 Liuying Li1†
Liuying Li1† Min Huang2†Ling Dao3,4†Xixi Feng5
Min Huang2†Ling Dao3,4†Xixi Feng5 Yifeng Liu4Changyou Wei1
Yifeng Liu4Changyou Wei1 Fangfang Liu6
Fangfang Liu6 Jing Zhang7*
Jing Zhang7* Fan Xu5*
Fan Xu5*- 1Department of Traditional Chinese Medicine, Zigong First People's Hospital, Zigong, Sichuan, China
- 2Department of Physiology, School of Basic Medicine, Chengdu Medical College, Sichuan, China
- 3Department of Cardiology, The First Affiliated Hospital of Zhengzhou University, Zhengzhou, China
- 4Department of Clinical Medicine, Chengdu Medical College, Sichuan, China
- 5Department of Public Health, Chengdu Medical College, Sichuan, China
- 6Art College, Southwest Minzu University, Sichuan, China
- 7MOEMIL Laboratory, School of Optoelectronic Information, University of Electronic Science and Technology of China, Chengdu, China
Heart sound detection technology plays an important role in the prediction of cardiovascular disease, but the most significant heart sounds are fleeting and may be imperceptible. Hence, obtaining heart sound information in an efficient and accurate manner will be helpful for the prediction and diagnosis of heart disease. To obtain heart sound information, we designed an audio data analysis tool to segment the heart sounds from single heart cycle, and validated the heart rate using a finger oxygen meter. The results from our validated technique could be used to realize heart sound segmentation. Our robust algorithmic platform was able to segment the heart sounds, which could then be compared in terms of their difference from the background. A combination of an electronic stethoscope and artificial intelligence technology was used for the digital collection of heart sounds and the intelligent identification of the first (S1) and second (S2) heart sounds. Our approach can provide an objective basis for the auscultation of heart sounds and visual display of heart sounds and murmurs.
Introduction
Heart sound signals contain valuable information on the physiology or pathophysiological status of the heart. For example, pathological murmurs can be heard in children with congenital heart disease (Wang J. et al., 2020), and a heart murmur and/or additional heart sounds may indicate a valve sexual heart disease (Long et al., 2020). Cardiac auscultation is currently considered to be the most reliable test for detecting cardiac abnormalities (Esquembre Menor and Castel Sánchez, 1988). For instance, an analysis of the heart sounds recorded using a left ventricular assist device can enable real-time, remote monitoring of the device and cardiac function, for early detection of the left ventricular assist device (LVAD) complications (Chen et al., 2021). A third heart sound (S3) on auscultation may be associated with cardiac insufficiency (Shah and Michaels, 2006), and in heart failure patients, this third heart sound has been independently associated with adverse outcomes, including the progression of heart failure (Drazner et al., 2001).
However, cardiac auscultation requires a qualified cardiologist, and relies on the sounds of the heart cycle (myocardial contraction and valve closure) for the detection of cardiac abnormalities during the pumping action (Boulares et al., 2021). These important heart sounds include the first heart sound (S1), the second heart sound (S2), the third heart sound (S3) and the fourth heart sound (S4). Heart murmurs are short-lived and difficult to capture via human hearing, which may lead to these fleeting physiological signals being ignored. There is therefore an urgent need to find better methods of heart sound analysis.
Recently, the significant growth of artificial intelligence (AI) in the biomedical field has demonstrated elevated levels of accuracy and sensitivity (Rodrigues et al., 2017; Gadaleta et al., 2019; Shen et al., 2021). When it comes to heart sound segmentation, some algorithms have shown strong automated functions. Authors presented a new technique to detect and categorize heart sounds using the self-similarity matrix (SSM) (Rodrigues et al., 2022) for retrieving data from multimodal time series. Their focus is on heart sound segmentation and future potential for automated labeling. Kui et al. (2020) proposed using a combination of the duration hidden Markov model (DHMM) and the Viterbi algorithm to evaluate the localization, feature extraction, and classification of heart sounds in an objective manner. To achieve segmentation results compatible with the sequential nature of heart sounds, authors used the Python package TSSEARCH (Folgado et al., 2022), which is based on the combination of subsequence search and time series similarity measurement with sequential time model. An image-based technology study (Delampady, 2021), inspired by a network utilized for image segmentation, was developed to identify the captured Joint Photographic Experts Group (JPEG) image pattern of the cardiac signal and classify using the hamming distance technique. The segmentation algorithms (Delampady, 2021) incorporated empirical wavelet transform and instantaneous techniques to distinguish heart sounds from murmurs and suppress background noise. Other techniques applied include Shannon entropy envelope extraction, instantaneous phase-based boundary determination, parameter extraction for heart sounds and murmurs, systole/diastole discrimination, and decision-rules based murmur classification. Specifically, measuring the starting point, peak point, and end point of the heart sound signal requires the robust algorithmic capabilities of artificial intelligence (AI).
From the perspective of physical characteristics of the heart sounds, the two dominant variables are the intensity and frequency, as these represent the essential information of the sound (El-Segaier et al., 2005). In addition, an electronic stethoscope was used to record the heart sounds digitally, thus providing a solid foundation for raw data analysis. Here, we introduce a method of automatically segmenting the heart sounds and extracting the fundamental frequency and intensity parameters in combination between audacity and customized MATLAB code. Our method represents a step forward in the artificial intelligence (AI) analysis of heart sounds, and is conducive to the diagnosis and prediction of heart disease.
Methods
Ethics statement
The study was approved by the Institute of Institutional Review Board and by Ethics Committee of the Chengdu Medical College. All participants gave informed consent in writing.
General workflow
First, we connected the electronic stethoscope and turned on the Moving Picture Experts Group Audio Layer III (mp3) recorder, while keeping the environment quiet. The candidate was asked to sit or take up a supine position with chest exposure. Next, a recorder was placed at the auscultation head with appropriate pressure on each of the five valve areas in turn: the mitral valve area (M), pulmonary valve area (P), first aortic auscultation area (A), second aortic auscultation area (E), and the tricuspid valve area (T), to record heart sounds for a period of at least 1 min. Data from each candidate were collected on three consecutive days, twice a day (8:00–11:00, 14:30–17:00), and 30 audio files were created for each person. Finally, we imported the Moving Picture Experts Group Audio Layer III (mp3) files into our Audio Data Analysis Tool, and automatically cut the audio data representing a cycle into four audio clips (S1, S2, systole, diastole). We then extracted the intensity and frequency parameters as shown in Figure 1.
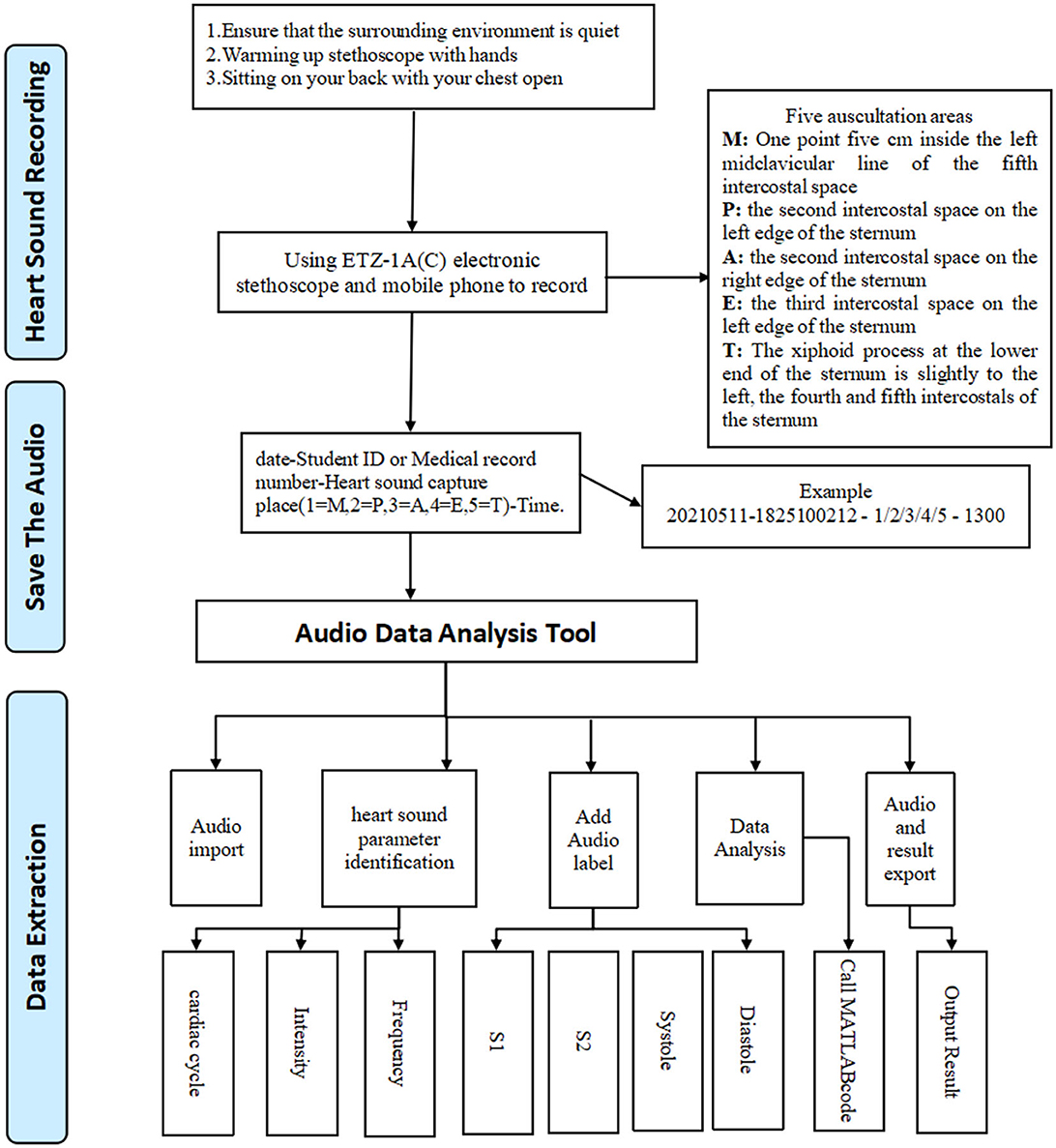
Figure 1. Workflow.
Inclusion and exclusion criteria
Healthy adults from Chengdu Medical College with no underlying chronic disease were included. Long-term users of drugs that may cause arrhythmia were excluded. The exclusion criteria were unwilling to continue receiving heart sound collection during the study period.
Heart sound segmentation
To ensure that the starting point in the audio file was the first heart sound, and to eliminate interference from breathing and external noise, Audacity (version 1.3.3) software was used to display the phonocardiogram. As part of the heart sound analysis, the specific characteristics of the phonocardiogram needed to be analyzed further in terms of the time domain, frequency domain, and loudness. From the results, we searched for the most regular, characteristic heart sound signals for segmentation.
Splitting the first heart sound (S1) and the second heart sound (S2)
First, our Audio Analysis Data Tool automatically screened the amplitude and time axis of the S1 vertex, according to the baseline at the end of preprocessing, and calculated the frequency range of the S1 peak and the previous wave of the valley. In this way, the start and end times of S1 could be located. Next, we extracted the S2 peak with the second peak between two adjacent S1 peaks as the features and filtered out the S2 peak, which showed a large difference from the average value. We then selected the data with the highest statistical significance and used the times corresponding to the data as labels to obtain the start and end points of S2. Finally, using the statistical data, the start and ending times, state, decibels, amplitude, and other information were calculated for each state. The systolic period, the diastolic period, and the starting time were calculated for S1 and S2.
Cutting the systolic and diastole segments
One cardiac cycle included a systolic period and a diastolic period, where the systolic period was defined as the time from the start of the first heart sound (S1) to the start of the second heart sound (S2), and the diastolic period was defined as the start of the second heart sound (S2) to the start of the first heart sound (S1) in the next cardiac cycle. The relevant audio clips were cut, and we divided the audio files into separate pieces. By running a customized MATLAB code, the relevant parameters of the systolic and diastolic periods could be extracted.
Automatic segment coding
Our audio data analysis tool automatically called audacity, using the time labels, to carry out segmentation of the audio files. The four segments were automatically imported into a MATLAB code to calculate the audio, and finally a summary of the data was output.
Results
Demographic dataset
We collected data from healthy adults from Chengdu Medical College between 11th May and 6th July 2022. We obtained informed consent from all participants before the experiment. A total of 12 students were recruited, aged between 20 and 22. Demographic information is given in Table 1.
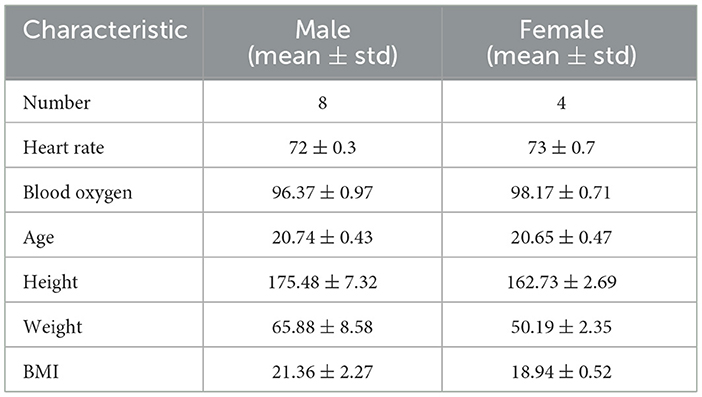
Table 1. Demographics of subjects.
Visualization of heart sound waves via audacity software
The signal amplitudes of the collected heart sounds were small and difficult to identify before standardization (Figure 2). After the standardization process, the amplitude of the heart sound was increased, thus achieving the effect of signal amplification, and the waveform was clearer (Figure 3).
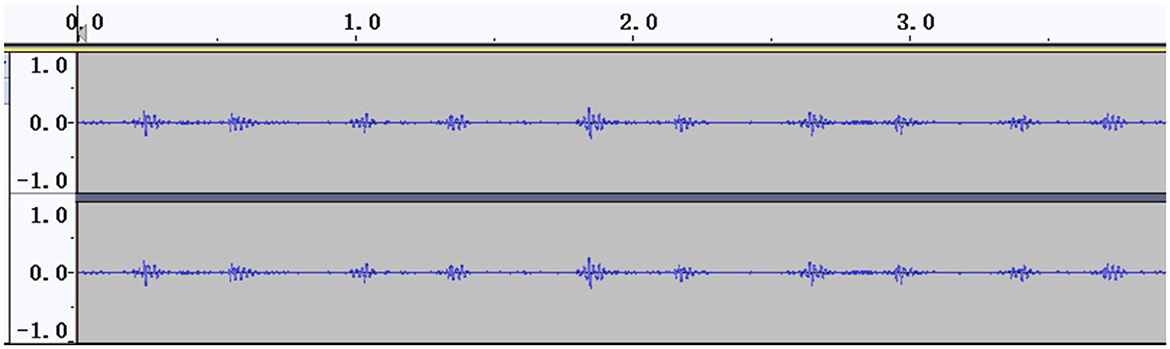
Figure 2. Heart sound cycle before standardization.
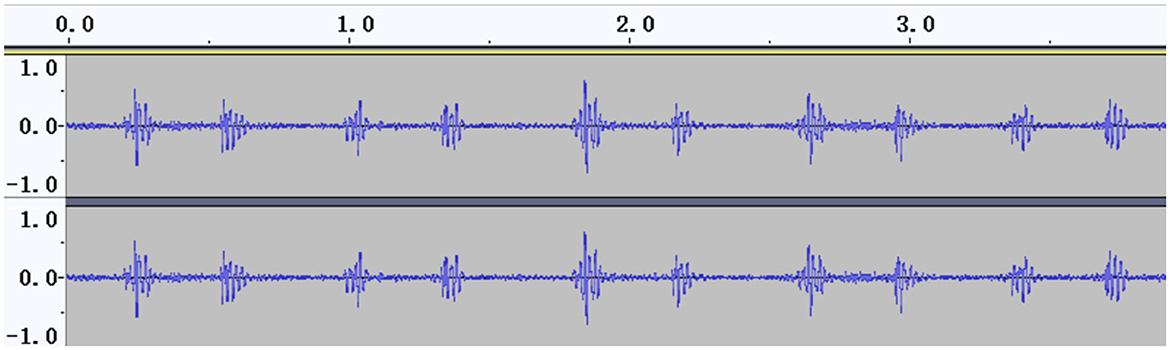
Figure 3. Heart sound cycle after standardization.
Cardiac cycle segmentation
Segmentation of multiple cardiac cycles from the audio files was carried out based on localization of two adjacent “similar images” (defined as two adjacent images with similar amplitude and duration) in the PCG (Figure 4).
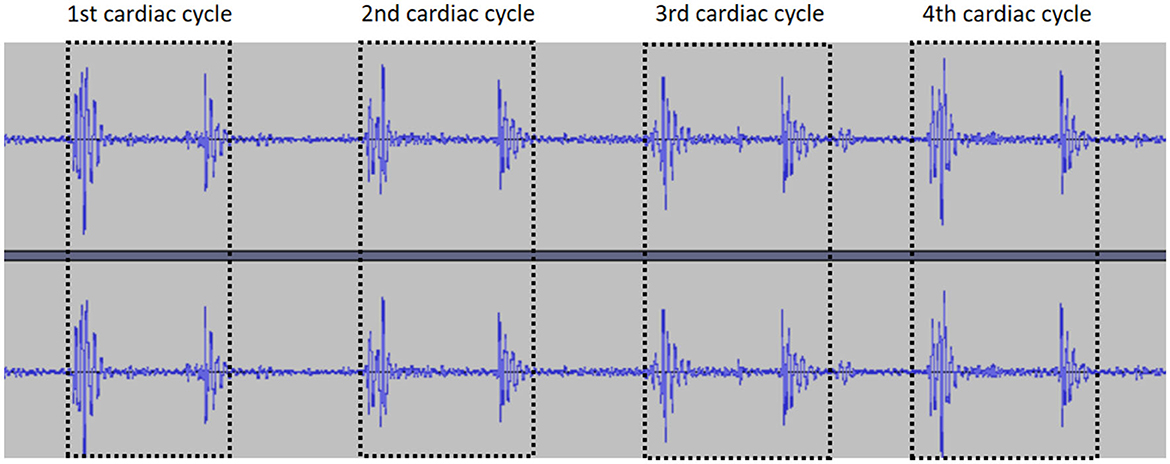
Figure 4. Segmentation of the cardiac cycle.
Splitting S1 and S2 by calculating the start and end positions
After locating and segmenting the cardiac cycle, the Audio Data Analysis Tool identified the intensity, time and frequency domain features of S1 and S2 as follows: (i) the duration of S1 is longer than S2; (ii) S1 and S2 have a range of frequencies in physiologically; (iii) S2 occurs between neighboring S1 signals in the PCG (Li et al., 2020). By combining the above features, we identified the start and end positions of S1 and S2 (Figure 5).
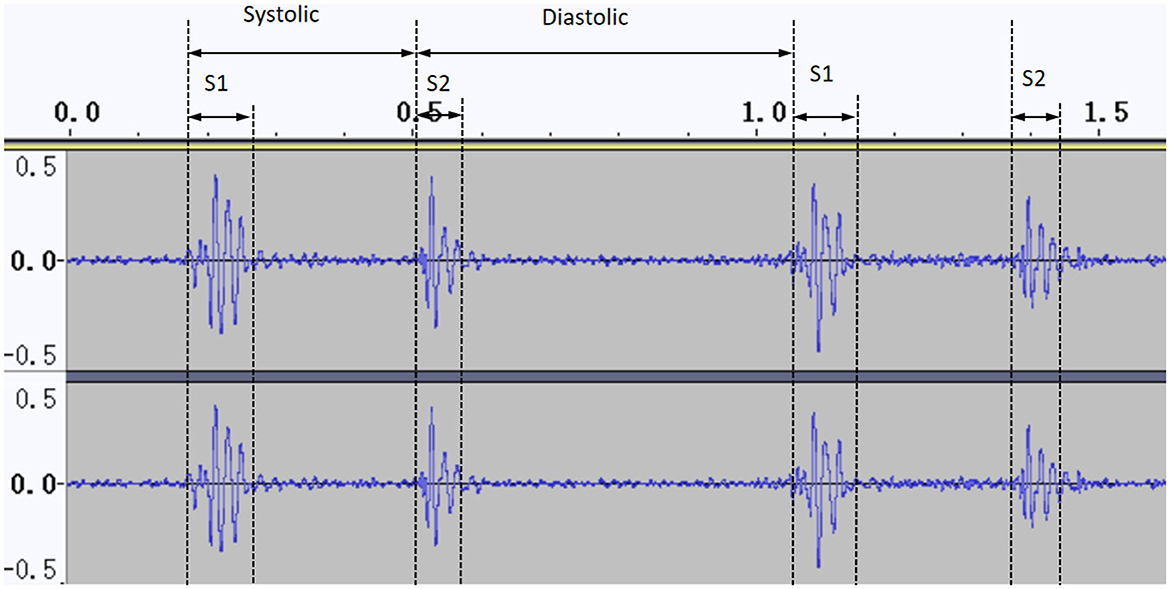
Figure 5. Normal cardiac phonogram signal in audacity.
Cutting the systolic and diastole segments based on label information
To segment the systolic and diastolic phases, we used the time label information to extract them from Audacity. When we had identified and located S1 and S2, we calculated the label value information (Figure 6) and cut the clips accurately.
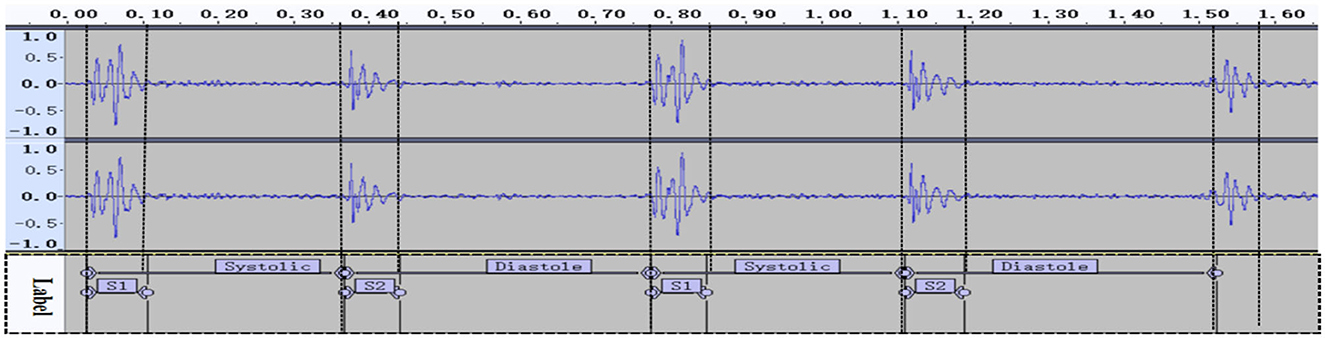
Figure 6. Segment labeling.
The recorded heart sounds consisted of the exact start and end time points of the cardiac cycle. These data parameters can be used to represent heart sounds as a set of characteristic signals, based on four parameters that represent and characterize the status of the heart.
Duration of S1, S2, systolic, and diastolic periods
After obtaining the start and end times of the first and second heart sounds (Figure 6), the duration of the cardiac cycle and the S1, S2, systolic and diastolic periods were calculated (see Table 2).
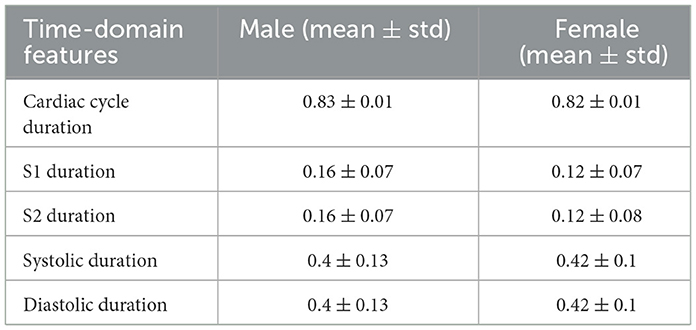
Table 2. Time-domain features.
Intensity of maxdb, mindb, meandb, middledb
The amplitudes of the heart sounds can represent the intensity of the mechanical activity of the heart, which may be helpful in the detection of coronary heart disease (Liu et al., 2021). Audacity was used to derive the loudness values, which were calculated and filtered. The amplitude of each segment of the cardiac cycle (S1, S2, systolic, and diastolic) was calculated. For this work, the mean value and SD of the amplitude features (maxdb, mindb, meandb, middledb) for the heart cycle were calculated, as shown in Table 3.

Table 3. Amplitude features.
Frequency
Spectral analysis is the most widely used method of heart sound analysis. In this study, a MATLAB code (see attachment) was used to perform formula calculation for the four segments (S1, S2, systolic, and diastolic). A detailed summary of the results is given in Table 4.
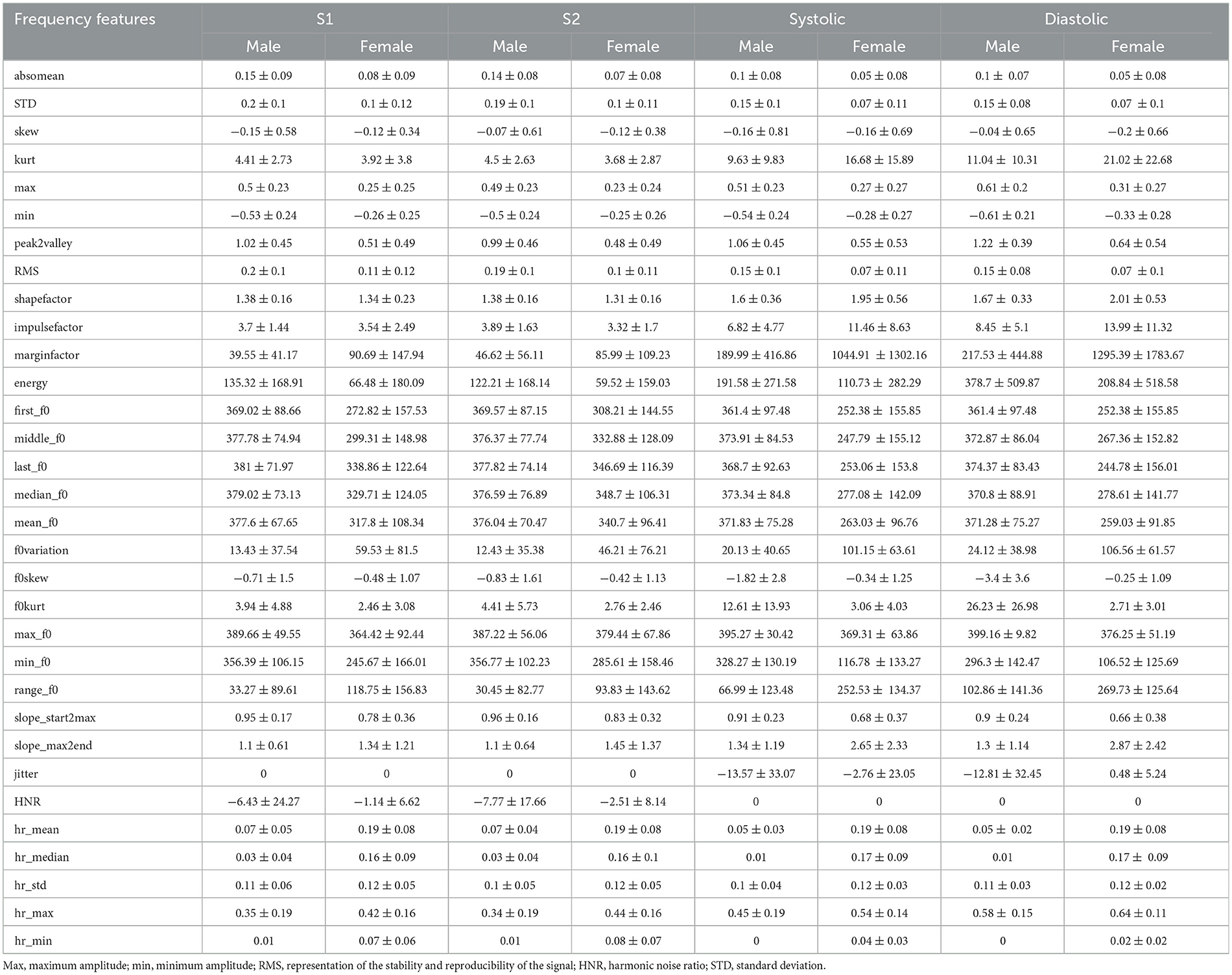
Table 4. Frequency features.
Cross-validation based on heart rate
To cross-validate the accuracy of our segmentation results, we also used a finger oxygen monitor to record the heart rates of the participants during the data collection process. The details of the measurement results are shown in Table 5. The result of a paired T-test indicated that no significant difference was found between the two methods.
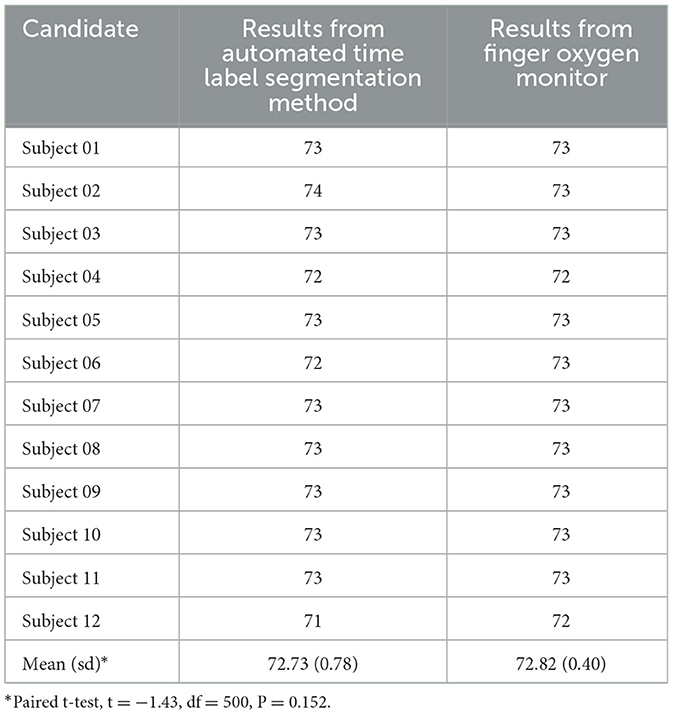
Table 5. Cross-validation based on heart rate.
Discussion
Cardiovascular disease is one of the most common diseases threatening human health worldwide, while the robust and non-invasive diagnostic techniques are urgently needed. In particular, heart sound detection techniques can play an important role in the prediction of cardiovascular disease. However, traditional cardiac auscultation requires a qualified cardiologist, as heart murmurs are short-lived and difficult to identify via human hearing.
Artificial intelligence recognition technology can detect the duration, intensity, frequency, and other acoustic information of the heart sound signal; this approach also has the advantages of batch processing and convenience in terms of the screening and detection of disease. In this work, we constructed and validated a method of automatically segmenting heart sounds and extracting the fundamental frequency and intensity parameters through our Audio Data Analysis Tool. We also showed that there were no differences in the heart rates found by the Audio Data Analysis Tool and a finger oxygen monitor, see Table 5.
Considerable amounts of work have been directed toward reaching the goal of diagnosis based on the detection of heart sounds recorded from the chest. One clinical trial demonstrated that deep learning algorithms were comparable to cardiologists in their ability to detect murmurs and clinically significant aortic stenosis and mitral regurgitation. An eighth-order Butterworth high-pass filter is used at the input end of the algorithm design. The model comprises a 1-dimensional convolution, batch normalization, rectified linear unit non-linearity, dropout for regularization, and maximum pooling (Chorba et al., 2021). A preliminary study by Ghanayim et al. (2022) found that an AI-based algorithm identified moderate or severe mitral stenosis with 86% sensitivity and 100% specificity. They proposed an AI-based algorithm that tests and validates multiple machine learning methods to determine the best algorithm, integrated into an intelligent stethoscope, was able to accurately diagnose aortostenosis (AS) in seconds. Wang J. K. et al. (2020) presented a neural network model consisting of convolution, recurrence, time-attentive pool (TAP), and dense slices that accurately identifies systolic heart sounds in patients with ventricular septal defects and may be able to classify heart sounds associated with several other structural heart diseases. The study shared similarities with ours, beginning with electronic stethoscope-based data collection and successive signal preprocessing, feature extraction, and final classification stages, resulting in a comprehensive analysis of heart sounds. However, it diverges in its application of machine learning models (Omarov et al., 2023).
A comparison of other methods of extracting heart sound signals shows that our innovation was to use Audacity to carry out time label aggregation of heart sounds, which made it easy to locate problems when outputting data errors. In addition, all of the acoustic parameters could be collected; for example, the data contained five duration indicators, 16 loudness indicators, and 60 frequency indicators. This also makes it convenient for researchers to process data diversification.
In general, the problem of analyzing heart sound signals arises from the substantial amount of noise involved, such as breath sounds, heartbeat rhythms and voices in the external environment. Unfortunately, we could only achieve noise reduction through the proficiency of trained cardiologists, and this will be a direction for future work. In addition, at the preprocessing stage, our process involved cutting at the beginning and ending of the audio files, which may lead to a little deviation.
Conclusion
A combination of an electronic stethoscope and artificial intelligence technology was applied to the digital collection of heart sounds and the intelligent identification of the first (S1) and second (S2) heart sounds. Our approach provides an objective basis for the auscultation of heart sounds and visual display of heart sounds and murmurs.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics statement
The studies involving humans were approved by the Zigong First People's Hospital. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation in this study was provided by the participants' legal guardians/next of kin.
Author contributions
LL: Investigation, Resources, Writing—original draft. MH: Data curation, Methodology, Validation, Visualization, Writing—review & editing. LD: Data curation, Formal analysis, Resources, Validation, Visualization, Writing—review & editing. XF: Data curation, Writing—original draft. YL: Formal analysis, Funding acquisition, Project administration, Resources, Writing—review & editing. CW: Methodology, Project administration, Writing—review & editing. FL: Conceptualization, Visualization, Writing—review & editing. JZ: Writing—review & editing. FX: Conceptualization, Formal analysis, Funding acquisition, Writing—original draft, Writing—review & editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This study was supported by the Chengdu Science and Technology Bureau focus on research and development support plan (2019-YF09-00097-SN) and the Key Discipline Construction Project of Sichuan Administration of Traditional Chinese Medicine (202072).
Acknowledgments
We thank the undergraduate candidates Xingjian Fang, Xueshi Yin, Xinghong Ling, Zedi Wu, Yanyan Wang, Hongyu He who performed clinical examinations in community hospitals and provided valuable suggestions for this study. Dr. Huang Kun provided valuable software segmentation experience for this study.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Boulares, M., Alotaibi, R., AlMansour, A., and Barnawi, A. (2021). Cardiovascular disease recognition based on heartbeat segmentation and selection process. Int. J. Environ. Res. Pub. Health 18, 10952. doi: 10.3390/ijerph182010952
Chen, X. J., LaPorte, E. T., Olsen, C., Collins, L. M., Patel, P., Karra, R., et al. (2021). Heart sound analysis in individuals supported with left ventricular assist devices. IEEE Trans. Biomed. Eng. 68, 3009–3018. doi: 10.1109/TBME.2021.3060718
Chorba, J. S., Shapiro, A. M., Le, L., Maidens, J., Prince, J., Pham, S., et al. (2021). Deep learning algorithm for automated cardiac murmur detection via a digital stethoscope platform. J. Am. Heart Assoc. 10, e019905. doi: 10.1161/JAHA.120.019905
Delampady, S. (2021). Analysis of heart murmur and its classification using Image-Based Heart Sound Signal with Augmented Reality. TURCOMAT 12, 4311–4320. doi: 10.17762/turcomat.v12i6.8416
Drazner, M. H., Rame, J. E., Stevenson, L. W., and Dries, D. L. (2001). Prognostic importance of elevated jugular venous pressure and a third heart sound in patients with heart failure. New Eng. J. Med. 345, 574–581. doi: 10.1056/NEJMoa010641
El-Segaier, M., Lilja, O., Lukkarinen, S., Sörnmo, L., Sepponen, R., Pesonen, E., et al. (2005). Computer-based detection and analysis of heart sound and murmur. Annal. Biomed. Eng. 33, 937–942. doi: 10.1007/s10439-005-4053-3
Esquembre Menor, C. T., and Castel Sánchez, V. (1988). Early diagnosis of cancer in children. An. Esp. Pediatr. 29, 181–187.
Folgado, D., Barandas, M., Antunes, M., Nunes, M. L., Liu, H., Hartmann, Y., et al. (2022). Tssearch: time series subsequence search library. SoftwareX 18, 101049. doi: 10.1016/j.softx.2022.101049
Gadaleta, M., Cisotto, G., Rossi, M., Rehman, R. Z. U., Rochester, L., Del Din, S., et al. (2019). “Deep learning techniques for improving digital gait segmentation,” in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Piscataway, NJ: IEEE, 1834–1837.
Ghanayim, T., Lupu, L., Naveh, S., Bachner-Hinenzon, N., Adler, D., Adawi, S., et al. (2022). Artificial intelligence-based stethoscope for the diagnosis of aortic stenosis. The Am. J. Med. 135, 1124–1133. doi: 10.1016/j.amjmed.2022.04.032
Kui, H., Pan, J., Zong, R., Yang, H., Su, W., Wang, W., et al. (2020). Segmentation of heart sound signals based on duration hidden Markov model. J. Biomed. Engi. 37, 765–774. doi: 10.7507/1001-5515.201911061
Li, S., Li, F., Tang, S., and Xiong, W. (2020). A review of computer-aided heart sound detection techniques. Biomed. Res. Int. 2020, 5846191. doi: 10.1155/2020/5846191
Liu, T., Li, P., Liu, Y., Zhang, H., Li, Y., Jiao, Y., et al. (2021). Detection of coronary artery disease using multi-domain feature fusion of multi-channel heart sound signals. Entropy 23, 642. doi: 10.3390/e23060642
Long, Q., Ye, X., and Zhao, Q. (2020). Artificial intelligence and automation in valvular heart diseases. Cardiol. J. 27, 404–420. doi: 10.5603/CJ.a2020.0087
Omarov, B., Tuimebayev, A., Abdrakhmanov, R., Yeskarayeva, B., Sultan, D., Aidarov, K., et al. (2023). Digital stethoscope for early detection of heart disease on phonocardiography data. Int. J. Adv. Comput. Sci. Appl. 14, 9. doi: 10.14569/IJACSA.2023.0140975
Rodrigues, J., Belo, D., and Gamboa, H. (2017). Noise detection on ECG based on agglomerative clustering of morphological features. Comput. Biol. Med. 87, 322–334. doi: 10.1016/j.compbiomed.2017.06.009
Rodrigues, J., Liu, H., Folgado, D., Belo, D., Schultz, T., Gamboa, H., et al. (2022). Feature-based information retrieval of multimodal biosignals with a self-similarity matrix: Focus on automatic segmentation. Biosensors 12, 1182. doi: 10.3390/bios12121182
Shah, S. J., and Michaels, A. D. (2006). Hemodynamic correlates of the third heart sound and systolic time intervals. Cong. Heart Failure 12, 8–13. doi: 10.1111/j.1527-5299.2006.05773.x-i1
Shen, Y., Wang, X., Tang, M., and Liang, J. (2021). Recognition of S1 and S2 heart sounds with two-stream convolutional neural networks. J. Biomed. Eng. 38, 138–144. doi: 10.7507/1001-5515.201909071
Wang, J., You, T., Yi, K., Gong, Y., Xie, Q., Qu, F., et al. (2020). Intelligent diagnosis of heart murmurs in children with congenital heart disease. J. Healthc. Eng. 2020, 9640821. doi: 10.1155/2020/9640821
Keywords: heart sounds, segmentation, artificial intelligence, audio data analysis tool, justified
Citation: Li L, Huang M, Dao L, Feng X, Liu Y, Wei C, Liu F, Zhang J and Xu F (2024) Construction and validation of a method for automated time label segmentation of heart sounds. Front. Artif. Intell. 6:1309750. doi: 10.3389/frai.2023.1309750
Received: 08 October 2023; Accepted: 26 December 2023;
Published: 11 January 2024.
Edited by:
Sathishkumar V. E., Sunway University, MalaysiaReviewed by:
Hui Liu, University of Bremen, GermanyBatyrkhan Omarov, Al-Farabi Kazakh National University, Kazakhstan
Copyright © 2024 Li, Huang, Dao, Feng, Liu, Wei, Liu, Zhang and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jing Zhang, emhhbmdqaW5nQHVlc3RjLmVkdS5jbg==; Fan Xu, eHVmYW5AY21jLmVkdS5jbg==
†These authors have contributed equally to this work