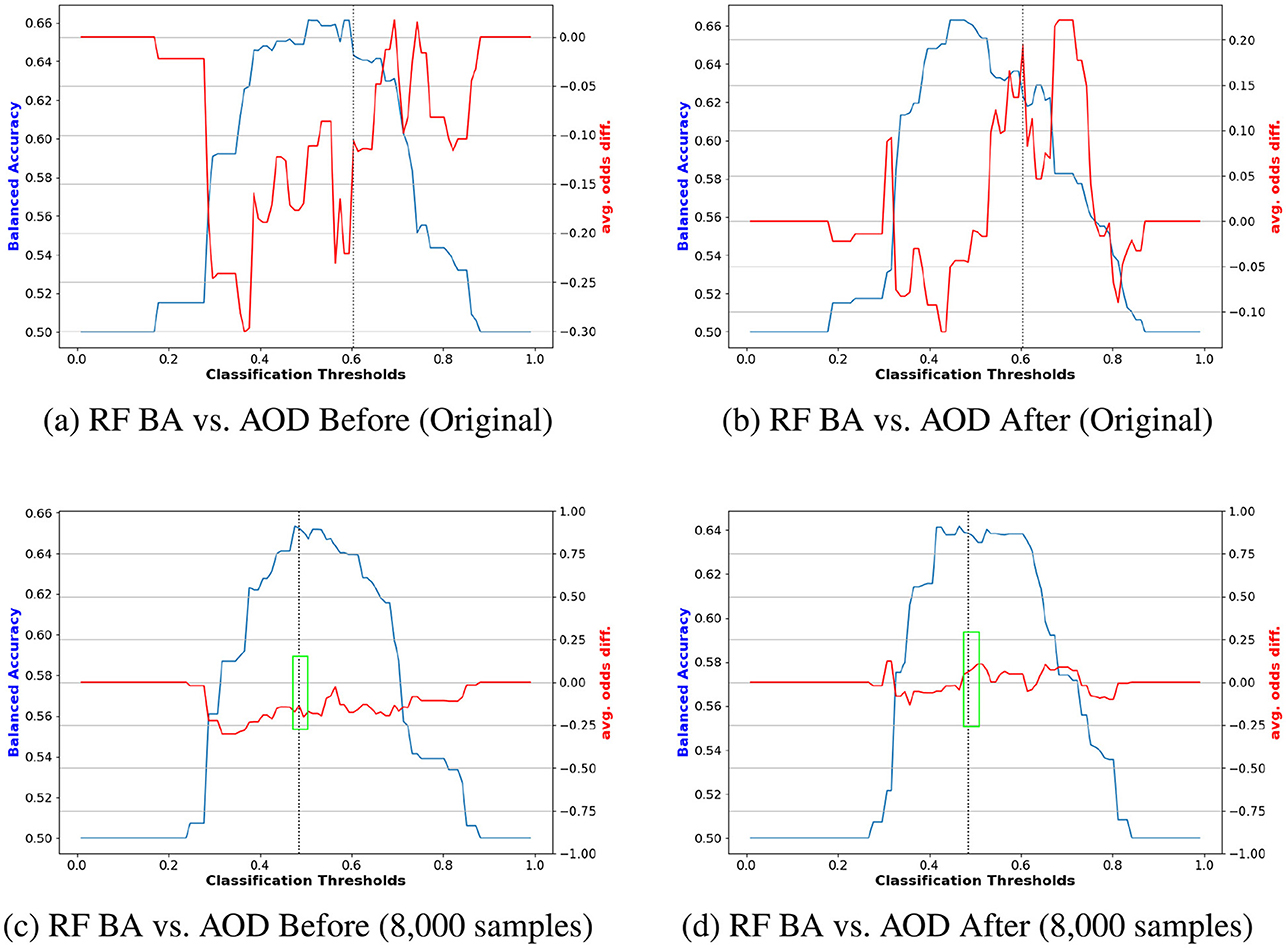
Figure 8. Performance comparison of BA and AOD in augmenting training data with 8, 000 synthetic samples on the COMPAS dataset, considering the protected attribute Race for RF. Subfigures (A) and (C) illustrate the performance comparison between the original training data and the augmented training data (with 8, 000 synthetic samples) before reweighting the samples. In contrast, Subfigures (B) and (D) present the comparison after reweighting the samples. (A) RF BA vs. AOD Before (Original). (B) RF BA vs. AOD After (Original). (C) RF BA vs. AOD Before (8,000 samples). (D) RF BA vs. AOD After (8,000 samples).
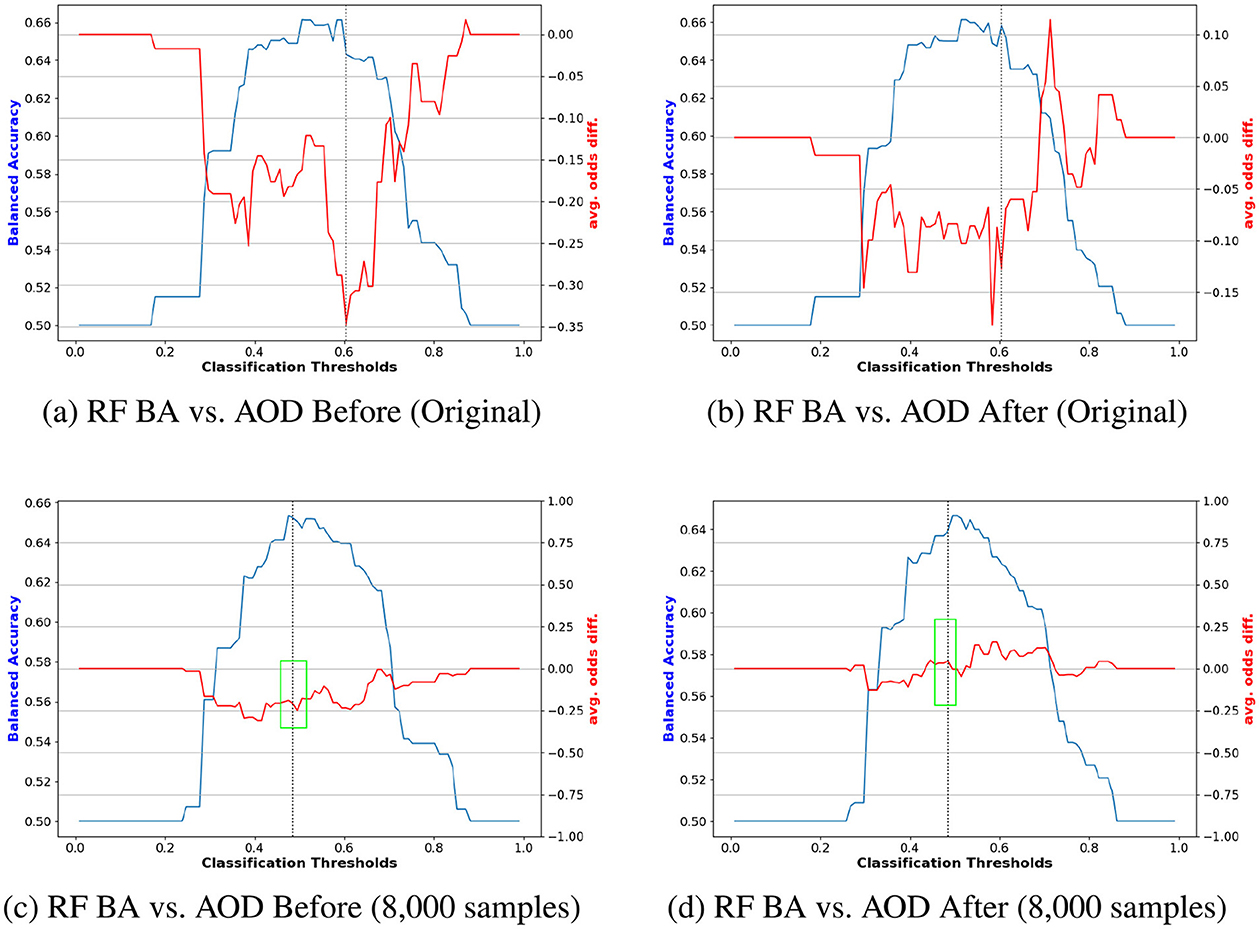
Figure 9. Performance comparison of BA and AOD in augmenting training data with 8, 000 synthetic samples on the COMPAS dataset, considering the protected attribute Sex for RF. Subfigures (A) and (C) illustrate the performance comparison between the original training data and the augmented training data (with 8, 000 synthetic samples) before reweighting the samples. In contrast, Subfigures (B) and (D) present the comparison after reweighting the samples. (A) RF BA vs. AOD Before (Original). (B) RF BA vs. AOD After (Original). (C) RF BA vs. AOD Before (8,000 samples). (D) RF BA vs. AOD After (8,000 samples).
In summary, data augmentation is a valuable approach for improving model fairness in machine learning. However, different models respond uniquely to synthetic data augmentation, underscoring the importance of selecting an appropriate model to achieve the desired balance between fairness and performance.
Generative models have a rich history in artificial intelligence, starting in the 1950s with the development of Hidden Markov Models (HMMs) (Knill and Young, 1997) and Gaussian Mixture Models (GMMs) (Reynolds et al., 2009), which were used to generate sequential data. However, significant advancements in generative models occurred with the rise of deep learning. In natural language processing (NLP), traditional methods for sentence generation involved learning word distributions using N-gram language models (Bengio et al., 2000) and then searching for the best sequence. To handle longer sentences, recurrent neural networks (RNNs) (Mikolov et al., 2010) were introduced for language modeling tasks, allowing for the modeling of relatively long dependencies, a capability enhanced by Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU), which use gating mechanisms to control memory during training. These methods can effectively attend to approximately 200 tokens in a sample manner (Khandelwal et al., 2018), marking a substantial improvement over N-gram models. In computer vision (CV), Generative Adversarial Networks (GANs) (Goodfellow et al., 2020) have achieved remarkable results across various applications. Additionally, Variational Autoencoders (VAEs) (Kingma, 2013) and diffusion models (Song and Ermon, 2019) have been developed to provide more fine-grained control over the image generation process, enabling the creation of high-quality images.
Diffusion models are powerful tools for generating synthetic data. The Denoising Diffusion Probabilistic Model (DDPM) is a type of latent variable model inspired by non-equilibrium thermodynamics, using a Gaussian distribution for data generation (Nichol and Dhariwal, 2021). These models are not only simple to define but also efficient to train, and they can be integrated with non-autoregressive text generation methods to improve text generation quality (Li et al., 2023b). Song et al. (2020) introduced a stochastic differential equation (SDE) that gradually transforms a complex data distribution into a known prior distribution by adding noise, and a reverse-time SDE that reconstructs the data distribution from the prior by gradually removing the noise. The reverse-time SDE relies solely on the time-dependent gradient field of the perturbed data distribution. Vahdat et al. (2021) proposed the Latent Score-based Generative Model (LSGM), a new method that trains Score-based Generative Models (SGMs) in a latent space within the framework of variational autoencoders for image generation.
AI fairness has emerged as one of the most critical challenges of the decade (Shaham et al., 2023). Although machine learning models are designed to intelligently avoid errors and biases in decision-making, they can sometimes unintentionally perpetuate bias and discrimination within society. Concerns have been raised about various forms of unfairness in ML, including racial biases in criminal justice, disparities in employment, and biases in loan approvals (Angwin et al., 2022). The entire lifecycle of an ML model, from input data through modeling, evaluation, and feedback, is vulnerable to both external and inherent biases, which can lead to unjust outcomes. Techniques to mitigate bias in ML models are generally divided into three categories: pre-processing, in-processing, and post-processing (Caton and Haas, 2020). Pre-processing recognizes that data itself can introduce bias, with distributions of sensitive or protected variables often being discriminatory or imbalanced. For example, Blow et al. (2024) conducted a systematic study of reweighting samples for traditional ML models, using five models for binary classification on datasets such as Adult Income and COMPAS, and incorporating various protected attributes. Notably, the study leveraged AI Fairness 360 (AIF360), a comprehensive open-source library designed to identify and mitigate bias in machine learning models throughout the AI application lifecycle.
Understanding the impact of generative modeling is crucial to preventing unintended bias when augmenting training data. This study explores data augmentation via diffusion models, aiming to reduce bias and improve overall performance. It involved evaluating model performance with the generated data added in various increments to the original dataset, and comparing the results to the original outputs using metrics including balanced accuracy and fairness metrics. Experimental results indicated the effectiveness of synthetic data generated by diffusion models for data augmentation. Future work will build on this exploration by incorporating additional datasets and comparing the effects of varying data increments. Additionally, different tools from AI Fairness 360 (AIF360) will be tested to further mitigate bias.
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
CH: Writing – original draft, Writing – review & editing, Data curation, Formal analysis, Investigation, Methodology, Project administration, Software, Validation, Visualization. LQ: Writing – original draft, Writing – review & editing, Conceptualization. CG: Writing – original draft, Writing – review & editing. PO: Writing – original draft, Writing – review & editing. XD: Project administration, Resources, Supervision, Writing – original draft, Writing – review & editing.
The author(s) declare that no financial support was received for the research and/or publication of this article.
This research work is supported by the NSF under award number 2323419 and by the Army Research Office under Cooperative Agreement Number W911NF-24-2-0133.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The author(s) declare that no Gen AI was used in the creation of this manuscript.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the NSF or the Army Research Office or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein.
Alqahtani, H., Kavakli-Thorne, M., and Kumar, G. (2021). Applications of generative adversarial networks (GANS): an updated review. Arch. Comput. Methods Eng. 28, 525–552. doi: 10.1007/s11831-019-09388-y
Angwin, J., Larson, J., Mattu, S., and Kirchner, L. (2022). “Machine bias,” in Ethics of Data and Analytics (Auerbach Publications), 254–264. doi: 10.1201/9781003278290-37
Bansal, M. A., Sharma, D. R., and Kathuria, D. M. (2022). A systematic review on data scarcity problem in deep learning: solution and applications. ACM Comput. Surv. 54, 1–29. doi: 10.1145/3502287
Bellamy, R. K., Dey, K., Hind, M., Hoffman, S. C., Houde, S., Kannan, K., et al. (2019). AI fairness 360: an extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 63, 4–1. doi: 10.1147/JRD.2019.2942287
Bengio, Y., Ducharme, R., and Vincent, P. (2000). “A neural probabilistic language model,” in Advances in Neural Information Processing Systems, 13.
Blow, C. H., Qian, L., Gibson, C., Obiomon, P., and Dong, X. (2024). Comprehensive validation on reweighting samples for bias mitigation via aif360. Appl. Sci. 14:3826. doi: 10.3390/app14093826
Calders, T., Kamiran, F., and Pechenizkiy, M. (2009). “Building classifiers with independency constraints,” in 2009 IEEE International Conference on Data Mining Workshops (IEEE), 13–18. doi: 10.1109/ICDMW.2009.83
Caton, S., and Haas, C. (2020). Fairness in machine learning: a survey. ACM Comput. Surv. 56, 1–38. doi: 10.1145/3616865
Chang, Z., Koulieris, G. A., and Shum, H. P. (2023). On the design fundamentals of diffusion models: a survey. arXiv preprint arXiv:2306.04542.
Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., and Le, Q. V. (2019). “Autoaugment: learning augmentation strategies from data,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 113–123. doi: 10.1109/CVPR.2019.00020
Cui, L., Li, H., Chen, K., Shou, L., and Chen, G. (2024). Tabular data augmentation for machine learning: progress and prospects of embracing generative AI. arXiv preprint arXiv:2407.21523.
Ding, J., Li, X., Kang, X., and Gudivada, V. N. (2019). A case study of the augmentation and evaluation of training data for deep learning. J. Data Inf. Qual. 11, 1–22. doi: 10.1145/3317573
Feldman, M., Friedler, S. A., Moeller, J., Scheidegger, C., and Venkatasubramanian, S. (2015). “Certifying and removing disparate impact,” in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 259–268. doi: 10.1145/2783258.2783311
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2020). Generative adversarial networks. Commun. ACM 63, 139–144. doi: 10.1145/3422622
Hu, B., Saragadam, A., Layton, A., and Chen, H. (2024). Synthetic data from diffusion models improve drug discovery prediction. arXiv preprint arXiv:2405.03799.
Khandelwal, U., He, H., Qi, P., and Jurafsky, D. (2018). Sharp nearby, fuzzy far away: How neural language models use context. arXiv preprint arXiv:1805.04623.
Kingma, D. P.Welling, M., et al. (2019). An introduction to variational autoencoders. Found. Trends Mach. Learn. 12, 307–392. doi: 10.1561/2200000056
Knill, K., and Young, S. (1997). “Hidden markov models in speech and language processing,” in Corpus-Based Methods in Language and Speech Processing (Springer), 27–68. doi: 10.1007/978-94-017-1183-8_2
Kotelnikov, A., Baranchuk, D., Rubachev, I., and Babenko, A. (2023). “Tabddpm: modelling tabular data with diffusion models,” in International Conference on Machine Learning (PMLR), 17564–17579.
Li, B., Qi, P., Liu, B., Di, S., Liu, J., Pei, J., et al. (2023a). Trustworthy AI: from principles to practices. ACM Comput. Surv. 55, 1–46. doi: 10.1145/3555803
Li, Y., Zhou, K., Zhao, W. X., and Wen, J.-R. (2023b). Diffusion models for non-autoregressive text generation: a survey. arXiv preprint arXiv:2303.06574.
Mikolov, T., Karafiát, M., Burget, L., Cernocký, J., and Khudanpur, S. (2010). “Recurrent neural network based language model,” in Interspeech (Makuhari), 1045–1048. doi: 10.21437/Interspeech.2010-343
Nguyen, Q., Vu, T., Tran, A., and Nguyen, K. (2024). “Dataset diffusion: diffusion-based synthetic data generation for pixel-level semantic segmentation,” Advances in Neural Information Processing Systems, 36.
Nichol, A. Q., and Dhariwal, P. (2021). “Improved denoising diffusion probabilistic models,” in International Conference on Machine Learning, 8162–8171. PMLR.
Reynolds, D. A. (2009). “Gaussian mixture models,” in Encyclopedia of Biometrics, eds. S. Z. Li, A. Jain (Boston, MA: Springer), 659–663. doi: 10.1007/978-0-387-73003-5_196
Richardson, B., and Gilbert, J. E. (2021). A framework for fairness: a systematic review of existing fair AI solutions. arXiv preprint arXiv:2112.05700.
Shaham, S., Hajisafi, A., Quan, M. K., Nguyen, D. C., Krishnamachari, B., Peris, C., et al. (2023). Holistic survey of privacy and fairness in machine learning. arXiv preprint arXiv:2307.15838.
Song, Y., and Ermon, S. (2019). “Generative modeling by estimating gradients of the data distribution,” in Advances in Neural Information Processing Systems, 32.
Song, Y., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2020). Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456.
Vahdat, A., Kreis, K., and Kautz, J. (2021). “Score-based generative modeling in latent space,” in Advances in Neural Information Processing Systems, 11287–11302.
Villaizán-Vallelado, M., Salvatori, M., Segura, C., and Arapakis, I. (2024). Diffusion models for tabular data imputation and synthetic data generation. arXiv preprint arXiv:2407.02549.
Keywords: generative AI, AI fairness, AIF360, reweighting samples, COMPAS dataset, adult income dataset
Citation: Hastings Blow C, Qian L, Gibson C, Obiomon P and Dong X (2025) Data augmentation via diffusion model to enhance AI fairness. Front. Artif. Intell. 8:1530397. doi: 10.3389/frai.2025.1530397
Received: 18 November 2024; Accepted: 24 February 2025;
Published: 19 March 2025.
Edited by:
Georgios Leontidis, University of Aberdeen, United KingdomReviewed by:
Bertrand Kian Hassani, University College London, United KingdomCopyright © 2025 Hastings Blow, Qian, Gibson, Obiomon and Dong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xishuang Dong, eGlkb25nQHB2YW11LmVkdQ==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.