 Mark Eshwar Lokanan
Mark Eshwar Lokanan Sana Ramzan
Sana Ramzan- 1Faculty of Management, Royal Roads University, Victoria, BC, Canada
- 2University Canada West, Victoria, BC, Canada
Introduction: This study investigates the application of machine learning (ML) algorithms, a subset of artificial intelligence (AI), to predict financial distress in companies. Given the critical need for reliable financial health indicators, this research evaluates the predictive capabilities of various ML techniques on firm-level financial data.
Methods: The dataset comprises financial ratios and firm-specific variables from 464 firms listed on the TSX. Multiple ML models were tested, including decision trees, random forests, support vector machines (SVM), and artificial neural networks (ANN). Recursive feature elimination with cross-validation (RFECV) and bootstrapped CART were also employed to enhance model stability and feature selection.
Results: The findings highlight key predictors of financial distress, such as revenue growth, dividend growth, cash-to-current liabilities, and gross profit margins. Among the models tested, the ANN classifier achieved the highest accuracy at 98%, outperforming other algorithms.
Discussion: The results suggest that ANN provides a robust and reliable method for financial distress prediction. The use of RFECV and bootstrapped CART contributes to the model’s stability, underscoring the potential of ML tools in financial health monitoring. These insights carry valuable implications for auditors, regulators, and company management in enhancing practices around financial oversight and fraud detection.
1 Introduction
Financial statement fraud (FSF) is a significant issue in corporate governance, often linked to instances of financial distress. Notable examples include Canadian companies like Livent and Nortel Networks, as well as international firms such as Enron, WorldCom, and Parmalat, where financial distress led to manipulative practices that violated generally accepted accounting principles (GAAP) and International Financial Reporting Standards. Although earnings management and fraud are distinct concepts, the literature demonstrates a strong correlation between financial distress and the likelihood of fraudulent financial reporting (Perols, 2011; Ramírez-Orellana et al., 2017; Trompeter et al., 2013).
The advent of machine learning (ML) offers promising opportunities to address these issues by enabling auditors and regulators to proactively identify high-risk firms and prevent financial fraud. Specifically, supervised learning within ML, including algorithms like logistic regression, support vector machines (SVM), and artificial neural networks (ANN), has shown potential in predicting financial distress and detecting earnings manipulation. This purpose of this research is to explore how these ML algorithms, alongside classification and regression trees (CART) with bootstrapping techniques, can be utilized to predict financial distress and identify instances of earnings manipulation using the Beneish M-score as a key indicator.
We aim to answer the central research question: “How can ML algorithms be leveraged to predict financial distress and detect earnings manipulation in companies using the Beneish M-score?” We employ these advanced techniques to forecast financial distress among companies listed on the Toronto Stock Exchange (TSX). Our central focus revolves around developing a model that not only predicts financial distress but also sheds light on potential earnings manipulations, leveraging readily available financial statement data from TSX-listed companies. We recognize the inherent connection between financial distress and earnings manipulation, as companies facing financial difficulties are more likely to engage in such practices (Ding et al., 2023; Fang et al., 2017; Farooq and Qamar, 2019). Therefore, our research encompasses both aspects to provide a comprehensive understanding of these intertwined phenomena.
This research contributes to the growing field of financial distress prediction by adopting a multi-faceted approach, integrating four distinct methodologies: predictive modeling, recursive feature elimination with cross-validation (RFECV), an AI feedforward model (specifically an ANN), and CART with bootstrapping.
In this paper, “feedforward model” refers to the architecture of the neural network, where information flows in one direction—from the input layer through the hidden layers to the output layer. This structure is commonly used for predictive tasks that do not involve temporal sequences or dependencies. By using a feedforward approach, we ensure that the model processes data in a straightforward manner, without any cyclical or recurrent connections between layers.
While each technique is established, our study’s innovation lies in combining these methods within a single framework to achieve a more comprehensive and robust prediction of financial distress. Specifically, the application of CART with bootstrapping is relatively new in the financial distress literature, providing a fresh perspective that enhances model stability and accuracy. This approach also addresses common issues like overfitting by improving generalization across different datasets.
By expanding beyond traditional predictive modeling and the commonly used AI techniques in financial distress research, this study fills a gap identified by previous researchers. Our work demonstrates the effectiveness of advanced ML techniques in diverse contexts, particularly using data from the TSX, thereby broadening the applicability of these methods beyond the Asian markets that have been the focus of much prior research.
Moreover, our study introduces RFECV and CART with Bootstrapping as innovative approaches in this field, offering alternatives to the conventional predictive modeling algorithms. We empirically assess these methods, highlighting the importance of considering the unique characteristics of specific datasets and problem domains when developing predictive models. This emphasis on context-specific solutions rather than generic predictive modeling insights underscores the value of our approach in addressing the complexities of financial distress prediction.
The remainder of this paper is organized as follows: Section 2 reviews the existing literature, emphasizing contemporary audit methodologies and the use of ML in research on predicting financial distress. Section 3 details the experimental design, covering aspects such as data collection, preprocessing, the algorithms used, and performance metrics. Section 4 presents the results and offers a thorough analysis of the findings. Lastly, Section 5 concludes the paper and highlights potential directions for future research.
2 Literature review
There has been a lot of work on financial distress prediction, with various methods and models developed to assess the likelihood of a company experiencing financial distress. Some of this scholarship has focused on bankruptcy prediction (du Jardin, 2015; Fedorova et al., 2022; Mai et al., 2019), while others focused on financial distress (Campa and Camacho-Miñano, 2015; Hammami and Hendijani Zadeh, 2022; Veganzones et al., 2023; Zhou et al., 2022). In the early stages of research, financial distress prediction models were primarily based on ratios of financial quantities. This approach was pioneered by researchers such as Altman and Beneish, who developed models like the Altman Z-Score and M-Score, respectively (Altman et al., 2017; Beneish, 1999). Later on, machine and deep learning techniques were also incorporated to enhance the accuracy of financial distress prediction models (Chen and Du, 2009; Song et al., 2023; Tang et al., 2020; Zhao et al., 2023). These models have been widely used in various domains, such as assessing credit risks for financial institutions, aiding investors in making informed decisions, supporting regulatory authorities in monitoring financial stability, and helping managers in evaluating corporate financial health, including the prediction of financial distress.
The literature on financial distress prediction is well-established and continues to evolve, with ongoing research and development focusing on improving the accuracy and effectiveness of these prediction models. In this literature review, we shift gears and discuss the challenges of detecting financial statement manipulation and the crucial role of auditors in maintaining financial credibility and detecting irregularities. We highlight the prevalence of fraud and the need for stakeholders to access accurate financial information through independent audits. The limitations of traditional auditing procedures and the potential of ML based technologies to identify financial distress predictors are also emphasized.
2.1 Current audit methodology and distress prediction
Financial statement manipulation is becoming increasingly prevalent due to auditors’ inability to identify red flags of fraud. Typically, fraudsters exaggerate positive financial positions and conceal negative ones, making it difficult to detect manipulation in financial statements (Blay et al., 2007; Firth et al., 2011; Hartwig et al., 2017; Hilal et al., 2022; Lokanan and Sharma, 2022). Companies manipulate their earnings either by inflating their revenues or deflating their expenses (Eulerich et al., 2018; Filip and Raffournier, 2014; Perols and Lougee, 2011). This manipulation not only limits stakeholders’ access to accurate financial information during corporate distress (DeZoort and Harrison, 2018; Khaksar et al., 2022) but also poses severe consequences for investors and creditors. To address these challenges and ensure the availability of reliable financial data, independent audits have become paramount (DeZoort and Harrison, 2018; Eulerich et al., 2018; Khaksar et al., 2022).
Auditors play a pivotal role in upholding the integrity of financial statements and must continually refine their audit procedures to effectively detect irregularities and manipulations (Akther and Xu, 2020; Oyerogba, 2021). However, they often face challenges in identifying transaction omissions due to inadequately designed audit procedures (Hamilton and Smith, 2021). Given this context, both financial statement users and auditors should prioritize vigilant monitoring of companies to uncover discrepancies, anomalies, or overstated positives in their engagements (Lokanan and Sharma, 2022). Rigorous monitoring can serve as early warning signs, enabling timely actions to mitigate the adverse effects of distorted financial statements (Aslam et al., 2022; Aviantara, 2021; Dechow et al., 1996).
While the engagement approach remains the standard practice in auditing financial statements, there is growing recognition of its limitations in identifying red flags that may indicate potential fraud (Aubert et al., 2019; DeZoort and Harrison, 2018; Sun et al., 2014). Traditional measures like the fraud triangle, as outlined in SAS No. 99, evaluate pressure, opportunity, and rationalization to detect fraudulent activities (Aubert et al., 2019; Davis and Pesch, 2013; DeZoort and Harrison, 2018). However, these methods have been criticized for their limited ability to assess patterns of financial distress that create the conditions for fraudulent activities (Davis and Pesch, 2013; Firth et al., 2011; Lokanan, 2018; Nasir et al., 2019).
As a result, researchers have concluded that more comprehensive investigative strategies are necessary to identify suspicious activities and prevent future instances of fraud (Lokanan, 2015; Morales et al., 2014). One promising approach involves the incorporation of ML technologies to identify predictors of financial distress (Campa and Camacho-Miñano, 2015; Mselmi et al., 2017; Zhao et al., 2023). ML-based approaches should be integrated into the audit process to provide auditors with additional insights and indicators that can help them focus their efforts more effectively. These advanced techniques, while not a replacement for traditional audit practices, offer valuable supplementary tools to enhance financial analysis and auditing, enabling a more effective response to the challenges posed by financial manipulation and distress detection.
2.2 Machine learning for financial distress prediction
Although the application of computational technology is in its early stages, recent studies have shown that ML hold a significant advantage over traditional audit approaches in detecting red flags of fraud in financial statements. More specifically, these researchers found that ML-based algorithms yield high precision, sensitivity, and accuracy scores in detecting fraud (Achakzai and Peng, 2023; Bao et al., 2020; Zhao et al., 2023). Essentially, ML-based tools are more adept at detecting anomalies and red flags of fraud in financial statements than the traditional sampling approach (Hilal et al., 2022; Mselmi et al., 2017). More specifically, researchers have found that ML can identify and report more accurately on true positives and negatives, lending greater support to the use of analytics in fraud risk management processes (Blay et al., 2007; Kuizinienė et al., 2022; Lokanan and Sharma, 2022; Qiu et al., 2021).
Researchers have employed various ML techniques to predict fraud in financial statements. Techniques such as neural networks, SVM, and decision trees have been employed to predict anomalies and uncover fraudulent accounting practices in organizations (Achakzai and Peng, 2023; Hilal et al., 2022; Kim and Kogan, 2014; Mselmi et al., 2017). The application of ML- technologies enables more effective processing of larger volumes of data, while generating more accurate predictions to reduce instances of false positives (Achakzai and Juan, 2022; Hilal et al., 2022; Kim and Kogan, 2014). Others have found that ML models capture patterns and trends in the data and provide opportunities to gain deeper insight into potential warning signs of fraud within financial statements that may often be missed by human analysts (Cho et al., 2020; Hajek and Henriques, 2017).
Integrating ML-based analytics with traditional statistical methods has proven more efficient than manual analysis to detect anomalies in financial statements (Achakzai and Juan, 2022; Albizri et al., 2019; Alden et al., 2012; Kim and Kogan, 2014). In particular, research has found that combining ML with the existing Beneish M-score produces superior results compared to manual computation as a means of predicting financial distress (Papík and Papíková, 2022). Subsequent work by Papík and Papíková (2022) also showed that predictive models developed using data mining and ML effectively identify accounting fraud at a much higher rate than traditional methods. By combining and utilizing the best features of ANN, SVM, and ensemble models, these algorithms have proven to be highly effective in predicting financial distress and detecting fraud (Mselmi et al., 2017; Nasir et al., 2021; Zhao et al., 2023). This paper adds to this stream of literature by presenting an investigation in which ML technology are used to predict financial distress and detect earnings manipulations using data from the TSX. The Beneish M-score serves as a proxy for manipulation. Based on the preceding literature review, we attempt to predict financial distress and detect earnings manipulations by asserting that:
Where,
“f” stands for “function” and indicates that financial distress is a function of, or is determined by, the variables listed—profitability, liquidity, efficiency, solvency, and operational performance indicators.
3 Experimental setting
This paper employs classification models to assess financial distress and detect earnings manipulation in TSX-listed companies. Our analysis aims to reveal critical factors for predicting financial distress and assess the likelihood of future distress occurrences. Our objective is to identify the most relevant features for predicting financial distress and build models that accurately classify firms at risk based on various financial ratios. This predictive approach has demonstrated effectiveness in the early detection of financial distress and warning of earnings manipulation (Mselmi et al., 2017; Sun et al., 2014; Zhao et al., 2023).
3.1 Data collection
The dataset used in this study was sourced from the TSX, one of the world’s largest stock exchanges and a constituent of the S&P/TSX Composite Index, encompassing the top 500 Canadian companies. This exchange boasts a substantial market capitalization of CAD$2.1 trillion and is home to numerous prominent Canadian banks, insurance companies, and financial institutions. The Toronto Stock Exchange (TSX) houses Canada’s leading publicly listed corporations, including diverse industries like banking, insurance, and financial services. A sample size of 464 enterprises was established by using meticulous data screening to exclude companies with missing data. These companies were selected based on their substantial contribution to the Canadian economy and their public accessibility of financial information. These enterprises function under a legal and political framework specific to Canada and may vary from the social, cultural, and political atmospheres experienced by companies in other areas. This differentiation enables the research to provide valuable contributions to financial distress prediction in the Canadian market. However, the conclusions of this study may have limited relevance to other international markets.
Compiled from the fiscal year-end financial reports as of March 31, 2021, the dataset covers a time significantly affected by the COVID-19 epidemic. The significance of this context cannot be overstated, since the epidemic has potentially obscured the distinction between financially distressed and financially stable companies, therefore confounding the investigation. The choice of the sample size was determined by the availability of comprehensive financial data for these firms, therefore assuring the reliability of the model’s predicted outcomes. The dataset comprises essential financial measures that are crucial for forecasting financial difficulties, including profitability, liquidity, solvency, and efficiency metrics. Hence, the aim of this study is to investigate the efficacy of machine learning algorithms in accurately forecasting financial hardship, with a specific emphasis on the distinctive setting of the TSX.
3.2 Variables and measurements
3.2.1 Independent variables
The independent variables used to predict financial distress, as detailed in Supplementary Appendix 1, encompass a range of essential indicators of corporate financial health, including profitability, liquidity, efficiency, solvency, and operating performance. Given their well-established status as standard metrics for assessing a company’s performance, we refrain from delving extensively into these common practices. Instead, our focus lies in elucidating their applicability for ML models in the context of financial distress prediction. These ratios serve as vital input features for our predictive models, enabling us to harness the power of ML to identify patterns, interactions, and predictive signals within these financial indicators.
3.2.2 Profitability ratios
Profitability ratios, such as return on assets (ROA), gross profit margin (GPM), net profit margin (NPM), return on equity (ROE), and net profit to total assets (NPTA), have been recognized as potent predictors of financial distress (Demetriades and Owusu-Agyei, 2022; Fang et al., 2017; Hajek and Henriques, 2017; Sun et al., 2014). In the context of ML, these ratios play a pivotal role as they capture a company’s financial performance, offering valuable insights into its ability to generate revenues efficiently. These ratios act as data-driven inputs, enabling ML models to discern intricate relationships between profitability metrics and the likelihood of financial distress. Profitability ratios are one of the most fraud-sensitive types of ratios in that their values differ significantly between financially distressed companies (true positives) and non-distressed companies (false positives), making them useful for predicting financial distress.
3.2.3 Liquidity ratios
Liquidity ratios evaluate a firm’s ability to meet short-term financial obligations (Hajek and Henriques, 2017; Huang et al., 2017). Some liquidity ratios used in previous research to predict financial distress are the current ratio (CR), quick ratio (QR), days receivable turnover (AccTR), working capital to total assets (WCTA), cash-to-current liabilities (CCL), and cash-to-total assets (CTA) (Albizri et al., 2019; Fang et al., 2017; Hajek and Henriques, 2017; Song et al., 2014). In the realm of ML, these ratios are invaluable as they provide a real-time snapshot of a company’s ability to meet its immediate financial obligations. Incorporating these liquidity ratios into our predictive models allow us to leverage ML to uncover trends and identify liquidity-driven indicators of financial distress.
3.2.4 Efficiency ratios
Previous research has shown that efficiency ratios, such as accounts days receivable turnover (AR), days accounts payable turnover (AP), asset turnover (AT), and inventory turnover (InvT), have been widely recognized as valuable indicators of a company’s financial health (Albizri et al., 2019; Dimitropoulos and Asteriou, 2009; Fang et al., 2017; Habib et al., 2020; Zainudin and Hashim, 2016). In the context of ML, these ratios are of paramount importance as they offer insights into the competitive landscape and profitability of a firm. Their incorporation in our analysis enables us to harness ML to uncover patterns related to operational efficiency and their implications for financial distress. By doing so, we enhance our predictive models’ ability to identify nuanced indicators of distress rooted in operational metrics.
3.2.5 Solvency ratios
Solvency ratios, such as debt to equity (DEQ), total liabilities to total assets (TLTA), net profit to total liabilities (NPTL), cash to total liabilities (CTL), current assets to total assets (CATA), and current liabilities to total assets (CLTA), have been used to assess organizations’ probability of default (Albizri et al., 2019; Craja et al., 2020; Fang et al., 2017; Huang et al., 2017). Within the fields of ML, these ratios provide valuable insights into a company’s ability to withstand financial challenges. By incorporating solvency ratios into our analysis, the ML models can be leveraged to explore the complex relationships between financial structure and financial distress. This approach enhances the capacity of our models to identify subtle yet crucial indicators of potential financial distress in companies.
3.2.6 Operating performance
Others have employed earnings and cash flow ratios to assess the operational performance of companies in the context of financial distress prediction. Ratios such as Earnings Before Interest and Taxes (EBIT), Earnings Before Interest, Taxes, Depreciation, Amortization, and Rent (EBITDAR), and Earnings Before Interest, Taxes, Depreciation, and Amortization (EBITDA) have been widely used in financial distress research (Albizri et al., 2019; Campa and Camacho-Miñano, 2015; Li, 2016). In the context of ML, these ratios provide crucial inputs that allow us to assess the financial health of a company based on its operational efficiency. By incorporating these ratios into our analysis, the ML models are able to delve deeper into the operational dynamics that underpin financial distress prediction.
3.2.7 Control variables
Several control variables were used to isolate and measure the specific effect of the independent variable on financial distress while keeping other relevant factors constant (Bernerth and Aguinis, 2016; Farber, 2005). In this study, a comprehensive set of control variables was included to evaluate the precise impact of profitability, liquidity, efficiency, solvency, and operational variables on predicting financial distress. These variables encompassed the firm’s credit rating, R-Score, Enterprise Value (EV), Market Capitalization (MarketCap), revenue growth (Rev_G), net income growth rates (NI_G), dividend growth (D_G), Corporate Governance Score (CG_Score), Audit and Risk Oversight (ARO), Board Structure (BoardS), Shareholder Relations (ShareR), and Compensation (Comp). By including these control variables in our analysis, we aimed to account for potential confounding factors and variations in firm characteristics (Becker et al., 2016; Bernerth and Aguinis, 2016). The inclusion of control variables provides insights into how the chosen financial and operational indicators worked alone and together to predict financial distress.
3.3 Dependent variable
The dependent variable for this project is the Beneish M-score (Beneish, 1999), which is used as a proxy for financial distress, given that companies often manipulate earnings when they are under financial pressure. The Beneish M-score is one of the best accounting indicators for predicting financial distress and detecting earnings manipulation (Albizri et al., 2019; Aviantara, 2021; Maniatis, 2022; Repousis, 2016). The Beneish M-score is a probabilistic model that uses financial ratios, which are categorized into eight variables, to detect earnings manipulation in a company’s earnings. Companies with higher M-Scores tend to manipulate their earnings because they are experiencing financial distress. Others noted that companies could use the “M-score models and data mining for an early indication of financial distress or red flags for detecting financial fraud” (Tarjo and Herawati, 2015, p. 2). In a more recent study of the M-score model, Beneish and Vorst (2022) claimed that a cost-based assessment of models is preferable to traditional model comparison measures. We use the M-score as an indicator of potential manipulation in financial statements. In our analysis, a higher absolute value of the M-score, whether positive or negative, is associated with a greater likelihood of manipulation. To operationalize this, we set a dummy variable to 1 for manipulators when the M-score is smaller than −2.22 and to 0 for non-manipulators when the M-score is greater than −2.22. Therefore, our approach considers both positive and negative M-score values as potential indicators of manipulation, with higher absolute M-score values suggesting a stronger likelihood of manipulation. The formula to represent financial distress in the earnings manipulation modeling is shown in Equation 1:
3.4 Machine learning workflow
Figure 1 illustrates the workflow employed in this project to construct a classification model capable of assessing whether a firm has engaged in financial manipulation. The process begins by gathering data suitable for building the classification model, followed by preprocessing the features to identify outliers or noise in the data. Preprocessing also includes standardizing the data so that all observations are within the same range. Subsequently, the data is split into train and test sets, with the test set acting as an unseen sample from which to evaluate model performance. Finally, the evaluation of the model takes place using validation techniques on the test set before making the final prediction.

Figure 1. Overview of the machine learning workflow.
3.4.1 Data cleaning and preprocessing
Data cleaning is a critical step in the data preprocessing pipeline and is essential for obtaining meaningful and reliable insights from the data. A check for duplicates indicates that there were none in the dataset. The feature “Rating” represents the ratings from Moody’s and ranges from “Aaa” to “C.” These letters were replaced with integers, where “Aaa” = 1 and “C” = 9 the lowest rating. Outliers were identified using the Z-score method, with a threshold of ±3 (Salgado et al., 2016). Data points exceeding this threshold were considered potential outliers (Chikodili et al., 2021) and removed to prevent them from disproportionately influencing the model’s performance and skewing results. While outliers can sometimes indicate distressed companies due to atypical or suspicious behavior, removing extreme outliers ensures that the model generalizes effectively across various scenarios. By focusing on the M-score as our primary measure of distress, we ensure that our model is identifying meaningful indicators of financial instability rather than being misled by extreme outliers that may obscure the true patterns of distress. Removing these outliers helps maintain the integrity of the dataset, allowing the model to focus on the relevant predictors of distress as defined by the M-score, without being disproportionately influenced by unrelated anomalies. Thus, while outliers may sometimes reflect distress, the M-score provides a more accurate and robust method for detecting such conditions.
Missing values were imputed using the K-nearest neighbors (K-NN) method, which is particularly effective when missing data is ≤40% (Zhang, 2012). Multicollinearity was addressed by removing any features with a Pearson correlation of 0.70 and above from the dataset. While certain preprocessing steps may imply normality, the robustness of our approach does not strictly depend on this assumption. We also performed a variance inflation factor analysis to eliminate features that were highly correlated within the dataset.
The dataset exhibited a notable imbalance, with approximately 88% of the firms categorized as “not distressed” and the remaining 12% classified as “distressed.” To rectify this imbalance and create a more equitable representation of both classes, we employed the SMOTE+ENN technique. SMOTE+ENN combines the Synthetic Minority Over-sampling Technique (SMOTE) with the Edited Nearest Neighbors (ENN) algorithm to effectively address the class imbalance issue (Puri and Kumar Gupta, 2022). SMOTE generates synthetic samples for the minority class by interpolating between existing instances, thus augmenting the distressed samples in the dataset (Lokanan, 2023). Subsequently, the ENN algorithm identifies and eliminates noisy or redundant data points to enhance the overall quality of the dataset (Sisodia et al., 2017). This process ensures that the models have a more balanced and representative dataset to learn from, ultimately improving their predictive performance in identifying financial distress. As seen in Equation 2, the financial distress class consists of only 12% of the labeled data. After oversampling, the train and test dataset had equal samples (195 instances) of class 1 and class 0.
The min-max scaling technique was applied to the dataset to normalize the features, ensuring that they all fall within the same range. Normalization is a crucial preprocessing step in ML as it compresses all the variables to a common scale, preventing certain features from dominating others during the modeling process (Islam, 2021; Singh and Singh, 2020). Min-max scaling specifically transforms the values of each feature to lie between a specified range, typically 0 and 1. By compressing the variables between 0 and 1, min-max normalization helps to maintain the integrity of the data’s distribution while ensuring that all attributes contribute equally to the modeling process.
3.4.2 Types of experiments
As can be seen in Table 1, the experiments conducted in this study encompass a diverse set of classifiers, algorithms, and techniques. Linear classifiers, such as logistic regression, are employed for predictive modeling. Ensemble classifiers, notably random forest, serve a dual purpose, facilitating both predictive modeling and feature selection. Tree-based classifiers, including decision trees and CART, are utilized for predictive modeling and RFECV. Finally, neural networks, specifically ANN, are harnessed for predictive modeling. These experiments provide a comprehensive evaluation of the effectiveness of these various methods in predicting financial distress within the specific context of TSX-listed firms.

Table 1. Types of experiments.
To perform our experiments, we divided the dataset into two subsets: a training set comprising 75% of the data and a test, or holdout set containing the remaining 25%. The model was then trained using the training data, enabling it to make predictions for the response variable on the test data, ensuring evaluation based on unseen observations. By randomly selecting samples from the dataset, we prevent any inherent data ordering from biasing our results. We also employed GridSearchCV to optimize the predictive models (Botchey et al., 2020; Lokanan, 2022).
3.4.3 Hypermeters used for tuning
Table 2 presents a detailed account of the parameters used to fine-tune the ML models within the study. The tuning process was important in optimizing the models to achieve the best possible performance. While some models, such as the predictive and AI feedforward models, benefited from the automated tuning provided by GridSearchCV, it is important to note that this approach came at the cost of computational resources due to its resource-intensive nature. In contrast, manual tuning was used for the RFECV and CART models. This hands-on calibration process allowed for a more tailored and efficient configuration of RFECV and CART models, resulting in noticeable improvements in predictive accuracy compared to default settings. By manually adjusting the hyperparameters, we gained valuable insights into how each parameter influenced the model’s predictions, particularly in the context of financial distress prediction. The ability to exert precise control and customization over model parameters proved invaluable, especially when dealing with intricate financial datasets or when specific constraints or requirements needed to be met for accurate distress prediction. This approach provided a deeper understanding of the interplay between hyperparameters and model performance, ultimately leading to enhanced predictive capabilities.

Table 2. Hyperparameter tuning.
4 Algorithms and parameters tuning
4.1 Logistic regression
In our analysis, logistic regression was employed as the benchmark algorithm to assess model performance. Logistic regression is a supervised learning technique used to estimate or predict the likelihood of a binary event occurring in linear data (Lokanan and Liu, 2021; Lokanan and Sharma, 2022; Papík and Papíková, 2022). To evaluate the model’s predictions, we compared them against a predefined threshold. This threshold, which determines the classification of instances into binary categories, was established based on best practices and domain expertise. It plays a crucial role in interpreting model output and making predictions. The selection of this threshold was made by considering the specific context and objectives of the analysis and ensuring that it aligns with the desired balance between sensitivity and specificity in the classification task. The mathematical formula of logistic regression is represented in Equation 3:
where,
y is the predicted output,
b0 is the bias or intercept term, and
b1 is the coefficient for the single input value (x).
Each column in the input data contains a b coefficient derived from the training data (Lokanan and Sharma, 2022; Papík and Papíková, 2022). Logistic regression is one of the most common ML classification techniques owing to its ease of implementation, functionality, and effectiveness in categorizing new information (Nasir et al., 2021; Wang and Song, 2011). To evaluate if a company is experiencing financial distress, logistic regression fits the data into a logistic function and compares their values against a predetermined threshold (Abbas et al., 2020; Papík and Papíková, 2022; Wang and Song, 2011).
4.1.1 Decision tree classifier
Decision trees are a type of ML algorithm used to help solve regression and classification problems. The algorithm works by creating a tree-like structure, with each branch representing a different decision (Botchey et al., 2020; Sahin et al., 2013). The tree is created by splitting the dataset into smaller and smaller subsets until each subset only contains one data point. Once the tree is created, it can be used to predict new data points. Decision trees are generally highly accurate and are often used in predictive modeling tasks (Sahin et al., 2013; Tian et al., 2020). However, a single decision tree is often insufficient to produce effective results. For more accurate prediction, random forest classifiers (RFC) have proven to be significantly effective in fraud classification tasks (Aslam et al., 2022; Nami and Shajari, 2018).
4.1.2 Random forest
The random forest algorithm is an extension of the decision tree algorithm that builds multiple trees and combines their predictions (Aria et al., 2021). The random forest classifier (RFC) is useful because it addresses nonlinearity in the data. Unlike the single decision tree, the RFC is a collection of decision-tree classifiers that generate a collection of decorrelated trees (random forest) based on multiple simulations of the actual training sample (Bhattacharyya et al., 2011; Breiman, 2001; Lokanan and Sharma, 2022; Papík and Papíková, 2022). The benefits of RFC over a single decision tree are increased stability, efficiency for large and small datasets, increased accuracy, robustness to noise, reduction of overfitting, adaptivity in handling multiple data attributes, and computational speed that is faster than other ensemble methods (Bhattacharyya et al., 2011; Breiman, 2001; Papík and Papíková, 2022; Wang and Song, 2011). Entropy is used to split the trees for the random forest model. Mathematically, entropy is represented in Equation 4:
where,
P is the probability of the +ve class,
(1-p) = The probability of the −ve class,
Hence, we are able to calculate H(y) for the dependent variable, financial distress.
4.1.3 Support vector machines
SVM is a powerful tool for ML models and has been successfully used in a variety of tasks such as classification, regression, and outlier detection (Ghosh et al., 2019; Rtayli and Enneya, 2020). The SVM algorithm works by finding a hyperplane that best separates the data into classes. To do this, the algorithm first computes a set of support vectors, which are points in the data that are closest to the hyperplane (Botchey et al., 2020; Rtayli and Enneya, 2020). The distance between the support vectors and the hyperplane is called the margin (Rtayli and Enneya, 2020). The SVM algorithm then maximizes the margin to find the optimal decision boundary. When the data are linearly separable from the hyperplanes, then the SVM is represented by the linear formula in Equation 5:
Where
B = (B1, … Bn), and
X = (X1, … Xn) are n-dimensional vectors.
In the event that the data is linearly inseparable, then kernel tricks such as polynomial, Gaussian radial basis, sigmoid, and hyperbolic tangent are applied to map the data into a higher-dimensional space (Botchey et al., 2020). SVM has proven to be a robust algorithm for fraud detection tasks (Botchey et al., 2020; Rtayli and Enneya, 2020). Researchers have used SVM to predict data patterns that may indicate fraud and aberrant patterns in financial transactions (Botchey et al., 2020). By studying historical transaction data, SVM can learn to recognize “typical” transaction characteristics from abnormal transactions (Li et al., 2021; Rtayli and Enneya, 2020).
4.1.4 ANN
ANN has been previously used in fraud prediction and financial distress research with very good performance (Bao et al., 2020; Lokanan, 2022; Mselmi et al., 2017). Owing to the presence of multiple neurons, ANN is a reliable algorithm because it can analyze large datasets, efficiently handle and process nonlinear data, and easily solve complicated tasks (Johnson and Khoshgoftaar, 2019; Lokanan, 2022). Figure 2 presents an illustration of a feedforward ANN. The neural network takes in three input features, processes them through two hidden layers, and produces a binary prediction (either “Distress” or “No Distress”) based on the activations of the neurons in the output layer. The feedforward method highlights factors influencing the output during every step in a neural network, thus allowing for improved predictive accuracy.
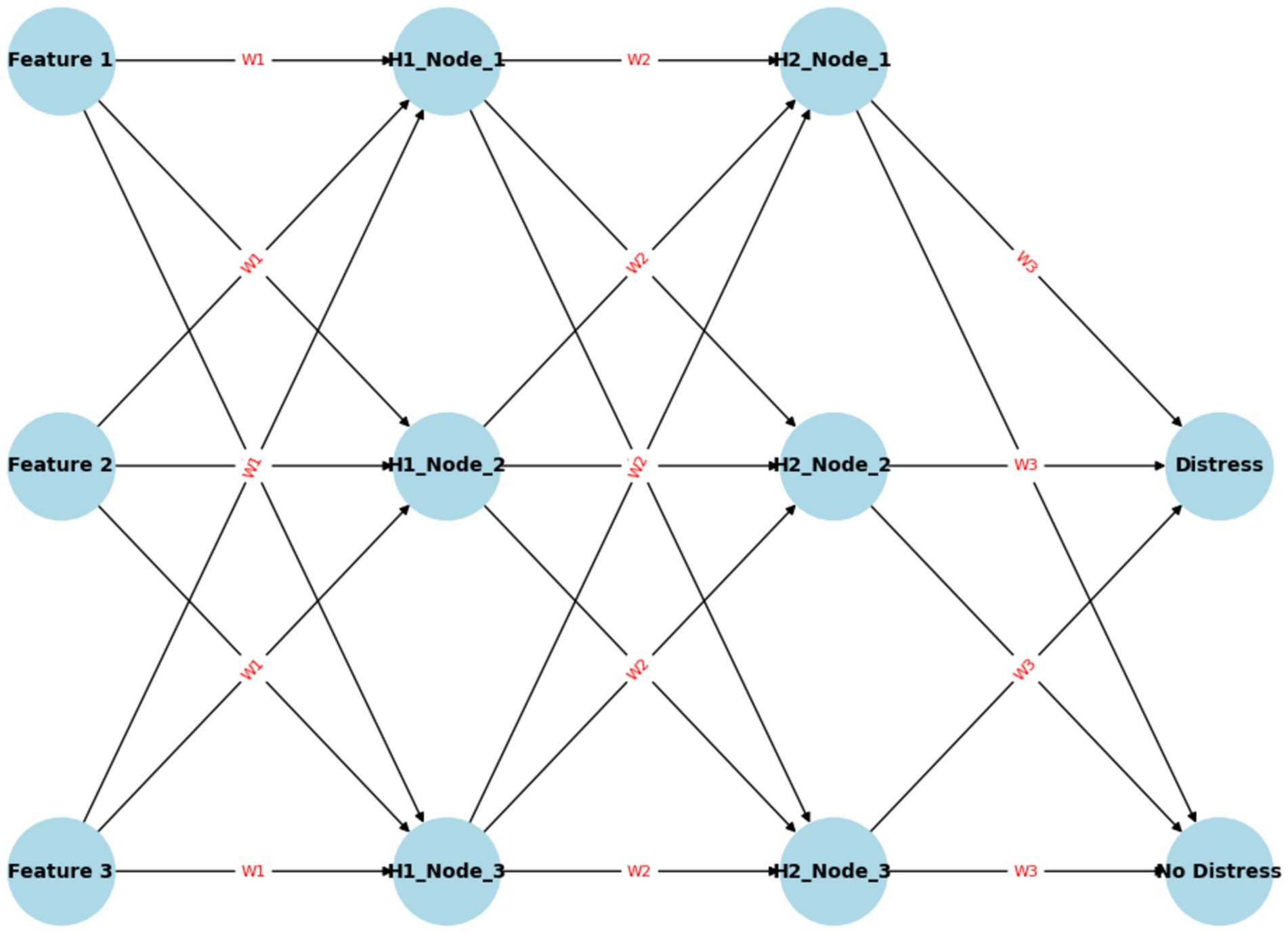
Figure 2. Neural network model.
The network consists of an input layer representing features such as financial metrics (e.g., revenue, debt, profit margins), two hidden layers that transform inputs using weighted sums and biases to capture complex patterns, and an output layer with nodes indicating “Distress” and “No Distress.” The ANN operates as a feedforward neural network, where data flows from the input through the hidden layers to the output, with each connection between neurons having weights (W) and biases (b) to adjust during training. The role of each layer, the parameters involved, and the process of classification are explained to demonstrate how the ANN learns to identify distress through adjusting weights and biases. The mathematical representation of the feedforward ANN is shown in Equation 6:
where,
∑i = 1 represents the summation of the weighted inputs from all connected neural networks.
Wi are the weights assigned to the connections between the input features (predictors) Xi and the neural network.
b is the bias or error term.
∑(x) is the function that computes the weighted sum of inputs and bias to predict the output y. This equation represents the basic operation of a neural network, where inputs are multiplied by their respective weights, summed up, and then passed through an activation function to produce the output.
4.1.5 CART with bootstrapped samples
Bootstrapping is a specific resampling technique where you repeatedly draw random samples, with replacement, from your original dataset to create new samples of the same size as the original. These bootstrapped samples will be analyzed using CART to assess the robustness and stability of the model when applied to different variations of the data. The bootstrapped samples consist of various ratios ranging from 1:1 to 10:1 and represent different ratios of non-distress firms to financial distress firms in a dataset. Each sample is characterized by the ratio, the number of non-distress firms, and the number of financial distress firms. For instance, the first sample has a 1:1 ratio, meaning there are an equal number of non-distressed and financially distressed firms. Subsequent samples exhibit varying levels of class imbalance, with the ratio increasing from 2:1 to 10:1, indicating a decreasing proportion of financial distress firms relative to non-distressed firms. These bootstrapped samples allow for the exploration of model performance under different class distributions of the data, aiding in the evaluation and optimization of predictive models for financial distress. Furthermore, bootstrapping helps estimate the variability of model performance and allows the model to generalize effectively across different data subsets.
4.2 Performance measures
The performance of a classifier can be visualized through a confusion matrix. As seen in Figure 3, the matrix is composed of four quadrants, each representing the predicted and actual values for one class. The quadrants are labeled true positive (TP), false positive (FP), true negative (TN), and false negative (FN). The true positive rate (TPR) is the proportion of cases correctly classified as positive, while the false positive rate (FPR) is the proportion of cases incorrectly classified as positive. The true negative rate (TNR) is the proportion of cases correctly classified as negative, while the false negative rate (FNR) is the proportion of cases incorrectly classified as negative. In general, a classifier with a high TPR and FPR will be more accurate than one with a lower TPR and higher FPR (Botchey et al., 2020; Lokanan and Liu, 2021; Lokanan, 2022).
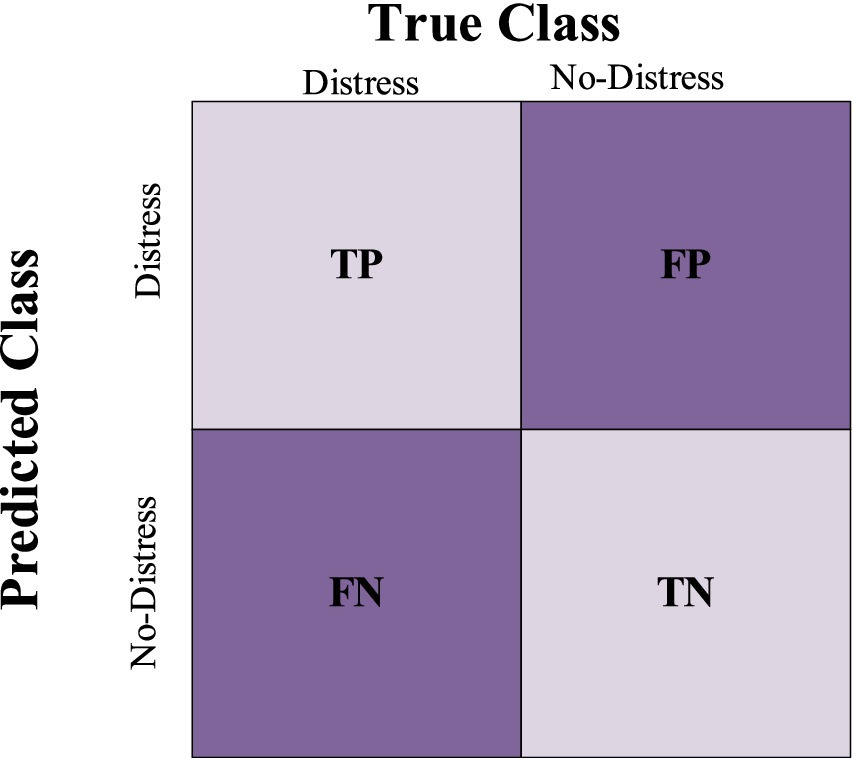
Figure 3. Confusion matrix.
The performance metrics used in this paper are shown in Table 3. Accuracy is the proportion of total observations that the model predicts correctly. Precision is a measure of accurate prediction. In the context of this paper, precision measures how often the classifier is correct when it predicts that a firm is experiencing financial distress. Precision attempts to answer the following question: what proportion of the positive identifications was actually correct? Recall is a measure of the completeness of the model. Recall measures how correct the model was in predicting actual financial distress and answers the following question: what proportion of actual distressed firms were identified correctly? The F-measure combines precision and recall into a single metric, while the receiver operating characteristics (ROC) curve visualizes the trade-off between sensitivity and specificity. Ultimately, the objective is to choose the model that strikes the best balance between accuracy and precision for deployment.
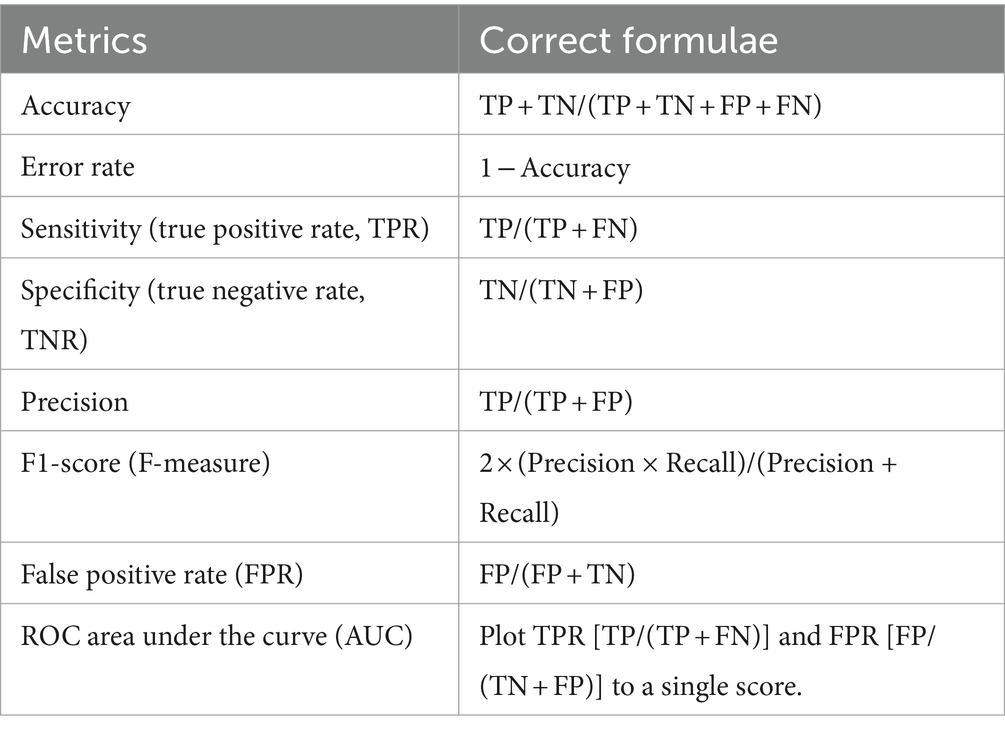
Table 3. Evaluation metrics.
5 Experimental results
5.1 Summary statistics
Table 4 shows the summary results of the explanatory features and their effects on financial distress. While ratios from profitability, solvency, and operational performance show potential signs of financial distress, there are no specific signs in the liquidity and efficiency ratios that strongly indicate financial distress. In terms of profitability, the mean values for ROA, GPM, NPM, ROE, and NPTA are generally lower than zero, indicating potential financial distress. These ratios typically reflect a firm’s ability to generate profits in relation to its assets and equity. As for the solvency ratios, the mean values for DEQ, TLTA, and CLTA are relatively high, suggesting potential financial distress. Higher debt ratios and total liability ratios may indicate increased financial risks. The mean values of the operational performance ratios, namely EBITDAR, EBITDA, and EBIT, are relatively low compared to their respective maximum values. These findings indicate potential financial distress, as these ratios represent the firm’s operational profitability and ability to cover its operating expenses and debts.
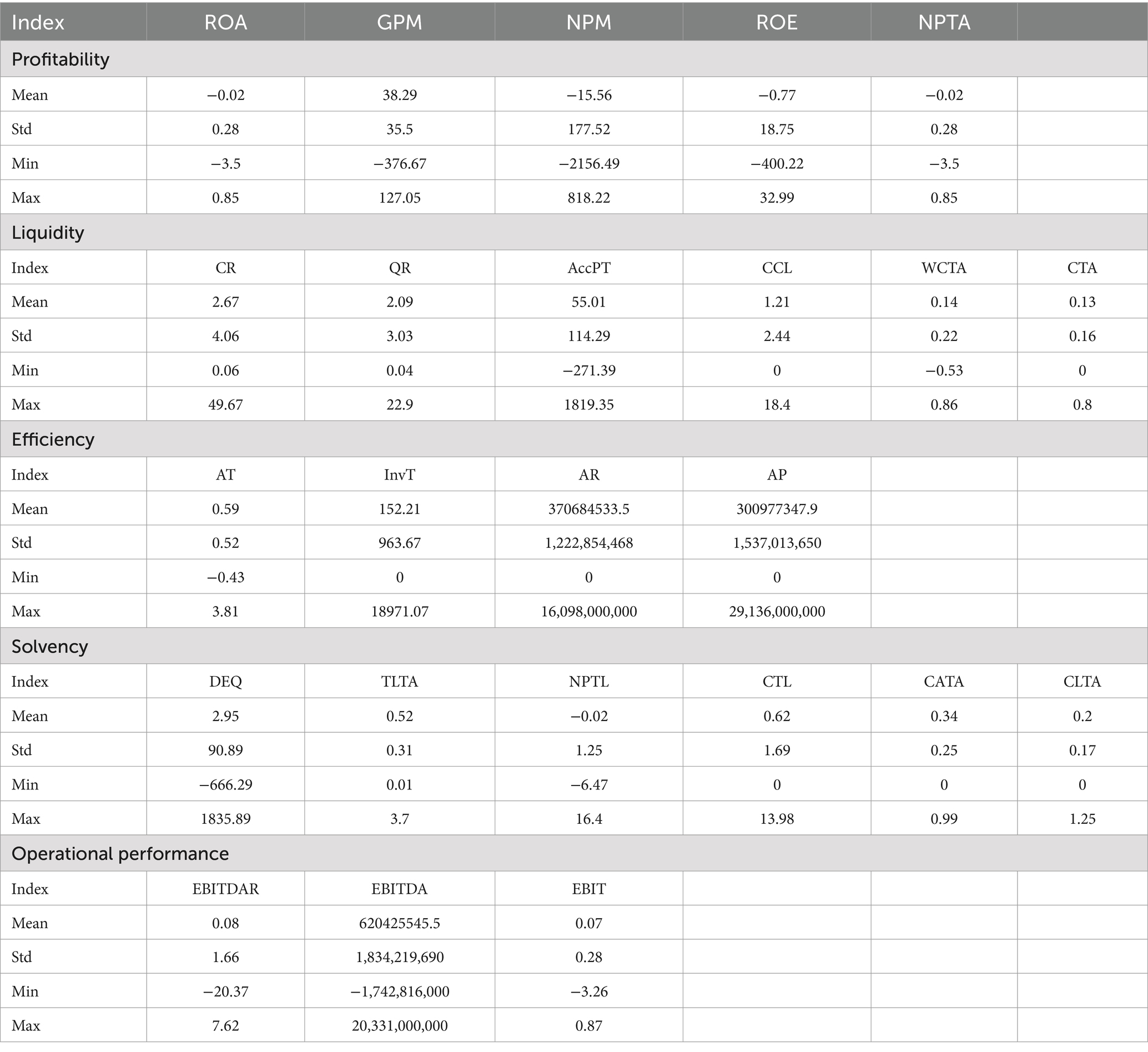
Table 4. Summary results.
5.2 Control variables
Table 5 displays the results of the control variables. The results provide valuable insights into various factors that can potentially influence a company’s financial health and stability. Among these metrics, credit ratings and R_Score are key indicators of a firm’s overall financial health, with an average rating of 6.79 suggesting that many companies in the dataset are relatively stable. However, there is some variability, with scores ranging from 1 to 9, indicating the presence of both strong and distressed firms. When examining financial performance, Enterprise Value and Market Capitalization are critical. The substantial variation in these scores, with a mean Enterprise Value of approximately $6.1 billion and a mean Market Capitalization of around $4.3 billion, reflects differences in company sizes and valuations within the dataset. It is noteworthy that there are companies with negative Enterprise Value, which could indicate severe financial distress. Revenue and income growth are also vital for assessing a company’s performance. The average Revenue Growth of 0.87% suggests relatively modest revenue expansion, while the average Net Income Growth of 1.51% shows a similar trend in profitability. However, the wide standard deviations in these figures suggest significant variations among firms, with some experiencing negative growth, possibly indicating financial distress. Dividend growth is another critical factor. The mean value of 0.58 suggests that, on average, companies experienced positive dividend growth, which may be seen as a favorable financial indicator. However, the wide standard deviation and the presence of negative values (minimum of −1) indicate that there is significant variability in dividend growth rates, and some companies experienced a decline in dividends.
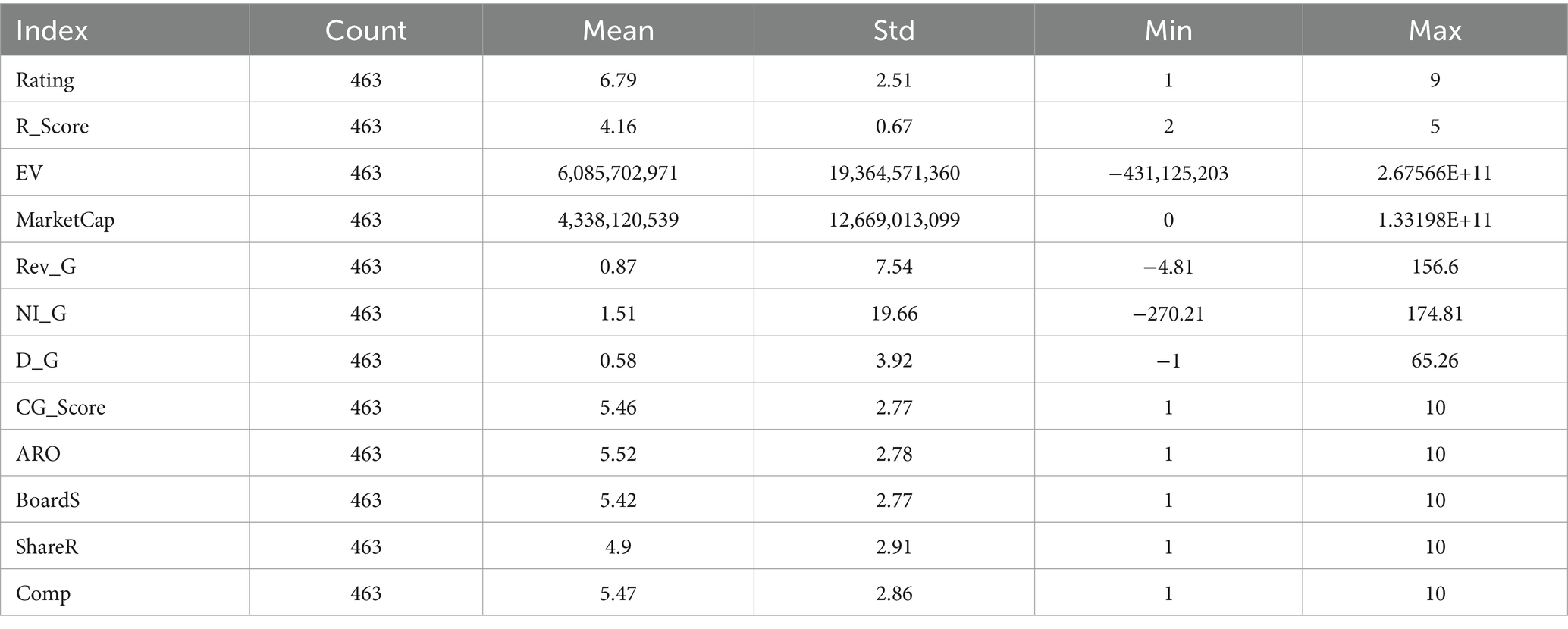
Table 5. Summary results control variables.
Corporate governance is fundamental to long-term stability (Farber, 2005; Nasir et al., 2019). The analysis of corporate governance measures (Corporate Governance Scores, Audit and Risk Oversight, Board Structure, Shareholder Relations, and Compensation Scores) indicates moderate to high scores on average but with significant variability among companies. These findings indicate that, on average, companies exhibit moderate to high scores in various aspects of corporate governance, such as the strengths of audit committees, board structure, executive compensation, and overall corporate governance practices (Basalat et al., 2023; Nour et al., 2024). However, the significant variability among companies in these measures suggests that financial distress is not solely determined by corporate governance scores. While stronger governance practices may exist on average, the presence of weaker governance in some companies implies that financial distress cannot be solely attributed to governance deficiencies (Basalat et al., 2023; Nasir et al., 2019; Nour et al., 2024). Other factors and circumstances likely play a substantial role in the occurrence of financial distress among firms.
Table 6 examines the financial ratios that indicate signs of financial distress in comparison to non-financially distressed firms. As expected, financially distressed firms show concerning signs. On average, these firms have a negative ROA of −0.05%, indicating inefficiency in generating profits from their assets. Although they have a positive GPM of 33.28%, the significantly negative NPM of −69.94% is alarming, pointing to significant losses. Interestingly, the ROE remains positive at 0.42%, indicating that these firms generate some returns for their equity holders. It is worth noting that some distressed firms maintain a negative DEQ ratio, implying a more equity-heavy capital structure. The negative EBITDAR of −0.42 suggests potential operational challenges. The results suggest that distressed firms generally struggle with profitability, incur substantial losses, and have a more conservative debt structure compared to their non-distressed counterparts. Non-distressed firms generally exhibit stronger profitability, more efficient operations, and a more stable financial position compared to their financially distressed counterparts. While these ratios show signs of potential financial distress, further statistical analysis is needed to confirm their predictive power.
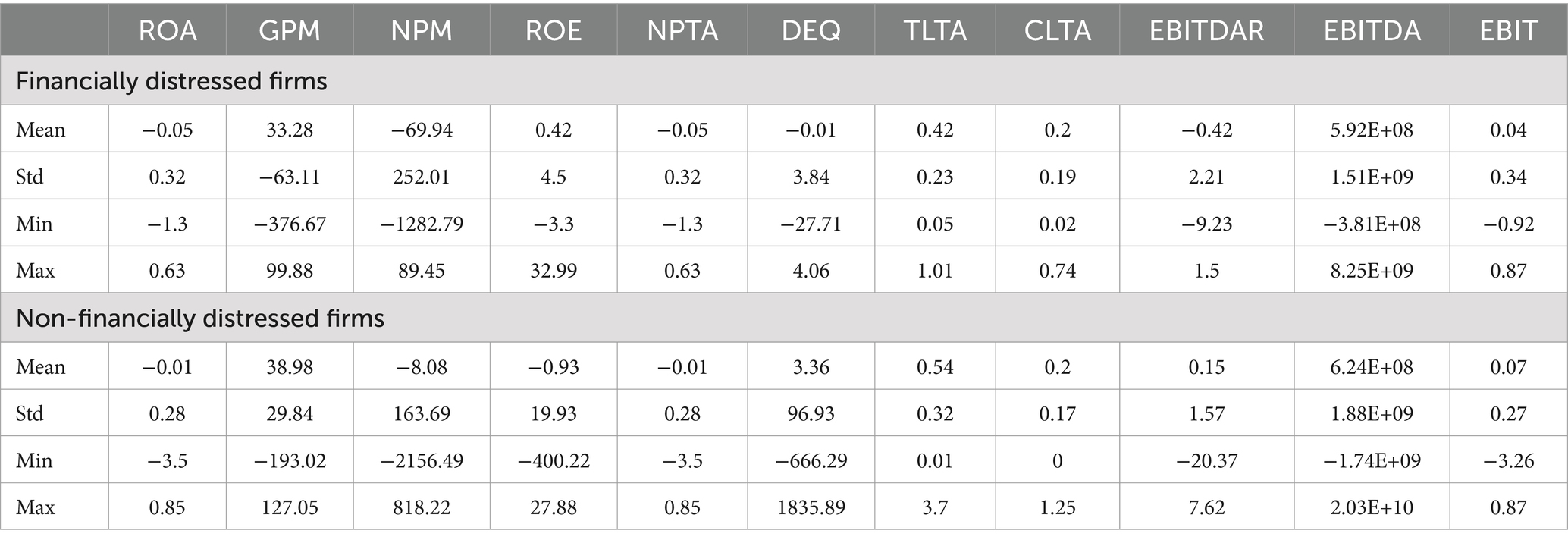
Table 6. Summary results of distressed versus non-distressed firms.
We use the t-test to assess whether there is a statistically significant difference between distressed and non-distressed firms. Table 7 displays the results from the t-tests for distressed and non-distressed firms. The results from the t-test indicate that several financial ratios were found to be statistically significant in distinguishing distressed firms from non-distressed firms. These statistically significant ratios include the QR, NPM, CCL, TLTA, CTL, EBITDAR, and CRA. To put it into context, distressed firms exhibit a significantly higher quick ratio and higher cash-to-current liabilities, indicating potential liquidity challenges. They also tend to have significantly lower net profit margins, which imply operational difficulties. Additionally, distressed firms show a higher TLTA, suggesting a heavier debt burden. Distressed firms tend to have lower EBITDAR compared to non-distressed firms. On the other hand, non-distressed firms have a higher proportion of CTA and CTL, indicating a stronger cash position. These findings underscore the importance of considering these financial metrics when assessing the financial health and risk profiles of companies in both distressed and non-distressed scenarios.
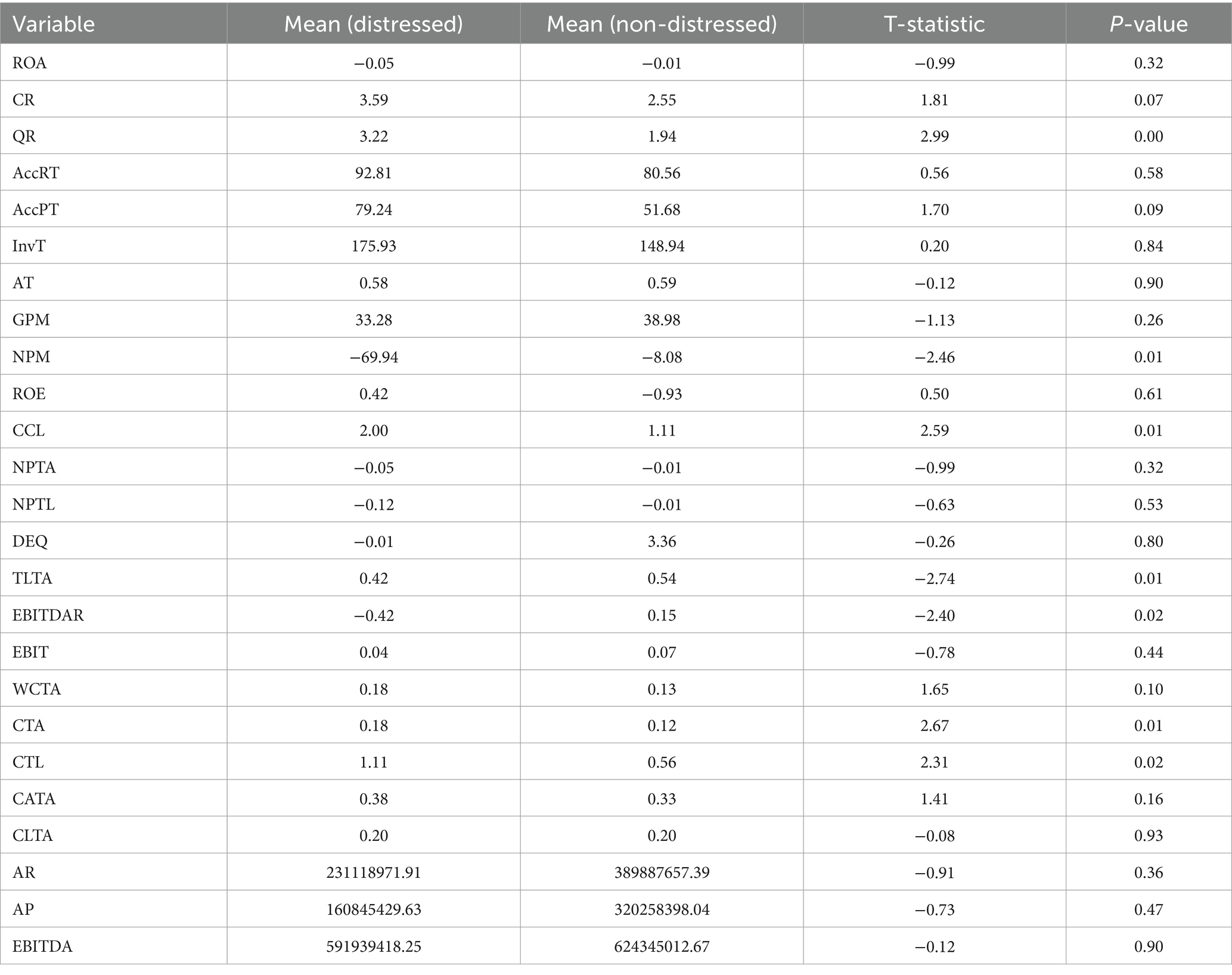
Table 7. Results from t-tests.
5.3 Results from machine learning classifiers
The results from the predictive modeling experiments reveal insightful patterns. As shown in Table 8, all of the predictive models demonstrate high overall accuracy, with logistic regression achieving 91% accuracy, decision tree, random forest, and SVM all achieving 96% accuracy. However, it is worth noting that these models have varying performance in terms of precision, recall, and F1-score. Decision tree and random forest outperform logistic regression and SVM in terms of recall and F1-score, suggesting that they may have better capabilities to correctly identify distressed firms.
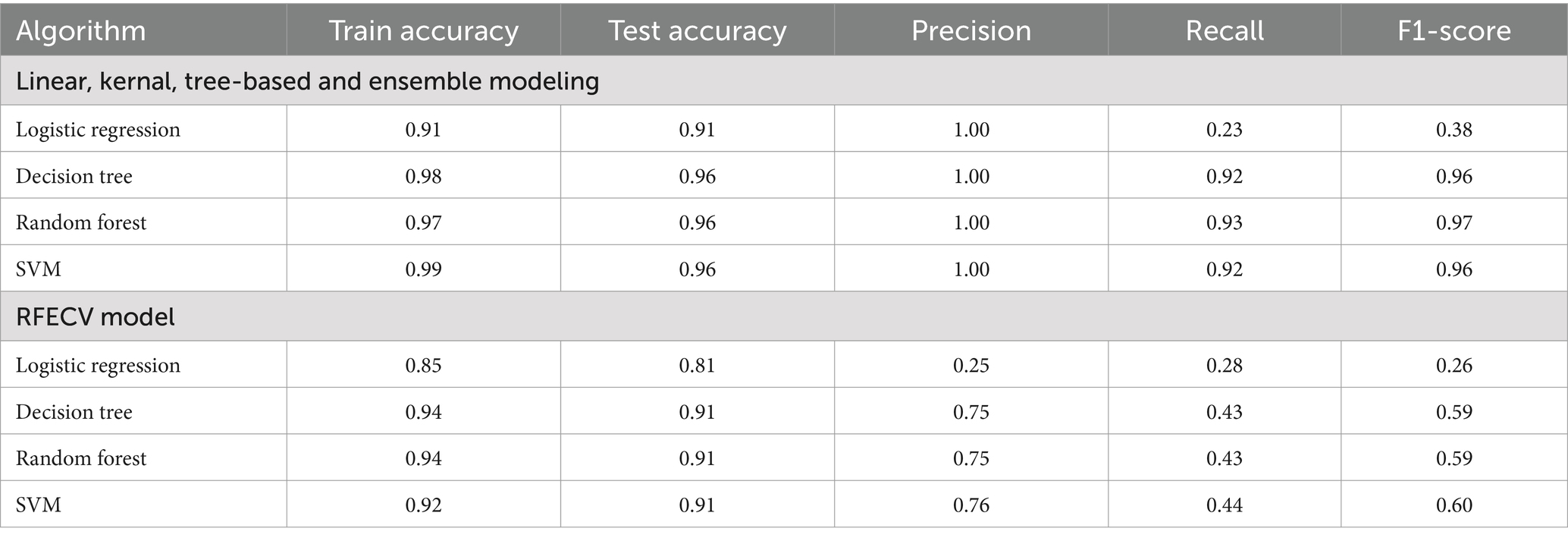
Table 8. Predictive modeling results.
The RFECV experiments indicate a slight decrease in overall accuracy across all algorithms. Logistic regression, decision tree, random forest, and SVM achieve accuracies of 81, 91, 91, and 91%, respectively. Notably, the precision, recall, and F1-score for logistic regression have decreased compared to the predictive model, indicating a potential loss of predictive power. Decision tree and random forest maintain relatively stable performance with strong precision and recall scores, suggesting their robustness in predicting financial distress.
These findings highlight the importance of balancing different evaluation metrics in predictive modeling for financial distress. Assessing the disparity between the training and testing scores, it appears that neither the predictive modeling nor the RFECV model displays indications of overfitting. While high accuracy is desirable, it is equally crucial to consider precision, recall, and the F1-score, as they provide insights into the model’s ability to correctly identify distressed firms and minimize false positives. The SVM, Decision Tree, and Random Forest models, with their balanced precision and recall scores, demonstrate their suitability for predicting financial distress, even in scenarios involving feature selection. Logistic regression, while initially accurate, may require careful feature selection to optimize its performance. Overall, these results emphasize the significance of algorithm selection and experimental engineering in developing effective predictive models for financial distress.
Detecting financial distress among firms boils down to professional judgment and domain knowledge. As shown in Figure 4, a more aggressive approach that flags a large number of firms as experiencing financial distress would have a high recall, as auditors would catch many instances of earnings manipulations that occur (Perols, 2011). However, this approach would also have low precision because it would falsely flag many healthy firms not involved in earnings manipulation as experiencing financial distress. In contrast, a highly conservative approach that only flags the most obvious cases of earnings management would likely have high precision (Perols and Lougee, 2011). However, it would overlook the more subtle instances of earnings manipulation and consequently have a lower recall. To strike the right balance between recall and precision, analysts need to carefully consider how they establish their systems and the criteria they use to flag potential cases of earnings manipulation or firms experiencing financial distress (Baryannis et al., 2019; Lokanan, 2022).

Figure 4. Approaches to detect distress in firms.
5.4 Results from ANN
As displayed in Table 9, the ANN model emerges as the most proficient algorithm for forecasting financial distress. The ANN model surpasses all other ML classifiers in performance, underscoring the potential for neural network models to enhance predictive accuracy in financial distress forecasting when contrasted with conventional classifiers. Notably, the recall score assumes particular significance in this context, as it effectively signifies the model’s capability to identify instances of financial distress, a vital aspect for company stakeholders aiming to preempt bankruptcy risks (Almaskati et al., 2021; Aviantara, 2021; Sun et al., 2021). The noticeable uptick in predictive accuracy offered by the ANN model, in comparison to its traditional ML classifiers, substantiates the rationale for corporations to persist in their investments in AI-based tools for financial distress prediction and detection.

Table 9. ANN performance.
5.5 CART with bootstrapping
Table 10 presents the outcomes derived from the CART model employing bootstrapped samples. The results indicate varying performance levels across different sample ratios, with the 3:01 and 6:01 ratios consistently outperforming the other samples. In this context, the ratio “3:01” means there are three normal transactions for every one financial distress transaction, helping to balance the dataset during model training. These two ratios consistently achieve higher test accuracy, test F1-scores, and test AUC values. Several factors could contribute to their superior performance, including the potential presence of more pertinent features for distinguishing between distressed and non-distressed firms or the model’s capacity to glean insights from the limited distressed samples. Additionally, dataset-specific characteristics or distinct financial behaviors exhibited by firms in the 3:01 and 6:01 ratios may favor the CART model’s predictive abilities. The model appears to generalize well to unseen data and accurately identify instances of financial distress. As the class imbalance ratio decreases, transitioning from 3:01 to 6:01, the models maintain their proficiency in accurately classifying the majority class (normal transactions) during training. Nevertheless, there is a slight decline in overall performance, particularly concerning the classification of the minority class (financial distress transactions). This decline is expected, as classifying the minority class becomes more challenging in the presence of a higher-class imbalance.
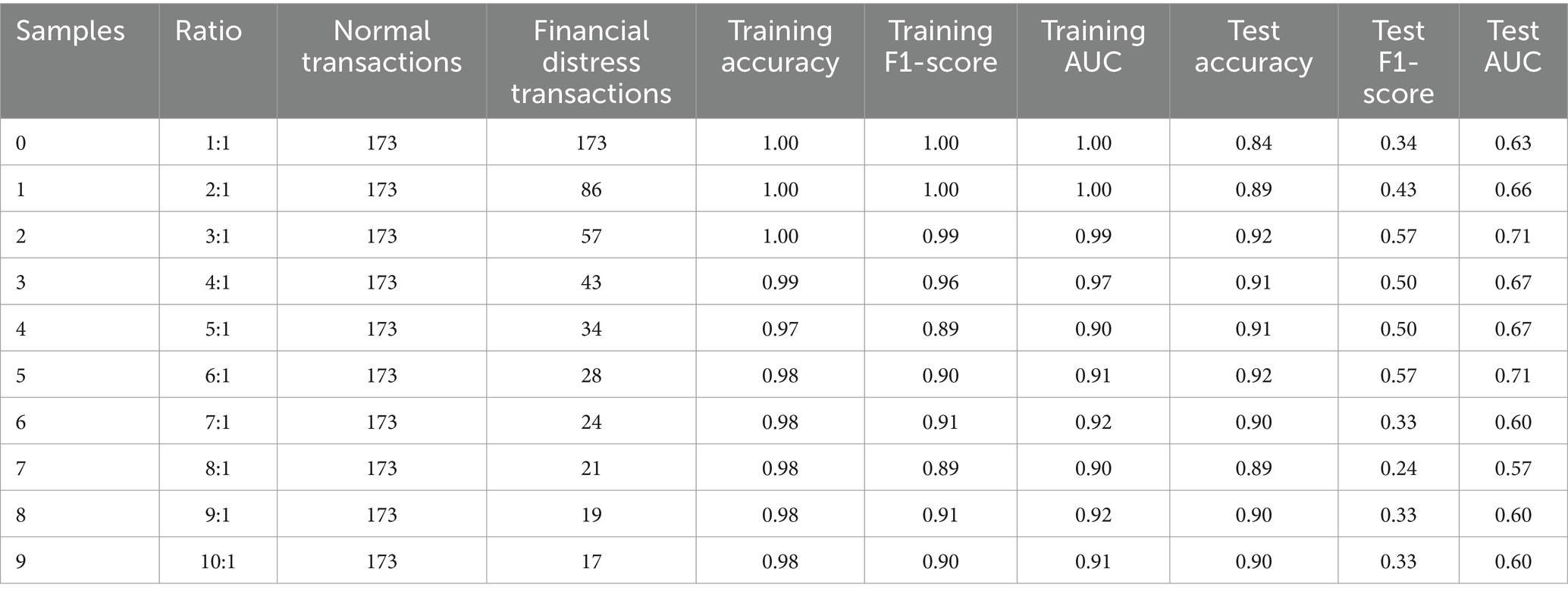
Table 10. Bootstrapped samples with CART.
5.6 Feature relevance
Figure 5 displays the coefficient analysis of the top 10 features for predicting financial distress, as determined by the random forest model. Revenue growth emerges as the most significant predictor, indicating that the rate of revenue growth strongly influences the likelihood of financial distress. Close behind is the dividend growth rate, which also plays a substantial role. A higher dividend growth rate can be a warning sign for potential financial instability, as it may suggest that the company is overcommitting to its shareholders at the expense of its financial stability. The random forest model’s ability to prioritize these features underscores their critical importance in the context of financial distress prediction.

Figure 5. Top 10 feature relevance.
Among the various financial ratios considered in the study, cash-to-current liabilities stands out as having a notable impact on the predictive accuracy of the models. This suggests that the amount of cash a company holds in relation to its current liabilities is a critical factor in assessing its financial stability. Additionally, the company’s profit margins stand out as an essential predictor. Lower GPM values may indicate that the company is struggling to maintain profitability, potentially leading to financial distress. The amount of cash available to pay off liabilities is also significant in predicting financial distress. A higher CTL ratio suggests that the company has sufficient cash to cover its liabilities, which can be a protective factor against distress. EBIT and EBITDAR are also prominent features. Their presence in the top 10 predictors underscores the importance of operational profitability for financial stability.
Table 11 provides insights into key features for predicting financial distress by analyzing the mean and standard deviation. Distressed firms tend to have higher mean values in revenue growth, but with significant variability. Their dividend growth rates are lower on average, with greater variations. On average, financially distressed companies tend to have a higher cash-to-current liabilities ratio compared to non-distressed companies. However, there is more variability in the CCL ratio among financially distressed companies, as indicated by the larger standard deviation. This finding may imply that having a relatively higher cash position in relation to current liabilities could be a financial characteristic somewhat associated with financial distress. Distressed firms have lower profitability, although with substantial variability. The CTL ratio suggests that distressed firms tend to have a higher cash reserve relative to total liabilities, but with greater variability. EBIT and EBITDAR ratios show minimal variations and minor differences in means. NPM stands out with significantly lower mean values and a wide standard deviation for distressed firms, highlighting their financial struggles and considerable profitability variation. These findings underscore the need for a nuanced financial distress prediction approach, considering central tendencies and variability.
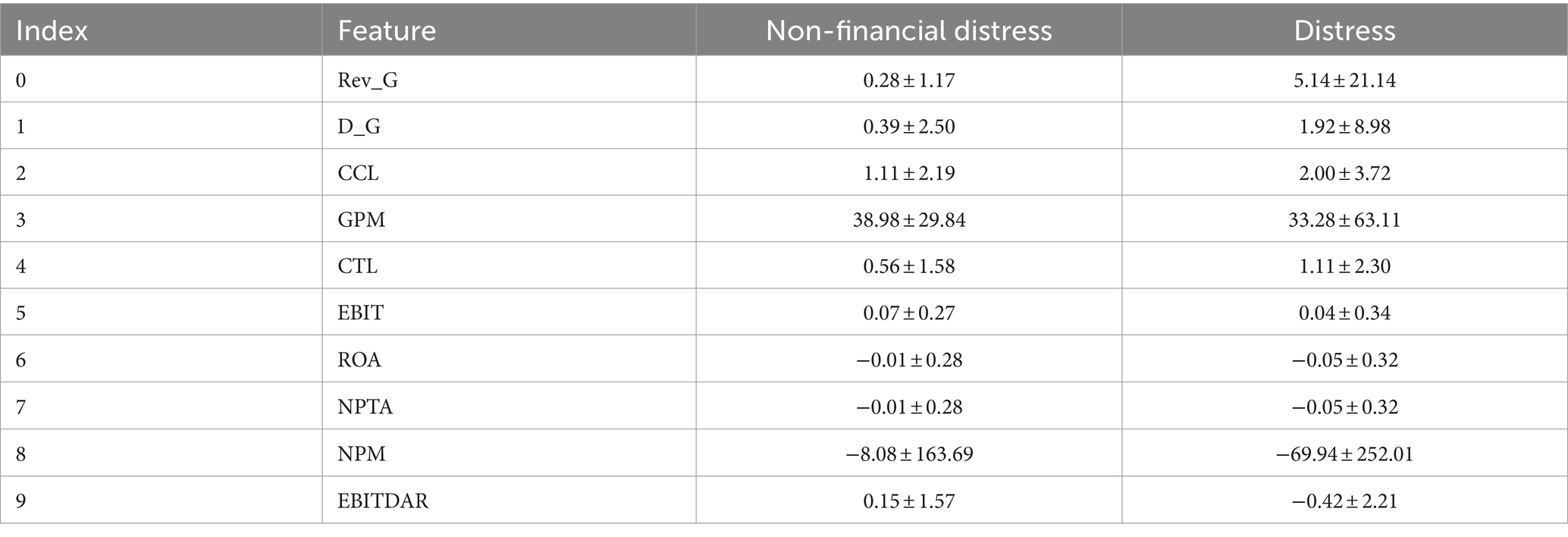
Table 11. Top features mean and standard deviation.
6 Discussion
In this study, we explored the potential of ML algorithms for predicting financial distress on the TSX using the Beneish M-score as a proxy for the target outcome. The TSX dataset includes a wide range of financial variables for listed companies, which, when evaluated using ML-based algorithms, can construct efficient predictive models. Our results reveal critical insights into the potential indicators of the financial health of companies listed on the TSX. Notably, revenue and dividend growth, cash-to-current liabilities, gross profit margins, and cash available to fund liabilities emerged as the top features for predicting financial distress. These findings align with prior research, such as Hajek and Henriques (2017), Mselmi et al. (2017), and Zhao et al. (2023), who also identified lower liquidity, profitability, and solvency ratios as key predictors of financial distress. However, our study contributes to the literature by providing a Canadian context, thereby broadening the geographical scope of financial distress prediction research, which has predominantly focused on Asian markets (Achakzai and Peng, 2023; Jiang and Jones, 2018).
Our results corroborate findings from global studies, such as those conducted in South Korea (Shaked and Altman, 2016; Bae, 2017), Taiwan (Huang and Yen, 2019), and the UAE (Sreedharan et al., 2020), which also emphasize the role of liquidity and profitability ratios in financial distress prediction. However, our study introduces new insights by highlighting the significance of revenue and dividend growth in the Canadian market, which may be reflective of unique economic conditions or corporate governance practices prevalent in Canada. These contrasts with other global studies underscore the need for context-specific models that can account for regional differences in financial behavior.
The integration of various ML algorithms, particularly the use of CART with bootstrapping and RFECV, underscores the importance of employing diverse methodologies to enhance the robustness of financial distress prediction models. Our findings suggest that while standalone ML models are effective, the combination of different techniques can lead to more accurate and interpretable outcomes. This study demonstrates that a multi-faceted approach to model development, which includes feature selection and dataset balancing, can significantly improve the prediction of financial distress.
One of the strengths of this study is the application of RFECV to systematically identify and select the most relevant features, enhancing both the interpretability and efficiency of the models. Additionally, the use of CART with bootstrapping provides a practical and transparent framework for predicting financial distress, particularly in the context of TSX-listed firms. However, the study also has limitations, including potential biases introduced by the selection of features and the possibility of overfitting due to the relatively small sample size. Furthermore, while our models performed well in a Canadian context, their generalizability to other markets may be limited, suggesting a need for further research in diverse geographical settings.
The findings from this study have important practical implications for auditors, regulators, and company management. By employing ML-based tools, these stakeholders can enhance the detection of financial distress and earnings manipulation, improving the accuracy and reliability of financial statements. The application of these predictive techniques to audit engagements can provide auditors with additional support, enabling them to react swiftly to signs of financial distress and protect the integrity of their engagements. Additionally, companies can use these models to proactively monitor their financial health, allowing them to take corrective actions before distress leads to more severe consequences.
7 Conclusion
Through the application of ML models to Canadian-listed businesses utilizing the Beneish M-score, this study has added to the expanding body of knowledge on financial distress prediction by closing the gap between conventional financial analysis and state-of-the-art data science approaches. This work addresses a significant knowledge gap by combining linear, kernel, tree-based, and ensemble algorithms, recursive feature elimination with cross-validation (RFECV), and bootstrapped classification and regression trees (CART) to understand how advanced algorithms can improve the detection of financial distress. An important addition to this research is the identification of pivotal indicators, including revenue growth, dividend growth, cash-to-current obligations, and gross profit margins, that greatly impact the probability of financial distress. Empirically, the results emphasize the efficacy of artificial neural networks (ANN) and ensemble models, such as random forests, in accurately forecasting distressed companies. A more proactive approach to monitoring business financial health is made possible by these sophisticated models, which provide auditors, regulators, and firm management with actionable data. The study’s usage of CART with bootstrapped samples offers an innovative method that improves the resilience and dependability of the model, hence assuring better generalization across various datasets.
Furthermore, the research underscores the distinctive circumstances of the Canadian market, underscoring that the increase in revenue and dividends are crucial measures of financial stability in this region. The findings of this study are profound for policymakers and regulators in Canada, as it indicates the need to develop region-specific prediction models that take into consideration the local economic and corporate governance circumstances. Through these sophisticated methodologies, Canadian authorities and auditors may enhance their ability to identify fraudulent activities, guaranteeing the highest adherence to financial reporting requirements. This equips policymakers with the necessary data to improve monitoring systems and decrease occurrences of earnings manipulation and financial misreporting. Future research should enhance the dataset by integrating macroeconomic statistics, market sentiment data, and industry-specific measures to construct more extensive prediction models. Moreover, using time-series data to analyze financial distress enables a more profound understanding of the temporal evolution of a company’s financial state. In addition, researchers should investigate the worldwide relevance of these results by doing comparable studies in other geographical areas and sectors to evaluate the resilience of the constructed models in other settings. Although this research furnishes useful insights, it is subject to various limitations. The dataset is restricted to measures of financial ratios and variables at the business level, which may not include the complexity of financially distressed situations. Furthermore, the research just examines one nation, restricting the results’ applicability to other markets. Moreover, the limited sample size and the restricted time period of the dataset (which coincides with the COVID-19 epidemic) can add biases, therefore impacting the transferability of the findings to other economic settings.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
ML: Writing – original draft, Writing – review & editing. SR: Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2024.1466321/full#supplementary-material
References
Abbas, K., Afaq, M., Ahmed Khan, T., and Song, W.-C. (2020). A Blockchain and machine learning-based drug supply chain management and recommendation system for smart pharmaceutical industry. Electronics 9:852. doi: 10.3390/electronics9050852
Achakzai, M. A. K., and Juan, P. (2022). Using machine learning Meta-classifiers to detect financial frauds. Financ. Res. Lett. 48:102915. doi: 10.1016/j.frl.2022.102915
Achakzai, M. A. K., and Peng, J. (2023). Detecting financial statement fraud using dynamic ensemble machine learning. Int. Rev. Financ. Anal. 89:102827. doi: 10.1016/j.irfa.2023.102827
Akther, T., and Xu, F. (2020). Existence of the audit expectation gap and its impact on stakeholders’ confidence: The moderating role of the Financial Reporting Council. Financ. Stud. 8:4. doi: 10.3390/ijfs8010004
Albizri, A., Appelbaum, D., and Rizzotto, N. (2019). Evaluation of financial statements fraud detection research: a multi-disciplinary analysis. Int. J. Discl. Gov. 16, 206–241. doi: 10.1057/s41310-019-00067-9
Alden, M. E., Bryan, D. M., Lessley, B. J., and Tripathy, A. (2012). Detection of financial statement fraud using evolutionary algorithms. J. Emerging Technol. Account. 9, 71–94. doi: 10.2308/jeta-50390
Almaskati, N., Bird, R., Yeung, D., and Lu, Y. (2021). A horse race of models and estimation methods for predicting bankruptcy. Adv. Account. 52:100513. doi: 10.1016/j.adiac.2021.100513
Altman, E. I., Iwanicz-Drozdowska, M., Laitinen, E. K., and Suvas, A. (2017). Financial distress prediction in an international context: a review and empirical analysis of Altman’s Z-score model. J. Int. Financ. Manag. Acc. 28, 131–171. doi: 10.1111/jifm.12053
Aria, M., Cuccurullo, C., and Gnasso, A. (2021). A comparison among interpretative proposals for random forests. Mach. Learn. Appl. 6:100094. doi: 10.1016/j.mlwa.2021.100094
Aslam, N., Khan, I. U., Alansari, A., Alrammah, M., Alghwairy, A., Alqahtani, R., et al. (2022). Anomaly detection using explainable random Forest for the prediction of undesirable events in oil Wells. Appl. Comput. Intell. Soft Comput. 2022, 1–14. doi: 10.1155/2022/1558381
Aubert, F., Wang, J. J., and Grudnitski, G. (2019). Convergence consensus analyst earnings estimates and option pricing in modeling material accounting misstatements. Rev. Acc. Financ. 18, 134–156. doi: 10.1108/RAF-05-2017-0101
Aviantara, R. (2021). Scoring the financial distress and the financial statement fraud of Garuda Indonesia with «DDCC» as the financial solutions. J. Model. Manag. 18, 1–16. doi: 10.1108/JM2-01-2020-0017
Bae, S. (2017). The association between corporate tax avoidance and audit efforts: evidence from korea. J. Appl. Bus. Res. 33, 153–172. doi: 10.19030/jabr.v33i1.9887
Bao, Y., Ke, B., Li, B., Yu, Y. J., and Zhang, J. (2020). Detecting accounting fraud in publicly traded U.S. firms using a machine learning approach. J. Account. Res. 58, 199–235. doi: 10.1111/1475-679X.12292
Baryannis, G., Dani, S., and Antoniou, G. (2019). Predicting supply chain risks using machine learning: the trade-off between performance and interpretability. Futur. Gener. Comput. Syst. 101, 993–1004. doi: 10.1016/j.future.2019.07.059
Basalat, H. A., Al Koni, S., and Nour, A. I. (2023). The impact of governance on the financial performance of companies listed in Amman and Palestine stock exchanges for the period 2013-2019. Jordan J. Bus. Admin. 19, 413–437. doi: 10.35516/jjba.v19i3.1124
Becker, T. E., Atinc, G., Breaugh, J. A., Carlson, K. D., Edwards, J. R., and Spector, P. E. (2016). Statistical control in correlational studies: 10 essential recommendations for organizational researchers. J. Organ. Behav. 37, 157–167. doi: 10.1002/job.2053
Beneish, M. D. (1999). The detection of earnings manipulation. Financ. Anal. J. 55, 24–36. doi: 10.2469/faj.v55.n5.2296
Beneish, M. D., and Vorst, P. (2022). The cost of fraud prediction errors. Account. Rev. 97, 91–121. doi: 10.2308/TAR-2020-0068
Bernerth, J. B., and Aguinis, H. (2016). A critical review and best-practice recommendations for control variable usage. Pers. Psychol. 69, 229–283. doi: 10.1111/peps.12103
Bhattacharyya, S., Jha, S., Tharakunnel, K., and Westland, J. C. (2011). Data mining for credit card fraud: a comparative study. Decis. Support. Syst. 50, 602–613. doi: 10.1016/j.dss.2010.08.008
Blay, A. D., Sneathen, L. D., and Kizirian, T. (2007). The effects of fraud and going-concern risk on auditors’ assessments of the risk of material misstatement and resulting audit procedures: effects of fraud and going-concern risk on auditors’ assessments of RMM. Int. J. Audit. 11, 149–163. doi: 10.1111/j.1099-1123.2007.00362.x
Botchey, F. E., Qin, Z., and Hughes-Lartey, K. (2020). Mobile money fraud prediction—a cross-case analysis on the efficiency of support vector machines, gradient boosted decision trees, and Naïve Bayes algorithms. Information 11:383. doi: 10.3390/info11080383
Campa, D., and Camacho-Miñano, M.-M. (2015). The impact of SME’s pre-bankruptcy financial distress on earnings management tools. Int. Rev. Financ. Anal. 42, 222–234. doi: 10.1016/j.irfa.2015.07.004
Chen, W.-S., and Du, Y.-K. (2009). Using neural networks and data mining techniques for the financial distress prediction model. Expert Syst. Appl. 36, 4075–4086. doi: 10.1016/j.eswa.2008.03.020
Chikodili, N. B., Abdulmalik, M. D., Abisoye, O. A., and Bashir, S. A. (2021). “Outlier detection in multivariate time series data using a fusion of K-Medoid, standardized Euclidean distance and Z-score” in Information and communication technology and applications. eds. S. Misra and B. Muhammad-Bello (Nigeria: Springer International Publishing), 259–271.
Cho, S., Vasarhelyi, M. A., Sun, T., and Zhang, C. (2020). Learning from machine learning in accounting and assurance. J. Emerging Technol. Account. 17, 1–10. doi: 10.2308/jeta-10718
Craja, P., Kim, A., and Lessmann, S. (2020). Deep learning for detecting financial statement fraud. Decis. Support. Syst. 139:113421. doi: 10.1016/j.dss.2020.113421
Davis, J. S., and Pesch, H. L. (2013). Fraud dynamics and controls in organizations. Acc. Organ. Soc. 38, 469–483. doi: 10.1016/j.aos.2012.07.005
Dechow, P. M., Sloan, R. G., and Sweeney, A. P. (1996). Causes and consequences of earnings manipulation: an analysis of firms subject to enforcement actions by the SEC. Contemp. Account. Res. 13, 1–36. doi: 10.1111/j.1911-3846.1996.tb00489.x
Demetriades, P., and Owusu-Agyei, S. (2022). Fraudulent financial reporting: an application of fraud diamond to Toshiba’s accounting scandal. J. Finan. Crime 29, 729–763. doi: 10.1108/JFC-05-2021-0108
DeZoort, F. T., and Harrison, P. D. (2018). Understanding auditors’ sense of responsibility for detecting fraud within organizations. J. Bus. Ethics 149, 857–874. doi: 10.1007/s10551-016-3064-3
Dimitropoulos, P. E., and Asteriou, D. (2009). The value relevance of financial statements and their impact on stock prices: evidence from Greece. Manag. Audit. J. 24, 248–265. doi: 10.1108/02686900910941131
Ding, S., Cui, T., Bellotti, A. G., Abedin, M. Z., and Lucey, B. (2023). The role of feature importance in predicting corporate financial distress in pre and post-COVID periods: evidence from China. Int. Rev. Financ. Anal. 90:102851. doi: 10.1016/j.irfa.2023.102851
du Jardin, P. (2015). Bankruptcy prediction using terminal failure processes. Eur. J. Oper. Res. 242, 286–303. doi: 10.1016/j.ejor.2014.09.059
Eulerich, M., Theis, J. C., Lao, J., and Ramon, M. (2018). Do fine feathers make a fine bird? The influence of attractiveness on fraud-risk judgments by internal auditors. Int. J. Audit. 22, 332–344. doi: 10.1111/ijau.12137
Fang, V. W., Huang, A. H., and Wang, W. (2017). Imperfect accounting and reporting Bias. J. Account. Res. 55, 919–962. doi: 10.1111/1475-679X.12170
Farber, D. B. (2005). Restoring trust after fraud: does corporate governance matter? Account. Rev. 80, 539–561. doi: 10.2308/accr.2005.80.2.539
Farooq, U., and Qamar, M. A. J. (2019). Predicting multistage financial distress: reflections on sampling, feature and model selection criteria. J. Forecast. 38, 632–648. doi: 10.1002/for.2588
Fedorova, E., Ledyaeva, S., Drogovoz, P., and Nevredinov, A. (2022). Economic policy uncertainty and bankruptcy filings. Int. Rev. Financ. Anal. 82:102174. doi: 10.1016/j.irfa.2022.102174
Filip, A., and Raffournier, B. (2014). Financial crisis and earnings management: the European evidence. Int. J. Account. 49, 455–478. doi: 10.1016/j.intacc.2014.10.004
Firth, M., Rui, O. M., and Wu, W. (2011). Cooking the books: recipes and costs of falsified financial statements in China. J. Corp. Finan. 17, 371–390. doi: 10.1016/j.jcorpfin.2010.09.002
Ghosh, S., Dasgupta, A., and Swetapadma, A. (2019). A study on support vector machine based linear and non-linear pattern classification. 2019 International Conference on Intelligent Sustainable Systems (ICISS), 24–28.
Habib, A., Costa, M. D., Huang, H. J., Bhuiyan, M. B. U., and Sun, L. (2020). Determinants and consequences of financial distress: review of the empirical literature. Account. Fin. 60, 1023–1075. doi: 10.1111/acfi.12400
Hajek, P., and Henriques, R. (2017). Mining corporate annual reports for intelligent detection of financial statement fraud – a comparative study of machine learning methods. Knowl.-Based Syst. 128, 139–152. doi: 10.1016/j.knosys.2017.05.001
Hamilton, E. L., and Smith, J. L. (2021). Error or fraud? The effect of omissions on Management’s fraud strategies and auditors’ evaluations of identified misstatements. Account. Rev. 96, 225–249. doi: 10.2308/tar-2017-0355
Hammami, A., and Hendijani Zadeh, M. (2022). Predicting earnings management through machine learning ensemble classifiers. J. Forecast. 41, 1639–1660. doi: 10.1002/for.2885
Hartwig, M., Voss, J. A., Brimbal, L., and Wallace, D. B. (2017). Investment professionals’ ability to detect deception: accuracy, Bias and metacognitive realism. J. Behav. Financ. 18, 1–13. doi: 10.1080/15427560.2017.1276069
Hilal, W., Gadsden, S. A., and Yawney, J. (2022). Financial fraud: a review of anomaly detection techniques and recent advances. Expert Syst. Appl. 193:116429. doi: 10.1016/j.eswa.2021.116429
Huang, S. Y., Lin, C.-C., Chiu, A.-A., and Yen, D. C. (2017). Fraud detection using fraud triangle risk factors. Inf. Syst. Front. 19, 1343–1356. doi: 10.1007/s10796-016-9647-9
Huang, Y.-P., and Yen, M.-F. (2019). A new perspective of performance comparison among machine learning algorithms for financial distress prediction. Appl. Soft Comput. 83:105663. doi: 10.1016/j.asoc.2019.105663
Islam, T. U. (2021). Min-max approach for comparison of univariate normality tests. PLoS One 16:e0255024. doi: 10.1371/journal.pone.0255024
Jiang, Y., and Jones, S. (2018). Corporate distress prediction in China: a machine learning approach. Account. Fin. 58, 1063–1109. doi: 10.1111/acfi.12432
Johnson, J. M., and Khoshgoftaar, T. M. (2019). Medicare fraud detection using neural networks. J. Big Data 6:63. doi: 10.1186/s40537-019-0225-0
Khaksar, J., Salehi, M., and Lari Dasht Bayaz, M. (2022). The relationship between auditor characteristics and fraud detection. J. Facil. Manag. 20, 79–101. doi: 10.1108/JFM-02-2021-0024
Kim, Y., and Kogan, A. (2014). Development of an anomaly detection model for a Bank’s transitory account system. J. Inf. Syst. 28, 145–165. doi: 10.2308/isys-50699
Kuizinienė, D., Krilavičius, T., Damaševičius, R., and Maskeliūnas, R. (2022). Systematic review of financial distress identification using artificial intelligence methods. Appl. Artif. Intell. 36:2138124. doi: 10.1080/08839514.2022.2138124
Li, N. (2016). Performance measures in earnings-based financial covenants in debt contracts. J. Account. Res. 54, 1149–1186. doi: 10.1111/1475-679X.12125
Li, Z., Huang, M., Liu, G., and Jiang, C. (2021). A hybrid method with dynamic weighted entropy for handling the problem of class imbalance with overlap in credit card fraud detection. Expert Syst. Appl. 175:114750. doi: 10.1016/j.eswa.2021.114750
Lokanan, M. E. (2015). Challenges to the fraud triangle: questions on its usefulness. Account. Forum 39, 201–224. doi: 10.1016/j.accfor.2015.05.002
Lokanan, M. (2018). Theorizing financial crimes as moral actions. Eur. Account. Rev. 27, 901–938. doi: 10.1080/09638180.2017.1417144
Lokanan, M. E. (2022). Predicting money laundering using machine learning and artificial neural networks algorithms in banks. J. Appl. Secur. Res. 19, 20–44. doi: 10.1080/19361610.2022.2114744
Lokanan, M. E. (2023). Predicting mobile money transaction fraud using machine learning algorithms. Appl. AI Lett. 4:e85. doi: 10.1002/ail2.85
Lokanan, M., and Liu, S. (2021). Predicting fraud victimization using classical machine learning. Entropy 23:300. doi: 10.3390/e23030300
Lokanan, M. E., and Sharma, K. (2022). Fraud prediction using machine learning: the case of investment advisors in Canada. Mach. Learn. Appl. 8:100269. doi: 10.1016/j.mlwa.2022.100269
Mai, F., Tian, S., Lee, C., and Ma, L. (2019). Deep learning models for bankruptcy prediction using textual disclosures. Eur. J. Oper. Res. 274, 743–758. doi: 10.1016/j.ejor.2018.10.024
Maniatis, A. (2022). Detecting the probability of financial fraud due to earnings manipulation in companies listed in Athens stock exchange market. J. Finan. Crime 29, 603–619. doi: 10.1108/JFC-04-2021-0083
Morales, J., Gendron, Y., and Guénin-Paracini, H. (2014). The construction of the risky individual and vigilant organization: a genealogy of the fraud triangle. Acc. Organ. Soc. 39, 170–194. doi: 10.1016/j.aos.2014.01.006
Mselmi, N., Lahiani, A., and Hamza, T. (2017). Financial distress prediction: the case of French small and medium-sized firms. Int. Rev. Financ. Anal. 50, 67–80. doi: 10.1016/j.irfa.2017.02.004
Nami, S., and Shajari, M. (2018). Cost-sensitive payment card fraud detection based on dynamic random forest and k-nearest neighbors. Expert Syst. Appl. 110, 381–392. doi: 10.1016/j.eswa.2018.06.011
Nasir, N. A. B. M., Ali, M. J., and Ahmed, K. (2019). Corporate governance, board ethnicity and financial statement fraud: evidence from Malaysia. Account. Res. J. 32, 514–531. doi: 10.1108/ARJ-02-2018-0024
Nasir, M., Simsek, S., Cornelsen, E., Ragothaman, S., and Dag, A. (2021). Developing a decision support system to detect material weaknesses in internal control. Decis. Support. Syst. 151:113631. doi: 10.1016/j.dss.2021.113631
Nour, A. I., Najjar, M., Al Koni, S., Abudiak, A., Noor, M. I., and Shahwan, R. (2024). The impact of corporate governance mechanisms on corporate failure: an empirical evidence from Palestine exchange. J. Account. Emerg. Econ. 14, 771–790. doi: 10.1108/JAEE-10-2022-0283
Oyerogba, E. O. (2021). Forensic auditing mechanism and fraud detection: the case of Nigerian public sector. J. Account. Emerg. Econ. 11, 752–775. doi: 10.1108/JAEE-04-2020-0072
Papík, M., and Papíková, L. (2022). Detecting accounting fraud in companies reporting under US GAAP through data mining. Int. J. Account. Inf. Syst. 45:100559. doi: 10.1016/j.accinf.2022.100559
Perols, J. (2011). Financial statement fraud detection: an analysis of statistical and machine learning algorithms. Audit. J. Pract. Theory 30, 19–50. doi: 10.2308/ajpt-50009
Perols, J., and Lougee, B. (2011). The relation between earnings management and financial statement fraud. Adv. Account. 27, 39–53. doi: 10.1016/j.adiac.2010.10.004
Puri, A., and Kumar Gupta, M. (2022). Improved hybrid bag-boost ensemble with K-means-SMOTE–ENN technique for handling Noisy class imbalanced data. Comput. J. 65, 124–138. doi: 10.1093/comjnl/bxab039
Qiu, S., Luo, Y., and Guo, H. (2021). Multisource evidence theory-based fraud risk assessment of China’s listed companies. J. Forecast. 40, 1524–1539. doi: 10.1002/for.2782
Ramírez-Orellana, A., Martínez-Romero, M. J., and Mariño-Garrido, T. (2017). Measuring fraud and earnings management by a case of study: evidence from an international family business. Eur. J. Fam. Bus. 7, 41–53. doi: 10.1016/j.ejfb.2017.10.001
Repousis, S. (2016). Using Beneish model to detect corporate financial statement fraud in Greece. J. Fin. Crime 23, 1063–1073. doi: 10.1108/JFC-11-2014-0055
Rtayli, N., and Enneya, N. (2020). Enhanced credit card fraud detection based on SVM-recursive feature elimination and hyper-parameters optimization. J. Inf. Secur. Appl. 55:102596. doi: 10.1016/j.jisa.2020.102596
Sahin, Y., Bulkan, S., and Duman, E. (2013). A cost-sensitive decision tree approach for fraud detection. Expert Syst. Appl. 40, 5916–5923. doi: 10.1016/j.eswa.2013.05.021
Salgado, C. M., Azevedo, C., Proença, H., and Vieira, S. M. (2016). “Noise versus outliers” in MIT critical data, secondary analysis of electronic health records. (USA: Springer International Publishing), 163–183.
Shaked, I., and Altman, E. (2016). Warning signs of financial distress. American Bankruptcy Institute Journal. 33, 611–626. Available at: https://www.proquest.com/scholarly-journals/warning-signs-financial-distress/docview/1844324285/se-2
Singh, D., and Singh, B. (2020). Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 97:105524. doi: 10.1016/j.asoc.2019.105524
Sisodia, D. S., Reddy, N. K., and Bhandari, S. (2017). Performance evaluation of class balancing techniques for credit card fraud detection. In 2017 IEEE International Conference on Power, Control, Signals and Instrumentation Engineering (ICPCSI), IEEE. Chennai, India. 2747–2752.
Song, X.-P., Hu, Z.-H., Du, J.-G., and Sheng, Z.-H. (2014). Application of machine learning methods to risk assessment of financial statement fraud: evidence from China: risk assessment of financial statement fraud. J. Forecast. 33, 611–626. doi: 10.1002/for.2294
Song, Y., Jiang, M., Li, S., and Zhao, S. (2023). Class-imbalanced financial distress prediction with machine learning: incorporating financial, management, textual, and social responsibility features into index system. J. Forecast. 43, 593–614. doi: 10.1002/for.3050
Sreedharan, M., Khedr, A. M., and El Bannany, M. (2020). A comparative analysis of machine learning classifiers and ensemble techniques in financial distress prediction. In 2020 17th International Multi-Conference on Systems, Signals & Devices (SSD), IEEE. Munastir, Tunisia. 653–657.
Sun, Y., Fang, S., and Zhang, Z. (2021). Impression management strategies on enterprise social media platforms: an affordance perspective. Int. J. Inf. Manag. 60:102359. doi: 10.1016/j.ijinfomgt.2021.102359
Sun, J., Li, H., Huang, Q.-H., and He, K.-Y. (2014). Predicting financial distress and corporate failure: a review from the state-of-the-art definitions, modeling, sampling, and featuring approaches. Knowl.-Based Syst. 57, 41–56. doi: 10.1016/j.knosys.2013.12.006
Tang, X., Li, S., Tan, M., and Shi, W. (2020). Incorporating textual and management factors into financial distress prediction: a comparative study of machine learning methods. J. Forecast. 39, 769–787. doi: 10.1002/for.2661
Tarjo,, and Herawati, N. (2015). Application of Beneish M-score models and data mining to detect financial fraud. Procedia Soc. Behav. Sci. 211, 924–930. doi: 10.1016/j.sbspro.2015.11.122
Tian, Z., Xiao, J., Feng, H., and Wei, Y. (2020). Credit risk assessment based on gradient boosting decision tree. Proc. Comput. Sci. 174, 150–160. doi: 10.1016/j.procs.2020.06.070
Trompeter, G. M., Carpenter, T. D., Desai, N., Jones, K. L., and Riley, R. A. (2013). A synthesis of fraud-related research. Audit. J. Pract. Theory 32, 287–321. doi: 10.2308/ajpt-50360
Veganzones, D., Séverin, E., and Chlibi, S. (2023). Influence of earnings management on forecasting corporate failure. Int. J. Forecast. 39, 123–143. doi: 10.1016/j.ijforecast.2021.09.006
Wang, Y. Q., and Song, Y. M. (2011). Appling data mining technology to analysis clearance efficiency in the port logistics. Key Eng. Mater. 480-481, 1144–1149. doi: 10.4028/www.scientific.net/KEM.480-481.1144
Zainudin, E. F., and Hashim, H. A. (2016). Detecting fraudulent financial reporting using financial ratio. J. Finan. Rep. Account. 14, 266–278. doi: 10.1108/JFRA-05-2015-0053
Zhang, S. (2012). Nearest neighbor selection for iteratively kNN imputation. J. Syst. Softw. 85, 2541–2552. doi: 10.1016/j.jss.2012.05.073
Zhao, Q., Xu, W., and Ji, Y. (2023). Predicting financial distress of Chinese listed companies using machine learning: to what extent does textual disclosure matter? Int. Rev. Financ. Anal. 89:102770. doi: 10.1016/j.irfa.2023.102770
Keywords: machine learning, artificial intelligence, financial distress, M-score model, earnings management
Citation: Lokanan ME and Ramzan S (2024) Predicting financial distress in TSX-listed firms using machine learning algorithms. Front. Artif. Intell. 7:1466321. doi: 10.3389/frai.2024.1466321
Edited by:
Alessia Paccagnini, University College Dublin, IrelandReviewed by:
Kristina Sutiene, Kaunas University of Technology, LithuaniaAbdul Naser Ibrahim Nour, An-Najah National University, Palestine
Copyright © 2024 Lokanan and Ramzan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mark Eshwar Lokanan, bWFyay5sb2thbmFuQHJveWFscm9hZHMuY2E=