 Balazs Feher
Balazs Feher Camila Tussie
Camila Tussie William V. Giannobile
William V. Giannobile
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
REVIEW article
Front. Artif. Intell., 23 July 2024
Sec. Medicine and Public Health
Volume 7 - 2024 | https://doi.org/10.3389/frai.2024.1427517
Artificial intelligence (AI) is increasingly applied across all disciplines of medicine, including dentistry. Oral health research is experiencing a rapidly increasing use of machine learning (ML), the branch of AI that identifies inherent patterns in data similarly to how humans learn. In contemporary clinical dentistry, ML supports computer-aided diagnostics, risk stratification, individual risk prediction, and decision support to ultimately improve clinical oral health care efficiency, outcomes, and reduce disparities. Further, ML is progressively used in dental and oral health research, from basic and translational science to clinical investigations. With an ML perspective, this review provides a comprehensive overview of how dental medicine leverages AI for diagnostic, prognostic, and generative tasks. The spectrum of available data modalities in dentistry and their compatibility with various methods of applied AI are presented. Finally, current challenges and limitations as well as future possibilities and considerations for AI application in dental medicine are summarized.
While the concept of artificial intelligence (AI), including its potential use in medicine, is several decades old (Turing, 1950), computing power remained a prohibitive bottleneck throughout most of the last century (Schwartz et al., 1987). Indeed, machine learning (ML), often considered the main branch of AI that identifies inherent patterns and connections in the input data similarly to how humans learn, is much more resource-intensive than most methods of classical statistics. Although classical statistics and ML are related fields, there is a key difference: ML models infer rules based on examples instead of being given explicit — if tentative — rules. Translated into clinical medicine, explicit rules describing straightforward causal relationships can be used for evidence-based decision making; nonetheless, complex patterns and interactions among numerous variables can be difficult to capture in this manner. In contrast, ML maps prior outcomes to the existing data to infer implicit rules (Figure 1). While this approach also requires more data than human learning and more processing power than classical statistics, ML models in turn can process massive datasets (Halevy et al., 2009), make predictions on new data, and use feedback for continuous training. The sustained, dramatic increase in semiconductor density — colloquially referred to as Moore’s law — and the availability of considerably larger datasets (i.e., big data) are two key factors that enabled the progressive development of ML. Big data and enhanced computing capabilities enable deep learning that leverages complex algorithms to model and understand intricate patterns in large volumes of data (Esteva et al., 2019; Topol, 2019). In today’s medicine, both deep learning and other forms of ML are increasingly used to augment the work of both clinicians and researchers (He et al., 2019).
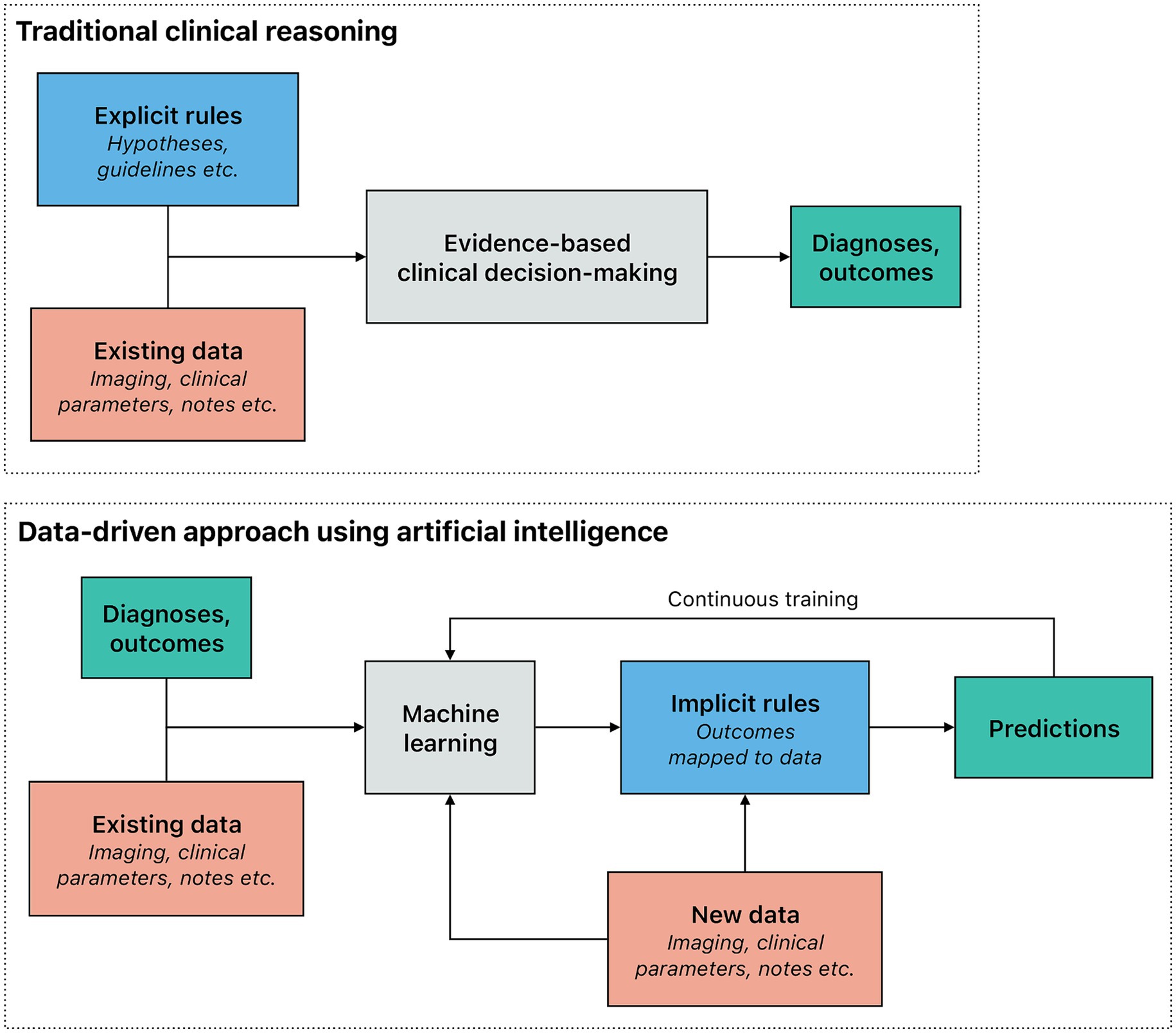
Figure 1. Traditional reasoning process compared to a data-driven approach using artificial intelligence in a clinical setting. In the traditional reasoning process within a clinical setting, explicit rules (e.g., those derived from pathophysiology) are applied to the observed data (e.g., a patient’s symptoms), to make a diagnosis or predict an outcome. Explicit rules should be based on scientific evidence. The traditional reasoning process is effective in situations where the underlying rules are straightforward and clear. However, it tends to fall short in more complex scenarios. In contrast, machine learning models, which are trained using numerous examples, infer implicit rules by correlating outcomes with the data. This data-driven approach not only adapts better to the presence of multicollinearity but also provides outcomes that are tailored to individual patients, making it particularly valuable for predictive modeling and personalized medicine. Machine learning models can be continuously improved as new data are acquired.
Algorithms of applied ML in medicine can be categorized into three broad paradigms based on their learning style and by the extent to which input data are labeled: supervised, unsupervised, and semi-supervised learning. Supervised learning requires input data to be labeled as the algorithms learn from datasets that include both input data and corresponding correct outputs (e.g., radiographs used for training are first diagnosed by a human observer). In many cases, obtaining a strong supervisory signal (i.e., labeling of most or all of the dataset) is challenging. A combination of labeled and unlabeled input data enables weak supervision (Zhou, 2017). The promised advantage of weak supervision is the ability to process larger datasets while still not completely foregoing expert labeling. Unsupervised learning only uses unlabeled data as the algorithms try to find underlying patterns of structures using methods including clustering (i.e., grouping of similar instances) or dimensionality reduction (i.e., data simplification while retaining structure). Biomedical research uses unsupervised learning to identify previously unknown connections in an agnostic manner (e.g., protein structure prediction). Reinforcement learning uses unlabeled data to optimize a sequence of decisions in order to maximize a pre-set outcome (Sutton and Barto, 2018). Based on their use cases in medicine, most ML models can also broadly be categorized based on their task, variables, and output into regression and classification models. Regression models can be used to predict continuous outcomes. In medicine, this often includes quantifying the risk of an event or predicting the outcome of an intervention. Classification models can be used to categorize data into predefined classes. In the medical context, this includes establishing preliminary diagnoses or stratifying patients into risk categories. Computer vision, arguably one of the most widespread methods of ML in medicine, uses a combination of both classification and regression models to locate and interpret structures in image data.
Dental medicine has seen a swift increase in AI application comparable to other medical disciplines (Schwendicke et al., 2021c). Research output, clinical application, as well as public interest are increasing considerably. Notably, use and reporting of AI methods in dental medicine, including quantitative performance metrics, are characterized by a substantial heterogeneity. In the succeeding sections, a comprehensive overview of how various AI methods, including diagnostic, prognostic, and generative modeling used in dental medicine, is presented. Notably, several recent reviews have discussed the application of AI-enabled tools depending on different dental disciplines (e.g., periodontology, operative dentistry, oral radiology, etc.) (Nguyen et al., 2021a; Ding et al., 2023). In contrast to previous work, this article adopts an ML perspective, providing a cross-section of the spectrum of available data modalities, and exploring their compatibility with various AI methodologies.
The amount of electronic health data generated globally is sharply increasing (Favaretto et al., 2020; Schwendicke and Krois, 2022). In dental medicine, this data can be divided into three major overarching modalities: image data, structured numerical data, and unstructured textual data (Figure 2).
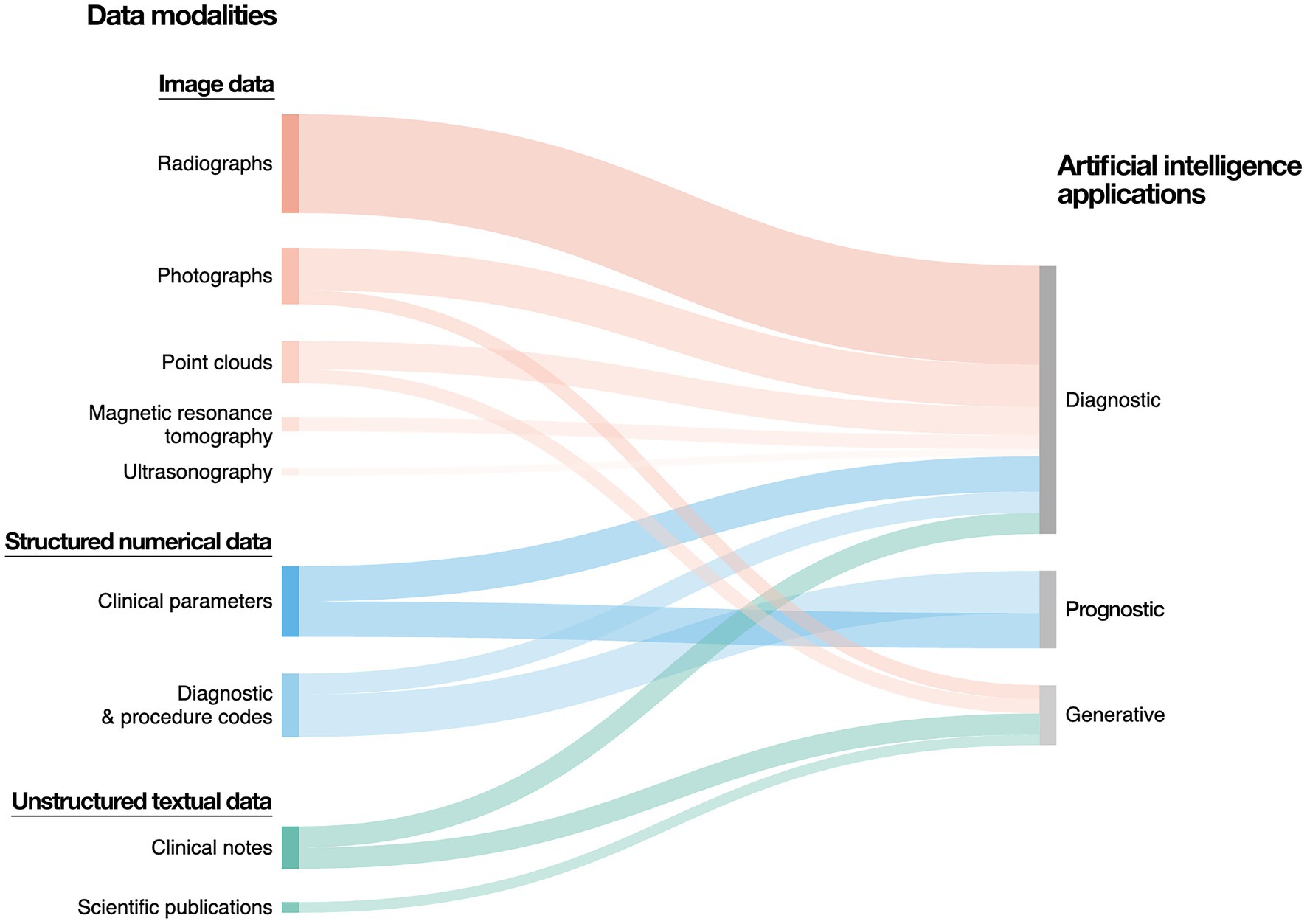
Figure 2. Data modalities and artificial intelligence applications in dental medicine. The majority of data generated in dental medicine can be categorized into image data, structured numerical data, as well as unstructured textual data. Image data predominantly includes radiographs, which can be two-dimensional (e.g., panoramic and periapical radiographs, bitewings) or three-dimensional (e.g., computed tomography scans). Further sources of image data include photographs and three-dimensional point clouds (e.g., intraoral scanning). Structured numerical data include demographic data, electronic dental records, as well as clinical parameters (e.g., periodontal probing depth, vertical alveolar bone loss). Unstructured text data include free-form clinical notes, patient testimonials, referrals, treatment plans, as well as academic publications and regulatory documentation.
Image data include radiography, photography, ultrasonography, near-infrared light transillumination, histology, and three-dimensional point clouds. Arguably the most prevalent form of imaging in dental medicine, dental radiography ranges from small, two-dimensional intraoral images (e.g., intraoral periapical radiographs, bitewings) to large, three-dimensional cranial computed tomography (CT) scans. Although still considerably less prevalent than CT, magnetic resonance tomography is increasingly used as a radiation-free alternative, especially in larger hospital settings. Intra- and extraoral photography is an important diagnostic and documentary tool in oral medicine. Dental ultrasonography is a noninvasive, real-time imaging method surging in popularity after the development of small probes suitable for intraoral use (Chan et al., 2018). Histological imaging in oral and maxillofacial pathology is routinely used to assess tissue biopsies, comparable to general pathology. Three-dimensional point clouds are generated through intra- and extraoral scanning. Image data constitute a large share of all data created in dental medicine, largely owing to the high number of radiographs. Notably, the number of radiographs created in dental medicine is much higher when compared to other medical disciplines. Dentistry generates approximately 1.1 billion radiographs annually, which account for 26% of all radiographic procedures worldwide (United Nations Scientific Committee on the Effects of Atomic Radiation, 2022).
Structured numerical data (e.g., clinical parameters measured for clinical care and research, dental insurance claims, billing records) require standardized entry at least on the provider level. A considerable share of numerical data in dental medicine is either created by research institutions for clinical studies (i.e., patient-feature matrices) or through the billing of the rendered dental services (e.g., procedure codes). In addition to being assessed by clinicians, numerical data can also be self-reported (e.g., through forms or surveys) or even automatically measured (e.g., using wearable sensors). However, some sources of structured numerical data regularly registered in other medical disciplines (e.g., serum- or saliva-based diagnostic tests) might not be captured as a part of routine dental care.
Unstructured textual data (e.g., clinical notes) are widespread in electronic dental records (EDRs) from dental clinics and offices. Most clinicians do not maintain numerical data in a structured manner within the EDR for future reference, instead including numerical data (e.g., working length of a root canal, clinical attachment level measurements) within freeform clinical notes. In a broader sense, unstructured textual data can include patient and vendor correspondence, journal articles, and other written material. Inevitably, unstructured textual data represent the data modality most contingent upon its author; while image or numerical data can vary among providers due to differences in quality or calibration, textual data further depends on personal writing style.
Considering the unique advantages of each data modality, their integration plays a key role in rendering comprehensive dental care. Notably, most dental patients see their providers regularly and over longer periods of time. Put into the context of ML, this yields rich sources of longitudinal, multimodal datasets (radiographs, EDRs, clinical parameters, etc.). When used in ML, multimodal datasets allow for more accurate, robust data that include various aspects of an individual’s clinical and treatment history, creating a more personalized, integrated model.
Diagnostic modeling typically involves recognizing structures and patterns in the input data or classifying these into largely predefined categories (e.g., health or disease). In dental medicine, these input data are predominantly visual, with structured numerical data playing a secondary role. Imaging methods require visual assessment by the observer; with increasing complexity, the diagnostic difficulty increases. In addition, human diagnostic accuracy is inherently a function of the observer’s experience and attention, as well as the prevalence of the diagnosis. To mitigate these limitations, computer-aided diagnostics use ML and computer vision to aid the human diagnostic process.
Computer vision refers to the inference of patterns from visual data (Esteva et al., 2021). To enable processing of the images by an ML model, a neural network fractionates images into single labeled pixels; convolutional neural networks (CNNs) are used for single images, while recurrent neural networks (RNNs) process a series of images (e.g., sequential images or videos). The neural network then uses the pixel-level labels to perform convolutions (i.e., a mathematical operation on functions and that produces a third function, ) and predict the content of the input data; the number of parameters to learn is reduced by down-sampling (e.g., pooling). This process’s accuracy depends on many factors, not least of which the chosen model and labeling method. Various labeling methods are demonstrated on a partial panoramic radiograph in Figure 3. At the basic level, image-level labeling enables classification of the entire image, without further separation of its contents (Figure 3A). Recognizing structures within images requires more detailed annotation. Bounding boxes (i.e., minimum enclosing rectangles) represent the simplest way to annotate a structure within a radiograph. While they can be quickly added to the image, they specifically enable basic object detection: the trained ML model coarsely localizes the structure, without accurate demarcation of its boundaries (Figure 3B). Meanwhile, pixel-wise masks assign a label to every annotated pixel. While the annotation process is considerably more labor-intensive, it enables the precise segmentation of an object (Figure 3C). For three-dimensional point clouds, point-wise masks are used analogously. A faster alternative to pixel-wise masks is the use of polygons, where the annotator fits geometric figures to the structure. Notably, masks and polygons can be assigned to different instances of the same class, enabling discrete segmentation of each instance (e.g., 18 and 28 are both third molars, but they are not the same third molar, Figure 3D).
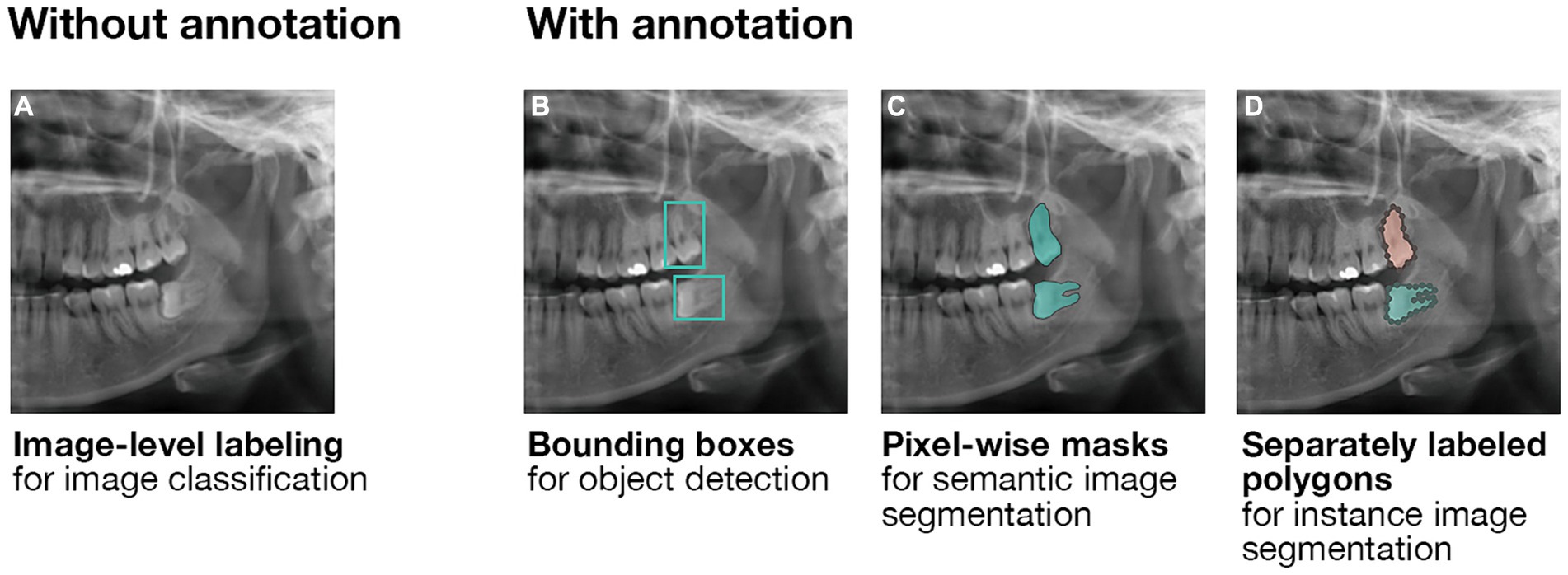
Figure 3. Labeling methods for computer vision. (A) Image-level labeling without further annotation enables the classification of entire images. (B) Annotating images using bounding boxes enables the training of object detection models. As the output of an object detection model is a predicted bounding box, it is unsuitable for the precise demarcation of anatomical structures. Here, third molar teeth are roughly localized. (C) Pixel-wise masks enable the training of semantic segmentation models whose outputs are pixel-wise masks as well. Importantly, no differentiation is made between multiple instances of the same structure. Here, all occurrences of a third molar are marked without differentiation between them. (D) Separately labeled pixel-wise masks enable further distinction between multiple instances of the same structure using instance segmentation models. Here, in addition to all occurrences of a third molar being marked, the two third molars are clearly distinguished from one another.
The reliance on radiographic imaging for dental diagnostics and the consequently large amount of available radiographic data makes computer vision one of the most relevant areas of ML in dentistry. Using computer vision to detect and segment anatomical structures (e.g., teeth) enables automated dental charting (Gao et al., 2022; Kabir et al., 2022). Dental caries and periodontitis, two of the most prevalent pathological conditions worldwide (Tonetti et al., 2017; Bernabe et al., 2020), are diagnosed using radiographs as well as visual and tactile examination. However, radiographic diagnostics remain highly variable among examiners (Akesson et al., 1992; Bader et al., 2001). Diagnostic sensitivity is especially low for early caries lesions (Schwendicke et al., 2015). Computer vision is increasingly used to aid or automate radiographic diagnostics. In addition, there is an apparent shift toward more sophisticated segmentation models as opposed to simpler object detection models (Arsiwala-Scheppach et al., 2023). Compared with human observers, computer vision yields a higher sensitivity while maintaining noninferior specificity (Schwendicke et al., 2021b). Notably, the accuracy of caries detection increases nonlinearly with an increasing size of the training dataset (Schwendicke et al., 2022). Various computer vision applications have been proposed for the diagnosis of gingivitis and periodontitis (Revilla-León et al., 2022). In the radiographic detection of periodontal bone loss, computer vision does not appear obviously superior to human observers, mostly owing to inconsistent reporting quality (Patil et al., 2023). Periodontal diagnostics routinely involve the use of intraoral radiographs of the entire dentition. Compared to panoramic radiographs, intraoral images only capture a portion of the dentition and jawbones. The diagnostic workflow thus includes the mounting (i.e., correct arrangement) of these smaller radiographs. Applying image classification to entire intraoral radiographic series has been proposed as an approach for automating the mounting process (Lin et al., 2023).
While radiographic data still represent the largest portion of training data for computer vision in dentistry, models are increasingly trained on other relevant sources of imaging data. Clinical dental practice increasingly involves the use of intra- and extraoral photography as well as scanning which create two-dimensional RGB images and three-dimensional point clouds, respectively. These data sources enable novel uses of computer vision. Trained on intraoral photographs, CNNs can diagnose carious lesions (Moharrami et al., 2023), tooth crowding (Ryu et al., 2023), as well as dental anomalies associated with orofacial clefts (Ragodos et al., 2022). The classification of entire intra- and extraoral photographs has further been proposed as a way of automating the sorting and archival of orthodontic images for documentation and treatment monitoring purposes (Li et al., 2022). Trained on intraoral scans, CNNs enable instance segmentation of individual teeth (Zanjani et al., 2021; Vinayahalingam et al., 2023). Multimodal data consisting of point clouds and radiographic imaging further enable CNN-based superimposition of intraoral scans and cone beam CT images, given they are noninferior to human operators (Ntovas et al., 2024). Extraoral scans can be used to train CNNs to automatically locate orthodontic soft tissue landmarks (Baysal et al., 2016) as well as predict morphological changes following orthognathic surgery (Tanikawa and Yamashiro, 2021). While dental ultrasonography is a novel imaging method whose adoption remains low, CNNs have been successfully trained to identify anatomical structures on sonograms (Nguyen et al., 2021b).
To a large extent, computer vision used in dentistry has concentrated on individual models and tasks as opposed to more complex, multi-step workflows (Schwendicke and Krois, 2022). Some models can simultaneously detect and classify structures on radiographs (Yang et al., 2020). Notwithstanding the efficacy of single-step architectures, their nature is somewhat in contrast with clinical diagnostics where the human observer often performs a sequence of tasks to make a diagnosis. The process of inferring from the observer’s own previous experience as well as contextual information has been described as clinical diagnostic reasoning. To replicate individual steps of the human clinical diagnostic reasoning process, composite ML workflows of multiple models have been proposed (Feher et al., 2022). While these methods offer good explainability, as they closely resemble clinical reasoning, it is crucial to note that precisely emulating the stepwise diagnostic process of a human clinician does not result in superior diagnostic performance when compared to end-to-end approaches.
Patterns in structured numerical data have been used for automated diagnostics based on classification since the 1970s (Leonard et al., 1973, 1974). From a technical standpoint, the modeling architectures for classification and prediction tasks are comparable. The term “prediction” itself can broadly refer to the output of any ML model (e.g., an object detection model “predicts” a bounding box). Essentially, classification determines categories for elements already within the dataset whereas prediction approximates elements missing from the dataset. Clinically, the distinction lies in whether the ML model’s output exists at the time of application: classification mainly establishes a present diagnosis (e.g., disease staging) whereas prediction can also estimate potential future events (e.g., risk of complications).
Classification algorithms used in dentistry are typically trained on labeled data. In addition to CNNs and related neural networks, several supervised non-deep learning approaches are routinely used. These include decision trees and Random Forests, Support Vector Machines, Bayesian networks, K Nearest Neighbors, and Voting Feature Intervals classifiers (Singh et al., 2016; Joshi and Jetawat, 2020). Random Forests and Support Vector Machines represent the most prevalent non-deep learning dental classification approaches, each operating upon a different base architecture and specialized in modeling different scenarios (Arsiwala-Scheppach et al., 2023).
Outside of computer vision, structured numerical data represent the primary data modality for classification models. Data derived from clinical examinations and radiographs can be used to train ML models that classify patients’ maxillofacial morphology (Ueda et al., 2023), establish primary orthodontic diagnoses, assess treatment need and support treatment planning (Thanathornwong, 2018; Prasad et al., 2023; Senirkentli et al., 2023). An advanced application of ML-supported treatment decision-making based on classification modeling involves the planning of removable partial dentures (RPDs) and the subsequent ability to autonomously generate customized RPD designs. Although this might resemble generative modeling, the underlying architecture actually classifies input structures into predefined Java curve functions, the collective arrangement of which constitutes the design for an RPD (Chen et al., 2020). Importantly, unstructured data cannot be processed natively by classification algorithms, thus the information contained therein remains unusable for classification purposes.
Dental medicine generates a large body of unstructured language data in the form of clinical notes (Pethani and Dunn, 2023), published research articles, clinical correspondence, and verbal transcriptions. Natural language processing (NLP) is a branch within AI that focuses on using models to understand, analyze, and structuralize human language; this applies to both written and spoken text. The application of NLP in medicine is highly logical, given that clinicians compile extensive patient information in unstructured text (Jensen et al., 2017; Sheikhalishahi et al., 2019). The application of NLP to extract information from clinical text is thus increasingly relevant (Kreimeyer et al., 2017; Wu et al., 2019). Named entity recognition and relation extraction, NLP techniques that identify key entities and their relation from text corpora, have demonstrated high precision and recall when extracting information from medical text (Li et al., 2023; Raza and Schwartz, 2023).
In dentistry, NLP has a wide range of potential use cases (Büttner et al., 2024); the most obvious one is presently the analysis of EDRs. NLP can be used to structure free-text EDRs to extract information pertaining to patients (e.g., prior clinical diagnoses) as well as previous treatments (e.g., previous restorative procedures, materials used, etc.) (Chen et al., 2021; Patel et al., 2022a). Analyzing longitudinal EDR data using NLP further enables the tracking of temporal changes, as shown in previous work monitoring periodontal disease progression (Patel et al., 2023b).
Compared to text corpora, the processing of spoken words involves the additional step of translating the audio signal; deep neural networks can be used to support this process (Nassif et al., 2019). Applied to the transcripts of clinical case vignettes, NLP shows noninferior dental charting performance compared to human experts (Zhang et al., 2021). NLP, coupled with speech recognition, thus shows high potential to increase administrative efficiency.
In addition to clinical practice, NLP has potential in dental education, with success identifying clinically relevant messages from a large dental online community forum (Bekhuis et al., 2011). Recent trends in the United States (US) show a decline in practice ownership among dentists, along with a growing tendency for new graduates to join dental service organizations; meanwhile, only a small fraction of graduating dental students envision a career in academia (Istrate et al., 2023). Outside academia, clinicians can use discussion groups, forums, or social media to acquire and exchange insights. As NLP has been shown to effectively extract relevant messages from online dental discussion groups, it can potentially aid clinicians in sifting through information and experiential cases from their peers (Bekhuis et al., 2011).
While AI has already demonstrated potential in diagnostic modeling across computer vision, classification, and NLP tasks, limitations exist regarding data quality and quantity, explainability, generalization, cost and infrastructure, as well as clinical validation. As diagnostic modeling is arguably the most important area of applied AI in medicine, these limitations are particularly important. Indeed, most studies on either computer vision or other classification models are limited by single-center datasets. AI’s diagnostic capabilities rely on the datasets used to train the model; consequently, the diagnosis will be biased toward the outcomes of the training set and will not account for potential variability between different patient populations. This pertains to the diversity of patients in the training sets, the accuracy of the labeling of the data, and the quality of the data itself. The inherent homogeneity of patients collected within a single clinical practice exacerbates this problem, and cross-center validity remains a challenge (Schwendicke et al., 2021a). Indeed, clinical validation requires the rigorous testing of AI-enabled tools against large, diverse datasets. Further constraints of certain diagnostic methods lie in the heterogeneity of reported performance metrics, as well as the models’ explainability and clinical applicability. The necessity for human supervision is presently a non-negotiable aspect of any clinical encounter, and transparency is of utmost importance in the decision-making process. Nonetheless, the utility of AI-enabled tools as clinical decision support systems still presupposes the interpretability of their predictions and recommendations (Kundu, 2021; Reddy, 2022).
While diagnostic modeling focuses on identifying existing conditions, ML models can also be trained to anticipate future events in a proactive manner in the form of prognostic modeling. Patterns identified in large longitudinal datasets can be extrapolated into the future, thereby estimating events like the onset of diseases, success rates of performed procedures, and epidemiological trends. In dentistry, prognostic modeling can be especially valuable for preventive care and early diagnosis to deliver more personalized, holistic clinical care.
Prognostic modeling uses various algorithms to forecast outcomes based on a set of inputs. Discriminative models, or models that learn , are particularly effective for classification tasks with discrete outputs. These models use training data to learn the boundaries between classes and then utilize the learned boundaries to predict a class, or a forecast, from a given input; for example, using input data like age, past medical history, past dental history, diagnostic biomarkers combined with other risk factors to classify individuals into categories of periodontal disease risk (low, medium, high) (Figure 4). Regression models are also widely used for prognostic modeling, particularly for continuous outputs. Regression is a form of supervised ML that aims to create a “best fit” line or curve to best describe the relationship between independent (input) and dependent (output) variables. This “best fit” model is then used to predict outputs given a set of new, unseen inputs.
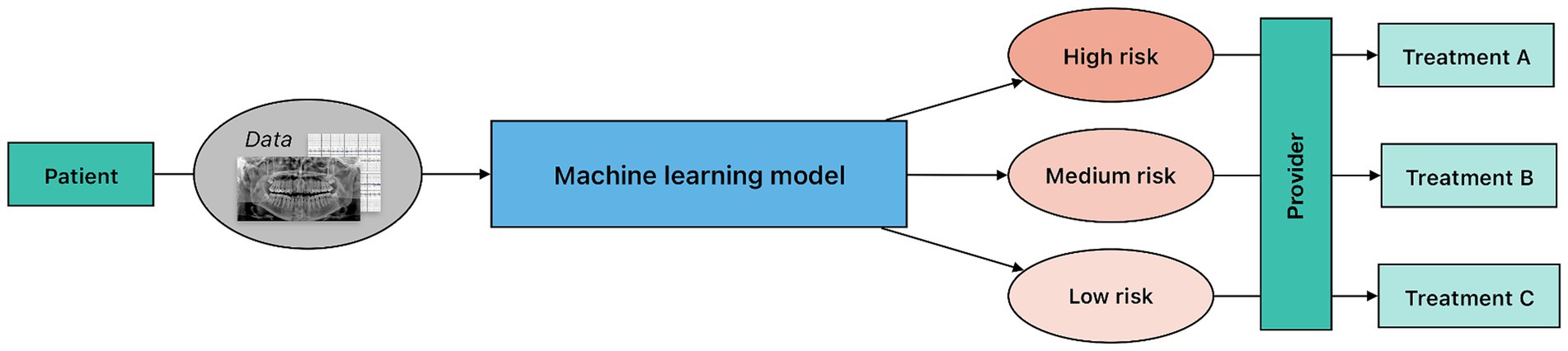
Figure 4. Overview of a clinical risk stratification workflow. In this process, predictive modeling is applied to patient data to classify individuals into predefined risk categories. Notably, although the underlying machine learning architecture may be similar to diagnostic modeling, risk stratification predictions lack a definitive ground truth. The provider uses the information from the model to guide the treatment planning and risk prediction at the patient level.
In addition to regression modeling, classification models can also be used for prognostic tasks, including Random Forests, Support Vector Machines, and neural networks (Arsiwala-Scheppach et al., 2023). Random Forests and Support Vector Machines are architectures mainly used for classification tasks, the latter focusing on the data points closest to the decision boundary by finding an optimal separating hyperplane. Neural networks function by possessing a network of nodes, referred to as neurons, that are connected based on weighted paths.
Temporal changes in parameters can be used to identify patterns more accurately through the use of longitudinal data. RNNs were designed to manage sequential data, enabling them to consider temporal changes. RNNs can further be enhanced using intra-attention mechanisms to emphasize the portion of sequences contributing the most to predictions (Bahdanau et al., 2014; Luong et al., 2015). In addition, RNNs can be enriched using different types of layers, including CNNs and graph neural networks (Ma et al., 2020; An et al., 2021).
Structured numerical data, the primary data modality for prognostic modeling, have been used to train prediction models for tooth loss (Hasuike et al., 2022), periodontitis (Patel et al., 2022b), peri-implantitis (Mameno et al., 2021; Fan et al., 2023), xerostomia (Lee et al., 2024), Sjögren’s disease (Mao et al., 2024), medication-related osteonecrosis of the jaw (Kim et al., 2018), the malignant progression of oral leukoplakia (Liu et al., 2017), as well as the survival of patients with oral squamous cell carcinoma (Kim et al., 2019). Further, prediction models based on structured numerical data have been proposed for the prognosis of certain dental treatments, including root canal treatment (Bennasar et al., 2023) and dental implants (Ha et al., 2018; Rekawek et al., 2023). As previously mentioned, structured numerical data can be collected from patients in a self-reported manner, as shown in previous work on predicting tooth mobility (Yoon et al., 2018).
Notably, AI can be used to obtain structured numerical data from other data modalities. Prediction models for postoperative neuropathy after mandibular third molar extraction showed noninferior performance when human observers evaluated native three-dimensional radiographs compared with STL files pre-processed with computer vision for anatomical segmentation (Picoli et al., 2023). Crucially, the prediction models still relied on structured numerical data compiled by human observers from the image assessments.
While prognostic modeling is not the predominant application of AI in dental medicine, estimating future risk and identifying patients at risk for diseases and complications is highly valuable for its clinical usefulness. However, a considerable distinction exists between diagnostic and prognostic modeling in the realm of trust. While the output of a diagnostic model can be immediately compared with other diagnostic tools to verify a diagnosis, a prognosis cannot be immediately validated. This increases the necessity of trust in the AI model’s forecast and underscores the importance of predictive accuracy and model calibration: miscalibration of the model can lead to overtreatment if a patient is incorrectly deemed at risk or, conversely, serious health issues if a risk is underestimated (Van Calster et al., 2019). This emphasizes the critical importance of AI interpretability, which remains the primary challenge in predictive modeling to eliminate the one-size fits all approach that exists in many facets of dental medicine (Giannobile et al., 2013a,b). Emerging diagnostics are creating expanded opportunities for clinicians to combine saliva diagnostics and chairside clinical innovations to advance precision care that can be advanced with these approaches (Steigmann et al., 2020).
Practically, the biggest limitation standing between clinical practice and prognostic models is the reliance on structured data. During a clinical trial, information is recorded into a patient-feature matrix, which makes the data readily accessible to algorithmic processing, including the training of ML models. In contrast, practicing clinicians routinely store information, including numerical measurements, in free-form clinical notes. Even though most health records are digitized, clinical notes are generally only comprehensible to humans. This limits not just the training of new prognostic models based on data routinely gathered through clinical practice, but also the application of existing prognostic models to patients outside of clinical study settings. To maximize patient benefit from AI-enabled tools, their applicability in clinical practice needs improvement. A crucial part of this improvement is making data progressively machine-readable.
Generative models learn the probabilistic distribution of the input space and use these probabilities to generate new data. Often in response to prompts (i.e., descriptions of the AI task in natural language), generative models create synthetic new data (e.g., text, images, audio, video) with similar characteristics to their training data. Numerous generative models each employ a distinct method for content creation. The most commonly used approaches include generative adversarial networks (GANs), transformer-based models, and diffusion models. A sample approach to generate synthetic radiographs using a GAN is demonstrated in Figure 5. Transformers build the basis of most contemporary large language models (LLMs), artificial neural networks for general-purpose language creation.
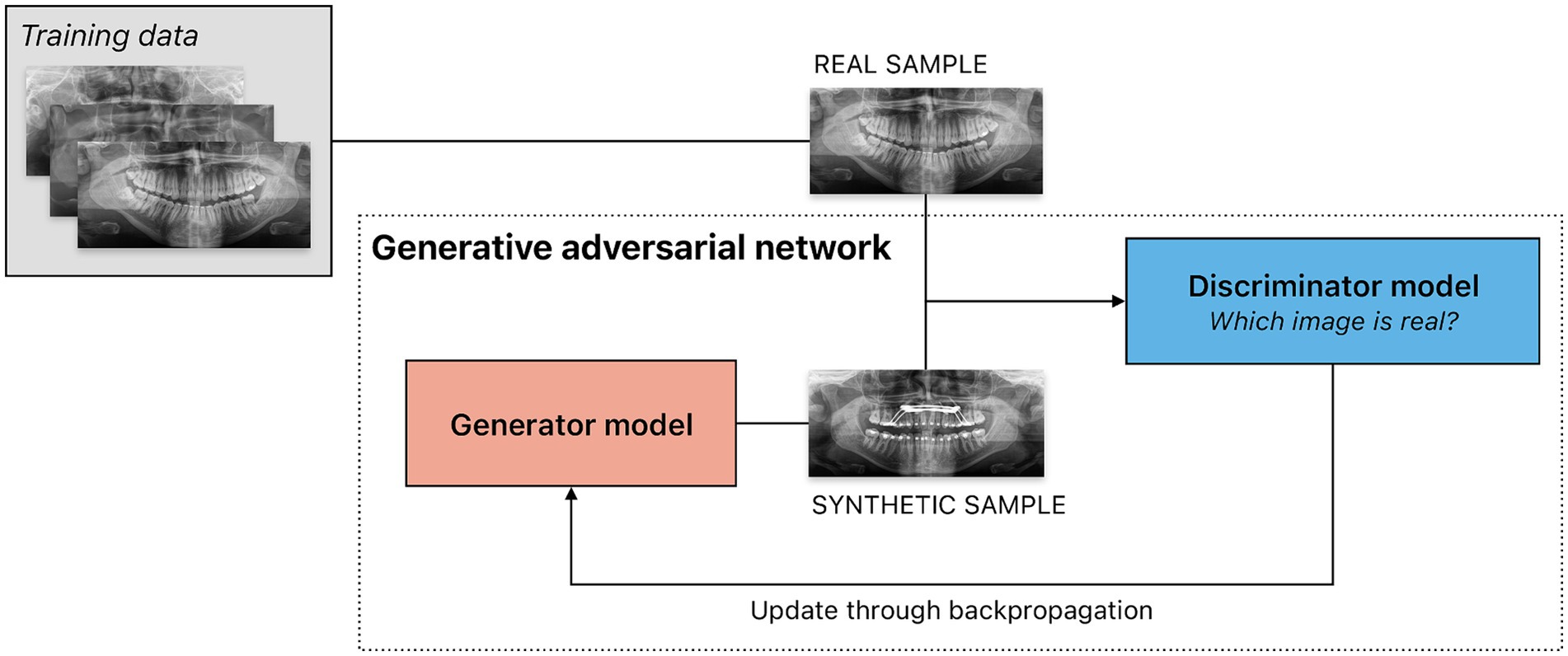
Figure 5. Sample scenario illustrating the use of a generative adversarial network (GAN) to create synthetic panoramic radiographs. GANs consists of two models, a generator and a discriminator, trained simultaneously through an adversarial process. The generator is tasked to create synthetic data intended to mimic real data — in this example, panoramic radiographs. The discriminator is a classifier that evaluates input from the generator as well as the training dataset, attempting to determine which are real or synthetic. The result of the classification task — success or failure — is used as feedback for both models. The generator thus aims to create data indistinguishable from real data to the discriminator, while the discriminator aims to distinguish generated data from real data. Feedback from the discriminator is used to train the generator. Through this iterative adversarial process, the generator improves at producing realistic data, while the discriminator improves at classifying data as real or synthetic.
Synthetic data produced by generative models can be useful for model training in research or educational purposes without compromising patient privacy (Umer and Adnan, 2024). Further, synthetic data can reference real information. Through generative summarization, LLMs can synthesize overwhelming amounts of electronic health data and create a clinical narrative summary (e.g., for the automation of clinical notes after a patient visit). Although the generation of dental-specific notes has yet to be detailed in scholarly work, summarization models have demonstrated success in creating clinical notes based on structured health record data from electronic health records (Gong and Guttag, 2018). LLMs have further been shown to generate discharge summaries (Patel and Lam, 2023) and correspondence to patients detailing their diagnoses and post-operative instructions (Ali et al., 2023). Notably, in some instances, health care professionals have been shown to prefer LLM-generated responses to questions asked by patients in an online forum over physicians’ answers in both information quality and empathy (Ayers et al., 2023). Current results from oral and maxillofacial surgery further suggest a higher quality of responses to patient questions than to technical questions asked by surgeons (Balel, 2023).
In addition to generating text corpora through LLMs, generative AI holds significant potential in creating synthetic images for settings where images from real patients cannot be utilized. Generative models, for example, have been shown to produce intraoral images that were, at a resolution of 512 px ∗ 512 px, indistinguishable from real images in a pediatric dental setting; rough artifacts remained visible at a resolution of 1,024 px ∗ 1,024 px (Kokomoto et al., 2021). The use of diffusion instead of GAN for image creation can potentially improve this limitation, as diffusion models have been shown to outperform GAN models on all tasks (Saharia et al., 2022). Still, GANs can achieve performance satisfactory for clinical application, including the generation of crown designs from point clouds obtained from intraoral scanning (Ding et al., 2023).
Besides research and practice, AI shows potential in medical education as well. LLMs have been shown to create viable, high-quality multiple-choice questions when given adequate guidance (i.e., question difficulty, number of questions, and answer choices) with prompt engineering (Johnson et al. 2023). While specific questions from the study still required improvement following faculty review, this technology could improve the quality of didactic questions, reduce faculty workload, and minimize cheating through exam reuse over time. Based on the performance of contemporary LLMs in other areas, it further seems plausible to retrain or fine-tune models with data relevant to oral health education and create a virtual patient with which students and educators can interact to enable learning in an interactive, immersive manner (Figure 6).
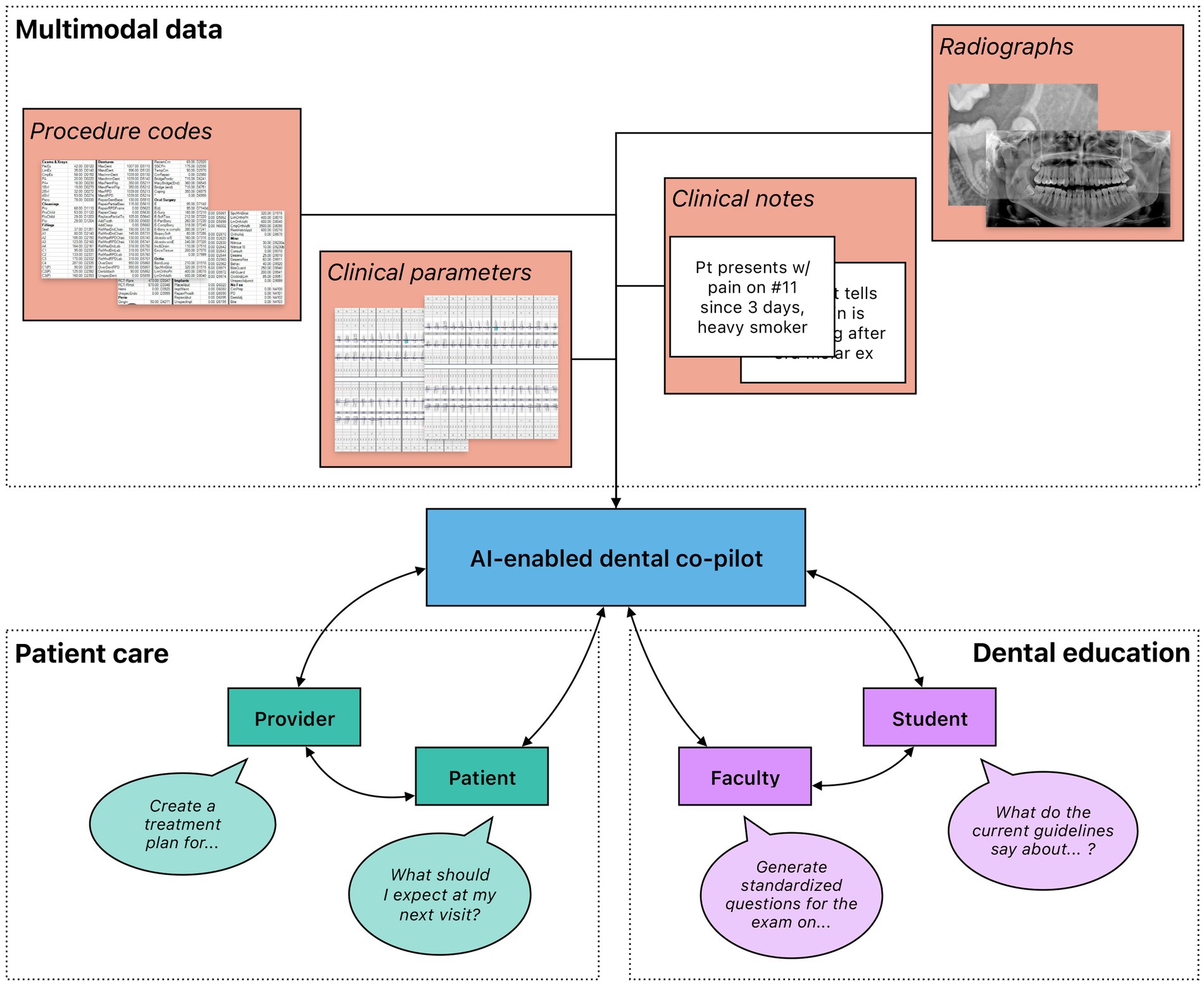
Figure 6. High-level overview of the potential use of generative AI in dental medicine. Rich, multimodal data gathered from clinical practice and dental research could be leveraged to train generative AI models that function as co-pilots to dental professionals. These models could be deployed in a variety of different settings, including patient care and dental education. Importantly, multiple stakeholders benefit from their interactions with the models. In patient care, both providers and patients could leverage generative AI to gain information; providers could further automate administrative processes to increase efficiency. In dental education, faculty and students could both engage with generative AI to create an immersive learning environment with individualized feedback.
Given how a generative AI model functions on probabilistic distributions, guessing the next token in a sequence through auto-regressive prediction, hallucinations (i.e., fabricated information presented as factual) present one of the most severe limitations. In the medical domain, hallucination has been demonstrated through asking an LLM to explain the pathophysiology of osteoporosis; none of the five articles referenced by the model existed, and all had PubMed IDs that were of different, unrelated papers (Alkaissi and McFarlane, 2023). Hallucinations are especially dangerous in the clinical context, where erroneous information can place patients at risk. It remains uncertain whether hallucinations can be prevented through gradual improvements in the existing LLM architecture, or if a deeper fundamental transformation in the LLM methodology may be necessary to prevent nonfactual responses. Creating an LLM that must provide citations for factual responses could be a potential solution (Glaese et al., 2022). Adjusting the prompt fed into the LLM with question-specific context has also proved successful (Feldman et al., 2023). The temperature of a model, a hyperparameter that can be fine-tuned by the engineer, controls how “random” the output of a generative model is; a higher pre-programmed temperature increases the chance of the model following a word-path with a lower initial probability, and consequently increases the risk of hallucinations. In dentistry, where hallucinations pose such large threats for patient care, a lower temperature parameter is essential.
Generative models are inherently reliant on the data used to train them. There are limitations both in finding sufficient, reliable training data and in the biased output that the training data can produce. In dental medicine, protecting patient privacy is paramount (Joda et al., 2019). When using generative models, the user must be aware of where the private patient data they input into a model are being stored. Commercially available LLMs might store user interaction data on their servers unless a user chooses to opt out (OpenAI, 2023a,b). Utilizing closed-sourced LLMs that are run by private companies means that potential patient data sent to the model will be sent to the company’s server, which may not be compliant with data privacy regulations. This limitation could be solved using open-sourced models that can be downloaded to run on an individual’s private server, one that can be compliant and already stores critical patient data. The unique characteristics of LLMs require a tailored, adaptive approach to regulatory oversight to ensure ethical use (Meskó, 2023). Further, the data used to train generative models must be stripped of patient identifiers, as the use of traceable information when outputting new responses must not be risked. Because of this risk of using identifiable data, acquiring sufficient and robust training data to produce accurate, reliable models is extremely difficult. Alternatively, data can be sanitized of sensitive or personally identifiable information, but the process is rigorous and reliant on human error and time. Moreover, even when training data are acquired and sufficiently sanitized, there is a risk of a biased output dependent upon biased training data. If only data from a certain population demographic or location are used to train the models, not only will the output be inherently biased, but it can consequently propagate the underlying bias. The difficulty of acquiring sufficient, accurate, robust training data increases the risk of engineers becoming less strict about the population and any clinical bias the data may possess. In the medical domain, it is of critical importance to ensure that the data used applied ML models are representative of the entire population.
Adopted by all stakeholders in a fair, ethical, transparent, and equitable manner, the application of AI has transformative potential in dental research and clinical care (Table 1). For clinicians, application of AI in dental medicine can enhance diagnostics, treatment planning, and outcome prediction. For providers, AI can improve operations, decision support, and case acceptance. For patients, AI can increase diagnostic transparency and enable more efficient treatment monitoring. In the optimization of administrative tasks and the generation and implementation of synthetic data in oral health education, AI can streamline workflows, reduce administrative burdens, and provide personalized patient care. To this end, explainability and generalizability of ML models used in dentistry must be maximized. Datasets used for training should be diversely sourced and validated across patient populations; single-center datasets should only be used for proof-of-principle reports or if there is a specific reason in connection with the research question. Ideally, both datasets and codebases should be made openly available to other researchers to enable thorough peer review and reproducibility. Transparency and interpretability are key desiderata for the application of AI in any medical setting.
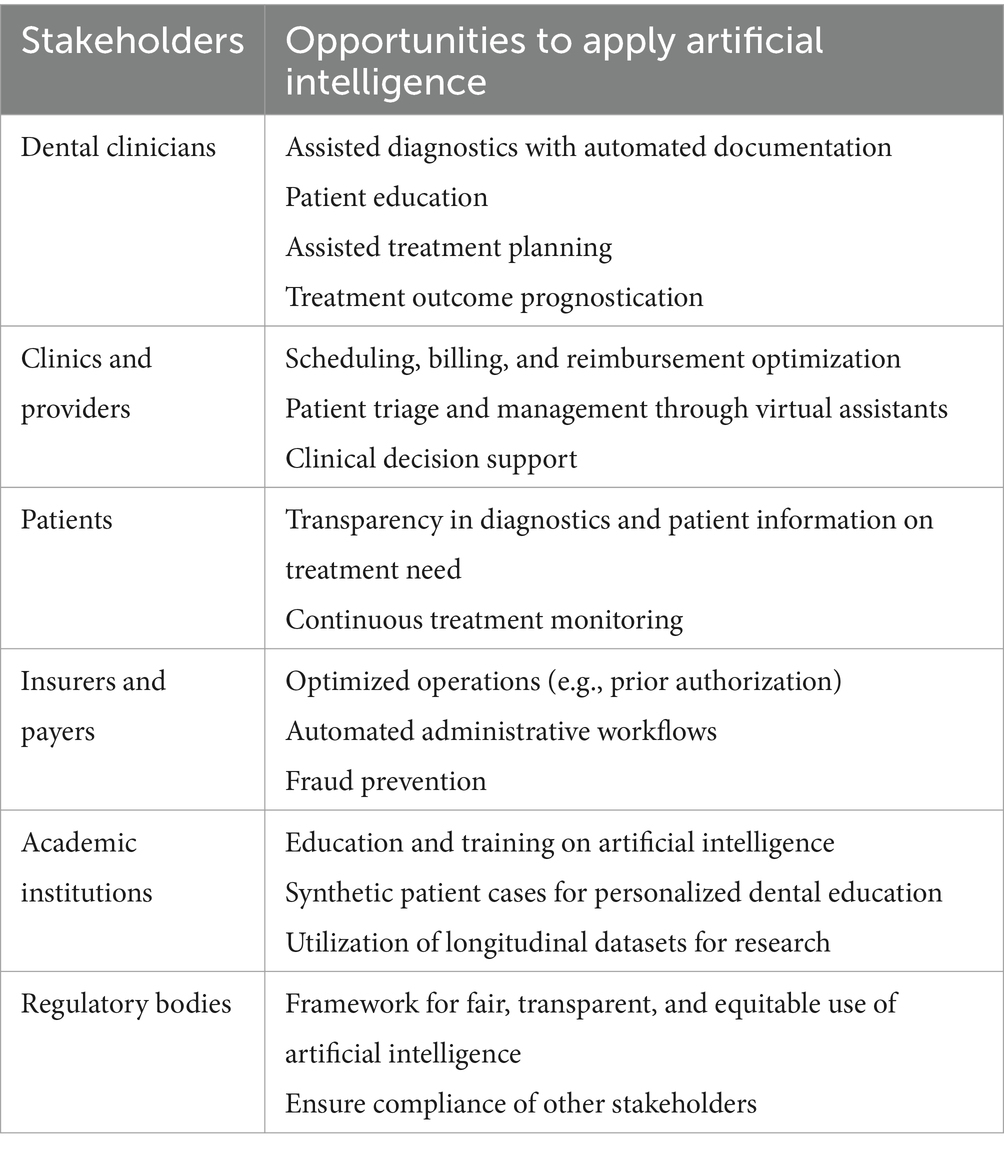
Table 1. Opportunities to apply artificial intelligence in dentistry [adapted from Elani and Giannobile (2024)].
The clinical use of AI is subject to medical device regulation. While this process is generally administered at the national level, supranational unions with specialized medical regulatory agencies streamline regulation for large populations: the European Medicines Agency of the European Union (EU, population: 450 million), the Medical Device Committee of the Association of Southeast Asian Nations (ASEAN, 670 million), and the forthcoming African Medicines Agency of the African Union (1.3 billion). Notably, supranational unions allow their members to regulate on the national level (e.g., the Health Services Authority in Singapore, an ASEAN member state). In stark contrast, regulation is strictly kept at the national level by some of the largest countries in the world by population, including India (Central Drug Standard Control Organization), China (National Medical Products Administration), and the US (Food and Drug Administration, FDA). The FDA has no distinct clearance process for AI-enabled products and a large share obtains regulatory clearance through the existing 510(k) premarket notification pathway, arguing substantial equivalence to a former FDA-cleared device (i.e., predicate) (Joshi et al., 2024). However, recent data show that 33% of devices cleared through the 510(k) pathway were cleared on the basis of predicates whose first generations did not have any AI-enabled functions; for an additional 8%, it was unclear whether the first-generation predicates had any AI-enabled functions (Muehlematter et al., 2023). Contrary to the non-medical software industry which, for the most part, represents a global market, the landscape of medical device regulation has resulted in considerable fragmentation in the market of AI-enabled medical software. Inevitably, this prevents the clinical adoption of AI in dental care on a global scale: with developers incentivized to maximize their return on investment, many are discouraged by the challenges of navigating non-standardized global regulatory and insurance environments.
The quality of training data critically influences an AI model’s outputs. Moreover, the AI model will be reflective of the patient population utilized in its training. High-quality datasets that represent diverse patients across various locations, ages, backgrounds, and clinical situations in large volumes are necessary for developing robust models. Additionally, the quality of data labeling is vital to the model’s quality. Accurate annotation requires domain expertise and is time-intensive with large datasets. This necessity for extensive and diverse data is a limiting factor to model creation and consequently, AI innovation in dental medicine, due to the challenges in acquiring and accurately labeling such data.
Data privacy is integral to the implementation of AI in dental medicine. Data privacy regulations, which vary by country, impose stringent restrictions on the transfer, storage, and processing of patient data to protect privacy. Developers of AI-enabled medical software must ensure compliance with local regulations, each country having their own policies on how patient data can be utilized. For any organization operating in the EU or using the personal data of its citizens, the General Data Protection Regulation must be followed. In the US, the Health Insurance Portability and Accountability Act applies to any organization acting primarily in the US or dealing with US healthcare data. For AI research involving data sharing, a data use/sharing agreement is essential to specify the terms of exchange and ensure regulatory compliance. Compared to other areas, adherence to data privacy regulations inevitably throttles development of medical AI technology, as the stringent legal requirements render the acquisition of patient data complex and resource-intensive.
From the patient’s perspective, data privacy considerations include informed consent. Generally, patients can revoke consent for the inclusion of their data in biomedical research. However, this becomes impractical for large ML models trained on millions of patient records; removing individual records and retraining models is unrealistic if consent is revoked. Moreover, much of the data used for contemporary model training was collected retrospectively before medical AI became mainstream, meaning patients were unaware that their consent would effectively become irreversible. It is thus essential that patients be adequately informed if their data are used to train ML models.
Technologically, understanding the processes and potential pitfalls of many ML algorithms can be challenging due to their inherent lack of transparency from input to output. ML models often exhibit a “black box” nature, obscuring decision-making processes and complicating error detection. This issue is particularly acute in medicine where precision is paramount. Explainability, or the aim to address this “black box” ambiguity, is essential to have proper accountability, trust, technological accuracy, compliance, and continued model improvement as AI evolves.
From a global health viewpoint, achieving equitable AI implementation in dental medicine is essential. Evidence suggests that AI could reduce health disparities between high-income nations with comprehensive health care systems and lower-income countries (Ciecierski-Holmes et al., 2022; Elani and Giannobile, 2024). Nonetheless, this requires global cooperation on knowledge as well as data sharing to facilitate robust, multi-center ML development and implementation worldwide, thereby earning the trust of clinicians and health care professionals. Further, dedicated efforts (e.g., scaling programs) should be directed toward assisting lower-income countries to adopt AI-enabled solutions in health care, including dental medicine.
Taken together, a growing body of literature underscores the considerable potential of AI in dental medicine, while also highlighting obstacles that hinder the integration of AI-enabled tool into routine clinical workflows. Enhancing the transparency, interpretability, and reliability of these technologies, establishing robust regulatory frameworks, and providing support in underserved regions could pave the way for a future where AI enables better and more equitable patient care on a global scale.
BF: Conceptualization, Data curation, Funding acquisition, Methodology, Visualization, Writing – original draft. CT: Conceptualization, Data curation, Funding acquisition, Methodology, Visualization, Writing – original draft. WVG: Conceptualization, Funding acquisition, Project administration, Supervision, Writing – review & editing.
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This work was supported by the NIH/NIDCR U01DE033239 (WVG) and the Osteology Foundation 22–005 (BF).
The authors acknowledge the advice of Magda Feres in drafting this manuscript.
BF reports prior speaking fees from dentalXr.ai and synMedico.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Akesson, L., Håkansson, J., and Rohlin, M. (1992). Comparison of panoramic and intraoral radiography and pocket probing for the measurement of the marginal bone level. J. Clin. Periodontol. 19, 326–332. doi: 10.1111/j.1600-051x.1992.tb00654.x
Alkaissi, H., and McFarlane, S. I. (2023). Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 15, e35179. doi: 10.7759/cureus.35179
Ali, S. R., Dobbs, T. D., Hutchings, H. A., and Whitaker, I. S. (2023). Using ChatGPT to write patient clinic letters. Lancet Digit. Health 5, e179–e181. doi: 10.1016/s2589-7500(23)00048-1
An, Y., Tang, K., and Wang, J. (2021). Time-aware multi-type data fusion representation learning framework for risk prediction of cardiovascular diseases. IEEE/ACM Trans. Comput. Biol. Bioinform. PP, 1–3734. doi: 10.1109/TCBB.2021.3118418
Arsiwala-Scheppach, L. T., Chaurasia, A., Müller, A., Krois, J., and Schwendicke, F. (2023). Machine learning in dentistry: a scoping review. J. Clin. Med. 12:1–4. doi: 10.3390/jcm12030937
Ayers, J. W., Poliak, A., Dredze, M., Leas, E. C., Zhu, Z., Kelley, J., et al. (2023). Comparing physician and artificial intelligence Chatbot responses to patient questions posted to a public social media forum. JAMA Intern. Med. 183, 589–596. doi: 10.1001/jamainternmed.2023.1838
Bader, J. D., Shugars, D. A., and Bonito, A. J. (2001). Systematic reviews of selected dental caries diagnostic and management methods. J. Dent. Educ. 65, 960–968. doi: 10.1002/j.0022-0337.2001.65.10.tb03470.x
Bahdanau, D., Cho, K., and Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473. doi: 10.48550/arXiv.1409.0473
Balel, Y. (2023). Can ChatGPT be used in oral and maxillofacial surgery? J. Stomatol. Oral. Maxillofac. Surg. 124:101471. doi: 10.1016/j.jormas.2023.101471
Baysal, A., Sahan, A. O., Ozturk, M. A., and Uysal, T. (2016). Reproducibility and reliability of three-dimensional soft tissue landmark identification using three-dimensional stereophotogrammetry. Angle Orthod. 86, 1004–1009. doi: 10.2319/120715-833.1
Bekhuis, T., Kreinacke, M., Spallek, H., Song, M., and O'Donnell, J. A. (2011). Using natural language processing to enable in-depth analysis of clinical messages posted to an internet mailing list: a feasibility study. J. Med. Internet Res. 13:e98. doi: 10.2196/jmir.1799
Bennasar, C., García, I., Gonzalez-Cid, Y., Pérez, F., and Jiménez, J. (2023). Second opinion for non-surgical root canal treatment prognosis using machine learning models. Diagnostics 13:7–9. doi: 10.3390/diagnostics13172742
Bernabe, E., Marcenes, W., Hernandez, C. R., Bailey, J., Abreu, L. G., Alipour, V., et al. (2020). Global, regional, and National Levels and trends in burden of Oral conditions from 1990 to 2017: a systematic analysis for the global burden of disease 2017 study. J. Dent. Res. 99, 362–373. doi: 10.1177/0022034520908533
Büttner, M., Leser, U., Schneider, L., and Schwendicke, F. (2024). Natural language processing: chances and challenges in dentistry. J. Dent. 141:104796. doi: 10.1016/j.jdent.2023.104796
Chan, H. L., Sinjab, K., Li, J., Chen, Z., Wang, H. L., and Kripfgans, O. D. (2018). Ultrasonography for noninvasive and real-time evaluation of peri-implant tissue dimensions. J Clin Periodontol 45:986–995. doi: 10.1111/jcpe.12918
Chen, Q., Lin, S., Wu, J., Lyu, P., and Zhou, Y. (2020). Automatic drawing of customized removable partial denture diagrams based on textual design for the clinical decision support system. J. Oral Sci. 62, 236–238. doi: 10.2334/josnusd.19-0138
Chen, Q., Zhou, X., Wu, J., and Zhou, Y. (2021). Structuring electronic dental records through deep learning for a clinical decision support system. Health Informatics J. 27:1460458220980036. doi: 10.1177/1460458220980036
Ciecierski-Holmes, T., Singh, R., Axt, M., Brenner, S., and Barteit, S. (2022). Artificial intelligence for strengthening healthcare systems in low- and middle-income countries: a systematic scoping review. NPJ Digit. Med. 5:162. doi: 10.1038/s41746-022-00700-y
Ding, H., Wu, J., Zhao, W., Matinlinna, J. P., Burrow, M. F., and Tsoi, J. K. H. (2023). Artificial intelligence in dentistry—a review [review]. Front. Dental Med. 4:5251. doi: 10.3389/fdmed.2023.1085251
Elani, H. W., and Giannobile, W. V. (2024). Harnessing artificial intelligence to address Oral health disparities. JAMA Health Forum 5:e240642. doi: 10.1001/jamahealthforum.2024.0642
Esteva, A., Chou, K., Yeung, S., Naik, N., Madani, A., Mottaghi, A., et al. (2021). Deep learning-enabled medical computer vision. NPJ Digit. Med. 4:5. doi: 10.1038/s41746-020-00376-2
Esteva, A., Robicquet, A., Ramsundar, B., Kuleshov, V., DePristo, M., Chou, K., et al. (2019). A guide to deep learning in healthcare. Nat. Med. 25, 24–29. doi: 10.1038/s41591-018-0316-z
Fan, W., Tang, J., Xu, H., Huang, X., Wu, D., and Zhang, Z. (2023). Early diagnosis for the onset of peri-implantitis based on artificial neural network. Open Life Sci. 18:20220691. doi: 10.1515/biol-2022-0691
Favaretto, M., Shaw, D., De Clercq, E., Joda, T., and Elger, B. S. (2020). Big data and digitalization in dentistry: a systematic review of the ethical issues. Int. J. Environ. Res. Public Health 17:1–2. doi: 10.3390/ijerph17072495
Feldman, P., Foulds, J. R., and Pan, S. (2023). Trapping llm hallucinations using tagged context prompts. arXiv preprint arXiv 2306:06085. doi: 10.48550/arXiv.2306.06085
Feher, B., Kuchler, U., Schwendicke, F., Schneider, L., Cejudo Grano de Oro, J. E., Xi, T., et al. (2022). Emulating clinical diagnostic reasoning for jaw cysts with machine learning. Diagnostics 12:8–9. doi: 10.3390/diagnostics12081968
Gao, S., Li, X., Li, X., Li, Z., and Deng, Y. (2022). Transformer based tooth classification from cone-beam computed tomography for dental charting. Comput. Biol. Med. 148:105880. doi: 10.1016/j.compbiomed.2022.105880
Giannobile, W. V., Braun, T. M., Caplis, A. K., Doucette-Stamm, L., Duff, G. W., and Kornman, K. S. (2013a). Patient stratification for preventive care in dentistry. J. Dent. Res. 92, 694–701. doi: 10.1177/0022034513492336
Giannobile, W. V., Kornman, K. S., and Williams, R. C. (2013b). Personalized medicine enters dentistry: what might this mean for clinical practice? J. Am. Dent. Assoc. 144, 874–876. doi: 10.14219/jada.archive.2013.0200
Glaese, A., McAleese, N., Trębacz, M., Aslanides, J., Firoiu, V., Ewalds, T., et al. (2022). Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv 2209, 14375. doi: 10.48550/arXiv.2209.14375
Gong, J. J., and Guttag, J. V. (2018). Learning to Summarize Electronic Health Records Using Cross-Modality Correspondences Proceedings of the 3rd Machine Learning for Healthcare Conference, Proceedings of Machine Learning Research. Available at: https://proceedings.mlr.press/v85/gong18a.html
Ha, S. R., Park, H. S., Kim, E. H., Kim, H. K., Yang, J. Y., Heo, J., et al. (2018). A pilot study using machine learning methods about factors influencing prognosis of dental implants. J. Adv. Prosthodont. 10, 395–400. doi: 10.4047/jap.2018.10.6.395
Halevy, A., Norvig, P., and Pereira, F. (2009). The unreasonable effectiveness of data. IEEE Intell. Syst. 24, 8–12. doi: 10.1109/MIS.2009.36
Hasuike, A., Watanabe, T., Wakuda, S., Kogure, K., Yanagiya, R., Byrd, K. M., et al. (2022). Machine learning in predicting tooth loss: a systematic review and risk of Bias assessment. J. Pers. Med. 12:1–4. doi: 10.3390/jpm12101682
He, J., Baxter, S. L., Xu, J., Xu, J., Zhou, X., and Zhang, K. (2019). The practical implementation of artificial intelligence technologies in medicine. Nat. Med. 25, 30–36. doi: 10.1038/s41591-018-0307-0
Istrate, E. C., Cooper, B. L., Singh, P., Gül, G., and West, K. P. (2023). Dentists of tomorrow 2023: An analysis of the results of the ADEA 2023 survey of U.S. dental school seniors. J. Dent. Educ. 87, 1607–1620. doi: 10.1002/jdd.13392
Jensen, K., Soguero-Ruiz, C., Oyvind Mikalsen, K., Lindsetmo, R. O., Kouskoumvekaki, I., Girolami, M., et al. (2017). Analysis of free text in electronic health records for identification of cancer patient trajectories. Sci. Rep. 7:46226. doi: 10.1038/srep46226
Joda, T., Waltimo, T., Probst-Hensch, N., Pauli-Magnus, C., and Zitzmann, N. U. (2019). Health Data in Dentistry: an Attempt to Master the Digital Challenge. Public Health Genomics 22:1–7. doi: 10.1159/000501643
Joshi, G., Jain, A., Araveeti, S. R., Adhikari, S., Garg, H., and Bhandari, M. (2024). FDA-approved artificial intelligence and machine learning (AI/ML)-enabled medical devices: An updated landscape. Electronics 13:498. doi: 10.3390/electronics13030498
Joshi, M., and Jetawat, A. (2020). Evaluation of classification algorithms used in medical decision support systems. IEEE. 27–31.
Kabir, T., Lee, C. T., Chen, L., Jiang, X., and Shams, S. (2022). A comprehensive artificial intelligence framework for dental diagnosis and charting. BMC Oral Health 22:480. doi: 10.1186/s12903-022-02514-6
Kim, D. W., Kim, H., Nam, W., Kim, H. J., and Cha, I. H. (2018). Machine learning to predict the occurrence of bisphosphonate-related osteonecrosis of the jaw associated with dental extraction: a preliminary report. Bone 116, 207–214. doi: 10.1016/j.bone.2018.04.020
Kim, D. W., Lee, S., Kwon, S., Nam, W., Cha, I.-H., and Kim, H. J. (2019). Deep learning-based survival prediction of oral cancer patients. Sci. Rep. 9:6994. doi: 10.1038/s41598-019-43372-7
Kreimeyer, K., Foster, M., Pandey, A., Arya, N., Halford, G., Jones, S., et al. (2017). Natural language processing systems for capturing and standardizing unstructured clinical information: a systematic review. J. Biomed. Inform. 73, 14–29. doi: 10.1016/j.jbi.2017.07.012
Kokomoto, K., Okawa, R., Nakano, K., and Nozaki, K. (2021). Intraoral image generation by progressive growing of generative adversarial network and evaluation of generated image quality by dentists. Sci Rep, 11:18517. doi: 10.1038/s41598-021-98043-3
Kundu, S. (2021). AI in medicine must be explainable. Nat. Med. 27:1328. doi: 10.1038/s41591-021-01461-z
Lee, Y. H., Won, J. H., Auh, Q. S., Noh, Y. K., and Lee, S. W. (2024). Prediction of xerostomia in elderly based on clinical characteristics and salivary flow rate with machine learning. Sci. Rep. 14:3423. doi: 10.1038/s41598-024-54120-x
Leonard, M. S., Kilpatrick, K. E., Fast, T. B., Mahan, P. E., and Mackenzie, R. S. (1974). Automated diagnosis and treatment planning for craniofacial pain. J. Dent. Res. 53, 1155–1159. doi: 10.1177/00220345740530051401
Leonard, M. S., Roberts, S. D., Fast, T. B., and Mahan, P. E. (1973). Automated diagnosis of craniofacial pain. J. Dent. Res. 52, 1297–1302. doi: 10.1177/00220345730520062401
Li, S., Guo, Z., Lin, J., and Ying, S. (2022). Artificial intelligence for classifying and archiving orthodontic images. Biomed. Res. Int. 2022, 1473977–1473911. doi: 10.1155/2022/1473977
Li, M., Yang, H., and Liu, Y. (2023). Biomedical named entity recognition based on fusion multi-features embedding. Technol. Health Care 31, 111–121. doi: 10.3233/thc-236011
Lin, Y.-C., Chen, M.-C., Chen, C.-H., Chen, M.-H., Liu, K.-Y., and Chang, C.-C. (2023). Fully automated film mounting in dental radiography: a deep learning model. BMC Med. Imaging 23:109. doi: 10.1186/s12880-023-01064-9
Liu, Y., Li, Y., Fu, Y., Liu, T., Liu, X., Zhang, X., et al. (2017). Quantitative prediction of oral cancer risk in patients with oral leukoplakia. Oncotarget 8, 46057–46064. doi: 10.18632/oncotarget.17550
Luong, M.-T., Pham, H., and Manning, C. D. (2015). Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025.
Ma, L., Gao, J., Wang, Y., Zhang, C., Wang, J., Ruan, W., et al. (2020). Adacare: Explainable clinical health status representation learning via scale-adaptive feature extraction and recalibration. Proceed. AAAI Conf. Art. Intellig. PKP Publishing Services Network. 34, 825–832. doi: 10.1609/aaai.v34i01.5427
Mameno, T., Wada, M., Nozaki, K., Takahashi, T., Tsujioka, Y., Akema, S., et al. (2021). Predictive modeling for peri-implantitis by using machine learning techniques. Sci. Rep. 11:11090. doi: 10.1038/s41598-021-90642-4
Mao, J., Gomez, G. G. F., Wang, M., Xu, H., and Thyvalikakath, T. P. (2024). Prediction of Sjögren's disease diagnosis using matched electronic dental-health record data. BMC Med. Inform. Decis. Mak. 24:43. doi: 10.1186/s12911-024-02448-9
Moharrami, M., Farmer, J., Singhal, S., Watson, E., Glogauer, M., Johnson, A. E., et al. (2023). Detecting dental caries on oral photographs using artificial intelligence: a systematic review. Oral Dis. 30, 1765–1783. doi: 10.1111/odi.14659
Meskó, B., and Topol, E. J. (2023). The imperative for regulatory oversight of large language models (or generative AI) in healthcare. NPJ Digit Med 6, 120. doi: 10.1038/s41746-023-00873-0
Muehlematter, U. J., Bluethgen, C., and Vokinger, K. N. (2023). FDA-cleared artificial intelligence and machine learning-based medical devices and their 510(k) predicate networks. Lancet Digit. Health 5, e618–e626. doi: 10.1016/s2589-7500(23)00126-7
Nassif, A. B., Shahin, I., Attili, I., Azzeh, M., and Shaalan, K. (2019). Speech recognition using deep neural networks: a systematic review. IEEE Access 7, 19143–19165. doi: 10.1109/ACCESS.2019.2896880
Nguyen, T. T., Larrivée, N., Lee, A., Bilaniuk, O., and Durand, R. (2021a). Use of artificial intelligence in dentistry: current clinical trends and research advances. J. Can. Dent. Assoc. 28:l7, 50–57. doi: 10.12816/0059360
Nguyen, K. T., le, B. M., Li, M., Almeida, F. T., Major, P. W., Kaipatur, N., et al. (2021b). Localization of cementoenamel junction in intraoral ultrasonographs with machine learning. J. Dent. 112:103752. doi: 10.1016/j.jdent.2021.103752
Ntovas, P., Marchand, L., Finkelman, M., Revilla-León, M., and Att, W. (2024). Accuracy of manual and artificial intelligence-based superimposition of cone-beam computed tomography with digital scan data, utilizing an implant planning software: a randomized clinical study. Clin. Oral Implants Res. doi: 10.1111/clr.14313
OpenAI (2023a). Privacy Policy. https://openai.com/policies/privacy-policy/, (Accessed July 8, 2024).
OpenAI (2023b). Europe Privacy Policy. https://openai.com/policies/eu-privacy-policy/, Version of: December 15, 2023, Access date: July 8, 2024.
Patel, J. S., Brandon, R., Tellez, M., Albandar, J. M., Rao, R., Krois, J., et al. (2022a). Developing automated computer algorithms to phenotype periodontal disease diagnoses in electronic dental records. Methods Inf. Med. 61, e125–e133. doi: 10.1055/s-0042-1757880
Patel, J. S., Kumar, K., Zai, A., Shin, D., Willis, L., and Thyvalikakath, T. P. (2023b). Developing automated computer algorithms to track periodontal disease change from longitudinal electronic dental records. Diagnostics 13:6–9. doi: 10.3390/diagnostics13061028
Patel, S. B., and Lam, K. (2023). ChatGPT: the future of discharge summaries? Lancet Digit. Health 5, e107–e108. doi: 10.1016/s2589-7500(23)00021-3
Patel, J. S., Su, C., Tellez, M., Albandar, J. M., Rao, R., Iyer, V., et al. (2022). Developing and testing a prediction model for periodontal disease using machine learning and big electronic dental record data. Front. Artif. Intell. 5:979525. doi: 10.3389/frai.2022.979525
Patil, S., Joda, T., Soffe, B., Awan, K. H., Fageeh, H. N., Tovani-Palone, M. R., et al. (2023). Efficacy of artificial intelligence in the detection of periodontal bone loss and classification of periodontal diseases: a systematic review. J. Am. Dent. Assoc. 154, 795–804.e1. doi: 10.1016/j.adaj.2023.05.010
Pethani, F., and Dunn, A. G. (2023). Natural language processing for clinical notes in dentistry: a systematic review. J. Biomed. Inform. 138:104282. doi: 10.1016/j.jbi.2023.104282
Picoli, F. F., Fontenele, R. C., Van der Cruyssen, F., Ahmadzai, I., and Politis, C. Trigeminal Nerve Injuries Research Group, et al. (2023). Risk assessment of inferior alveolar nerve injury after wisdom tooth removal using 3D AI-driven models: a within-patient study. J. Dent. 139:104765. doi: 10.1016/j.jdent.2023.104765
Prasad, J., Mallikarjunaiah, D. R., Shetty, A., Gandedkar, N., Chikkamuniswamy, A. B., and Shivashankar, P. C. (2023). Machine learning predictive model as clinical decision support system in orthodontic treatment planning. Dent J. 11:5–12. doi: 10.3390/dj11010001
Ragodos, R., Wang, T., Padilla, C., Hecht, J. T., Poletta, F. A., Orioli, I., et al. (2022). Dental anomaly detection using intraoral photos via deep learning. Sci. Rep. 12:11577. doi: 10.1038/s41598-022-15788-1
Raza, S., and Schwartz, B. (2023). Entity and relation extraction from clinical case reports of COVID-19: a natural language processing approach. BMC Med. Inform. Decis. Mak. 23:20. doi: 10.1186/s12911-023-02117-3
Reddy, S. (2022). Explainability and artificial intelligence in medicine. Lancet Digit. Health 4, e214–e215. doi: 10.1016/s2589-7500(22)00029-2
Rekawek, P., Herbst, E. A., Suri, A., Ford, B. P., Rajapakse, C. S., and Panchal, N. (2023). Machine learning and artificial intelligence: a web-based implant failure and Peri-implantitis prediction model for clinicians. Int. J. Oral Maxillofac. Implants 38, 576–582b. doi: 10.11607/jomi.9852
Revilla-León, M., Gómez-Polo, M., Barmak, A. B., Inam, W., Kan, J. Y. K., Kois, J. C., et al. (2022). Artificial intelligence models for diagnosing gingivitis and periodontal disease: a systematic review. J. Prosthet. Dent. 130, 816–824. doi: 10.1016/j.prosdent.2022.01.026
Ryu, J., Kim, Y.-H., Kim, T.-W., and Jung, S.-K. (2023). Evaluation of artificial intelligence model for crowding categorization and extraction diagnosis using intraoral photographs. Sci. Rep. 13:5177. doi: 10.1038/s41598-023-32514-7
Saharia, C., Chan, W., Chang, H., Lee, C., Ho, J., Salimans, T., et al. (2022). “Palette: Image-to-image diffusion models,” in ACM SIGGRAPH 2022 conference proceedings, 1–10.
Schwartz, W. B., Patil, R. S., and Szolovits, P. (1987). Artificial intelligence in medicine. Where do we stand? N. Engl. J. Med. 316, 685–688. doi: 10.1056/nejm198703123161109
Schwendicke, F., Arsiwala, L. T., Krois, J., Bäumer, A., Pretzl, B., Eickholz, P., et al. (2021a). Association, prediction, generalizability: cross-center validity of predicting tooth loss in periodontitis patients. J. Dent. 109:103662. doi: 10.1016/j.jdent.2021.103662
Schwendicke, F., Cejudo Grano de Oro, J., Garcia Cantu, A., Meyer-Lueckel, H., Chaurasia, A., Krois, J., et al. (2022). Artificial intelligence for caries detection: value of data and information. J. Dent. Res. 101, 1350–1356. doi: 10.1177/00220345221113756
Schwendicke, F., and Krois, J. (2022). Data dentistry: how data are changing clinical care and research. J. Dent. Res. 101, 21–29. doi: 10.1177/00220345211020265
Schwendicke, F., Rossi, J. G., Göstemeyer, G., Elhennawy, K., Cantu, A. G., Gaudin, R., et al. (2021b). Cost-effectiveness of artificial intelligence for proximal caries detection. J. Dent. Res. 100, 369–376. doi: 10.1177/0022034520972335
Schwendicke, F., Singh, T., Lee, J. H., Gaudin, R., Chaurasia, A., Wiegand, T., et al. (2021c). Artificial intelligence in dental research: checklist for authors, reviewers, readers. J. Dent. 107:103610. doi: 10.1016/j.jdent.2021.103610
Schwendicke, F., Tzschoppe, M., and Paris, S. (2015). Radiographic caries detection: a systematic review and meta-analysis. J. Dent. 43, 924–933. doi: 10.1016/j.jdent.2015.02.009
Senirkentli, G. B., İnce Bingöl, S., Ünal, M., Bostancı, E., Güzel, M. S., and Açıcı, K. (2023). Machine learning based orthodontic treatment planning for mixed dentition borderline cases suffering from moderate to severe crowding: An experimental research study. Technol. Health Care 31, 1723–1735. doi: 10.3233/thc-220563
Sheikhalishahi, S., Miotto, R., Dudley, J. T., Lavelli, A., Rinaldi, F., and Osmani, V. (2019). Natural language processing of clinical notes on chronic diseases: systematic review. JMIR Med. Inform. 7:e12239. doi: 10.2196/12239
Singh, A., Thakur, N., and Sharma, A. (2016). “A review of supervised machine learning algorithms,” 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 1310–1315.
Steigmann, L., Maekawa, S., Sima, C., Travan, S., Wang, C. W., and Giannobile, W. V. (2020). Biosensor and lab-on-a-chip biomarker-identifying Technologies for Oral and Periodontal Diseases. Front. Pharmacol. 11:588480. doi: 10.3389/fphar.2020.588480
Sutton, R. S., and Barto, A. G. (2018). Reinforcement learning: An introduction. Cambridge, MA, USA: MIT press.
Tanikawa, C., and Yamashiro, T. (2021). Development of novel artificial intelligence systems to predict facial morphology after orthognathic surgery and orthodontic treatment in Japanese patients. Sci. Rep. 11:15853. doi: 10.1038/s41598-021-95002-w
Thanathornwong, B. (2018). Bayesian-based decision support system for assessing the needs for orthodontic treatment. Healthc Inform. Res. 24, 22–28. doi: 10.4258/hir.2018.24.1.22
Tonetti, M. S., Jepsen, S., Jin, L., and Otomo-Corgel, J. (2017). Impact of the global burden of periodontal diseases on health, nutrition and wellbeing of mankind: a call for global action. J. Clin. Periodontol. 44, 456–462. doi: 10.1111/jcpe.12732
Topol, E. J. (2019). High-performance medicine: the convergence of human and artificial intelligence. Nat. Med. 25, 44–56. doi: 10.1038/s41591-018-0300-7
Turing, A. M. (1950). Computing machinery and intelligence. Mind LIX, 433–460. doi: 10.1093/mind/LIX.236.433
Ueda, A., Tussie, C., Kim, S., Kuwajima, Y., Matsumoto, S., Kim, G., et al. (2023). Classification of maxillofacial morphology by artificial intelligence using cephalometric analysis measurements. Diagnostics 13:5–8. doi: 10.3390/diagnostics13132134
Umer, F., and Adnan, N. (2024). Generative artificial intelligence: synthetic datasets in dentistry. BDJ Open 10:13. doi: 10.1038/s41405-024-00198-4
United Nations Scientific Committee on the Effects of Atomic Radiation (2022). Sources and Effects of Ionizing Radiation, United Nations Scientific Committee on the Effects of Atomic Radiation (UNSCEAR) 2020/2021 Report, Volume I, United Nations Publications. doi: 10.18356/9789210010030
Van Calster, B., McLernon, D. J., van Smeden, M., Wynants, L., and Steyerberg, E. W. (2019). Calibration: the Achilles heel of predictive analytics. BMC Med. 17:230. doi: 10.1186/s12916-019-1466-7
Vinayahalingam, S., Kempers, S., Schoep, J., Hsu, T.-M. H., Moin, D. A., van Ginneken, B., et al. (2023). Intra-oral scan segmentation using deep learning. BMC Oral Health 23:643. doi: 10.1186/s12903-023-03362-8
Wu, S., Roberts, K., Datta, S., du, J., Ji, Z., Si, Y., et al. (2019). Deep learning in clinical natural language processing: a methodical review. J. Am. Med. Inform. Assoc. 27, 457–470. doi: 10.1093/jamia/ocz200
Yang, H., Jo, E., Kim, H. J., Cha, I. H., Jung, Y. S., Nam, W., et al. (2020). Deep learning for automated detection of cyst and tumors of the jaw in panoramic radiographs. J. Clin. Med. 9:2. doi: 10.3390/jcm9061839
Yoon, S., Odlum, M., Lee, Y., Choi, T., Kronish, I. M., Davidson, K. W., et al. (2018). Applying deep learning to understand predictors of tooth mobility among urban Latinos. Stud. Health Technol. Inform. 251, 241–244
Zanjani, F. G., Pourtaherian, A., Zinger, S., Moin, D. A., Claessen, F., Cherici, T., et al. (2021). Mask-MCNet: tooth instance segmentation in 3D point clouds of intra-oral scans. Neurocomputing 453, 286–298. doi: 10.1016/j.neucom.2020.06.145
Zhang, Y., Bogard, B., and Zhang, C. (2021). Development of natural language processing algorithm for dental charting. SN Comp. Sci. 2:309. doi: 10.1007/s42979-021-00673-x
Keywords: artificial intelligence, machine learning, diagnostic modeling, prognostic modeling, generative modeling, dental medicine, dental radiography
Citation: Feher B, Tussie C and Giannobile WV (2024) Applied artificial intelligence in dentistry: emerging data modalities and modeling approaches. Front. Artif. Intell. 7:1427517. doi: 10.3389/frai.2024.1427517
Edited by:
Tuan D. Pham, Queen Mary University of London, United KingdomReviewed by:
Antonio Sarasa-Cabezuelo, Complutense University of Madrid, SpainCopyright © 2024 Feher, Tussie and Giannobile. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: William V. Giannobile, V2lsbGlhbV9HaWFubm9iaWxlQGhzZG0uaGFydmFyZC5lZHU=
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.