
94% of researchers rate our articles as excellent or good
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.
Find out more
SYSTEMATIC REVIEW article
Front. Artif. Intell., 05 January 2024
Sec. Natural Language Processing
Volume 6 - 2023 | https://doi.org/10.3389/frai.2023.1270749
 Faiza Farhat1
Faiza Farhat1 Emmanuel Sirimal Silva2
Emmanuel Sirimal Silva2 Hossein Hassani3
Hossein Hassani3 Dag Øivind Madsen4*
Dag Øivind Madsen4* Shahab Saquib Sohail5
Shahab Saquib Sohail5 Yassine Himeur6M. Afshar Alam5Aasim Zafar7
Yassine Himeur6M. Afshar Alam5Aasim Zafar7This paper presents a comprehensive analysis of the scholarly footprint of ChatGPT, an AI language model, using bibliometric and scientometric methods. The study zooms in on the early outbreak phase from when ChatGPT was launched in November 2022 to early June 2023. It aims to understand the evolution of research output, citation patterns, collaborative networks, application domains, and future research directions related to ChatGPT. By retrieving data from the Scopus database, 533 relevant articles were identified for analysis. The findings reveal the prominent publication venues, influential authors, and countries contributing to ChatGPT research. Collaborative networks among researchers and institutions are visualized, highlighting patterns of co-authorship. The application domains of ChatGPT, such as customer support and content generation, are examined. Moreover, the study identifies emerging keywords and potential research areas for future exploration. The methodology employed includes data extraction, bibliometric analysis using various indicators, and visualization techniques such as Sankey diagrams. The analysis provides valuable insights into ChatGPT's early footprint in academia and offers researchers guidance for further advancements. This study stimulates discussions, collaborations, and innovations to enhance ChatGPT's capabilities and impact across domains.
The rapid advancements in artificial intelligence (AI) have led to the development of sophisticated language models that can understand and generate human-like text. One such notable AI language model is ChatGPT (https://openai.com/chatgpt), an autoregressive language model that uses deep learning techniques to generate coherent and contextually relevant responses to user inputs. Since its launch, ChatGPT has gained significant attention and adoption in various domains, includinrg content generation, healthcare, education, data science, accounting, finance, tourism, and customer support/assistance (Carvalho and Ivanov, 2023; Dowling and Lucey, 2023; Dwivedi et al., 2023a,b; Gupta et al., 2023; Ray, 2023; Sallam, 2023; Sohail et al., 2023a; Wood et al., 2023). The introduction of ChatGPT has also sparked discussions and debates surrounding its potential implications across various domains (Baumgartner, 2023; Ivanov and Soliman, 2023; Lo, 2023). Notably, issues related to ethical considerations and biases (Ray, 2023; Sohail et al., 2023b) and the impact of large language models on knowledge assessment (Farhat et al., 2023b; Gilson et al., 2023) have garnered attention in recent discourse. Scholarly investigation of ChatGPT has emerged as a critical area of research, aiming to understand its impact, applications, and future directions (Dave et al., 2023; Gupta et al., 2023; Ray, 2023; Roumeliotis and Tselikas, 2023; Sohail et al., 2023a).
To date, however, only a few authors have used bibliometric and scientometric methods to analyze ChatGPT. Khosravi et al. (2023) carried out an analysis of the broader chatbot literature, while Levin et al. (2023) used bibliometrics to explore publications on ChatGPT in the field of obstetrics and gynecology. Our study differs by focusing especially on ChatGPT publications and by considering the latest developments up until June 2023. In our view, bibliometric and scientometric analysis can provide valuable insights into the research landscape surrounding ChatGPT, including the evolution of research outputs, citation patterns, collaborative networks, application domains, and emerging research trends. By analyzing a comprehensive dataset of scholarly publications, this study aims to shed light on the scholarly footprint of ChatGPT and its influence in academia.
This study employs a multifaceted approach, utilizing bibliometric and scientometric methods to analyze the scholarly footprint of ChatGPT. Bibliometric analysis (see, for example Donthu et al., 2021) offers a quantitative approach to evaluate the scholarly impact of ChatGPT research. By carefully gathering and analyzing relevant data from the Scopus database, we address several pivotal research questions:
➢ Publication trends: How has research output related to ChatGPT evolved over time? What are the prominent publication venues and journals that feature research on ChatGPT?
➢ Citation analysis: How has ChatGPT been referenced in scholarly literature? Which papers, authors, countries, and journals have made significant contributions to the understanding and advancement of ChatGPT?
➢ Collaborative networks: Who are the key contributors and collaborators in the ChatGPT research landscape? What patterns of collaboration and co-authorship exist among researchers, institutions, and countries working on ChatGPT-related topics?
➢ Application domains: In which primary domains has ChatGPT found an application? How are researchers leveraging its capabilities in fields such as customer support, content generation, and virtual assistance?
➢ Future directions: Based on the keyword analysis related to ChatGPT's scholarly footprint, what emerging keywords and potential research areas for future research can be identified? What challenges and opportunities lie ahead in enhancing ChatGPT's capabilities and impact?
By addressing these research questions, this paper aims to provide a comprehensive and up-to-date analysis of ChatGPT's scholarly footprint. Our findings not only contribute to a better understanding of ChatGPT's influence in academia but also serve as valuable insights for researchers interested in the development and utilization of AI language models. Ultimately, through mapping its progress and identifying future trends, we aim to stimulate discussions, collaborations, and innovations that drive the continued advancement of ChatGPT and its applications across various domains.
By utilizing data from the Scopus database, we identified 533 relevant articles published between November 2022 and early June 2023 that focus on ChatGPT. The selected articles underwent thorough evaluation based on various criteria, including organization, country/region, journal, total citations, and keywords. This analysis revealed several key insights, as presented in our findings and discussion later on. For example, there has been a remarkable surge in scholarly publications related to ChatGPT, with 533 articles produced within a short span of 6 months. This indicates a thriving research interest and highlights the growing recognition of the potential applications of ChatGPT. Furthermore, the high collaboration rate of 88.91% among authors suggests a strong community of researchers working on ChatGPT, sharing ideas and resources to advance the field. In addition, we also uncover interesting details about the publication venues contributing to ChatGPT research, which evidences its impact in diverse scientific disciplines, the contributions of different countries to ChatGPT research, and top authors and institutions.
The remainder of this paper is organized such that Section 2 presents the methodology, and Section 3 provides an overview of the main findings. Section 4 discusses the findings in relation to the existing literature on ChatGPT. Finally, Section 5 concludes the paper by highlighting contributions, limitations, and directions for further research.
Figure 1 provides an overview of the methodology. On June 6, 2023, we used the Scopus database to search for articles that contain the search queries “chatgpt,” “ChatGPT,” or “Chat-GPT” in the title, abstract, or keywords. By employing the specified keywords, 555 articles were initially retrieved. Following the initial exclusion criteria, which involved omitting “errata,” the remaining count was reduced to 552 articles encompassing various types such as journal articles, reviews, notes, conference papers, letters, editorials, and short reviews. Subsequently, we applied the second exclusion criterion, which involved excluding articles in languages other than English, resulting in a final selection of 538 articles written in English. These chosen papers were then subjected to a meticulous analysis, during which the third exclusion criterion was employed to remove articles that did not exclusively focus on the topic of ChatGPT. The selected 533 articles are used for our bibliometric review study and evaluated using the following criteria: organization, country/region, journal, total citations, and keywords. We downloaded the complete records for bibliometric analysis and imported them into the Biblioshiny (Bibiliometrix) and VOSviewer software packages. Biblioshiny was employed for the overview analysis of the retrieved documents, relevant keyword analysis, and plotting the three-field Sankey Diagrams. VOSviewer software was used to illustrate various collaboration networks, perform citation and co-citation analysis, and identify the top five keywords along with their co-occurrence networks. Various indicators have been used in the literature for bibliometric analysis, including total article count, average citations per article (ACPA), total citation count, total link strength, and Hirsch index (H-index). These metrics are commonly used in bibliometric studies, with the H-index being a widely recognized measure of research quality and quantity for authors and research areas (Farhat et al., 2023a). ACPA is also widely accepted as a measure of research impact for individual works, authors, and publication outlets. Citation analysis is conducted to explore the scientific impact and themes of the study under consideration, and co-authorship and co-occurrence have also been investigated to analyze scientific collaboration. Three-field Sankey diagrams are also used to identify the relationship among three interrelated sets of values (Aria and Cuccurullo, 2017). All of these indicators have been taken into account in this bibliometric study.
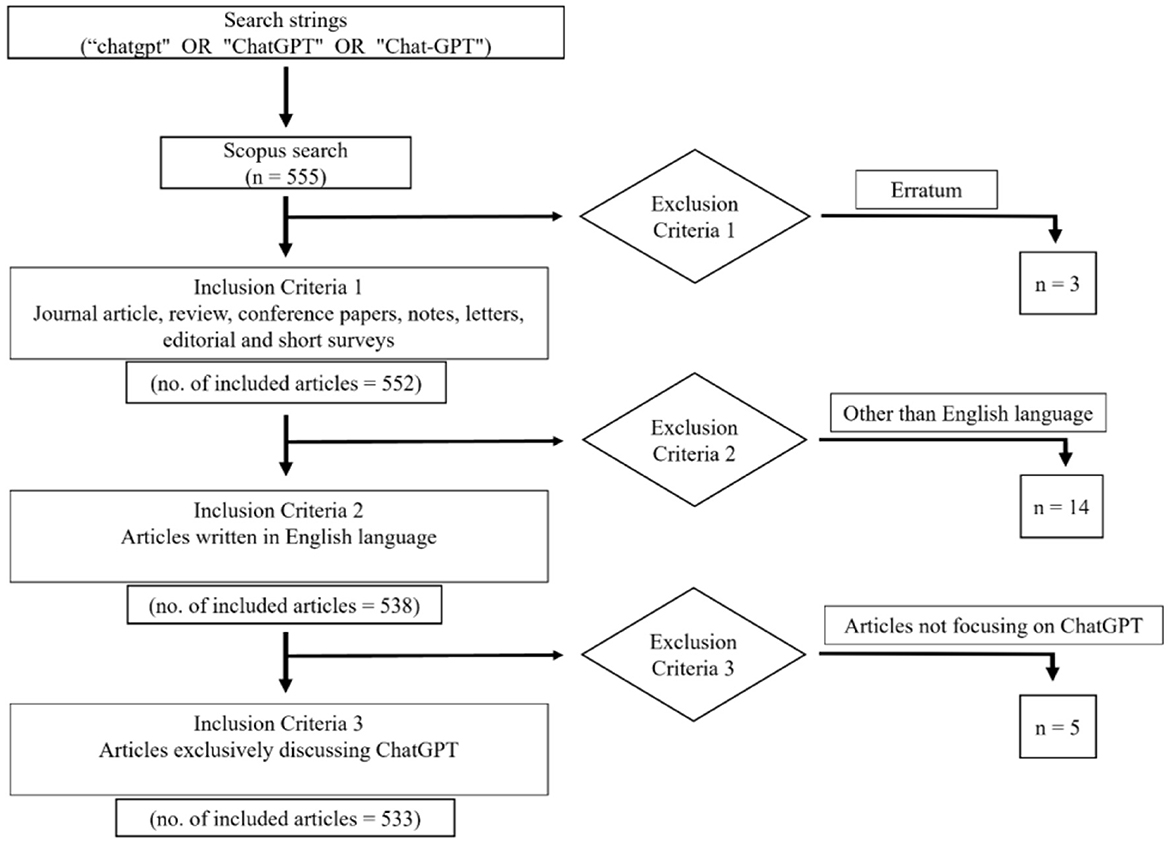
Figure 1. Methodology flow chart.
In conducting our bibliometric analysis of ChatGPT research, several critical assumptions underpin our interpretations. Firstly, we have considered Scopus as a foundational dataset for our work, and we assume the completeness and representativeness of our dataset, trusting that it adequately captures the vast landscape of publications in the field. Simultaneously, we acknowledge the inherent challenge of achieving absolute comprehensiveness and recognizing potential omissions or biases. Excluding other datasets, for example, Google Scholar, may cause the omission of a few articles. However, on the other hand, Scopus provides unbiased, reliable, and standard articles from reputed journals. Our analysis relies on the accuracy of metadata, presuming that author names, publication titles, and affiliations are error-free. Furthermore, we assume consistency in citation practices across publications and authors, understanding that variations can exist and impact citation-based analyses. The representativeness of citation metrics, temporal patterns, and research topics within the dataset is also assumed, acknowledging the potential for variations and heterogeneity. We also assume that the dataset is current, reflecting the contemporary state of the field. Finally, we operate under the assumption that the data used in our analysis adheres to ethical standards, with due consideration for potential biases or ethical concerns related to our data sources.
In light of these assumptions, a comprehensive analysis of ChatGPT research was conducted, encompassing 533 publications from 87 countries and 1,195 institutions. These publications, originating from 341 different sources, were authored by 1,434 individuals and received a total of 1,362 citations. Moreover, a total of 1,998 keywords were identified. The analysis involved employing the full counting approach, which focuses on elements connected to one another. This approach facilitated citation analysis and co-authorship analysis. Collaboration networks among authors, institutions, and countries were visualized using illustration maps. The size of the circles in these maps indicates the strength and frequency of collaborations between individuals and organizations. The connecting lines among these circles, termed “links,” represent the connections or relationships between various elements, such as authors, documents, or keywords. These links can represent co-authorships, co-citations, or co-occurrences of keywords in a bibliometric network. “Total Link Strength” is a metric used in network analysis and refers to the overall strength or significance of connections within a network. It measures the combined influence or importance of all the links or connections between nodes or entities in a network.
Additionally, citation maps displayed the connections and citations between different partners, with larger circles representing higher citation counts and stronger linkages. To analyze the relationships between keywords, a keyword map was generated using the complete counting method. To examine the interactions among three distinct interconnected variables, three-field Sankey diagrams were utilized. These diagrams enable the analysis of relationships involving authors, author's keywords, and keywords. Similarly, the interplay between country, publication source, and keywords, as well as author, title-term, and source, were also investigated using these diagrams. Furthermore, the research trends and popular topics in ChatGPT research were explored through the identification of significant research terms, word cloud analysis, and examination of keyword co-occurrence. This map grouped related keywords together and assigned equal weight to each co-occurrence link. Consequently, terms with higher frequency were represented by larger circles in the map.
We begin by providing a comprehensive overview of the research conducted on ChatGPT during the period of 2022–2023. In a short span of only 6 months (November 2022 to early June 2023), a total of 533 documents were produced from 341 sources from 87 different countries involving 1,434 authors, indicating a thriving research interest (see Supplementary material). The total corpus involved 1,434 authors, with 159 of them contributing to single-authored documents. This represents a significant collaboration rate of 88.91%, highlighting the collaborative network within the research area. This collaboration suggests that there is a strong community of researchers working on ChatGPT, and that they are sharing ideas and resources to advance the field. Among the documents, 420 were single-country contributions, while 113 demonstrated collaboration between multiple countries. The involvement of 1,195 institutions highlighted diverse organizational contributions.
This section provides an overview of the distribution of document types represented in ChatGPT research. Both traditional documents (e.g., articles, reviews, notes, and conference papers) and other documents, such as editorials and letters, are often not subject to peer review. Out of the total of 533 publications obtained, a considerable portion comprises empirical papers, representing 36.77% (196 articles) of the corpus. Letters constitute 19.51% (104 articles), editorials make up 18.57% (99 publications), and notes account for 14.55% (Figure 2). Interestingly, it is observed that besides empirical papers, a substantial portion of the ChatGPT corpus consists of letters, notes, and editorials, making up 52.63% of the total publications. On the other hand, the number of review articles published was relatively low. Figure 3 provides an overview of the thematic subject categories of ChatGPT research. It can be seen that the most frequent categories are medicine, social sciences, computer science, and engineering.
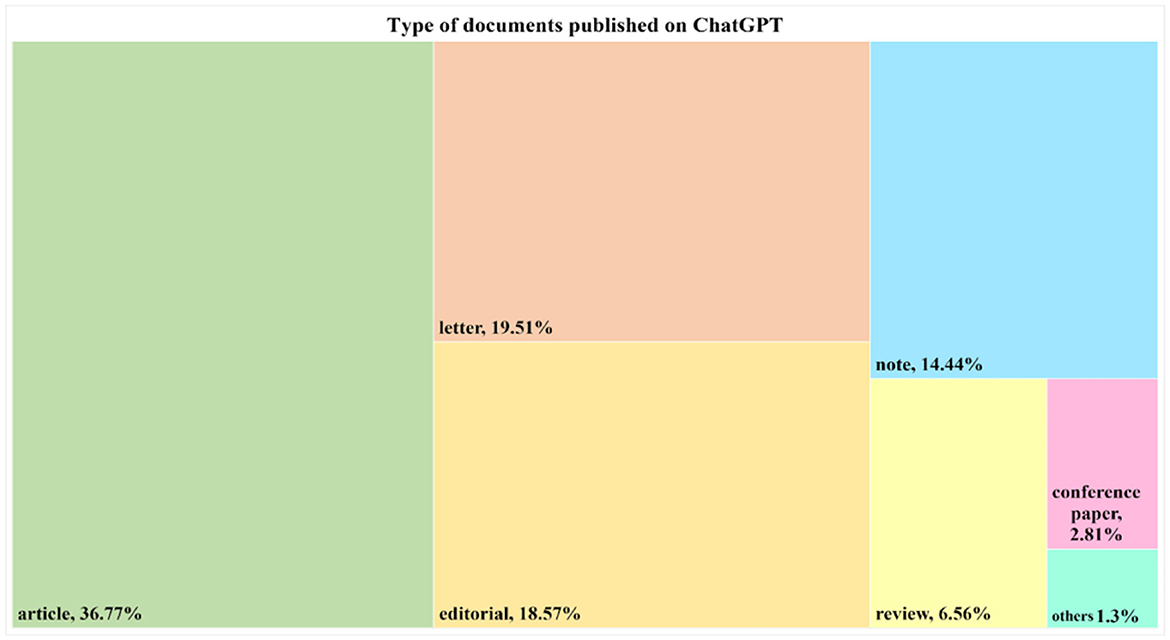
Figure 2. Tree map representing the type of documents published on ChatGPT.
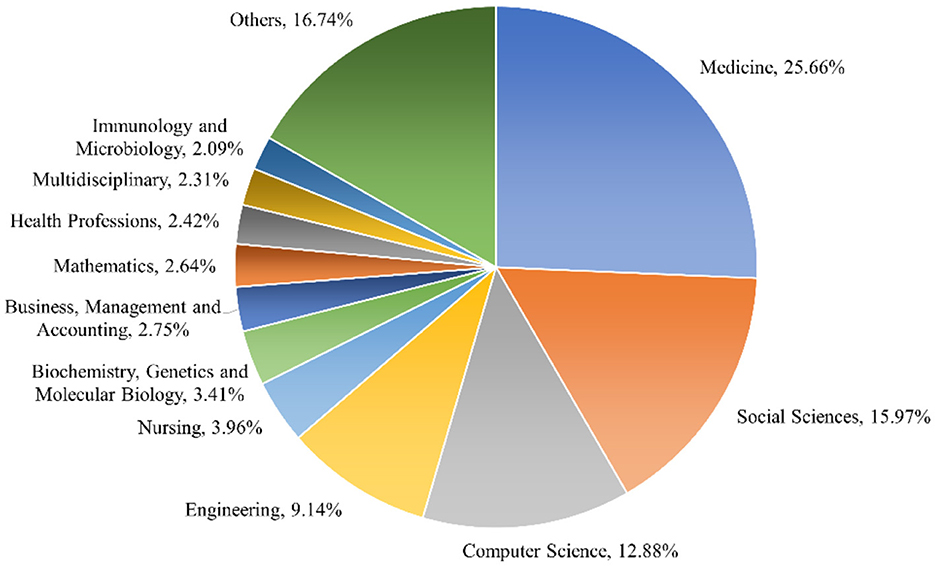
Figure 3. Thematic subject categories of research on ChatGPT.
There are 533 publications relating to ChatGPT in 341 different journals. The top 10 journals account for 17.63% of the corpus and 44.65% of the total citations. As Table 1 shows, Annals of Biomedical Engineering has thus far published the most articles (28), followed by Nature (17) and Library Hi Tech News (12). Nature was the most cited journal (367 citations), followed by Radiology (100) and Science (93). Based on their H-index, Nature ranks first (1,331), Radiology ranks second (320), and Annals of Surgical Oncology ranks third (192).
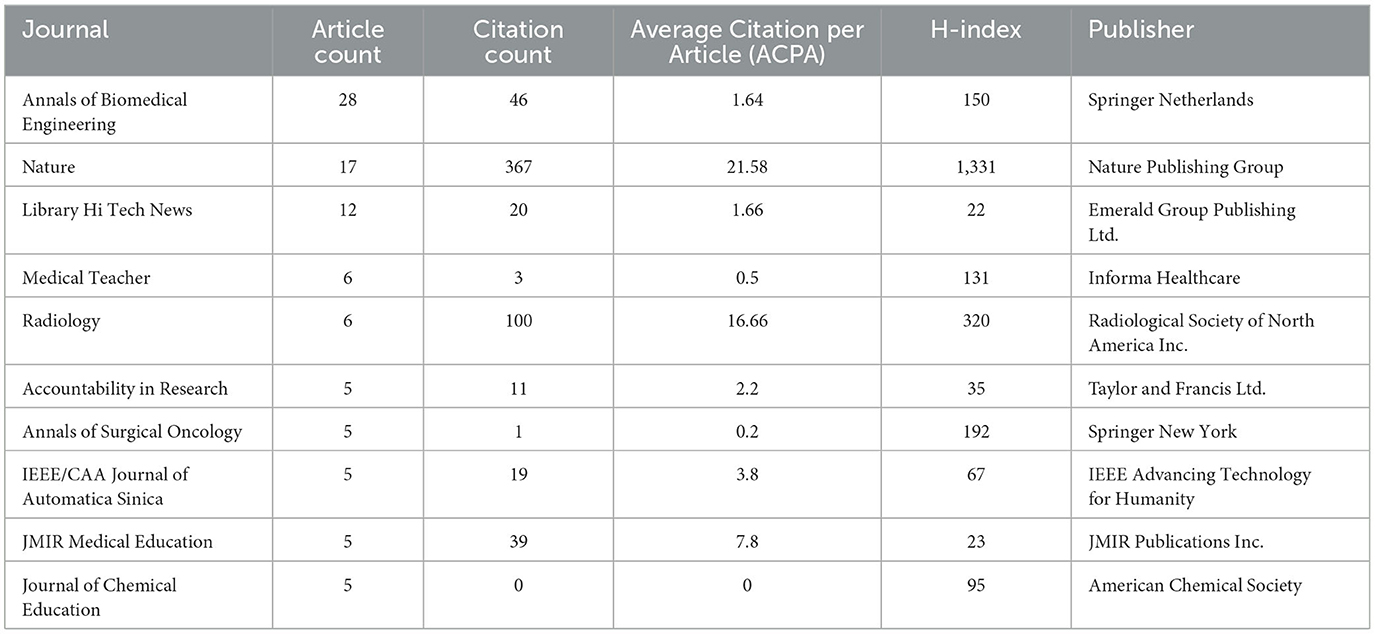
Table 1. Top 10 most relevant journals based on article count.
A total of 87 different countries have contributed to research on the topic of ChatGPT. Table 2 displays the top 10 countries on the basis of article count. The USA ranked first in terms of publications, with 173 articles, accounting for over 32.54% of the entire corpus. India (48 articles, 9%) and the UK (47 articles, 8.81%) rank second and third, respectively, in terms of contribution. In addition, the USA has a more considerable global academic impact than any other country, as demonstrated by the highest citation count (391). The UK ranks second in terms of citations with 153. Moreover, countries such as Australia, China, and Italy have made significant contributions, with citation counts of 76, 73, and 67, respectively.
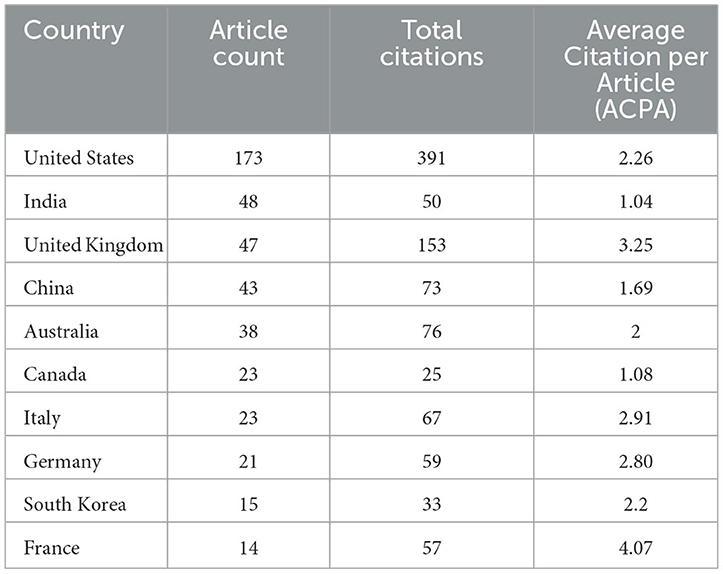
Table 2. Top 10 most relevant countries based on article count.
Table 3 presents the top 10 authors and their corresponding article metrics. Wang F.Y. from the Institute of Automation Chinese Academy of Sciences in China stands out with the highest article count of 9 and a total of 23 citations. Following closely is Wu H. from Duke University School of Medicine in the USA, with seven articles and 16 citations. Interestingly, Kleebayoon A. from Joseph Ayo Babalola University in Nigeria and Wiwanitkit V. from Chandigarh University in India have published 6 articles each but have not received any citations. On the other hand, authors with a lower article count have also garnered significant citation numbers. For instance, Ali M. J. from L. V. Prasad Eye Institute in India, Lu Y. from Zhengzhou University in China, and Gu S. from Duke University School of Medicine in the USA have achieved 8, 10, and 15 citations, respectively, with just five articles each. Among the top 10 authors, three authors represent China and three represent the USA, while two hail from India.
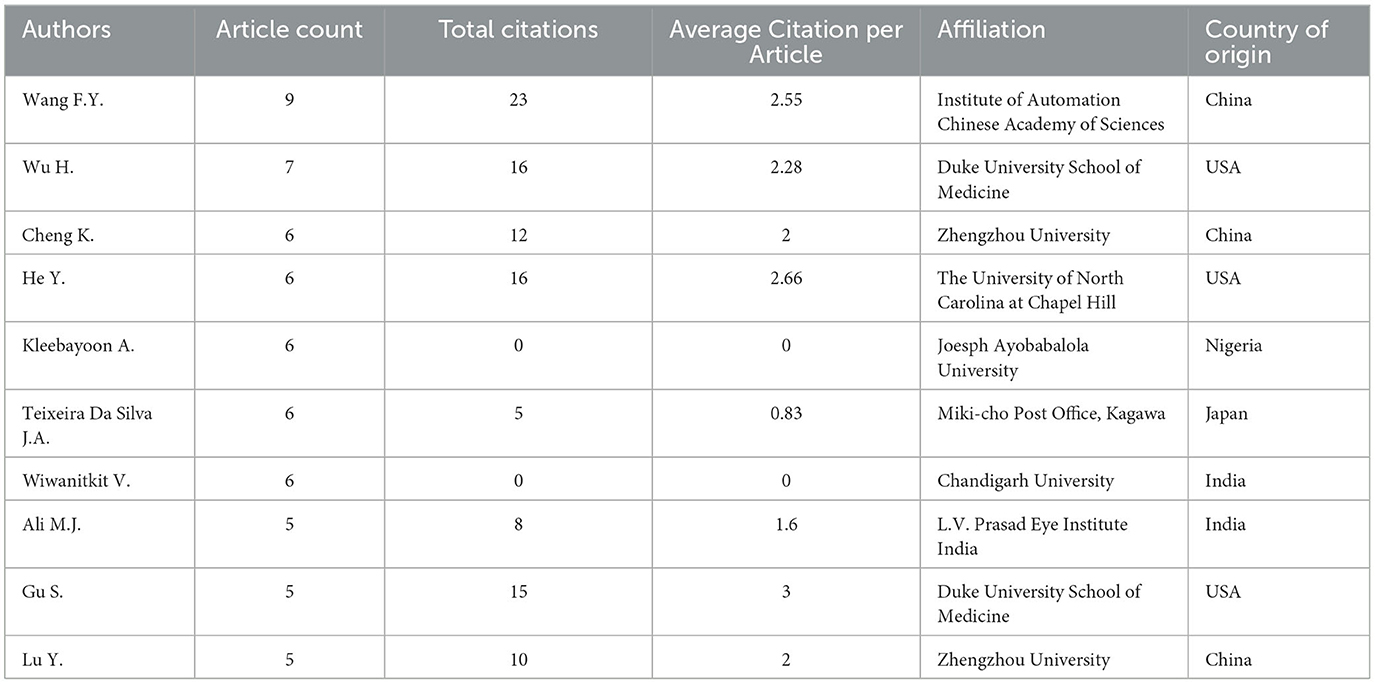
Table 3. Top 10 most relevant authors based on article count.
A total of 1,195 institutions have contributed to the 533 publications, with Duke University participating in the most papers (14). Chinese Academy of Sciences (9) and Chandigarh University (8) make up the top three organizations based on article count (Table 4). Duke University has received the most citations, cited 32 times, followed by Chinese Academy of Sciences and the University of Chinese Academy of Sciences with 23 citations each. In terms of average citations per article, the University of Chinese Academy of Sciences takes the top position with 3.28, followed by the Beijing Sport University with 2.66. Among the top 10 institutions, five institutions are from China, representing the highest contribution to the field, and two are from the USA.
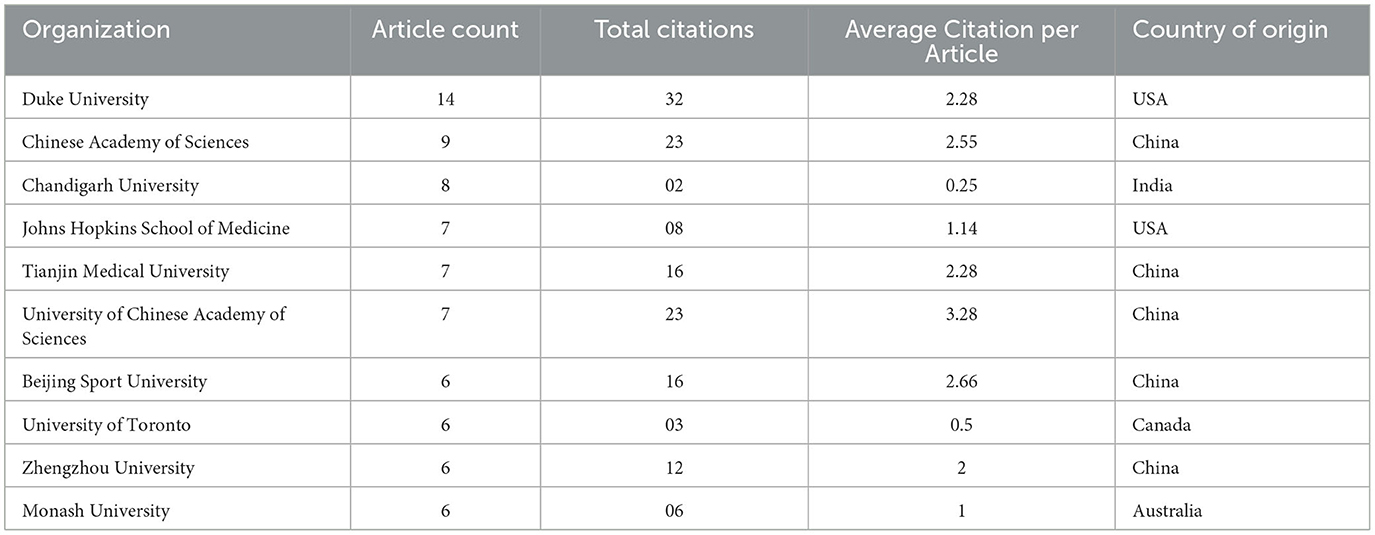
Table 4. Top 10 most relevant Institutions based on article count.
When the citation network analysis was carried out in VOSviewer, it was observed that 34 articles have at least 10 citations, 15 articles have 20 citations, and only five articles have received 50 citations (Figure 4A). The size of the circle denotes the number of citations, and the connecting lines represent their citation network. The larger the circle larger the citation count of an article, and the more connecting lines reflect that the articles are citing another article or cited by other articles (Van Eck and Waltman, 2010). A total of 22 articles organized in 8 different clusters are linked among each other with 28 links (Figure 4B). The largest citation network is associated with Sallam (2023) with 13 links, followed by Biswas (2023) and Dwivedi et al. (2023a) with five links independently. The most cited document in the field of ChatGPT research is the editorial titled “ChatGPT is fun, but not an author” by Thorp (2023), with 93 citations. The second most cited document is a note titled “ChatGPT listed as an author on research papers: many scientists disapprove” by Stokel-Walker (2023), with 88 citations. These two influential works have significantly raised awareness and initiated critical conversations about the ethical implications of attributing authorship to AI language models.
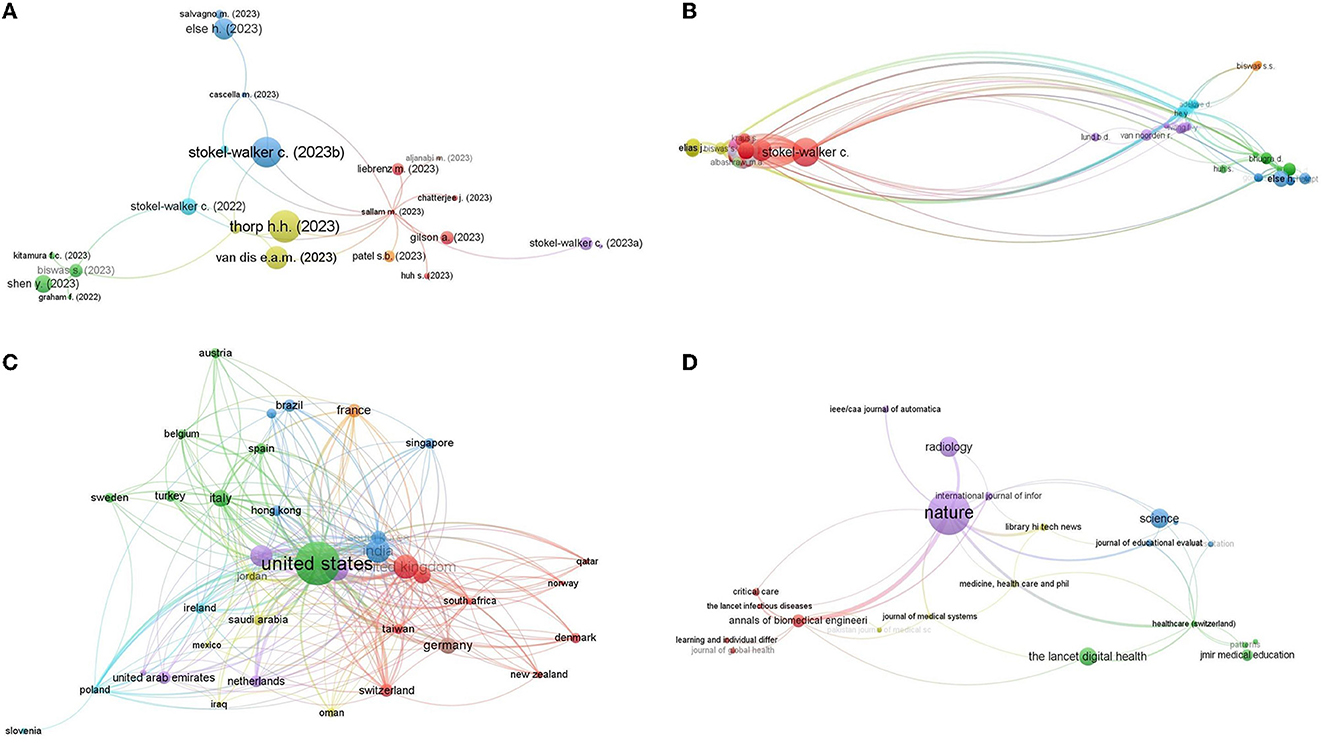
Figure 4. (A) Most cited articles and their citation network. (B) Most cited authors and their citation network. (C) Most cited countries and their citation network. (D) Most cited journals and their citation network.
The top 20 most cited documents are listed in Table 5. Of the top 20 most cited documents, eight are notes, six are editorials, four are articles, and only two are reviews. The only research article that is among the top 10 most cited documents is “How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment” (Gilson et al., 2023), otherwise it is either a note or editorial that forms the top 10 most cited document list. Seven of the top 20 most cited documents have been published by Nature, while Radiology and The Lancet Digital Health each have published 3.
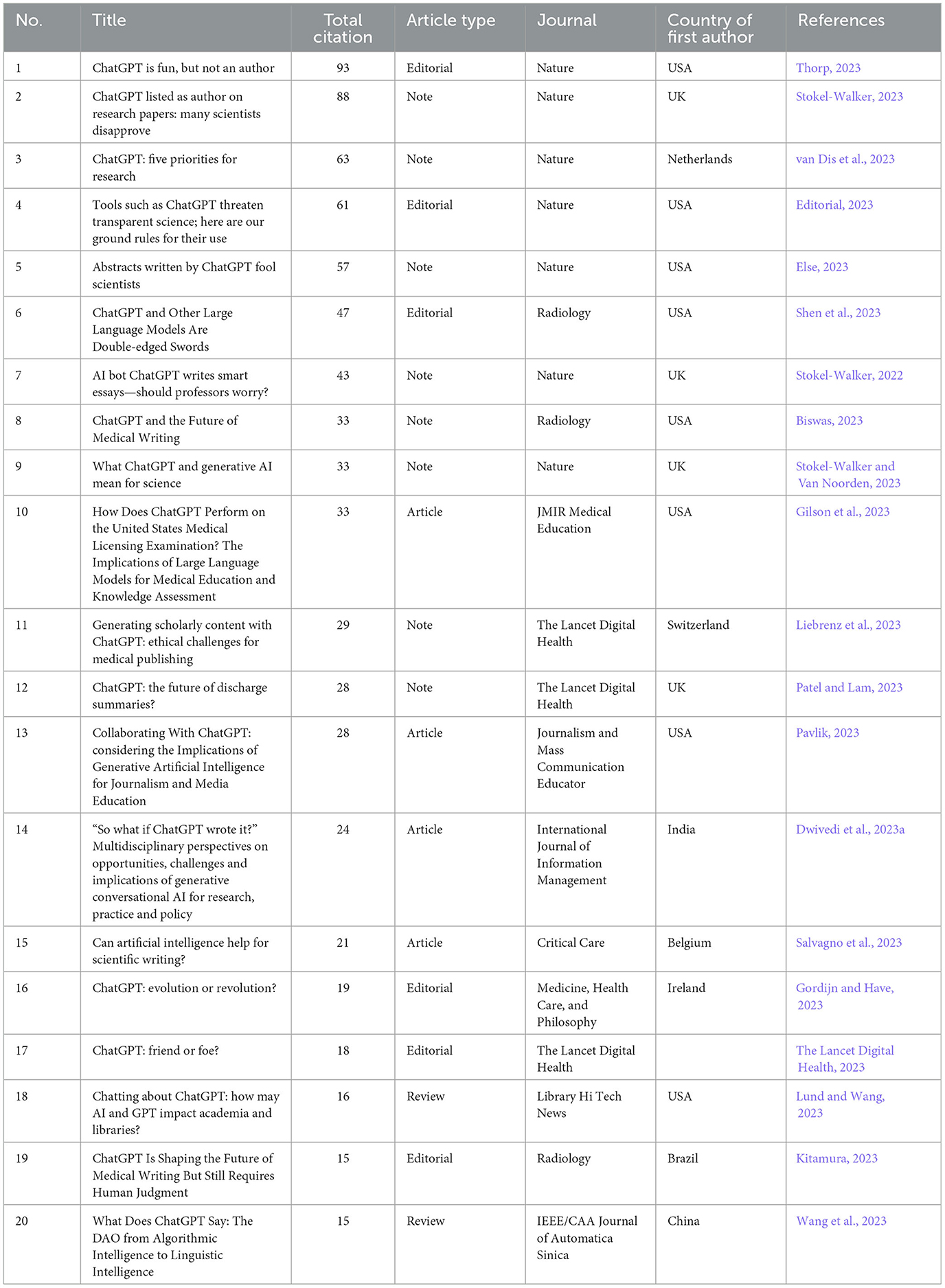
Table 5. Top 20 most cited documents on ChatGPT.
The citation analysis of authors visualizes the most cited authors and their citation networks. It is observed that 187 authors have at least 10 citations. Stokel-Walker, C. is the most cited author, followed by Thorp, H. H., Bockting, C. L., and Else, H. with 93, 63, and 57 citations, in respective order (Figure 4B). Besides having the most citations, Stokel-Walker, C. has the largest citation network with 93 citing partners. The second largest citation network is associated with Biswas, S. with 88 different citing partners. The most frequent citing partners are Wu, H. and Cheng, K., who cited each other at least 13 times, the next in line are Wu, H. and Lu, Y., having 12 link strength.
The citation analysis of countries showed that a large number of countries are actively citing each other's work. There are 38 countries that have received at least 10 citations, 29 countries that have received at least 20 citations, and 10 countries that have received at least 50 citations. The citation network of countries is very dense, meaning that there are a lot of connections between countries (Figure 4C). The most citing partners are the United States and the United Kingdom, with a link strength of 31. The United States and India are the second most citing partners, with a link strength of 30. The United States and Australia are the third most citing partners, with a link strength of 25. In terms of citation network, the United States has the largest network, with 35 links. India and China are tied for second place, with 30 links each.
The citation network analysis of journals revealed that the largest citation network consisted of 22 journals citing each other frequently (Figure 4D). Twenty-first journals have at least 10 citations. The most cited journal on the topic of ChatGPT is Nature, with 367 citations, followed by Radiology, with 100 citations, and Science, with 93 citations. Nature and Annals of Biomedical Engineering are the most frequent citing partners (Link strength 6). Afterward, Nature, along with Healthcare, Radiology, and Library Hitech News, makes the next frequent citing partners citing each other at least four times.
Of the 118 authors who have published at least two articles on ChatGPT, only 29 have collaborated with each other. These 29 authors are divided into five clusters, with the largest cluster (cluster 1) consisting of 10 authors. The second largest cluster (cluster 2) consists of eight authors, followed by cluster 3 (five authors), cluster 4 (four authors), and cluster 5 (two authors; Figure 5). The two most collaborative authors, Wang, F. Y. and Wang, X, belong to cluster 1 with 11 (17 link strengths) and 9 (14 link strengths) collaborations, respectively. Afterward, Li, Z., with a link strength of 13 and 9 collaboration, contributed to the 5th cluster. All eight authors of green cluster Wu, H., Quo, Q., Hey, Y., Lu, Y., Gu, S, Cheng, K, Li, C and Xie, R., have eight collaborations each. Wu, H with Cheng, K., and Hey, Y. are the most frequent collaborating partners (Link strength). Wu, H. and Gu, S. are the second most collaborative partners with a link strength of 5.
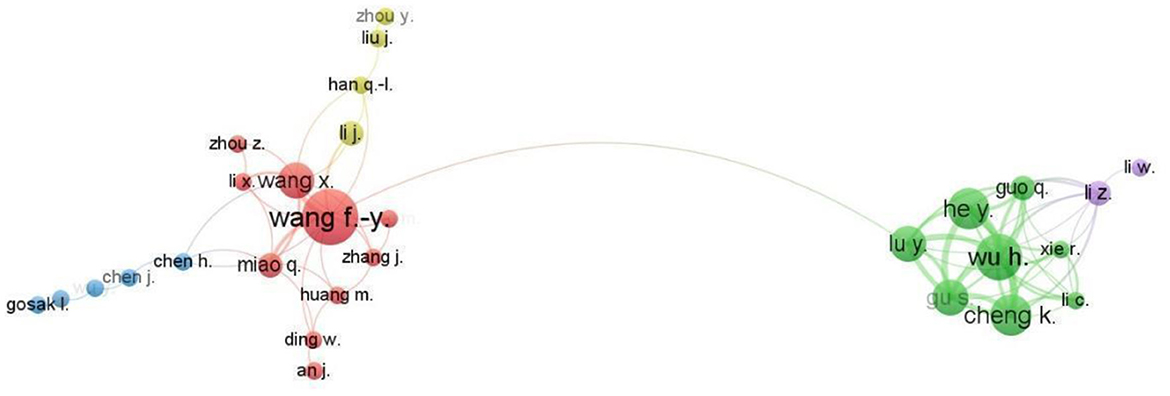
Figure 5. Largest collaboration network of authors.
Out of 1,195 institutions around the world, 53 have published at least two articles on ChatGPT. The largest collaborating network consists of only nine institutions, six from China and three from the United States (Figure 6). All nine institutions have an equal number of collaborating links, with eight each. However, Duke Molecular Physiology Institute, Duke University School of Medicine, Durham, NC, United States, has published the most articles on ChatGPT in collaboration with eight different institutions. It is followed by the Department of Graduate School, Tianjin Medical University, Tianjin, China, the Department of Intensive Care Unit, The Second Affiliated Hospital of Zhengzhou University, Henan, Zhengzhou, China, and the School of Sport Medicine and Rehabilitation, Beijing Sport University, Beijing, China, which have published five articles each.
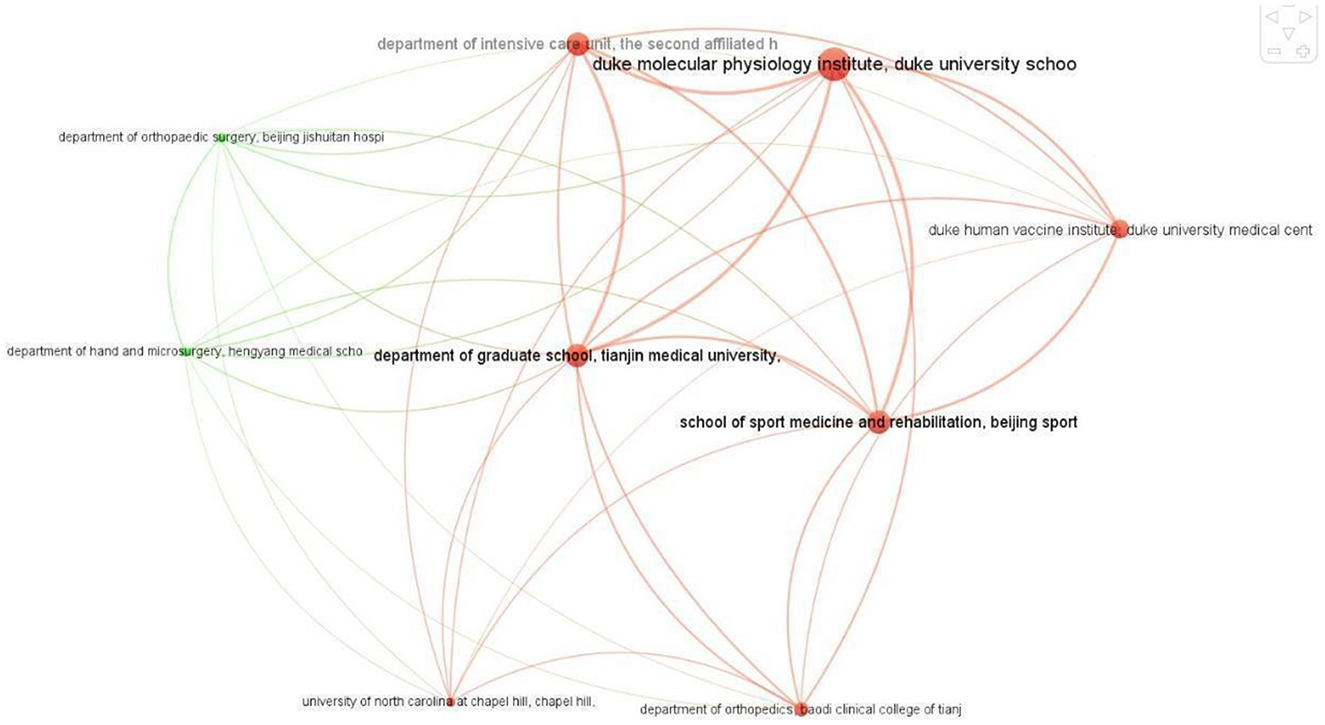
Figure 6. Largest collaboration network of institutions.
A total of 56 countries have published at least two papers on ChatGPT, and 53 countries have collaborated with each other on these papers. The United States has the most collaborating partners (35 countries), with China being the most frequent collaborator (link strength of 12; Figure 7). The United Kingdom, India, Australia, and Italy are also frequent collaborators (link strength of 7 each). Australia and the United Kingdom have the second most collaborating partners (29 countries each). Afterward, India and Nigeria, and India and Cambodia are the most frequent collaborators (link strength of 6 each). The United States also leads in single-country publications (SCP) with 75 articles, followed by China and India with 25 and 22 articles, respectively (Figure 8). China has the highest number of multiple-country publications (MCP) with 12 articles, followed by the United States with nine articles. The United Kingdom and Italy have 7 and 6 MCPs, respectively.
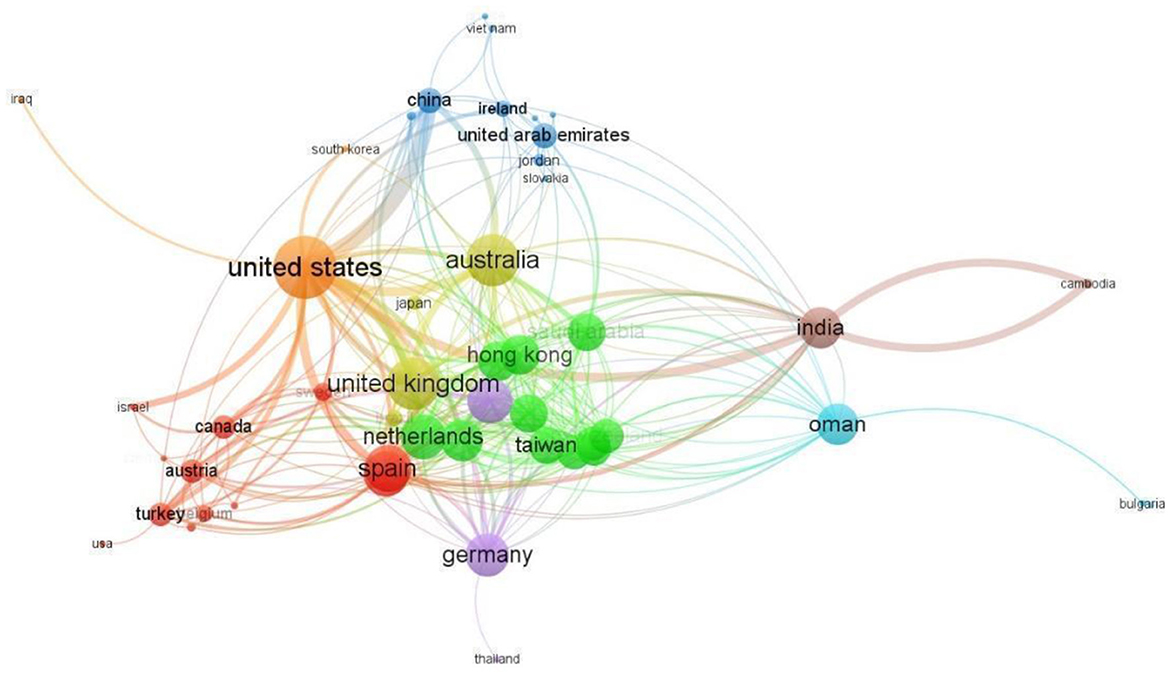
Figure 7. Largest collaboration network of countries.
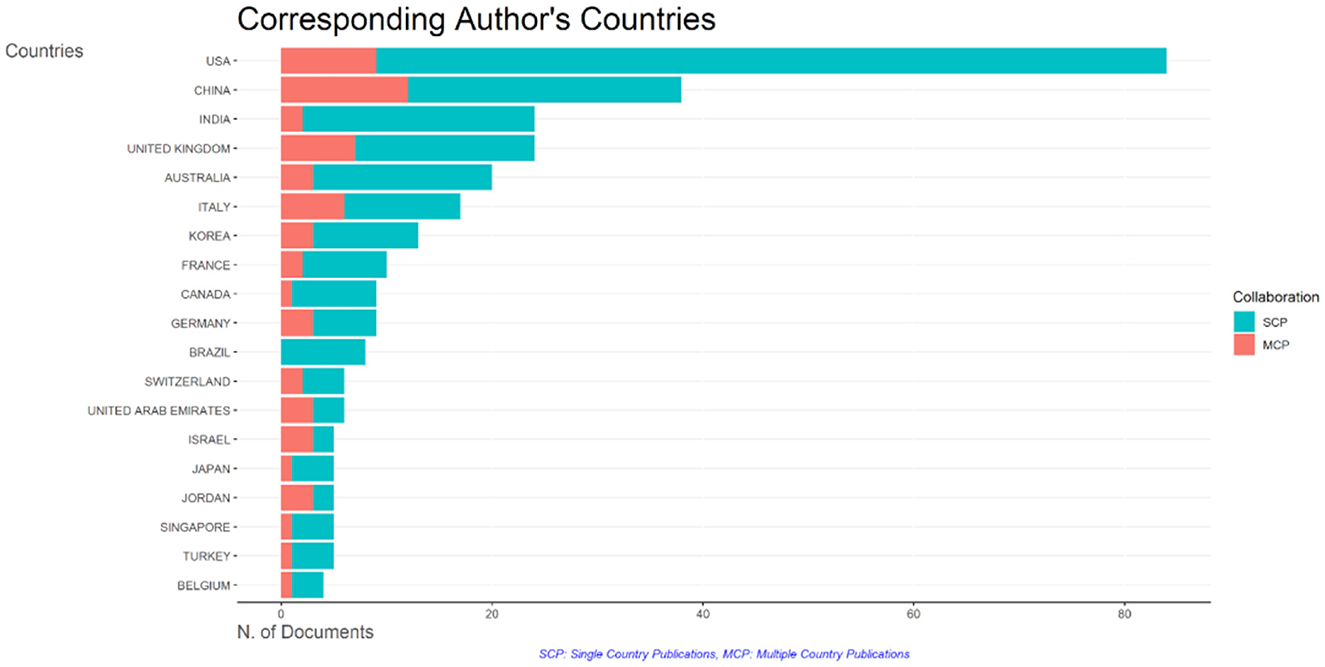
Figure 8. Graph representing single country and multiple country publications on ChatGPT.
We found a lot of inter-disciplinary and intra-disciplinary collaboration in ChatGPT research. The data also indicate that there is much institutional collaboration exploration. The institutions with the most collaboration tend to be located in countries with strong ties with other countries in research and education, such as Australia, Canada, and the United States. These institutions also have a diverse and global faculty and student body, which facilitates cross-cultural and cross-national exchanges.
A Sankey diagram, also known as a three-field plot, is used to visualize the flow of values from one set to another. These plots are used to depict the relationships and data transitions between three distinct categories, providing a three-dimensional perspective on the evolution and exchange of information among these categories. These graphical representations showcase data from three distinct sources, using lines to represent the links between the fields. The width of these lines illustrates the quantity or strength of the connections. Figure 9 illustrates the relationship among the author's country, sources of their publications, and keywords chosen by them. The analysis reveals that authors from the United States have published their articles in 12 different journals, indicating a wide range of publication sources compared to other countries. In contrast, Chinese authors predominantly publish their work in three journals: Annals of Biomedical Engineering, IEEE Transactions on Vehicles, and IEEE/CAA Journal of Automatica Sinica. Canadian and Australian authors exhibit the next highest levels of publication diversity, with seven and six different journals, respectively.
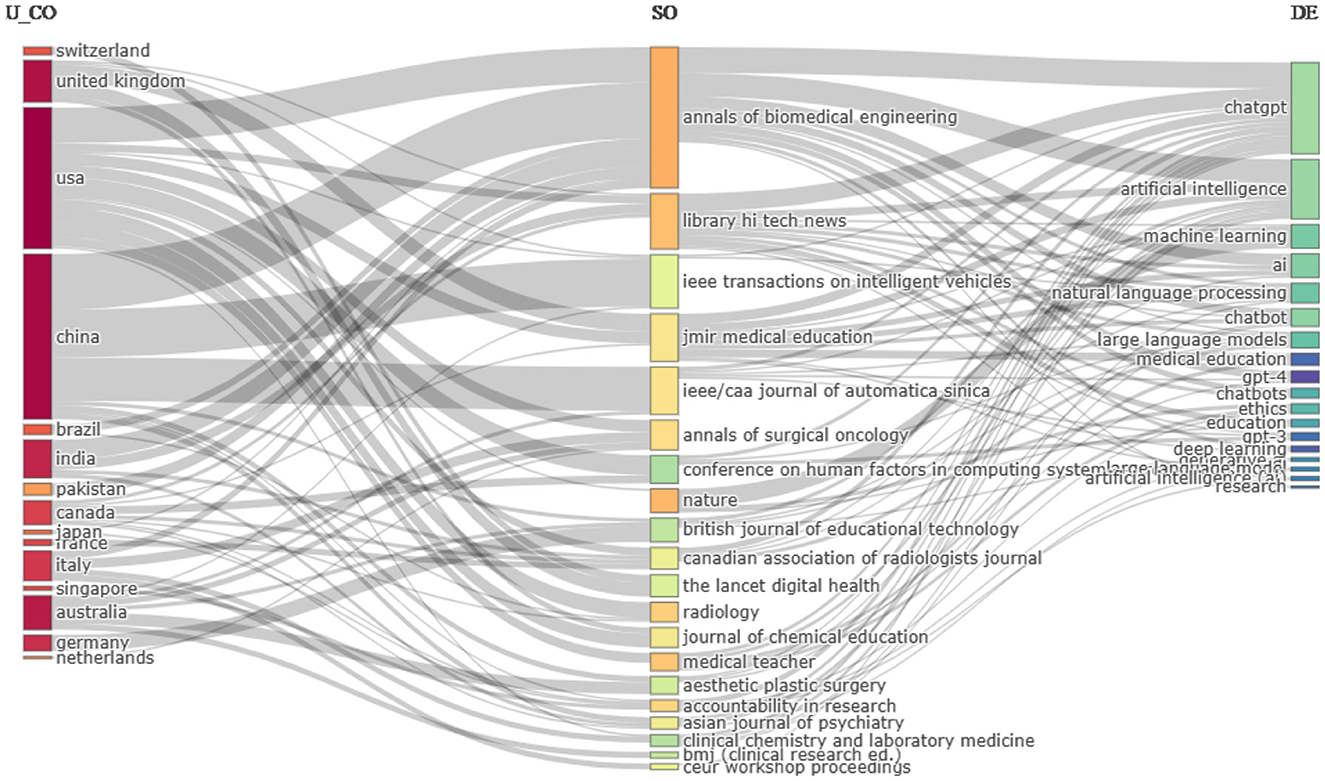
Figure 9. Three-field plot of countries, journals, and author's keywords. AU_CO, Author's countries; SO, source; and DE, Author's keywords.
Annals of Biomedical Engineering is a favored choice among authors from seven different countries, with the majority of publications coming from China, the United States, and India, in respective order. The most commonly selected keywords by authors include “ChatGPT,” “artificial intelligence,” “natural language processing,” “large language model,” “chatbot,” and “machine learning.” Notably, the most diverse keyword is “ChatGPT,” followed by “artificial intelligence,” which is highly popular among authors as well as sources. Among the journals, Library Hi Tech News has indexed 13 out of the top 20 most frequently used author's keywords, whereas Nature has only three keywords in common with the author's keywords, viz., “machine learning,” “ethics,” and “education.”
Figure 10 shows the relationship between author keywords, authors, and Keywords Plus. Author keywords are chosen by authors, while Keywords Plus is automatically chosen by journals based on the frequency of cited and referenced title words. It is observed that author keywords and Keywords Plus are quite different from each other. For example, “ChatGPT” is the most frequently used keyword by authors, while Keywords Plus tends to favor “artificial intelligence.” There are some common keywords in both categories, but their frequencies vary. For example, “ChatGPT” is a favorite choice of authors, but it is one of the least appearing according to Keywords Plus. Notably, authors such as Wu, H., Cheng, K., Hey, Y., Gu, S., and Lu, Y. share common keywords that fall under both keyword categories, viz., “artificial intelligence,” “chatbot,” and “chatbots.”
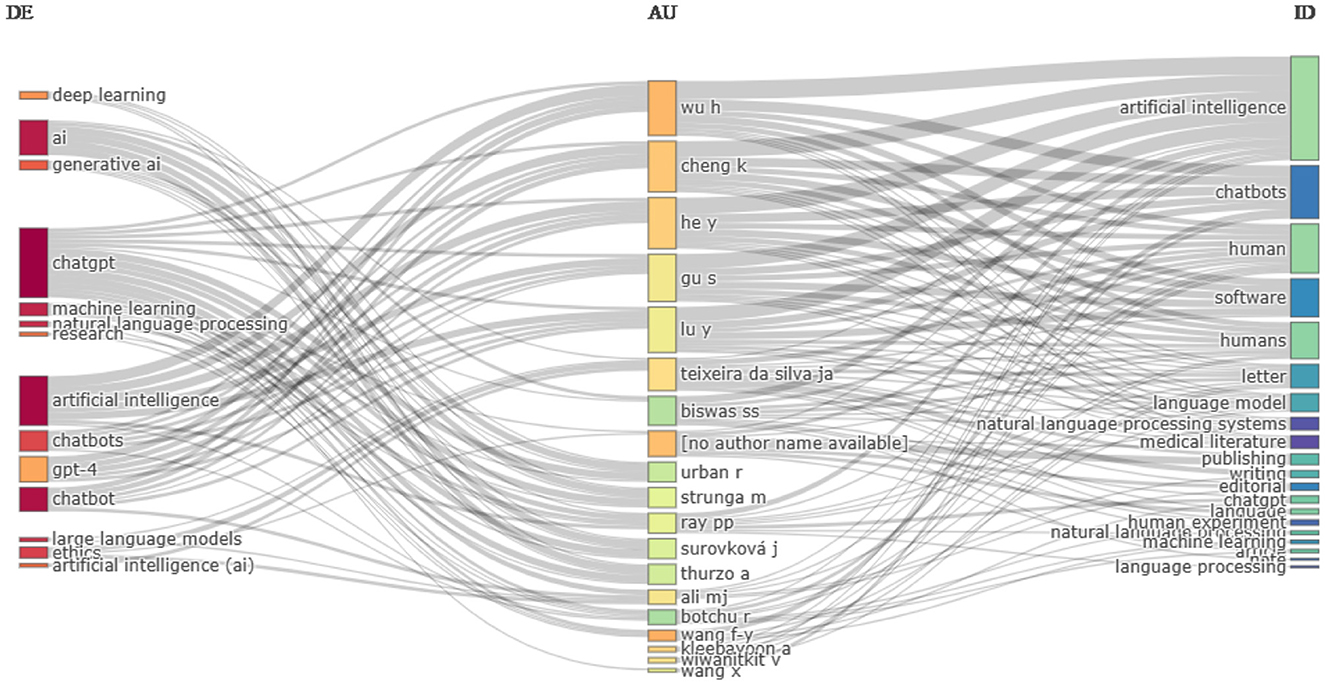
Figure 10. Three-field plot of Keyword Plus, authors and author's keywords. DE, Author's keywords; AU, Author; and ID, Keyword Plus.
The three-field plot Sankey diagram (Figure 11) shows the relationship between the author, title-term used by them, and sources. It is obvious that “ChatGPT” is the most widely used title term by the authors as well as the most widely accepted title term of journal publications. Terms like “Intelligence” and “potential” in the titles of publications show the trending research topics related to the ChatGPT. Apart from machine learning-related terms such as “AI,” “language,” “model,” “artificial,” and “intelligence,” the most frequent title terms are “medical,” “academic,” “writing,” “education,” “medicine” etc. reflecting the recent thrust area of ChatGPT research. These title-terms are very frequently accepted by top journals like Nature, Annals of Biomedical Engineering, Radiology, and Library Hi Tech News.
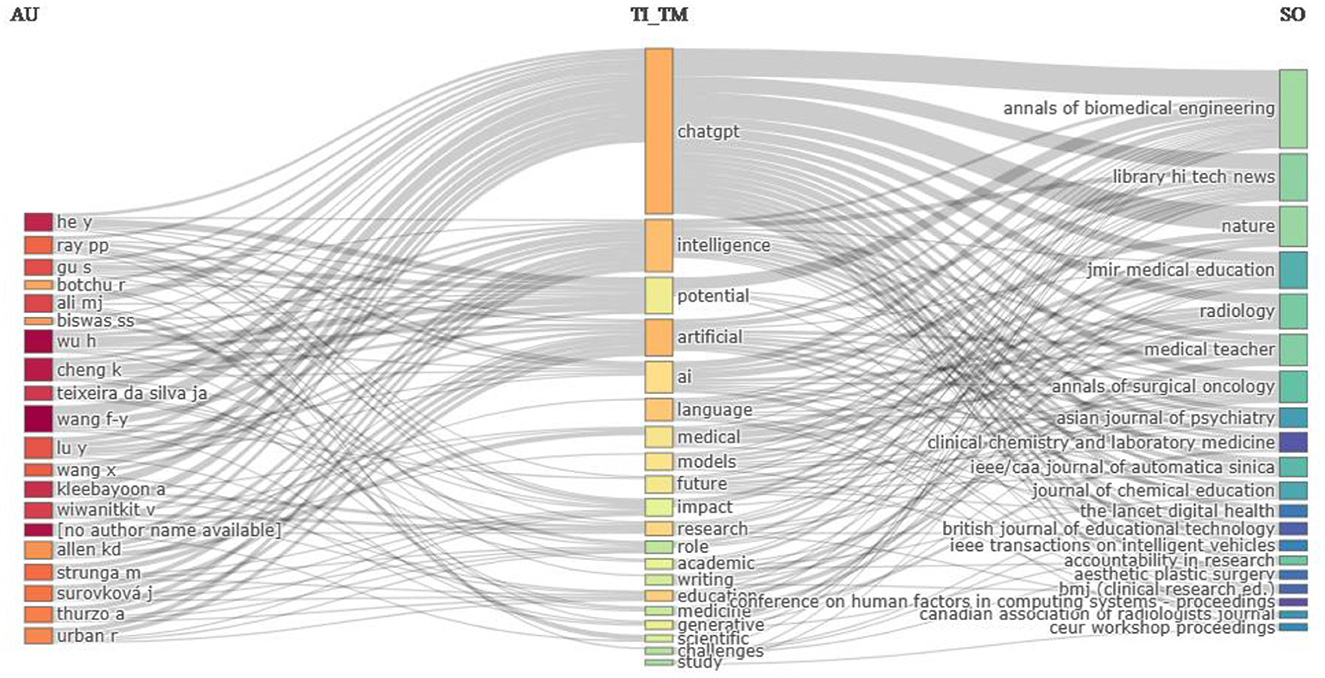
Figure 11. The three-field plot of authors, title-terms, and sources. AU, Author; Tl_TM, Title-term; and SO, Source.
For keyword analysis, the most relevant keywords are retrieved using Bibliometric software package. As Figure 12 shows, the most occurring keyword is “artificial intelligence” with 205 occurrences, followed by “human,” “humans,” “language,” and “chatgpt” with 151, 94, 55, and 39 occurrences, respectively. Other keywords with high occurrences are “article,” “natural language processing,” “publishing,” and “writing.” Additionally, a word cloud of the most frequent keywords is plotted to illustrate the highly used terms in the field of ChatGPT research (Figure 13).
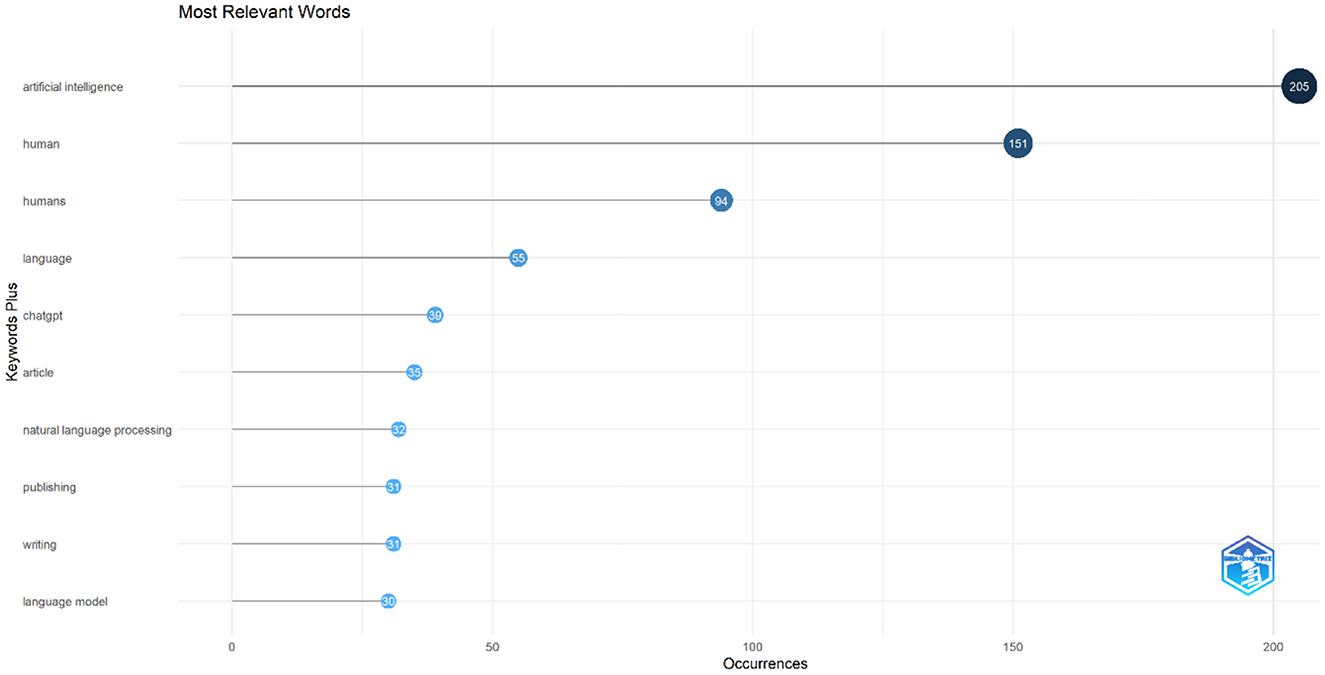
Figure 12. Most relevant keywords and their occurrences.

Figure 13. Word cloud of keywords on ChatGPT.
To conduct co-occurrence analysis of keywords, a threshold of at least 10 occurrences was chosen, resulting in a selection of 49 keywords that appeared at least 10 times. Synonyms of the keywords were excluded, and network maps were generated to visualize the top five most frequently occurring keywords and their co-occurring keywords. It was observed that “artificial intelligence” (Figure 14 K1) and “chatgpt” (Figure 14 K2) were the two most commonly co-occurring keywords in ChatGPT literature, each appearing alongside 47 distinct keywords. The third and fourth most frequently co-occurring keywords were “human” (Figure 14 K3) and “natural language processing” (Figure 14 K4), with co-occurrence network strengths of 46 and 43, respectively. “Machine learning” secured the fifth position, co-occurring with 39 different keywords in the network (Figure 14 K5).
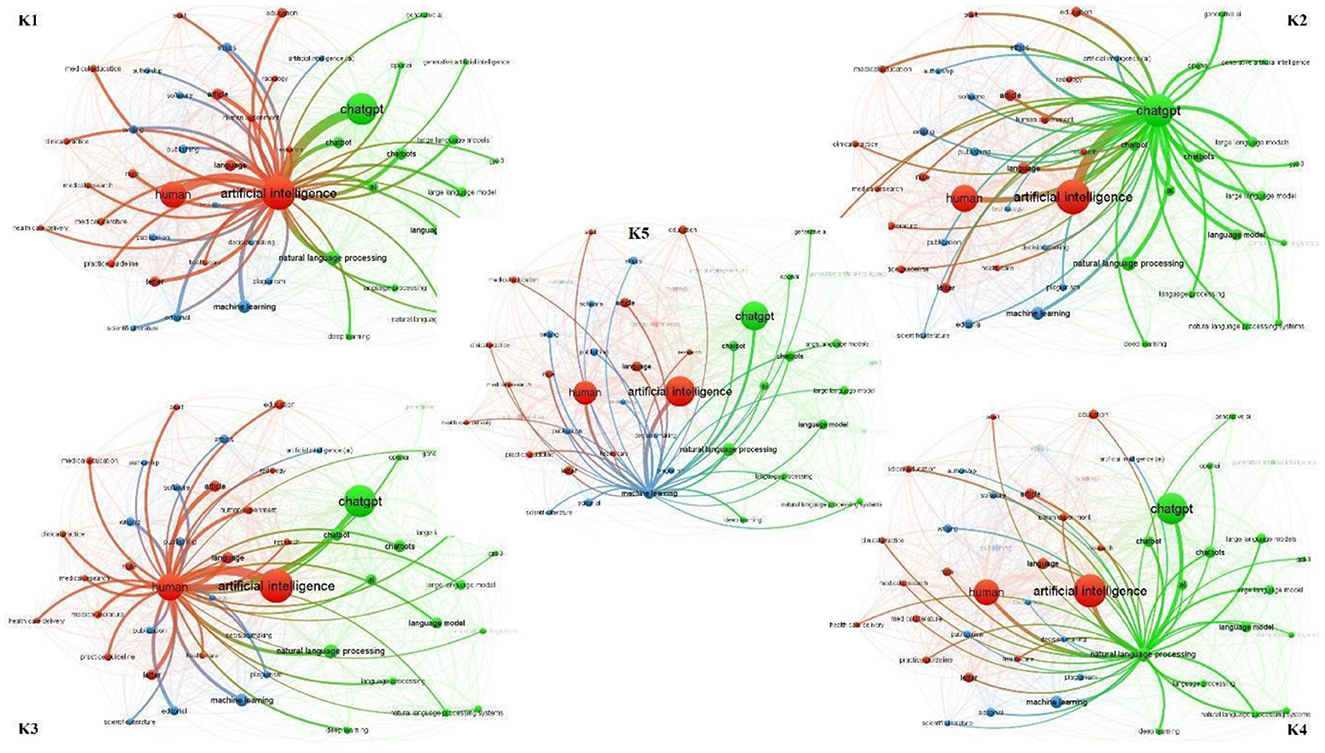
Figure 14. Top 5 most occurred keywords and co-occurred keyword their network.
Furthermore, Table 6 presents the top 10 pairs of keywords with the highest frequency of co-occurrence. The pair “artificial intelligence” and “chatgpt” exhibited the most frequent co-occurrence, appearing together 117 times. The second most frequent pair was “artificial intelligence” and “human,” which co-occurred 102 times. Additionally, “human” and “chatgpt” were found to co-occur 38 times.
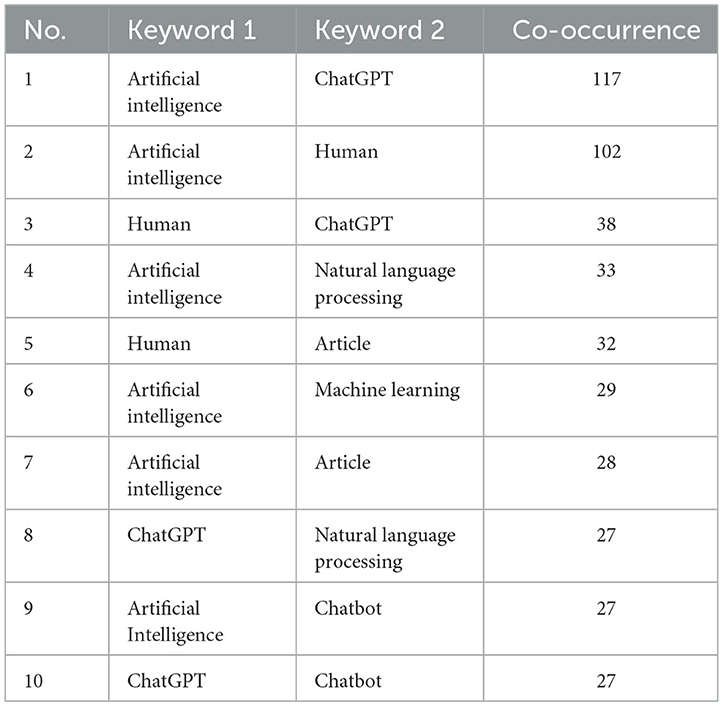
Table 6. Top 10 pairs of co-occurred keywords.
The comprehensive analysis of ChatGPT research conducted in the period from November 2022 to early June 2023 reveals a thriving research interest in the field. During this short timeframe, a total of 533 documents were produced, indicating a significant surge in scholarly publications related to ChatGPT. The rapid surge in the number of publications highlights the growing interest in the potential applications of ChatGPT and the profound influence it has had on humans across the globe. Google Trends for the search term “ChatGPT” during this same period shows how the interest in the topic increased gradually over time. The level of interest reached a peak in April 2023, and the interest remained relatively stable until the end of May 2023 (see Supplementary material).
Collaboration among researchers is evident in the analysis, with a high collaboration rate of 88.91% observed among the authors. This suggests a strong community of researchers working on ChatGPT who are actively sharing ideas and resources to advance the field. The involvement of 1,195 institutions from various countries highlights research collaboration. This reflects the ability of technological innovations and artificial intelligence to unite researchers from diverse backgrounds for interdisciplinary work. Additionally, it underscores the motivation to be a “first mover” in new scientific fields, with collaboration facilitating rapid and impactful publication. This can be seen in light of the findings of Sabatier and Chollet (2017), who found that pioneers in new research fields have, over time, had higher scientific production.
The type of documents published on ChatGPT shows a diverse range of contributions. Empirical papers constitute the largest portion of the documents, followed by letters, editorials, and notes. The significant presence of letters, notes, and editorials within the corpus indicates that there is a variety of perspectives and opinions surrounding ChatGPT. This also underscores the level of interest and excitement surrounding the rise of ChatGPT. Furthermore, these types of outputs are also a route to swift publication, which benefits authors not only in terms of enabling themselves to gain recognition as key thinkers within the field but also benefit from a potential surge in citations. However, it should be noted that researchers should exercise caution when citing and referring to work that is published in outlets that are not peer-reviewed, as the information contained could be misleading in some cases, leading to a flawed impression of this emerging field. We also uncovered that the number of review articles published is relatively low, suggesting an area for further exploration and synthesis of existing knowledge.
The analysis of the top journals reveals the leading platforms for ChatGPT research. Annals of Biomedical Engineering published the highest number of articles, followed by Nature and Library Hi Tech News. Nature also stands out as the most cited journal, indicating its influence and reputation in the field. Given the wide-ranging implications of ChatGPT we would expect the list of journals that feature relevant research to expand exponentially over the coming months and years as the understanding of the implications of this innovation improves over time. In terms of countries, the United States emerges as the most prolific contributor with the highest number of publications. India and the United Kingdom follow closely behind. The USA also demonstrates the highest citation count, indicating its global academic impact. Other countries such as Australia, China, and Italy have also made significant contributions to ChatGPT research.
The top authors in the field showcase their contributions and impact. Wang F. Y. from the Institute of Automation Chinese Academy of Sciences leads with the highest article count, while authors from Duke University School of Medicine in the USA also feature prominently. Notably, authors with a lower article count have achieved significant citation numbers, highlighting the quality and impact of their work. The top institutions contributing to ChatGPT research represent a mix of organizations from different countries. Duke University participates in the highest number of papers, followed by the Chinese Academy of Sciences and Chandigarh University. Duke University also received the highest number of citations, indicating the institution's research excellence and impact. The analysis of citation networks reveals the most cited documents, authors, countries, and journals. “ChatGPT is fun, but not an author” by Thorp (2023) emerges as the most cited document, followed by “ChatGPT listed as author on research papers: many scientists disapprove” by Stokel-Walker (2023). These documents highlight the discussions and controversies surrounding ChatGPT and its use in research. The presence of notes and editorials in the top cited documents suggests that discussions and opinions are driving the conversation in the field.
Keyword analysis is an essential aspect of bibliometric research, providing insights into the most relevant terms and their co-occurrence patterns (Farhat et al., 2023c). In the case of ChatGPT, a bibliometric software package was utilized to retrieve the most occurred keywords. Among these keywords, “Artificial intelligence” emerged as the most frequent, appearing 205 times. Following closely were “human,” “humans,” “language,” and “ChatGPT” with 151, 94, 55, and 39 occurrences, respectively. The emergence of “human” and “humans” as significant co-occurring keywords is important given the nature of the innovation. In a world where artificial intelligence is taking over and automating many processes, there is considerable concern about its impact on human nature, which could result in significant political and economic issues if not addressed and considered carefully. For example, even before the emergence of ChatGPT, Hassani et al. (2020) argued the importance of focusing on intelligence augmentation as the way forward and the urgent need for ethical frameworks that can regulate the growth of AI whilst protecting the wellbeing and interest of humans. Other significant keywords included “article,” “natural language processing,” “publishing,” and “writing.”
In this paper, we have carried out a comprehensive bibliometric analysis of the scholarly footprint of ChatGPT, zooming in on the early outbreak phase. Our findings have theoretical, methodological, practical, societal, and ethical implications.
From a theoretical perspective, our study provides an interesting view of the early developments in the establishment of a research field around a new technology. By employing bibliometric and scientometric methods, we have explored various dimensions of ChatGPT research, including overall publication trends, citation patterns, collaborative networks, application domains, and possible future directions.
The analysis of publication trends revealed a remarkable surge in scholarly output related to ChatGPT within a short time frame of about 6 months. The analysis also examines the publication venues contributing to ChatGPT research and evidences the impact of ChatGPT on diverse scientific disciplines. Furthermore, the study explores the contributions of different countries to ChatGPT research and finds that the United States has the most significant global academic impact in the field of ChatGPT, but other countries such as China, Australia, and Italy have also made notable contributions to ChatGPT research. In terms of influential authors, Wang F. Y. from the Chinese Academy of Sciences and Wu H. from Duke University are among the top authors based on article count and total citations.
In terms of practical implications, our study serves as a valuable resource for researchers and other experts involved in the broader AI field, offering a comprehensive understanding of the scholarly footprint of ChatGPT. It can serve as a quick reference guide for new researchers who orient themselves in the landscape of GPT research by highlighting the most influential authors, studies, and institutions thus far. Moreover, the findings can guide future research endeavors, collaborations, and innovations in enhancing ChatGPT's capabilities and impact. By mapping early research on ChatGPT and identifying trends, we aim to stimulate discussions and contribute to the continuous advancement of ChatGPT and its applications across domains.
Finally, our study has societal and ethical implications. The bibliometric analysis clearly demonstrates that ChatGPT, in just a span of a few months, garnered much attention among researchers working across different scholarly fields (Sohail, 2023). Many commentators have pointed out societal and ethical issues related to ChatGPT and similar AI models (Rahimi and Abadi, 2023; Zhuo et al., 2023; see, for example, Farina and Lavazza, 2023), such as bias and fairness, privacy concerns, employment impact, over-reliance on technology, and security risks. Some have even gone as far to suggest that AI can be an existential threat to humanity (Chomsky et al., 2023; Harari, 2023). From a bibliometric perspective, it becomes interesting to follow the extent to which societal and ethical aspects will become key areas of future ChatGPT research or whether researchers will primarily focus on technical and instrumental aspects.
Like any study, our analysis has certain limitations that should be considered carefully. First, our study relies on bibliometric and scientometric methods that are mostly quantitative and provide limited qualitative insight. Therefore, follow-up studies could employ content analysis of the most influential articles or gather primary data via interviews with authors and experts involved in the AI field, which may enable a more multifaceted analysis. Second, bibliometric analyses might also be subject to other biases, such as self-citations. Future studies could examine publication patterns in more detail, in particular the role played by prolific researchers and journals that specialize in publishing research on “hot” topics such as ChatGPT to boost their own citation metrics and impact factors. It would also be interesting to follow the scientific trajectories of some of the “first movers” in the field of ChatGPT research to see if they gain long-term career advantages and increased scientific productivity (Sabatier and Chollet, 2017). The same can possibly be done at the journal level to explore whether journals with high market shares of ChatGPT publications obtain increased citation metrics or other reputational effects in the long run.
Another limitation of our bibliometric analysis is that based on bibliometric data collected and analyzed at one point in time. Therefore, it is difficult to make predictions about the future evolution of the research literature on ChatGPT. Donthu et al. (2021, p. 295) point out that “bibliometric studies can only offer a short-term forecast of the research field” and highlight that it is important to be careful when making assertions about its future importance and impact. This is especially the case regarding research on ChatGPT since it has been rapidly expanding, and there is much uncertainty related to its future evolution and trajectory. Therefore, it becomes of great importance to revisit and update the findings of this bibliometric study. Such updated analyses can also shed light on the dynamics and evolution of the scientific field and community involved in the field of ChatGPT research.
Publicly available datasets were analyzed in this study. This data can be found at: https://www.scopus.com/.
FF: Conceptualization, Data curation, Formal analysis, Investigation, Resources, Software, Visualization, Writing – original draft, Writing – review & editing. ES: Resources, Validation, Visualization, Writing – original draft, Writing – review & editing. HH: Resources, Validation, Writing – original draft, Writing – review & editing. DM: Project administration, Resources, Validation, Writing – original draft, Writing – review & editing. SS: Conceptualization, Project administration, Resources, Writing – original draft, Writing – review & editing. YH: Resources, Validation, Writing – original draft, Writing – review & editing. MA: Resources, Validation, Writing – review & editing. AZ: Resources, Validation, Writing – review & editing.
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frai.2023.1270749/full#supplementary-material
Aria, M., and Cuccurullo, C. (2017). Bibliometrix: an R-tool for comprehensive science mapping analysis. J. Informetr. 11, 959–975. doi: 10.1016/j.joi.2017.08.007
Baumgartner, C. (2023). The potential impact of ChatGPT in clinical and translational medicine. Clin. Transl. Med. 13, 1206. doi: 10.1002/ctm2.1206
Biswas, S. (2023). ChatGPT and the future of medical writing. Radiol. Soc. North Am. 307, e223312. doi: 10.1148/radiol.223312
Carvalho, I., and Ivanov, S. (2023). ChatGPT for tourism: applications, benefits and risks. Tour. Rev. 2023, 88. doi: 10.1108/TR-02-2023-0088
Chomsky, N., Roberts, I., and Watumull, J. (2023). Noam Chomsky: The False Promise of ChatGPT. New York, NY: The New York Times, 8.
Dave, T., Athaluri, S. A., and Singh, S. (2023). ChatGPT in medicine: an overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 6, 1169595. doi: 10.3389/frai.2023.1169595
Donthu, N., Kumar, S., Mukherjee, D., Pandey, N., and Lim, W. M. (2021). How to conduct a bibliometric analysis: an overview and guidelines. J. Bus. Res. 133, 285–296. doi: 10.1016/j.jbusres.2021.04.070
Dowling, M., and Lucey, B. (2023). ChatGPT for (finance) research: the bananarama conjecture. Fin. Res. Lett. 2023, 103662. doi: 10.1016/j.frl.2023.103662
Dwivedi, Y. K., Kshetri, N., Hughes, L., Slade, E. L., Jeyaraj, A., Kar, A. K., et al. (2023a). “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inform. Manag. 71, 102642. doi: 10.1016/j.ijinfomgt.2023.102642
Dwivedi, Y. K., Pandey, N., Currie, W., and Micu, A. (2023b). Leveraging ChatGPT and other generative artificial intelligence (AI)-based applications in the hospitality and tourism industry: practices, challenges and research agenda. Int. J. Contemp. Hospital. Manag. 2023, 686. doi: 10.1108/IJCHM-05-2023-0686
Editorial (2023). Tools such as ChatGPT threaten transparent science; here are our ground rules for their use. Nature 613, 612. doi: 10.1038/d41586-023-00191-1
Else, H. (2023). Abstracts written by ChatGPT fool scientists. Nature 613, 423. doi: 10.1038/d41586-023-00056-7
Farhat, F., Athar, M. T., Ahmad, S., Madsen, D. Ø., and Sohail, S. S. (2023a). Antimicrobial resistance and machine learning: past, present, and future. Front. Microbiol. 14, 1717. doi: 10.3389/fmicb.2023.1179312
Farhat, F., Sohail, S. S., and Madsen, D. Ø. (2023b). How trustworthy is ChatGPT? The case of bibliometric analyses. Cogent Eng. 10, 2222988. doi: 10.1080/23311916.2023.2222988
Farhat, F., Sohail, S. S., Siddiqui, F., Irshad, R. R., and Madsen, D. Ø. (2023c). Curcumin in wound healing—a bibliometric analysis. Life 13, 143. doi: 10.3390/life13010143
Farina, M., and Lavazza, A. (2023). ChatGPT in society: emerging issues. Front. Artif. Intell. 6, 1130913. doi: 10.3389/frai.2023.1130913
Gilson, A., Safranek, C. W., Huang, T., Socrates, V., Chi, L., Taylor, R. A., et al. (2023). How does ChatGPT perform on the United States medical licensing examination? The implications of large language models for medical education and knowledge assessment. JMIR Med. Educ. 9, e45312. doi: 10.2196/45312
Gordijn, B., and Have, H. (2023). ChatGPT: evolution or revolution? Med. Health Care Philos. 23, 10136. doi: 10.1007/s11019-023-10136-0
Gupta, B., Mufti, T., Sohail, S. S., and Madsen, D. Ø. (2023). ChatGPT: a brief narrative review. Cogent Bus. Manag. 10, 2275851. doi: 10.1080/23311975.2023.2275851
Harari, Y. N. (2023). Yuval Noah Harari argues that AI has hacked the operating system of human civilisation. Economist 28. Available online at: https://www.economist.com/by-invitation/2023/04/28/yuval-noah-harari-argues-that-ai-has-hacked-the-operating-system-of-human-civilisation
Hassani, H., Silva, E. S., Unger, S., TajMazinani, M., and Mac Feely, S. (2020). Artificial intelligence (AI) or intelligence augmentation (IA): what is the future? Artif. Intell. 1, 143–155. doi: 10.3390/ai1020008
Ivanov, S., and Soliman, M. (2023). Game of algorithms: ChatGPT implications for the future of tourism education and research. J. Tour. Fut. 2023, 38. doi: 10.1108/JTF-02-2023-0038
Khosravi, H., Shafie, M. R., Hajiabadi, M., Raihan, A. S., and Ahmed, I. (2023). Chatbots and ChatGPT: a bibliometric analysis and systematic review of publications in web of science and scopus databases. arXiv preprint arXiv:2304.05436. doi: 10.48550/arXiv.2304.05436
Kitamura, F. C. (2023). ChatGPT is shaping the future of medical writing but still requires human judgment. Radiol. Soc. North America 307, e230171. doi: 10.1148/radiol.230171
Levin, G., Brezinov, Y., and Meyer, R. (2023). Exploring the use of ChatGPT in OBGYN: a bibliometric analysis of the first ChatGPT-related publications. Archiv. Gynecol. Obstetr. 23, 7081. doi: 10.1007/s00404-023-07081-x
Liebrenz, M., Schleifer, R., Buadze, A., Bhugra, D., and Smith, A. (2023). Generating scholarly content with ChatGPT: ethical challenges for medical publishing. Lancet Digit. Health 5, e105–e106. doi: 10.1016/S2589-7500(23)00019-5
Lo, C. K. (2023). What is the impact of ChatGPT on education? A rapid review of the literature. Educ. Sci. 13, 410. doi: 10.3390/educsci13040410
Lund, B. D., and Wang, T. (2023). Chatting about ChatGPT: how may AI and GPT impact academia and libraries? Libr. Hi Tech News 40, 26–29. doi: 10.1108/LHTN-01-2023-0009
Patel, S. B., and Lam, K. (2023). ChatGPT: the future of discharge summaries? Lancet Digit. Health 5, e107–e108. doi: 10.1016/S2589-7500(23)00021-3
Pavlik, J. V. (2023). Collaborating with ChatGPT: considering the implications of generative artificial intelligence for journalism and media education. J. Mass Commun. Educat. 2023, 10776958221149577. doi: 10.1177/10776958221149577
Rahimi, F., and Abadi, A. T. B. (2023). ChatGPT and publication ethics. Archiv. Med. Res. 54, 272–274. doi: 10.1016/j.arcmed.2023.03.004
Ray, P. P. (2023). ChatGPT: a comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber-Phys. Syst. 3, 121–154. doi: 10.1016/j.iotcps.2023.04.003
Roumeliotis, K. I., and Tselikas, N. D. (2023). ChatGPT and open-AI models: a preliminary review. Fut. Internet 15, 192. doi: 10.3390/fi15060192
Sabatier, M., and Chollet, B. (2017). Is there a first mover advantage in science? Pioneering behavior and scientific production in nanotechnology. Res. Pol. 46, 522–533. doi: 10.1016/j.respol.2017.01.003
Sallam, M. (2023). ChatGPT utility in healthcare education, research, and practice: systematic review on the promising perspectives and valid concerns. Healthcare 11:887. doi: 10.3390/healthcare11060887
Salvagno, M., Taccone, F. S., and Gerli, A. G. (2023). Can artificial intelligence help for scientific writing? Crit. Care 27, 1–5. doi: 10.1186/s13054-023-04380-2
Shen, Y., Heacock, L., Elias, J., Hentel, K. D., Reig, B., Shih, G., et al. (2023). ChatGPT and other large language models are double-edged swords. Radiol. Soc. North America 307, e230163. doi: 10.1148/radiol.230163
Sohail, S. S. (2023). A promising start and not a panacea: ChatGPT's early impact and potential in medical science and biomedical engineering research. Ann. Biomed. Eng. 6, 1–5. doi: 10.1007/s10439-023-03335-6
Sohail, S. S., Farhat, F., Himeur, Y., Nadeem, M., Madsen, D. Ø., Singh, Y., et al. (2023a). Decoding ChatGPT: a taxonomy of existing research, current challenges, and possible future directions. J. King Saud Univ. 2023, 101675. doi: 10.2139/ssrn.4413921
Sohail, S. S., Madsen, D. Ø., Himeur, Y., and Ashraf, M. (2023b). Using ChatGPT to navigate ambivalent and contradictory research findings on artificial intelligence. Front. Artif. Intell. 6, 1195797. doi: 10.3389/frai.2023.1195797
Stokel-Walker, C. (2022). AI bot ChatGPT writes smart essays — should academics worry? Nature 22, 7. doi: 10.1038/d41586-022-04397-7
Stokel-Walker, C. (2023). ChatGPT listed as author on research papers: many scientists disapprove. Nature 613, 620–621. doi: 10.1038/d41586-023-00107-z
Stokel-Walker, C., and Van Noorden, R. (2023). What ChatGPT and generative AI mean for science. Nature 614, 214–216. doi: 10.1038/d41586-023-00340-6
The Lancet Digital Health (2023). ChatGPT: friend or foe? Lancet Digit. Health 5, e102. doi: 10.1016/S2589-7500(23)00023-7
Thorp, H. H. (2023). ChatGPT is fun, but not an author. Science 379, 313. doi: 10.1126/science.adg7879
van Dis, E. A. M., Bollen, J., Zuidema, W., van Rooij, R., and Bockting, C. L. (2023). ChatGPT: five priorities for research. Nature 614, 224–226. doi: 10.1038/d41586-023-00288-7
Van Eck, N. J., and Waltman, L. (2010). Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 84, 523–538. doi: 10.1007/s11192-009-0146-3
Wang, F.-Y., Miao, Q., Li, X., Wang, X., and Lin, Y. (2023). What does ChatGPT say: the DAO from algorithmic intelligence to linguistic intelligence. IEEE/CAA J. Automat. Sin. 10, 575–579. doi: 10.1109/JAS.2023.123486
Wood, D. A., Achhpilia, M. P., Adams, M. T., Aghazadeh, S., Akinyele, K., Akpan, M., et al. (2023). The ChatGPT artificial intelligence Chatbot: how well does it answer accounting assessment questions? Iss. Account. Educ. 2023, 1–28. doi: 10.2308/ISSUES-2023-013
Keywords: ChatGPT, bibliometric analysis, scientometric methods, research trends, citation analysis, collaborative networks, application domains, future directions
Citation: Farhat F, Silva ES, Hassani H, Madsen DØ, Sohail SS, Himeur Y, Alam MA and Zafar A (2024) The scholarly footprint of ChatGPT: a bibliometric analysis of the early outbreak phase. Front. Artif. Intell. 6:1270749. doi: 10.3389/frai.2023.1270749
Received: 01 August 2023; Accepted: 08 December 2023;
Published: 05 January 2024.
Edited by:
Lili Mou, University of Alberta, CanadaReviewed by:
Hiram Calvo, National Polytechnic Institute (IPN), MexicoCopyright © 2024 Farhat, Silva, Hassani, Madsen, Sohail, Himeur, Alam and Zafar. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dag Øivind Madsen, ZGFnLm9pdmluZC5tYWRzZW5AdXNuLm5v
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Research integrity at Frontiers
Learn more about the work of our research integrity team to safeguard the quality of each article we publish.