
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
OPINION article
Front. Artif. Intell., 02 November 2023
Sec. Medicine and Public Health
Volume 6 - 2023 | https://doi.org/10.3389/frai.2023.1274975
 Tedi Rustandi1,2*
Tedi Rustandi1,2* Erna Prihandiwati1
Erna Prihandiwati1 Fatah Nugroho3Fakhriah Hayati4,5Nita Afriani6Riza Alfian1Noor Aisyah1Rakhmadhan Niah1Aulia Rahim1Hasbi As-Shiddiq7
Fatah Nugroho3Fakhriah Hayati4,5Nita Afriani6Riza Alfian1Noor Aisyah1Rakhmadhan Niah1Aulia Rahim1Hasbi As-Shiddiq7Indonesia has a mega biodiversity that includes plants, animals, and microorganisms. Six thousand plant species have been used empirically as natural resources for traditional medicines by nearly 40 million Indonesians (Elfahmi et al., 2014; Erlina et al., 2022; Sanka et al., 2023). Jamu is a traditional Indonesian medicine that has not undergone preclinical or clinical trials but has been empirically proven to maintain health and treat disease as it has been used by Indonesian people for centuries (Elfahmi et al., 2014; Laplante, 2016; Ministry of Health, Republik Indonesia, 2022). Jamu, which is a part of Javanese medicinal culture, is also recorded in several classic books such as Serat Centhini, Serat Primbon Reracikan Jampi Jawi, and Serat Kawruh. These could be the references for further development of current standardized herbal medicine.
The traditional Indonesian herbal medicine (Jamu) products that are produced from Indonesia's biodiversity are difficult to examine (Sanka et al., 2023). The development of Jamu into phytopharmaceuticals or standardized herbal medicine requires a long research phase and high costs with a risk of an extended research time (Brendler, 2021; Chen et al., 2023). Other challenges in the development of traditional medicine into new standardized pharmaceuticals include the need for sophisticated and high-risk procedures with no certainty of a beneficial pharmacological outcome (Zhu, 2020; Vijayan et al., 2022). Furthermore, high research costs for an extended research period will result in high prices, making it less competitive than modern drugs (Osakwe, 2016). Developing a new drug is estimated to take 10–15 years of research and cost ~US$ 2.8 billion, with an 80–90% failure rate when entering the clinical trial phase (Vijayan et al., 2022).
Taxol (Paclitaxel) is an example of a successfully developed bioactive compound derived from herbs. Taxol is a drug used for cancer that was derived from the Pacific yew tree (Taxus brevifolia) (Li G. et al., 2022). It was discovered and developed as an anticancer agent in 1960. The discovery of its anticancer potential began with a screening of extracts of the bark of the Pacific yew tree. The discovery of the Taxol component, Paclitaxel, in 1967 highlighted the accomplishment of the screening stage for bioactive compounds with anticancer action (Wani and Horwitz, 2014). The extraction stage was then developed to facilitate the production of Paclitaxel, thereby encouraging the development stage of the extraction process for the bark of the Pacific yew tree. The extraction method achieved satisfactory results in 1980 with the discovery of the taxol precursor extraction method (10-deacetyl-baccatin III). Phase I clinical trials were conducted in 1984 against several types of cancer and industrial-scale production began a few years later (Horwitz, 2023). The lengthy process of each stage of using Taxol as an anticancer agent can hinder the development of drug discovery and development. Faster discovery and development methods of new drugs from natural products need to be applied to answer future challenges.
One current technology that can overcome the challenges of standardized herbal medicine development from Jamu is Artificial Intelligence (AI) (Xiaotong et al., 2022). Implementing AI in developing new drugs from Jamu has considerable potential (Erlina et al., 2022) by accelerating preliminary data with the help of an existing database so that several initial screening stages can be done more efficiently. Moreover, searching and matching the input data can be more accessible because AI aids selection with its algorithm and then predicts the possible outcome of the previous study.
AI could play a role in accelerating the development of new drugs by connecting big data on bioactive molecules, pharmacology, metabolomics, and target diseases (Xiaotong et al., 2022). AI application is highly recommended to complement experimental drug discovery, which requires a more extended stage. AI can assist the drug discovery process with high accuracy to avoid failures in drug development. In previous research, many studies that have gone through a long process and cost money did not find bioactives with benefits (Chen et al., 2022). AI can help select many drug candidates from currently available big data with dynamic, heterogeneous, and significant characteristics (Zhu, 2020).
Drug repurposing for Jamu products in Indonesia is the right concept to be combined with AI technology due to several factors, including shortening the 2–14-year research process and utilizing herbal medicine traditionally used by the community (Erlina et al., 2022). The ability of AI to learn from existing data, both data from modern drugs and drugs derived from traditional herbal medicine, makes it possible to obtain new, more effective drugs. Another approach that can be combined is the quantitative structure-activity relationship (QSAR), which is the creation of a model that relates physicochemical properties to biological activity (Zhu, 2020). This system's approach is almost identical to the mechanism approach to drugs and diseases developed to obtain more effective drugs from Jamu. The systematic scheme of applying AI in the discovery of new products originating from Traditional Herbal Medicine can be seen in Figure 1 and is described in the following order:
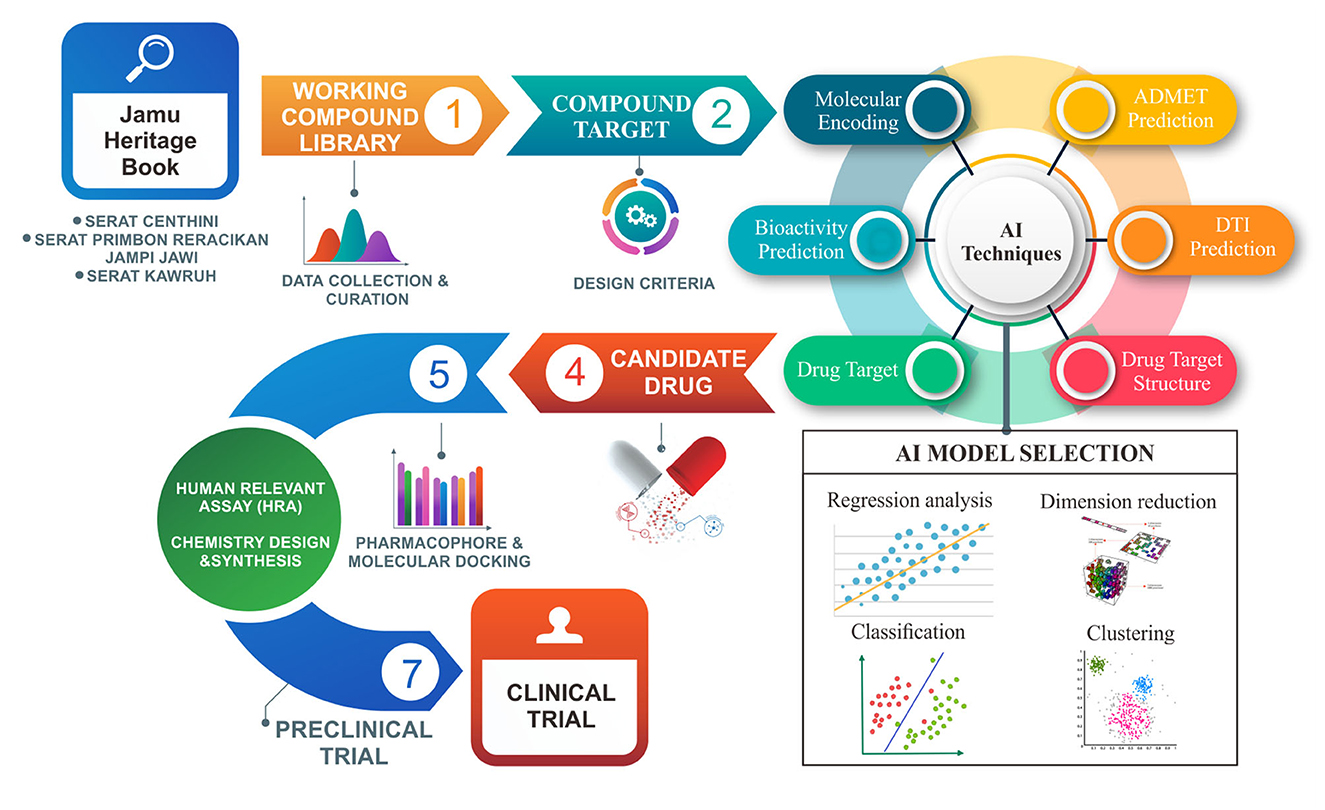
Figure 1. Framework of AI technique application for drug discovery and evaluation.
Databases that can be used and have been tested in several studies include Science Online (http://www.sciencemag.org/), Elsevier Science Direct (https://www.Sciencedirect.com), Springer (https://link.springer.com/), PubMed (https://www.ncbi.nlm.nih.gov/pubmed/), Wiley (https://onlinelibrary.wiley.com/), Nature (https://www.nature.com/), Oxford Academic (https://academic.oup.com/journals/), and Pubchem (https://pubchem.ncbi.nlm.nih.gov/) (Chen et al., 2022; Suttithumsatid et al., 2022). Another database that can be used is the Protein Databank (PDB), an open database with information related to the molecular structure of proteins, nucleic acids, and biological complexes from the results of previous studies (Suttithumsatid et al., 2022). The Indonesian database that contains information on compounds related to Jamu is HerbalDB (Erlina et al., 2022). The database has a good data reputation for forming the basis of the big data concept.
A data processing database connects several databases, including ChEMBL (Mendez et al., 2019), ChemDB (Jackson et al., 2020), COCONUT (Sorokina et al., 2021), DGIdb (Freshour et al., 2021), DTC (Li X. et al., 2022), INPUT (Li X. et al., 2022), SIDER (Kuhn et al., 2016), and STITCH (Szklarczyk et al., 2021). The database applies the concept of AI in processing data to produce data that can be used in the development of Jamu products. In order to get specific results, the available data need to go through a process called data mining. This process is a data extraction process to obtain valuable data. An AI tool that can be used for data mining is natural language processing (NLP). NLP is a technique in the machine learning (ML) branch that works through sentiment analysis, named entity recognition, machine translation, text summarization, and speech recognition. This technique connects human language in manuscripts with computer language so that data from large databases can get specific results (Saldívar-González et al., 2022).
Research success in developing new drugs that have therapeutic effects is paramount. Target protein determination must be determined early in development, and bioactive mechanisms may occur. UniProt can be used to determine potential therapeutic targets and signaling pathways involved in the disease being studied (https://www.uniprot.org/). This tool classifies the targets obtained in the database into the following classifications: Druggability, Structure, Diseases, Biology, Genetics, Chemistry, Safety, and Information (De Cesco et al., 2020).
This approach consists of several steps: the first step is a literature study on the database to obtain data on drugs and protein target interactions. The extraction process in the previous stage was to obtain chemical structure and genomic sequence features data. The resulting data is then used as a training dataset. The hyperparameters obtained from the training data set are used to obtain the optimal model. The prediction model for Jamu compounds uses data obtained through the previous process (Erlina et al., 2022).
The AI approach uses one of the commonly used branches, including several models tested in previous studies: KNN, SVM, SGD, NB, ANN, Adaboost, LR, MLP, DT, and RF. In addition, the DL model can be combined with the ML model, namely DBN (Chen et al., 2022; Erlina et al., 2022). Through-branch approaches in AI, such as ML and DL, have the same goals but differ in how they work (Vijayan et al., 2022). The ML processes data trained on the program to get a new model prediction. The ML is designed as a model that learns from training data through supervised learning, unsupervised learning, and reinforcement learning (RL). The ML approach to DL uses an artificial neural network (ANN) system to process the data provided and processes the data like a neural network by carrying out learning automatically. The DL approach is suitable for more complex and abstract data but takes longer than the ML approach (Chen et al., 2022, 2023; Vijayan et al., 2022).
Previous research has measured the accuracy of some MLs: 90.1% for RF (Random Forest), 88.2% for MLP (Multilayer Perceptron), 87.4–94.5% for SVM (Support Vector Machine), 84.3% for NB (Naive Bayer), and 78–82.5% for k-NN (k-Nearest Neighbor). These accuracy percentages are not absolute numbers since they can change and depend on the data entered in the ML system, but they can be used as an illustration for selecting the ML system (Kumar and Kumar, 2017; Kaur and Kaur, 2019). The ML is used for preclinical drug development by producing several pieces of information such as on bioactivity, ADMET (Absorption, Distribution, Metabolism, Excretion, and Toxicity), and physicochemical properties (Vijayan et al., 2022). The results of the development of herbal medicine using AI can be seen in Table 1.
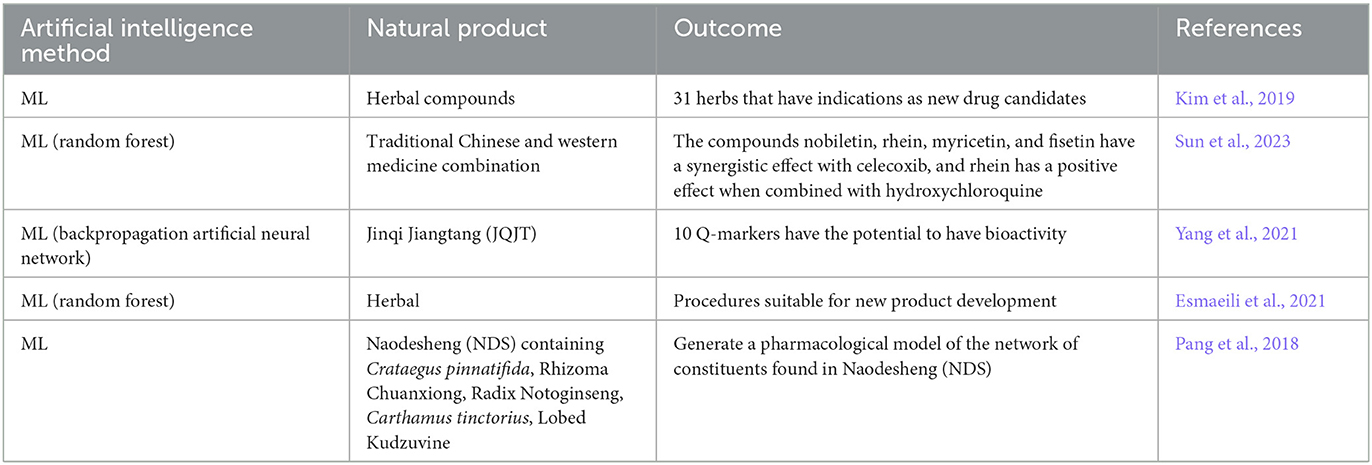
Table 1. Application of AI to drug development research.
The prediction process begins with normalization, and the scaler data is obtained, which is used as the test protein data. The drug data from the database is then merged with the test protein data. This amalgamation is then processed in the ML system in the training data set to obtain the final results of positive and negative interactions. Positive interaction means the drug compound reacts positively with its target protein (Erlina et al., 2022).
Another approach for predicting new compounds in molecules de novo obtained from the previous step is the DL system. The currently used DLs are VAEs, generative adversarial networks (GANs), RLs, and RNNs. This approach is also called a generative modeling approach, where AI can produce new models from the training data provided (Vijayan et al., 2022).
Pharmacophore is used to identify critical molecules in the target compounds (bioactive) in Jamu against receptors or biological targets. This technique creates a model that is similar to known drug molecules. This technique guides the drug development process to speed up new bioactive compound development (Erlina et al., 2022). Meanwhile, Molecular Docking assesses chemical compounds' interaction with proteins or biological targets in traditional herbal medicine. This modeling method can speed up the development of bioactive compounds that act as ligands at a lower cost than conventional methods (Scior, 2021; Suttithumsatid et al., 2022).
Combining pharmacophore and molecular docking techniques is the final stage in developing new drugs derived from Jamu. Pharmacophore modeling can identify critical molecular features, and molecular docking is used to predict the binding of drug molecules obtained with biological targets. After identifying the bioactive structure, the next step is to evaluate ADMET using SwissADME (http://www.swissadme.ch/). SwissADME is a computational-based prediction platform that evaluates drug compounds in terms of their pharmacokinetic and toxicological profiles (Suttithumsatid et al., 2022). ADMET modeling for new compounds can also be done using the ML approach—predictive models developed with neural networks, RF, and SVM systems. The ML used in all three tools is suitable for algorithms with endpoints that have complex and non-linear relationships.
Human-relevant Assays (HRA) is used to observe responses that occur in humans using the In Silico method based on molecular data and information relating to biological systems. The final test is Chemical Design and Synthesis to ensure potential drug candidates will be easy to synthesize and produce to meet sustainability aspects (Singh et al., 2023).
AI can shorten the research process and have a higher success rate for new drug development. The development of new medicines from Jamu, which are native Indonesian products and part of the culture of the Indonesian people, can be carried out with AI technology. The stages of drug development from Jamu are database identification and data mining, AI Technique, and the systematic review of proven drugs.
TR: Writing – original draft. EP: Formal analysis, Funding acquisition, Project administration, Resources, Validation, Visualization, Writing – review & editing. FN: Writing – review & editing. FH: Writing – review & editing. NAf: Writing – review & editing. RA: Formal analysis, Funding acquisition, Project administration, Resources, Validation, Visualization, Writing – review & editing. NAi: Formal analysis, Funding acquisition, Project administration, Resources, Validation, Visualization, Writing – review & editing. RN: Conceptualization, data curation, Investigation, Methodology, Software, Supervision, Writing – review & editing. AR: Conceptualization, Data curation, Investigation, Methodology, Software, Supervision, Writing – review & editing. HA-S: Conceptualization, Data curation, Investigation, Methodology, Software, Supervision, Writing – review & editing.
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
The authors would like to thank Freepik for its help in using and modifying the infographic for Figure 1.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
AI, Artificial intelligence; Adaboost, adaptive boosting; ADMET, absorption, distribution, metabolism, excretion, and toxicity; ANN, Artificial neural network; DT, Decision tree; GANs, generative adversarial networks; HRA, human-relevant assays; k-NN, k-nearest neighbor; LR, logistic regression; ML, machine learning; MLP, multilayer perceptron; NB, Naive Bayer; NLP, natural language processing; RF, random forest; RL, reinforcement learning; RNNs, recurrent neural networks; SGD, stochastic gradient descent; SVM, support vector machines; VAEs, variational autoencoders.
Brendler, T. (2021). From bush medicine to modern phytopharmaceutical: a bibliographic review of Devil's Claw (Harpagophytum spp.). Pharmaceuticals 14, 726. doi: 10.3390/ph14080726
Chen, W., Liu, X., Zhang, S., and Chen, S. (2023). Artificial intelligence for drug discovery: resources, methods, and applications. Mol. Ther. Nucleic Acids 31, 691–702. doi: 10.1016/j.omtn.2023.02.019
Chen, Z., Zhao, M., You, L., Zheng, R., Jiang, Y., Zhang, X., et al. (2022). Developing an artificial intelligence method for screening hepatotoxic compounds in traditional chinese medicine and western medicine combination. Chin. Med. 17, 58. doi: 10.1186/s13020-022-00617-4
De Cesco, S., Davis, J. B., and Brennan, P. E. (2020). TargetDB: a target information aggregation tool and tractability predictor. PLoS ONE 15, e0232644. doi: 10.1371/journal.pone.0232644
Elfahmi Woerdenbag, H. J., and Kayser, O. (2014). Jamu: Indonesian traditional herbal medicine towards rational phytopharmacological use. J. Herbal Med. 4, 51–73. doi: 10.1016/j.hermed.2014.01.002
Erlina, L., Paramita, R. I., Kusuma, W. A., Fadilah, F., Tedjo, A., Pratomo, I. P., et al. (2022). Virtual screening of indonesian herbal compounds as COVID-19 supportive therapy: machine learning and pharmacophore modeling approaches. BMC Complem. Med. Therap. 22, 207. doi: 10.1186/s12906-022-03686-y
Esmaeili, F., Lohrasebi, T., Mohammadi-Dehcheshmeh, M., and Ebrahimie, E. (2021). Evaluation of the effectiveness of herbal components based on their regulatory signature on carcinogenic cancer cells. Cells 10, 3139. doi: 10.3390/cells10113139
Freshour, S. L., Kiwala, S., Cotto, K. C., Coffman, A. C., McMichael, J. F., Song, J. J., et al. (2021). Integration of the drug-gene interaction database (DGIdb 4.0) with open crowdsource efforts. Nucleic Acids Res. 49, D1144–D1151. doi: 10.1093/nar/gkaa1084
Horwitz, S. (2023). Success Story Taxol® (NSC 125973). National Cancer Institute (2023). Available online at: https://dtp.cancer.gov/timeline/flash/success_stories/s2_taxol.htm (accessed June 6, 2023).
Jackson, S. S., Sumner, L. E., Finnegan, M. A., Billings, E. A., Huffman, D. L., and Rush, M. A. (2020). A 35-year review of pre-clinical HIV therapeutics research reported by NIH ChemDB: influences of target discoveries, drug approvals and research funding. J. AIDS Clin. Res. 11, 1–17.
Kaur, S., and Kaur, P. (2019). Plant species identification based on plant leaf using computer vision and machine learning techniques. J. Multim. Inform. Syst. 6, 49–60. doi: 10.33851/JMIS.2019.6.2.49
Kim, E., Choi, A. S., and Nam, H. (2019). Drug repositioning of herbal compounds via a machine-learning approach. BMC Bioinformatics 20(Suppl. 10), 247. doi: 10.1186/s12859-019-2811-8
Kuhn, M., Letunic, I., Jensen, L. J., and Bork, P. (2016). The SIDER database of drugs and side effects. Nucleic Acids Res. 44, D1075–D1079. doi: 10.1093/nar/gkv1075
Kumar, A., and Kumar, B. (2017). Automatic recognition of medicinal plants using machine learning techniques. Int. J. Adv. Comp. Sci. Appl. 8, 166–175. doi: 10.14569/IJACSA.2017.080424
Laplante, J. (2016). “Becoming-plant: Jamu in Java, Indonesia,” in Plants and Health: New Perspectives on the Health-Environment-Plant Nexus, eds E. A. Olson and J. R., Stepp (Cham: Springer International Publishing), 17–65. Available online at: http://link.springer.com/10.1007/978-3-319-48088-6_2 (accessed September 2, 2023).
Li, G., Lin, P., Wang, K., Gu, C. C., and Kusari, S. (2022). Artificial intelligence-guided discovery of anticancer lead compounds from plants and associated microorganisms. Trends Cancer 8, 65–80. doi: 10.1016/j.trecan.2021.10.002
Li, X., Tang, Q., Meng, F., Du, P., and Chen, W. (2022). INPUT: an intelligent network pharmacology platform unique for traditional chinese medicine. Comput. Struct. Biotechnol. J. 20, 1345–1351. doi: 10.1016/j.csbj.2022.03.006
Mendez, D., Gaulton, A., Bento, A. P., Chambers, J., De Veij, M., Félix, E., et al. (2019). ChEMBL: towards direct deposition of bioassay data. Nucleic Acids Res. 47, D930–D940. doi: 10.1093/nar/gky1075
Ministry of Health Republik Indonesia. (2022). Fitofarmaka Phytopharmacy Formulary. 1st ed. Vol. 13. Jakarta: Ministry of Health, Republik Indonesia.
Osakwe, O. (2016). “Chapter 12 - drug pricing and control for pharmaceutical drugs,” in Social Aspects of Drug Discovery Rizvi Development and Commercialization, eds O. Osakwe and A. A. B. T. Syed (Boston: Academic Press), 255–265.
Pang, X. C., Kang, D., Fang, J. S., Zhao, Y., Xu, L. J., Lian, W. W., et al. (2018). Network Pharmacology-Based Analysis of Chinese Herbal Naodesheng Formula for Application to Alzheimer's Disease. Chin. J. Nat. Med. 16, 53–62. doi: 10.1016/S1875-5364(18)30029-3
Saldívar-González, F. I., Aldas-Bulos, V. D., Medina-Franco, J. L., and Plisson, F. (2022). Natural product drug discovery in the artificial intelligence era. Chem. Sci. 13, 1526–1546. doi: 10.1039/D1SC04471K
Sanka, I., Kusuma, A. B., Martha, F., Hendrawan, A., Pramanda, I. T., Wicaksono, A., et al. (2023). Synthetic biology in Indonesia: potential and projection in a country with mega biodiversity. Biotechnol. Notes 4, 41–48. doi: 10.1016/j.biotno.2023.02.002
Scior, T. (2021). “Chapter 10 - Do it yourself—dock it yourself: general concepts and practical considerations for beginners to start molecular ligand–target docking simulations,” in Molecular Docking for Computer-Aided Drug Design Coumar, eds S. B. T. Mohane (Academic Press), 205–227. doi: 10.1016/B978-0-12-822312-3.00003-5
Singh, A. V., Chandrasekar, V., Paudel, N., Laux, P., Luch, A., Gemmati, D., et al. (2023). Integrative toxicogenomics: advancing precision medicine and toxicology through artificial intelligence and OMICs technology. Biomed. Pharmacother. 163, 114784. doi: 10.1016/j.biopha.2023.114784
Sorokina, M., Merseburger, P., Rajan, K., Yirik, M. A., and Steinbeck, C. (2021). COCONUT online: collection of open natural products database. J. Cheminform. 13, 1–13. doi: 10.1186/s13321-020-00478-9
Sun, J., Ni, Q., Jiang, F., Liu, B., Wang, J., Zhang, L., et al. (2023). Discovery and validation of traditional chinese and western medicine combination antirheumatoid arthritis drugs based on machine learning (random forest model). BioMed Res. Int. 2023, 6086388. doi: 10.1155/2023/6086388
Suttithumsatid, W., Shah, M. A., Bibi, S., and Panichayupakaranant, P. (2022). α-Glucosidase inhibitory activity of cannabidiol, tetrahydrocannabinol and standardized cannabinoid extracts from cannabis sativa. Curr. Res. Food Sci. 5, 1091–1097. doi: 10.1016/j.crfs.2022.07.002
Szklarczyk, D., Gable, A. L., Nastou, K. C., Lyon, D., Kirsch, R., Pyysalo, S., et al. (2021). The STRING database in 2021: customizable protein–protein networks, and functional characterization of user-uploaded gene/measurement sets. Nucleic Acids Res. 49, D605–D612. doi: 10.1093/nar/gkaa1074
Vijayan, R. S. K., Kihlberg, J., Cross, J. B., and Poongavanam, V. (2022). Enhancing preclinical drug discovery with artificial intelligence. Drug Discovery Today 27, 967–984. doi: 10.1016/j.drudis.2021.11.023
Wani, M. C., and Horwitz, S. B. (2014). Nature as a remarkable chemist: a personal story of the discovery and development of Taxol®. Anticancer Drugs 25, 482–487. doi: 10.1097/CAD.0000000000000063
Xiaotong, C. H., Alice, L. Y., and Jiangang, S. H. (2022). Artificial intelligence and its application for cardiovascular diseases in Chinese medicine. Digital Chin. Med. 5, 367–376. doi: 10.1016/j.dcmed.2022.12.003
Yang, L., Xue, Y., Wei, J., Dai, Q., and Li, P. (2021). Integrating metabolomic data with machine learning approach for discovery of Q-markers from jinqi jiangtang preparation against type 2 diabetes. Chin. Med. 16, 1–12. doi: 10.1186/s13020-021-00438-x
Keywords: traditional Indonesian medicine, Jamu, artificial intelligence, machine learning, deep learning
Citation: Rustandi T, Prihandiwati E, Nugroho F, Hayati F, Afriani N, Alfian R, Aisyah N, Niah R, Rahim A and As-Shiddiq H (2023) Application of artificial intelligence in the development of Jamu “traditional Indonesian medicine” as a more effective drug. Front. Artif. Intell. 6:1274975. doi: 10.3389/frai.2023.1274975
Received: 09 August 2023; Accepted: 16 October 2023;
Published: 02 November 2023.
Edited by:
Mai Oudah, New York University Abu Dhabi, United Arab EmiratesReviewed by:
Gregory R. Hart, Institute for Disease Modeling (IDM), United StatesCopyright © 2023 Rustandi, Prihandiwati, Nugroho, Hayati, Afriani, Alfian, Aisyah, Niah, Rahim and As-Shiddiq. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tedi Rustandi, dGVkaXJ1c3RhbmRpMjZAZ21haWwuY29t
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.