 Monir Abdullah
Monir Abdullah- Department of Computer Science and Artificial Intelligence, College of Computing and Information Technology, University of Bisha, Bisha, Saudi Arabia
Cardiac disease refers to diseases that affect the heart such as coronary artery diseases, arrhythmia and heart defects and is amongst the most difficult health conditions known to humanity. According to the WHO, heart disease is the foremost cause of mortality worldwide, causing an estimated 17.8 million deaths every year it consumes a significant amount of time as well as effort to figure out what is causing this, especially for medical specialists and doctors. Manual methods for detecting cardiac disease are biased and subject to medical specialist variance. In this aspect, machine learning algorithms have proved to be effective and dependable alternatives for detecting and classifying patients who are affected by heart disease. Precise and prompt detection of human heart disease can assist in avoiding heart failure within the initial stages and enhance patient survival. This study proposed a novel Enhanced Multilayer Perceptron (EMLP) framework complemented by data refinement techniques to enhance predictive accuracy. The classification model asses using the CDC cardiac disease dataset and achieved 92% accuracy by surpassing all the traditional methods. The proposed framework demonstrates significant potential for the early detection and prediction of cardiac-related diseases. Experimental results indicate that the Enhanced Multilayer Perceptron (EMLP) model outperformed the other algorithms in terms of accuracy, precision, F1-score, and recall, underscoring its efficacy in cardiac disease detection.
1 Introduction
Cardiac illness is one of the furthermost prevalent illnesses nowadays (Kaur and Kaur, 2023). For many healthcare professionals, the diagnosis of cardiac illness at an initial phase is very crucial to protect their patients from severe conditions and save lives. Early disease identification might save countless lives, and the death rate could be lowered if patients consume their medicines during the right period. Cardiac illnesses cover a wide range of dangers including Arrhythmia, stroke, valve disease, heart failure, and so on. These types of illnesses are becoming more widespread in younger age groups as a result of a lack of physical activity caused by lifestyle changes. Smoking, lack of physical activity, bad mental health, high cholesterol foods, unhealthy foods, and lifestyle choices are the main reasons for getting affected by heart disease. Recent advancements in machine learning and artificial intelligence (AI) have significantly improved the detection and classification of medical conditions, particularly in cardiovascular diseases. Several studies have explored the integration of AI and IoT for healthcare applications, especially for heart disease detection (Alghamedy et al., 2022). Additionally, AI-based multimodal approaches in medical imaging, such as those proposed by Bilal et al. (2024a), have shown promise for improving diagnostic accuracy.
Heart failure is a major disorder that may be the reason behind several dangerous situations in the modern world. Nearly 26 million people worldwide suffer from this type of disease each year. This disorder is a clinical illness with many etiologies in which the cardiac system cannot supply enough blood to the body's crucial organs. Doctors could use electronic medical records to detect heart failure based on the patient's symptoms and clinical laboratory tests. However, a good diagnosis of HF necessitates access to specialists and medical resources (Al-Yarimi et al., 2021), which is not always possible, making the diagnosis difficult. To save time and effort, it is essential to predict the patients' state using machine learning algorithms. We need to develop a system that would be prepared to quickly identify the symptoms of a heart stroke and prevent it, as there is a rapid increase in cardiac disease ratios in young people. Since it is unaffordable for the normal person to often conduct expensive tests such as the electrocardiogram (ECG) which is a mechanism that can accurately predict the possibility of emerging cardiac disease must be in place.
Artificial intelligence is becoming progressively common in the healthcare sector (Baashar et al., 2022), as computer examination may reduce manual faults and improve accuracy. Algorithms make illness detection extremely reliable. These techniques are utilized to forecast illnesses such as cardiac illness (Mahesh et al., 2022), liver disease (Almazroi, 2022), skin cancer, breast cancer (Sonawane and Patil, 2022), tumors, etc. For the accurate classification and prediction of heart disease conditions with limited variables, a comparison examination of several models was conducted for the detection of the cardiac disease dataset in this article. The dataset contains 18 variables including the class attribute collected from the annual CDC (Centers for Disease Control) survey dataset of 300,000 adults. K-Nearest Neighbor (KNN) (Tasnim and Habiba, 2021), Naïve Bayes (NB), Random Forest (RF), Support Vector Machine (SVM) (Dharmendra, 2022), multilayer perceptron (MLP) (Kishor and Jeberson, 2021), Decision Tree (DT) (Dharmendra, 2022), as well as Enhanced Multilayer Perceptron (EMLP) classifiers, were used in the algorithms to determine how fine the selected classification algorithms perform in classifying or detecting cardiac disease conditions.
The Enhanced Multilayer Perceptron (EMLP) model is particularly well-suited for this study due to its ability to address the limitations of traditional MLP and other models. Unlike standard MLPs, the EMLP integrates advanced techniques such as optimized weight initialization, adaptive learning rates, and additional layers tailored for feature extraction. These enhancements enable the EMLP to effectively capture complex, non-linear relationships in the data, which is critical for predicting cardiac disease conditions with high accuracy. Moreover, the EMLP's robustness to overfitting, achieved through regularization techniques such as dropout and L2 regularization, makes it highly effective in scenarios with diverse or imbalanced datasets like the one used in this study.
This study aims to predict or detect cardiac diseases by employing machine learning techniques in the optimal way possible to figure out the best-performing model on the annual CDC (Centers for Disease Control and Prevention) survey dataset among the proposed models or classifiers. This study evaluated various machine learning models along with the Enhanced Multilayer Perceptron (EMLP) on the CDC cardiac disease dataset. 92% was the highest accuracy achieved by the Enhanced Multilayer Perceptron (EMLP) model.
2 Related work
To gain a clearer insight into the progress made in the prediction of heart disease, the current body of literature can be classified into three principal categories: traditional methods, ensemble methods, and deep learning approaches. This classification offers a systematic overview of the various methodologies, emphasizing their development and individual contributions.
2.1 Traditional methods
Various approaches have been addressed by the research public for early diagnosis of heart-related diseases such as Heart Arrhythmias, Heart Attacks, and Heart Failure. Traditional machine learning techniques have been widely applied to predict and analyze cardiac illnesses. For example, David and Antony Belcy (2018) introduced a trio of prediction models consisting of a decision tree classifier, a naïve Bayes classification model, and a random forest algorithm. Among these, the random forest classifier outperformed both the decision tree and naïve Bayes classifiers in terms of accuracy. Similarly, Hashi and Zaman (2020) utilized five machine learning models for prediction and assessment based on accuracy, precision, and recall. The study highlighted the effectiveness of a logistic model tree, boosted by ADA and bagging models, with Random Forest showing the highest predictionprecision.
Other studies also leveraged traditional methods. Otoom et al. (2015) employed Naïve Bayes (NB), support vector machine (SVM), and functional trees, achieving a maximum accuracy of 84.5%. Using the same dataset, Vembandasamyp et al. (2015) focused solely on the NB classification algorithm, achieving a moderately better accuracy of 86.4%. Moreover, Usha and Kanchana (2022) explored seven machine learning classifiers, including logistic regression (LR), decision trees (DT), and random forests (RF), using a Kaggle dataset of 4240 patient records. The LR model emerged as the best performer, achieving 85.84% accuracy.
2.2 Ensemble methods
Ensemble techniques have been a key focus for improving cardiac disease prediction. Latha and Jeeva (2019) proposed a majority voting system involving multiple machine learning classifiers such as Naïve Bayes, multilayer perceptron (MLP), and random forest. This ensemble method showed promising results in diagnosing cardiac illnesses at early stages. Additionally, Kavitha et al. (2021) proposed a hybrid method combining decision tree and random forest models. This hybrid approach leveraged the probabilistic capabilities of random forests, resulting in improved prediction accuracy.
Another ensemble-based study (Haq et al., 2018) employed attribute selection techniques such as Relief, LASSO, and mRMR, alongside algorithms like logistic regression, KNN, and ANN. The logistic regression classifier achieved the highest prediction accuracy of 89%.
2.3 Deep learning approaches
Deep learning methods have significantly advanced the diagnosis of cardiac illnesses. Many existing works have focused on machine learning algorithms for disease detection, especially in medical imaging. For instance, Shafiq et al. (2023) introduced DeepSVDNet, a deep learning-based approach for diabetic retinopathy detection, which showcases the potential of deep learning frameworks in medical applications. Furthermore, Bilal et al. (2024b) presented a dual-stream feature transfer framework for ophthalmic image classification, demonstrating the effectiveness of multimodal frameworks in disease detection. Verma and Mathur (2020) developed a system utilizing deep learning to predict heart disease by selecting only relevant features, leading to improved accuracy and precision. Convolutional Neural Networks (CNNs) were also used by Raju et al. (2022), where optimized weights, activation functions, and hidden neurons enhanced the prediction rate and reduced errors.
Hybrid deep learning techniques have also been explored. For instance, Paragliola and Coronato (2020) integrated an LSTM model with a CNN network to analyze ECG signals, achieving significant improvements in detecting heart disease risk for individuals with hypertension. Furthermore, Ali et al. (2019) combined a linear SVM model with an L2-regularized variant to achieve a 3.3% performance improvement compared to traditional SVM models.
In an attempt to enhance the organization of the related work section, a summary table (Table 1) which gives a comparative analysis of previous methodologies with their drawbacks has been added. This table provide the information about which datasets was used, which models were trained and what was the maximum achieved accuracy in each paper. This brief representation reveals the usage of numerous methods that are common in heart disease detection: Decision Trees (Figure 3); Random Forest (Figure 4); Convolutional Neural Networks (Figure 5); Long-Short Term Memory (Figure 6). Also, the limitations column raises awareness of serious issues that apply to these methods including data bias, data overfitting and scant validation across various populations. And this table clearly best illustrates the need to establish a comprehensive and generalizable model which can overcome these lacks. The proposed methodology intends to fill these gaps with the help of advanced techniques and range of datasets promising a higher accuracy level.
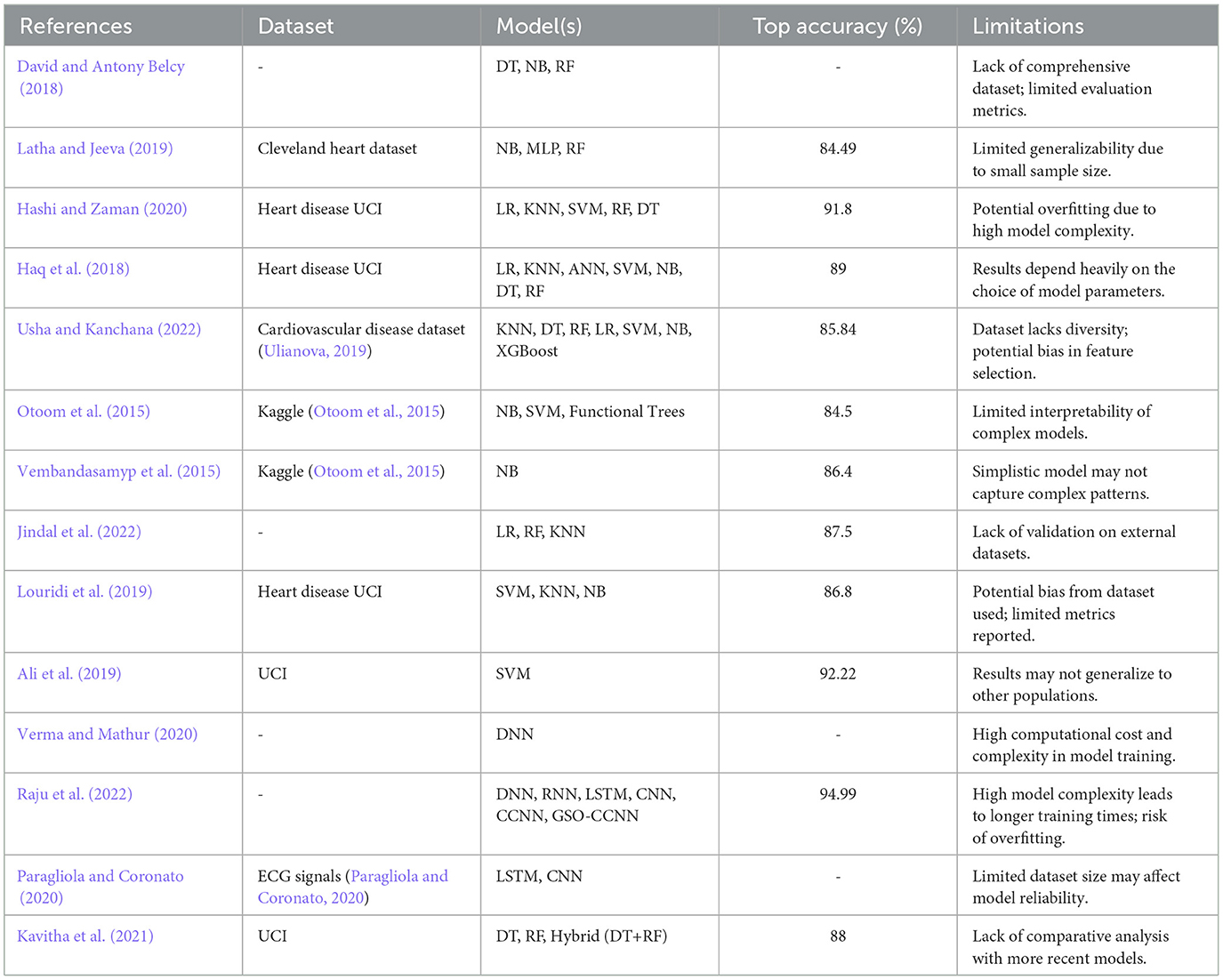
Table 1. Comparison of related work.
3 Material and methods
3.1 Methodology
The current study presented several ML classification algorithms in order to assess as well as achieve the best possible combination regarding the diagnosis of cardiac diseases in relationships of performance. At the stage of preprocessing and cleaning the data, certain features were selected and optimized in order to manage to fit each model specifically. Categorical features were preprocessed and converted to features or attributes in numerical shape, furthermore, the attributes that would have been negatively contributing to the training process were removed from the training datasets in order to avoid deviating the training procedure out of the planned method. The research workflow is explained in Figure 1. In our study, we adopted a machine learning approach that builds upon the principles outlined by Tahir et al. (2022), who employed feature optimization techniques to improve model performance in physical activity recognition (Hamza et al., 2019). These methodologies are also applicable in optimizing disease detection models, such as the one presented in this work. To assess the efficiency of the presented system along with other ML algorithms different machine learning techniques were employed in this research along with the Enhanced Multilayer Perceptron (EMLP) which is a modified and improved version of the Multilayer Perceptron (MLP). All these models were trained on the same dataset to evaluate and examine the efficiency of every single classifier. Furthermore, the architecture and theoretical details of the models are explained in the classification algorithms subsection.
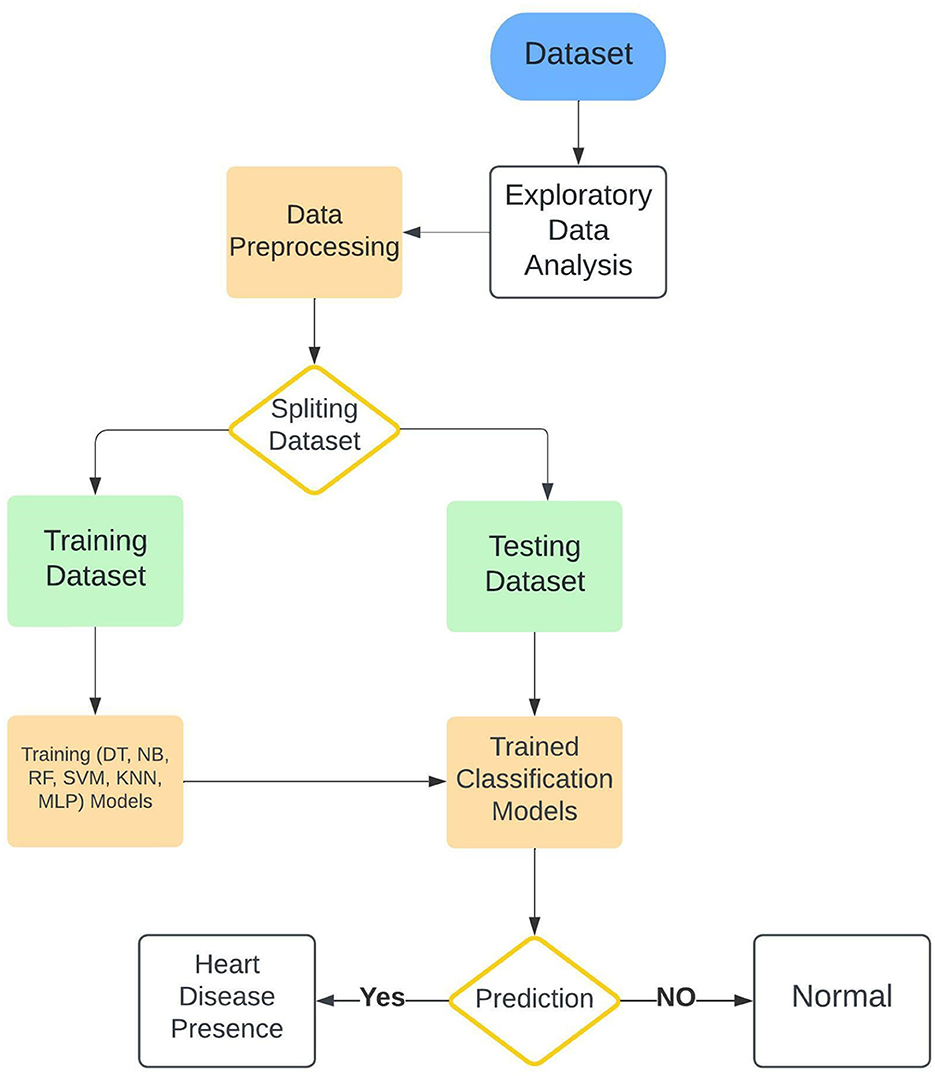
Figure 1. Architecture of the proposed cardiac disease prediction system that demonstrates a structured approach for early cardiac disease detection.
The workflow Refined data is processed by the Enhanced Multilayer Perceptron (EMLP) model, which analyzes complex patterns to deliver precise predictions. This framework supports early diagnosis, aiming to reduce cardiac mortality by enabling prompt medical intervention.
3.2 Dataset
The CDC dataset was utilized to conduct several experiments. Details of the data are described in Table 2. This dataset comprises data from more than 300,000 adults, providing detailed information about their health status. It contains 17 attributes, including 12 categorical features and 5 numerical features. Missing values, where present, were handled using an imputation strategy based on the type of feature: mean imputation for numerical features and mode imputation for categorical features. This ensures the completeness of the data while maintaining its integrity. Figures 2, 3 provide a statistical description of the CDC (Centers for Disease Control and Prevention) dataset.
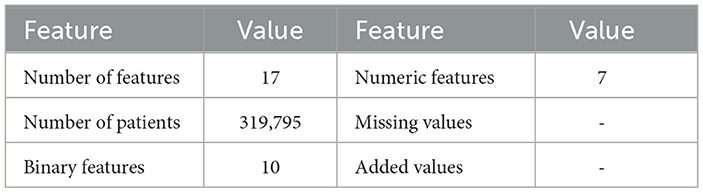
Table 2. Details of the CDC dataset.

Figure 2. Statistical description of categorical attributes.
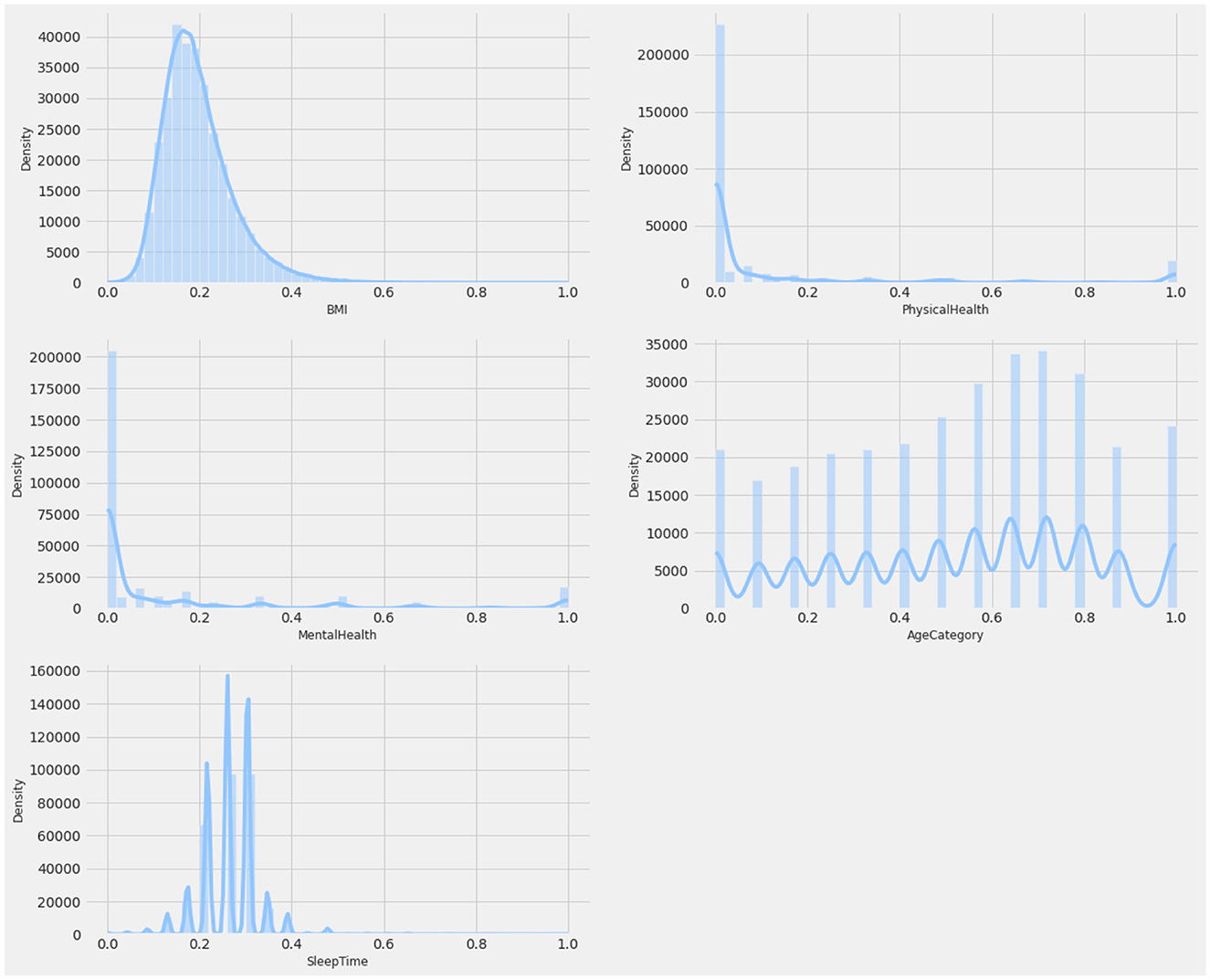
Figure 3. Statistical description of numerical attributes.
Attribute BMI explains the body mass index of an individual in numerical form. The Smoking feature shows whether a person has smoked a total of 100 cigarettes in his/her entire life, as it is a boolean feature having only a yes or no option. Alcohol Drinking Attribute explains whether a mature male drinks more than 14 intoxicating beverages per week or a grown female drinks more than seven intoxicating beverages per week. The stroke feature indicates if a person suffered or had a stroke in his/her entire life for at least one time.
Physical Health attribute shows how many days in the past 30 days a person has suffered from illness or had any type of injuries. The Mental Health feature explains from the last 30 days, how many days a person had a bad mental health status or his/her mental health wasn't good. The diffWaking feature explains whether a person has any type of difficulty in walking or climbing stairs.
The Gender feature indicates a person's sex whether it's male or female. Age Category attribute indicates the age ranging from 18 years up to above 80. Race attribute contains information regarding the ethnicity of an individual containing five race categories White, Black, Asian, American Indian/Alaskan Native, or Other. The diabetic feature shows if an individual is suffering from diabetes. The Physical Activity attribute is a boolean feature that indicates whether an individual is doing any type of health activity such as running, walking, or working out or not. The GenHealth attribute contains information about the overall condition of the health of an individual ranging from poor, fair, good, very good, to excellent. The sleep Time feature contains information about the average sleep time in hours of an individual ranging from 5 to 23 h per day. Asthma is a two-option attribute that explains if an individual is suffering from asthma illness or not. Kidney Disease is a binary feature that has a value of 1 if an individual is suffering from any kind of kidney disease otherwise the value would be 0. The Skin Cancer feature exposes whether a person is suffering from skin cancer or not as it has two options (Yes, No). The dataset description is mentioned in Table 3.
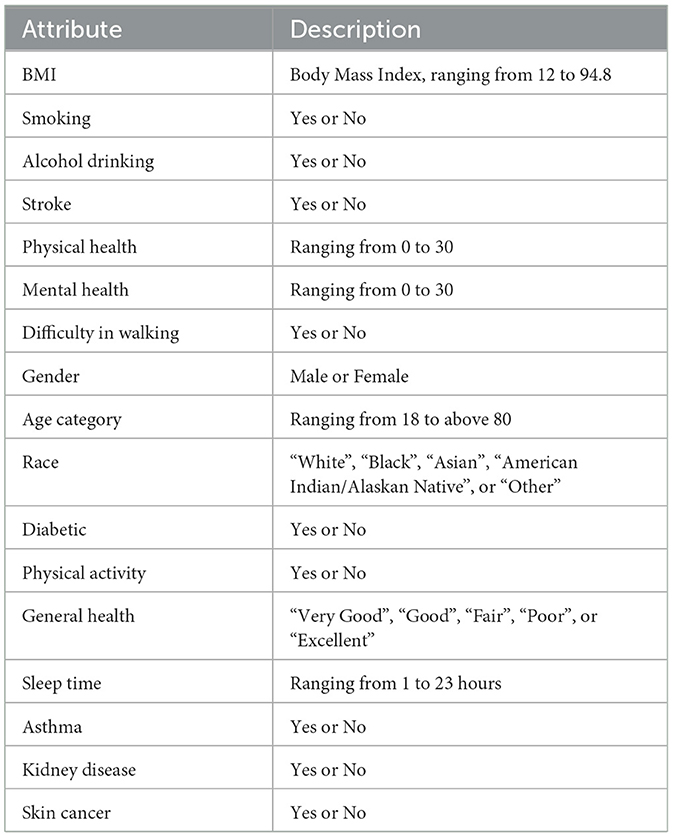
Table 3. Dataset description.
Figure 4 displays the heatmaps. These are graphic demonstrations of correlation matrices that demonstrate links between numerous variables (Almazroi, 2022). The relationship coefficient might include any quantity between -1 and 1. A correlation is the type of statistical word expressing an association between a couple of variables that are linearly correlated. It's known as the correlation measure of a couple of parameters. The purpose of this situation is to discover a correlation between numerous factors and afterwards consolidate the outcomes.
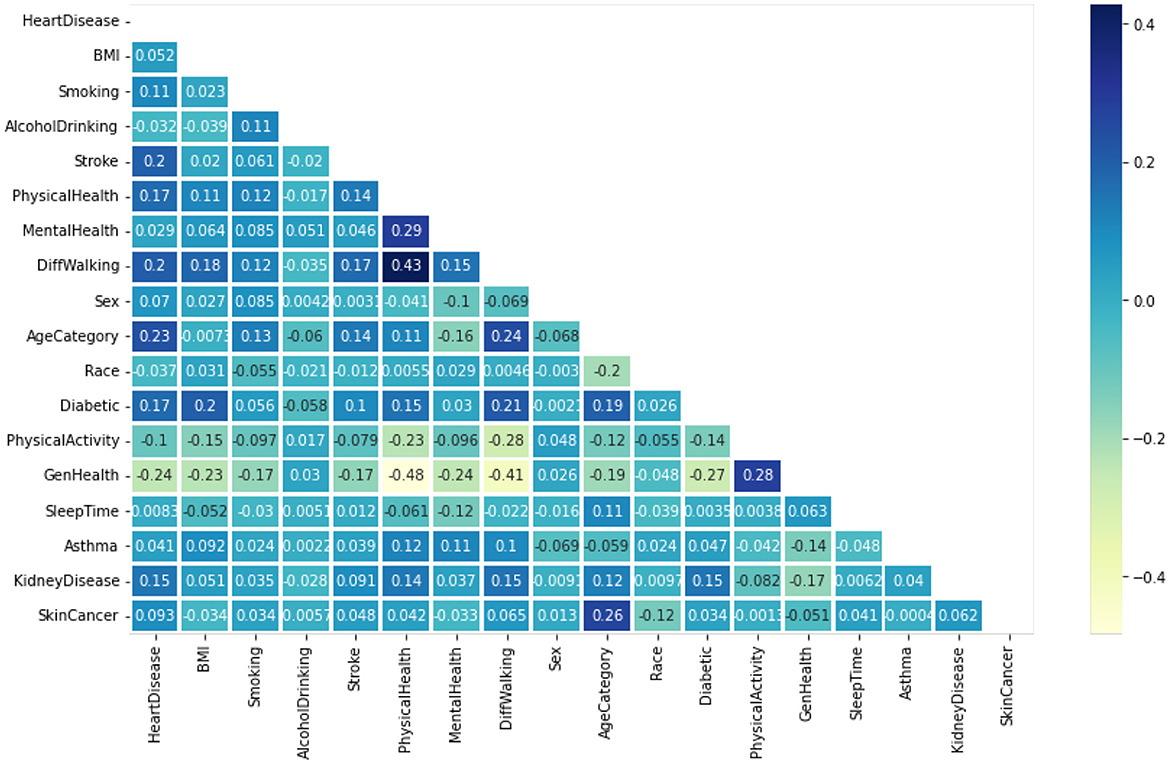
Figure 4. Features heatmap of the dataset.
3.3 Preprocessing
Most of the attributes had to be processed to make the dataset ready for training and evaluating the classification algorithms. The Age Category feature in the dataset in its raw form was categorical and had to be converted to a numerical feature to be processed and thought to the classification algorithms. On the other hand, when speaking about the multilayer perceptron model all the categorical features that contained “Yes” and “No” options had to be converted to 1 or 0 respectively, likewise in the Gender category, the “Male” and “Female” options had to be converted into numerical values in the form of 1 and 0 to be fed to MLP and the EMLP models.
For the attributes that were in numerical form but ranging more than 0 and 1, a scaling function was applied to that type of attribute that would shrink down the huge numerical values to values ranging from 0 to 1 to be easily processed by the classification algorithms. Eventually, all the attributes were scaled to have numerical values ranging from 0 to 1 depending upon the attribute type.
3.4 Classification algorithms
All the classification models that have been trained and utilized for the experiments are demonstrated and explained in this section.
3.4.1 Decision tree (DT)
This technique is a supervised learning technique and it is one of the best as well as most often used models for categorization and prediction (Charbuty and Abdulazeez, 2021). In a decision tree, which looks like a flowchart, every interior node specifies an assessment of a feature, each division demonstrates the examination's outcome, and every leaf node includes a category tag. Within a decision tree, there exists a couple of nodes, the choice node, and the leaf node. Choice nodes are employed to make decisions and include many divisions, where leaf nodes represent the results of the choices (Kumar, 2022). Figure 5 shows the different components of the explained algorithm.
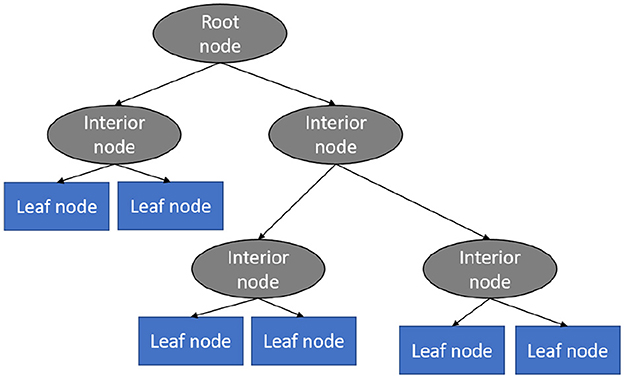
Figure 5. Decision tree algorithm (Vidhya, 2023b).
This classification model predicts cases by categorizing them along the chart from the root to some leaf node that offers the case's prediction or classification (Riyaz et al., 2022). Beginning at the origin node of the chart, a case is predicted by examining the feature indicated by the node, afterwards going along the chart division according to the value of the feature. This method is then repeated for the new node's subtree.
3.4.2 Naïve Bayes (NB)
This classification model is a supervised classification algorithm that works based on the Bayes formula. It is a probabilistic classification model that classifies or performs predictions based on the probability of an entity (Marathe et al., 2021). The Naive Bayes algorithm computes the posterior probability of the feature or the category by utilizing the equation shown in Equation 1.
It can perform prediction efficiently such as disease prediction, spam filtering, and classification of documents. Naive Bayes is a frequently used model as it helps build rapid machine learning models that can perform rapid predictions.
3.4.3 K-nearest neighbor (KNN)
This is a simple classification algorithm that employs the supervised learning method. It is included among the most frequently utilized models as it is easy to implement and utilize (Yunus et al., 2021). It is a non-parametric classification model, which means it does not create any expectations regarding the fundamental entities.
K-Nearest Neighbor (KNN) categorizes the entities based on common similarity within the data points. K-Nearest Neighbor Computes the Euclidean distance in-between K count of neighboring points and considers the K nearest neighbors based on Euclidean space calculated by Equation 2. It is called a lazy learner algorithm as well since it does not rapidly acquire any patterns from the training chunk, as an alternative, it saves the training entities afterwards it takes an action based on it throughout the classification process. Through the training stage, the KNN classification model saves the data and afterwards categorizes it into a class that is similar to the new entities.
3.4.4 Random forest (RF)
RF is considered a supervised learning classification algorithm which consists of several decision trees, that works based on the majority voting of every single tree when considering a prediction or classification of an entity or an object (Asadi et al., 2021). The functioning method of the mentioned algorithm is demonstrated in Figure 6 The RF classification model utilizes ensemble learning, which is a technique used in machine learning. Ensemble learning acts upon the basis of combining multiple classification models in one classifier to resolve complex categorization and prediction difficulties.
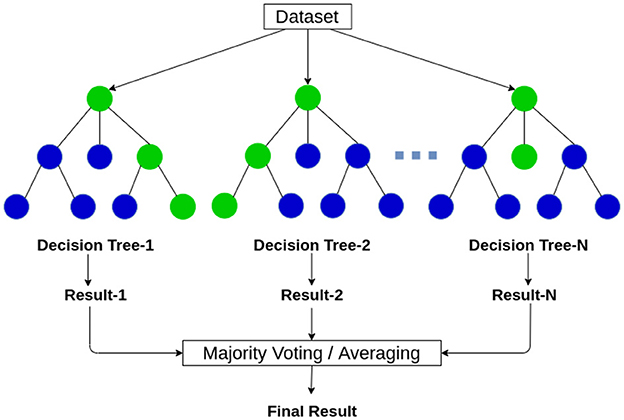
Figure 6. The working of the random forest algorithm (Vidhya, 2023a).
The RF classification model predicts output based on the outcome of several decision trees. It calculates the average of the result of several trees to produce a final prediction. The more count of decision trees more precise the prediction would get. The random forest algorithm eliminates the restrictions in a single decision tree algorithm as it reduces the overfitting of the training dataset, and elevates the precision.
3.4.5 Support vector machine (SVM)
SVM classification model is widely utilized for regression as well as classification problems (Faieq and Mijwil, 2022). Nonetheless, in most cases, SVM is employed for classification difficulties. The aim of the Support Vector Machine classifier is to discover the best boundary stripe or decision line to separate an n-dimension space into multiple categories so it could be feasible to classify new data into its suiting category. This optimal boundary line is called a hyperplane. Figure 7 shows an optimal hyperplane separating two classes.
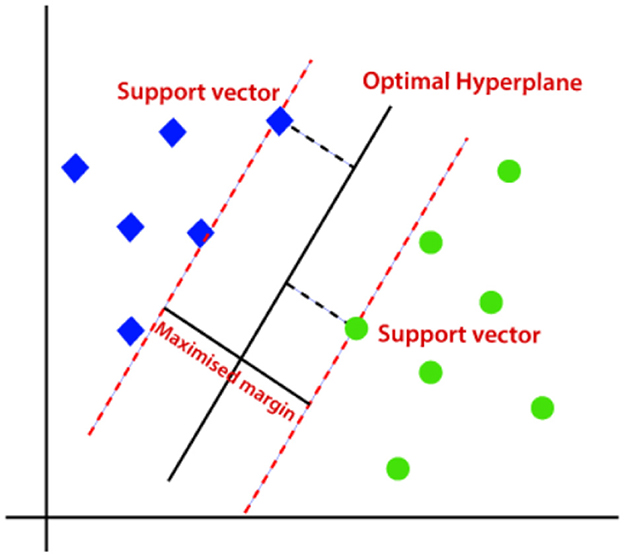
Figure 7. Optimal hyperplane separating two classes (Javatpoint, 2024).
The optimal decision boundary (Hyperplane) can be constructed or created by utilizing the equation shown in Equation 3 (Rani et al., 2021).
The Support Vector Machine considers the extreme spikes which assist in the formation of a hyperplane. Those extreme samples are called support vectors, hence the classification model is identified as Support Vector Machine. These vectors are referred to as Support vectors since these vectors support the hyperplane.
3.4.6 Multilayer perceptron (MLP)
This model is a feed-forward artificial neural network model. It contains three main components, which are the input layer in which the input is injected, and the hidden layer which could be more than one layer in which the outcome of the input layer is fed to it (Ahmadian et al., 2022). The last layer is the output layer, in which the classification and prediction are performed, Figure 8 demonstrates the assembly of an MLP classifier. The data is transmitted forward from the input section to the output section, identical to a feed-forward network. Each layer in a multilayer perceptron (MLP) consists of multiple numbers of neurons. These neurons learn patterns in the dataset in the training phase by the backpropagation learning algorithm. The main advantage of the multilayer perceptron (MLP) classification model is that it can solve complex problems that cannot be linearly separated.
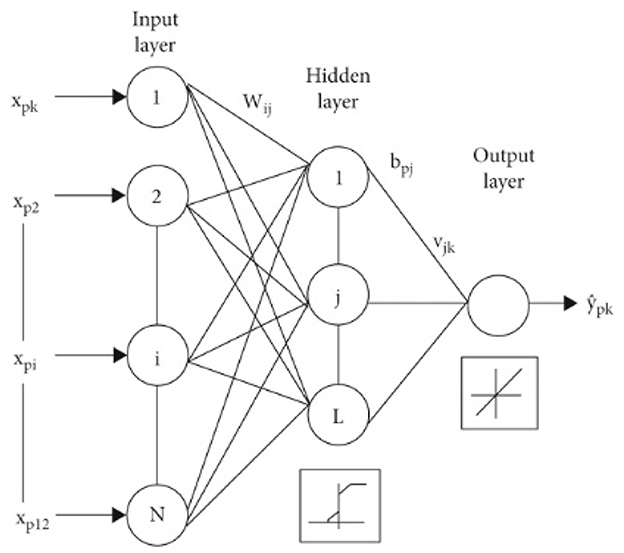
Figure 8. Structure of MLP model (Alnuaim et al., 2022).
3.4.7 Enhanced multilayer perceptron (EMLP)
The EMLP or the enhanced multilayer perceptron model is fundamentally a multilayer perceptron model that has gone through several improvements and modifications in terms of the count of hidden layers, the count of perceptrons in each hidden section, as well as the learning rate.
The first hidden layer on the enhanced multilayer perceptron model consisted of sixty-eight perceptrons which were taking input from the input layer that consisted of sixteen input perceptrons, each perceptron for each feature. The second hidden layer consisted of thirty-four perceptrons which were taking input from the first hidden layer which contained sixty-eight perceptrons. Eventually, the second hidden section was linked to the output section that contained a single perceptron to indicate the presence of heart disease. In the enhanced multilayer perceptron (EMLP) architecture, the learning rate was set to 0.01, which proved to reduce the loss by a noticeable rate and improve the accuracy by 1% from the multilayer perceptron (MLP) classification model.
3.5 Evaluation parameters
The experiment outcomes regarding the efficiency of the classification algorithms were evaluated based on the scale of precision, recall, accuracy (Ali et al., 2021), and f1-score achieved by the classification algorithms. If an individual is diagnosed or suffering from heart disease and it was classified by the model it would be considered as a true positive prediction, on the other hand, if it was not detected by the model it would be considered a false negative. If an individual wasn't suffering from heart disease and the classification model predicted or diagnosed that the person is suffering from heart disease, this type of prediction is categorized as false positive otherwise it would be truly negative.
• Accuracy is a performance scale that measures in percentage the accurately predicted data points out of all data points.
• Precision is the performance scale that measures in percentage count of positive entities predicted actually from the positive class.
• Recall is the performance scale that measures the positive entities that were correctly predicted as positive to the total number of positive entities.
• F1-Score (F-Measure) is the performance measure that combines both recall and precision in one metric by computing their harmonic mean.
4 Results and discussions
Multiple classification algorithms were utilized including the enhanced multilayer perceptron (EMLP) to predict cardiac illness. The CDC's key indicators of the cardiac disease dataset were utilized to execute the experiments. The heart disease diagnosis or prediction was performed using multiple parameters available in the CDC dataset. These parameters or attributes were utilized to classify heart disease with 1 indicating a positive diagnosis of heart disease, and 0 of not suffering from heart disease. The dataset had multiple imbalanced features such as age category, body mass index, mental health, physical health, and sleep time which had to be stabilized to achieve an optimal result in techniques such as multilayer perceptron.
All of the suggested classification methods were trained on a separate training dataset created by separating the CDC dataset into a training and testing set. The ROC (Receiver Operating Characteristic Curve) plots in Figures 9–12 demonstrate the training performance of the decision tree classifier, random forest classifier, naïve Bayes classifier, and k-nearest neighbor model. The accuracy of the multilayer perceptron (MLP) and enhanced multilayer perceptron (EMLP) classification models is shown in Figures 13, 14, respectively, and the loss in the multilayer perceptron (MLP) and enhanced multilayer perceptron (EMLP) models is demonstrated in Figures 15, 16, respectively. The evaluation regarding the performance of the classification models that have been employed in this study was assessed by the scale of accuracy, recall, precision, and F1-score.
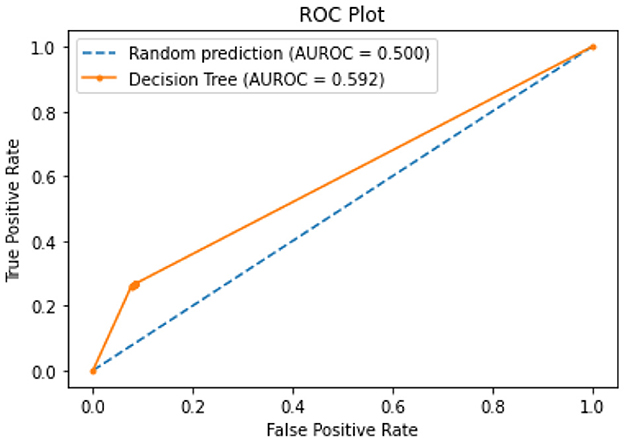
Figure 9. DT model ROC curve.
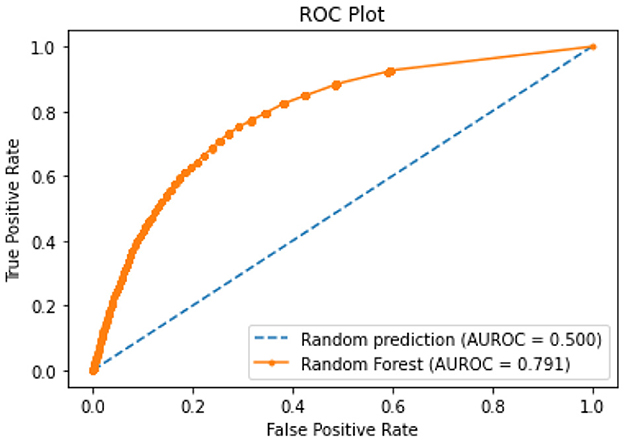
Figure 10. RF model ROC curve.
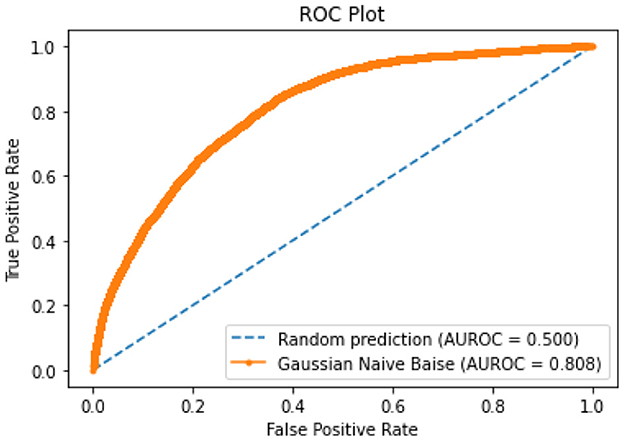
Figure 11. NB model ROC curve.

Figure 12. KNN model ROC curve.
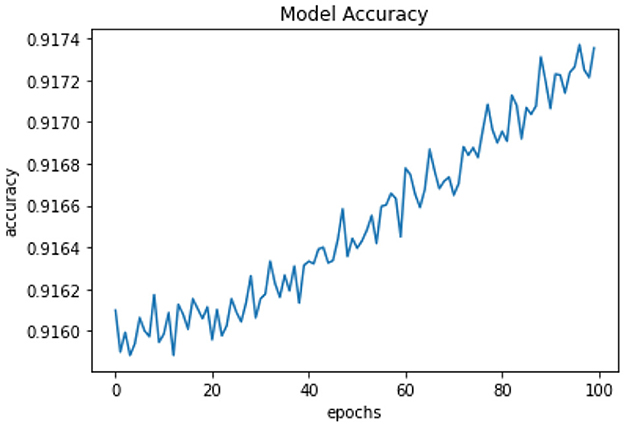
Figure 13. Accuracy graph of the MLP model.
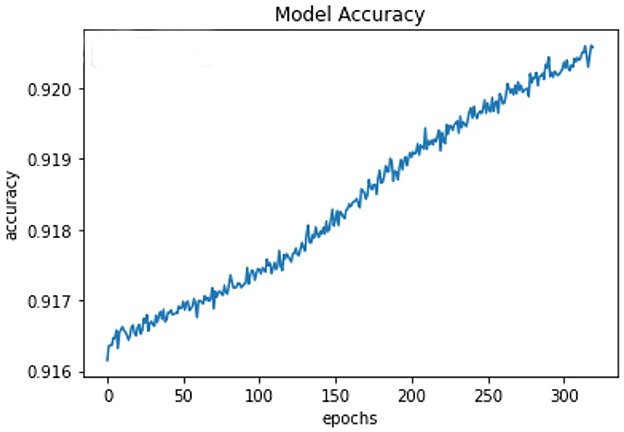
Figure 14. Accuracy graph of the EMLP model.
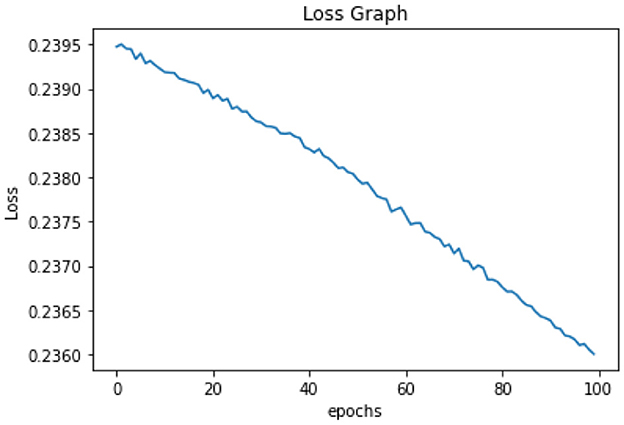
Figure 15. Loss graph of the MLP model.
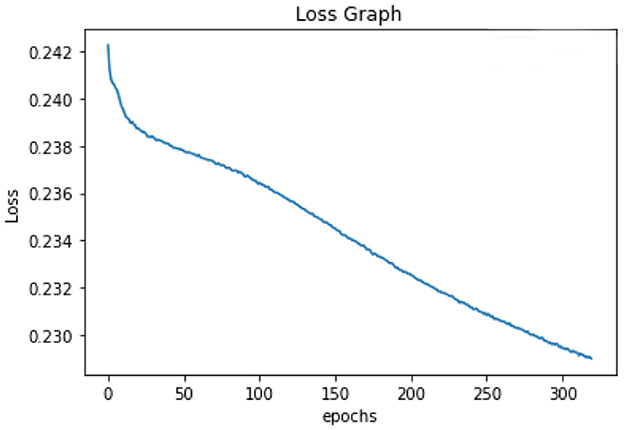
Figure 16. Loss graph of the EMLP model.
After processing the dataset to fit our proposed classification models and balancing the imbalanced attributes or features, the outcomes of the experiments are presented in Table 4, which displays the results obtained by the classification models.
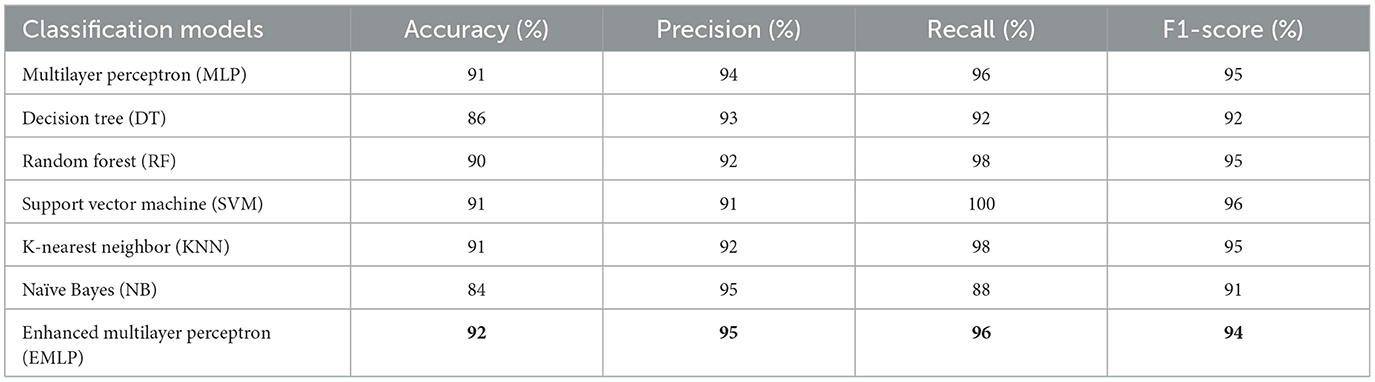
Table 4. Experimental results.
Naïve Bayes achieved 84% accuracy, and the decision tree model achieved 86% accuracy, Figures 17, 18 show the result achieved by the decision tree and naive Bayes models respectively in confusion matrices. random forest classifier achieved 90% accuracy, and the k-nearest neighbor model with seven neighbors achieved 91% accuracy in the testing phase. Figures 19, 20 show the result achieved by the random forest and k-nearest neighbor models respectively in the confusion matrices. The support vector machine achieved 91% accuracy in the testing phase. Figure 21 shows the result achieved by the support vector machine model in the confusion matrix. Enhanced multilayer perceptron classifier achieved 92% accuracy. Figure 22 displays the performance of different classification algorithms based on accuracy, precision, recall, and F1-score.

Figure 17. DT model confusion matrix.
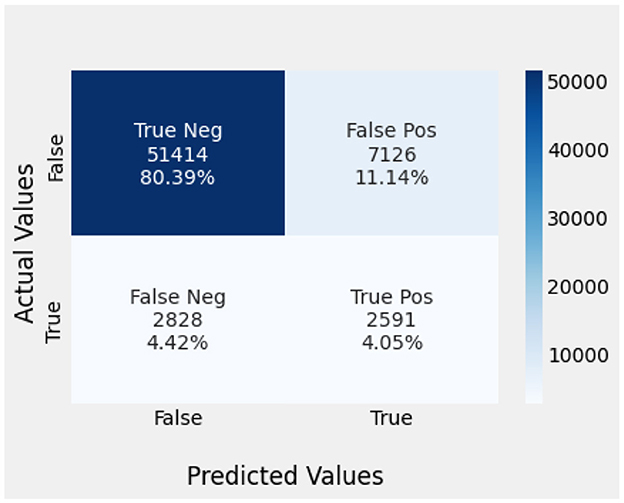
Figure 18. NB model confusion matrix.

Figure 19. RF model confusion matrix.

Figure 20. KNN confusion matrix.
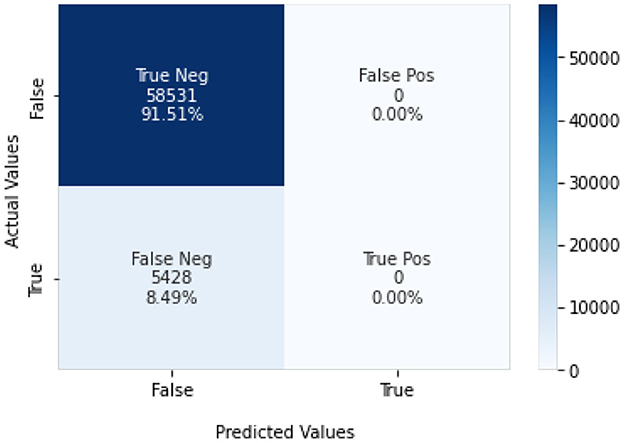
Figure 21. SVM model confusion matrix.
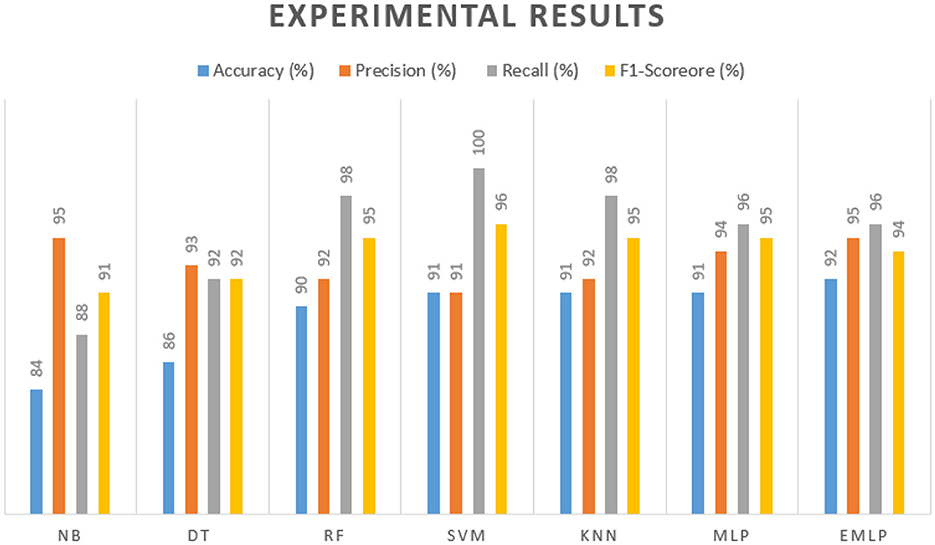
Figure 22. Experimental results of classification models.
One of the key challenges in deploying AI in healthcare is addressing privacy and security concerns, especially when integrating AI with IoT devices. Shafiq et al. (2024) examined these risks and emphasized the need for robust security frameworks to ensure the safe usage of AI in healthcare environments. The integration of AI in medical diagnostics has immense potential. However, challenges such as privacy concerns, model optimization, and data diversity remain, as highlighted in previous works (Alghamedy et al., 2022; Bilal et al., 2024a; Shafiq et al., 2023).
5 Conclusion
Cardiac illness is included among the most dangerous illnesses as it is the main reason for mortality. That is why the timely diagnosis of heart disease will help save lives. To efficiently treat patients before a cardiac attack, it is necessary to properly forecast cardiac illness by employing ML techniques. This study proposes seven ML models to be evaluated on the CDC survey dataset for heart illness prediction. This research shows how by utilizing machine learning algorithms and a few simple clinical indicators available even during the patient's initial visit, the beginning of heart disease can be predicted in an efficient way and timely manner. The collected findings indicate that classifiers based upon enhanced multilayer perceptron are superior in terms of prediction accuracy.
The future work of this study can be performed by employing deep learning techniques, which have proved to perform better in multiple scenarios when compared with machine learning algorithms, but compromising in time complexity as well as space complexity, as it consumes more time while training to achieve much better performance based on prediction/classification accuracy, recall, precision, and f1-score. By Utilizing different technologies like Cloud Computing, big data technologies like Hadoop may be utilized to manage and store massive amounts of data from users all over the world. An Internet of Medical Things (IoMT) system can be developed in future research work, in which an individual can provide symptoms or general attributes on a cloud service, In which the cloud service would pass the person's details through multiple trained machine learning algorithms, that will show the result in an output from. The output will indicate, in the form of a Yes or No answer, whether the subject has a heart condition or not. The outcome will be Yes if the subject is predisposed to having heart disease, and vice versa. In the event of a positive result, a cardiologist should be consulted for a more thorough diagnosis to predict or diagnose heart-related disease in its early stages.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
MA: Conceptualization, Formal analysis, Investigation, Methodology, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Acknowledgments
The authors are thankful to the Deanship of Graduate Studies and Scientific Research at University of Bisha for supporting this work through the Fast-Track Research Support Program.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ahmadian, S., Jalali, S. M. J., Raziani, S., and Chalechale, A. (2022). An efficient cardiovascular disease detection model based on multilayer perceptron and moth-flame optimization. Expert Syst. 39:e12914. doi: 10.1111/exsy.12914
Alghamedy, F. H., Shafiq, M., Liu, L., Yasin, A., Khan, R. A., and Mohammed, H. S. (2022). Machine learning–based multimodel computing for medical imaging for classification and detection of alzheimer disease. Comput. Intell. Neurosci. 2022:9211477. doi: 10.1155/2022/9211477
Ali, L., Niamat, A., Khan, J. A., Golliarz, A., Xingzhong, X., Noor, A., et al. (2019). An optimized stacked support vector machines based expert system for the effective prediction of heart failure. IEEE Access 7, 54007–54014. doi: 10.1109/ACCESS.2019.2909969
Ali, M. M., Paul, B. K., Ahmed, K., Bui, F. M., Quinn, J. M., and Moni, M. A. (2021). Heart disease prediction using supervised machine learning algorithms: performance analysis and comparison. Comput. Biol. Med. 136:104672. doi: 10.1016/j.compbiomed.2021.104672
Almazroi, A. A. (2022). Survival prediction among heart patients using machine learning techniques. Mathem. Biosci. Eng. 19, 134–145. doi: 10.3934/mbe.2022007
Alnuaim, A. A., Zakariah, M., Shukla, P. K., Alhadlaq, A., Hatamleh, W. A., Tarazi, H., et al. (2022). Human-computer interaction for recognizing speech emotions using multilayer perceptron classifier. J. Healthc. Eng. 2022:6005446. doi: 10.1155/2022/6005446
Al-Yarimi, F. A. M., Munassar, N. M. A., Bamashmos, M. H. M., and Ali, M. Y. S. (2021). Feature optimization by discrete weights for heart disease prediction using supervised learning. Soft Comp. 25, 1821–1831. doi: 10.1007/s00500-020-05253-4
Asadi, S., Roshan, S., and Kattan, M. W. (2021). Random forest swarm optimization-based for heart diseases diagnosis. J. Biomed. Inform. 115:103690. doi: 10.1016/j.jbi.2021.103690
Baashar, Y., Alkawsi, G., Alhussian, H., Capretz, L. F., Alwadain, A., Alkahtani, A. A., et al. (2022). Effectiveness of artificial intelligence models for cardiovascular disease prediction: network meta-analysis. Comput. Intell. Neurosci. 2022:5849995. doi: 10.1155/2022/5849995
Bilal, A., Imran, A., Baig, T. I., Liu, X., Long, H., Alzahrani, A., et al. (2024a). Deepsvdnet: A deep learning-based approach for detecting and classifying vision-threatening diabetic retinopathy in retinal fundus images. Comp. Syst. Sci. Eng. 48:39672. doi: 10.32604/csse.2023.039672
Bilal, A., Imran, A., Baig, T. I., Liu, X., Long, H., Alzahrani, A., et al. (2024b). Improved support vector machine based on cnn-svd for vision-threatening diabetic retinopathy detection and classification. PLoS ONE 19:e0295951. doi: 10.1371/journal.pone.0295951
Charbuty, B., and Abdulazeez, A. (2021). Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2:20–28. doi: 10.38094/jastt20165
David, H., and Antony Belcy, S. (2018). Heart disease prediction using data mining techniques. ICTACT J. Soft Comput. 9:1. doi: 10.21917/ijsc.2018.0254
Dharmendra, D. (2022). “Prediction of heart failure using support vector machine compared with decision tree algorithm for better accuracy,” in 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS) (Erode: IEEE), 1535–1540.
Faieq, A. K., and Mijwil, M. M. (2022). Prediction of heart diseases utilising support vector machine and artificial neural network. Indon. J. Electr. Eng. Comp. Sci. 26, 374–380. doi: 10.11591/ijeecs.v26.i1.pp374-380
Hamza, M., Akbar, M. A., Shafiq, M., Kamal, T., and Baddour, A. M. (2019). Identification of privacy and security risks of internet of things: an empirical investigation. Rev. Comp. Eng. Res. 6, 35–44. doi: 10.18488/journal.76.2019.61.35.44
Haq, A. U., Li, J. P., Memon, M. H., Nazir, S., Sun, R., and Garciá-Magarinõ, I. (2018). A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms. Mob. Inf. Syst. 2018. doi: 10.1155/2018/3860146
Hashi, E. K., and Zaman, M. S. U. (2020). Developing a hyperparameter tuning based machine learning approach of heart disease prediction. J. Appl. Sci. Proc. Eng. 7, 631–647. doi: 10.33736/jaspe.2639.2020
Javatpoint (2024). Machine Learning Support Vector Machine Algorithm. Available at: https://www.javatpoint.com/machine-learning-supportvector-machine-algorithm (Retrieved June 23, 2024).
Jindal, H., Agrawal, S., Khera, R., Jain, R., and Nagrath, P. (2022). Heart Disease Prediction Using Machine Learning Algorithms. IOP Publishing Bristol.
Kaur, B., and Kaur, G. (2023). “Heart disease prediction using modified machine learning algorithm,” in International Conference on Innovative Computing and Communications (Singapore: Springer), 189–201.
Kavitha, M., Gnaneswar, G., Dinesh, R., Sai, Y. R., and Suraj, R. S. (2021). “Heart disease prediction using hybrid machine learning model,” in 2021 6th International Conference on Inventive Computation Technologies (ICICT) (Coimbatore: IEEE), 1329–1333.
Kishor, A., and Jeberson, W. (2021). “Diagnosis of heart disease using internet of things and machine learning algorithms,” in Proceedings of Second International Conference on Computing, Communications, and Cyber-Security (Singapore: Springer), 691–702.
Kumar, G. (2022). Analysis of accuracy in heart disease diagnosis system using decision tree classifier over logistic regression based on recursive feature selection. ECS Trans. 107:15661. doi: 10.1149/10701.15661ecst
Latha, C. B. C., and Jeeva, S. C. (2019). Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. Inform. Med. Unlocked 16:100203. doi: 10.1016/j.imu.2019.100203
Louridi, N., Amar, M., and El Ouahidi, B. (2019). “Identification of cardiovascular diseases using machine learning,” in 7th Mediterr. Congr. Telecommunication (Fez: IEEE Conference), 2–7.
Mahesh, T. R., Dhilip Kumar, V., Vinoth Kumar, V., Asghar, J., Geman, O., Arulkumaran, G., et al. (2022). Adaboost ensemble methods using k-fold cross validation for survivability with the early detection of heart disease. Comput. Intell. Neurosci. 2022:9005278. doi: 10.1155/2022/9005278
Marathe, N., Gawade, S., and Kanekar, A. (2021). Prediction of heart disease and diabetes using naive bayes algorithm. Int. J. Scient. Res. Comp. Sci. Eng. Inform. Technol. 7, 447–453. doi: 10.32628/CSEIT217399
Otoom, A. F., Abdallah, E. E., Kilani, Y., Kefaye, A., and Ashour, M. (2015). Effective diagnosis and monitoring of heart disease. Int. J. Softw. Eng. its Appl. 9, 143–156. doi: 10.14257/ijseia.2015.9.1.12
Paragliola, G., and Coronato, A. (2020). An hybrid ECG-based deep network for the early identification of high-risk to major cardiovascular events for hypertension patients. J. Biomed. Inform. 113:103648. doi: 10.1016/j.jbi.2020.103648
Raju, K. B., Dara, S., Vidyarthi, A., Gupta, V. M., and Khan, B. (2022). Smart heart disease prediction system with iot and fog computing sectors enabled by cascaded deep learning model. Comput. Intell. Neurosci. 2022:1070697. doi: 10.1155/2022/1070697
Rani, P., Kumar, R., Ahmed, N. M., and Jain, A. (2021). A Decision Support System for Heart Disease Prediction Based Upon Machine Learning. Cham: Springer Nature.
Riyaz, L., Butt, M. A., Zaman, M., and Ayob, O. (2022). “Heart disease prediction using machine learning techniques: a quantitative review,” in International Conference on Innovative Computing and Communications (Singapore: Springer), 81–94.
Shafiq, M., Du, C., Jamal, N., Abro, J. H., Kamal, T., Afsar, S., et al. (2023). Smart e-health system for heart disease detection using artificial intelligence and internet of things integrated next-generation sensor networks. J. Sensors 2023:6383099. doi: 10.1155/2023/6383099
Shafiq, M., Quanrun, F., Alghamedy, F. H., and Obidallah, W. J. (2024). Dualeye-featurenet: a dual-stream feature transfer framework for multi-modal ophthalmic image classification. IEEE Access. 12. doi: 10.1109/ACCESS.2024.3469244
Sonawane, R., and Patil, H. (2022). Automated heart disease prediction model by hybrid heuristic-based feature optimization and enhanced clustering. Biomed. Signal Process. Control, 72:103260. doi: 10.1016/j.bspc.2021.103260
Tahir, S. B., Dogar, A. B., Fatima, R., Yasin, A., Shafiq, M., Khan, J. A., et al. (2022). Stochastic recognition of human physical activities via augmented feature descriptors and random forest model. Sensors 22:6632. doi: 10.3390/s22176632
Tasnim, F., and Habiba, S. U. (2021). “A comparative study on heart disease prediction using data mining techniques and feature selection,” in 2021 2nd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST) (Dhaka: IEEE), 338–341.
Usha, S., and Kanchana, S. (2022). Effective Analysis of Heart Disease Prediction Using Machine Learning Techniques. Tamil Nadu: IEEE Conference.
Vembandasamyp, K., Sasipriyap, R. R., and Deepap, E. (2015). Heart diseases detection using naive bayes algorithm. Int. J. Innov. Sci. Eng. Technol. 2:9. Available at: https://web.archive.org/web/20180411132513id_/http://www.ijiset.com/vol2/v2s9/IJISET_V2_I9_54.pdf
Verma, L., and Mathur, M. K. (2020). Deep learning based model for decision support with case based reasoning. Int. J. Innov. Technol. Explor Eng. 8, 149–153. Available at: https://www.ijitee.org/portfolio-item/F12340486C19/
Vidhya, A. (2023a). Decision Tree vs. Random Forest Algorithm. Available at: https://www.analyticsvidhya.com/blog/decision-tree-vsrandom-forest-algorithm (Retrieved July 2, 2024).
Vidhya, A. (2023b). A Deep Dive to Decision Trees. Available at: https://www.analyticsvidhya.com/blog/2021/08/decisiontree-algorithm/ (Retrieved August 9, 2024).
Keywords: heart disease, cardiac disease, machine learning, cardiovascular diseases, multilayer perceptron, detection
Citation: Abdullah M (2025) Artificial intelligence-based framework for early detection of heart disease using enhanced multilayer perceptron. Front. Artif. Intell. 7:1539588. doi: 10.3389/frai.2024.1539588
Received: 04 December 2024; Accepted: 26 December 2024;
Published: 10 January 2025.
Edited by:
Anas Bilal, Hainan Normal University, ChinaReviewed by:
Muhammad Shafiq, Qujing Normal University, ChinaAzhar Imran, Air University, Pakistan
Adnan Riaz, University of Bologna, Italy
Copyright © 2025 Abdullah. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Monir Abdullah, bWthaWRAdWIuZWR1LnNh