
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
ORIGINAL RESEARCH article
Front. Artif. Intell., 08 December 2023
Sec. Medicine and Public Health
Volume 6 - 2023 | https://doi.org/10.3389/frai.2023.1290022
 Tiago de Oliveira Barreto1*
Tiago de Oliveira Barreto1* Nícolas Vinícius Rodrigues Veras1,2
Nícolas Vinícius Rodrigues Veras1,2 Pablo Holanda Cardoso1,2
Pablo Holanda Cardoso1,2 Felipe Ricardo dos Santos Fernandes1
Felipe Ricardo dos Santos Fernandes1 Luiz Paulo de Souza Medeiros3
Luiz Paulo de Souza Medeiros3 Maria Valéria Bezerra4
Maria Valéria Bezerra4 Filomena Marques Queiroz de Andrade4
Filomena Marques Queiroz de Andrade4 Chander de Oliveira Pinheiro4
Chander de Oliveira Pinheiro4 Ignacio Sánchez-Gendriz1
Ignacio Sánchez-Gendriz1 Gleyson José Pinheiro Caldeira Silva1,2
Gleyson José Pinheiro Caldeira Silva1,2 Leandro Farias Rodrigues5
Leandro Farias Rodrigues5 Antonio Higor Freire de Morais1,2
Antonio Higor Freire de Morais1,2 João Paulo Queiroz dos Santos1,2
João Paulo Queiroz dos Santos1,2 Jailton Carlos Paiva1,2
Jailton Carlos Paiva1,2 Ion Garcia Mascarenhas de Andrade1
Ion Garcia Mascarenhas de Andrade1 Ricardo Alexsandro de Medeiros Valentim1
Ricardo Alexsandro de Medeiros Valentim1The COVID-19 pandemic is already considered one of the biggest global health crises. In Rio Grande do Norte, a Brazilian state, the RegulaRN platform was the health information system used to regulate beds for patients with COVID-19. This article explored machine learning and deep learning techniques with RegulaRN data in order to identify the best models and parameters to predict the outcome of a hospitalized patient. A total of 25,366 bed regulations for COVID-19 patients were analyzed. The data analyzed comes from the RegulaRN Platform database from April 2020 to August 2022. From these data, the nine most pertinent characteristics were selected from the twenty available, and blank or inconclusive data were excluded. This was followed by the following steps: data pre-processing, database balancing, training, and test. The results showed better performance in terms of accuracy (84.01%), precision (79.57%), and F1-score (81.00%) for the Multilayer Perceptron model with Stochastic Gradient Descent optimizer. The best results for recall (84.67%), specificity (84.67%), and ROC-AUC (91.6%) were achieved by Root Mean Squared Propagation. This study compared different computational methods of machine and deep learning whose objective was to classify bed regulation data for patients with COVID-19 from the RegulaRN Platform. The results have made it possible to identify the best model to help health professionals during the process of regulating beds for patients with COVID-19. The scientific findings of this article demonstrate that the computational methods used applied through a digital health solution, can assist in the decision-making of medical regulators and government institutions in situations of public health crisis.
The COVID-19 pandemic is already considered one of the biggest global health crises of the century (Hu et al., 2021). The first cases appeared in the city of Wuhan, China, and in December 2019, the disease quickly spread among the other continents of the world, manifesting itself as a dry cough, fever, and fatigue (Huang et al., 2020; Zhu et al., 2020; Dashboard, 2022). In Brazil, the first confirmed cases appeared in February 2020 and, the following month it was declared a pandemic situation (Aquino et al., 2020; Bastos and Cajueiro, 2020; Costa et al., 2021; Valentim et al., 2021).
Statistical data indicate that about 82% of COVID-19 patients have the mildest symptoms of the disease. However, the evolution to the most serious phase causes severe acute respiratory syndrome, pneumonia, and multiple organ failure, requiring hospitalization inward or intensive care unit (ICU) beds (Ahsan et al., 2020; Sales-Moioli et al., 2022). In Brazil, more than 60 thousand ICU beds were made available to treat patients, however, there were still more than 680 thousand deaths (Cotrim Junior and Cabral, 2020; Dashboard, 2022). Thus, with the daily increase in case numbers, several officials had difficulties in monitoring and providing access to beds for patients (Perondi et al., 2021; Shahzad et al., 2022).
In addition, the Brazilian Northeast region faced another aggravating factor, as it is historically one of the regions with the lowest healthcare resources, and consequently presented the second lowest proportion of bed availability per capita (Cotrim Junior and Cabral, 2020; Lino et al., 2020). According to Valentim et al. (2021), expectations of coping with COVID-19 for a state like Rio Grande do Norte (RN) in the Northeast Region of Brazil, were quite pessimistic. One of the support measures taken by the federal government, specifically the Ministry of Health (MoH), was the provision of financial resources to reduce the effects of the pandemic. However, some states received less funding regionally, with RN being one of the states that obtained the lowest amount of resources per capita, as available at the transparency portal of the federal government of Brazil itself (https://www.portaltransparencia.gov.br/coronavirus?ano=2020).
In this context, considering the difficulty of monitoring and regulating access to beds for COVID-19 patients, particularly due to high pressure (demand for beds), the State Secretariat of Public Health of Rio Grande do Norte (SESAP/RN) in Brazil, through technical-scientific cooperation with the Laboratory for Technological Innovation in Health (LAIS) developed a digital health solution to mitigate these problems. This solution was called RegulaRN Platform, whose objective was to monitor and control access to clinical and intensive care unit (ICU) beds for patients with COVID-19 in the State of RN/Brazil (Valentim et al., 2021; Sales-Moioli et al., 2022). Furthermore, the RegulaRN Platform acted as a tool for public transparency by publishing online several indicators on COVID-19, daily data used by the local press and the national press consortium to disseminate the epidemiological scenarios of the State (Valentim et al., 2021).
The bed regulation process is a critical sector in public health management, as it acts directly in the management of sectors that can impact the lives of patients, especially those who need hospitalization in emergency cases (Maldonado et al., 2021). Therefore, it is necessary to develop techniques that can contribute to the continuous improvement of the work process of health professionals working at this healthcare level.
In response to the challenges pointed out, the use of digital health solutions based on intelligent computational methods can help reduce impacts and enhance better decision-making by public agencies, especially in situations of a public health crisis, such as the COVID-19 pandemic (Shailaja et al., 2018; Bian and Modave, 2020). Intelligent computational models, when well applied and aligned with a good governance policy, can contribute in a more effective way, to promote the reduction of uncertainties, ambiguities, subjective gaps, and better support for decision-making (Ghaderzadeh and Aria, 2021; Moulaei et al., 2022). Moreover, these models are able to identify non-linear relationships and interactions between variables, which enables better performance of the systems where they are applied (Subudhi et al., 2020).
Thus, the research presented in this article aimed, firstly, to analyze a set of data from a bed regulation system, used during a period of the COVID-19 pandemic. Secondly, select and compare different machine learning and deep learning models, to elect the most relevant classification model, which can predict with the best accuracy, precision, recall, specificity, F1-score, and ROC-AUC curve, the mortality of patients with COVID-19 who were regulated to be hospitalized. Finally, to discuss the potential of this tool in the decision-making of health professionals and public entities during a public health crisis situation, such as the one seen during the COVID-19 pandemic.
The methodological procedure used in this study consisted of analyzing the regulation data profile for data extraction, features selection, classification of data, and cleaning data. Then the data were analyzed and use of the data for application in computational models which involved five steps: (1) definition of evaluation metrics, (2) data balance, (3) segmentation of training and validation data, (4) definition of data classification models, and (5) definition of hyperparameters for training. In the following topics, the data will be presented and discussed from the perspective of using computational intelligence tools to support decision-making in the health axis.
This study used the RegulaRN COVID-19 bed regulation database, a system used to meet the regulatory flows of Rio Grande do Norte (RN)/Brazil. The database was extracted on 08/02/2022, when it contained 25,366 effective regulations, considering the two health regions of the State: West and Metropolitan. The data sample covered the period from April 30, 2020, to August 2, 2022.
The raw database (before preprocessing) had twenty characteristics, of which nine were considered relevant for data classification because they were data more correlated to the patient's clinical condition. Table 1 presents all the data present in the database and their respective descriptions. Characteristics that referred to: (a) request date, (b) patient's municipality, (c) patient's federal unit, (d) if pregnancy, (e) gestational age, (f) date of entry to the bed, (g) date of output from the bed, (h) requesting hospital unit, (i) municipality of the requesting hospital unit, (j) providing hospital unit, and (k) municipality of the providing hospital, because they are not definitive for determining the outcome and this could affect the results of the study. In this way, the characteristics that were most related to the patient's health condition and the bed offered were considered, as follows: (a) age, (b) case type, (c) Unified Prioritization Score (EUP score), (d) if on orotracheal intubation (OTI), (e) type of bed requested, (f) type of entrance bed, (g) type of output bed, (h) length of stay, and (i) the outcome; because they are variables that have more correspondence with the outcome (target).
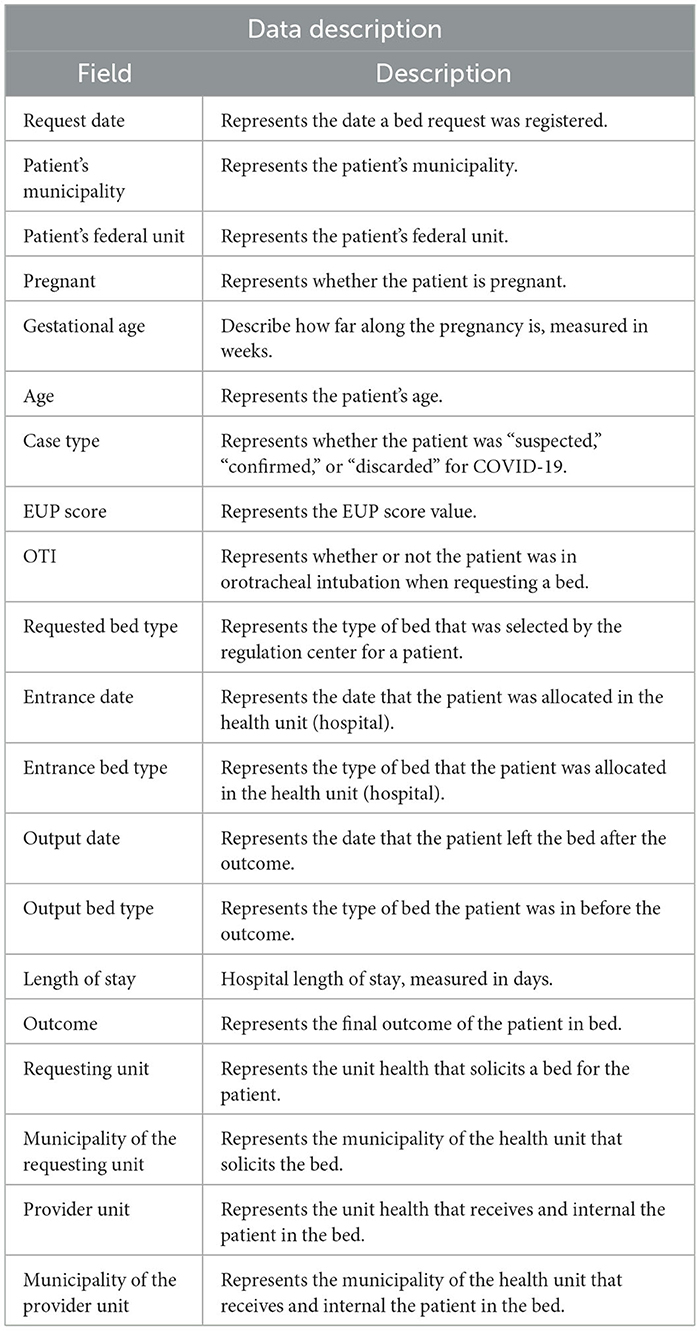
Table 1. Description of database.
The determination of the nine pivotal characteristics, delineated as Feature Selection in Figure 1, was guided by insightful consultations with clinical specialists, thereby categorizing our feature selection approach as specialist-driven. It is imperative to note that feature selection strategies are encompassed within the overarching strategy known as dimensionality reduction, which concurrently includes a subset of methodologies recognized in academic literature as feature extraction (Jia et al., 2022). Our methodology hinged on the exclusive employment of a feature selection strategy, substantiated by its intrinsic ability to preserve the clinical interpretability of the variables, thereby enhancing the model's explicability—a facet of paramount importance in medical and public health applications. Although feature extraction techniques like Principal Component Analysis (PCA) are renowned for their adeptness in dimensionality reduction, they also inherently possess a disadvantage, notably, the potential for the newly derived features to lose their original clinical meaning (Jia et al., 2022). This facet is not favorable for our application in the clinical domain, where preserving the comprehensibility and interpretability of variables is crucial.
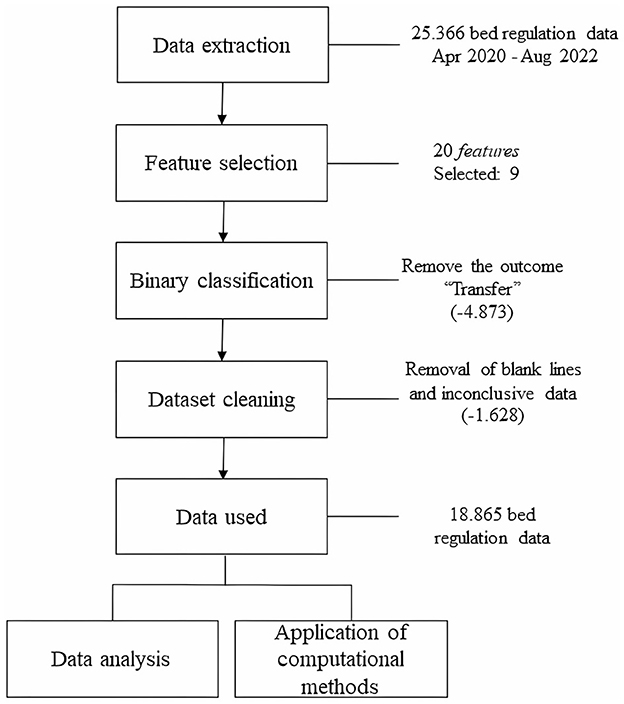
Figure 1. Pipeline for the use of RegulaRN data.
In terms of preparing the dataset, to normalize and standardize the data, lines in the database with blank data or with incorrectly registered information were removed. In addition, the “outcome” characteristic could assume three results: “discharge,” “death,” and “transfer.” However, the outcome “transfer” indicates that the patient was transferred from one hospital to another or from one bed to another. Therefore, it is not a determining factor as to whether the patient was discharged or died at the end of hospitalization. Thus, lines with “Transfer” as the outcome were removed, and the final definition was kept as a binary classification (“discharge” or “death”). In the end, 74.37% of the data was kept, representing 18,865 effective regulations (inpatients). To ensure the reproducibility of the experiment, the database with all the pre-processed information is available in the following repository https://zenodo.org/record/8122564. According to Resolution 674, 2022 of the National Health Council (NHC) of the Ministry of Health (MoH) this research is exempt from registration with the Research Ethics Committee (CEP)/Brazil or the National Research Ethics Commission (CONEP)/Brazil, as it works with databases, whose information is gathered without the possibility of individual identification.
Once the dataset elements had been defined, analyses were carried out to evaluate and characterize them for use in the models of the computational methods to be selected. Figure 1 shows schematically how the procedures described were carried out.
The data analyzed was the same as that selected for the computer model applications so that it was divided into categories and outcomes. During the analysis, a statistical evaluation was carried out with a 99% confidence interval (p-value < 0.01) between the selected characteristics and also segmented by the outcome.
A possible relation was found between two independent variables, age, and length of stay, which do not have direct causality with the outcome. For these two data, the chi-square statistical distribution was applied (CI 99%, (p < 0.01) and from this, we can categorize the different risk criteria that are linked to the outcome.
To assess the correlation between the variables we used the Phik correlation (https://phik.readthedocs.io/). The Phik correlation is a variation of the Pearson hypothesis test with some refinements, such as the correlational evaluation of categorical, ordinal, and interval features. As 67% of the features in the dataset use categorical (non-numerical) values, the Phik correlation was selected for the correlational presentation of the data. We used the pandas-profilereports library (https://github.com/ydataai/ydata-profiling) to identify direct proportional correlations between the selected variables. The correlation matrix obtained was compared with the feature importances of the computational models to analyze a relational convergence between the data used.
The evaluation metrics used in this study were similar to other research, which used machine learning and/or deep learning, presented in the works of Sokolova and Lapalme (2009), Ghaderzadeh et al. (2021b), and Endo et al. (2022), namely: accuracy, precision, recall, F1-score, specificity, and ROC-AUC curve. These metrics are formulated from the confusion matrix. The confusion matrix shows the relationship between the real event and the prediction suggested by the model (Sokolova and Lapalme, 2009; Grandini et al., 2020). The composition of the confusion matrix consists of true positive (TP)—when the event is positive and the model predicts positive; false positive (FP)—when the event is negative and the model predicts positive; false negative (FN)—when the event is positive and the model predicts negative; and true negative (TN)—when the event is negative and the model predicts negative. Figure 2 illustrates the confusion matrix.
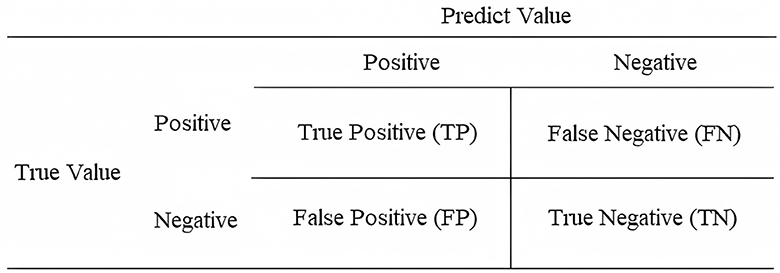
Figure 2. Structure of the confusion matrix.
In this respect, the accuracy of a model relates to the number of data points that were predicted correctly, compared to the total number of possibilities. Thus, it is calculated from the sum of TP and TN, divided by the sum of possible events (Equation 1).
Precision involves predicting the number of truly positive classification data compared to what the model has judged to be positive. It is calculated by dividing TP by the sum of TP and FP (Equation 2).
Recall consists of predicting the number of truly positive rating data compared to what the model has judged to be positive and negative. It is calculated by dividing TP by the sum of TP and FN (Equation 3).
Specificity refers to the correct prediction of truly negative values from the database. It is calculated by dividing TN by the sum of TN and FP (Equation 4).
The F1-score is the harmonic mean of precision and recall. For learning systems with greater vulnerability, to further optimize the Recall and Precision values, the F1-score can be used (Lipton et al., 2014; Endo et al., 2022). The formula involves the product of precision and recall divided by the sum of these metrics, multiplied by 2 (Equation 5).
The ROC (Receiver Operating Characteristic) is obtained from the ratio between the true positive rate (TP/TP+FN) and the false positive rate (FP/FP+TN). Overall, it can be obtained by dividing the recall value by the complement of the specificity (Equation 6).
One of the main problems when working with machine learning is data imbalance. This phenomenon occurs when there is a disproportionate categorization of data (Moulaei et al., 2022). RegulaRN's data composition is naturally unbalanced due to the low lethality of COVID-19. Therefore, in the hospitalization process, an asymmetry between the number of discharges and deaths is to be expected. As for the data used, 72% of the outcomes were classified as discharges and 28% as deaths. It should be noted that all the data used in this experiment is from the real world, i.e., from real patients who have been infected with the SARS CoV-2 virus, who have developed the moderate or more severe form of the COVID-19 disease and have needed to be hospitalized for more appropriate care. Thus, it is not patient data that has been previously selected for training the algorithms, the database used was built organically, from bed regulations for COVID-19 patients.
An imbalanced base may therefore have higher hits for metrics in which the most representative class is more dominant, which can be a negative aspect, as the algorithms or computer models may act in a discriminatory way. To reduce instability, the SMOTE (Synthetic Minority Over-sampling) balancing method was used. The SMOTE consists of increasing the sample of the minority class and minimizing the majority class, producing an over-sample (Chawla et al., 2002; Fernández et al., 2018). Thus, the SMOTE makes the sample used in the experiment less asymmetrical concerning the classes.
The separation process of training and validation data in this study corroborates the methodological procedures found in other similar studies with a significant volume of data. The study by Endo et al. (2022) used around 11,382 data points with classifier models to make predictions about the dissemination of information about COVID-19. Meanwhile, Vaughan et al. (2023) used more than 10,849 wastewater samples from different European regions to predict COVID-19 contamination. Yu et al. (2021) used 5,471 datas of patients with COVID-19 to predict mortality and mechanical ventilation.
Thus, considering the large volume of data processed and the scientific approach of separating the data in the model into 80% for training and 20% for test, the same method was used in this scientific study.
At first, the process of selecting classification models involved algorithms that according to the literature performed well with a high volume of data (Charbuty and Abdulazeez, 2021; Yu et al., 2021). Thus, two classical models of machine learning were selected, the decision tree and random forest algorithms, and the deep learning model with the multilayer perceptron (MLP) algorithm. In MLP, to obtain better computational performance, especially since there is a large volume of data times the number of variables (this increases the dimensions in the hyperplane), it is necessary to select optimizing algorithms during the training stage (Sutskever et al., 2013; Yu et al., 2021). Optimizing algorithms are used to improve time and accuracy in the data classification process. Therefore, the following optimization algorithms were selected: Stochastic Gradient Descent (SGD) (Zhang et al., 2018), Adam (Kingma and Ba, 2014), Adagrad (Duchi et al., 2011), and Root Mean Square Propagation (RMSprop) (Dauphin et al., 2015).
The selected models were applied to a training pipeline with the aim of selecting the best hyperparameters and maximizing the selected metrics, as well as evaluating the importance of the variables for the model's decision.
In machine and deep learning, hyperparameters are variables that help in the definition of classifiers during learning, they cannot be altered during training (Yu et al., 2021). Table 2 shows the hyperparameters used in each model and the range of values adopted for the experiment. The highlighted values show the best-performing combinations.
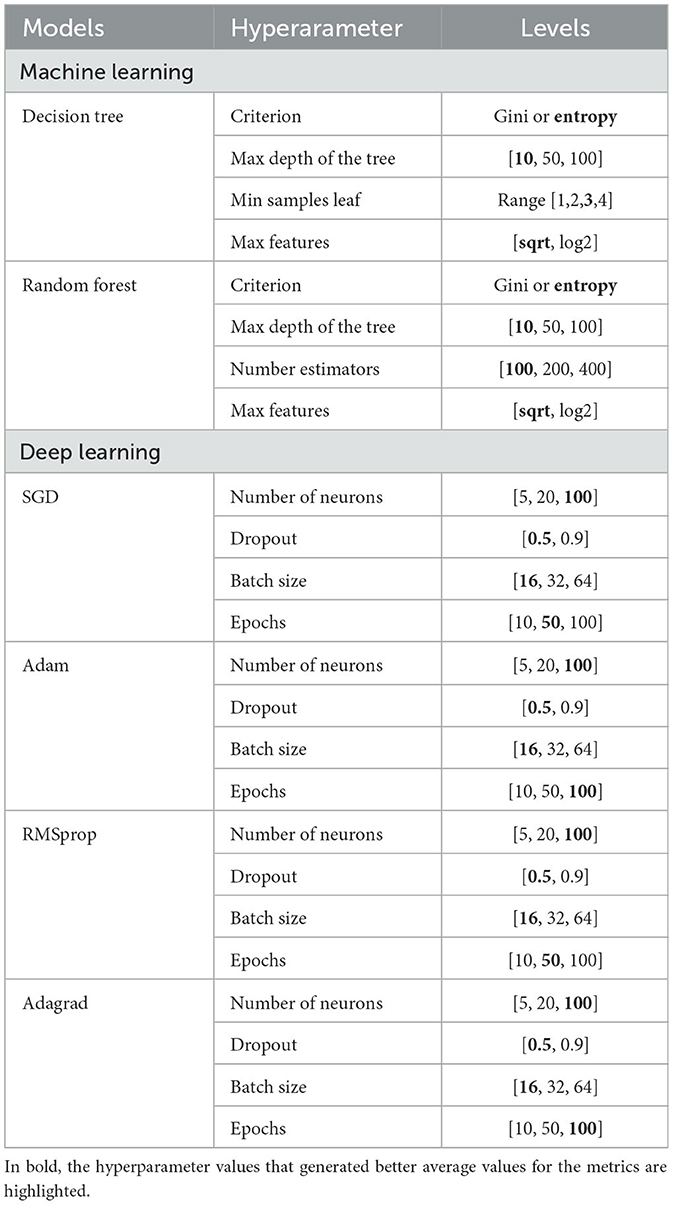
Table 2. Hyperparameter segmentation by model.
For the Decision Tree model—executed by DecisionTreeClassifier from the sckitlearn python library Pedregosa et al. (2011), the hyperparameters used were: criterion, max depth of the tree, min samples leaf, and max features. As for the criterion, the possibilities adopted were gini or entropy, which are mathematical tools that calculate the possibility of incorrect classification of a given characteristic. Depending on the homogeneity of the data, there may be variations in the final results. The max depth of the tree considers the number of nodes from the root to the furthest element. The min samples leaf considers the smallest possible number of samples for a node. The max features take into account the number of features that must be used in each operation. In the Random Forest model, sckitlearn's RandomForestClassifier library was used to select the hyperparameters: criterion, max depth of the tree, number estimators, and max features. The number estimator parameter considers the number of forest trees.
For the models using the multilayer perceptron, the python Keras library (https://keras.io/) was applied, and the hyperparameters selected: number of neurons, dropout, batch size, and epochs. The number of neurons represents the number of neurons in each hidden layer of the perceptron. Dropout acts to select the number of neurons that will indeed be active in a hidden layer. Batch size involves the number of examples used to estimate the error gradient before updating the model parameters. Epochs means the number of complete passes through the data set before the training process is terminated.
For all the models, the GridSearchCV tool, a Python library, was used to explore all possible possibilities to find the best parameters for the grid (Ensor and Glynn, 1997; Bergstra and Bengio, 2012). In addition, the cross-validation method was used with a value of 10 (Moulaei et al., 2022), and the models were run five times, a method used in other academic works, such as Ahsan et al. (2020), to guarantee the selection of the best parameters even if there was variation in any of them. For each run, we calculate the average values and standard deviation of the metrics during the test stage.
As for the data profile, Table 3 shows the number of patients classified by their outcome (divided into percentage and absolute values) and divided by the main characteristics selected. According to this exploration, it is possible to identify that the number of deaths is proportionally higher in patients aged over 60, who had a higher EUP score, who started the hospitalization process already intubated, who used an ICU bed and required a hospital stay of more than 7 days.
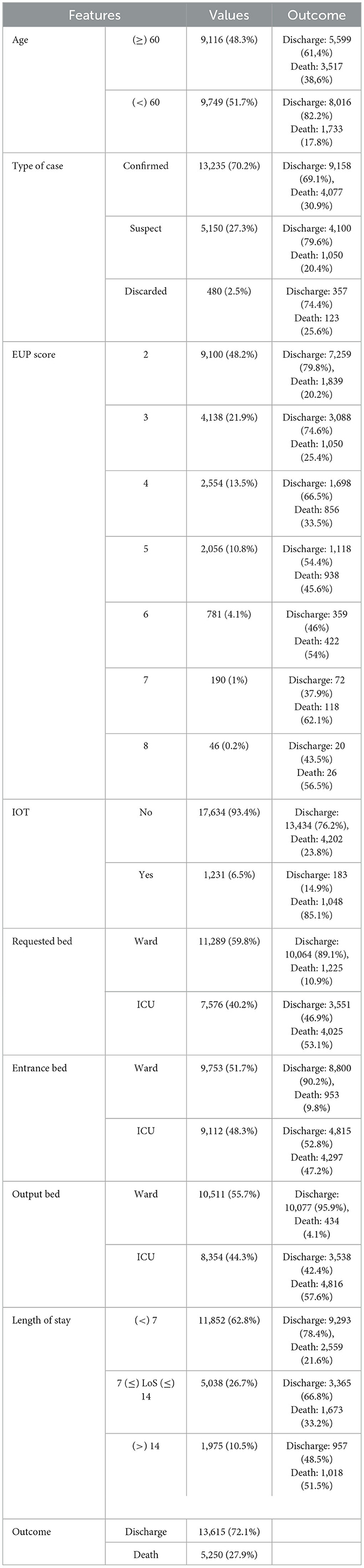
Table 3. Hyperparameter segmentation by model.
With regard to the statistical profile, when evaluating the data as a whole, the average age of the patients who needed some kind of hospitalization was 55.8 years, with a standard deviation of 23.7. The median age was 59, which indicates that the average population of RN needing hospitalization is an intermediate age group close to the elderly. As for the EUP score, the mean value was 3 and the median also had the same value. It can therefore be said that patients who were regulated on the platform had lower EUP scores and therefore fewer health complications. Concerning the length of stay, the average length of stay was 6.87 days, with a standard deviation of 7 days. Figure 3 shows a distribution of these data in a boxplot.
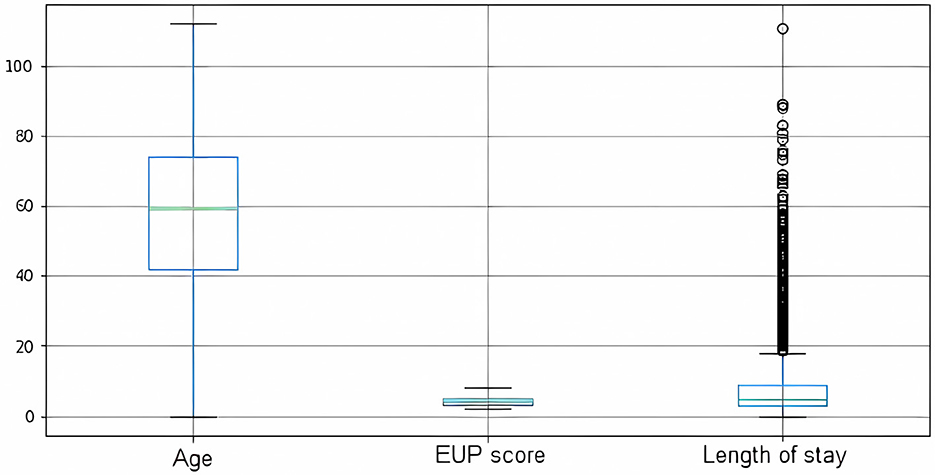
Figure 3. Boxplot representation of numerical data.
The literature does not provide an accurate definition of the expected length of stay for a patient with COVID who will need hospitalization, because this determination depends on several factors such as the patient's current state of health, the assistance capacity of the place of care, and socio-regional factors. However, academic studies indicate a length of stay of between 5 and 29 days (Rees et al., 2020; Vekaria et al., 2021). The RegulaRN data shows some outliers in the length of stay (Figure 3) that can be evaluated in future studies on the efficiency of care utilization.
As for the level of correlation between the variables (Figure 4), evaluating the entire database (Figure 4A), the pandas-profilereports function manages to identify directly proportional correlations between the selected variables, so that age, EUP score, orotracheal intubation, requested bed, entrance bed, and output bed appear to be more relevant in defining the outcome. When evaluating the dataset based on the outcome, it can be seen that the behavior of the data when the final outcome is “discharge” (Figure 4B) is similar to the complete data structure. This result is to be expected given that the predominant volume of data is from patients who had “discharge” outcomes. However, when evaluating the structure of data whose outcome was “death” (Figure 4C), it is possible to identify the existence of negative correlations between the variables age, length of stay, and EUP score. This information also points to expected narratives, given that older patients tend to spend less time in the hospital (when correlating age and length of stay), just as patients with more fragile health, who score higher on the EUP score, are also more likely to die in a shorter period.
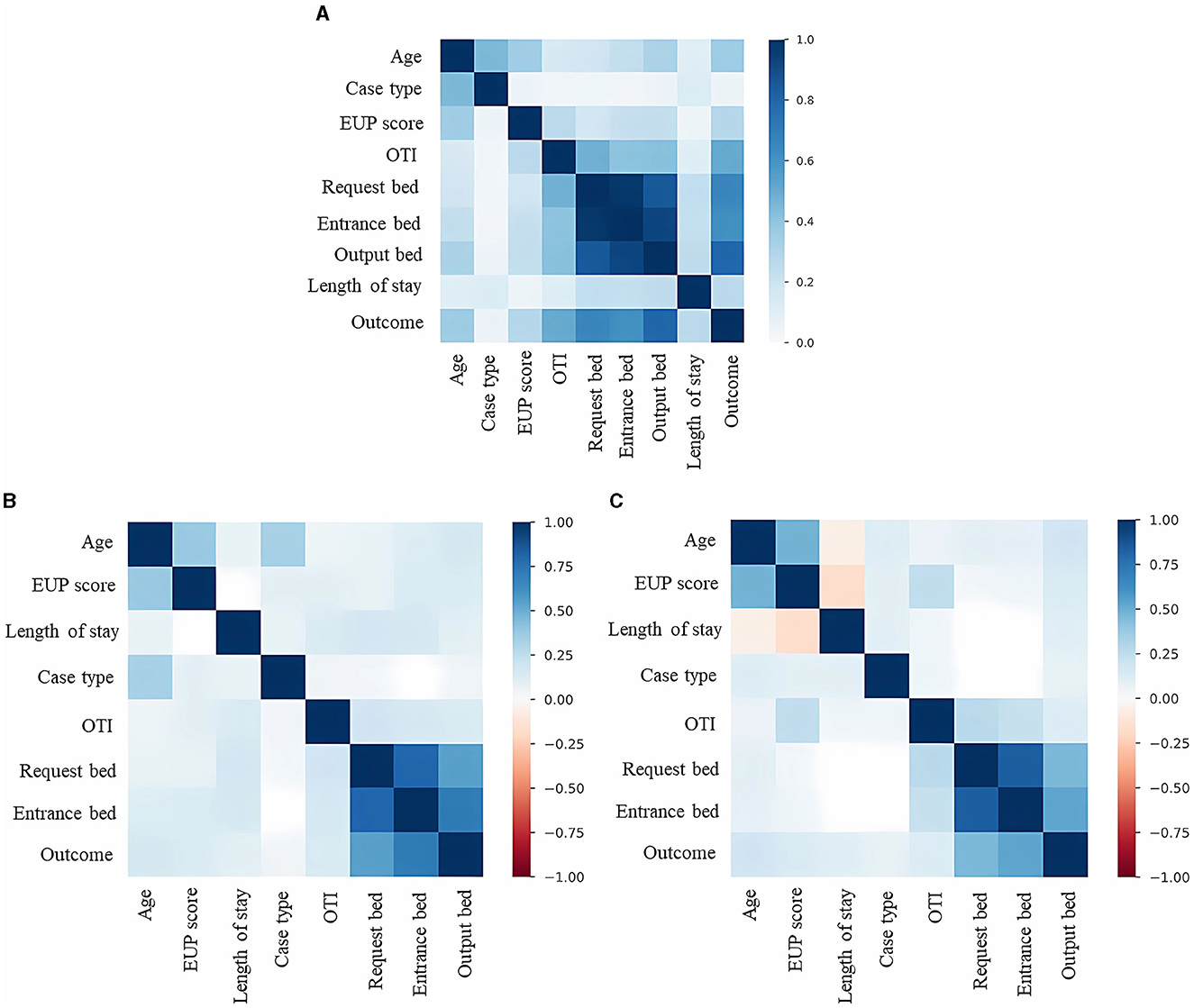
Figure 4. Correlation between dataset features. (A) Correlations between the characteristics of the dataset involving discharge and death results. (B) Correlations between the characteristics of the dataset involving only the discharge results. (C) Correlations between the characteristics of the dataset involving only the death results.
Evaluating the data profile by discharge and death (Table 4), non-survivors are older, have higher scores on the EUP score, started hospitalization already under orotracheal intubation have a higher indication for an ICU bed, and stay for more than eight days in hospital on average. Survivors are younger, have lower scores on the EUP score, started hospitalization without orotracheal intubation, have a higher indication for a ward bed, and stay less than 7 days in hospital.
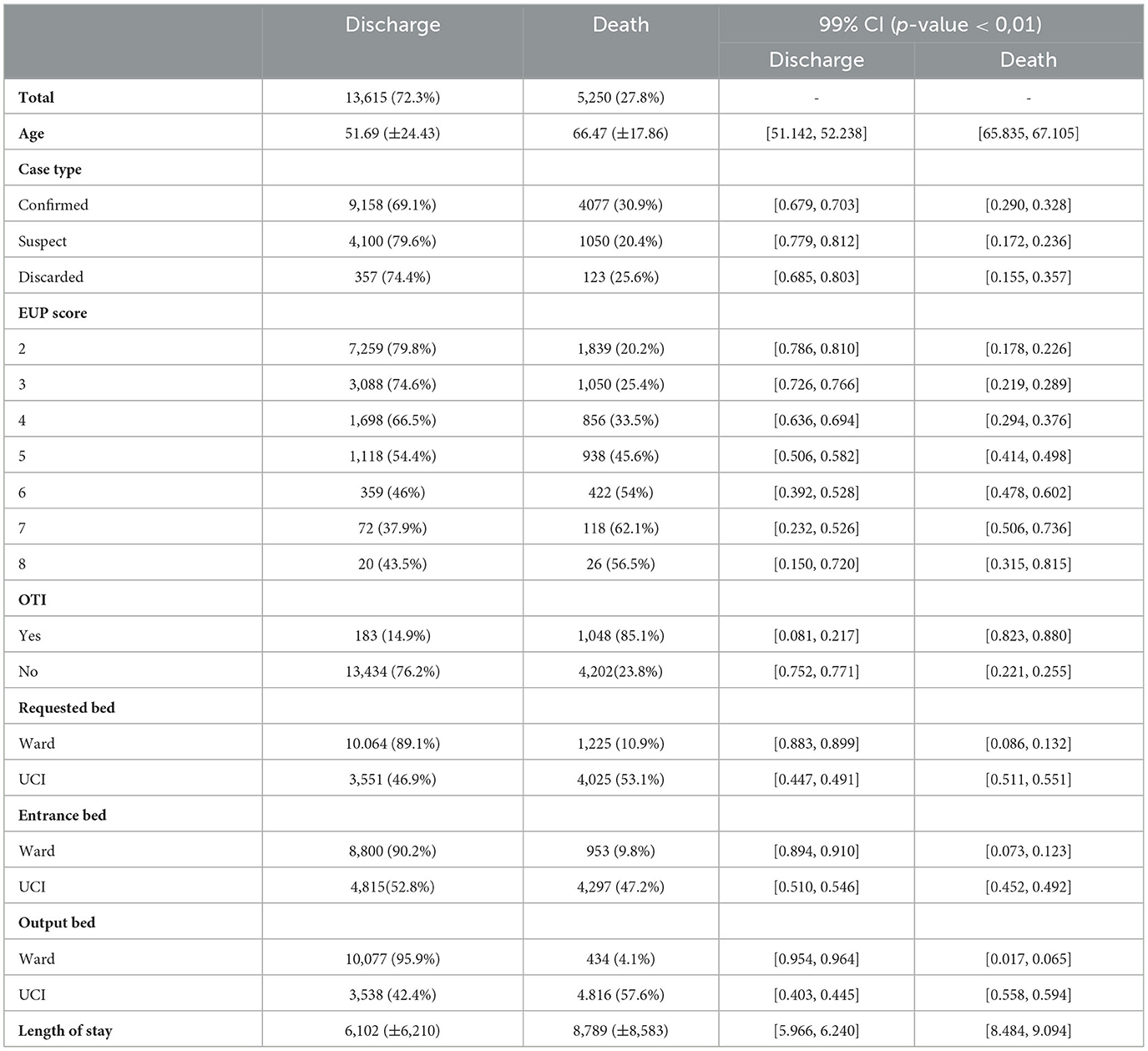
Table 4. Patient data profile divided by discharge and death.
After applying the chi-square, we identified a strong correlation between the independent variables age and length of hospital stay. By making a selection based on the average length of hospitalization and age groups, it was able to establish risk criteria based on how these variables present themselves and thus help decision-making at the care level (Table 5). A patient who is over 80 years old and has been hospitalized for more than seven days has a 53% chance of death, reaching the maximum risk criterion. In this way, they can be relocated from an ICU bed to a palliative care bed.
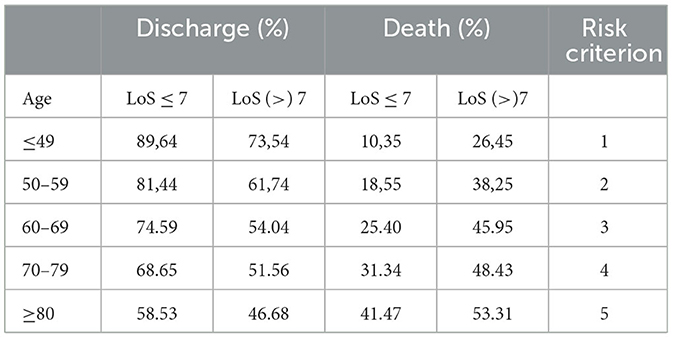
Table 5. Categorization of risk criteria based on age and length of stay (LoS).
In Table 2, displayed in the materials and methods section, the selected hyperparameters and their respective defined values are shown. The best hyperparameters have been highlighted in bold so that it is possible to identify an equivalence between similar parameters in the different models. The machine learning models maintained better results with the same levels of criterion, max depth of the tree, and max features, this correspondence phenomenon also occurred among the deep learning models, in which there was the same selection of the number of neurons, dropout, and batch size among all the optimizers.
As for the evaluation metrics (Table 6), among the machine learning models, Random Forest showed the best accuracy (82.97%), precision (79.35%), recall (84.80%), F1-score (80.74%), and specificity (84.79%) with the lowest standard deviation values. In the deep learning models, the highest accuracy (84.01%), precision (79.57%), and F1-score (81%) were achieved by SGD, while RMSProp was responsible for the highest recall (84.67%) and specificity (84.67%). A significant variation in the standard deviation was found between the deep learning models.
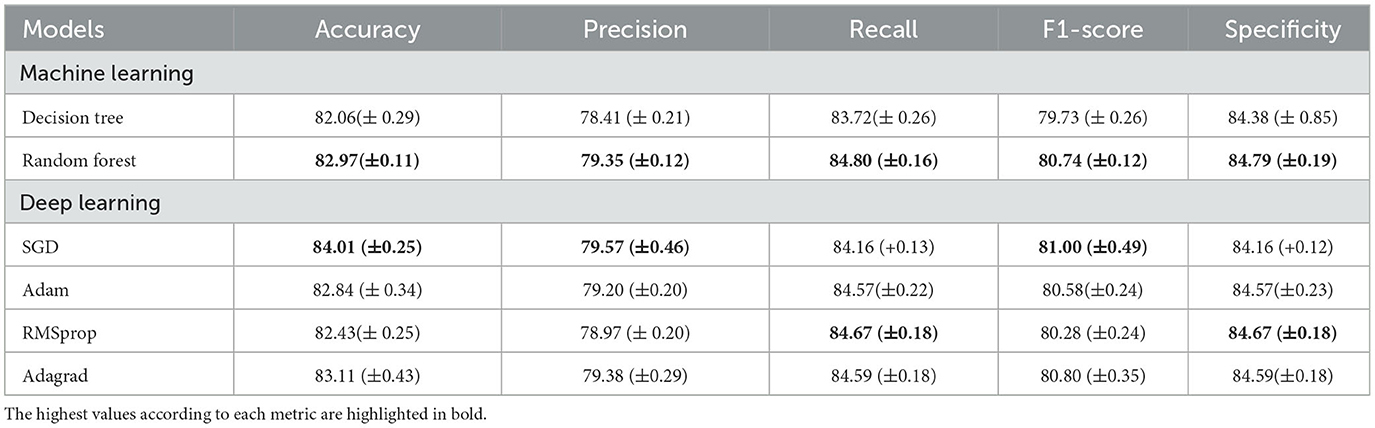
Table 6. Categorization of risk criteria based on age and length of stay (LoS).
When evaluating the features importances of the tree models (Figure 5), there is a convergence of results. The characteristics of output bed, age, and length of stay are among the most important for model selection. The EUP score is also relevant between the models, although the entrance bed and requested bed have a greater influence on Random Forest. The type of case and whether the patient was under orotracheal intubation during the request were not very decisive for the models. In the MLP models (Figure 6), the types requested bed entrance bed and output bed are among the most relevant characteristics for RMSProp and Adagrad, while SGD and Adam consider output bed, requested bed, and age to be the most relevant ones. Among all the models, the type of case (discarded) is the least important variable in determining the outcome. It was noted that length of stay stands out more in Decision Tree and Random Forest decision-making, while in the other classifiers, it is a variable that is not highly valued.
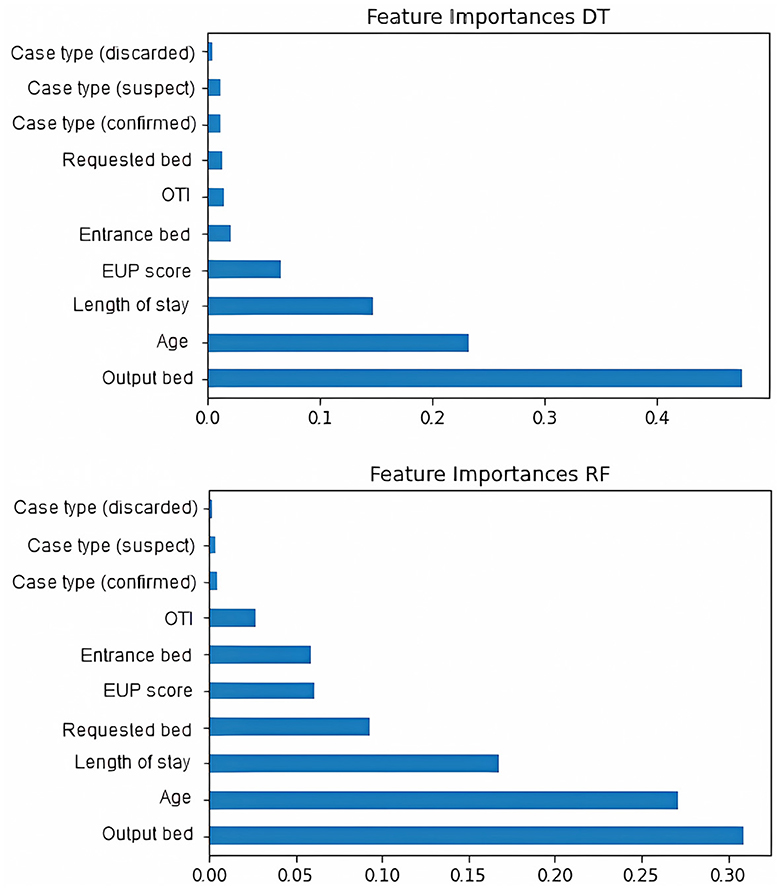
Figure 5. Features importances of machine learning models. The figure initially shows decision tree and then Random Forest.
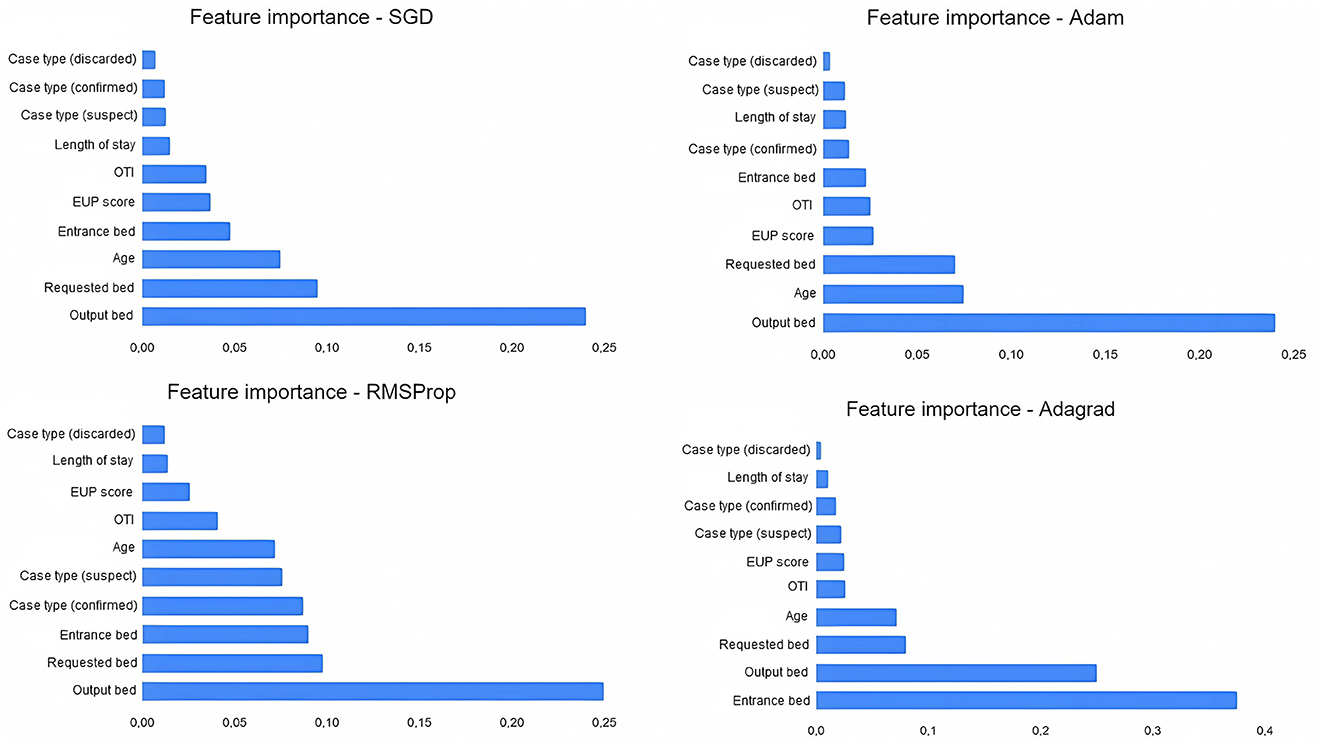
Figure 6. Features importances of multiperceptron layers models (deep learning). The figure shows the SGD optimizer, followed by Adam, RMSProp, and Adagrad.
Comparing our results with the correlation of variables from the Phik model, the deep learning models selected the most important features similarly to the correlations presented; output bed, requested bed, and entrance bed are among the most relevant in RMSProp and Adagrad; output bed and requested bed appear among the most relevant for SGD and Adam. This correspondence points to a relational convergence between Phik and the best selection of variables to determine the outcome carried out by MLP models.
ROC and AUC are efficient techniques for summarizing the prediction accuracy of models. The ROC is obtained from the ratio between the recall and the complement of specificity, while the area under the curve varies from 0 to 1, indicating a totally correct prediction or not (Shanbehzadeh et al., 2022). The machine learning ROC-AUC models obtained similar results to each other. Random Forest showed the best classification of true and false positives with an AUC of 0.852, Decision Tree showed an AUC of 0.843, a result that was expected given that it had the lowest average recall. Meanwhile, among the deep learning classifiers, Adagrad had the lowest value (AUC = 0.912), followed by SGD (AUC = 0.913), Adam (AUC = 0.914), and RMSProp (0.916). All these data are displayed in Figure 7. Overall, an AUC of 0.7 to 0.8 is considered acceptable, 0.8 to 0.9 is considered excellent, and above 0.9 is considered outstanding (Shanbehzadeh et al., 2022).
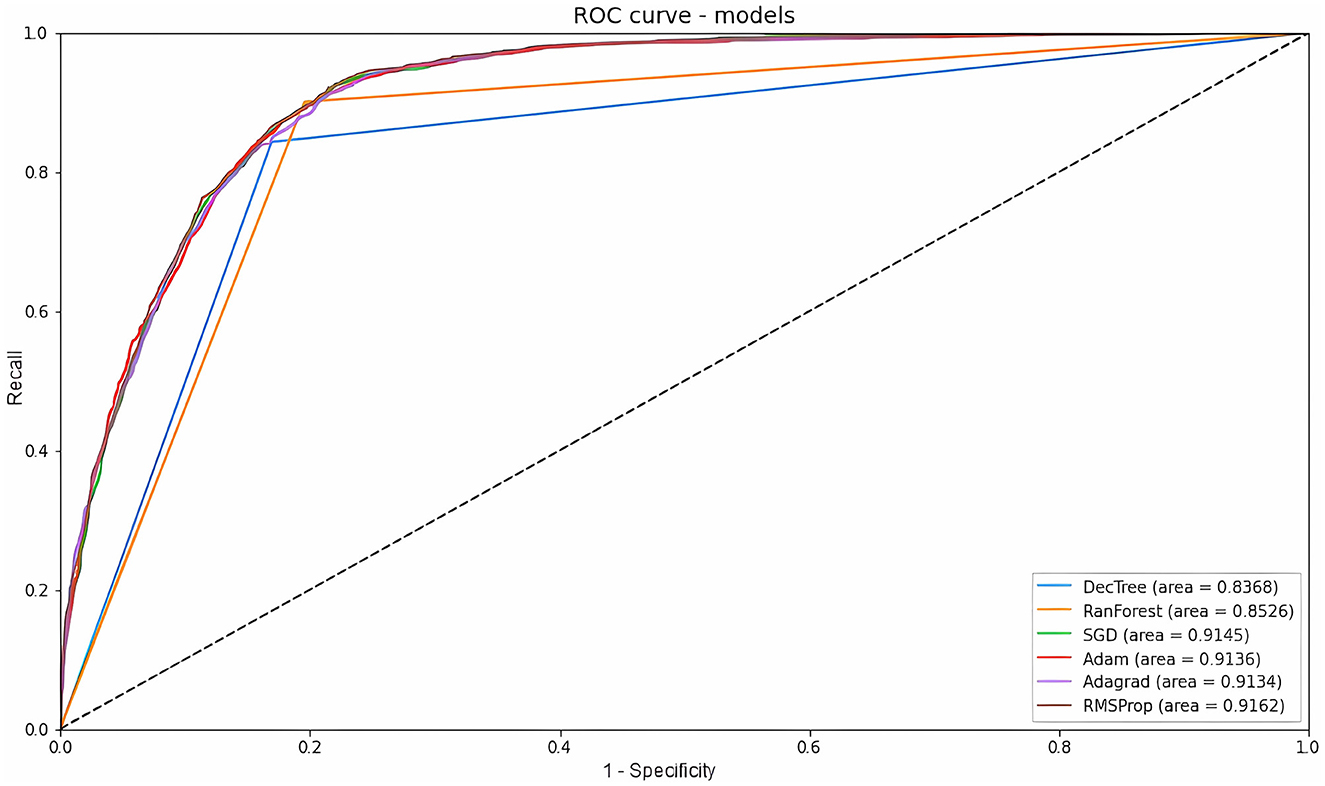
Figure 7. ROC curve and AUC value of all models.
Investments in efficient health systems have been decisive for the better performance of several regions in acquiring data for decision-making in the midst of the pandemic. In addition, the use of artificial intelligence systems has been widely disseminated in academic literature as an aid in various issues to combat COVID-19, whether through patient health data (Debnath et al., 2020; Moulaei et al., 2022; Shanbehzadeh et al., 2022), interventions with radiological images (Ahsan et al., 2020; Ghaderzadeh et al., 2021a, 2022), dissemination of false information about COVID-19 (Endo et al., 2022), forecast of the number of ICU beds in times of crisis (Goic et al., 2021), predicting the time needed to transfer a patient to an ICU bed (Cheng et al., 2020), among others.
Our results compared the performance of six different computational methods in predicting patient mortality from bed regulation data. As for the machine learning models, Random Forest showed the best results in terms of accuracy (82.97%), precision (79.35%), recall (84.80%), F1-score (80.74%), Specificity (84.79%), and ROC-AUC (85.2%). The good performance of this classifier is also highlighted in the work of Prakash et al. (2020), Gupta et al. (2021), Endo et al. (2022), and several others in the literature. As for the deep learning models, SGD showed the best results in terms of accuracy (84.01%), precision (79.57%) and F1-score (81.00%), and RMSprop showed the highest recall (84.67%), specificity (84.67%), and ROC-AUC (91.6%). The selection of SGD as the top optimizer for increasing accuracy also appears in the work of Andrade et al. (2022), however, it does not converge with the work of Ahsan et al. (2020), in which SGD was the worst optimizer selected. Nevertheless, it should be noted that the variability of the data model used to structure the neural network can produce different results, so experimentation with different classifiers is essential to determine the best one.
The MLP with SGD optimizer proved to be the best model for determining the outcome of discharge and death and in terms of assertiveness for predicting discharges. Therefore, if the health professional's goal is to determine whether that patient will have a positive outcome, the SGD is the most recommended optimizer. Whereas, if the operator's objective is to identify which of the total samples selected were best classified, RMSProp is the most recommended optimizer.
When it comes to decision-making, besides the model assertively predicting the outcome, it is also interesting to minimize the worst-case scenarios. In a pandemic scenario, where there is great competition for the number of beds, it is important that the model minimizes situations in which there would be a death and the model classified it as a discharge (false negatives) because this would ensure better management and efficiency of bed allocation so that a patient who had a greater chance of a positive outcome was referred. For this reason, besides having high accuracy and precision, recall and ROC-AUC should be maximized. Similarly, a patient who would have been discharged and the tool classified as death could lead the regulator to make the wrong decision, sending a patient who had a chance of survival to palliative care. Thus, we recommend a joint evaluation of the results of the SGD and RMSProp for a definitive decision.
It is important to highlight that all the data used are real-world data and the variables length of stay and output bed are not controlled data. Therefore, we carried out new tests to ensure that there would be no variability in our metrics, zeroing the length of stay and keeping the output bed the same as the entrance bed. And as expected, there were no significant changes in the metrics of the models evaluated. This is because these models aim, based on the patient's clinical data, to evaluate whether the choice of bed had a better outcome and, consequently, a better length of stay. In other words, dwell time, and outcome are expected results of our model. So, what actually happens is that the model looks at the patient's clinical parameters to analyze whether the choice of bed was the most appropriate for a better outcome and shorter length of stay.
The proposed models enhance the decision-making process of the regulatory professional, to reduce the subjectivity of indicating a patient who would have a better chance of survival for a given hospital bed. Muhammad et al. (2021) also point to a reduction in the burden on care operators and promote more effective care. It must be emphasized that the medical appraisal should be sovereign in all situations so that the models can only suggest the best course of action. Moreover, models have the added benefit of being flexible to changes, allowing for different forecasts (Subudhi et al., 2020). That is, if during the regulation process, there is a need to adjust some new information about the regulation process, the model is able to suggest, in real time, a new forecast for that case.
In the context of global health to tackle COVID-19, widespread investment in health sectors is essential. Brazil already experienced bed overcrowding even before the health crisis (Soares, 2017), thus a difficult performance in dealing with the pandemic was expected. When comparing the situation in Europe, which began a policy of reducing the number of active beds between 2010 and 2017 due to the low use of hospitalization services, Pecoraro, Luzi, and Clemente (Pecoraro et al., 2021) showed an explicit relationship between the increase in investment in the health area and its results in the face of health crises. It was found that Germany invested more in health policies, the number of professionals, and the number of beds, and achieved a more significant performance in minimizing the effects of the pandemic compared to Spain, France, and Italy.
With regard to digital health, there has been pressure for government entities to adopt efficient strategies by implementing computerized systems that help obtain relevant information for the population and assist decision-makers and health agents (Budd et al., 2020; Valentim et al., 2021). For this to be possible, maintaining transparency as well as a cyclical and incremental evolution is fundamental to guaranteeing quality data, with the aim of understanding the scenario in due course (Rasheed et al., 2020; Valentim et al., 2021). The RegulaRN and other systems are examples of this, so utilizing its data to strengthen future decision-making in the bed regulation process corroborates the expectations proposed by the academic, governmental, and social community.
This paper presents the results of an epidemiological analysis of bed regulation data combined with a methodology of computational models. Thus, aside from presenting new information based on COVID-19, the main characteristics of the inpatient outcome were identified. The data allowed us to present mean and absolute values with statistical significance superior to other studies (Baqui et al., 2021), besides making it possible to suggest a risk criterion scale, including the independent variables age and length of stay, which can be used by health units during the hospitalization process. This scale may contribute to the process of providing beds so that patients with the highest values on the scale would be allocated to palliative care beds.
This work complies with the first three stages (data preparation, model development, and model validation) suggested by the review work proposed by de Hond et al. (2022) and is under development to be integrated into RegulaRN, to ensure compliance with the stages of software, evaluation, and implementation in daily healthcare practice.
Furthermore, the use of computational methods can be of great value in the regulatory management of patients with COVID-19. The selected models showed good values for the main metrics evaluated and could optimize the work of regulators and minimize failures in terms of the real outcome of the patient or the government's costs in funding hospital articles and beds in an expensive manner. It should be emphasized that the costs involved in keeping a patient in an intensive care unit bed are substantially higher than in a ward. Moreover, the results indicated by the models themselves may indirectly indicate the need for government action to open or close new beds.
This model, presented in this article, was validated together with the technical team of the Public Health Secretariat of the State of Rio Grande do Norte. Therefore, it is incorporated into RegulaRN with the aim of helping regulatory doctors make decisions. According to the selected characteristics, the models can be consulted by regulatory doctors at any stage of the regulation, whether at the first indication (when the patient has not yet been assigned to a bed), or also when the patient is already in a bed (already hospitalized) to use the data generated to suggest a new outcome prediction. It is noteworthy that in addition to the team of regulatory doctors, this is an important tool for health managers, as they now obtain timely information (on-time) for decision-making and the formulation of public health policies that can guarantee better access to health services.
Among the limitations of our study and the possibility of future work, is to integrate and interoperate with the patients' vaccination data, because Brazil started the vaccination process against COVID-19 in January 2021. In this sense, even those who may have been partially immunized and needed hospitalization may contain enough antibodies to promote a different outcome than a patient without any dose of vaccine (Sales-Moioli et al., 2022). Furthermore, the database sent by the health department, which was used in this research, did not have a breakdown of patients by gender, so this analysis was not included in this first work but has already been requested for future work. Finally, another limitation of the article is to better work with censored data on output bed and length of stay, considering that these are variables that occur stochastically. Therefore, during the initial regulation process, the output bed and length of stay are information that is not yet completely defined, requiring some time for the model to be able to present a good prediction quality.
This study used the RegulaRN database from April 2020 to August 2022 to select computational models based on artificial intelligence to predict the outcome of patients who were regulated during the COVID-19 pandemic in the state of Rio Grande do Norte. Among the selected models, the MLP with SGD optimizer obtained the highest accuracy, precision, and f1 score for predicting the outcome (discharge or death), selecting the output bed, requested bed, and age as the most relevant. On the other hand, RMSprop obtained higher scores in recall, specificity, and ROC-AUC, selecting output bed, requested bed, and entry bed as important variables for the outcome. In addition, we propose a scale of risk criteria that can be used by healthcare facilities to control and make beds available.
The models can be used by the regulation center to assist regulatory professionals during the indication for a bed, increasing the assertiveness of the patient's referral and minimizing the impacts of mistaken regulation, i.e., directing a patient with a lower chance of survival to an ICU bed when the best option would be palliative care, or referring a patient who can be treated in a ward bed to an ICU. In a pandemic situation, in addition to the effects on human health, the computer model could help government decisions on the costs involved with hospital beds.
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://zenodo.org/record/8122564.
The requirement of ethical approval was waived by Research Ethics Committee (CEP) of the Federal University of Rio Grande do Norte for the studies involving humans because according to resolution 674, 2022 of the National Health Council (NHC) of the Ministry of Health (MoH) this research is exempt from registration with the Research Ethics Committee (CEP)/Brazil or the National Research Ethics Commission (CONEP)/Brazil. The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation in this study was provided by the participants' legal guardians/next of kin.
TB: Conceptualization, Data curation, Formal analysis, Methodology, Software, Writing—original draft, Writing—review & editing. NV: Conceptualization, Data curation, Methodology, Writing—original draft, Writing—review & editing. PC: Conceptualization, Data curation, Methodology, Writing—review & editing. FF: Data curation, Methodology, Writing—review & editing. LM: Data curation, Methodology, Software, Writing—review & editing. MB: Conceptualization, Methodology, Writing—review & editing. FA: Conceptualization, Methodology, Writing—review & editing. CP: Investigation, Methodology, Writing—review & editing. IS-G: Data curation, Methodology, Software, Writing—review & editing. GS: Data curation, Methodology, Software, Writing—review & editing. LR: Data curation, Methodology, Software, Writing—review & editing. AM: Methodology, Supervision, Writing—review & editing. JS: Conceptualization, Supervision, Writing—review & editing. JP: Conceptualization, Supervision, Writing—review & editing. IA: Writing—review & editing, Formal analysis, Supervision. RV: Funding acquisition, Methodology, Project administration, Supervision, Writing—original draft, Writing—review & editing.
The author(s) declare financial support was received for the research, authorship, and/or publication of this article. The present study was funded through the Project Regula SESAP-RN/FUNCERN, grant No. 69/2021, carried out by the Laboratory of Technological Innovation in Health (LAIS) of the Federal University of Rio Grande do Norte (UFRN) in cooperation with the Secretary of Public Health of Rio Grande do Norte.
We would like to thank the Public Health Secretary of Rio Grande do Norte (SESAP/RN), the Brazilian Company of Hospital Services (EBSERH), the Laboratory of Technological Innovation in Health (LAIS) of the Federal University of Rio Grande do Norte (UFRN), and to the Advanced Innovation Nucleus (NAVI) of the Federal Institute of Rio Grande do Norte (IFRN), Natal, Rio Grande do Norte (IFRN) for the necessary support for the development of this research.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Ahsan, M. M. E, Alam, T., Trafalis, T., and Huebner, P. (2020). Deep mlp-cnn model using mixed-data to distinguish between COVID-19 and non-COVID-19 patients. Symmetry 12, 1526. doi: 10.3390/sym12091526
Andrade, E. C. d., Pinheiro, P. R., Barros, A. L. B. d. P., Nunes, L. C., Pinheiro, L. I. C., Pinheiro, P. G. C. D., et al. (2022). Towards machine learning algorithms in predicting the clinical evolution of patients diagnosed with covid-19. Appl. Sci. 12, 8939. doi: 10.3390/app12188939
Aquino, E. M., Silveira, I. H., Pescarini, J. M., Aquino, R., Souza-Filho, J. A., Rocha, A. S., et al. (2020). Social distancing measures to control the COVID-19 pandemic: potential impacts and challenges in brazil. Ciencia Saude Colet. 25, 2423–2446. doi: 10.1590/1413-81232020256.1.10502020
Baqui, P., Marra, V., Alaa, A. M., Bica, I., Ercole, A., and van der Schaar, M. (2021). Comparing COVID-19 risk factors in brazil using machine learning: the importance of socioeconomic, demographic and structural factors. Scient. Rep. 11, 15591. doi: 10.1038/s41598-021-95004-8
Bastos, S. B., and Cajueiro, D. O. (2020). Modeling and forecasting the early evolution of the COVID-19 pandemic in brazil. Scient. Rep. 10, 19457. doi: 10.1038/s41598-020-76257-1
Bergstra, J., and Bengio, Y. (2012). Random search for hyper-parameter optimization. J. Mach. Lear. Res. 13, 281–305.
Bian, J., and Modave, F. (2020). The rapid growth of intelligent systems in health and health care. Health Inform. J. 26, 5–7. doi: 10.1177/1460458219896899
Budd, J., Miller, B. S., Manning, E. M., Lampos, V., Zhuang, M., Edelstein, M., et al. (2020). Digital technologies in the public-health response to COVID-19. Nat. Med. 26, 1183–1192. doi: 10.1038/s41591-020-1011-4
Charbuty, B., and Abdulazeez, A. (2021). Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2, 20–28. doi: 10.38094/jastt20165
Chawla, N. V., Bowyer, K. W., Hall, L. O., and Kegelmeyer, W. P. (2002). Smote: synthetic minority over-sampling technique. J. Artif. Intell. Res. 16, 321–357. doi: 10.1613/jair.953
Cheng, F.-Y., Joshi, H., Tandon, P., Freeman, R., Reich, D. L., Mazumdar, M., et al. (2020). Using machine learning to predict icu transfer in hospitalized COVID-19 patients. J. Clin. Med. 9, 1668. doi: 10.3390/jcm9061668
Costa, K. T. S., Morais, T. N. B. d., Justino, D. C. P., and Andrade, F. B. (2021). Evaluation of the epidemiological behavior of mortality due to COVID-19 in Brazil: a time series study. PLoS ONE 16, e0256169. doi: 10.1371/journal.pone.0256169
Cotrim Junior, D. F., and Cabral, L. M. d. S. (2020). Crescimento dos leitos de uti no país durante a pandemia de COVID-19: desigualdades entre o público x privado e iniquidades regionais. Phys. Rev. Saúde Colet. 30, e300317. doi: 10.1590/s0103-73312020300317
Dashboard, W. C. C. (2022). Who coronavirus (COVID-19) dashboard. Available online at: https://covid19.who.int/ (accessed October 20, 2022).
Dauphin, Y., De Vries, H., and Bengio, Y. (2015). “Equilibrated adaptive learning rates for non-convex optimization,” in Advances in Neural Information Processing Systems 28.
de Hond, A. A., Leeuwenberg, A. M., Hooft, L., Kant, I. M., Nijman, S. W., van Os, H. J., et al. (2022). Guidelines and quality criteria for artificial intelligence-based prediction models in healthcare: a scoping review. NPJ Digital Med. 5, 2. doi: 10.1038/s41746-021-00549-7
Debnath, S., Barnaby, D. P., Coppa, K., Makhnevich, A., Kim, E. J., Chatterjee, S., et al. (2020). Machine learning to assist clinical decision-making during the COVID-19 pandemic. Bioelectr. Med. 6, 1–8. doi: 10.1186/s42234-020-00050-8
Duchi, J., Hazan, E., and Singer, Y. (2011). Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 12, 2121–2159.
Endo, P. T., Santos, G. L., de Lima Xavier, M. E., Nascimento Campos, G. R., de Lima, L. C., Silva, I., et al. (2022). Illusion of truth: analysing and classifying COVID-19 fake news in brazilian portuguese language. Big Data Cogn. Comput. 6, 36. doi: 10.3390/bdcc6020036
Ensor, K. B., and Glynn, P. W. (1997). Stochastic optimization via grid search. Appl. Mathem. Am. Mathem. Soc. 33, 89–100.
Fernández, A., Garcia, S., Herrera, F., and Chawla, N. V. (2018). Smote for learning from imbalanced data: progress and challenges, marking the 15-year anniversary. J. Artif. Intell. Res. 61, 863–905. doi: 10.1613/jair.1.11192
Ghaderzadeh, M., and Aria, M. (2021). “Management of COVID-19 detection using artificial intelligence in 2020 pandemic,” in Proceedings of the 5th International Conference on Medical and Health Informatics 32–38. doi: 10.1145/3472813.3472820
Ghaderzadeh, M., Aria, M., and Asadi, F. (2021a). X-ray equipped with artificial intelligence: changing the COVID-19 diagnostic paradigm during the pandemic. BioMed. Res. Int. 2021, 9942873. doi: 10.1155/2021/9942873
Ghaderzadeh, M., Asadi, F., Jafari, R., Bashash, D., Abolghasemi, H., and Aria, M. (2021b). Deep convolutional neural network-based computer-aided detection system for COVID-19 using multiple lung scans: design and implementation study. J. Med. Internet Res. 23, e27468. doi: 10.2196/27468
Ghaderzadeh, M., Eshraghi, M. A., Asadi, F., Hosseini, A., Jafari, R., Bashash, D., et al. (2022). Efficient framework for detection of COVID-19 omicron and delta variants based on two intelligent phases of cnn models. Comput. Mathem. Methods Med. 2022, 4838009. doi: 10.1155/2022/4838009
Goic, M., Bozanic-Leal, M. S., Badal, M., and Basso, L. J. (2021). Covid-19: Short-term forecast of icu beds in times of crisis. PLoS ONE 16, e0245272. doi: 10.1371/journal.pone.0245272
Grandini, M., Bagli, E., and Visani, G. (2020). Metrics for multi-class classification: an overview. arXiv preprint arXiv:2008.05756.
Gupta, V. K., Gupta, A., Kumar, D., and Sardana, A. (2021). Prediction of COVID-19 confirmed, death, and cured cases in india using random forest model. Big Data Min. Analy. 4, 116–123. doi: 10.26599/BDMA.2020.9020016
Hu, B., Guo, H., Zhou, P., and Shi, Z.-L. (2021). Characteristics of SARS-CoV-2 and COVID-19. Nat. Rev. Microbiol. 19, 141–154. doi: 10.1038/s41579-020-00459-7
Huang, C., Wang, Y., Li, X., Ren, L., Zhao, J., Hu, Y., et al. (2020). Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet 395, 497–506. doi: 10.1016/S0140-6736(20)30183-5
Jia, W., Sun, M., Lian, J., and Hou, S. (2022). Feature dimensionality reduction: a review. Complex Intell. Syst. 8, 2663–2693. doi: 10.1007/s40747-021-00637-x
Kingma, D. P., and Ba, J. (2014). Adam: Amazon.com method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Lino, D. O. d. C, Barreto, R., Souza, F. D. d., Lima, C. J. M. d., et al. (2020). Impact of lockdown on bed occupancy rate in a referral hospital during the COVID-19 pandemic in northeast Brazil. Brazil. J. Infect. Dis. 24, 466–469. doi: 10.1016/j.bjid.2020.08.002
Lipton, Z. C., Elkan, C., and Naryanaswamy, B. (2014). “Optimal thresholding of classifiers to maximize F1 measure”, in Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2014, (Nancy: Springer), 225–239. doi: 10.1007/978-3-662-44851-9_15
Maldonado, R. N., Savio, R. O., Feijó, V. B. E. R., Aroni, P., Rossaneis, M. A., Haddad, M., et al. (2021). Hospital indicators after implementation of bed regulation strategies: an integrative review. Rev. Brasil. de Enferm. 74, e20200022. doi: 10.1590/0034-7167-2020-0022
Moulaei, K., Shanbehzadeh, M., Mohammadi-Taghiabad, Z., and Kazemi-Arpanahi, H. (2022). Comparing machine learning algorithms for predicting COVID-19 mortality. BMC Med. Inform. Decis. Making 22, 1–12. doi: 10.1186/s12911-021-01742-0
Muhammad, L., Algehyne, E. A., Usman, S. S., Ahmad, A., Chakraborty, C., and Mohammed, I. A. (2021). Supervised machine learning models for prediction of COVID-19 infection using epidemiology dataset. SN Comput. Sci. 2, 1–13. doi: 10.1007/s42979-020-00394-7
Pecoraro, F., Luzi, D., and Clemente, F. (2021). The efficiency in the ordinary hospital bed management: a comparative analysis in four european countries before the COVID-19 outbreak. PLoS ONE 16, e0248867. doi: 10.1371/journal.pone.0248867
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: machine learning in python. J. Mach. Learn. Res. 12, 2825–2830.
Perondi, B., Miethke-Morais, A., Montal, A. C., Harima, L., and Segurado, A. C. (2021). Setting up hospital care provision to patients with COVID-19: lessons learnt at a 2400-bed academic tertiary center in Sao Paulo, Brazil. Brazil. J. Infect. Dis. 24, 570–574. doi: 10.1016/j.bjid.2020.09.005
Prakash, K. B., Imambi, S. S., Ismail, M., Kumar, T. P., and Pawan, Y. (2020). Analysis, prediction and evaluation of COVID-19 datasets using machine learning algorithms. Int. J. 8, 2199–2204. doi: 10.30534/ijeter/2020/117852020
Rasheed, J., Jamil, A., Hameed, A. A., Aftab, U., Aftab, J., Shah, S. A., et al. (2020). A survey on artificial intelligence approaches in supporting frontline workers and decision makers for the COVID-19 pandemic. Chaos, Solit. Fractals 141, 110337. doi: 10.1016/j.chaos.2020.110337
Rees, E. M., Nightingale, E. S., Jafari, Y., Waterlow, N. R., Clifford, S. B., et al. (2020). COVID-19 length of hospital stay: a systematic review and data synthesis. BMC Med. 18, 1–22. doi: 10.1186/s12916-020-01726-3
Sales-Moioli, A. I. L., Galv ao-Lima, L. J., Pinto, T. K., Cardoso, P. H., Silva, R. D., Fernandes, F., et al. (2022). Effectiveness of COVID-19 vaccination on reduction of hospitalizations and deaths in elderly patients in Rio Grande do Norte, Brazil. Int. J. Environ. Res. Public Health 19, 13902. doi: 10.3390/ijerph192113902
Shahzad, A., Zafar, B., Ali, N., Jamil, U., Alghadhban, A. J., Assam, M., et al. (2022). COVID-19 vaccines related users response categorization using machine learning techniques. Computation 10, 141. doi: 10.3390/computation10080141
Shailaja, K., Seetharamulu, B., and Jabbar, M. (2018). “Machine learning in healthcare: a review,” in 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA) (IEEE), 910–914. doi: 10.1109/ICECA.2018.8474918
Shanbehzadeh, M., Yazdani, A., Shafiee, M., and Kazemi-Arpanahi, H. (2022). Predictive modeling for COVID-19 readmission risk using machine learning algorithms. BMC Med. Inform. Decis. Mak. 22, 139. doi: 10.1186/s12911-022-01880-z
Soares, V. S. (2017). Analysis of the internal bed regulation committees from hospitals of a southern brazilian city. Einstein 15, 339–343. doi: 10.1590/s1679-45082017gs3878
Sokolova, M., and Lapalme, G. (2009). A systematic analysis of performance measures for classification tasks. Inform. Process. Manage. 45, 427–437. doi: 10.1016/j.ipm.2009.03.002
Subudhi, S., Verma, A., and Patel, A. B. (2020). Prognostic machine learning models for COVID-19 to facilitate decision making. Int. J. Clin. Pract. 74, e13685. doi: 10.1111/ijcp.13685
Sutskever, I., Martens, J., Dahl, G., and Hinton, G. (2013). “On the importance of initialization and momentum in deep learning,” in International Conference on Machine Learning (PMLR), 1139–1147.
Valentim, R. A. d. M, Lima, T. S., Cortez, L. R., Barros, D. M. d. S., Silva, R. D. d., et al. (2021). The relevance a technology ecosystem in the brazilian national health services COVID-19 response: the case of Rio Grande do Norte, Brazil. Ciênc. Saúde Colet. 26, 2035–2052. doi: 10.1590/1413-81232021266.44122020
Vaughan, L., Zhang, M., Gu, H., Rose, J. B., Naughton, C. C., Medema, G., et al. (2023). An exploration of challenges associated with machine learning for time series forecasting of COVID-19 community spread using wastewater-based epidemiological data. Sci. Total Environ. 858, 159748. doi: 10.1016/j.scitotenv.2022.159748
Vekaria, B., Overton, C., Wiśniowski, A., Ahmad, S., Aparicio-Castro, A., Curran-Sebastian, J., et al. (2021). Hospital length of stay for COVID-19 patients: data-driven methods for forward planning. BMC Infect. Dis. 21, 1–15. doi: 10.1186/s12879-021-06371-6
Yu, L., Halalau, A., Dalal, B., Abbas, A. E., Ivascu, F., Amin, M., et al. (2021). Machine learning methods to predict mechanical ventilation and mortality in patients with COVID-19. PLoS ONE 16, e0249285. doi: 10.1371/journal.pone.0249285
Zhang, C., Liao, Q., Rakhlin, A., Miranda, B., Golowich, N., and Poggio, T. (2018). Theory of deep learning iib: Optimization properties of sgd. arXiv preprint arXiv:1801.02254.
Keywords: machine learning, deep learning, computational methods, bed regulation, COVID-19, RegulaRN
Citation: Barreto TO, Veras NVR, Cardoso PH, Fernandes FRS, Medeiros LPS, Bezerra MV, Andrade FMQ, Pinheiro CO, Sánchez-Gendriz I, Silva GJPC, Rodrigues LF, Morais AHF, dos Santos JPQ, Paiva JC, Andrade IGM and Valentim RAM (2023) Artificial intelligence applied to analyzes during the pandemic: COVID-19 beds occupancy in the state of Rio Grande do Norte, Brazil. Front. Artif. Intell. 6:1290022. doi: 10.3389/frai.2023.1290022
Received: 08 September 2023; Accepted: 17 November 2023;
Published: 08 December 2023.
Edited by:
Ovidiu Constantin Baltatu, Anhembi Morumbi University, BrazilReviewed by:
Gregory R. Hart, Institute for Disease Modeling (IDM), United StatesCopyright © 2023 Barreto, Veras, Cardoso, Fernandes, Medeiros, Bezerra, Andrade, Pinheiro, Sánchez-Gendriz, Silva, Rodrigues, Morais, dos Santos, Paiva, Andrade and Valentim. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tiago de Oliveira Barreto, dGlhZ28uYmFycmV0b0BsYWlzLmh1b2wudWZybi5icg==
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.